Detection and Validation of Tow-Away Road Sign Licenses through Deep Learning Methods




Abstract
1. Introduction
2. Related Works
3. System Design and Image Dataset
- It must to be cheap and suitable for portable devices;
- It must already be working and applicable on an industrial level without (a lot) of optimization;
- It must to be easily used by non-IT skilled people (policemen and public officials) and mounted on official law enforcement vehicles in a transparent way;
- It must provide the validation while interacting with public offices’ databases (also in real-time) as well as saving the image together with other meta-data (acquisition date, place, author).
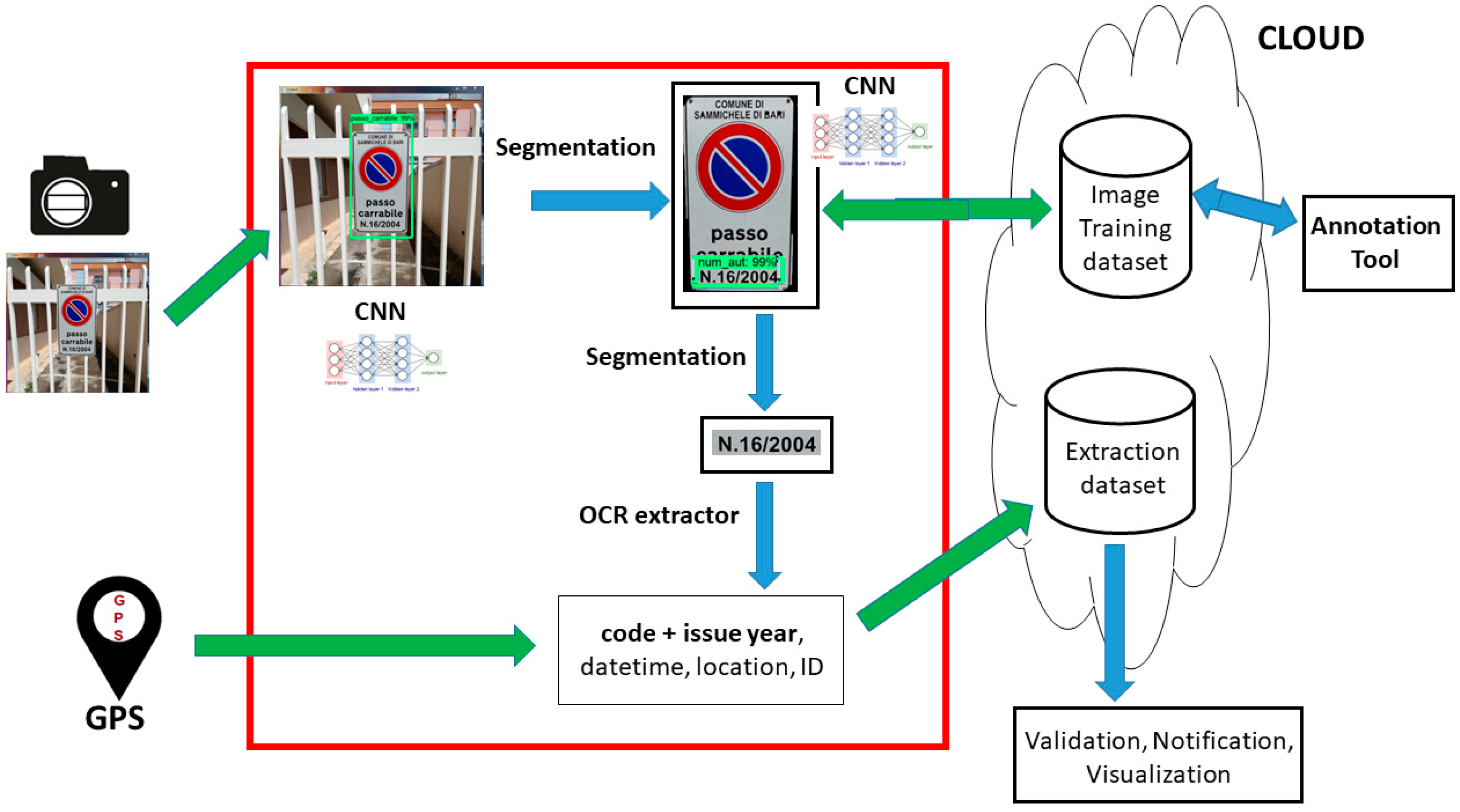
- Acquisition system: The hardware devices used for the images input, consisting of a portable photo/video recorder and a GPS (Global Positioning System) locator for the geographical metadata;
- Core system: Manages the raw input and exploits different technologies such as CNN, image segmentation, and optical character recognition (OCR) into a pipeline that accomplishes three tasks (object detection, pattern extraction, text extraction);
- Archive system: Constituted by an informative system (logically) dedicated to store the image dataset and the extracted metadata (sign code and year, date, time, location); moreover, there are two external modules dedicated respectively to the extracted data management (code validation, info visualization, alerts notification) and to the new images annotation through a visual tool.
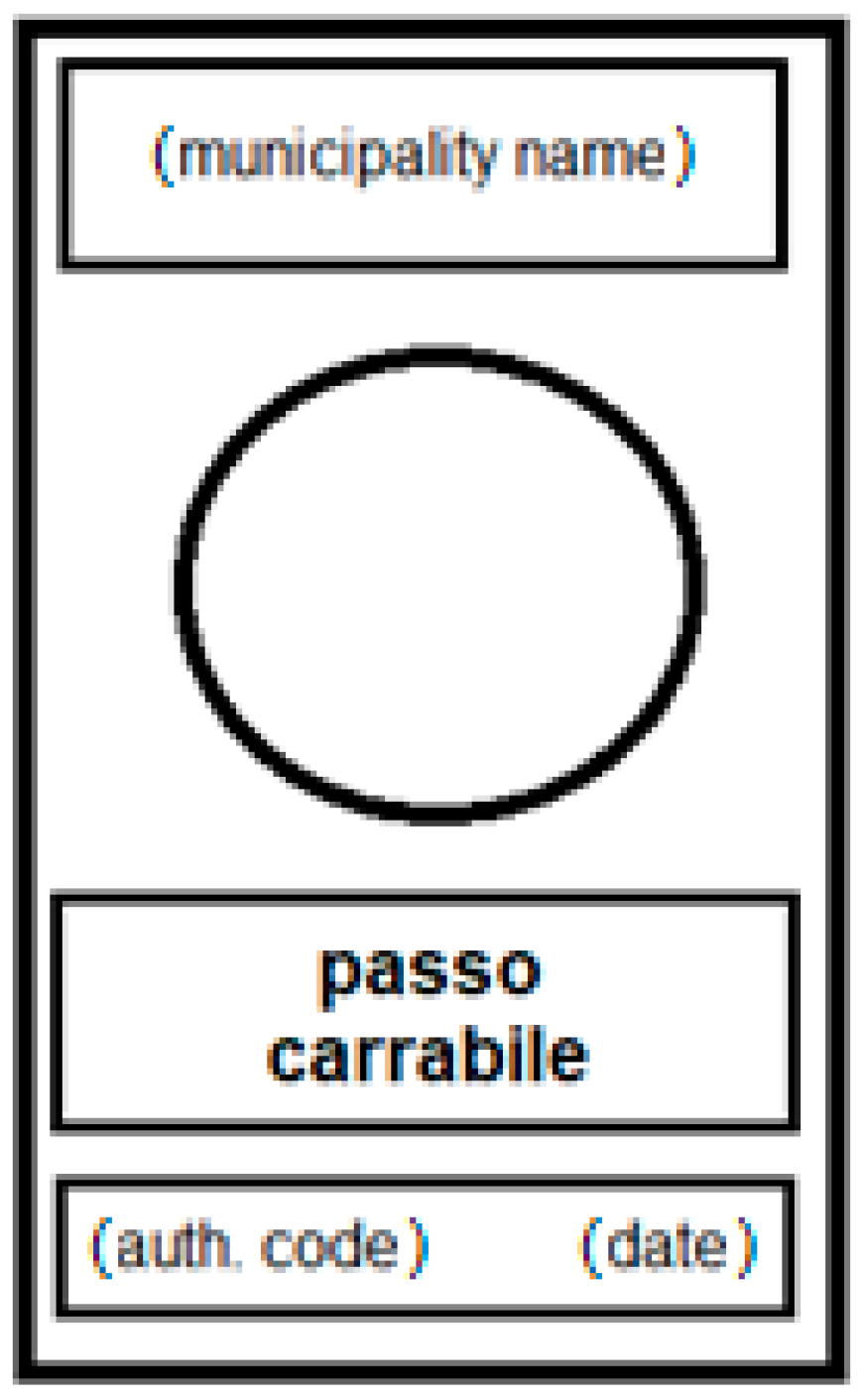
The Tow-Away Road Sign Image Dataset
- C1: 160 tow-away road sign closely photographed in a simple scenario;
- C2: 160 tow-away road sign photographed from a distance, in a complex scenario with other elements (plants, machines, light poles, etc.);
- C3: 160 tow-away road sign photographed in low light (photos taken in late afternoon/ evening);
- C4: 160 tow-away road sign without authorization number and/or date and city name (a false license);
- C5: 160 photos featuring a scenario without the tow-away road sign.
- D1: 2976 × 3968 photos:
- 48 photos belonging to the C1 class;
- 15 photos belonging to the C3 class;
- 86 photos belonging to the C4 class;
- 79 photos belonging to the C5 class.
- D2: 3120 × 4160 photos:
- 112 photos belonging to the C1 class;
- 106 photos belonging to the C2 class;
- 145 photos belonging to the C3 class;
- 74 photos belonging to the C4 class;
- 81 photos belonging to the C5 class.
- D3: 4608 × 3072 photos:
- 54 photos belonging to the C2 class.
4. System Development: Technologies and Algorithms
4.1. Tensorflow and Region-based Convolutional Neural Networks Model
4.2. Image Segmentation
- Take as input the foreground, the background, and the unknown part of the image that may be in the foreground or in the background. This is normally done by selecting a rectangle around the object of interest and marking the region within this rectangle as unknown. The pixels outside this rectangle are marked as a ‘known background’;
- Create an initial segmentation of the image where unknown pixels are placed in the foreground class and all known background pixels are classified as backgrounds;
- The foreground and the background are modeled using the Gaussian Mixture Models (GMMs) in Equation (1);
- Each foreground pixel is assigned to the most probable Gaussian component in the GMM in the foreground and the same process is done with the pixels in the background, but with GMM components in the background;
- The new GMMs are learned from the pixel sets that were created in the previous steps;
- A graph chart is created and a graph cut is used to find a new classification of pixels both in the foreground and in the background;
- Steps 4–6 are repeated until the classification converges.
4.3. Optical Character Recognition Extractor
- Adaptive thresholding that converts the image into a binary version;
- Analysis of the page layout to extract the blocks of the document;
- Detection of the baselines of each line and division of the text into pieces using spaces;
- Characters are extracted from the words and the text recognition is performed in two steps. In the first, using the static classifier each word found is passed to an adaptive classifier as training data; later, the second pass is performed on the whole page using the newly learned adaptive classifier, where words that have not been recognized well enough are recognized again.
5. Metrics, Experiments, and Results
5.1. Performance Evaluation Metrics
- TP are true positive cases, road sign present in the image and detected by the system;
- TN are true negative cases, road sign not in the image and not detected by the system;
- FP are false positive cases, road sign not in the image, but detected by the system;
- FN are false negative cases, road sign present in the image, but not detected by the system.
5.2. Experimental Design
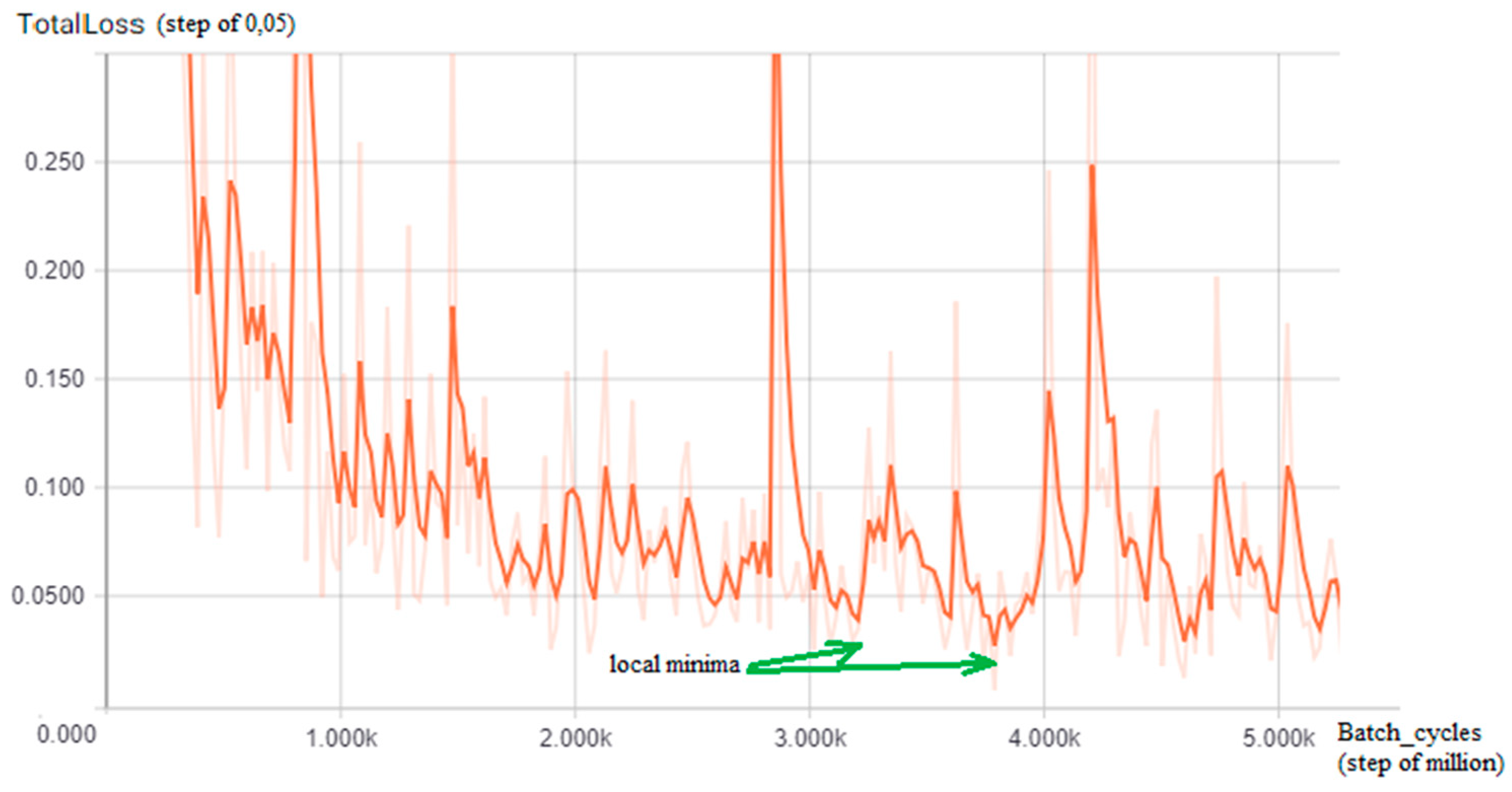
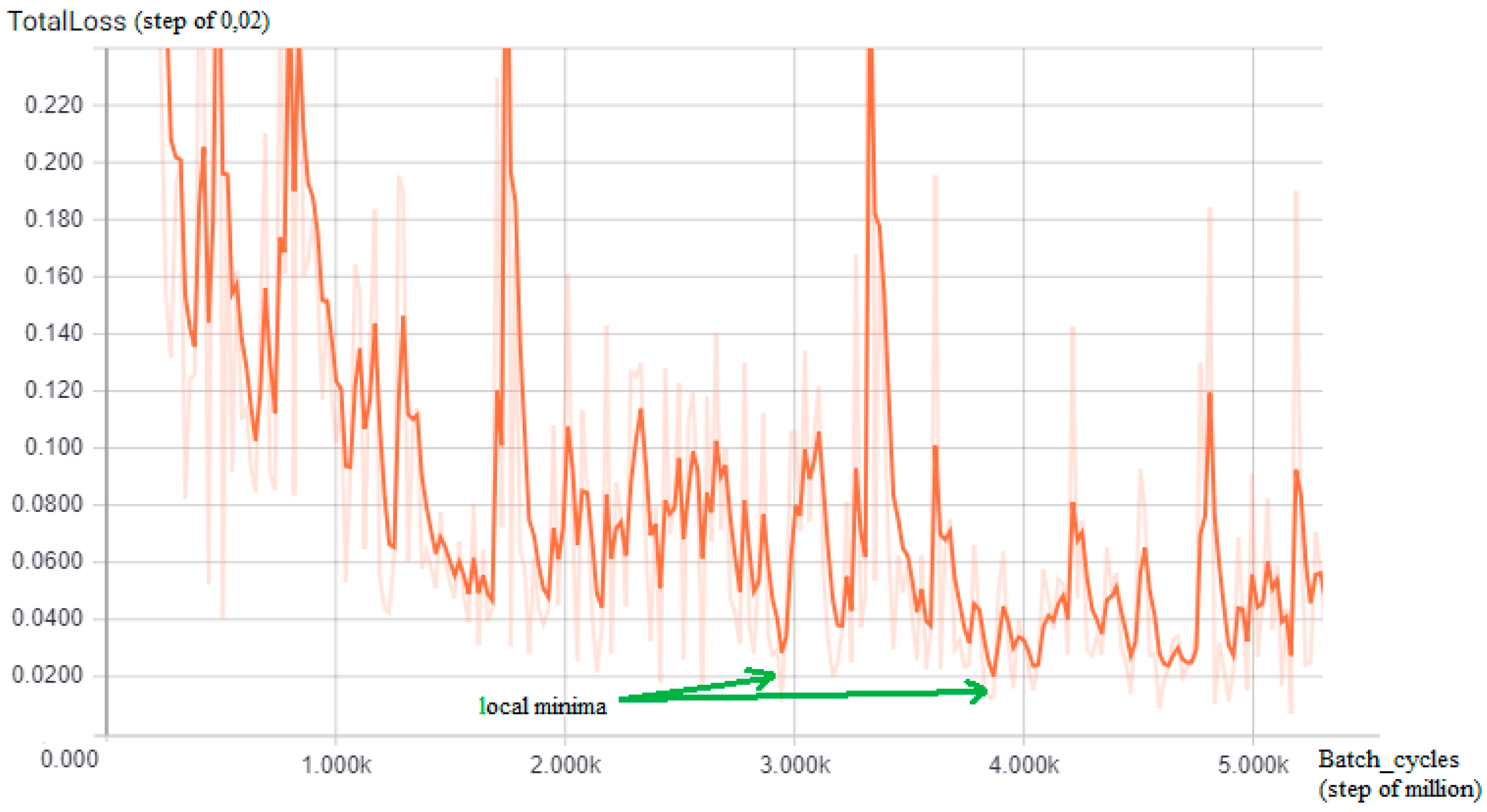
5.3. Experiment Execution and Discussion
Probabilistic Score
6. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
References
- Berder, G.O.; Quemerais, P.; Sentieys, O.; Astier, J.; Nguyen, T.D.; Menard, J.; Mestre, G.L.; Roux, Y.L.; Kokar, Y.; Zaharia, G.; et al. Cooperative communications between vehicles and intelligent road signs. In Proceedings of the 8th International Conference on ITS Telecommunications, Phuket, Thailand, 24 October 2008; pp. 121–126. [Google Scholar]
- Katajasalo, A.; Ikonen, J. Wireless identification of traffic signs using a mobile device. In Proceedings of the Third International Conference on Mobile Ubiquitous Computing, Systems, Services and Technologies, Sliema, Malta, 11–16 October 2009; pp. 130–134. [Google Scholar]
- Nejati, O. Smart recording of traffic violations via m-rfid. In Proceedings of the 7th International Conference on Wireless Communications, Networking and Mobile Computing, Wuhan, China, 23–25 September 2011; pp. 1–4. [Google Scholar]
- Guo, R.; Wei, Z.; Li, Y.; Rong, J. Study on encoding technology of urban traffic signs based on demands of facilities management. In Proceedings of the 7th Advanced Forum on Transportation of China (AFTC 2011), Beijing, China, 22 October 2011; pp. 201–207. [Google Scholar]
- Paul, A.; Jagriti, R.; Bharadwaj, N.; Sameera, S.; Bhat, A.S. An rfid based in-vehicle alert system for road oddities. In Proceedings of the IEEE Recent Advances in Intelligent Computational Systems, Trivandrum, India, 22–24 September 2011; pp. 019–024. [Google Scholar]
- Paul, A.; Bharadwaj, N.; Bhat, A.; Shroff, S.; Seenanna, V.; Sitharam, T. Design and prototype of an in-vehicle road sign delivery system using rfid. In Proceedings of the International Conference on ITS Telecommunications, Taipei, Taiwan, 5–8 November 2012; pp. 220–225. [Google Scholar]
- Qiao, F.; Wang, J.; Wang, X.; Jia, J.; Yu, L. A rfid based e-stop sign and its impacts to vehicle emissions. In Proceedings of the 15th International IEEE Conference on Intelligent Transportation Systems, Anchorage, AK, USA, 16–19 September 2012; pp. 206–211. [Google Scholar]
- Li, Q.; Qiao, F.; Wang, X.; Yu, L. ‘Drivers’ smart advisory system improves driving performance at stop sign intersections. J. Traffic Transp. Eng. 2017, 4, 262–271. [Google Scholar] [CrossRef]
- Lauziere, Y.B.; Gingras, D.; Ferrie, F.P. A model-based road sign identification system. In Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR 2001), Kauai, HI, USA, 8–14 December 2001; Volume 1. [Google Scholar]
- Gil-Jimenez, P.; Lafuente-Arroyo, S.; Gomez-Moreno, H.; Lopez-Ferreras, F.; Maldonado-Bascon, S. Traffic sign shape classification evaluation. part ii. fft applied to the signature of blobs. In Proceedings of the IEEE Intelligent Vehicles Symposium, Las Vegas, NV, USA, 6-8 June 2005; pp. 607–612. [Google Scholar]
- Islam, K.T.; Raj, R.G.; Mujtaba, G. Recognition of traffic sign based on bag-of-words and artificial neural network. Symmetry 2017, 9, 8. [Google Scholar]
- Carrasco, J.P.; de la Escalera, A.E.; Armingol, J.M. Recognition Stage for a Speed Supervisor Based on Road Sign Detection. Sensors 2012, 12, 12153–12168. [Google Scholar] [CrossRef]
- Miyata, S. Automatic Recognition of Speed Limits on Speed-Limit Signs by Using Machine Learning. J. Imaging 2017, 3, 25. [Google Scholar] [CrossRef]
- Bose, N.; Shirvaikar, M.; Pieper, R. A real time automatic sign interpretation system for operator assistance. In Proceedings of the 2006 Proceeding of the Thirty-Eighth Southeastern Symposium on System Theory, Cookeville, TN, USA, 5–7 March 2006; pp. 11–15. [Google Scholar]
- Marmo, R.; Lombardi, L. Road bridge sign detection and classification. In Proceedings of the 2006 IEEE Intelligent Transportation Systems Conference, Toronto, ON, Canada, 17–20 September 2006; pp. 823–826. [Google Scholar]
- Nguwi, Y.Y.; Kouzani, A.Z. A study on automatic recognition of road signs. In Proceedings of the 2006 IEEE Conference on Cybernetics and Intelligent Systems, Bangkok, Thailand, 7–9 June 2006; pp. 1–6. [Google Scholar]
- Bui-Minh, W.T.; Ghita, O.; Whelan, P.F.; Hoang, T. A robust algorithm for detection and classification of traffic signs in video data. In Proceedings of the 2012 International Conference on Control, Automation and Information Sciences (ICCAIS), Ho Chi Minh City, Vietnam, 26–29 November 2012; pp. 108–113. [Google Scholar]
- Bui-Minh, T.; Ghita, O.; Whelan, P.F.; Hoang, T.; Truong, V.Q. Two algorithms for detection of mutually occluding traffic signs. In Proceedings of the International Conference on Control, Automation and Information Sciences (ICCAIS), Ho Chi Minh City, Vietnam, 26–29 November 2012; pp. 120–125. [Google Scholar]
- Krishnan, A.; Lewis, C.; Day, D. Vision system for identifying road signs using triangulation and bundle adjustment. In Proceedings of the 12th International IEEE Conference on Intelligent Transportation Systems, St. Louis, MO, USA, 4–7 October 2009; pp. 1–6. [Google Scholar]
- Belaroussi, R.; Foucher, P.; Tarel, J.; Soheilian, B.; Charbonnier, P.; Paparoditis, N. Road sign detection in images: A case study. In Proceedings of the 20th International Conference on Pattern Recognition, Istanbul, Turkey, 23–26 August 2010; pp. 484–488. [Google Scholar]
- Hazelhoff, L.; Creusen, I.; de With, P.H.N. Robust detection, classification and positioning of traffic signs from street-level panoramic images for inventory purposes. In Proceedings of the IEEE Workshop on the Applications of Computer Vision (WACV), Breckenridge, CO, USA, 9–11 January 2012; pp. 313–320. [Google Scholar]
- Hazelhoff, L.; Creusen, I.; With, P.H.N.D. Mutation detection system for actualizing traffic sign inventories. In Proceedings of the International Conference on Computer Vision Theory and Applications (VISAPP), Lisbon, Portugal, 5–8 January 2014; Volume 2, pp. 705–713. [Google Scholar]
- Perry, O.; Yitzhaky, Y. Automatic understanding of road signs in vehicular active night vision system. In Proceedings of the Int. Conference on Audio, Language and Image Processing, Shanghai, China, 16–18 July 2012; pp. 7–13. [Google Scholar]
- Lombardi, L.; Marmo, R.; Toccalini, A. Automatic recognition of road sign passo-carrabile. In Proceedings of the Image Analysis and Processing—ICIAP 2005; Roli, F., Vitulano, S., Eds.; Springer: Berlin/Heidelberg, Germany, 2005; pp. 1059–1067. [Google Scholar]
- Russell, M.; Fischaber, S. OpenCV based road sign recognition on zynq. In Proceedings of the 11th IEEE International Conference on Industrial Informatics (INDIN), Bochum, Germany, 29–31 July 2013; pp. 596–601. [Google Scholar]
- Ding, D.; Yoon, J.; Lee, C. Traffic sign detection and identification using surf algorithm and gpgpu. In Proceedings of the International SoC Design Conference (ISOCC), Jeju Island, South Korea, 4–7 November 2012; pp. 506–508. [Google Scholar]
- Bay, H.; Ess, A.; Tuytelaars, T.; Van Gool, L. Speeded Up Robust Features (SURF). Comput. Vis. Image Underst. 2008, 110, 346–359. [Google Scholar] [CrossRef]
- Lin, C.-C.; Wang, M.-S. Road Sign Recognition with Fuzzy Adaptive Pre-Processing Models. Sensors 2012, 12, 6415–6433. [Google Scholar] [CrossRef] [PubMed]
- Afridi, M.J.; Manzoor, S.; Rasheed, U.; Ahmed, M.; Faraz, K. Performance evaluation of evolutionary algorithms for road detection. In Proceedings of the 12th Annual Conference on Genetic and Evolutionary Computation, ser. GECCO ’10, Portland, OR, USA, 7–11 July 2010; pp. 1331–1332. [Google Scholar]
- Bousnguar, H.; Kamal, I.; Housni, K.; Hadi, M.Y. Detection and recognition of road signs. In Proceedings of the 2nd International Conference on Big Data, Cloud and Applications, ser. BDCA’17, Marrakech, Morocco, 8–9 November 2017; pp. 87:1–87:6. [Google Scholar]
- Athrey, K.S.; Kambalur, B.M.; Kumar, K.K. Traffic sign recognition using blob analysis and template matching. In Proceedings of the Sixth International Conference on Computer and Communication Technology 2015, ser. ICCCT ’15, Allahabad, India, 25–27 September 2015; pp. 219–222. [Google Scholar]
- Adorni, G.; D’Andrea, V.; Destri, G.; Mordonini, M. Shape searching in real world images: A CNN-based approach. In Proceedings of the Fourth IEEE International Workshop on Cellular Neural Networks and their Applications Proceedings (CNNA-96), Seville, Spain, 24–26 June 1996; pp. 213–218. [Google Scholar]
- Li, C.; Yang, C. The research on traffic sign recognition based on deep learning. In Proceedings of the 16th International Symposium on Communications and Information Technologies, Qingdao, China, 26–28 September 2016; pp. 156–161. [Google Scholar]
- Yang, S.; Wang, M. Identification of road signs using a new ridgelet network. In Proceedings of the IEEE International Symposium on Circuits and Systems, Kobe, Japan, 23–26 May 2005; Volume 4, pp. 3619–3622. [Google Scholar]
- Kouzani, A.Z. Road-sign identification using ensemble learning. In Proceedings of the IEEE Intelligent Vehicles Symposium, Istanbul, Turkey, 13–15 June 2007; pp. 438–443. [Google Scholar]
- Hoferlin, B.; Zimmermann, K. Towards reliable traffic sign recognition. In Proceedings of the IEEE Intelligent Vehicles Symposium, Xi’an, China, 3–5 June 2009; pp. 324–329. [Google Scholar]
- Islam, K.T.; Raj, R.G. Real-Time (Vision-Based) Road Sign Recognition Using an Artificial Neural Network. Sensors 2017, 17, 853. [Google Scholar] [CrossRef] [PubMed]
- Schmidhuber, J. Deep learning in neural networks: An overview. Neural Netw. 2015, 61, 85–117. [Google Scholar] [CrossRef] [PubMed]
- Stallkamp, J.; Schlipsing, M.; Salmen, J.; Igel, C. Man vs. computer: Benchmarking machine learning algorithms for traffic sign recognition. Neural Netw. 2012, 32, 323–332. [Google Scholar] [CrossRef] [PubMed]
- Huang, Z.; Yu, Y.; Gu, J. A novel method for traffic sign recognition based on extreme learning machine. In Proceedings of the 11th World Congress on Intelligent Control and Automation, Shenyang, China, 29 June–4 July 2014; pp. 1451–1456. [Google Scholar]
- Filatov, D.M.; Ignatiev, K.V.; Serykh, E.V. Neural network system of traffic signs recognition. In Proceedings of the XX IEEE International Conference on Soft Computing and Measurements (SCM), St. Petersburg, Russia, 24–26 May 2017; pp. 422–423. [Google Scholar]
- Vokhidov, H.; Hong, H.; Kang, J.; Hoang, T.; Park, K. Recognition of damaged arrow-road markings by visible light camera sensor based on convolutional neural network. Sensors 2016, 16, 12. [Google Scholar] [CrossRef] [PubMed]
- Fulco, J.; Devkar, A.; Krishnan, A.; Slavin, G.; Morato, C. Empirical evaluation of convolutional neural networks prediction time in classifying German traffic signs. In Proceedings of the 3rd International Conference on Vehicle Technology and Intelligent Transport Systems (VEHITS 2017), Porto, Portugal, 22–24 April 2017; pp. 260–267. [Google Scholar]
- Hemadri, V.; Kulkarni, U. Recognition of traffic sign based on support vector machine and creation of the Indian traffic sign recognition benchmark. Commun. Comput. Inf. Sci. 2018, 801, 227–238. [Google Scholar]
- Hemadri, B.V.; Kulkarni, P.U. Detection and recognition of mandatory and cautionary road signals using unique identifiable features. In Proceedings of the ICWET ’11 International Conference & Workshop on Emerging Trends in Technology, Mumbai, India, 25–26 February 2011; 2011; pp. 1376–1377. [Google Scholar]
- Zhang, K.; Sheng, Y.; Zhao, D. Automatic detection of road traffic sign in visual measurable image. Yi Qi Yi Biao Xue Bao/Chin. J. Sci. Instrum. 2012, 33, 2270–2278. [Google Scholar]
- Borowsky, A.; Shinar, D.; Parmet, Y. Sign location, sign recognition, and driver expectancies. Transp. Res. Part F Traffic Psychol. Behav. 2008, 11, 459–465. [Google Scholar] [CrossRef]
- Cornia, M.; Baraldi, L.; Serra, G.; Cucchiara, R. Predicting human eye fixations via an lstm-based saliency attentive model. IEEE Trans. Image Process. 2018, 27, 5142–5154. [Google Scholar]
- Abdi, L.; Meddeb, A. Deep learning traffic sign detection, recognition and augmentation. In Proceedings of the Symposium on Applied Computing, ser. SAC ’17, Marrakech, Morocco, 3–7 April 2017; pp. 131–136. [Google Scholar] [CrossRef]
- Tensorflow.org. Available online: https://www.tensorflow.org/ (accessed on 14 November 2018).
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MS, USA, 8-10 June 2015; pp. 1–9. [Google Scholar]
- Han, Y.; Oruklu, E. Traffic sign recognition based on the nvidia jetson tx1 embedded system using convolutional neural networks. In Proceedings of the IEEE 60th International Midwest Symposium on Circuits and Systems (MWSCAS), Boston, MA, USA, 6–9 August 2017; pp. 184–187. [Google Scholar]
- Impedovo, D.; Pirlo, G. Updating Knowledge in Feedback-Based Multi-classifier Systems. In Proceedings of the International Conference on Document Analysis and Recognition, Beijing, China, 18–21 September 2011; pp. 227–231. [Google Scholar] [CrossRef]
- Pirlo, G.; Trullo, C.A.; Impedovo, D. A Feedback-Based Multi-Classifier System. In Proceedings of the 10th International Conference on Document Analysis and Recognition, Barcelona, Spain, 26–29 July 2009; pp. 713–717. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| TP | TN | FP | FN | Accuracy | Precision | Recall | f1-score | |
|---|---|---|---|---|---|---|---|---|
| Road Sign det. | 616 | 0 | 14 | 10 | 96.25 | 97.78 | 98.40 | 98.09 |
| License Info det. | 465 | 0 | 4 | 11 | 96.88 | 99.15 | 97.69 | 98.41 |
| Road Sign Det. | License Info Det. | OCR Extr. | |
|---|---|---|---|
| Fold 1 | 95.3 | 96.3 | 89.2 |
| Fold 2 | 97.8 | 98.1 | 90.8 |
| Fold 3 | 98.3 | 97.2 | 87.5 |
| Fold 4 | 98.3 | 94.8 | 86.6 |
| s0 | Road Sign Det. | License Info Det. | OCR Extr. | Mean | |
|---|---|---|---|---|---|
| C1 | 10.23 | 99.00 | 96.85 | 85.85 | 72.98 |
| C2 | -- | -- | -- | -- | -- |
| C3 | 2.58 | 99.00 | 98.95 | 94.25 | 73.69 |
| C4 | 13.48 | 96.73 | 99.28 | -- | 100,00 |
| C5 | -- | 100,00 | -- | -- | 100,00 |
| Mean | 8.76 | 98.68 | 98.36 | 90.05 |
| s0 | Road Sign Det. | License Info Det. | OCR Extr. | Mean | |
|---|---|---|---|---|---|
| C1 | 7.95 | 97.25 | 98.05 | 92.73 | 73.99 |
| C2 | 0.25 | 96.03 | 90.45 | 80.20 | 66.73 |
| C3 | 1.40 | 96.90 | 98.95 | 90.40 | 71.91 |
| C4 | 11.75 | 97.78 | 98.90 | -- | 69.48 |
| C5 | -- | 100,00 | -- | -- | 100,00 |
| Mean | 5.34 | 97.59 | 96.59 | 87.78 |
| s0 | Road Sign Det. | License Info Det. | OCR Extr. | Mean | |
|---|---|---|---|---|---|
| C2 | 0.13 | 99.00 | 98.95 | 92.60 | 72.67 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Balducci, F.; Impedovo, D.; Pirlo, G. Detection and Validation of Tow-Away Road Sign Licenses through Deep Learning Methods. Sensors 2018, 18, 4147. https://doi.org/10.3390/s18124147
Balducci F, Impedovo D, Pirlo G. Detection and Validation of Tow-Away Road Sign Licenses through Deep Learning Methods. Sensors. 2018; 18(12):4147. https://doi.org/10.3390/s18124147
Chicago/Turabian StyleBalducci, Fabrizio, Donato Impedovo, and Giuseppe Pirlo. 2018. "Detection and Validation of Tow-Away Road Sign Licenses through Deep Learning Methods" Sensors 18, no. 12: 4147. https://doi.org/10.3390/s18124147
APA StyleBalducci, F., Impedovo, D., & Pirlo, G. (2018). Detection and Validation of Tow-Away Road Sign Licenses through Deep Learning Methods. Sensors, 18(12), 4147. https://doi.org/10.3390/s18124147