1. Introduction
Due to the imaging characteristics of high resolution, day-and-night and weather-independent, Synthetic Aperture Radar (SAR) has been widely used for Earth remote sensing for more than 30 years, and it has come to play a significant role in geographical surveys, climate change research, environment and Earth system monitoring, multi-dimensional mapping and other applications [
1]. In the foreseeable future, more multi-platform, multi-mode and multi-band SAR systems will be developed to satisfy the practical demands. Due to the time consuming and high-cost of SAR flight experiments, computer simulation is often applied to assist the key technology research, system design, system development, and even the data applications. In order to fulfill aforementioned support, the accurate and reliable raw data that contain various actual system errors and simulate large areas are necessary. Thus, the requirement poses a challenge for SAR raw data simulation accuracy and efficiency.
Currently, the SAR raw data simulation algorithm can be mainly divided into two categories: forward processing and inverse processing. The forward processing algorithms simulate the physical process of microwave transmitting and receiving, and then calculate the SAR raw data, including the time domain pulse coherent algorithm [
2], the frequency domain pulse coherent algorithm [
2], the 2D frequency domain algorithm [
3] and its improved algorithms [
4,
5]. Comparatively, the inverse processing algorithms simulate the SAR raw data through the inverse SAR imaging processing, including the inverse fourth-order extended exact transfer function (EETF4) algorithm [
6], the inverse
algorithm [
7,
8], the inverse Chirp Scaling algorithm [
9] and the inverse frequency scaling algorithm [
10]. Furthermore, the 2D frequency domain algorithm and the inverse processing algorithm are efficient although difficult for considering the actual system errors. To account for these errors, some assumptions need to be introduced into these algorithms, resulting in the loss of accuracy and efficiency to some extent. On the other hand, the time-domain algorithm can easily consider the systematic errors and motion errors, so it is always employed for practical SAR simulators [
11,
12].
With the increased spatial resolution and swath width of SAR systems, the simulated targets increase massively, which causes the rapid growth of computational time. Although the time-domain SAR raw data simulation algorithm has been improved for smaller time complexity, the optimization still does not achieve satisfactory performance. Due to the independence of raw signal collection, parallelization is the most straightforward idea and can greatly shorten the simulation time with state-of-the-art high performance computing (HPC) technologies. Thus, several classical HPC methods have been introduced into the SAR raw data simulation for speedup, such as open multiple processing (OpenMP) with multi-cores [
13], message passing interface (MPI) with multi-CPUs [
14], grid computing with multi-computers [
15] and graphics processing unit (GPU) computing with massive cores [
16]. These methods are all computing oriented, and seldom consider the big data input/output (I/O) solution. On the other hand, the cost of these methods are high in that the required computers and servers are expensive and energy consuming. Furthermore, the last decades have seen an unprecedented development in the remote sensing industry, which demands a big data solution of data producing and applications. Compared with these HPC technologies, cloud computing is the best solution for these three issues.
Cloud computing is a large-scale distributed computing paradigm that is driven by economies of scale, in which a pool of abstracted, virtualized, dynamically-scalable, managed computing power, storage, platforms and services are delivered on demand to external customers over the internet [
17]. To realize these merits, programming model, distributed storage, data management and virtualization constitute the key technologies of cloud computing. Programming model is mainly used to solve the large-scale distributed computing issue. The most popular programming model is Google’s MapReduce [
18], which simplifies the distributed programming process only through map and reduce function design. Then, the cloud system will automatically manage the specific task partition, scheduling, processing and storage. In addition, there are some other similar programming models, such as Dryad [
19], Pregel [
20] and so on. Distributed storage technology is a key to the solution of the data intensive issue. It spreads the single node pressure of data access to multiple nodes, thereby breaking the data access bottleneck. The frequently-used distributed data storage systems are, respectively, Google File System (GFS) [
21] and Apache Hadoop Distributed File System (HDFS) [
22]. Based on distributed storage technology, the distributed data management system is employed to handle the big data issue over the Petabyte level, e.g., Google BigTable [
23] and Amazon Dynamo [
24]. Virtualization is the key technology to integrate various computing and storage resources, and makes them available for different levels of users. With the development of cloud computing technologies, several cloud computing platforms have sprung up to support the big data applications, such as IBM’s Blue cloud, Google cloud, Amazon elastic cloud, Apache Hadoop and so on. With the further application of cloud computing, some new programming models have emerged to enhance the computing ability over the MapReduce model, including Tez [
25], Spark [
26] and Storm [
27]. Meanwhile, a new resource management framework, named YARN [
28] has been introduced into cloud computing to separate the resource management and task scheduling, and has brought great benefits for resource utilization and data sharing.
As the outstanding capacity of the cloud computing framework, the MapReduce implementations of classical algorithms have drawn increasing attention. Cloud computing has been applied to remote sensing processing [
29], geoscience [
30], SAR interferometry [
31], image processing [
22] and other remote sensing areas. Cloud computing is the future trend of the remote sensing big data processing. Predictably, cloud computing not only boosts the big data I/O efficiency, but also improves the processing efficiency by large scale computing resources. Therefore, cloud computing is first introduced to the SAR raw data simulation for an initial attempt of service-oriented solutions. Compared to previous work [
11,
15,
16,
32], we make the following contributions:
a first cloud computing implementation for SAR raw data simulation;
applying the MapReduce model for irregular accumulation of SAR return signals, which is a hard issue for fine-grained parallelization, like GPU;
optimizing the computing efficiency through introducing combine method, tuning of Hadoop configuration and scheduling strategies.
The rest of the paper is organized as follows:
Section 2 briefly introduces the SAR raw data simulation algorithm, its parallelization analysis and the principle of cloud computing;
Section 3 presents the proposed cloud computing based raw data simulation algorithm. Then, the experimental results and analysis are discussed in
Section 4. Finally, conclusions are drawn in
Section 5.
2. Related Work
In this section, we will briefly introduce some background knowledge on Fast Fourier Transform (FFT) based time domain stripmap SAR raw data simulation and its parallel analysis, cloud computing, respectively. It is noted that the geometry calculation is not discussed in the paper. Except for the classical stripmap mode, other main stream SAR modes, namely the spotlight, sliding spotlight, ScanSAR and Terrain Observation by Progressive Scans (TOPS) SAR modes, perform complex beam steering in azimuth and range direction, and lead to different geometry calculation in raw data simulation. Except for the FFT based time domain raw data simulation of different SAR modes, the kernel part of signal simulations are all the same. Therefore, the proposed cloud computing method can be applied to all of the SAR modes by introducing corresponding geometry calculation steps.
2.1. SAR Raw Data Simulation Algorithm
The echo signal model in [
33] is applicable for airborne, spaceborne SAR data. Assuming that the transmitting pulse is a linear frequency modulated (FM) signal pulse, i.e.,
Through coherent receiving, the single point echo is expressed as 2D
where
t is the azimuth time,
τ is the range time,
σ is the scattering coefficient,
is the antenna gain,
θ is the antenna look angle,
is the signal pulse width,
is the synthetic aperture time,
is the distance between target point and the radar antenna phase center at time
t,
is the signal modulation frequency rate, and
is a rectangular envelope.
When the simulation objects are distributed targets, the SAR echo signal can be obtained by
where
i is the order number of distributed points in scattering matrix,
n is the order number in azimuth time,
T is the number of azimuth samples, and
M is the total number of target points.
In a practical engineering calculation, the FFT based time-domain method, which calculates the scattering target points accumulation by frequency domain multiplication, is often applied for raw data generation as follows:
with
where
is the Fourier transform operator,
is the inverse Fourier transform operator, and
is the linear FM Signal spectrum. In the procedure of simulation, the linear FM signal spectrum
does not change, while the azimuth signal spectrum changes with different scattering points and azimuth time. According to
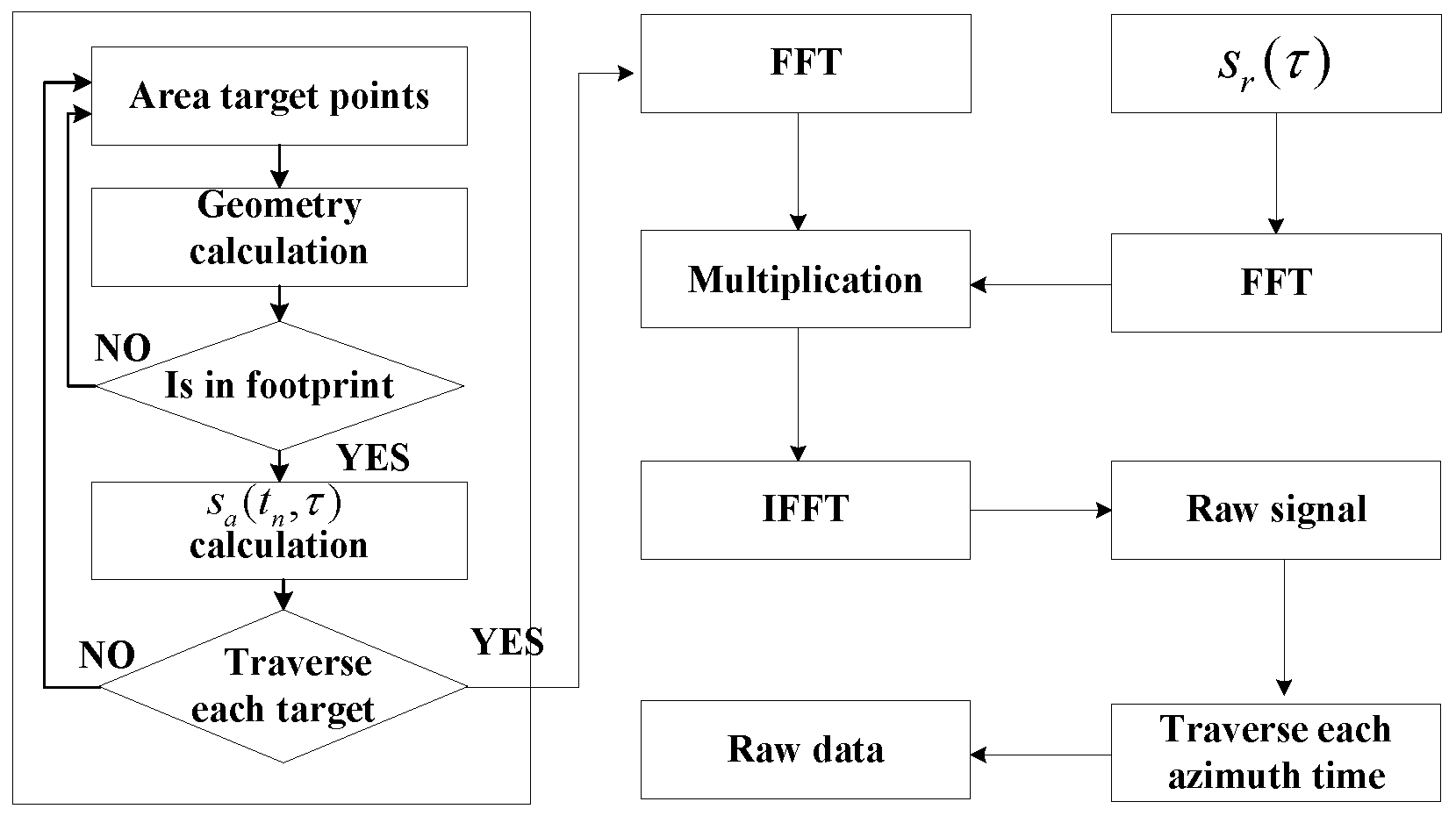
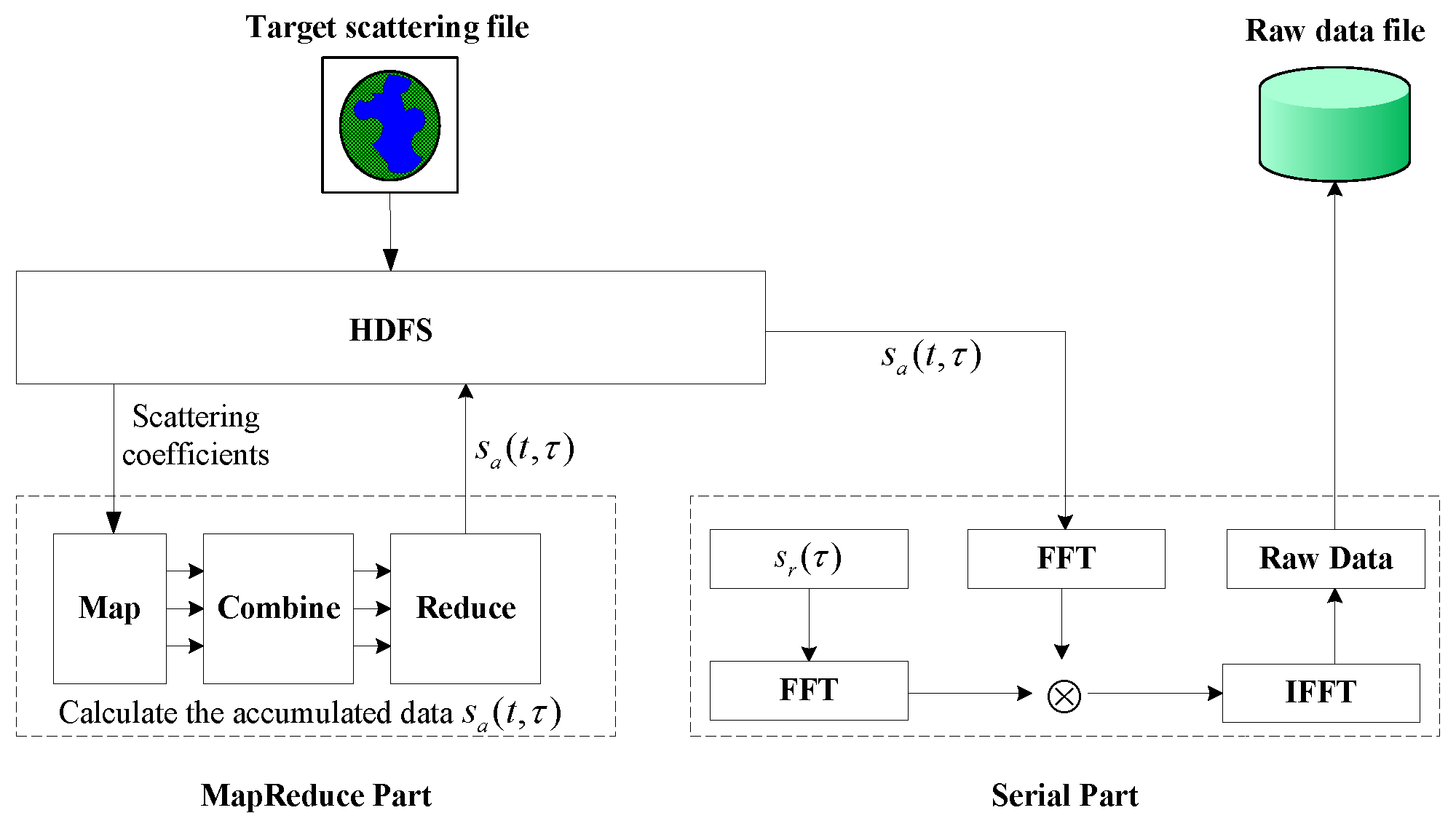
Figure 1 and Algorithm 1, the raw data simulation algorithm includes the following five steps:
the linear FM signal spectrum is calculated;
the azimuth signals of all scattering points are calculated and accumulated into , and then transformed into the frequency domain;
the spectrum multiplication of azimuth signal and linear FM signal is completed;
the raw signal is achieved by the inverse Fourier transform of results in Step 3;
for all the azimuth sampling time, steps are repeated to get the complete simulated raw data.
2.2. Parallelization of Raw Data Simulation
According to the stop-and-go model, SAR raw data simulation is a serial time process, and then the coupling of transmitting and receiving pulses at different azimuth time is small. Therefore, we can take the pulses transmitting and receiving as the task unit, which will be dispatched to every computation node and calculated quickly by MPI, grid computing or other parallel technologies.
| Algorithm 1 Serial SAR raw data simulation algorithm. |
Input: The simulated target scattering coefficients with size M, radar signal spectrum with size
Output: SAR raw data: 2D complex array with size - 1:
for each do - 2:
for each do - 3:
compute the distance between radar and target i; - 4:
compute the angle of deviating from the beam center; - 5:
if then - 6:
; - 7:
end if - 8:
compute the range gate number of return signal; - 9:
; - 10:
; - 11:
; - 12:
end for - 13:
compute the FFT of ; - 14:
Multiplication of and ; - 15:
compute the inverse FFT of the product; - 16:
for each do - 17:
; - 18:
end for - 19:
end for
|
The parallelism of SAR raw data simulation can be divided into a coarse-grained strategy and a fine-grained one, as shown in
Figure 1. The traditional parallel approach belongs to the former, which takes the repetitious transmitting and receiving pulses process as one task. The process completes the task assignment through dispatching a reasonable number of simulated pulses to different nodes, CPUs, and CPU cores, as shown in Equation (
6), i.e.,
in which
represents the calculation task of node
k, and
m indicates the number of sub-tasks.
Comparatively, the parallel simulation based on GPU is a fine-grained parallel method, which optimizes the largest time-consuming step. The task of every thread is the azimuth signal calculation of a single scattering point and a single sampling point multiplication, as shown in
Figure 1 and Equation (
7), i.e.,
where
is the azimuth signal of point
i in time
,
is the spectrum product of linear FM signal and azimuth signal at range gate
j in time
, and
N is the number of range gates. With parallel task decomposition from coarse-grained
to fine-grained
and
, higher efficiency of the parallel simulation is achieved.
2.3. Cloud Computing
The popular cloud computing platform is Hadoop, which was originated from a Google cluster system. It is composed of the common module, the HDFS module, the YARN module and the MapReduce module. Among them, common module is a set of utilities that supports other Hadoop modules, HDFS is a distributed file system that provides high-throughput access to application data, YARN is a framework for job scheduling and cluster resource management and MapReduce is a YARN-based system for distributed processing of big data. For a cloud computing application, MapReduce and HDFS are the core factors of cloud algorithm design.
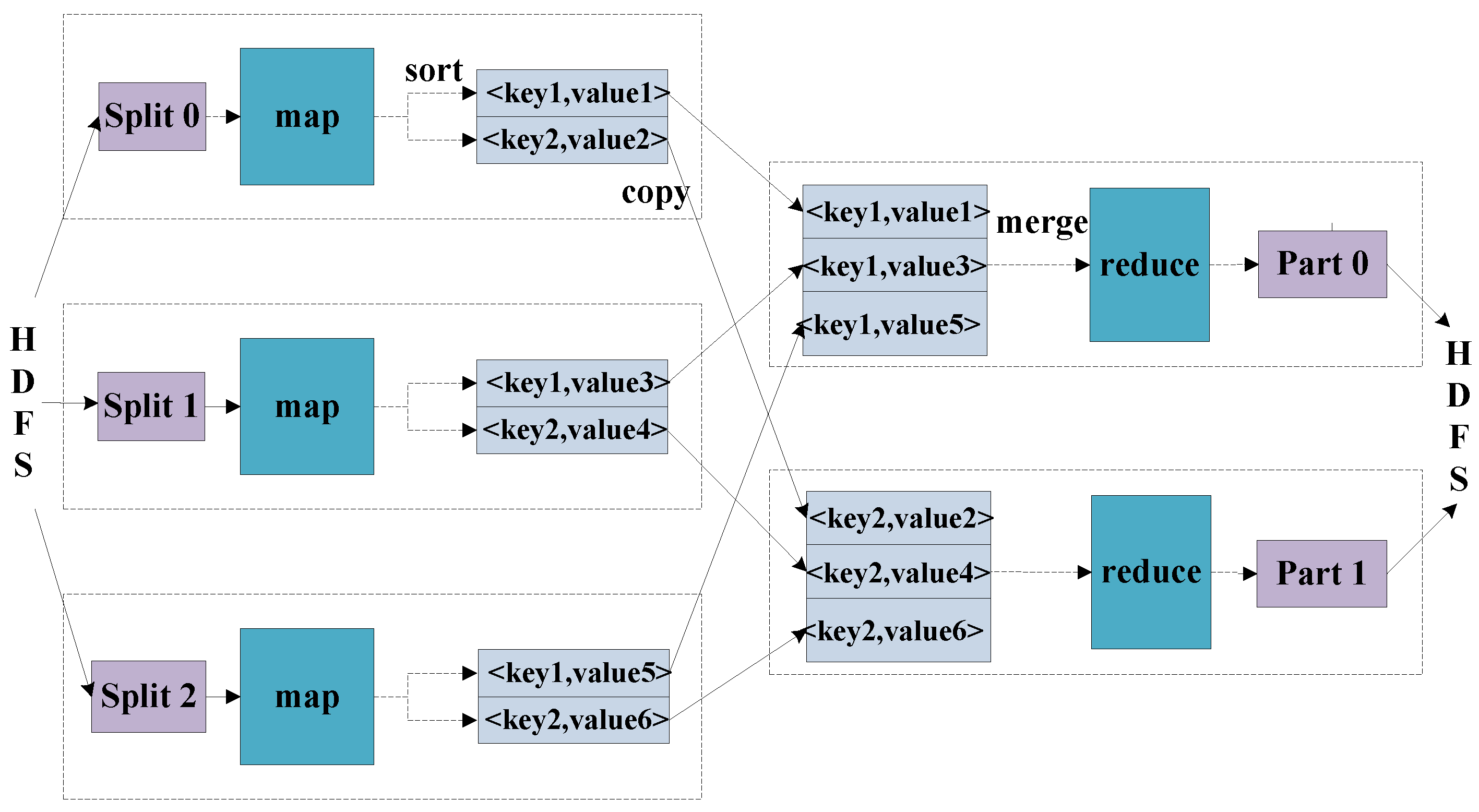
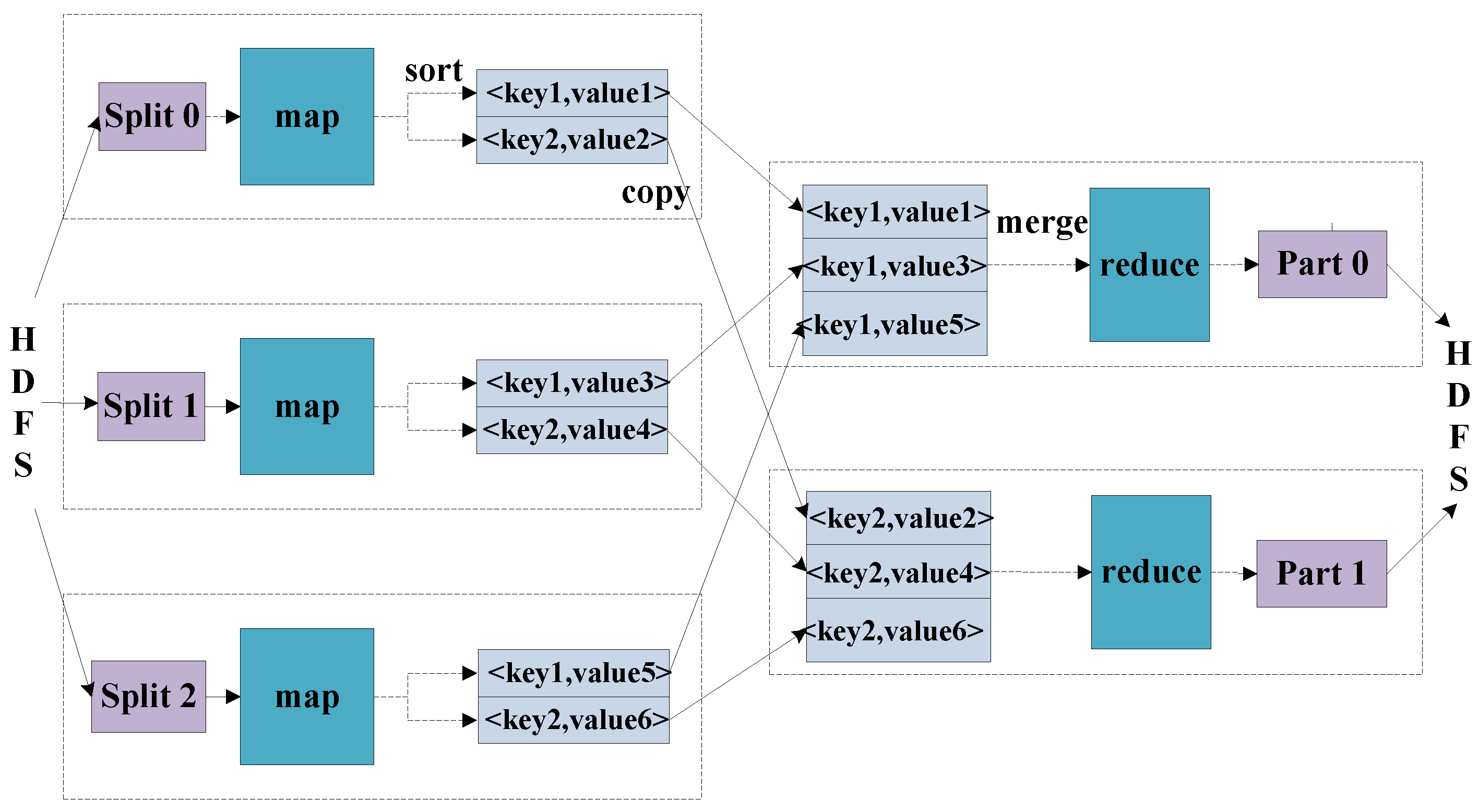
MapReduce is a programming model for the parallel processing of distributed large-scale data [
18]. The whole implementation of MapReduce is mainly divided into two stages: the map stage and the reduce stage, respectively. The inputs and outputs of them are all based on the form of
pairs, whose data types can be conveniently modified by the programmer. In some cases, more than one value needs to be output, and the interface should be modified in addition to the SAR raw data simulation. Due to raw data being complex data, a complex type is assigned for the pair as
. Firstly, the MapReduce process divides all the data sources into pieces, and dispatches them to the map tasks for them to deal with. Then, the intermediate
pairs produced by the Map function are buffered in memory. Secondly, the reduce tasks merge all the intermediate values that are associated with the same key, as shown in
Figure 2.
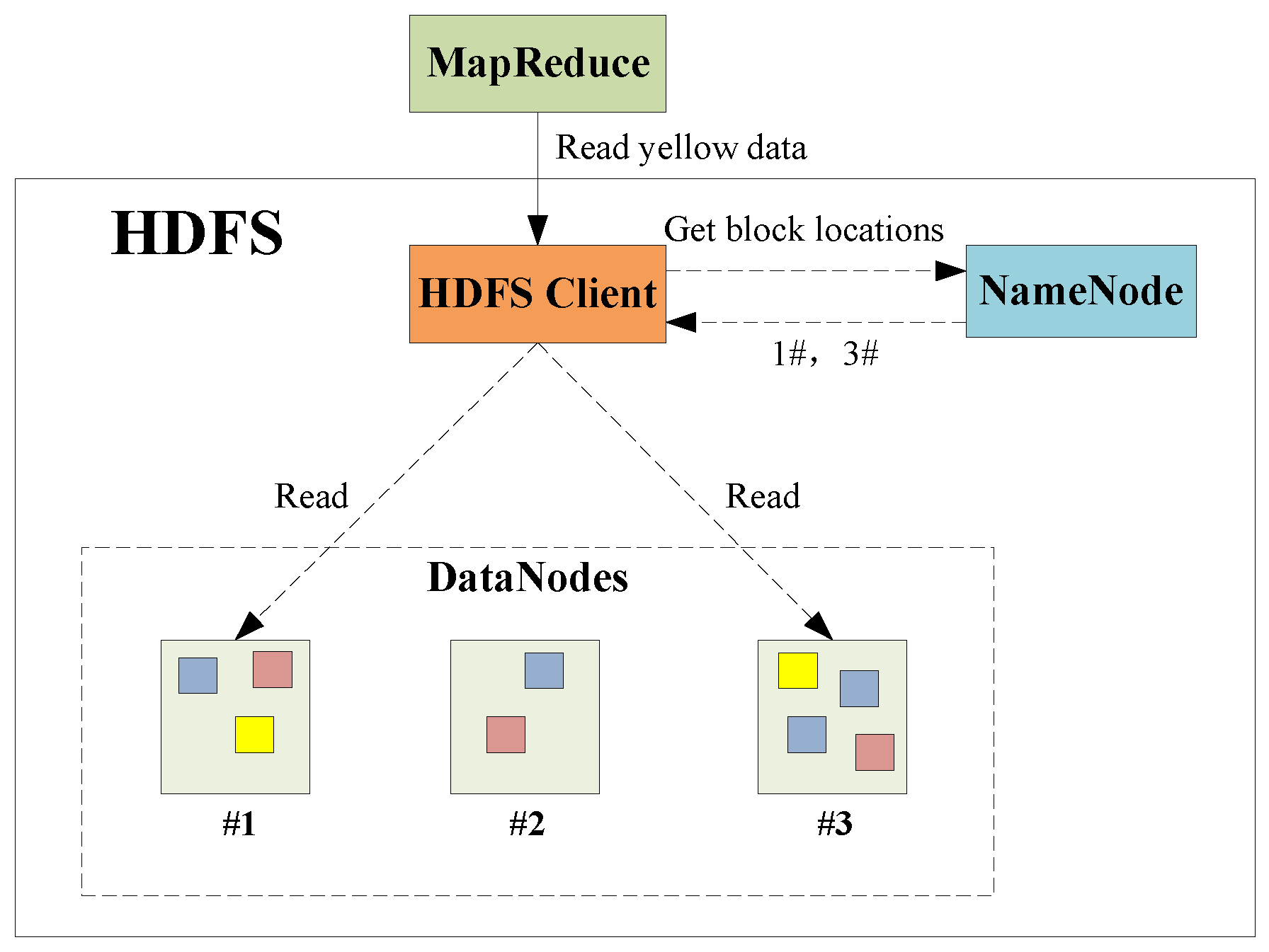
The HDFS is a master–slave structure system, as shown in
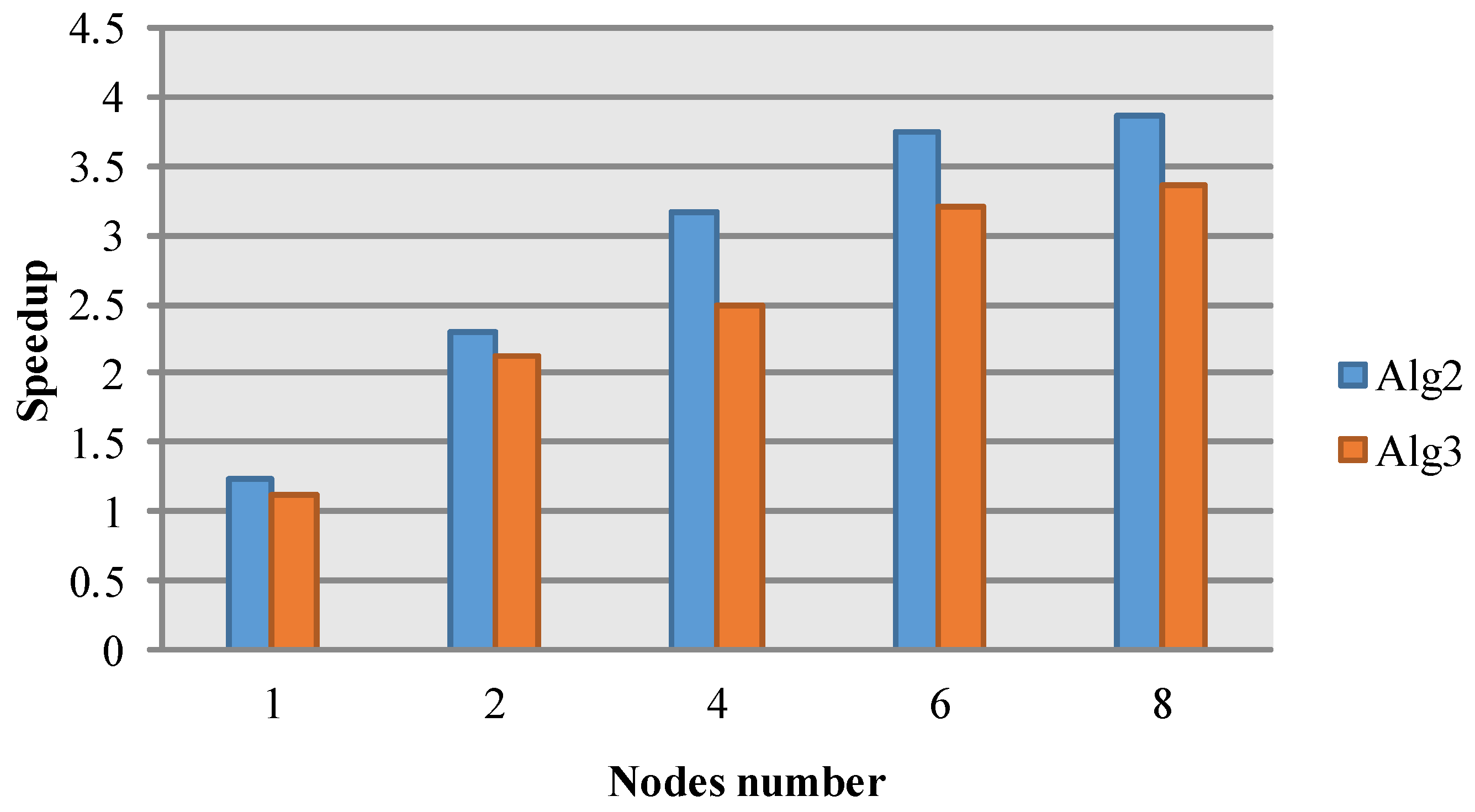
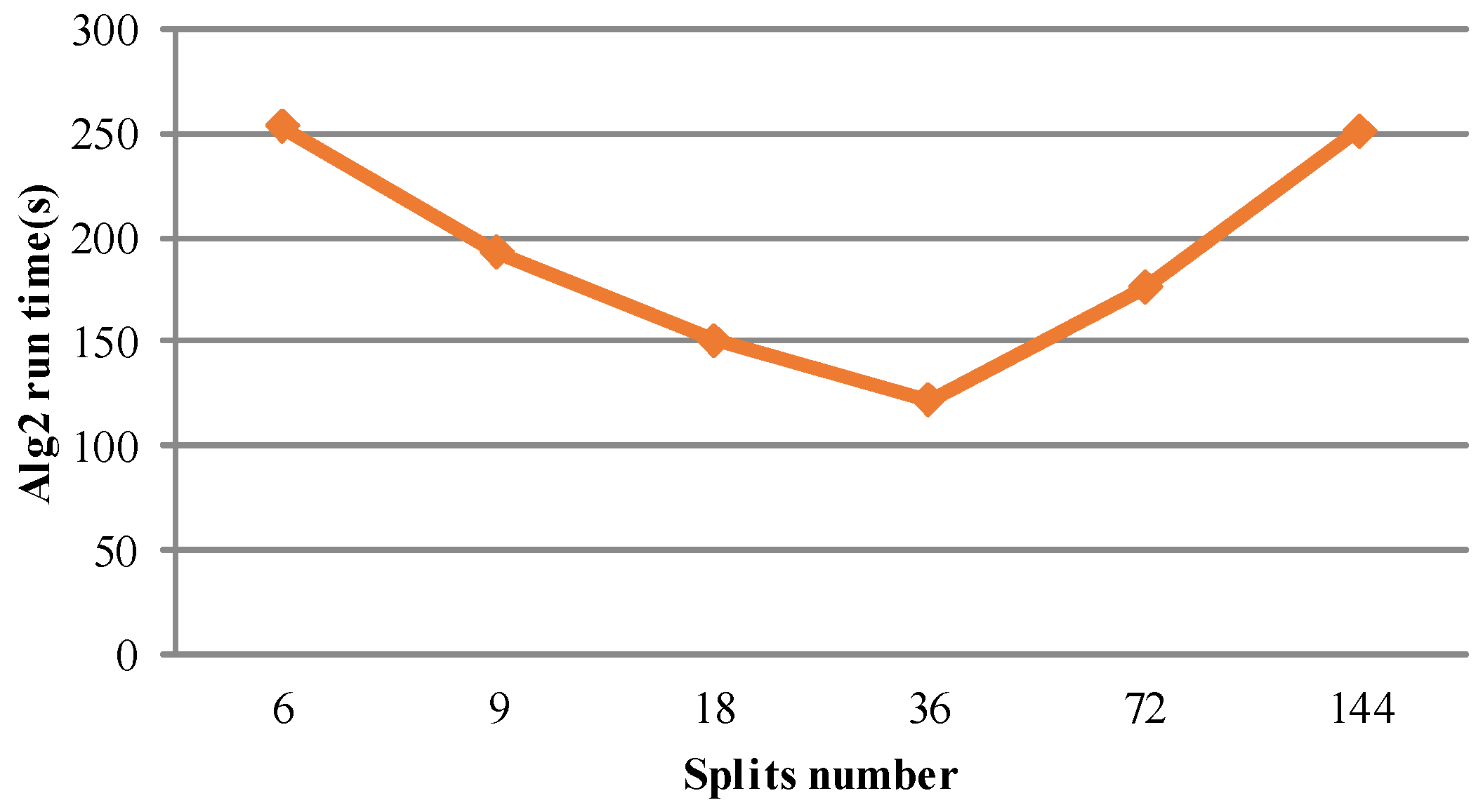
Figure 3. It consists of client, namenode and datanode, which are, respectively, responsible for the execution of the internal and external instructions, the management of the file system name space and the management of cluster data storage. Taking data reading for example, the MapReduce firstly requests the HDFS client to read the yellow type data. Secondly, the HDFS client queries the namenode for detail data block information. Then, the HDFS client contacts the responding DataNodes directly and requests the transfer of the desired data block. Otherwise, data stored in HDFS can be divided into multiple independent data blocks. A read/write operation in HDFS is composed of multiple datanodes’ simultaneous read/write operations, thus boosting the I/O operation efficiency.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}