1. Introduction
In recent years, due to global warming, many regions of the Earth have suffered from drastic climate change, which has increased the frequency of extreme climate events. Not only does this cause certain inconveniences for the lives of human beings, but it also threatens our lives and property. The growth of crops has an intimate relationship with the climate, so any climatic change could impact the amount and the quality of crop production [
1,
2,
3,
4,
5,
6,
7,
8,
9,
10,
11]. In the past, in order to control the production surface area and the amount of production, governments would generally monitor the sensitive crops with prices that fluctuate according to the weather, disasters, or public preferences so as to prevent price collapses, which could cause financial damage to farmers. Therefore, it is important to have a comprehensive understanding of the acreage of crop production and the market situation of various crops in order to propose important contingency measures in response to the economic losses and potential food crises caused by extreme climate phenomena. In the sub-tropical region in Taiwan, for example, tea is a sensitive crop of high economic value and a featured export product. About 3306 tons of teas of various special varieties are exported annually, and the number is still growing. According to the United Nations Food and Agriculture Organization (FAO), the global production of tea grew from 3.059 million tons in 2001 to 4.162 million tons in 2010, while the global area planted with tea grew from 2.41 million hectares in 2001 to 3.045 million hectares in 2010. This is certainly an amazing growth rate, and many studies conducted in different countries found that global warming would result in tea production losses [
12,
13,
14,
15], so adopting effective measures for productivity control is necessary.
Timely and accurate LULC interpretation and dynamic agriculture structure monitoring are the key points of agricultural productivity control to ensure a sustainable food supply [
16,
17,
18,
19,
20,
21,
22]. In actual operation, on-site investigation and orthogonal photograph interpretation are two methods widely used, especially by government agencies, to obtain information about tree characteristics and crop species composition. However, on-site investigation requires a lot of time and manpower and even though the working process is very detailed and precise, the ineffective investigation results in incomplete, unstable and sporadic LULC products. Aerial photograph interpretation and vector digitizing on GIS platforms (e.g., ArcGIS, MapInfo, QGIS) is also time-consuming and expensive for large crop mapping and classification. Besides, it is easier for the researchers to obtain extensive LULC information with high temporal resolution by using satellite imagery rather than aerial photographs or other methods. This information is fundamental for agricultural monitoring because the farmer compensation and the recognition of production losses are highly time-dependent. Therefore, daily transmission satellite imagery could be a very useful tool for LULC mapping.
However, the accurate interpretation ability for individual stands with the highly heterogeneous farm or shape characters of single canopies, is limited by the relatively low spatial resolution if we apply moderate-resolution satellite imagery (e.g., SPOT 4 and SPOT 5 provided by Airbus Defence and Space) [
23,
24,
25,
26,
27,
28,
29,
30,
31]. Over the last few years, the spectral resolution, spatial resolution and temporal resolution have undergone rapid and substantial progress (e.g., Formosat-2 multispectral images offer 8 m resolution and panchromatic band images at 2 m resolution). For some urban and flat areas, individual stands, such as a tree or a shrub, can be easily distinguished by using very high resolution (VHR) imagery [
32,
33,
34,
35]. This provides opportunities to differentiate farm and crop types. High spatial resolution satellite imagery has thus become a cost-effective alternative to aerial photography for distinguishing individual crops or tree shapes [
36,
37,
38,
39,
40,
41,
42,
43,
44,
45,
46]. For example, WorldView-2 images and support vector machine classifier (SVM) have been used to identified three dominant tree species and canopy gap types (accuracy = 89.32.1%) [
47]. Previous study has applied a reproducible geographic object-based image analysis (GEOBIA) methodology to find out the location and shape of tree crowns in urban areas using high resolution imagery, and the identification rates were up to 70% to 82% [
36]. QuickBird image classification with GEOBIA has also been proved useful to identify urban LULC classes and obtained a high overall accuracy (90.40%) [
32].
Apart of the impact of satellite imagery resolution, image segmentation methods and classification algorithms also play essential roles in LULC classification workflows. In early years, many studies focused on developing pixel-based image analysis (PBIA) by taking the advantage of VHR image characteristics [
48,
49,
50,
51,
52,
53,
54], but it is obvious that recent studies mapping vegetation composition or individual feature have demonstrated the advantages of object-based image analysis (OBIA) [
55,
56,
57,
58,
59,
60,
61,
62]. In OBIA, researchers first have to transfer the original pixel-image into object units based on specific arrangement or image characteristics, which is called image segmentation, and then assign the category of every object unit by using classifiers. OBIA can improve the deficiency of PBIA, such as the salt and pepper effect, therefore it has become one of the most popular workflows. For example, Ke and Quackenbush classified five tree species (spruce, pine, hemlock, larch and deciduous) in a sampled area of New York (USA) by applying object-based image analysis with QuickBird multispectral imagery and obtained an average accuracy of 66% [
63]. Pu and Landry presented a significantly higher classification accuracy of five vegetation types (including broad-leaved, needle-leaved and palm trees) using object-based IKONOS image analysis [
39]. The results were much better than using pixel-based approaches. Kim
et al. obtained a higher overall accuracy of 13% with object-based image analysis by using an optimal segmentation of IKONOS image data to identify seven tree species/stands [
64]. Ghosh and Joshi compared several classification algorithms on mapping bamboo patches using very high resolutionWorldView-2 imagery, and achieved 94% producer accuracy with an object-based SVM classifier [
65].
According to the abovementioned reasons and background, the main objectives of this study include: (1) to investigate the classification accuracy of a combined workflow applied on WorldView-2 imagery to identify tea crop LULC; (2) to compare the capabilities of several ordinary LULC classification algorithms (e.g., maximum likelihood (ML), logistic regression (LR) random forest (RF) and support vector machine (SVM) based on pixel and object-based domains) in identifying tea LULC; and (3) to explore the potential of using high spatial/spectral/time resolution WorldView-2 imagery to identify tea crop LULC classification, and the details about image segmentation and feature extraction will also be discussed. The main content of this paper is divided into four major sections.
Section 1 and
Section 2 include descriptions and introductions of the study, introductions to on site investigation and satellite imagery data sets, frameworks of feature extraction and classification developed for this study.
Section 3 contains the main findings and breakthroughs of this study, followed by their discussion. The final part consists of the conclusions.
4. Discussion
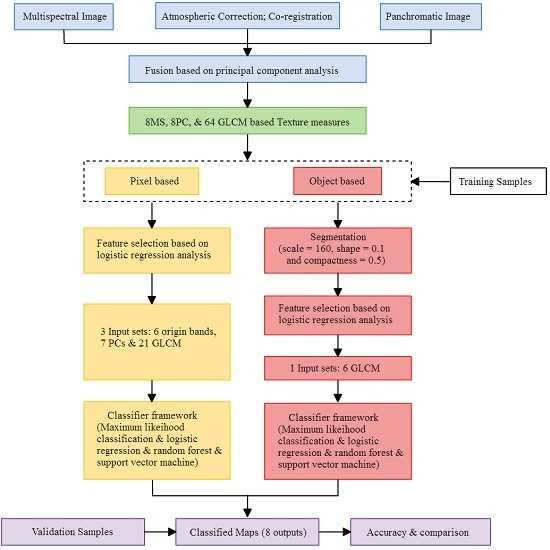
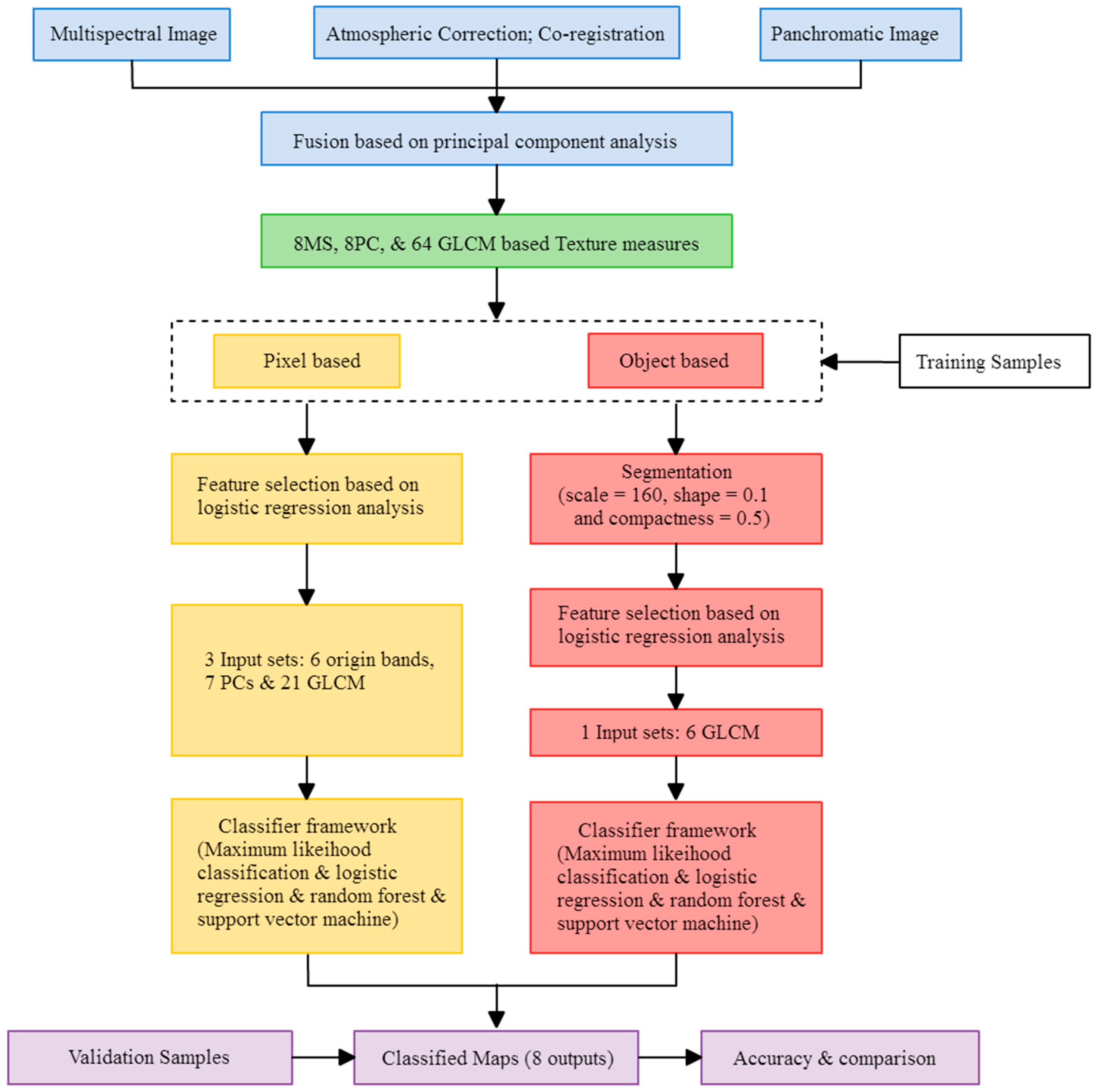
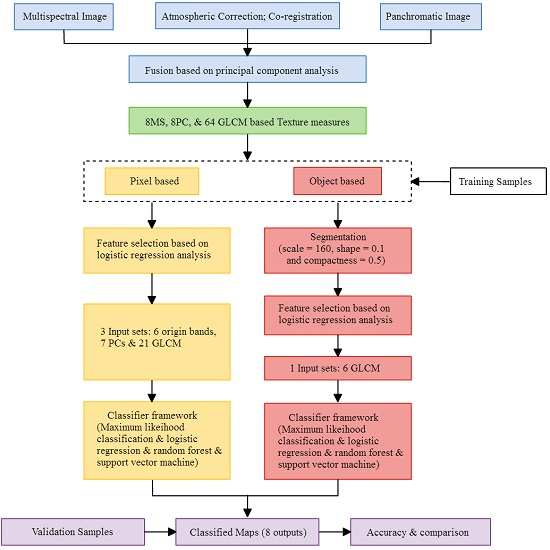
In the feature selection stage, adding variables such as GLCM layer would increase the interpretation capability of land-use/land cover, but it requires a lot of time and efforts. This study tried to find the most useful variables to be added here so we can promote the efficiency of interpretation with lowest cost. As mentioned in
Figure 2, the feature selection stage based on LR model delineated 34 useful variables in PBIA and 6 GLCM variables in OBIA. All selected variables were significant related factor for LR function (
p < 0.05, and B coefficient can be considered as the weights of importance). It means that we only need to input 34 variables in PBIA classifier, and six variables in the OBIA classifier. We think it is important for saving money if the government (e.g., Council of Agriculture) needs to lower the cost of crop cultivation investigation.
Previous studies have already discussed the use of four newly available spectral bands (coastal, green, yellow, red edge) for the classification of the tree species [
39,
80]. In this research, the results of feature selection using LR analysis showed that the influence of band 6 (red edge) and band 4 of its derivative texture indices were significant to the tea classification.
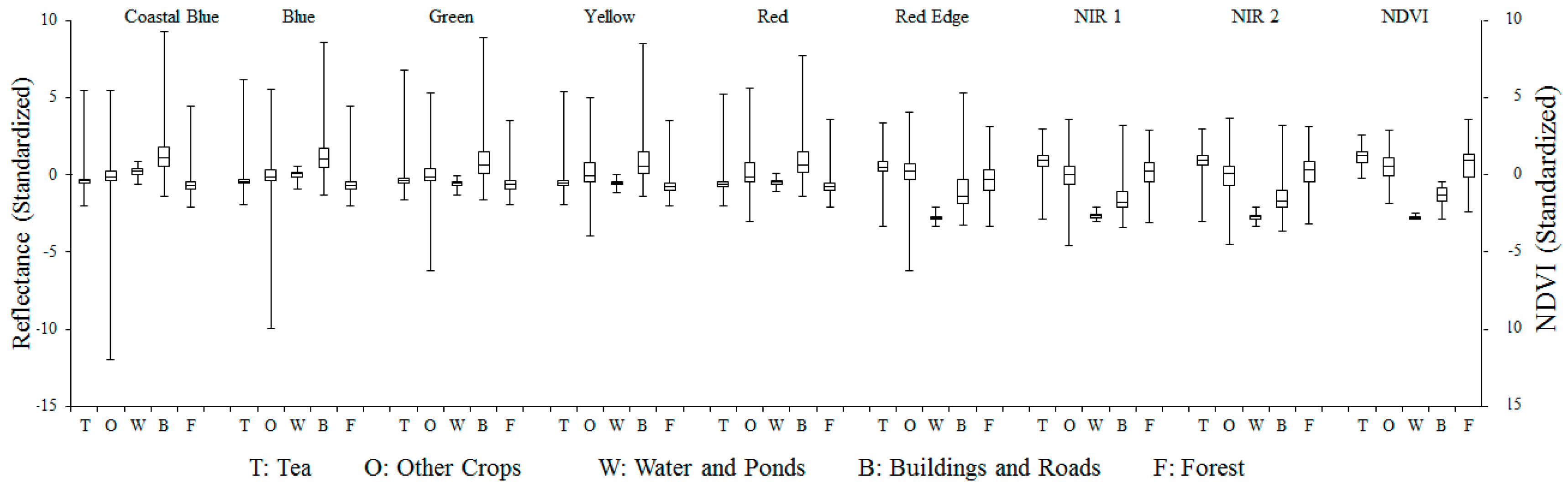
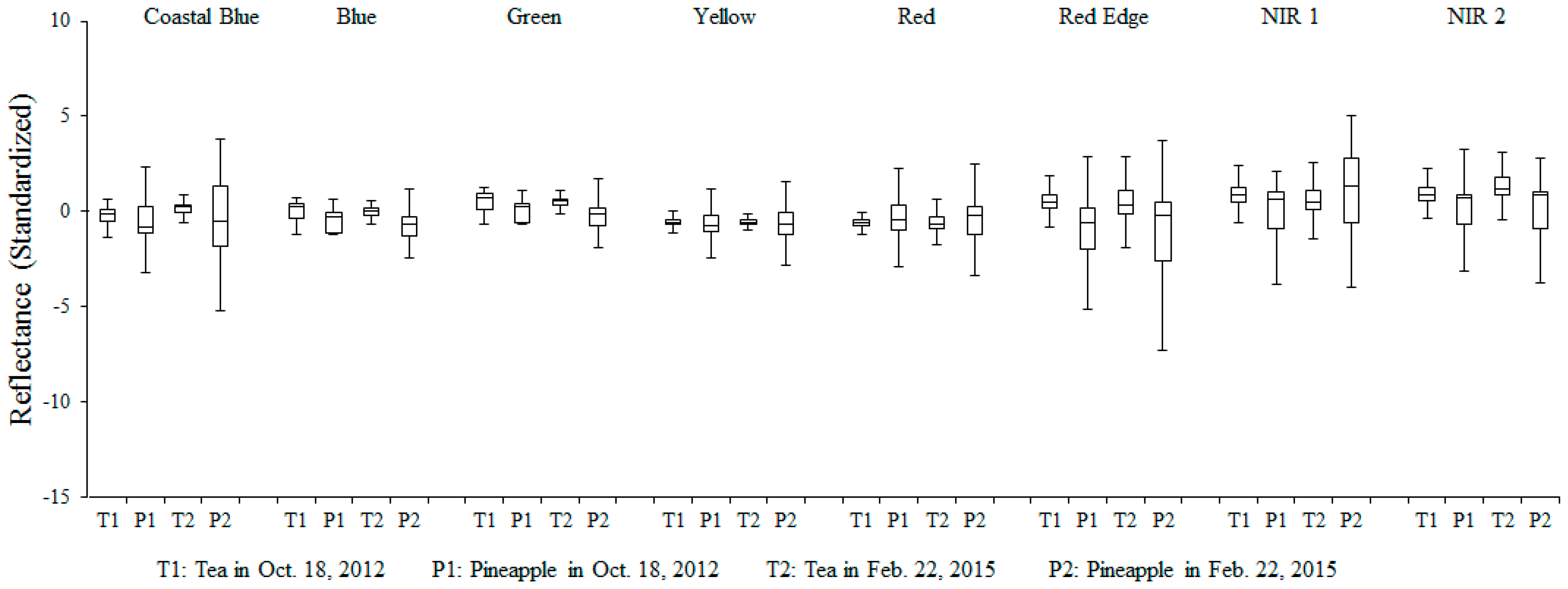
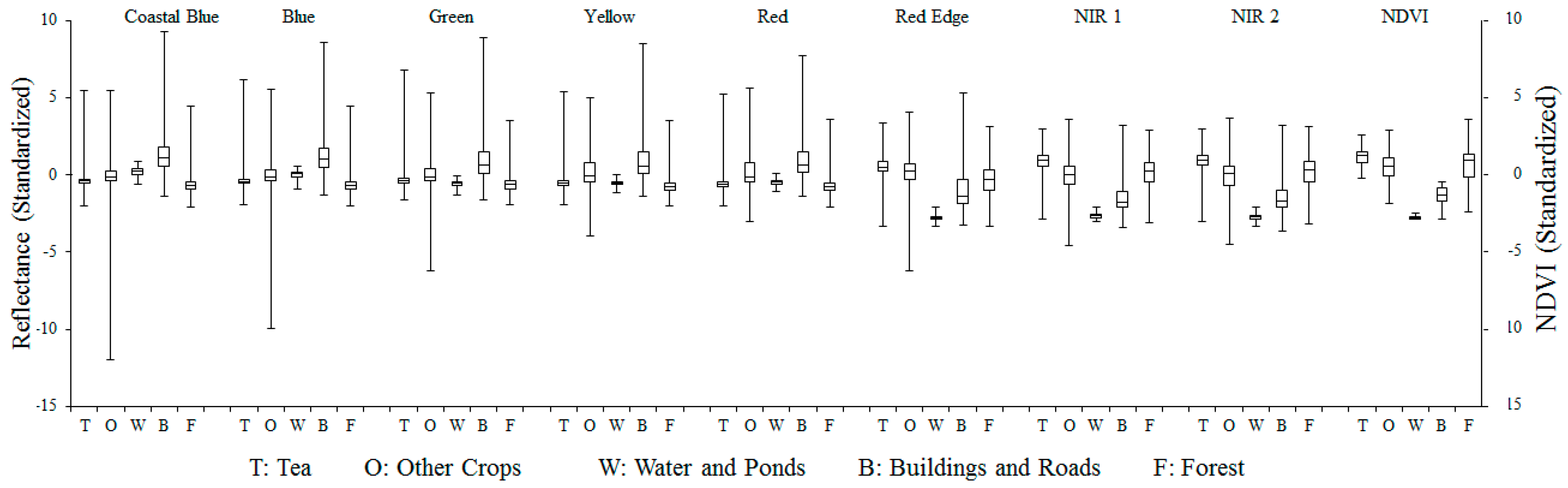
Figure 8 shows the signature comparison between tea, betel nut, pineapple and forest fields using input variables with different band combination. Obviously, the visual differences became clear when standardized CONTRAST6, DISSIMI6, HOMO2, CORREL6 and PC2 were included in classification process. This means red edge spectrum and some texture indices were useful in distinguishing between tea and non-tea LULC. It also supports the conclusions of the previous studies concerning vegetation classification [
39,
81]. The superiority of the red edge spectrum indicates that it can reflect the chlorophyll concentration and the physiological status of crops [
82]; and thus it can also be helpful for land cover classification [
81]. Besides, principal component transformation is commonly considered a good method to reduce data dimension and to extract useful information. After the processing of 8-band WorldView-2 imagery, the most abundant information was transformed into the first PC (PC1) and the information decreases gradually to the last PC (PC8). According to the LR analysis results, however, PC2 to PC8 except PC6 were still helpful for tea and non-tea LULC discrimination. This implies that every component may have to be thought about when conducting binary classification. LR analysis also indicates the importance of each variable. Taking tea, betel nut, pineapple fields and forest as the examples,
Figure 8 shows that the input variables with higher absolute B coefficient values differentiate the LULC above more than those with lower B coefficients.
As for textural information, LR analysis in feature selection showed that GLCM MEAN and DISSIMI were the two most dominant variables for the tea LULC classification. GLCM MEAN represented the local mean value of the processing window and had high relation with the original spectral information. The processing window also called moving window, is the basic unit for calculating grid layer features. The value of each pixel is calculated by shifting the window one pixel at a time until all pixels are calculated. The size of moving window was 3 × 3 pixels in this study. B coefficients of the MEAN which were higher than those of other variables suggested that the spectral information was more useful than the structural characteristics of WorldView-2 imagery. Nevertheless, the dissimilarity measures, which were based on empirical estimates of the feature distribution, were also critical for enhancing the structural difference between tea and non-tea LULC.
Though previous studies seldom used MEAN and DISSIMI for tea classification, these two measures had been proven effective in improving classification accuracy for agricultural and forest areas [
65,
83] and the idea also indirectly support the findings of this study. The tea trees in the study area were planted in rows with totally different characteristics from those of the crops observed on the ground in structure and arrangement. However, in
Table 3, the overall spectral variables of B coefficient are still larger than the structural variables when using pixel-approach. This means that in pixel-based classification, the spectral variables were more effective in distinguishing the differences of the ground coverage of tea trees and non-tea trees comparing to the structural variables. This could be explained with the two examples in
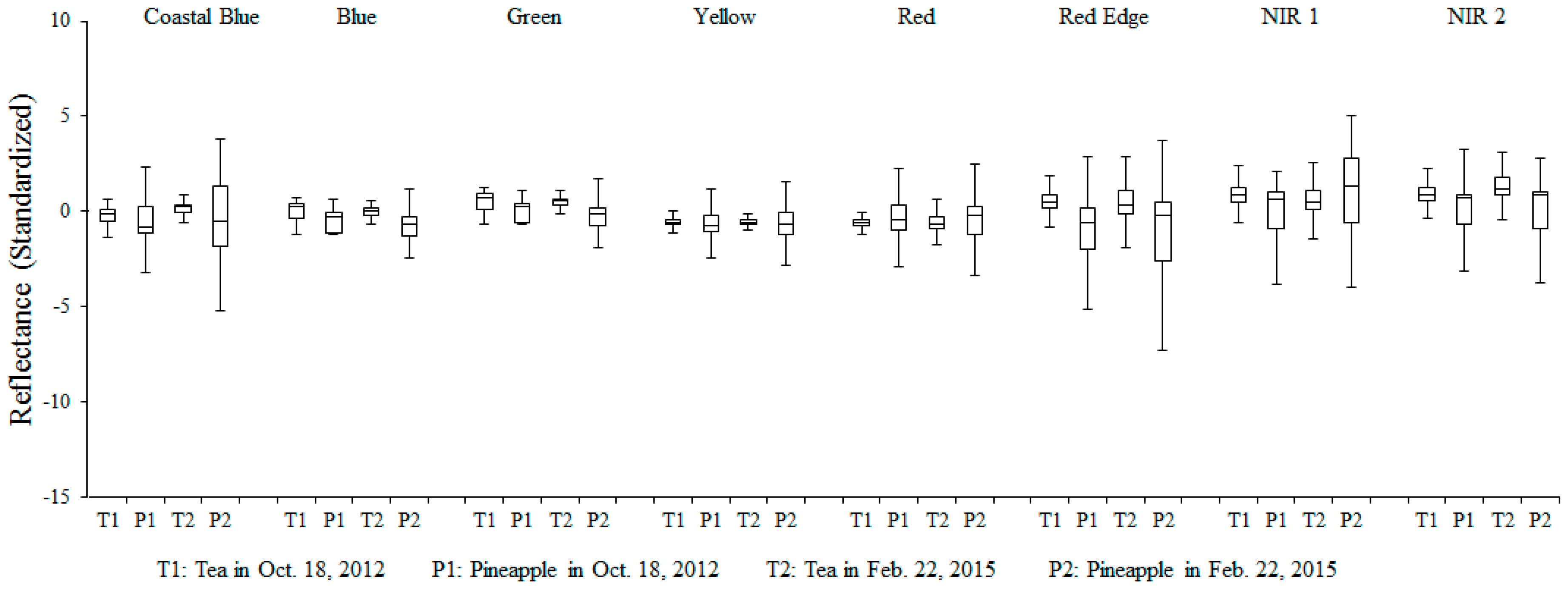
Figure 9. Even in the pan-sharpened WorldView-2 imagery with 0.5-m high spatial resolution, there are not all characteristics of the line by line formation could be clearly presented due to the narrow interval between tea trees. For this reason, it seems to be much harder for the structural variables to play to their strengths.
As for the issues for reducing data dimensions and the number of input variables, the comparative analysis between PBIA and OBIA in this study demonstrated a significant difference that using OBIA was more effective and sensitive in conducting variable filtering process than using PBIA. The strength of OBIA was attributed to the less amount of samples and the reduction of spectral heterogeneity within each variable layer when producing objects from pixels. Taking this study for example, it means that people could spend less time generating input variables and achieve satisfactory results compared to using PBIA if OBIA is applied. However, it is worth noting that OBIA demands more computational resources, requires specialized software (i.e., eCognition Suite) and is hard to applied in a large study area even the number of objects is much less than the total number of pixels. The above mentioned factors often set limitations on the use of OBIA.
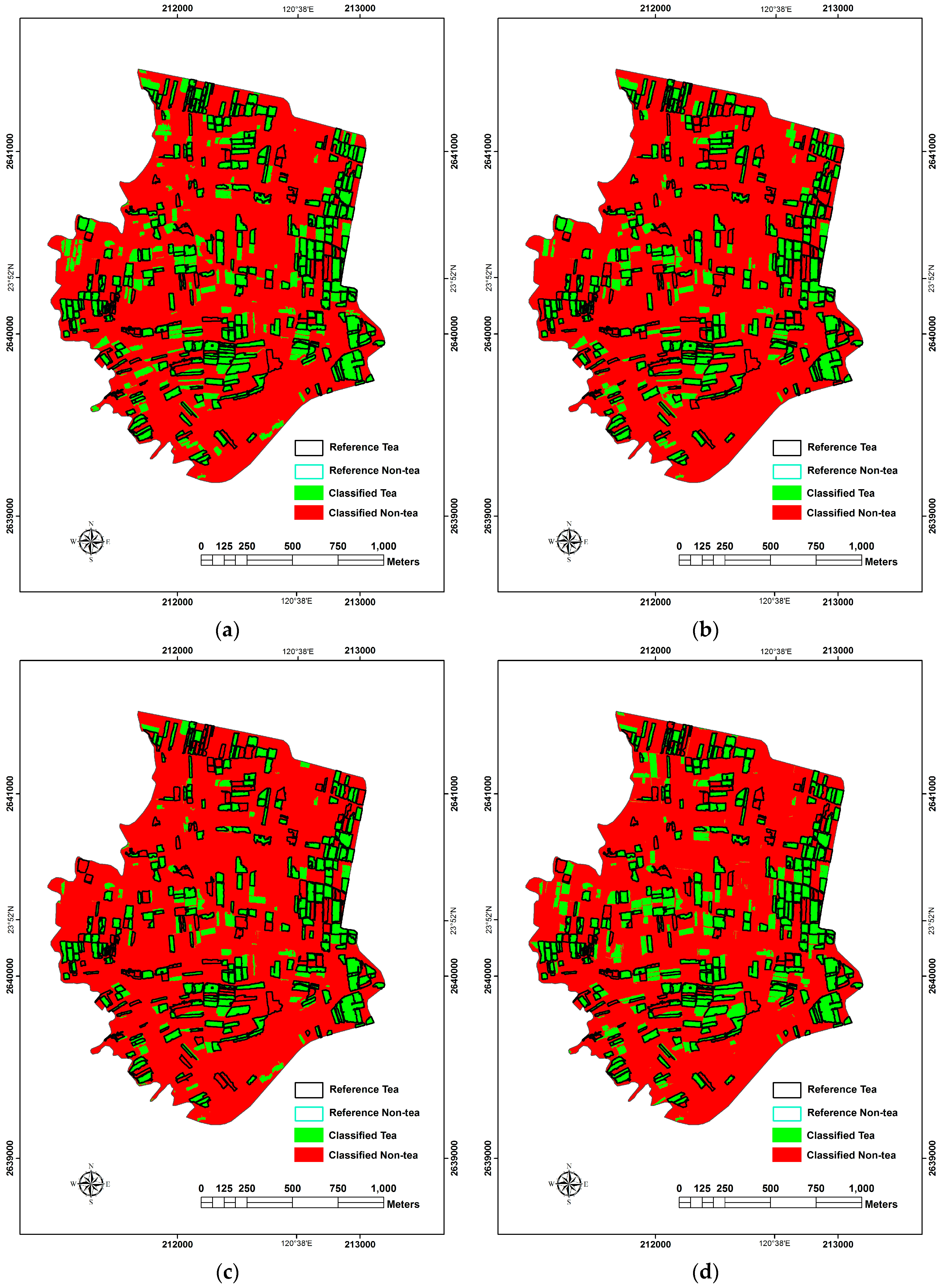
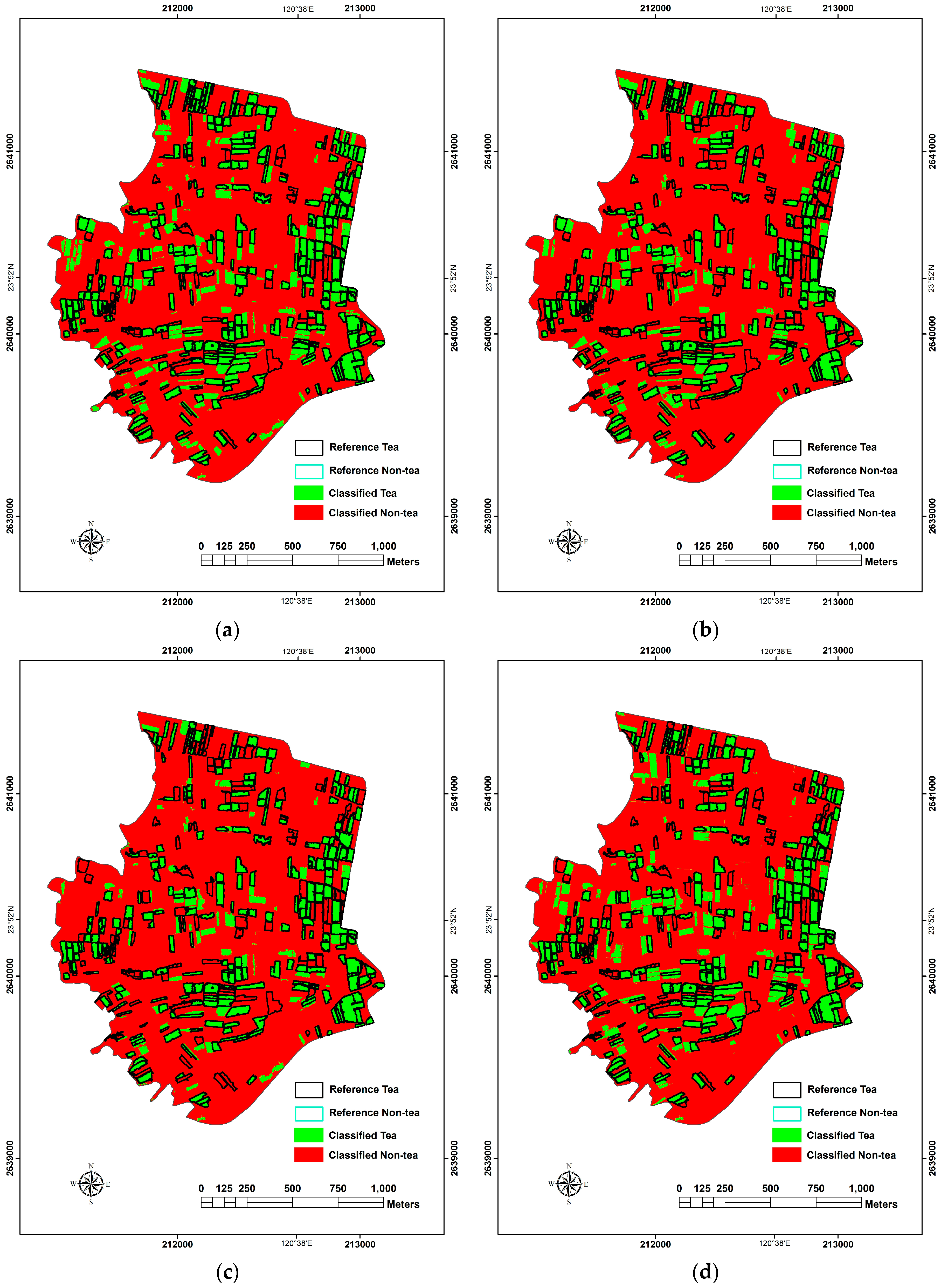
One parametric classifier (ML) and three non-parametric classifiers (LR, SVM and RF) were applied in this study. According to the accuracy assessment of PBIA and OBIA approaches, almost all OA values were found to exceed 82.97%. The use of OBIA + ML obviously got the best OA value among OBIA approaches, but the use of PBIA+ML did not. The main reason that the overall accuracy of ML classifier was not as good as non-parametric approach (SVM or RF) in PBIA comes from the bimodal data distribution of tea-farm training samples due to the alternate permutation of tea plants and corridors. The special arrangement might lead tea farms divided into two LULC types in PBIA when ML classier was applied. However, in OBIA, the basic unit was polygon that contained many WorldView-2 image pixels, the average treatment effect within tea farm training samples would decrease the difference of every basic unit, eliminate the spectral heterogeneity within every tea LULC patches, and lead sample distribution more like normal distribution. The ML classifier performs well for normally distributed data, this is why the classification result of the use of OBIA + ML was much better than PBIA + ML.
Minimum distance classifier has been commonly used to classify remote sensing imagery [
84,
85]. This classifier works well when the distance between means is large compared to the spread (or randomness) of each class with respect to its mean; moveover, it is very good approach dealing with non-normal distribution data. However, this study did not consider this classifier as one of the methods in PBIA and OBIA approaches. The reason is that the non-tea class spreads much wider in the feature space and thus the distance between the means of non-tea and tea classes is not large compared to the spread of non-tea class. In this case, if there is an unclassed sample situating near the boundary of non-tea and tea classes in the feature space, the classification result may not be ideal. As for the ML classifier, the occurrence frequencies of non-tea and tea classes are used to aid the classification process. Without this frequency information, the minimum distance classifier can yield biased classifications. Although salt and pepper effect may influence the distribution normality of the data, OBIA approach can decrease the possibility of salt and pepper effect. Therefore, we think ML classifier still has the superiority especially in OBIA approach.
As for SVM classifier, its superior classifying effects toward high-dimensional feature space, capability on processing non-linear data, characteristics to avoid over fitting and under fitting, and the stability to decrease the salt and pepper effect made it the best classifier of PBIA. However, it was not the best algorithm of OBIA. We inferred the most possible reasons: (1) the OBIA image segmentation stage in this study made the sample data look like a case of normal distribution, decreased the possibility of salt and pepper effect, and promoted the effects of ML algorithm; (2) OBIA image segmentation was possible to combine tea farms and pineapple farms together due to the line by line arrangements of tea trees and pineapples with unfixed interval. Although the advantages of SVM with soft margin were not presented in the application of OBIA, the OA and Kappa values were still good.
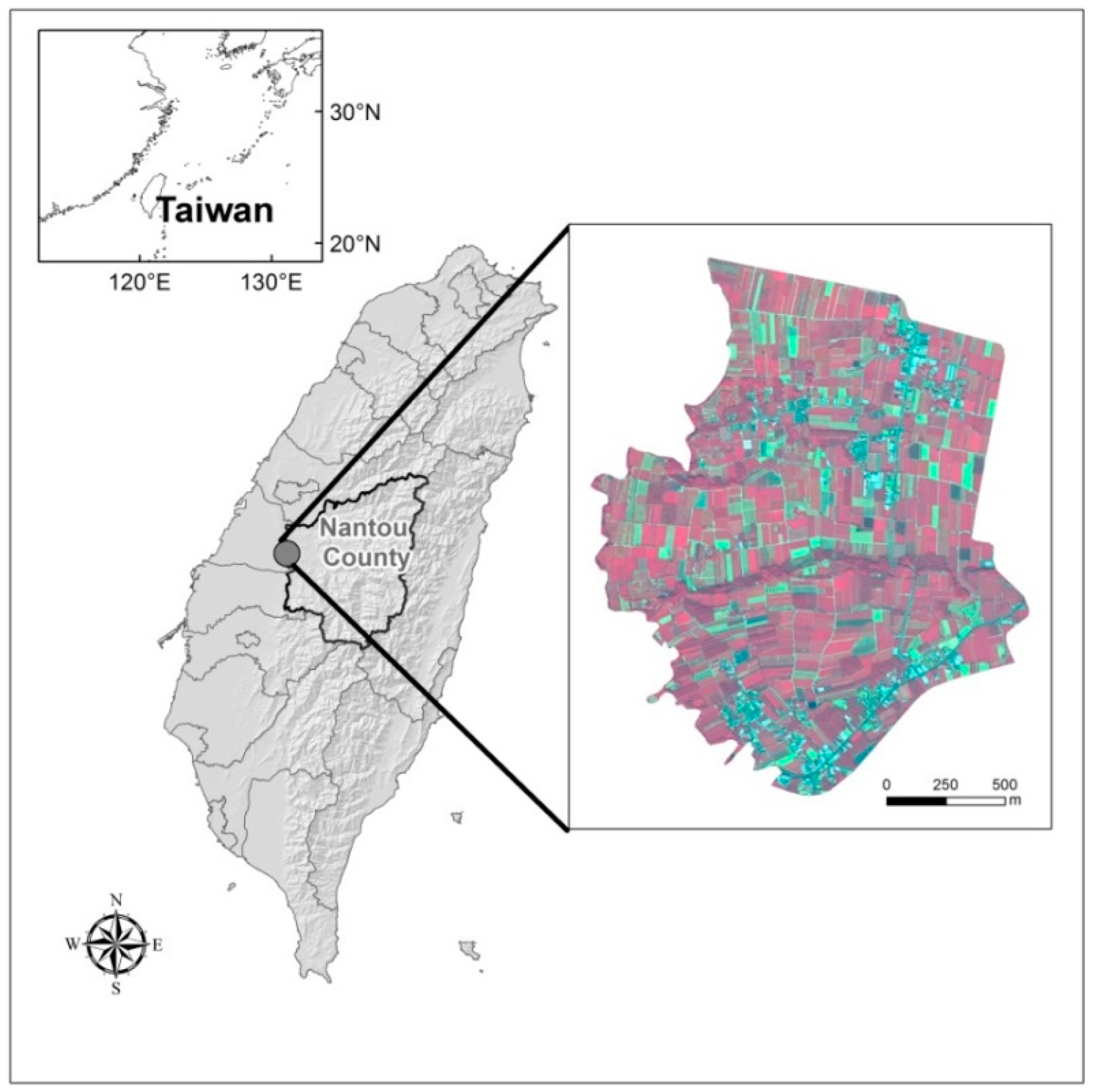
As for the LULC monitoring frequency, compared with many herbaceous crops, the monitoring task on tea trees with high spatial resolution commercial satellite imagery is much easier because of the long-lived perennial characteristics of tea tree. The relatively stable life cycle of tea production in Taiwan often starts on the 3rd year after the planting of saplings, and then there is going to be one to two harvests every season for at least 30 years. Therefore, people do not need to collect a series of period images as frequently as in the monitoring on herbaceous crops. Nevertheless, it is worth mentioning that this study still has some limitations. The first one is the study area of this research was limited to a flat and gentle sloping area, yet some tea farms are in the high mountains where the terrain effect would certainly have an influence due to the shadow-effect of satellite images. For this reason, we suggest the users to apply our workflow in flat or gentle slope areas. Besides, at some places, physiological changes among non-tea plants might influence the spectral reflection of satellite images, so we considered that our workflow is suitable for the use in sub-tropical places where most plants are evergreen.
After all, in order to achieve tea production prediction or evaluation of high efficiency and low costs, we suggest the governments apply the methodology used in this study as a standardized framework, while field surveys and re-investigation with manpower resources should be the backup option for calibration or supplementary once people want to totally eliminate the commission and omission errors. The classification method in this study can be further applied in two different ways. The first one is of benefit to countries with the largest tea planting areas (e.g., China, India, Kenya, Sri Lanka, and Vietnam). Besides, it can also be applied in other crop classification studies such as banana, pineapple, sugar cane, and watermelon with particular type of plantation and farming arrangement.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}