1. Introduction
Direction of arrival (DOA) estimation has played an important role in many fields, such as radar, medical imaging and array signal processing [
1,
2]. In the last decades, many classical methods have been developed, among which multiple signal classification (MUSIC) [
3] and estimation of signal parameter via rotational invariance technique. (ESPRIT) [
4] are the most popular and have high resolution for DOA estimation. However, these methods are very sensitive to the number of snapshots, signal to noise ratio (SNR) and the correlation between sources. Small number of snapshots, low SNR and high correlation or coherent sources can all make the performance of these methods degrade severely. More recently, the emerging field of compressed sensing (CS) [
5,
6] has attracted enormous attention and it can reconstruct the sparse source using nonadaptive linear projection measurement obtained by the measurement matrix that satisfies the restricted isometry property (RIP) [
7,
8]. Support denotes the set that contains the indices of the nonzero elements in the sparse source. Once the support is determined, the sparse source can be reconstructed.
Due to the fact that sources are intrinsically sparse in the spatial domain, the DOA estimation problem can be regarded as a sparse reconstruction in the framework of CS. The CS-based estimation methods have much better estimation performance than conventional estimation methods. Malioutov
et al. [
9] firstly adopted the sparse signal reconstruction (SSR) perspective for DOA estimation and utilized the singular value decomposition (SVD) of the data matrix to propose
-SVD method. In [
10], CS-MUSIC was proposed by revisiting the link between CS and MUSIC. This method identifies the parts of support using CS, after which the remaining parts are estimated by a novel generalized MUSIC criterion. Xu
et al. [
11] utilized the Capon spectrum to design a weighted
-norm penalty in order to further enforce the sparsity and approximate the original
-norm for DOA estimation. Wei
et al. [
12] proposed a modified greedy block coordinate descent (R-GBCD) method and the corresponding version with weight refinement (R-GBCD+) to improve the estimation performance.
The key to guarantee the performance of conventional CS-based estimation methods is that all true DOAs are exactly located on the grid. However, when true DOAs are not on the grid set, the performance may severely degrade due to the grid error caused by mismatch, which is defined as the distance from the true direction to the nearest grid. In order to address this issue, Zhu
et al. [
13] proposed the sparse total least square (STIS) to perform the off-grid DOA estimation, in which perturbations of the model are assume to be Gaussian. In [
14], Yang
et al. introduced the Bayesian theory in off-grid DOA estimation and proposed an off-grid sparse Bayesian inference based on the singular value decomposition (OGSBI-SVD). Liang
et al. [
15] proposed an off-grid synchronous approach based on distributed compressed sensing to obtain larger array aperture. Zhang
et al. [
16] formulated a novel model based on the sampling covariance matrix and solved the off-grid DOA estimation problem by the block sparse Bayesian method even if the number of sources are unknown.
In this paper, a novel alternating block coordinate descent method called ABCD is proposed for off-grid DOA estimation in CS. The proposed method solves the mixed k-l norm minimization problem to reconstruct the sparse source and estimate the grid error. Since joint estimation will lead to a nonconvex optimization problem, the proposed method adopts an iterative process that minimizes the mixed k-l norm alternately over two sparse vectors. Instead of conventional sparse source, the block sparse source is exploited to achieve better reconstruction properties. The block is updated by the proposed block selection criterion, which can improve efficiency of the proposed method. In addition, we give a detailed derivation process of proving the global convergence of the proposed method. Simulation results illustrate the superior performance of the proposed method as compared with existing methods.
The rest of the paper is organized as follows. An off-grid DOA estimation model is formulated in
Section 2 and
Section 3 introduces the proposed method in detail. The global convergence of the proposed method is proved in
Section 4 and
Section 5 shows the performance of the proposed method. Conclusions are provided in
Section 6.
2. Problem Formulation
Consider
K far-field narrowband sources
impinging on the uniform linear array (ULA) consisting of
M omnidirectional sensors with inter-sensor spacing
. Assume that each source
is located at different direction
with the power
,
. At time instant
t, the received source by ULA can be expressed as
where
and
denote the steering vector and noise vector, respectively. Since the first point of ULA is set as the origin of sensor array, the
mth element of
is written as
with the wavelength of source
.
To incorporate the CS theory with the DOA estimation, the entire angular space is divided into a fine grid
, where
L denotes the number of the grid and
denotes the transpose. Due to the fact that true directions
are random in the entire angular space,
for some
are likely to be not on the grid set. To reduce the grid error caused by mismatch, we formulate the off-grid model, which has a close relationship with the on-grid model. Let
satisfy the uniform distribution so that the grid interval
. Without loss of generality, by assuming
and that
is the nearest grid to
, the steering vector
can be approximated as
where
is the grid error and
is the partial derivative of
with respective to
. Then, if
are respectively nearest grids to the true directions
, we have
Then, by imposing the approximation error on the noise, the received source
can be rewritten as the following sparse form
where
is the
array manifold matrix corresponding to all potential directions, which is defined as an overcomplete dictionary in CS, and
. In addition, the matrix
is the noise matrix and
is a diagonal matrix with
being the diagonal elements. Since
has
K nonzero elements in
L elements, it is a
K-sparse vector, where
K is referred to as sparsity. More specifically,
is also a
K-sparse vector and has the same support as
. It is evident that the on-grid sparse model is a special case by simply setting
in Equation (4). Since
are jointly
K-sparse, the matrix
has
K nonzero rows and is called row
K-sparse.
To solve the off-grid DOA estimation problem, we need to jointly estimate the support of sparse sources,
, and grid error
from the matrix
Y which is given by
where
is the
noise matrix,
is the
measurement matrix with
and
N is the number of nonadaptive linear projection measurement.
3. Off-DOA Estimation
In this section, an alternating block coordinate descent (ABCD) method and a block selection criterion are elaborated in the CS scenario. The proposed method not only has the advantages of conventional BCD [
17] strategy, but also uses an iterative process that minimizes the mixed
k-
l norm alternately over two sparse vectors. Note that due to solving the minimization alternately, a tractable convex problem is obtained and the global convergence of ABCD can be easily determined, which is proved in the next section.
By applying the central limit theorem, the components
,
, of
are independently white Gaussian noise with zero mean and covariance
, where
denotes an
identity matrix. Thus, the covariance matrix of
with the size
is expressed as
where
is a
covariance matrix of the sparse source and
denotes the conjugate transpose. Since all potential directions are one to one corresponding to the powers
and we are interested in estimating DOAs,
can be reduced to a diagonal matrix
, where
is a
K-sparse vector. Then, by denoting
and
, (6) can be further rewritten as
Due to the vector form of
in Equation (7), the following measurement vector is given by
with
and
, where
and
denote the Kronecker product and the stack operation by placing the columns of a matrix on the top of one another in order, respectively. Moreover,
is also a
K-sparse vector, which has the same support as
. In the conventional sparse source, the nonzero elements of the sparse vector
or
can appear anywhere in the vector. However, in this paper, our goal is to explicitly take block sparse source into account,
i.e., the nonzero elements of the sparse vector
or
tend to cluster in blocks. The motivations to exploit block sparse source are the following two main reasons. As can be seen in [
18], the first reason is that block sparse source has been applied in many applications, such as unions of subspaces and multiband sources [
19]. Secondly, block sparse source has better reconstruction properties than sparse source in the conventional sense, which is proved in [
20]. To exploit block sparse source, denote
and
as the
hth blocks of
and
with the length
d, respectively, so that we have
where
. Following the similar manner, the matrices
and
can be respectively viewed as a concatenation of block matrices
and
of the size
,
i.e.,
where
and
. Obviously, the conventional sparse source is a special case of block sparse source by simply setting
. If
has at most
K nonzero elements, the vector
is referred to as block
K-sparse, where
denotes the Euclidean norm for vectors. In contrast to conventional sparsity,
K is called block-sparsity.
Since
has the same support as
,
and
are jointly sparse. Thus, a mixed
k-
l norm minimization problem [
21] is utilized to jointly reconstruct
and
. Given a
block sparse vector
, the mixed
k-
l norm of
is defined as
Combining the definition given by Equation (13), this mixed
k-
l norm minimization problem is formulated as
where
. It is worth mentioning that an important class of methods for solving the constrained optimization problem is to form the auxiliary function. By introducing the Lagrange multiplier method, the Lagrange function with respect to Equation (14) is given by
where
and
are regularized parameters. As can be seen in Equation (15), the minimization problem with respect to
and
is nonconvex so as to make DOA estimation intractable. But note that if we fix one of two sparse vectors, that is, either
or
, the minimization problem in Equation (15) turns out to be convex with respect to the other sparse vector alone. Thus,
and
can be reconstructed by alternately solving the following two minimization problems under the condition that the other sparse vector is fixed.
It is clear that Equations (16) and (17) have the same structure and can be solved in a similar manner. In the following, we only need to find the optimal solution for Equation (16). Then, the minimization problem in Equation (17) can be handled in the same way.
The objective function in Equation (16) can be expressed as
where
and
. Assume that
is obtained at the
kth iteration. Then, by the quadratic approximation of
at the fixed point
,
can be approximated as
where
is the partial derivation of
with respect to
.
is set to be
, where
denotes one norm for vectors,
is a
vector and
,
. Moreover,
can be shown to be a block vector,
i.e.,
where
is the
hth block of
with the length
d. For the convenience of analysis, denote
, and we can also represent
as a block vector,
i.e.,
where
is the
hth block of
with the length
d. At the
kth iteration,
is updated by minimizing
in Equation (19) so that the next iteration
is given by
By further derivation, Equation (22) can be simplified to
where
. As one may note, the objective function in Equation (23) is separable, and thus
H blocks of
can be solved in a parallel manner. Although it is hard to solve
H blocks, the classical BCD method has provided a critical inspiration, fortunately. The solution to the
hth block of
is given by a soft-thresholding operator [
22]
where
denotes an indicator function. Instead of reconstructing
directly,
can be reconstructed by
H blocks, which may be zero vectors during the iteration. It can be seen in Equation (24) that we just need to determine the relation of
and
to judge whether
is a zero vector. If
is less than
,
must be a zero vector. Therefore, a considerable amount of computations can be avoided in the process of solving
H blocks. Similarly, by utilizing the soft-thresholding operator, the solution to the
hth block of
is expressed as
where
and
are the
hth blocks of
and
with the length
d, respectively, and
. Following the similar derivation, we have
where
is a
vector and
,
. Based on Equations (24) and (25),
and
can be reconstructed alternately until the following criterion is satisfied
where
and
is the small tolerance.
To reduce the computational complexity, a block selection criterion is given. This criterion is of great importance in the whole ABCD method. By utilizing the block selection criterion, we can only update the block that is the closest to
,
i.e.,
where
. This means that
and
at the
kth iteration are updated as Equations (24) and (25) while the remaining blocks keep unchanged. The purpose of utilizing this block selection criterion is to avoid the update of repetitive and unnecessary blocks and reduce the computational complexity. The major steps of reconstructing
and
by the ABCD method are given as follows:
Initialization: set
and
.
- (1)
Calculate and in terms of Equations (21) and (26).
- (2)
Due to H blocks of and , calculate and , .
- (3)
Calculate and , , in terms of (24) and (25).
- (4)
Choose the block index according to (28). Then, and are respectively updated as and .
- (5)
If , stop the iteration. Otherwise, set and return to step (1).
4. Global Convergence of the ABCD Method
The global convergence of the ABCD method is proved in this section. By combining the existing convergence proof of the general BCD framework [
23] with ABCD method, a detailed derivation process for proving the global convergence is shown as follows.
First, we introduce the general BCD framework. Note that
in Equation (18) is a continuous convex function and
in (18) is a non-smooth convex function. Given a fixed point
,
in Equation (18) can be approximated as the following form by exploiting the second order Taylor expansion of
in the general BCD framework.
where
is the
Hessian matrix of
with respect to
. It is clear that minimizing Equation (29) involves finding the next iteration
. Assume that
is an
H-dimensional index set and
is a subset of
consisting of at most
K indexes obtained by Equation (28). Hence, the next iteration
is represented as
Then, to prove the global convergence, we give the modified Armijo rule and modified Gauss-Southwell-
r rule that are prerequisites to guarantee the global convergence. These two rules are described in the following.
- (1)
Modified Armijo rule: If
,
and
, the following inequality holds:
where
and
.
- (2)
Modified Gauss-Southwell-
r rule: In the iteration, the index set
obtained by Equation (28) must satisfy
where
.
It is well known that the problem of proving the global convergence is quite complex and intractable. However, fortunately, since Equations (16) and (17) are both convex and have both only one global point, we only need to show that Equations (16) and (17) satisfy the modified Armijo rule and modified Gauss-Southwell-r rule to prove the global convergence of the ABCD method. Furthermore, since Equation (16) has the same structure as Equation (17), it is enough to just prove that Equation (16) satisfies the modified Armijo rule and modified Gauss-Southwell-r rule. Regarding Equation (17), the derivation process is given in the same way.
To see the first, the following inequality holds according to Equation (30).
By substituting Equation (33) into Equation (29), we have
Based on the fact that
, Equation (34) can be further simplified to
Since
, by dividing by
and setting
, we have
For
, it can be deduced from (36) that
Subsequently, by exploiting the convexity of
, we obtain
Since
, it is nature to have
Following the fact in Equation (37), the following inequality holds
where
. Combining Equations (39) and (40), we have
It is worth pointing out that Equation (41) is equal to Equation (31) with and . Thus, it has been proved that Equation (16) satisfies the modified Armijo rule.
Secondly, in order to prove that Equation (16) satisfies the modified Gauss-Southwell-
r rule, the following form is shown
where the cardinality of
is the same as that of
. Without loss of generality, consider the worst case,
i.e., the cardinality of
is the maximization
K, and assume
so that
is expressed as
. Thus, we have
Based on the following equation
it is easy to have
Since Equation (45) is equal to Equation (32) with , Equation (16) satisfies the modified Gauss-Southwell-r rule. Therefore, based on the above analysis, the global convergence of the ABCD method has been proved.
5. Simulation Results
This section presents several simulations to validate the superior performance of the proposed method as compared with R-GBCD+ and OGSBI-SVD. The angular space [−90°, 90°] is taken the grid with grid interval τ = 3° to perform three methods for off-grid targets. We set the length of block, the number of ULA sensors and spacing between adjacent sensors to be
,
and
, respectively. In the simulation, the root mean squared error (RMSE) and success rate of DOA estimation are two significant performance indexes. RMSE is defined as
where
is the number of Monte Carlo runs and
is the estimate of
in the
ith Monte Carlo run, and success rate is declared if the estimation error is within a certain small Euclidean distance of the true directions.
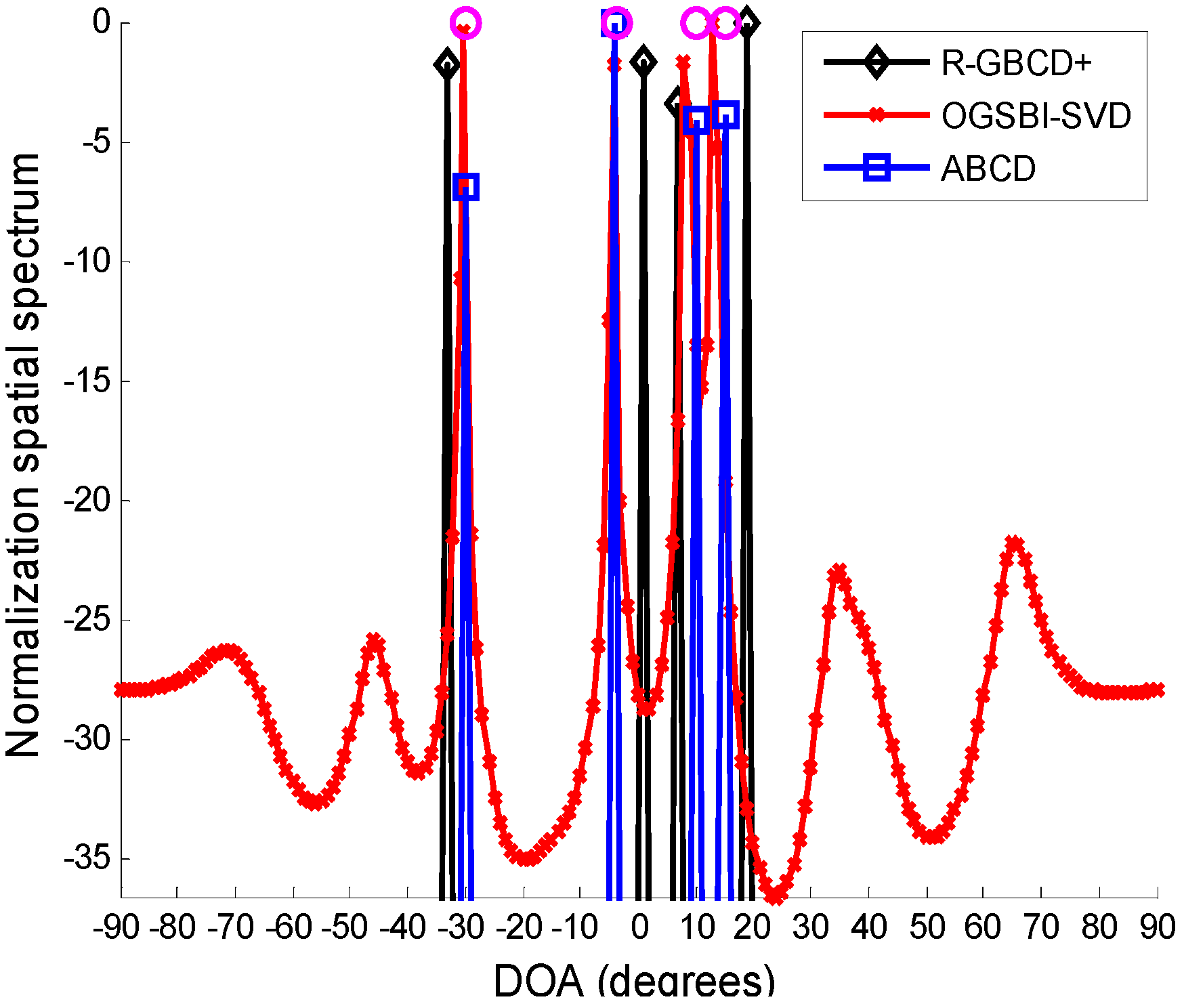
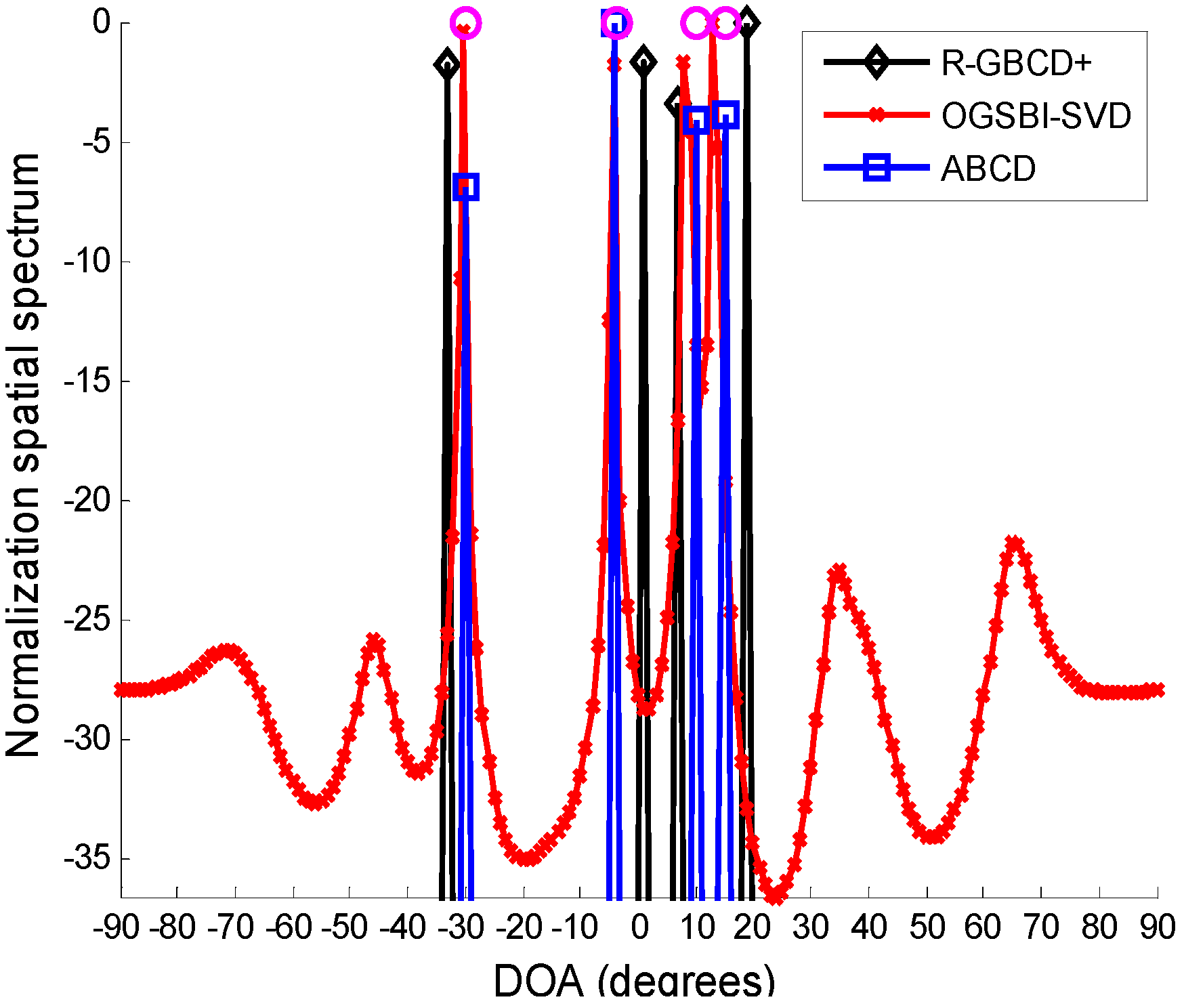
In the first simulation, we compare the spatial spectra of R-GBCD+, OGSBI-SVD and ABCD. Consider four far-field narrowband sources impinging on the ULA from [−30.4° −3.8° 10.1° 15.3°], where the latter two most closely spaced sources are coherent and the remaining sources are independent of other sources.
Figure 1 presents the spatial spectra of R-GBCD+, OGSBI-SVD and ABCD with SNR 3 dB and number of snapshots 100. For the convenience of analysis, the spatial spectra are normalized. We can see from
Figure 1 that the spatial spectra of three methods are able to detect four sources, but the spatial spectrum obtained by R-GBCD+ has obvious bias at the true directions and OGSBI-SVD can yield slight bias in the vicinity of the coherent sources. Note that ABCD has a nearly ideal spatial spectrum, and thus it outperforms R-GBCD+ and OGSBI-SVD in terms of the spatial spectrum.
Figure 1.
Spatial spectra of R-GBCD+, OGSBI-SVD and ABCD, where the pink circles denote the true DOAs.
Figure 1.
Spatial spectra of R-GBCD+, OGSBI-SVD and ABCD, where the pink circles denote the true DOAs.
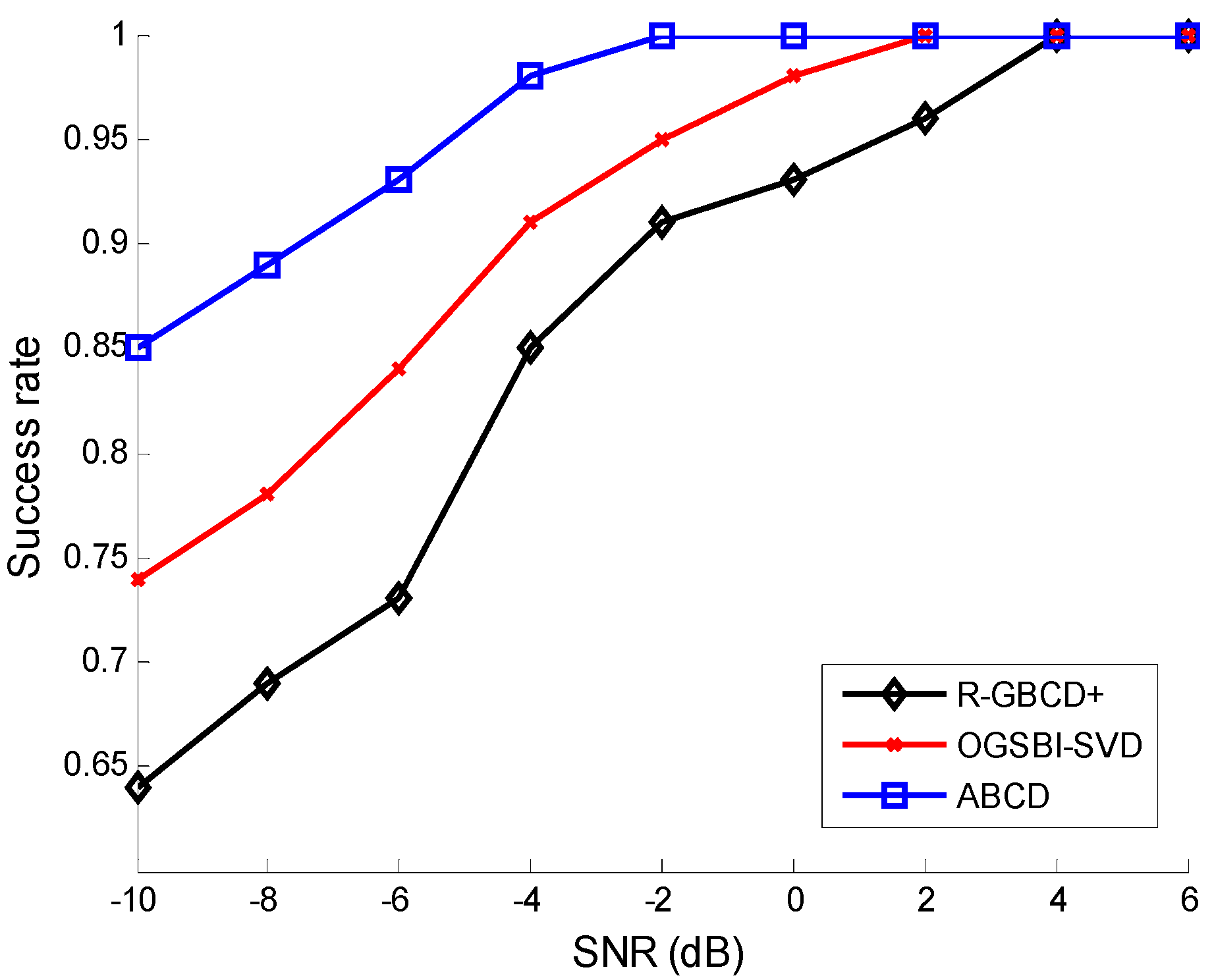
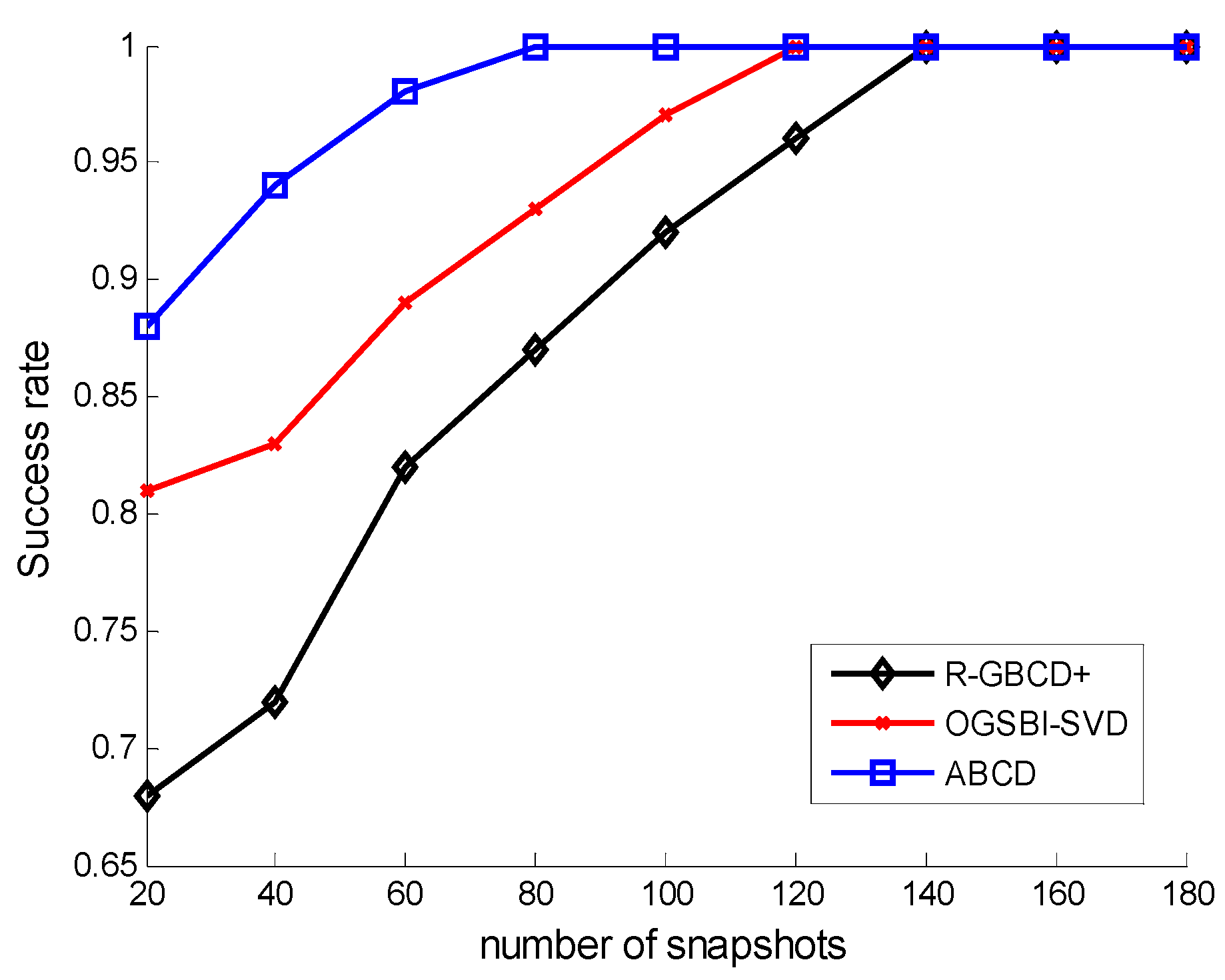
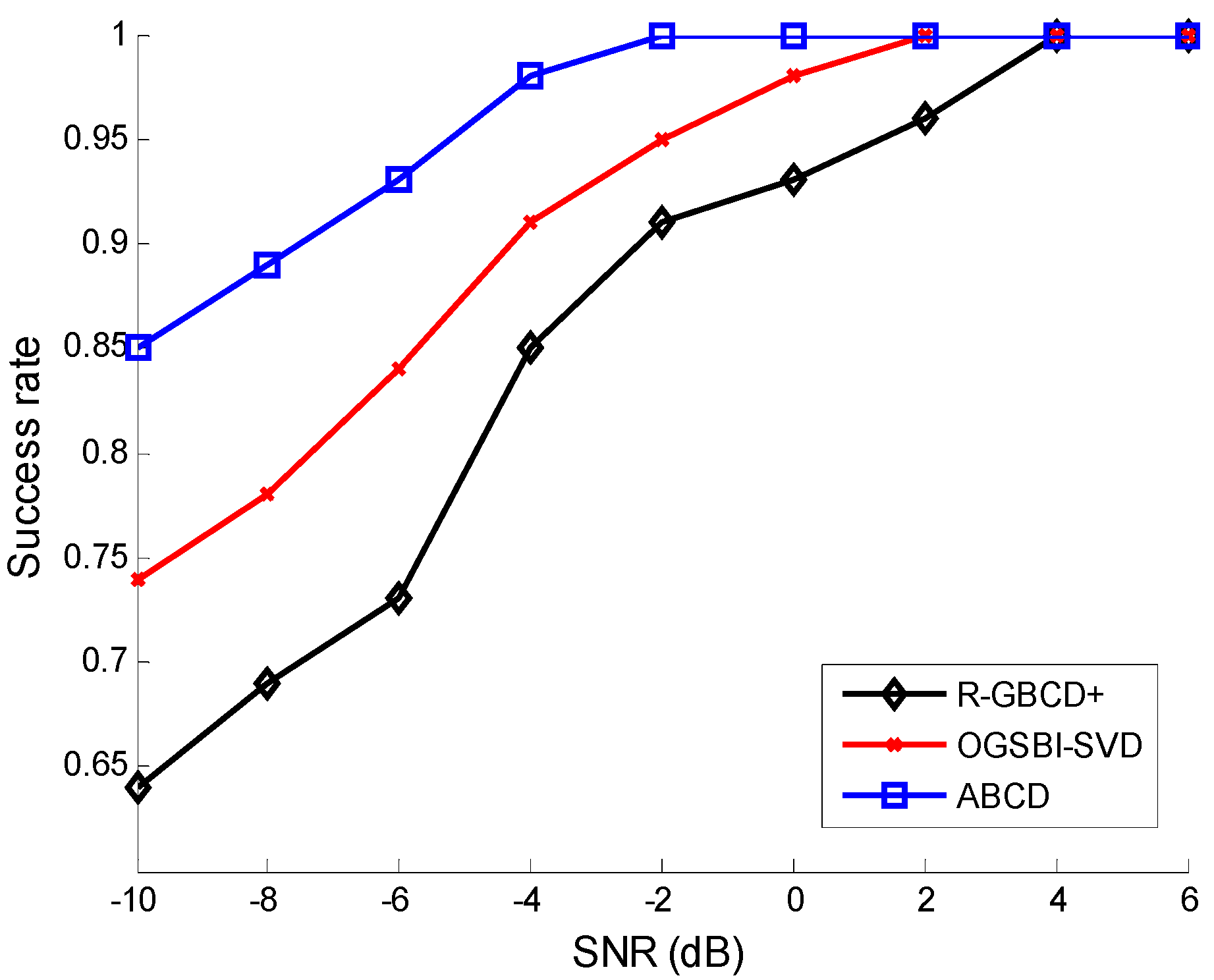
The success rates of three methods
vs. SNR and the number of snapshots are analyzed in the second simulation. The source mode is the same as the first simulation.
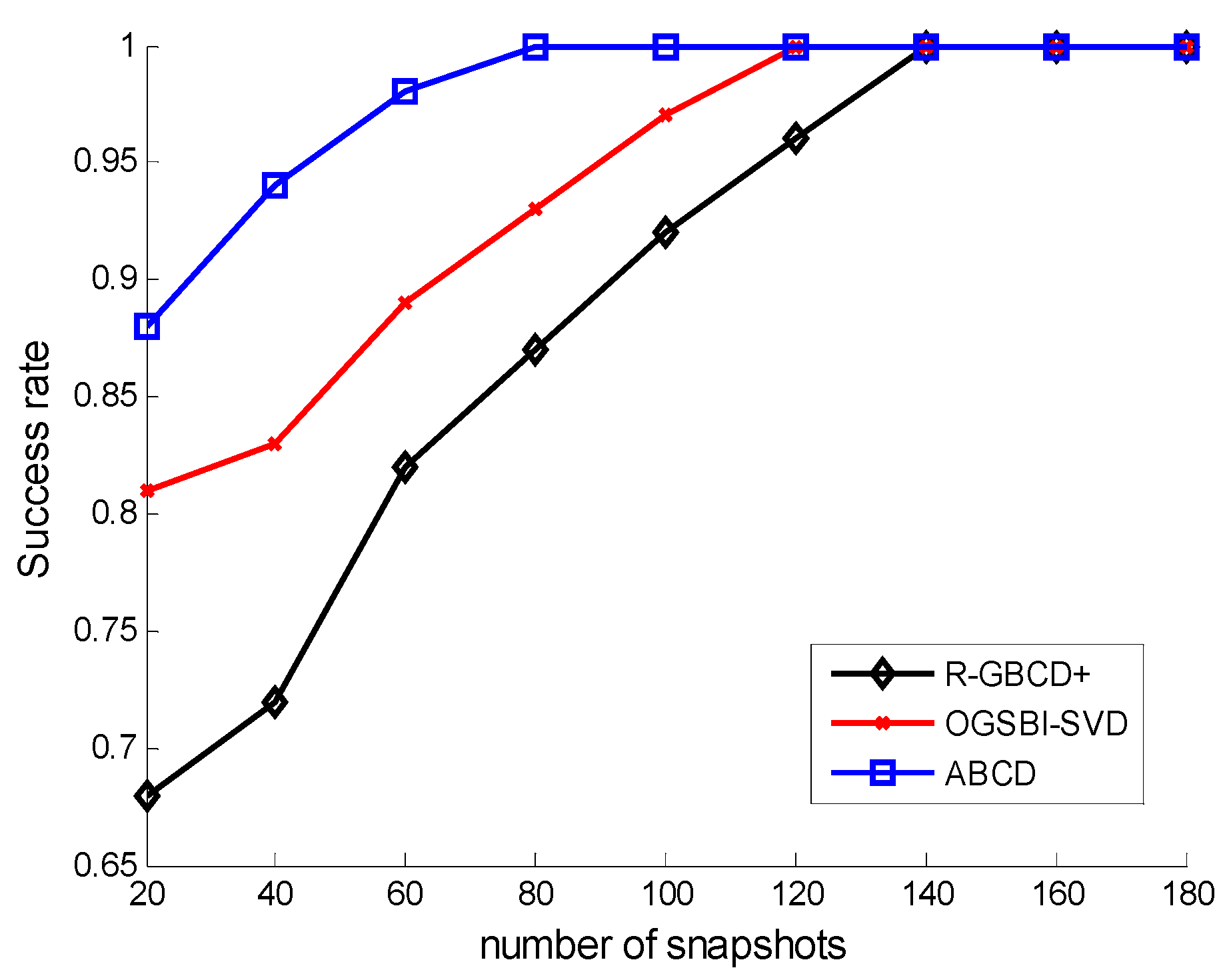
Figure 2 shows the success rates of three methods
vs. SNR with the fixed number of snapshots 100, whereas the success rates of three methods
vs. number of snapshots are depicted with the fixed SNR 0 dB in
Figure 3. The following facts can be acquired from
Figure 2 and
Figure 3 that three methods can estimate correctly for high SNR or large number of snapshots and ABCD has a higher success rate than the other two methods for low SNR or a small number of snapshots.
Figure 2.
Success rates vs. SNR with the fixed number of snapshots 100.
Figure 2.
Success rates vs. SNR with the fixed number of snapshots 100.
Figure 3.
Success rates vs. number of snapshots with the fixed SNR 0 dB.
Figure 3.
Success rates vs. number of snapshots with the fixed SNR 0 dB.
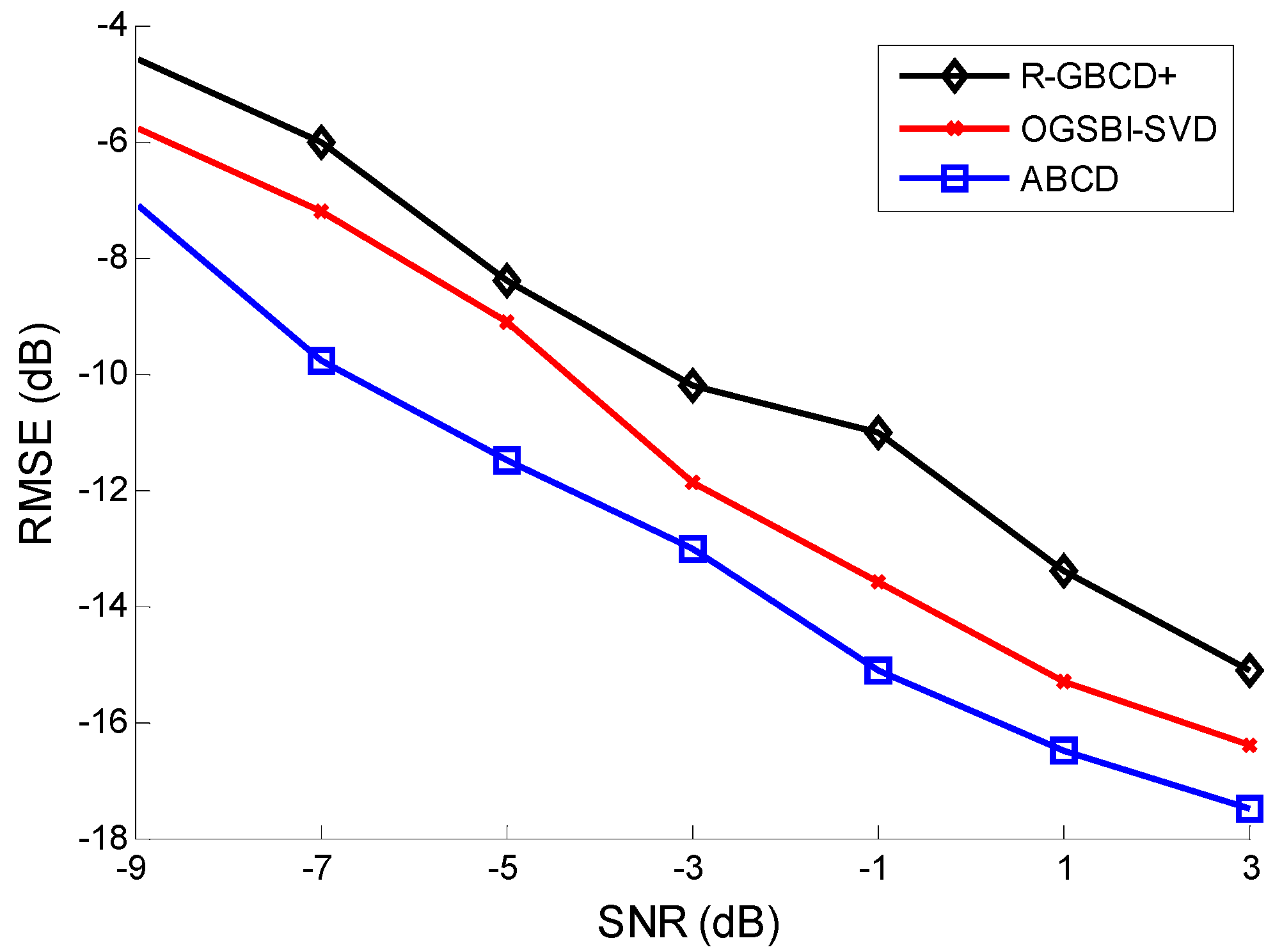
Figure 4.
RMSE vs. SNR with the fixed number of snapshots 100.
Figure 4.
RMSE vs. SNR with the fixed number of snapshots 100.
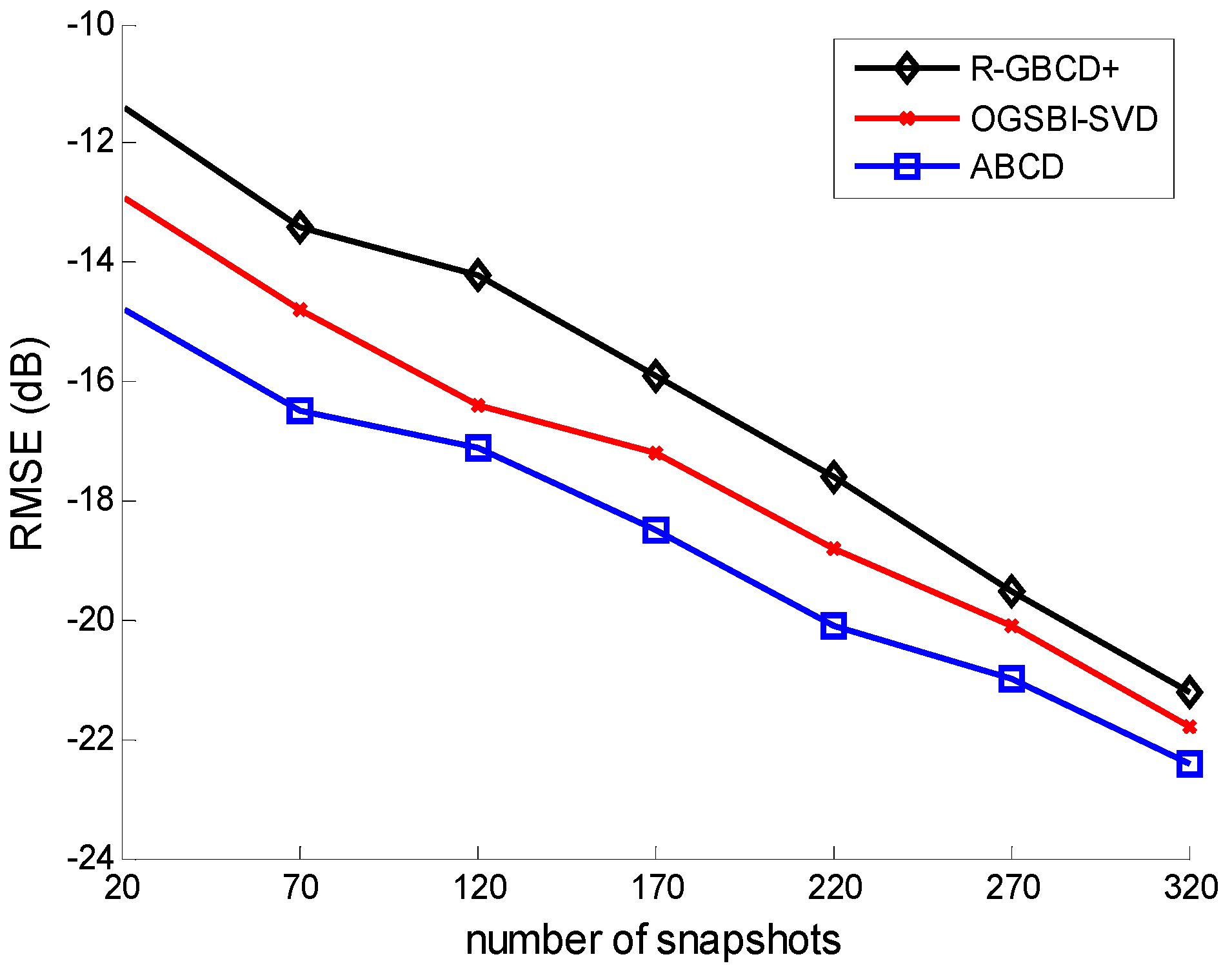
Figure 5.
RMSE vs. number of snapshots with the fixed SNR 0 dB.
Figure 5.
RMSE vs. number of snapshots with the fixed SNR 0 dB.
The third simulation considers the RMSE of three methods
vs. SNR and the number of snapshots. All the conditions are the same as the second simulation.
Figure 4 and
Figure 5 show the RMSE of three methods
vs. SNR and the number of snapshots, respectively. It is indicated in
Figure 4 and
Figure 5 that ABCD has the best estimation accuracy among all three methods. Moreover, the accuracy of three methods is gradually improving with SNR or the number of snapshots increasing.
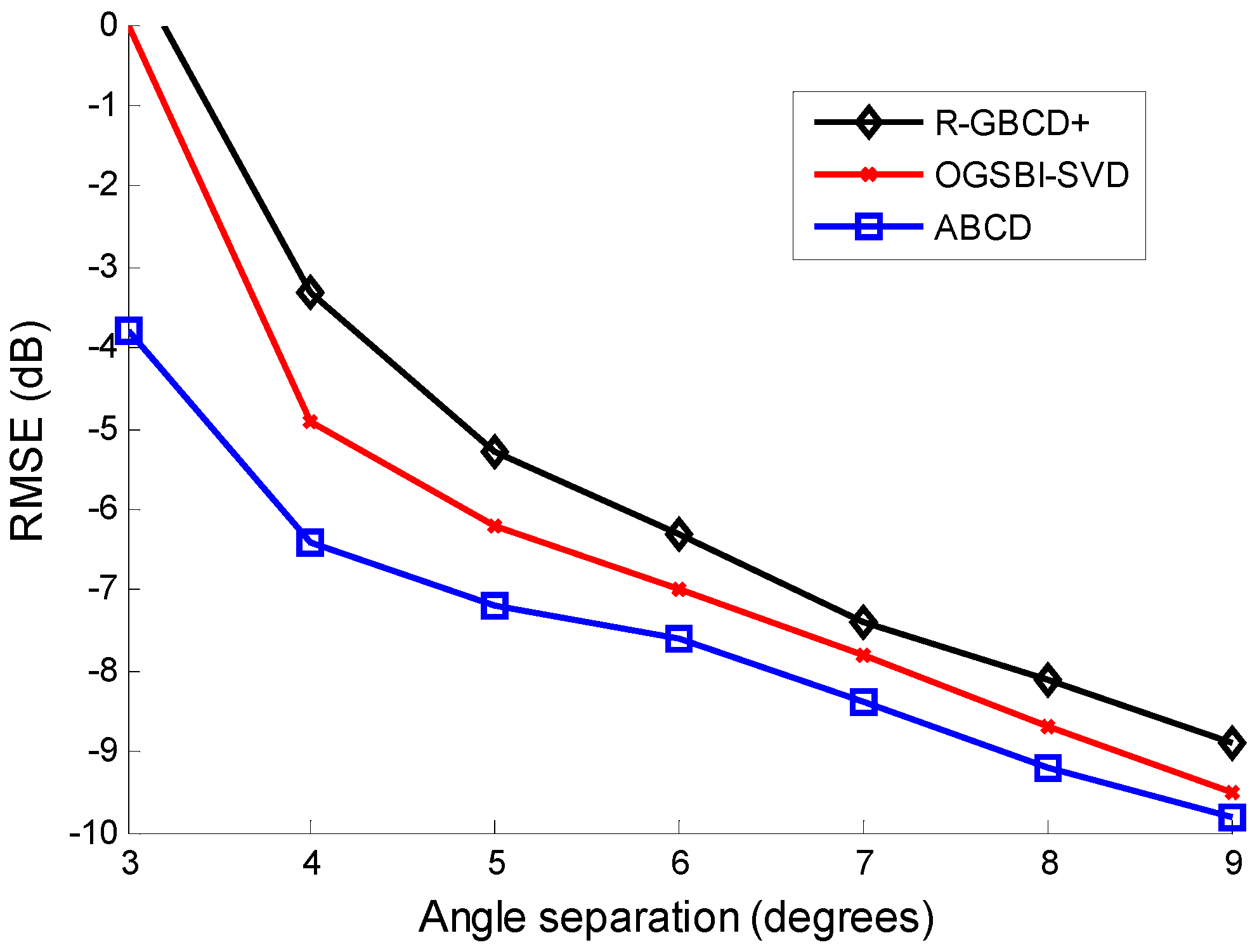
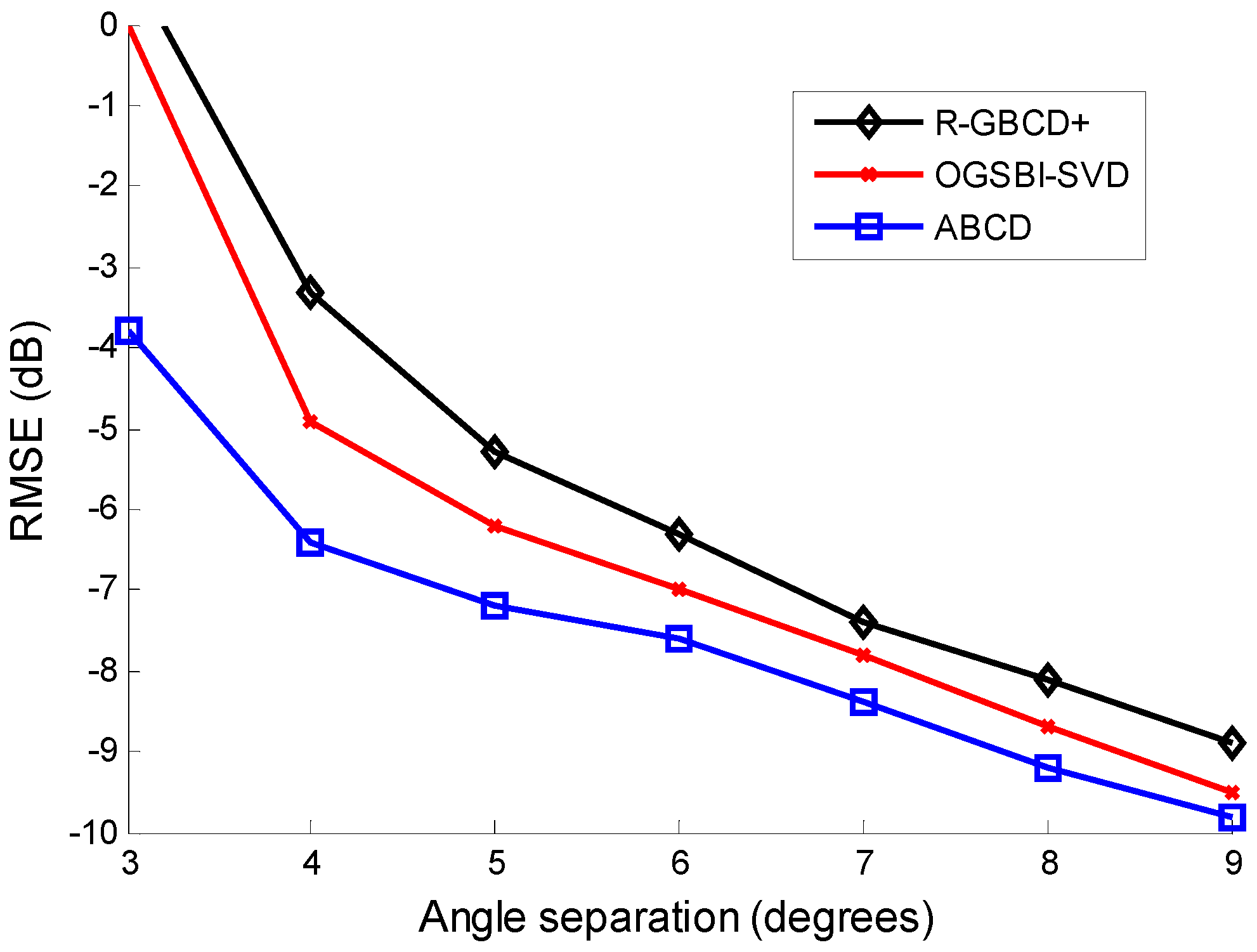
Finally, we test the resolving ability by showing the relation between RMSE of three methods and angle separation of sources, which is illustrated in
Figure 6 Consider two coherent sources impinging on the ULA from
and
, where the step of
is 1°. The SNR is 0 dB and the number of snapshots is 100. As can be seen from
Figure 6, the performance of R-GBCD+ and OGSBI-SVD degrades severely as angle separation is 3°, while ABCD can still provide a precise estimation as long as angle separation is no less than 3°. The proposed ABCD is the most accurate method and has higher resolution than the other two methods.
Figure 6.
RMSE vs. angle separation with the fixed SNR 0 dB and number of snapshots 100 for coherent sources.
Figure 6.
RMSE vs. angle separation with the fixed SNR 0 dB and number of snapshots 100 for coherent sources.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}