1. Introduction
The Internet of Things (IoT) [
1,
2,
3,
4,
5] is promising for many new applications by enabling many objects around us to connect, communicate, and interact over the Internet without human intervention. Huge data processing and data collection from sensors and other IoT devices are performed for those applications. Because IoT devices (sensors, actuators, etc.) are normally resource-constraint (i.e., storage and processing capabilities), IoT-cloud [
6,
7,
8] was proposed as a promising approach to address the limitations. However, with a large number of devices and huge data generation, the development of IoT applications and services is a challenging task, even with the IoT-cloud architecture. Transmitting all these data to the cloud may expose excessive network bandwidth and delay. Fog/edge computing was introduced as a solution to reduce the amount of data transmitted to the cloud, improve performance, latency, and efficiency for IoT services. As a result, IoT services tend to be deployed over fog-core cloud networks. Many IoT applications such as mission-critical IoT and V2X communication require highly available services. Therefore, availability guaranteed deployment for services of those applications over fog-core cloud networks is critical.
For service deployments over cloud environments, network function virtualization (NFV) [
9] is a trend. Network function virtualization (NFV) technologies are changing how network operators install and maintain their services. NFV enables operators to implement network functions (NFs) as software, known as virtual network functions (VNFs), which can be deployed on standard servers using virtual machines (VMs) or containers [
10], instead of using dedicated hardware. VNFs can be used for network function deployments in both fog/edge [
11,
12,
13] and core cloud networking [
7,
14].
As a typical and successful case of NFV, the service function chain (SFC) [
15,
16] attracts more and more attention from the industry and academia. The delivery of end-to-end IoT services often requires various network service functions. These may include traditional network service functions like firewall, load balancer, HTTP header enrichment, DPI (deep packet inspection), NAT (network address translation), etc., as well as IoT application specific functions like data aggregator, data compressor, feature extractor, or IoT gateway. Linkage of an ordered set of service functions to form a service is termed service function chaining. In IoT networks, the customers or providers can use SFC services to form a sequence of heterogeneous VNF instances for filtering, learning, using, compressing and processing the massive data flows of their applications flexibly. These SFCs can make IoT network services more efficient, scalable, and economical.
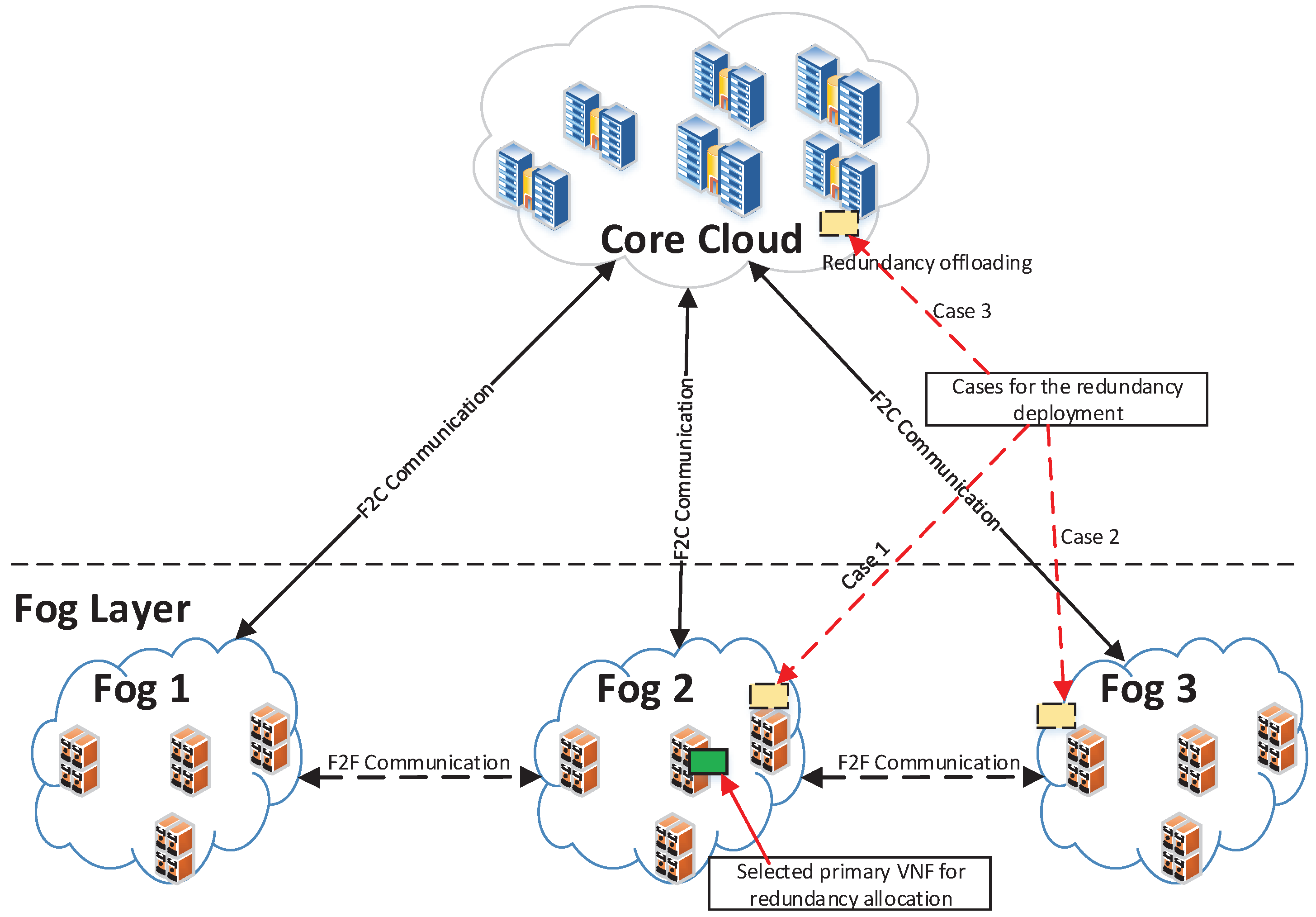
With the fog computing [
17,
18], several NFV-enabled network functions (i.e., virtual device driver, data aggregator, data compressor, or feature extractor, etc.) [
15,
16] can be deployed at the edge, so service function chains (SFCs) for various IoT services are extended across the core cloud and fog networking, as illustrated in
Figure 1. Our previous implementation study [
19] has shown benefits of fog/edge networking for interactive digital signage services.
However, this approach may result in vulnerabilities such as soft- and hard-ware failures. Availability/reliability is a well-known issue in NFV [
20]. Once VNFs’ failures happen, especially for VNFs on fog computing domains whose infrastructure availability/reliability and resources are normally limited compared to the core cloud, the entire service function chaining (SFC) operations can be broken down. Therefore, NFV-based networks indicate higher availability requirements than conventional networks, especially for IoT services. As a result, simply embedding primary VNFs is not enough for achieving high availability and additional improvement/protection schemes are required as discussed in [
20].
According to ETSI NFV architecture [
9], one of the main implementation objectives of NFV is to guarantee the end-to-end availability/reliability of network services in such that not every service is required to be built to the peak. Different given resilience classes can be defined and applied depending on Service Level Agreements (SLAs). This is due to the fact that each service, or SFC, may require a different availability level depending on its demand and budget. Many applications like mission-critical Internet of Things (IoT) [
8,
21,
22] systems, autonomous vehicular systems, and smart health-care systems require a high level of availability guarantee while web browsing services could tolerate about
of service interruption.
VNF redundancy deployment is one of the main protection schemes for SFCs to achieve a target service availability recommended by ETSI VNF REL 003 [
20]. However, the ETSI deliverable does not provide guidance on which case and which VNFs should be selected for redundancy deployments. Applying redundancy deployment (in other words, backup) for the whole SFC is not necessary and costly as network resources are normally limited, especially in the fog computing domain. Several studies on enhancing the availability/reliability of SFCs have been introduced [
23,
24,
25]. The current studies in this topic select the least available/reliable VNF [
23] for redundancy deployment or recursively add one redundancy [
24] until the availability/reliability requirement is satisfied. Those VNF redundancy allocation selections may lead to cost-inefficient protection schemes while resources at fog instances are usually limited.
According to our survey, there is currently lack of a study for availability/reliability guaranteed SFC deployment across the fog-core cloud networking. Fog computing enables to move the data transfer and processing to the edge of the cloud. However, in that environment, due to the resource limitation of fog nodes, we highlight the necessity of a cost efficient VNF redundancy deployment scheme for SFCs. According to our observation, a cost efficient VNF selection for VNF redundancy deployment depends on various factors, not just simply selecting the least reliable VNFs for redundancy deployment as studied in the recent works [
23,
24]. In addition, the improvement potential of VNFs in SFCs is not the same. Some VNFs require a lower cost for redundancy improvement and are more potential than others to be selected for redundancy deployment to improve the overall system availability. Initially, a cost efficient VNF selection for VNF redundancy deployment should give the priority for VNFs with a high availability improvement potential for their corresponding SFC and the low cost (i.e., CPU cost, storage cost, etc.) for redundancy deployment.
In this paper, we propose a cost-efficient availability guaranteed deployment scheme for IoT service chains over fog-core cloud networks. We first design an efficient availability-aware primary VNF embedding mechanism. We then formulate the VNF redundancy allocation cost minimization problem. For VNF redundancy allocation, we propose a metric, namely availability improvement potential per a unit cost (IPC), to measure the availability improvement potential of a VNF if the VNF is selected for redundancy allocation. The metric is used to find which VNFs are the most potential to improve, which leads to the greatest improvement to the service reliability within a limited resource required. Based on IPC, we design a cost-efficient VNF redundancy allocation scheme (IPS). Compared to the preliminary version [
26], this paper provides more insight into the detailed design of the scheme with new mechanisms like the guaranteed deployment scheme for SFCs and the collaborative scheme for VNF redundancy deployment. We also present the detailed analytical model, and analyze the complexity of the scheme. We conduct more experiments and present new significant results. Analysis and Simulation results show that the proposed scheme achieves a significant enhancement in term of cost efficiency and reliability compared to REACH [
23,
25] and the minimum cost algorithm.
2. Related Work
Fog computing is proposed to extend the centralised core cloud to the edge, close proximity to the users and things in IoT [
1,
2,
3,
4,
5]. The design of fog computing is to potentially improve various network services in terms of performance like reducing latency and saving network bandwidth. The fog computing pushes most of data processes out to the network edge, so several network functions are deployed at the edge. As a result, SFCs are also extended to the edge. For end-to-end SFCs over fog-core cloud networking, various technical issues are required to be solved such as task and resource allocation [
27,
28], service orchestration [
29], fault tolerance (i.e., service reliability/availability), and management [
29,
30,
31,
32,
33]. A comprehensive survey on various technical issues of fog computing can be found at [
34].
With the advantages of NFV technologies, network functions including those for the edge can be implemented as software, thus facilitating the fog as well as cloud deployment [
10,
11,
12,
13,
17]. Van Lingen et al. [
12] argue that fog computing will become a part of convergence with NFV. Li et al. [
11] design a virtual fog framework which takes the advantages of the flexibility of networking service provisioning using NFV. Ricart et al. [
13] propose the TelcoFog architecture for a unified fog and cloud computing with SDN and decentralised NFV services. Richard et al. [
10] implement a container-based NFV platform to facilitate the VNF deployment at the edge.
In NFV environments, guaranteeing reliability is very critical because the failure of any VNF of a particular SFC may break operations of the entire chain leading to the suspension of the network services [
23,
35,
36,
37]. In traditional network systems, all services and application are normally deployed with the same floor of availability/reliability without any distinguishment. The requirement for on-demand availability/reliability of services has not been considered in the implementation. For example, web browsing services could tolerate about 30 s of service interruption without affecting the user experience while critical IoT services are very time-sensitive and require very high availability/reliability. One of the main implementation objectives of VNF is to guarantee the end-to-end availability/reliability of network services in such that not every service is required to be built to the peak [
9,
20]. Different given resilience classes can be defined and applied depending on Service Level Agreements (SLAs).
A popular approach to achieve a predefined service availability/reliability is the redundancy deployment which is recommended by ETSI VNF REL 003 [
20]. However, the ETSI deliverable does not provide guidance on which redundancy models should be used in which case and which VNFs should be selected for backups. Backing up the whole SFC is not necessary and costly as network resources are normally limited. In addition, we consider the VNF redundancy deployment as the cost. Therefore, optimizing the cost for VNF redundancy deployments is desirable to increase the revenue of services providers and maintain an appropriate price for network services.
Several studies on enhancing the availability/reliability in NFV environments have been introduced [
23,
24,
25,
36,
38]. Long et al. [
23] present an SFC deployment scheme to achieve adequate reliability guarantees for network services. In the study, the authors propose a greedy algorithm for redundant VNFs placement. The scheme first deploys primary VNFs along the chain. After the deployment of primary VNFs, if the provisioned chain has not yet met the network service reliability requirement, redundant VNFs are then deployed for the least reliable VNFs along the chain until the reliability requirement is satisfied. Similar ILP-based solutions for single-link single-node are also discussed in [
38]. In GREP [
36], the authors consider the whole network as a composition of several independent sub-networks. In each round, GREP selects two primary VNFs whose have the lowest reliability to provide with a backup. One backup is used for two VNFs to minimize the number of backups for a request. In [
24], the authors highlight that the Internet of Things’ applications may require higher service availability for various machine control and safety-critical operations, so the availability/reliability guarantee is very important. For that purpose, a VNF deployment scheme is proposed. The scheme first embeds the primary VNF chain and then recursively deploy one redundant chain. The service availability/reliability is then updated. The scheme completes once the request reliability/availability is met or the maximum number of redundant chains is over.
According to our survey, there is currently a lack of a study for SFC deployments over the fog-core cloud networking, in which the same availability requirements are applied while the network resources are more constrained. This paper is to fulfill the gap.
3. The Analytical Models
This section describes the analytical model for the VNF availability used in this paper.
Table 1 summarizes the parameters and variables used in this paper.
3.1. Network Model
We model an SFC-enabled network as a directed graph , where N is a set of nodes including ingress node, egress node, service nodes (SNs) including nodes in core cloud as well as in fog networking, and service function forwarders (SFFs), L represents a set of links between nodes. indicates the connectivity between node m and node n (i.e., ). The ingress and egress node are incoming and outgoing points of flows for a given SFC. Each link is associated with a bandwidth capacity. A service node represents a cloud server or fog server that hosts virtual network functions (VNFs).
3.2. VNF Model
Each VNF i is deployed and provided several resources such as the number of CPU cores, storage, … VNF instances can be created with various virtual machine (VM) sizes depending on the incoming traffic flow rates. VNF instances are implemented with specific functions (i.e., firewall, proxy, video/image optimizer, data aggregator …) and embedded into nodes on the core cloud or at the edge. A VNF may serve for several SFCs. For example, a video/image optimizer or data aggregator at the edge or firewall on the core cloud may serve various services simultaneously. Each VNF type i is deployed on a server e having a reliability and availability . Assume that we have a set of VNF types . Intuitively, the amount of incoming flows to a VNF instance or a link cannot exceed their capacity.
3.3. Service Function Chaining Model
We consider a set S of SFC requests, . Each SFC consists of m VNFs in order . Please note that an SFC represents an order set of VNFs which are deployed for some services. As a result, traffic flows of an SFC are processed in the VNF order vector . Each SFC s may have a different QoS requirement (i.e., availability requirement ). To deploy an SFC, a provider has to plan a right placement of VNFs and chain them through VNF forwarding graph embedding so that the end-to-end SFC’s availability satisfies the given requirement. Several SFCs may share a VNF instance as long as the VNF and links have enough capacities.
3.4. Availability/Reliability Model
This section presents the availability/reliability model for a given SFC. We assume the availability/reliability of service functions is configured independently, so the failure of VNFs happens independently. The assumption is the same as stated in ETSI GS NFV REL 003 [
20]. The definitions of VNF availability/reliability are given in [
20]. Please note that availability and reliability can be used interchangeably in this paper.
The availability and reliability of a complex composed system like SFC deployment can be modeled by disintegrating it down to its subcomponents like VNFs, of which the availability and reliability are known. There are two basic forms of combination, parallel and serial. In this paper, we use serial dependence mainly as all SFCs can be transformed into serial dependency. A serial dependency of two VNFs indicates that both are required to operate in order for the SFC to operate. Therefore, the availability of an SFC consisting of M serial VNFs is as follows.
VNF redundancy deployments normally use a parallel dependency to improve the availability/reliability. In that case, the availability of a subcomponent consisting of 2 parallel dependent VNFs, VNF1 and VNF2, is calculated as follows.
3.5. Cost Model
3.5.1. Capital Expenditure (CAPEX)
We denote
as the deployment cost of an SFC
in term of a resource type
i
where
is the number of VNF instances of type
used.
The deployment cost can be the financial cost (i.e., license cost for VNFs), processing (i.e., the number of CPUs), or storage cost. In this paper, we use the number of CPUs as the deployment cost.
3.5.2. Operating Expenditure (OPEX)
We denote
as the operating cost of an SFC
.
where
is the operating cost consumption rate of an instance of VNF type
. The operating cost consumption can be the energy cost, bandwidth cost, or even management cost.
4. An Efficient Availability-Aware Primary VNF Embedding Mechanism
We assume there is several SFCs for deployments. The task is to deploy the SFCs to meet their predefined availability requirement with a cost efficiency. For a given SFC request , we first need to deploy the primary VNFs before redundancy deployments are performed. For the above objective, we design an efficient availability-aware primary VNF embedding mechanism as follows.
We call as the hop count distance between VNF i and VNF j, where i is a current VNF in the chain and j is a candidate for next hop of i in the chain . The availability score of j is and the availability-cost ratio () for i to select j as the next hop is defined as follows.
The detailed algorithm for the primary VNF embedding is presented in Algorithm 1. For an SFC consists of M VNF types in order , the embedding scheme for the primary VNFs starts from . If there are N VNF instances of are available and have enough capacity for , the VNF instance with the greatest value of the availability-cost ratio is selected as a primary VNF for deploying . The purpose is to maximize the availability of within a limited cost (i.e., bandwidth).
If there is no available VNF instance of having enough capacity for , a new VNF instance of needs to be instantiated. The new VNF deployment policy is as follows. The new VNF instance is deployed as close as possible to the previous VNF to minimize the bandwidth consumption. This proximity-based policy is also aligned with the deployment strategy of fog instances to save the network resources and improve the performance. The procedures are executed repeatedly until all of the primary VNFs of the chain are deployed.
After all of the primary VNFs are deployed, an availability score check is executed for . If the requested availability requirement of is satisfied, the mechanism stops and the SFC deployment is completed. Otherwise, the below redundancy allocation scheme is called.
| Algorithm 1 Primary VNF Embedding Scheme |
INPUT:, A set of SFC requests ,
OUTPUT: The primary VNF embedding plan
Initialize: Calculate for related VNF instance j
Repeat
for all do
for do
if then
SelectMaxRCR(AvailableVNFInstances());
else
ProximityBasedNewVNFDeployment();
end if
end for
= AvailabilityScoreCheck();
if then
Complete();
else
IPS-RedudancyAllocation();
end if
end for
UNTIL , is embedded or resources run out. |
5. The VNF Redundancy Allocation Cost Minimization Problem
As the primary VNF deployments of SFCs is normally not enough to satisfy the availability requirements of services, VNF redundancy deployments are thus required. In this section, we define a VNF redundancy cost minimization problem to meet a predefined availability and formulate the problem using an Integer Linear Programming (ILP) model as follows.
5.1. Objective Function
Given a set S of SFCs consisting of primary VNFs deployed in the network, we find the optimal VNF redundancy deployment so that
Availability requirements of the SFCs are satisfied
The redundancy deployment cost (i.e., the number of CPUs) is minimized.
We define a decision binary variable . if the primary VNF of SFC on the physical server p is selected for redundancy deployment. Otherwise, . We call , , and as the general cost, the compute cost, and the storage cost for a redundancy deployment, respectively. is the required bandwidth of service at VNF . We assume is equal to the resource required by the primary VNF and a redundancy of has the same availability of . The objective of the ILP model is to minimize the redundancy deployment cost. Mathematically, this objective is given as follows.
5.2. Constraints
The total used capacity of VNFs hosted by a physical server p should be equal to or smaller than the total compute capacity of p (
).
where
is the set of VNFs hosted by a physical server
p.
Similarly, the total used memory capacity of VNFs hosted by the physical server
p should be equal to or smaller than the total memory capacity of p (
)
where
is the set of VNFs hosted by a physical server
p. Required bandwidth capacity of a set
of VNFs mapped using a substrate link
l must be equal or less than the link capacity of
l (
)
The total required processing resources of a set of SFCs that pass a VNF should not exceed the processing capacity of the VNF .
This means that a new SFC can be embedded through a shared VNF i if and only if the VNF i has enough capacity for processing.
is the binary variable, so we have the following constraint.
7. Performance Evaluation
This section presents the performance evaluation for the proposed scheme in comparison with REACH [
23,
25], the state-of-the-art VNF redundancy deployment scheme, and MC, the scheme which selects the VNF with the minimum resource requirement for redundancy deployment. As REACH and current schemes do not distinguish fog nodes and core cloud nodes, to make results compatible, we consider the whole fog and core-cloud networks in a single network graph and provide the general results.
We use CPLEX solver to solve the ILP model and analysis which are also used in REACH [
23,
25]. The simulations [
42] and analysis are run on a PC equipped with an Intel 3.5 GHz and 10 GB RAM. All analysis and simulations are performed with a network composed of 40 physical servers for the core-cloud and 4 fogs with 4 physical nodes for each. Each server can provide three types of resources, namely CPU, memory, and storage, with a capacity of 20 to 100 units for each type of resource. We assume the resources of a fog node equal to one-third of a cloud server. Each SFC requests from 4 to 8 VNFs. We assume there are 20 types of VNFs for core-cloud and 5 types of VNFs for fog networking. Each type of VNFs requires the three types of resources. The VNF demand for each type of resource is distributed between 1 and 8. Similar to REACH, SFCs are composed randomly and the links are assumed to have a perfect reliability.
The reliability of each VNF is randomly distributed within 0.9 and 0.99. Each SFC request has the reliability requirement among 95%, 99%, 99.9%, 99.95%, following the configuration in the previous studies [
23,
25]. The link rates between fog nodes in one domain are 100 Mbps and that of the path from fog nodes to cloud servers are 10 Gbps. For a fair comparison, other parameters are similar to those used in REACH [
23,
25]. We reuse the theoretical modeling and setting for the fog layer presented in [
43]. Our previous implementation study [
19] also illustrates the benefits of fog/edge networking and processing operations between the edge and the core cloud.
7.1. Complexity Analysis
In this subsection, we discuss the complexity analysis for the VNF placement algorithm. It is obvious that the proposed VNF placement algorithm is a heuristic iterative-based algorithm. It has a similar complexity compared to REACH [
23,
25]. The generation of an SFC path has a complexity of
=
(
and
), where
is a set of VNF instances of the network service
i and
M is the length of the path. The worse case of VNF placements has a complexity of
.
7.2. IPS and ILP
This subsection compares the performance as well as the overhead of IPS and ILP. Results are presented in
Table 2.
The results show that both the ILP and IPS achieve the availability requirement of the network services. The ILP solution requires a much longer time to solve the problem. For example, ILP needs 9425 s to solve the problem for the requirement of 0.95 and 26,263 for the requirement of 0.9995, even for this small network. On the other hand, IPS is able to find the solutions within only 0.72 s while the cost efficiency of IPS is only slightly lower than the ILP. The results are due to the fact that the ILP solution resorts to solve the ILP model at each iteration of the algorithm. The results clearly indicate that IPS achieves much better scalability than the ILP while the ILP may be not appropriate to use in operations due to time complexity. Therefore, we focus on evaluating the performance of IPS in the remaining of this section.
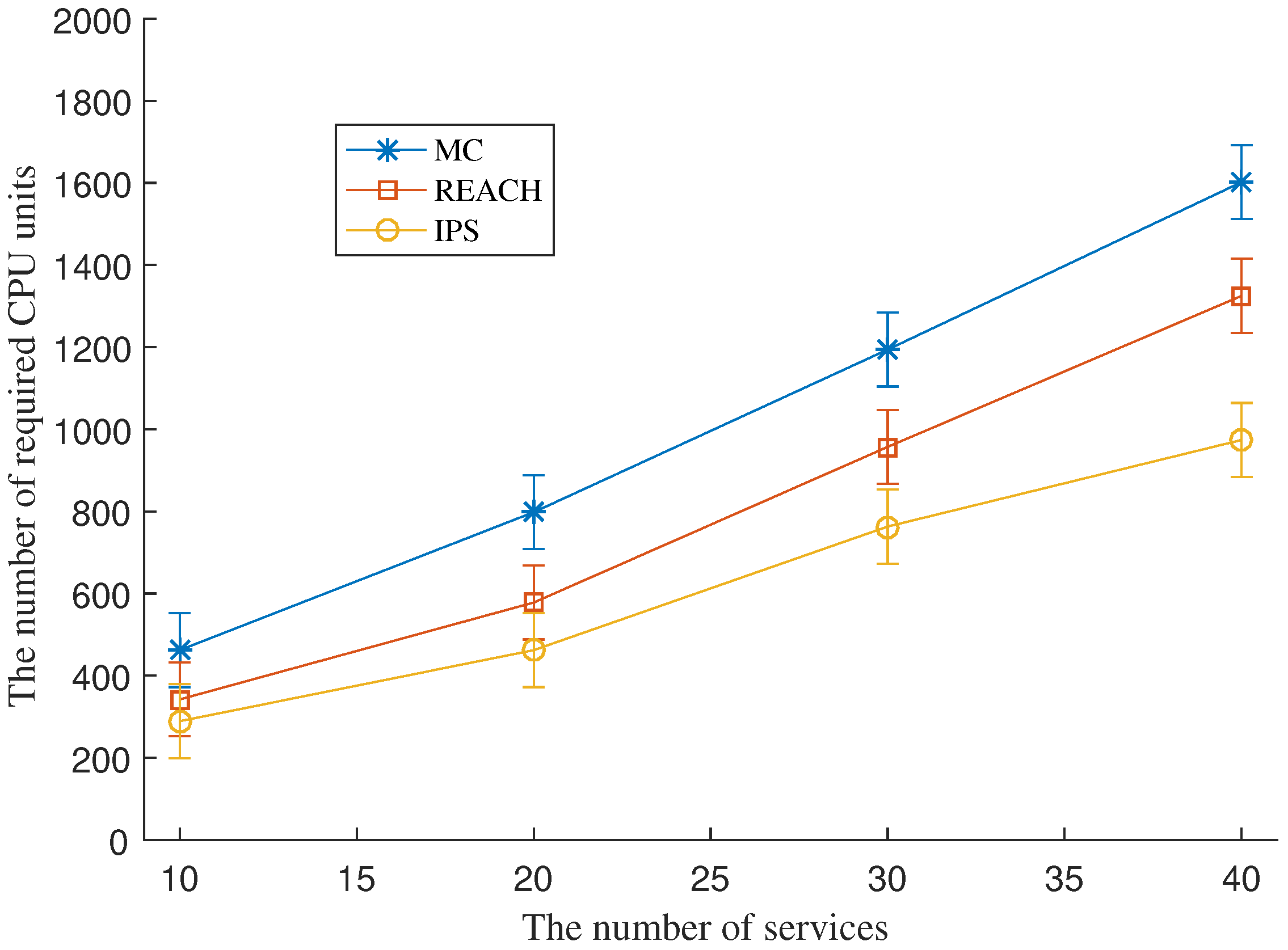
7.3. CPU Unit Cost for Redundancy Deployment
We set a fixed service availability requirement to 0.99 and vary the number of SFC requests. The schemes select VNFs for redundancy deployment until the service availability requirement of SFCs is satisfied.
Figure 3 shows the number of CPU units required by each scheme under a various number of SFC requests. The figure shows that IPS consumes fewer CPU resources for the same number of SFC requests, compared to REACH and MC. The higher the number of SFC requests the better the cost efficiency IPS can achieve compared to REACH. MC is the most expensive mechanism among the three.
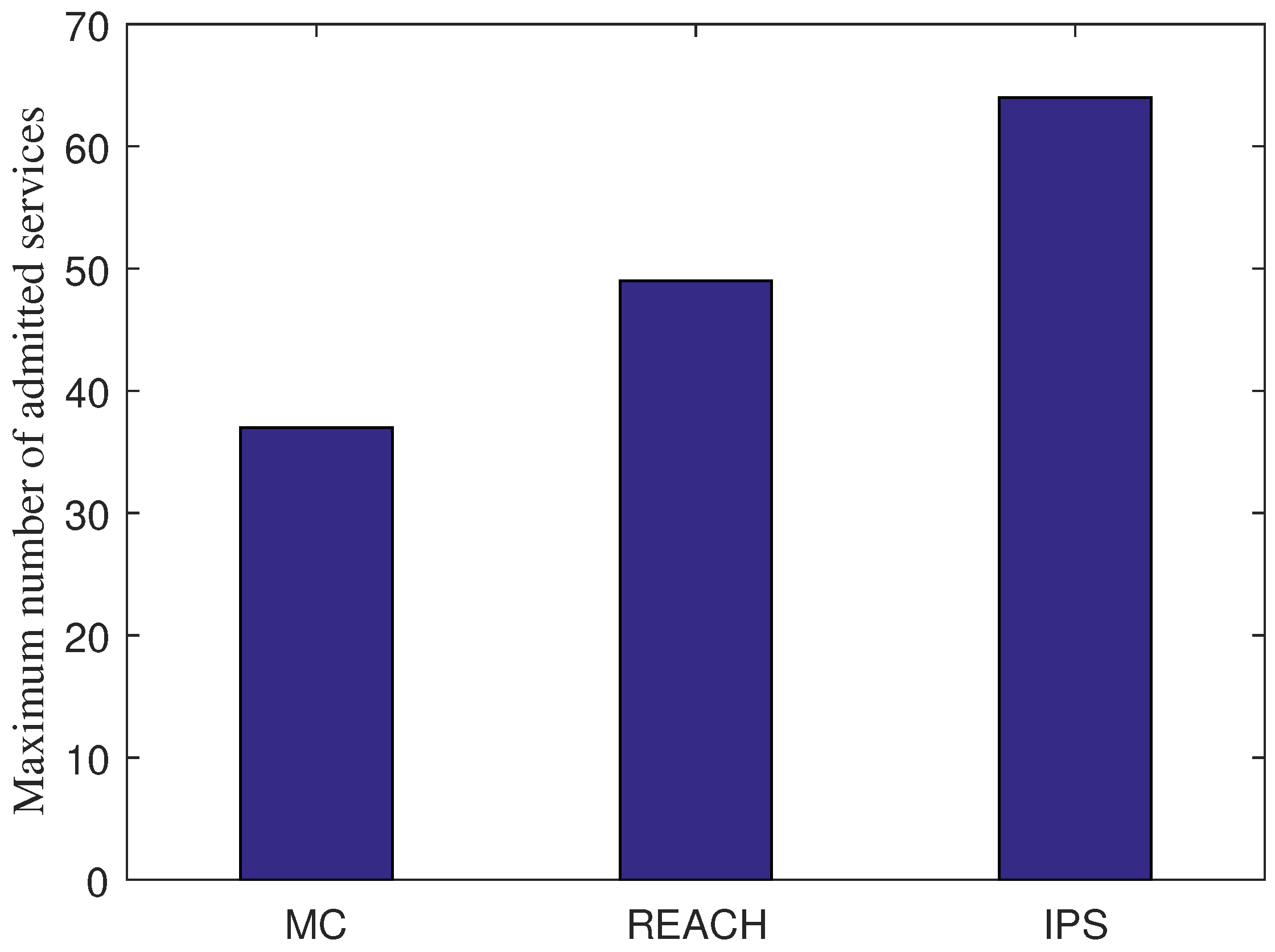
7.4. Scalability Test
We perform a scalability test by adding more SFC requests until there is not enough resource for more SFC deployment. Through the scalability test, we find the maximum number of admitted services that each scheme can afford, as shown in
Figure 4. It is obvious that IPS achieves the better scalability by allowing more services can be admitted (i.e., 64 services) compared to 49 services in the case of REACH and 37 services in the case of MC. This figure implicates that by saving the redundancy deployment resource, the service providers can deploy more services within a limited amount of resource. As a result, IPS can help increase the revenue of the service providers.
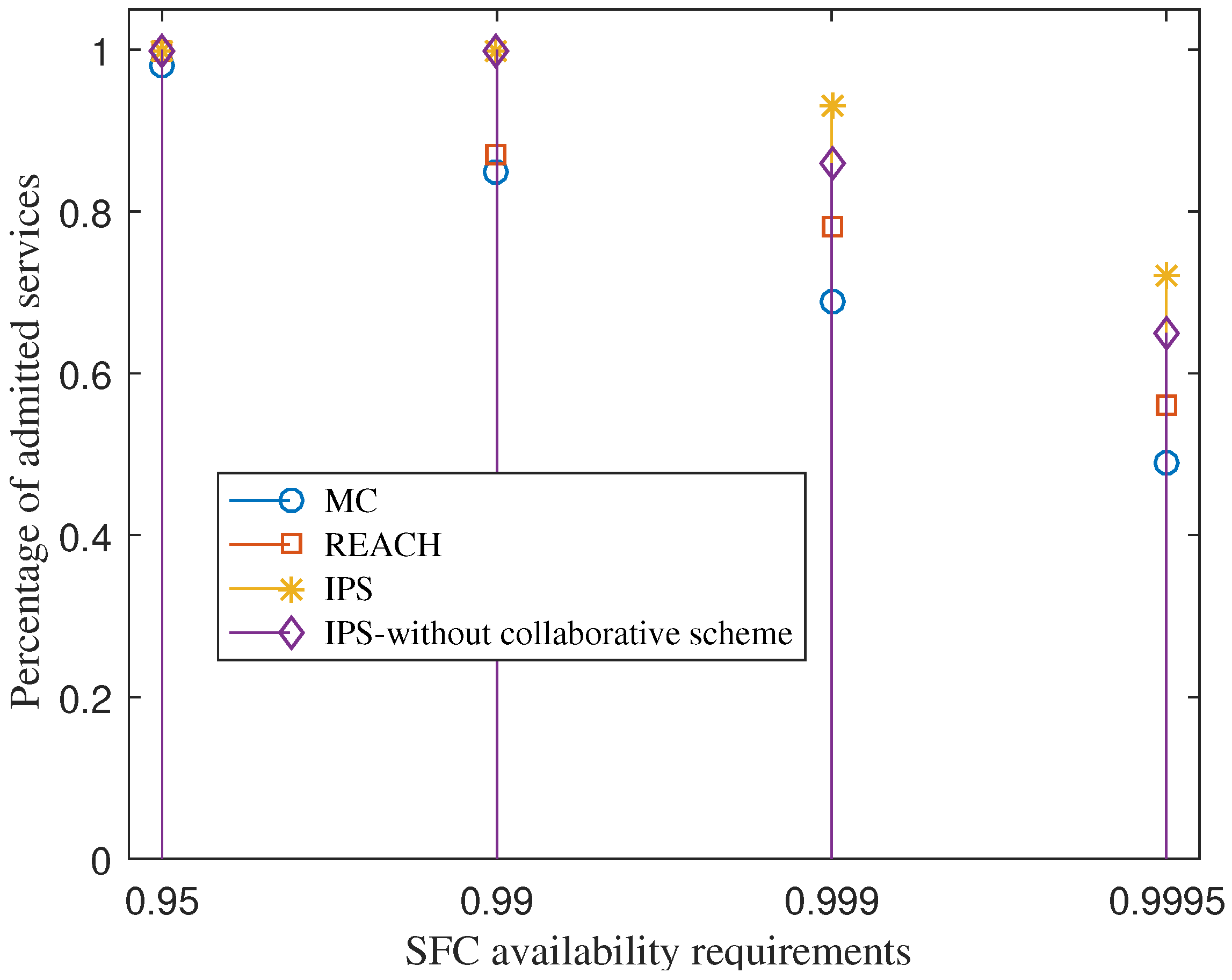
7.5. Under Service Availability Requirement Variation
We now deploy totally 60 SFC requests and vary the availability requirement of services. This experiment is to study the performance behavior of each scheme in the case of fixed network resources under various service requirements.
Figure 5 shows the percentage of admitted services when the service availability requirements increase. The figure indicates that within a limited resource, the higher the service availability requirement the lower the number of SFC requests can be admitted. The reason is that more redundancy deployment is required for each service. By considering the availability improvement potential of VNFs and its redundancy cost seriously, IPS can enable a greater number of services that are admitted, compared to REACH and MC. This helps increase the revenue of service providers.
The figure also shows that IPS with the collaboration scheme achieves a greater percentage of admitted services than IPS without collaborative under the SFC availability requirements of 0.999 and 0.9995. Both of the schemes achieve the same percentage of admitted services under the SFC availability requirements of 0.95 and 0.99. The reason is that under the requirements of 0.95 and 0.99, IPS can admit all the SFC requests without requiring offloading VNF redundancies. The fog layers have enough resources for the SFC deployments. At the higher requirements of 0.999 and 0.9995, each SFC requires a greater number of VNF redundancy deployments, so resources at the fog layer maybe not enough for all services. By using the collaborative scheme, IPS can increase the percentage of admitted services, compared to IPS without the collaborative scheme.
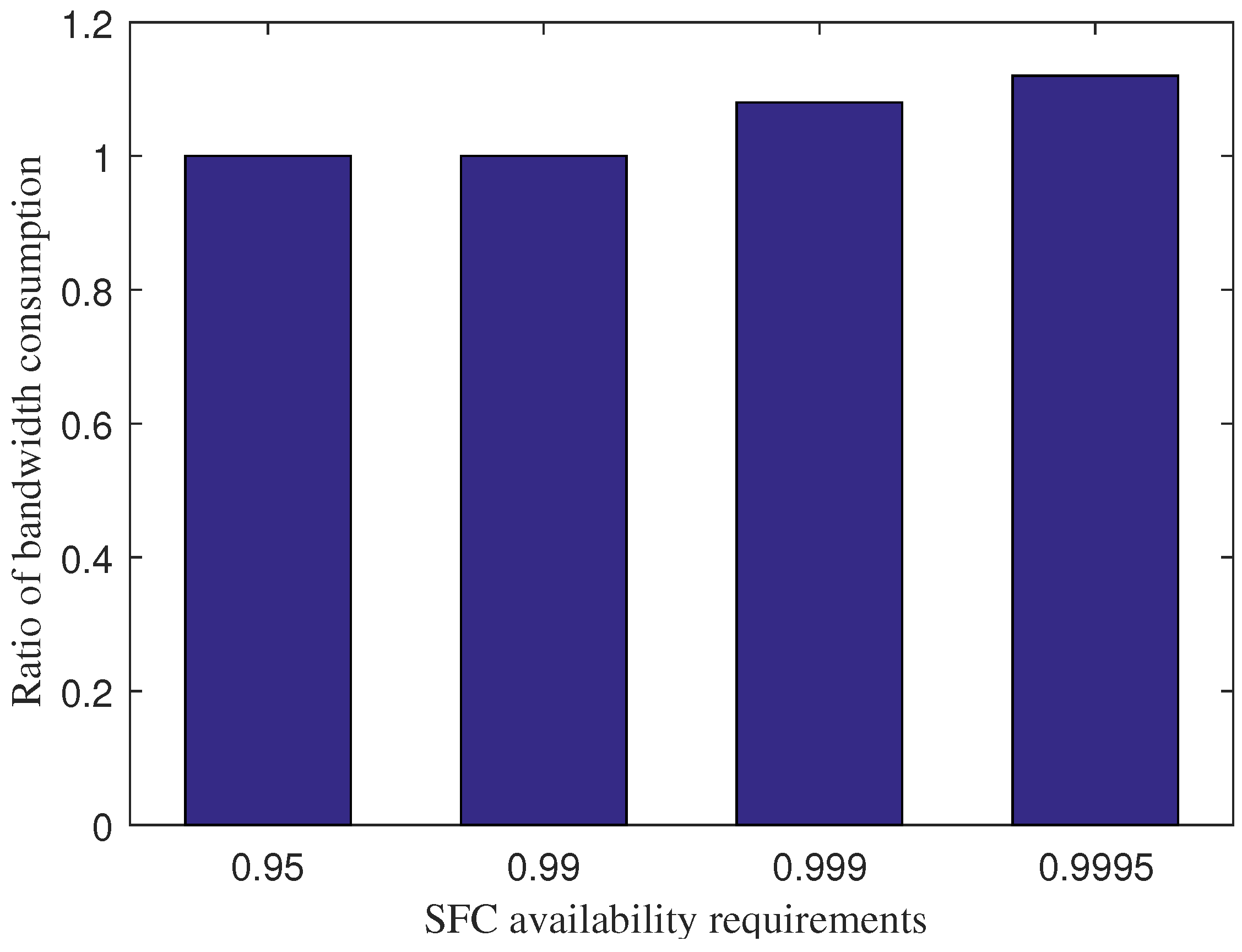
The trade-off of IPS for increasing the percentage of admitted services is the higher bandwidth consumption for information exchange during the VNF redundancy deployment, as shown in
Figure 6. Under the requirements of 0.95 and 0.99, IPS and IPS without the collaborative scheme consume the same amount of bandwidth. However, the bandwidth consumption of IPS is higher than IPS with the collaborative scheme by 8 % and 12 % under the requirements of 0.999 and 0.9995, respectively. The reason is that IPS performs offloading several VNF redundancies for several primary VNFs at the fog layer to the core cloud at a longer distance. The trade-off is appropriate as the bandwidth consumption is relatively small during the VNF redundancy deployment and for the cases with a high availability requirement only.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}