
Effectiveness of Semi-Supervised Active Learning in Automated Wound Image Segmentation

 , , , ,
, , , , 
Abstract
1. Introduction
2. Results
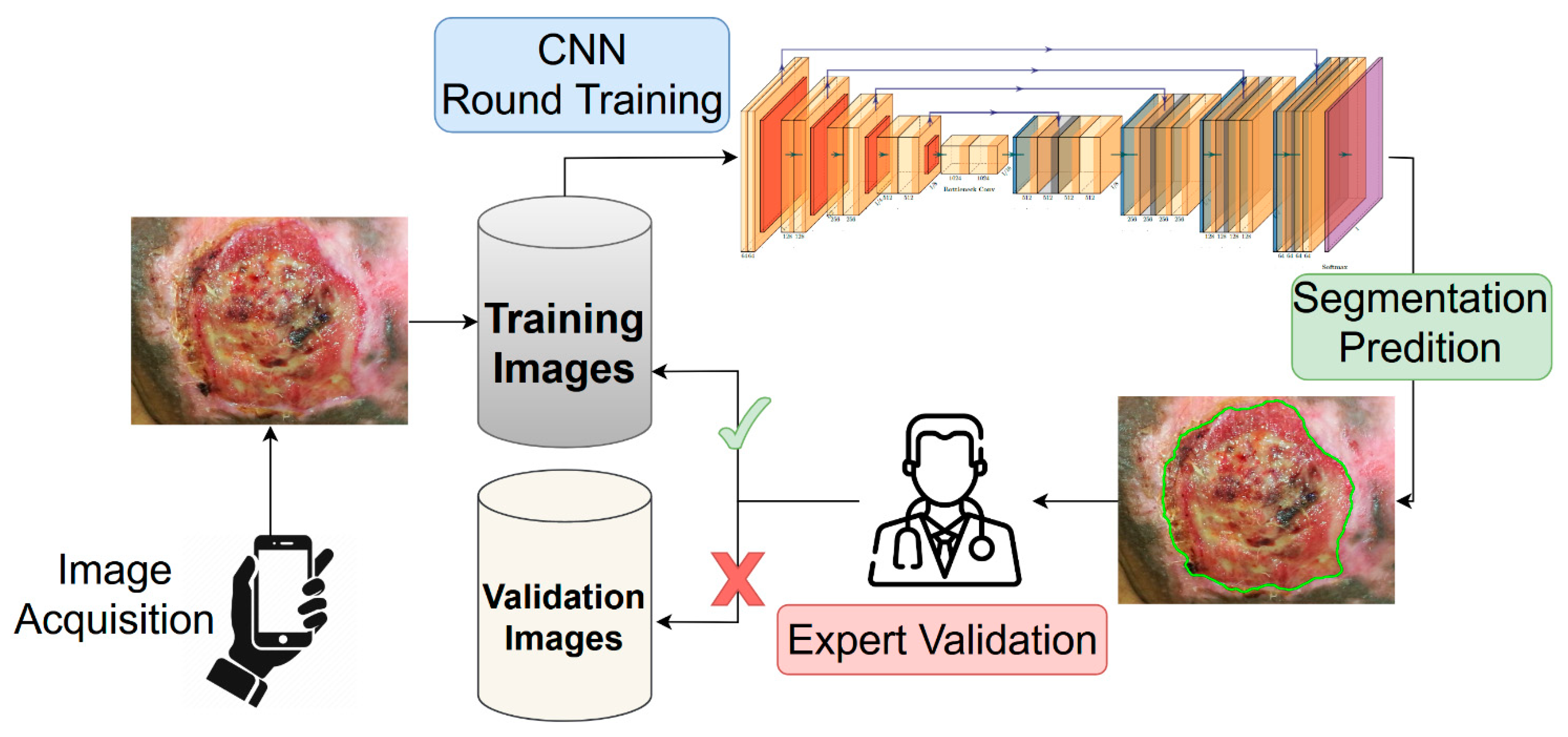
2.1. Training with Active Learning
2.2. Results on Deepskin Dataset
2.3. Results on Public Dataset
3. Discussion
4. Materials and Methods
4.1. Patient Selection
4.2. Data Acquisition
4.3. Data Annotation
4.4. Training Strategy
4.5. Segmentation Model
4.6. Testing on Public Dataset
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Gethin, G. The importance of continuous wound measuring. Wounds UK 2006, 2, 60–68. [Google Scholar]
- Sibbald, R.; Elliot, J.A.; Persaud-jaimangal, R.; Goodman, L.; Armstrong, D.G.; Harely, C.; Coelho, S.; Xi, N.; Evans, R.; Mayer, D.O.; et al. Wound Bed Preparation 2021. Adv. Ski. Wound Care 2021, 34, 183–195. [Google Scholar] [CrossRef] [PubMed]
- Levit, E.; Kagen, M.; Scher, R.; Grossman, M.; Altman, E. The ABC rule for clinical detection of subungual melanoma. J. Am. Acad. Dermatol. 2000, 42, 269–274. [Google Scholar] [CrossRef] [PubMed]
- Stremitzer, S.; Wild, T.; Hoelzenbein, T. How precise is the evaluation of chronic wounds by health care professionals? Int. Wound J. 2007, 4, 156–161. [Google Scholar] [CrossRef] [PubMed]
- Phillips, C.; Humphreys, I.; Fletcher, J.; Harding, K.; Chamberlain, G.; Macey, S. Estimating the costs associated with the management of patients with chronic wounds using linked routine data. Int. Wound J. 2016, 13, 1193–1197. [Google Scholar] [CrossRef]
- Newton, H. Cost-effective wound management: A survey of 1717 nurses. Br. J. Nurs. 2017, 26, S44–S49. [Google Scholar] [CrossRef] [PubMed]
- Guest, J.F.; Fuller, G.W.; Vowden, P. Cohort study evaluating the burden of wounds to the UK’s National Health Service in 2017/2018: Update from 2012/2013. BMJ Open 2020, 10, e045253. [Google Scholar] [CrossRef] [PubMed]
- Nussbaum, S.R.; Carter, M.J.; Fife, C.E.; DaVanzo, J.; Haught, R.; Nusgart, M.; Cartwright, D. An Economic Evaluation of the Impact, Cost, and Medicare Policy Implications of Chronic Nonhealing Wounds. Value Health 2018, 21, 27–32. [Google Scholar] [CrossRef]
- Hjort, A.M.; Gottrup, F. Cost of wound treatment to increase significantly in Denmark over the next decade. J. Wound Care 2010, 19, 173–184. [Google Scholar] [CrossRef]
- Norman, R.E.; Gibb, M.; Dyer, A.; Prentice, J.; Yelland, S.; Cheng, Q.; Lazzarini, P.A.; Carville, K.; Innes-Walker, K.; Finlayson, K. Improved wound management at lower cost: A sensible goal for Australia. Int. Wound J. 2016, 13, 303–316. [Google Scholar] [CrossRef]
- Haghpanah, S.; Bogie, K.; Wang, X.; Banks, P.; Ho, C. Reliability of electronic versus manual measurement techniques. Arch. Phys. Med. Rehabil. 2006, 87, 1396–1402. [Google Scholar] [CrossRef] [PubMed]
- Chan, K.S.; Lo, Z. Wound assessment, imaging and monitoring systems in diabetic foot ulcers: A systematic review. Int. Wound J. 2020, 17, 1909–1923. [Google Scholar] [CrossRef] [PubMed]
- Ahn, C.; Salcido, S. Advances in Wound Photography and Assessment Methods. Adv. Ski. Wound Care 2008, 21, 85–93. [Google Scholar] [CrossRef] [PubMed]
- Dhane, D.M.; Krishna, V.; Achar, A.; Bar, C.; Sanyal, K.; Chakraborty, C. Spectral Clustering for Unsupervised Segmentation of Lower Extremity Wound Beds Using Optical Images. J. Med. Syst. 2016, 40, 207. [Google Scholar] [CrossRef]
- Sarp, S.; Kuzlu, M.; Pipattanasomporn, M.; Güler, Ö. Simultaneous wound border segmentation and tissue classification using a conditional generative adversarial network. J. Eng. 2021, 2021, 125–134. [Google Scholar] [CrossRef]
- Zhou, J.; Cao, R.; Kang, J.; Guo, K.; Xu, Y. An Efficient High-Quality Medical Lesion Image Data Labeling Method Based on Active Learning. IEEE Access 2020, 8, 144331–144342. [Google Scholar] [CrossRef]
- Mahapatra, D.; Schüffler, P.J.; Tielbeek, J.A.W.; Vos, F.M.; Buhmann, J.M. Semi-Supervised and Active Learning for Automatic Segmentation of Crohn’s Disease. In Medical Image Computing and Computer-Assisted Intervention—MICCAI 2013; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2013; Volume 8150. [Google Scholar]
- Zhou, T.; Li, L.; Bredell, G.; Li, J.; Unkelbach, J.; Konukoglu, E. Volumetric memory network for interactive medical image segmentation. Med. Image Anal. 2023, 83, 102599. [Google Scholar] [CrossRef]
- Shin, H.-C.; Roth, H.R.; Gao, M.; Lu, L.; Xu, Z.; Nogues, I.; Yao, J.; Mollura, D.; Summers, R.M. Deep Convolutional Neural Networks for Computer-Aided Detection: CNN Architectures, Dataset Characteristics and Transfer Learning. IEEE Trans. Med. Imaging 2016, 35, 1285–1298. [Google Scholar] [CrossRef]
- Harris, C.; Raizman, R.; Singh, M.; Parslow, N.; Bates-Jensen, B. Bates-Jensen Wound Assessment Tool (BWAT) Pictorial Guide Validation Project. J. Wound Ostomy Cont. Nurs. 2010, 37, 253–259. [Google Scholar] [CrossRef]
- Wang, C.; Anisuzzaman, D.M.; Williamson, V.; Dhar, M.K.; Rostami, B.; Niezgoda, J.; Gopalakrishnan, S.; Yu, Z. Fully automatic wound segmentation with deep convolutional neural networks. Sci. Rep. 2020, 10, 21897. [Google Scholar] [CrossRef]
- Analytics, B.D.; Lab, V. Wound Segmentation. In GitHub Repository; GitHub: San Francisco, CA, USA, 2021. [Google Scholar]
- Curti, N.; Giampieri, E.; Guaraldi, F.; Bernabei, F.; Cercenelli, L.; Castellani, G.; Versura, P.; Marcelli, E. A Fully Automated Pipeline for a Robust Conjunctival Hyperemia Estimation. Appl. Sci. 2021, 11, 2978. [Google Scholar] [CrossRef]
- Wang, C.; Yan, X.; Smith, M.; Kochhar, K.; Rubin, M.; Warren, S.M.; Wrobel, J.; Lee, H. A unified framework for automatic wound segmentation and analysis with deep convolutional neural networks. In Proceedings of the 2015 37th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Milan, Italy, 25–29 August 2015; pp. 2415–2418. [Google Scholar] [CrossRef]
- Camargo, G.; Bugatti, P.H.; Saito, P.T.M. Active semi-supervised learning for biological data classification. PLoS ONE 2020, 15, e0237428. [Google Scholar] [CrossRef] [PubMed]
- Gal, Y.; Islam, R.; Ghahramani, Z. Deep Bayesian Active Learning with Image Data. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; Volume 70, pp. 1183–1192. [Google Scholar]
- Xie, S.; Feng, Z.; Chen, Y.; Sun, S.; Ma, C.; Song, M. Deal: Difficulty-aware Active Learning for Semantic Segmentation. In Proceedings of the Asian Conference on Computer Vision (ACCV), Kyoto, Japan, 30 November–4 December 2020. [Google Scholar]
- Zhou, T.; Wang, W.; Konukoglu, E.; Van Gool, L. Rethinking Semantic Segmentation: A Prototype View. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–20 June 2022; pp. 2582–2593. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015; Lecture Notes in Computer Science; Navab, N., Hornegger, J., Wells, W., Frangi, A., Eds.; Springer: Cham, Switzerland, 2015; Volume 9351. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid Scene Parsing Network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, Hawaii, 22–25 July 2017; pp. 2881–2890. [Google Scholar]
- Yakubovskiy, P. Segmentation Models. In GitHub Repository; GitHub: San Francisco, CA, USA, 2019. [Google Scholar]
- Tan, M.; Le, Q.V. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. arXiv 2020, arXiv:1905.11946. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; Li, F.-F. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. TensorFlow: Large-Scale Machine Learning on Heterogeneous Systems. arXiv 2015, arXiv:1603.04467. [Google Scholar]



{kind=link}
{kind=link}
| Round 0 | Round 1 | Round 2 | Round 3 | |
|---|---|---|---|---|
| N° training images | 145 (9%) | 368 (24%) | 916 (59%) | 1365 (87%) |
| N° validation images | 1419 (91%) | 1196 (76%) | 648 (41%) | 199 (13%) |
| N° correct segmentation | 223 (16%) | 548 (46%) | 449 (69%) | 112 (56%) |
| DSC metric | 0.95 | 0.98 | 0.97 | 0.96 |
| Precision metric | 0.93 | 0.98 | 0.97 | 0.96 |
| Recall metric | 0.96 | 0.98 | 0.97 | 0.96 |
| a | Mobile NetV2 | Our U-Net | b | Mobile NetV2 | Our U-Net |
|---|---|---|---|---|---|
| DSC | 0.64 | 0.96 | DSC | 0.90 | 0.78 |
| Precision | 0.53 | 0.96 | Precision | 0.91 | 0.83 |
| Recall | 0.85 | 0.96 | Recall | 0.90 | 0.72 |
| Deepskin | FUSC |
| a | Male | Female | Tot | b | Foot | Leg | Chest | Arm | Head | Tot |
|---|---|---|---|---|---|---|---|---|---|---|
| N° patients | 210 | 264 | 474 | N° wounds | 97 | 354 | 14 | 6 | 2 | 473 |
| Age | 71 ± 17 | 77 ± 17 | 74 ± 20 | N° images | 364 | 1142 | 38 | 13 | 7 | 1564 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Curti, N.; Merli, Y.; Zengarini, C.; Giampieri, E.; Merlotti, A.; Dall’Olio, D.; Marcelli, E.; Bianchi, T.; Castellani, G. Effectiveness of Semi-Supervised Active Learning in Automated Wound Image Segmentation. Int. J. Mol. Sci. 2023, 24, 706. https://doi.org/10.3390/ijms24010706
Curti N, Merli Y, Zengarini C, Giampieri E, Merlotti A, Dall’Olio D, Marcelli E, Bianchi T, Castellani G. Effectiveness of Semi-Supervised Active Learning in Automated Wound Image Segmentation. International Journal of Molecular Sciences. 2023; 24(1):706. https://doi.org/10.3390/ijms24010706
Chicago/Turabian StyleCurti, Nico, Yuri Merli, Corrado Zengarini, Enrico Giampieri, Alessandra Merlotti, Daniele Dall’Olio, Emanuela Marcelli, Tommaso Bianchi, and Gastone Castellani. 2023. "Effectiveness of Semi-Supervised Active Learning in Automated Wound Image Segmentation" International Journal of Molecular Sciences 24, no. 1: 706. https://doi.org/10.3390/ijms24010706
APA StyleCurti, N., Merli, Y., Zengarini, C., Giampieri, E., Merlotti, A., Dall’Olio, D., Marcelli, E., Bianchi, T., & Castellani, G. (2023). Effectiveness of Semi-Supervised Active Learning in Automated Wound Image Segmentation. International Journal of Molecular Sciences, 24(1), 706. https://doi.org/10.3390/ijms24010706