
Smartphone Application for the Analysis of Prosodic Features in Running Speech with a Focus on Bipolar Disorders: System Performance Evaluation and Case Study

 ,
,  and
and 
Abstract
:1. Introduction
2. Experimental Section
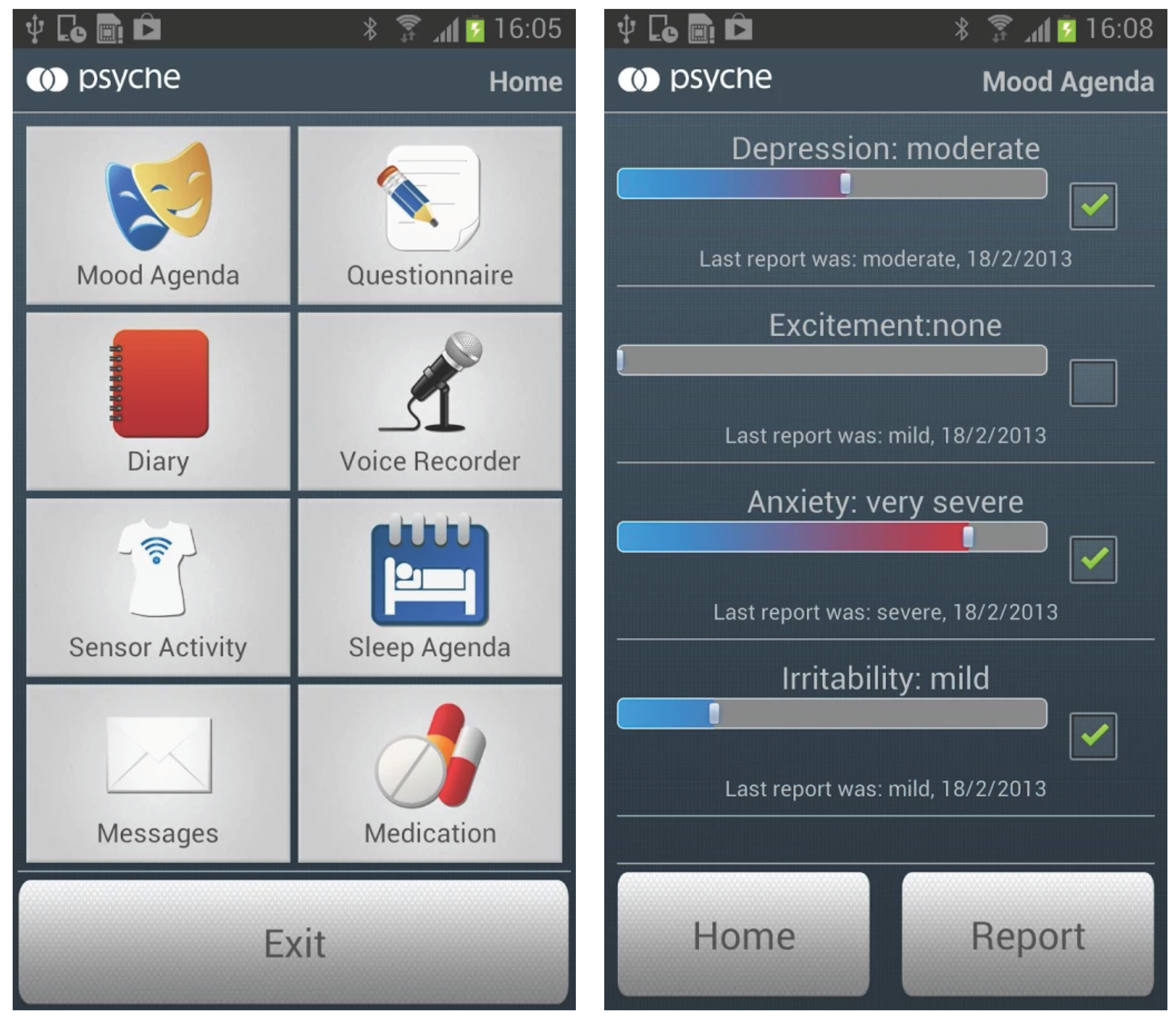
2.1. Application

2.2. Testing of the System
2.2.1. Audio Quality Testing
2.2.2. Algorithm Reliability
2.2.3. Overall System Testing
2.2.4. Statistical Analysis
2.3. Patient Data
3. Results and Discussion
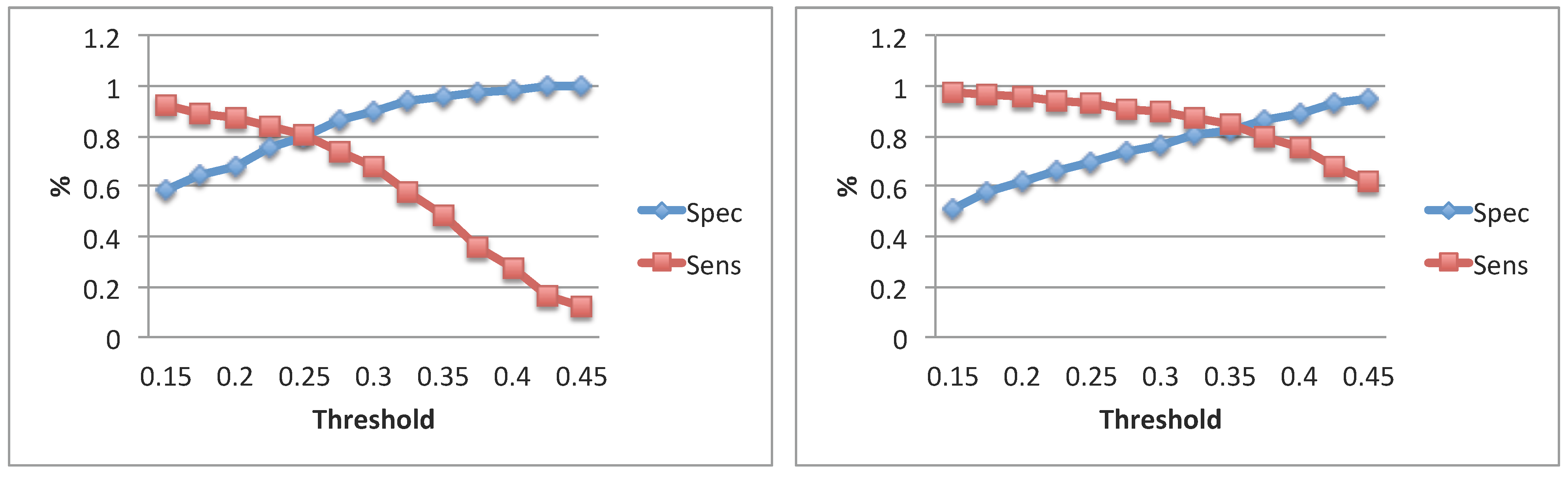
3.1. Audio Quality Testing

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| GTal: Microphones Comparison | ||||
|---|---|---|---|---|
| GTal: HQmic vs. | ||||
| Subj. | [ms] | [ms] | Spec | Sens |
| 1 | 136 ± 56 | 160 ± 80 | 0.89 | 0.81 |
| 2 | 128 ± 64 | 168 ± 88 | 0.85 | 0.83 |
| GTal: HQmic SPmic | ||||
| Subj. | [ms] | [ms] | Spec | Sens |
| 1 | 136 ± 56 | 152 ± 72 | 0.89 | 0.77 |
| 2 | 128 ± 64 | 128 ± 64 | 0.90 | 0.81 |
| GTal: Microphones Comparison | |||
|---|---|---|---|
| Subj. | Comparison | Feature | [p-value] |
| HQmic | 1.00 [<] | ||
| 1 | vs. | 0.96 [<] | |
| 0.81 [2.3] | |||
| HQmic | 0.95 [1.90] | ||
| 1 | vs. | 0.90 [1.68] | |
| 0.90 [1.69] | |||
| HQmic | 1.00 [<] | ||
| 2 | vs. | 0.92 [<] | |
| 0.76 [1.72] | |||
| HQmic | 1.00 [<] | ||
| 2 | vs. | 0.99 [<] | |
| 0.91 [<] | |||
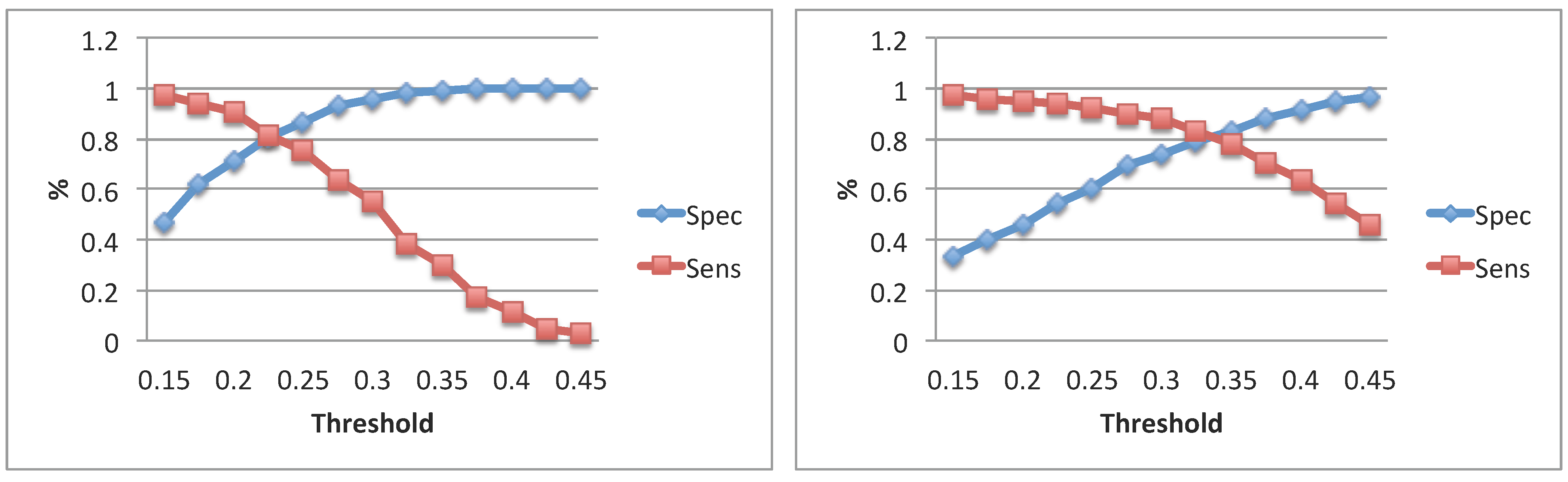
3.2. Evaluation of the Algorithm
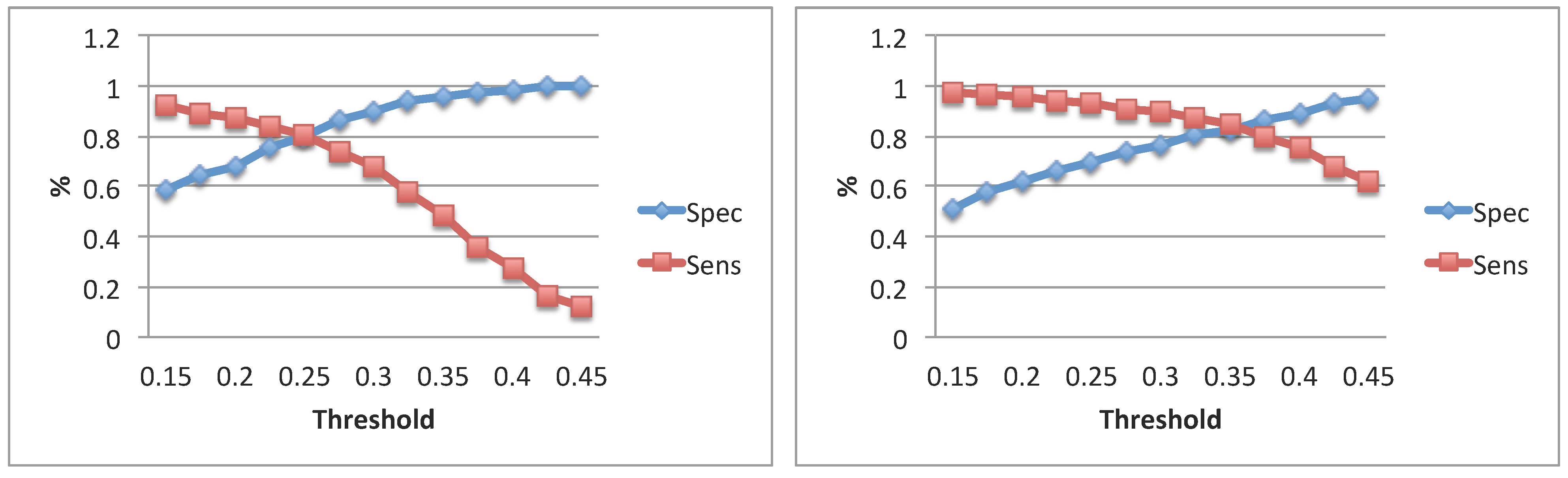
| HQmic: Algorithms Comparison | ||||
|---|---|---|---|---|
| HQmic: GTal vs. ANDal | ||||
| Subj. | [ms] | [ms] | Spec | Sens |
| 1 | 136 ± 56 | 90 ± 60 | 0.90 | 0.68 |
| 2 | 128 ± 64 | 40 ± 30 | 0.95 | 0.62 |
| HQmic: Algorithms Comparison | |||
|---|---|---|---|
| Subj. | Comparison | Feature | [p-value] |
| GTal | 0.98 [<] | ||
| 1 | vs. | 0.92 [<] | |
| ANDal | 0.86 [1.52] | ||
| GTal | 0.93 [<] | ||
| 2 | vs. | 0.81 [<] | |
| ANDal | 0.71 [3.28] | ||
3.3. Evaluation of the System
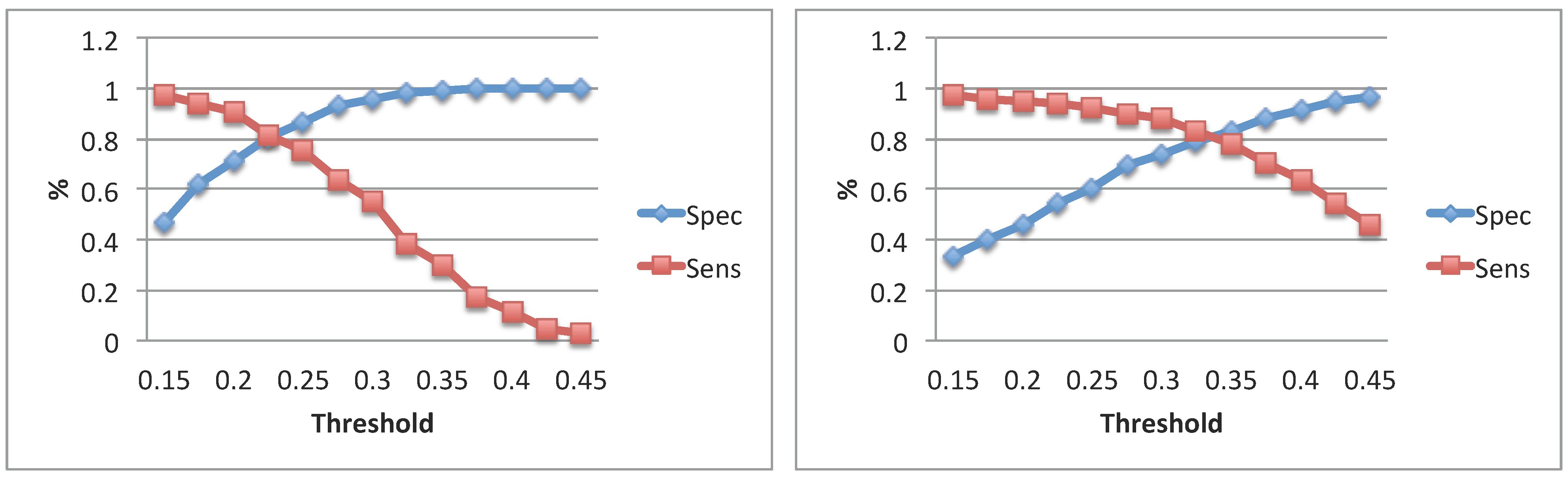
| System Evaluation | ||||
|---|---|---|---|---|
| HQmic + GTal vs. + ANDal | ||||
| Subj. | [ms] | [ms] | Spec | Sens |
| 1 | 136 ± 56 | 85 ± 35 | 0.96 | 0.56 |
| 2 | 128 ± 64 | 40 ± 25 | 0.93 | 0.46 |
| HQmic + GTal vs. + ANDal | ||||
| subj. | [ms] | [ms] | Spec | Sens |
| 1 | 136 ± 54 | 70 ± 30 | 0.96 | 0.47 |
| 2 | 128 ± 64 | 40 ± 20 | 0.97 | 0.40 |
| System Evaluation | |||
|---|---|---|---|
| Subj. | Comparison | Feature | [p-value] |
| HQmic + GTal | 1.00 [<] | ||
| 1 | vs. | 0.92 [8.25] | |
| + ANDal | 0.84 [1.63] | ||
| HQmic + GTal | 0.99 [<] | ||
| 1 | vs. | 0.94 [<] | |
| + ANDal | 0.78 [6.48] | ||
| HQmic + GTal | 0.89 [<] | ||
| 2 | vs. | 0.77 [<] | |
| + ANDal | 0.79 [<] | ||
| HQmic + GTal | 0.91 [<] | ||
| 2 | vs. | 0.78 [<] | |
| + ANDal | 0.74 [<] | ||
3.4. Smartphone Model Comparison
| Comparison between Different Smartphone Models | |||
|---|---|---|---|
| Subj. | Algorithm | Feature | |
| 1.00 | |||
| 1 | ANDal | 0.97 | |
| 0.90 | |||
| 1.00 | |||
| 2 | ANDal | 0.82 | |
| 0.90 | |||
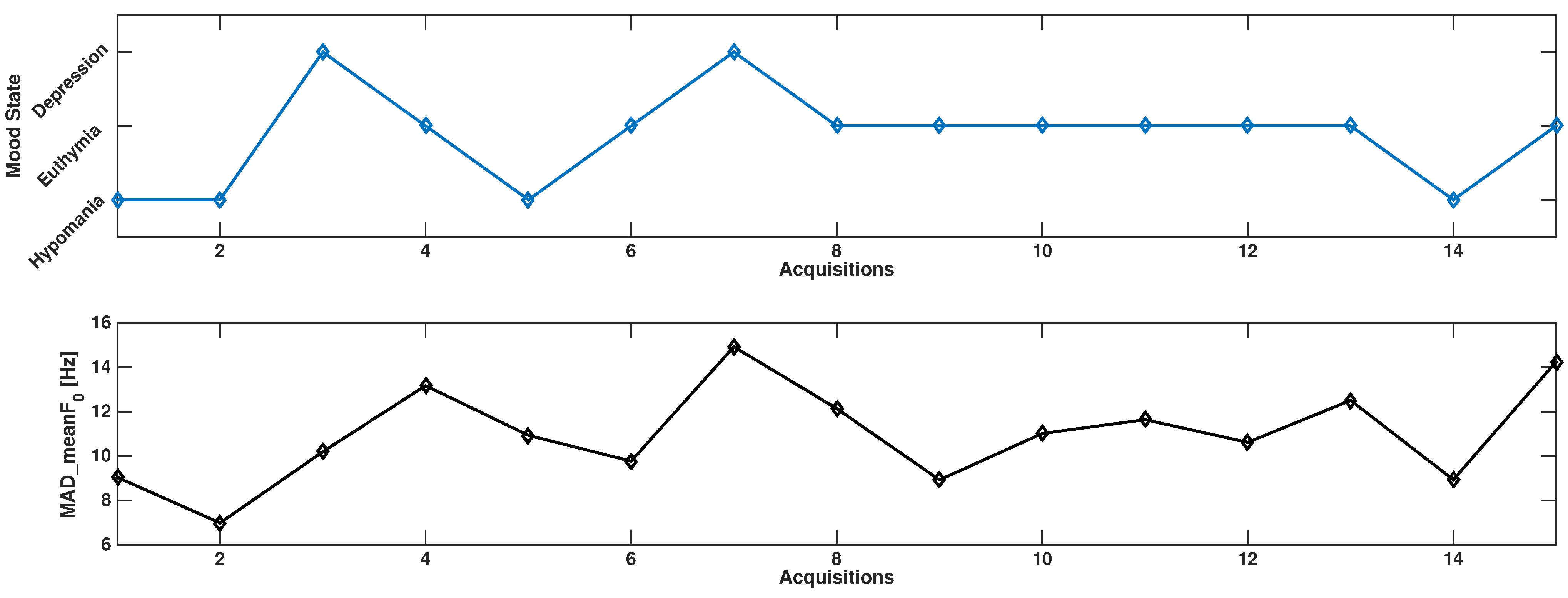
3.5. Results on Bipolar Data
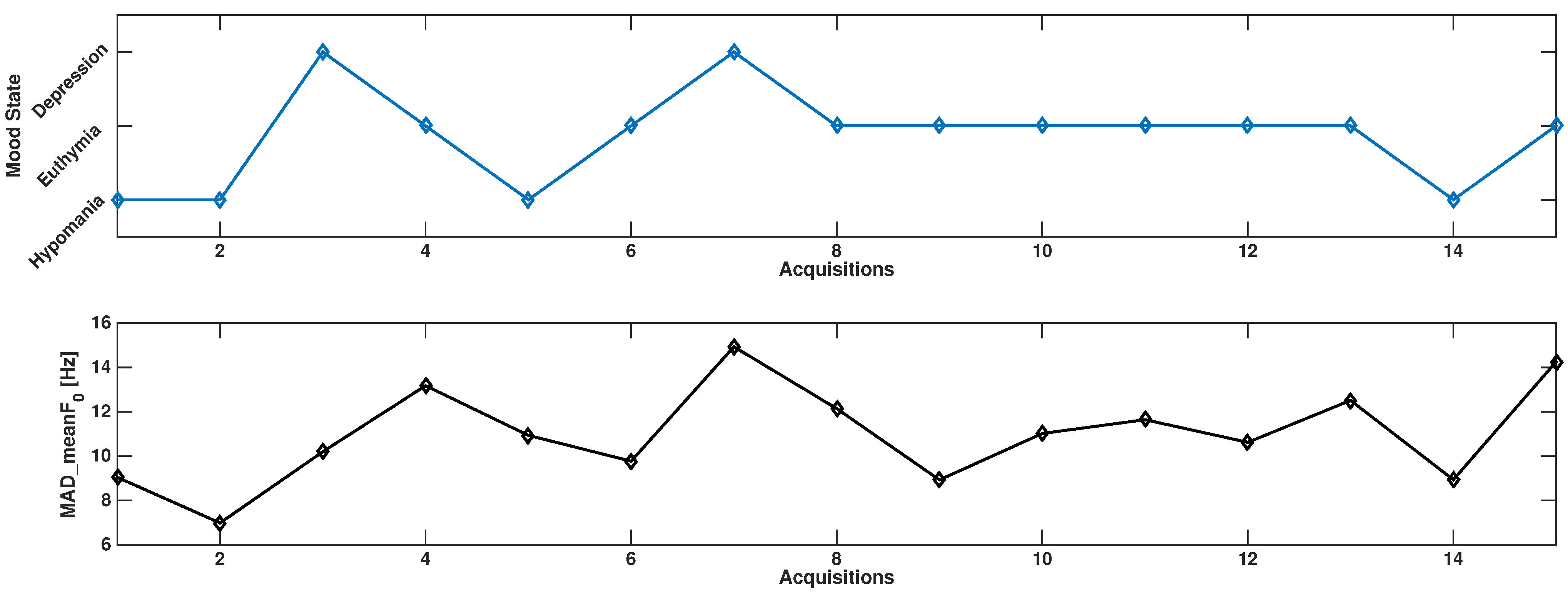
4. Discussion
5. Conclusions
Supplementary Files
Supplementary File 1Acknowledgments
Author Contributions
Conflicts of Interest
References
- Cardoso, T.; Bauer, I.; Meyer, T.; Kapczinski, F.; Soares, J. Neuroprogression and Cognitive Functioning in Bipolar Disorder: A Systematic Review. Curr. Psychiatry Rep. 2015, 17, 75. [Google Scholar] [CrossRef] [PubMed]
- Hasler, G.; Wolf, A. Toward stratified treatments for bipolar disorders. Eur. Neuropsychopharmacol. 2015, 25, 283–294. [Google Scholar] [CrossRef] [PubMed]
- Riva, G.; Baños, R.; Botella, C.; Gaggioli, A.; Wiederhold, B.K. Personal health systems for mental health: The European projects. Stud. Health Technol. Inform. 2011, 163, 496–502. [Google Scholar] [PubMed]
- Quraishi, S.; Frangou, S. Neuropsychology of bipolar disorder: A review. J. Affect. Disord. 2002, 72, 209–226. [Google Scholar] [CrossRef]
- Merikangas, K.; Jin, R.; He, J.P.; Kessler, R.; Lee, S.; Sampson, N.; Viana, M.; Andrade, L.; Hu, C.; Karam, E.; et al. Prevalence and correlates of bipolar spectrum disorder in the World Mental Health Survey Initiative. Arch. Gen. Psychiatry 2011, 68, 241–251. [Google Scholar] [CrossRef] [PubMed]
- Ketter, T. Strategies for monitoring outcomes in patients with bipolar disorder. Prim. Care Companion J. Clin. Psychiatry 2010, 12, 10–16. [Google Scholar] [CrossRef] [PubMed][Green Version]
- Schärer, L.; Hartweg, V.; Valerius, G.; Graf, M.; Hoern, M.; Biedermann, C.; Walser, S.; Boensch, A.; Dittmann, S.; Forsthoff, A.; et al. Life charts on a palmtop computer: First results of a feasibility study with an electronic diary for bipolar patients. Bipolar Disord. 2002, 4, 107–108. [Google Scholar] [CrossRef] [PubMed]
- Paradiso, R.; Bianchi, A.; Lau, K.; Scilingo, E. PSYCHE: Personalised monitoring systems for care in mental health. In Proceedings of the 2010 Annual International Conference of the IEEE on Engineering in Medicine and Biology Society (EMBC), Buenos Aires, Argentina, 31 August–4 September 2010; pp. 3602–3605.
- Mayora, O.; Arnrich, B.; Bardram, J.; Drager, C.; Finke, A.; Frost, M.; Giordano, S.; Gravenhorst, F.; Grunerbl, A.; Raring, C.; et al. Personal health systems for bipolar disorder anecdotes, challenges and lessons learnt from monarca project. In Proceedings of the 2013 7th International Conference on Pervasive Computing Technologies for Healthcare (PervasiveHealth), Venice, Italy, 5–8 May 2013; pp. 424–429.
- Botella, C.; Moragrega, I.; Baños, R.; García-Palacios, A. Online predictive tools for intervention in mental illness: The OPTIMI project. Stud. Health Technol. Inform. 2011, 163, 86–92. [Google Scholar] [PubMed]
- Park, C.K.; Lee, S.; Park, H.J.; Baik, Y.S.; Park, Y.B.; Park, Y.J. Autonomic function, voice, and mood states. Clin. Auton. Res. 2011, 21, 103–110. [Google Scholar] [CrossRef] [PubMed]
- Scherer, K.R. Expression of emotion in voice and music. J. Voice 1995, 9, 235–248. [Google Scholar] [CrossRef]
- Cummins, N.; Scherer, S.; Krajewski, J.; Schnieder, S.; Epps, J.; Quatieri, T.F. A review of depression and suicide risk assessment using speech analysis. Speech Commun. 2015, 71, 10–49. [Google Scholar] [CrossRef]
- Low, L.S.A.; Maddage, N.C.; Lech, M.; Sheeber, L.B.; Allen, N.B. Detection of clinical depression in adolescents’ speech during family interactions. IEEE Trans. Biomed. Eng. 2011, 58, 574–586. [Google Scholar] [CrossRef] [PubMed]
- Cannizzaro, M.; Harel, B.; Reilly, N.; Chappell, P.; Snyder, P.J. Voice acoustical measurement of the severity of major depression. Brain Cogn. 2004, 56, 30–35. [Google Scholar] [CrossRef] [PubMed]
- Moore, E.; Clements, M.; Peifer, J.W.; Weisser, L. Critical analysis of the impact of glottal features in the classification of clinical depression in speech. IEEE Trans. Biomed. Eng. 2008, 55, 96–107. [Google Scholar] [CrossRef] [PubMed]
- Ozdas, A.; Shiavi, R.G.; Silverman, S.E.; Silverman, M.K.; Wilkes, D.M. Investigation of vocal jitter and glottal flow spectrum as possible cues for depression and near-term suicidal risk. IEEE Trans. Biomed. Eng. 2004, 51, 1530–1540. [Google Scholar] [CrossRef] [PubMed]
- Vanello, N.; Guidi, A.; Gentili, C.; Werner, S.; Bertschy, G.; Valenza, G.; Lanata, A.; Scilingo, E.P. Speech analysis for mood state characterization in bipolar patients. In Proceedings of the 2012 Annual International Conference of the IEEE on Engineering in Medicine and Biology Society (EMBC), San Diego, CA, USA, 28 August–1 September 2012; pp. 2104–2107.
- Vásquez Correa, J.C.; Orozco Arroyave, J.R.; Arias-Londoño, J.D.; Vargas Bonilla, J.F.; Noth, E. New computer aided device for real time analysis of speech of people with Parkinson’s disease. Rev. Fac. Ing. 2014, 72, 87–103. [Google Scholar]
- Carullo, A.; Vallan, A.; Astolfi, A. Design issues for a portable vocal analyzer. IEEE Trans. Instrum. Meas. 2013, 62, 1084–1093. [Google Scholar] [CrossRef]
- Mehta, D.D.; Zañartu, M.; Feng, S.W.; Cheyne, H.A.; Hillman, R.E. Mobile voice health monitoring using a wearable accelerometer sensor and a smartphone platform. IEEE Trans. Biomed. Eng. 2012, 59, 3090–3096. [Google Scholar] [CrossRef] [PubMed]
- Popolo, P.S.; Svec, J.G.; Titze, I.R. Adaptation of a Pocket PC for use as a wearable voice dosimeter. J. Speech Lang. Hear. Res. 2005, 48, 780–791. [Google Scholar] [CrossRef]
- Karam, Z.N.; Provost, E.M.; Singh, S.; Montgomery, J.; Archer, C.; Harrington, G.; Mcinnis, M.G. Ecologically valid long-term mood monitoring of individuals with bipolar disorder using speech. In Proceedings of the 2014 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Florence, Italy, 4–9 May 2014; pp. 4858–4862.
- Camacho, A.; Harris, J.G. A sawtooth waveform inspired pitch estimator for speech and music. J. Acoust. Soc. Am. 2008, 124, 1638–1652. [Google Scholar] [CrossRef] [PubMed]
- Lanata, A.; Valenza, G.; Nardelli, M.; Gentili, C.; Scilingo, E.P. Complexity index from a personalized wearable monitoring system for assessing remission in mental health. IEEE J. Biomed. Health Inf. 2015, 19, 132–139. [Google Scholar] [CrossRef] [PubMed]
- Tsanas, A.; Zañartu, M.; Little, M.A.; Fox, C.; Ramig, L.O.; Clifford, G.D. Robust fundamental frequency estimation in sustained vowels: Detailed algorithmic comparisons and information fusion with adaptive Kalman filtering. J. Acoust. Soc. Am. 2014, 135, 2885–2901. [Google Scholar] [CrossRef] [PubMed]
- Camacho, A. Detection of Pitched/Unpitched Sound using Pitch Strength Clustering. In Proceedings of the 9th International Conference on Music Information Retrieval (ISMIR), Philadelphia, PA, USA, 14–18 September 2008; pp. 533–537.
- Gorman, K. Swipe. Available online: https://github.com/kylebgorman/swipe/blob/master/swipe.c (accessed on 24 July 2015).
- Liang, S. Java Native Interface: Programmer’s Guide and Reference; Addison-Wesley: Boston, MA, USA, 1999. [Google Scholar]
- Frigo, M.; Johnson, S.G. The design and implementation of FFTW3. IEEE Proc. 2005, 93, 216–231. [Google Scholar] [CrossRef]
- De Castro Lopo, E. Libsndfile. Available online: http://www.mega-nerd.com/libsndfile/ (accessed on 24 July 2015).
- Guidi, A.; Vanello, N.; Bertschy, G.; Gentili, C.; Landini, L.; Scilingo, E. Automatic analysis of speech F0 contour for the characterization of mood changes in bipolar patients. Biomed. Signal Proc. Control 2015, 17, 29–37. [Google Scholar] [CrossRef]
- Vanello, N.; Martini, N.; Milanesi, M.; Keiser, H.; Calisti, M.; Bocchi, L.; Manfredi, C.; Landini, L. Evaluation of a pitch estimation algorithm for speech emotion recognition. In Proceedings of the 6th International Workshop on Models and Analysis of Vocal Emissions for Biomedical Applications (MAVEBA 2009), Firenze, Italy, 14–16 December 2009; pp. 29–32.
- Bauer, M.S.; Crits-Christoph, P.; Ball, W.A.; Dewees, E.; McAllister, T.; Alahi, P.; Cacciola, J.; Whybrow, P.C. Independent assessment of manic and depressive symptoms by self-rating: Scale characteristics and implications for the study of mania. Arch. Gen. Psychiatry 1991, 48, 807–812. [Google Scholar] [CrossRef] [PubMed]
© 2015 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guidi, A.; Salvi, S.; Ottaviano, M.; Gentili, C.; Bertschy, G.; De Rossi, D.; Scilingo, E.P.; Vanello, N. Smartphone Application for the Analysis of Prosodic Features in Running Speech with a Focus on Bipolar Disorders: System Performance Evaluation and Case Study. Sensors 2015, 15, 28070-28087. https://doi.org/10.3390/s151128070
Guidi A, Salvi S, Ottaviano M, Gentili C, Bertschy G, De Rossi D, Scilingo EP, Vanello N. Smartphone Application for the Analysis of Prosodic Features in Running Speech with a Focus on Bipolar Disorders: System Performance Evaluation and Case Study. Sensors. 2015; 15(11):28070-28087. https://doi.org/10.3390/s151128070
Chicago/Turabian StyleGuidi, Andrea, Sergio Salvi, Manuel Ottaviano, Claudio Gentili, Gilles Bertschy, Danilo De Rossi, Enzo Pasquale Scilingo, and Nicola Vanello. 2015. "Smartphone Application for the Analysis of Prosodic Features in Running Speech with a Focus on Bipolar Disorders: System Performance Evaluation and Case Study" Sensors 15, no. 11: 28070-28087. https://doi.org/10.3390/s151128070
APA StyleGuidi, A., Salvi, S., Ottaviano, M., Gentili, C., Bertschy, G., De Rossi, D., Scilingo, E. P., & Vanello, N. (2015). Smartphone Application for the Analysis of Prosodic Features in Running Speech with a Focus on Bipolar Disorders: System Performance Evaluation and Case Study. Sensors, 15(11), 28070-28087. https://doi.org/10.3390/s151128070