All articles published by MDPI are made immediately available worldwide under an open access license. No special
permission is required to reuse all or part of the article published by MDPI, including figures and tables. For
articles published under an open access Creative Common CC BY license, any part of the article may be reused without
permission provided that the original article is clearly cited. For more information, please refer to
https://www.mdpi.com/openaccess.
Feature papers represent the most advanced research with significant potential for high impact in the field. A Feature
Paper should be a substantial original Article that involves several techniques or approaches, provides an outlook for
future research directions and describes possible research applications.
Feature papers are submitted upon individual invitation or recommendation by the scientific editors and must receive
positive feedback from the reviewers.
Editor’s Choice articles are based on recommendations by the scientific editors of MDPI journals from around the world.
Editors select a small number of articles recently published in the journal that they believe will be particularly
interesting to readers, or important in the respective research area. The aim is to provide a snapshot of some of the
most exciting work published in the various research areas of the journal.
We study the secure distributed detection problems under energy constraint for IoT-oriented sensor networks. The conventional channel-aware encryption (CAE) is an efficient physical-layer secure distributed detection scheme in light of its energy efficiency, good scalability and robustness over diverse eavesdropping scenarios. However, in the CAE scheme, it remains an open problem of how to optimize the key thresholds for the estimated channel gain, which are used to determine the sensor’s reporting action. Moreover, the CAE scheme does not jointly consider the accuracy of local detection results in determining whether to stay dormant for a sensor. To solve these problems, we first analyze the error probability and derive the optimal thresholds in the CAE scheme under a specified energy constraint. These results build a convenient mathematic framework for our further innovative design. Under this framework, we propose a hybrid secure distributed detection scheme. Our proposal can satisfy the energy constraint by keeping some sensors inactive according to the local detection confidence level, which is characterized by likelihood ratio. In the meanwhile, the security is guaranteed through randomly flipping the local decisions forwarded to the fusion center based on the channel amplitude. We further optimize the key parameters of our hybrid scheme, including two local decision thresholds and one channel comparison threshold. Performance evaluation results demonstrate that our hybrid scheme outperforms the CAE under stringent energy constraints, especially in the high signal-to-noise ratio scenario, while the security is still assured.
With the rapid advances in low-cost wireless sensors, radio frequency identification (RFID), Web technologies and wireless communications recently, connecting various smart objects to Internet and realizing the communications of machine-to-human and machine-to-machine with the physical world have been expected widely [1]. That is the concept of Internet of Things (IoT), which can provide ubiquitous connectivity, information gathering and data transmitting capabilities in different fields, such as health monitoring, emergencies, environment control, military and industries. The pervasive sensing and control capabilities brought by IoT will change our daily life significantly [2,3,4].
In an era of IoT, there are billions of devices linked to the Internet. Cisco predicts that 50 billion devices are going to be in use in 2020 [3]. Such a large number of devices deployed in the IoT lead to many technical challenges including spectrum scarcity, energy consumption and security [4,5,6]. Aiming to the spectrum scarcity problem, some enhanced technologies with high spectrum efficiency are advocated, for example, the cognitive Internet of Things (CIoT) who introduces the cognitive radio technology to the IoT network [5]. A decentralized inference network where the nodes transmit the compressed observations to reduce the required bandwidth is another solution [7], and the distributed detection technique utilized in sensor networks is a typical instance [8,9,10,11]. Since a huge number of devices are included in IoT, the energy to be spent for communication and computation is extremely large and improving energy efficiency becomes more important. Although the energy harvesting techniques can use the external energy source and relieve devices from the constraints induced by battery usage, energy as a scarce resource should always be utilized carefully. Thus, an energy efficiency solution has a significant role in IoT [4,12]. With the developing of IoT network, devices will become smarter and start to handle more tasks of human. Thus, the devices have to be more reliable and trustable [1]. However, there are a variety of attacks over different protocol layers which attempt to disrupt the network or intercept the information in the IoT, including denial of service (DoS) attacks, spoofed routing information attacks at network layer, flooding attacks at transport layer, resource exhaustion attacks at link layer, jamming and tampering attacks at physical layer and many others [13]. Now security has turned into an important aspect for IoT deployments [14,15]. Among various attacks, eavesdropping attack is the most common form of attack on data privacy [2,13]. In order to realize secure transmission, traditional key-based enciphering techniques at network layer have been entrusted. However, in IoT networks with low-complex devices, the key distribution for symmetric cryptosystems and the highly complex computation of asymmetric cryptosystems can be very challenging [16]. Therefore, the robust physical-layer security methods with little or no aid of encryption key and with low computational complexity can be adopted in IoT [2,5,17], further, they could be combined with other lightweight cryptographic protocols to fulfill different security targets of IoT.
An IoT system would integrate various technologies and communications solutions, such as identification and tracking techniques, wired and wireless sensor and actuator networks and enhanced communication protocols [1,18,19,20]. Sensor networks, especially the wireless sensor networks (WSN), will play a crucial role in the IoT. Ubiquitous sensing provided by WSN can offer the ability to measure, infer and understand environmental indicators. Cooperating with RFID system, WSN can track the status of things better and build a bridge between the physical and digital world [18,21]. With the size and complication of WSN growing, the spectrum scarcity and energy consumption problems become more serious [22]. Furthermore, the broadcasting nature of wireless communications from sensors to the controllers or fusion centers makes WSN vulnerable to eavesdropping. The physical layer security solutions with low complexity and low overhead are obviously more suitable for WSN, since the sensors have some practical constraints including limited computing capabilities, limited storage memories and severe energy constraints [2,10].
Due to the low bandwidth and power requirement at sensors and the robustness to the environments’ rapid changes, distributed detection in WSN has been utilized in a wide range of fields such as emergency response, environment monitoring, medical monitoring and military surveillance [10,23]. For distributed detection, sensors are deployed over a certain area to sense the physical phenomena with binary state in a decentralized fashion. Each sensor makes a binary decision based on its local observation and then transmits the local decision to a fusion center (FC) over wireless channels [23]. For the practical resource constraints and the serious security issues in front of WSN, secure distributed detection schemes under energy constraints are necessary for the development of an efficient IoT. Various secure strategies for distributed detection have been proposed under different assumptions on the eavesdroppers and transmission channels [8,9,10,23,24,25,26,27,28,29]. However, these studies focused on either the local detection at sensors or the information transmission from sensors to the FC. Moreover, the vast majority of them did not involve an energy constraint. Therefore, an efficient hybrid solution combining the local decision with the transmission under an energy constraint, along with a mathematic framework of analyzing error performance and optimizing parameters for the developed schemes are selected as the research contents of this paper. The contributions of this paper can be summarized as follows.
(1) In order to enhance the operability of the channel aware flipping method [10] in an energy constrained WSN, a specific energy limit indicator represented by the sensors’ activity probability is taken as the additional design constraint over the perfect secrecy. We call this modified scheme the transmission channel based only (TCBO) secure detection under energy constraint. Then, the simplified log-likelihood ratios (LLR) computed approximately under the low and high signal-to-noise ratio (SNR) conditions are derived. Following that, we obtain asymptotic error probabilities of the ally fusion center (AFC) at the worst and best noise situations with help of the central limit theorem (CLT). Next, the optimization problems with the perfect secrecy and energy constraint are established to find three comparison thresholds used in the randomly flipping operation. After simplifying the optimization target functions, the optimal thresholds are discussed and achieved. The above framework for error probability analysis and parameters optimization will also be taken as the mathematic approach in our newly designed scheme to solve for the main parameters.
(2) Considering local detection performance also affects the decision fusion evidently, we combine the local observation quality with the transmission channel information to design a more efficient hybrid scheme. Here, the energy constraint is satisfied by censoring the sensor with a less informative local LLR and transmission security is guaranteed through randomly flipping the local decisions based on the estimated channel gains. This innovative scheme is called the joint local decision and wireless transmission (JLDWT) scheme. Then, following the mathematic framework given by the first work, two local detection thresholds and one flipping comparison threshold are optimized to minimize the AFC’s error rates, besides, satisfy the perfect secrecy condition and the energy limitation.
(3) At last, through an overall simulation from diffident perspectives, the above two schemes are evaluated in a practical wireless transmission environment. The simulation results demonstrate that the new proposed hybrid scheme can improve the error performance of the AFC under a relatively high SNR transmission environment with a more severe energy constraint, as well as, maintain the perfect secrecy.
The rest of the paper is organized as follows: an overview of related work is discussed in Section 2. Section 3 describes the system model. The TCBO and JLDWT schemes are presented in Section 4 and Section 5, respectively. The simulation results are discussed in Section 6. Section 7 concludes the paper.
2. Related Work
In this section, we summarize the related work about physical layer security suitable for the IoT. The communication network consisting of controllers and actuators and the sensor network composed of sensors and controllers are two main subsystems of an abstracted IoT network [2]. The physical layer security solutions possibly available for both subsystems will be presented in the following text.
In the communication network of the IoT, the controllers are the signal transmitters, which could be equipped with multiple antennas and an adequate energy supply. Then, some of the classical secure schemes at physical layer proposed for the downlink in LTE-Advanced network may be usable [30,31,32,33,34,35,36,37,38,39]. When the main channel (the transmitter to legitimate receiver channel) and the eavesdropper channel are perfectly known, the beamforming (precoding) techniques can be adopted to maximize the signal quality difference between the destination and the eavesdropper by strengthening or weakening signals in certain dimensions. For the scenario of multiple-input, single-output and multi-antenna eavesdropper (MISOME) with a single legitimate receiver, the optimal beamforming vector is the generalized eigenvector corresponding to the largest generalized eigenvalue of the receiver and the eavesdropper channel covariance matrice [30]. While, under the multiple-input, multiple-output and multi-antenna eavesdropper (MIMOME) scenario, the search for the optimal precoder with a total power constraint has a non-convex form and the solution can be found numerically. If the power covariance constraint is considered, a closed form solution based on the generalized eigenvalue decomposition (GEVD) can be obtained [31]. As for the case of multiple receivers and eavesdroppers, the achievable secrecy rates can be used to build optimization problems to find a secrecy beamformer or precoder [32], further, a simpler but less effective design can be achieved using the channel inversion technique [33]. In addition, when the eavesdropper’s CSI is unknown, emitting artificial noise (AN) is helpful to prevent the eavesdropper from getting a good channel. The AN is often added in the null space of the main channel with single destination and eavesdropper [34]. While, for the case with multiple receivers and eavesdroppers, the AN would be placed in the null space of the effective channels of all receivers [35]. Since AN may reduce the transmission power of the useful data, power allocation between data and AN should be examined to ensure good performance under secrecy constraint [36]. Another novel strategy to degrade the eavesdropper’s channel quality is based on noise aggregation [40,41], where two adjacent timeslots are bounded to transmit two packets and the transmitter performs bitwise exclusive-or (XOR) operation on the even packet with previous odd one. Because the legitimate receiver can detect the packets in odd slots correctly by an ARQ protocol while eavesdropper may only have a noisy observation, the channel noise in odd slots is aggregated to even slots [41]. Obviously, many of the above security schemes are difficult to be directly employed in an IoT setting, because the accurate legitimate channel state information at the transmitter (CSIT) is difficult to acquire for the channel training opportunities are limited and the high rate feedback channels are lack in the IoT. Moreover, the eavesdropper CSIT is more difficult to yield since eavesdroppers remain completely passive. As for the AN based methods are also not desirable due to their higher energy expenditure [2].
In addition, a variety of physical layer security solutions have been proposed in literature for the distributed detection in sensor networks. With the assumption that the eavesdropping fusion center (EFC) can only distinguish busy-idle state of sensor’s transmission, an optimal sensor censoring scheme with a perfect secrecy and energy constraint was given in [8]. But the processing capability of the EFC was too limited. Another category of effective scheme is the probabilistic ciphering based one, where the sensor’s observation is randomly mapped to a set of quantization levels according to an optimal mapping probabilities matrix [9,24,25]. However, the security is assured by assuming the EFC being completely ignorant about the mapping probabilities. Moreover, the crucial energy efficient issue was not discussed. In [26,27], the optimal local quantizer was examined through minimizing the detection cost at the AFC meanwhile satisfying the constraints to the EFC detection cost or error performance, but the energy consumption problem was not concerned, either. In addition, all of the above solutions were not evaluated over a practical wireless channel and the effect of the transmission channel on their security was not discussed. Afterwards, a category of channel aware encryption method was proposed to realize the perfect secrecy from the EFC, including the type-based multiple access scheme proposed in [23] and the channel-based bit flipping scheme designed in [10], where not the accurate channel coefficients were needed, but only the channel gains had to be estimated using the pilot signal from the AFC. In channel aware encryption, the good energy efficiency could be realized through introducing the dormant sensors. The inherent significant difference of the wireless channels for the EFC and the AFC was explored to achieve the perfect secrecy of the sensor’s information transmission, due to the channels from sensors to the EFC and the AFC are independent of each other. Especially, the channel-based randomly flipping method is very suitable for the distributed detection due to its low complexity, good scalability and less limitation on the EFC. However, the work in [10] did not give an efficient solution to optimize three comparison thresholds. In addition, when the sleeping sensor was chosen, the channel gain was taken as the only metric while the local decision quality was not concerned although it may induce more important influence on the fusion performance. In addition, AN based mechanisms that let a part of sensors or the AFC transmit the jamming signal to degrade the SINR of the EFC were also introduced to the sensor network [28,29]. However, the performance of the AFC would also be reduced when the jamming signal worsens the EFC channel [29] or the external energy would be spent by the AFC to interfere the EFC [28]. Based on the above drawbacks of the previous works, we propose the secure and energy efficient JLDWT scheme, which is a hybrid method combing the local detection and the wireless transmission, after designing an analysis framework to complete the performance analysis and thresholds optimization of TCBO scheme.
3. System Model
In this section, the concerned IoT sensor network scenario is given. The local detection and the transmission scheme of local decisions from the sensors to the fusion center are introduced.
3.1. IoT Sensor Network
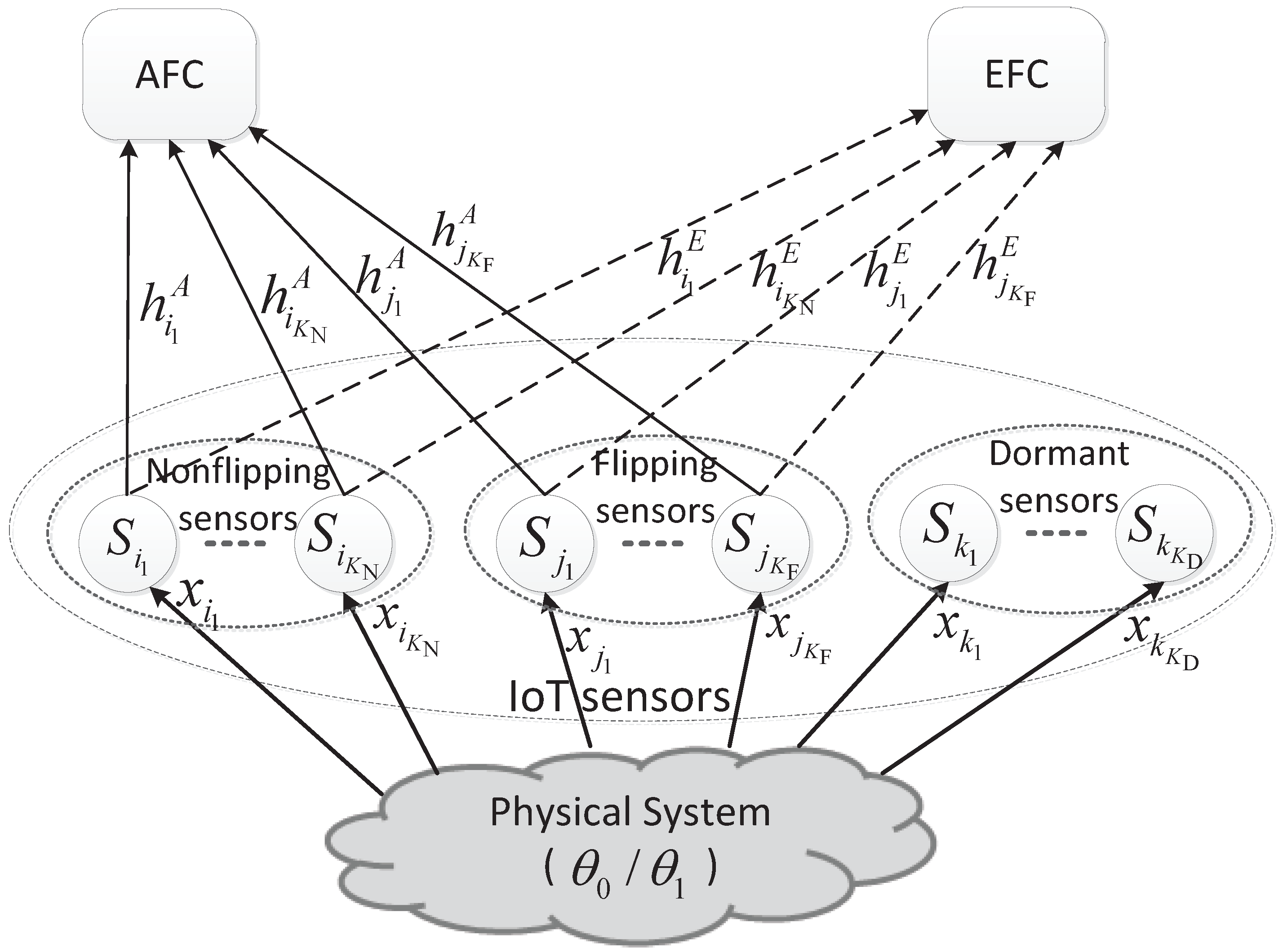
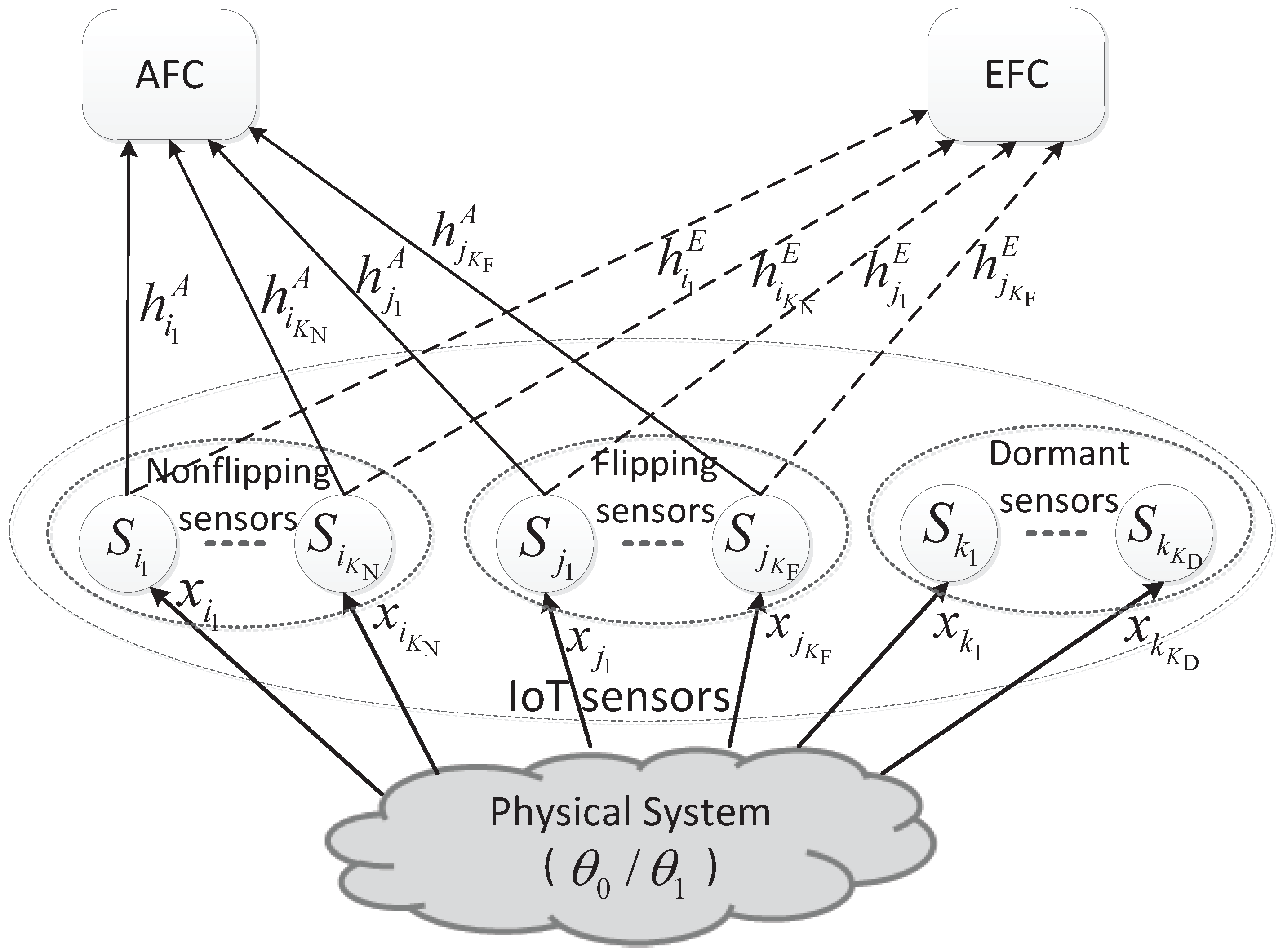
Consider a sensor network in IoT system illustrated by Figure 1, which performs distributed detection for a binary hypothesis test of against . A number of sensors are distributed near the physical system to detect a binary target state and transmit their local decision results to an AFC through a wireless parallel access channel (PAC). Meanwhile, a passive EFC overhears the communications between the sensors and AFC and also attempts to detect the state of θ. The channels from sensors to the AFC and the EFC are called the main and eavesdropping channels, respectively. Moreover, the concerned sensor network is energy-constrained for the power supplies of the sensors are usually severely constrained. Obviously, the security and energy saving are the main challenges faced by our senor network. Therefore, in each local decision reporting slot, some sensors will keep dormant to meet the energy constraint and some sensors among the active ones will transmit the bit-flipping version of local detection results to make the EFC confused.
In Figure 1, the sensors with the indices in the sets of , and are included in the non-flipping group, flipping group and the dormant group, respectively. Thus, the total number of sensors in the network is . In addition, the observation to the physical system of the k-th sensor is denoted by . The communication channels from sensors to the AFC and the EFC are represented by and , respectively. And they are assumed to be independent and identically distributed (i.i.d.) Rayleigh block fading channels. Moreover, a transmission probability or an activation probability β, which is proportional to the per-sensor energy consumption, is introduced to represent the energy constraint.
3.2. Local Detection of Sensors
For the k-th sensor, the acquired observation corrupted by additive noise is modeled as:
where is an i.i.d zero-mean Gaussian random variable with variance , i.e., . Thus the SNR of local detection can be computed and denoted by . Based on the observation, the sensor makes a one-bit local decision to indicate the absence or presence of θ by using the Bayesian detection criteria:
where is the posterior probability distribution function (PDF) of based on for . The main difference of Equation (2) from the traditional Bayesian detection is that two rather than one local decision thresholds are set here. and , which meet , are the upper and lower thresholds and assumed to be identical at all the sensors. If the ratio of the posterior probability distribution lies inside the region of , it means that the observation appears less informative for discriminating between and , so the corresponding decision result is more likely to be false. As for such kind of sensors, it is better to keep them silent for energy efficiency. Of course, this is the basic idea of the sensor censoring technique [8,42]. However, in this paper, we adopt it to realize the energy saving for the secure transmission of sensors and the details are described in Section 5.
The prior probabilities of and are assumed to be and , respectively. Then the Equation (2) can be transformed into:
where is the conditional PDF of under the hypothesis , and is the likelihood ratio (LR). From Equation (1), it can be obtained that
Furthermore, the log-likelihood ratio (LLR) can be written as
Combining Equations (4) and (5), it can be easily derived that the conditional PDFs of are
Furthermore, we can obtain that the equation is satisfied and this is the nesting property of the LR.
There are four possible cases for local detection, namely correct decisions under two states, missed detection and false alarm. Based on Equations (3) and (6), we can calculate the probabilities of four cases and obtain
where is the probability of correct detection under θ being non-existent and . In addition, the error probability of local detection for each sensor can be defined as . If we set , this error probability can be given by
Furthermore, the first-order derivation of with respect to λ is
Through letting , it can be obtained that the optimized meeting to minimize is .
3.3. Transmission of Local Decisions from Sensors to FC
After the local decisions are achieved, the sensors would deliver them to the AFC. In this paper, a wireless PAC between the sensors and the AFC is considered and the transmission channels from different sensors to the fusion center are orthogonal. However, the sensors’ transmissions are overheard by the EFC, who also wishes to detect the target state. From the literature [2,7,9], we have seen that the stochastic ciphering could be employed to protect the information of the sensors from the EFC efficiently, since each sensor would flip its decision randomly and the EFC would be confused when it was ignorant about the flipping probability (i.e., the encryption key). However, the key exchange between the AFC and the sensor itself may be not secure from the EFC. In this case, the channel-aware stochastic cipher [10], whose seeds are based on the randomness of the transmission channels, are preferable. Because the channels to the AFC and the EFC from a sensor are independent, it is impossible for the EFC to deterministically know the flipping action of a sensor based on the main channel gain. Thus, the formation leaked to the EFC reduces, although the flipping probability is completely known by the EFC. Therefore, the channel-based stochastic ciphering is still adopted by us to realize the secure transmission of local decisions from sensors to the AFC.
In order to sense the channel information, the sensors would firstly receive the known pilot signal from the AFC, as well as three thresholds for comparison. Then the estimated channel gain would be compared with the thresholds to determine which action should be selected by a sensor. The sensor may report an unaltered local decision, a “flipped” decision, or stay dormant to satisfy the energy constraint.
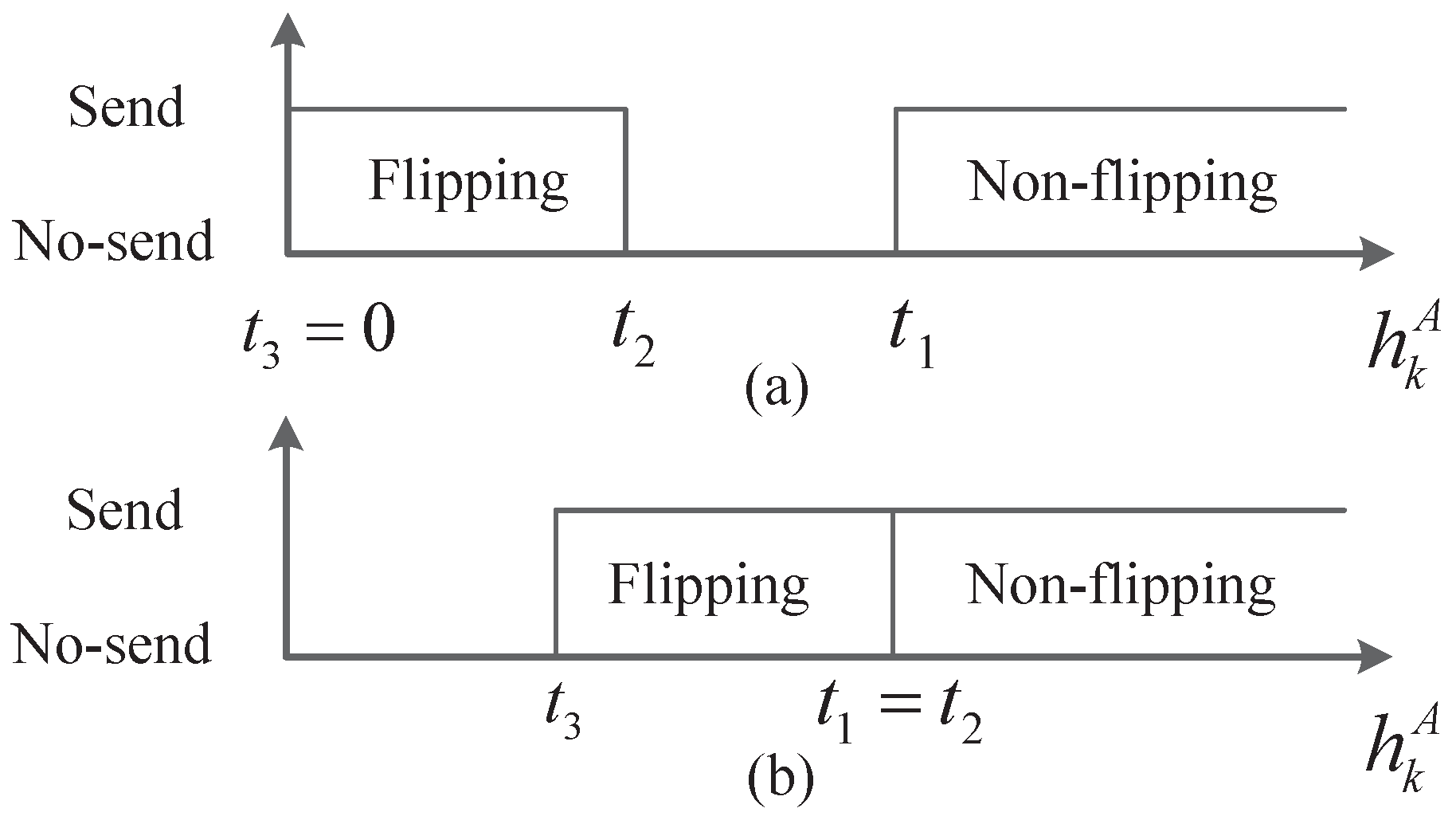
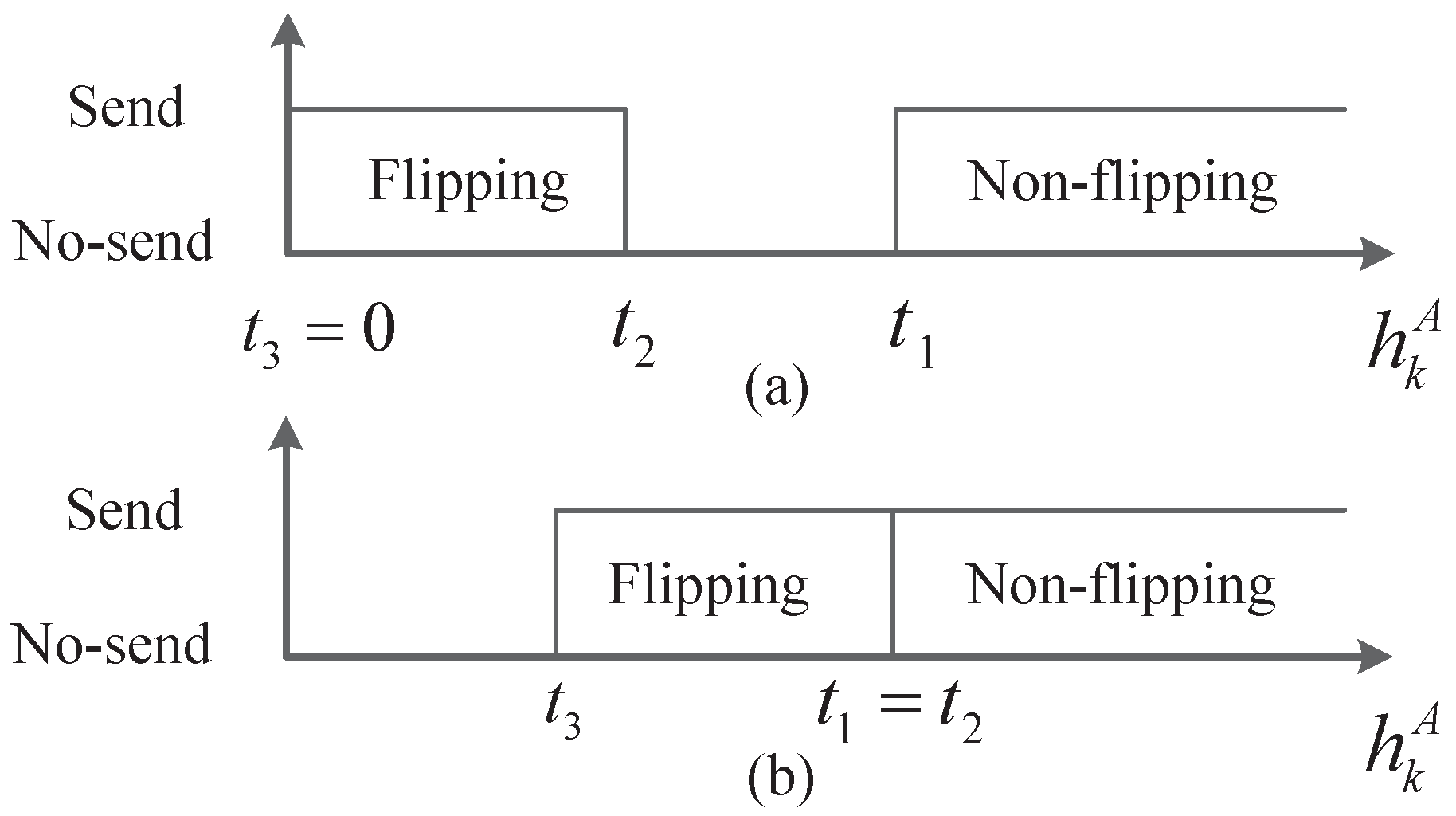
Assume the main channel and the eavesdropping channel both follow the Rayleigh distribution with unit power, i.e., and , which is usually considered in existing studies [10,23,42]. Assume the pilot signal is so strong that the sensors can obtain the exact channel gains. Basing on the channel reciprocity, the sensors’ estimated channel gains can be used to indicate the sensor-to-AFC channels. Moreover, they are unknown by the EFC due to the statistical independence of the main channel and the eavesdropping channel. The thresholds broadcasted by the AFC are with . Thus, the secure transmission strategy with energy limitation is that, sensor k reports its original local decision if , reports a bit-flipping decision if and stays silent for energy efficiency otherwise. From the security analysis given in [10], we can see that the condition for perfect secrecy is . Obviously, to meet the energy constraint of network, the inequality of should also be held. Moreover, the case with a single “no-send” region is concerned in this paper. That is to say either or , which is illustrated in Figure 2.
4. Transmission Channel Based Only Secure Detection under Energy Constraint
In [10], the authors designed a confidential and energy efficient distributed detection method, called channel aware encryption, only from the view of the wireless transmission between sensors and the fusion center. And the condition for perfect secrecy was derived. Moreover, the LLR based decision fusion was studied, further, a simplified decision fusion rule in high SNR region was given. However, the more detailed analysis about the error probability of decision fusion and the optimization of thresholds were absent. In this section, we will analyze the error performance of the AFC based on the approximated LLRs derived under low and high SNR conditions, respectively. Afterwards, three thresholds will be optimized to minimize the probability of error at the AFC while ensuring the perfect secrecy from the EFC and satisfying the energy constraint. It should be noted that a specified energy constraint of is introduced by us. And the adjusted scheme is called the TCBO secure detection under energy constraint in our paper.
4.1. Approximation of LLR and Error Probabilities of FC
For the secure scheme only basing on transmission channels, the confidentiality from the eavesdropper and the energy saving are both provided by the reporting strategy of local decisions. Thus, the thresholds used in the local detection are set as to optimize the sensor’s local performance. Then, we have and . In addition, the common binary phase shift keying (BPSK) modulation is utilized by each sensor to deliver its one-bit decision. At the fusion center, the LLR based fusion rule is used and the transmission channel information is unknown. In addition, it is assumed that the fusion rules and the Prior information at the EFC are identical with those at the AFC and this is a worst case from the view of security.
The received signals at the AFC and EFC from sensor k are denoted as and , respectively. They can be described as
where and . Thus, the transmission channel SNR for the AFC and EFC can be written as and , respectively. Following the channel-aware flipping rule, we have for , for and for other . The LLR at the AFC can be expressed in terms of as
where (a) is due to the independence of different and denotes the likelihood function of sensor k for the hypothesis . For the Bayesian setup, the optimal decision rule can be given by log(q0/q1).
By using the similar derivation method in Section IV of [10], it can be achieved
where
Note that the LLR based on Equation (12) requires numerical integrations. It is greatly unfavorable to the performance analysis of decision fusion and the optimization of comparison thresholds. Therefore, the approximations of LLR under low SNR and high SNR scenarios would be examined. Moreover, the error probabilities based on these approximations would be analyzed in follows.
4.1.1. Approximation of LLR and Error Performance under Low SNR
As the channel noise variance , we can get
where . The detailed derivation of Equation (14) is given in the Appendix A. Applying Equation (14) to Equation (12), it can be obtained that
Following the assumption of and the fact that with x closing to zero, we can further reduce Equation (18) to
From Equation (19), we can see that the calculation of LLR can be simplified significantly for large noise variance. Note that the formulas from Equation (11) to Equation (19) are also available for the EFC provided it has the same prior information as the AFC. The only variation is the different received signal from .
Since is independent from each other, can be taken as the average of K i.i.d. random variables. Then, invoking the central limit theorem [9,23], we can deem that the statistic of converges to a normal distribution for a large K. That is , where and are the mean and variance of conditioned on , respectively. And they are directly related with the mean and the variance of , which can be seen from Equation (19). Next, our target is to calculate and .
where (a) is due to and , whose derivations are described in Appendix B.
In order to obtain , we firstly calculate
where (a) follows the fact of verified also in Appendix B. Obviously, . Then can be achieved through .
Combing Equations (19)∼(22), along with the Bayesian decision rule, we can yield the error probability for the AFC as follows:
Clearly, the error probability for large has been expressed as a function of some specific parameters, namely and . In Section 4.2, this asymptotic error probability would be taken as the optimization objection for finding the optimal comparison thresholds.
4.1.2. Approximation of LLR and Error Performance under High SNR
Considering the high SNR scenario, i.e., , we derive a simplified LLR referring to the idea of [10]. Assume the FC can estimate the instantaneous sensor-to-FC channel gain as since and except under the dormant case. Then, a simple hard decision rule determining which one a received signal comes from among three groups can be realized. A hard decision threshold is selected to satisfy . Thus, the following conditional probability can reduce to
where is the Kronecker delta function. Thus, the likelihood function can be calculated as
Further derivation whose detail is provided in Appendix C gives that
Replacing and with and in Equation (26), the simplified LLR under high SNR for the EFC is got.
In order to yield the error probability, the mean and variance of are needed when the CLT is still used. Because , we have is equivalent to and corresponds to . Further, with the assumption of , it can be derived
The derivations of Equations (27) and (28) are referred to Appendix D. Moreover, applying Equations (27) and (28) to calculate the error probability obtains
4.2. Optimization of Comparison Thresholds
In Section 4.1, the asymptotic error probabilities at the AFC for extremely low and high SNR scenarios are obtained. They would be taken as the utility function for optimizing and in this section. Our design target is to minimize the error probability of the AFC while satisfying the constraints of perfect secrecy and energy limitation. This problem can be stated as follows:
where the first constraint is the perfect secrecy condition to make the EFC totally be confused [10]. The second inequality constraint is to guarantee the specified energy efficiency.
Observing the Equations (23) and (29), we find that the numerical integration is included in and the variables to be optimized exist in the integral limits in a complicated form. These raise the difficulty to solve the problem. The utility function should be simplified.
Fortunately, it can be seen that decreases with and increases with since the impact of the variance of can be ignored compared with its mean for a large K. Therefore, can be used to replace the cost function in . The same idea was used in [9] to find the optimal encryption matrix. Thus, the optimization problem under the case of low SNR is given by
Because the first item of the right side in Equation (32) is independent on the variables to be optimized, the final object is to maximize while keep and . Moreover, according to the Rayleigh distribution function, we have
Now, in order to determine three appropriate thresholds, we should discuss the relationship of the target function and the actual energy consumption indicator, i.e., . Taking the as a function of α, we can derive that
The detail of the calculation process for Equation (34) is shown in Appendix E.
From Equation (34), it can be easily seen that for both cases of and due to the fact . This results in that is strictly increasing with α. In particular, we can get for . Thus, there is at the whole range of and then the absolute calculation in the target function can be omitted. The above analysis contributes to that the equality (i.e., ) should be selected in the second constraint to maximize the cost function in Problem .
Moreover, we also find from Equation (34) that, with , there is for , while for . This finding further tells us will decrease faster for than for when α reduces from 1. Then, from the view of network robustness, choosing is preferred and this result will also be confirmed by the simulations given in Section 6.
Summarizing the above analysis can directly obtain the optimized thresholds given by
Now, let’s come to the case of high SNR. Referring to the analyzing methods for the low SNR, the following optimization problem is established
Obviously, the cost function is strictly increasing with , since the local detection probability is always larger than the false alarm probability in practice so the item is larger than zero. Thus, we should also choose . However, which is better between and could not be determined from Equation (37). Actually, they have the identical detection performances for the extreme case of . This phenomenon will be demonstrated in our simulations. Consequently, the thresholds given in Equation (35) should also be used under the high SNR situation.
5. Joint Local Decision and Wireless Transmission Based Secure Detection under Energy Constraint
In TCBO secure detection scheme, in order to meet the energy constraint of network, the sensors whose channel gains fall in the region between and (Consider the case of .) will keep inactive. Of course, this gap between and can facilitate the AFC to tells the signals from flipping group and non-flipping group to some extent. However, the decision quality of the sensor’s local detection is not considered. That is to say the sensor with an error decision may be permitted to report its detection result to the FC, while the one with a correct decision perhaps is forbidden. We think this phenomenon maybe worsen the performance of decision fusion .
Therefore, we propose to select the dormant sensor basing on its local decision quality that can be quantified by the local Log-Likelihood Ratio . Sensors with very small or very large LLR will send data to the fusion center, while the others stay silent to save energy. Obviously, this is the core idea of censoring sensor technique [8,11]. In particular, a perfectly secure distributed detection scheme with censoring sensors was given in [8]. But a comparatively ideal assumption was set that the EFC had no access to the data from sensors and only monitored the transmission activity of sensors. Moreover, the strategy in [8] did not consider the effect of the wireless transmission between the sensors and the fusion center on the reliability and security, so its applicability was limited. Basing on the above considerations, a joint local decision and wireless transmission based scheme for secure distributed detection with energy constraint is proposed in this section.
The JLDWT method is performed as follows: each sensor first calculates the local and compares it with two local decision thresholds. If locates between and , it will stay inactive in current report timeslot for it appears less informative to make a correct decision about the target state. Otherwise, the sensor will make a 1bit-decision regarding the state of the hypothesis and then deliver it to the FC over a wireless PAC. While, in order to keep secret from the eavesdropping FC, the active sensor still should encrypt its local decision by randomly flipping it before transmitting. A single comparison threshold is used here instead of tree thresholds in TCBO scheme. If the sensor has the channel gain satisfying , it is involved in the non-flipping group. Otherwise, it is chosen to be in the flipping group. At the fusion center, the LLR based fusion rule is still used. Three thresholds, namely , and , along with the encryption scheme at the sensors are assumed to be known by both the AFC and EFC.
5.1. Security Analysis
Now the condition of perfect secrecy in JLDWT scheme will be derived. Our analysis begins with the conditional likelihood function of the k-th sensor calculated by the EFC, which is given by
where (a) is valid as forms a Markov chain and is uncorrelated with , and . And (b) follows the fact that and for , while and for . In addition, corresponds to the sensor’s dormant state and accordingly. Furthermore, define and we can easily yield
To achieve perfect secrecy, two likelihood function and should be identical [10]. Then we can establish the following group of equations based on Equation (39).
Through simply computing, we obtain the perfect secrecy condition given by
The first condition in Equation (41) directly results in . And the second condition means that the activation probability under the hypothesis , indicated by , equates to the activation probability under , denoted by . Comparing this condition with the perfect secrecy setting given in section II of [8], we find they are identical. Next, our task is to find two suitable thresholds and used in local Bayesian detection Equation (2) to minimize the error probability at the AFC, meanwhile, meet the perfect security and energy constraint of .
5.2. Optimization of Local Detection Thresholds
Referring to the derivation methods of Equations (12) and (38), we can obtain the conditional likelihood functions at the AFC, which are expressed as
5.2.1. Optimization of Local Detection Thresholds under Low SNR
Following the deducing process in Section 4.1.1, we can obtain the calculation formula of the error probability under low SNR for AFC, which can be written as
where
In Equation (44), , , and have the expressions given in Equation (7). Further, referring to the optimization problem , we build
where
Applying Equation (46) to Equation (45), it can be achieved the rewritten object function is . Due to being independent on the variables to be optimized, the final target function can reduce to
In addition, because the probability of correct detection is always larger than the incorrect one in practice, we have . Moreover, the condition contributes to , and then .
First of all, we should find a good that meets the constraint in Equation (45) to maximize . Combining Equations (7) and (47), we have
Let’s first focus on the following function:
Applying the condition , we can get the result of , which is derived in detail in Appendix F. Substituting Equation (6) into Equation (49), it can be obtained
where the error function . Due to , we further get
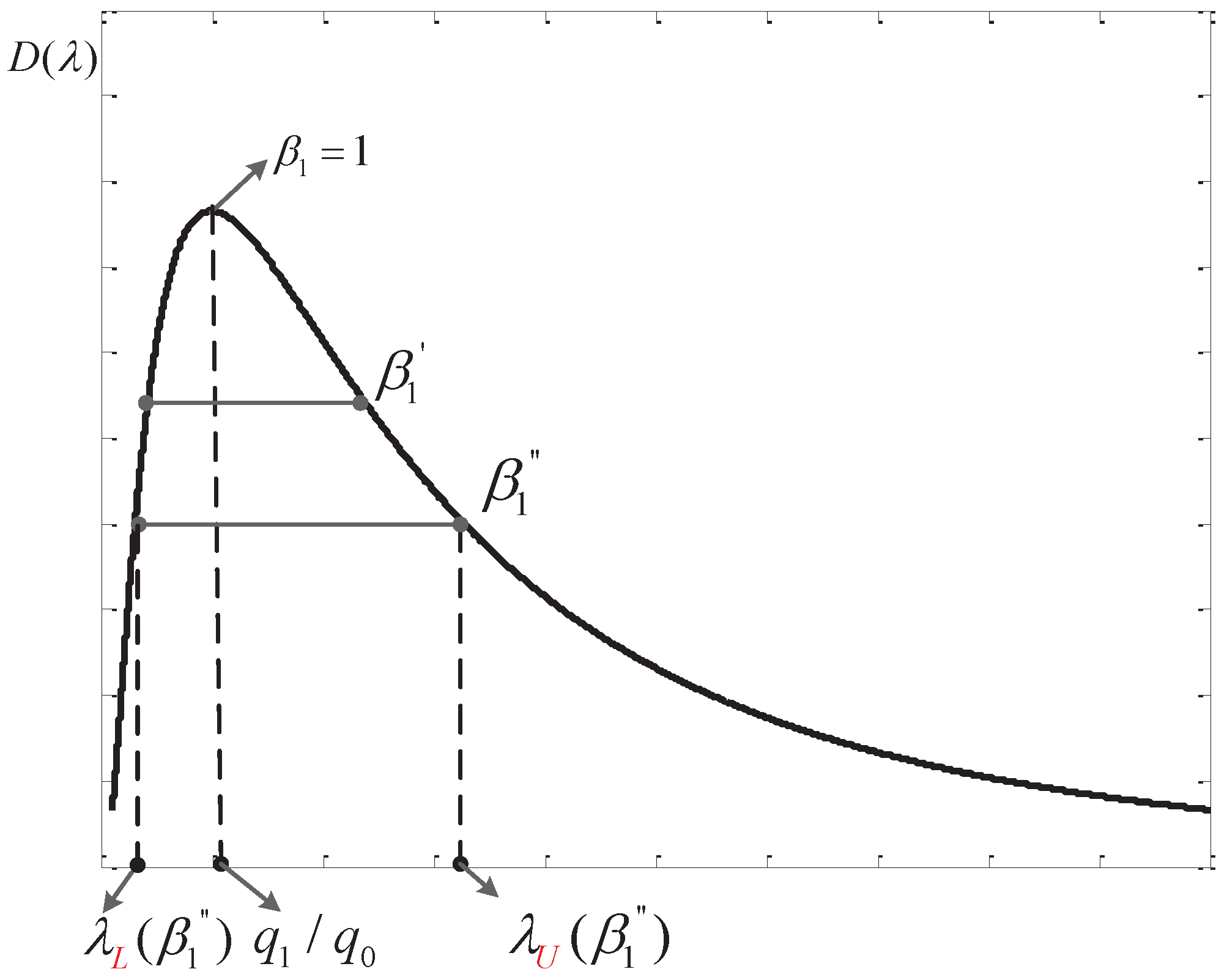
Through setting , we can find three extreme points
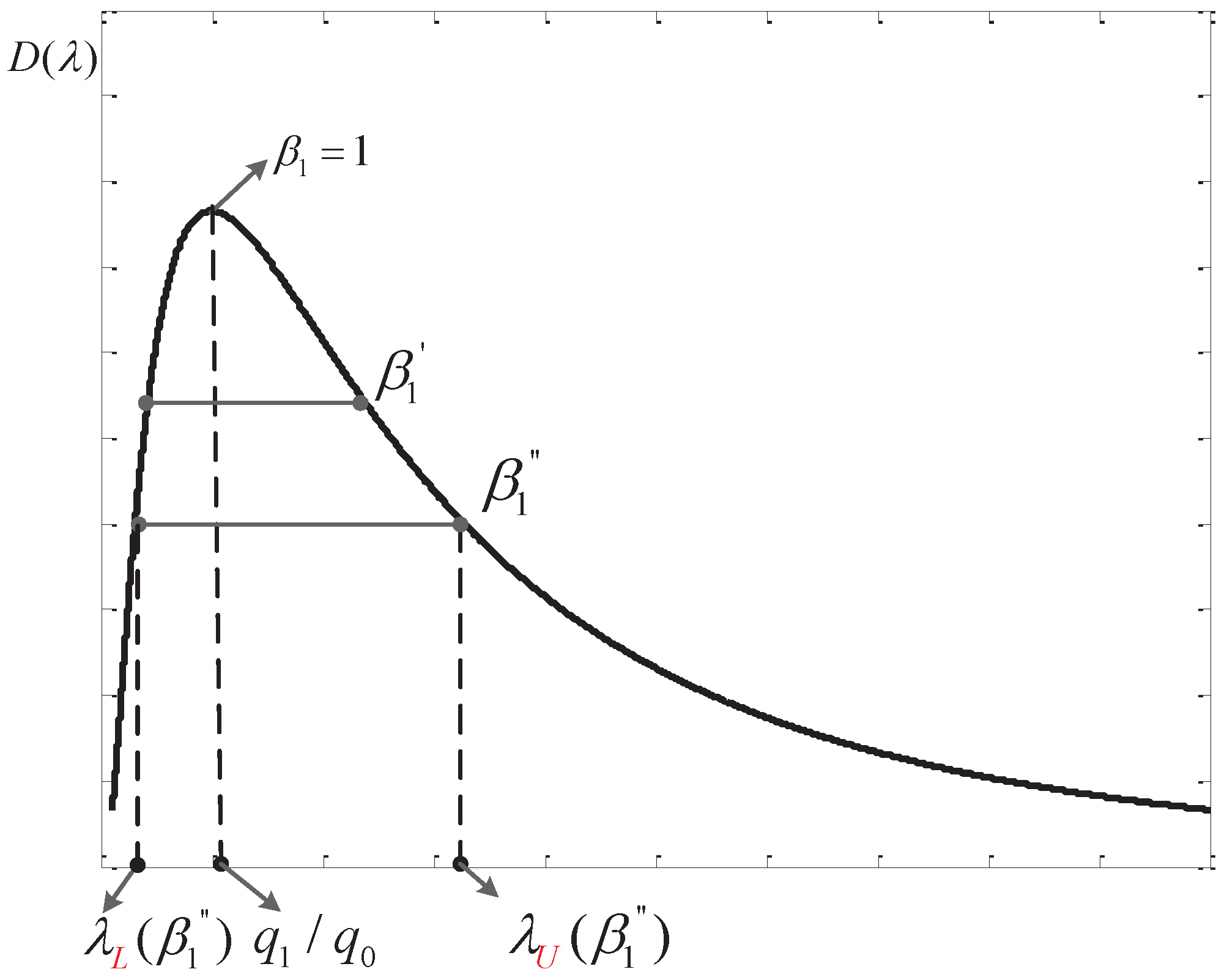
Based on Equation (53), we can draw a notional curve of as in Figure 3.
From Figure 3, we can see that there are two thresholds corresponding to one value of , further, this actually maps to a single . When , two thresholds overlap at a point of and has the maximum value. While decreases, we know that moves towards ∞ and approaches zero further. Thus, from Figure 3, we can see that the corresponding reduces. That is to say a larger is preferred in order to get a higher .
Moreover, the reduced target function for can be written as . Therefore, should be chosen to achieve the maximum , along with the optimal performance of AFC, and the corresponding pair of thresholds are the optimal thresholds to be found. However, the expressions in Equations (7) and (49) are so complex that a closed-form expression of and couldn’t be obtained. In this situation, a pre-calculated table corresponding to each could be used to get the required and , just as the processing method in our simulations.
5.2.2. Optimization of Local Detection Thresholds under High SNR
For the very high SNR scenario, the analysis methods in Section 4.1.2 are consulted. Firstly, the simplified LLR similar as Equation (26) are obtained, which is given by
where is set as . Referring to the derivation of Equation (27), it is achieved that
Then the design problem is built as
Here, the object function can be written as . Because , maximizing could also make and largest. Therefore, the object function in Equation (56) can be transformed into , so Problem is equivalent to Problem and they have the identical optimization results.
6. Simulation Results and Discussions
In this section, simulation results are presented to evaluate the TCBO and the proposed JLDWT schemes in a sensor network of IoT. Their error probabilities are compared from various perfectives, including with the changing of transmission channel SNR, energy constraint and local detection SNR. The performance of a degraded form of the JLDWT scheme, where the random flipping is not included, is also given to represent the performance of secure detection designed in [8] over a practical rather than an idea wireless PAC.
6.1. Simulation Settings
A wireless sensor network with K sensors is modeled. The local detection SNR and the transmission channel SNR to fusion center for different sensors are assumed to be identical, as well as, the transmission channel SNR to the AFC and the EFC is also supposed to be equal. In addition, the LLR computation at the EFC is same as the AFC except the received signals from the sensors. Detail simulation parameters are listed in Table 1. Moreover, Table 2 and Table 3 give the specific local decision thresholds corresponding to different energy constraints under and , respectively.
6.2. Simulation Results for TCBO Scheme
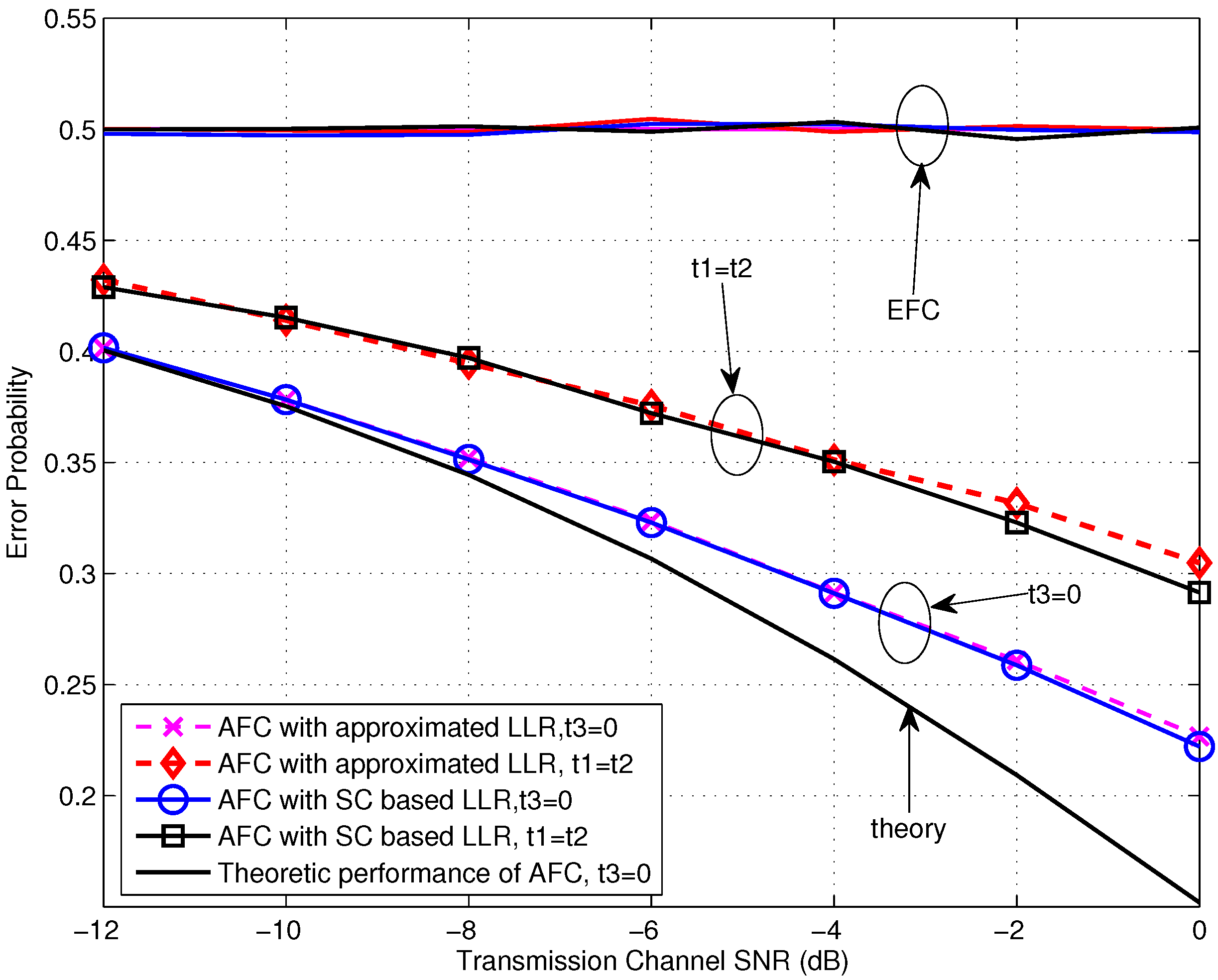
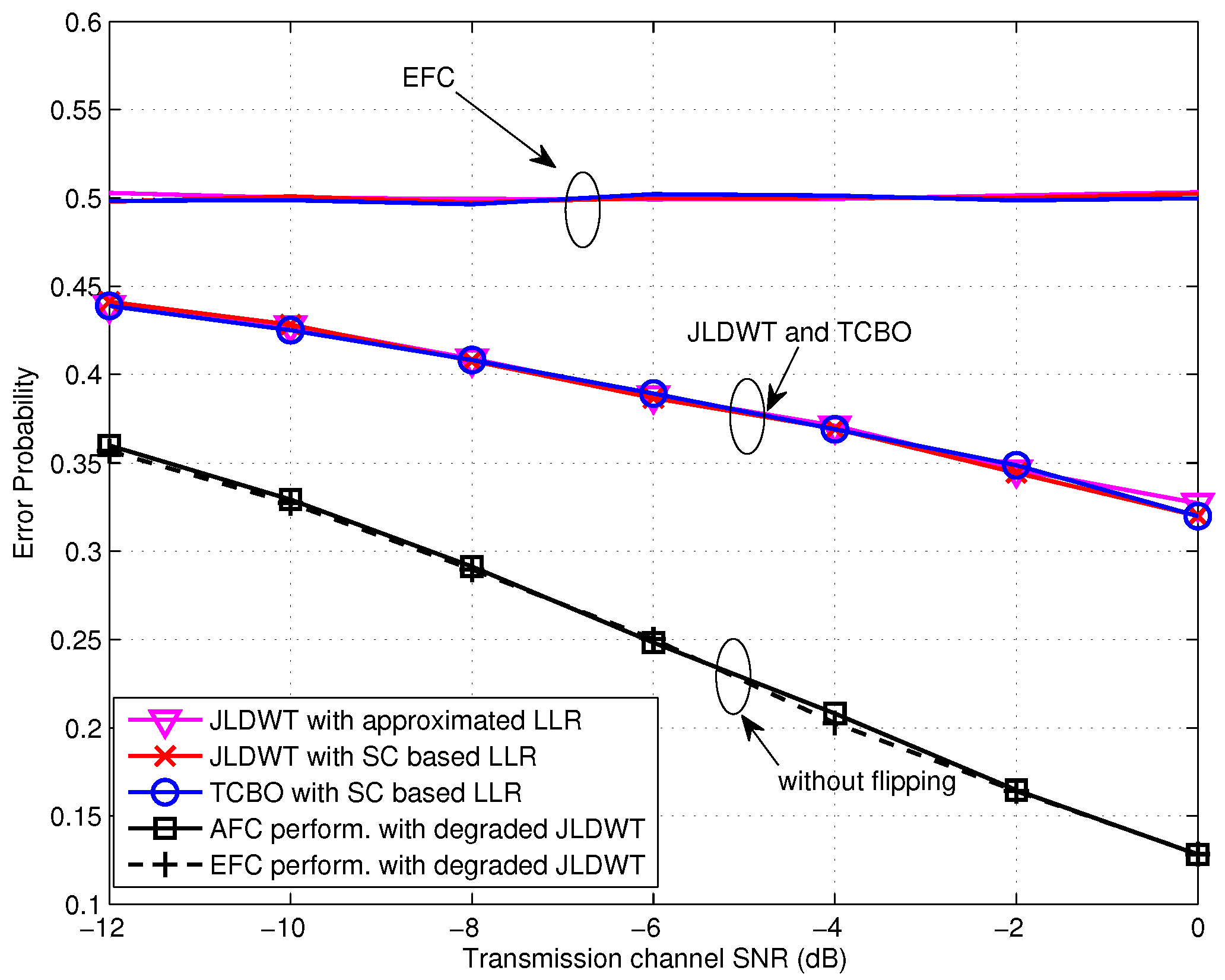
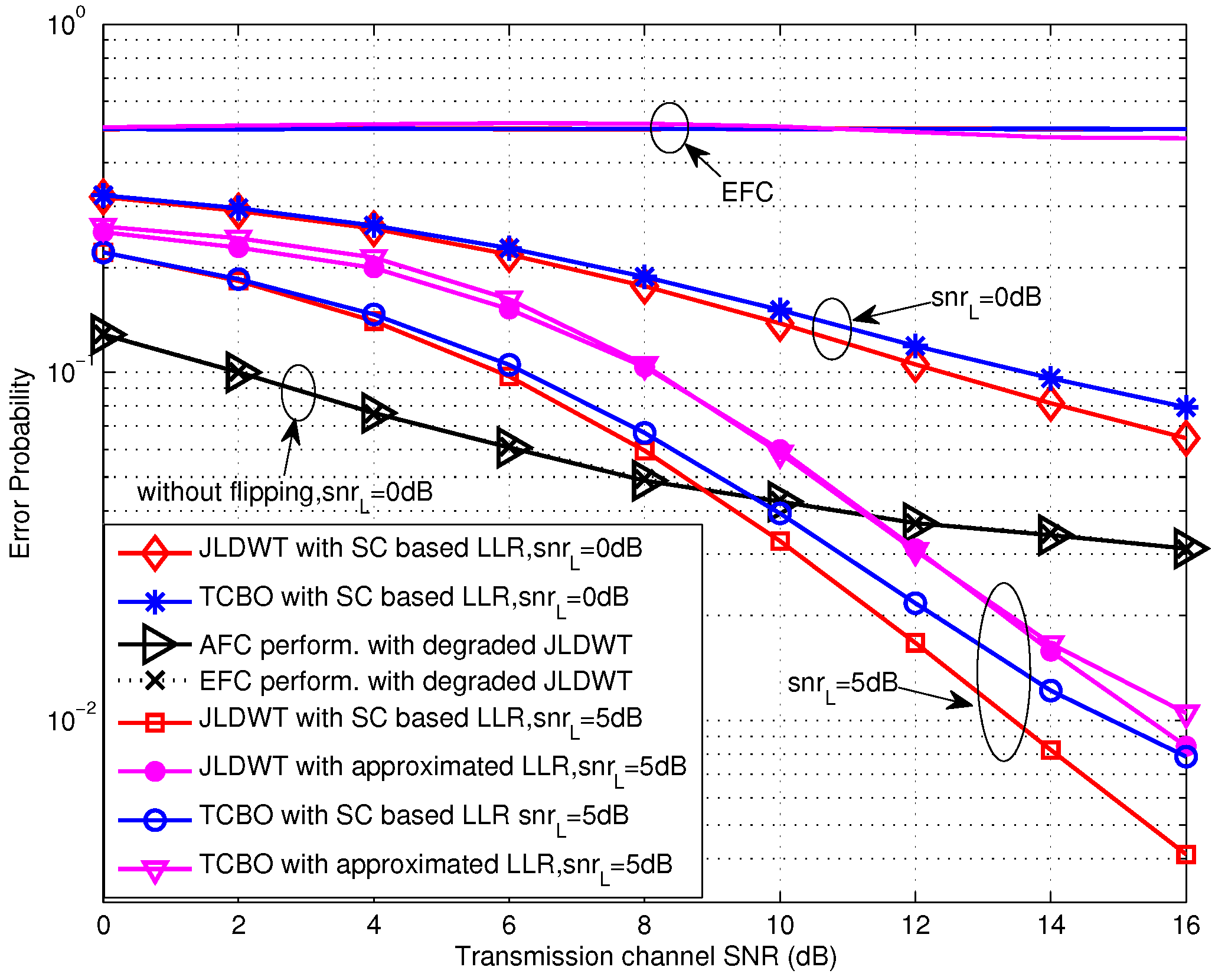
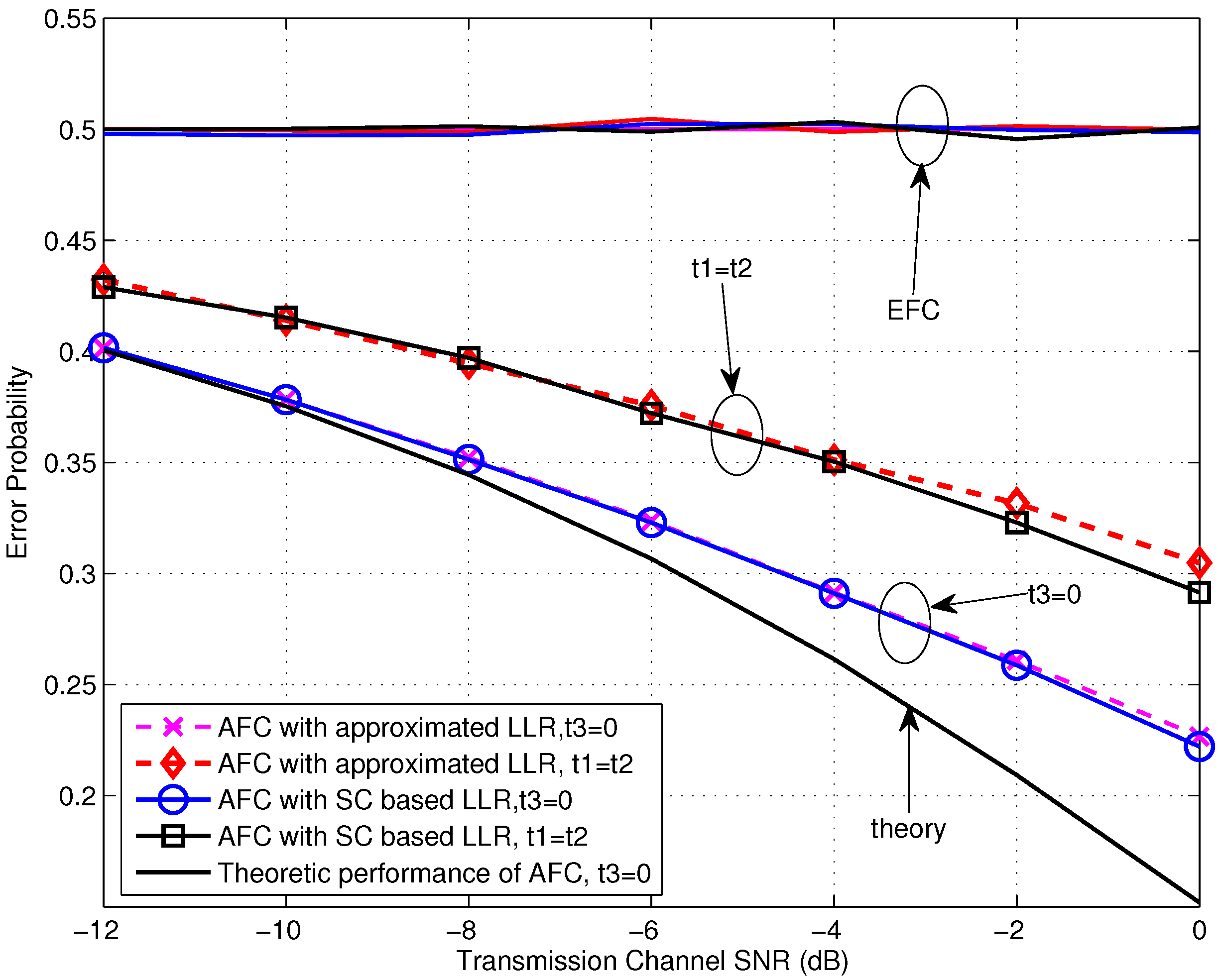
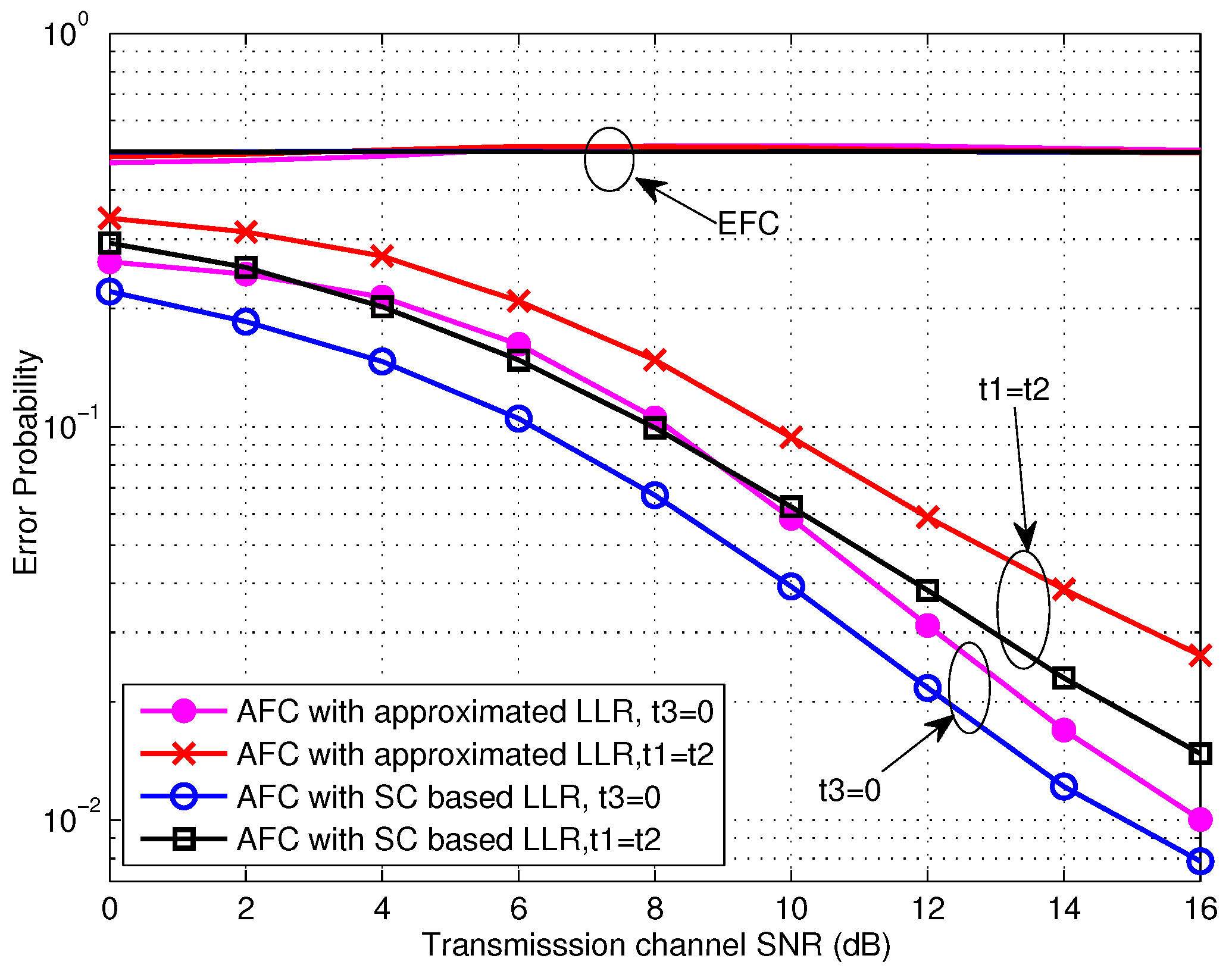
Let’s begin with the performance evaluation for the low SNR scenarios, where the SNR is not larger than 0 dB. From Figure 4, we first notice that the error probabilities for various settings at the EFC all locate around 0.5, which is our expected situation of perfect secrecy. Moreover, it is obvious that the AFC performance for the case of expresses better than the case of and there is a gain of about 4 dB obtained by the former one. This may be contributed by two aspects. On one side, the dormant region (or a gap) locates between the flipping and non-flipping group for the case of and it is beneficial for the AFC to discriminate between the flipping and non-flipping case, especially with serious noise. On the other side, the flipped decisions also disturb the fusion process at the AFC. For , the power of received interference is lower since the flipping sensor has the lower channel gain. Thus the interference would have less effect on the fusion decision of the AFC. In addition, the error performances of using the approximated LLR (given in Equation (19)) are almost identical with the ones of using the statistic channel (SC) based LLR (Here, numerical integrations are needed.), particularly during the very low SNR region. This demonstrates the availability of the approximated LLR under low SNR. The theoretic performance calculated by using Equation (23) for is also drawn in Figure 4. It can be seen that the simulation result fits the theoretic one well for the SNR lower than −10 dB, and the gap between them becomes larger with the growing of SNR due to the noise variance being farther from the assumption of included in Equation (23).
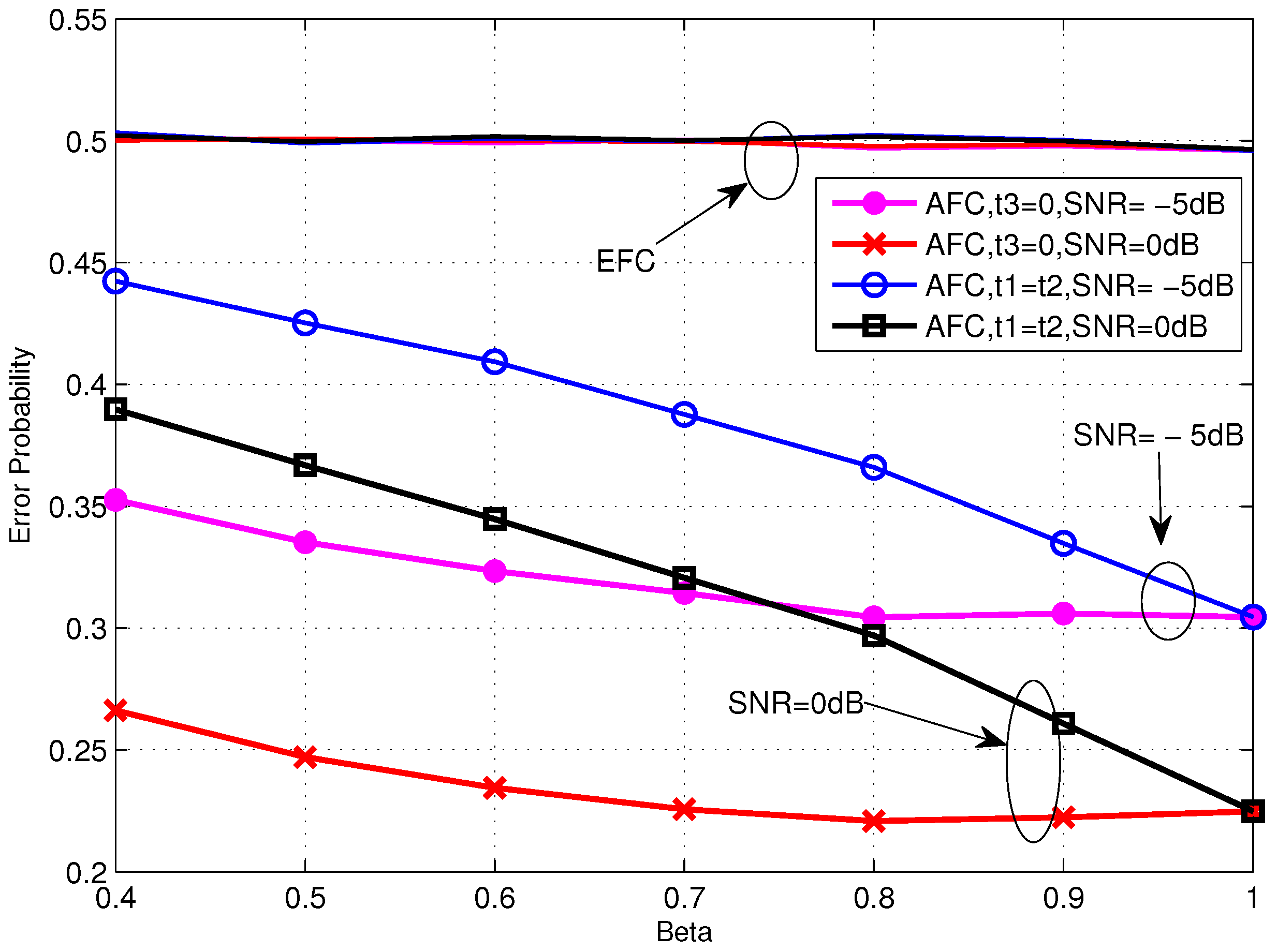
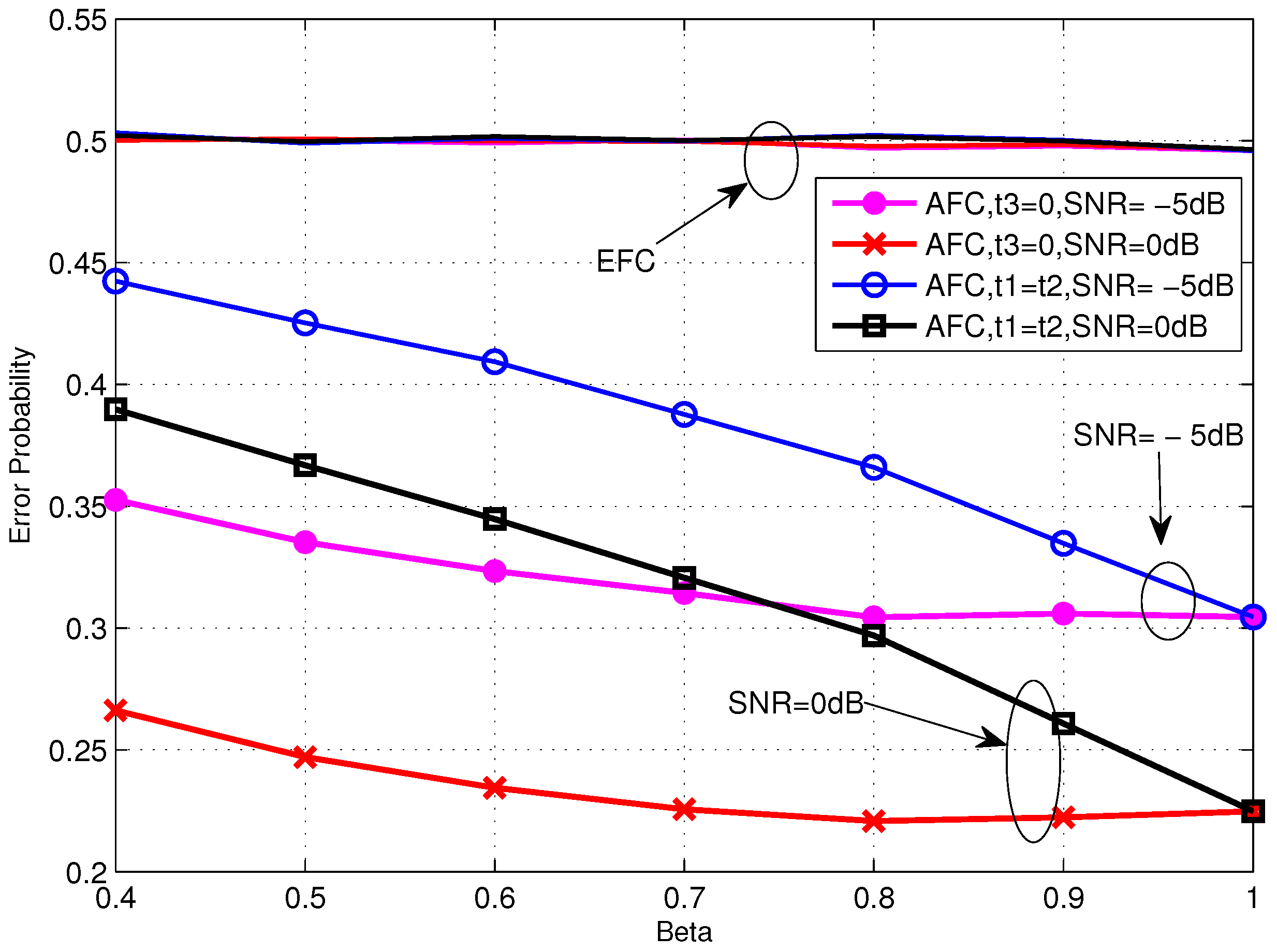
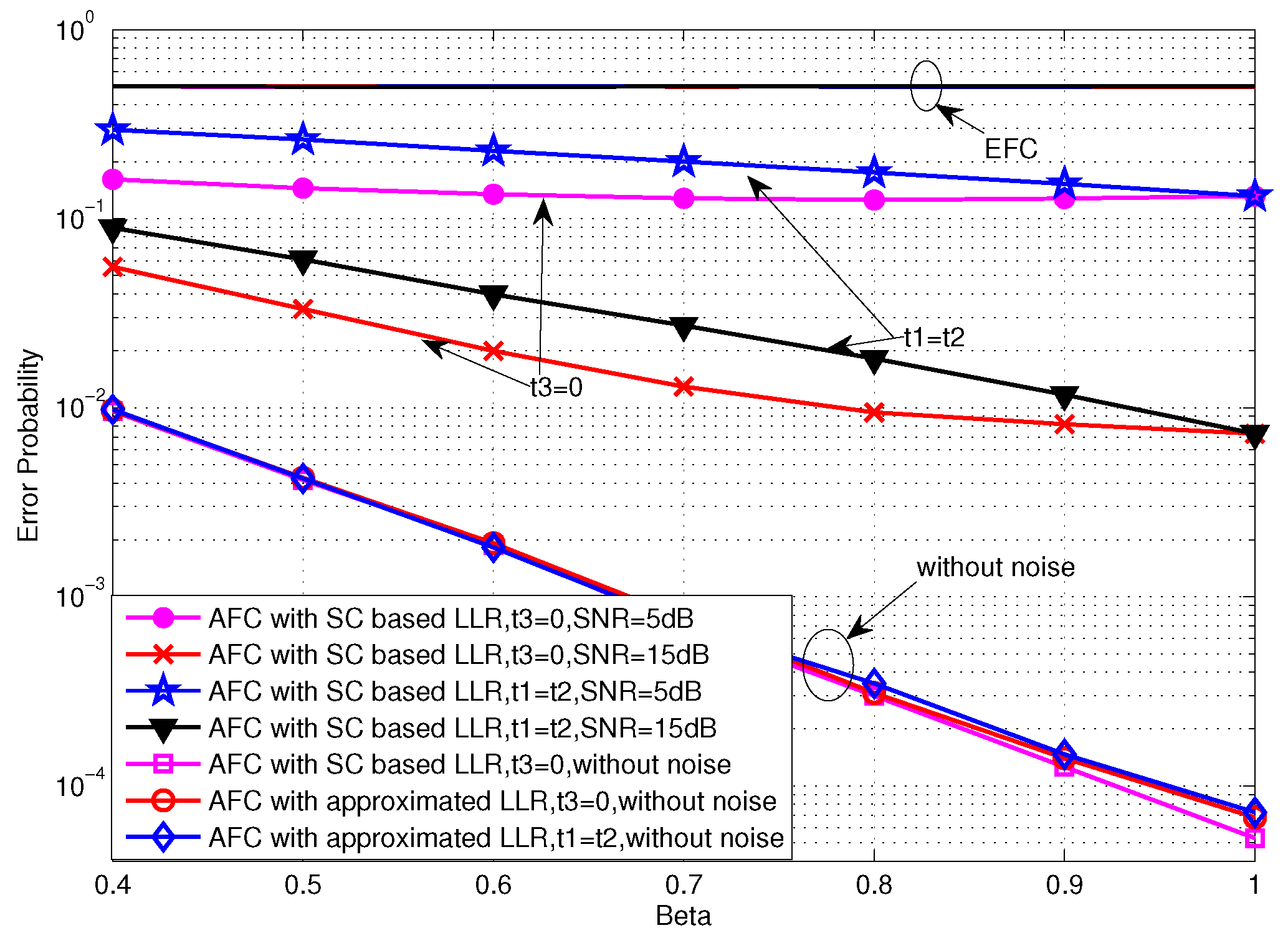
Figure 5 shows the performance of TCBO scheme with the SC based LLR varying with β. It can be seen that the error probabilities for and are identical with and they would increase with β reducing from 1. But the increasing of the former one is slower than the latter one, which is correspondent to the analysis about Equation (34) in Section 4.2. Moreover, carefully observing the curves corresponding to , we find that the error probabilities even rise slowly when we continue improving β and this phenomenon is more obvious for the moderate SNR, for example dB. It is because the reduced gap between the flipping and non-flipping group with a larger β leads to the confusion of the AFC to judge between two groups. It is noted that the confusion is created by the noise of channels. When the noise is very strong (or there is no such gap and the case follows this situation), the confusion always exits, so the more energy consumes and the better performance gets, just as the analytical result under low SNR in Section 4.2. However, with the noise reducing, the confusion disappears when the gap is large (Corresponding to a small β), while it appears when the gap becomes small. Therefore, although the energy consumption increases with β becoming large, the appeared confusion would worsen the performance. Of course, when the noise reduces to zero, the confusion never appears and the error probability will strictly decrease with β. This is the asymptotical analysis result under high SNR in Section 4.2 and also will be seen in the following simulations.
The performance curves of TCBO scheme for the high SNR scenarios, where the SNR is larger than 0 dB, are shown in Figure 6. Obviously, the error probabilities for various simulation conditions at the EFC are all about 0.5 and perfect secrecy is maintained. Moreover, the AFC performance for the case of is still better than the one for the case of , and the performance gap is about 2 dB. However, we find that the performance loss induced by the approximation of LLR with (seen in Equation (26)) is obvious. And this loss for will decrease with improving SNR, since the noise variance is closer to zero. In fact, the performance loss for will also reduce with the growing of SNR. In particular, this loss will reduce to zero for the extreme case of with two kinds of threshold setting, which can be seen in Figure 7. Therefore, the approximated LLR given in Equation (26) is still usable in terms of the reducing computation complexity, especially under high SNR scenarios.
From the other perspective, Figure 7 draws the error performance varying with β under the high SNR case. It can be seen that the threshold setting of demonstrates higher robustness than when the energy constraint is more severe. In addition, for the extreme case that the noise disappears, the error probabilities for various settings converge to an identical value and they decrease strictly as β increases. Because the confusion of the AFC for discriminating between the flipping and non-flipping group does not exist when the noise is absent, the case of would be equivalent to the case of . Furthermore, the approximated LLR could obtain the similar performance as the SC based LLR.
6.3. Simulation Results for JLDWT Scheme
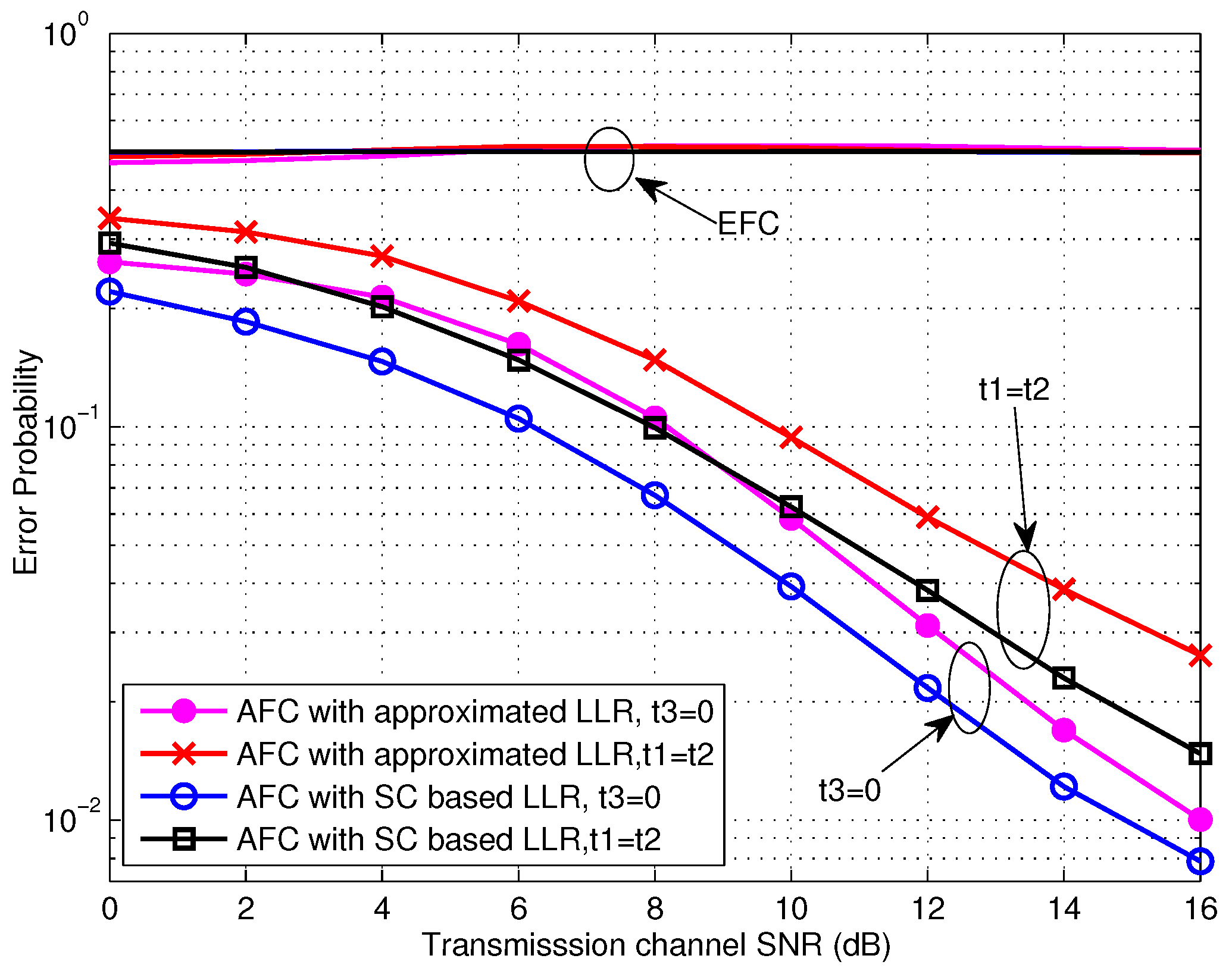
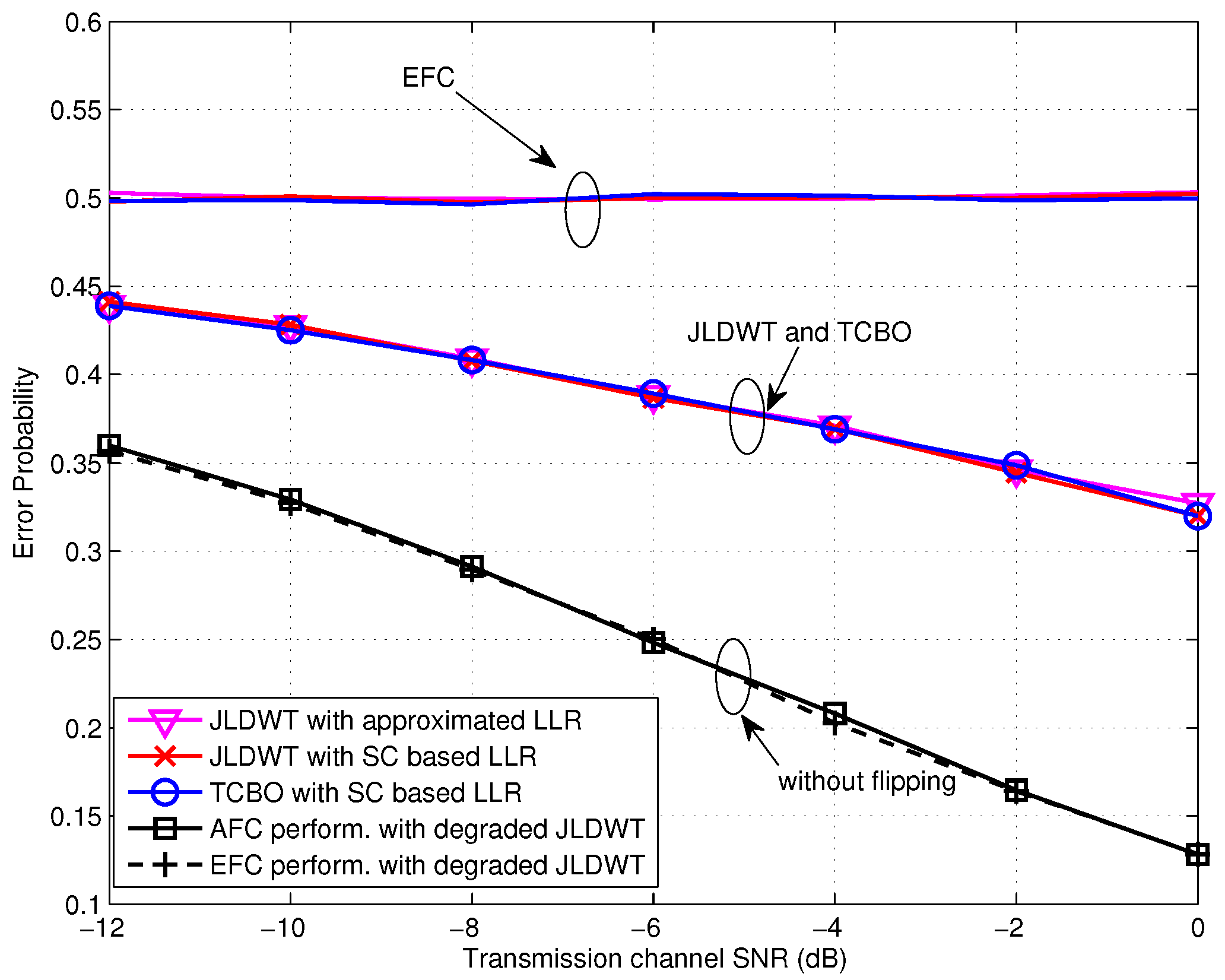
In this section, the performances of the TCBO and the proposed JLDWT schemes are compared from various perspectives. Figure 8 gives the error probabilities of two schemes for low SNR case. We can see that the JLDWT using the SC based LLR, the JLDWT using the approximated LLR and the TCBO using the SC based LLR have almost identical performance. Because the strong channel noise dominates in low SNR, the JLDWT’s advantage is not shown up. The simplified LLR for low SNR is very effective for maintaining the performance as well as reducing complexity of FC. Furthermore, all these schemes could achieve the perfect secrecy.
For comparison, the degraded JLDWT method without random flipping is also evaluated. Concretely, in the degraded JLDWT scheme, each sensor still executes the local detection based on the Bayesian criteria with two local decision thresholds and keeping , while the active sensor will deliver the local 1bit-decision in its original form to the FC no matter what the estimated channel gain is. That is to say the difference of the degraded JLDWT from the JLDWT is that the flipping process is not involved. As comparing it with the secure strategy given in [8], we can easily see that and used by the degraded JLDWT are identical with the ones used by the scheme in [8], because their optimization targets to find the optimal and are equivalent and the perfect secrecy constraint conditions are same. Thus, the degraded JLDWT can be seen equivalent to the scheme of [8] except that it is applied under a more realistic scenario considering the wireless transmission and a looser constraint on the EFC ability relative to the case in [8]. From Figure 8, it can be seen that the secrecy from the EFC is totally lost and the EFC has the same performance as the AFC when the secure strategy in [8] is used. That is to say the strategy given in [8] is ineffective if the EFC has the same process capability and the prior information as the AFC. Thus, random flipping is necessary to assure the information confidentiality with the enhanced EFC. Certainly, this information security is exchanged by certain performance loss of the AFC.
As for the case of high SNR, it can be seen from Figure 9 that the JLDWT scheme with the SC based LLR outperforms the TCBO using the SC based LLR and the performance gain for the AFC would increase with the transmission channel SNR going higher. That is to say preventing the worse local decision from contributing to the data fusion would facilitate to improve the performance at the FC when the disadvantage effect of transmission channel reduces. Moreover, similar as the result seen in Figure 8, the AFC and the EFC have the identical error probabilities with the degraded JLDWT and the information confidentiality is not guaranteed. In addition, the approximated LLR contributes to the performance loss for both the JLDWT and the TCBO schemes, but the JLDWT scheme still outperforms the TCBO one slightly.
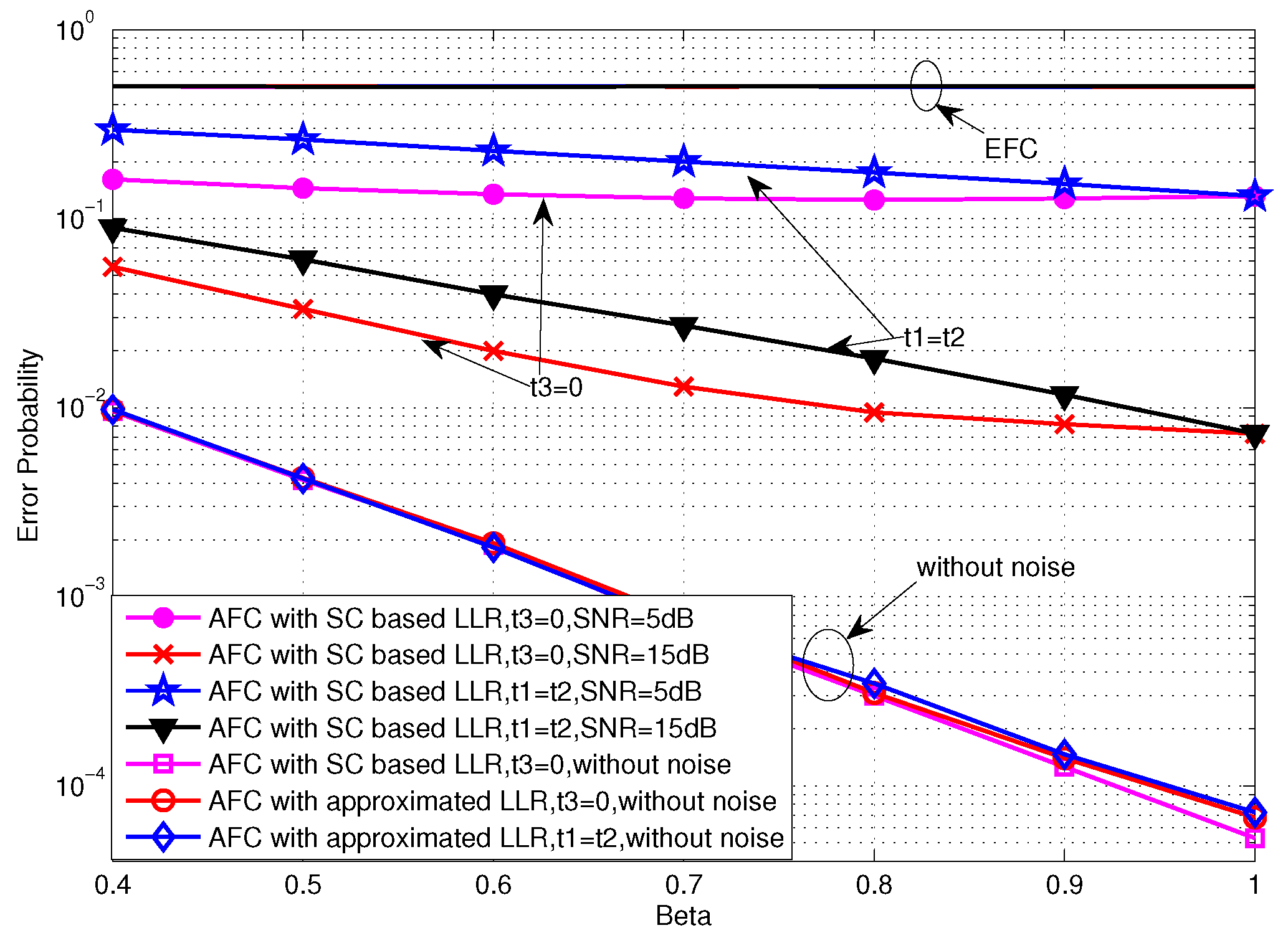
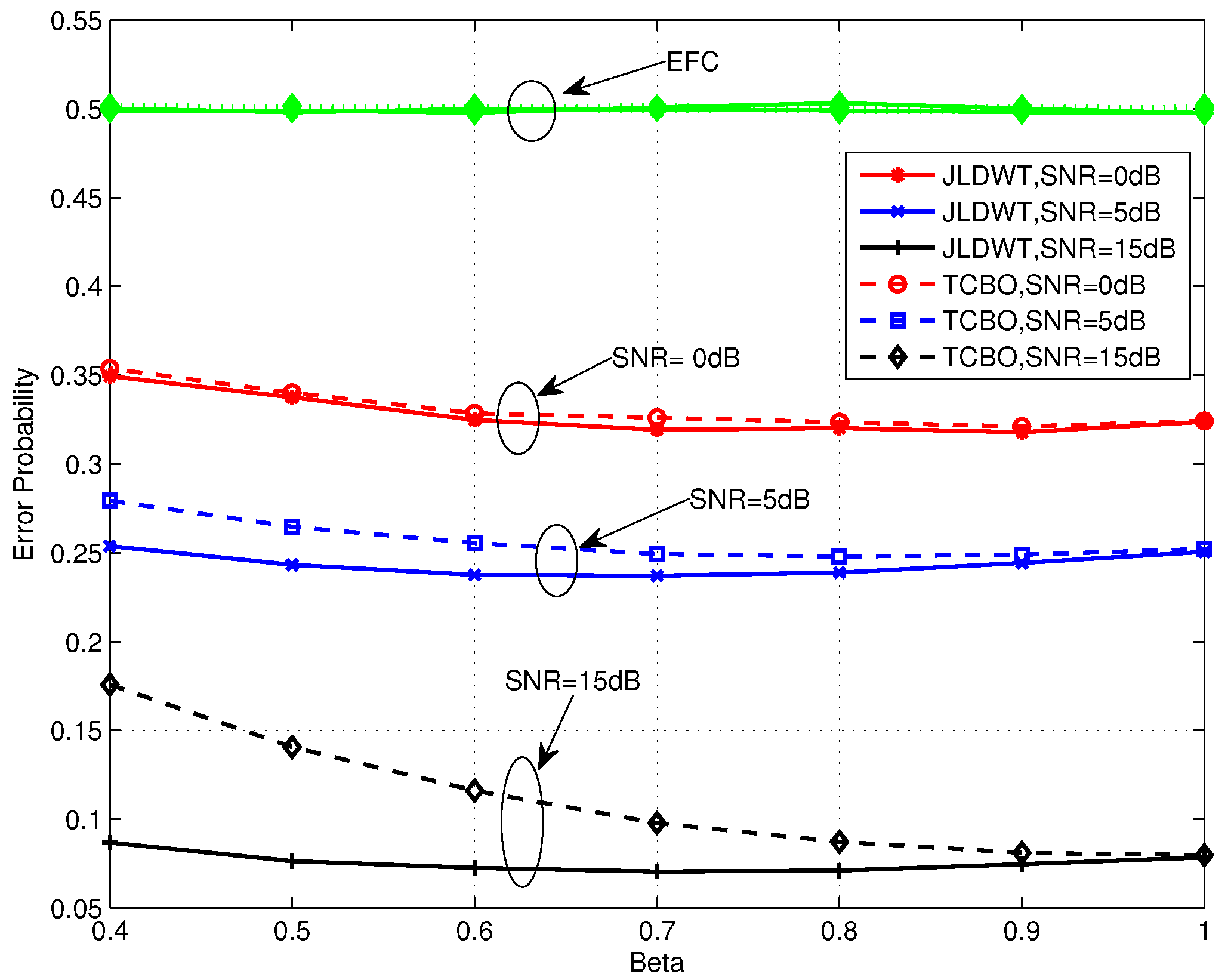
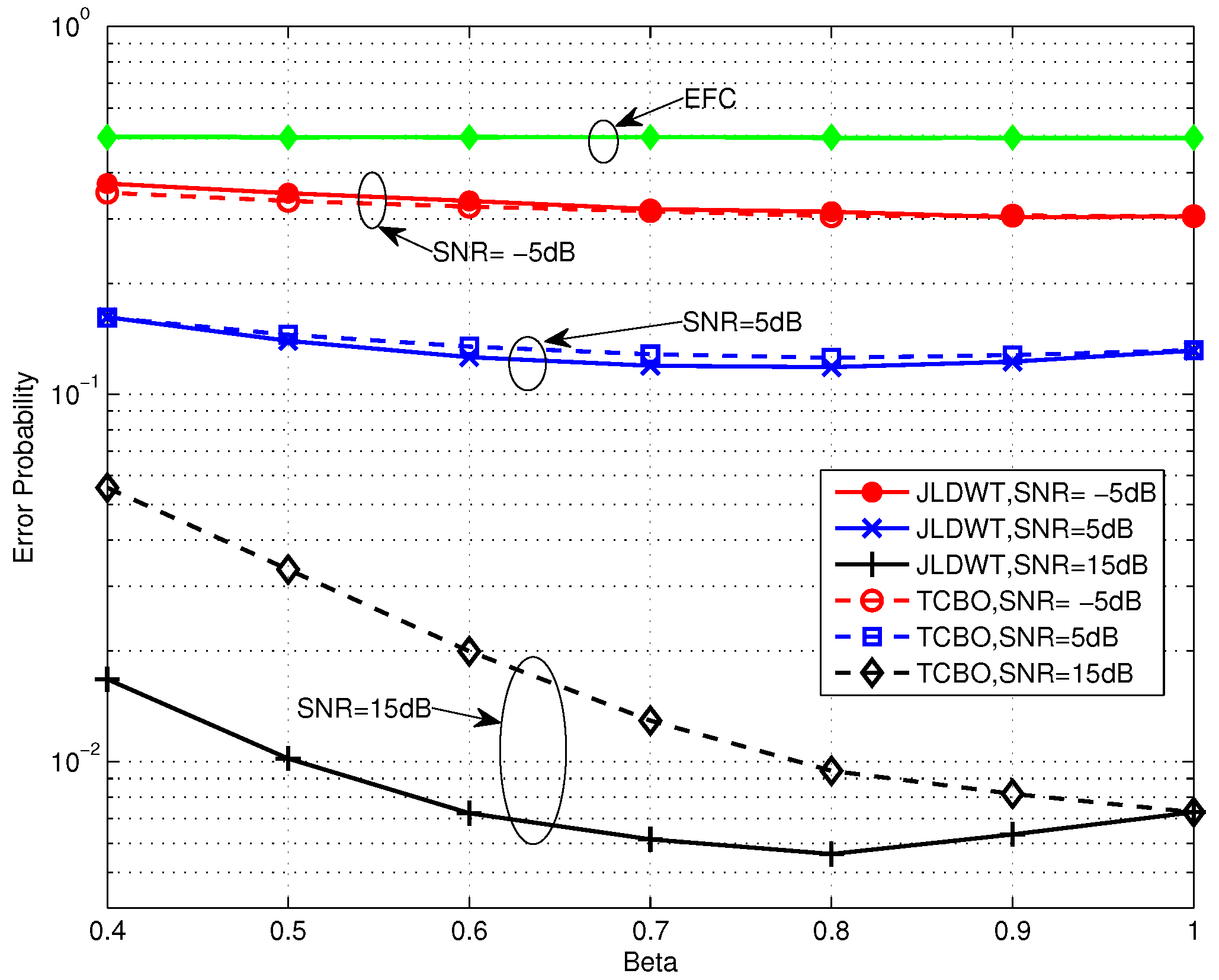
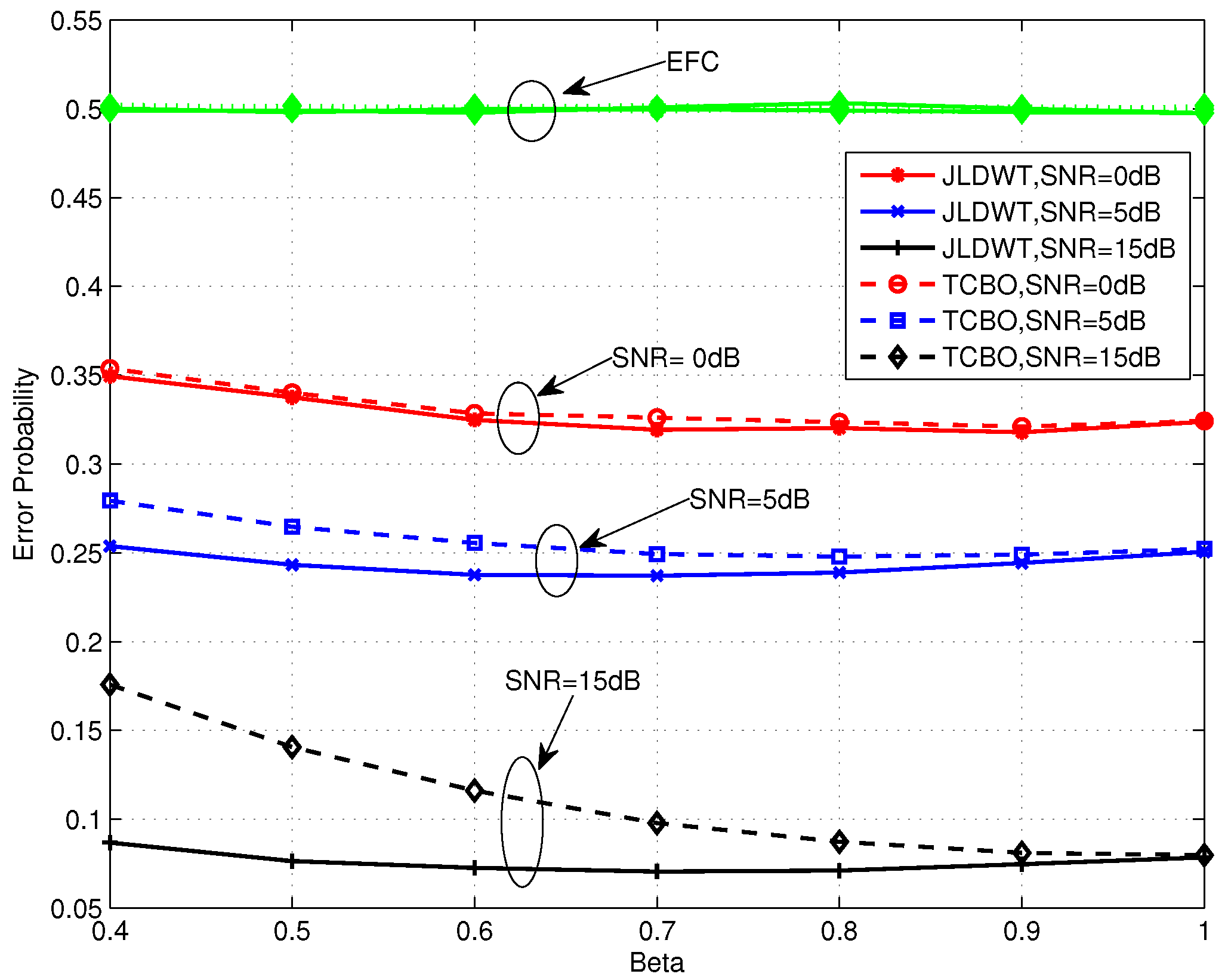
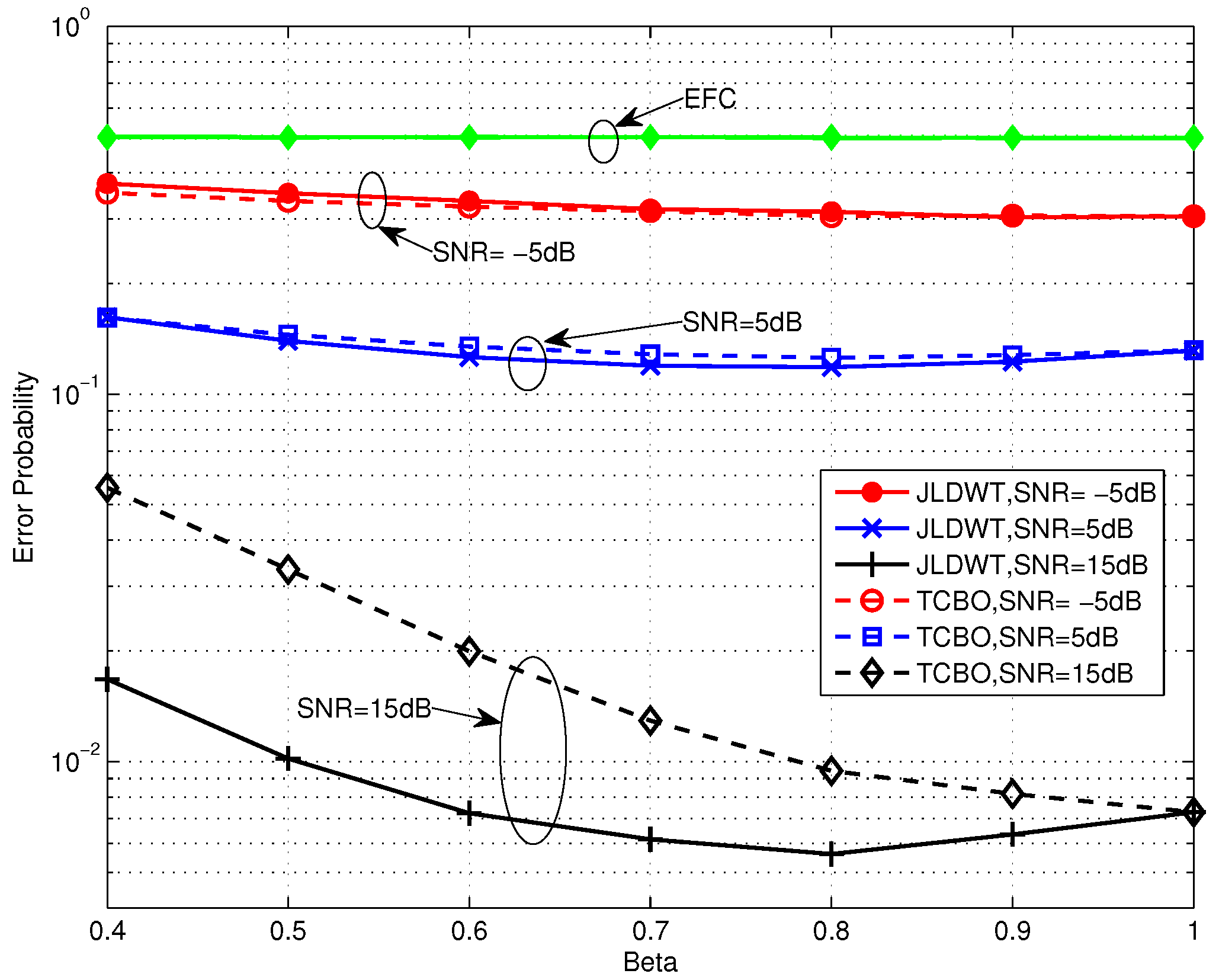
Figure 10 and Figure 11 compare the error performance of TCBO and JLDWT schemes with the SC based LLR under and , respectively. It can be seen that the gain of the JLDWT scheme against the TCBO method increases with the growing of transmission channel SNR. That is correspondent to the result seen in Figure 9. Furthermore, this gain at the high SNR, for example SNR = 15 dB, becomes larger for a smaller β. That is the advantage induced by cancelling the worse local detection results from the fusion data and it would dominant the final decision fusion when the transmission channel becomes good. Furthermore, we also find the performance inflection phenomenon over the curves of the JLDWT, which is similar as seen in Figure 5. While, it is induced by the confusion of the sensor to judge between two hypothesis of and , rather than the confusion of the AFC for discriminating between the flipping and non-flipping group.
Based on the above simulation results and discussions, we suggest that the TCBO scheme with the approximated LLR is a good selection over the low transmission channel SNR region. While, under a good wireless transmission scenario with a severe energy constraint, the JLDWT scheme with the SC based LLR is preferred in order to obtain the higher detection accuracy at the AFC. Moreover, a moderate β around 0.7∼0.8 is more appropriate for a practical sensor network in terms of both the energy consumption and the detection performance. In addition, it is to be noted that the TCBO and JLDWT schemes both can be easily extended to a larger sensor network, although only the case of K = 20 is studied in our simulations.
7. Conclusions and Future Work
Distributed detection scheme with good security and energy efficiency plays an important role in the implement of sensor network in IoT. In this paper, two secure decentralized detection schemes under energy constraint are studied comprehensively. Firstly, a specific energy constraint is introduced to the existing channel aware encryption scheme and we call it TCBO scheme. Next, the simplified LLRs under the low and high SNR are derived, respectively. Based on the new LLRs, the asymptotic error probabilities for the worst and best noise situations at the AFC are calculated. Then, three comparison thresholds are optimized through minimizing the error probability while satisfying the perfect secrecy and energy constraints. Secondly, combing the local detection and the wireless transmission of local decision at the sensor, a hybrid scheme named JLDWT is proposed, where the energy efficiency is provided by censoring the sensor with less informative local LLR and the confidentiality from the EFC is guaranteed by the channel based random flipping. Then, the asymptotic error probabilities under low and high SNR environment are also given. Furthermore, two local detection thresholds and one flipping comparison threshold are optimized to minimize the error rates, as well as, assure the perfect secrecy and the required energy efficiency. At last, we evaluate the detection performance of the TCBO and the proposed JLDWT schemes through computer simulations. The simulation results demonstrate that the perfect secrecy is assured by both schemes. The JLDWT scheme outperforms the TCBO one under the better wireless transmission environment with a severe energy constraint.
The perfect secrecy is guaranteed at the cost of reducing the detection accuracy at the AFC in the TCBO and JLDWT schemes. However, in some scenarios, a limited information leakage to the EFC maybe is permitted, while the high detection performance at the AFC is more important. In future work, the modified forms of the above two schemes will be designed to support the more flexible constraint on the EFC’s performance. Moreover, except the eavesdropping attack, there are many other attack modes faced by IoT networks in practice, such as the denial of services (DOS) attack, node outage attack, signal jamming attack and intentional attack. Among them, the intentional attack could incur fatal threat on network by paralyzing a small fraction of nodes with highest degrees. As to IoT networks, if some important nodes, such as the fusion center and the controller, suffer the intentional attack, the whole IoT system may be disrupted. Therefore, the robust defense mechanism against the intentional attack for IoT will be studied in our future work.
Acknowledgments
The authors would like to thank the support from the National Natural Science Foundation of China (NSFC) under Grant No. 61461136001, No. 61431011 and No. 61401350, the National 863 Program of China under Grant No. 2014AA01A707 and the Fundamental Research Funds for the Central Universities.
Author Contributions
Guomei Zhang has done the research on the related topic of this paper, designed the analyzing methods and developed the schemes, simulated them in MATLAB, extracted results and wrote the paper. Hao Sun participated in the literature research and the simulation programming, edited formulas and drew the simulation figures.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A. Approximation of Φ (ta, tb, xk, y, δ) under the Low Channel SNR
The derivation of the approximated formulation for is given by
where (a) is based on the fact that for small x and (b) is due to the assumption of .
Appendix B. Calculation of Three Integrations Used in Equations (20) and (22)
Furthermore, with , we have for , for and for . Substituting them into Equation (C1), we can rewrite it as the Equation (26).
Appendix D. Derivation of Equations (27) and (28)
From Equation (26), we see that is a discrete random variable, so its mean can be given by . Moreover, the non-negative channel coefficient makes that is equivalent to , corresponds to and means . In addition, holds for the large SNR scenario. Combining the above facts, we have
where (a) follows the condition that is uncorrelated with and , and (b) is due to Equation (24). Similarly, it can be obtained that
Appendix E. Calculation of the Derivative of to α
Rewrite as a function of α
whose derivative is given by
Moreover, we can calculate
Specially, for the case , we obtain
And because has to be satisfied, the following equation is achieved
Substituting Equation (E6) into Equation (E5) yields
Otherwise, for the case , we have
Also due to , it can be achieved
Further, is given.
Appendix F. Proof of D (λU) = D (λL )
Beginning with , we get
From the total probability theory, we have
Then can be rewritten as
References
Gil, D.; Ferrandez, A.; Mora-Mora, H.; Peral, J. Internet of Things: A Review of Surveys Based on Context Aware Intelligent Services. Sensors2016, 16, 1069. [Google Scholar] [CrossRef] [PubMed]
Mukherjee, A. Physical-Layer Security in the Internet of Things: Sensing and Communication Confidentiality Under Resource Constraints. Proc. IEEE2015, 103, 1747–1761. [Google Scholar] [CrossRef]
Ghayvat, H.; Mukhopadhyay, S.; Gui, X.; Suryadevara, N. WSN- and IOT-Based Smart Homes and Their Extension to Smart Buildings. Sensors2015, 15, 10350–10379. [Google Scholar] [CrossRef] [PubMed]
Rani, S.; Talwar, R.; Malhotra, J.; Ahmed, S.H.; Sarkar, M.; Song, H. A Novel Scheme for an Energy Efficient Internet of Things Based on Wireless Sensor Networks. Sensors2015, 15, 28603–28626. [Google Scholar] [CrossRef] [PubMed]
Li, Z.; Tao, J.; Ma, L.; Qian, J. Worst-Case Cooperative Jamming for Secure Communications in CIoT Networks. Sensors2016, 16, 339. [Google Scholar] [CrossRef] [PubMed]
Ndibanje, B.; Lee, H.J.; Lee, S.G. Security analysis and improvements of authentication and access control in the Internet of Things. Sensors2014, 14, 14786–14805. [Google Scholar] [CrossRef] [PubMed]
Kailkhura, B.; Nadendla, V.S.S.; Varshney, P.K. Distributed inference in the presence of eavesdroppers: A survey. IEEE Commun. Mag.2015, 53, 40–46. [Google Scholar] [CrossRef]
Marano, S.; Matta, V.; Willett, P.K. Distributed detection with censoring sensors under physical layer secrecy. IEEE Trans. Signal Proc.2009, 57, 1976–1986. [Google Scholar] [CrossRef]
Soosahabi, R.; Naraghi-Pour, M. Scalable PHY-Layer Security for Distributed Detection in Wireless Sensor Networks. IEEE Trans. Inf. Forensics Secur.2012, 7, 1118–1126. [Google Scholar] [CrossRef]
Jeon, H.; Choi, J.; Mclaughlin, S.W.; Ha, J. Channel aware encryption and decision fusion for wireless sensor networks. IEEE Trans. Inf. Forensics Secur.2013, 8, 619–625. [Google Scholar] [CrossRef]
Appadwedula, S.; Veeravalli, V.V.; Jones, D.L. Decentralized Detection With Censoring Sensors. IEEE Trans. Signal Proc.2008, 56, 1362–1373. [Google Scholar] [CrossRef]
Miorandi, D.; Sicari, S.; Pellegrini, F.D.; Chlamtac, I. Internet of things: Vision, applications and research challenges. Ad Hoc Netw.2012, 10, 1497–1516. [Google Scholar] [CrossRef]
Sen, J. A Survey on Wireless Sensor Network Security. Comput. Sci.2010, 43, 90–95. [Google Scholar]
Weber, R.H. Internet of Things—New security and privacy challenges. Comput. Law Secur. Rep.2010, 26, 23–30. [Google Scholar] [CrossRef]
Keoh, S.L.; Kumar, S.S.; Tschofenig, H. Securing the Internet of Things: A Standardization Perspective. IEEE Internet Things J.2014, 1, 265–275. [Google Scholar] [CrossRef]
Mukherjee, A.; Fakoorian, S.A.A.; Huang, J.; Swindlehurst, A.L. Principles of Physical Layer Security in Multiuser Wireless Networks: A Survey. IEEE Commun. Surv. Tutor.2014, 16, 1550–1573. [Google Scholar] [CrossRef]
Xu, Q.; Ren, P.; Song, H.; Du, Q. Security enhancement for IoT communications exposed to eavesdroppers with uncertain locations. IEEE Access2016, 4, 2840–2853. [Google Scholar] [CrossRef]
Atzori, L.; Iera, A.; Morabito, G. The Internet of Things: A survey. Comput. Netw.2010, 54, 2787–2805. [Google Scholar] [CrossRef]
Su, Z.; Xu, Q.; Zhu, H.; Wang, Y. A novel design for content delivery over software defined mobile social networks. IEEE Netw.2015, 29, 62–67. [Google Scholar] [CrossRef]
Du, Q.; Zhao, W.; Li, W.; Zhang, X.; Sun, B.; Song, H.; Ren, P.; Sun, L.; Wang, Y. Massive access control aided by knowledge-extraction for co-existing periodic and random services over wireless clinical networks. J. Med. Syst.2016, 40, 1–8. [Google Scholar] [CrossRef] [PubMed]
Gubbi, J.; Buyya, R.; Marusic, S.; Palaniswami, M. Internet of Things (IoT): A vision, architectural elements, and future directions. Future Gener. Comput. Syst.2012, 29, 1645–1660. [Google Scholar] [CrossRef]
Soosahabi, R.; Naraghi-Pour, M.; Perkins, D.; Bayoumi, M.A. Optimal Probabilistic Encryption for Secure Detection in Wireless Sensor Networks. IEEE Trans. Inf. Forensics Secur.2014, 9, 375–385. [Google Scholar] [CrossRef]
Bhavya, K.; Thakshila, W.; Lixin, S.; Pramod, K. Distributed Compressive Detection with Perfect Secrecy. In Proceedings of the IEEE 11th International Conference on Mobile Ad Hoc and Sensor Systems, Philadelphia, PA, USA, 28–30 October 2014; pp. 674–679.
Li, Z.; Oechtering, T.J.; Kittichokechai, K. Parallel distributed Bayesian detection with privacy constraints. In Proceedings of the IEEE International Conference on Communications, Sydney, Australia, 10–14 June 2014; pp. 2178–2183.
Li, Z.; Oechtering, T.J.; Jalde, N.J. Parallel distributed Neyman-Pearson detection with privacy constraints. In Proceedings of the IEEE International Conference on Communications Workshops, Sydney, Australia, 10–14 June 2014.
Nadendla, V.S.S.; Chen, H.; Varshney, P.K. Secure distributed detection in the presence of eavesdroppers. In Proceedings of the 11th Asilomar Conference on Circuits, Systems and Computers, Pacific Grove, CA, USA, 7–10 November 2010; pp. 1437–1441.
Araujo, A.; Blesa, J.; Romero, E.; Nieto-Taladriz, O. Artificial noise scheme to ensure secure communications in CWSN. In Proceedings of the Wireless Communications and Mobile Computing Conference, Limassol, Cyprus, 27–31 August 2012; pp. 1023–1027.
Khisti, A.; Wornell, G. Secure transmission with multiple antennas-I: The MISOME wiretap channel. IEEE Trans. Inform. Theory2010, 56, 3088–3104. [Google Scholar] [CrossRef]
Khisti, A.; Wornell, G. Secure transmission with multiple antennas-II: The MIMOME wiretap channel. IEEE Trans. Inform. Theory2010, 56, 5515–5532. [Google Scholar] [CrossRef]
Li, Q.; Ma, W.-K. Multicast secrecy rate maximization for MISO channels with multiple multiantenna eavesdroppers. In Proceedings of the 2011 IEEE International Conference on Communications (ICC), Victoria, BC, Canada, 5–9 June 2011; pp. 1–5.
Geraci, G.; Egan, M.; Yuan, J.; Razi, A.; Collings, I.B. Secrecy sum-rates for multi-user MIMO regularized channel inversion precoding. IEEE Trans. Commun.2012, 60, 3472–3482. [Google Scholar] [CrossRef]
Goel, S.; Negi, R. Guaranteeing secrecy using artificial noise. IEEE Trans. Wireless Commun.2008, 7, 2180–2189. [Google Scholar] [CrossRef]
Mukherjee, A.; Swindlehurst, A.L. Utility of beamforming strategies for secrecy in multiuser MIMO wiretap channels. In Proceedings of the 47th Allerton Conference on Communication, Control, and Computing, Monticello, IL, USA, 30 September–2 October 2009; pp. 1134–1141.
Gerbracht, S.; Scheunert, C.; Jorswieck, E.A. Secrecy outage in MISO systems with partial channel information. IEEE Trans. Inform. Forensics Sec.2012, 7, 704–716. [Google Scholar] [CrossRef]
Sun, L.; Du, Q.; Ren, P.; Wang, Y. Two birds with one stone: Towards secure and interference-free D2D transmissions via constellation rotation. IEEE Trans. Veh. Technol.2016, 65, 8767–8774. [Google Scholar] [CrossRef]
Xu, H.; Sun, L.; Ren, P.; Du, Q.; Wang, Y. Cooperative privacy preserving scheme for downlink transmission in multiuser relay networks. IEEE Trans. Inf. Forensics Secur. published online. 2016. [Google Scholar] [CrossRef]
Hussain, M.; Du, Q.; Sun, L.; Ren, P. Security enhancement for video transmission via noise aggregation in immersive systems. Multimed. Tools Appl.2016, 75, 5345–5357. [Google Scholar] [CrossRef]
Xu, Q.; Ren, P.; Du, Q.; Sun, L.; Wang, Y. On achievable secrecy rate by noise aggregation over wireless fading channels. In Proceedings of the IEEE International Conference on Communications, Kuala Lumpur, Malaysia, 22–27 May 2016.
Jiang, R.; Chen, B. Fusion of censored decisions in wireless sensor networks. IEEE Trans. Wireless Commun.2005, 4, 2668–2673. [Google Scholar] [CrossRef]
Figure 1.
IoT sensor network with the ally fusion center and eavesdropping fusion center.
Figure 1.
IoT sensor network with the ally fusion center and eavesdropping fusion center.
Figure 2.
Single “No-send” region: (a) Case of ; (b) Case of .
Figure 2.
Single “No-send” region: (a) Case of ; (b) Case of .
Figure 3.
Diagram of the function .
Figure 3.
Diagram of the function .
Figure 4.
Error probabilities at the AFC and EFC as functions of various SNR for and dB over low SNR region.
Figure 4.
Error probabilities at the AFC and EFC as functions of various SNR for and dB over low SNR region.
Figure 5.
Error probabilities at the AFC and EFC as functions of various β for dB over low SNR region.
Figure 5.
Error probabilities at the AFC and EFC as functions of various β for dB over low SNR region.
Figure 6.
Error probabilities at the AFC and EFC as functions of various SNR for and dB over high SNR region.
Figure 6.
Error probabilities at the AFC and EFC as functions of various SNR for and dB over high SNR region.
Figure 7.
Error probabilities at the AFC and EFC as functions of various β for dB over high SNR region.
Figure 7.
Error probabilities at the AFC and EFC as functions of various β for dB over high SNR region.
Figure 8.
Error probabilities of TCBO and JLDWT schemes as functions of various SNR for and dB over low SNR region.
Figure 8.
Error probabilities of TCBO and JLDWT schemes as functions of various SNR for and dB over low SNR region.
Figure 9.
Error probabilities of TCBO and JLDWT schemes as functions of various SNR for over high SNR region.
Figure 9.
Error probabilities of TCBO and JLDWT schemes as functions of various SNR for over high SNR region.
Figure 10.
Error probabilities of TCBO and JLDWT schemes with SC based LLR as functions of various β for dB.
Figure 10.
Error probabilities of TCBO and JLDWT schemes with SC based LLR as functions of various β for dB.
Figure 11.
Error probabilities of TCBO and JLDWT schemes with SC based LLR as functions of various β for dB.
Figure 11.
Error probabilities of TCBO and JLDWT schemes with SC based LLR as functions of various β for dB.
Table 1.
Simulation Parameters in Wireless Sensor Network.
Table 1.
Simulation Parameters in Wireless Sensor Network.
Parameters
Assumption
Number of sensors
20
Prior probabilities of target states
Transmission channel model
Rayleigh distribution with
Energy constraint
Local detection SNR
dB
Transmission channel SNR
dB
Table 2.
Two local decision thresholds and for dB.
Table 2.
Two local decision thresholds and for dB.
β
0.4
0.5
0.6
0.7
0.8
0.9
1
2.585
2.145
1.810
1.545
1.330
1.155
1.000
0.387
0.466
0.553
0.647
0.752
0.866
1.000
Table 3.
Two local decision thresholds and for dB.
Table 3.
Two local decision thresholds and for dB.
Zhang, G.; Sun, H.
Secure Distributed Detection under Energy Constraint in IoT-Oriented Sensor Networks. Sensors2016, 16, 2152.
https://doi.org/10.3390/s16122152
AMA Style
Zhang G, Sun H.
Secure Distributed Detection under Energy Constraint in IoT-Oriented Sensor Networks. Sensors. 2016; 16(12):2152.
https://doi.org/10.3390/s16122152
Chicago/Turabian Style
Zhang, Guomei, and Hao Sun.
2016. "Secure Distributed Detection under Energy Constraint in IoT-Oriented Sensor Networks" Sensors 16, no. 12: 2152.
https://doi.org/10.3390/s16122152
APA Style
Zhang, G., & Sun, H.
(2016). Secure Distributed Detection under Energy Constraint in IoT-Oriented Sensor Networks. Sensors, 16(12), 2152.
https://doi.org/10.3390/s16122152
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.
Article Metrics
No
No
Article Access Statistics
For more information on the journal statistics, click here.
Multiple requests from the same IP address are counted as one view.
Zhang, G.; Sun, H.
Secure Distributed Detection under Energy Constraint in IoT-Oriented Sensor Networks. Sensors2016, 16, 2152.
https://doi.org/10.3390/s16122152
AMA Style
Zhang G, Sun H.
Secure Distributed Detection under Energy Constraint in IoT-Oriented Sensor Networks. Sensors. 2016; 16(12):2152.
https://doi.org/10.3390/s16122152
Chicago/Turabian Style
Zhang, Guomei, and Hao Sun.
2016. "Secure Distributed Detection under Energy Constraint in IoT-Oriented Sensor Networks" Sensors 16, no. 12: 2152.
https://doi.org/10.3390/s16122152
APA Style
Zhang, G., & Sun, H.
(2016). Secure Distributed Detection under Energy Constraint in IoT-Oriented Sensor Networks. Sensors, 16(12), 2152.
https://doi.org/10.3390/s16122152
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}