Matching SDN and Legacy Networking Hardware for Energy Efficiency and Bounded Delay †

 ,
,  ,
,  and
and 
Abstract
1. Introduction
2. Related Work
3. SDN Application Design
3.1. Background and Problem Statement
- The ideal algorithm considers that the switch individually decides for each packet which port will be used to forward it, based on the instantaneous occupation of the ports, a packet-level operation. SDN does not allow forwarding each packet individually, since its data plane works at the flow level, applying the same actions to the packets of a flow once a matching rule is found in its flow table (i.e., forwarding the packets to the same port). In addition to the action prescribed by the flow rule, the counters associated with the port are updated.
- The current queue occupation of each port is used to determine the forwarding port. Unfortunately, this state variable is not usually provided by SDN switches (e.g., it is not considered in OpenFlow).
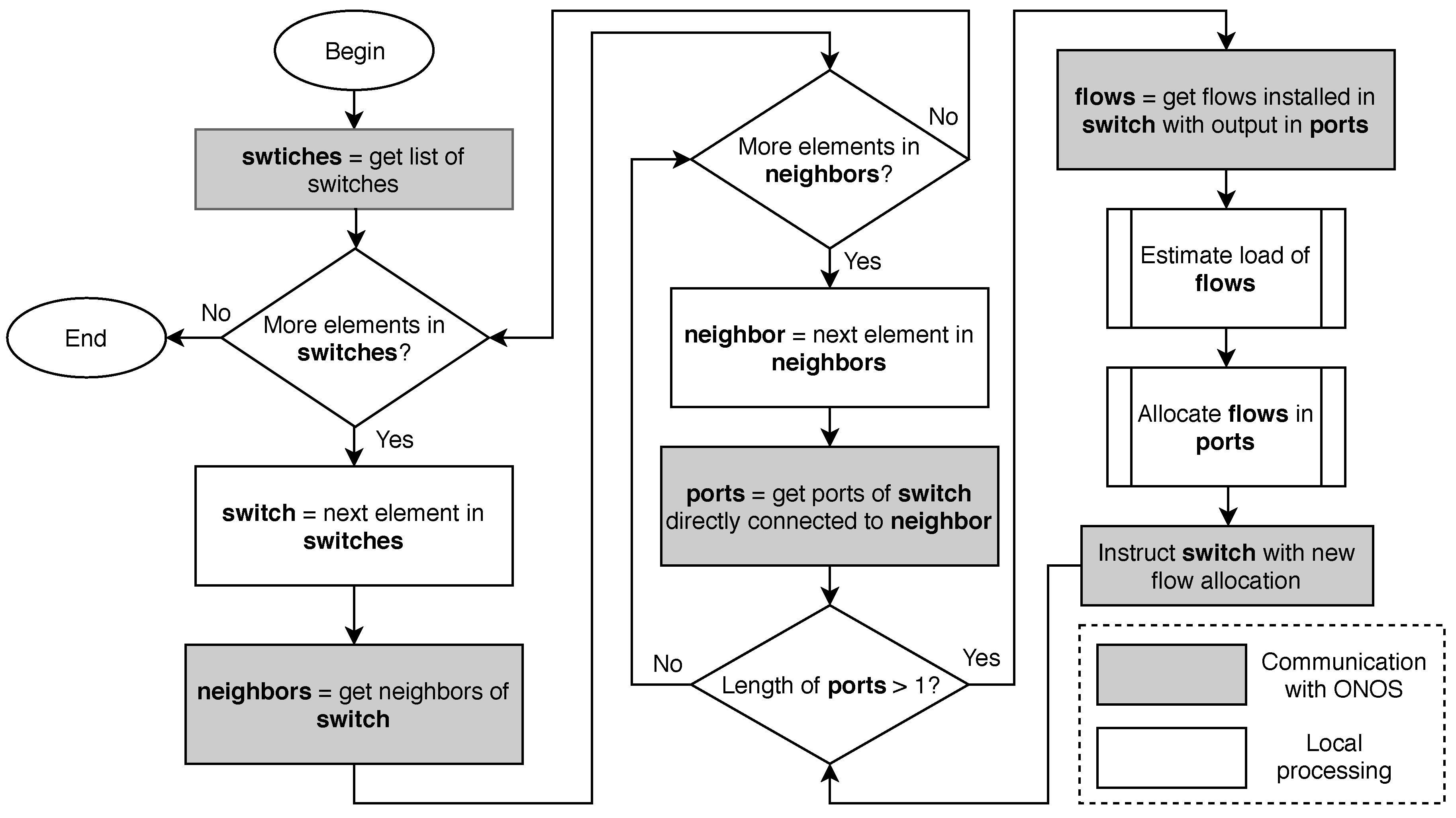
3.2. Designing the SDN Application
- Retrieve the list of switches.
- For each switch, identify the neighbors of the switch (i.e., the switches that a link to it).
- For each neighbor, retrieve the ports in the switch that are connected with the neighbor.
- If there is more than one port (i.e., there is a bundle between the two switches), retrieve the flows installed in the switch that forward packets to a port of this bundle.
- Predict the rate of each flow; that is to say, the amount of traffic that the flow will transmit in the next interval.
- Compute a new allocation for these flows to the ports of the bundle in a way that energy consumption is minimized.
- Instruct the switch to modify the flow rules that have changed their allocation.
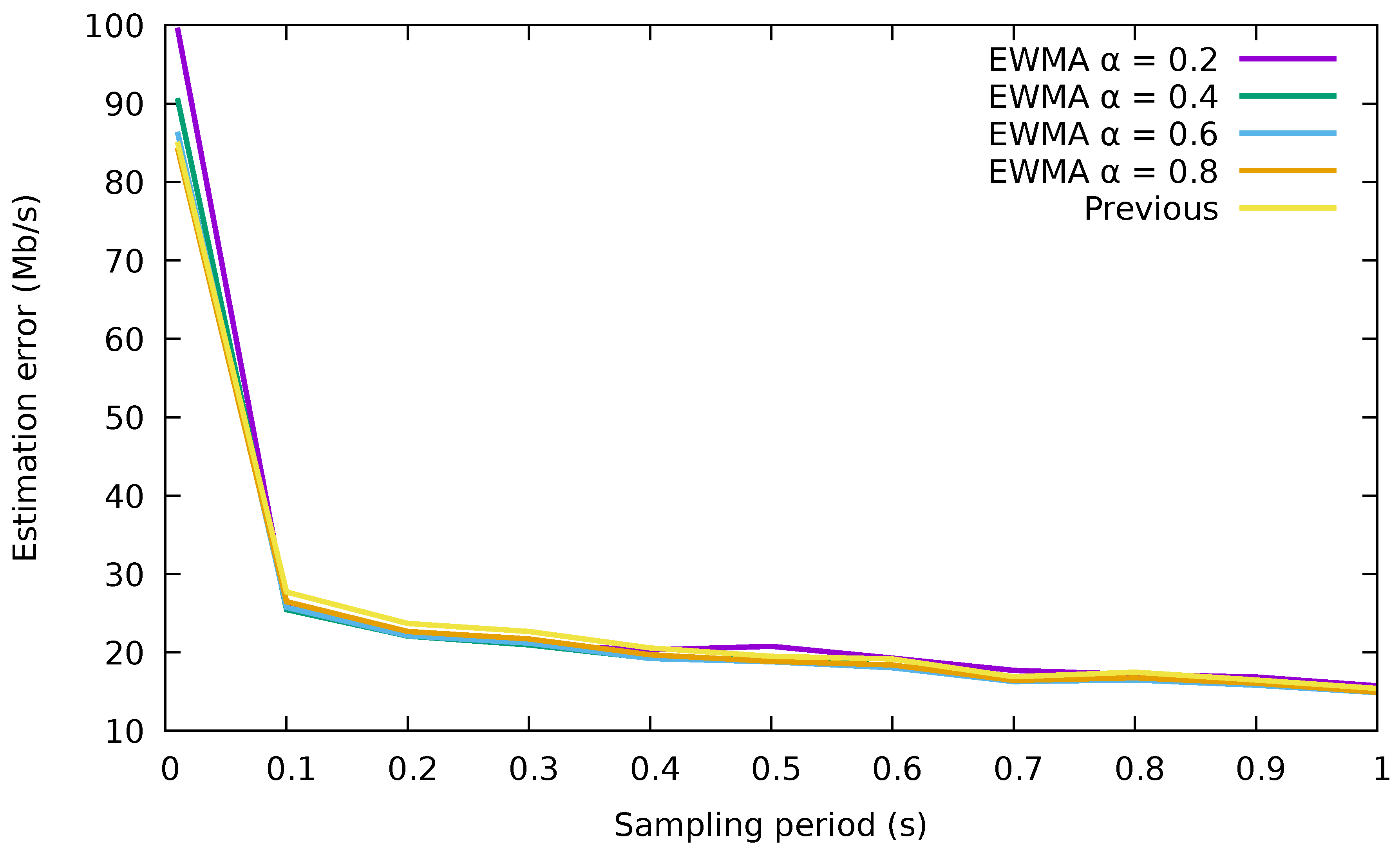
3.3. Flow Rate Prediction
- The measured value in the previous interval.
- An exponentially-weighted moving average (EWMA) with the measured rates of the flow in past intervals. The estimated rate is:
3.4. Flow Allocation Algorithm
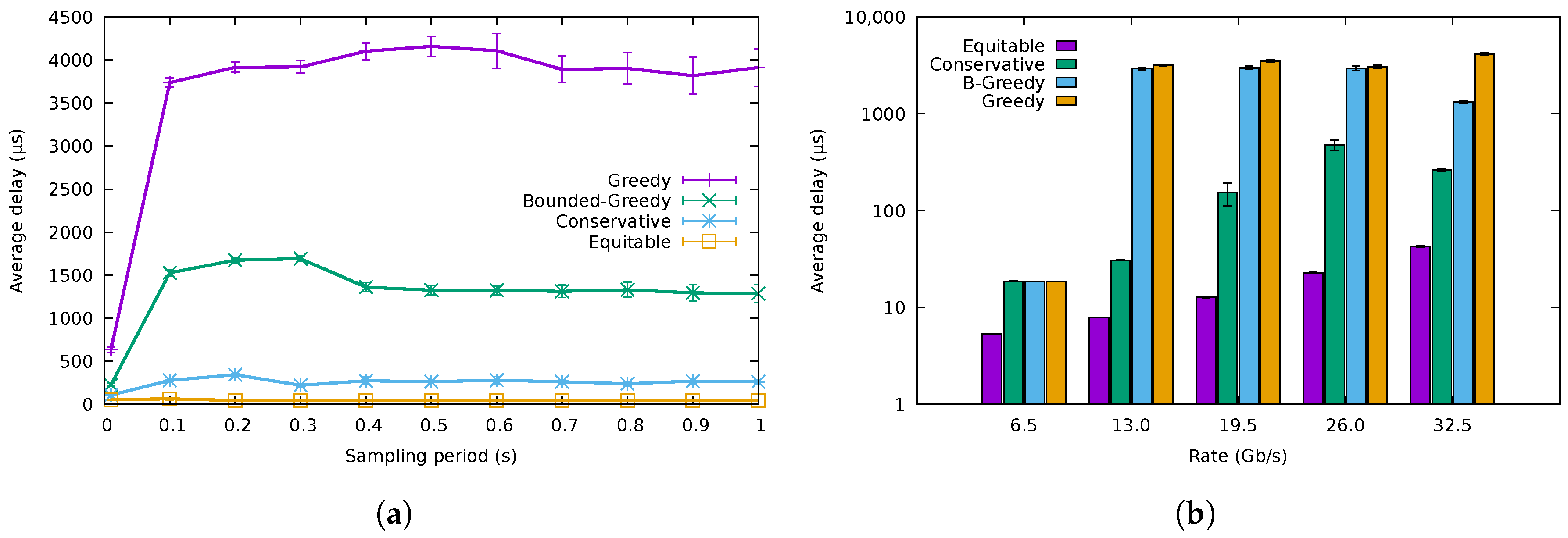
3.4.1. Greedy Algorithm
3.4.2. Bounded Greedy Algorithm
3.4.3. Conservative Algorithm
4. Energy-Efficient Algorithms with Bounded Delay
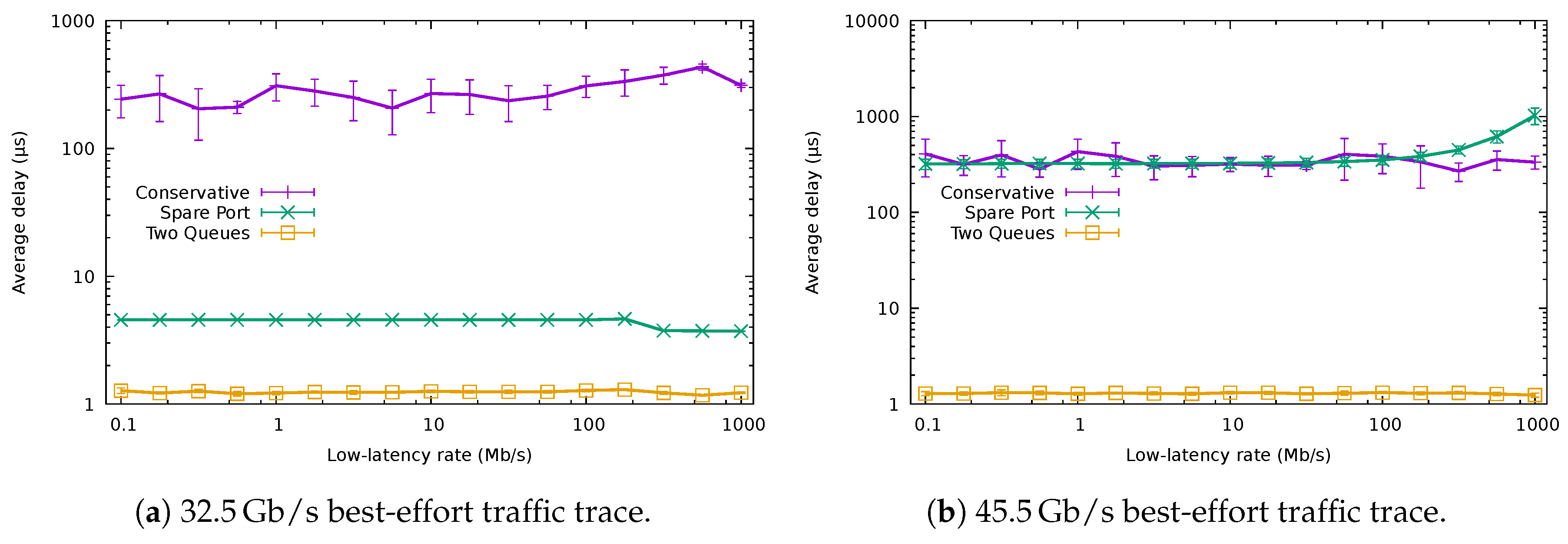
4.1. Spare Port Algorithm
- In the first phase, the energy-saving algorithm is directly applied without modifications, but only to the best-effort flows.
- In the second phase, the remaining low-latency flows are assigned to the least occupied port among those in the bundle.
- If the traffic demand is so high such that all the ports in the bundle must be dedicated to best-effort flows, low-latency traffic will not be forwarded through a single port. As a result, both low-latency and best-effort traffic will be treated in the same way, without meeting the needs of premium traffic.
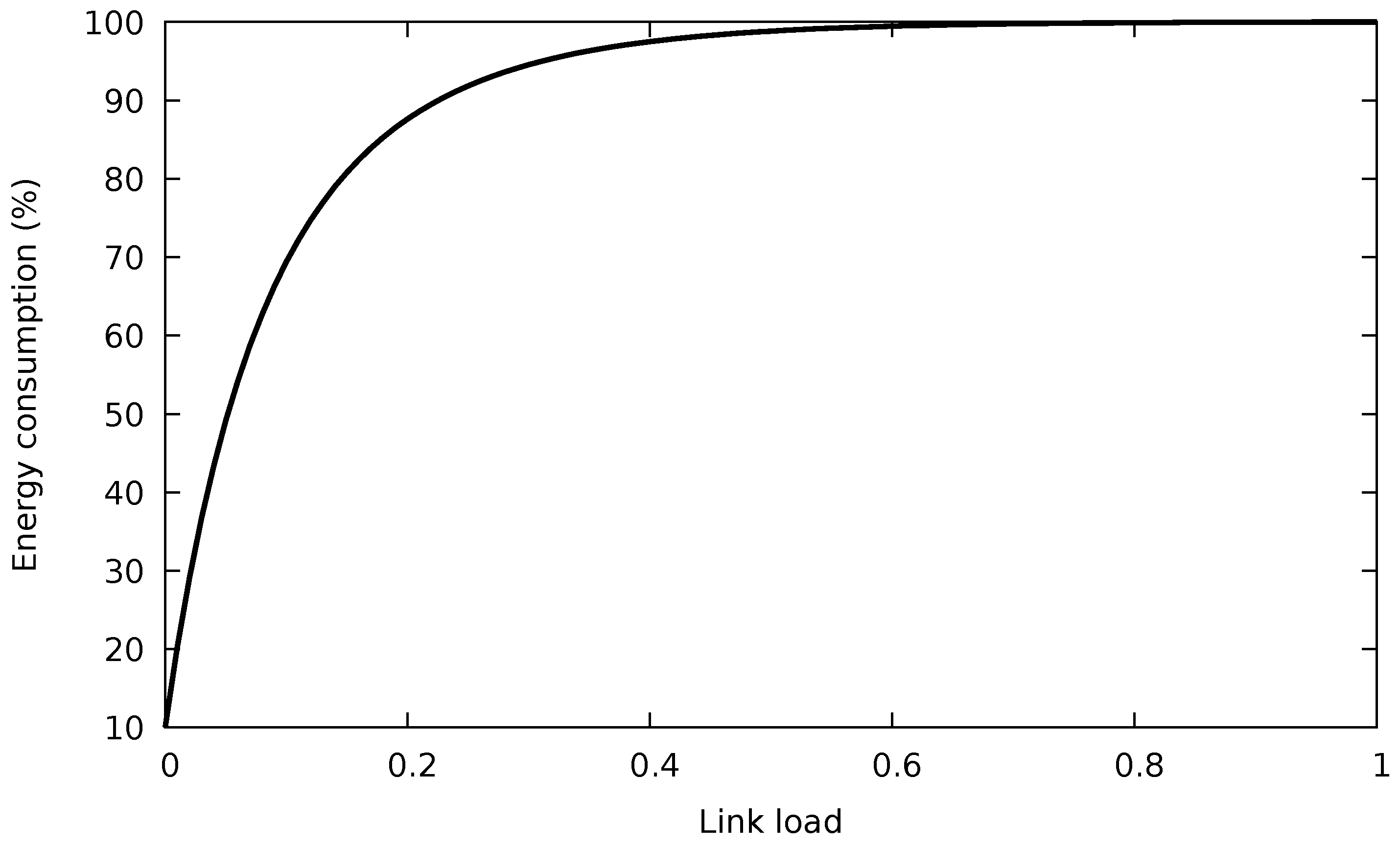
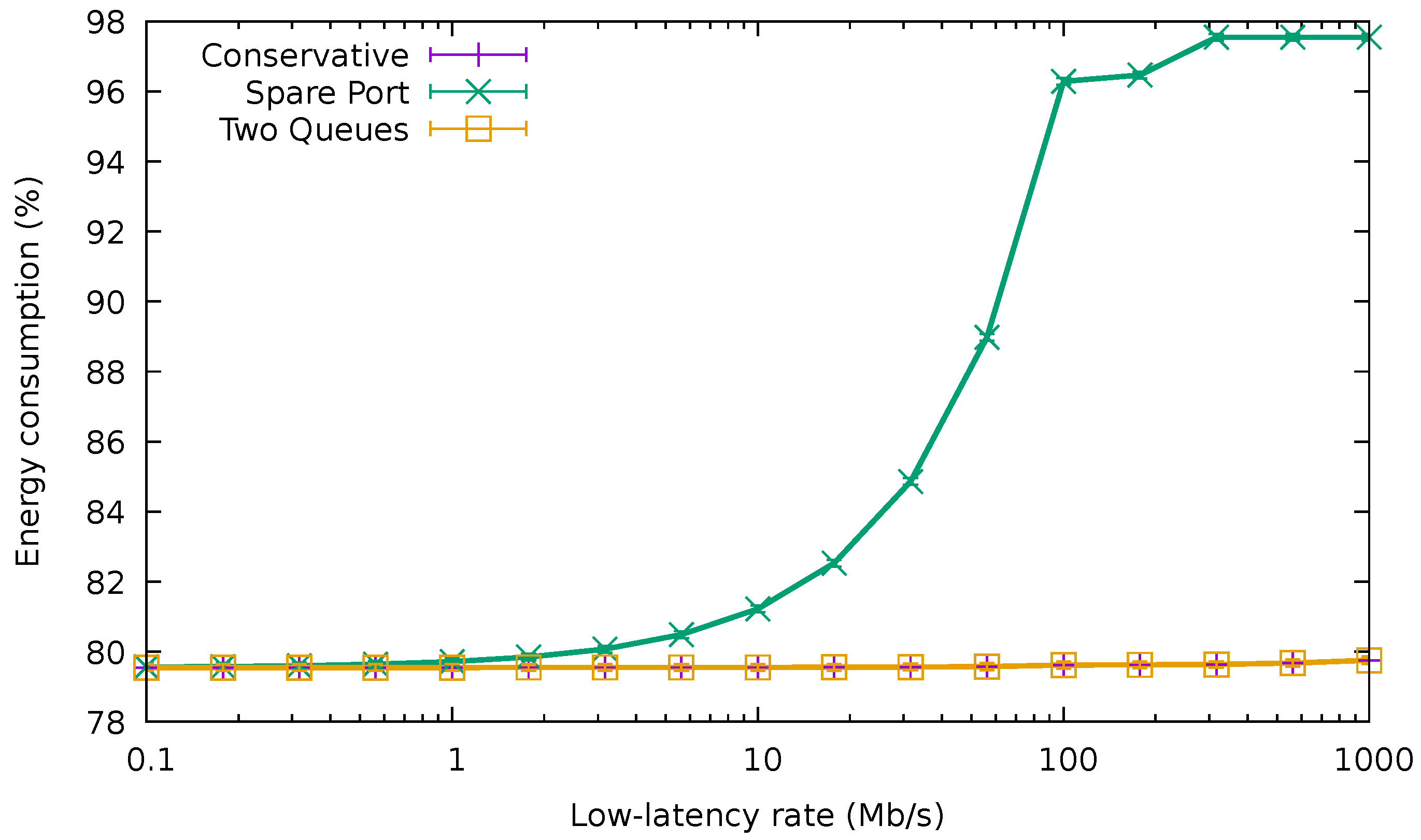
- If the amount of low-latency traffic is significant, the energy consumption of the spare port can drastically increase because of the energy profile of an EEE link, which rises very quickly with the port occupation (cf. Figure 1).
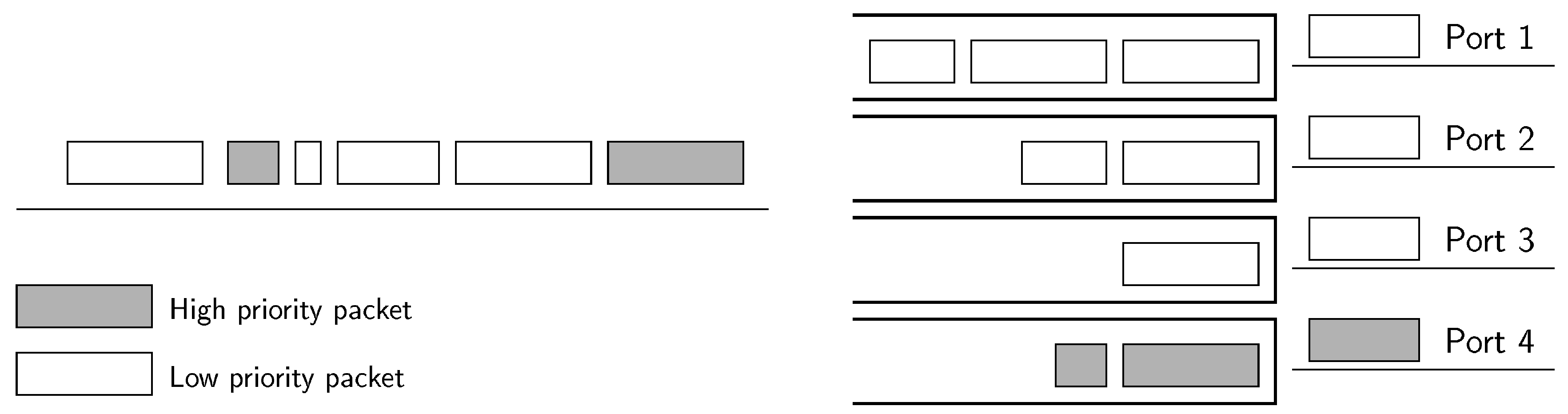
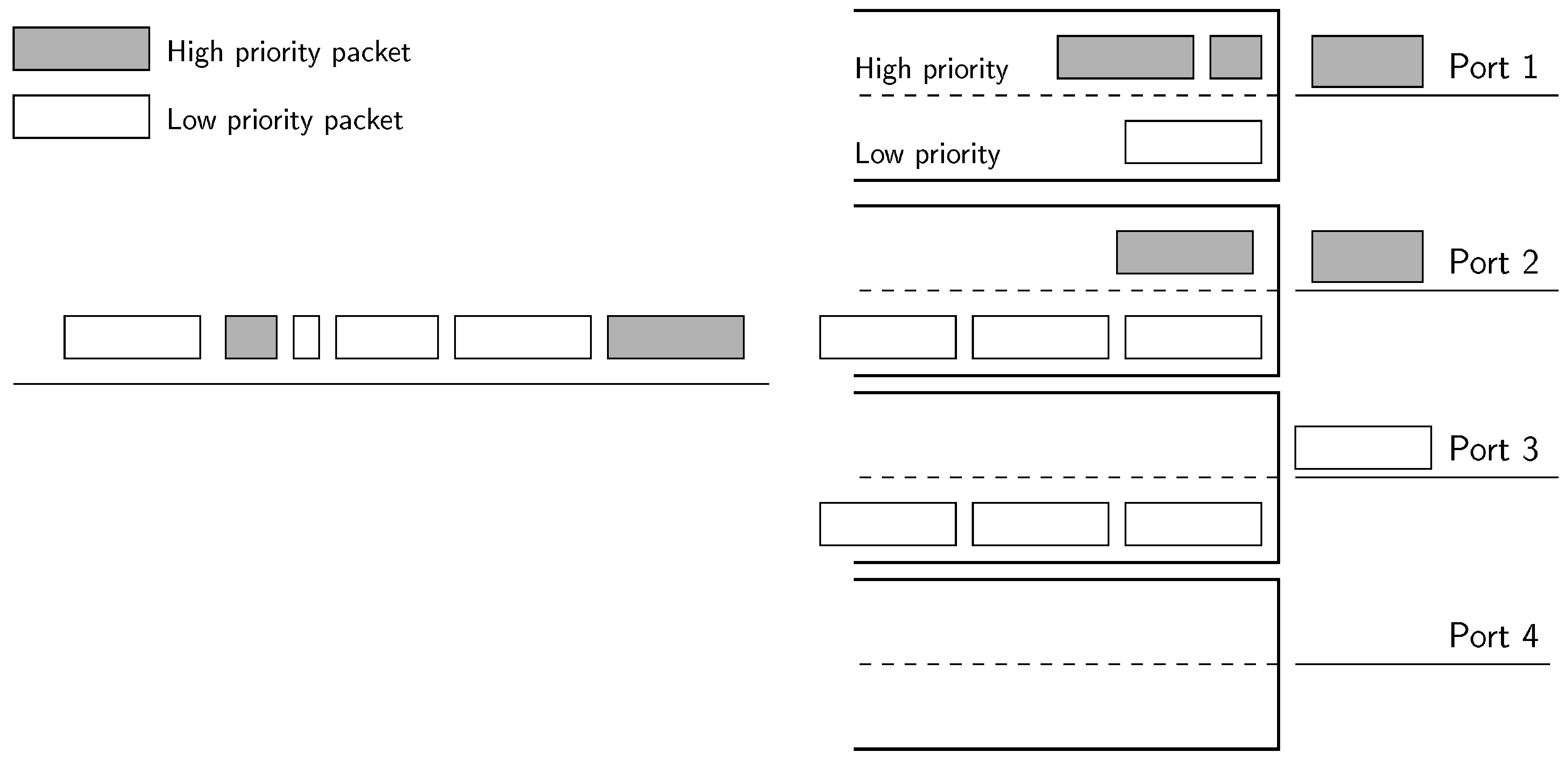
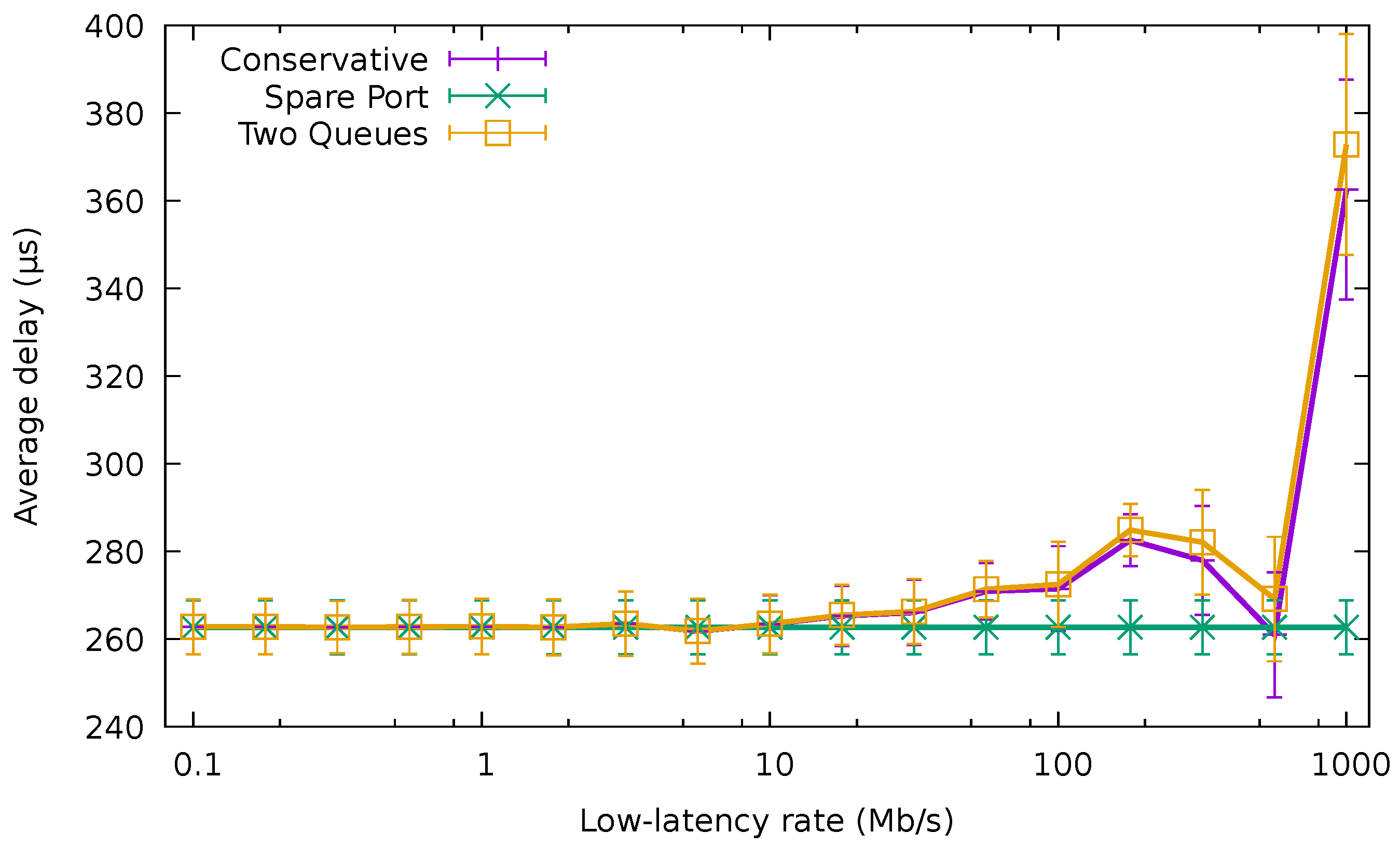
4.2. Two Queues Algorithm
- The first phase consists of directly applying the unmodified energy-efficient algorithm described in Section 3 to the whole set of flows, both including low-latency and best-effort, treated equally. The whole set of flows is allocated in a few ports.
- The second phase sets the queue inside the assigned port for every flow. Low-latency flows are assigned to the high-priority queue of the ports, whilst best-effort flows are assigned to the low-priority queue.
5. Results
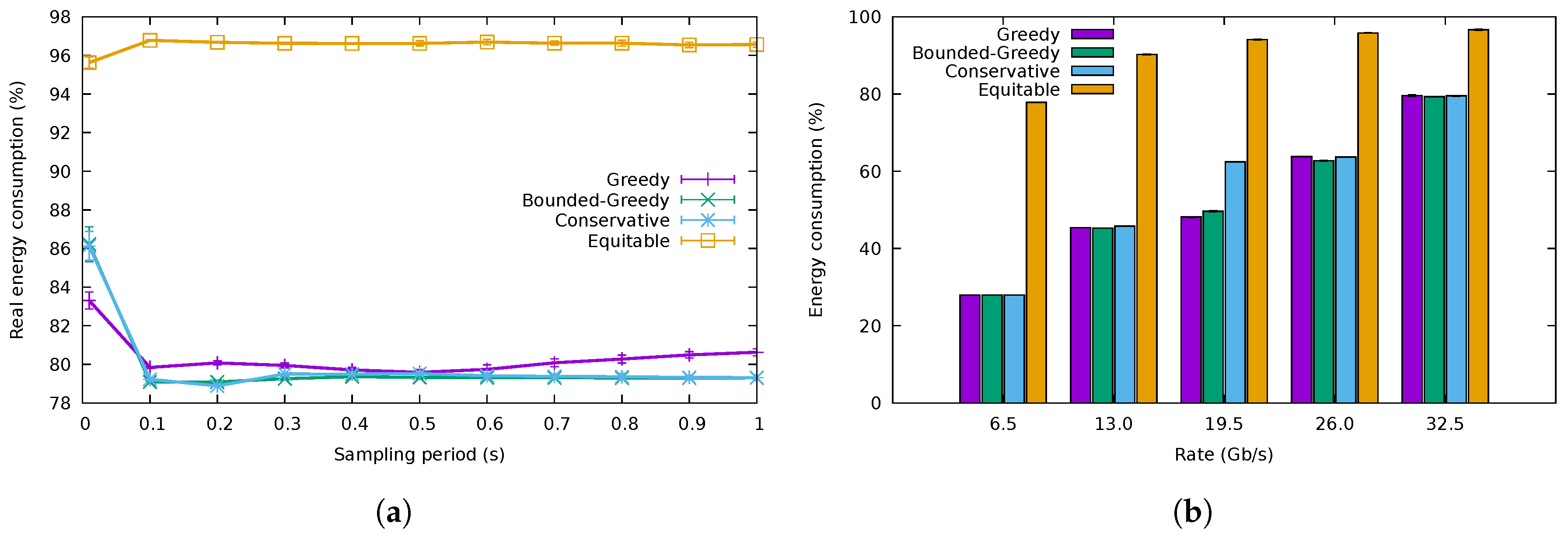
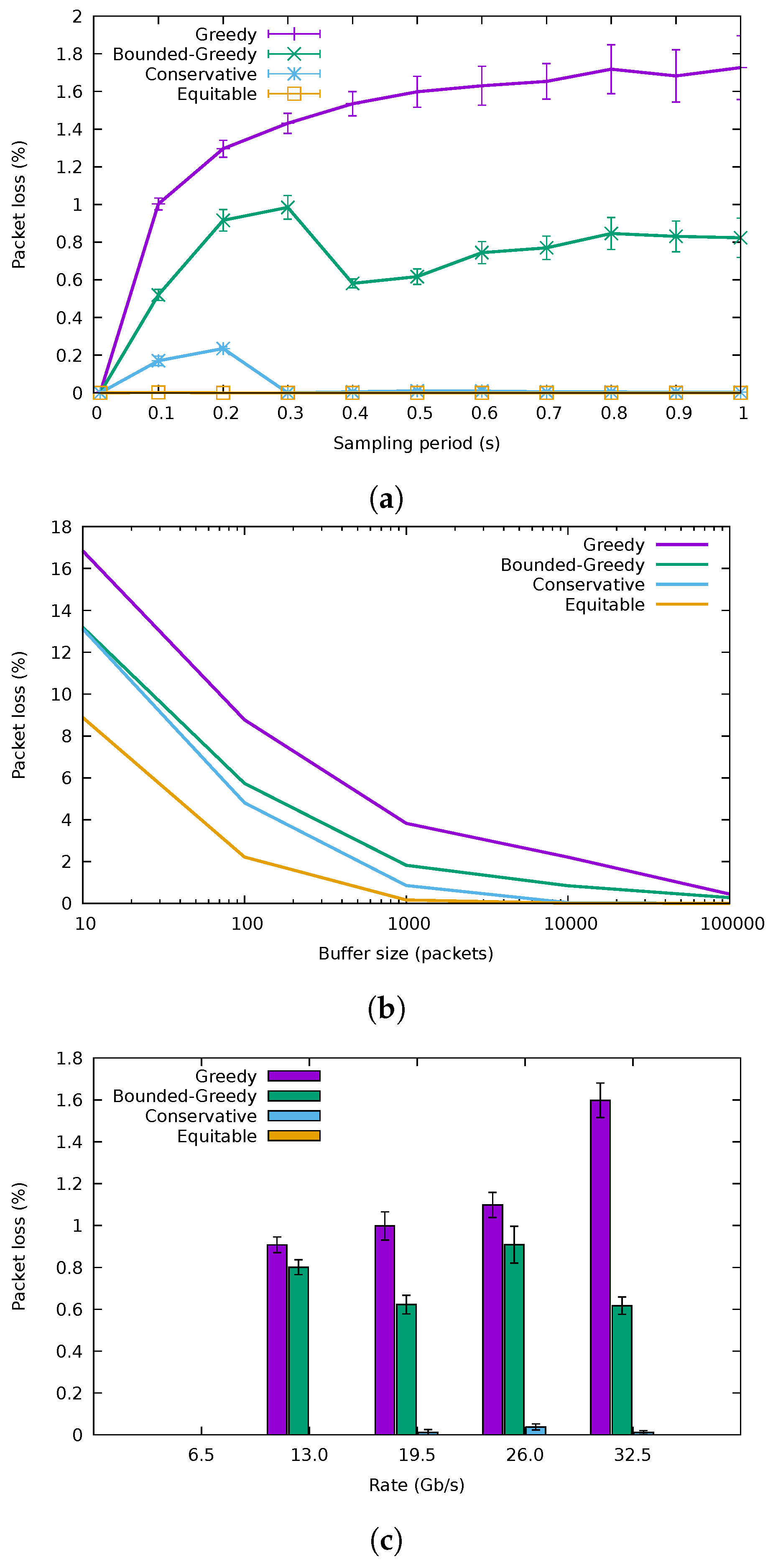
5.1. Flow Allocation Algorithms
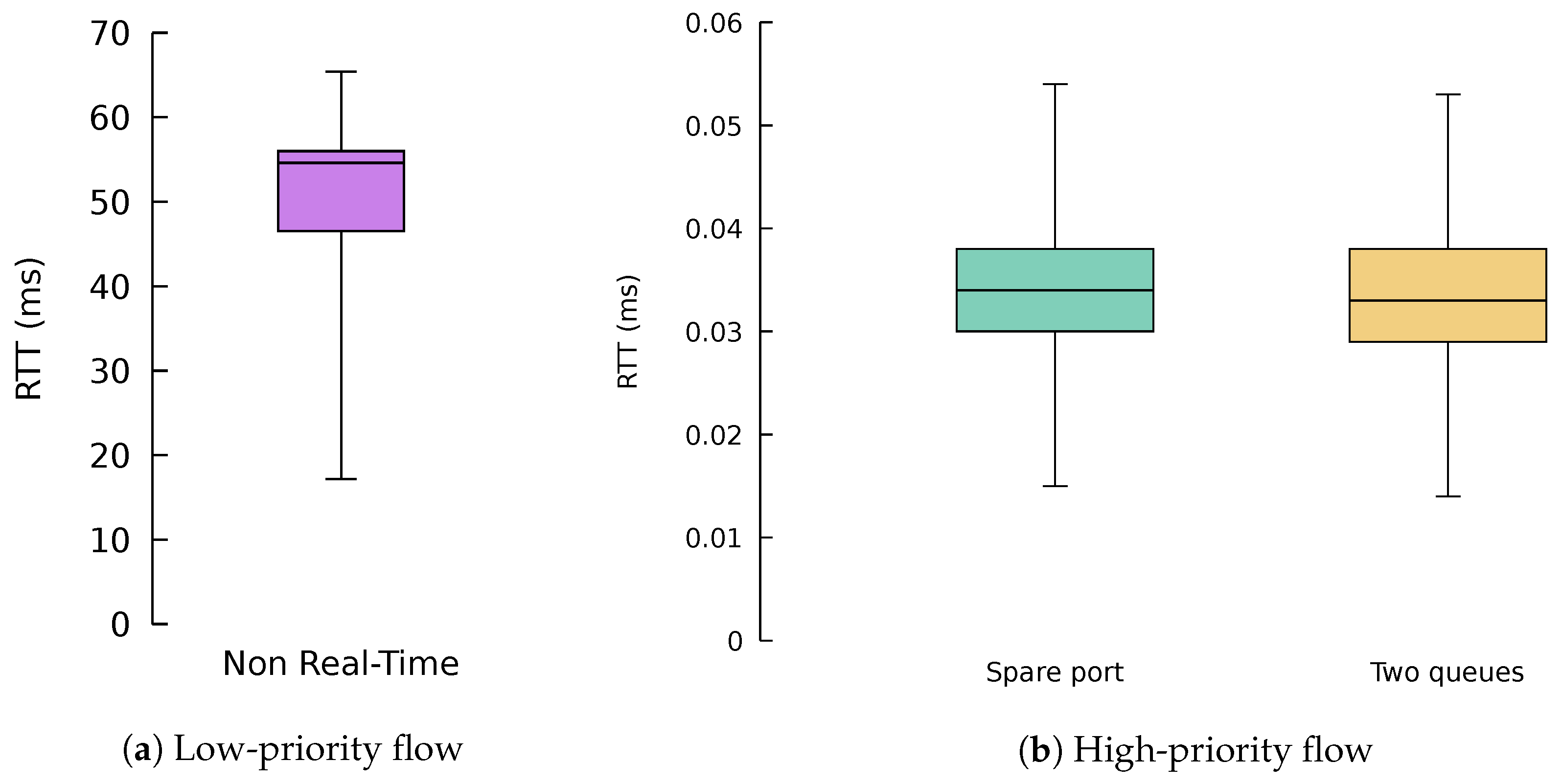
5.2. QoS-Aware Algorithms
5.3. ONOS Application Results
5.4. Discussion
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Heller, B.; Seetharaman, S.; Mahadevan, P.; Yiakoumis, Y.; Sharma, P.; Banerjee, S.; McKeown, N. Elastictree: Saving energy in data center networks. NSDI 2010, 10, 249–264. [Google Scholar]
- The 5G Infrastructure Public Private Partnership KPIs. Available online: https://5g-ppp.eu/kpis/ (accessed on 10 November 2018).
- Chiaraviglio, L.; Mellia, M.; Neri, F. Minimizing ISP Network Energy Cost: Formulation and Solutions. IEEE/ACM Trans. Netw. 2012, 20, 463–476. [Google Scholar] [CrossRef]
- Jung, D.; Kim, R.; Lim, H. Power-saving strategy for balancing energy and delay performance in WLANs. Comput. Commun. 2014, 50, 3–9. [Google Scholar] [CrossRef]
- Kim, Y.M.; Lee, E.J.; Park, H.S.; Choi, J.K.; Park, H.S. Ant colony based self-adaptive energy saving routing for energy efficient Internet. Comput. Netw. 2012, 56, 2343–2354. [Google Scholar] [CrossRef]
- Rodríguez Pérez, M.; Fernández Veiga, M.; Herrería Alonso, S.; Hmila, M.; López García, C. Optimum Traffic Allocation in Bundled Energy-Efficient Ethernet Links. IEEE Syste. J. 2018, 12, 593–603. [Google Scholar] [CrossRef]
- Agiwal, M.; Roy, A.; Saxena, N. Next generation 5G wireless networks: A comprehensive survey. IEEE Commun. Surv. Tutor. 2016, 18, 1617–1655. [Google Scholar] [CrossRef]
- IEEE Standard for Information Technology–Local and Metropolitan Area Networks–Specific Requirements–Part 3: CSMA/CD Access Method and Physical Layer Specifications Amendment 5: Media Access Control Parameters, Physical Layers, and Management Parameters for Energy-Efficient Ethernet; IEEE Std 802.3az-2010 (Amendment to IEEE Std 802.3-2008); IEEE: Piscataway, NJ, USA, 2010; pp. 1–302. [CrossRef]
- Christensen, K.; Reviriego, P.; Nordman, B.; Bennett, M.; Mostowfi, M.; Maestro, J.A. IEEE 802.3az: The road to Energy Efficient Ethernet. IEEE Commun. Mag. 2010, 48, 50–56. [Google Scholar] [CrossRef]
- Fondo-Ferreiro, P.; Rodríguez-Pérez, M.; Fernández-Veiga, M. Implementing Energy Saving Algorithms for Ethernet Link Aggregates with ONOS. In Proceedings of the 2018 Fifth International Conference on Software Defined Systems (SDS), Barcelona, Spain, 23–26 April 2018; pp. 118–125. [Google Scholar] [CrossRef]
- Fondo Ferreiro, P.; Rodríguez Pérez, M.; Fernández Veiga, M. QoS-aware Energy-Efficient Algorithms for Ethernet Link Aggregates in Software-Defined Networks. In Proceedings of the 9th Symposium on Green Networking and Computing (SGNC 2018), Split-Supetar, Croatia, 13–15 September 2018. In press. [Google Scholar]
- Tuysuz, M.F.; Ankarali, Z.K.; Gözüpek, D. A Survey on Energy Efficiency in Software Defined Networks. Comput. Netw. 2017, 113, 188–204. [Google Scholar] [CrossRef]
- Rodrigues, B.B.; Riekstin, A.C.; Januário, G.C.; Nascimento, V.T.; Carvalho, T.C.M.B.; Meirosu, C. GreenSDN: Bringing energy efficiency to an SDN emulation environment. In Proceedings of the 2015 IFIP/IEEE International Symposium Integrated Network Managment, Ottawa, ON, Canada, 11–15 May 2015; pp. 948–953. [Google Scholar] [CrossRef]
- Tadesse, S.S.; Casetti, C.; Chiasserini, C.F.; Landi, G. Energy-efficient traffic allocation in SDN-based backhaul networks: Theory and implementation. In Proceedings of the 2017 14th IEEE Annual, IEEE, Consumer Communications & Networking Conference (CCNC), Las Vegas, NV, USA, 8–11 January 2017; pp. 209–215. [Google Scholar]
- Huong, T.; Schlosser, D.; Nam, P.; Jarschel, M.; Thanh, N.; Pries, R. ECODANE—Reducing energy consumption in data center networks based on traffic engineering. In Proceedings of the 11th Würzburg Workshop on IP: Joint ITG and Euro-NF Workshop Visions of Future Generation Networks (EuroView2011), Wurzburg, Germany, 1–3 August 2011. [Google Scholar]
- Yang, Y.; Xu, M.; Li, Q. Towards fast rerouting-based energy efficient routing. Comput. Netw. 2014, 70, 1–15. [Google Scholar] [CrossRef]
- Cianfrani, A.; Eramo, V.; Listanti, M.; Polverini, M.; Vasilakos, A.V. An OSPF-integrated routing strategy for QoS-aware energy saving in IP backbone networks. IEEE Trans. Netw. Serv. Manag. 2012, 9, 254–267. [Google Scholar] [CrossRef]
- Lorincz, J.; Mujaric, E.; Begusic, D. Energy consumption analysis of real metro-optical network. In Proceedings of the 2015 38th International Convention on Information and Communication Technology, Electronics and Microelectronics (MIPRO), Opatija, Croatia, 25–29 May 2015; pp. 550–555. [Google Scholar] [CrossRef]
- Chiaraviglio, L.; Ciullo, D.; Mellia, M.; Meo, M. Modeling sleep mode gains in energy-aware networks. Comput. Netw. 2013, 57, 3051–3066. [Google Scholar] [CrossRef]
- Garroppo, R.; Nencioni, G.; Tavanti, L.; Scutella, M.G. Does Traffic Consolidation Always Lead to Network Energy Savings? IEEE Commun. Lett. 2013, 17, 1852–1855. [Google Scholar] [CrossRef]
- Lu, T.; Zhu, J. Genetic Algorithm for Energy-Efficient QoS Multicast Routing. IEEE Commun. Lett. 2013, 17, 31–34. [Google Scholar] [CrossRef]
- Galán-Jiménez, J.; Gazo-Cervero, A. Using bio-inspired algorithms for energy levels assessment in energy efficient wired communication networks. J. Netw. Comput. Appl. 2014, 37, 171–185. [Google Scholar] [CrossRef]
- Huin, N. Energy Efficient Software Defined Networks. Ph.D. Thesis, Université Côte d’Azur, Nice, France, 2017. [Google Scholar]
- Herrería-Alonso, S.; Rodríguez-Pérez, M.; Fernández-Veiga, M.; López-García, C. How efficient is energy-efficient Ethernet? In Proceedings of the 2011 3rd International Congress on IEEE, Ultra Modern Telecommunications and Control Systems and Workshops (ICUMT), Budapest, Hungary, 5–7 October 2011; pp. 1–7. [Google Scholar]
- Herrería Alonso, S.; Rodríguez Pérez, M.; Fernández Veiga, M.; López García, C. A GI/G/1 Model for 10 Gb/s Energy Efficient Ethernet Links. IEEE Trans. Commun. 2012, 60, 3386–3395. [Google Scholar] [CrossRef]
- Johnson, D.S. Near-Optimal Bin Packing Algorithms. Ph.D. Thesis, Massachusetts Institute of Technology, Cambridge, MA, USA, 1973. [Google Scholar]
- ONF. OpenFlow® Switch Specification, Version 1.5.1. Available online: http://sdn.ifmo.ru/Members/shkrebets/sdn_4115/sdn_theory/openflow-switch-v1.5.1.pdf/view (accessed on 10 November 2018).
- Fondo-Ferreiro, P. SDN Bundle Network Simulator. Available online: https://pfondo.github.io/sdn-bundle-simulator/ (accessed on 10 November 2018).
- The CAIDA UCSD Anonymized Internet Traces 2016. 6 April 2016 13:03:00 UTC. Available online: https://www.caida.org/data/passive/passive_2016_dataset.xml (accessed on 10 November 2018).
- Carpa, R.; de Assuncao, M.D.; Glück, O.; Lefèvre, L.; Mignot, J.C. Evaluating the Impact of SDN-Induced Frequent Route Changes on TCP Flows. In Proceedings of the 2017 13th International Conference on Network and Service Management (CNSM), Tokyo, Japan, 26–30 November 2017; pp. 1–9. [Google Scholar] [CrossRef]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm | Occupation (%) | |||||
|---|---|---|---|---|---|---|
| Port 1 | Port 2 | Port 3 | Port 4 | Port 5 | Average | |
| Greedy | 92.57 | 97.83 | 97.05 | 30.36 | 0.02 | 63.57 |
| Bounded-Greedy | 83.46 | 81.16 | 95.08 | 61.27 | 0.02 | 64.20 |
| Conservative | 84.17 | 83.60 | 80.78 | 79.76 | 0.02 | 65.67 |
| Equitable | 83.89 | 80.52 | 54.13 | 53.63 | 57.23 | 65.88 |
| Algorithm | Energy Consumption (%) | |||||
|---|---|---|---|---|---|---|
| Port 1 | Port 2 | Port 3 | Port 4 | Port 5 | Average | |
| Greedy | 99.89 | 99.99 | 99.99 | 92.36 | 10.24 | 80.49 |
| Bounded-Greedy | 99.80 | 99.90 | 99.98 | 99.38 | 10.24 | 81.86 |
| Conservative | 99.77 | 99.92 | 99.88 | 99.89 | 10.24 | 81.94 |
| Equitable | 99.78 | 99.90 | 99.04 | 98.97 | 99.27 | 99.39 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fondo-Ferreiro, P.; Rodríguez-Pérez, M.; Fernández-Veiga, M.; Herrería-Alonso, S. Matching SDN and Legacy Networking Hardware for Energy Efficiency and Bounded Delay. Sensors 2018, 18, 3915. https://doi.org/10.3390/s18113915
Fondo-Ferreiro P, Rodríguez-Pérez M, Fernández-Veiga M, Herrería-Alonso S. Matching SDN and Legacy Networking Hardware for Energy Efficiency and Bounded Delay. Sensors. 2018; 18(11):3915. https://doi.org/10.3390/s18113915
Chicago/Turabian StyleFondo-Ferreiro, Pablo , Miguel Rodríguez-Pérez, Manuel Fernández-Veiga, and Sergio Herrería-Alonso. 2018. "Matching SDN and Legacy Networking Hardware for Energy Efficiency and Bounded Delay" Sensors 18, no. 11: 3915. https://doi.org/10.3390/s18113915
APA StyleFondo-Ferreiro, P., Rodríguez-Pérez, M., Fernández-Veiga, M., & Herrería-Alonso, S. (2018). Matching SDN and Legacy Networking Hardware for Energy Efficiency and Bounded Delay. Sensors, 18(11), 3915. https://doi.org/10.3390/s18113915