Abstract
A practical probabilistic data association filter is proposed for tracking multiple targets in clutter. The number of joint data association events increases combinatorially with the number of measurements and the number of targets, which may become computationally impractical for even small numbers of closely located targets in real target-tracking applications in heavily cluttered environments. In this paper, a Markov chain model is proposed to generate a set of feasible joint events (FJEs) for multiple target tracking that is used to approximate the multi-target data association probabilities and the probabilities of target existence of joint integrated probabilistic data association (JIPDA). A Markov chain with the transition probabilities obtained from the integrated probabilistic data association (IPDA) for single-target tracking is designed to generate a random sequence composed of the predetermined number of FJEs without incurring additional computational cost. The FJEs generated are adjusted for the multi-target tracking environment. A computationally tractable set of these random sequences is utilized to evaluate the track-to-measurement association probabilities such that the computational burden is substantially reduced compared to the JIPDA algorithm. By a series of simulations, the track confirmation rates and target retention statistics of the proposed algorithm are compared with the other existing algorithms including JIPDA to show the effectiveness of the proposed algorithm.
1. Introduction
Multi-target tracking [1,2,3,4,5] is an important task of radar, sonar, acoustic, electro-optical, and infrared systems and various other tracking applications. The measurements obtained by sensors may be originated from real targets and clutter. In a multi-target environment, each target is detected with a certain probability of detection, the number of targets is unknown, and a random number of false alarms or clutter measurements are generated at the random locations in the surveillance region. Under these situations, true as well as false tracks are initiated, and a track quality measure is needed for false track discrimination (FTD) and track maintenance.
A well-known algorithm for multi-target tracking in cluttered environments is joint probabilistic data association (JPDA) [6,7], which extends probabilistic data association (PDA) for single-target tracking in clutter with a known number of targets in a cluttered environment to multi-target tracking environments. The JPDA algorithm is used to compute the track-to-measurement association probabilities for all the feasible joint events (FJEs), and the complexity of the calculation grows combinatorially with the number of targets and the number of measurements. In addition, these JPDA and PDA approaches do not have measures for discriminating false or true tracks. FTD involves confirming the tracks that follow true targets and terminating false tracks. The probability of target existence (PTE) is used as a track quality measure for FTD in integrated probabilistic data association (IPDA) [8,9].
For multi-target tracking in clutter with FTD, joint integrated PDA (JIPDA) [10] and joint ITS (JITS) [11] with PTE have been proposed for autonomous target tracking. JIPDA and JITS enumerate all the FJEs as JPDA and evaluate the data association probabilities and the PTE of each track. They become impractical for even a small number of closely located targets in heavily cluttered environments due to intractable number of all the FJEs for the tracking environments. To alleviate the computational burden of the multi-target data association algorithms, linear multi-target IPDA (LMIPDA) [12], linear multi-target ITS [12], and iterative JIPDA (iJIPDA) [13,14] along with efficient implementations have recently been proposed. Several deterministic approximation approaches such as suboptimal JPDA have been proposed in [15,16]. The multiple hypothesis tracking (MHT) filters [17,18] employ multi-scan data association schemes to maintain a set of measurement history hypotheses with high track scores. There are many versions of the MHT filter. Most of them can be grouped into two classes: the track-oriented MHT [18] and the measurement-oriented MHT [17]. The original random finite set (RFS) approach [2,3] to multi-target filtering does not require track-to-measurement association. However, it lacks track management functions for target tracking such as labeling and track scoring that are important in practice. Recently the RFS approaches become more practical as they are equipped with tools for track scoring, labeling and data association [19]. Markov chain Monte Carlo (MCMC) data association [20] is a stochastic method recently proposed for solving data association problems in multi-target tracking. It uses the Metropolis-Hastings algorithm to generate the FJEs. The MH algorithm is known to be an MCMC method, in which the parameters of interest or samples follow a proposed distribution to determine moving to another state or staying at the current state according to an acceptance probability. The move to a new FJE is determined by the acceptance probability which is based on the ratio of the probabilities of old and new events. As shown in the simulation experiments of [20], this MCMC data association method should generate about 10,000 burn-in samples and large MCMC samples are needed for calculation of the multi-target data association probabilities at every scan. Regarding real-time applications, this method may not be practical even though it is flexible and executable in polynomial time.
In this paper, we present a new data association algorithm that uses a Markov chain [21] to approximate the probabilities of the FJEs of JIPDA. It is called a Markov chain–based JIPDA (MCJIPDA) filter for multi-target tracking in cluttered environments. The MCJIPDA algorithm does not utilize a Monte-Carlo technique and is different from the MCMC method of [20]. The proposed method sequentially generates a Markov chain for each cluster target based on the transition probability matrix of the Markov chain model developed from IPDA for single-target tracking, which can be calculated without imposing additional computation load. The Markov chain sequences for all tracks are used to evaluate the data association probabilities of the FJEs. The number of FJEs is predetermined and the FJEs are generated from the transition probabilities based on IPDA for single target tracking at first, and later they are adjusted for the multi-target tracking environment in clutter. It is shown by simulation studies that a few hundred measurement states for each track generated by the proposed Markov chain are enough to compute the posterior data association probabilities and to maintain performance similar to that of JIPDA. This makes a big difference between the proposed algorithm and the MCMC method of [20]. Simulation studies also show that the execution time is substantially reduced compared to that of JIPDA.
The rest of this paper is organized as follows. Section 2 revisits JIPDA for a brief introduction. The Markov chain data association algorithm for joint integrated target tracking is described in Section 3. Section 4 shows the performance of the MCJIPDA via simulations, followed by the concluding remarks in Section 5.
2. Target Tracking with JIPDA
This section provides an overview of JIPDA with models of target dynamics and sensor measurements. It also introduces a reformulation of the posterior probabilities of the FJEs for JIPDA to aid understanding how the sequences of the Markov chain for each target can be used to represent the FJEs. In this paper, we use superscript to denote a track, and a true target that track follows.
2.1. Mathematical Models
Consider a linear dynamic model of target described by
where is the target state vector at time k, is the transition matrix, and is a zero-mean, white Gaussian noise sequence with known variance .
Let denote the set of validated measurements at time k for target , denotes the i th measurement of , and denotes the number of measurements received at scan k in the validation gate of track that follows target . Each target can generate at most one detection per each k with the probability of detection .
Then, the set of measurements collected up to time k from the entire surveillance region is denoted as
and contains the measurements of all the targets as well as the clutter measurements in the surveillance region at scan and its cardinality is denoted as . The number of clutter measurements is assumed to follow a Poisson distribution, and they are uniformly distributed over the entire surveillance region with the clutter measurement density .
The measurement model from a sensor for target is given by
where is the measurement matrix and is a white, zero-mean Gaussian measurement noise sequence with known variance .
2.2. JIPDA
Tracks may be initiated from target or clutter measurements. True tracks should be confirmed fast and kept confirmed, while false tracks should be terminated effectively through a proper track management method. JIPDA utilizes the PTE for track management.
The event that the target exists at time k is denoted by . Then, the PTE at time k conditioned on is denoted by , and the probability that the target does not exist satisfies
The Markov chain-one model [8] for the propagation of the PTE for target is given by
where the transition probabilities are defined as
The a posteriori probability density function (pdf) of the target state is given by
The estimated probability density function (pdf) of the target state is conditioned on . This pdf can be divided into the sum of the data association probabilities for the set of measurements by using the total probability theorem, which is given by
where is the hypothesis that the th measurement of is the measurement of target (for = 0, target is not detected) and the data association probability can be expressed as
A feasible joint event (FJE) is one possible mapping of the measurements to the tracks that follow targets. For each joint event, it is assumed that each track can be assigned to zero or one of the measurements which falls in the validation gate of the track, and each measurement can be allocated to zero or one of the tracks in order to be a FJE. Therefore, the FJE condition implies that no two tracks in a FJE share the same measurement.
Let and denote the jth FJE and the number of all the FJEs for data association at time k, respectively. Then, the sum of the a posteriori probabilities of all the FJEs satisfies
The data association probabilities of track are obtained by summing over all the probabilities of FJEs that contain track and the measurement of interest. Denote by the set of FJEs in which track is allocated to measurement (0 means no measurement allocation), we have
where is the gating probability of track .
The a posteriori PTE for track in JIPDA is obtained from the sum of the joint probabilities by
Let denote the truncated measurement likelihood function of track for measurement in the validation gate of track ,
Now, the a posteriori probability of FJE in JIPDA [10] is defined. Denote by and the set of tracks allocated with no measurements and the set of tracks allocated with one measurement for the joint event in Equation (11), respectively. The a posteriori probability of FJE is defined by
where is the index of the measurement allocated to track in FJE , can be obtained by replacing the subscript with in Equation (16), is the clutter measurement density, and the normalization constant C is calculated from Equation (11).
In fact, tracks are partitioned into clusters [10]. A cluster is a set of tracks and the measurements these tracks select. In other words, the tracks not belonging to the cluster do not share any of the cluster measurements. The purpose of clustering is to minimize the number of all the FJEs by limiting the numbers of tracks and measurements inside a cluster.
The following is an example to illustrate the set of all the FJEs of JIPDA and the a posteriori probability calculation for the set. Consider the two-dimensional multi-target tracking situation depicted in Figure 1. There are two cluster tracks, labeled and , and three measurements to in the cluster. For this cluster, the total number of FJEs is 8.
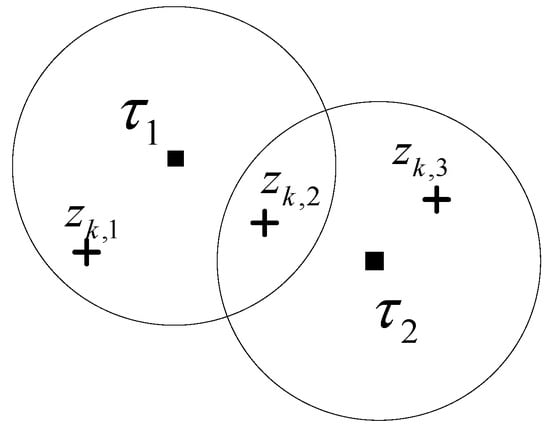
Figure 1.
An example of a cluster for two tracks and three measurement.
Each track is assigned to zero or one measurement, and each measurement is allocated to zero or one track. Two FJEs are different if at least one track-to-measurement assignment is different. All the FJEs for the cluster shown in Figure 1 are listed in Table 1. Note that we use j to denote the j-th FJE in Table 1.

Table 1.
Joint event set of the cluster in Figure 1 (‘ ’ means no allocation of measurements).
Let denote the total number of tracks in a cluster. Let and denote the total number of measurements in the cluster and the number of measurements in the validation gate of track in the cluster, respectively. The set of tracks in the cluster, and the sets of and measurements are defined by
The number of unique assignments of measurements to tracks, assuming that all tracks select all measurements satisfies [10]
The number of all the FJEs depends only on the number of measurements, the number of tracks, and the measurements.
Since and in Equation (17) are mutually exclusive and exhaustive in the set of cluster tracks,
The tracks in are assigned to non-detection and the tracks in are assigned to one of the cluster measurements that is not shared by other tracks in . The a posteriori probability is assigned to the tracks in and the a posteriori probability is assigned to the tracks in .
Therefore, the a posteriori probability of FJE can be expressed by
where denotes the measurement state of measurement allocated to track in the FJE , and the measurement state can be no detection or a member of , as described in Equation (25).
If we denote that the number of all FJEs for and is , then the following matrix of which the element represents the a posteriori probability of track , of FJE . The matrix is called the a posteriori probability matrix of FJEs (PMFJE) and is denoted by such as
where the rows represent tracks and the columns represent FJEs. The th element of represents the a posteriori probability of track to measurement association for track and the measurement with state for FJE . The a posteriori probability of FJE is calculated by multiplying all the elements in the column j of such as
where is an element in the th row and the th column of . Each column j of represents the collection of elements in of FJE . Any two measurement states and that are assigned to track and , respectively, in FJE should be different according to the FJE condition described in Section 2.1, i.e., if . The PMFJE for the cluster tracks shown in Figure 1 can be obtained as follows:
3. Markov Chain Based JIPDA (MCJIPDA)
The number of feasible joint events increases combinatorially with the number of measurements and the number of tracks involved, as shown in Equations (21) and (22). For tracking closely located multiple targets in heavily cluttered environments, , the total number of all the FJEs, becomes too large for the association probability computation to be feasibly handled. This is the main reason why JPDA or JIPDA cannot be applied in real-time applications for these environments. Since the computational resource involved in two consecutive scans can vary significantly depending on the number of all the FJES for the tracking environment. It is hard to predict in advance. However, the tracking algorithms must be executed in a predictable cycle for real-time applications. Therefore, the algorithms with the reduced number FJEs are needed. The reduced size PMFJE should represent the significant joint events for data association effectively while neglecting most of insignificant joint events to approximate the data association probabilities and thus to maintain similar performance to JIPDA.
An approximated version of PMFJE is determined by the Markov chain approach in this paper by generating a matrix, with much smaller than , using the Markov chain approach. In this paper, the proposed Markov chain data association algorithm utilizes a Markov chain to generate the FJEs. For the PMFJE, of in every row of for each track is generated sequentially according to the Markov chain property.
A Markov chain is a sequential stochastic process. Assume that has state at step n satisfying the Markov property
then the probability of moving to the next state at step n+1 depends on the present state but not on the past state history. By utilizing the Markov chain property of Equation (29), the state generation becomes computationally efficient as one does not need to store the entire past state histories but only the current states to generate the next states. A Markov chain process with the Metropolis-Hasting algorithm is presents for generating FJEs in [20]. A Markov chain process with randomized transition probabilities instead of deterministic values to improve modelling of stroke disease is proposed in [22]. This approach is known to be useful for decision making with real medical data.
A direct consequence of the Markov property is that the Markov chain can be generated sequentially (). For a finite discrete state set, a Markov chain can be represented by a transition probability matrix of which the element denoted by represents the transition probability from state u to state v in one step. The transition probability of a homogeneous Markov chain is given by
and the transition probabilities satisfy
for every u. Note that u and v belong to the same measurement state set.
To obtain the reduced size FJEs for data association with the Markov chain in this paper, the states of the Markov chain are defined as elements of the set for every track in . The move from to is accepted with the transition probability , for . A sequence with N elements is generated from the set with the transition probability matrix developed from IPDA for single target tracking in clutter. We call it a Markov chain measurement allocation sequence (MCMAS). The MCMAS is applied for other tracks to form a FJE. Design of the Markov chain with the transition probabilities developed from IPDA is illustrated in Section 4. If is the same as that is the measurement state selected by another track, then regenerate until it avoids to ensure the FJE condition of multi-target tracking. The procedure can be illustrated with an example shown in Figure 1, each MCMAS of length for each track is generated as following. For track , the first MCMAS is generated from a measurement set where ‘0’ means no assignment case. By the same way, the second MCMAS of track is generated from a measurement set . For example, the first MCMAS in length 5 can be , which is generated from the Markov chain random process, as shown in Figure 2. The second MCMAS can be obtained as . The next is to check the measurement-to-track assignment from the MCMAS for the FJE condition for , which is represented by . In this case, , , , and . Among them violates the FJE condition that implies no two tracks share the same measurement. In the above example, of track is the same as of track , so of track is regenerated to avoid and to ensure the FJE condition. This can be done by checking the assigned elements in the same column of before moving to the next column.
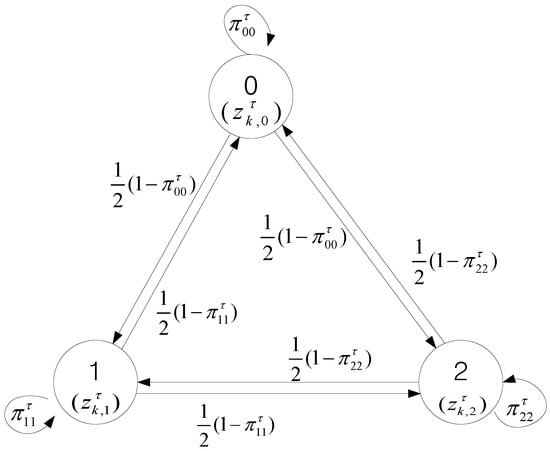
Figure 2.
An example of a three-state Markov chain for track with two measurements.
The approximated PMFJE, is completed by using the probability weight defined in Equation (25), and the a posteriori probability of joint event is obtained by replacing index with the index in Equation (27). The normalization constant for the approximated is obtained from .
After the Markov chain track sequences, for cluster tracks is obtained, the approximated PMFJE is completed. From the approximated , the track to measurement association probabilities and are obtained from Equation (10) and the a posteriori PTE for track in is obtained from Equation (15).
4. Design of Transition Probabilities for MCJIPDA
The data association probabilities of IPDA are utilized for developing the transition probabilities of the proposed Markov chain. Consider validated measurements for a track among the cluster tracks of a multi-target tracking situation. Denote by the joint set of measurements in the validation gate, where represents the case that no measurement is allocated to track . The transition matrix of track for the purpose of generating the sequence of length to represent the FJEs can be defined as
where
which is based on the posterior probability of joint event in Equation (25). Besides, it is assumed that the state of measurement assignment changes to another state at the next step with the transition probability given by
The measurement likelihood ratio in the diagonal terms of the transition matrix is given by [8]
Furthermore, is defined to sum to one for every from the property of Markov chain
which implies that the non-diagonal elements in the same row of the transition matrix have the same likelihood for transition. For example, the Markov chain for track with the set of measurements is depicted in Figure 2. In this example, the transition probability matrix becomes
If the (n−1)-th assignment of MCMAS for track is , the n-th element of MCMAS is generated according to the second row of the transition probability matrix in Equation (38) and a uniform random number in the interval [0, 1]. If the random number satisfies , then . If the random number satisfies , then the measurement is assigned to . Similarly, if , then .
By utilizing the data association probabilities of IPDA for each track in the cluster as acceptance probabilities of the measurement state generation in the form of transition probabilities of the Markov chain, the proposed method does not need a Monte Carlo algorithm that may produce a large number of burn-in samples.
The MCMAS of length for track is the key to resolve the computational risks of JIPDA. It is obvious that the FJEs of JIPDA are within the tractable range in the situations where targets are not closely located in the surveillance region. However, the target-crossing situations, the FJEs increase to prohibitively high numbers. Therefore, we propose an algorithm switch method according to the number of FJEs. If the number of FJEs is less than the length of the MCMAS predetermined for the Markov chain data association, the JIPDA algorithm is applied, and otherwise, the Markov chain data association algorithm is used and plays an important role in reducing the computational load.
The proof of convergence of the target tracking performance of the proposed algorithm to that of the JIPDA algorithm is left for future studies. However, the convergence is shown through a series of simulations in Section 5.
5. Simulations
The two-dimensional surveillance region considered in the simulation study is shown in Figure 3. The surveillance area is 1000 m long (x-axis) and 1000 m wide (y-axis), and the sensor scan time . Eight targets move uniformly at a constant speed of 22.5 m/s during the time of 40 scans and cross each other at about scan 20. The clutter measurements follow a Poisson distribution with clutter densities of in the sparse clutter region and in the dense clutter region, which is 500 m long and 500 m wide as indicated by the gray area in Figure 3. Three cases for performance comparison with different detection probability and different clutter density are listed in Table 2.
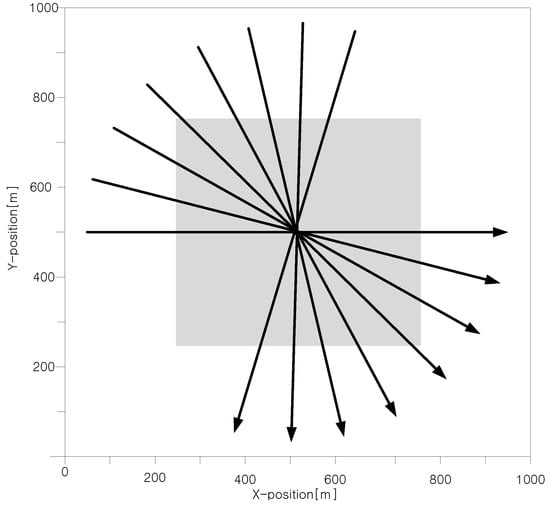
Figure 3.
Target scenario for simulation.
Table 2.
Simulation cases.
The state vector of target in Equation (1) consists of the two-dimensional position and velocity in Cartesian coordinates with transition matrix
where is a 2 × 2 null matrix. The variance of the process noise in Equation (1) is known to be
where .
The measurement noise covariance matrix for the sensor is
The propagation probabilities of Markov chain-one target existence in Equation (5) are given by
Each simulation experiment consists of 300 Monte Carlo runs. The tracks are initiated using two-point differencing initialization [10] with an initial PTE of 0.01. The tracks are confirmed if the PTE exceeds the confirmation threshold and they are eliminated if the PTE falls below the termination threshold of 0.006.
Figure 4 shows the average number of all the FJEs of JIPDA for Case #1 at every scan, in which the maximum mean number of FJEs is shown to be 44,209,586 at scan 20. The scenario of this simulation corresponds to that in Figure 3. The x-axis indicates the scan number, and the y-axis represents the mean number of FJEs in a logarithmic scale obtained from 300 Monte Carlo simulation runs, and the length of the MCMAS ( = 200) is shown for comparison. The number of all the FJEs increases sharply toward the target-crossing time.
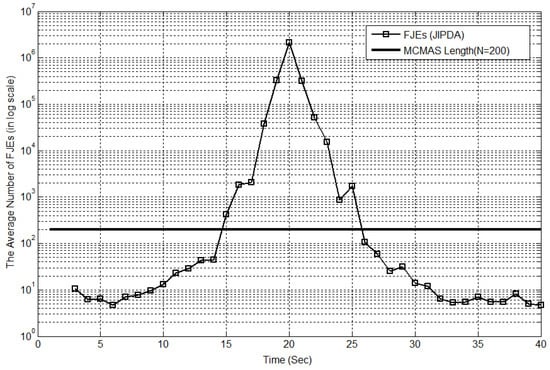
Figure 4.
The average number of feasible joint events (FJEs) of joint integrated probabilistic data association (JIPDA) for Case #1.
The track retention statistics to check the number of the confirmed true tracks after the target crossing at scan 20 are obtained by counting the number and identifying the track label of the confirmed true tracks at scan 15 before the target crossing and at scan 35 after the target crossing. The following statistics are accumulated:
- nCases: the total number of targets being followed by a confirmed track at scan 15;
- nOK: the number of “nCases” tracks that still follow their original tracks at scan 35;
- nSwitched: the number of “nCases” tracks that follow different targets at scan 35;
- nLost: the number of “nCases” tracks becoming false or terminated at scan 35;
- nMerge: the number of “nCases” tracks lost due to merging among “nCases tracks” at scan 35;
- nResult [CT]: the total number of targets being followed by a confirmed track at the last scan 40;
- CFT: the total number of confirmed false tracks during the entire simulation;
- CPU [sec]: the total CPU times for 300 Monte Carlo runs, in seconds, on a 3.6G Intel PC, running Windows 7, and C++ programs.
To determine the MCMAS lengths, we simulate the same scenario for N = 200, N = 500 and N = 1000 with the proposed MCJIPDA algorithm. The confirmed true track (CTT) rates are shown in Figure 5 and track retention statistics are shown in Table 3. The CTT rate indicates that the number of CTTs versus the number of targets at each scan of the Monte Carlo runs. As the length of MCMAS increases, the performance of MCJIPDA becomes improved. However, the computational load also increases as shown in Table 3. For the 3 MCMAS lengths, the CTT rates are almost same whereas the other track retention statistics are different. Table 3 indicates that the track retention statistics of N = 500 show improvement compared to those with N = 200. However, the target retention statics are shown to be similar for N = 500 and N = 1000. To save the computational sources without deteriorating the tracking performances, N = 500 is selected for MCJIPDA in the simulation studies.
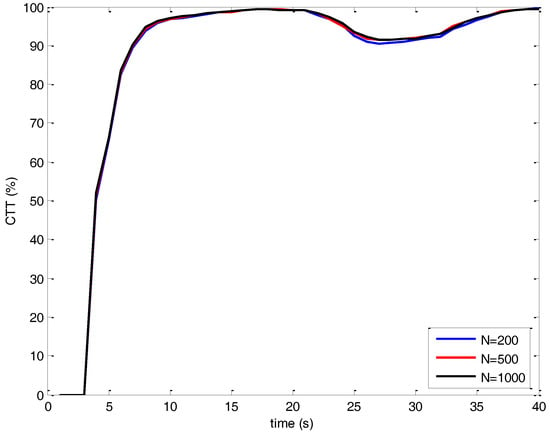
Figure 5.
Confirmed true track (CTT) rate for different Markov Chain (MC) lengths.
Table 3.
Statistics for different MC lengths.
We compare the proposed MCJIPDA with IPDA, LMIPDA, JIPDA, and iJIPDA with level 2 in terms of the FTD performance and the track retention statistics obtained from Monte Carlo runs. The MCJIPDA algorithm is simulated by using Markov chain sequences with the length of 500 for data association at every scan when the number of cluster tracks is more than 1. As mentioned in the previous section, when the FJEs in the cluster tracks is less than , JIPDA can be used instead of the proposed MCJIPDA. Otherwise, the MCJIPDA generates the -length FJEs for the cluster tracks.
The FTD is shown as the CTT rate in Figure 6, Figure 7 and Figure 8. The number of confirmed false tracks (for the scenarios with different parameters listed in Table 2) for each multi-target tracking algorithm should be kept almost same for fair comparison. To achieve this, the initial PTEs of all the algorithms are set to be the same, whereas the confirmation threshold of each algorithm is adjusted within the range from 0.995 to 0.9999 to produce approximately 71 to 75 confirmed false tracks. In this scenario, the complete number of confirmed true tracks is 2400 for 300 Monte Carlo runs. As the maximum numbers of FJEs of JIPDA in Case #2 and Case #3 are over . The JIPDA algorithm cannot perform tracking in real time. The simulation results of JIPDA are not shown for these two cases.
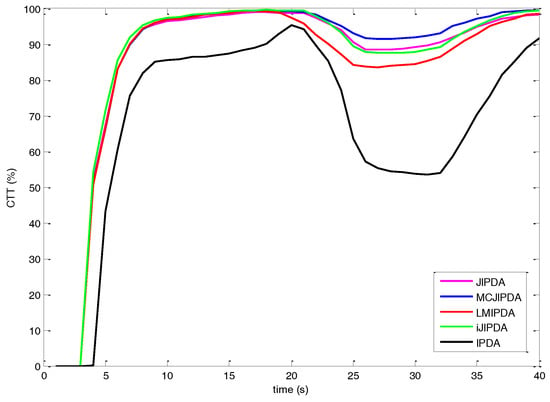
Figure 6.
The confirmed true tracks rate for Case #1.
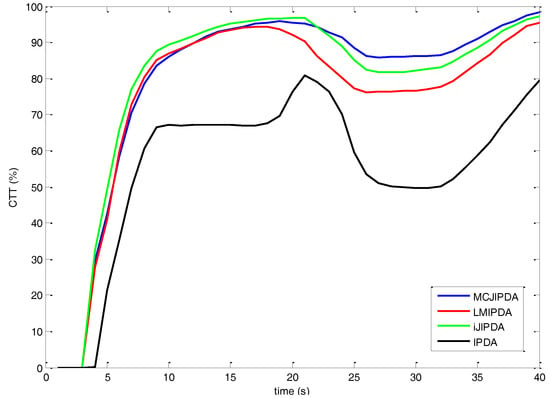
Figure 7.
The confirmed true tracks rate for Case #2.
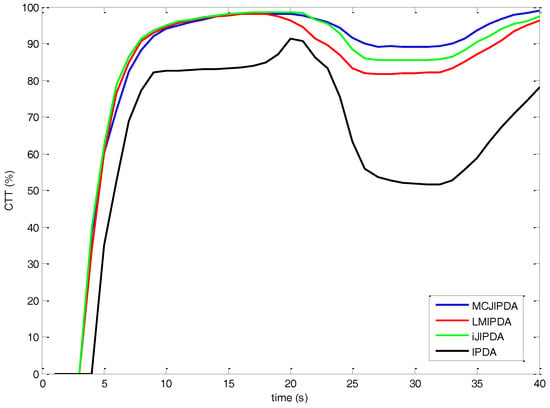
Figure 8.
The confirmed true tracks rate for Case #3.
The simulation results and the CTT rates of Case #1 are shown in Figure 6 and Table 4. As shown in Figure 6, the MCJIPDA has the best performance on the CTT rate after the target crossing. The single-target tracker, IPDA, has poor performance in this multi-target tracking scenario. The CTT rates of JIPDA and iJIPDA are almost same. In Table 4, though the MCJIPDA has a larger number of nSwitched than the other trackers, it has much smaller number of nMerged. Besides, the nResults of MCJIPDA and iJIPDA are bigger than that of IPDA, LMIPDA, and JIPDA.
Table 4.
Track retention statistics for Case #1.
The simulation results for Case #2 are shown in Figure 7 and Table 5. Compared to Figure 6, the CTT rates of all the algorithms are sluggish and smaller in this reduced environment. As shown in Figure 7, though increase of the CTT rate of MCJIPDA is slower than those of LMIPDA and iJIPDA in the initial phase, the MCJIPDA has the best performance on the CTT rate after targets crossing. The single-target tracker, IPDA, also shows poor performance in this multi-target tracking scenario. In Table 5, though nSwitched of MCJIPDA is the biggest, but nMerged is the smallest among the algorithms in comparison. Besides, nResults of MCJIPDA is the biggest.
Table 5.
Track retention statistics for Case #2.
The simulation results for Case #3 are shown in Figure 8 and Table 6. The CTT rate for each algorithm shows similar trend shown in Figure 6 and Figure 7. Compared to Figure 6, the increase of the clutter densities affects the performance of the CTT rate, which shows slower and smaller than Case #1 for each algorithm compared to Case #1 in general. As shown in Figure 8, the increase of the CTT rate of MCJIPDA is slower than those of LMIPDA and iJIPDA, and MCJIPDA has the best performance on the CTT rate after target crossing.
Table 6.
Track retention statistics for Case #3.
In Figure 9, it is shown that how the computational cost varies with the number of targets and the number of measurements. When the number of target varies from 1 to 8, the computational load represented by CPU time is shown for IPDA, LMIPDA, iJIPDA, JIPDA, and MCJIPDA with the length 500 of MCMAS for the tracking environment of Case #1. IPDA, LMIPDA, iJIPDA, and MCJIPDA have linearly increasing CPU time for the number of targets. JIPDA has exponentially increasing time as the number of target increases. CPU times are measured on a 3.6G Intel PC running Windows 7 and C++ programs. All the algorithms in comparison are programmed by the authors and implemented without performance optimization and parallel computation.
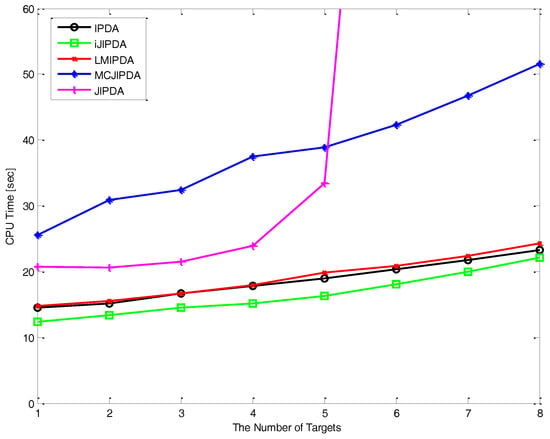
Figure 9.
Computational costs of algorithms vary with the number of targets.
6. Conclusions
This paper presents a practical Markov chain data association algorithm for approximating the probabilities of the FJEs of JIPDA, which would otherwise incur a prohibitively heavy computational load for closely located multi-target tracking in clutter. The proposed MCJIPDA algorithm sequentially generates the measurements by a Markov chain of events for each cluster target based on the transition probabilities established from IPDA for single target tracking. The events are adjusted by event regeneration to satisfy the feasible joint event condition for multi-target tracking. The length of MCMAS for the MCJIPDA algorithm is selected through simulation studies by checking the tracking performance as well as the computation time. In the simulation studies, the proposed MCJIPDA algorithm is compared with the other existing data association methods for several simulation scenarios. The simulation results show that the MCJIPDA with 500 selected events for joint data association is comparable to JIPDA with respect to false track discrimination and target retention outcomes but with substantially less computational load. This implies that the proposed MCJIPDA algorithm provides a viable solution for multi-target tracking in clutter, especially for tracking closely located targets in dense clutter.
Acknowledgments
This work was supported by the LIG-Nex1 Co. through Grant Y17-006.
Author Contributions
Taek Lyul Song conceived and designed the research; Eui Hyuk Lee and Qian Zhang performed simulation and analyzed the results.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Challa, S.; Moreland, M.; Musicki, D.; Evans, R. Fundamentals of Object Tracking; Cambridge University Press: Cambridge, UK, 2011. [Google Scholar]
- Zhang, Q.; Song, T.L. Improved Bearings-Only Multi-Target Tracking with GM-PHD Filtering. Sensors 2016, 16, 1469. [Google Scholar] [CrossRef] [PubMed]
- Mahler, R. Multitarget Bayes filtering via first-order multitarget moments. IEEE Trans. Aerosp. Electron. Syst. 2003, 39, 1152–1178. [Google Scholar] [CrossRef]
- Vo, B.T.; Vo, B.N.; Cantoni, A. Analytic implementations of the cardinalized probability hypothesis density filter. IEEE Trans. Signal Process. 2007, 55, 3553–3567. [Google Scholar] [CrossRef]
- Vo, B.T.; Vo, B.N.; Cantoni, A. The cardinality balanced multi-target multi-Bernoulli filter and its implementations. IEEE Trans. Signal Process. 2009, 57, 409–423. [Google Scholar]
- Bar-Shalom, Y.; Fortmann, T.E. Tracking and Data Association; Academic Press: New York, NY, USA, 1988. [Google Scholar]
- Bar-Shalom, Y.; Tse, E. Tracking in a cluttered environment with probabilistic data association. Automatica 1975, 11, 451–460. [Google Scholar] [CrossRef]
- Mušicki, D.; Evans, R.; Stanković, S. Integrated Probabilistic Data Association (IPDA). IEEE Trans. Autom. Control 1994, 39, 1237–1241. [Google Scholar] [CrossRef]
- Mušicki, D. Automatic Tracking of Maneuvering Targets in Clutter Using IPDA. Ph.D. Dissertation, University of Newcastle, New South Wales, Australia, 1992. [Google Scholar]
- Mušicki, D.; Evans, R. Joint Integrated Probabilistic Data Association: JIPDA. IEEE Trans. Aerosp. Electron. Syst. 2004, 40, 1093–1099. [Google Scholar] [CrossRef]
- Mušicki, D.; Evans, R. Multi-scan multi-target tracking in clutter with integrated track splitting filter. IEEE Trans. Aerosp. Electron. Syst. 2009, 45, 1432–1447. [Google Scholar] [CrossRef]
- Mušicki, D.; La Scala, B.; Evans, R. Multi-target tracking in clutter without measurement assignment. IEEE Trans. Aerosp. Electron. Syst. 2008, 44, 877–896. [Google Scholar] [CrossRef]
- Song, T.L.; Kim, H.W.; Mušicki, D. Iterative Joint Integrated Probabilistic Data Association. In Proceedings of the 16th International Conference on Information Fusion, Istanbul, Turkey, 9–12 July 2013; pp. 1714–1720. [Google Scholar]
- Song, T.L.; Kim, H.W.; Mušicki, D. Iterative Joint Integrated Probabilistic Data Association for Multitarget Tracking. IEEE Trans. Aerosp. Electron. Syst. 2015, 51, 642–653. [Google Scholar] [CrossRef]
- Roecker, J.A.; Phillis, G.L. Suboptimal joint probabilistic data association. IEEE Trans. Aerosp. Electron. Syst. 1993, 29, 510–517. [Google Scholar] [CrossRef]
- Romeo, K.; Crouse, D.F.; Bar-Shalom, Y.; Willett, P. The JPDA in practical system: Approximations. In Proceedings of the SPIE, Signal and Data Processing of Small Targets, Orlando, FL, USA, 16 April 2010. [Google Scholar]
- Reid, D.B. An algorithm for tracking multiple targets. IEEE Trans. Autom. Control 1979, 24, 843–854. [Google Scholar] [CrossRef]
- Blackman, S.; Popolis, R. Design and Analysis of Modern Tracking Systems; Artech House: Boston, MA, USA, 1999. [Google Scholar]
- Reuter, S.; Vo, B.T.; Vo, B.N.; Dietmayer, K. The labelled multi-Bernoulli filter. IEEE Trans. Signal Process. 2014, 62, 3246–3260. [Google Scholar]
- Oh, S.; Russel, S.; Sastry, S. Markov chain Monte Carlo Data Association for Multi-Target Tracking. IEEE Trans. Autom. Control 2009, 54, 481–497. [Google Scholar]
- Brereton, T. Stochastic Simulation of Processes, Fields and Structures; Institute of Stochastic: Ulm, Germany, 2014. [Google Scholar]
- Cortés, J.C.; Navarro-Quiles, A.; Romero, J.V.; Roselló, M.D. Randomizing the parameters of a Markov chain to model the stroke disease: A technical generalization of established computational methodologies towards improving real applications. J. Comput. Appl. Math. 2017, 324, 225–240. [Google Scholar] [CrossRef]
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).