An Artificial Neural Network for Movement Pattern Analysis to Estimate Blood Alcohol Content Level


Abstract
:1. Introduction
- Exploring and identifying gait properties and extracting some features from gait signals measured by smartphone sensors that could estimate BAC values in a typical drinking environment.
- Comparing different machine-learning techniques to predict BAC values.
- Demonstrating the feasibility of smartphone sensors measurements in estimating BAC value.
2. Background: Methods to Measure Alcohol Consumption
3. Data Collection
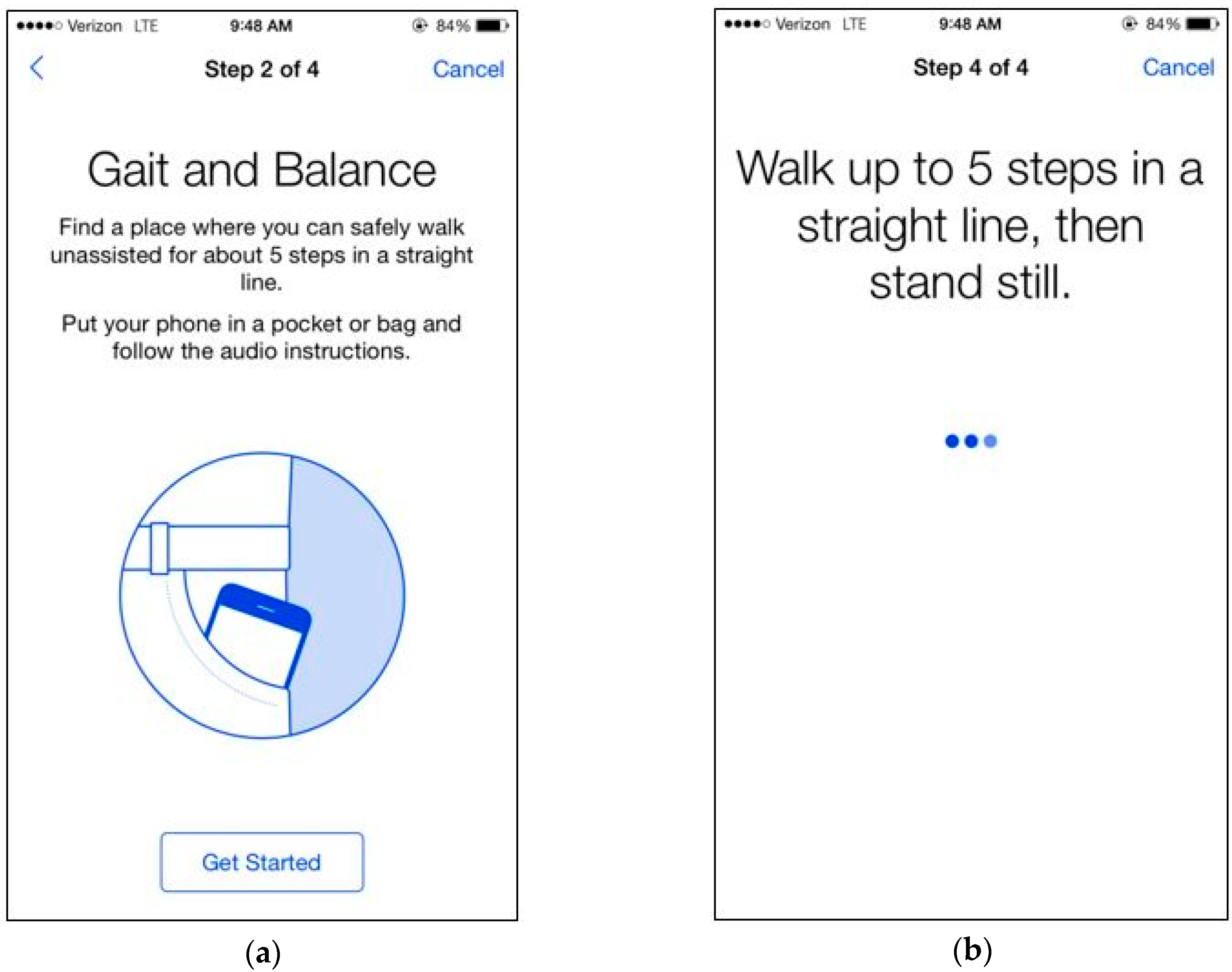
3.1. Smartphone Application (“DrinkTRAC”) for Data Collection
3.2. Participants
3.3. Smartphone Application Design
3.4. Estimated Blood Alcohol Concentration
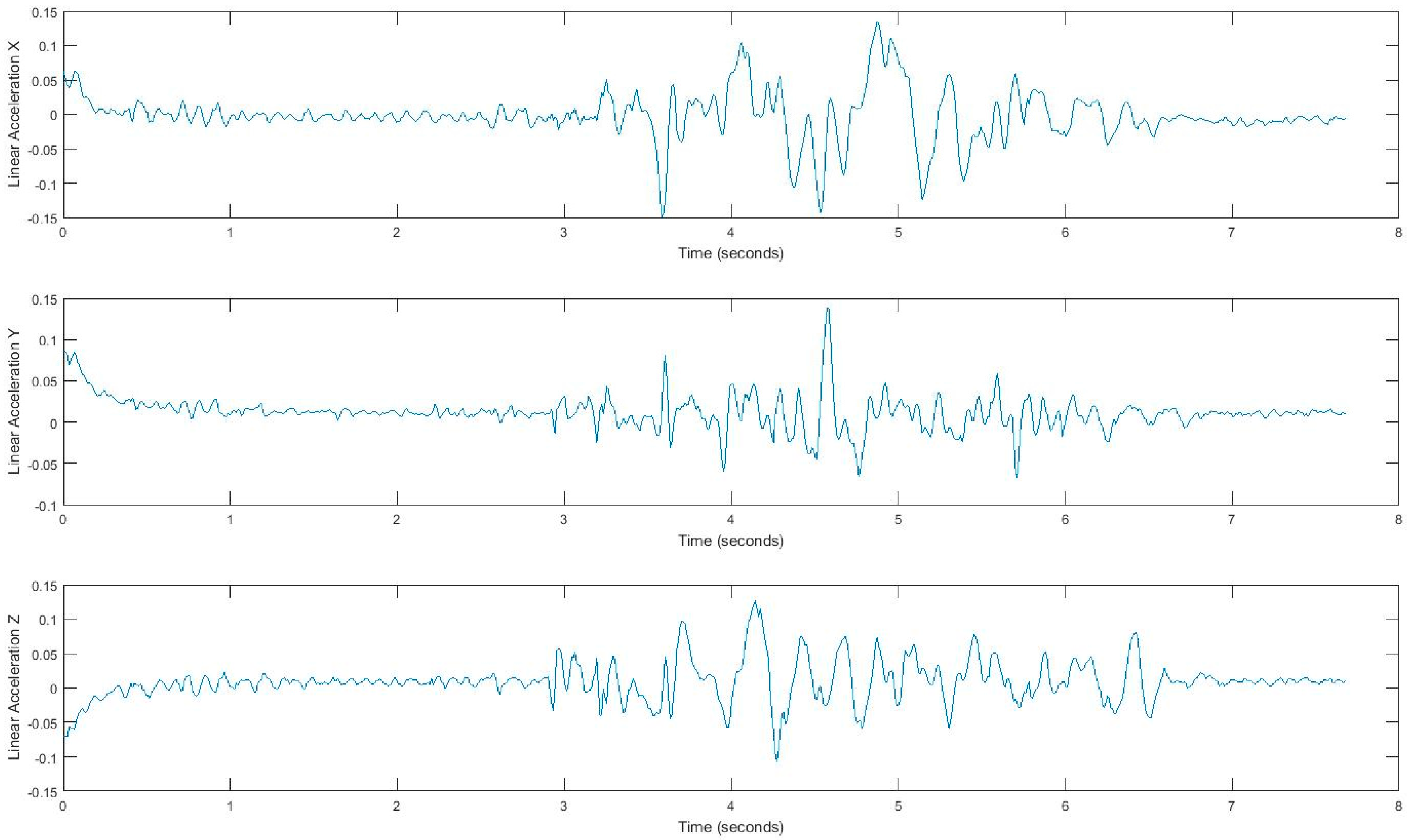
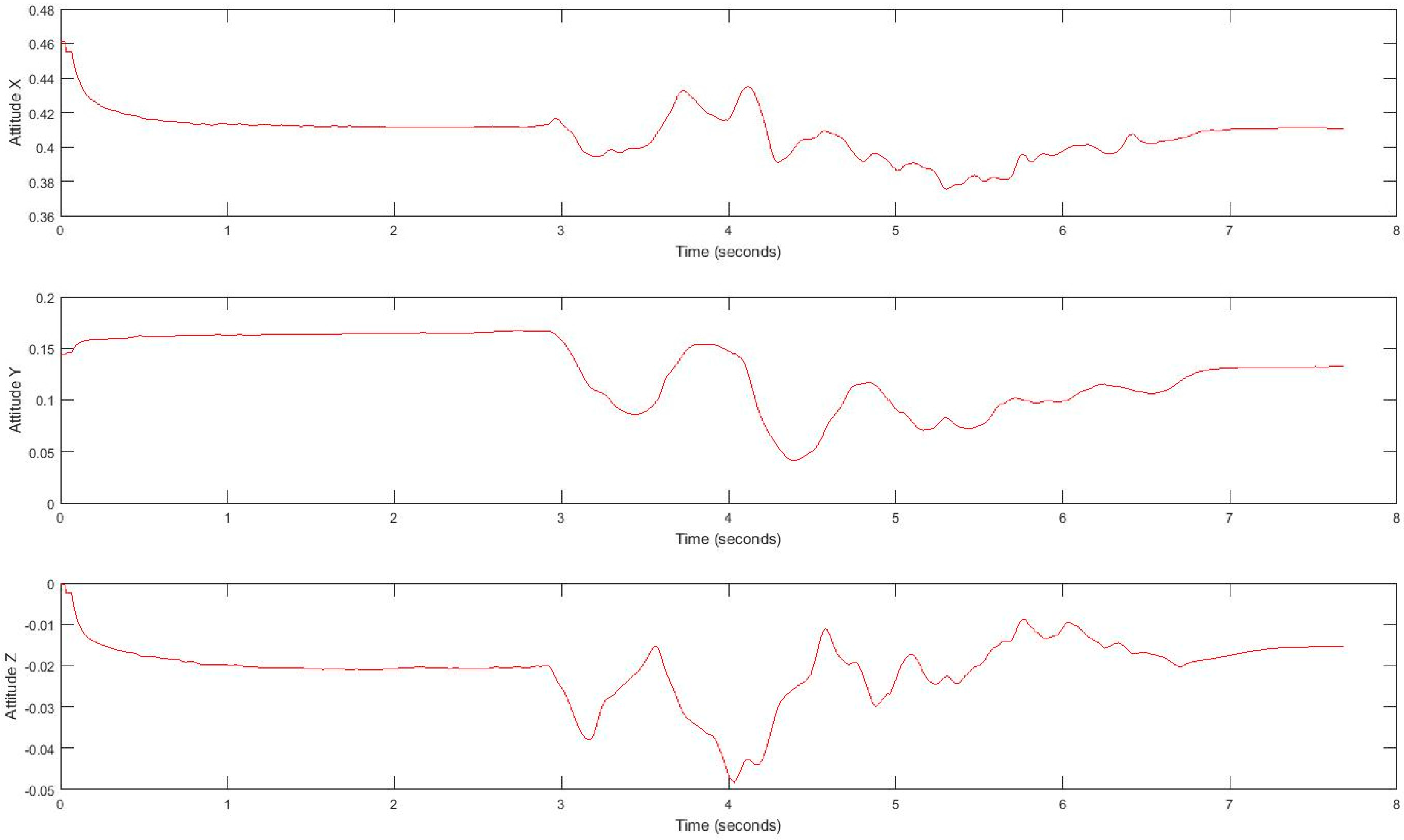
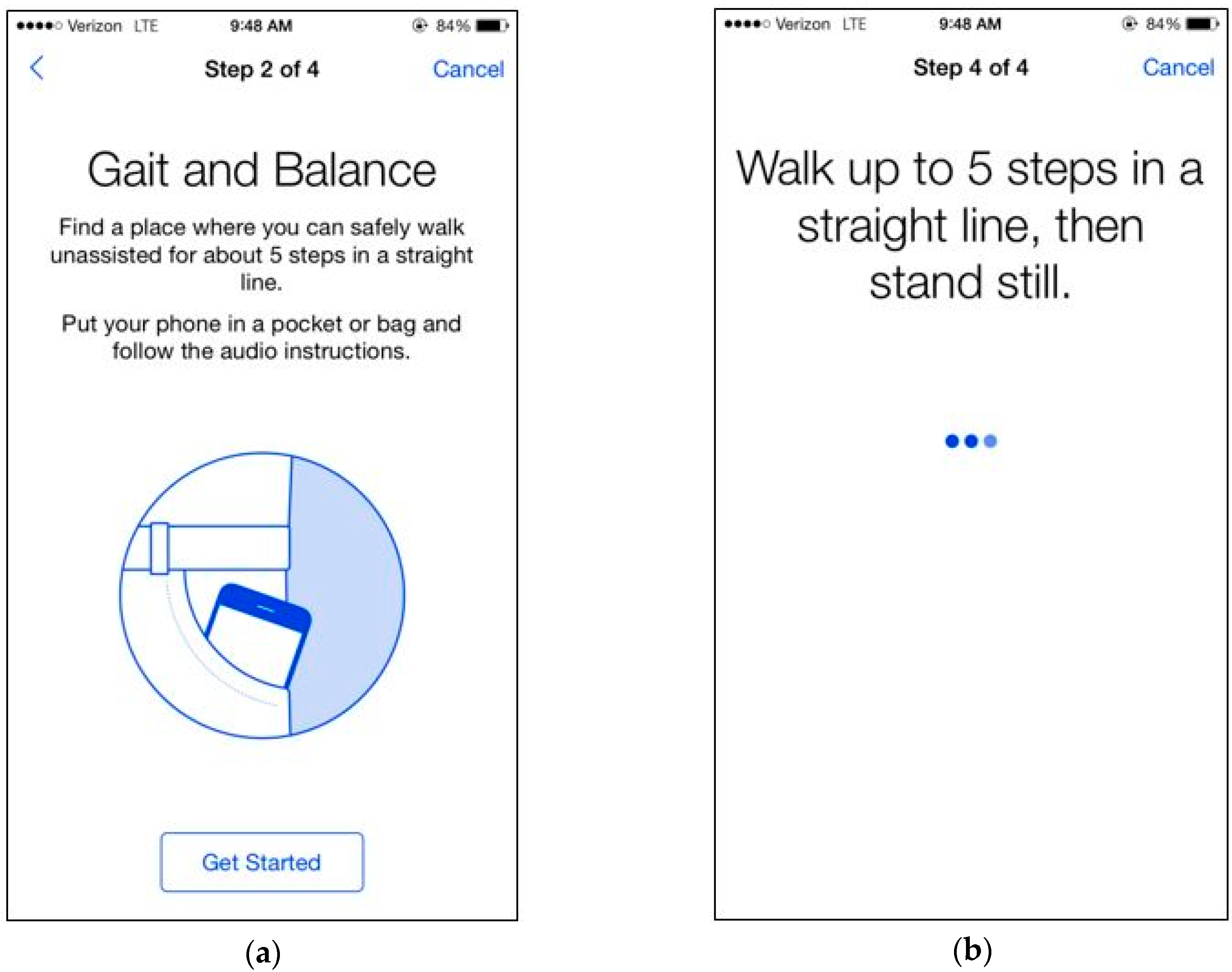
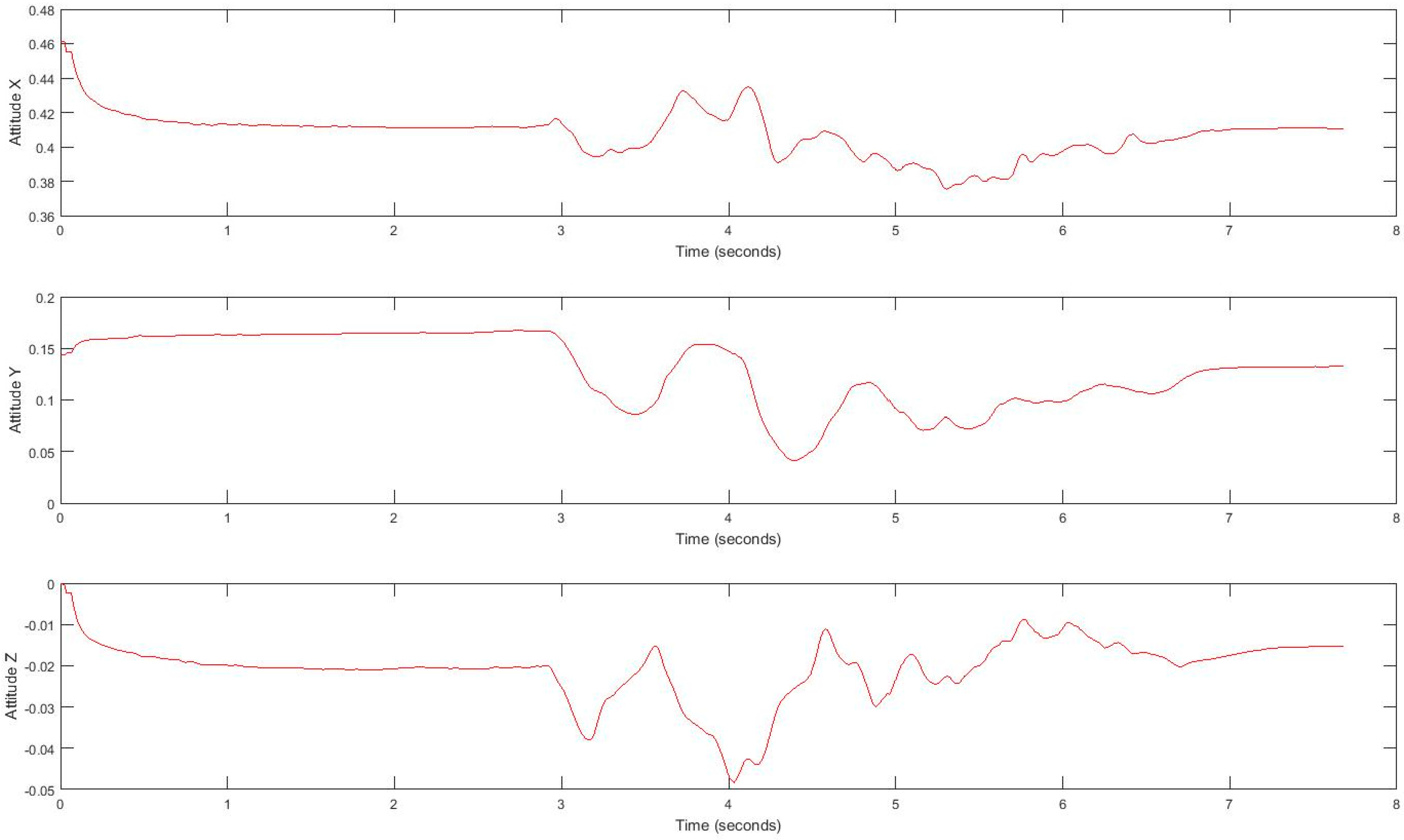
3.5. Inertial Data Acquisition During Tandem Gait Task
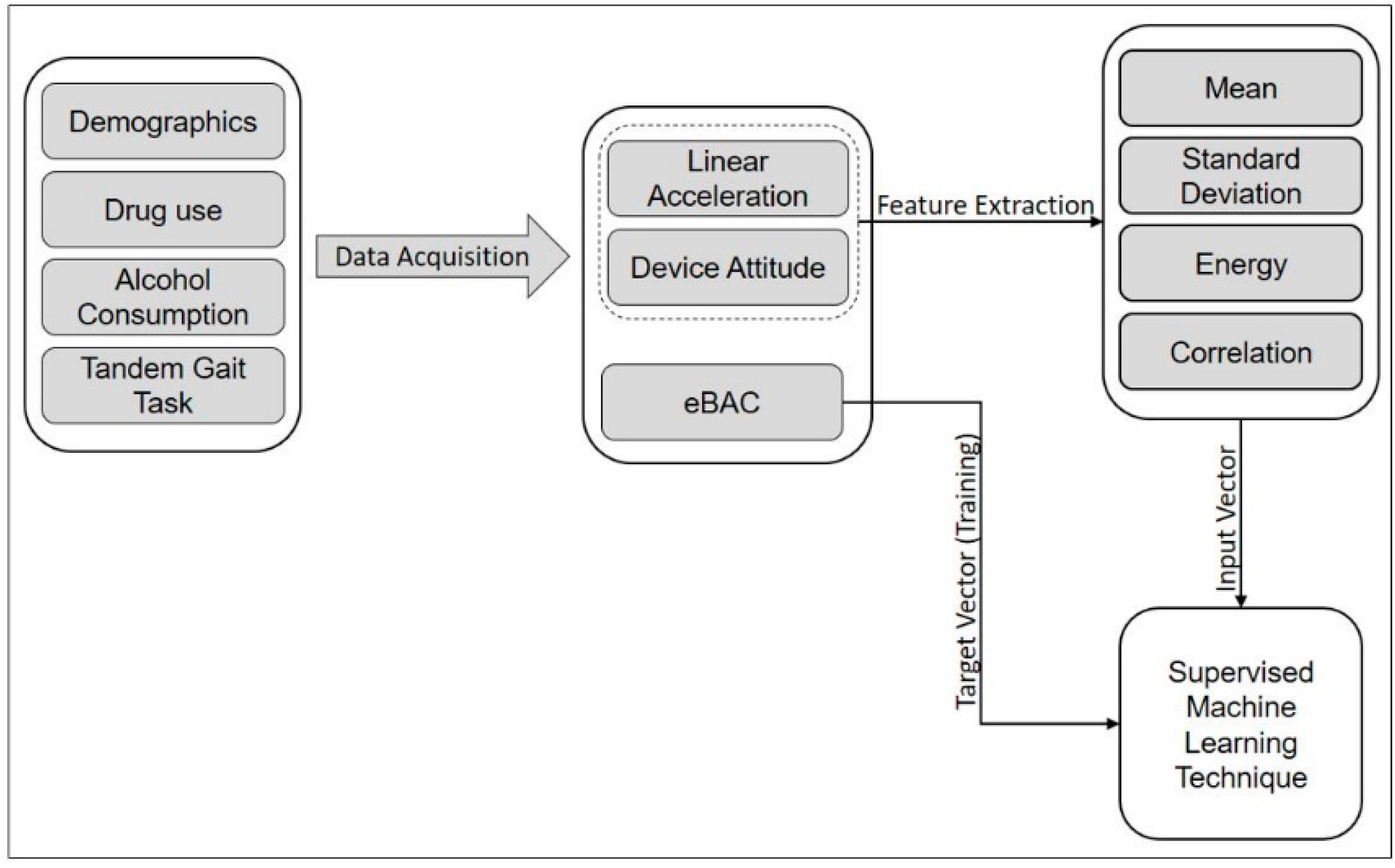
4. BAC Regression with Movement Pattern and Gait Features
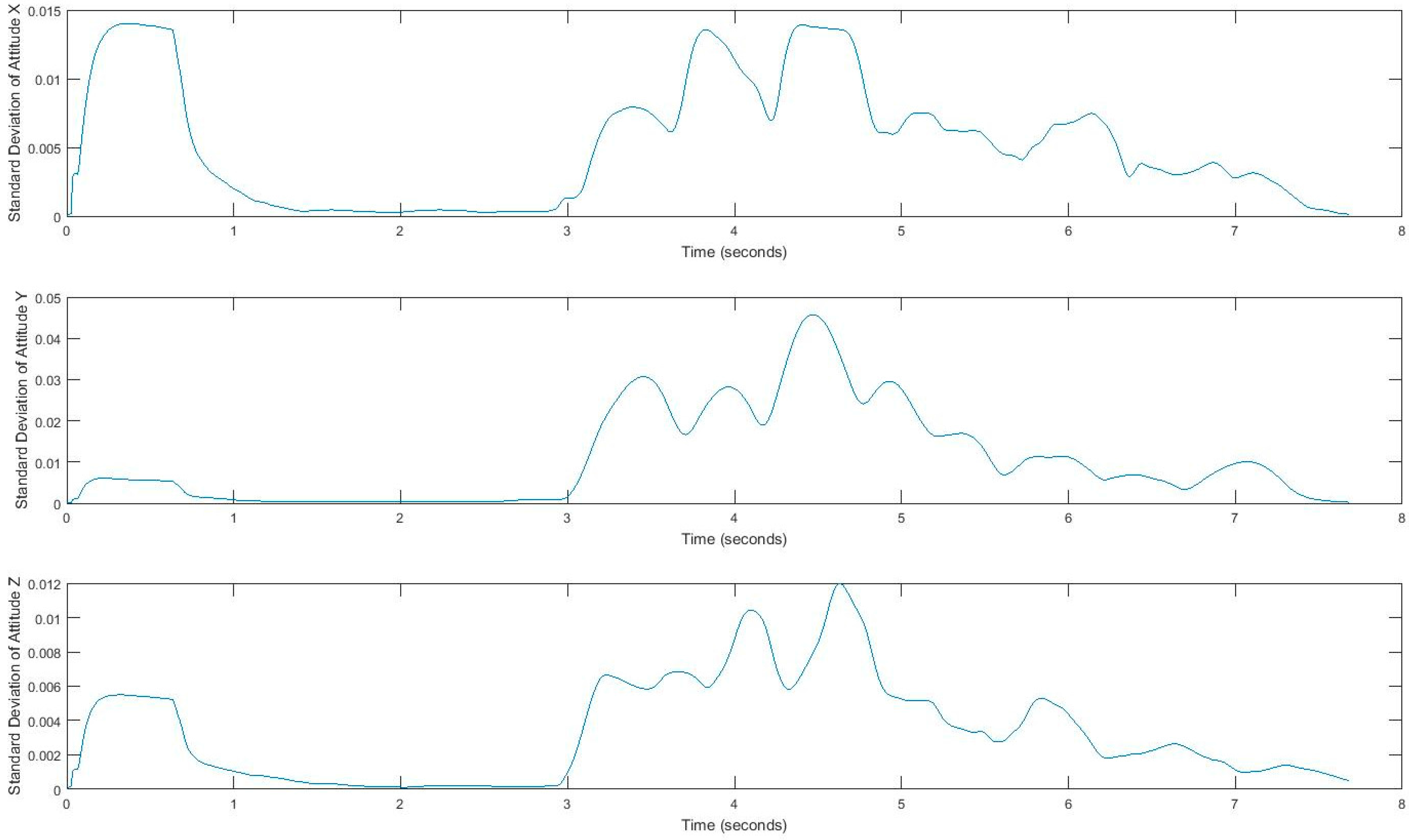
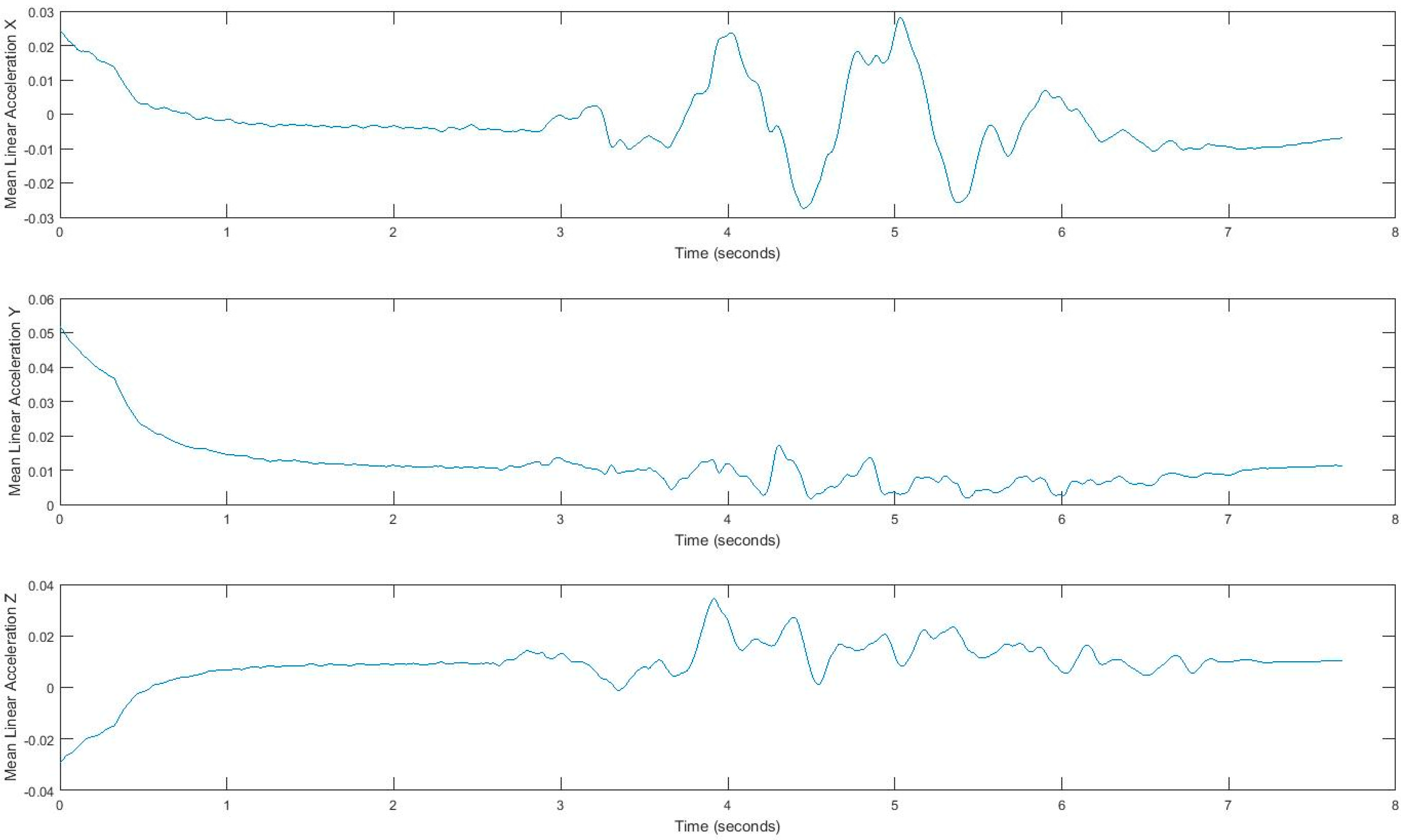
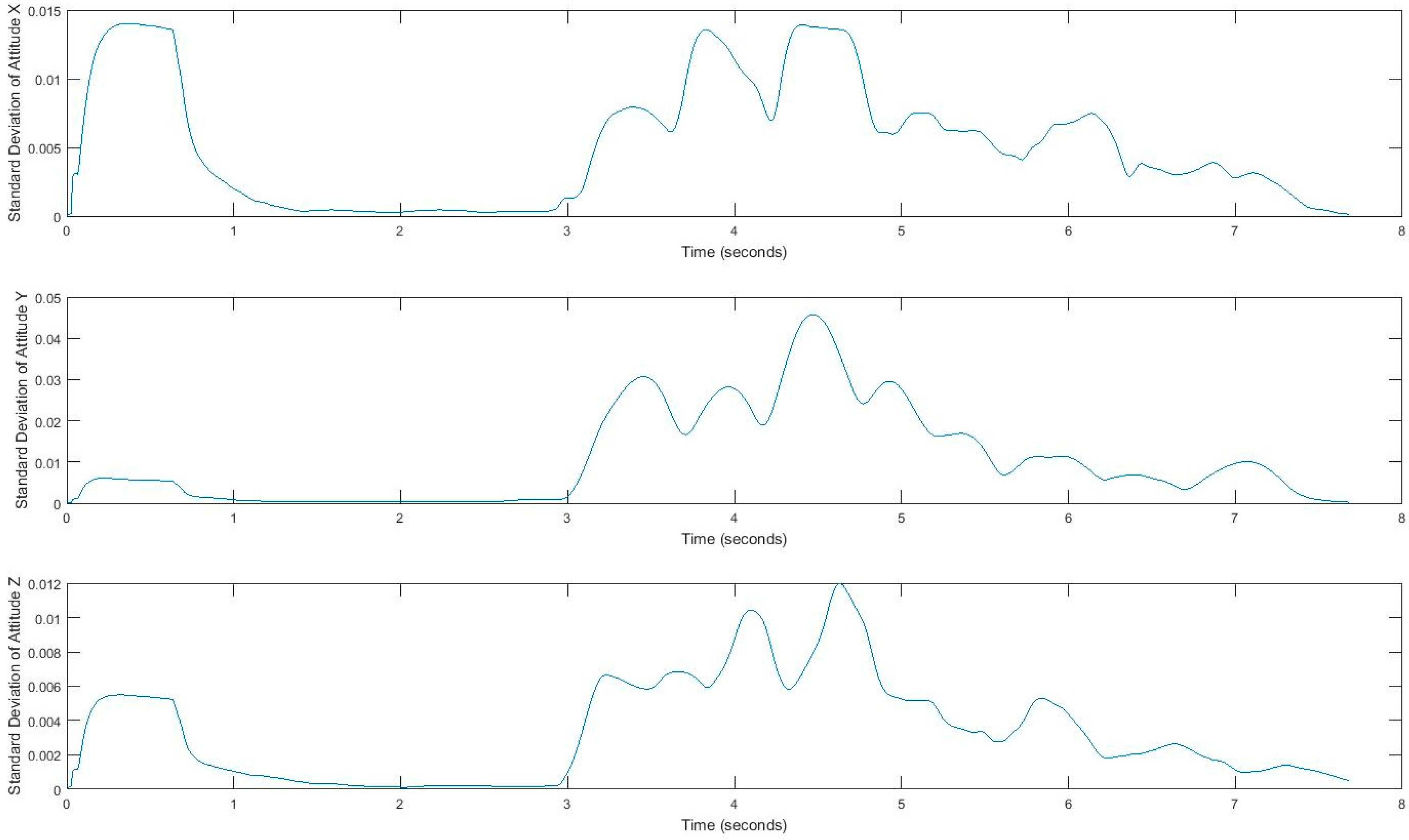
4.1. Feature Extraction for Gait Exploration.
4.2. Bayesian Regularized Neural Network (BRNN) for BAC Regression
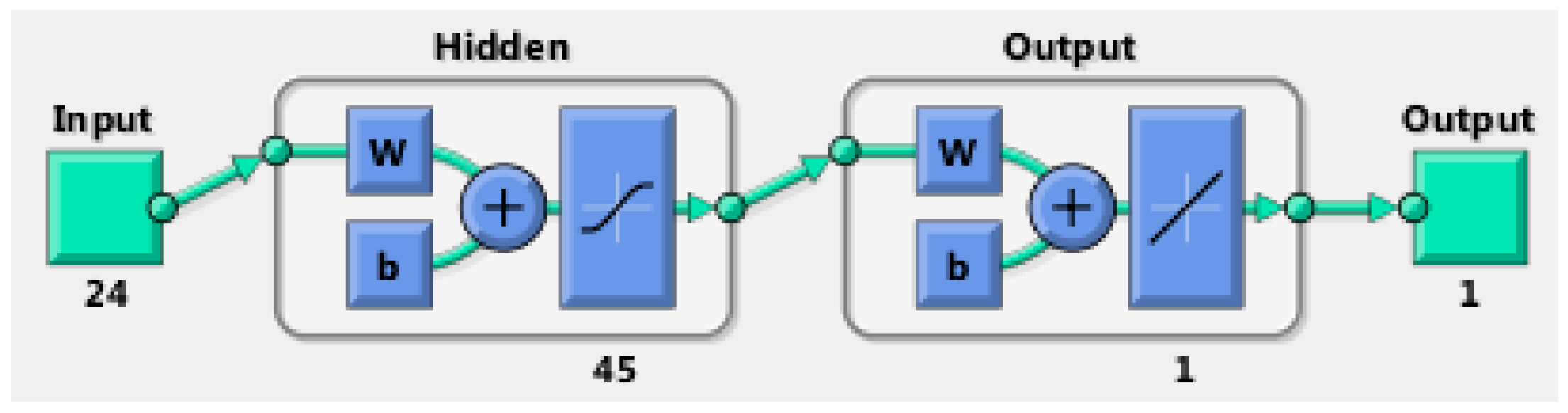
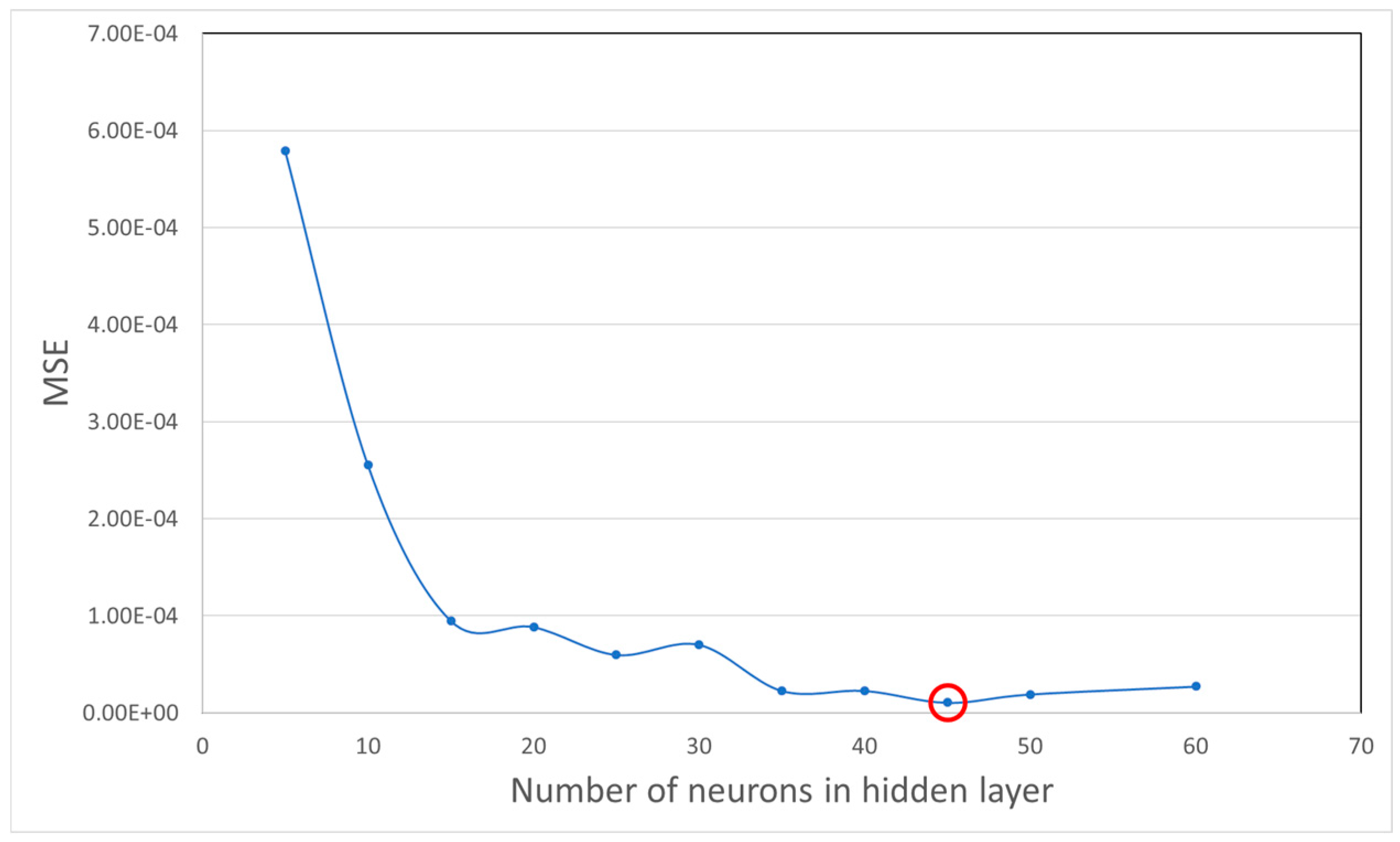
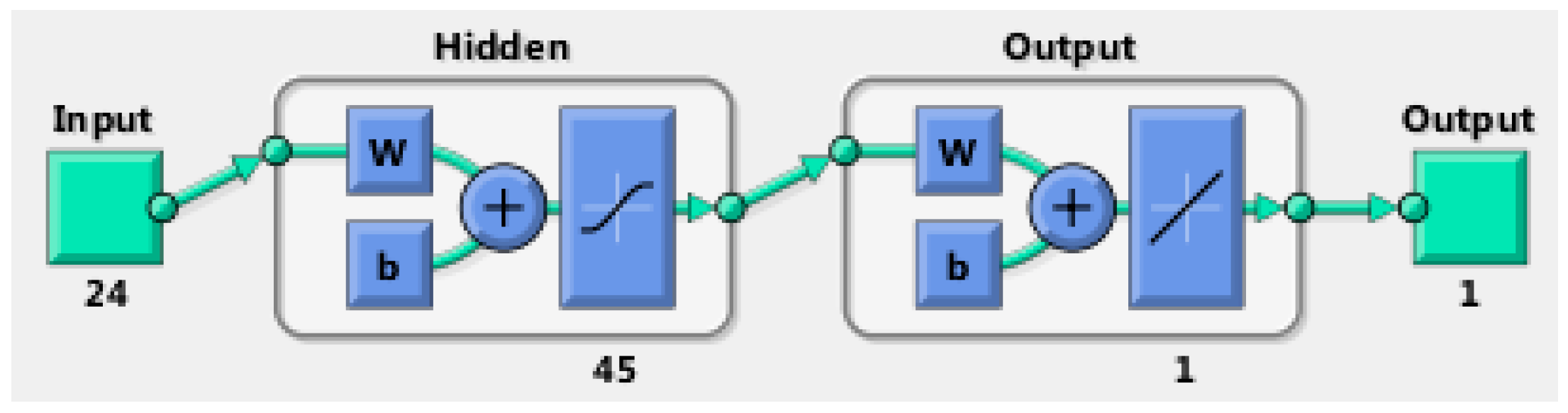
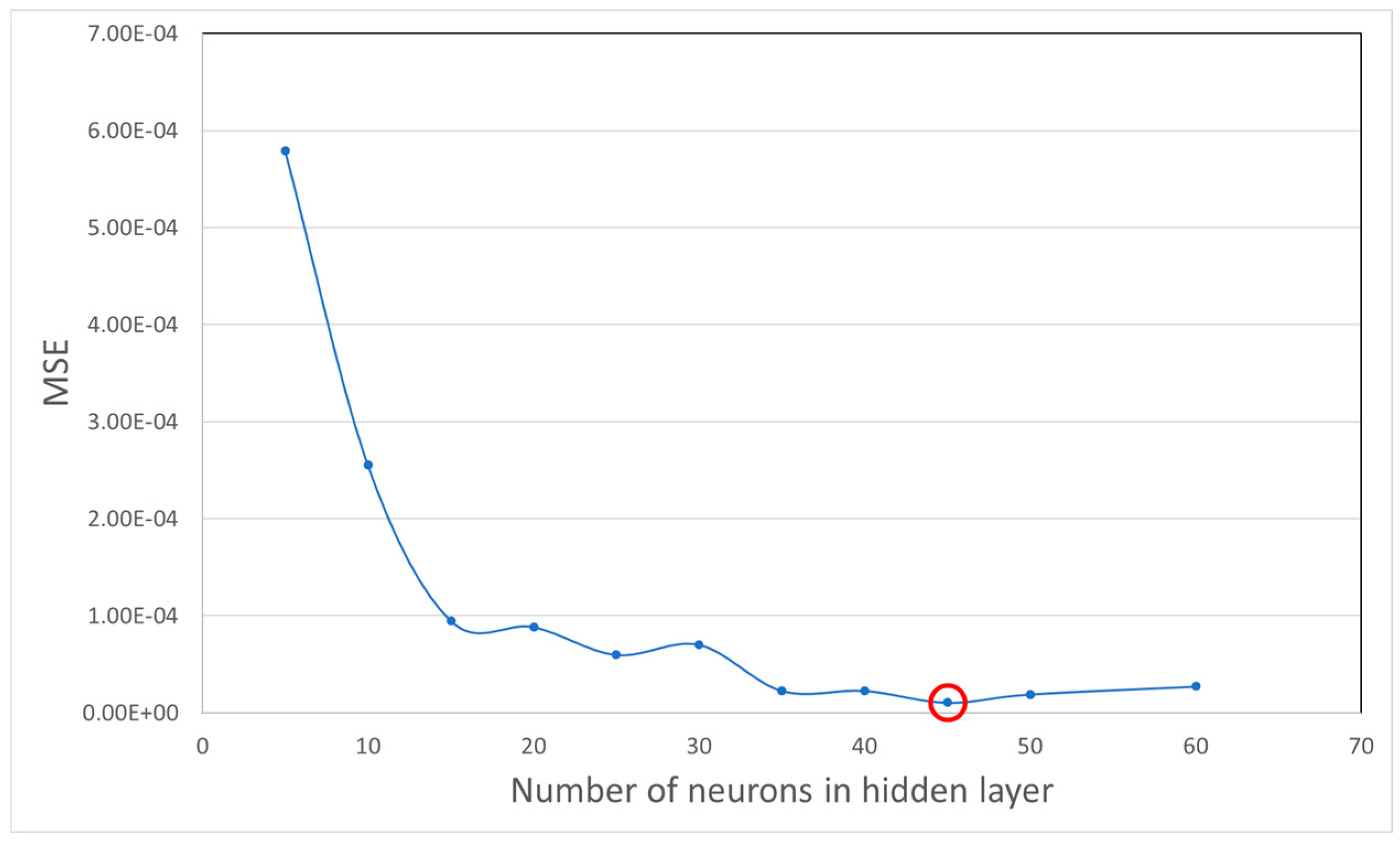
4.3. Neural Network Architecture
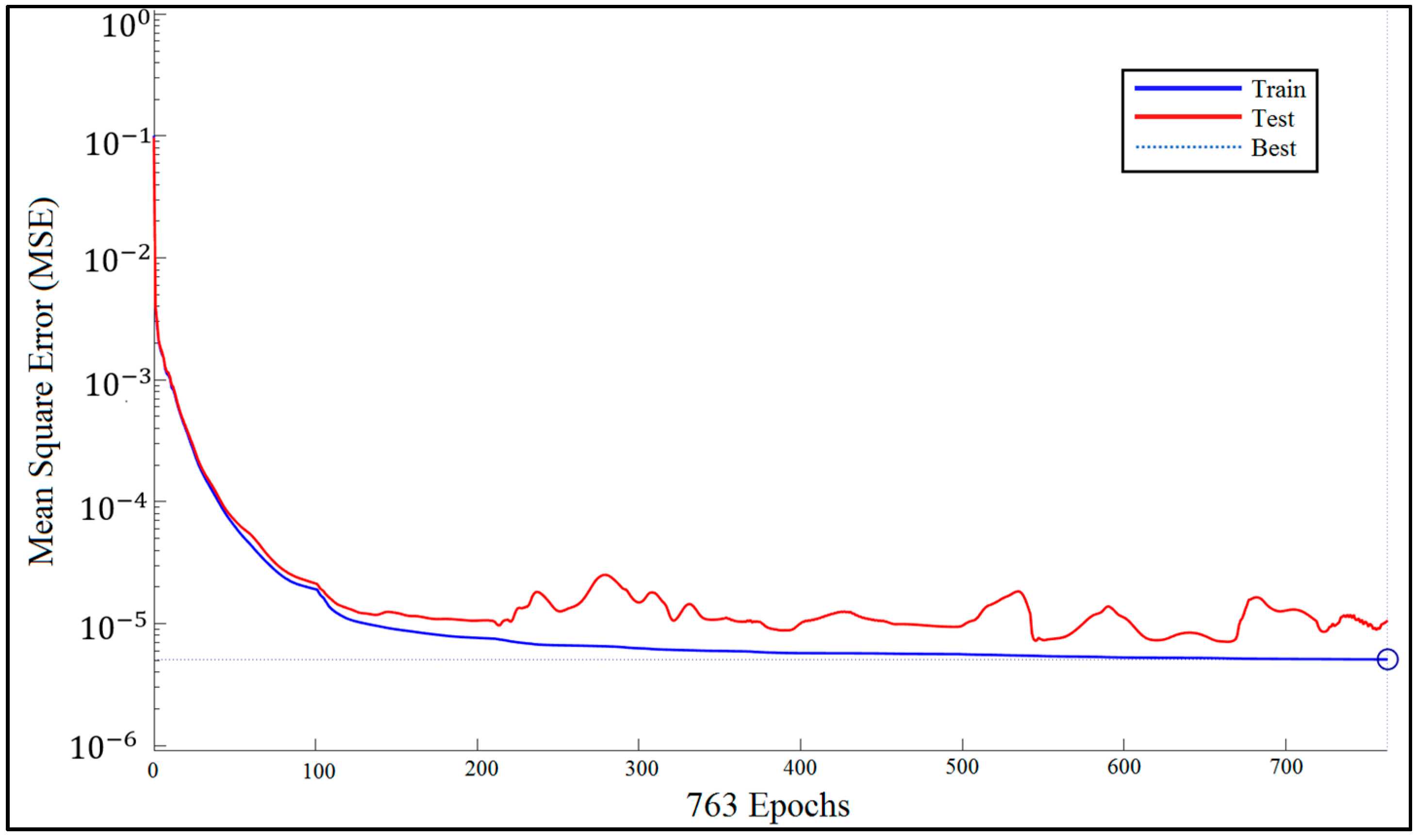
4.4. Training
4.5. Levenberg—Marquardt Algorithm
4.6. Bayesian Regularization of Neural Networks
5. Results and Validation
5.1. Comparison of Different Training Algorithms
5.2. Performance
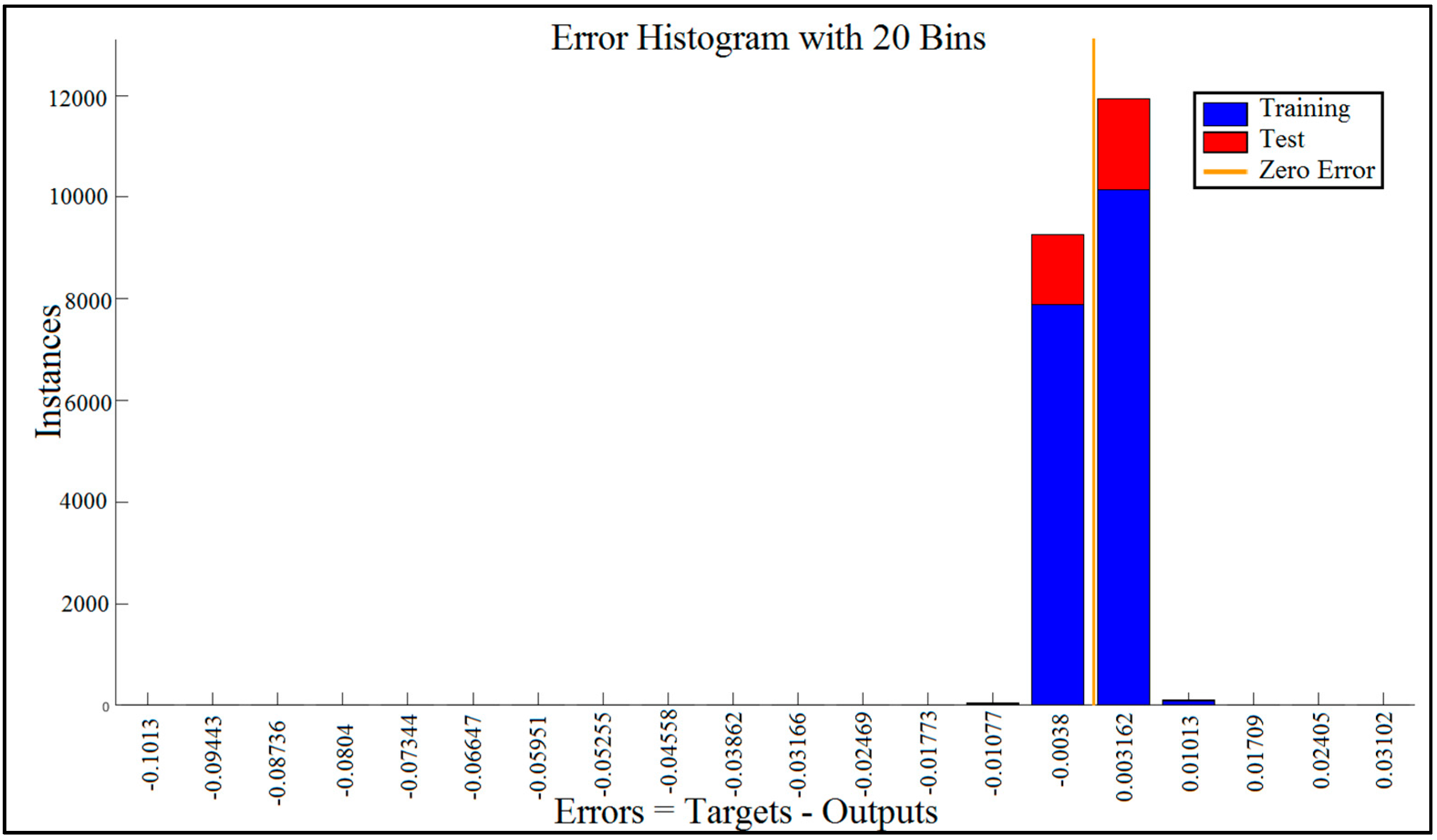
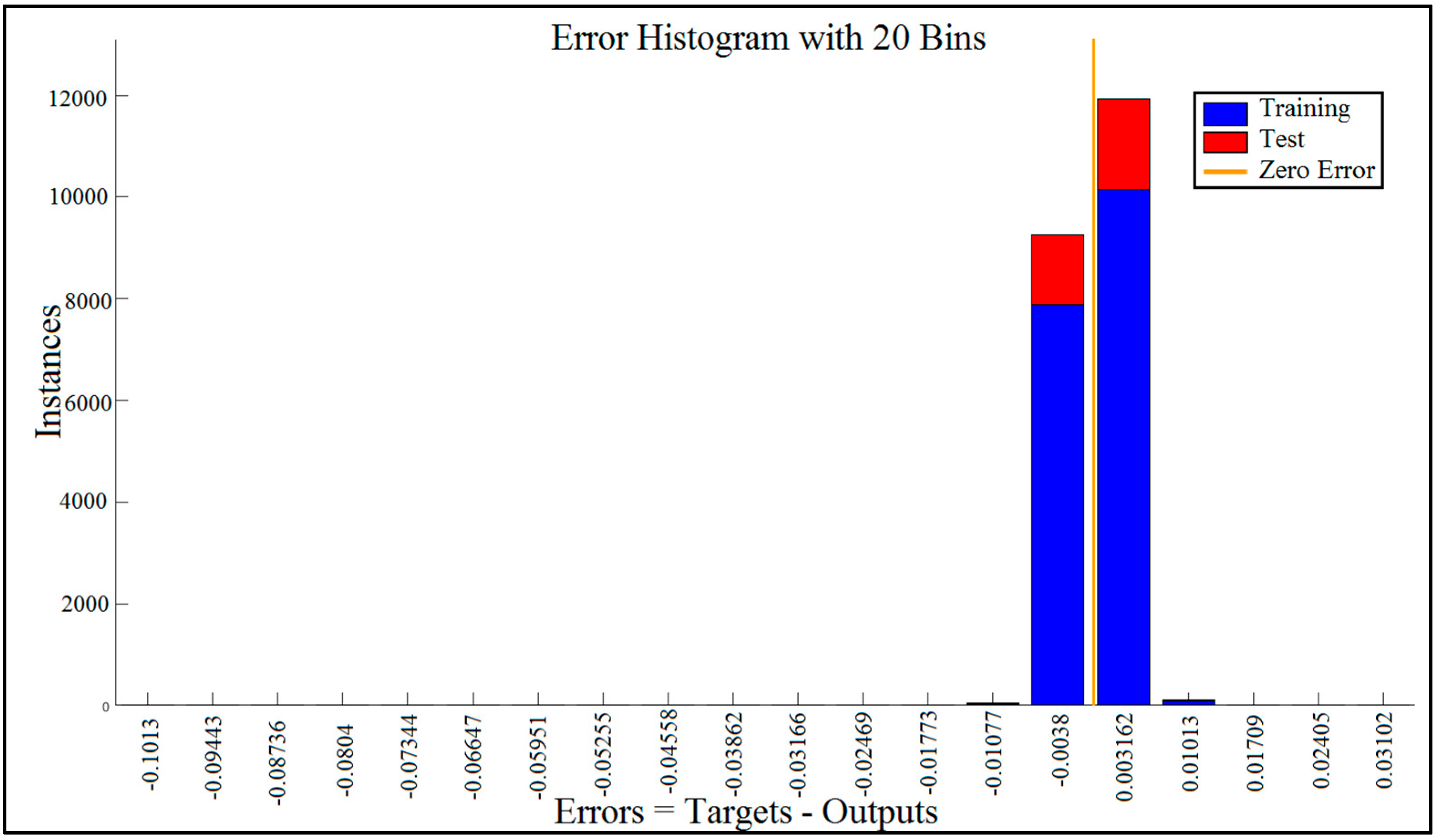
5.3. Error Histogram
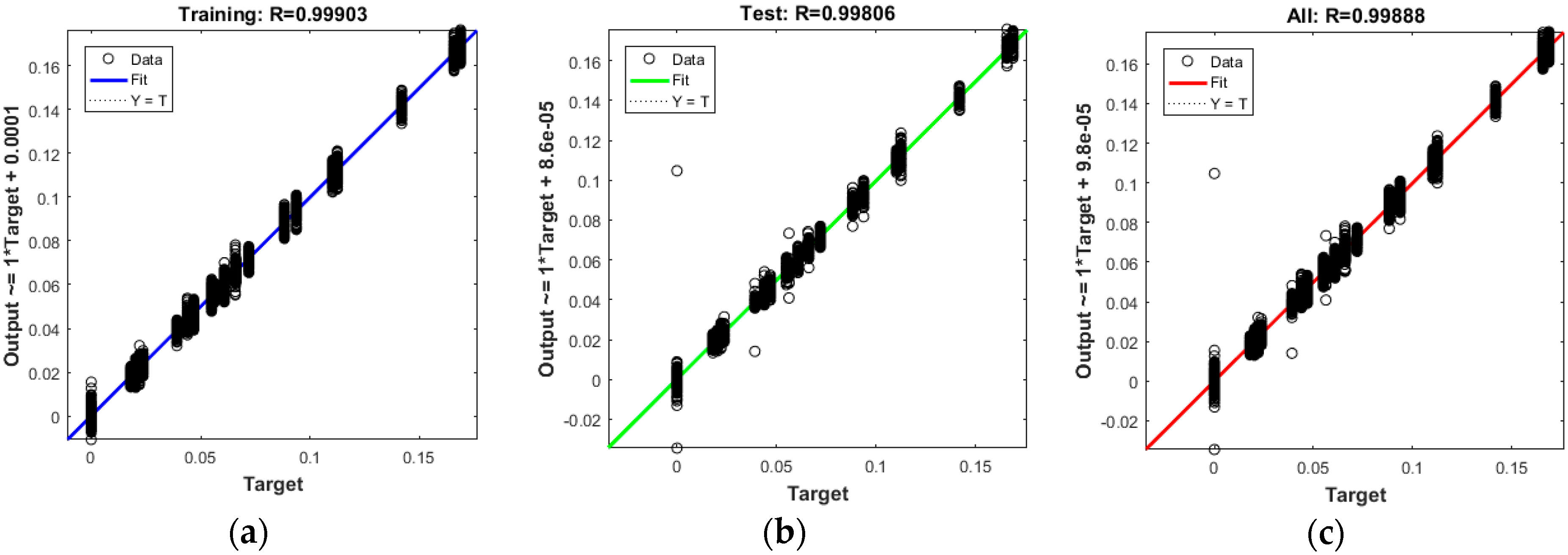
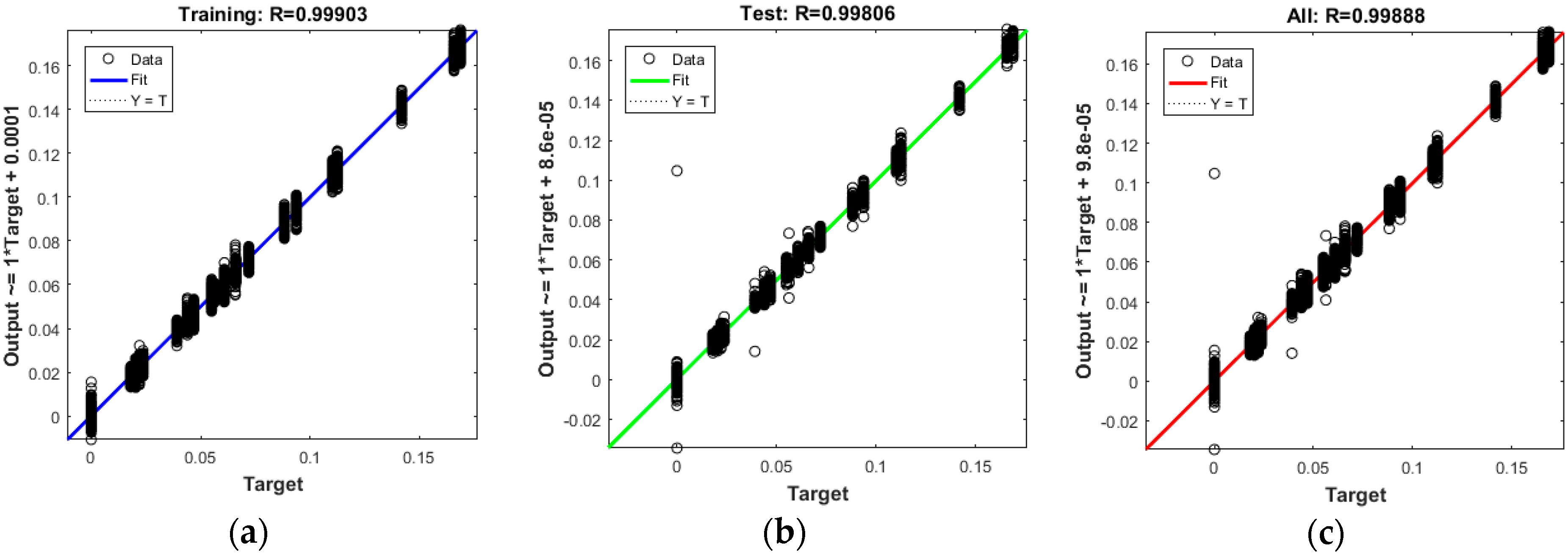
5.4. Regression Results
5.5. Comparison with Other Regression Techniques
6. Related Work
7. Conclusions and Future Directions
Acknowledgments
Author Contributions
Conflicts of Interest
Abbreviations
| ANN | Artificial neural network |
| BAC | Blood Alcohol Content |
| BRNN | Bayesian Regularized Neural Network |
| eBAC | Estimated Blood Alcohol Content |
| EMA | Ecological momentary assessment |
| FFT | Fast Fourier transform |
| MLP | Multilayer perceptron |
| SVM | Support Vector Machine |
References
- National Center for Statistics and Analysis. Alcoholimpaired Driving: 2014 Data; Traffic Safety Facts, DOT HS 812 231; National Highway Traffic Safety Administration: Washington, DC, USA, 2015. Available online: https://crashstats.nhtsa.dot.gov/Api/Public/Publication/812231 (accessed on 13 December 2017).
- Christoforou, Z.; Karlaftis, M.G.; Yannis, G. Reaction times of young alcohol-impaired drivers. Accid. Anal. Prev. 2013, 61, 54–62. [Google Scholar] [CrossRef] [PubMed]
- Steele, C.M.; Josephs, R.A. Alcohol myopia: Its prized and dangerous effects. Am. Psychol. 1990, 45, 921–933. [Google Scholar] [CrossRef] [PubMed]
- Morris, D.H.; Treloar, H.R.; Niculete, M.E.; McCarthy, D.M. Perceived danger while intoxicated uniquely contributes to driving after drinking. Alcohol. Clin. Exp. Res. 2014, 38, 521–528. [Google Scholar] [CrossRef] [PubMed]
- Shults, R.A.; Elder, R.W.; Sleet, D.A.; Nichols, J.L.; Alao, M.O.; Carande-Kulis, V.G.; Zaza, S.; Sosin, D.M.; Thompson, R.S. Reviews of evidence regarding interventions to reduce alcohol-impaired driving. Am. J. Prev. Med. 2001, 21, 66–88. [Google Scholar] [CrossRef]
- Nieschalk, M.; Ortmann, C.; West, A.; Schmal, F.; Stoll, W.; Fechner, G. Effects of alcohol on body-sway patterns in human subjects. Int. J. Leg. Med. 1999, 112, 253–260. [Google Scholar] [CrossRef]
- Jansen, E.C.; Thyssen, H.H.; Brynskov, J. Gait analysis after intake of increasing amounts of alcohol. Int. J. Leg. Med. 1985, 94, 103–107. [Google Scholar] [CrossRef]
- Pew Research Center Internet & Technology. Available online: http://www.pewinternet.org/2015/10/29/the-demographics-of-device-ownership/ (accessed on 12 December 2017).
- Arnold, Z.; Larose, D.; Agu, E. Smartphone Inference of Alcohol Consumption Levels from Gait. In Proceedings of the 2015 International Conference on Healthcare Informatics, Dallas, TX, USA, 21–23 October 2015; pp. 417–426. [Google Scholar]
- Aiello, C.; Agu, E. Investigating postural sway features, normalization and personalization in detecting blood alcohol levels of smartphone users. In Proceedings of the IEEE Wireless Health (WH), Bethesda, MD, USA, 25–27 October 2016; pp. 1–8. [Google Scholar]
- Bae, S.; Chung, T.; Ferreira, D.; Dey, K.A.; Suffoletto, B. Mobile phone sensors and supervised machine learning to identify alcohol use events in young adults: Implications for just-in-time adaptive interventions. Addict. Behav. 2017. [Google Scholar] [CrossRef] [PubMed]
- Winek, C.L.; Esposito, F.M. Blood alcohol concentrations: Factors affecting predictions. Leg. Med. 1985, 34–61. Available online: http://europepmc.org/abstract/med/3835425 (accessed on 13 December 2017).
- Greenfield, T.K.; Bond, J.; Kerr, W.C. Biomonitoring for improving alcohol consumption surveys: The new gold standard? Alcohol Res. Curr. Rev. 2014, 36, 39–45. [Google Scholar]
- Wechsler, H.; Lee, J.E.; Kuo, M.; Seibring, M.; Nelson, T.F.; Lee, H. Trends in college binge drinking during a period of increased prevention efforts: Findings from 4 Harvard School of Public Health College Alcohol Study surveys: 1993–2001. J. Am. Coll. Health 2002, 50, 203–217. [Google Scholar] [CrossRef] [PubMed]
- Widmark, E.M.P. Die Theoretischen Grundlagen und die Praktische Verwendbarkeit der Gerichtlich-Medizinischen Alkoholbestimmung; Urban & Schwarzenberg: Berlin, Germany, 1932. (In German) [Google Scholar]
- Matthews, D.B.; Miller, W.R. Estimating blood alcohol concentration: Two computer programs and their applications in therapy and research. Addict. Behav. 1979, 4, 55–60. [Google Scholar] [CrossRef]
- Hustad, J.T.P.; Carey, K.B. Using calculations to estimate blood alcohol concentrations for naturally occurring drinking episodes: A validity study. J. Stud. Alcohol 2005, 66, 130–138. [Google Scholar] [CrossRef] [PubMed]
- Babor, T.F.; Steinberg, K.; Anton, R.A.Y.; del Boca, F. Talk is cheap: Measuring drinking outcomes in clinical trials. J. Stud. Alcohol 2000, 61, 55–63. [Google Scholar] [CrossRef] [PubMed]
- Alessi, S.M.; Barnett, N.P.; Petry, N.M. Experiences with SCRAMx alcohol monitoring technology in 100 alcohol treatment outpatients. Drug Alcohol Depend. 2017, 178, 417–424. [Google Scholar] [CrossRef] [PubMed]
- Simons, J.S.; Wills, T.A.; Emery, N.N.; Marks, R.M. Quantifying alcohol consumption: Self-report, transdermal assessment, and prediction of dependence symptoms. Addict. Behav. 2015, 50, 205–212. [Google Scholar] [CrossRef] [PubMed]
- Alessi, S.M.; Petry, N.M. A randomized study of cellphone technology to reinforce alcohol abstinence in the natural environment. Addiction 2013, 108, 900–909. [Google Scholar] [CrossRef] [PubMed]
- Suffoletto, B.; Gharani, P.; Chung, T.; Karimi, H. Using Phone Sensors and an Artificial Neural Network to Detect Gait Changes During Drinking Episodes in the Natural Environment. Gait Posture 2017. [Google Scholar] [CrossRef] [PubMed]
- Leffingwell, T.R.; Cooney, N.J.; Murphy, J.G.; Luczak, S.; Rosen, G.; Dougherty, D.M.; Barnett, N.P. Continuous objective monitoring of alcohol use: Twenty-first century measurement using transdermal sensors. Alcohol. Clin. Exp. Res. 2013, 37, 16–22. [Google Scholar] [CrossRef] [PubMed]
- Karns-Wright, T.E.; Roache, J.D.; Hill-Kapturczak, N.; Liang, Y.; Mullen, J.; Dougherty, D.M. Time Delays in Transdermal Alcohol Concentrations Relative to Breath Alcohol Concentrations. Alcohol Alcohol. 2017, 52, 35–41. [Google Scholar] [CrossRef] [PubMed]
- Muraven, M.; Collins, R.L.; Shiffman, S.; Paty, J.A. Daily fluctuations in self-control demands and alcohol intake. Psychol. Addict. Behav. 2005, 19, 140–147. [Google Scholar] [CrossRef] [PubMed]
- US Department of Health and Human Services. Helping Patients Who Drink Too Much: A Clinician’s Guide; National Institute on Alcohol Abuse and Alcoholism: Bethesda, MD, USA, 2005. Available online: http://pubs.niaaa.nih.gov/publications/Practitioner/CliniciansGuide2005/guide.pdf (accessed on 13 December 2017).
- Shiffman, S. Ecological momentary assessment (EMA) in studies of substance use. Psychol. Assess. 2009, 21, 486–497. [Google Scholar] [CrossRef] [PubMed]
- Wray, T.B.; Merrill, J.E.; Monti, P.M. Using Ecological Momentary Assessment (EMA) to Assess Situation-Level Predictors of Alcohol Use and Alcohol-Related Consequences. Alcohol Res. 2014, 36, 19–27. [Google Scholar] [PubMed]
- Lucas, G.M.; Gratch, J.; King, A.; Morency, L.-P. It’s only a computer: Virtual humans increase willingness to disclose. Comput. Hum. Behav. 2014, 37, 94–100. [Google Scholar] [CrossRef]
- Babor, T.F.; de la Fuente, J.R.; Saunders, J.B.; Grant, M. AUDIT: The Alcohol Use Disorders Identification Test: Guidelines for Use in Primary Health Care; World Health Organization: Geneva, Switzerland, 1992. [Google Scholar]
- Del Boca, F.K.; Darkes, J.; Greenbaum, P.E.; Goldman, M.S. Up close and personal: Temporal variability in the drinking of individual college students during their first year. J. Consult. Clin. Psychol. 2004, 72, 155–164. [Google Scholar] [CrossRef] [PubMed]
- Suffoletto, B.; Goyal, A.; Puyana, J.C.; Chung, T. Can an App Help Identify Psychomotor Function Impairments During Drinking Occasions in the Real World? A Mixed Method Pilot Study. Subst. Abus. 2017, 38, 438–449. [Google Scholar] [CrossRef] [PubMed]
- Bao, L.; Intille, S.S. Activity Recognition from User-Annotated Acceleration Data. In Pervasive Computing; Pervasive 2004; Ferscha, A., Mattern, F., Eds.; Springer: Heidelberg, Germany, 2004. [Google Scholar]
- Ravi, N.; Dandekar, N.; Mysore, P.; Littman, M.L. Activity recognition from accelerometer data. In Proceedings of the 17th Conference on Innovative Applications of Artificial Intelligence, Pittsburgh, PA, USA, 9–13 July 2005; Volume 5, pp. 1541–1546. [Google Scholar]
- Gharani, P.; Karimi, H.A. Context-aware obstacle detection for navigation by visually impaired. Image Vis. Comput. 2017, 64, 103–115. [Google Scholar] [CrossRef]
- Burden, F.; Winkler, D. Bayesian regularization of neural networks. In Artificial Neural Network: Method and Application; Livingstone, D.J., Ed.; Humana Press: Totowa, NJ, USA, 2008; pp. 25–44. [Google Scholar]
- Masters, T. Advanced Algorithms for Neural Networks: A C++ Sourcebook; John Wiley & Sons, Inc.: New York, NY, USA, 1995. [Google Scholar]
- Mohanty, S.; Jha, M.K.; Kumar, A.; Sudheer, K.P. Artificial neural network modeling for groundwater level forecasting in a river island of eastern India. Water Resour. Manag. 2010, 24, 1845–1865. [Google Scholar] [CrossRef]
- Roweis, S. Levenberg-Marquardt Optimization; Notes; University of Toronto: Toronto, ON, Canada, 1996. [Google Scholar]
- Gavin, H.P. The Levenberg-Marquardt Method for Nonlinear Least Squares Curve-Fitting Problems; Duke Civil and Environmental Engineering—Duke University: Durham, NC, USA, 2013; pp. 1–17. [Google Scholar]
- Hornik, K.; Stinchcombe, M.; White, H. Multilayer feedforward networks are universal approximators. Neural Netw. 1989, 2, 359–366. [Google Scholar] [CrossRef]
- Hornik, K. Some new results on neural network approximation. Neural Netw. 1993, 6, 1069–1072. [Google Scholar] [CrossRef]
- Mackay, D.J.C. Bayesian Methods for Adaptive Models. Ph.D. Thesis, California Institute of Technology, Pasadena, CA, USA, 1991; p. 98. [Google Scholar]
- Lourakis, M.I.A. A Brief Description of the Levenberg-Marquardt Algorithm Implemened by levmar. Matrix 2005, 3, 2. [Google Scholar]
- Foresee, F.D.; Hagan, M.T. Gauss-Newton approximation to Bayesian regularization. In Proceedings of the International Conference on Neural Networks, Houston, TX, USA, 12 June 1997; pp. 1930–1935. [Google Scholar]
- MacKay, D.J.C. A Practical Bayesian Framework for Backpropagation Networks. Neural Comput. 1992, 4, 448–472. [Google Scholar] [CrossRef]
- Kayri, M. Predictive Abilities of Bayesian Regularization and Levenberg–Marquardt Algorithms in Artificial Neural Networks: A Comparative Empirical Study on Social Data. Math. Comput. Appl. 2016, 21, 20. [Google Scholar] [CrossRef]
- Kao, H.-L.; Ho, B.-J.; Lin, A.C.; Chu, H.-H. Phone-based gait analysis to detect alcohol usage. In Proceedings of the 2012 ACM Conference on Ubiquitous Computing, Pittsburgh, PA, USA, 5–8 September 2012; p. 661. [Google Scholar]
- Park, E.; Lee, S.I.; Nam, H.S.; Garst, J.H.; Huang, A.; Campion, A.; Arnell, M.; Ghalehsariand, N.; Park, S.; Chang, H.J.; et al. Unobtrusive and Continuous Monitoring of Alcohol-impaired Gait Using Smart Shoes. Methods Inf. Med. 2017, 56, 74–82. [Google Scholar] [CrossRef] [PubMed]
- Nassi, B.; Rokach, L.; Elovici, Y. Virtual Breathalyzer. arXiv, 2016; arXiv:1612.05083. Available online: https://arxiv.org/abs/1612.05083 (accessed on 12 December 2017).
- Piasecki, T.M.; Alley, K.J.; Slutske, W.S.; Wood, P.K.; Sher, K.J.; Shiffman, S.; Heath, A.C. Low sensitivity to alcohol: Relations with hangover occurrence and susceptibility in an ecological momentary assessment investigation. J. Stud. Alcohol Drugs 2012, 73, 925–932. [Google Scholar] [CrossRef] [PubMed]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Characteristics | N = 10 | |
|---|---|---|
| Age in years, mean (SD) | 23.1 (2.6) | |
| Female, n (%) | 7 (70%) | |
| Race, n (%) | ||
| African American | 2 (20%) | |
| White | 6 (60%) | |
| Other | 2 (20%) | |
| Hispanic Ethnicity, n (%) | 1 (10%) | |
| Education, n (%) | ||
| Some college | 5 (50%) | |
| College graduate or post-graduate | 5 (50%) | |
| Employment, n (%) | ||
| For wages | 7 (70%) | |
| Student | 3 (30%) | |
| Married, n (%) | 1 (10%) | |
| Alcohol Use Severity (AUDIT-C score), mean (SD) | 5 (1.3) | |
| Weight in pounds, mean (SD) | 179 (35) | |
| Training Algorithm | MSE | R |
|---|---|---|
| Conjugate-gradient | 0.883389 | |
| Levenberg-Marquardt | 0.996381 | |
| Bayesian regularization | 0.999034 |
| Training Algorithm | MSE | R |
|---|---|---|
| Conjugate-gradient | 0.881084 | |
| Levenberg-Marquardt | 0.994294 | |
| Bayesian regularization | 0.998056 |
| Regression Technique | Correlation Coefficient | Mean Absolute Error | Root Mean Squared Error | Relative Absolute Error | Root Relative Squared Error |
|---|---|---|---|---|---|
| MLP | 0.9009 | 0.0174 | 0.0226 | 40.6458% | 43.8853% |
| SVM | 0.3939 | 0.0362 | 0.0482 | 84.5348% | 93.6504% |
| Linear Regression | 0.4367 | 0.0378 | 0.0463 | 88.2747% | 89.9583% |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gharani, P.; Suffoletto, B.; Chung, T.; Karimi, H.A. An Artificial Neural Network for Movement Pattern Analysis to Estimate Blood Alcohol Content Level. Sensors 2017, 17, 2897. https://doi.org/10.3390/s17122897
Gharani P, Suffoletto B, Chung T, Karimi HA. An Artificial Neural Network for Movement Pattern Analysis to Estimate Blood Alcohol Content Level. Sensors. 2017; 17(12):2897. https://doi.org/10.3390/s17122897
Chicago/Turabian StyleGharani, Pedram, Brian Suffoletto, Tammy Chung, and Hassan A. Karimi. 2017. "An Artificial Neural Network for Movement Pattern Analysis to Estimate Blood Alcohol Content Level" Sensors 17, no. 12: 2897. https://doi.org/10.3390/s17122897
APA StyleGharani, P., Suffoletto, B., Chung, T., & Karimi, H. A. (2017). An Artificial Neural Network for Movement Pattern Analysis to Estimate Blood Alcohol Content Level. Sensors, 17(12), 2897. https://doi.org/10.3390/s17122897