
Visual Object Tracking Based on Cross-Modality Gaussian-Bernoulli Deep Boltzmann Machines with RGB-D Sensors


Abstract
:1. Introduction
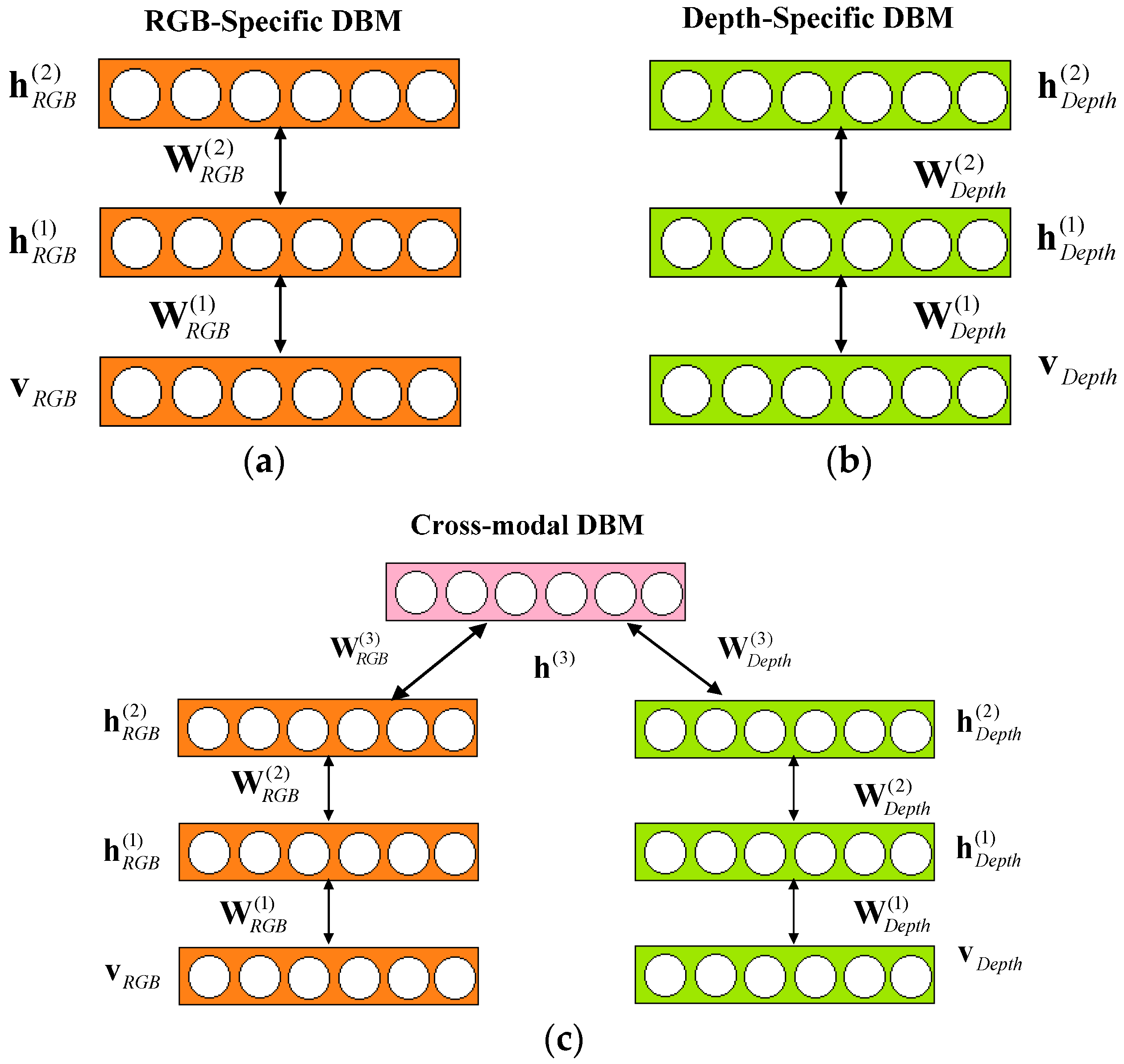
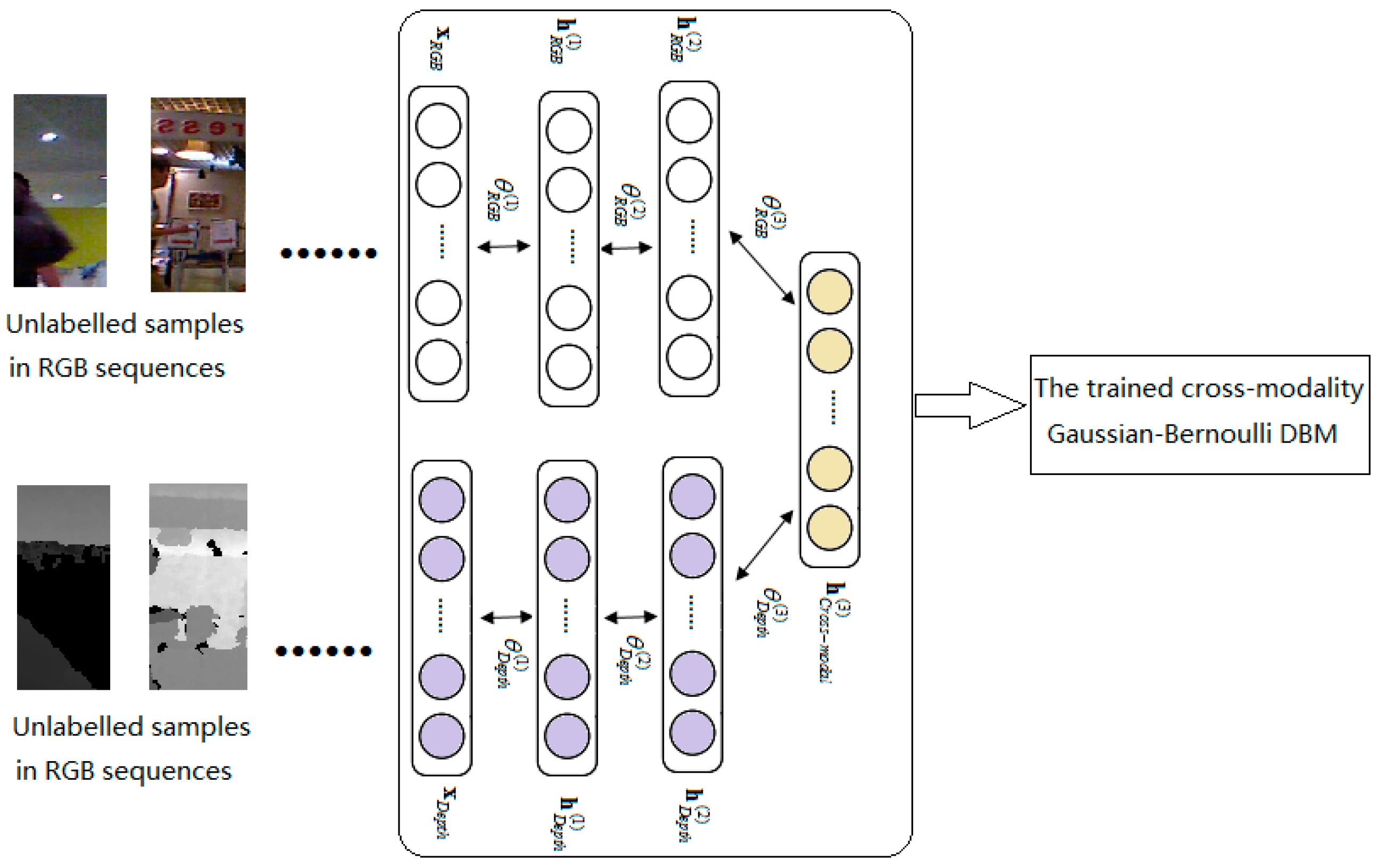
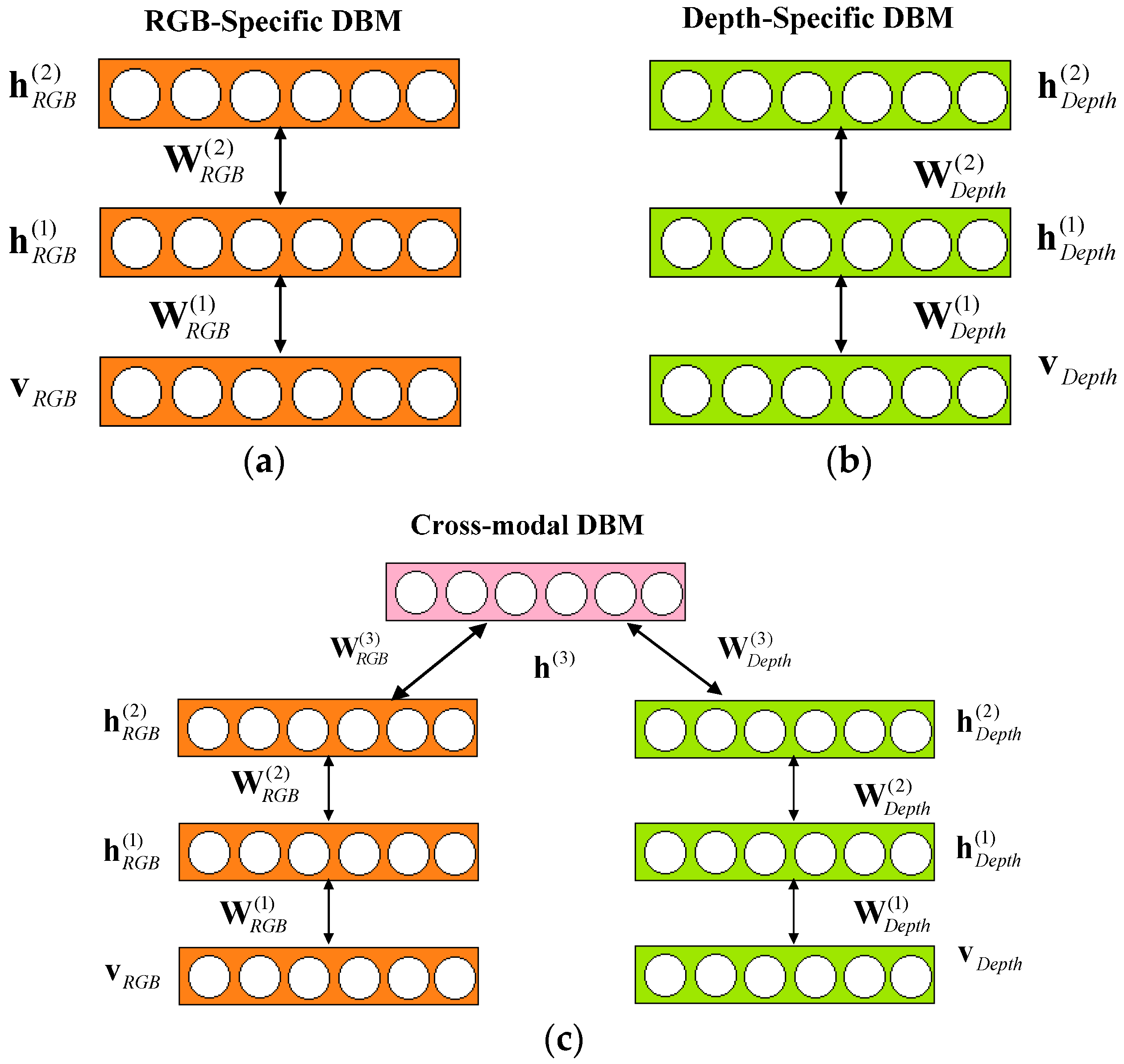
- We present a cross-modality Gaussian-Bernoulli deep Boltzmann machine (DBM) to learn the cross-modality features of target objects in RGB-D data. The proposed cross-modality Gaussian-Bernoulli DBM is constructed with two single-modality Gaussian-Bernoulli DBMs by adding an additional layer of binary hidden units on top of them, which can fuse RGB information and depth information effectively.
- A unified RGB-D tracking framework based on Bayesian MAP is proposed, in which the robust appearance description with cross-modality features deep learning, temporal continuity is fully considered in the state transition model.
- Extensive experiments are conducted to compare our tracker with several state-of-the-art methods on the recent benchmark dataset [21]. From experimental results, we can see that the proposed tracker performs favorably against the compared state-of-the-art trackers.
2. Related Work
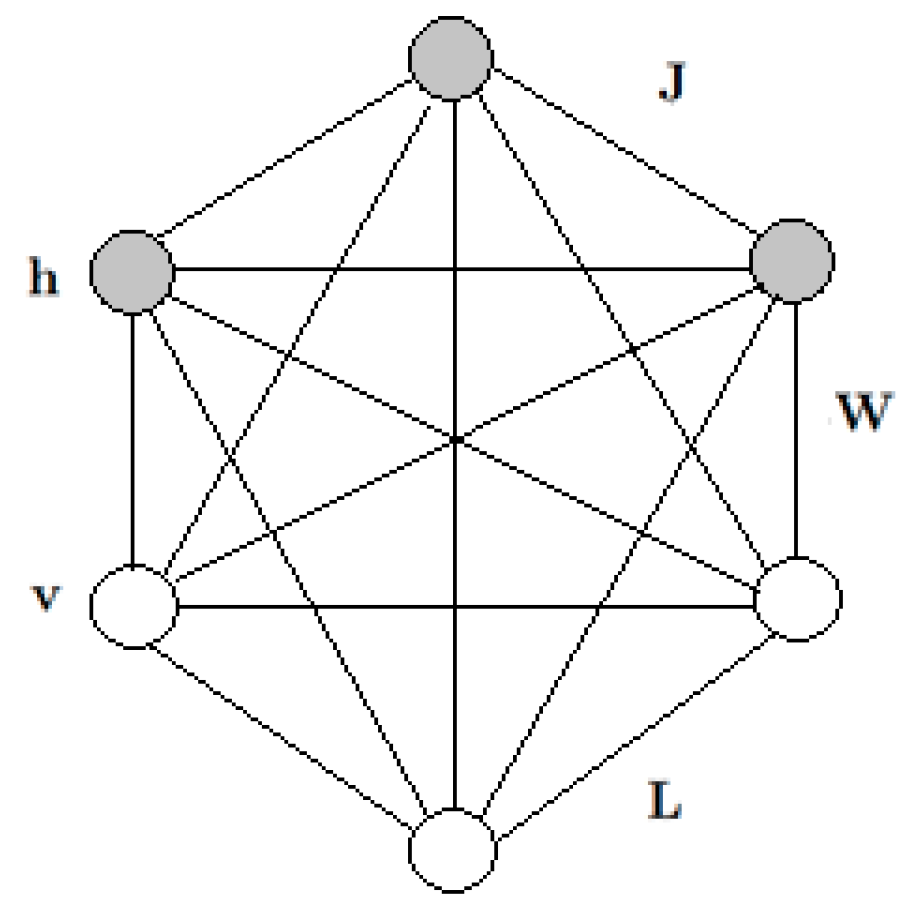
2.1. Boltzmann Machine
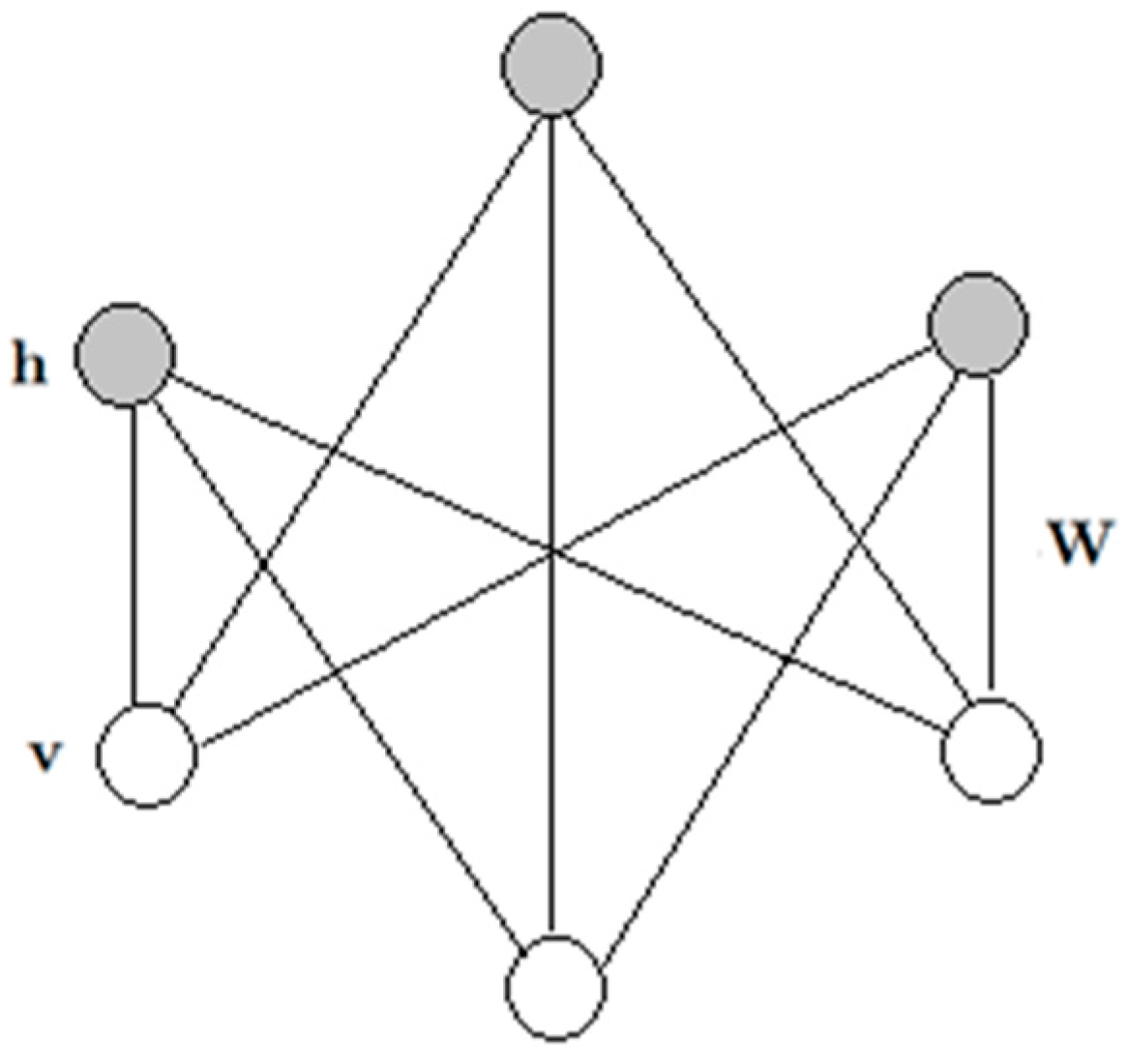
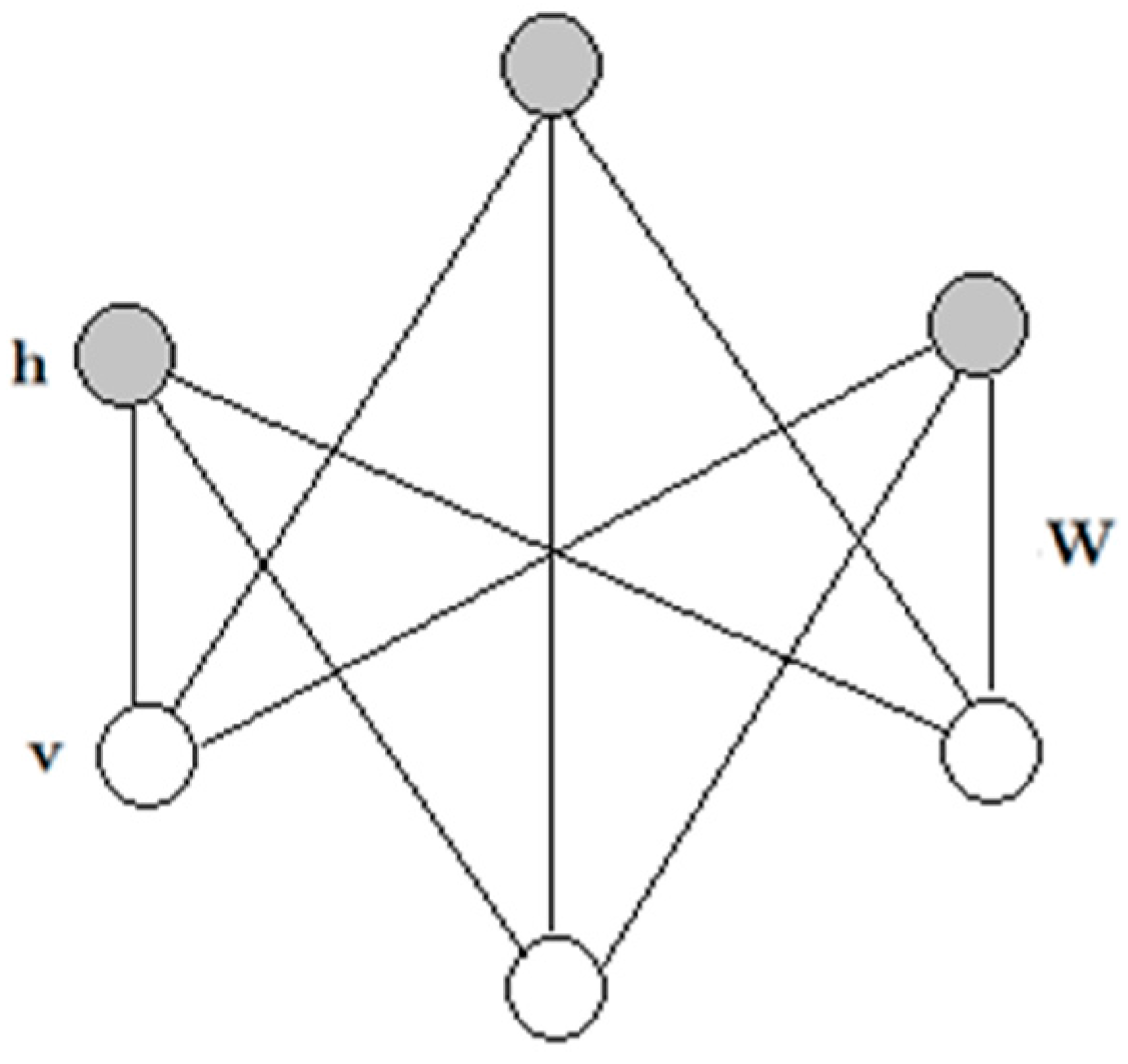
2.2. Restricted Boltzmann Machine
2.3. Gaussian-Bernoulli Restricted Boltzmann Machines
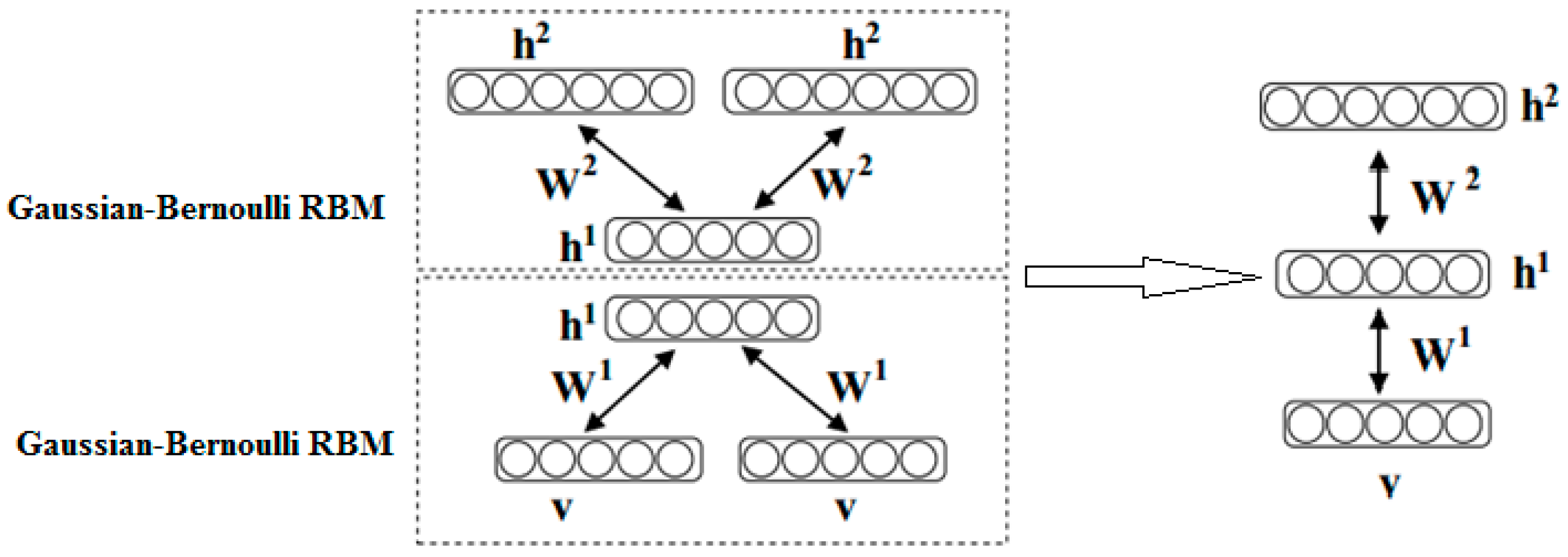
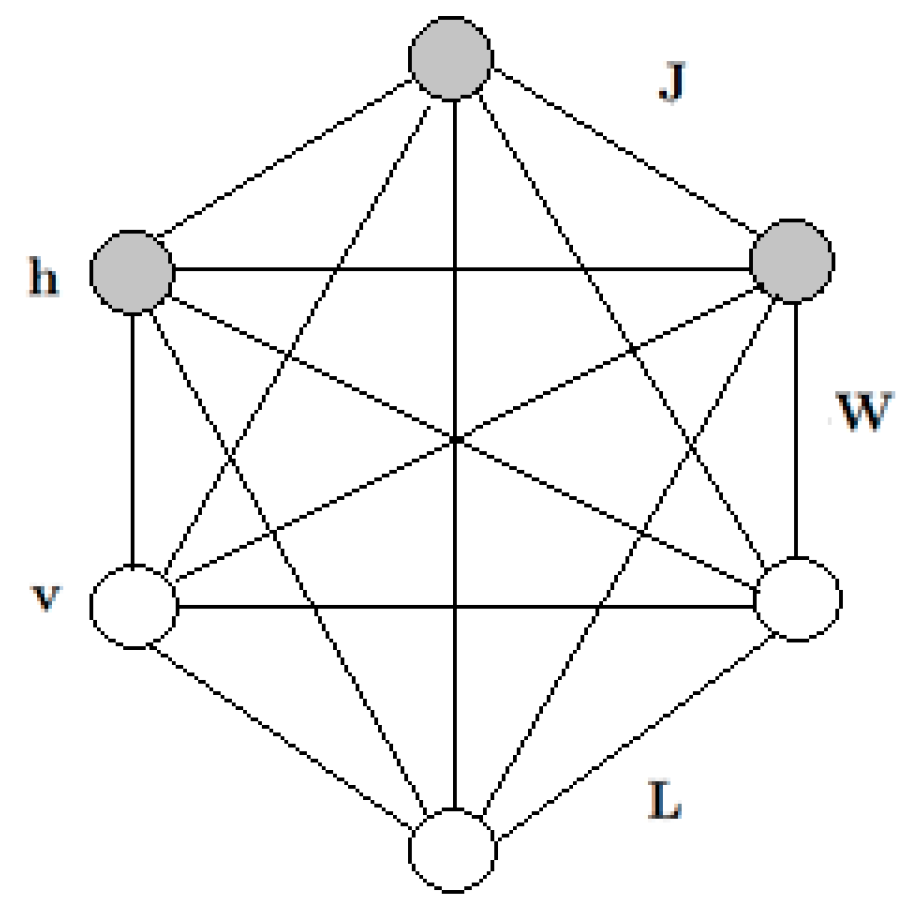
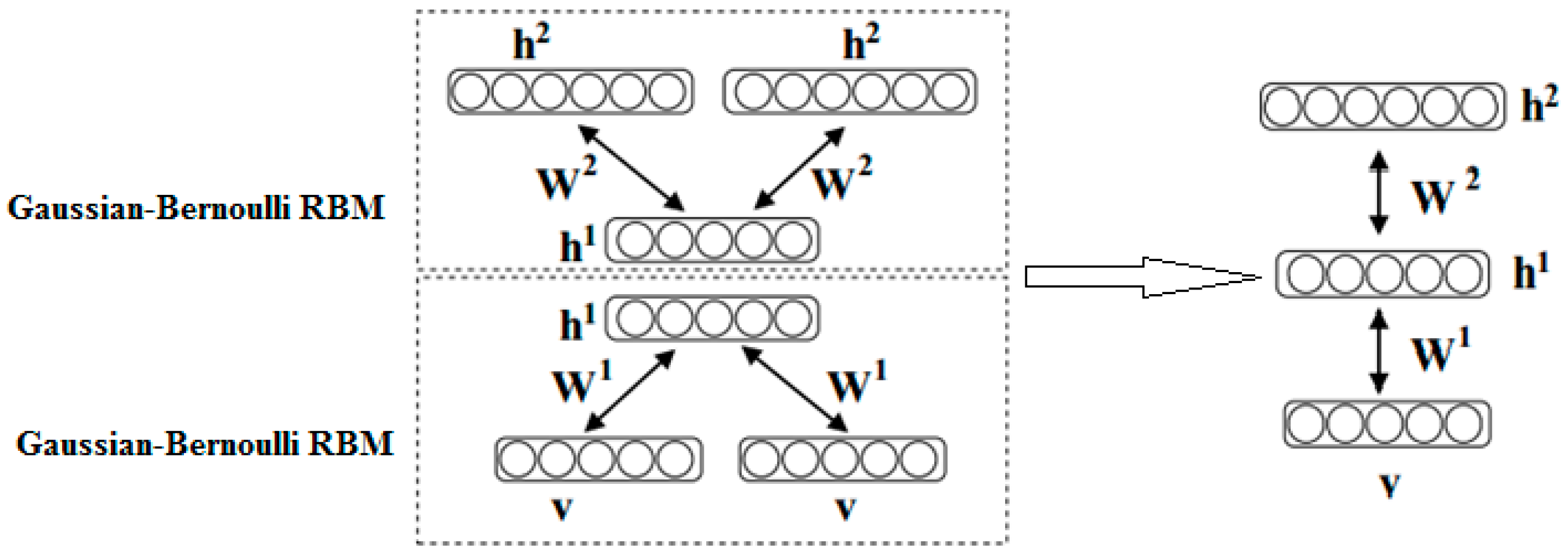
2.4. Gaussian-Bernoulli Deep Boltzmann Machine
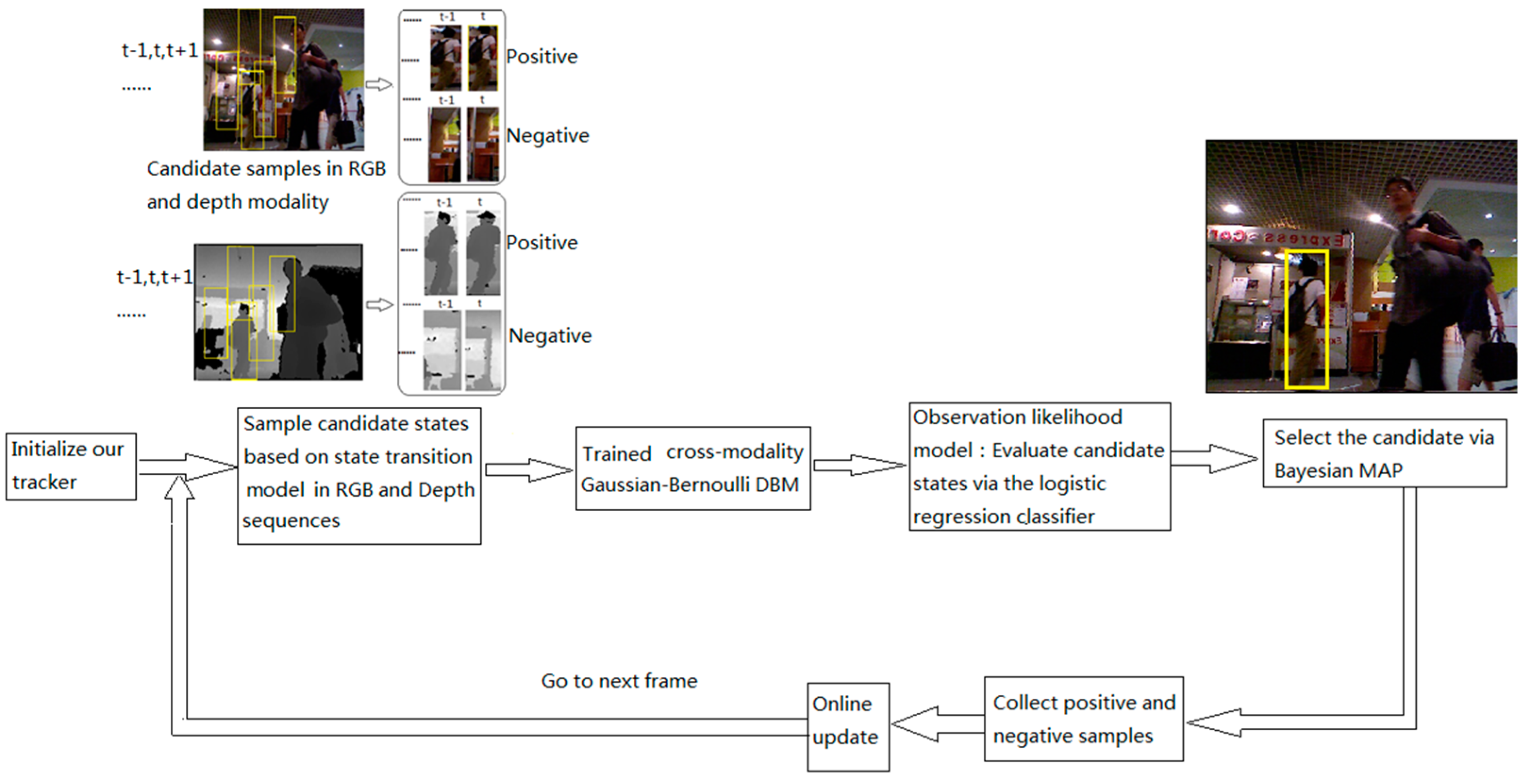
3. Proposed Tracking framework
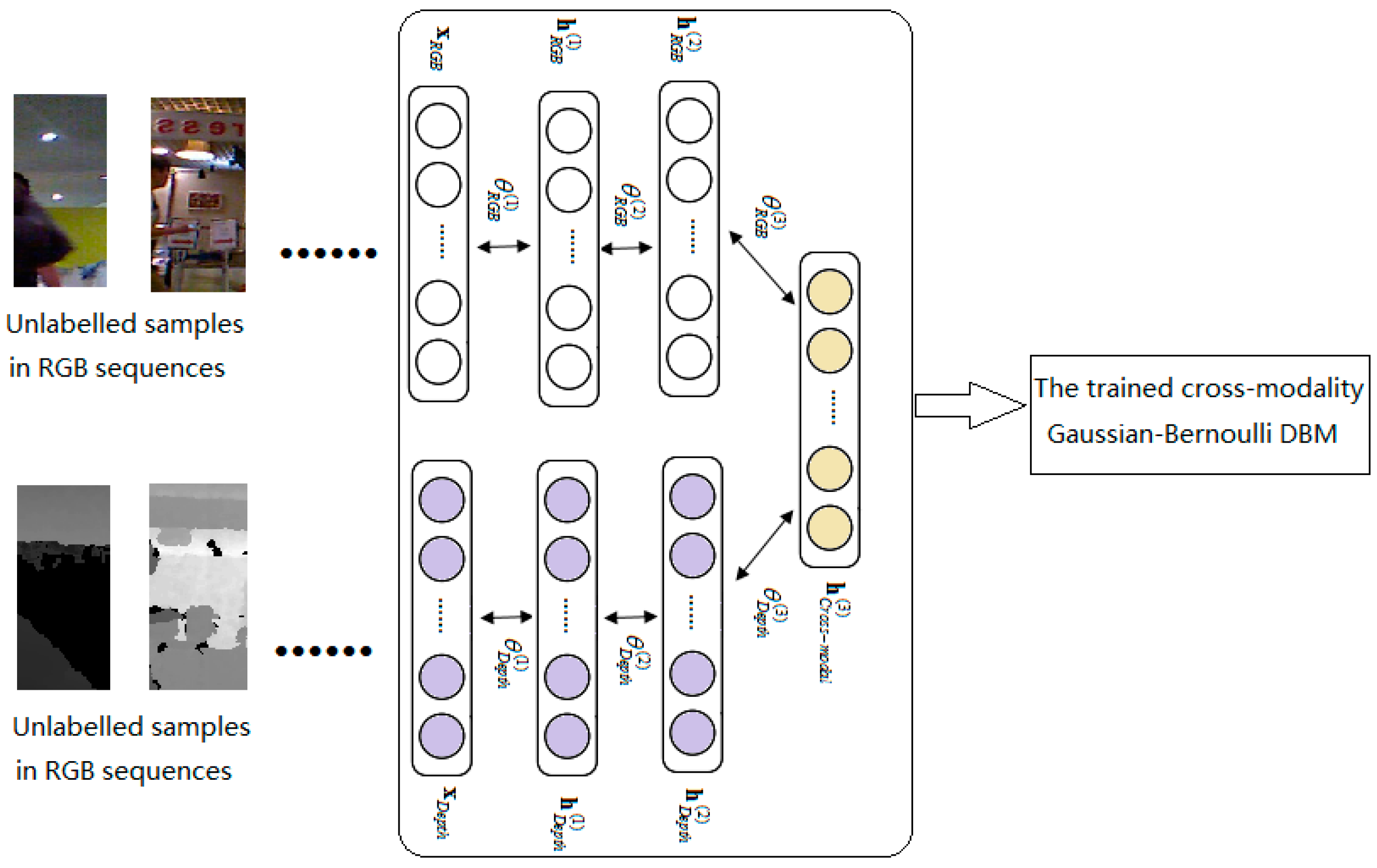
3.1. Feature Learning UsingCross-Modality Deep Boltzmann Machines over RGB-D Data
3.2. Bayesian Framework
3.2.1. State Transition Model
3.2.2. Observation Likelihood Model
4. The Implementation of Our Proposed Method
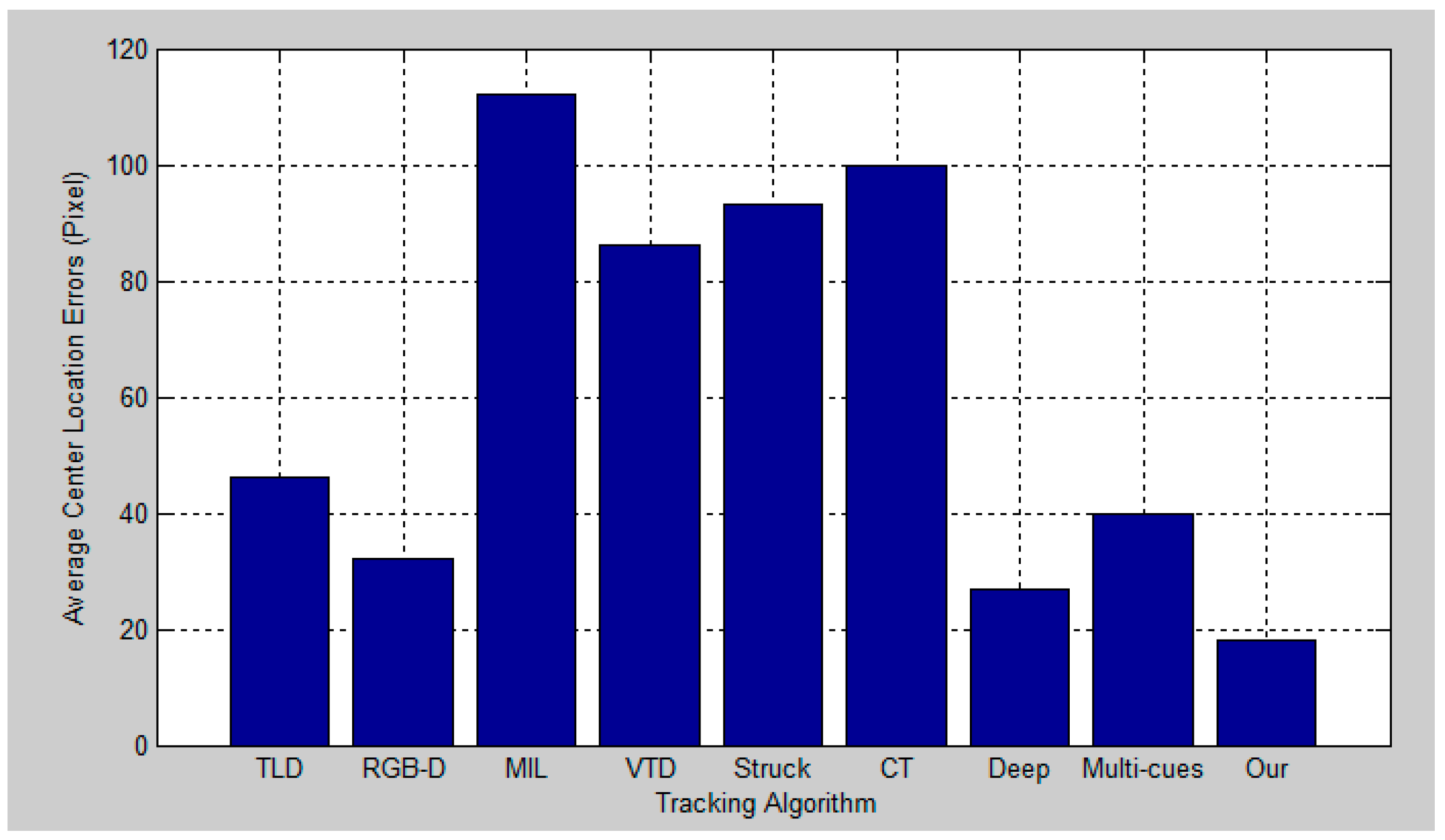
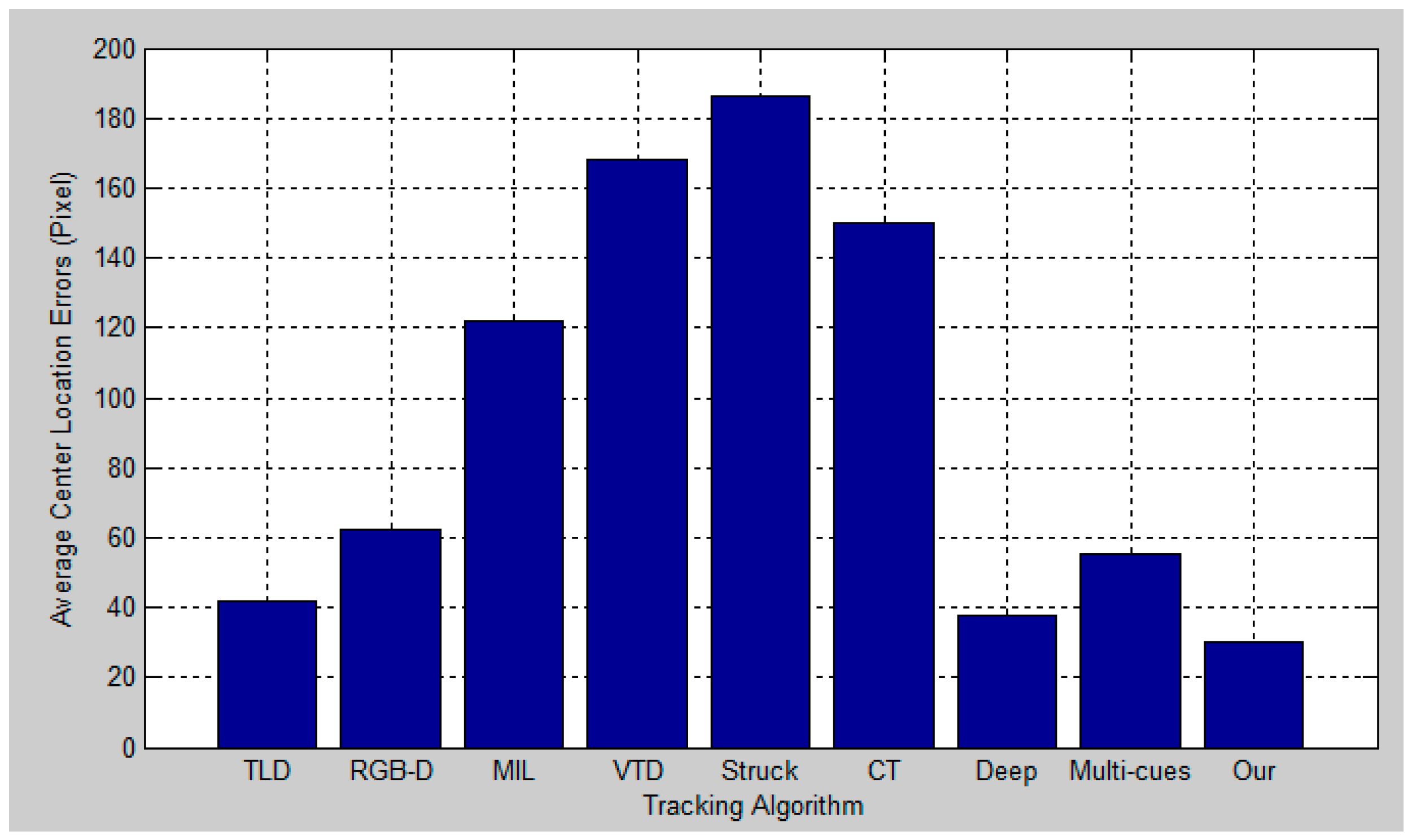
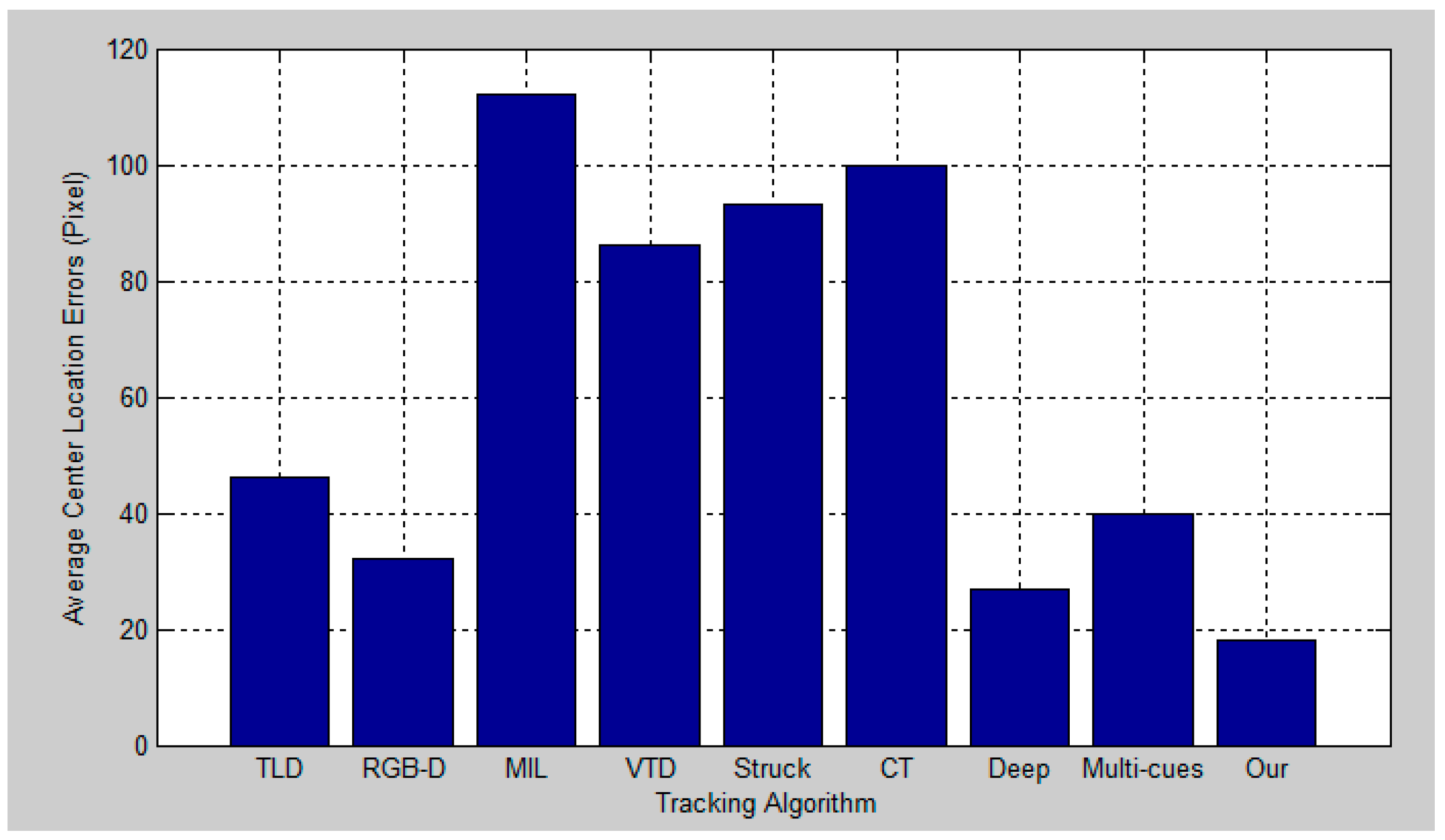
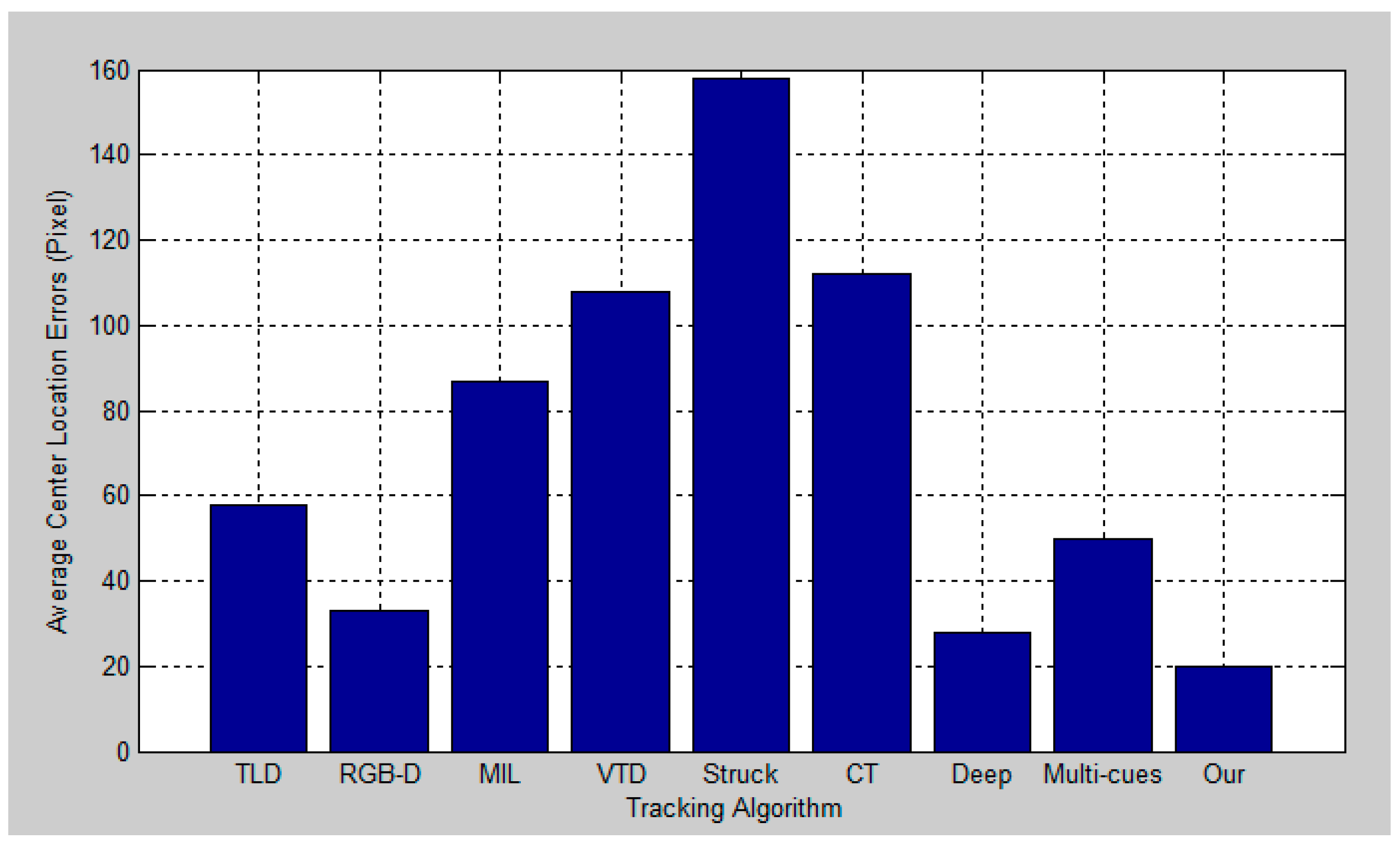
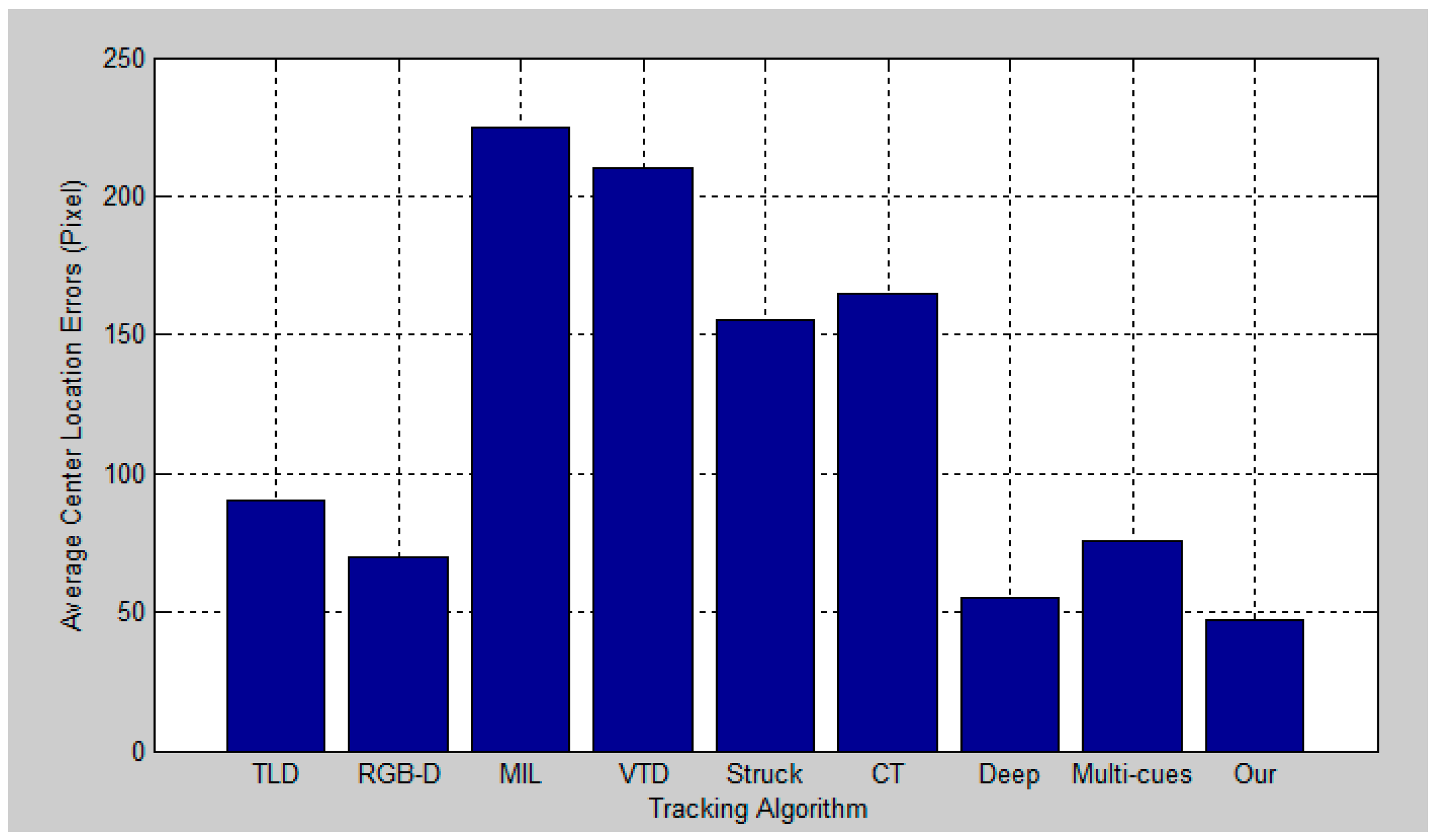
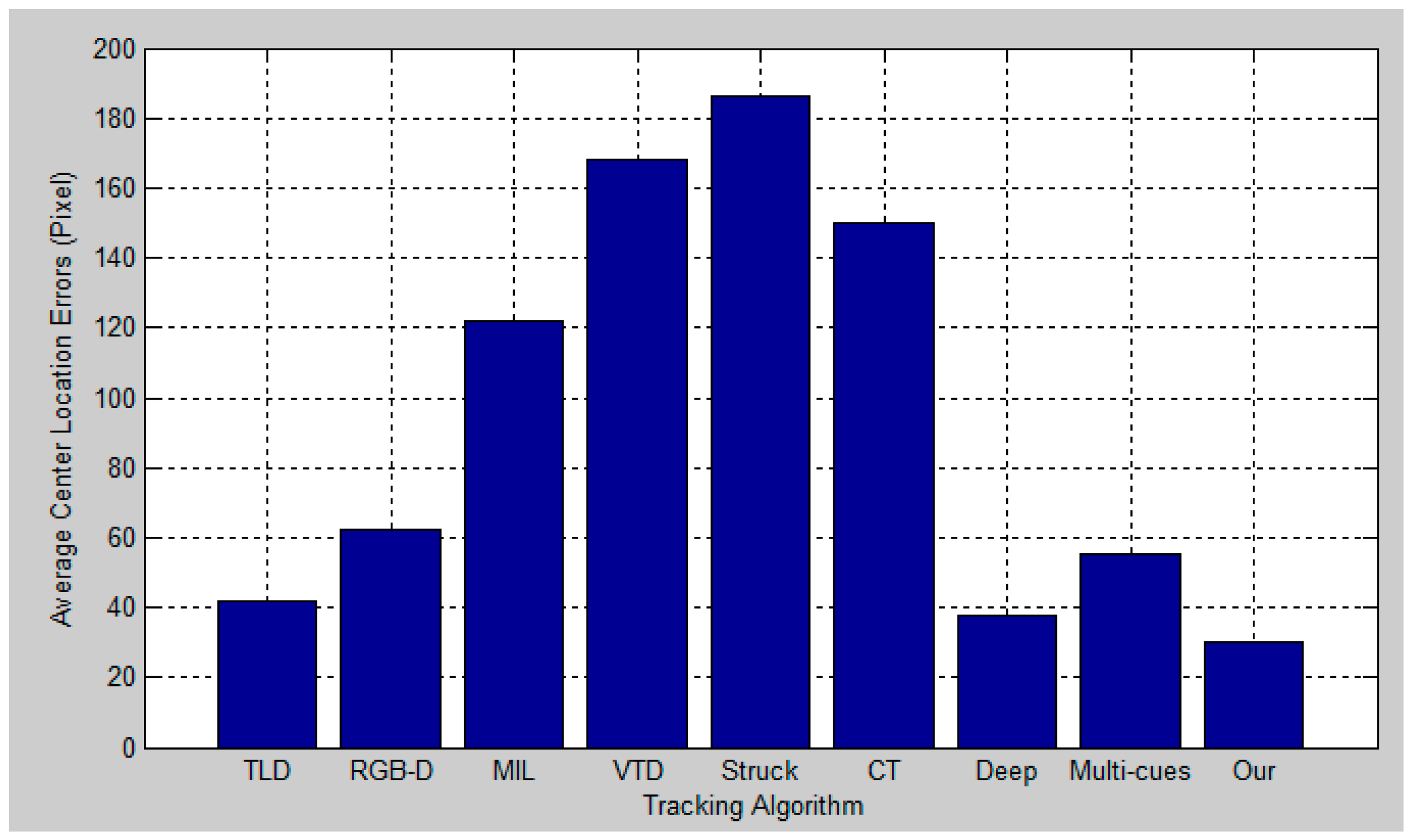
5. Experimental Results and Analysis
5.1. Qualitative Evaluation
5.2. Quantitative Evaluation
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Coppi, D.; Calderara, S.; Cucchiara, R. Transductive People Tracking in Unconstrained Surveillance. IEEE Trans. Circuits Syst. Video Technol. 2016, 26, 762–775. [Google Scholar] [CrossRef]
- Daniel, P.J.; Doherty, J.F. Track Detection of Low Observable Targets Using a Motion Model. IEEE Access 2015, 3, 1408–1415. [Google Scholar]
- Doulamis, A. Dynamic tracking re-adjustment: A method for automatic tracking recovery in complex visual environments. Multimed. Tools Appl. 2010, 50, 49–73. [Google Scholar] [CrossRef]
- Wang, B.X.; Tang, L.B.; Yang, J.L.; Zhao, B.J.; Wang, S.G. Visual tracking based on extreme learning machine and sparse representation. Sensors 2015, 15, 26877–26905. [Google Scholar] [CrossRef] [PubMed]
- Li, X.L.; Han, Z.F.; Wang, L.J.; Lu, H.C. Visual Tracking via Random Walks on Graph Model. IEEE Trans. Cybern. 2016, 46, 2144–2155. [Google Scholar] [CrossRef] [PubMed]
- Munaro, M.; Basso, F.; Menegatti, E. Tracking People within Groups with RGB-D Data. In Proceedings of the IEEE International Conference on Intelligent Robots and Systems(IROS), Vilamoura, Portugal, 7–11 October 2012.
- Spinello, L.; Luber, M.; Arras, K.O. Tracking people in 3D using a bottom-up top-down people detector. In Proceedings of the International Conference on Robotics and Automation (ICRA), Shanghai, China, 9–13 May 2011.
- Spinello, L.; Arras, K.O. People Detection in RGB-D Data. In Proceedings of the IEEE International Conference on Intelligent Robots and Systems(IROS), San Francisco, CA, USA, 25–30 September 2011.
- Viola, P.; Jones, M.J. Robust real-time face detection. Int. J. Comput. Vis. 2004, 57, 137–154. [Google Scholar] [CrossRef]
- Navneet, D.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), San Diego, CA, USA, 20–26 June 2005.
- Wang, X.Y.; Han, T.X.; Yan, S.C. An HOG-LBP human detector with partial occlusion handling. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Kyoto, Japan, 29 September–2 October 2009.
- Li, H.X.; Li, Y.; Porikli, F. DeepTrack: Learning Discriminative Feature Representations Online for Robust Visual Tracking. IEEE Trans. Image Process. 2016, 25, 1834–1848. [Google Scholar] [CrossRef] [PubMed]
- Felzenszwalb, P.; Girshick, R.; McAllester, D.; Ramanan, D. Object Detection with Discriminatively Trained Part Based Models. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 1627–1645. [Google Scholar] [CrossRef] [PubMed]
- Lu, J.W.; Wang, G.; Deng, W.H.; Moulin, P.; Zhou, J. Multi-manifold deep metric learning for image set classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015.
- Wang, N.Y.; Yeung, D.Y. Learning a deep compact image representation for visual tracking. In Proceedings of the Conference and Workshop on Neural Information Processing Systems (NIPS), South Lake Tahoe, NV, USA, 5–10 December 2013.
- Wang, L.; Liu, T.; Wang, G.; Chan, K.L.; Yang, Q.X. Video Tracking Using Learned Hierarchical Features. IEEE Trans. Image Process. 2015, 24, 1424–1435. [Google Scholar] [CrossRef] [PubMed]
- Ding, J.; Huang, Y.; Liu, W.; Huang, K.Q. Severely Blurred Object Tracking by Learning Deep Image Representations. IEEE Trans. Circuits Syst. Video Technol. 2016, 26, 319–331. [Google Scholar] [CrossRef]
- Kalal, Z.; Mikolajczyk, K.; Matas, J. Tracking-learning-detection. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 1409–1422. [Google Scholar] [CrossRef] [PubMed]
- Babenko, B.; Yang, M.H.; Belongie, S. Visual tracking with online multiple instance learning. In Proceedings of the IEEE International Conference on Computer Vision (CVPR), Miami Beach, FL, USA, 20–21 June 2009.
- Kwon, J.; Lee, K.M. Visual tracking decomposition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), San Francisco, CA, USA, 13–18 June 2010.
- Song, S.; Xiao, J.X. Tracking revisited using RGBD camera: Unified benchmark and baselines. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Darling Harbour, Sydney, 3–6 December 2013.
- Hinton, G.E.; Sejnowski, T.J. Optimal perceptual inference. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition (CVPR), Los Alamitos, CA, USA, 8–10 June 1983.
- Keronen, S.; Cho, K.; Raiko, T.; Ilin, A.; Palomäki, K.J. Gaussian-Bernoulli restricted Boltzmann machines and automatic feature extraction for noise robust missing data mask estimation. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing(ICASSP), Vancouver, BC, Canada, 26–30 May 2013.
- Salakhutdinov, R.; Hinton, G.E. Deep Boltzmann Machines. In Proceedings of the International Conference on Artificial Intelligence and Statistics (AISTATS), Clearwater Beach, FL, USA, 16–18 April 2009.
- Ngiam, J.; Khosla, A.; Kim, M.; Nam, J.; Lee, H.; Ng, A.Y. Multimodal Deep Learning. In Proceedings of the International Conference on Machine Learning (ICML), Bellevue, WA, USA, 28 June–2 July 2011.
- Srivastava, N.; Salakhutdinov, R. Multimodal Learning with Deep Boltzmann Machines. In Proceedings of the International Conference and Workshop on Neural Information Processing Systems (NIPS), Lake Tahoe, NV, USA, 3–8 December 2012.
- Jiang, M.X.; Li, M.; Wang, H.Y. Visual Object Tracking Based on 2DPCA and ML. Math. Probl. Eng. 2013, 2013, 404978–404985. [Google Scholar] [CrossRef]
- Luber, M.; Spinello, L.; Arras, K.O. People tracking in RGB-D Data with on-line boosted target models. In Proceedings of the IEEE International Conference on Intelligent Robots and Systems (IROS), San Francisco, CA, USA, 25–28 September 2011.
- Hare, S.; Saffari, A.; Torr, P.H.S. Struck: Structured output tracking with kernels. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Barcelona, Spain, 6–13 November 2011; pp. 263–270.
- Zhang, K.; Zhang, L.; Yang, M.-H. Real-Time Compressive Tracking. In Proceedings of the European Conference on Computer Vision (ECCV), Firenze, Italy, 7–13 October 2012; pp. 864–877.
- Ruan, Y.; Wei, Z. Real-Time Visual Tracking through Fusion Features. Sensors 2016, 16, 949. [Google Scholar] [CrossRef] [PubMed]
- Kuen, J.; Lim, K.M.; Lee, C.P. Self-taught learning of a deep invariant representation for visual tracking via temporal slowness principle. Pattern Recognit. 2015, 48, 2964–2982. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Object Type | Movement | Occlusion | |||
|---|---|---|---|---|---|---|
| Human | Animal | Fast | Slow | Yes | No | |
| Our Tracker | 80.1% | 72.9% | 77.5% | 82.3% | 81.2% | 82.6% |
| TLD Tracker | 29.0% | 35.1% | 29.7% | 51.6% | 33.8% | 38.7% |
| VTD Tracker | 30.9% | 48.8% | 37.2% | 57.3% | 28.3% | 63.1% |
| MIL Tracker | 32.2% | 37.2% | 31.5% | 45.5% | 25.6% | 49.0% |
| RGB-D Tracker | 47.1% | 47.0% | 51.8% | 56.7% | 46.9% | 61.9% |
| Struck Tracker | 35.4% | 47.0% | 39.0% | 58.0% | 30.4% | 63.5% |
| CT Tracker | 31.1% | 46.7% | 31.5% | 48.6% | 34.8% | 46.8% |
| Deep Tracker | 72.1% | 64.8% | 70.1% | 76.3% | 71.4% | 72.6% |
| Multi-cues Tracker | 33.2% | 49.5% | 52.3% | 55.6% | 44.7% | 57.5% |
| Method | The Average Speed (fps) |
|---|---|
| Our Tracker | 0.14 |
| TLD Tracker | 28.5 |
| VTD Tracker | 6.7 |
| MIL Tracker | 38.9 |
| RGB-D Tracker | 2.6 |
| Struck Tracker | 20.8 |
| CT Tracker | 64.7 |
| Deep Tracker | 0.23 |
| Multi-cues Tracker | 40.7 |
© 2017 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jiang, M.; Pan, Z.; Tang, Z. Visual Object Tracking Based on Cross-Modality Gaussian-Bernoulli Deep Boltzmann Machines with RGB-D Sensors. Sensors 2017, 17, 121. https://doi.org/10.3390/s17010121
Jiang M, Pan Z, Tang Z. Visual Object Tracking Based on Cross-Modality Gaussian-Bernoulli Deep Boltzmann Machines with RGB-D Sensors. Sensors. 2017; 17(1):121. https://doi.org/10.3390/s17010121
Chicago/Turabian StyleJiang, Mingxin, Zhigeng Pan, and Zhenzhou Tang. 2017. "Visual Object Tracking Based on Cross-Modality Gaussian-Bernoulli Deep Boltzmann Machines with RGB-D Sensors" Sensors 17, no. 1: 121. https://doi.org/10.3390/s17010121
APA StyleJiang, M., Pan, Z., & Tang, Z. (2017). Visual Object Tracking Based on Cross-Modality Gaussian-Bernoulli Deep Boltzmann Machines with RGB-D Sensors. Sensors, 17(1), 121. https://doi.org/10.3390/s17010121