
Compressive Video Recovery Using Block Match Multi-Frame Motion Estimation Based on Single Pixel Cameras


Abstract
:1. Introduction
2. Compressive Sensing
2.1. Measurement Matrix
2.2. Signal Reconstruction Algorithm
- (1)
- The TV model can be described by Equation (6):where is the discrete gradient of at pixel .
- (2)
- The corresponding augmented Lagrangian problem is described by Equation (7):
- (3)
- An alternating minimization scheme is applied to solving Equation (6). For a fixed , the minimizing for all i can be obtained via Equation (8):where and can be calculated as follows:here, is primary penalty parameter and is secondary penalty parameter. For fixed , is taken one steepest descent step with the step length computed by a back-tracking on-monotone line search scheme [20] starting from a Barzilai-Borwein (BB) step length [21]:
3. Compressed Video Sampling Perception
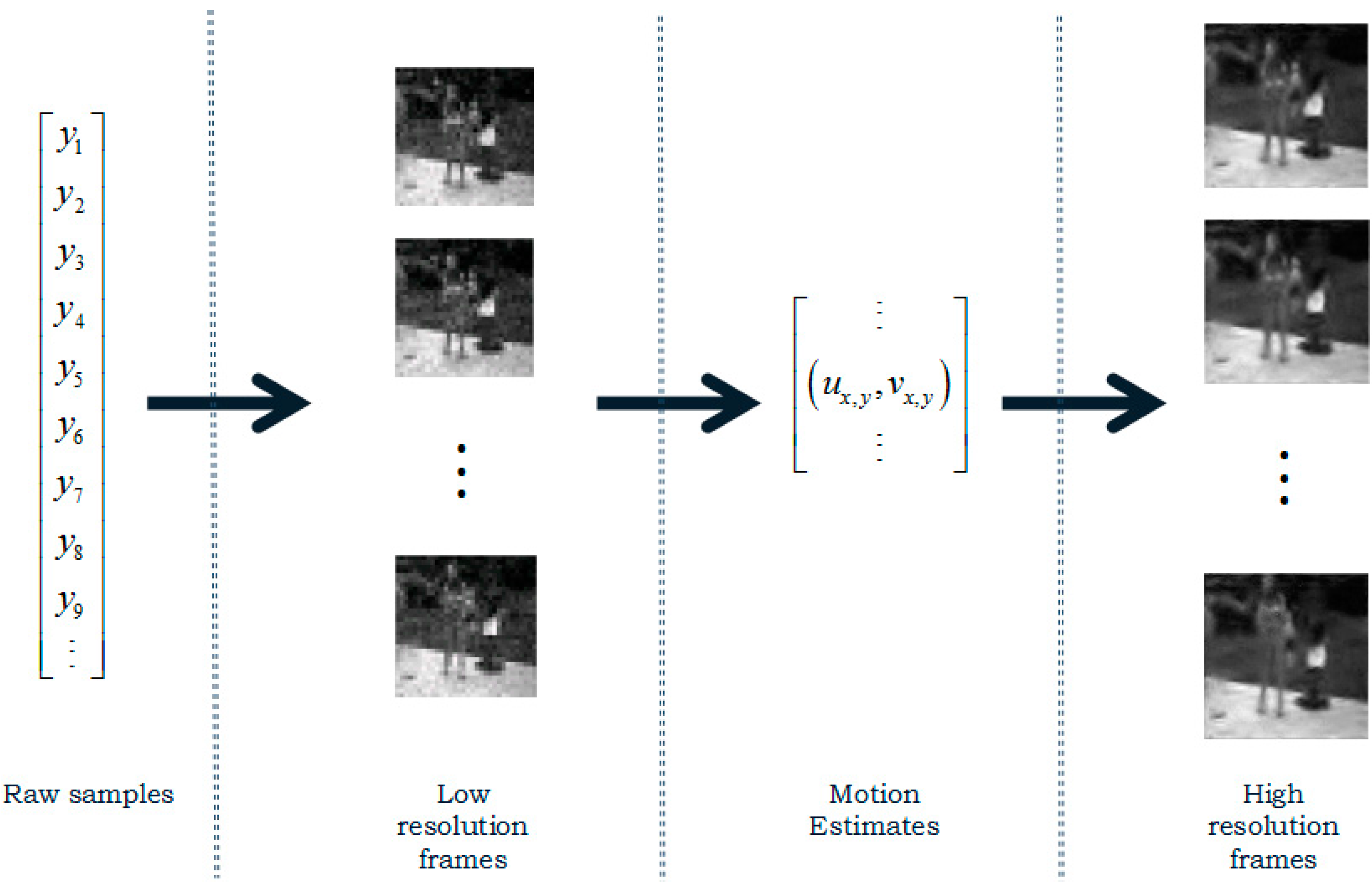
3.1. Single Pixel Video Camera Model
3.2. Errors in the Static Scene Model
3.3. CS-MUVI Scheme
3.3.1. Sensing Matrix
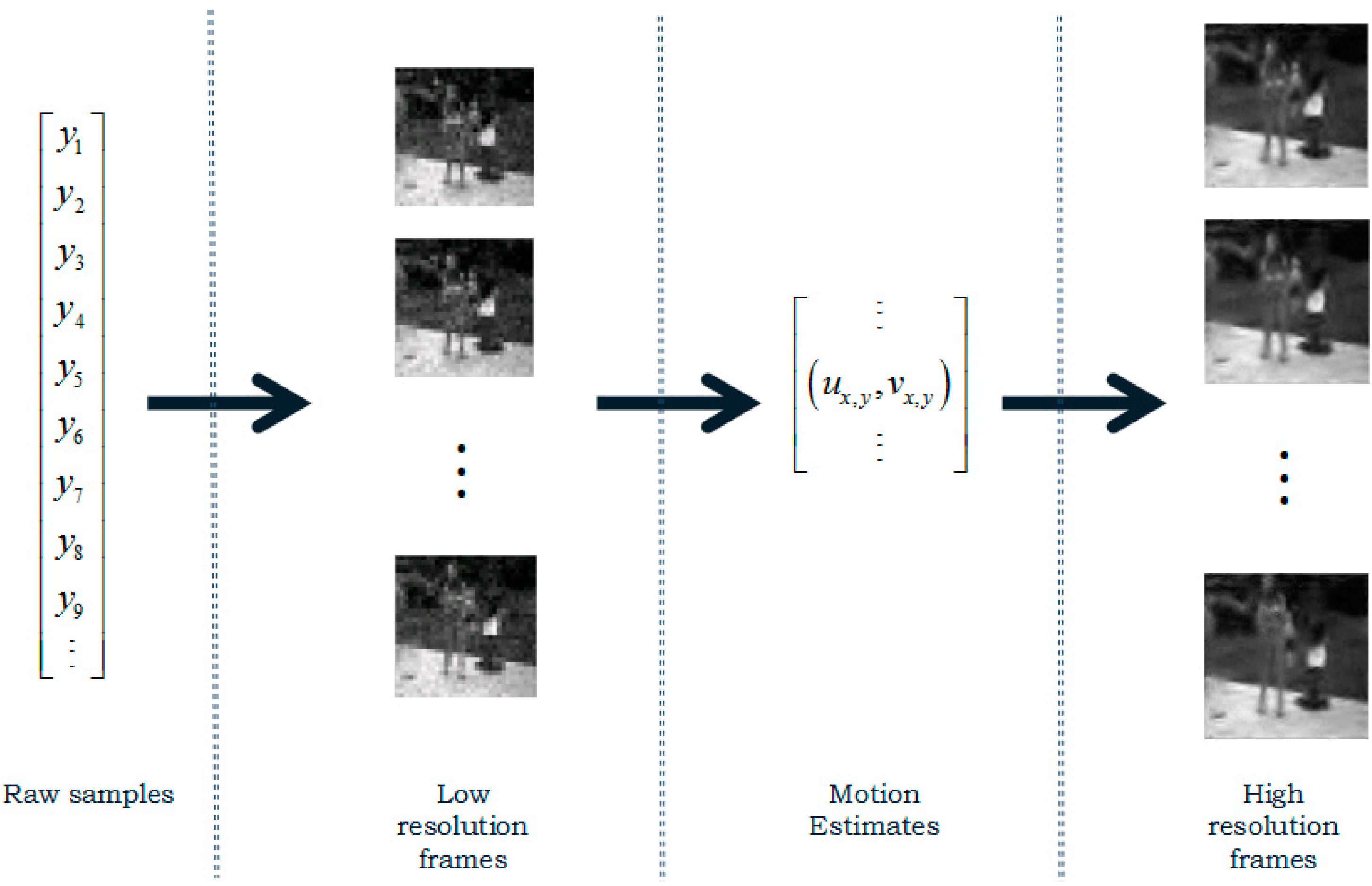
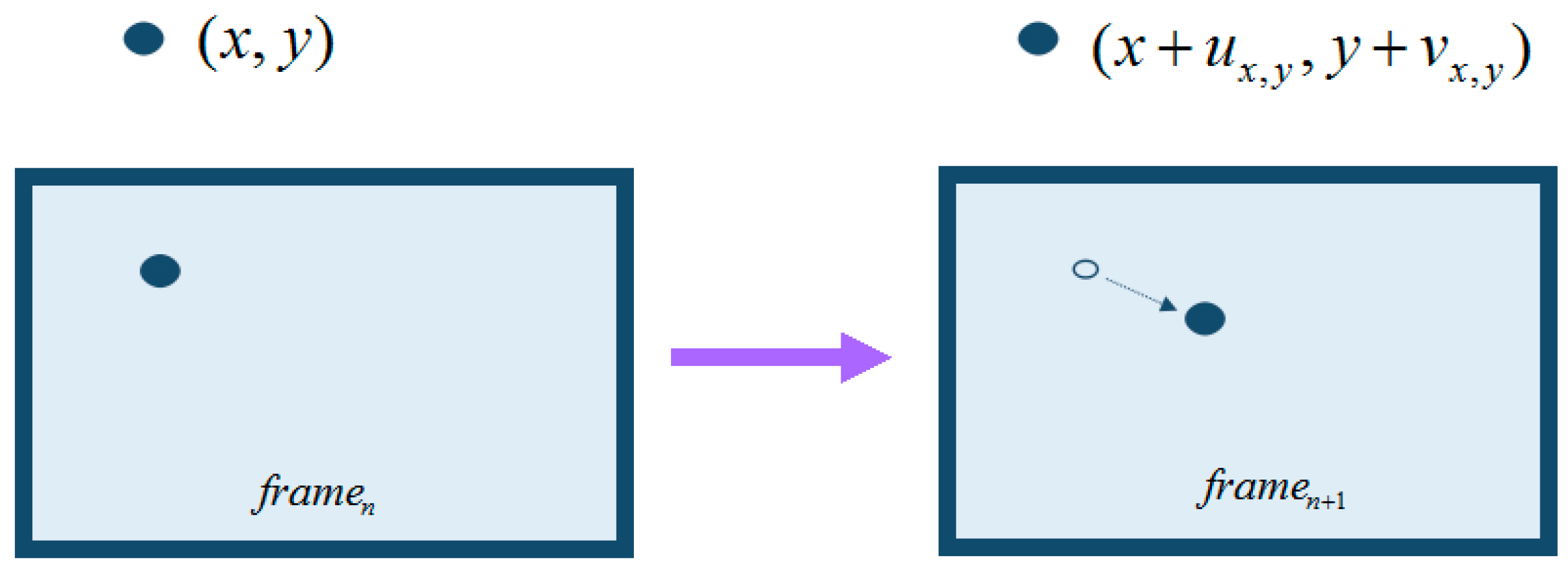
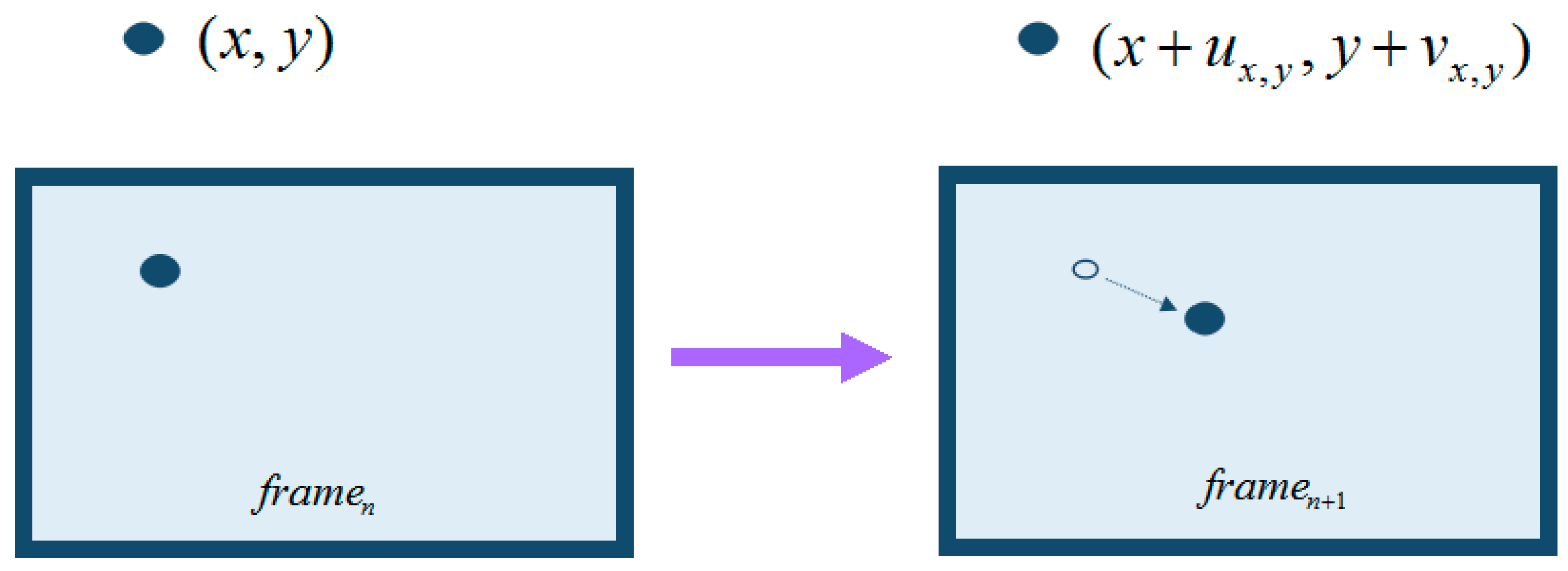
3.3.2. Motion Estimation
3.3.3. Block Match Algorithm
| Algorithm 1: |
| Initialize , |
| For each block in frame Do |
| While stop criteria unsatisfied Do |
| For each Do |
| if then |
| End if |
| End Do |
| , ; |
| End Do |
| End Do |
| Output of each block . |
3.3.4. Recovery of High-Resolution Frames
4. Experiments
4.1. Experimental Setup of the Single Pixie Video Camera
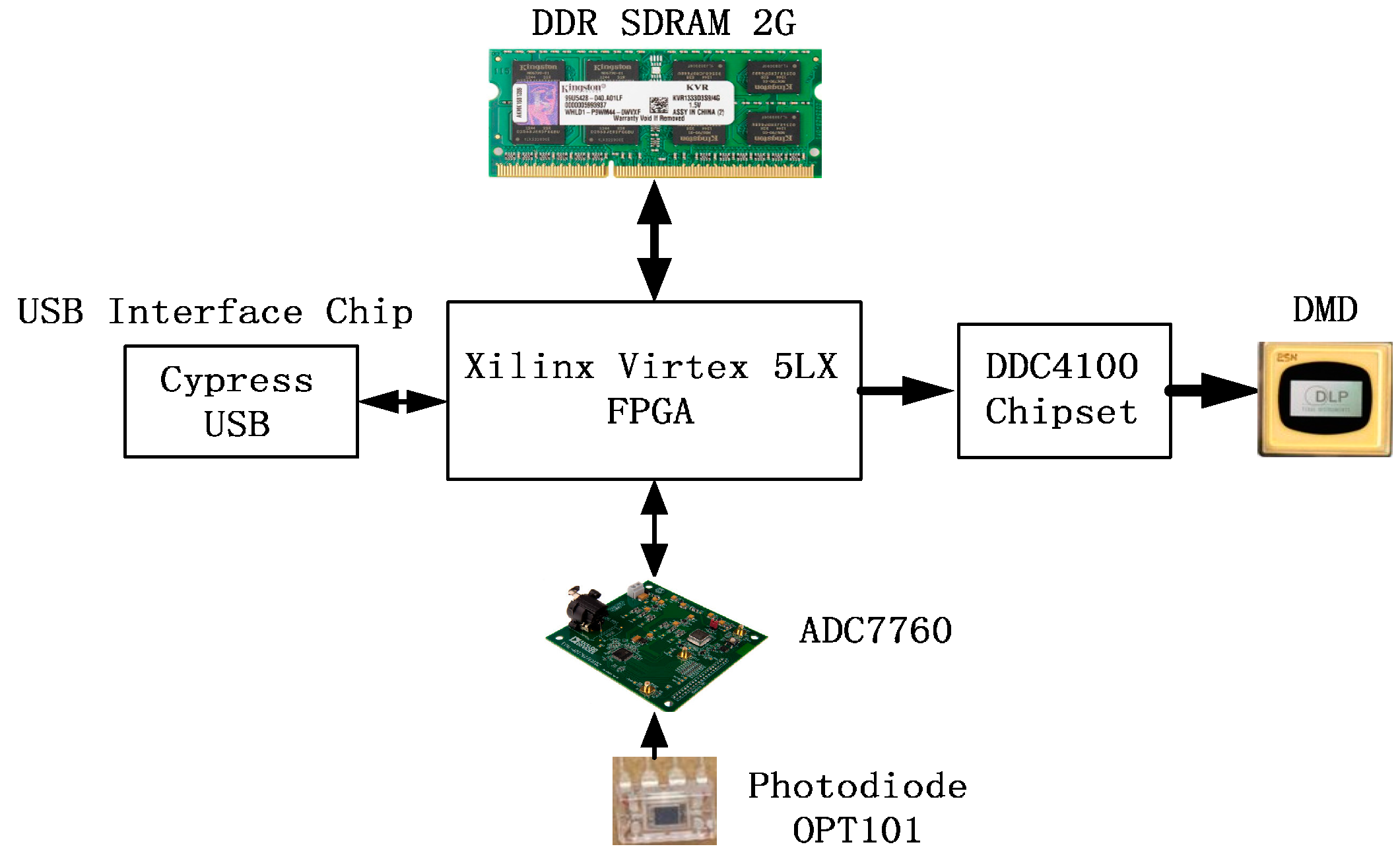
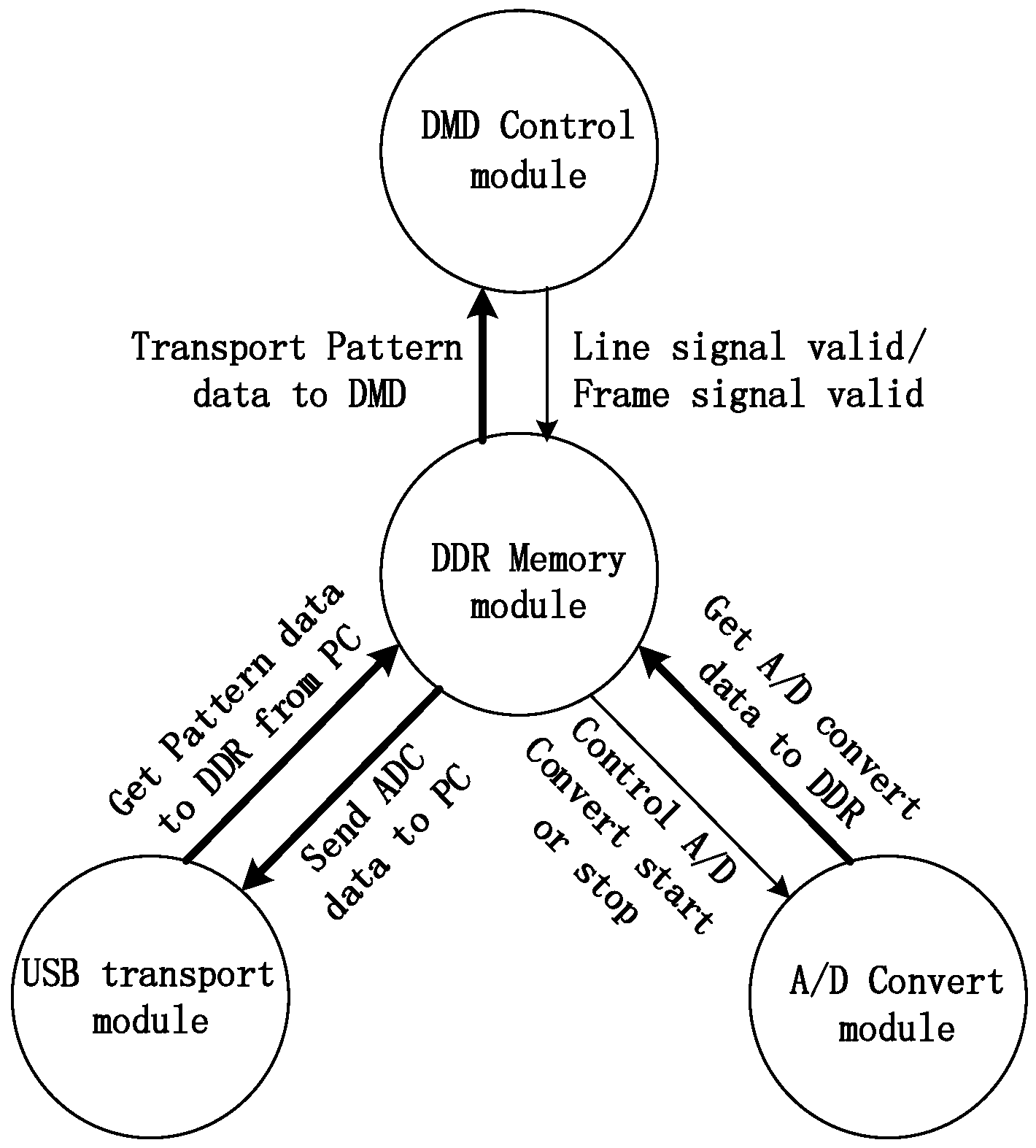
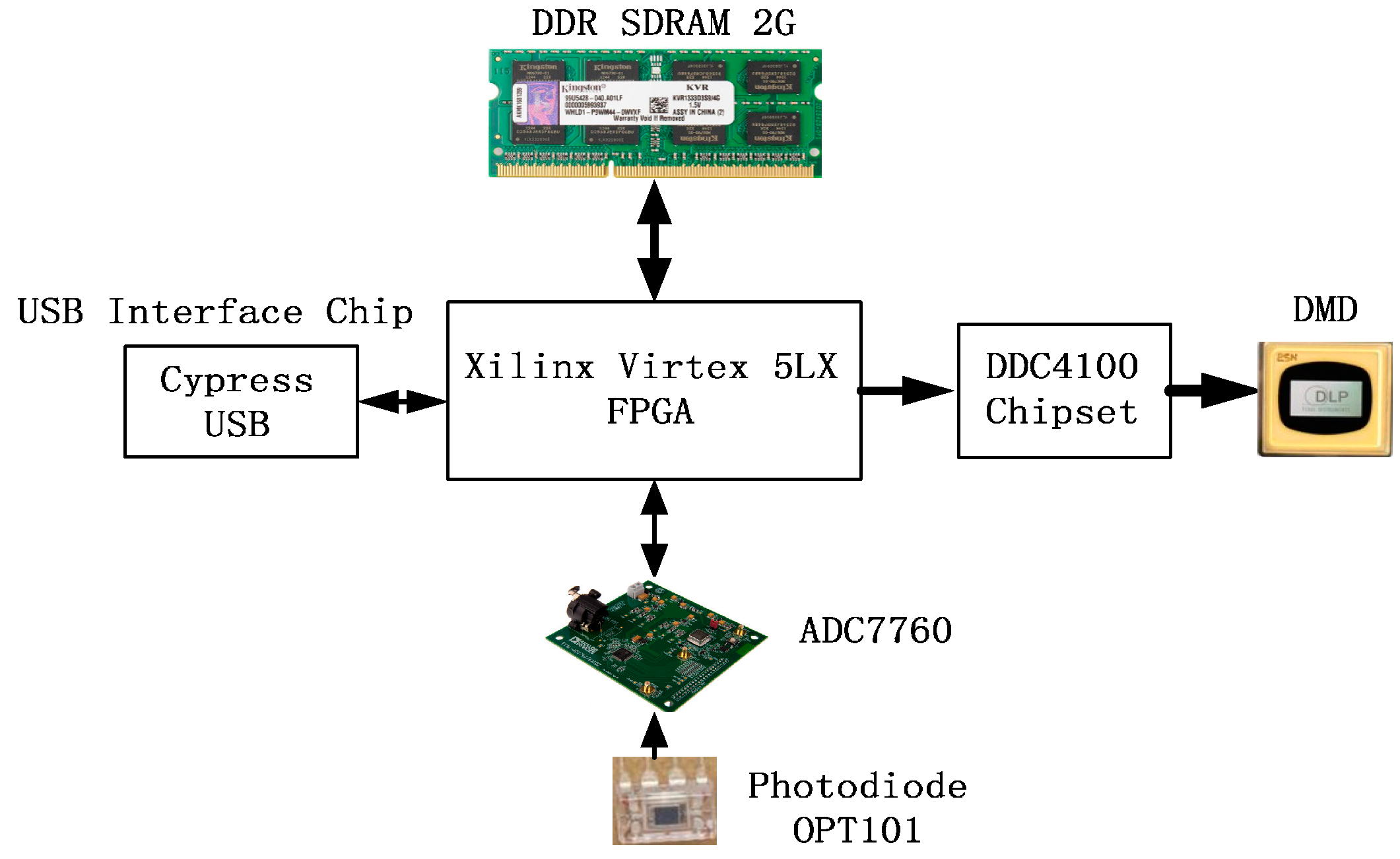
4.1.1. Components of the SYSTEM
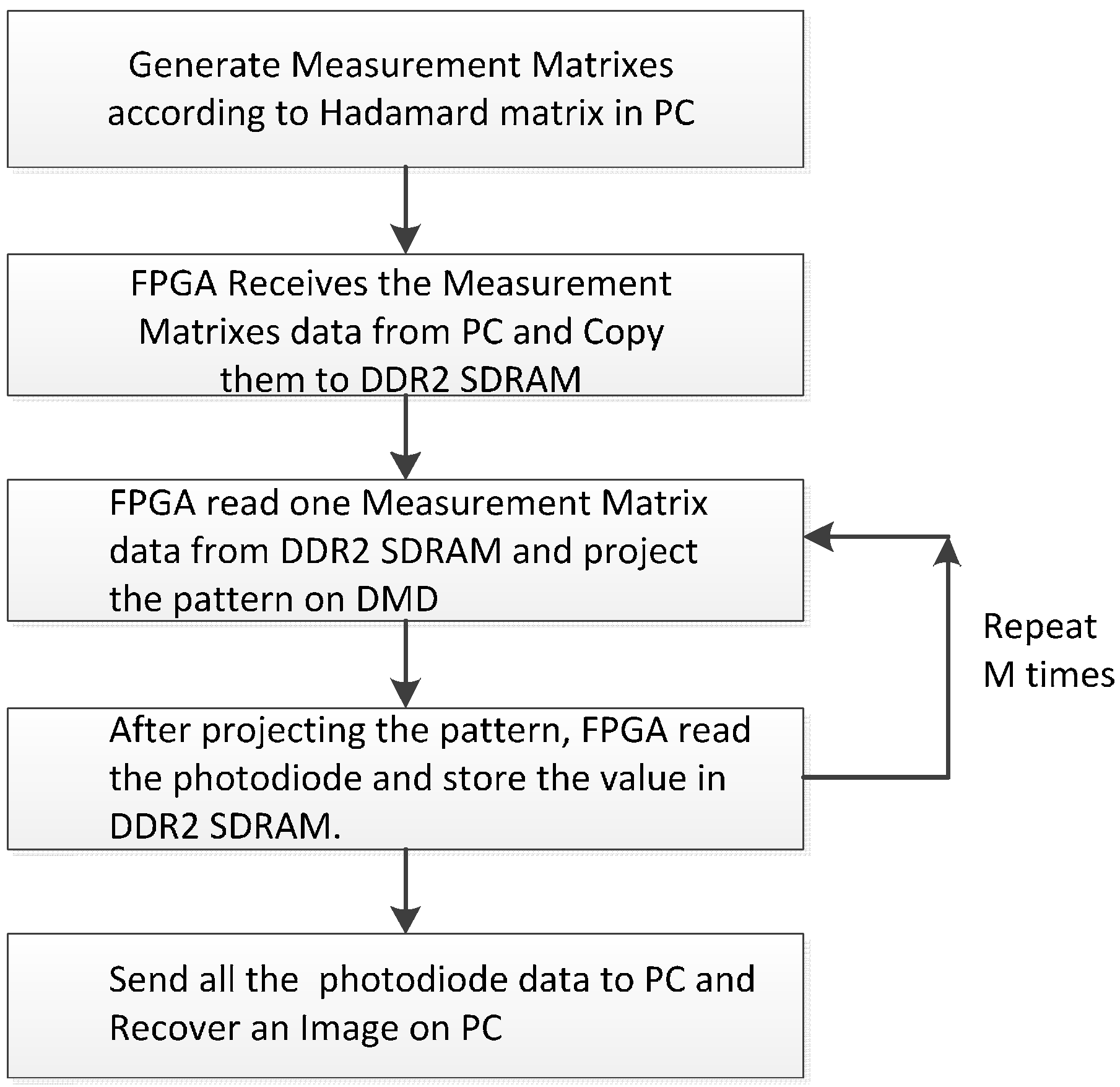
4.1.2. The Workflow of the Single-Pixel Camera
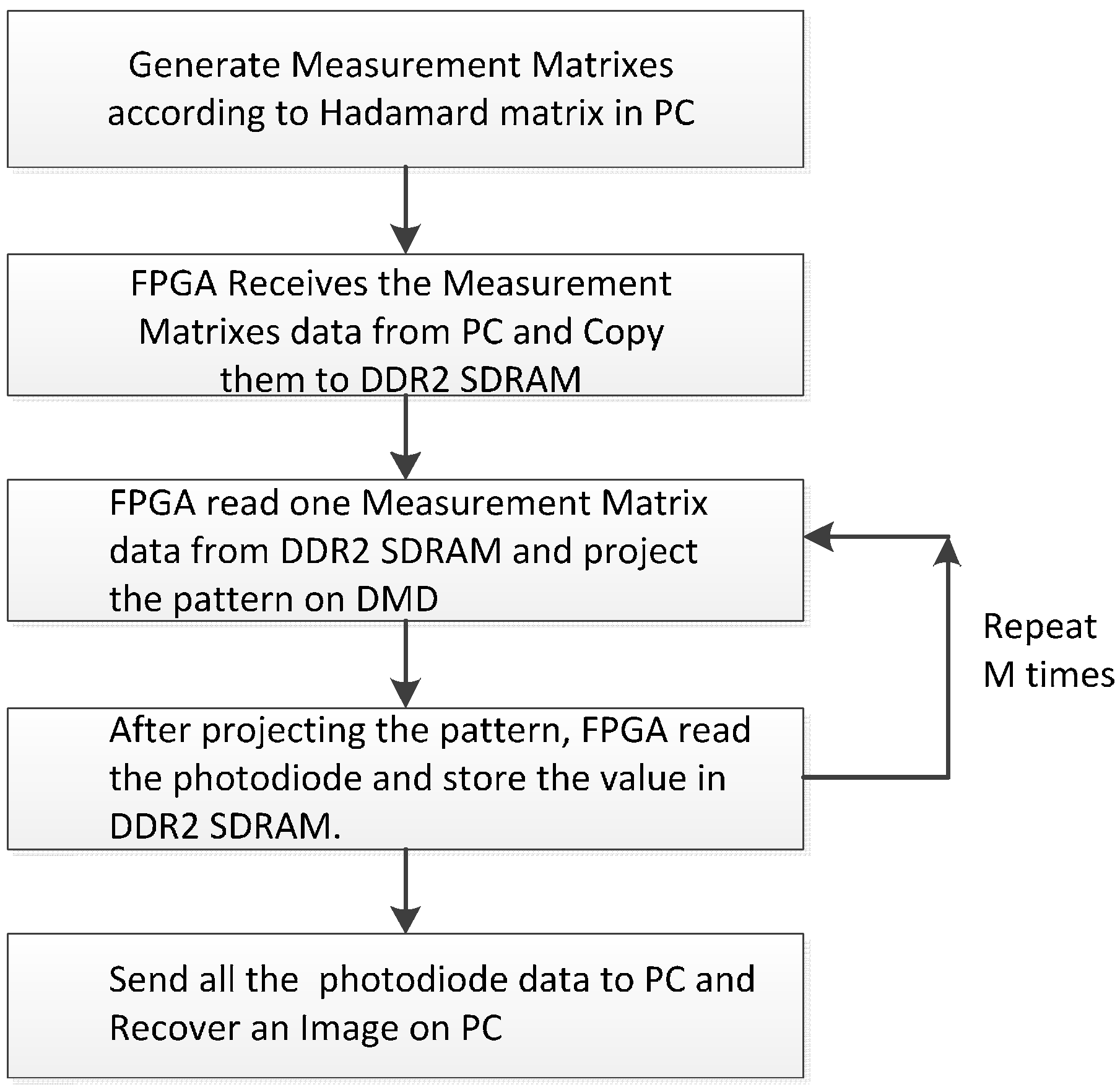
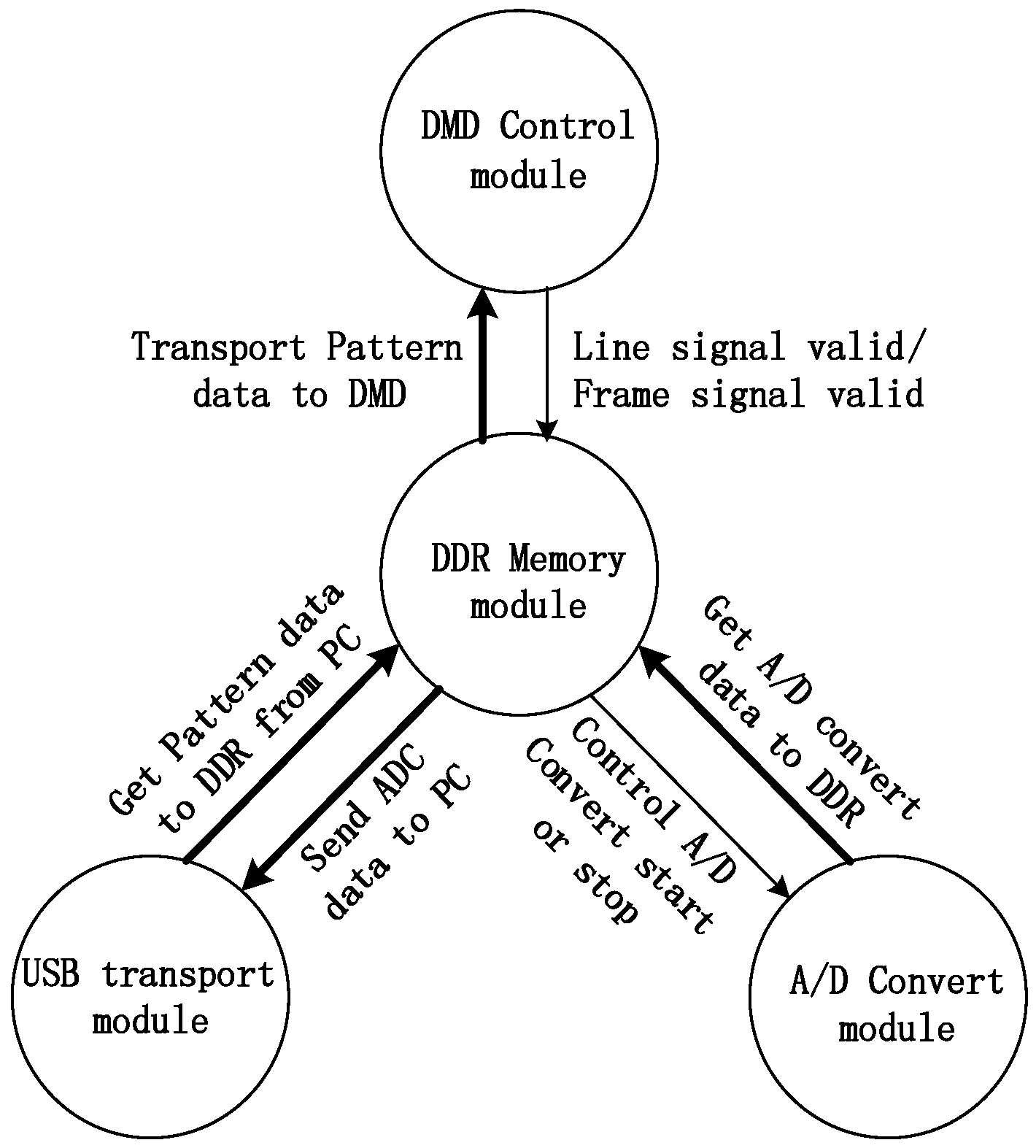
4.1.3. Parallel Control System Based on FPGA
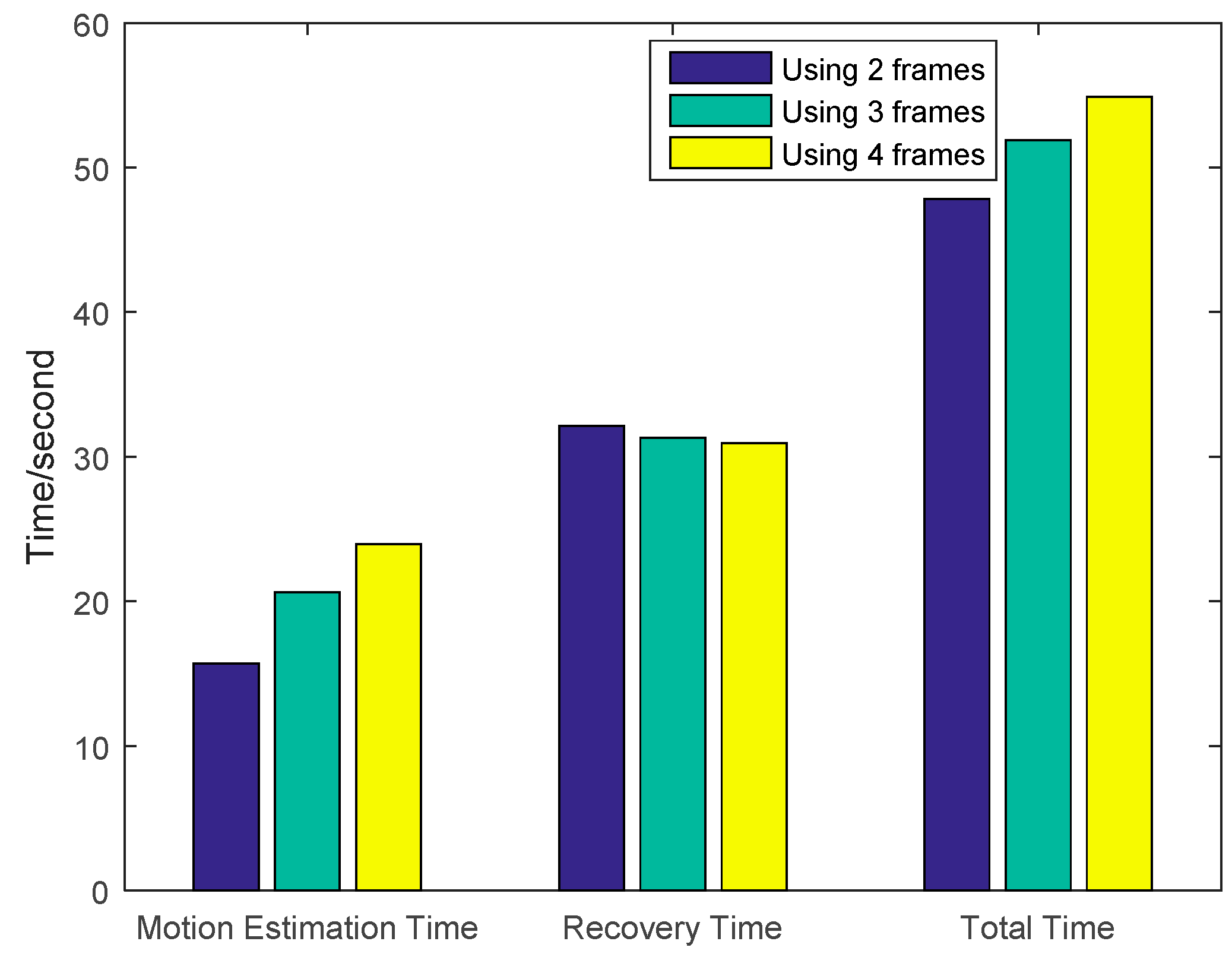
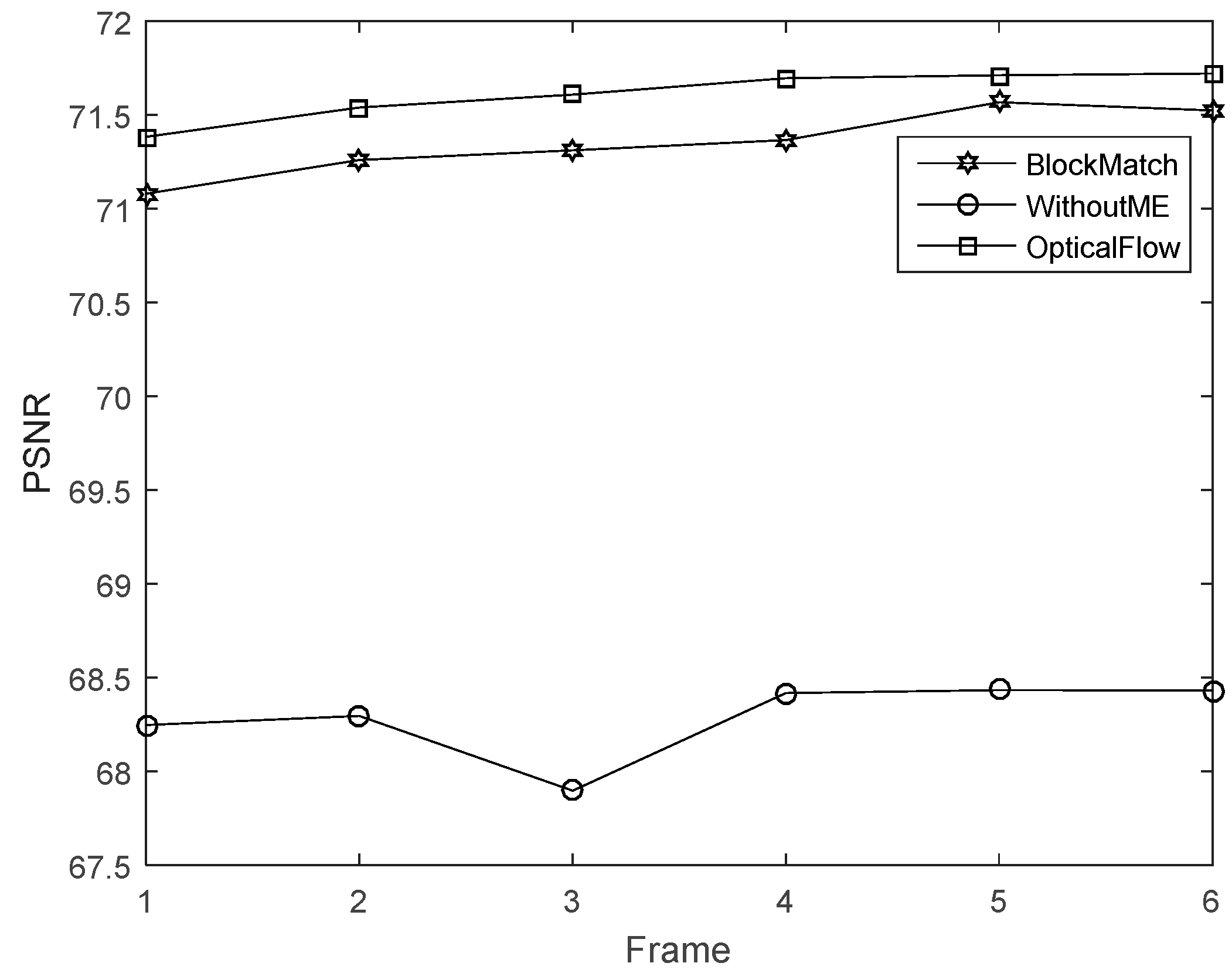
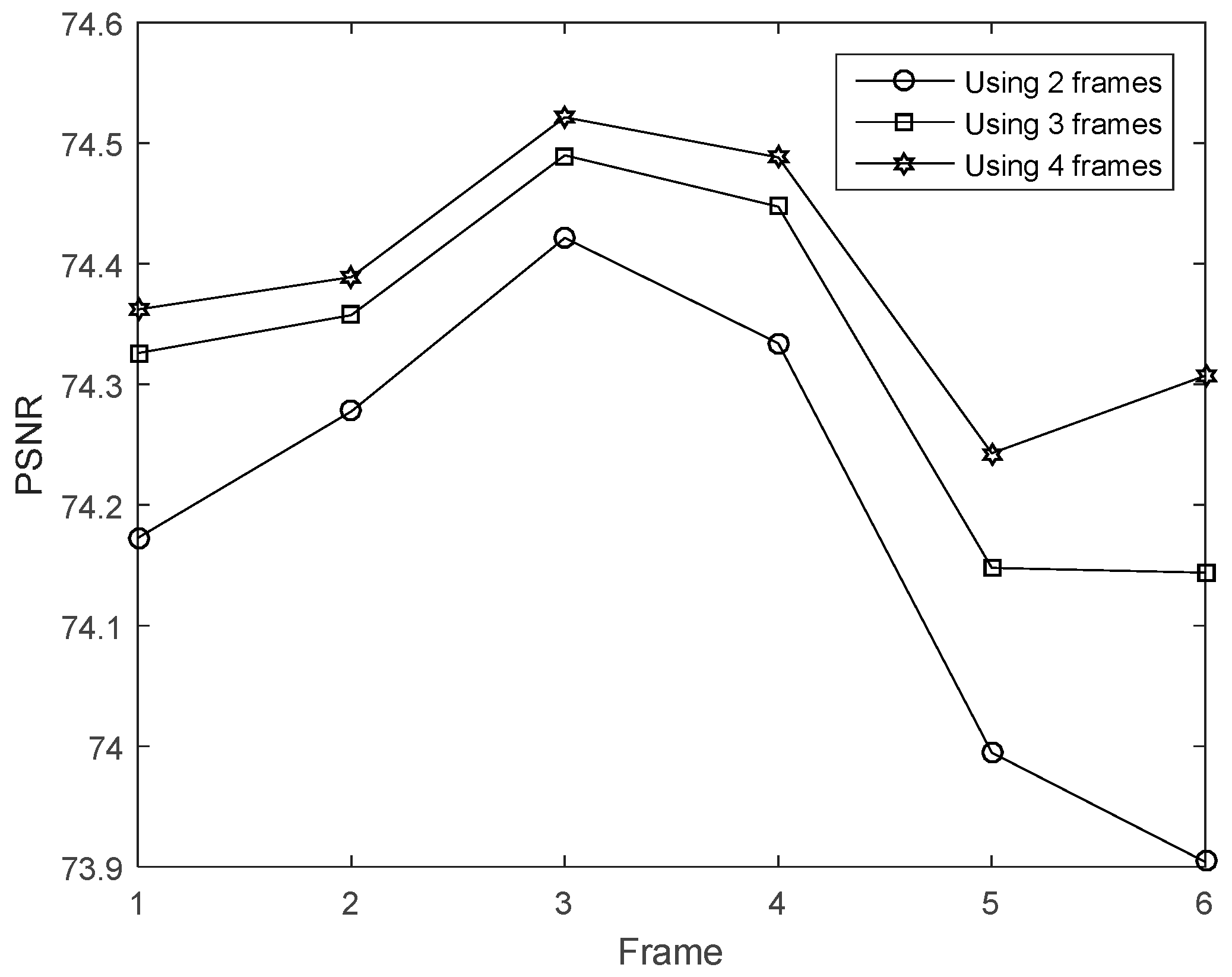
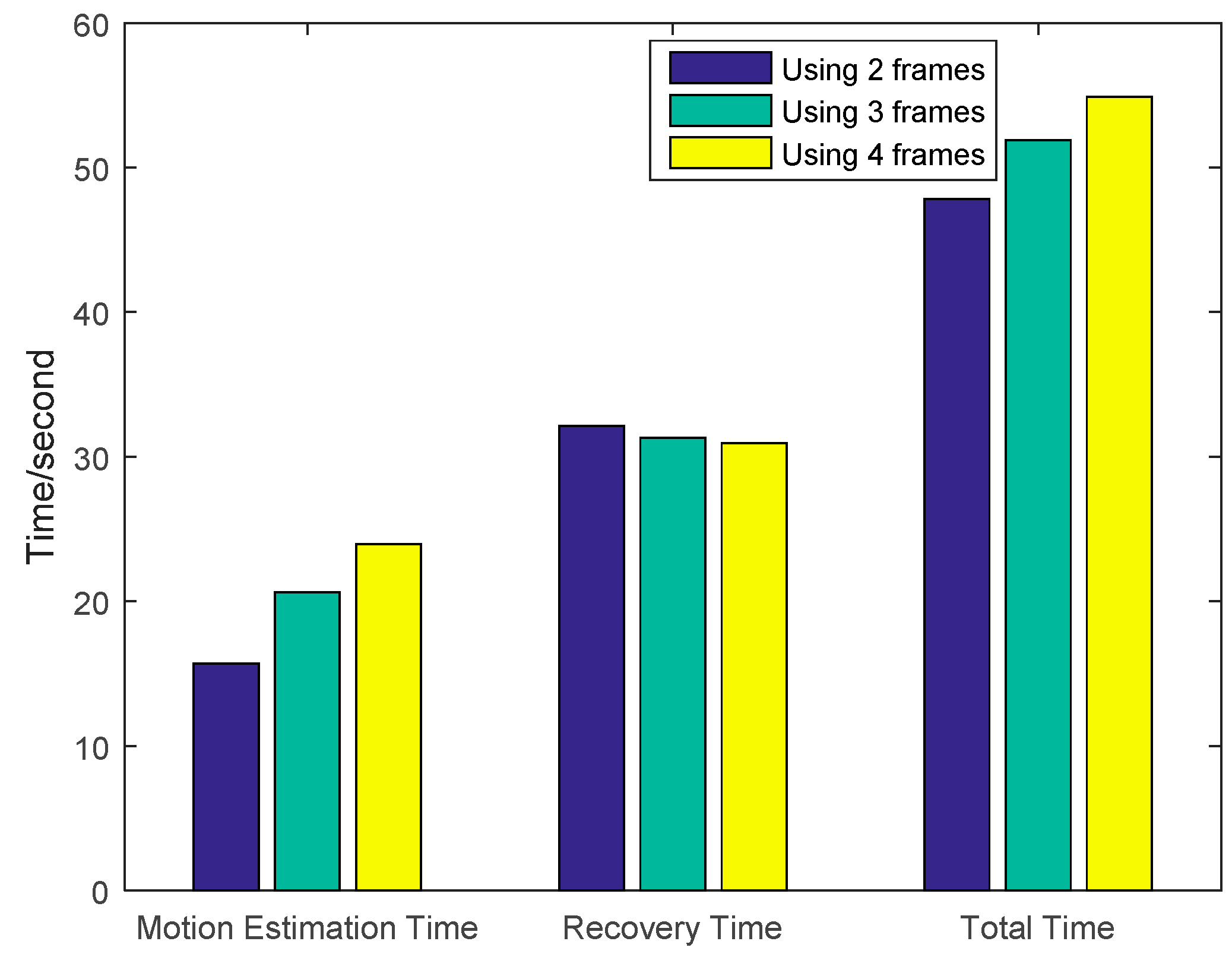
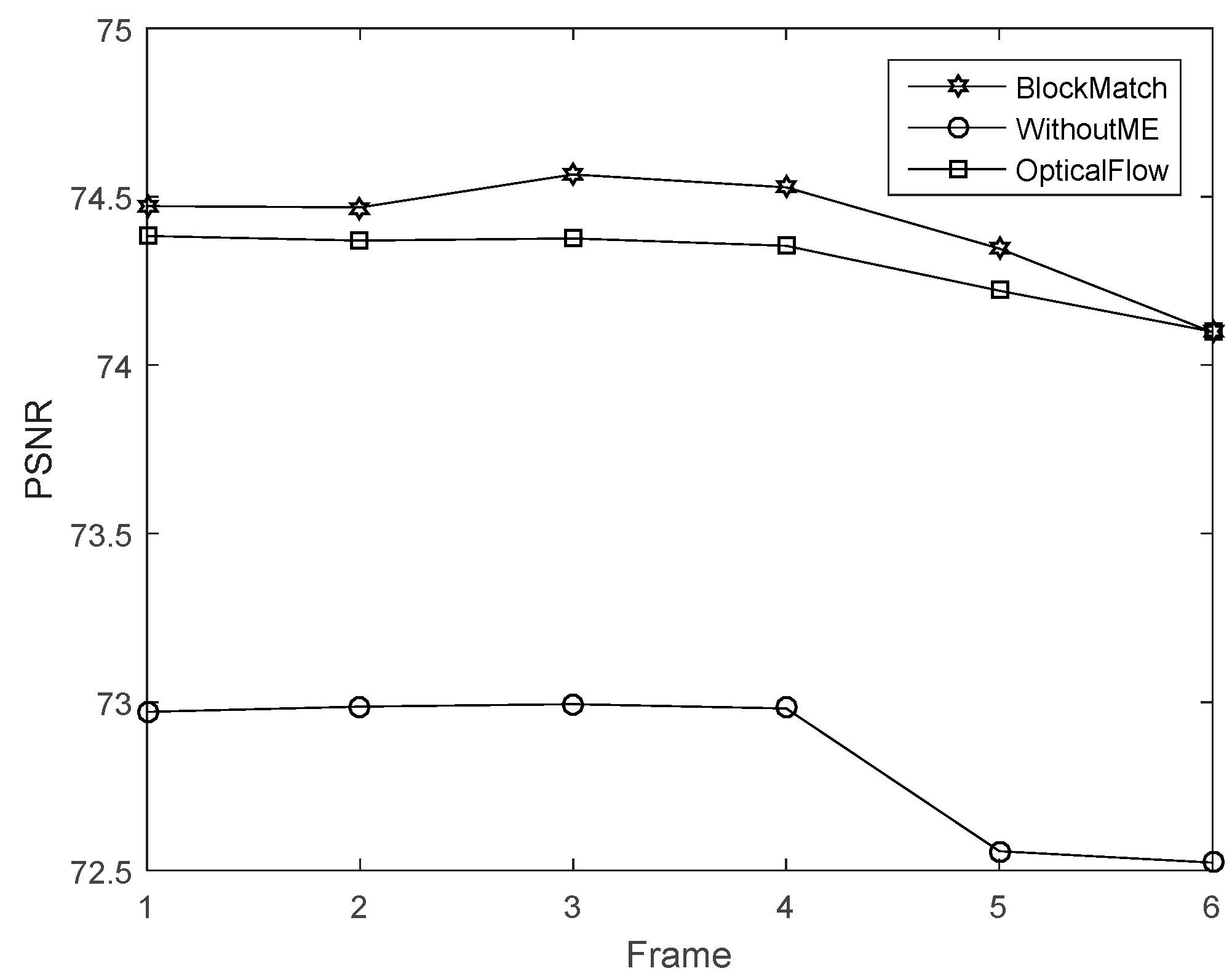
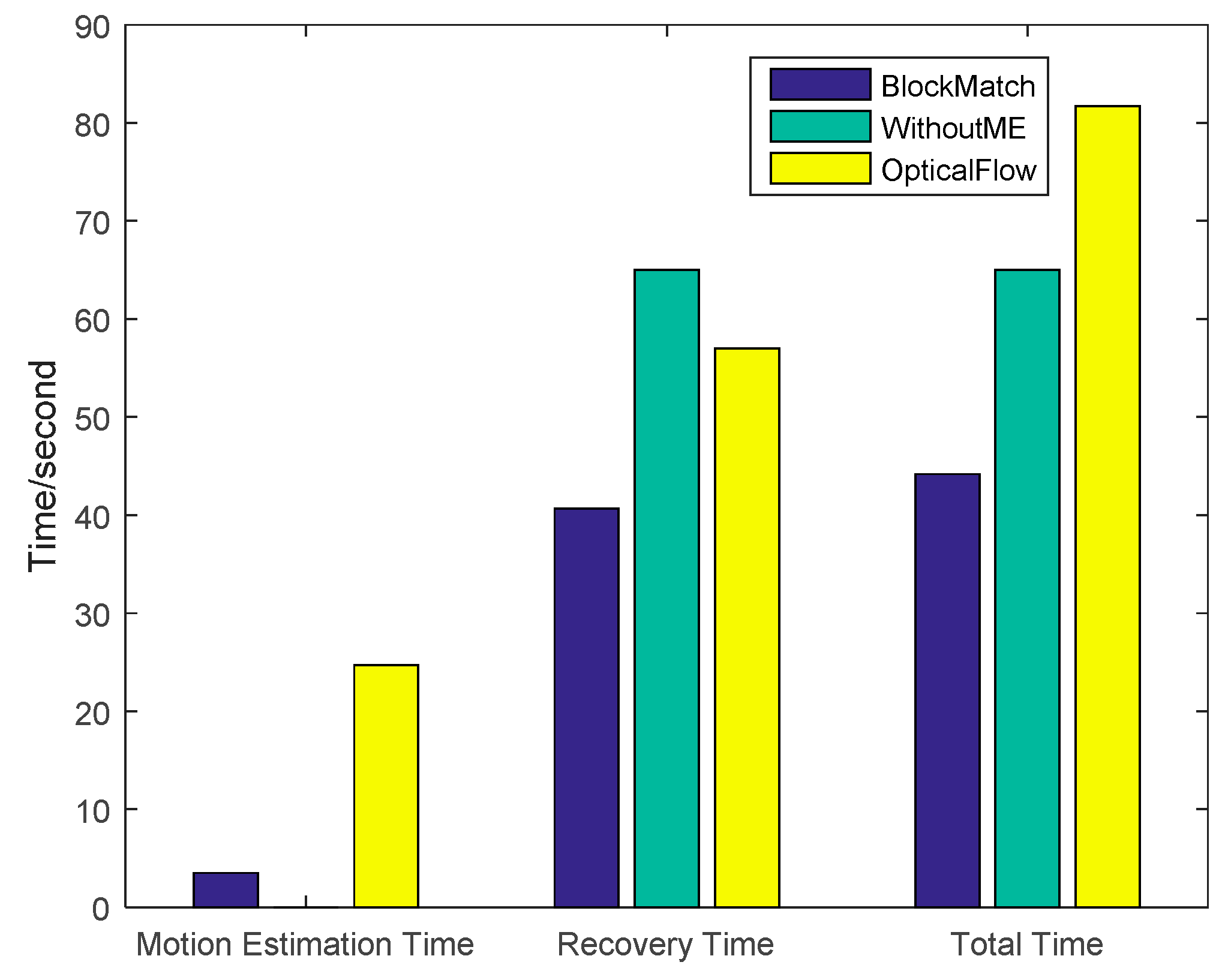
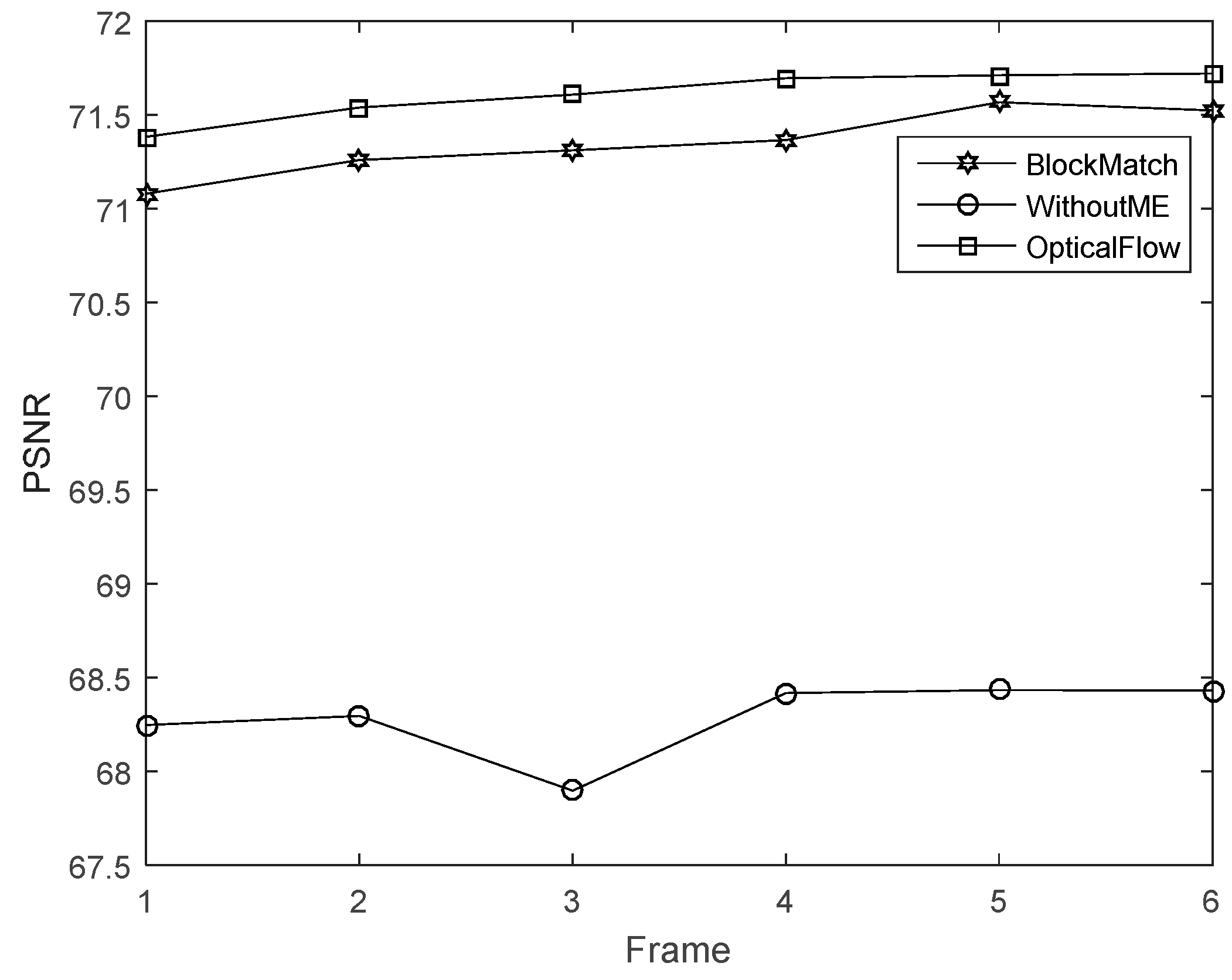
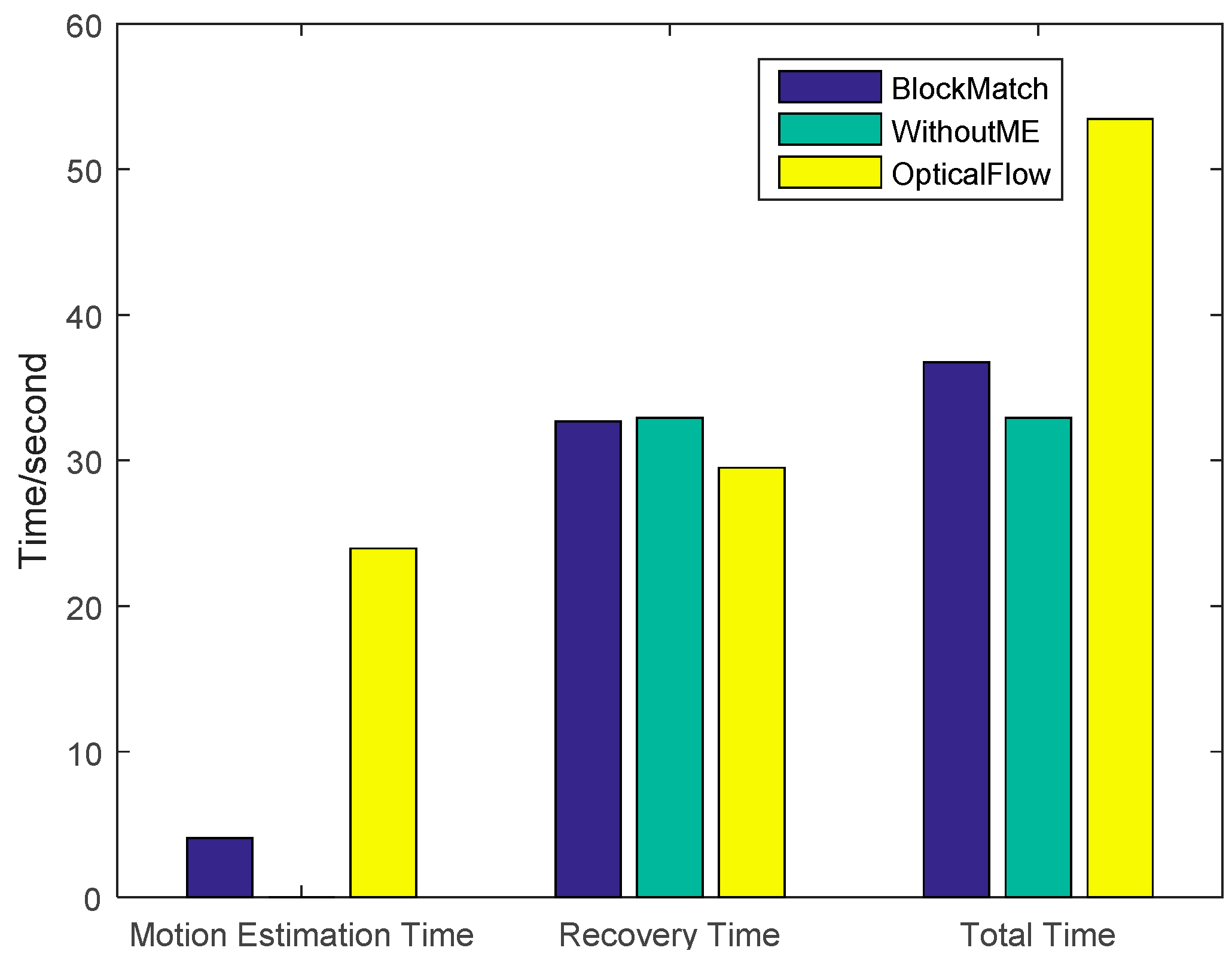
4.2. Multi-Frame Motion Estimation
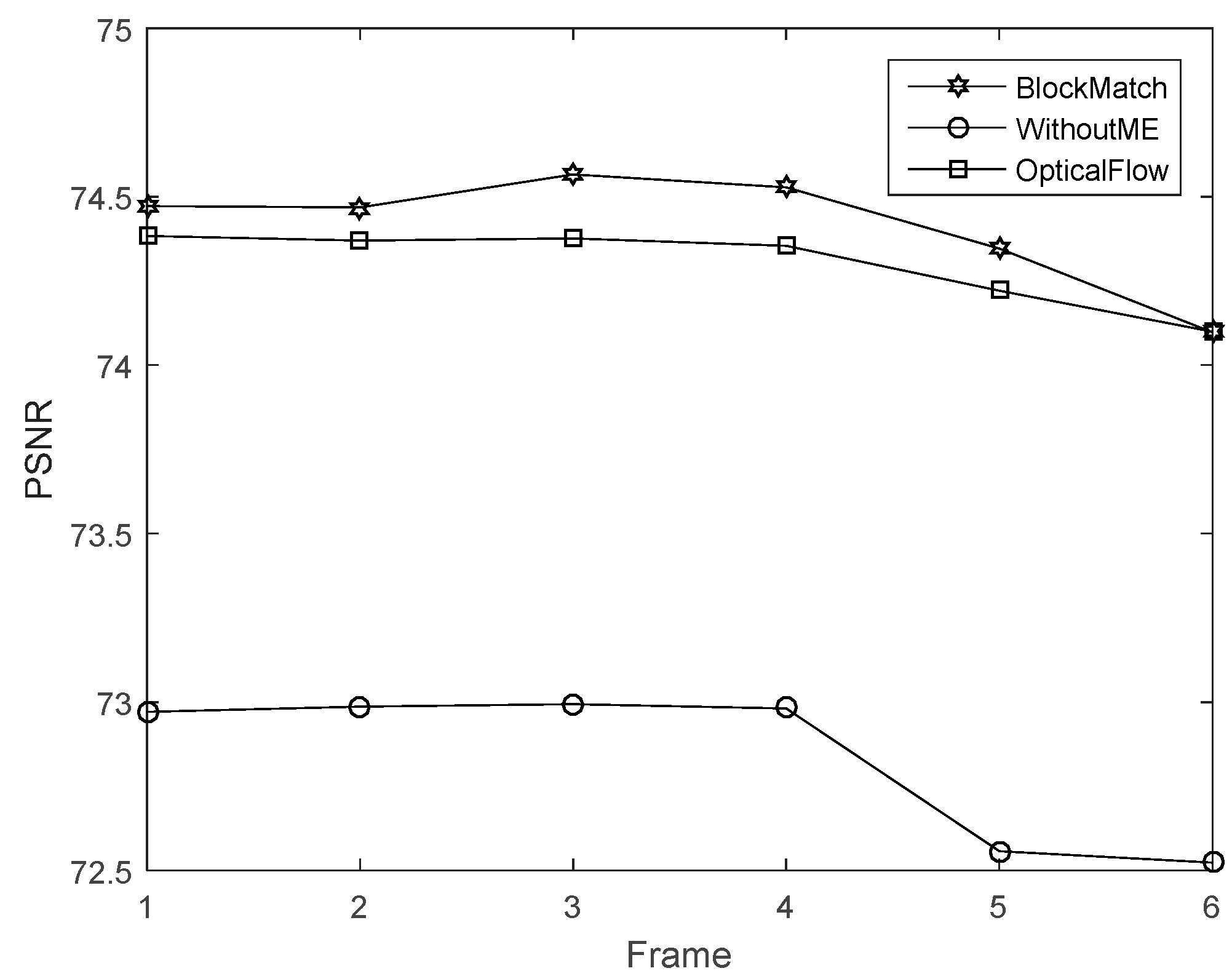
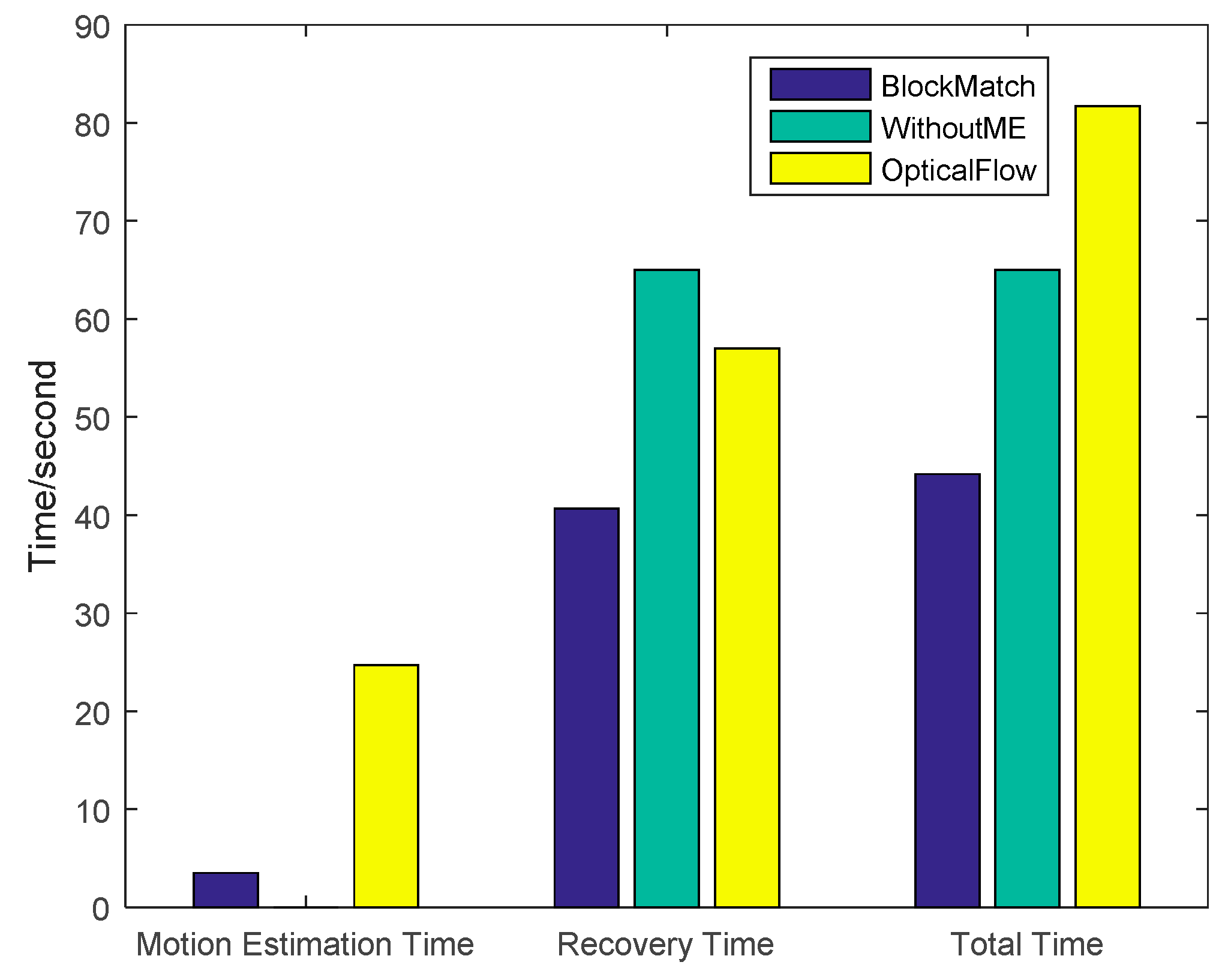
4.3. Block Match Motion Estimation
4.4. Analysis of Experiments
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Duarte, M.F.; Davenport, M.A.; Takhar, D.; Laska, J.N.; Sun, T.; Kelly, K.E.; Baraniuk, R.G. Single-pixel imaging via compressive sampling. IEEE Signal Process. Mag. 2008, 25, 83–91. [Google Scholar] [CrossRef]
- Bi, S.; Xi, N.; Lai, K.W.C.; Min, H.; Chen, L. Multi-objective optimizing for image recovering in compressive sensing. In Proceedings of the 2012 IEEE International Conference on Robotics and Biomimetics (ROBIO), Guangzhou, China, 1–14 December 2012; pp. 2242–2247.
- Reddy, D.; Veeraraghavan, A.; Chellappa, R. P2C2: Programmable pixel compressive camera for high speed imaging. In Proceedings of the 2011 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Colorado Springs, CO, USA, 20–25 June 2011; pp. 329–336.
- Mun, S.; Fowler, J.E. Residual reconstruction for block-based compressed sensing of video. In Proceedings of the Data Compression Conference (DCC), Snowbird, UT, USA, 29–31 March 2011; pp. 183–192.
- Park, J.Y.; Wakin, M.B. A multiscale framework for compressive sensing of video. In Proceedings of the 27th Conference on Picture Coding Symposium, Chicago, IL, USA, 7–9 November 2009; pp. 197–200.
- Noor, I.; Jacobs, E.L. Adaptive compressive sensing algorithm for video acquisition using a single-pixel camera. J. Electron. Imaging 2013, 22, 1–16. [Google Scholar] [CrossRef]
- Sankaranarayanan, A.C.; Turaga, P.K.; Baraniuk, R.G.; Chellappa, R. Compressive acquisition of dynamic scenes. In Computer Vision—ECCV 2010; Springer: Heraklion, Greece, 2010; pp. 129–142. [Google Scholar]
- Sankaranarayanan, A.C.; Studer, C.; Baraniuk, R.G. CS-MUVI: Video compressive sensing for spatial-multiplexing cameras. In Proceedings of the International Conference on Computational Photography, Seattle, WA, USA, 27–29 April 2012; pp. 1–10.
- Donoho, D.L. Compressed sensing. IEEE Trans. Inf. Theory 2006, 52, 1289–1306. [Google Scholar] [CrossRef]
- Baraniuk, R. Compressive sensing. IEEE Signal Process. Mag. 2007, 24, 118–120. [Google Scholar] [CrossRef]
- Candès, E.J. Compressive sampling. In Proceedings of the International Congress of Mathematicians, Madrid, Spain, 22–30 August 2006; pp. 1433–1452.
- Candes, E.J.; Romberg, J. Quantitative robust uncertainty principles and optimally sparse decompositions. Found. Comput. Math. 2006, 6, 227–254. [Google Scholar] [CrossRef]
- Candès, E.J.; Romberg, J.; Tao, T. Robust uncertainty principles: Exact signal reconstruction from highly incomplete frequency information. IEEE Trans. Inf. Theory 2006, 52, 489–509. [Google Scholar] [CrossRef]
- Candes, E.J.; Romberg, J.K.; Tao, T. Stable signal recovery from incomplete and inaccurate measurements. Commun. Pure Appl. Math. 2006, 59, 1207–1223. [Google Scholar] [CrossRef]
- Wu, K.; Guo, X. Compressive sensing with sparse measurement matrices. In Proceedings of the IEEE Vehicular Technology Conference (VTC Spring), Budapest, Hungary, 15–18 May 2011; pp. 1–5.
- Bah, B.; Tanner, J. Improved bounds on restricted isometry constants for Gaussian matrices. SIAM J. Matrix Anal. Appl. 2010, 31, 2882–2898. [Google Scholar] [CrossRef]
- Beck, A.; Teboulle, M. A fast iterative shrinkage-thresholding algorithm for linear inverse problems. SIAM J. Imaging Sci. 2009, 2, 183–202. [Google Scholar] [CrossRef]
- Blumensath, T.; Davies, M.E. Gradient pursuits. IEEE Trans. Signal Process. 2008, 56, 2370–2382. [Google Scholar] [CrossRef]
- Li, C. An Efficient Algorithm for Total Variation Regularization with Applications to the Single Pixel Camera and Compressive Sensing. Available online: http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.207.2383&rep=rep1&type=pdf (accessed on 29 February 2016).
- Zhang, H.; Hager, W.W. A nonmonotone line search technique and its application to unconstrained optimization. SIAM J. Optim. 2004, 14, 1043–1056. [Google Scholar] [CrossRef]
- Barzilai, J.; Borwein, J.M. Two-point step size gradient methods. IMA J. Numer. Anal. 1988, 8, 141–148. [Google Scholar] [CrossRef]
- Horn, B.K.; Schunck, B.G. Determining optical flow. In 1981 Technical Symposium East; International Society for Optics and Photonics: Washington, DC, USA, 1981; pp. 319–331. [Google Scholar]
- Richardson, I.E.H. 264 and MPEG-4 Video Compression: Video Coding for Next-Generation Multimedia; John Wiley & Sons: Hoboken, NJ, USA, 2004. [Google Scholar]
- Kuglin, C.D.; Hines, D.C. The phase correlation image alignment method. In Proceedings of the International Conference on Cybernetics and Society, New York, NY, USA, 23–25 September 1975; pp. 163–165.
- Rubinstein, M.; Liu, C.; Freeman, W.T. Towards longer long-range motion trajectories. In Proceedings of the BMVC, London, UK, 3–7 September 2012; pp. 1–11.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Optical Flow Method [22] | Block Match Algorithm [23] | Phase Correlation Algorithm [24] | |
|---|---|---|---|
| Target | pixel velocity | block displacement | linear phase differences |
| Object | pixel | block | whole image |
| Method | iterative least square method | independent search | fourier Shift property |
| Cost | high | low | low |
| Accuracy | high | medium | low |
| Parallelization | low | high | low |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons by Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bi, S.; Zeng, X.; Tang, X.; Qin, S.; Lai, K.W.C. Compressive Video Recovery Using Block Match Multi-Frame Motion Estimation Based on Single Pixel Cameras. Sensors 2016, 16, 318. https://doi.org/10.3390/s16030318
Bi S, Zeng X, Tang X, Qin S, Lai KWC. Compressive Video Recovery Using Block Match Multi-Frame Motion Estimation Based on Single Pixel Cameras. Sensors. 2016; 16(3):318. https://doi.org/10.3390/s16030318
Chicago/Turabian StyleBi, Sheng, Xiao Zeng, Xin Tang, Shujia Qin, and King Wai Chiu Lai. 2016. "Compressive Video Recovery Using Block Match Multi-Frame Motion Estimation Based on Single Pixel Cameras" Sensors 16, no. 3: 318. https://doi.org/10.3390/s16030318
APA StyleBi, S., Zeng, X., Tang, X., Qin, S., & Lai, K. W. C. (2016). Compressive Video Recovery Using Block Match Multi-Frame Motion Estimation Based on Single Pixel Cameras. Sensors, 16(3), 318. https://doi.org/10.3390/s16030318