

Molecular Characterization and SNP-Based Molecular Marker Development of Two Novel High Molecular Weight Glutenin Genes from Triticum spelta L.

Abstract
1. Introduction
2. Results and Discussion
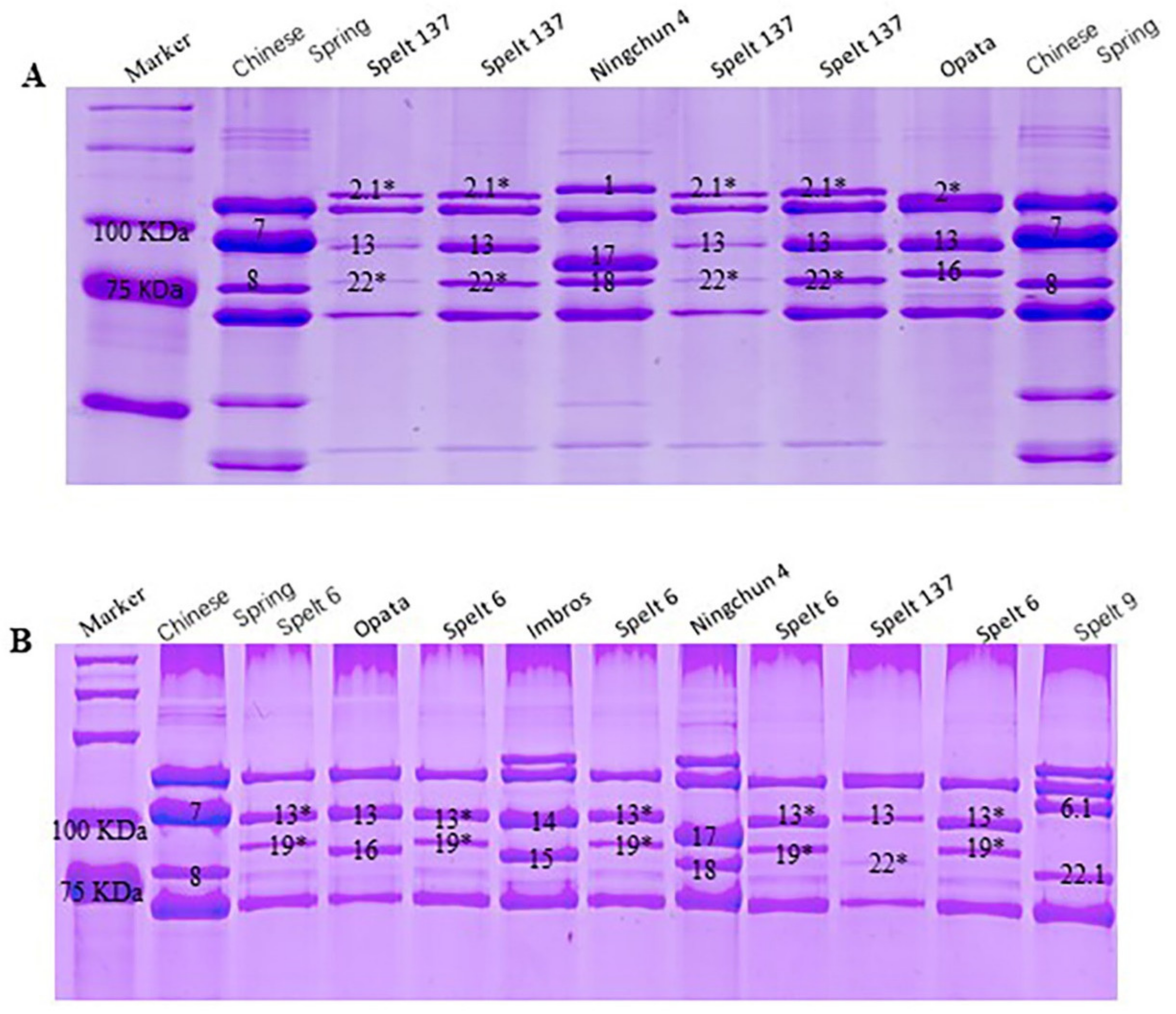
2.1. Identification of Novel HMW-GS in Spelt Wheat
2.2. Molecular Cloning and Characterization of 1Ax2.1* and 1By19* Genes from Spelt Wheat
2.3. SNP and InDel Variations in 1Ax2.1* and 1By19* Genes
2.4. Verification of the Cloned 1Ax2.1* and 1By19* Genes from Spelt Wheat by Tandem Mass Spectrometry Analysis
2.5. Phylogenetic Analysis of Ax2.1* and 1By19* Genes
2.6. Secondary Structure and 3D Structure Analysis of 1Ax2.1* and 1By19* Protein Subunits
2.7. Development and Validation of SNP-Based Molecular Markers for 1Ax2.1 * and 1By19* Genes
3. Materials and Methods
3.1. Plant Materials
3.2. HMW-GS Extraction and SDS-PAGE
3.3. DNA Isolation, AS-PCR Amplication and Sequencing
3.4. Sequence Alignment and SNP/InDel Identification
3.5. MALDI-TOF/TOF-MS
3.6. Construction of Phylogenetic Tree and Estimation of Divergence Time
3.7. Secondary Structure and 3D Structure Prediction of HMW-GS
3.8. Development and Validation of SNP-Based Molecular Markers
4. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| HMW-GS | High molecular weight glutenin subunit |
| LMW-GS | Low molecular weight glutenin subunit |
| MATE | Multidrug and toxin efflux |
| PCR | Polymerase chain reaction |
| AS-PCR | Allele specific polymerase chain reaction |
| SNP | Single nucleotide polymorphism |
| ORF | Open reading frame |
| InDels | Insertion/Deletion variations |
| CTAB | Hexadecyl trimethyl ammonium bromide |
| RILs | Recombinant inbred lines |
| MYA | Million years ago |
| SDS-PAGE | Sodium dodecyl sulfate polyacryl amide gel electrophoresis |
| MALDI-TOF-MS | Matrix-assisted laser desorption ionization tandem time of flight mass spectrometry Molecular weight |
References
- Kumar, R.; Mamrutha, H.M.; Kaur, A.; Venkatesh, K.; Sharma, D.; Singh, G.P. Optimization of Agrobacterium-mediated transformation in spring bread wheat using mature and immature embryos. Mol. Biol. Rep. 2019, 46, 1845–1853. [Google Scholar] [CrossRef] [PubMed]
- Spannagl, M.; Martis, M.M.; Pfeifer, M.; Nussbaumer, T.; Mayer, K.F. Analysing complex Triticeae genomes–concepts and strategies. Plant Methods 2013, 9, 1–9. [Google Scholar] [CrossRef] [PubMed][Green Version]
- Kumar, A.; Kapoor, P.; Chunduri, V.; Sharma, S.; Garg, M. Potential of Aegilops sp. for improvement of grain processing and nutritional quality in wheat (Triticum aestivum). Front. Plant Sci. 2019, 10, 308. [Google Scholar] [CrossRef]
- Biesiekierski, J.R. What is gluten? J. Gastroenterol. Hepatol. 2017, 32, 78–81. [Google Scholar] [CrossRef] [PubMed]
- Wrigley, C.W. Giant proteins with flour power. Nature 1996, 381, 738–739. [Google Scholar] [CrossRef]
- Mioduszewski, Ł.; Cieplak, M. Viscoelastic properties of wheat gluten in a molecular dynamics study. PLoS Comput. Biol. 2021, 17, e1008840. [Google Scholar] [CrossRef] [PubMed]
- Bonilla, J.C.; Erturk, M.Y.; Schaber, J.A.; Kokini, J.L. Distribution and function of LMW glutenins, HMW glutenins, and gliadins in wheat doughs analyzed with ‘in situ’ detection and quantitative imaging techniques. J. Cereal Sci. 2020, 93, 102931. [Google Scholar] [CrossRef]
- Payne, P.I.; Holt, L.M.; Law, C.N. Structural and genetical studies on the high-molecular-weight subunits of wheat glutenin. Theor. Appl. Genet. 1981, 60, 229–236. [Google Scholar] [CrossRef]
- Law, C.N.; Payne, P.I. Genetical aspects of breeding for improved grain protein content and type in wheat. J. Cereal Sci. 1983, 1, 79–93. [Google Scholar] [CrossRef]
- Li, Y.; Fu, J.; Shen, Q.; Yang, D. High-molecular-weight glutenin subunits: Genetics, structures, and relation to end use qualities. Int. J. Mol. Sci. 2020, 22, 184. [Google Scholar] [CrossRef]
- Branlard, G.; Dardevet, M. Diversity of grain protein and bread wheat quality: II. Correlation between high molecular weight subunits of glutenin and flour quality characteristics. J. Cereal Sci. 1985, 3, 345–354. [Google Scholar] [CrossRef]
- Brönneke, V.; Zimmermann, G.; Killermann, B. Effect of high molecular weight glutenins and D-zone gliadins on bread-making quality in German wheat varieties. Cereal Res. Commun. 2000, 28, 187–194. [Google Scholar] [CrossRef]
- Lama, S.; Kabir, M.R.; Akhond, M.A.Y. Biochemical and molecular characterization of Bangladeshi wheat varieties for bread-making quality. Plant Tissue Cult. Biotechnol. 2018, 28, 57–68. [Google Scholar] [CrossRef]
- Pang, B.S.; Zhang, X.Y. Isolation and molecular characterization of high molecular weight glutenin subunit genes 1Bx13 and 1By16 from hexaploid wheat. J. Integr. Plant Biol. 2008, 50, 329–337. [Google Scholar] [CrossRef] [PubMed]
- Shewry, P.R.; Halford, N.G.; Tatham, A.S. The high molecular weight subunits of wheat glutenin. J. Cereal Sci. 1992, 15, 105–120. [Google Scholar] [CrossRef]
- Tatham. A.S.; Drake, A.F.; Shewry. P.R. Contormational studies of synthetic peptides corresponding to the repetitive region of the high molecular weight (HMW) glutenin subunits of wheat. J. Cereal Sci. 1990, 11, 189–200. [Google Scholar] [CrossRef]
- Pézolet, M.; Bonenfant, S.; Dousseau, F.; Popineau, Y. Conformation of wheat gluten proteins Comparison between functional and solution states as determined by infrared spectroscopy. FEBS Lett. 1992, 299, 247–250. [Google Scholar] [CrossRef]
- Lafiandra, D.; Shewry, P.R. Wheat Glutenin polymers 2, the role of wheat glutenin subunits in polymer formation and dough quality. J. Cereal Sci. 2022, 106, 103487. [Google Scholar] [CrossRef]
- Huebner, F.R.; Bietz, J.A.; Wall, J.S. Disulfide bonds: Key to wheat protein functionality. Adv. Exp. Med. Biol. 1977, 86A, 67–88. [Google Scholar]
- Tatham, A.S.; Miflin, B.J.; Shewry, P.R. The beta-turn conformation in wheat gluten proteins: Relationship to gluten elasticity. Cereal Chem. 1985, 62, 405–442. [Google Scholar]
- Gao, J.H.; Yu, P.X.; Liang, H.R.; Fu, J.H.; Luo, Z.Y.; Yang, D. The wPDI Redox Cycle coupled conformational change of the repetitive domain of the HMW-GS 1Dx5-A computational study. Molecules 2020, 25, 4393. [Google Scholar] [CrossRef] [PubMed]
- Cazalis, R.; Aussenac, T.; Rhazi, L.; Marin, A.; Gibrat, J.F. Homology modeling and molecular dynamics simulations of the N-terminal domain of wheat high molecular weight glutenin subunit 10. Protein Sci. 2003, 12, 34–43. [Google Scholar] [CrossRef]
- Robert, A.; Barkoutsos, P.K.; Woerner, S.; Tavernelli, I. Resource-efficient quantum algorithm for protein folding. npj Quantum Inform. 2021, 7, 1–5. [Google Scholar] [CrossRef]
- Magoshi, J.; Becker, M.; Han, Z.; Nakamura, S. Thermal properties of seed proteins. J. Therm. Anal. Calorim. 2002, 70, 833–839. [Google Scholar] [CrossRef]
- Calucci, L.; Pinzino, C.; Capocchi, A.; Galleschi, L.; Ghiringhelli, S.; Saviozzi, F.; Zandomeneghi, M. Structure and dynamics of high molecular weight glutenin subunits of durum wheat (Triticum durum) in water and alcohol solutions studied by electron paramagnetic resonance and circular dichroism spectroscopies. J. Agric. Food Chem. 2001, 49, 359–365. [Google Scholar] [CrossRef] [PubMed]
- Porath, J. From gel filtration to adsorptive size exclusion: Communications from the 11th international conference on methods in protein structure analysis. J. Protein. Chem. 1997, 16, 463–468. [Google Scholar] [CrossRef]
- Bryant, P.; Pozzati, G.; Elofsson, A. Improved prediction of protein-protein interactions using alphafold2. Nat. Commun. 2022, 13, 1265. [Google Scholar] [CrossRef]
- Jumper, J.; Evans, R.; Pritzel, A.; Green, T.; Hassabis, D. Highly accurate protein structure prediction with alphafold. Nature 2021, 596, 583–589. [Google Scholar] [CrossRef]
- Zweckstetter, M. NMR hawk-eyed view of AlphaFold2 structures. Protein Sci. 2021, 30, 2333–2337. [Google Scholar] [CrossRef]
- Duan, W.; Lu, F.; Cui, Y.; Zhang, J.; Du, X.; Hu, Y.; Yan, Y. Genome-wide identification and characterisation of wheat MATE genes reveals their roles in aluminium tolerance. Int. J. Mol. Sci. 2022, 23, 4418. [Google Scholar] [CrossRef]
- Yan, Y.; Hsam, S.L.K.; Yu, J.Z.; Jiang, Y.; Ohtsuka, I.; Zeller, F.J. HMW and LMW glutenin alleles among putative tetraploid and hexaploid European spelt wheat (Triticum spelta L.) progenitors. Theor. Appl. Genet. 2003, 107, 1321–1330. [Google Scholar] [CrossRef] [PubMed]
- An, X.; Li, Q.; Yan, Y.; Xiao, Y.; Hsam, S.L.K.; Zeller, F.J. Genetic diversity of European spelt wheat (Triticum aestivum ssp. spelta L. em. Thell.) revealed by glutenin subunit variations at the Glu-1 and Glu-3 loci. Euphytica 2005, 146, 193–201. [Google Scholar] [CrossRef]
- Li, Q.Y.; Yan, Y.M.; Wang, A.L.; An, X.L.; Zhang, Y.Z.; Hsam, S.L.K.; Zeller, F.J. Detection of HMW glutenin subunit variations among 205 cultivated emmer accessions (Triticum turgidum ssp. dicoccum. Plant Breed. 2006, 125, 120–124. [Google Scholar] [CrossRef]
- Yan, Y.; Hsam, S.L.K.; Yu, J.; Jiang, Y.; Zeller, F.J. Allelic variation of the HMW glutenin subunits in Aegilops tauschii accessions detected by sodium dodecyl sulphate (SDS-PAGE), acid polyacrylamide gel (A-PAGE) and capillary electrophoresis. Euphytica 2003, 130, 377–385. [Google Scholar] [CrossRef]
- Zhang, Y.; Li, X.; Wang, A.; An, X.; Zhang, Q.; Pei, Y.; Gao, L.; Ma, W.; Appels, R.; Yan, Y. Novel x-type high-molecular-weight glutenin genes from Aegilops tauschii and their implications on the wheat origin and evolution mechanism of Glu-D1-1 proteins. Genetics 2008, 178, 23–33. [Google Scholar] [CrossRef][Green Version]
- Cui, D.; Wang, J.; Li, M.; Lu, Y.; Yan, Y. Functional assessment and SNP-based molecular marker development of two 1Sl-encoded HMW glutenin subunits in Aegilops longissima L. Mol. Breed. 2019, 39, 1–15. [Google Scholar] [CrossRef]
- Hu, J.; Wang, J.; Deng, X.; Yan, Y. Cloning and characterization of special HMW glutenin subunit genes from Aegilops longissima L. and their potential for wheat quality improvement. 3 Biotech. 2019, 9, 1–13. [Google Scholar] [CrossRef] [PubMed]
- Ma, C.; Yang, Y.; Li, X.; Ge, P.; Guo, G.; Subburaj, S.; Zeller, F.J.; Hsam, S.L.K.; Yan, Y. Molecular cloning and characterization of six novel HMW-GS genes from Aegilops speltoides and Aegilops kotschyi. Plant Breed. 2013, 132, 284–289. [Google Scholar] [CrossRef]
- Pu, Z.E.; Liu, Y.X.; Li, W. Origin and genetics of spelt wheat (Triticum spelta L.) and its utilization in the genetic improvement of common wheat (Triticum aestivum L.). J. Plant. Genet. Resour. 2009, 10, 475–479. [Google Scholar]
- Liu, M.; Zhao, Q.; Qi, F.; Stiller, J.; Tang, S.; Miao, J.; Liu, C. Sequence divergence between spelt and common wheat. Theor. Appl. Genet. 2018, 131, 1125–1132. [Google Scholar] [CrossRef]
- Campbell, K.G. Spelt: Agronomy, genetics, and breeding. Plant Breed. Rev. 1997, 15, 187–213. [Google Scholar]
- Frakolaki, G.; Giannou, V.; Topakas, E.; Tzia, C. Chemical characterization and breadmaking potential of spelt versus wheat flour. J. Cereal Sci. 2018, 79, 50–56. [Google Scholar]
- Zeven, A.C.; Turkensteen, L.J.; Stubbs, R.W. Spelt (Triticum spelta L.) as a possible source of race-non-specific resistance to yellow rust (Puccinia striiformis West.). Euphytica 1968, 17, 381–384. [Google Scholar] [CrossRef]
- Piergiovanni, A.R.; Rizzi, R.; Pannacciulli, E.; Gatta, C.D. Mineral composition in hulled wheat grains: A comparison between emmer (Triticum dicoccon Schrank) and spelt (T. spelta L.) accessions. Int. J. Food Sci. Nutr. 1997, 48, 381–386. [Google Scholar] [CrossRef]
- Akel, W.; Thorwarth, P.; Mirdita, V.; Weissman, E.A.; Liu, G.; Würschum, T.; Longin, C.F.H. Can spelt wheat be used as heterotic group for hybrid wheat breeding? Theor. Appl. Genet. 2018, 131, 973–984. [Google Scholar] [CrossRef]
- Halford, N.G.; Field, J.M.; Blair, H.; Urwin, P.; Moore, K.; Robert, L.; Thompson, R.; Flavell, R.B.; Shewry, P.R. Analysis of HMW glutenin subunits encoded by chromosome 1A of bread wheat (Triticum aestivum L.) indicates quantitative effects on grain quality. Theor. Appl. Genet. 1992, 83, 373–378. [Google Scholar] [CrossRef] [PubMed]
- D’Ovidio, R.; Lafiandra, D.; Porceddu, E. Identification and molecular characterization of a large insertion within the repetitive domain of a high-molecular-weight glutenin subunit gene from hexaploid wheat. Theor. Appl. Genet. 1996, 93, 1048–1053. [Google Scholar] [CrossRef]
- Yan, Y.M.; Jiang, Y.; An, X.L.; Pei, Y.H.; Li, X.H.; Zhang, Y.Z.; Wang, A.L.; He, Z.H.; Xia, X.C.; Bekes, F.; et al. Cloning, expression and functional analysis of HMW glutenin subunit 1By8 gene from Italy pasta wheat (Triticum turgidum L. ssp. durum). J. Cereal Sci. 2009, 50, 398–406. [Google Scholar] [CrossRef]
- Liang, X.; Zhen, S.; Han, C.; Chang, W.; Yan, Y. Molecular characterization and marker development for hexaploid wheat-specific HMW glutenin subunit 1By18 gene. Mol. Breed. 2015, 35, 221. [Google Scholar]
- Fevzioglu, M.; Ozturk, O.K.; Hamaker, B.R.; Campanella, O.H. Quantitative approach to study secondary structure of proteins by FT-IR spectroscopy, using a model wheat gluten system. Int. J. Biol. Macromol. 2020, 164, 2753–2760. [Google Scholar] [CrossRef]
- Ruomei, W.; Junwei, Z.; Fei, L.; Nannan, L.; Prodanović, S.; Yueming, Y. Cloning and molecular characterization of two novel LMW-m type glutenin genes from Triticum spelta L. Genetika 2021, 53, 141–155. [Google Scholar]
- Wang, Y.; Zhen, S.; Luo, N.; Han, C.; Lu, X.; Li, X.; Xia, X.; He, Z.; Yan, Y. Low molecular weight glutenin subunit gene Glu-B3h confers superior dough strength and breadmaking quality in wheat (Triticum aestivum L.). Sci. Rep. 2016, 6, 27182. [Google Scholar] [CrossRef] [PubMed]
- Skolnick, J.; Gao, M.; Zhou, H.; Singh, S. Alphafold 2: Why it works and its implications for understanding the relationships of protein sequence, structure, and function. J. Chem. Inf. Model. 2021, 61, 4827–4831. [Google Scholar] [CrossRef] [PubMed]
- Lutz, E.; Wieser, H.; Koehler, P. Identification of disulfide bonds in wheat gluten proteins by means of mass spectrometry/electron transfer dissociation. J. Agric. Food Chem. 2012, 60, 3708–3716. [Google Scholar] [CrossRef] [PubMed]
- Shewry, P.; Gilbert, S.; Savage, A.; Tatham, A.S.; Wan, Y.F.; Belton, P.S.; Wellner, N.; D’Ovidio, R.; Békés, F.; Halford, N.G. Sequence and properties of HMW subunit IBx20 from pasta wheat (Triticum durum) which is associated with poor end use properties. Theor. Appl. Genet. 2003, 106, 744–750. [Google Scholar] [CrossRef] [PubMed]
- Pirozi, M.R.; Margiotta, B.; Lafiandra, D.; MacRitchie, F. Composition of polymeric proteins and bread-making quality of wheat lines with allelic HMW-GS differing in number of cysteines. J. Cereal Sci. 2008, 48, 117–122. [Google Scholar] [CrossRef]
- Shewry, P.R.; Halford, N.G. Cereal seed storage proteins: Structures, properties and role in grain utilization. J. Exp. Bot. 2002, 53, 947–958. [Google Scholar] [CrossRef]
- Wang, N.; Ma, S.; Li, L.; Zheng, X. Aggregation characteristics of protein during wheat flour maturation. J. Agric. Food Chem. 2019, 99, 719–725. [Google Scholar] [CrossRef]
- Andrews, J.L.; Skerritt, J.H. Quality-related epitopes of high Mr subunits of wheat glutenin. J. Cereal Sci. 1994, 19, 219–229. [Google Scholar] [CrossRef]
- Ramesh, P.; Mallikarjuna, G.; Sameena, S.; Kumar, A.; Gurulakshmi, K.; Reddy, B.V.; Sekhar, A.C. Advancements in molecular marker technologies and their applications in diversity studies. J. Biosci. 2020, 45, 1–15. [Google Scholar] [CrossRef]
- Ravel, C.; Faye, A.; Ben-Sadoun, S.; Ranoux, M.; Gérard Branlard. SNP markers for early identification of high molecular weight glutenin subunits (HMW-GSs) in bread wheat. Theor. Appl. Genet. 2020, 133, 751–770. [Google Scholar] [CrossRef] [PubMed]
- Schwarz, G.; Sift, A.; Wenzel, G.; Mohler, V. DHPLC scoring of a SNP between promoter sequences of HMW glutenin x-type alleles at the Glu-D1 locus in wheat. J. Agric. Food Chem. 2003, 51, 4263–4267. [Google Scholar] [CrossRef] [PubMed]
- Mackie, A.M.; Sharp, P.J.; Lagudah, E.S. The nucleotide and derived amino acid sequence of a HMW glutenin gene from Triticum tauschii and comparison with those from the D genome of bread wheat. J. Cereal Sci. 1996, 24, 73–78. [Google Scholar] [CrossRef]
- Allaby, R.G.; Banerjee, M.; Brown, T.A. Evolution of the high molecular weight glutenin loci of the A, B, D, and G genomes of wheat. Genome 1999, 42, 296–307. [Google Scholar] [CrossRef] [PubMed]
- Buchan, D.W.; Jones, D.T. The PSIPRED protein analysis workbench: 20 years on. Nucleic Acids Res. 2019, 47, W402–W407. [Google Scholar] [CrossRef]
- Buchan, D.W.; Ward, S.M.; Lobley, A.E.; Nugent, T.C.O.; Bryson, K.; Jones, D.T. Protein annotation and modelling servers at University College London. Nucleic Acids Res. 2010, 38, W563–W568. [Google Scholar] [CrossRef]
- Mirdita, M.; Schütze, K.; Moriwaki, Y.; Heo, L.; Ovchinnikov, S.; Steinegger, M. ColabFold: Making protein folding accessible to all. Nat. Methods 2022, 19, 679–682. [Google Scholar] [CrossRef]
- Varadi, M.; Anyango, S.; Deshpande, M.; Nair, S.; Natassia, C.; Yordanova, G.; Velankar, S. AlphaFold Protein Structure Database: Massively expanding the structural coverage of protein-sequence space with high-accuracy models. Nucleic Acids Res. 2022, 50, D439–D444. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Positions (bp) | 198 | 288 | 325 | 1076 | 1302 | 1448 | 1696 | 1777 | 1813 | 1815 | 2066 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1Ax2.1* | T | G | C | T | T | A | A | A | G | G | T |
| 15 other x-type HMW-GS genes | C | A | T | C/-- | A/C | G | G | G/-- | C/T | A | C |
| HMW-GS | Identified Protein | Accession No | Tryptic Fragments Identified by MS Data | Positions | Matched Peptides | Protein Score C. I. % |
|---|---|---|---|---|---|---|
| 1Ax2.1* | x-type | MK395158 | QVVDQQLRDVSPECQPVGGGPVARQYEQQVVVPPK QQPGQGQQLRQGQQGQQSGQGQPR QQDQQSGQGQQPGQRQPGYYSTSPQQLGQGQPRYYPTSPQQPGQEQQPR QWLQPR AQQLAAQLPAMCRLEGGDALLASQ | 45–79 195–218 357–405 725–730 792–815 | 5 | 100 |
| 1By19* | y-type | MK395159 | QLQCERELQESSLEACRQVVDQQLAGRLPWSTGLQMRCCQQLR | 28–70 | 1 | 100 |
| HMW-GS (Accession No.) | Type | Structure Motifs | Content (%) | Total | Amino Acid Length |
|---|---|---|---|---|---|
| 1Ax2.1* (MK395158) | x-type | α-helix | 9.58 | 7 | 824 |
| β-strand | 0.82 | 4 | |||
| 1Ax2* (M22208) | x-type | α-helix | 9.33 | 7 | 815 |
| β-strand | 0.98 | 2 | |||
| 1Ax1 (X61009) | x-type | α-helix | 9.40 | 6 | 830 |
| β-strand | 0.00 | 0 | |||
| 1By19* (MK395159) | y-type | α-helix | 12.36 | 8 | 720 |
| β-strand | 0.00 | 0 | |||
| 1By8 (AY245797) | y-type | α-helix | 16.81 | 8 | 720 |
| β-strand | 0.00 | 0 | |||
| 1By9 (X61026) | y-type | α-helix | 13.19 | 8 | 705 |
| β-strand | 0.00 | 0 | |||
| 1By15 (DQ086215) | y-type | α-helix | 12.03 | 6 | 723 |
| β-strand | 0.00 | 0 | |||
| 1By16 (EF540765) | y-type | α-helix | 11.65 | 8 | 738 |
| β-strand | 0.00 | 0 | |||
| 1By18 (KF430649) | y-type | α-helix | 12.22 | 8 | 720 |
| β-strand | 0.00 | 0 | |||
| 1By20 (LN828972) | y-type | α-helix | 11.85 | 8 | 717 |
| β-strand | 0.00 | 0 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cao, Y.; Zhang, J.; Wang, R.; Sun, H.; Yan, Y. Molecular Characterization and SNP-Based Molecular Marker Development of Two Novel High Molecular Weight Glutenin Genes from Triticum spelta L. Int. J. Mol. Sci. 2022, 23, 11104. https://doi.org/10.3390/ijms231911104
Cao Y, Zhang J, Wang R, Sun H, Yan Y. Molecular Characterization and SNP-Based Molecular Marker Development of Two Novel High Molecular Weight Glutenin Genes from Triticum spelta L. International Journal of Molecular Sciences. 2022; 23(19):11104. https://doi.org/10.3390/ijms231911104
Chicago/Turabian StyleCao, Yuemei, Junwei Zhang, Ruomei Wang, Haocheng Sun, and Yueming Yan. 2022. "Molecular Characterization and SNP-Based Molecular Marker Development of Two Novel High Molecular Weight Glutenin Genes from Triticum spelta L." International Journal of Molecular Sciences 23, no. 19: 11104. https://doi.org/10.3390/ijms231911104
APA StyleCao, Y., Zhang, J., Wang, R., Sun, H., & Yan, Y. (2022). Molecular Characterization and SNP-Based Molecular Marker Development of Two Novel High Molecular Weight Glutenin Genes from Triticum spelta L. International Journal of Molecular Sciences, 23(19), 11104. https://doi.org/10.3390/ijms231911104