
Recognition of Activities of Daily Living with Egocentric Vision: A Review




Abstract
:1. Introduction
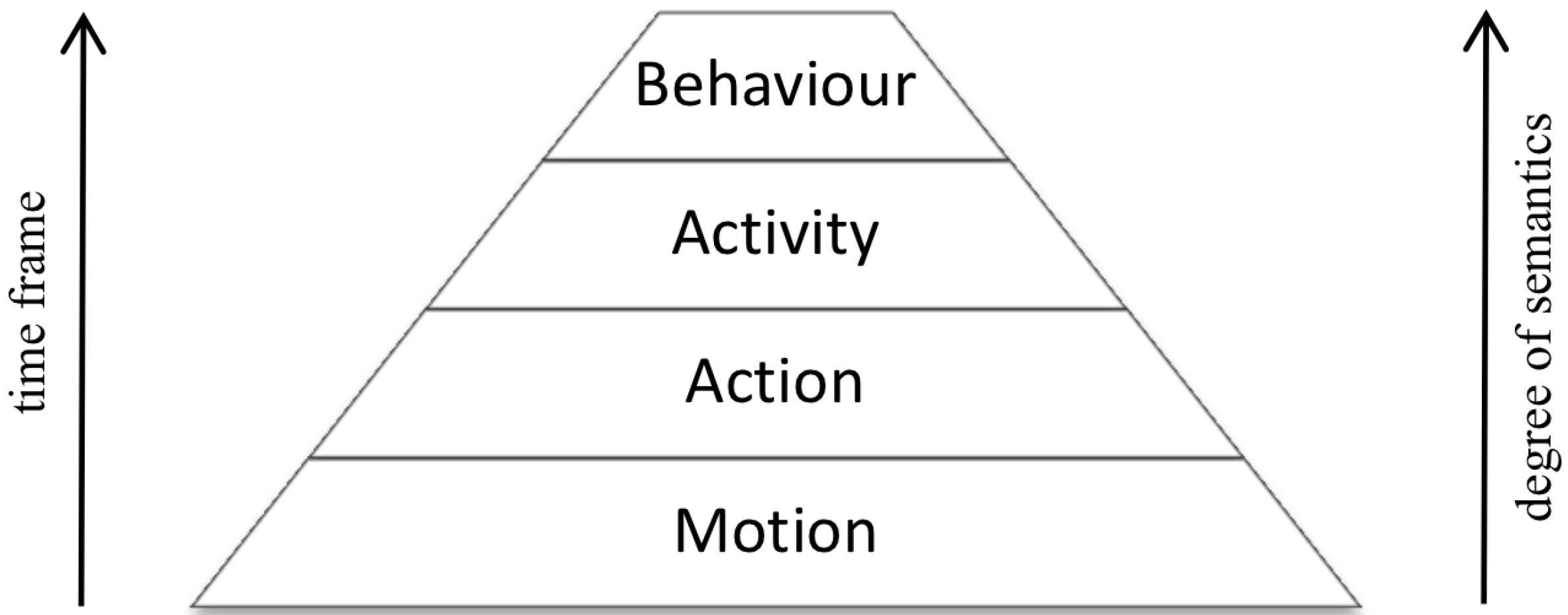
2. Recognition of Elements of Activities at the Motion Level
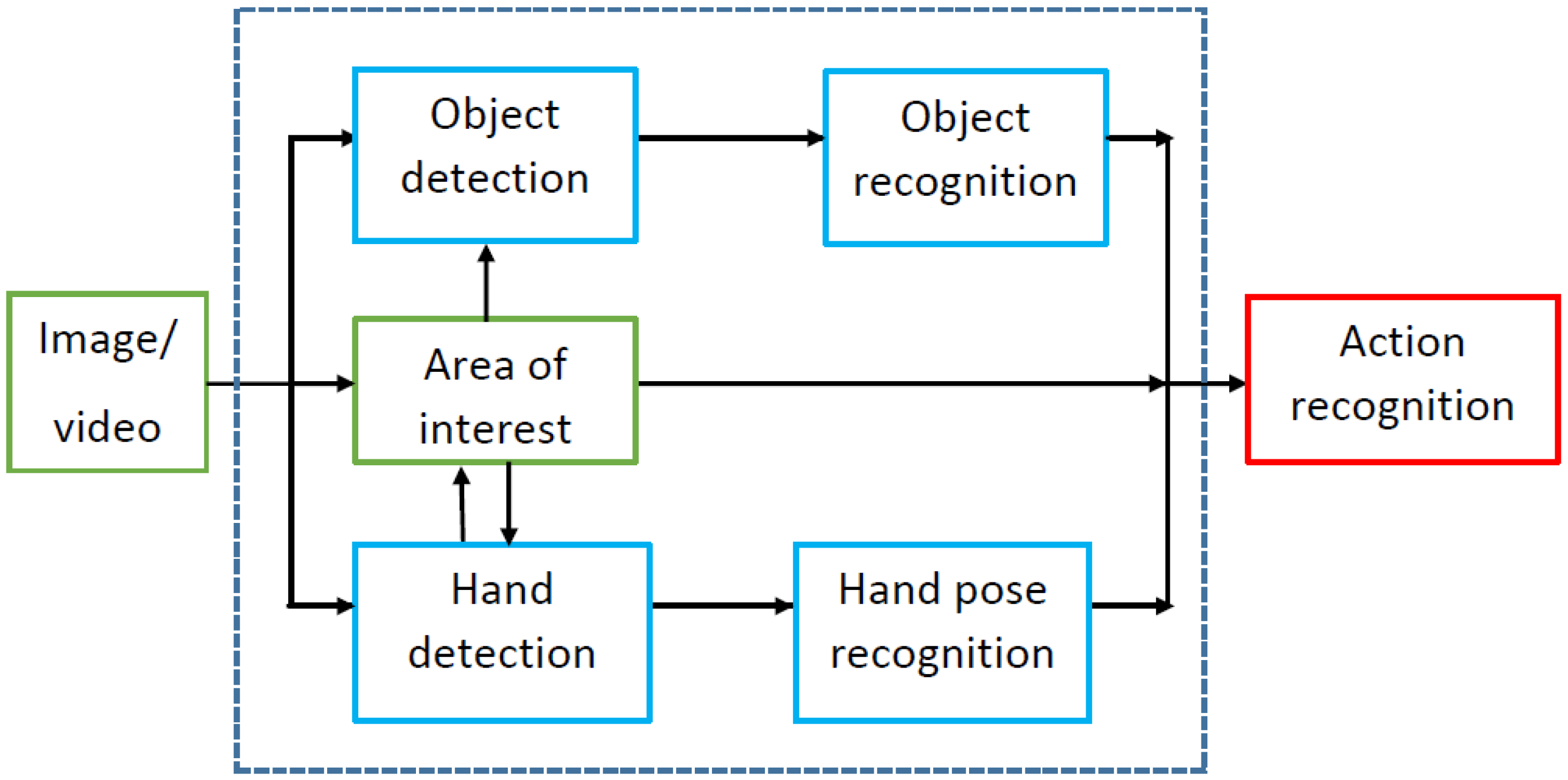
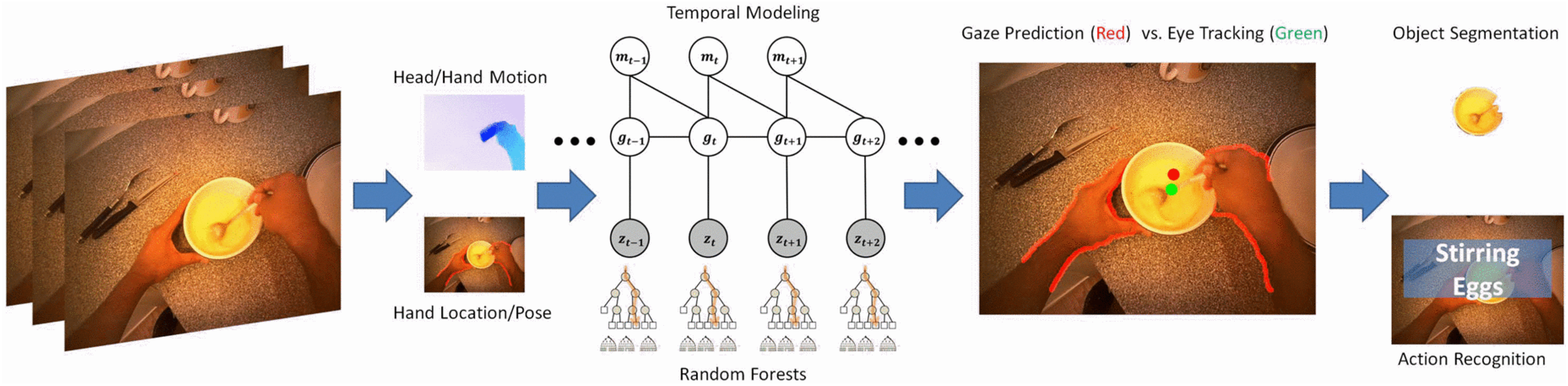
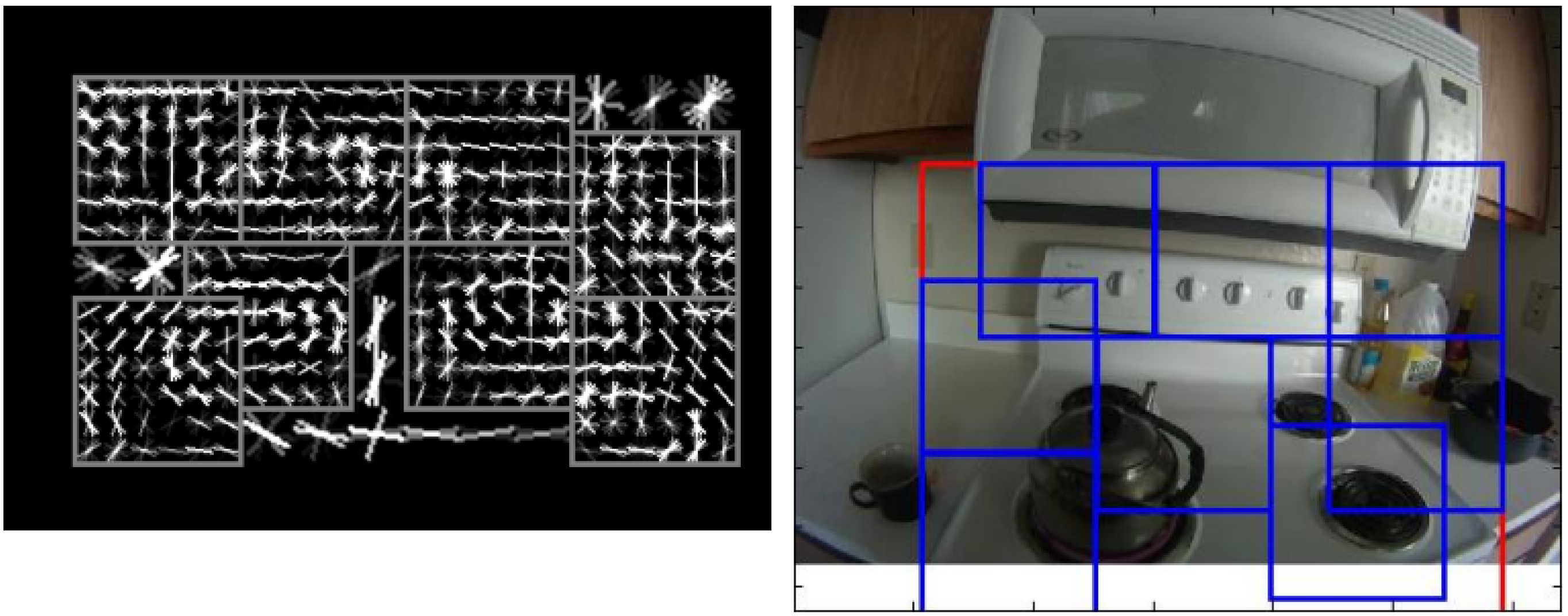
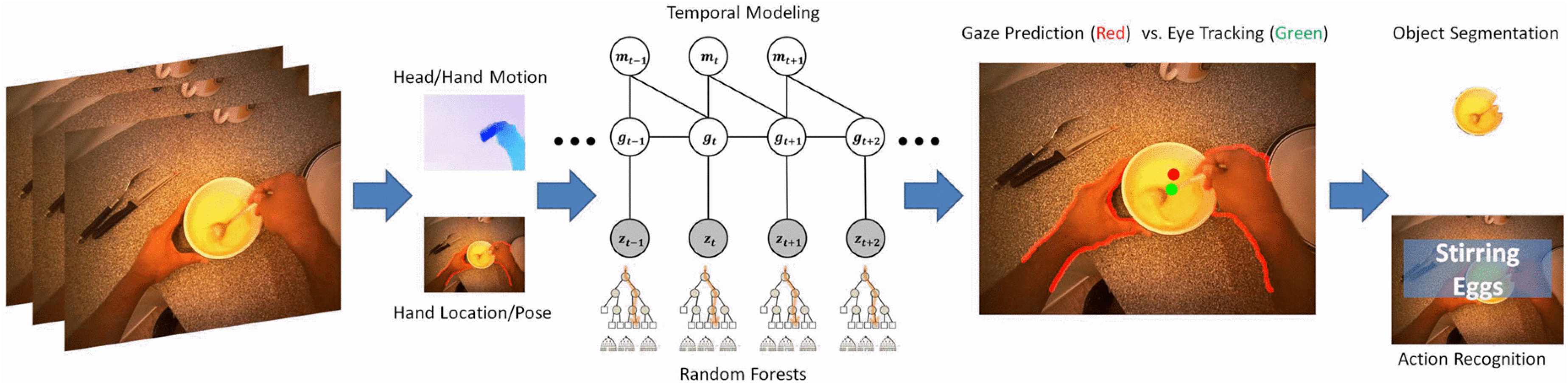
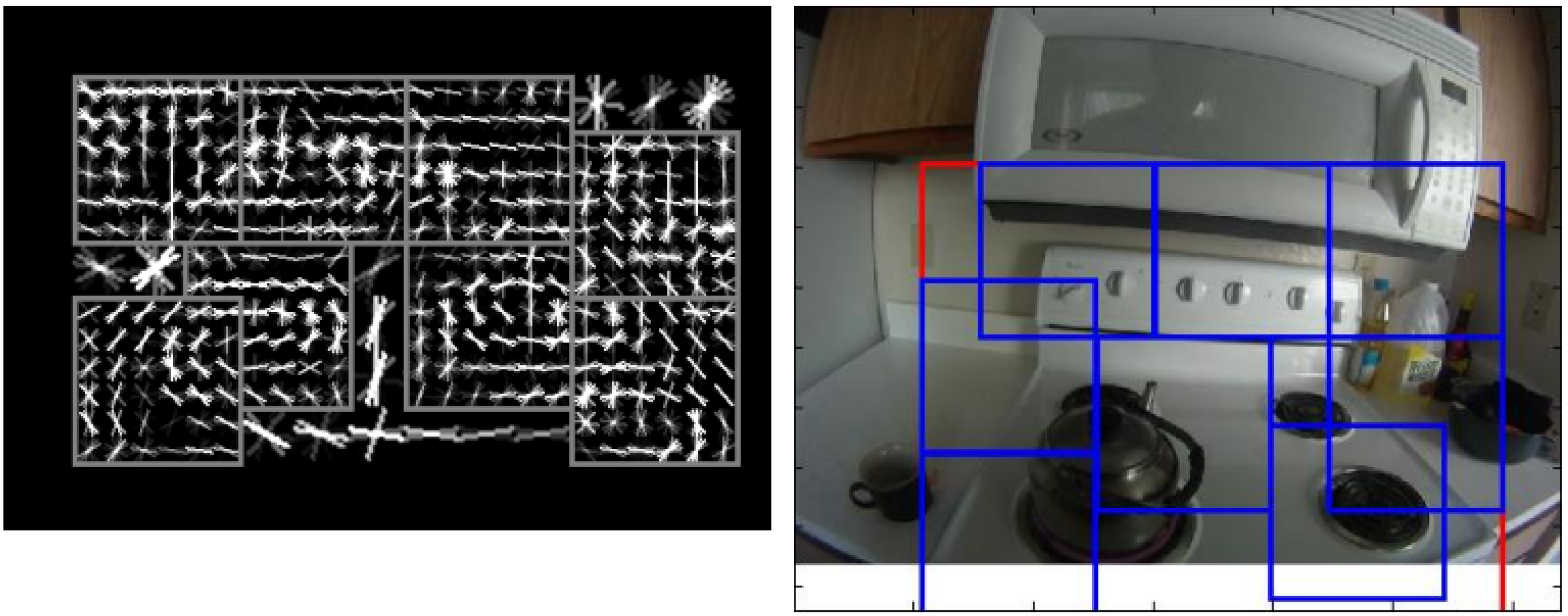
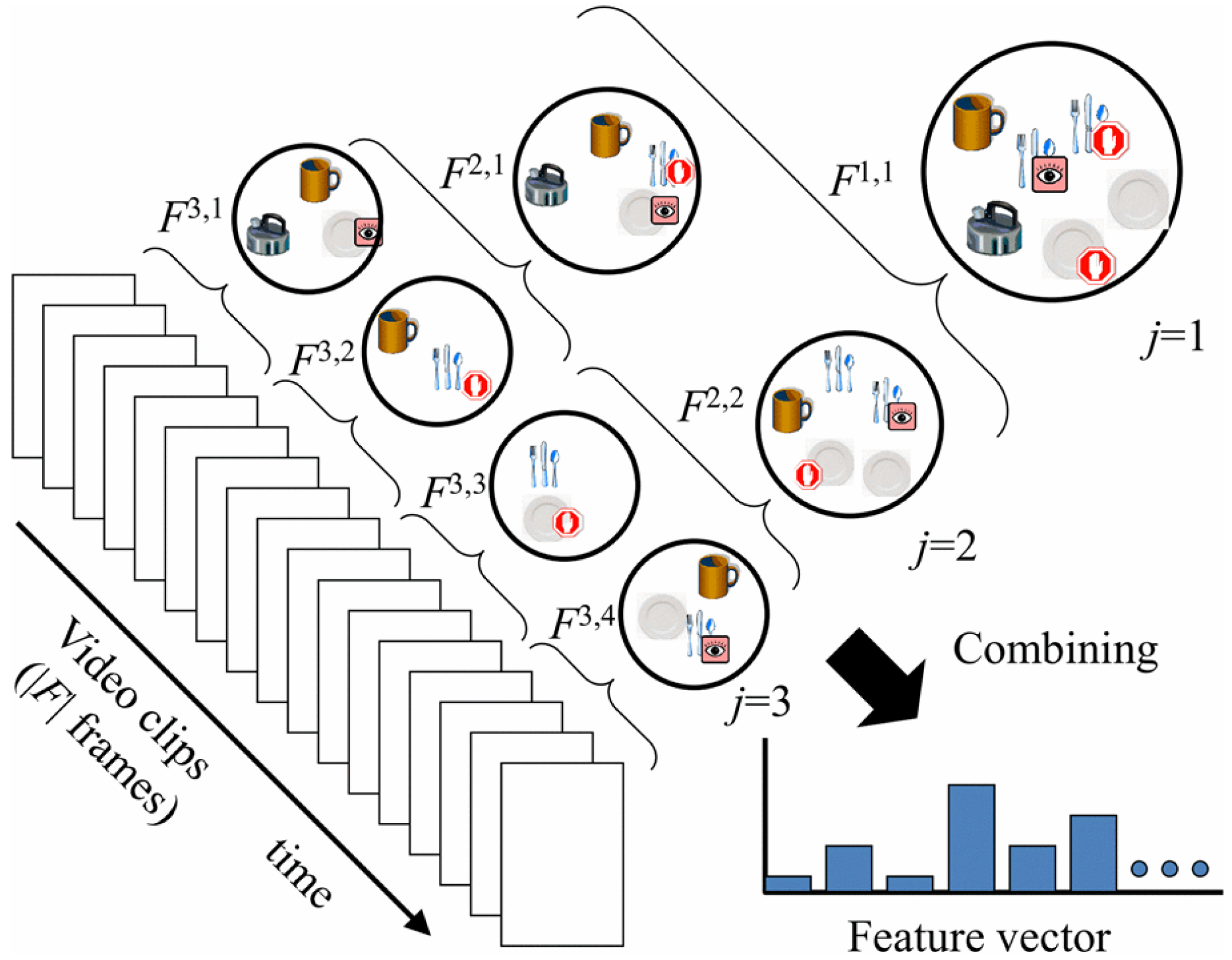
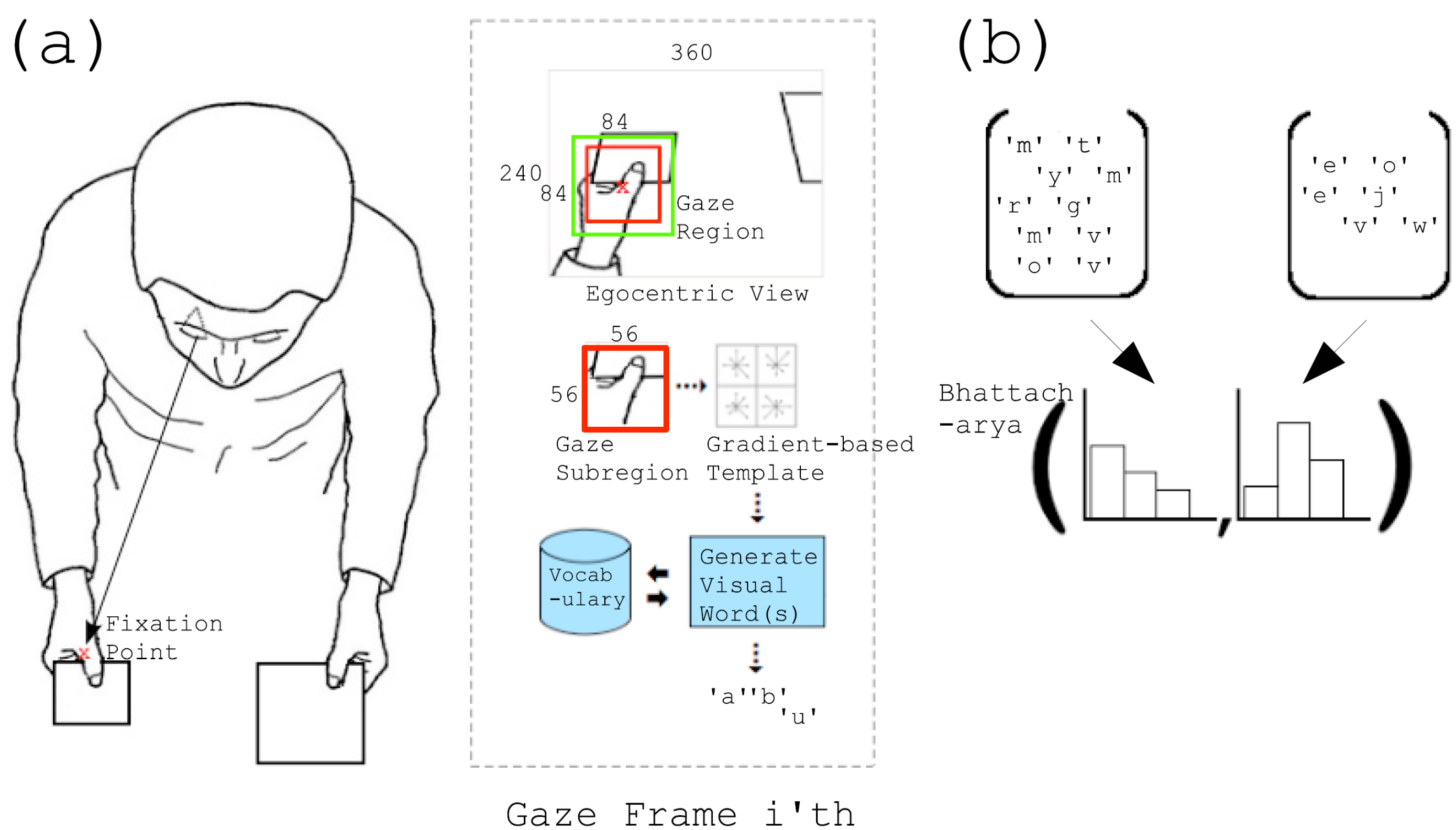
2.1. Detection of the Area of Interest
2.2. Object Detection and Recognition
- Salient/non-salient objects: objects in egocentric videos that are fixated, i.e., focused on by the user’s gaze or not;
- Manipulated/non-manipulated objects: objects in egocentric videos that are in hands or not;
- Active/passive objects: objects that are relevant to tasks, i.e., salient or manipulated, or not.
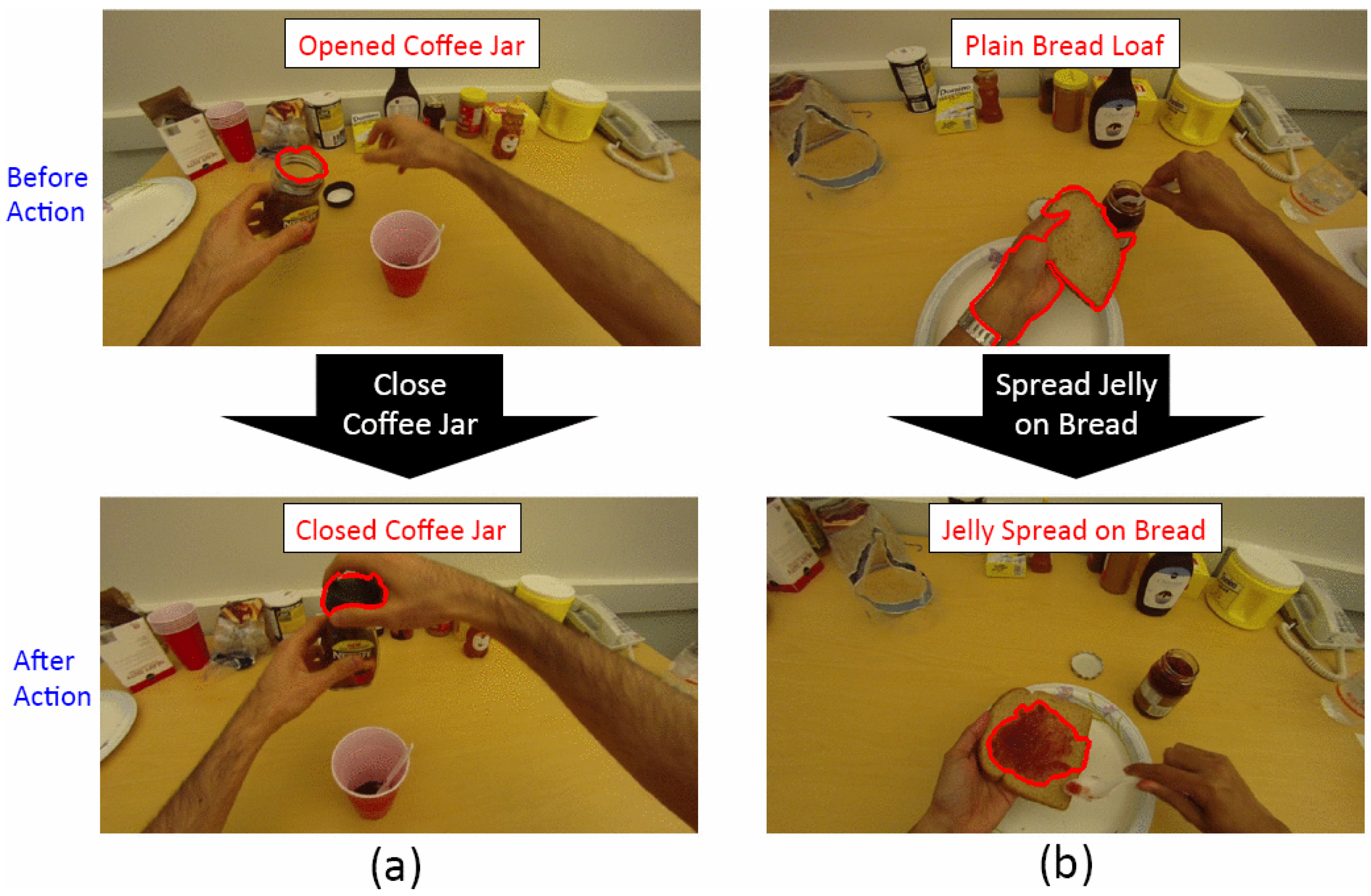
- Multi-state objects: objects that have changes in terms of colour or shape.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Target | Paper Year | Approach | Dataset | Results |
|---|---|---|---|---|
| [38] 2009 | Standard SIFT + multi-class SVM | Intel 42 objects | 12% | |
| [19] 2010 | Background segmentation + temporal integration + SIFT, HOG + SVM | Intel 42 objects | 86% | |
| [18] 2011 | Background segmentation + multiple instance learning + transductive SVM [49] | GTEA | in a table, but stated 35% according to [28] | |
| Active objects (manipulated or observed) | [13] 2012 | Background segmentation + colour and texture histogram + SVM super-pixel classifier | GTEA Gaze, GTEA Gaze+ | n/a |
| [11] 2012 | Part-based object detector (latent SVM) on active images + spatial + skin detector | ADL | n/a | |
| [12] 2014 | Part-based object detector (latent SVM) + “salient” assignment based on estimated gaze point | ADL | n/a | |
| [28] 2014, [14] 2013 | Visual attention maps (spatial + geometry + temporal) combined with SURF + BoVW+ SVM | GTEA, GTEA Gaze, ADL | 36.8% 12% | |
| [27] 2014 | Their own dataset | 50% | ||
| General objects (All objects in the scene) | [11] 2012 | Part-based object detector (2010) + latent SVM | ADL | 19.9% fridge to 69% TV |
2.3. Hand Detection and Recognition

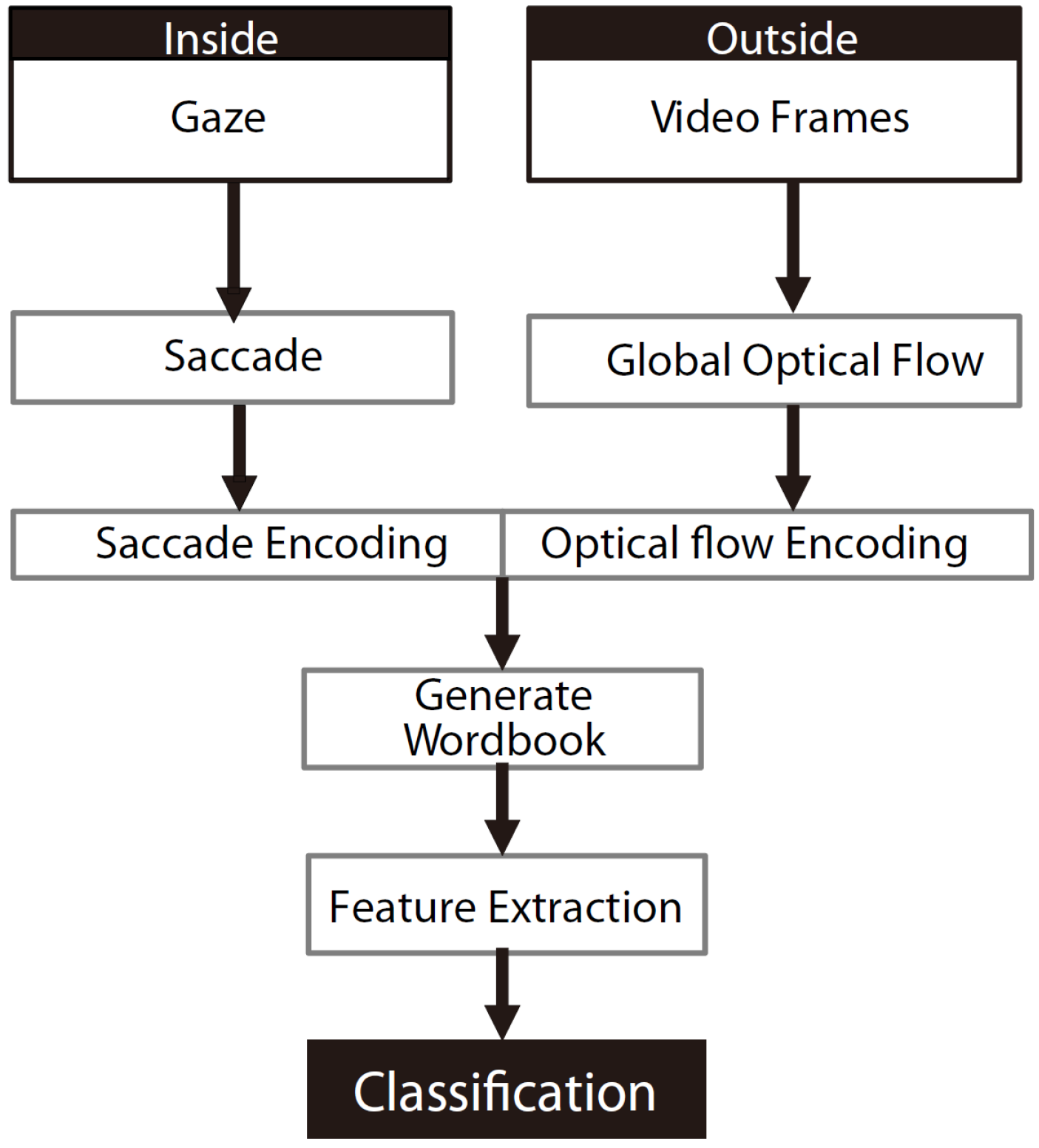
3. Recognition of Elementary Actions
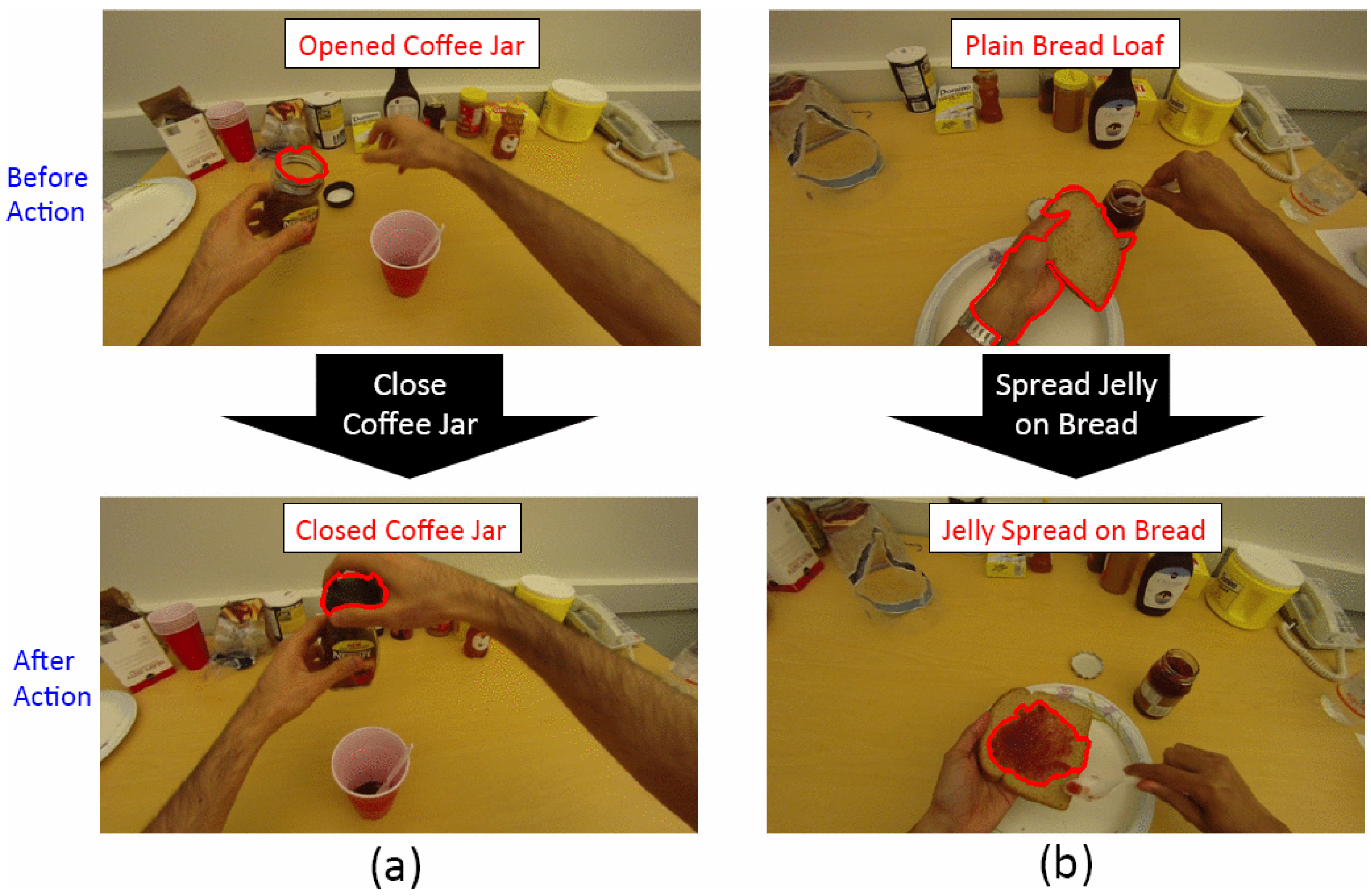
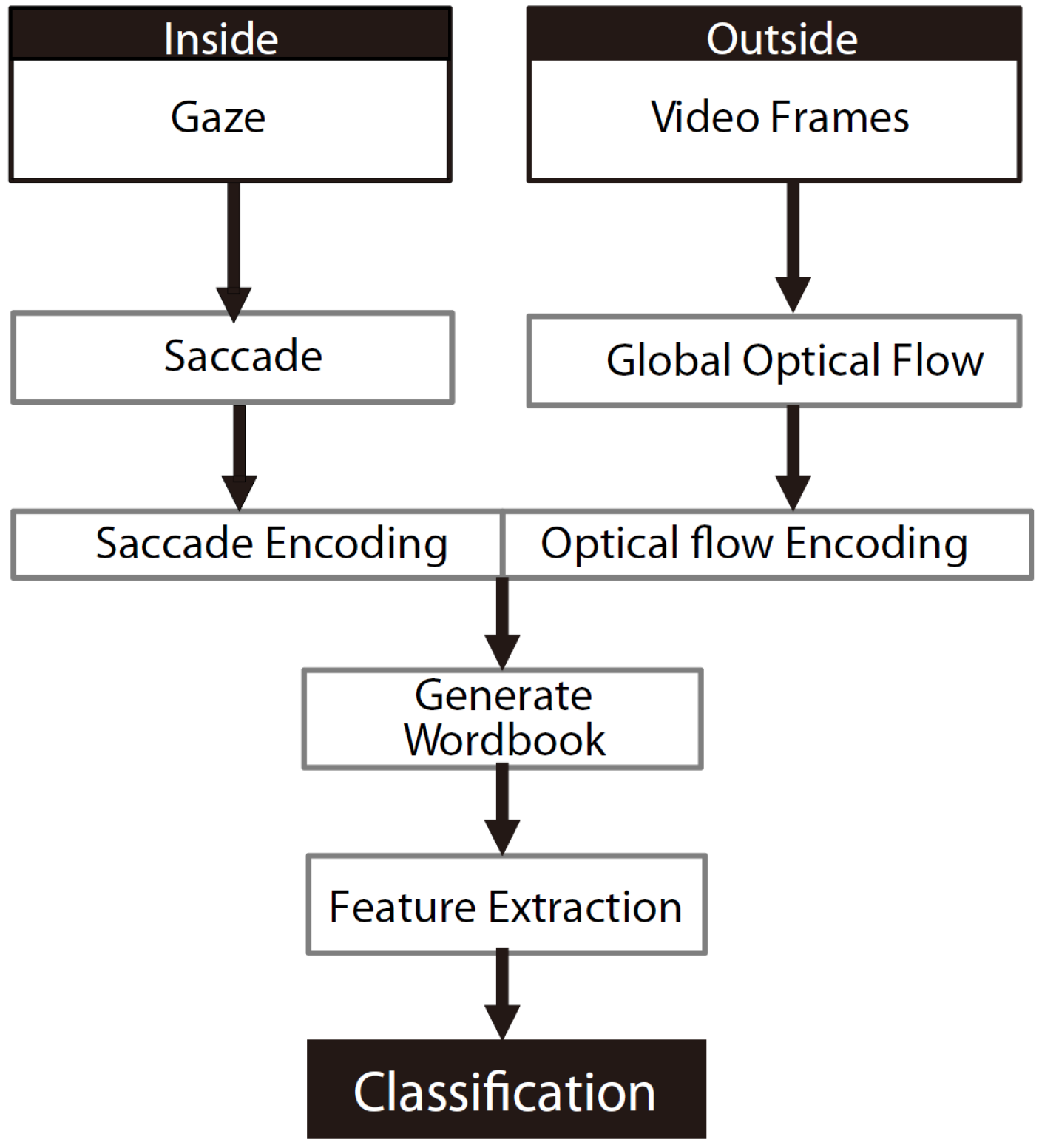
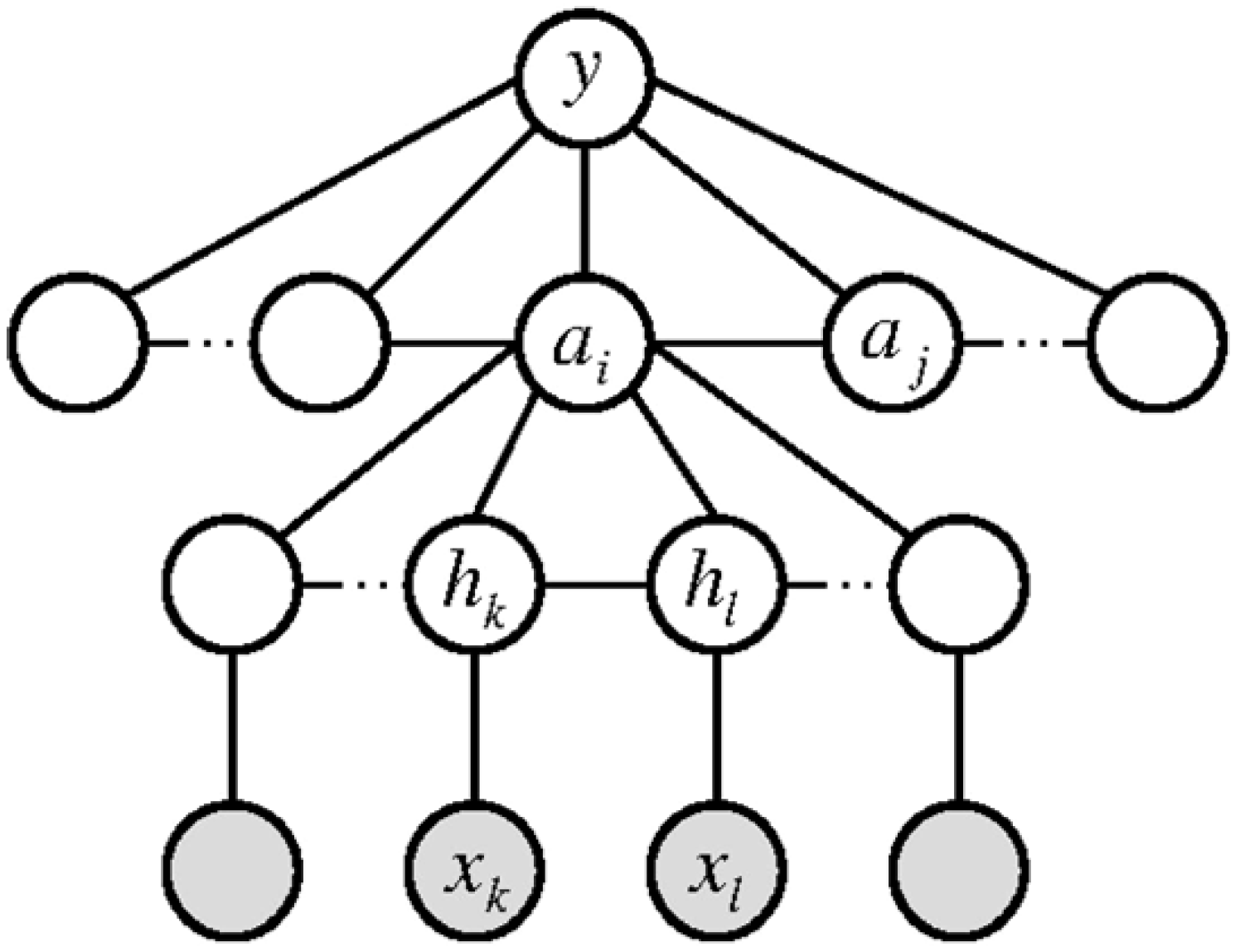
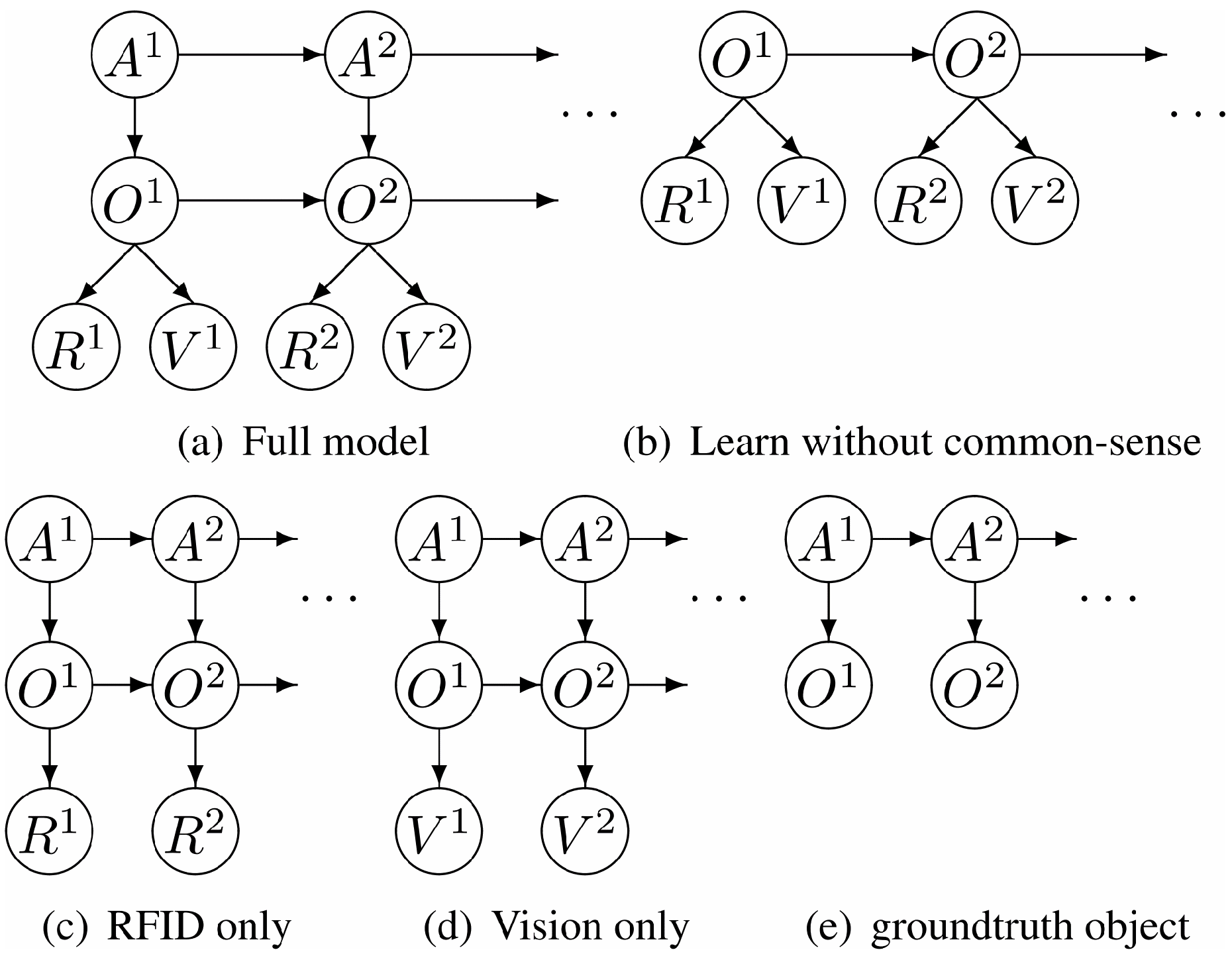
4. Recognition of Complex Activities
- Activity is a combination of active objects and hand movements [20];
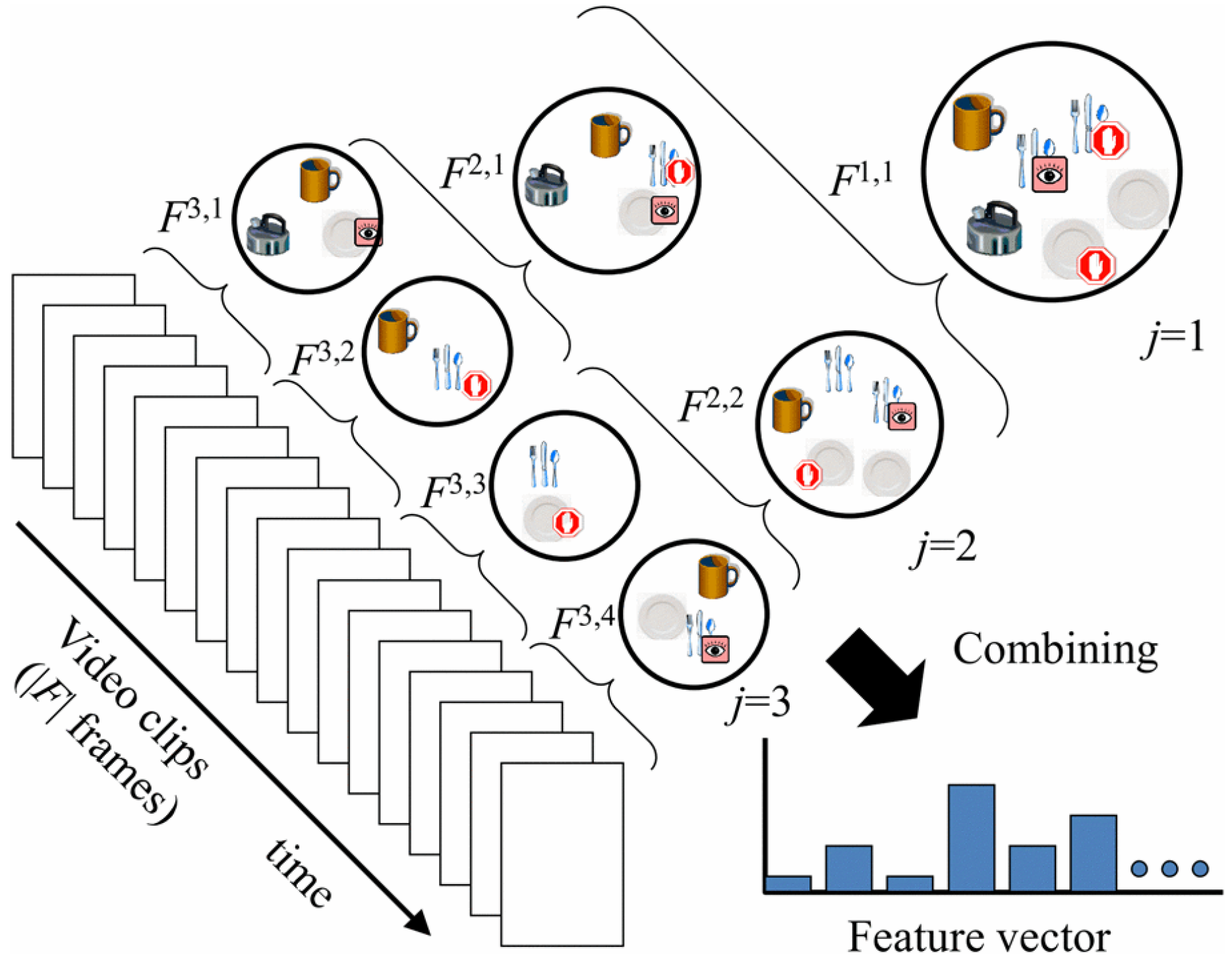

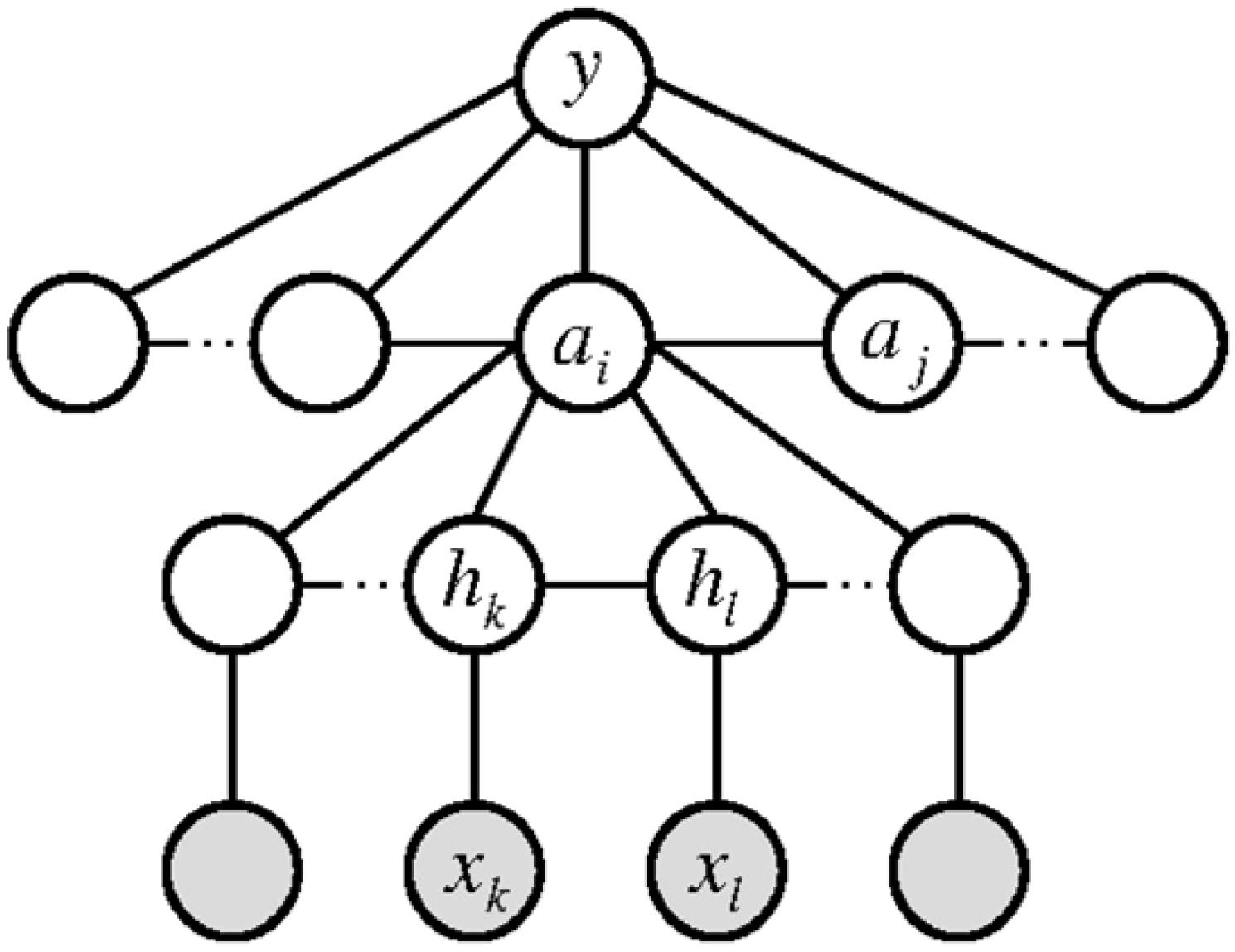
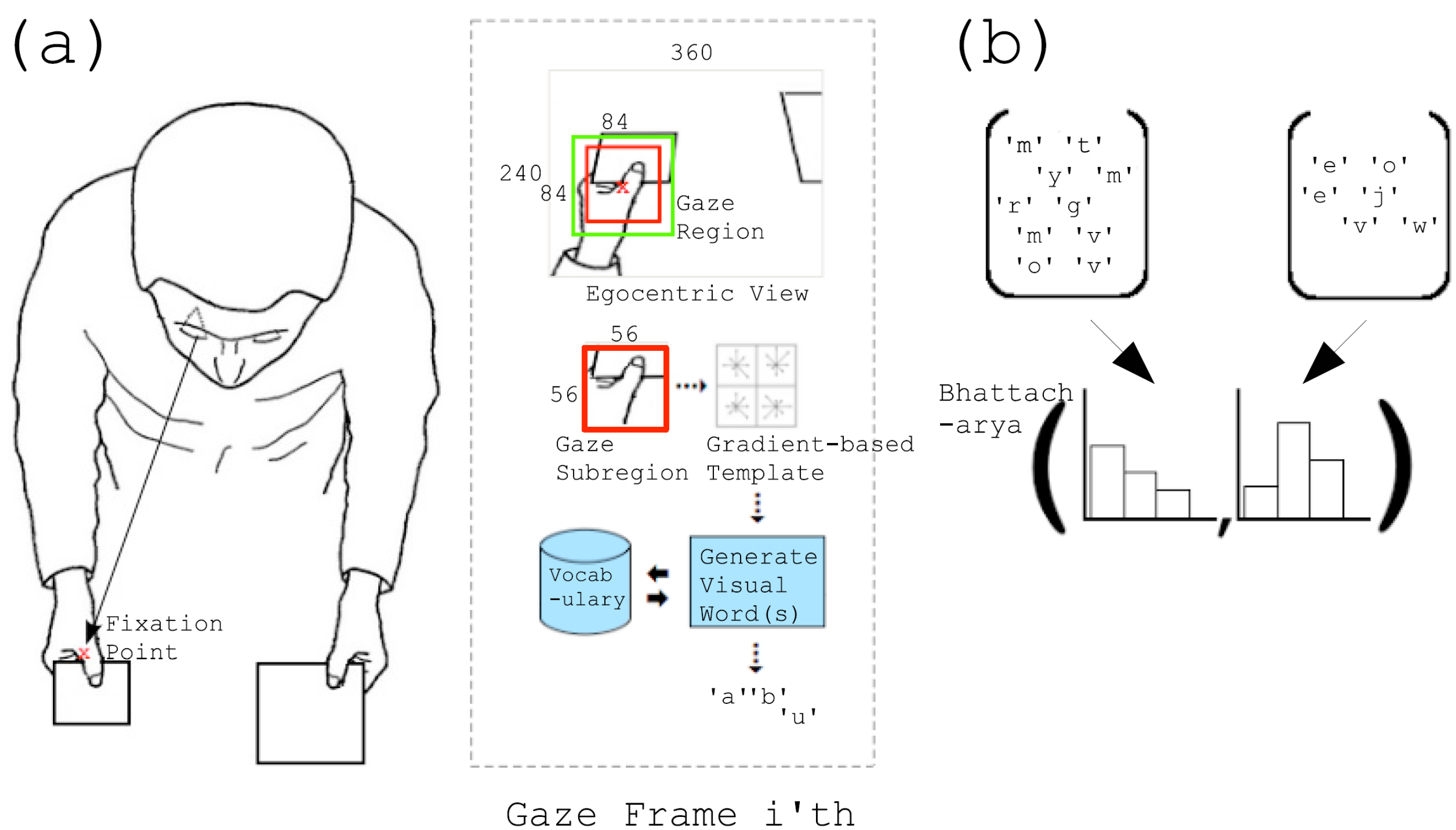
5. Relevant Datasets
- Constrained scenarios: the subjects execute a set of activities in the same environment with the same objects involved, e.g., in a lab setting.
- Unconstrained scenarios: the subjects perform activities in different environments, and objects of the same category, but different appearance are involved, e.g., at home.
| Name | Description | URL | Citations |
| Activities of Daily Living (ADL) [11] | Unconstrained: A dataset of 1 million frames of dozens of people performing unscripted, everyday activities. The dataset is annotated with activities, object tracks, hand positions and interaction events. | http://people.csail.mit.edu/hpirsiav/codes/ADLdataset/adl.html | 143 |
| The University of Texas at Austin Egocentric (UT Ego) Dataset [80] | Unconstrained: The UT Ego Dataset contains 4 videos captured from head-mounted cameras. Each video is about 3–5 h long, captured in a natural, uncontrolled setting. They used the Looxcie wearable camera, which captures video at 15 fps at 320 × 480 resolution. The videos capture a variety of daily activities. | http://vision.cs.utexas.edu/projects/egocentric/index.html | 134 |
| First-person social interactions dataset [81] | Unconstrained: This dataset contains day-long videos of 8 subjects spending their day at Disney World Resort in Orlando, Florida. The cameras are mounted on a cap worn by subjects. Elanannotations for the number of active participants in the scene and the type of activity: walking, waiting, gathering, sitting, buying something, eating, etc. | http://ai.stanford.edu/~alireza/Disney/ | 100 |
| Carnegie Mellon University Multi-Modal Activity Database (CMU-MMAC) [67] | Constrained: Multimodal dataset of 18 subjects cooking 5 different recipes (brownies, pizza, etc.) containing visual, audio, body motion capture and IMU data. Each frame is labelled with an action, such as take oil or crack egg. | http://kitchen.cs.cmu.edu/ | 83 |
| Georgia Tech Egocentric Activities (GTEA) [18] | Constrained: This dataset contains 7 types of daily activities, each performed by 4 different subjects. The camera is mounted on a cap worn by the subject. | http://ai.stanford.edu/~alireza/GTEA/ | 74 |
| Georgia Tech Egocentric Activities-Gaze+ [13] | Constrained: This dataset consists of 7 meal preparation activities collected using eye-tracking glasses, each performed by 10 subjects. Subjects perform the activities based on the given cooking recipes. | http://ai.stanford.edu/~alireza/GTEA_Gaze_Website/ | 63 |
| EDSH-kitchen [50] | Unconstrained: A video was taken in a kitchenette area while making tea. | https://www.youtube.com/watch?v=N756YmLpZyY | 58 |
| Zoombie Dataset [50] | Unconstrained: This dataset consists of three ego-centric videos containing indoor and outdoor scenes where hands are purposefully extended outwards to capture the change in skin colour. | http://www.cs.cmu.edu/~kkitani/datasets/ | 58 |
| Jet Propulsion Laboratory (JPL) First-person Interaction Dataset [69] | Constrained: This dataset is composed of human activity videos taken from a first-person viewpoint. The dataset particularly aims to provide first-person videos of interaction-level activities, recording how things visually look from the perspective (i.e., viewpoint) of a person/robot participating in such physical interactions. | http://michaelryoo.com/jpl-interaction.html | 46 |
| Name | Description | URL | Citations |
| Intel 42 Egocentric Objects dataset [38] | Unconstrained: This is a dataset for the recognition of handled objects using a wearable camera. It includes ten video sequences from two human subjects manipulating 42 everyday object instances. | Not currently available | 33 |
| The Hebrew University of Jerusalem (HUJI) EgoSeg Dataset [82] | Unconstrained: This dataset consists of 29 videos captured from an ego-centric camera annotated in Elan format. The videos prefixed with “youtube*” were downloaded from YouTube; the rest of the videos were taken by the Hebrew University of Jerusalem researchers and contain various daily activities. | http://www.vision.huji.ac.il/egoseg/videos/dataset.html | 18 |
| National University of Singapore (NUS) First-person Interaction Dataset [70] | Unconstrained: 260 videos including 8 interactions in 2 perspectives, third-person and first-person) to create a total of 16 action classes, such as handshake and open doors, captured by a GoPro Camera | https://sites.google.com/site/sanathn/Datasets | 5 |
| LENA [74] | Unconstrained: This Google Glass life-logging dataset contains 13 distinct activities performed by 10 different subjects. Each subject recorded 2 clips for one activity. Therefore, each activity category has 20 clips. Each clip takes exactly 30 seconds. Their set of activities are: watching videos, reading, using the Internet, walking straightly, walking back and forth, running, eating, walking up and downstairs, talking on the phone, talking to people, writing, drinking and housework. | http://people.sutd.edu.sg/~1000892/dataset | 2 |
6. Discussion and Conclusions
- Current DBN systems for activity recognition, which exploit the order in which the actions take place, are sensitive to noise, as there could be not only one, but multiple orders in which an activity can be completed. Therefore, another approach that takes into account alternative orders in which actions occur within an activity should be investigated; and
- The problem of intra-class variation in object recognition in an unconstrained environment can be tackled by bio-inspired algorithms motivated by the idea that an object with its variations shares the same characteristics.
Author Contributions
Conflicts of Interest
References
- European Commission (DG ECFIN) and the Economic Policy Committee (AWG). The 2015 Ageing Report: Underlying Assumptions and Projection Methodologies. 2015. Available online: http://ec.europa.eu/economy_finance/publications/european_economy/2014/pdf/ee8|_en.pdf (accessed on 31 December 2015).
- Colby, S.L.; Ortman, J.M. Projections of the Size and Composition of the US Population: 2014 to 2060. Available online: https://www.census.gov/content/dam/Census/library/publications/2015/demo/p25-1143.pdf (accessed on 31 December 2015).
- European Commission. Active Ageing: Special Eurobarometer 378. 2012. Available online: http://ec.europa.eu/public_opinion/archives/ebs/ebs_378_en.pdf (accessed on 31 December 2015).
- Suzuki, T.; Murase, S.; Tanaka, T.; Okazawa, T. New approach for the early detection of dementia by recording in-house activities. Telemed. J. E Health 2007, 13, 41–44. [Google Scholar] [CrossRef] [PubMed]
- BREATHE Consortium. BREATHE—Platform for Self-Assessment and Efficient Management for Informal Caregivers. Available online: http://www.breathe-project.eu (accessed on 20 October 2015).
- Cardinaux, F.; Bhowmik, D.; Abhayaratne, C.; Hawley, M.S. Video based technology for ambient assisted living: A review of the literature. J. Ambient Intell. Smart Environ. 2011, 3, 253–269. [Google Scholar]
- Chaaraoui, A.A.; Padilla-López, J.R.; Ferrández-Pastor, F.J.; Nieto-Hidalgo, M.; Flórez-Revuelta, F. A vision-based system for intelligent monitoring: Human behaviour analysis and privacy by context. Sensors 2014, 14, 8895–8925. [Google Scholar] [CrossRef] [PubMed]
- Fathi, A.; Farhadi, A.; Rehg, J.M. Understanding egocentric activities. In Proceedings of the 2011 IEEE International Conference on Computer Vision (ICCV), Barcelona, Spain, 6–13 November 2011; pp. 407–414.
- Chaaraoui, A.A.; Climent-Pérez, P.; Flórez-Revuelta, F. A review on vision techniques applied to human behaviour analysis for ambient-assisted living. Expert Syst. Appl. 2012, 39, 10873–10888. [Google Scholar] [CrossRef]
- Betancourt, A.; Morerio, P.; Regazzoni, C.; Rauterberg, M. The Evolution of first person vision methods: A survey. IEEE Trans. Circuits Syst. Video Technol. 2015, 25, 744–760. [Google Scholar] [CrossRef]
- Pirsiavash, H.; Ramanan, D. Detecting activities of daily living in first-person camera views. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012; pp. 2847–2854.
- Matsuo, K.; Yamada, K.; Ueno, S.; Naito, S. An attention-based activity recognition for egocentric video. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Columbus, Ohio, USA, 23–28 June 2014; pp. 565–570.
- Fathi, A.; Li, Y.; Rehg, J.M. Learning to recognize daily actions using gaze. In Computer Vision–ECCV 2012; Springer: Cham, Switzerland, 2012. [Google Scholar]
- González Díaz, I.; Buso, V.; Benois-Pineau, J.; Bourmaud, G.; Megret, R. Modeling Instrumental Activities of Daily Living in Egocentric Vision as Sequences of Active Objects and Context for Alzheimer Disease Research. In Proceedings of the 1st ACM International Workshop on Multimedia Indexing and Information Retrieval for Healthcare, Barcelona, Spain, 21–25 October 2013.
- Ogaki, K.; Kitani, K.M.; Sugano, Y.; Sato, Y. Coupling eye-motion and ego-motion features for first-person activity recognition. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Providence, RI, USA, 16–21 June 2012; pp. 1–7.
- Shiga, Y.; Toyama, T.; Utsumi, Y.; Kise, K.; Dengel, A. Daily Activity Recognition Combining Gaze Motion and Visual Features. In Proceedings of the 2014 ACM International Joint Conference on Pervasive and Ubiquitous Computing: Adjunct Publication, Seattle, WA, USA, 13–17 September 2014.
- Karaman, S.; Benois-Pineau, J.; Dovgalecs, V.; Mégret, R.; Pinquier, J.; André-Obrecht, R.; Gaëstel, Y.; Dartigues, J.F. Hierarchical Hidden Markov Model in detecting activities of daily living in wearable videos for studies of dementia. Multimed. Tools Appl. 2014, 69, 743–771. [Google Scholar] [CrossRef]
- Fathi, A.; Ren, X.; Rehg, J.M. Learning to recognize objects in egocentric activities. In Proceedings of the 2011 IEEE International Conference on Computer Vision and Pattern Recognition (CVPR), Colorado Springs, CO, USA, 20–25 June 2011; pp. 3281–3288.
- Ren, X.; Gu, C. Figure-ground segmentation improves handled object recognition in egocentric video. In Proceedings of the 2010 IEEE International Conference on Computer Vision and Pattern Recognition (CVPR), San Francisco, CA, USA, 13–18 June 2010; pp. 3137–3144.
- Yu, C.; Ballard, D.H. Understanding Human Behaviors Based on Eye-Head-Hand Coordination. In Proceedings of the Second International Workshop on Biologically Motivated Computer Vision, TÃijbingen, Germany, 22–24 November 2002.
- Walther, D.; Koch, C. Modeling attention to salient proto-objects. Neural Netw. 2006, 19, 1395–1407. [Google Scholar] [CrossRef] [PubMed]
- Tsukada, A.; Shino, M.; Devyver, M.; Kanade, T. Illumination-free gaze estimation method for first-person vision wearable device. In Proceedings of the 2011 IEEE International Conference on Computer Vision Workshops (ICCVW), Barcelona, Spain, 6–13 November 2011; pp. 2084–2091.
- Yamada, K.; Sugano, Y.; Okabe, T.; Sato, Y.; Sugimoto, A.; Hiraki, K. Can saliency map models predict human egocentric visual attention? In Proceedings of the Asian Conference on Computer Vision (ACCV 2010) Workshops, Queenstown, New Zealand, 8–12 November 2010; Springer: Berlin, Germany, 2011; pp. 420–429. [Google Scholar]
- Borji, A.; Sihite, D.N.; Itti, L. Probabilistic learning of task-specific visual attention. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012; pp. 470–477.
- Cheng, M.; Mitra, N.J.; Huang, X.; Torr, P.H.; Hu, S. Global contrast based salient region detection. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 569–582. [Google Scholar] [CrossRef] [PubMed]
- Yamada, K.; Sugano, Y.; Okabe, T.; Sato, Y.; Sugimoto, A.; Hiraki, K. Attention prediction in egocentric video using motion and visual saliency. In Advances in Image and Video Technology; Springer: Berlin, Germany, 2012; pp. 277–288. [Google Scholar]
- Buso, V.; Benois-Pineau, J.; Domenger, J.P. Geometrical Cues in Visual Saliency Models for Active Object Recognition in Egocentric Videos. In Proceedings of the 1st International Workshop on Perception Inspired Video Processing, Orlando, FL, USA, 3–7 November 2014.
- González-Díaz, I.; Benois-Pineau, J.; Buso, V.; Boujut, H. Fusion of Multiple Visual Cues for Object Recognition in Videos. In Fusion in Computer Vision; Springer: Cham, Switzerland, 2014; pp. 79–107. [Google Scholar]
- Boujut, H.; Benois-Pineau, J.; Megret, R. Fusion of multiple visual cues for visual saliency extraction from wearable camera settings with strong motion. In Proceedings of the European Conference on Computer Vision (ECCV 2012) Workshops and Demonstrations, Florence, Italy, 7–13 October 2012.
- Borji, A.; Itti, L. State-of-the-art in visual attention modelling. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 185–207. [Google Scholar] [CrossRef] [PubMed]
- Buso, V.; González-Díaz, I.; Benois-Pineau, J. Goal-oriented top-down probabilistic visual attention model for recognition of manipulated objects in egocentric videos. Signal Process. Image Commun. 2015, 39, 418–431. [Google Scholar] [CrossRef]
- Li, Y.; Fathi, A.; Rehg, J.M. Learning to predict gaze in egocentric video. In Proceedings of the 2013 IEEE International Conference on Computer Vision (ICCV), Sydney, Australia, 8–12 April 2013; pp. 3216–3223.
- Damen, D.; Leelasawassuk, T.; Haines, O.; Calway, A.; Mayol-Cuevas, W. You-do, i-learn: Discovering task relevant objects and their modes of interaction from multi-user egocentric video. In Proceedings of the British Machine Vision Conference 2014, Nottingham, UK, 1–5 September 2014.
- Kang, H.; Hebert, M.; Kanade, T. Discovering object instances from scenes of daily living. In Proceedings of the 2011 IEEE International Conference on Computer Vision (ICCV), Barcelona, Spain, 6–13 November 2011; pp. 762–769.
- Sun, L.; Klank, U.; Beetz, M. EYEWATCHME-3D hand and object tracking for inside out activity analysis. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Kyoto, Japan, 27 September–4 October 2009; pp. 9–16.
- Mishra, A.K.; Aloimonos, Y.; Cheong, L.F.; Kassim, A. Active visual segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 639–653. [Google Scholar] [CrossRef] [PubMed]
- Liu, Y.; Jang, Y.; Woo, W.; Kim, T.K. Video-based object recognition using novel set-of-sets representations. In Proceedings of the 2014 IEEE International Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Columbus, OH, USA, 24–27 June 2014; pp. 533–540.
- Ren, X.; Philipose, M. Egocentric recognition of handled objects: Benchmark and analysis. In Proceedings of the 2009 IEEE International Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Kyoto, Japan, 27 September–4 October 2009; pp. 1–8.
- Brown, M.; Lowe, D.G. Invariant Features from Interest Point Groups. In Proceedings of the British Machine Vision Conference (BMVC), Cardiff, UK, 2–5 September 2002.
- Bay, H.; Ess, A.; Tuytelaars, T.; Van Gool, L. Speeded-up robust features (SURF). Comput. Vis. Image Underst. 2008, 110, 346–359. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), San Diego, CA, USA, 20–26 June 2005; Volume 1, pp. 886–893.
- Wu, J.; Osuntogun, A.; Choudhury, T.; Philipose, M.; Rehg, J.M. A scalable approach to activity recognition based on object use. In Proceedings of the 2007 IEEE International Conference on Computer Vision (ICCV), Rio de Janeiro, Brazil, 14–20 October 2007; pp. 1–8.
- Juan, L.; Gwun, O. A comparison of sift, pca-sift and surf. Int. J. Image Process. 2009, 3, 143–152. [Google Scholar]
- Felzenszwalb, P.F.; Girshick, R.B.; McAllester, D.; Ramanan, D. Object detection with discriminatively trained part-based models. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 1627–1645. [Google Scholar] [CrossRef] [PubMed]
- Felzenszwalb, P.; McAllester, D.; Ramanan, D. A discriminatively trained, multiscale, deformable part model. In Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Anchorage, AK, USA, 24–26 June 2008; pp. 1–8.
- Tomas McCandless, K.G. Object-Centric Spatio-Temporal Pyramids for Egocentric Activity Recognition. In Proceedings of the British Machine Vision Conference, Bristol, UK, 9–13 September 2013.
- Andreopoulos, A.; Tsotsos, J.K. 50 Years of object recognition: Directions forward. Comput. Vis. Image Underst. 2013, 117, 827–891. [Google Scholar] [CrossRef]
- Bramão, I.; Faísca, L.; Petersson, K.M.; Reis, A. The Contribution of Color to Object Recognition; InTech: Rijeka, Croatia, 2012. [Google Scholar]
- Joachims, T. Transductive Inference for Text Classification Using Support Vector Machines. In Proceedings of the Sixteenth International Conference on Machine Learning, Bled, Slovenia, 27–30 June 1999; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 1999; pp. 200–209. [Google Scholar]
- Li, C.; Kitani, K.M. Pixel-level hand detection in ego-centric videos. In Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Portland, OR, USA, 23–28 June 2013; pp. 3570–3577.
- Wang, H.; Kläser, A.; Schmid, C.; Liu, C.L. Dense trajectories and motion boundary descriptors for action recognition. Int. J. Comput. Vis. 2013, 103, 60–79. [Google Scholar] [CrossRef]
- Serra, G.; Camurri, M.; Baraldi, L.; Benedetti, M.; Cucchiara, R. Hand Segmentation for Gesture Recognition in Ego-Vision. In Proceedings of the 3rd ACM International Workshop on Interactive Multimedia on Mobile & Portable Devices, Barcelona, Spain, 21–25 October 2013.
- Betancourt, A.; López, M.M.; Regazzoni, C.S.; Rauterberg, M. A sequential classifier for hand detection in the framework of egocentric vision. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Columbus, OH, USA, 23–28 June 2014; pp. 600–605.
- Zariffa, J.; Popovic, M.R. Hand contour detection in wearable camera video using an adaptive histogram region of interest. J. NeuroEng. Rehabil. 2013. [Google Scholar] [CrossRef] [PubMed]
- Li, C.; Kitani, K.M. Model recommendation with virtual probes for egocentric hand detection. In Proceedings of the 2013 IEEE International Conference on Computer Vision (ICCV), Sydney, Australia, 1–8 December 2013; pp. 2624–2631.
- Rogez, G.; Khademi, M.; Supančič, J., III; Montiel, J.M.M.; Ramanan, D. 3D Hand Pose Detection in Egocentric RGB-D Images. In Computer Vision (ECCV 2014) Workshops; Springer: Cham, Switzerland, 2014; pp. 356–371. [Google Scholar]
- Lee, S.R.; Bambach, S.; Crandall, D.J.; Franchak, J.M.; Yu, C. This hand is my hand: A probabilistic approach to hand disambiguation in egocentric video. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Columbus, OH, USA, 23–28 June 2014; pp. 557–564.
- Morerio, P.; Marcenaro, L.; Regazzoni, C.S. Hand detection in first person vision. In Proceedings of the 16th International Conference on Information Fusion (FUSION), Istanbul, Turkey, 9–12 July 2013; pp. 1502–1507.
- Pai, Y.T.; Lee, L.T.; Ruan, S.J.; Chen, Y.H.; Mohanty, S.; Kougianos, E. Honeycomb model based skin colour detector for face detection. Int. J. Comput. Appl. Technol. 2010, 39, 93–100. [Google Scholar] [CrossRef]
- Yang, G.; Li, H.; Zhang, L.; Cao, Y. Research on a skin color detection algorithm based on self-adaptive skin color model. In Proceedings of the 2010 IEEE International Conference on Communications and Intelligence Information Security (ICCIIS), Nanning, China, 13–14 October 2010; pp. 266–270.
- Oliva, A.; Torralba, A. Modeling the shape of the scene: A holistic representation of the spatial envelope. Int. J. Comput. Vis. 2001, 42, 145–175. [Google Scholar] [CrossRef]
- Sarkar, A.R.; Sanyal, G.; Majumder, S. Hand gesture recognition systems: A survey. Int. J. Comput. Appl. 2013, 71, 25–37. [Google Scholar]
- Surie, D.; Pederson, T.; Lagriffoul, F.; Janlert, L.E.; Sjölie, D. Activity recognition using an egocentric perspective of everyday objects. In Ubiquitous Intelligence and Computing; Lecture Notes in Computer Science; Indulska, J., Ma, J., Yang, L., Ungerer, T., Cao, J., Eds.; Springer: Berlin, Germany; Heidelberg, Germany, 2007; Volume 4611, pp. 246–257. [Google Scholar]
- Fathi, A.; Rehg, J.M. Modeling actions through state changes. In Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Portland, OR, USA, 23–28 June 2013; pp. 2579–2586.
- Behera, A.; Hogg, D.; Cohn, A. Egocentric activity monitoring and recovery. In Computer Vision-ACCV 2012; Lecture Notes in Computer Science; Lee, K., Matsushita, Y., Rehg, J., Hu, Z., Eds.; Springer: Berlin, Germany, 2013; Volume 7726, pp. 519–532. [Google Scholar]
- Behera, A.; Chapman, M.; Cohn, A.G.; Hogg, D.C. Egocentric activity recognition using histograms of oriented pairwise relations. In Proceedings of the 9th International Conference on Computer Vision Theory and Applications (VISSAP), Lisbon, Portugal, 5–8 January 2014; SciTePress: Setúbal, Portugal; Volume 2, pp. 22–30.
- Spriggs, E.H.; de la Torre, F.; Hebert, M. Temporal segmentation and activity classification from first-person sensing. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Miami, FL, USA, 20–25 June 2009; pp. 17–24.
- Yu, C.; Ballard, D.H. Learning to recognize human action sequences. In Proceedings of the 2nd IEEE International Conference on Development and Learning, Cambridge, MA, USA, 12–15 June 2002; pp. 28–33.
- Ryoo, M.S.; Matthies, L. First-person activity recognition: What are they doing to me? In Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Portland, OR, USA, 23–28 June 2013; pp. 2730–2737.
- Narayan, S.; Kankanhalli, M.S.; Ramakrishnan, K.R. Action and interaction recognition in first-person videos. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Columbus, OH, USA, 23–28 June 2014; pp. 526–532.
- Sundaram, S.; Cuevas, W.W.M. High level activity recognition using low resolution wearable vision. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition Workshops, Miami Beach, FL, USA, 20–25 June 2009; pp. 25–32.
- Yan, Y.; Ricci, E.; Liu, G.; Sebe, N. Recognizing daily activities from first-person videos with multi-task clustering. In Asian Conference on Computer Vision (ACCV); Springer: Cham, Switzerland, 2014; pp. 522–537. [Google Scholar]
- Hipiny, I.M.; Mayol-Cuevas, W. Recognising Egocentric Activities from Gaze Regions with Multiple-Voting Bag of Words; Technical Report CSTR-12-003; University of Bristol: Bristol, UK, 2012. [Google Scholar]
- Song, S.; Chandrasekhar, V.; Cheung, N.M.; Narayan, S.; Li, L.; Lim, J.H. Activity Recognition in Egocentric Life-Logging Videos, Proceedings of the Asian Conference on Computer Vision (ACCV 2014) Workshops, Singapore, Singapore, 1–5 November 2014.
- Doherty, A.R.; Caprani, N.; Conaire, C.Ó.; Kalnikaite, V.; Gurrin, C.; Smeaton, A.F.; O’Connor, N.E. Passively recognising human activities through lifelogging. Comput. Hum. Behav. 2011, 27, 1948–1958. [Google Scholar] [CrossRef]
- Karaman, S.; Benois-Pineau, J.; Mégret, R.; Dovgalecs, V.; Dartigues, J.F.; Gaëstel, Y. Human daily activities indexing in videos from wearable cameras for monitoring of patients with dementia diseases. In Proceedings of the 20th International Conference on Pattern Recognition (ICPR), Istanbul, Turkey, 23–26 August 2010; pp. 4113–4116.
- Csurka, G.; Perronnin, F. Fisher Vectors: Beyond Bag-of-Visual-Words Image Representations. In Computer Vision, Imaging and Computer Graphics. Theory and Applications; Springer: Berlin, Germany, 2011; Volume 229, pp. 28–42. [Google Scholar]
- Hinterstoisser, S.; Lepetit, V.; Ilic, S.; Fua, P.; Navab, N. Dominant orientation templates for real-time detection of texture-less objects. In Proceedings of the 2010 IEEE Internationcal Conference on Computer Vision and Pattern Recognition (CVPR), San Francisco, CA, USA, 13–18 June 2010; pp. 2257–2264.
- Yi, W.; Ballard, D. Recognizing behaviour in hand-eye coordination patterns. Int. J. Hum. Robot. 2009, 6, 337–359. [Google Scholar] [CrossRef] [PubMed]
- Ghosh, J.; Lee, Y.J.; Grauman, K. Discovering important people and objects for egocentric video summarization. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 1346–1353.
- Fathi, A.; Hodgins, J.K.; Rehg, J.M. Social interactions: A first-person perspective. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012; pp. 1226–1233.
- Poleg, Y.; Arora, C.; Peleg, S. Temporal segmentation of egocentric videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 24–27 June 2014; pp. 2537–2544.
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. Imagenet large scale visual recognition challenge. Int. J. Comput. Vision 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Oquab, M.; Bottou, L.; Laptev, I.; Sivic, J. Is object localization for free?–Weakly-supervised learning with convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 685–694.
- Sermanet, P.; Eigen, D.; Zhang, X.; Mathieu, M.; Fergus, R.; LeCun, Y. Overfeat: Integrated recognition, localization and detection using convolutional networks. arXiv preprint. 2013; arXiv:1312.6229. [Google Scholar]
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons by Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nguyen, T.-H.-C.; Nebel, J.-C.; Florez-Revuelta, F. Recognition of Activities of Daily Living with Egocentric Vision: A Review. Sensors 2016, 16, 72. https://doi.org/10.3390/s16010072
Nguyen T-H-C, Nebel J-C, Florez-Revuelta F. Recognition of Activities of Daily Living with Egocentric Vision: A Review. Sensors. 2016; 16(1):72. https://doi.org/10.3390/s16010072
Chicago/Turabian StyleNguyen, Thi-Hoa-Cuc, Jean-Christophe Nebel, and Francisco Florez-Revuelta. 2016. "Recognition of Activities of Daily Living with Egocentric Vision: A Review" Sensors 16, no. 1: 72. https://doi.org/10.3390/s16010072
APA StyleNguyen, T.-H.-C., Nebel, J.-C., & Florez-Revuelta, F. (2016). Recognition of Activities of Daily Living with Egocentric Vision: A Review. Sensors, 16(1), 72. https://doi.org/10.3390/s16010072