
Pedestrian Detection at Day/Night Time with Visible and FIR Cameras: A Comparison



Abstract
:1. Introduction
- An extensive evaluation of pedestrian detectors for a number of combinations of the former three factors: visible/FIR modalities, pedestrian models and lighting conditions.
- We make available the new CVC-14 dataset in the Dataset section of http://adas.cvc.uab.es. CVC-14 is a new dataset of multimodal (FIR plus visible) videosequences and the corresponding detection groundtruth, comparable to the only other publicly available KAIST dataset [36].
- We assess the relevance of simultaneously using two cameras of different modality (FIR, Visible) by applying early fusion, which is done on KAIST.
2. Related Works
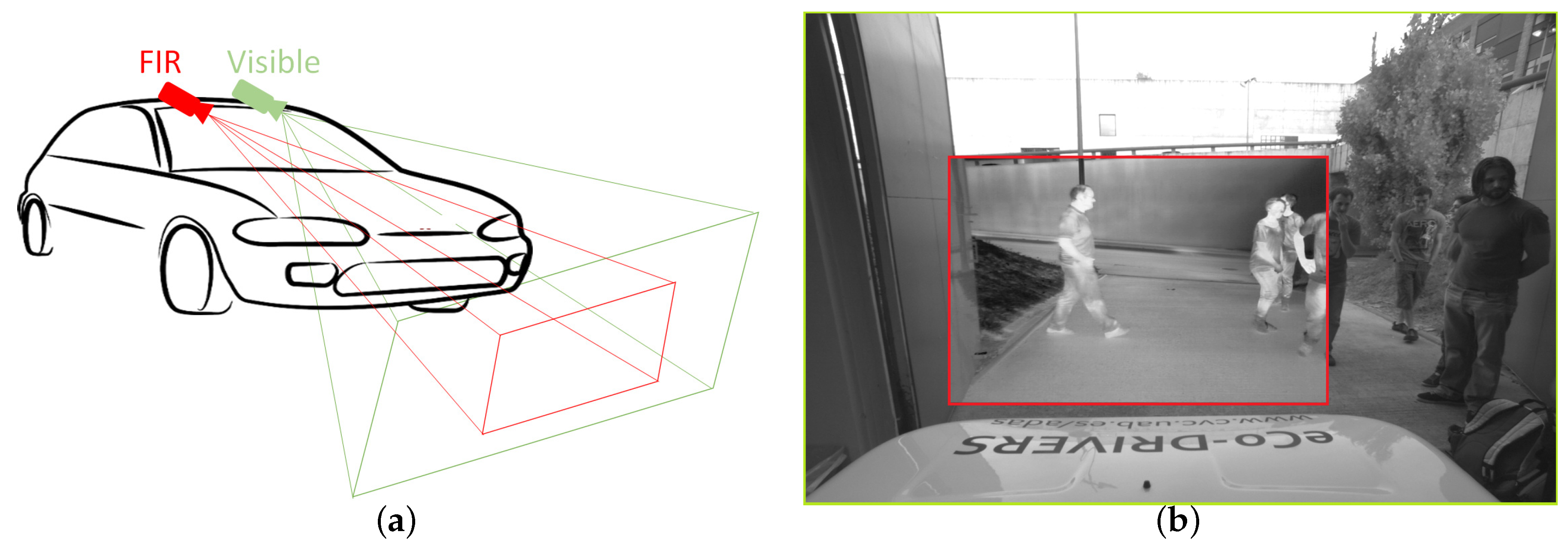
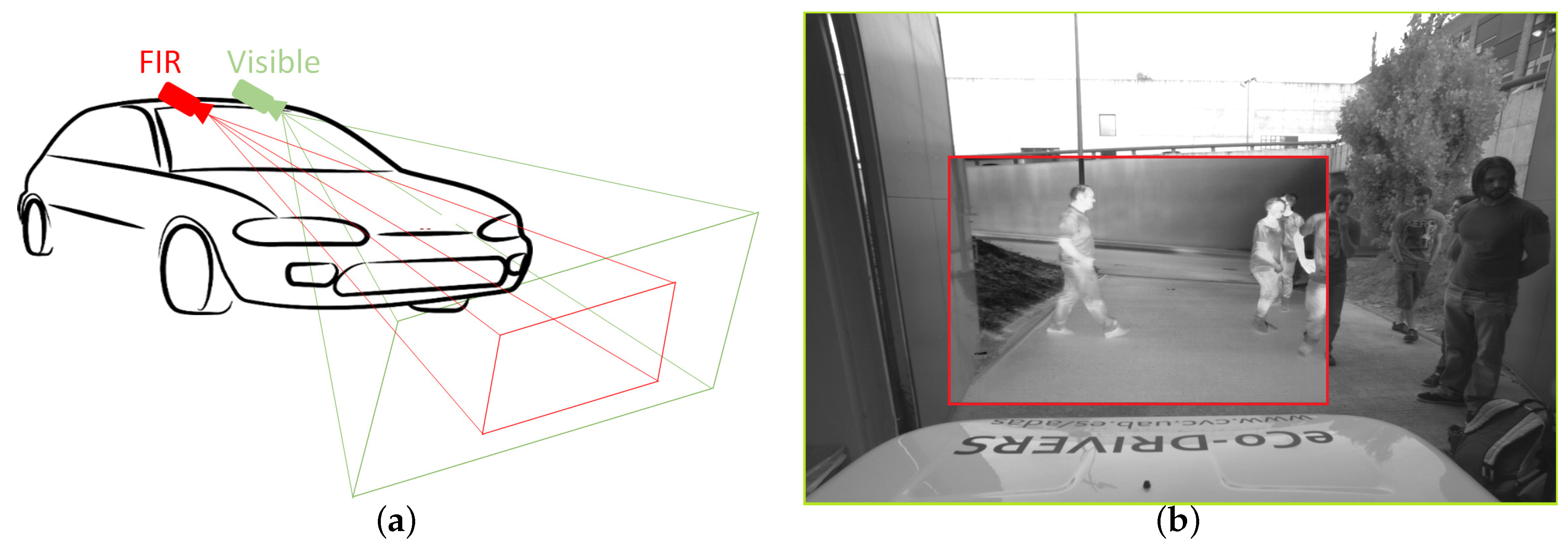
3. Datasets
4. Features and Classifiers
5. Experiments
5.1. Evaluation Protocol
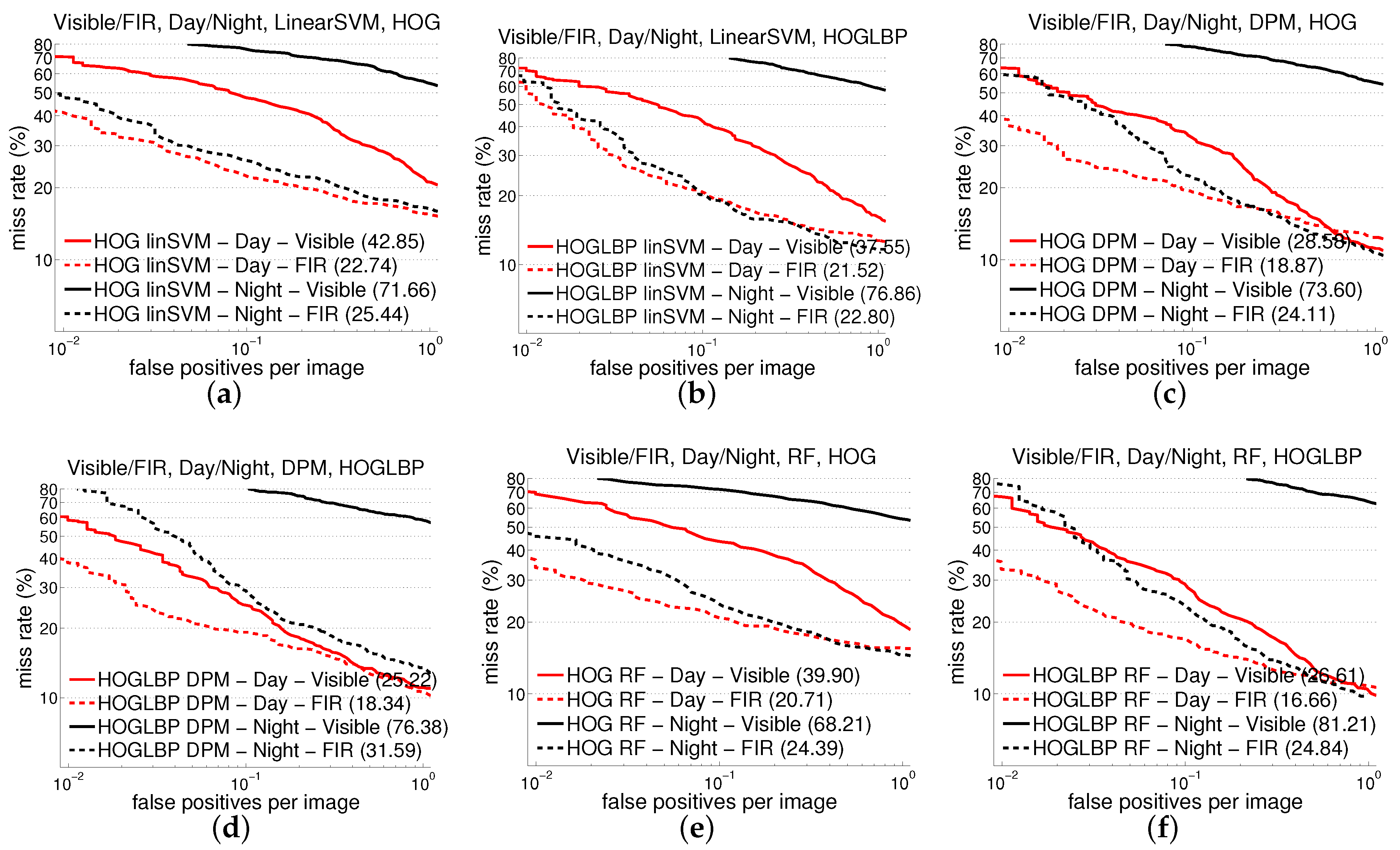
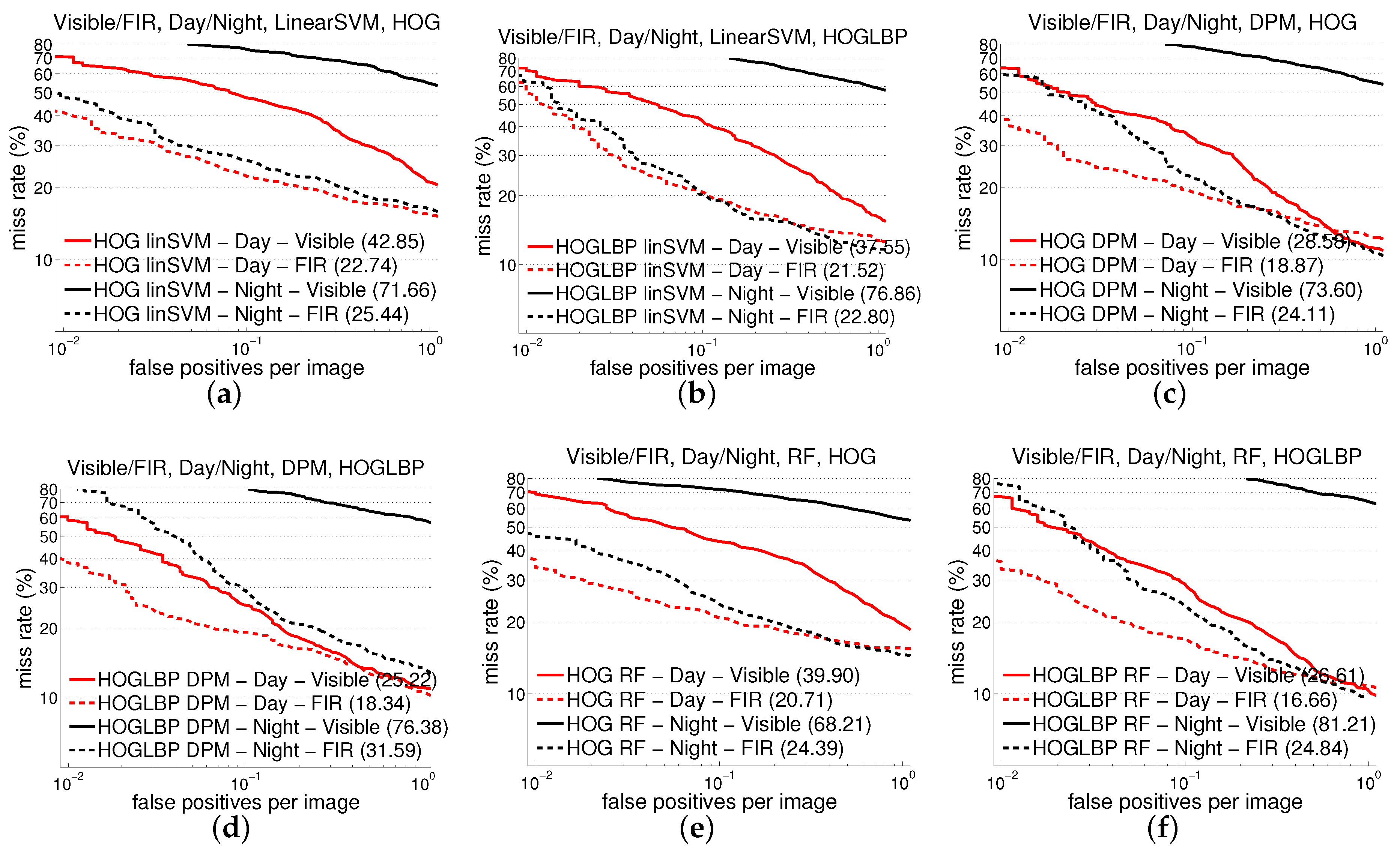
5.2. Experiments on the CVC-14 Dataset
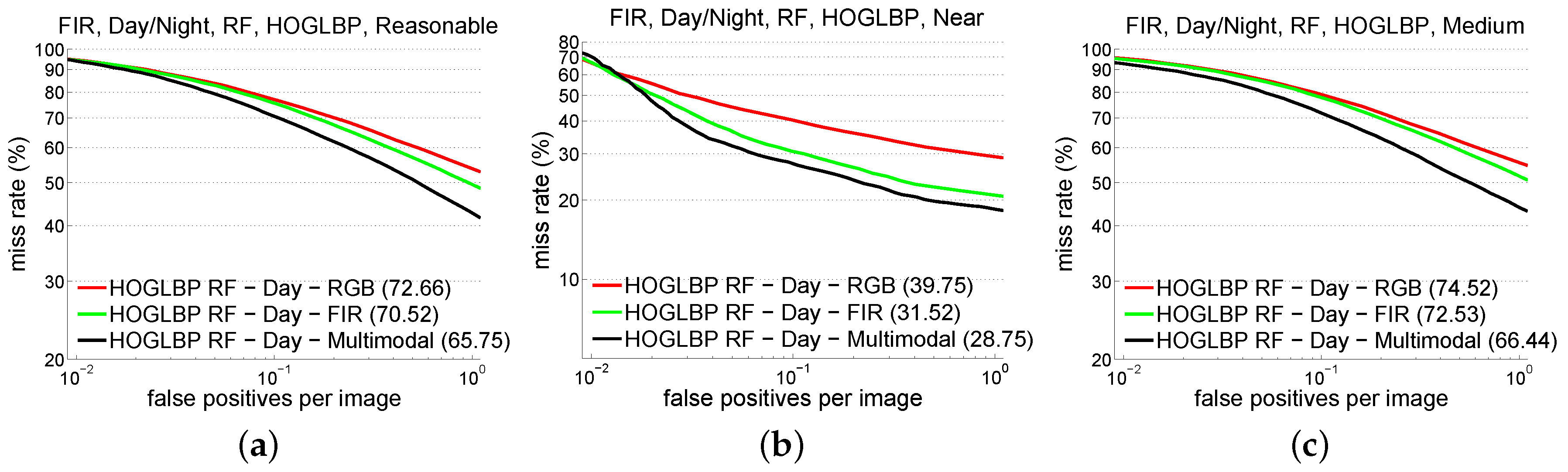
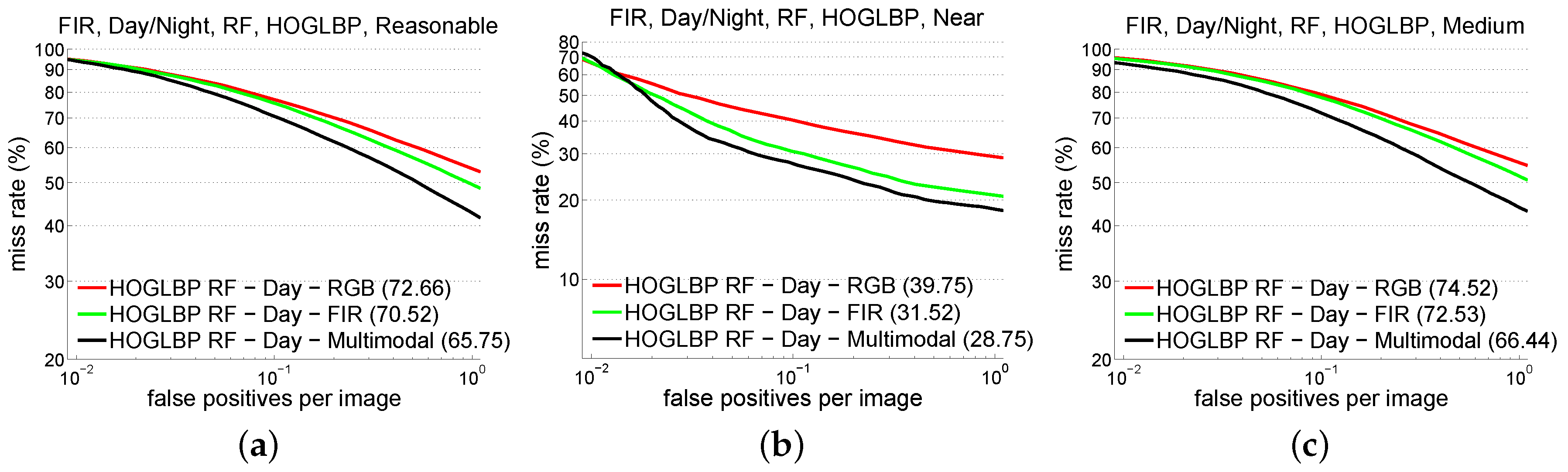
5.3. Experiments on KAIST Dataset
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Gerónimo, D.; López, A.M.; Sappa, A.D.; Graf, T. Survey of pedestrian detection for advanced driver assistance systems. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 1239–1258. [Google Scholar] [CrossRef] [PubMed]
- Enzweiler, M.; Gavrila, D.M. Monocular pedestrian detection: Survey and experiments. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 31, 2179–2195. [Google Scholar] [CrossRef] [PubMed]
- Dollár, P.; Wojek, C.; Schiele, B.; Perona, P. Pedestrian detection: An evaluation of the state of the art. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 743–761. [Google Scholar] [CrossRef] [PubMed]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for Autonomous Driving? The KITTI Vision Benchmark Suite. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012.
- Portmann, J.; Lynen, S.; Chli, M.; Siegwart, R. People detection and tracking from aerial thermal views. In Proceedings of the 2014 IEEE International Conference on Robotics and Automation (ICRA), Hong Kong, China, 31 May–7 June 2014.
- Teutsch, M.; Mller, T.; Huber, M.; Beyerer, J. Low resolution person detection with a moving thermal infrared camera by hotspot classification. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition Workshops, Columbus, OH, USA, 23–28 June 2014.
- Torabi, M.; Mass, G.; Bilodeau, G.A. An interative integrated framework for thermal-visible image registration, sensor fusion, and people tracking for video serveillance applications. Comput. Vis. Image Underst. 2012, 116, 210–221. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of Oriented Gradients for Human Detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 25 June 2005.
- Wang, X.; Han, T.X.; Yan, S. An HOG-LBP human detector with partial occlusion handling. In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision, Kyoto, Japan, 29 September–2 October 2009.
- Walk, S.; Majer, N.; Schindler, K.; Schiele, B. New features and insights for pedestrian detection. In Proceedings of the 2010 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), San Diego, CA, USA, 13–18 June 2010.
- Gerónimo, D.; Sappa, A.; Ponsa, D.; López, A. 2D-3D based on-board pedestrian detection system. Comput. Vis. Image Underst. 2010, 114, 583–595. [Google Scholar] [CrossRef]
- Dollár, P.; Tu, Z.; Perona, P.; Belongie, S. Integral channel features. In Proceedings of the British Machine Vision Conference, London, UK, 7 September 2009.
- Nam, W.; Han, B.; Han, J. Improving object localization using macrofeature layout selection. In Proceedings of the International Conference on Computer Vision—Workshop on Visual Surveillance, Barcelona, Spain, 13 November 2011.
- Felzenszwalb, P.; Girshick, R.; McAllester, D.; Ramanan, D. Object detection with discriminatively trained part based models. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 1627–1645. [Google Scholar] [CrossRef] [PubMed]
- Ramanan, D. Part-Based Models for Finding People and Estimating Their Pose; Springer: Berlin, Germany, 2009. [Google Scholar]
- Lafferty, J.; McCallum, A.; Pereira, F. Real-time Pedestrian Detection with Deformable Part Models. In Proceedings of the IEEE Intelligent Vehicles Symposium, Alcala de Henares, Spain, 3 June 2012.
- Marin, J.; Vázquez, D.; López, A.; Amores, J.; Leibe, B. Random Forests of Local Experts for Pedestrian Detection. In Proceedings of the IEEE Intelligent Vehicles Symposium, Sydney, Australia, 1 December 2013.
- Shashua, A.; Gdalyahu, Y.; Hayun, G. Pedestrian detection for driving assistance systems: Single-frame classification and system level performance. In Proceedings of the IEEE Intelligent Vehicles Symposium, Parma, Italy, 14 June 2004; pp. 1–6.
- Park, D.; Ramanan, D.; Fowlkes, C. Multiresolution models for object detection. In Proceedings of the European Conference on Computer Vision, Heraklion, Greece, 5 September 2010.
- Benenson, R.; Mathias, M.; Timofte, R.; Van Gool, L. Pedestrian detection at 100 frames per second. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16 June 2012.
- Wojek, C.; Walk, S.; Schiele, B. Multi-cue onboard pedestrian detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Miami Beach, FL, USA, 19 June 2009.
- Enzweiler, M.; Gavrila, D.M. A multi-level mixture-of-experts framework for pedestrian classification. IEEE Trans. Image Process. 2011, 20, 2967–2979. [Google Scholar] [CrossRef] [PubMed]
- Premebida, C.; Carreira, J.; Batista, J.; Nunes, U. Pedestrian Detection Combining RGB and Dense LIDAR Data. In Proceedings of the International Conference on Intelligent Robots and Systems, Chicago, IL, USA, 14 September 2014.
- González, A.; Vázquez, D.; Ramos, S.; López, A.M.; Amores, J. Spatiotemporal Stacked Sequential Learning for Pedestrian Detection. In Proceedings of the Iberian Conference on Pattern Recognition and Image Analysis, Santiago de Compostela, Spain, 17 June 2015.
- González, A.; Villalonga, G.; Xu, J.; Vázquez, D.; Amores, J.; López, A.M. Multiview Random Forest of Local Experts Combining RGB and LIDAR data for Pedestrian Detection. In Proceedings of the IEEE Intelligent Vehicles Symposium, Seoul, Korea, 28 June 2015.
- Oliveira, L.; Nunes, U.; Peixoto, P. On exploration of classifier ensemble synergism in pedestrian detection. IEEE Trans. Intell. Transp. Syst. 2010, 11, 16–27. [Google Scholar] [CrossRef]
- Chen, Y.T.; Chen, C.S. Fast human detection using a novel boosted cascading structure with meta stages. IEEE Trans. Image Process. 2008, 17, 1452–1464. [Google Scholar] [CrossRef] [PubMed]
- Enzweiler, M.; Gavrila, D. A mixed generative-discriminative framework for pedestrian classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23 June 2008.
- Yang, T.; Li, J.; Pan, Q.; Zhao, C.; Zhu, Y. Active Learning Based Pedestrian Detection in Real Scenes. In Proceedings of the 18th International Conference on Pattern Recognition (ICPR’06), Hong Kong, China, 20 August 2006; Volume 4, pp. 904–907.
- Vázquez, D.; López, A.M.; Ponsa, D.; Marin, J. Cool World: Domain adaptation of virtual and real worlds for human detection usind active learning. In Proceedings of the Conference on NIPS Domain Adaptation Workshop: Theory and Application, Sierra Nevada, Spain, 17 December 2011.
- Xu, J.; Vázquez, D.; Ramos, S.; López, A.; Ponsa, D. Domain Adaptation of Deformable Part-Based Models. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 2367–2380. [Google Scholar] [PubMed]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. In Advances in Neural Information Processing Systems 28, Proceedings of Neural Information Processing Systems 2015, Montreal, QC, Canada, 7–12 December 2015; pp. 91–99.
- Yuan, Y.; Lu, X.; Chen, X. Multi-spectral pedestrian detection. Signal Process. 2015, 11, 94–100. [Google Scholar] [CrossRef]
- St-Laurent, L.; Maldague, X.; Prévost, D. Combination of colour and thermal sensors for enhanced object detection. In Proceedings of the 2007 10th International Conference on Information Fusion, Quebec City, QC, Canada, 9–12 July 2007; pp. 1–8.
- Socarras, Y.; Ramos, S.; Vázquez, D.; López, A.M.; Gevers, T. Adapting Pedestrian Detection from Synthetic to Far Infrared Images. In Proceedings of the International Conference on Computer Vision, Workshop on Visual Domain Adaptation and Dataset Bias, Sydney, Australia, 7 December 2011.
- Hwang, S.; Park, J.; Kim, N.; Choi, Y.; So Kweon, I. Multispectral Pedestrian Detection: Benchmark Dataset and Baseline. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015.
- Miron, A.; Rogozan, A.; Ainouz, S.; Bensrhair, A.; Broggi, A. An Evaluation of the Pedestrian Classification in a Multi-Domain Multi-Modality Setup. Sensors 2015, 15, 13851–13873. [Google Scholar] [CrossRef] [PubMed]
- Li, X.; Guo, R.; Chen, C. Robust Pedestrian Tracking and Recognition from FLIR Video: A Unified Approach via Sparse Coding. Sensors 2014, 14, 11245–11259. [Google Scholar] [CrossRef] [PubMed]
- Besbes, B.; Rogozan, A.; Rus, A.M.; Bensrhair, A.; Broggi, A. Pedestrian Detection in Far-Infrared Daytime Images Using a Hierarchical Codebook of SURF. Sensors 2015, 15, 8570–8594. [Google Scholar] [CrossRef] [PubMed]
- Lee, J.H.; Choi, J.S.; Jeon, E.S.; Kim, Y.G.; Le, T.T.; Shin, K.Y.; Lee, H.C.; Park, K.R. Robust Pedestrian Detection by Combining Visible and Thermal Infrared Cameras. Sensors 2015, 15, 10580–10615. [Google Scholar] [CrossRef] [PubMed]
- Olmeda, D.; Premebida, C.; Nunes, U.; Armingol, J.M.; de la Escalera, A. Pedestrian detection in far infrared images. Integr. Comput. Aided Eng. 2013, 20, 347–360. [Google Scholar]
- Cortes, C.; Vapnik, V. Support-Vector Networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Specifications | FLIR Tau 2 | IDS UI-3240CP |
|---|---|---|
| Resolution | 640 × 512 pixels | 1280 × 1024 pixels |
| Pixel size | 17 m | 5.3 m |
| Focal length | 13 mm | Adjustable (fixed 4 mm) |
| Sensitive area | 10.88 mm × 8.7 mm | 6.784 mm × 5.427 mm |
| Frame rate | 30/25 Hz (NTSC/PAL) | 60 fps |
| Set | Variable | FIR | Visible | ||
|---|---|---|---|---|---|
| Day | Night | Day | Night | ||
| Training | Positive Frames | 2232 | 1386 | 2232 | 1386 |
| Negative Frames | 1463 | 2004 | 1463 | 2004 | |
| Annotated Pedestrians | 2769 | 2222 | 2672 | 2007 | |
| Mandatory Pedestrians | 1327 | 1787 | 1514 | 1420 | |
| Testing | Frames | 706 | 727 | 706 | 727 |
| Annotated Pedestrians | 2433 | 1895 | 2302 | 1589 | |
| Mandatory Pedestrians | 2184 | 1541 | 2079 | 1333 | |
| Detector | Day | Night | |||
|---|---|---|---|---|---|
| Visible | FIR | Visible | FIR | ||
| SVM | HOG | 42.9 | 22.7 | 71.8 | 25.4 |
| LBP | 40.6 | 21.6 | 87.6 | 32.1 | |
| HOG+LBP | 37.6 | 21.5 | 76.9 | 22.8 | |
| DPM | HOG | 28.6 | 18.9 | 73.6 | 24.1 |
| HOG+LBP | 25.2 | 18.3 | 76.4 | 31.6 | |
| RF | HOG | 39.9 | 20.7 | 68.2 | 24.4 |
| HOG+LBP | 26.6 | 16.7 | 81.2 | 24.8 | |
| Detector | Day | Night | |||||
|---|---|---|---|---|---|---|---|
| Visible | FIR | Visible + FIR | Visible | FIR | Visible + FIR | ||
| RF | HOG + LBP | 39.7 | 31.5 | 28.7 | 76.0 | 25.3 | 29.4 |
| 74.5 | 72.5 | 66.4 | 93.2 | 60.0 | 61.7 | ||
| 72.7 | 70.5 | 65.7 | 91.4 | 53.5 | 56.7 | ||
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
González, A.; Fang, Z.; Socarras, Y.; Serrat, J.; Vázquez, D.; Xu, J.; López, A.M. Pedestrian Detection at Day/Night Time with Visible and FIR Cameras: A Comparison. Sensors 2016, 16, 820. https://doi.org/10.3390/s16060820
González A, Fang Z, Socarras Y, Serrat J, Vázquez D, Xu J, López AM. Pedestrian Detection at Day/Night Time with Visible and FIR Cameras: A Comparison. Sensors. 2016; 16(6):820. https://doi.org/10.3390/s16060820
Chicago/Turabian StyleGonzález, Alejandro, Zhijie Fang, Yainuvis Socarras, Joan Serrat, David Vázquez, Jiaolong Xu, and Antonio M. López. 2016. "Pedestrian Detection at Day/Night Time with Visible and FIR Cameras: A Comparison" Sensors 16, no. 6: 820. https://doi.org/10.3390/s16060820
APA StyleGonzález, A., Fang, Z., Socarras, Y., Serrat, J., Vázquez, D., Xu, J., & López, A. M. (2016). Pedestrian Detection at Day/Night Time with Visible and FIR Cameras: A Comparison. Sensors, 16(6), 820. https://doi.org/10.3390/s16060820