Author Contributions
Conceptualization, J.C.; Data curation, J.C.; Formal analysis, J.C.; Funding acquisition, E.A.; Methodology, J.C.; Project administration, E.A.; Supervision, E.A.; Writing—original draft, J.C.; and Writing—review and editing, J.C. and E.A.
Figure 1.
Roof classification data fusion and processing pipeline. LiDAR, building outlines, and satellite images are processed to construct RGB and LiDAR images of a building rooftop. In Stage 1, these images are fed into a CNN for feature extraction, while Stage 2 uses these features with a random forest for roof classification. These data can be stored for quick reference, e.g., navigation or emergency landing site purposes.
Figure 1.
Roof classification data fusion and processing pipeline. LiDAR, building outlines, and satellite images are processed to construct RGB and LiDAR images of a building rooftop. In Stage 1, these images are fed into a CNN for feature extraction, while Stage 2 uses these features with a random forest for roof classification. These data can be stored for quick reference, e.g., navigation or emergency landing site purposes.
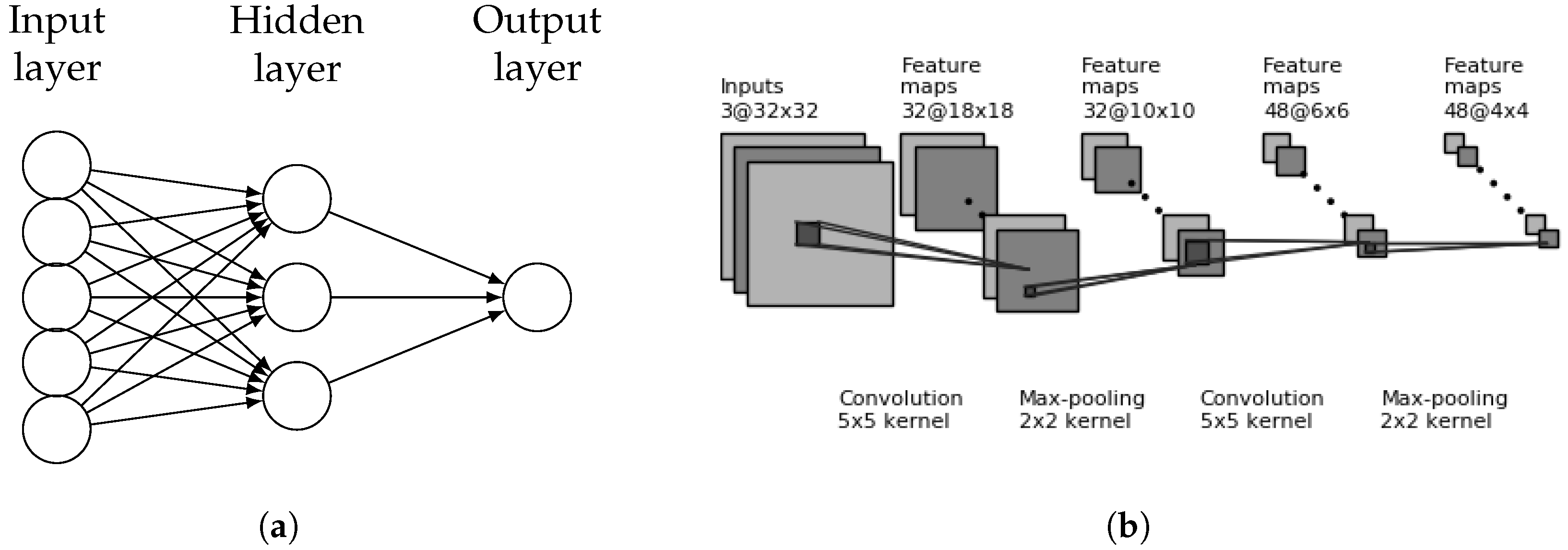
Figure 2.
(a) Example of a fully connected neural network with one hidden layer. (b) Example of a CNN with two convolutional blocks.
Figure 2.
(a) Example of a fully connected neural network with one hidden layer. (b) Example of a CNN with two convolutional blocks.
Figure 3.
(a) Example of an SVM separating two classes with a hyperplane. Optimal class separation is guaranteed by maximizing margin size. (b) Example of a random forest with multiple decision trees being trained on random samples from the training data.SVM and Random Forest
Figure 3.
(a) Example of an SVM separating two classes with a hyperplane. Optimal class separation is guaranteed by maximizing margin size. (b) Example of a random forest with multiple decision trees being trained on random samples from the training data.SVM and Random Forest
Figure 4.
LiDAR data of a gabled roof. Histogram of height distribution and generated image (a) before filtering and (b) after filtering, using median absolute deviation. (c) Projection of filtered point cloud.Results of LiDAR Filtering
Figure 4.
LiDAR data of a gabled roof. Histogram of height distribution and generated image (a) before filtering and (b) after filtering, using median absolute deviation. (c) Projection of filtered point cloud.Results of LiDAR Filtering
Figure 5.
(a) Witten building outline in red shading overlaid on the satellite image. The enlarged crop area is shown in cyan shading. (b) The final generated image, resized.
Figure 5.
(a) Witten building outline in red shading overlaid on the satellite image. The enlarged crop area is shown in cyan shading. (b) The final generated image, resized.
Figure 6.
CNN architecture templates.
Figure 6.
CNN architecture templates.
Figure 7.
Feature extraction for use in SVM and Random Forest model training. The “dual” model refers to both LiDAR and RGB features being combined as input for model training and prediction.
Figure 7.
Feature extraction for use in SVM and Random Forest model training. The “dual” model refers to both LiDAR and RGB features being combined as input for model training and prediction.
Figure 8.
RGB and LiDAR example images of roof shapes.
Figure 8.
RGB and LiDAR example images of roof shapes.
Figure 9.
RGB and LiDAR example images classified as unknown. This category includes buildings with poor quality images as well as complex roof structures.
Figure 9.
RGB and LiDAR example images classified as unknown. This category includes buildings with poor quality images as well as complex roof structures.
Figure 10.
Comparison between CNN validation set accuracy. Colors indicate the base model used while the horizontal axis specifies whether a fully connected layer is part of the architecture. (a) RGB (satellite) image input and (b) LiDAR image input.
Figure 10.
Comparison between CNN validation set accuracy. Colors indicate the base model used while the horizontal axis specifies whether a fully connected layer is part of the architecture. (a) RGB (satellite) image input and (b) LiDAR image input.
Figure 11.
Comparison between region-specific and combined training datasets. Results labeled “combined dataset” are trained on images from both Witten and Manhattan. Validation set accuracy on the vertical axis is specific to the region indicated on the horizontal axis. (a) RGB (satellite) image input and (b) LiDAR image input.
Figure 11.
Comparison between region-specific and combined training datasets. Results labeled “combined dataset” are trained on images from both Witten and Manhattan. Validation set accuracy on the vertical axis is specific to the region indicated on the horizontal axis. (a) RGB (satellite) image input and (b) LiDAR image input.
Figure 12.
Test Set 1 (Witten/Manhattan) accuracy using CNN feature extraction coupled with SVM and decision tree classifiers.
Figure 12.
Test Set 1 (Witten/Manhattan) accuracy using CNN feature extraction coupled with SVM and decision tree classifiers.
Figure 13.
Confusion Matrices for Test Set 1 (Witten/Manhattan) and Test set 2 (Ann Arbor).
Figure 13.
Confusion Matrices for Test Set 1 (Witten/Manhattan) and Test set 2 (Ann Arbor).
Figure 14.
Test Set 1 confidence threshold impact on precision and recall for multiple classes.
Figure 14.
Test Set 1 confidence threshold impact on precision and recall for multiple classes.
Figure 15.
Test Set 2 confidence threshold impact on precision and recall for multiple classes.
Figure 15.
Test Set 2 confidence threshold impact on precision and recall for multiple classes.
Table 1.
CNN architectures and hyperparameters.
Table 1.
CNN architectures and hyperparameters.
| Base CNN Model | FC1 Size | Frozen Layers |
|---|
| Resnet50 | 0, 100 | 50, 80 |
| Inceptionv3 | 0, 100 | 11, 18, 41 |
| Inception-Resnet | 0, 100 | 11, 18, 41 |
Table 2.
SVM and random forest training configurations.
Table 2.
SVM and random forest training configurations.
| Classifier | Parameters |
|---|
| SVM | Regularization Constant (C): 1, 10, 100 |
| | Kernel: linear, rbf, poly, sigmoid |
| Random Forest | Criterion: gini, entropy |
| | Number of Estimators: 5, 10, 50 |
| | Max Depth: 5, 10, 50 |
Table 3.
Satellite, LiDAR, and building data sources.
Table 3.
Satellite, LiDAR, and building data sources.
| City | Satellite | LiDAR | Buildings |
|---|
| Provider | Resolution | Provider | Spacing | Provider |
|---|
| Witten | Land NRW [36] | 0.10 m/px | Open NRW [37] | 0.30 m | OSM [3] |
| New York | NY State [38] | 0.15 m/px | USGS [39] | 0.70 m | NYC Open Data [40] |
| Ann Arbor | Bing [41] | 0.15 m/px | USGS [42] | 0.53 m | OSM [3] |
Table 4.
Breakdown of roof labels by city.
Table 4.
Breakdown of roof labels by city.
| Roof Shape | Witten | Manhattan | Ann Arbor |
|---|
| unknown | 133 | 792 | 14 |
| complex-flat | 125 | 785 | 37 |
| flat | 454 | 129 | 24 |
| gabled | 572 | 7 | 96 |
| half-hipped | 436 | 0 | 3 |
| hipped | 591 | 3 | 20 |
| pyramidal | 110 | 0 | 0 |
| skillion | 189 | 0 | 2 |
| Total | 2610 | 1716 | 196 |
| Removed | 212 | 65 | 0 |
Table 5.
Best CNN model architectures.
Table 5.
Best CNN model architectures.
| Input | Base Model | FC Layer? | Frozen Layers |
|---|
| RGB | Inception-Resnet | Yes | 11 |
| LiDAR | Resnet50 | No | 80 |
Table 6.
Best Classifiers using CNN extracted features.
Table 6.
Best Classifiers using CNN extracted features.
| Input | Model | Parameters | Test Set 1 Accuracy |
|---|
| RGB | Random Forest | Criteria: Entropy, # Estimators: 50, Max Depth: 10 | 73.2% |
| LiDAR | SVM | Regularization Coefficient: 10, kernel: rbf | 84.8% |
| Dual | Random Forest | Criteria: Entropy, #Estimators: 50, Max Depth: 10 | 87.2% |
Table 7.
Results for recall, precision, and quality evaluation metrics for Test Set 1.
Table 7.
Results for recall, precision, and quality evaluation metrics for Test Set 1.
| Type | Recall | Precision | Quality |
|---|
| Unknown | 0.90 | 0.88 | 0.80 |
| Complex-Flat | 0.79 | 0.83 | 0.68 |
| Flat | 0.81 | 0.84 | 0.70 |
| Gabled | 0.97 | 0.90 | 0.87 |
| Half-Hipped | 0.88 | 0.91 | 0.81 |
| Hipped | 0.95 | 0.92 | 0.87 |
| Pyramidal | 0.82 | 1.00 | 0.82 |
| Skillion | 0.82 | 0.77 | 0.66 |
Table 8.
Results for recall, precision, and quality evaluation metrics for Test Set 2.
Table 8.
Results for recall, precision, and quality evaluation metrics for Test Set 2.
| Type | Recall | Precision | Quality |
|---|
| Unknown | 0.86 | 0.60 | 0.55 |
| Complex-Flat | 0.76 | 0.90 | 0.70 |
| Flat | 0.92 | 0.82 | 0.76 |
| Gabled | 0.93 | 0.96 | 0.88 |
| Half-Hipped | N/A | N/A | N/A |
| Hipped | 0.80 | 0.84 | 0.70 |
| Pyramidal | N/A | N/A | N/A |
| Skillion | N/A | N/A | N/A |




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}