Reasoning and Knowledge Acquisition Framework for 5G Network Analytics




Abstract
:1. Introduction
- In depth study of recent 5G-related research contributions. Several research topics related with the definition of the 5G technology, European research projects and network incidence management approaches have been studied with the purpose of laying the foundations, design principles and architectural components of the introduced framework. On the one hand, 5G provides research challenges to be addressed by innovative network architectures that are still under development, many of them targeted by recent European research projects. In particular, the SELFNET project offers a baseline architecture for network self-management in 5G mobile networks, under which the proposed framework was developed. On the other hand, advances on network incidence management in dynamic scenarios have been considered. Special interest has been put on the Endsley inspired architectures, since they motivated the adoption of a situational-awareness model in the proposed framework.
- A novel reasoning 5G-oriented architecture. A novel framework composed by functional elements arranged on an orchestrated workflow is proposed to enable reasoning capabilities in a 5G network. As a result, the framework generates conclusions about the 5G network status. The introduced architecture distinguishes two types of knowledge: procedural and factual. Procedural knowledge corresponds to the use case configuration loaded to the system. Initial factual knowledge is acquired by discovery methods applied on data previously collected by several sensors distributed along the 5G network, whereas factual knowledge is generated by the prediction, pattern recognition and knowledge inference modules introduced in this proposal. Thereby, the framework approaches the perception, comprehension and projection steps of the Endsley model.
- Instantiation of the framework. An instance of the proposed framework has been created to enhance the understanding of the proposal. To this end, well-known multiplatform open source technologies and a battery of prediction and machine learning algorithms have been integrated in accordance with the framework design. In addition, publicly available datasets were applied to allow its experimental replicability. The generation of knowledge was successfully demonstrated in a datacenter-oriented use case, even though the current instance of the framework can be applied to several use cases just by modifying its configuration.
- Comprehensive experimentation on a real use case. To assess the accuracy of the instantiation, a set of experiments have been conducted. They were oriented either for the evaluation of the pattern recognition and prediction modules; and for the evaluation of a real use case. Prediction and pattern recognition features exposed good accuracy levels when applied over the reference datasets. Likewise, a particular use case configuration to generate conclusions about traffic behaviour has been tested. The experiments were conducted on real network traffic samples where the inference of suspicious network traffic volumes in a datacenter exposed good precision rates contrasted with the real reference scenario.
2. Background
2.1. Research in Fifth Generation Networks
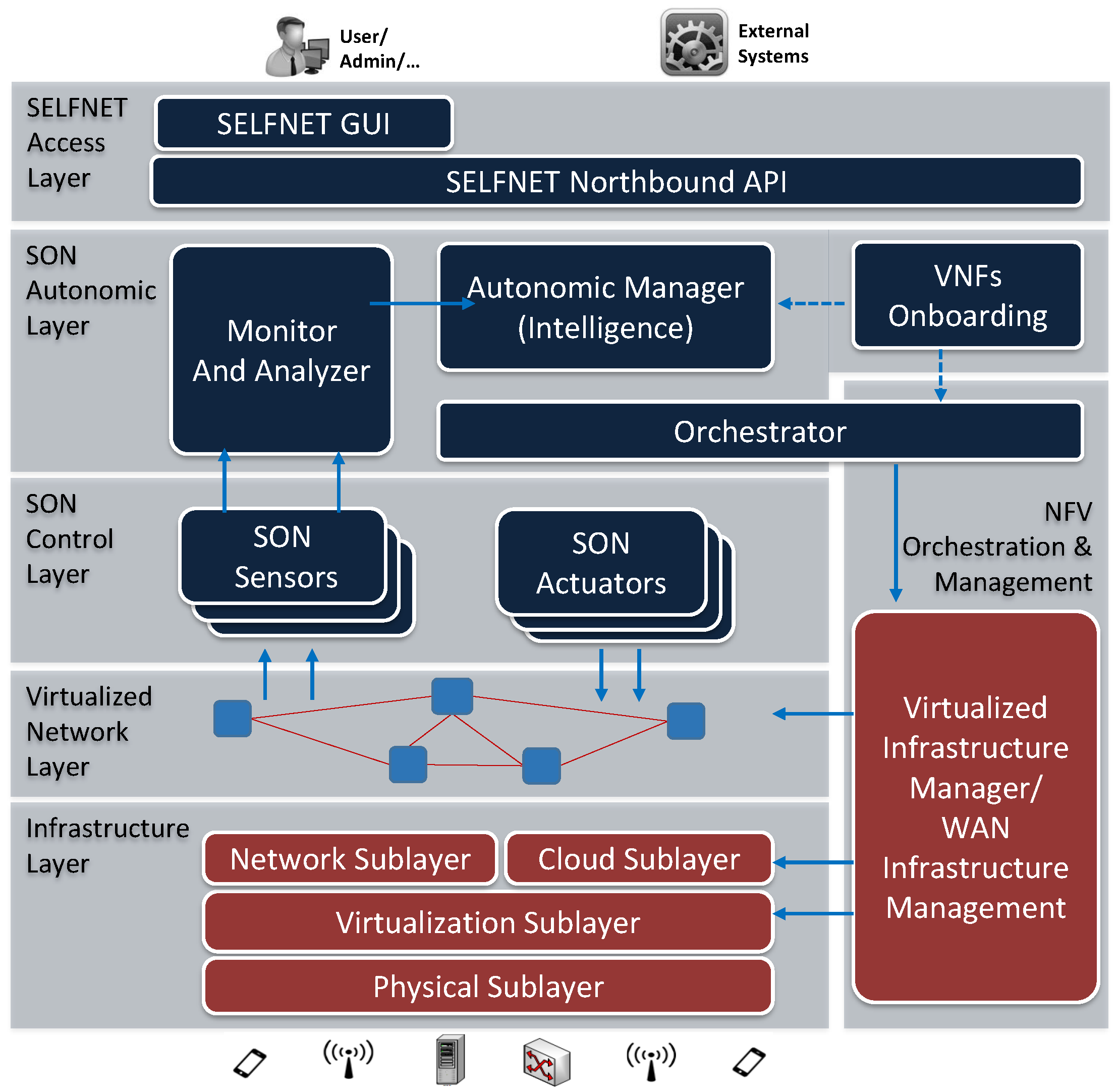
2.2. SELFNET
- Monitoring has the main objective of collecting a wide range of low level metrics and events from the physical and virtual network infrastructure, as well as from deployed sensors.
- Aggregation and Correlation methods reduce the amount of monitored information, by inferring aggregated metrics about a specific network domain. Meanwhile, events are correlated and filtered to avoid redundant or non-sensitive information.
- Analysis is aimed for reasoning and knowledge acquisition about the operational network context deducted from the analysis of aggregated monitored metrics. This process is accomplished by pattern recognition capabilities, prediction methods, and knowledge inference procedures in order to deduce conclusions regarding potential network failure or degradation scenarios projected from the observations.
2.3. Network Incident Management
3. Reasoning and Knowledge Acquisition Framework
3.1. Design Principles and Constraints
- Scalability. The proposed framework must accommodate the 5G design principles, and in particular, those associated with scalability, such as “Extensibility by design”, “Expandability by design” or “Multi-level scalability by design” [33], through the combination of scalable modular design, open interfaces and APIs to enable third parties to create their own automatic network management services.
- Support of use case onboarding. The knowledge acquisition framework adopts a use case driven research methodology. Because of this it is required that from design, it must support the onboarding of new different use case specifications. Given the heavy reliance of the tasks performed with the characteristics of use cases, the basic definition of the observations to be studied (knowledge-base objects, rules, prediction metrics, etc.) must be provided as factual knowledge by use case operators, thus being the framework scalable to alternative contexts. In addition, use case operators must provide procedural knowledge, thus configuring the analytic tasks to be performed per use case. More information about these knowledge representations is detailed in [55].
- Reference datasets. Laskov et al. [56] realized two essential observations necessary to understand the different strategies for acquiring reference knowledge and to decide the most appropriate for each use case: firstly, it must be taken into account that labeled samples are very difficult to obtain, a situation that can be aggravated if the sensor operates in real time, and/or on monitoring environments where is not possible to extract all the data; on the other hand, there is no way of collecting labeled samples which cover every possible incidence, so the system is potentially vulnerable to unknown situations. To these difficulties it is added the problem that there are no collections of traffic captures in 5G networks, and that the existing datasets of current traffic traces often have drawbacks such as lack of completeness or labeling errors. Because of this, the proposed framework does not go deep into the issue of the innate knowledge acquisition. The current approach assumes that the reference datasets are provided by skilled operators or by accurate machine learning algorithms, which therefore are valid for the specified use cases.
- Granularity. 5G environments are complex monitoring scenarios where large amounts of sensors collect information about the state of the network in real time. In SELFNET all this information is processed in the Aggregation sub-layer, which provides the necessary metrics to infer knowledge from them. However, this information is not raw processed. As described in [54], it is compiled into Aggregated Data Bundles (ADBs), which summarize all the system information observed over a time period related with the previously declared uses cases. The length of the observation period defines the data granularity, which may be determinant for the proper functioning of certain uses cases. However, the decision of the best granularity is out of the scope of this paper.
- Stationary monitoring environment. By definition, the features monitored on a stationary scenario are similar to those considered when building data mining models. The assumption of operating on a stationary monitoring environment entails ignoring in terms of learning process any variation in the characteristics of the information to be studied, such as dimensionality or distribution. The main disadvantage of this approach is the loss of precision when such changes occur, in large part because the initially performed calibrations are not adapted to the current status of the network. On the other hand, their proper accommodation tends to retain the acquired calibration at the expense of addressing many other issues, emphasizing among them to discover relevant variations in the data nature, calibration upgrades based on the new features, or improvement of the original datasets [57]. Being aware that the last approach poses important challenges, and in order to facilitate the understanding of the proposed research, all those aspects related to the management of the non-stationary characteristics of the information are overlooked.
- High dimensional data. When the dimensions of the data to be studied are more extensive than usual, it is possible that some reasoning and knowledge acquisitions implementations lose effectiveness, either in terms of efficiency or accuracy. Because of this, the bibliography provides a wide variety of publications focused on the optimization of this kind of processes, as is discussed in [58]. Note that the battery of algorithms included in the current instantiation of the framework does not adapt any of these contributions, which does not mean that it is incompatible with them. However, throughout the document the risks of operating with high dimensional data are not taken into account, in this way postponing this problem to future instantiations.
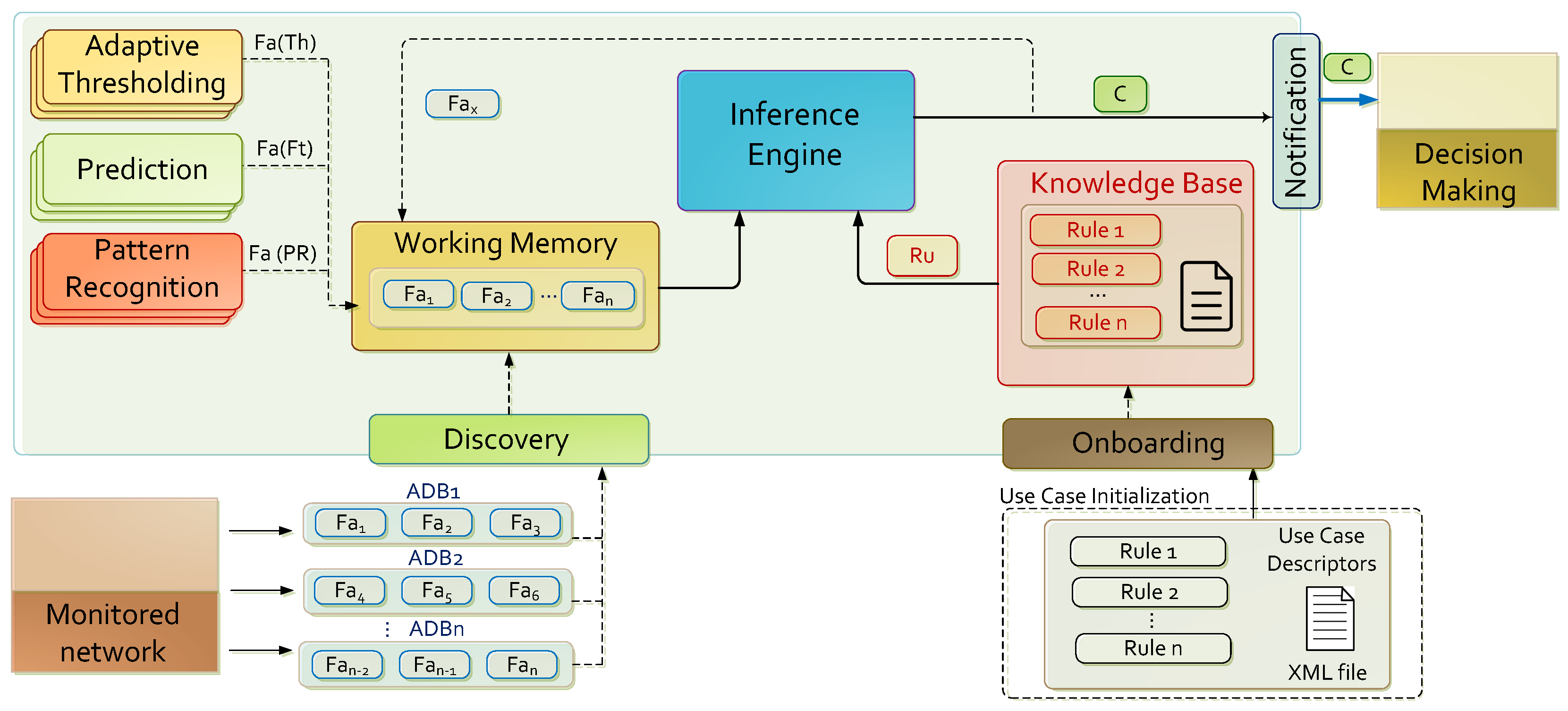
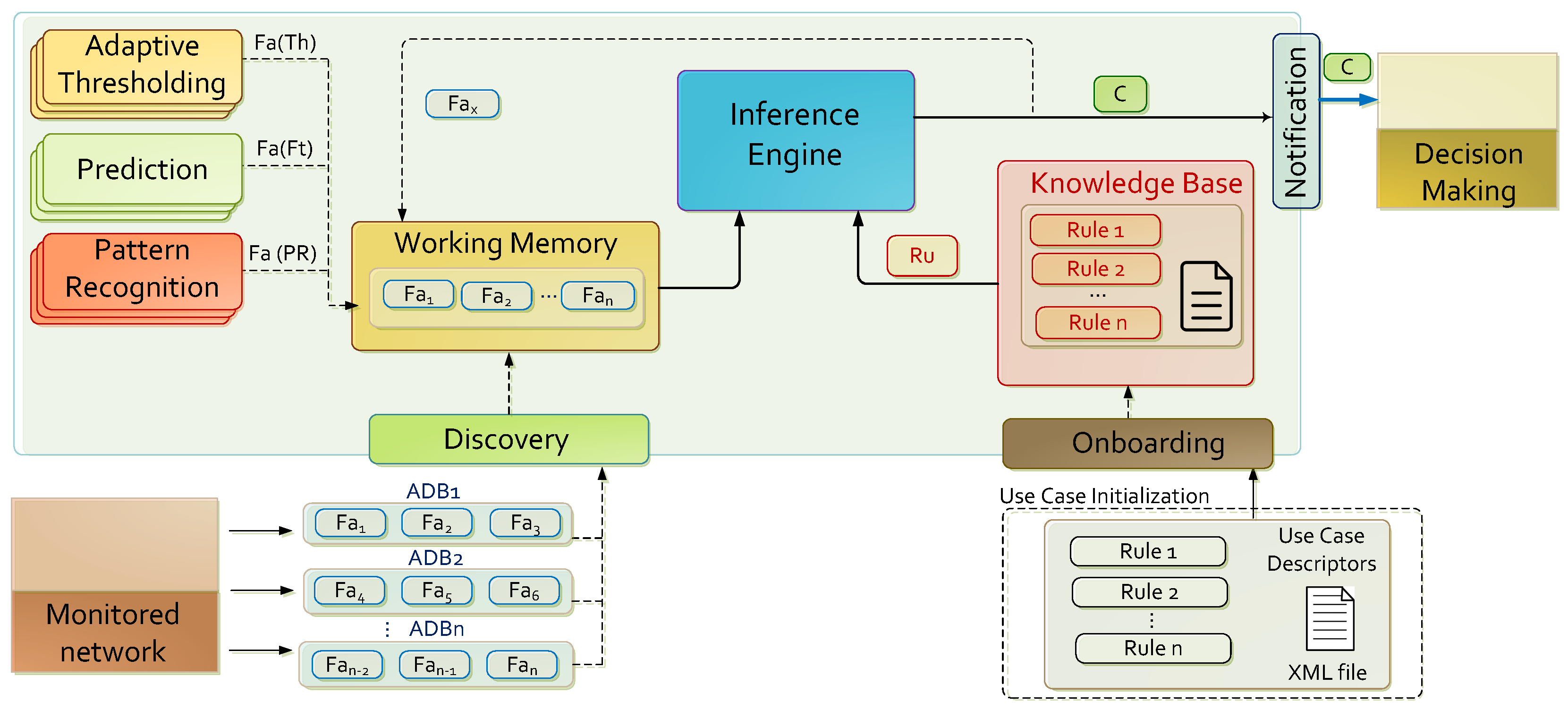
3.2. Architecture
3.2.1. Initial Knowledge and Notification
3.2.2. Prediction Module
3.2.3. Adaptive Thresholding Module
3.2.4. Pattern Recognition Module
3.2.5. Knowledge Inference Module
3.3. Instantiation
3.3.1. Initial Knowledge and Notifications Implementation
3.3.2. Prediction Implementation
3.3.3. Adaptive Thresholding Implementation
3.3.4. Pattern Recognition Implementation
3.3.5. Knowledge Inference Implementation
4. Experiments
4.1. Evaluation Scenario
4.2. Reference Datasets
4.2.1. NSL-KDD
- Denial of Service attack (DoS): classes back, land, neptune, pod, smurf and teardrop; 391,458 (79.24%) instances.
- User to Root attack (U2R): classes Buffer overfow, loadmodule, perl and rootkit; 52 (0.01%) instances.
- Remote to Local attack (R2L); classes Guess_passwd, ftp_write, imap, phf, multihop, warezmaster, warezclient and spy; 1126 (0.23%) instances.
- Probing attacks: classes satan, ipsweet, nmap and portsweep; 4107 (0.83%) instances.
4.2.2. M3 Competition
4.2.3. CAIDA Anonymized Internet Traces 2016
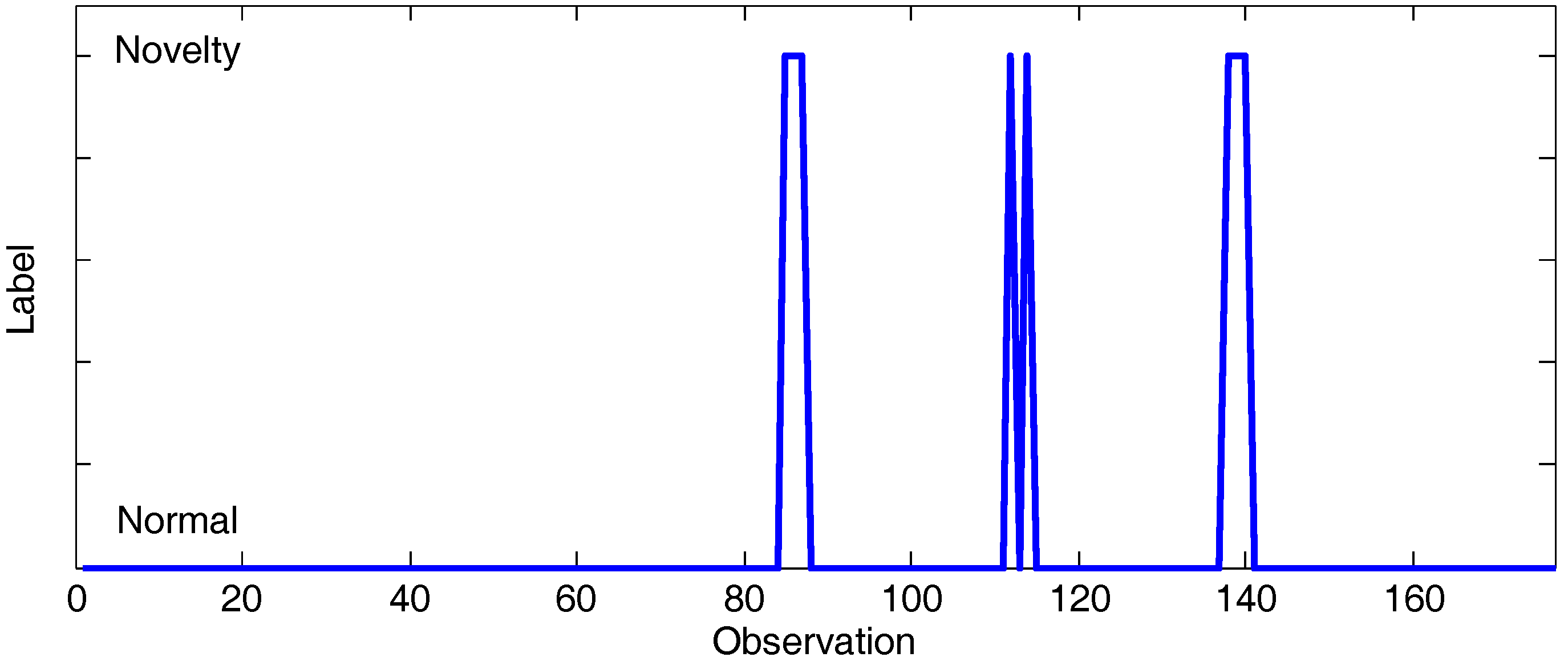
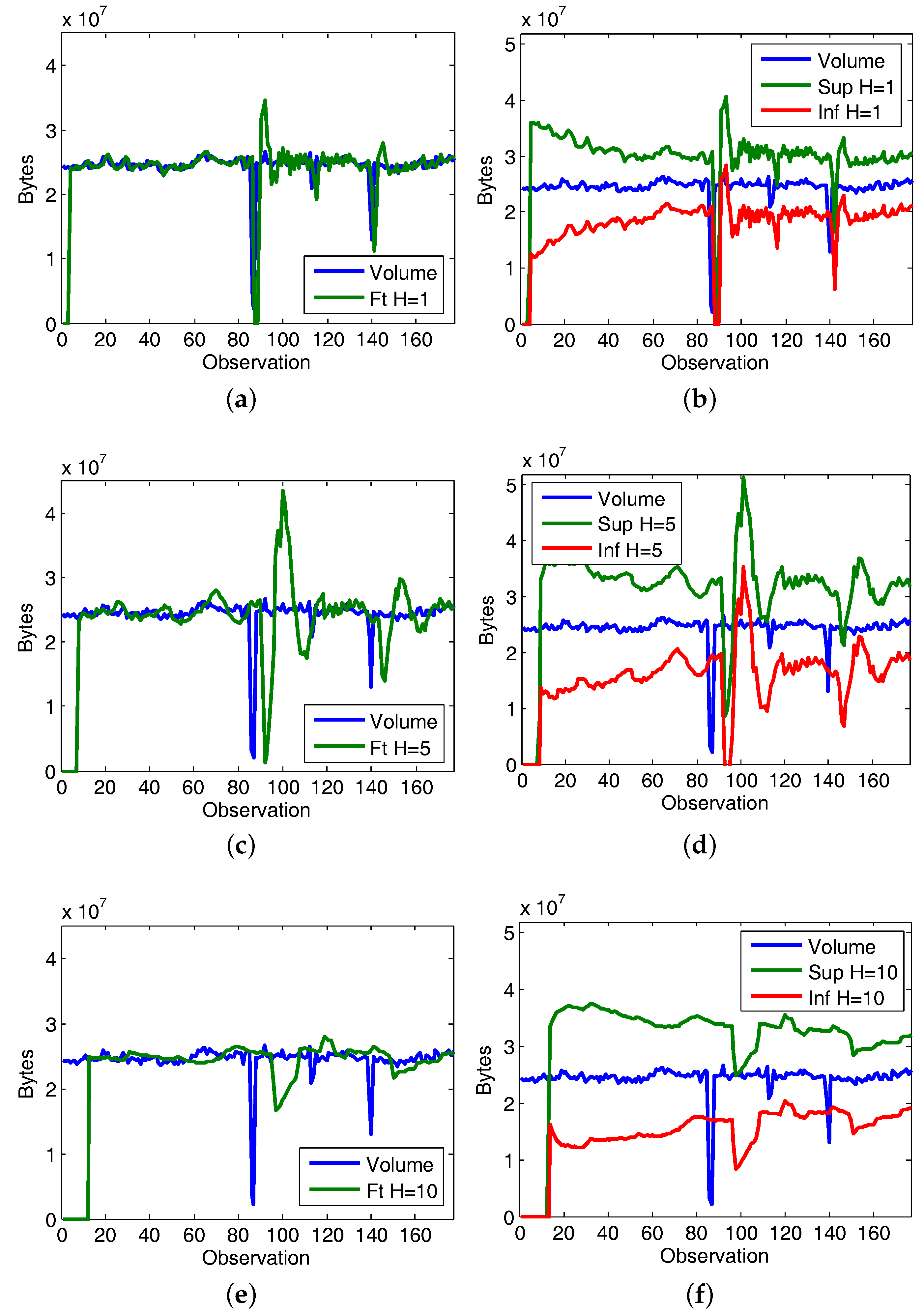
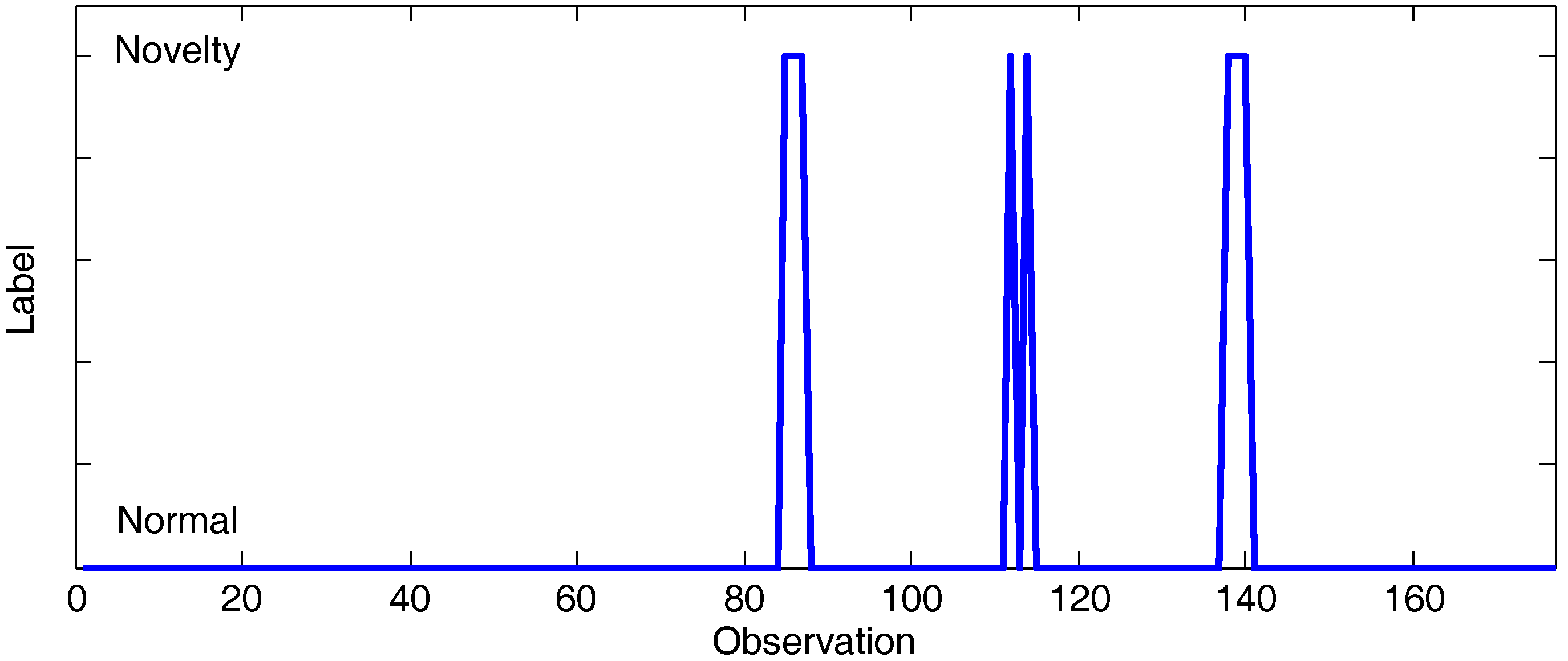
4.3. Use Case: Detection of Anomalous Traffic Volume Variations
5. Results
5.1. Prediction Capabilities Evaluation
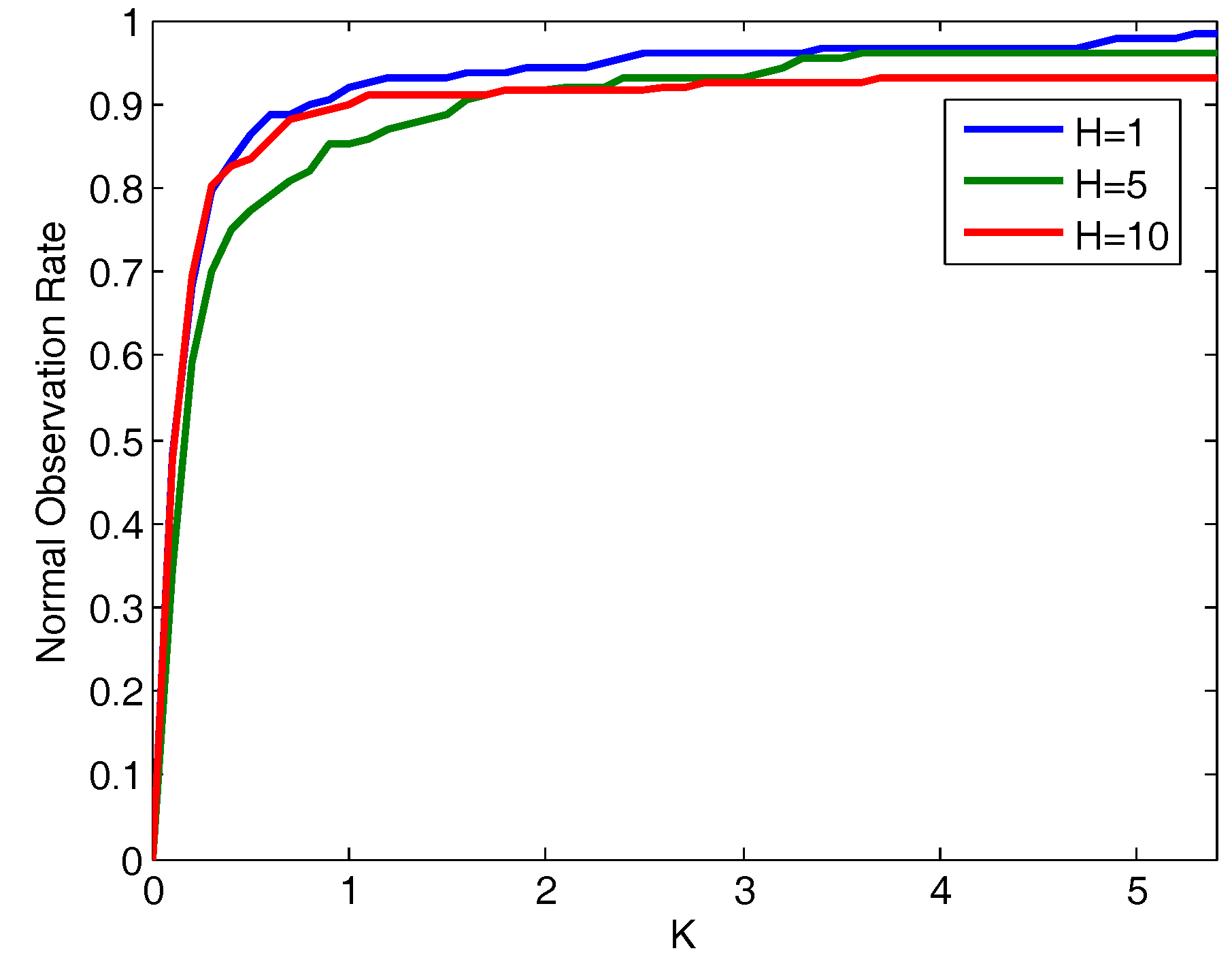
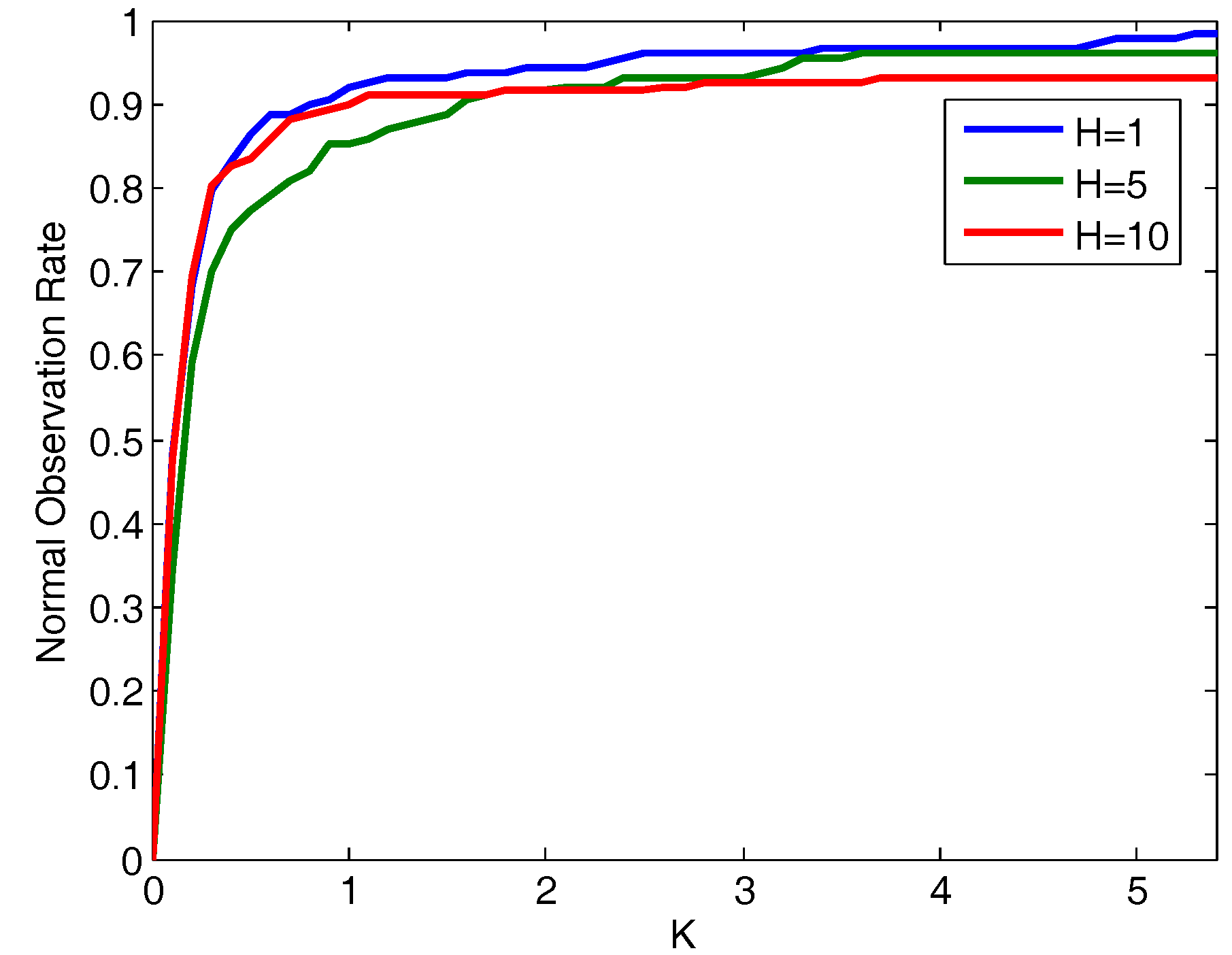
5.2. Pattern Recognition Capabilities Evaluation
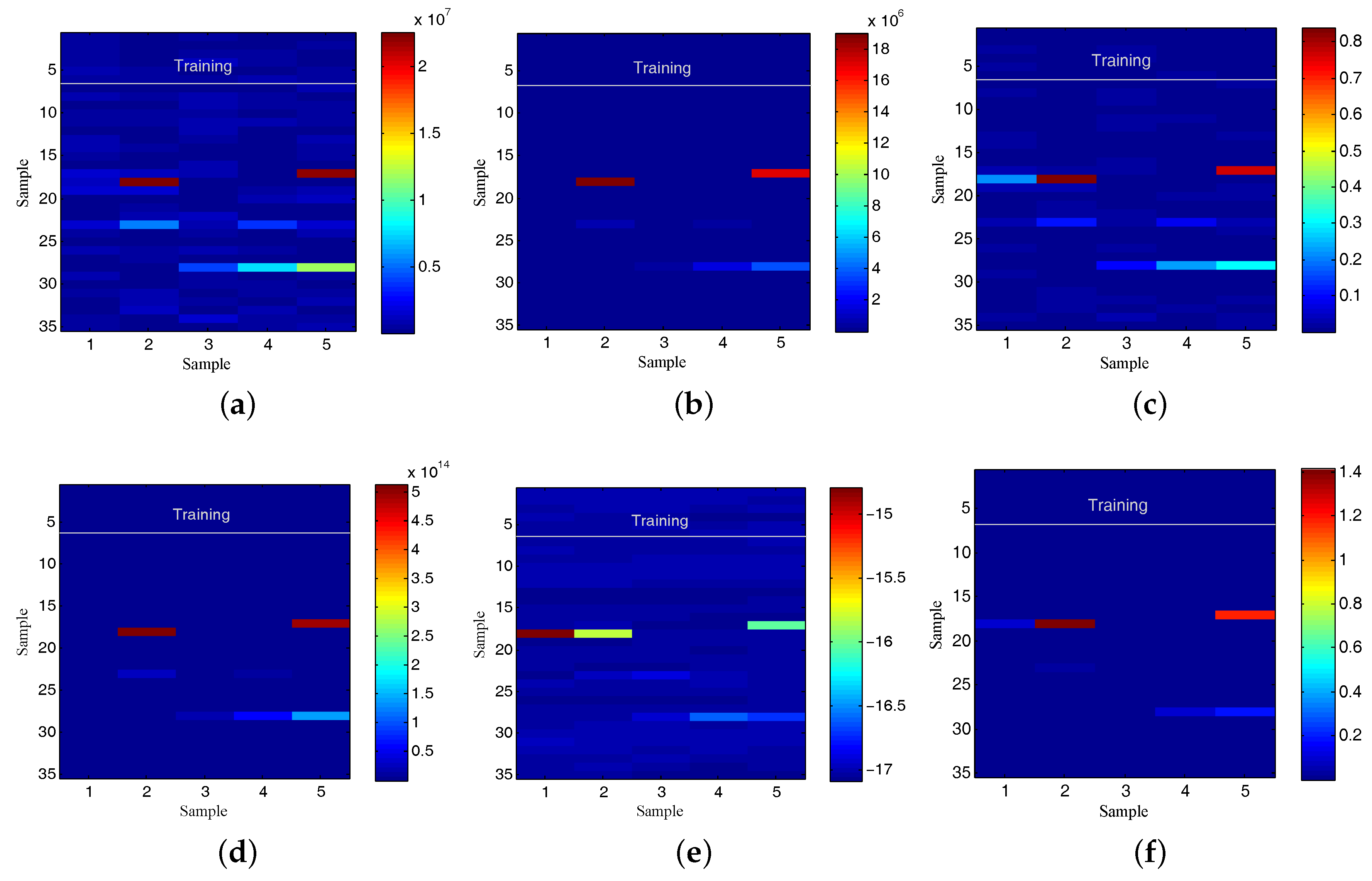
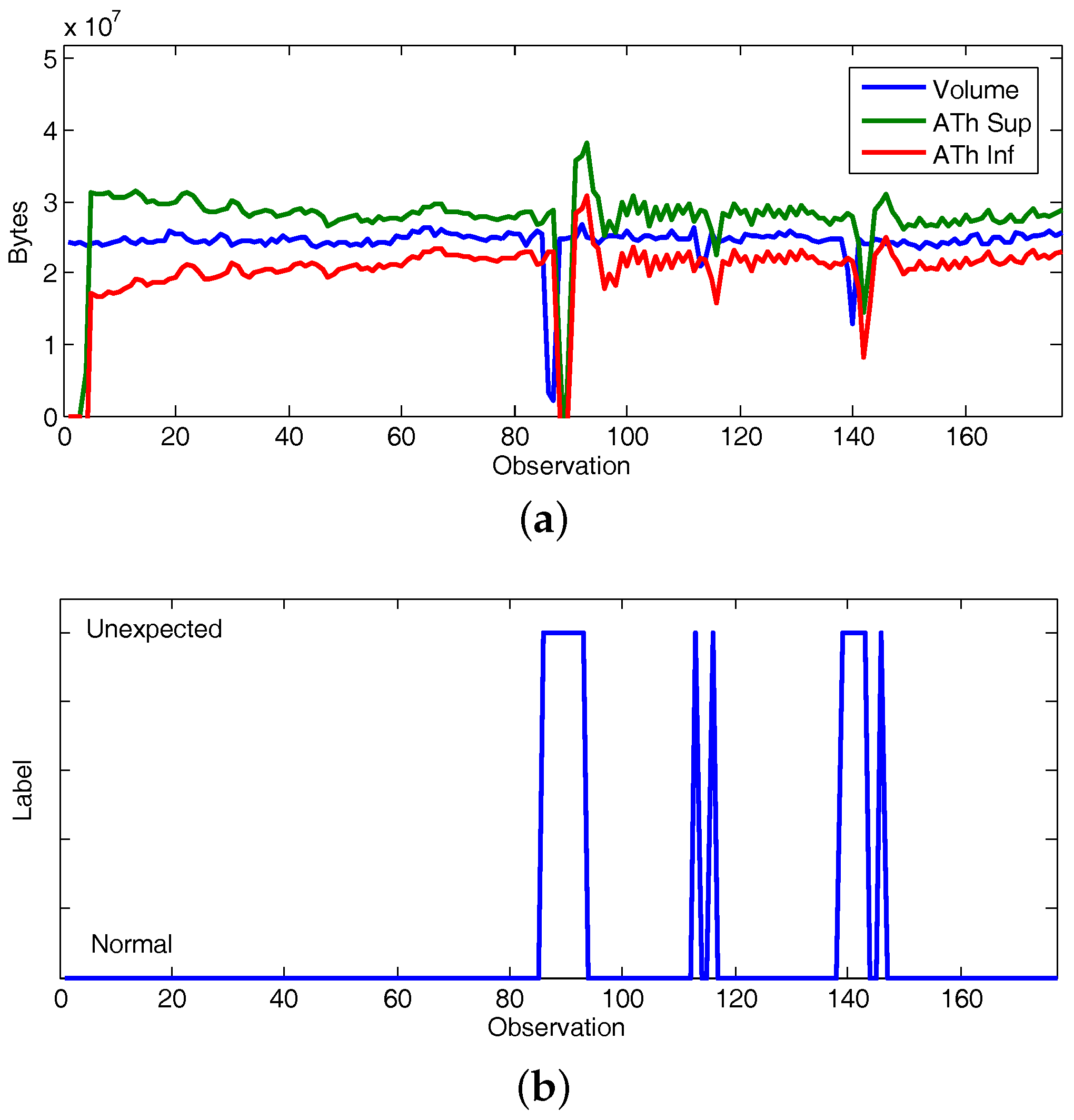
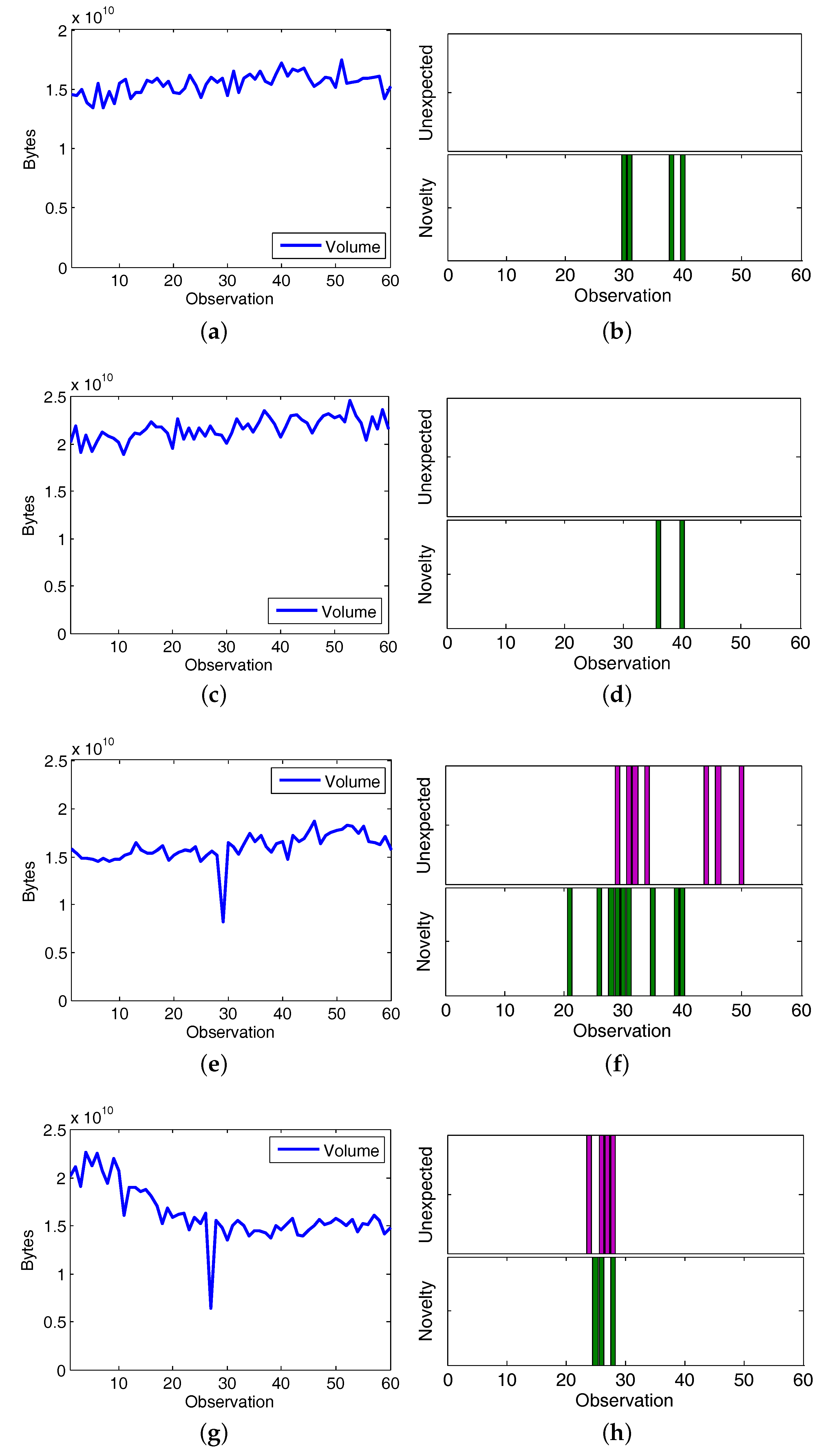
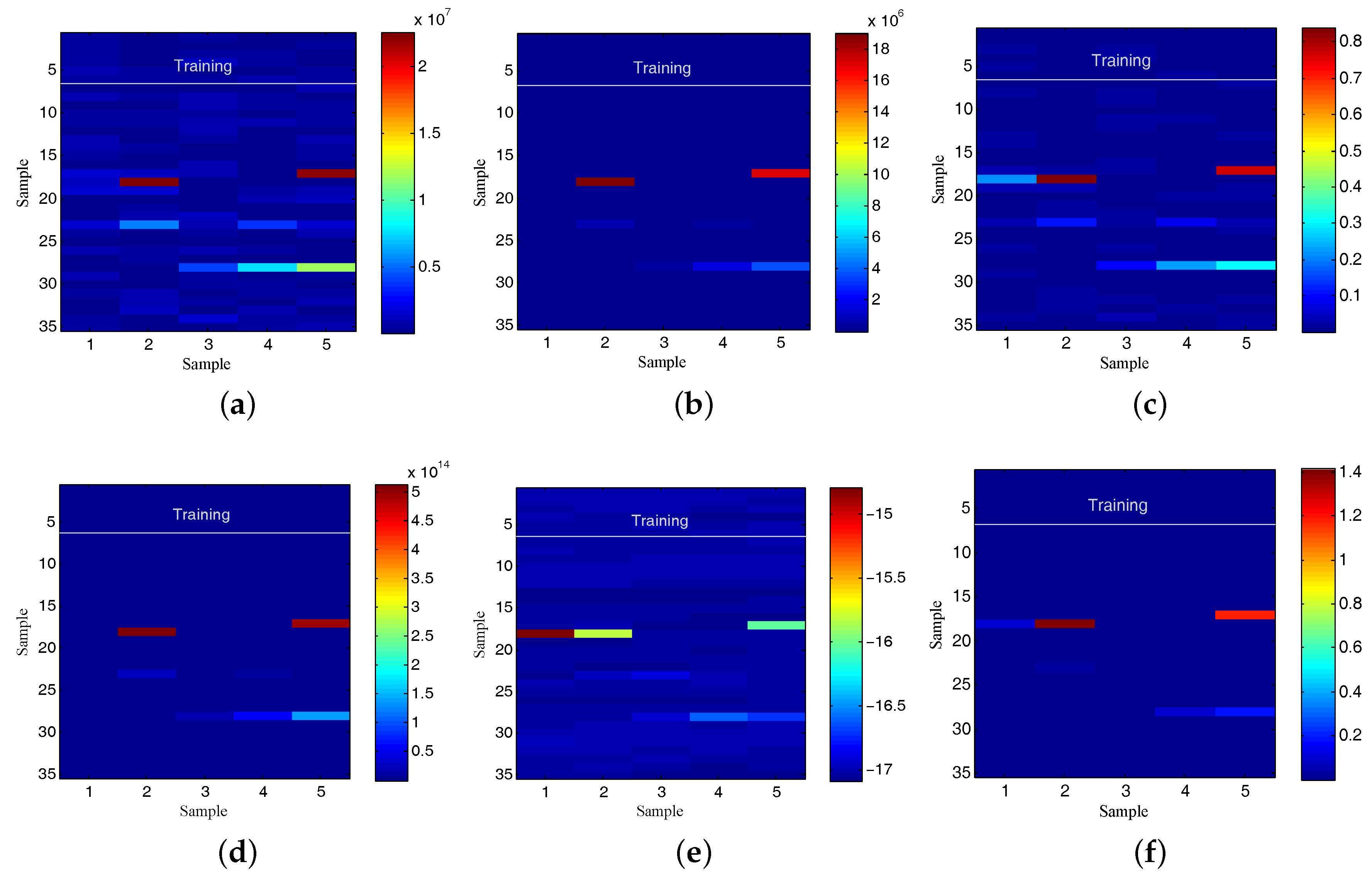
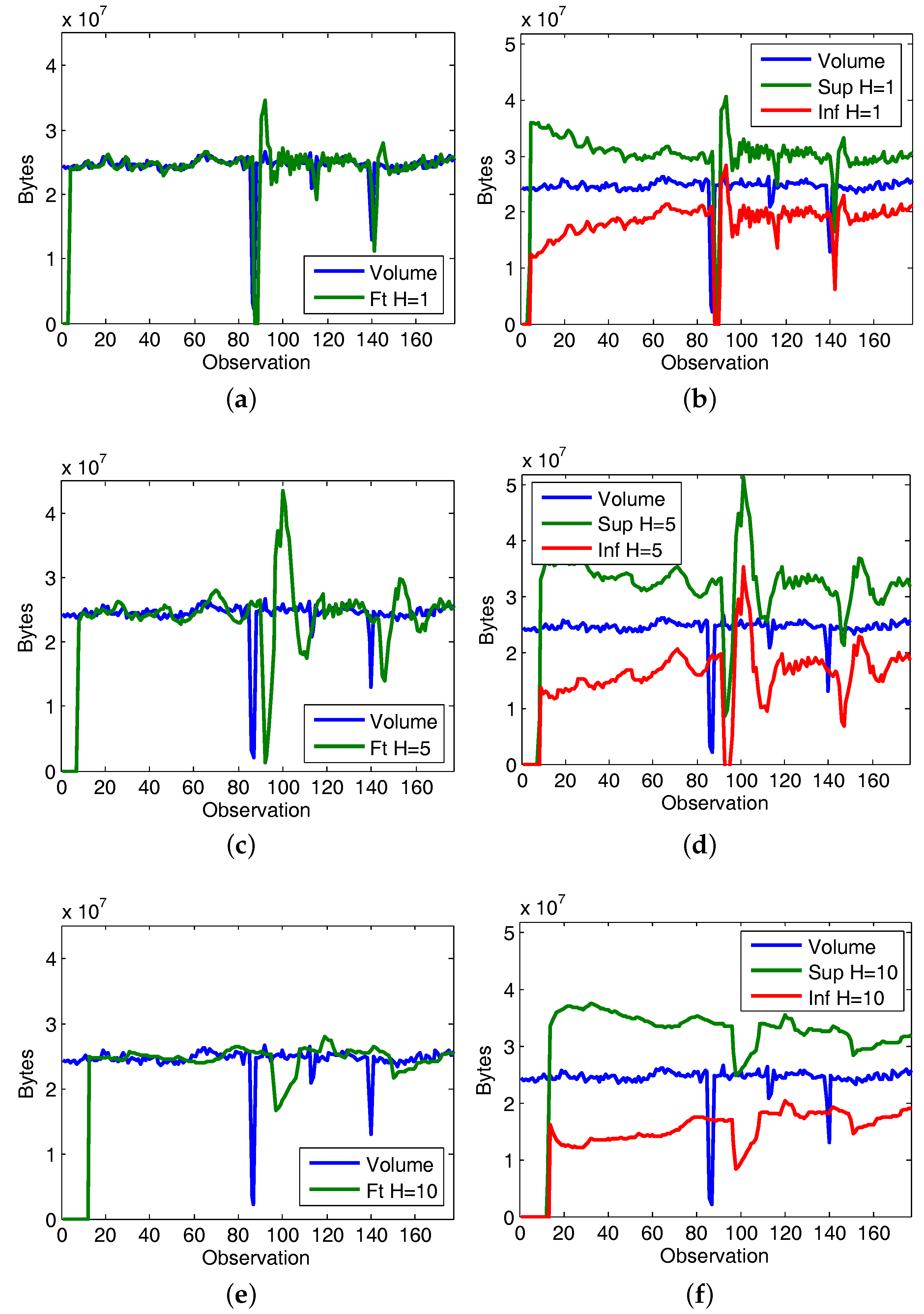
5.3. Use Case Evaluation
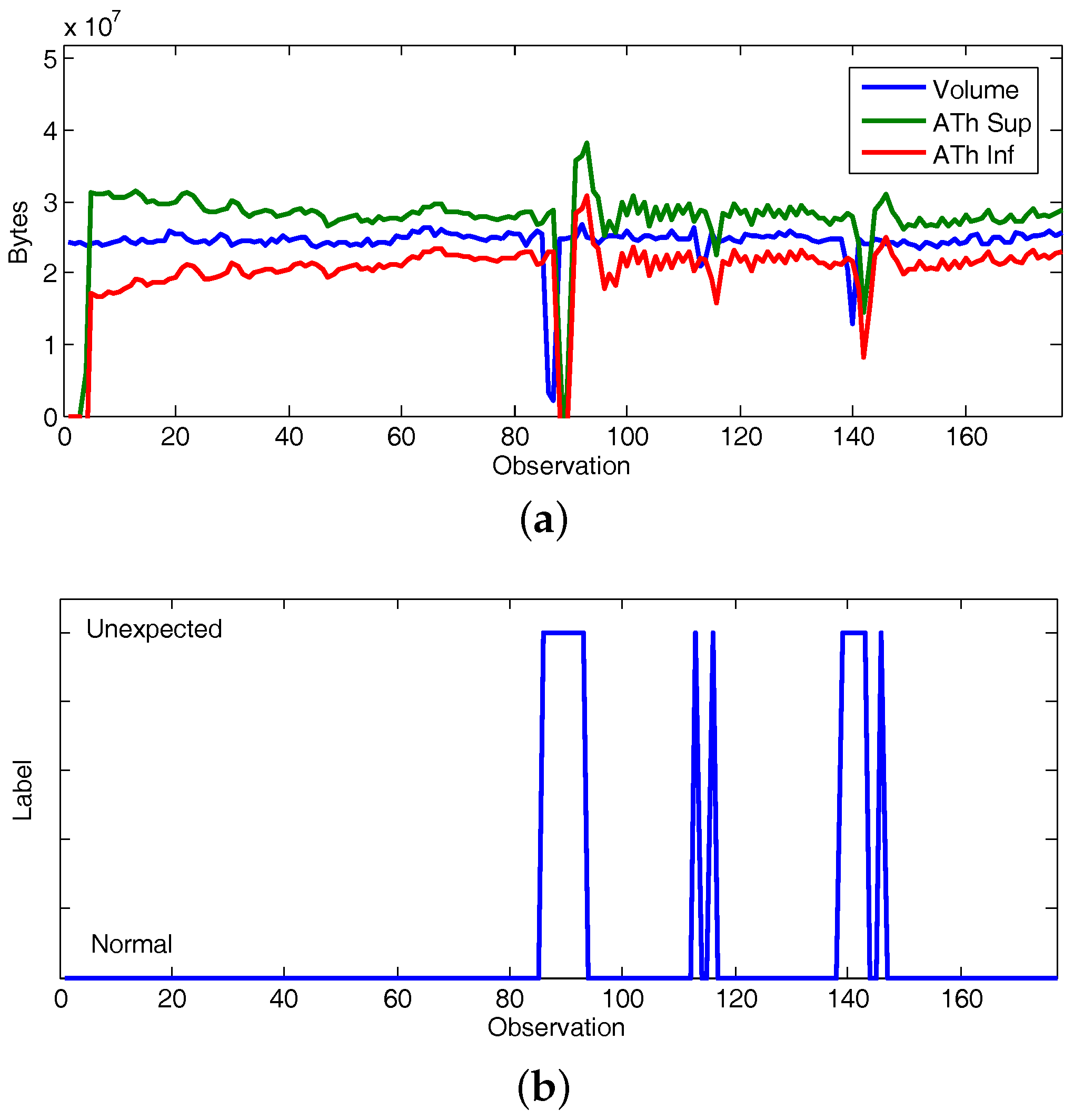
5.3.1. Experiment 1: CAIDA’16-Sample
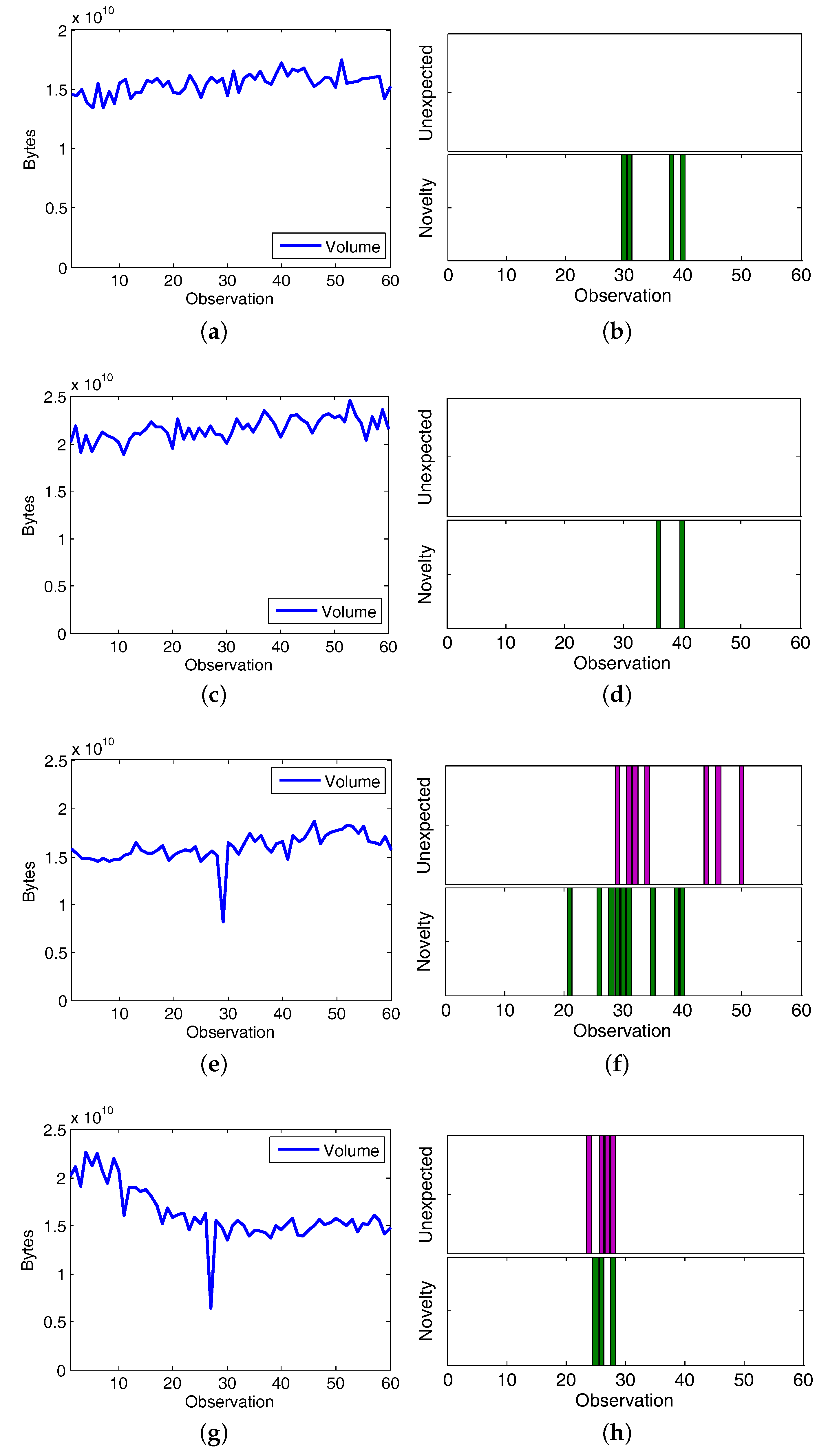
5.3.2. Experiment 2: CAIDA’16-monthly
5.4. Discussion
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Demestichas, P.; Georgakopoulos, A.; Karvounas, D.; Tsagkaris, K.; Stavroulaki, V.; Lu, J.; Xiong, C.; Yao, J. 5G on the horizon: Key challenges for the radio-access network. IEEE Veh. Technol. Mag. 2013, 8, 47–53. [Google Scholar] [CrossRef]
- Future Internet 2020: Visions of an Industry Expert Group. Available online: http://www.future-internet.eu/news/view/article/future-intenet-2020.html (accessed on 16 July 2017).
- Barona López, L.I.; Valdivieso Caraguay, A.L.; Sotelo Monge, M.A.; García Villalba, L.J. Key Technologies in the Context of Future Networks: Operational and Management Requirements. Future Internet 2016, 9, 1. [Google Scholar] [CrossRef]
- 5G-PPP. Advanced 5G Network Infrastructure for the Future Internet. Available online: http://5g-ppp.eu/wp-content/uploads/2014/02/Advanced-5G-Network-Infrastructure-PPP-in-H2020_Final_November-2013.pdf (accessed on 3 August 2017).
- NGMN Alliance. 5G White Paper. Available online: https://www.ngmn.org/uploads/media/NGMN_5G_White_Paper_V1_0.pdf (accessed on 26 July 2017).
- Gavrilovska, L.; Rakovic, V.; Atanasovski, V. Visions Towards 5G: Technical Requirements and Potential Enablers, Wireless Personal Communications. Wirel. Pers. Commun. 2015, 87, 731–757. [Google Scholar] [CrossRef]
- Expert Working Group on 5G: Challenges, Research Priorities, and Recommendations. European Technology Platform for Communications Networks and Services (NetWorld2020 ETP), 5G White Paper. Available online: https://networld2020.eu/wp-content/uploads/2014/02/NetWorld2020_Joint-Whitepaper-V8_public-consultation.pdf (accessed on 13 June 2017).
- Andrews, J.G.; Buzzi, S.; Choi, W.; Hanly, S.V.; Lozano, A.; Soong, A.C.K.; Zhang, J.C. What Will 5G Be? IEEE J. Sel. Areas Commun. 2014, 32, 1065–1082. [Google Scholar] [CrossRef]
- Kreutz, D.; Ramos, F.M.; Verissimo, P.E.; Rothenberg, C.E.; Azodolmolky, S.; Uhlig, S. What Will 5G Be? Proc. IEEE 2015, 103, 14–76. [Google Scholar] [CrossRef]
- Abdelwahab, S.; Hamdaoui, B.; Guizani, M.; Znati, T. Network Function Virtualization in 5G. IEEE Commun. Mag. 2016, 54, 84–91. [Google Scholar] [CrossRef]
- Dinh, H.T.; Lee, C.; Niyato, D.; Wang, P. A survey of mobile cloud computing: Architecture, applications, and approaches. Wirel. Commun. Mob. Comput. 2013, 13, 1587–1611. [Google Scholar] [CrossRef]
- Imran, A.; Zoha, A. Challenges in 5G: How to Empower SON with Big Data for Enabling 5G. IEEE Netw. 2014, 28, 27–33. [Google Scholar] [CrossRef]
- Aissioui, A.; Ksentini, A.; Gueroui, A.M.; Taleb, T. Toward Elastic Distributed SDN/NFV Controller for 5G Mobile Cloud Management Systems. IEEE Access 2015, 3, 2055–2064. [Google Scholar] [CrossRef]
- Next Generation Mobile Networks Alliance: 5G White Paper. Available online: https://www.ngmn.org/uploads/media/NGMN_5G_White_Paper_V1_0.pdf (accessed on 16 July 2017).
- European Telecommunications Standards Institute: GANA—Generic Autonomic Networking Architecture. Available online: http://www.etsi.org/images/files/ETSIWhitePapers/etsi_wp16_gana_Ed1_20161011.pdf (accessed on 4 August 2017).
- Han, Q.; Liang, S.; Zhang, H. Mobile cloud sensing, big data, and 5G networks make an intelligent and smart world. IEEE Netw. 2015, 29, 40–45. [Google Scholar] [CrossRef]
- Khatib, E.J.; Barco, R.; Munoz, P.; Serrano, I. Knowledge Acquisition for Fault Management in LTE Networks. Wirel. Pers. Commun. 2017, 95, 2895–2914. [Google Scholar] [CrossRef]
- Service Programming and Orchestration for Virtualized Software Networks (SONATA). Available online: https://5g-ppp.eu/sonata (accessed on 27 June 2017).
- Building an Intelligent System of Insights and Action for 5G Network Management (CogNet). Available online: http://www.cognet.5g-ppp.eu (accessed on 7 July 2017).
- Barco, R.; Lazaro, P.; Wille, V.; Dize, L.; Patelm, S. Knowledge acquisition for diagnosis model in wireless networks. Expert Syst. Appl. 2009, 31, 4745–4752. [Google Scholar] [CrossRef]
- Self-Organized Network Management in Virtualized and Software Defined Networks (SELFNET). Available online: http://www.selfnet-5g.eu (accessed on 22 July 2017).
- Horizon 2020: The EU Framework Programme for Research and Innovation. Available online: https://ec.europa.eu/programmes/horizon2020/ (accessed on 29 June 2017).
- International Mobile Telecommunication 2020 5G (IMT-2020). Available online: http://www.imt-2020.cn (accessed on 30 June 2017).
- 5G Americas. Available online: http://www.5gamericas.org/en/ (accessed on 24 May 2017).
- Mobile and Wireless Communications Enablers for Twenty-Twenty (2020) Information Society (METIS). Available online: https://www.metis2020.com/ (accessed on 21 July 2017).
- Network Functions As-a-Service Over Virtualised Infrastructures (T-NOVA). Available online: http://www.t-nova.eu/ (accessed on 14 June 2017).
- Unifying Cloud and Carrier Networks (UNIFY). Available online: http://www.fp7-unify.eu/ (accessed on 4 June 2017).
- Connectivity Management for EneRgy Optimised Wireless Dense Networks (CROWD). Available online: http://www.ict-crowd.eu/ (accessed on 2 July 2017).
- Mobile and Wireless Communications Enablers for Twenty-Twenty II (2020) Information Society (METIS II). Available online: https://metis-ii.5g-ppp.eu/ (accessed on 27 July 2017).
- Converged Heterogeneous Advanced 5G Cloud-RAN Architecture for Intelligent and Secure Media Access (CHARISMA). Available online: http://www.charisma5g.eu/ (accessed on 2 August 2017).
- Enablers for Network and System Security and Resilience (5G-Ensure). Available online: http://www.5gensure.eu (accessed on 11 July 2017).
- Pirinen, P. A brief overview of 5G research activities. In Proceedings of the 1st International Conference on 5G for Ubiquitous Connectivity (5GU), Akaslompolo, Finland, 26–28 November 2014; pp. 17–22. [Google Scholar]
- Neves, P.; Calé, R.; Costa, M.R.; Parada, C.; Parreira, B.; Alcaraz-Calero, J.; Wang, Q.; Nightingale, J.; Chirivella-Perez, E.; Jiang, W.; et al. The SELFNET Approach for Autonomic Management in an NFV/SDN Networking Paradigm. Int. J. Distrib. Sens. Netw. 2016, 2016, 1–14. [Google Scholar] [CrossRef]
- Nightingale, J.; Wang, Q.; Alcaraz Calero, J.M.; Chirivella-Perez, E.; Ulbricht, M.; Alonso-López, J.A.; Preto, R.; Batista, T.; Teixeira, T.; Barros, M.J.; et al. QoE-driven, energy-aware video adaptation in 5G networks: The SELFNET self-optimisation use case. Int. J. Distrib. Sens. Netw. 2016, 2016, 1–15. [Google Scholar] [CrossRef]
- Sotelo Monge, M.A.; Garcia Villalba, L.J.; Jiang, W.; Schotten, H.; Wang, Q.; Barros, M.J. SELFNET Framework self-healing capabilities for 5G mobile networks. Trans. Emerg. Telecommun. Technol. 2016, 27, 1225–1232. [Google Scholar]
- Terje, A. Risk Assessment and Risk Management: Review of Recent Advances on their Foundation. Eur. J. Oper. Res. 2016, 253, 1–13. [Google Scholar]
- Shameli-Sendi, A.; Aghababaei-Barzegar, R.; Cheriet, M. Taxonomy of Information Security Risk Assessment (ISRA). Comput. Secur. 2016, 57, 14–30. [Google Scholar] [CrossRef]
- Hansson, S.O.; Aven, T. Is Risk Analysis Scientific? Risk Anal. 2014, 34, 1173–1183. [Google Scholar] [CrossRef] [PubMed]
- Philip, D. US Homeland Security and Risk Assessment. Gov. Inf. Q. 2015, 32, 342–352. [Google Scholar]
- Smith, R.E. A Contemporary Look at Saltzer and Schroeder’s 1975 Design Principles. IEEE Secur. Priv. 2012, 10, 20–25. [Google Scholar] [CrossRef]
- Parker, D.B. Fighting Computer Crime: A New Framework for Protecting Information; John Wiley & Sons: New York, NY, USA, 1998; ISBN 0-471-16378-3. [Google Scholar]
- McCumber, J. Information Systems Security: A Comprehensive Model. In Proceedings of the 14th NIST National Computer Security Conference, Baltimore, MD, USA, 11–14 October 1994; pp. 328–337. [Google Scholar]
- International Organization for Standardization and the International Electrotechnical Commission (ISO/IEC). ISO/IEC 27002: Information Technology, Security Techniques, Code of Practice for Information Security Management. Available online: http://www.iso.org/iso/catalogue_detail?csnumber=54533 (accessed on 1 August 2017).
- National Institute of Standards and Technology (NIST). NIST-SP800 Series Special Publications on Computer Security. Available online: http://csrc.nist.gov/publications/PubsSPs.html#SP800 (accessed on 9 July 2017).
- CVSS: Common Vulnerability Scoring System. Available online: https://www.first.org/cvss/specification-document (accessed on 19 July 2017).
- MAGERIT: Risk Analysis and Management Methodology for Information Systems. Available online: http://administracionelectronica.gob.es/pae_Home/pae_Documentacion/pae_Metodolog/pae_Magerit.html?idioma=en#.VqfJ1JrhDDc (accessed on 31 July 2017).
- Ben-Asher, N.; Gonzalez, C. Effects of cyber security knowledge on attack detection. Comput. Hum. Behav. 2015, 48, 51–61. [Google Scholar] [CrossRef]
- Endsley, M.R. Design and Evaluation for Situation Awareness Enhancement. In Proceedings of the Human Factors and Ergonomics Society Annual Meeting, Chicago, IL, USA, 5–9 October 1998; pp. 97–101. [Google Scholar]
- Chatzimichailidou, M.M.; Stanton, N.A.; Dokas, I.M. The Concept of Risk Situation Awareness Provision: Towards a New Approach for Assessing the DSA about the Threats and Vulnerabilities of Complex Socio-technical Systems. Saf. Sci. 2015, 79, 126–138. [Google Scholar] [CrossRef]
- Franke, U.; Brynielsson, J. Cyber Situational Awareness—A Systematic Review of the Literature. Comput. Secur. 2014, 46, 18–31. [Google Scholar]
- Leau, Y.B.; Manickam, S. Network Security Situation Prediction: A Review and Discussion. Intell. Era Big Data 2015, 516, 424–435. [Google Scholar]
- Barona López, L.I.; Valdivieso Caraguay, A.L.; Maestre Vidal, J.; Sotelo Monge, M.A.; García Villalba, L.J. Towards Incidence Management in 5G Based on Situational Awareness. Future Internet 2017, 3. [Google Scholar] [CrossRef]
- Valdivieso Caraguay, A.L.; García Villalba, L.J. Monitoring and Discovery for Self-Organized Network Management in Virtualized and Software Defined Networks. Sensors 2017, 17. [Google Scholar] [CrossRef]
- Barona López, L.I.; Maestre Vidal, J.; García Villalba, L.J. Orchestration of use-case driven analytics in 5G scenarios. J. Ambient Intell. Humaniz. Comput. 2017, 1–21. [Google Scholar] [CrossRef]
- Barona López, L.I.; Maestre Vidal, J.; García Villalba, L.J. An Approach to Data Analysis in 5G Networks. Entropy 2017, 19, 74. [Google Scholar] [CrossRef]
- Laskov, P.; Dussel, P.; Schafer, C.; Rieck, K. Learning Intrusion Detection: Supervised or Unsupervised? In Proceedings of the 13th International Conference on Image Analysis and Processing (ICIAP 2005), Cagliari, Italy, 6–8 September 2005; pp. 50–57. [Google Scholar]
- Ditzler, G.; Roveri, M.; Alippi, C.; Polikar, R. Learning in Nonstationary Environments: A Survey. IEEE Comput. Intell. Mag. 2015, 10, 12–25. [Google Scholar] [CrossRef]
- Aggarwal, C.C.; Yu, P.S. Outlier detection for High Dimensional data. In Proceedings of the 2001 ACM SIGMOD International Conference on Management of data (SIGMOD’01), Santa Barbara, CA, USA, 21–24 May 2001; pp. 37–46. [Google Scholar]
- Apache Kafka: A Distributed Streaming Platform. Available online: https://kafka.apache.org (accessed on 15 July 2017).
- RabbitMQ: Messaging that Just Works. Available online: https://www.rabbitmq.com (accessed on 24 June 2017).
- European Telecommunications Standards Institute (ETSI), Mobile Edge Computing A Key Technology towards 5G. Available online: http://www.etsi.org/images/files/ETSIWhitePapers/etsi_wp11_mec_a_key_technology_towards_5g.pdf (accessed on 8 August 2017).
- Zimek, A.; Campello, R.J.G.B.; Sander, J. Ensembles for unsupervised outlier detection: Challenges and research questions. ACM SIGKDD Explor. Newsl. 2013, 15, 11–12. [Google Scholar] [CrossRef]
- Rokah, L. Ensemble-based classifiers. Artif. Intell. Rev. 2010, 33, 1–39. [Google Scholar] [CrossRef]
- Kohavi, R. A study of cross-validation and bootstrap for accuracy estimation and model selection. In Proceedings of the 14th International Joint Conference on Artificial Intelligence (IJCAI’95), Quebec City, QC, Canada, 20–25 August 1995; pp. 1137–1143. [Google Scholar]
- Pimentel, M.A.F.; Clifton, D.A.; Clifton, L.; Tarassenko, L. A review of novelty detection. Signal Process. 2014, 99, 215–249. [Google Scholar] [CrossRef]
- Forgy, C. Rete: A Fast Algorithm for the Many Pattern/Many Object Pattern Match Problem. Artif. Intell. 1982, 19, 17–37. [Google Scholar] [CrossRef]
- Makridakis, S.; Hibon, M. Applications of Support Vector Machines for Pattern Recognition: A Survey. M3 Compet. Results Conclus. Implic. 2000, 16, 451–476. [Google Scholar]
- Mendes, P. Combining data naming and context awareness for pervasive networks. J. Netw. Comput. Appl. 2015, 50, 114–125. [Google Scholar] [CrossRef]
- Mulloy, P.G. Smoothing Data with Faster Moving Averages. Stocks Commod. 1994, 12, 11–19. [Google Scholar]
- Feng, H.; Li, S. Active disturbance rejection control based on weighed-moving-average-state-observer. J. Math. Anal. Appl. 2014, 411, 354–361. [Google Scholar] [CrossRef]
- Aly, A.A.; Salem, N.A.; Mahmoud, M.A.; Woodall, W.H. A Reevaluation of the Adaptive Exponentially Weighted Moving Average Control Chart When Parameters are Estimated. Qual. Reliab. Eng. Int. 2015, 31, 1611–1622. [Google Scholar] [CrossRef]
- Mulloy, P.G. Smoothing data with less lag. Tech. Anal. Stocks Commod. 1994, 12, 72–80. [Google Scholar]
- Brown, R.G. Exponential Smoothing for Predicting Demand; Arthur D. Little Inc.: Cambridge, Massachusetts, USA, 1956. [Google Scholar]
- Gardner, E.S. Exponential smoothing: The state of the art-Part II. Int. J. Forecast. 2006, 22, 637–666. [Google Scholar] [CrossRef]
- Winters, P.R. Forecasting Sales by Exponentially Weighted Moving Averages. Manag. Sci. 1960, 6, 324–342. [Google Scholar] [CrossRef]
- Makridakis, S.; Wheelwright, S.C.; Hyndman, R.J. Forecasting: Methods and Applications; John Wiley & Sons: New York, NY, USA, 1998; ISBN 9780471532330. [Google Scholar]
- The Attribute-Relation File Format (ARFF). Available online: http://www.cs.waikato.ac.nz/ml/weka/arff.html (accessed on 5 June 2017).
- Fayyad, M.; Irani, K.B. On the handling of continuous-valued attributes in decision tree generation. Mach. Learn. 1992, 8, 87–102. [Google Scholar] [CrossRef]
- Safavian, R.; Landgrebe, D. A survey of decision tree classifier methodology. IEEE Trans. Syst. Man Cybern. 1991, 21, 660–674. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Breiman, L. Bagging Predictors. Mach. Learn. 1996, 24, 123–140. [Google Scholar] [CrossRef]
- Ratsch, G.; Onoda, T.; Muller, K.R. Soft Margins for AdaBoost. Mach. Learn. 2001, 42, 287–320. [Google Scholar] [CrossRef]
- Buczak, A.L.; Guven, E. A Survey of Data Mining and Machine Learning Methods for Cyber Security Intrusion Detection. IEEE Commun. Surv. Tutor. 2015, 18, 1153–1176. [Google Scholar] [CrossRef]
- John, G.H.; Langley, P. Estimating continuous distributions in Bayesian classifiers. In Proceedings of the 11th Conference on Uncertainty in Artificial Intelligence, Montreal, QU, Canada, 18–20 August 1995; pp. 338–345. [Google Scholar]
- Byun, H.; Lee, S.W. Applications of Support Vector Machines for Pattern Recognition: A Survey. Lect. Notes Comput. Sci. 2002, 2388, 213–236. [Google Scholar]
- Hempstalk, K.; Frank, E.; Witten, I.H. One-Class Classification by Combining Density and Class Probability Estimation. In Proceedings of the 12th European Conference on Principles and Practice of Knowledge Discovery in Databases and 19th European Conference on Machine Learning, Antwerp, Belgium, 15–19 September 2008; pp. 505–519. [Google Scholar]
- Drools: Business Rules Management System (BRMS). Available online: https://www.drools.org (accessed on 16 June 2017).
- A Novel Reconfigurable by Design highly Distributed Applications Development Paradigm Over Programmable Infraestructure (ARCADIA). Available online: http://www.arcadia-framework.eu (accessed on 8 July 2017).
- Developing Data-Intensive Cloud Applications with Iterative Quality Enhancement (DICE). Available online: http://www.dice-h2020.eu (accessed on 3 June 2017).
- The CAIDA UCSD Anonymized Internet Traces 2016. Available online: http://www.caida.org/data/passive/passive_2016_dataset.xml (accessed on 24 June 2017).
- Tavallaee, M.; Bagheri, E.; Lu, W.; Ghorbani, A.A. A detailed analysis of the KDD CUP 99 data set. In Proceedings of the 2nd IEEE international conference on Computational intelligence for security and defense applications (CISDA’09), Ottawa, ON, Canada, 8–10 July 2009; pp. 53–58. [Google Scholar]
- McHugh, J. Esting Intrusion detection systems: A critique of the 1998 and 1999 DARPA intrusion detection system evaluations as performed by Lincoln Laboratory. ACM Trans. Inf. Syst. Secur. (TISSEC) 2000, 3, 262–294. [Google Scholar] [CrossRef]
- Bhatia, S.; Schmidt, D.; Mohay, G.; Tickle, A. A framework for generating realistic traffic for Distributed Denial-of-Service attacks and Flash Events. Comput. Secur. 2014, 40, 95–107. [Google Scholar] [CrossRef]
- Equinix Inc. Available online: http://www.equinix.com (accessed on 24 June 2017).
- Bhuyan, M.H.; Bhattacharyya, D.K.; Kalita, J.K. Network Anomaly Detection: Methods, Systems and Tools. IEEE Commun. Surv. Tutor. 2014, 16, 303–336. [Google Scholar] [CrossRef]
- Ashfaq, R.A.R.; Wang, X.Z.; Huang, J.Z.; Abbas, H. Learning from Imbalanced Data. Inf. Sci. 2017, 378, 484–497. [Google Scholar] [CrossRef]
- Hernández-Pereira, E.; Suárez-Romero, J.A.; Fontenla-Romero, O.; Alonso-Betanzos, A. A Survey on 5G: The Next Generation of Mobile Communication. Expert Syst. Appl. 2009, 36, 10612–10617. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Initial Factual Knowledge | |
| Element | Description |
| Object | Traffic volume monitored per sensor (). |
| Acquisition | Via ADB. |
| Procedural Knowledge | |
| Component | Behavior |
| Prediction | Forecast traffic volume () given a certain prediction horizon. |
| Adaptive Thresholding | Construction of decision thresholds from forecasted metrics. |
| Pattern Recognition | Novelty detection based on several distances and similarity metrics related with and . |
| Knowledge Inference | It is deduced that if observations exceed adaptive thresholds, they are unexpected. If observations are considered novelties, it is deduced that they are fluctuations. If is unexpected and fluctuation then it is suspicious. |
| Notification | Reports suspicious events are reported via message broker software. |
| Method | Type |
|---|---|
| Cumulative Moving Average (CMA) [68] | Moving Average |
| Simple Moving Average (SMA) [69] | Moving Average |
| Double Moving Average (DMA) [69] | Moving Average |
| Weighted Moving Average (WMA) [70] | Moving Average |
| Simple Exponential Smoothing (EMA) [71] | Moving Average |
| Double Exponential Moving Average (DEMA) [72] | Moving Average |
| Triple Exponential Moving Average (TEMA) [69] | Moving Average |
| Simple Exponential Smoothing (SES) [73] | Smoothing |
| Double Exponential Smoothing (DES) [74] | Smoothing |
| Triple Exponential Smoothing (TES) [75] | Smoothing |
| Method | Action |
|---|---|
| Decision Stump [78] | Classification |
| Reducing Error Pruning Tree [79] | Classification |
| Random Forest [80] | Classification |
| Bootstrap Aggregation [81] | Classification |
| Adaptive Boosting [82] | Classification |
| Bayesian Network [83] | Classification |
| Naive Bayes [84] | Classification and Novelty detection |
| Support Vector Machines (SVM) [85] | Classification and Novelty detection |
| Generation of synthetic data + Bootstrap Aggregation [86] | Novelty detection |
| Micro | Industry | Macro | Finance | Demographic | Other | Total | |
|---|---|---|---|---|---|---|---|
| Year | 146 | 102 | 83 | 58 | 245 | 11 | 645 |
| Quart. | 204 | 83 | 336 | 76 | 57 | 756 | |
| Month | 474 | 334 | 312 | 145 | 111 | 141 | 1428 |
| Other | 4 | 29 | 141 | 174 | |||
| Total | 828 | 519 | 731 | 308 | 413 | 204 | 3003 |
| Method | Forecasting Horizon | Average | #Obs | ||||||
|---|---|---|---|---|---|---|---|---|---|
| t + 1 | t + 2 | t + 3 | t + 4 | t + 5 | t + 6 | 1 to 4 | 1 to 6 | ||
| Naive | 8.5 | 13.2 | 17.8 | 19.9 | 23 | 24.9 | 14.85 | 17.88 | 645 |
| Single | 8.5 | 13.3 | 17.6 | 19.8 | 22.8 | 24.8 | 14.82 | 17.82 | 645 |
| Holt | 8.3 | 13.7 | 19 | 22 | 25.2 | 27.3 | 15.77 | 19.27 | 645 |
| Dampen | 8 | 12.4 | 17 | 19.3 | 22.3 | 24 | 14.19 | 17.18 | 645 |
| Winter | 8.3 | 13.7 | 19 | 20 | 25.2 | 27.3 | 15.77 | 19.27 | 645 |
| Comb S-H-D | 7.9 | 12.4 | 16.9 | 24.1 | 22.2 | 23.7 | 14.11 | 17.07 | 645 |
| B-J automatic | 8.6 | 13 | 17.5 | 18.2 | 22.8 | 24.5 | 14.78 | 17.73 | 645 |
| Autobox 1 | 10.1 | 15.2 | 20.8 | 22.5 | 28.1 | 31.2 | 17.57 | 21.59 | 645 |
| Autobox 2 | 8 | 12.2 | 16.2 | 19 | 21.2 | 23.3 | 13.65 | 16.52 | 645 |
| Autobox 3 | 10.7 | 15.1 | 20 | 20.4 | 25.7 | 28.1 | 17.09 | 20.36 | 645 |
| Robust-Trend | 7.6 | 11.8 | 16.6 | 20.3 | 22.1 | 23.5 | 13.75 | 16.78 | 645 |
| ARARMA | 9 | 13.4 | 17.9 | 19.1 | 23.8 | 25.7 | 15.17 | 18.36 | 645 |
| Automat ANN | 9.2 | 13.2 | 17.5 | 19.7 | 23.2 | 25.4 | 15.04 | 18.13 | 645 |
| Flores/Pearce 1 | 8.4 | 12.5 | 16.9 | 19.1 | 22.2 | 24.2 | 14.22 | 17.21 | 645 |
| Flores/Peace 2 | 10.3 | 13.6 | 17.6 | 19.7 | 21.9 | 23.9 | 15.31 | 17.84 | 645 |
| PP-autocast | 8 | 12.3 | 16.9 | 19.1 | 22.1 | 23.9 | 14.08 | 17.05 | 645 |
| ForecastPro | 8.3 | 12.2 | 16.8 | 19.3 | 22.2 | 24.1 | 14.15 | 17.14 | 645 |
| SmartFcs | 9.5 | 13 | 17.5 | 19.9 | 22.1 | 24.1 | 14.95 | 17.68 | 645 |
| Theta-sm | 8 | 12.6 | 17.5 | 20.2 | 13.4 | 25.4 | 14.6 | 17.87 | 645 |
| Theta | 8 | 12.2 | 16.7 | 19.2 | 21.7 | 23.6 | 14.02 | 16.9 | 645 |
| RBF | 8.2 | 12.1 | 16.4 | 18.3 | 20.8 | 22.7 | 13.75 | 16.42 | 645 |
| ForecastX | 8.6 | 12.4 | 16.1 | 18.2 | 21 | 22.7 | 13.8 | 16.48 | 645 |
| This proposal | 6.9 | 6.6 | 7.6 | 7.2 | 8.5 | 9.4 | 7.1 | 7.7 | 645 |
| Method | Forecasting Horizon | Average | #Obs | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| t + 1 | t + 2 | t + 3 | t + 4 | t + 5 | t + 6 | t + 8 | 1 to 4 | 1 to 6 | 1 to 8 | ||
| Naive | 5.4 | 7.4 | 8.1 | 9.2 | 10.4 | 12.4 | 13.7 | 7.55 | 8.82 | 9.95 | 756 |
| Single | 5.3 | 7.2 | 7.8 | 9.2 | 10.2 | 12 | 13.4 | 7.38 | 8.63 | 9.72 | 756 |
| Holt | 5 | 6.9 | 8.3 | 10.4 | 11.5 | 13.1 | 15.6 | 7.67 | 9.21 | 10.67 | 756 |
| Dampen | 5.1 | 6.8 | 7.7 | 9.1 | 9.7 | 11.3 | 12.8 | 7.18 | 8.29 | 9.33 | 756 |
| Winter | 5 | 7.1 | 8.3 | 10.2 | 11.4 | 13.2 | 15.3 | 7.65 | 9.21 | 10.61 | 756 |
| Comb S-H-D | 5 | 6.7 | 7.5 | 8.9 | 9.7 | 11.2 | 12.8 | 7.03 | 8.16 | 9.22 | 756 |
| B-J automatic | 5.5 | 7.4 | 8.4 | 9.9 | 10.9 | 12.5 | 14.2 | 7.79 | 9.1 | 10.26 | 756 |
| Autobox 1 | 5.4 | 7.3 | 8.7 | 10.4 | 11.6 | 13.7 | 15.7 | 7.95 | 9.52 | 10.96 | 756 |
| Autobox 2 | 5.7 | 7.5 | 8.1 | 9.6 | 10.4 | 12.1 | 13.4 | 7.73 | 8.89 | 9.9 | 756 |
| Autobox 3 | 5.5 | 7.5 | 8.8 | 10.7 | 11.8 | 13.4 | 15.4 | 8.1 | 9.6 | 10.93 | 756 |
| Robust-Trend | 5.7 | 7.7 | 8.2 | 8.9 | 10.5 | 12.2 | 12.7 | 7.63 | 8.86 | 9.79 | 756 |
| ARARMA | 5.7 | 7.7 | 8.6 | 9.8 | 10.6 | 12.2 | 13.5 | 7.96 | 9.09 | 10.12 | 756 |
| Automat ANN | 5.5 | 7.6 | 8.3 | 9.8 | 10.9 | 12.5 | 14.1 | 7.8 | 9.1 | 10.2 | 756 |
| Flores/Pearce 1 | 5.3 | 7 | 8 | 9.7 | 10.6 | 12.2 | 13.8 | 7.48 | 8.78 | 9.95 | 756 |
| Flores/Peace 2 | 6.7 | 8.5 | 9 | 10 | 10.8 | 12.2 | 13.5 | 8.57 | 9.54 | 10.43 | 756 |
| PP-autocast | 4.8 | 6.6 | 7.8 | 9.3 | 9.9 | 11.3 | 13 | 7.12 | 8.28 | 9.36 | 756 |
| ForecastPro | 4.9 | 6.8 | 7.9 | 9.6 | 10.5 | 11.9 | 13.9 | 7.28 | 8.57 | 9.77 | 756 |
| SmartFcs | 5.9 | 7.7 | 8.6 | 10 | 10.7 | 12.2 | 13.5 | 8.02 | 9.16 | 10.15 | 756 |
| Theta-sm | 7.7 | 8.9 | 9.1 | 9.7 | 10.2 | 11.3 | 12.1 | 8.86 | 9.49 | 10.07 | 756 |
| Theta | 5 | 6.7 | 7.4 | 8.8 | 9.4 | 10.9 | 12 | 7 | 8.04 | 8.96 | 756 |
| RBF | 5.7 | 7.4 | 8.3 | 9.3 | 9.9 | 11.4 | 12.6 | 7.69 | 8.67 | 9.57 | 756 |
| ForecastX | 4.8 | 6.7 | 7.7 | 9.2 | 10 | 11.6 | 13.6 | 7.12 | 8.35 | 9.54 | 756 |
| AAM1 | 5.5 | 7.3 | 8.4 | 9.7 | 10.9 | 12.5 | 13.8 | 7.71 | 9.05 | 10.16 | 756 |
| AAM2 | 5.5 | 7.3 | 8.4 | 9.9 | 11.1 | 12.7 | 14 | 7.75 | 9.13 | 10.26 | 756 |
| This proposal | 5.3 | 5.2 | 4.5 | 4.7 | 4.4 | 4.8 | 4.9 | 6.0 | 4.9 | 4.8 | 756 |
| Method | Forecasting Horizon | Average | #Obs | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| t + 1 | t + 2 | t + 3 | t + 4 | t + 5 | t + 6 | t + 8 | t + 12 | t + 15 | t + 18 | 1 to 4 | 1 to 6 | 1 to 8 | 1 to 12 | 1 to 15 | 1 to 18 | ||
| Naive | 15 | 13.5 | 15.7 | 17 | 14.9 | 14.7 | 15.6 | 15 | 19.3 | 20.47 | 15.3 | 15.13 | 15.29 | 15.57 | 16.18 | 16.91 | 1428 |
| Single | 13 | 12.1 | 12.1 | 15.1 | 13.5 | 13.1 | 13.8 | 14.5 | 18.3 | 19.4 | 13.53 | 13.44 | 13.6 | 13.83 | 14.51 | 15.32 | 1428 |
| Holt | 12.2 | 11.6 | 13.4 | 14.6 | 13.6 | 13.3 | 13.7 | 14.8 | 18.8 | 20.2 | 12.95 | 13.11 | 13.33 | 13.77 | 15.51 | 15.36 | 1428 |
| Dampen | 11.9 | 11.4 | 13 | 14.2 | 12.9 | 12.6 | 13 | 13.9 | 17.5 | 18.9 | 12.63 | 12.67 | 12.85 | 13.1 | 13.77 | 14.59 | 1428 |
| Winter | 12.5 | 11.7 | 13.7 | 14.7 | 13.6 | 13.4 | 14.1 | 14.6 | 18.9 | 20.2 | 13.17 | 13.28 | 13.52 | 13.88 | 14.62 | 15.44 | 1428 |
| Comb S-H-D | 12.3 | 11.5 | 13.2 | 14.3 | 12.9 | 12.5 | 13 | 13.6 | 17.3 | 18.3 | 12.83 | 12.79 | 12.92 | 13.11 | 13.75 | 14.48 | 1428 |
| B-J automatic | 12.3 | 11.4 | 12.8 | 14.3 | 12.7 | 12.6 | 13 | 14.1 | 17.8 | 19.3 | 12.78 | 12.74 | 12.89 | 13.21 | 13.96 | 14.81 | 1428 |
| Autobox 1 | 13 | 12.2 | 13 | 14.5 | 14.1 | 13.4 | 14.3 | 15.4 | 19.1 | 20.4 | 13.27 | 13.42 | 13.71 | 14.1 | 14.93 | 15.83 | 1428 |
| Autobox 2 | 13.1 | 12.1 | 13.5 | 15.3 | 13.3 | 13.8 | 13.9 | 15.2 | 18.2 | 19.9 | 13.51 | 13.52 | 13.76 | 14.16 | 14.86 | 15.69 | 1428 |
| Autobox 3 | 12.3 | 12.3 | 13 | 14.4 | 14.6 | 14.2 | 14.8 | 16.1 | 19.2 | 21.2 | 12.99 | 13.47 | 13.89 | 14.43 | 15.2 | 16.18 | 1428 |
| Robust-Trend | 15.3 | 13.8 | 15.5 | 17 | 15.3 | 15.6 | 17.4 | 17.5 | 22.2 | 24.3 | 15.39 | 15.42 | 15.89 | 16.58 | 17.47 | 18.4 | 1428 |
| ARARMA | 13.1 | 12.4 | 13.4 | 14.9 | 13.7 | 14.2 | 15 | 15.2 | 18.5 | 20.3 | 13.42 | 13.59 | 14 | 14.41 | 15.08 | 15.84 | 1428 |
| Automat ANN | 11.6 | 11.6 | 12 | 14.1 | 12.2 | 13.9 | 13.8 | 14.6 | 17.3 | 19.6 | 12.31 | 12.55 | 12.92 | 13.42 | 14.13 | 14.93 | 1428 |
| Flores/Pearce 1 | 12.4 | 12.3 | 14.2 | 16.1 | 14.6 | 14 | 14.6 | 14.4 | 19.1 | 20.8 | 13.74 | 13.93 | 14.22 | 14.29 | 15.02 | 15.96 | 1428 |
| Flores/Peace 2 | 12.6 | 12.1 | 13.7 | 14.7 | 13.2 | 12.9 | 13.4 | 14.4 | 18.2 | 19.9 | 13.26 | 13.21 | 13.33 | 13.53 | 14.31 | 15.17 | 1428 |
| PP-autocast | 12.7 | 11.7 | 13.3 | 14..3 | 13.2 | 13.4 | 14 | 14.3 | 17.7 | 19.6 | 13.02 | 13.11 | 13.37 | 13.72 | 14.36 | 15.15 | 1428 |
| ForecastPro | 11.5 | 10.7 | 11.7 | 12.9 | 11.8 | 12.3 | 12.6 | 13.2 | 16.4 | 18.3 | 11.72 | 11.82 | 12.06 | 12.46 | 13.09 | 13.86 | 1428 |
| SmartFcs | 11.6 | 11.2 | 12.2 | 13.6 | 13.1 | 13.7 | 13.5 | 14.9 | 18 | 19.4 | 12.16 | 12.58 | 12.9 | 13.51 | 14.22 | 15.03 | 1428 |
| Theta-sm | 12.6 | 12.9 | 13.2 | 13.7 | 13.4 | 13.3 | 13.7 | 14 | 16.2 | 18.3 | 13.1 | 13.2 | 13.44 | 13.65 | 14.09 | 14.66 | 1428 |
| Theta | 11.2 | 10.7 | 11.8 | 12.4 | 12.2 | 12.4 | 12.7 | 13.2 | 16.2 | 18.2 | 11.54 | 11.8 | 12.3 | 12.5 | 13.11 | 13.85 | 1428 |
| RBF | 13.7 | 12.3 | 13.7 | 14.3 | 12.3 | 12.8 | 13.5 | 14.1 | 17.3 | 17.8 | 13.49 | 13.18 | 13.4 | 13.67 | 14.21 | 14.77 | 1428 |
| ForecastX | 11.6 | 11.2 | 12.6 | 14 | 12.4 | 12.2 | 12.8 | 13.9 | 17.8 | 18.7 | 12.32 | 12.31 | 12.46 | 12.83 | 13.6 | 14.45 | 1428 |
| AAM1 | 12 | 12.3 | 12.7 | 14.1 | 14 | 14 | 14.3 | 14.9 | 18 | 20.4 | 12.8 | 13.2 | 13.63 | 14.05 | 14.78 | 15.69 | 1428 |
| AAM2 | 12.3 | 12.4 | 12.9 | 14.4 | 14.3 | 14.2 | 14.5 | 15.1 | 18.4 | 20.7 | 13.03 | 13.45 | 13.87 | 14.25 | 15.01 | 15.93 | 1428 |
| This proposal | 11.0 | 11.2 | 11.7 | 12.5 | 11.6 | 11.4 | 10.6 | 9.6 | 11 | 12.7 | 11.6 | 11.6 | 11.4 | 11.1 | 11.2 | 11.4 | 1428 |
| Method | Forecasting Horizon | Average | #Obs | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| t+1 | t+2 | t+3 | t+4 | t+5 | t+6 | t+8 | 1 to 4 | 1 to 6 | 1 to 8 | ||
| Naive | 2.2 | 3.6 | 5.4 | 6.3 | 7.8 | 7.6 | 9.2 | 4.38 | 5.49 | 6.3 | 174 |
| Single | 2.1 | 3.6 | 5.4 | 6.3 | 7.8 | 7.6 | 9.2 | 4.36 | 5.48 | 6.29 | 174 |
| Holt | 1.9 | 2.9 | 3.9 | 4.7 | 5.7 | 5.6 | 7.2 | 3.32 | 4.13 | 4.81 | 174 |
| Dampen | 1.8 | 2.7 | 3.9 | 4.7 | 5.8 | 5.4 | 6.6 | 3.28 | 4.06 | 4.61 | 174 |
| Winter | 1.9 | 2.9 | 3.9 | 4.7 | 5.8 | 5.6 | 7.2 | 3.32 | 4.13 | 4.81 | 174 |
| Comb S-H-D | 1.8 | 2.8 | 4.1 | 4.7 | 5.8 | 5.3 | 6.2 | 3.36 | 4.09 | 4.56 | 174 |
| B-J automatic | 1.8 | 3 | 4.5 | 4.9 | 6.1 | 6.1 | 7.5 | 3.52 | 4.38 | 5.06 | 174 |
| Autobox 1 | 2.4 | 3.3 | 4.4 | 4.9 | 5.8 | 5.4 | 6.9 | 3.76 | 4.38 | 4.93 | 174 |
| Autobox 2 | 1.6 | 2.9 | 4 | 4.3 | 5.3 | 5.1 | 6.4 | 3.19 | 3.86 | 4.41 | 174 |
| Autobox 3 | 1.9 | 3.2 | 4.1 | 4.4 | 5.5 | 5.5 | 7 | 3.39 | 4.09 | 4.71 | 174 |
| Robust-Trend | 1.9 | 2.8 | 3.9 | 4.7 | 5.7 | 5.4 | 6.4 | 3.32 | 4.07 | 4.58 | 174 |
| ARARMA | 1.7 | 2.7 | 4 | 4.4 | 5.5 | 5.1 | 6 | 3.17 | 3.87 | 4.38 | 174 |
| Automat ANN | 1.7 | 2.9 | 4 | 4.5 | 5.7 | 5.7 | 7.4 | 3.26 | 4.07 | 4.8 | 174 |
| Flores/Pearce 1 | 2.1 | 3.2 | 4.3 | 5.2 | 6.2 | 5.8 | 7.3 | 3.71 | 4.47 | 5.09 | 174 |
| Flores/Peace 2 | 2.3 | 2.9 | 4.3 | 5.1 | 6.2 | 5.7 | 6.5 | 3.67 | 7.73 | 4.89 | 174 |
| PP-autocast | 1.8 | 2.7 | 4 | 4.7 | 5.8 | 5.4 | 6.6 | 3.29 | 4.07 | 4.62 | 174 |
| ForecastPro | 1.9 | 3 | 4 | 4.4 | 5.4 | 5.4 | 6.7 | 3.31 | 4 | 4.6 | 174 |
| SmartFcs | 2.5 | 3.3 | 4.3 | 4.7 | 5.8 | 5.5 | 6.7 | 3.68 | 4.33 | 4.86 | 174 |
| Theta-sm | 2.3 | 3.2 | 4.3 | 4.8 | 6 | 5.6 | 6.9 | 3.66 | 4.37 | 4.93 | 174 |
| Theta | 1.8 | 2.7 | 3.8 | 4.5 | 5.6 | 5.2 | 6.1 | 3.2 | 3.93 | 4.41 | 174 |
| RBF | 2.7 | 3.8 | 5.2 | 5.8 | 6.9 | 6.3 | 7.3 | 4.38 | 5.12 | 5.6 | 174 |
| ForecastX | 2.1 | 3.1 | 4.1 | 4.4 | 5.6 | 5.4 | 6.5 | 3.42 | 4.1 | 4.64 | 174 |
| This proposal | 1.8 | 2.3 | 2.2 | 2.0 | 2.3 | 1.5 | 2.4 | 2.1 | 2.0 | 2.0 | 174 |
| Classifier | Class | TPR | FPR | Precision | Recall | F-Measure | MCC | AUC | PRC Area | Accuracy |
|---|---|---|---|---|---|---|---|---|---|---|
| Decision Stump | Normal | 0.955 | 0.731 | 0.695 | 0.955 | 0.804 | 0.642 | 0.819 | 0.683 | 0.799 |
| Anomaly | 0.683 | 0.045 | 0.952 | 0.683 | 0.795 | 0.642 | 0.819 | 0.831 | ||
| Average | 0.8 | 0.162 | 0.841 | 0.8 | 0.8 | 0.642 | 0.819 | 0.767 | ||
| RepTree | Normal | 0.909 | 0.256 | 0.729 | 0.909 | 0.809 | 0.649 | 0.822 | 0.721 | 0.815 |
| Anomaly | 0.744 | 0.091 | 0.915 | 0.744 | 0.821 | 0.649 | 0.822 | 0.858 | ||
| Average | 0.815 | 0.162 | 0.835 | 0.815 | 0.816 | 0.649 | 0.822 | 0.799 | ||
| Random Forest | Normal | 0.973 | 0.323 | 0.695 | 0.973 | 0.811 | 0.658 | 0.959 | 0.947 | 0.803 |
| Anomaly | 0.677 | 0.027 | 0.971 | 0.677 | 0.798 | 0.658 | 0.959 | 0.961 | ||
| Average | 0.804 | 0.155 | 0.852 | 0.804 | 0.803 | 0.658 | 0.959 | 0.955 | ||
| Bootstrap Aggregation | Normal | 0.917 | 0.249 | 0.736 | 0.917 | 0.816 | 0.663 | 0.928 | 0.909 | 0.822 |
| Anomaly | 0.751 | 0.083 | 0.923 | 0.751 | 0.828 | 0.663 | 0.928 | 0.916 | ||
| Average | 0.822 | 0.155 | 0.842 | 0.822 | 0.823 | 0.663 | 0.928 | 0.913 | ||
| Adaptive Boosting | Normal | 0.968 | 0.399 | 0.648 | 0.968 | 0.776 | 0.589 | 0.935 | 0.919 | 0.822 |
| Anomaly | 0.601 | 0.032 | 0.961 | 0.601 | 0.74 | 0.589 | 0.935 | 0.941 | ||
| Average | 0.759 | 0.19 | 0.826 | 0.759 | 0.755 | 0.589 | 0.935 | 0.932 | ||
| Bayesian Network | Normal | 0.973 | 0.429 | 0.632 | 0.973 | 0.766 | 0.57 | 0.945 | 0.94 | 0.759 |
| Anomaly | 0.571 | 0.027 | 0.965 | 0.571 | 0.718 | 0.57 | 0.945 | 0.955 | ||
| Average | 0.744 | 0.2 | 0.822 | 0.744 | 0.739 | 0.57 | 0.945 | 0.949 | ||
| Naive Bayes | Normal | 0.931 | 0.367 | 0.657 | 0.931 | 0.771 | 0.572 | 0.895 | 0.844 | 0.761 |
| Anomaly | 0.633 | 0.69 | 0.924 | 0.633 | 0.751 | 0.572 | 0.914 | 0.911 | ||
| Average | 0.761 | 0.198 | 0.809 | 0.761 | 0.759 | 0.572 | 0.908 | 0.882 | ||
| SVM | Normal | 0.954 | 0.355 | 0.670 | 0.954 | 0.787 | 0.608 | 0.799 | 0.659 | 0.77 |
| Anomaly | 0.645 | 0.046 | 0.948 | 0.645 | 0.768 | 0.608 | 0.799 | 0.814 | ||
| Average | 0.778 | 0.179 | 0.829 | 0.778 | 0.776 | 0.608 | 0.799 | 0.747 | ||
| Synthetic data | Normal | 0.922 | 0.302 | 0.698 | 0.922 | 0.794 | 0.620 | 0.916 | 0.901 | 0.794 |
| Anomaly | 0.698 | 0.078 | 0.922 | 0.698 | 0.794 | 0.620 | 0.918 | 0.913 | ||
| Average | 0.794 | 0.175 | 0.825 | 0.794 | 0.794 | 0.620 | 0.917 | 0.908 |
| Classifier | Class | TPR | FPR | Precision | Recall | F-Measure | MCC | AUC | PRC Area | Accuracy |
|---|---|---|---|---|---|---|---|---|---|---|
| Decision Stump | Normal | 0.848 | 0.416 | 0.311 | 0.848 | 0.456 | 0.33 | 0.716 | 0.292 | 0.631 |
| Anomaly | 0.584 | 0.152 | 0.945 | 0.584 | 0.722 | 0.33 | 0.716 | 0.893 | ||
| Average | 0.632 | 0.2 | 0.83 | 0.632 | 0.674 | 0.33 | 0.716 | 0.783 | ||
| RepTree | Normal | 0.635 | 0.342 | 0.292 | 0.963 | 0.4 | 0.231 | 0.751 | 0.372 | 0.643 |
| Anomaly | 0.658 | 0.365 | 0.89 | 0.658 | 0.757 | 0.231 | 0.751 | 0.923 | ||
| Average | 0.654 | 0.361 | 0.782 | 0.654 | 0.692 | 0.231 | 0.751 | 0.823 | ||
| Random Forest | Normal | 0.875 | 0.425 | 0.314 | 0.875 | 0.462 | 0.347 | 0.794 | 0.576 | 0.629 |
| Anomaly | 0.575 | 0.125 | 0.954 | 0.575 | 0.718 | 0.347 | 0.794 | 0.935 | ||
| Average | 0.63 | 0.179 | 0.838 | 0.63 | 0.671 | 0.347 | 0.794 | 0.87 | ||
| Bootstrap Aggregation | Normal | 0.637 | 0.35 | 0.281 | 0.637 | 0.396 | 0.225 | 0.743 | 0.465 | 0.647 |
| Anomaly | 0.65 | 0.363 | 0.89 | 0.65 | 0.751 | 0.225 | 0.743 | 0.922 | ||
| Average | 0.647 | 0.361 | 0.78 | 0.647 | 0.687 | 0.225 | 0.743 | 0.839 | ||
| Adaptive Boosting | Normal | 0.866 | 0.518 | 0.217 | 0.866 | 0.413 | 0.272 | 0.724 | 0.394 | 0.522 |
| Anomaly | 0.482 | 0.134 | 0.942 | 0.482 | 0.638 | 0.272 | 0.724 | 0.901 | ||
| Average | 0.552 | 0.204 | 0.82 | 0.552 | 0.597 | 0.272 | 0.724 | 0.809 | ||
| Bayesian Network | Normal | 0.878 | 0.563 | 0.257 | 0.878 | 0.398 | 0.25 | 0.744 | 0.486 | 0.516 |
| Anomaly | 0.437 | 0.122 | 0.942 | 0.437 | 0.597 | 0.25 | 0.744 | 0.928 | ||
| Average | 0.517 | 0.202 | 0.817 | 0.517 | 0.561 | 0.25 | 0.744 | 0.848 | ||
| Naive Bayes | Normal | 0.678 | 0.469 | 0.243 | 0.678 | 0.358 | 0.161 | 0.648 | 0.294 | 0.557 |
| Anomaly | 0.531 | 0.322 | 0.882 | 0.531 | 0.663 | 0.161 | 0.65 | 0.876 | ||
| Average | 0.558 | 0.348 | 0.766 | 0.558 | 0.607 | 0.161 | 0.65 | 0.77 | ||
| SVM | Normal | 0.180 | 0.001 | 0.982 | 0.180 | 0.304 | 0.385 | 0.589 | 0.325 | 0.850 |
| Anomaly | 0.999 | 0.820 | 0.846 | 0.999 | 0.916 | 0.385 | 0.589 | 0.846 | ||
| Average | 0.851 | 0.672 | 0.871 | 0.851 | 0.805 | 0.385 | 0.589 | 0.752 | ||
| Synthetic data | Normal | 0.905 | 0 | 1 | 0.095 | 0.905 | N/A | N/A | N/A | 0.899 |
| Anomaly | 0 | 0.095 | 0 | 0 | 0 | N/A | N/A | N/A | ||
| Average | 0.905 | 0 | 1 | 0.095 | 0.95 | N/A | N/A | N/A |
| Method | NSL-KDD’9(%) | NSL-KDD’9(%) |
|---|---|---|
| J48 | 81.05 | 63.97 |
| Naive Bayes | 76.56 | 55.77 |
| NB tree | 82.02 | 66.16 |
| Random forests | 80.67 | 63.25 |
| Random tree | 81.59 | 58.51 |
| M-L perceptron | 77.41 | 57.34 |
| SVM | 69.52 | 42.29 |
| Fuzzy | 82.41 | 67.06 |
| Fuzzy D&D | 84.12 | 68.82 |
| This proposal (Classification) | 82.2 | 64.7 |
| Forecasting Horizon (H) | Selected Algorithm | Parameter Calibration | SMPAPE |
|---|---|---|---|
| 1 | Multiplicative Holt-Winters | alpha = 0.5, beta = 0.1, gamma = 0.9 | 0.0004 |
| 5 | Multiplicative Holt-Winters | alpha = 0.1, beta = 0.3, gamma = 0.9 | 0.6972 |
| 10 | Additive Holt-Winters | alpha = 0.1, beta = 0.3, gamma = 0.1 | 1.7622 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sotelo Monge, M.A.; Maestre Vidal, J.; García Villalba, L.J. Reasoning and Knowledge Acquisition Framework for 5G Network Analytics. Sensors 2017, 17, 2405. https://doi.org/10.3390/s17102405
Sotelo Monge MA, Maestre Vidal J, García Villalba LJ. Reasoning and Knowledge Acquisition Framework for 5G Network Analytics. Sensors. 2017; 17(10):2405. https://doi.org/10.3390/s17102405
Chicago/Turabian StyleSotelo Monge, Marco Antonio, Jorge Maestre Vidal, and Luis Javier García Villalba. 2017. "Reasoning and Knowledge Acquisition Framework for 5G Network Analytics" Sensors 17, no. 10: 2405. https://doi.org/10.3390/s17102405
APA StyleSotelo Monge, M. A., Maestre Vidal, J., & García Villalba, L. J. (2017). Reasoning and Knowledge Acquisition Framework for 5G Network Analytics. Sensors, 17(10), 2405. https://doi.org/10.3390/s17102405