1. Introduction
Wireless sensor networks and mobile sensor networks [
1,
2,
3,
4] have received unprecedented attention because of their exciting potential applications in military, industrial and civilian areas (e.g., environmental and habitat monitoring). Wireless communication is often used to transfer data among nodes in these networks, and most nodes are equipped with a battery as the energy unit, which means the energy capacity is limited. Generally, wireless transmission consumes much more energy than data processing. How to save the overall energy resources and extend the lifetime of networks is a popular research topic.
Data aggregation [
5,
6,
7,
8,
9,
10,
11,
12,
13,
14] is one of the most important solutions in minimizing the transmitted data size in large-scale wireless networks and is also one of the most important tasks in other distributed applications [
15,
16,
17,
18,
19,
20,
21]. Data aggregation can be achieved via
In-server or
In-network aggregation.
In-server aggregation, where data aggregation is performed directly at the server based on the raw data received from each client, is an energy cost approach in large-scale distributed systems.
In-network aggregation (
i.e., aggregating partial results at intermediate nodes along the routing path) significantly reduces the total communication cost and obtains load balance, especially when we only need the aggregation result instead of much raw data.
The data aggregation scheme also faces many security challenges. For example, wireless sensor networks are usually deployed in remote and hostile environments in military applications; thus, sensor nodes are prone to node compromise attacks, and security issues, such as data confidentiality and integrity, are extremely important. Wireless sensors are also being increasingly used to monitor/collect information in healthcare medical systems. It is important to effectively process the ever-growing healthcare data and simultaneously protect patients’ data privacy.
The traditional encryption technology is not suitable for secure data aggregation (SDA) because it only provides concealment and does not support cipher text operations. To realize in-network secure data aggregation based on traditional encryption technology, intermediate aggregators will have to decrypt the data received from all children before operating on them, and then, an encryption will be needed for the aggregated result before sending the message. Frequent encryption and decryption of data in intermediate nodes will increase the computing cost and energy consumption. Moreover, secret key management is more difficult, because the decryption key storage at an intermediate node can be easily obtained by an attacker.
To solve this problem, several secure data aggregation schemes have been proposed, such as synopsis diffusion-based [
7,
8,
9], shuffling-based [
6], and homomorphic encryption-based [
10,
11,
12,
13,
14] data aggregation. Homomorphic encryption-based data aggregation, which has a better theoretical foundation, will be used in the proposed schemes. A comprehensive review on secure data aggregation protocols was presented by Ozdemir
et al. [
22].
Enabling multi-function support is also a challenge in the In-network data aggregation scheme. Statistics can be divided into two categories according to the aggregation functions used, i.e., summation-based and comparison-based. For example, aggregation operations, such as median computation or finding the maximum/minimum, rely exclusively on comparison operations. Moreover, aggregation operations, such as count, mean, variance or standard deviation (STD), rely on summation operations. Most of the existing secure data aggregation schemes can only obtain a single type of statistics. To obtain summation-based and comparison-based statistical results simultaneously is still an open problem.
Take
homomorphic encryption (HE)-based SDA for example. In [
10,
11], an additive homomorphism property was used for aggregation on encrypted messages, so that
summation-based statistics results, such as
CNT (Count) and
SUM , can be obtained by these algorithms. However, it could not obtain
comparison-based statistics, such as
MAX and
MIN . Rivest
et al. [
23] noted that any privacy homomorphism is insecure, even against cipher text-only attacks, if it supports comparison operations. Acharya
et al. [
24] applied the order-preserving encryption [
25] in SDA to obtain
comparison-based statistics; however,
summation-based statistics were not supported in the order-preserving encryption. Ertaul
et al. [
26] and Samanthula
et al. [
27] also only supported
comparison-based statistics.
Multifunction is also important in other areas. For example, Lu
et al. [
28] presented a multi-function secure data aggregation scheme for smart grid communications. The Boneh–Goh–Nissim cryptosystem was adopted for data privacy, and only summation-based statistics (such as average and variance) were supported in the scheme.
More details regarding the functionality comparison results are listed in
Table 1. The second and third columns indicate whether
summation-based or
comparison-based statistical results are supported, while the last column indicates whether all statistics can be derived from a single query. “P” means partly supported; “Y” and “N” are “yes” and “no”, respectively. The last row is the proposed scheme. More details regarding
Table 1 and the proposed scheme will be given in the following sections.
To enable arbitrary aggregation operations on a
server, RCDA (Recoverable Concealed Data Aggregation) [
12] designed a scheme that can recover all sensing data, even data that have been aggregated. In RCDA, a homomorphic encryption algorithm is used to provide end-to-end confidentiality, and an encode step is used to enable recovery of all sensing data, which means that the scheme can achieve arbitrary method support. However, the final data are formed as concatenations of all sensing data, and no information compression method is used; thus, the communication cost is too heavy.
Nodes do not always remain active in dynamic networks. Some of them may sleep to save energy, and some of them may be dead due to energy exhaustion and other reasons. Most existing SDA schemes are not efficient for dynamic networks due to the varying number of active nodes. For example, [
10,
11] use extra communication costs to report the number of active (or inactive) nodes in each query, which cost considerable energy. These extra communication costs were even more than those used for sensing data when the percent of active (or inactive) nodes was large enough. The extra traffic increased dramatically along the router path, which easily formed a network bottleneck, reducing the overall network life cycle. More details are listed in
Table 2.
In this paper, we propose two multi-functional secure data aggregation (MFSDA) schemes, i.e., MFSDA-I and MFSDA-II. Both of them can obtain addition-based and comparison-based statistics at the same query. The first one can obtain accurate results, while the second one is an approximate version that can significantly reduce communication cost and prolong the network life cycle at the expense of less accuracy loss. More specifically, to provide value-preserving and order-preserving during in-network aggregation and then enabling arbitrary statistics support, we introduce a mapping step and a coding step in the proposed scheme. A compressing step is introduced to further reduce the packet size in MFSDA-I.
The remaining part of this paper is organized as follows:
Section 2 introduces the network model and the background knowledge.
Section 3 and
Section 4 introduce MFSDA-I and MFSDA-II, respectively.
Section 5 presents functionality and security analysis.
Section 6 presents performance analysis and evaluation. Sections 7 and 8 offer a summary and acknowledgment.
3. Multi-Functional Secure Data Aggregation Scheme: MFSDA-I
Two multi-functional secure data Aggregation schemes are proposed: MFSDA-I and MFSDA-II. MFSDA-I is given in this section, while MFSDA-II will be given in the next.
3.1. MFSDA-I
MFSDA-I consists of four parts (procedures): setup and operations on the three types of nodes, i.e., cluster member (CM, e.g., 1, 2, etc.), cluster head (CH, e.g., H1, H2, etc.) and server.
The setup procedure includes network initialization, as well as the initialization of encryption and signature. Both non-homomorphic and homomorphic encryption are used in the proposed scheme. The former is used in intra-cluster data transmission; the latter is used in inter-cluster data transmission. Intra-cluster encryption is the same as the one used in RCDA [
12]. For Details regarding inter-cluster encryption, refer to
Section 2.3.1. An IBS signature mechanism (see
Section 2.3.2) is used for all packets.
Each CM encrypts the raw data with the non-homomorphic encryption mentioned above. Then, a timestamp and other information are attached to the cipher text before IBS signature application. The final packets sent to the cluster head (CH) consist of all of them.
Each CH first verifies the signature of all of the received packets. The received packets can be divided into two categories: one is intra-cluster data, which are received from the CM node within a cluster, and inter-cluster data, which are from other cluster heads.
For the intra-cluster data, the CH first decrypts the data and then maps and encodes it to obtain a vector. All vectors generated in the same cluster are added up in plaintext to obtain an intra-cluster data aggregation result. The aggregated vector will be encrypted using the homomorphic encryption scheme with the public key of the server.
For the inter-cluster data, because they have been encrypted using the homomorphic encryption scheme in other CH nodes, there is no need to also decrypt it. The CH will sum two types of cipher text above directly in the cipher text domain. The final packet sent to the parent node (cluster head or server) also contains a time stamp, other information and the signature generated from them using IBS with the private key of the cluster head.
All packets received by the server are from cluster heads. The server first verifies them, then extracts the encrypted data and aggregates them in the cipher domain. Finally, the server decrypts it to obtain the aggregation result of the whole network.
We can extract all common statistics from the aggregation result, which is in a vector form, using the functions provided in following section.
3.1.1. Setup
The setup procedure initializes the network topological structure, as well as initializes each encryption and signature mechanism. The following key pairs will be generated during the setup.
1. :
This type of key pair, which was used in RCDA [
12], is used for intra-cluster data encryption, namely data transmitted between
CM and its
CH.
In a large-scale distributed system, the
server does not know the cluster information before deployment, and the key preload scheme is infeasible. A key exchange scheme [
12] is introduced to solve this challenge.
Each CM loads its own key pair, generated by the server. All CH will generate a span tree, with the server as its root. Each CM joins a suitable cluster based on a certain criterion (e.g., delay in a wired network and signal strength in a wireless network), encrypts the cluster choice with its private key and transmits it to the server. After decryption, the server will send the CM’s key pairs to its CH. Thus, the CH can obtain all of the key pairs of its CMs.
2. :
This type of key pair is used for the IBS signature mechanism (
Section 2.3.2). To ensure the integrity of the data, all packets, including intra-cluster and inter-cluster, must be attached with a signature.
The identifier of each node is also the public key for signature verification. The private key of each node is generated by the server using the master key. This key pair is preloaded into each node before deployment. Each packet contains a public key and a signature generated by the sender using its private key. The receiver will verify all of the packets before further processing.
3. :
This key pair is used for homomorphic encryption (
Section 2.3.1) to achieve inter-cluster data confidential, namely the data transmission between
CHs or between the
CH and the server. The public key of the
server (
i.e.,
) is used for data encryption at the
CH. The
server keeps the private key
for decryption. In the proposed scheme, all of the data contained in the inter-cluster packets are homomorphism encrypted, so data aggregation is performed directly without decryption.
3.1.2. Operations on CM
Operations on the CM are composed of three parts: encryption, signature and data transmission.
First, each CM encrypts the sensing data with the encryption key to obtain . Then, using the private key , the CM generates the signature from the transmitting data Msg, which consists of ciphertext, a timestamp and other information. Finally, the CM transmits Msg and to the CH.
and are the identification (ID) of the CM and its cluster head (CH), respectively. A is adopted to avoid message duplication and to process data by intervals. In addition, if an adversary attempts to modify the without a valid private key for the signature, the receiver can detect it by a signature verification mechanism. There are two types of messages in the scheme, defined as : one for intra-cluster communication, denoted as ; another is used for inter-cluster communication, denoted as . Here, the message type is the former, namely .
The final data packet sent by
CM to its
CH is
3.1.3. Operations on CH
Operations on the CH consist of five parts: data receiving and verification, classification, operations on the intra-cluster dataset, operations on inter-cluster dataset and packet construction and transmission.
The CH will verify all received message and eliminate the one that fails. The verification process includes: check the legality of and ; check the effectiveness of the timestamp; and verify the signature.
Legitimate messages will be divided into two categories, i.e., and , according to the . contains the intra-cluster packets received from each CM in the cluster. contains the inter-cluster packets received from other CH as its children.
The process for the intra-cluster dataset consists of five steps: decryption, mapping, encoding, aggregation and re-encryption. “Mapping, encoding and aggregation”, which will be further explained in the following section, are the key to ensuring the simultaneous extraction of various types of statistics. The public key of the server (i.e., ) is used in homomorphic encryption.
All of the messages contained in are encrypted by the public key of the server. The data aggregation of the dataset can be performed directly in the encrypted domain due to the homomorphic attribution of the encryption mechanism.
Messages in and , have been transformed into and at previous two steps. The CH firstly sums them up in the cipher text domain and attaches other information, such as the timestamp. Then, the CH generates a signature using the private key. Finally, the CH sends Msg and to the parent node.
Data receiving and verification:
Operations on - (1)
Decryption:
- (2)
Mapping:
- (3)
Encoding: while
- (4)
Aggregation:
- (5)
Operations on :
Signature and Send- (1)
- (2)
- (3)
Messages send:
The packet sent to the parent is:
3.1.4. Operations on the Server
To simplify the analysis, all of the children of the server are assumed to be the CH.
Operations on the server consist of four parts: data receiving and verification, aggregation, decryption and statistical results acquisition.
3.2. Mapping, Encoding and Aggregation
In this subsection, we first present details regarding mapping and encoding and then introduce the aggregation step.
3.2.1. Details of Mapping and Encoding
As mentioned above, statistics results can be divided into two types: addition-based statistics (such as SUM, AVG, VAR, etc.) and comparison-based statistics (such as MAX, MIN, etc.). The former requires value-preserving, while the latter requires order-preserving.
Obtaining the statistical results of many types effectively using only one query is difficult because it is hard to keep value-preserving and order-preserving attributions simultaneously during the aggregation of encrypted data.
In the proposed scheme, we can maintain the two types of information mentioned previously in the secure data aggregation process by using mapping and encoding.
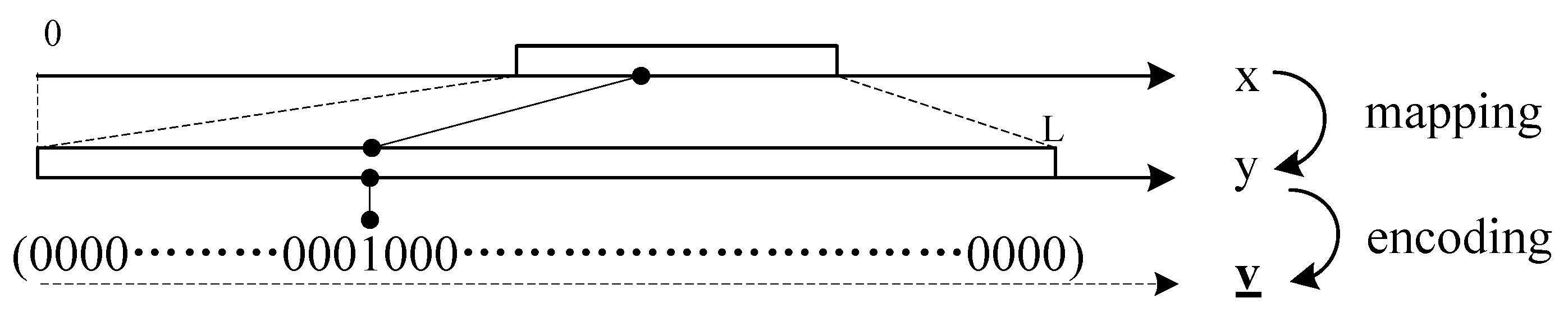
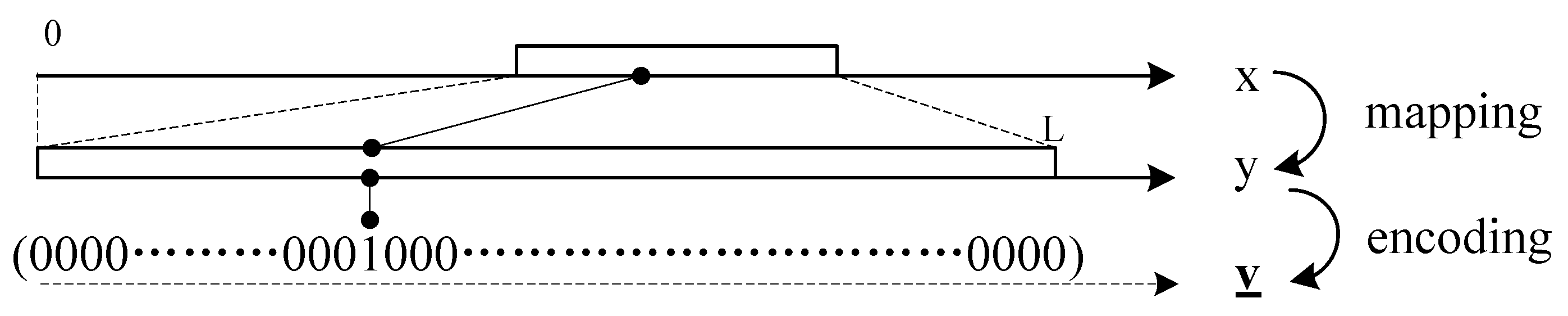
As shown in
Figure 2, there are three types of data in the proposed scheme: sensing data
x, mapped data
y and encoded data
. Mutual conversion can be performed through the mapping, encoding and inversion of them.
Sensing data are the original data gathered at node k. belong to a subset of real domain, i.e., , where and are the lower and upper bounds, respectively.
is transformed into mapped data using the mapping step. belong to a subset of the natural numbers, i.e., , where , and a is the accuracy requirement of .
The conversion between
and
is achieve by the
mapping function and its inverse,
i.e.,
and
.
is converted into
by
encoding.
is a vector,
; its elements’ number is
L. The element of
-th is one; other elements are zero; that is to say:
The conversion between
and
is achieve by the encoding function and its inverse,
i.e.,
and
.
3.2.2. Aggregation
Aggregation is performed on the plaintext or cipher text of
. An example for the former is the 3-(4)th step in
Section 3.1.3; an example for the latter is the fourth step in
Section 3.1.3 and the second step in
Section 3.1.4. The following theorem proves that the
server could finally obtain the aggregated result of all sensing data of active nodes.
Theorem 2: The homomorphic encryption used in the proposed scheme can ensure that the vector obtained at the server after decryption is the aggregated result of all encoded data of active nodes.
Despite that the elements of can only be zero or one, but usually the vector elements of the final aggregated, result may be arbitrary natural numbers that are not greater than N.
3.3. A Concrete Example
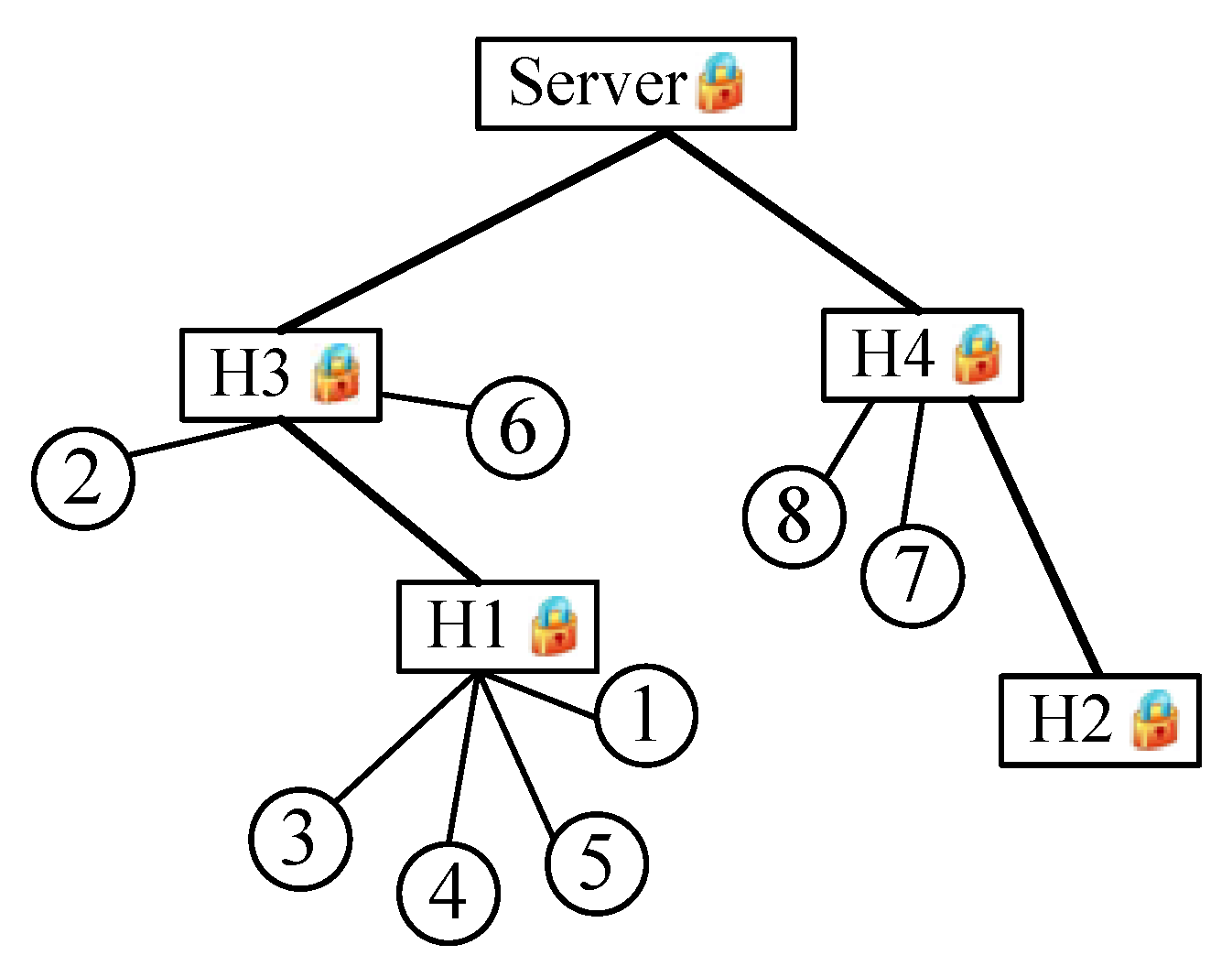
Figure 1 is the network model of this example. Assume that
and that the accuracy requirement is
. Sensing data gathered from each node are listed in the second column in
Table 4. The third and fourth columns present mapped data
and encoded data
, respectively.
Each CM encrypts the sensing data, attaches the signature and other information and transfers these to the cluster head (CH).
The CH verifies the received message and obtains the sensing data via decryption. Mapped data () are transformed from using the mapping function.
Because the sensing data of Nodes 3 and 5 are outside of the valid data range , the CH node will regard them as illegal data and discard them.
Other valid mapped data are encoded as a vector
whose length is L. The
-th element is one, while all of the remaining elements are set to zero. Let us take Node 1 as an example; the sensing data are
; mapped data
are obtained after the mapping step; and then, the third element of the vector is set to one; while other elements are zero,
i.e.,
. The values of each step are listed in
Table 2.
For all of the intra-cluster data, the CH encodes them first, then sums and encrypts the summation using the server public key of homomorphic encryption. For all of the inter-cluster data, the CH adds them up directly in the cipher text domain after verification. Both the intra-cluster and inter-cluster data are homomorphic encrypted data in the server public key; thus, they can be summed up directly in the cipher text domain, which is equivalent to getting the cipher text of the regional data aggregation result. Finally, this regional result is transmitted to the parents, attached with other information, such as time stamp, signature, etc.
According to the homomorphic property, the summation arithmetic of vectors in the cipher text domain is equivalent to that in plaintext. Therefore, the
server can obtain the final aggregation result
by decrypting the received data. For example, in this case, the final data the
server obtains are the summation of the vector in the fourth column of
Table 4.
Each statistic can be calculated directly from
.
6. Performance Analysis and Evaluation
In this section, we will analyze the performance of the two schemes proposed in this paper, namely MFSDA-I and MFSDA-II. The former provides an exact result, while the latter can significantly reduce network traffic at the expense of less accuracy loss.
6.1. Evaluation Settings
A cluster-based network model is used here. Cluster heads are selected in advance and assumed to be trusted nodes. For smaller scale networks, cluster heads can communicate directly with the server. For a relatively large-scale network, all cluster heads form a tree with the server as its root.
Since network construction and maintenance is not the research focus of this article. We have tried to weaken the impact of the problem with reasonable simplification. In the proposed schemes, the cluster head can be pre-selected. Because of their small numbers, they can be equipped with more batteries. Therefore, these cluster head can be kept active during the lifetime of the WSN or kept active within a predetermined period for data receiving.
To simplify the analysis, the position of each cluster head is assumed to never change, and the tree structure among these cluster heads is assumed to be predetermined. This is feasible due to the limited number of cluster heads. Each cluster head broadcasts its own cluster formation requests periodically.
The interval of these cluster formation requests can be predefined based on the possible maximum move speed of the network nodes. For example, if the position of the node changes slowly or never changes, then it is necessary to enlarge this interval to reduce energy consumption. Other nodes join a cluster based on the signal strength of each cluster head. If more than one cluster head has the same signal strength, the cluster head with a low ID will be selected. More details regarding the network construction will be omitted, as this is not the focus of this article.
The dataset is obtained from the TAO (Tropical Atmosphere Ocean) project [
37] of NOAA (National Oceanic and Atmospheric Administration). The TAO project enabled real-time collection of high quality oceanographic and surface meteorological data for monitoring, forecasting and understanding of climate swings associated with El Nino and La Nina. More detail of the dataset will be given later.
There are three datasets with different distribution used here. The first one is a uniform distribution dataset generated by "unifrnd" function in Matlab ; the second one is a Poisson distribution dataset, generated by "poissrnd" function in Matlab (with Lambda = 200); and the last one is an actual dataset from wind direction of the TAO project. More detail of the real dataset is given in
Table 6. It contains 2000 samples, selected from a continuous time interval (1992–1993) with invalid data removed. The measure range of wind direction is [0, 360); the resolution is 1.4. The accuracy is 5–7.8, which is much greater than the resolution. Here, we choose the highest accuracy, so
. For comparison, the other two datasets also have the same N and L,
i.e., N = 2000 and L = 72.
6.2. Analysis and Evaluations of MFSDA-I
Both theoretic analysis and experimental evaluation of MFSDA-I will be given in this section. As we discussed earlier, the concerned topic of RCDA is similar to the one of this paper, and EERCDA is an improve scheme of RCDA regarding the reduction of communication costs. Both of them will be chosen as candidates.
6.2.1. Communication Cost of MFSDA-I
Communication cost can be measured by considering the package size. In the proposed scheme, data transmission can be divided into two categories.
One is intra-cluster data transmission, namely data transmission between CM and CH. The package size is .
The other is inter-cluster data transmission, namely, data transmission between CHs or data transmission between the CH and the server. The package size is .
The sensing data do not need to be coded in intra-cluster data transmission; thus, the length of plaintext corresponding to is .
Data will be encoded before inter-cluster data transmission. Because the number of elements in the encoded vector is L and the length of each element is at least , so the total plaintext length is .
Let us assume that the ratio of the ciphertext and plaintext length in both stages is linear and the ratio
and
, respectively. Then:
where
.
For a uniform distribution, the inter-cluster data transmission can be further reduced to:
6.2.2. Communication Cost of RCDA
In the first step of RCDA-HETE, namely intra-cluster data transmission, the packet size is .
Note that, although the packet sizes of MFSDA, RCDA and EERCDA are different, because all of them use the same signature,
can still be the same, as long as the appropriate elliptic curve and parameters are chosen. If we choose the same test platform, the
will also be the same. The encryption algorithm is consistent with MFSDA in the same stage, so:
In the second stage of RCDA-HETE and all stages of RCDA-HOMO, the packet size is .
The aggregation of sensing data is the concatenation of all messages from
CM. The data length of each sensing datum is at least
, so the total plaintext size is at least
; the encryption algorithm is the same as the one used in the second stage of MFSDA, so the packet size is:
, so , which means that RCDA-HETE is much more efficient than RCDA-HOMO in terms of communication cost.
6.2.3. Communication Cost of EERCDA
To reduce the energy consumption of message transmission in RCDA [
12] and to achieve more energy and bandwidth efficiency, EERCDA [
13] uses a
differential data transfer method. In EERCDA, the difference data, rather than raw data from the sensor node, are transmitted to the cluster head.
EE-RCDA includes two data transmission phase: reference data transfer session and subsequent data transfer session.
The first stage is the same as RCDA-HOMO. Each senor transmits raw data (reference data) to the server; thus, the packet size in this stage is still:
The differential data are transmitted to cluster head in the second stage. Then, the server can recover the raw data using reference data and differential data. The total packet size is .
Assume that the number of nodes whose data has changed is ęÂN at each query in this stages, then:
Let us compare EERCDA with RCDA-HOMO first. EERCDA is much more efficient than RCDA-HOMO, if , which means .
Now, let us compare EERCDA with RCDA-HETE. Because , we only need to compare to . In general, , , so: .
That is to say, , which also means EERCDA will consume more energy than RCDA-HETE.
6.2.4. Evaluation of MFSDA-I
According to the analysis above, the communication cost of EERCDA is much greater than that of RCDA-HETE, while only in specific conditions is it much more efficient than RCDA-HOMO. To highlight the advantages of this scheme, we compare MFSDA to RCDA-HETE.
in MFSDA is used to achieve a much higher security level. The bits will also be needed by RCDA and EERCDA, if they want to achieve similar security property. At the same time, the packet header may contain , timestamp, etc. in platforms, such as TinyOS 2.x. Therefore, it can be ignored during the comparison. only need one bit, so can also be ignored. Therefore, there is no need to consider and during the comparison. Therefore, , that is to say, MFSDA and RCDA-HETE have a similar communication cost in the first stage.
When
,
. That is, MFSDA is more efficient than RCDA-HETE when
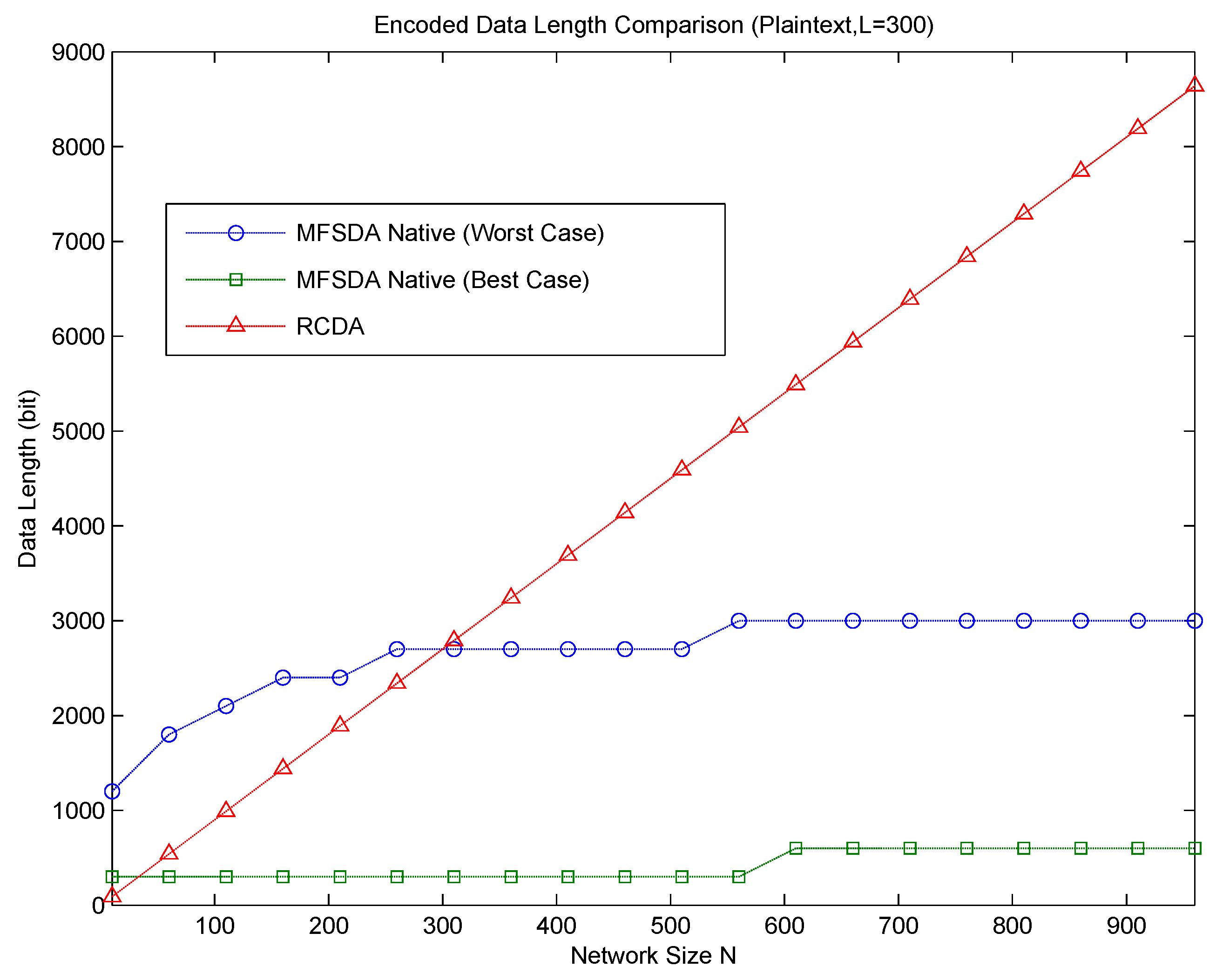
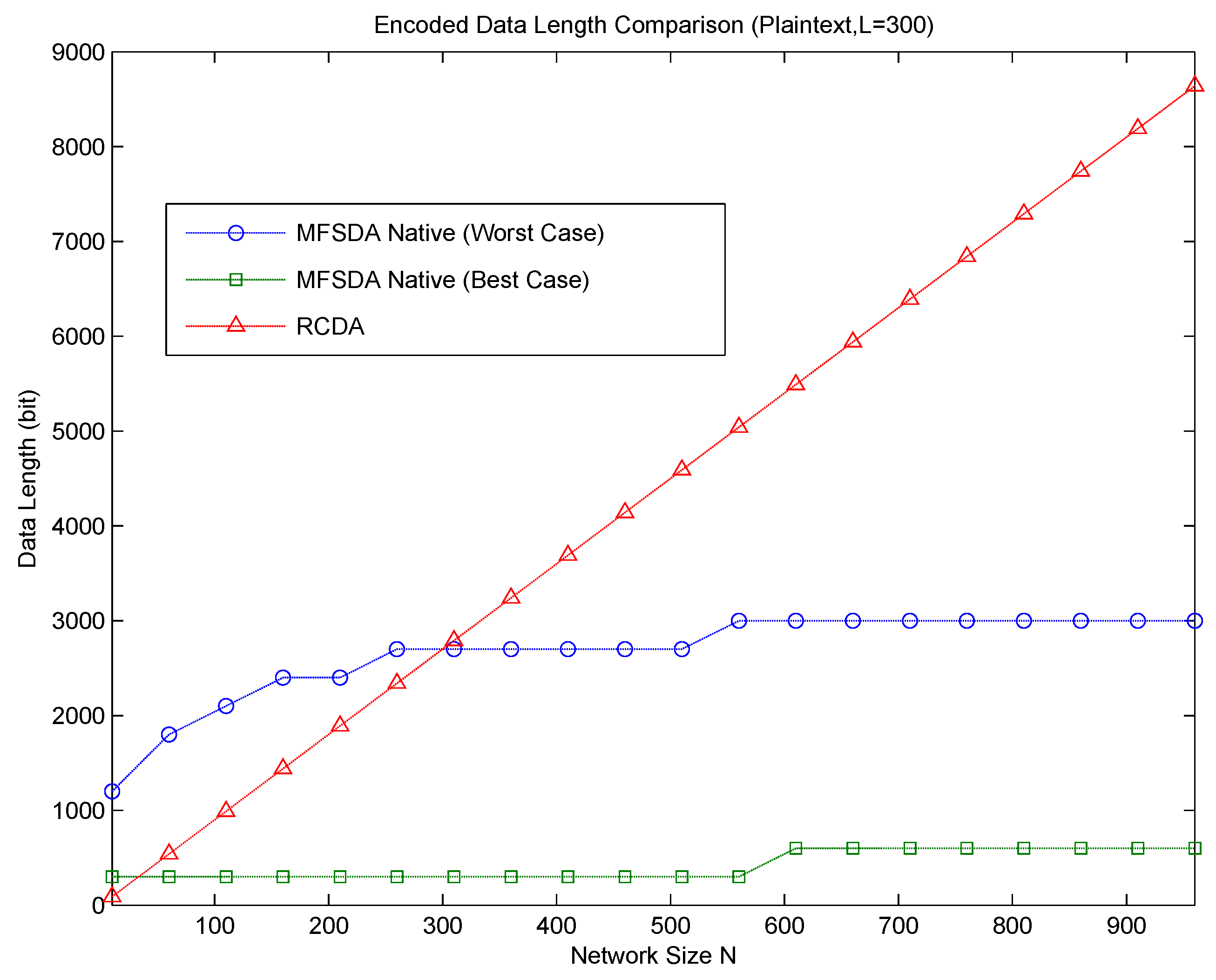
. Obviously, MFSDA is also more efficient than RCDA-HOMO and EERCDA in this condition. A case of communication cost comparison between RCDA and MFSDA is given in
Figure 3.
Now, let us compare RCDA to MFSDA-I on wind direction, which is a real dataset obtained from the TAO project. According to the comparison result, MFSDA-II can reduce the communication cost dramatically at the cost of less accuracy loss. The measure rang TAO wind direction is [0,359], and the accuracy is five. When N = 100, the data length of RCDA is 700 bits, while the data length of MFSDA-I is 504 bits. The latter one is only 72% of the former one. When N = 300, the data length of RCDA and MFSDA-I are 2100 and 648, respectively. The data length of MFSDA-I has been reduced to 31% of RCDA. More detail is listed in
Table 7.
6.3. Analysis and Evaluations of MFSDA-II
For MFSDA-II, we focus on the influence of the compression factor on communication cost and accuracy.
6.3.1. Comparison with MFSDA-I
The data transmission of the intra-cluster, i.e., data transmission from CM to CH, in the approximate scheme is the same as that in MFSDA-I. The compression step only has influence on inter-cluster data transmission, i.e., data transmission between CHs or from CH to the server.
Because of the compression step, the item numbers of
and
are reduced from L to
, so the total data transmission will be reduced, as well. Then,
For a uniform distribution, the result above can be further reduced to:
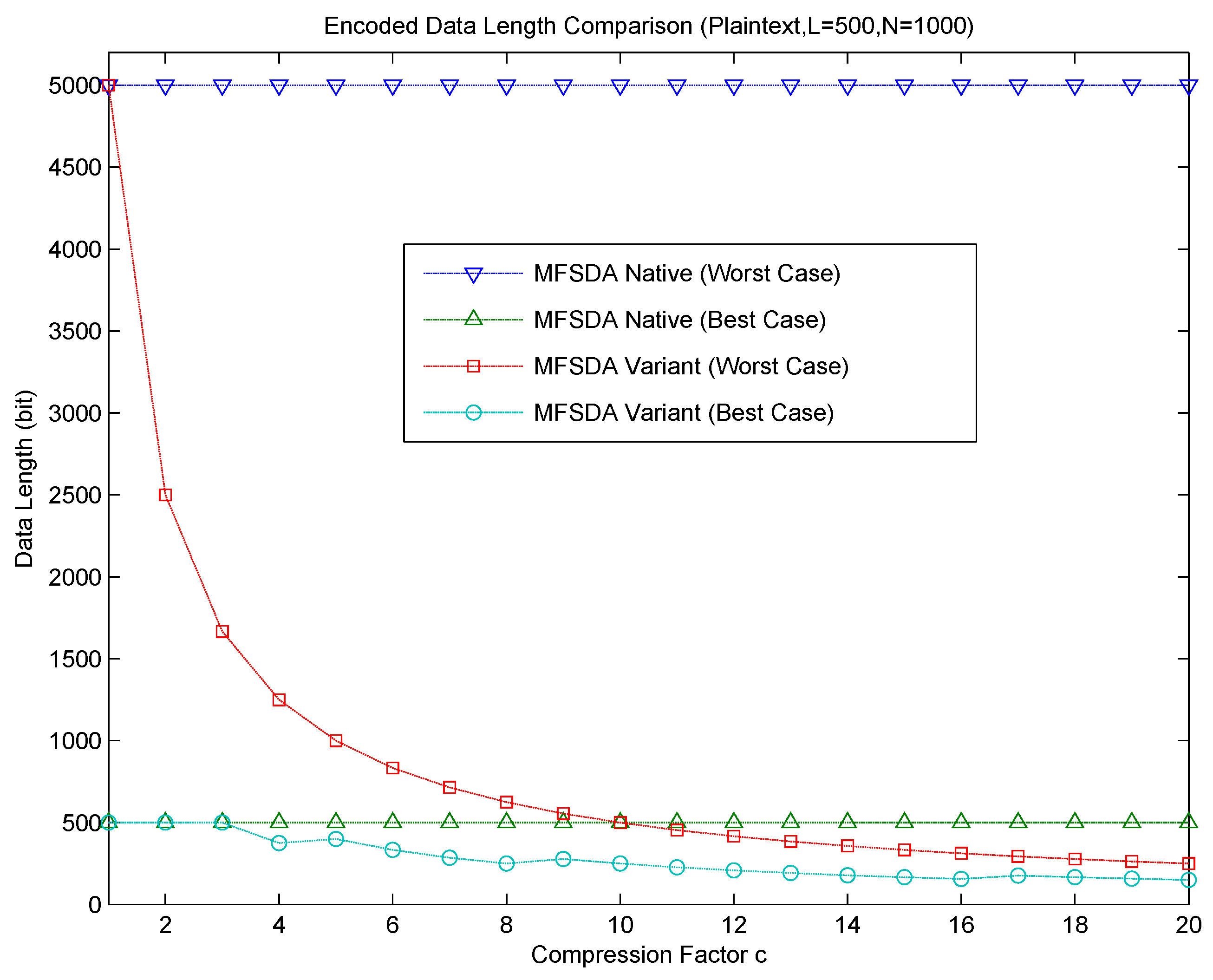
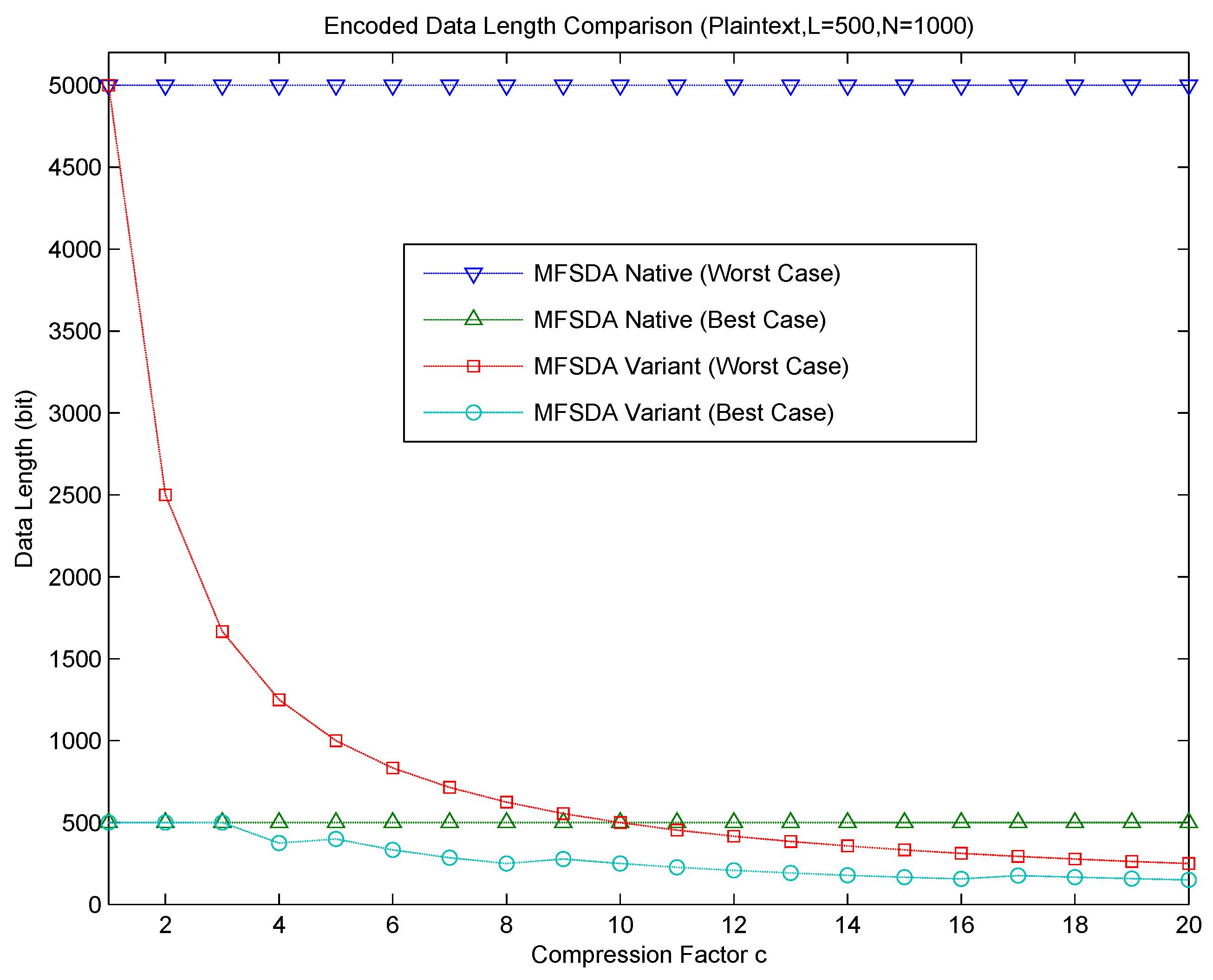
The relationship between communication cost and the compression factor is shown in
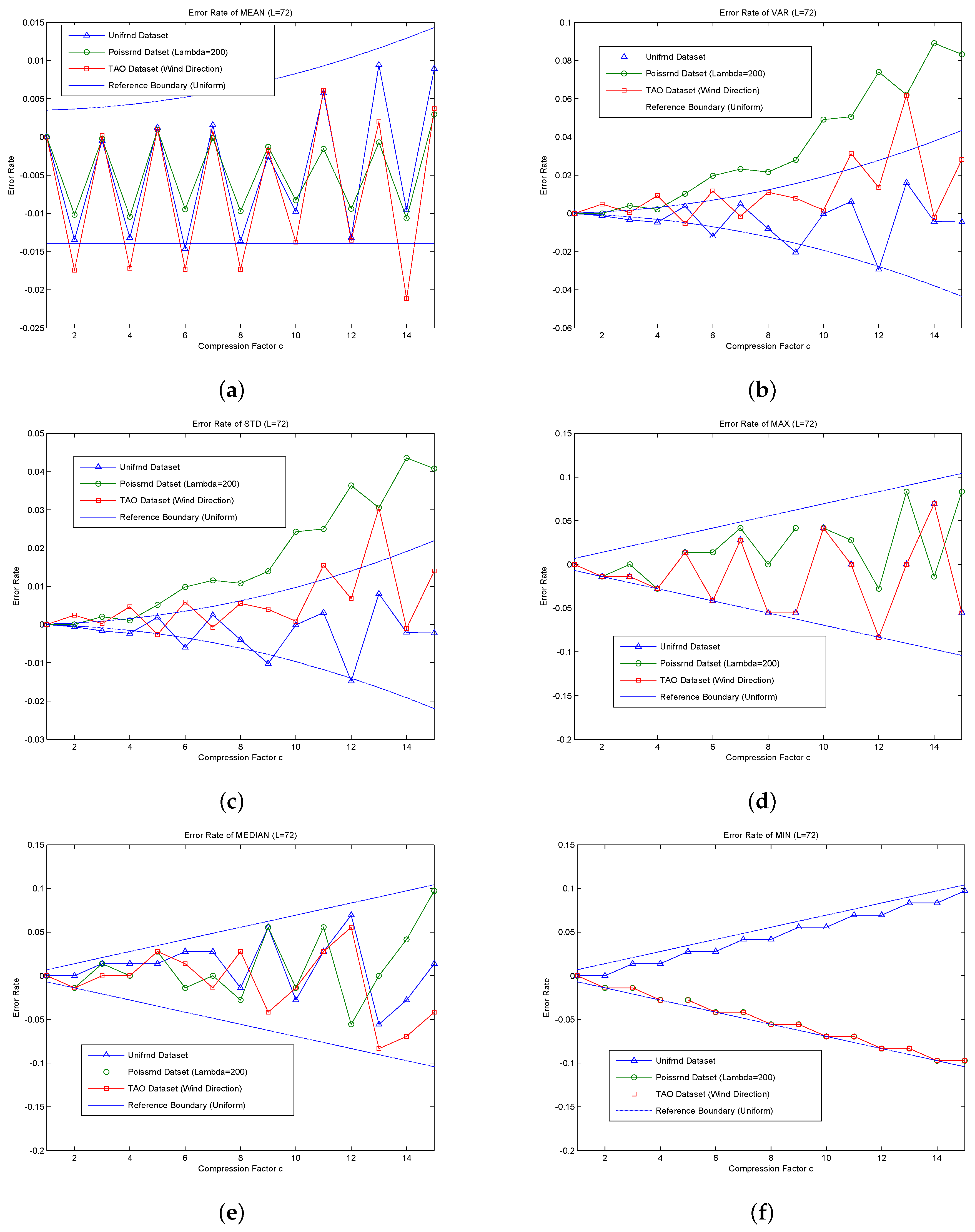
Figure 4. The communication cost significantly decreases as the compression factor c increases in MFSDA-II. Error is introduced due to the loss of compression; accuracy analysis will be given next.
6.3.2. Accuracy Analysis of MFSDA-II
Due to the use of the loss compression operation, this communication cost reduction will inevitably introduce errors. The final error may be modest due to the positive and negative errors existing simultaneously and offsetting each other.
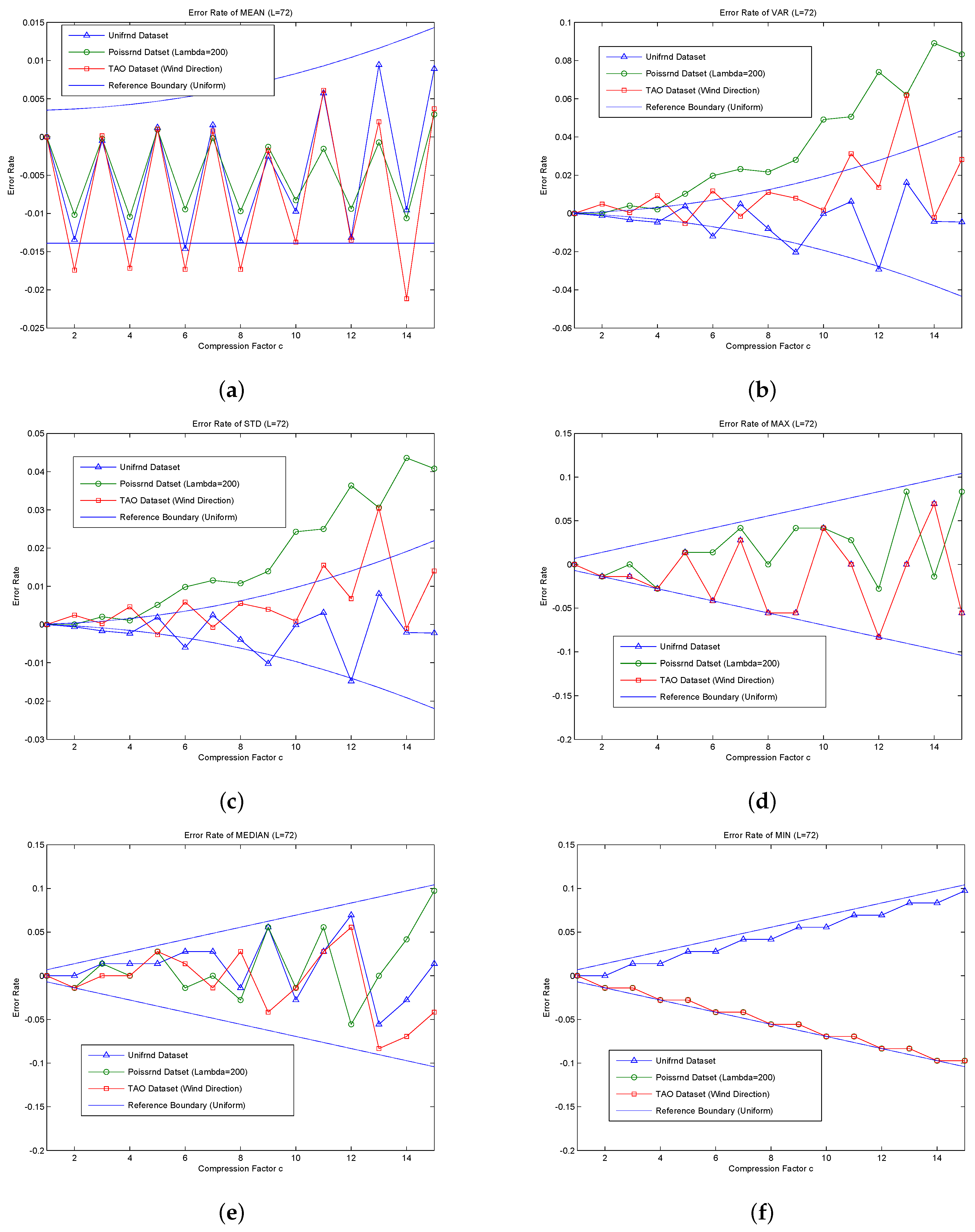
The error rate of each statistic is in inverse proportion to or has a reverse trend with L and is proportional to or has a positive trend with c. For the same error rate request, the bigger the L, the bigger the value of maximum acceptable c. For the error rate of comparison-based statistics, such as ER(Error)MAX , ERMED and ERMIN, the reference boundaries are the determined ones, i.e., the error rate is not beyond the borders. For the error rate of addition-based statistics, except for ERCNT, which is zero, the error rates of several other statistics constitute the reference boundary; the boundary is also used to describe the error variation trend and reference boundary range, and several specific case may out of the reference bounds. The reference boundaries of ERMAX, ERMED are , i.e., the boundary is directly related to and shockingly enlarges as c increases. The upper bound of ERMIN, ERMAX and ERMED is the same. Due to rounding used in the compression step, ERMIN has a one-way increasing trend, and its lower bound is zero.
The CNT is the total active nodes number in the current query; thus, no error exists, namely ERCNT is zero. Therefore, the error reference bounds of ERMEAN and ERSUM are the same. Their lower bound is independent of c. Their upper bound is proportional to and is shockingly amplified as c increases.
The error reference bounds of ERVAR and ERSTD are also shockingly amplified as c increases, more so for ERVAR.
Compared to the comparison-based statistics, the coefficients of the addition-based statistics (such as ERVAR, ERMEAN, etc.) are times the former ones. c is much less than L; thus, is much smaller than one. Therefore, the error rate of comparison-based statistics is much greater than that of addition-based statistics. This is mainly because the addition-based statistics are calculated by using the data of all nodes, even though the data error of a single node is large; partial offset of the negative error and positive error exists simultaneously. While the comparison-based statistics are obtained from a single point of data, there is no such type of compensation.
6.3.3. Evaluation of MFSDA-II
The statistical results obtained by MFSDA-I are accurate; thus, the accuracy evaluation is only performed on the MFSDA-II. The following experiments will analyze the error rate of each statistic as it changes with the increase of the compression factor. The results are listed in
Figure 5.
Now, let us compared MFSDA-I with MFSDA-II based on the wind direction dataset of TAO, where the network size is N = 2000. The data length of MFSDA-I is 792 bits. When the compression factor is c = 2, the data length of MFSDA-II is 396 bits, which is only 50% of MFSDA-I. The maximum error rate of all statistical results is 2%, while the minimum error rate is 0.2%. When the compression factor is c = 4, the data length of MFSDA-II is 198 bits, which is only 25% of MFSDA-I. The maximum error rate of all statistical results is 2%, while the minimum error rate is 0.5%. More detail of the comparison result is listed in
Table 8. More detailed accuracy analysis results of MFSDA-II will be given later.
The reference boundary is derived based on a uniform distribution. The more the actual data are similar to a uniform distribution, the higher the reference value that the boundaries will provide. As shown in
Figure 5, the majority of error rates are in the reference boundary, though some statistical error rates are still beyond the reference boundary.
The majority of error rates of the unifrnd dataset are in the reference boundary. Compared to the other dataset, it can achieve higher accuracy (less error rate) for the same compression factor. The error rate reference formula of each statistic has a good prediction ability for the unifrnd dataset; thus, it can be used directly for compression factor choosing. For example, assuming that the accuracy requirement of ERSTD is approximately 2%, we can choose C = 15; the amount of data is compressed from L = 72 to , which means that the final communication cost is only of that in MFSDA-I.
For the non-uniform distribution, some statistic error rates may be beyond the reference boundary. ERSTD and ERVAR of poissrnd dataset are beyond the reference boundary, so the reference error formula cannot be used directly. However, even in this condition, the error rate is still related to c. By the choice of a much less C, we can still greatly reduce the amount of communication cost and achieve high precision. For example, the ERVAR of poissrnd dataset reaches to 10% when c = 15. If we choose c = 10, the ERVAR will reduce to about 4%. The communication cost is reduced to of that in MFSDA-I.
As show in
Figure 5, ERMAX, ERMIN and ERMED of all three datasets are in the reference boundary range; this is because the reference boundary of comparison-based statistics is the absolute boundary.
As the TAO dataset of wind direction is very similar to a uniform distribution, the greatest error rate is in the boundary range. In contrast, poissrnd dataset is less similar to a uniform distribution. If we calculate a suitable compression factor according the error formula, we can directly apply it to the TAO dataset of wind direction, and we may need to choose a much smaller c for the poissrnd dataset.
According the reference boundary formula, the error rate of each statistic is directly proportional to C and inversely proportional to L. That is to say, for the same accuracy requirement (error rate) of each statistic, the bigger the L, the largest the c. Due to the reduction of communication cost in MFSDA-II being , therefore, the bigger the L, the more the energy saved.
For example, in the barometric pressure of the TAO project, , still N = 2000. The experimental results show that, when c = 30, ERVAR is about 20%, and ERSTD is about 10%. The rest of the4 error rates are all less than 1%. L’ is reduced from 3000 to 100. Therefore, the amount of communication cost is only of MFSDA-I. Even if we choose a much smaller c = 20, to reduced ERVAR to 10%, the cost is still only of MFSDA-I.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}