1. Introduction
Drug discovery often relies on the identification of a therapeutic target, usually a protein playing a role in a disease. Then, small molecular drugs that interact with the protein target to alter disease development are designed or searched for among large molecular databases. However, there has been a renewed interest in recent years for phenotypic drug discovery, which does not rely on prior knowledge of the target. In particular, the pharmaceutical industry has invested more efforts in poorly understood rare diseases, and for which therapeutic targets have not been discovered yet. While phenotypic drug discovery has made possible the identification of a few first-in class drugs [
1], once a phenotypic hit is identified, not knowing its mechanism of action is a strong limitation to fill the gap between the hit and a drug that can reach the market [
2]. More fundamentally, the target points at key biological pathways involved in the disease, helping to better understand its molecular basis.
Our work aims at helping determination of the protein targets for hit molecules discovered in phenotypic screens. Identification of a drug target based solely on experiments is out of reach because it would require to design biological assays for all possible proteins. In that context, in silico approaches can reduce number of experimental tests by focusing on a limited number of high probable protein targets. Among them, Quantitative Structure-Activity Relationship (QSAR) methods were developed for that purpose [
3]. They are efficient methods for the inverse problem of finding new molecules against a given target, when ligands are already known for this target. However, using them to identify the targets of a given molecule would require training a model for each protein across the protein space, which is not possible because many proteins have only few, or even no, known ligand.
Docking approaches can address this question [
4], but they are restricted to proteins with known 3D structures, which is far from covering the human proteome.
In the present paper, we tackle target identification in the form of Drug-Target Interaction (DTI) prediction based on machine learning (ML) chemogenomic algorithms [
5]. These approaches can be viewed as an attempt to complete a large matrix of binary interactions relating molecules to proteins (1 if the protein and molecule interact, 0 otherwise). This matrix is partially filled with known interactions reported in the literature and gathered in large databases such as the PubChem database at NCBI [
6]. They can be used to train ML chemogenomic algorithms by formulating the problem of DTIs prediction as a binary classification task, where the goal is predict the probability for pairs
of molecules and proteins to interact. They can be used both to predict drugs against protein targets, or protein targets for a drug, the latter being relevant to our topic.
Various ML algorithms have been proposed for DTI predictions. They include similarity-based (or kernel-based) methods such as kernel ridge linear regression, Support Vector Machines [
7], or Neighborhood Regularized Logistic Matrix Factorization (NRLMF) that decompose the interaction matrix into the product of two matrices of lower ranks that operate in two latent spaces of proteins and molecules [
8]. Other ML algorithms are featured-based, which means that they rely on explicit descriptors for molecules and proteins, such as Random Forests (RF) [
9], or Sparse Canonical Correspondence Analysis (SCCA) [
10]. Their prediction performances are usually very high when the training data are not too “far” from the
pairs in the test set [
11]. Deep learning approaches relying on protein and molecule descriptors have also been proposed, but their prediction performances outperforms those of shallow learning methods only when the training data are very abundant, or when various heterogeneous sources of information are used in the context of transfer learning [
12].
However, whatever the algorithm used, training a good ML chemogenomic model is hindered by biases in the DTI databases, such as whether the molecule for which one wishes to make predictions has known interactions or not [
13]. An additional issue arises when the databases only contain positive examples of
pairs known to interact, but no negative examples of
known not to interact. In this context, it is classical to assume that most unlabeled interactions are negatives, and to randomly sample negative examples among them [
11]. In this work, we explore how to best choose negative examples to correct the statistical bias of databases, and reduce the number of false positive predictions, which is essential to reduce the number of biological experiments required for validation of the true protein targets. While the goal of the present paper was not to compare the prediction performances of various ML algorithms, we first compared the performances of two algorithms, namely SVM and RF, on the DrugBank dataset considered in the present study. We found that overall, SVM displayed the best results, and therefore, this algorithm was further kept to study how to correct learning bias.
3. Results
3.1. Performance of the SVM and RF Algorithms on the RN-Datasets
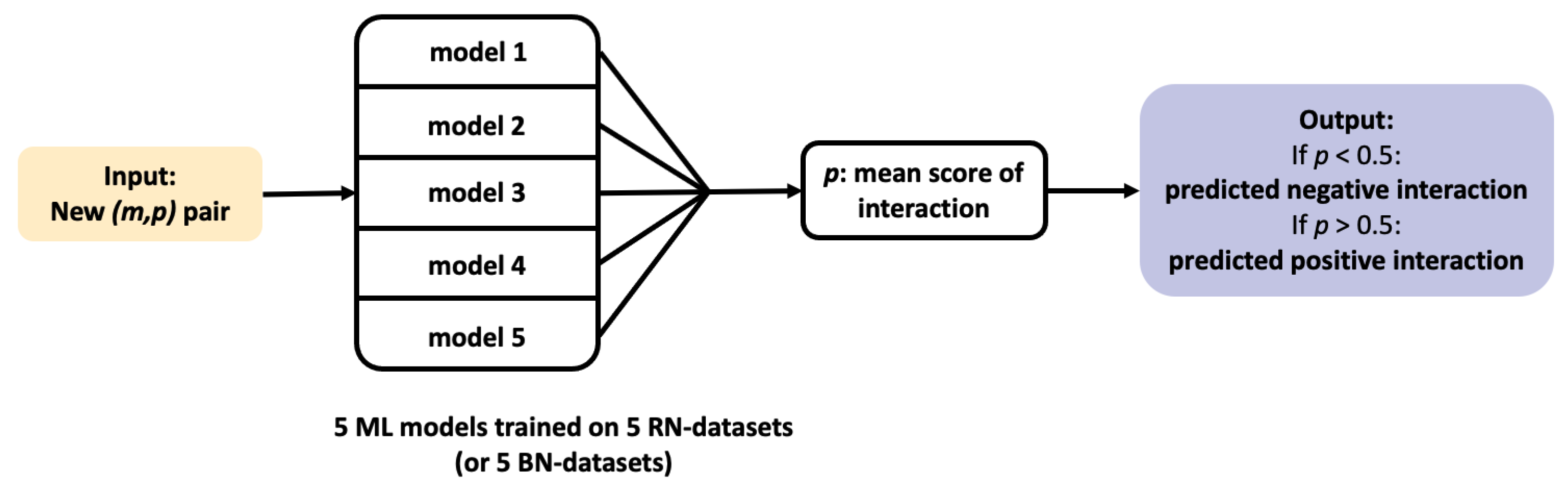
In the present paper, we focus on using ML chemogenomics approaches to identify target candidates for phenotypic hit molecules. The first step is to train the ML algorithms. More precisely, training a ML chemogenomics algorithm from a large DTIs database is an example of Positive-Unlabelled (PU) learning problem. Indeed, in practice, most databases only contain positive examples (that is to say, known DTIs), while all other possible interactions between molecules and proteins present in the data are unlabeled, whether because they have never been tested, or because they are negative interactions that have not been published or included in the database. Most of the unlabeled interactions are usually considered as true negatives. Therefore, in chemogenomics, the classical approach is to label as negatives a randomly chosen subset of the unlabeled interactions. This allows to convert a PU learning problem a into Positive-Negative (PN) learning problem for which many efficient ML algorithms are available.
We considered a ML algorithm based on SVM, with the
LAkernel [
27] and the Tanimoto kernel [
20] for proteins and molecules, respectively, because these methods displayed good prediction performances in previous chemogenomic studies, on average [
11,
28,
29]. The
LAkernel is related to the Smith–Waterman score [
19], but while the latter only keeps the contribution of the best local alignment between two sequences to quantify their similarity, the
LAkernel sums up the contributions of all possible local alignments, which proved to be efficient for detecting remote homology.
While the purpose of this paper is not to discuss the choice of the ML algorithm, but rather to study how best to train it for the particular task of target identification, we also include a comparison of the SVM with a feature-based ML algorithm, i.e., Random Forests (RF) [
30,
31].
The two algorithms were trained on the 5 RN-datasets described in
Section 2.1, using a 5-fold nested cross-validation scheme, as detailed in
Section 2.2 and
Section 2.3. A threshold of 0.5 on the output score was chosen to discriminate between positive and negative predictions.
Table 1 shows the mean performance scores of the SVM and RF algorithms, when cross-validated on the RN-datasets. In the context of target identification, it is important to limit the FPR, to avoid unnecessary experimental validation. However, a threshold of
over the probability scores was used to separate predicted positive interactions from predicted negative interactions, as classically, although in practical cases, a higher threshold would be chosen to select target candidates, in order to reduce the number of experimental tests to the predictions with the highest confidence. The results in
Table 1 show that the SVM clearly outperforms RF across all performance scores, including FPR. We therefore retained the SVM for the rest of the paper.
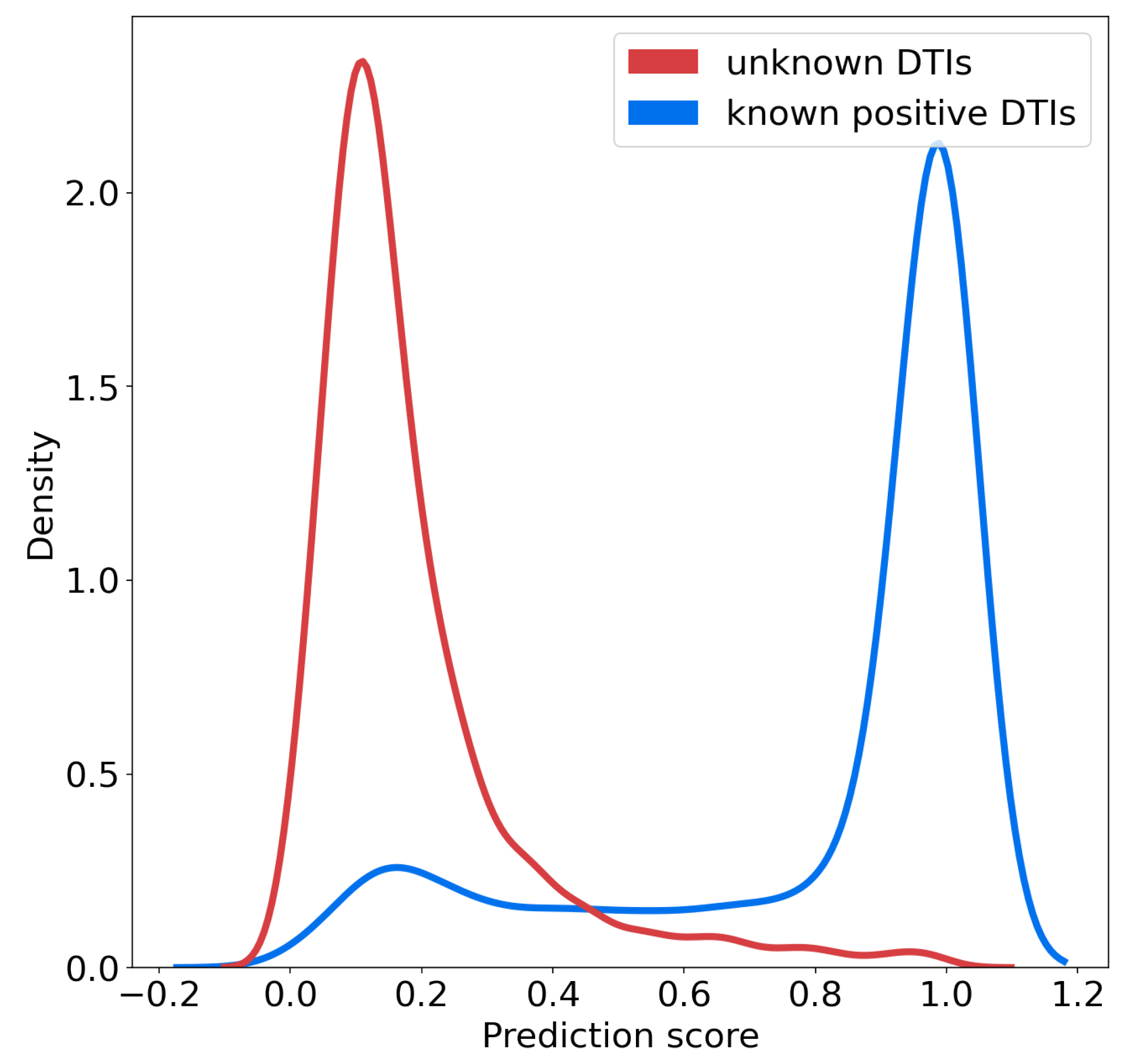
We studied the distributions of the probability scores for positive and unlabeled (presumably, mainly negative) interactions for the SVM algorithm, according to the nested CV scheme.
Figure 4 shows that these two distributions are well separated, and also suggests that on the RN-dataset, a threshold of 0.7 over the prediction score can be used to predict positive interactions with high confidence. In addition, the rank of a predicted interaction is also an important criterion to consider, because the goal of virtual screens is to drastically reduce the number of experiments to perform. When the goal is to identify hit molecules against a given therapeutic target, typically, the top 5% percent of the best-ranked molecules are screened [
32]. Usually, an experimental assay with a simple readout has been set up for the target of interest, which allows to evaluate relatively high numbers of candidate molecules selected in the virtual screen. The inverse problem of target identification is more difficult because validation requires to test the phenotypic hit molecule in a different biological assay for each predicted target considered for experimental evaluation. This obviously requires much more time and effort, because these assays may not all be available, and therefore, may have to be designed. This can be a real challenge if the function of a candidate target is not suitable to design a simple biological test. Therefore, we added the stringent but realistic threshold of top 1% in rank. In other words, in the following, we will consider as candidate targets proteins with a predicted score above 0.7 and ranked among the top 1% of the tested proteins, to simulate a realistic experimental setting. We discuss how to best train the algorithm in order to minimize the number of useless biological experiments that would be undertaken for false positive targets satisfying these two criteria, because this represents a real bottleneck for real-case studies. Consequently, in what follows, since the DB-Database comprises 2 670 proteins, we will consider as candidate targets only proteins with a probability score above 0.7 and rank smaller than or equal to 27.
3.2. Statistical Analysis of the DrugBank Database
The DrugBank database [
15] is a widely used bio-activity database. While much smaller than PubChem or ChEMBL, it provides high-quality information for approved and experimental drugs along with their targets. It contains around 15,000 curated DTIs involving 2670 human proteins (this set of proteins can be viewed as the “druggable” human proteome), and 5070 druglike molecules, corresponding to the DB-Database described in
Section 2.1. This database is relevant for training of ML models for DTI predictions involving human proteins and drug-like molecules. However,
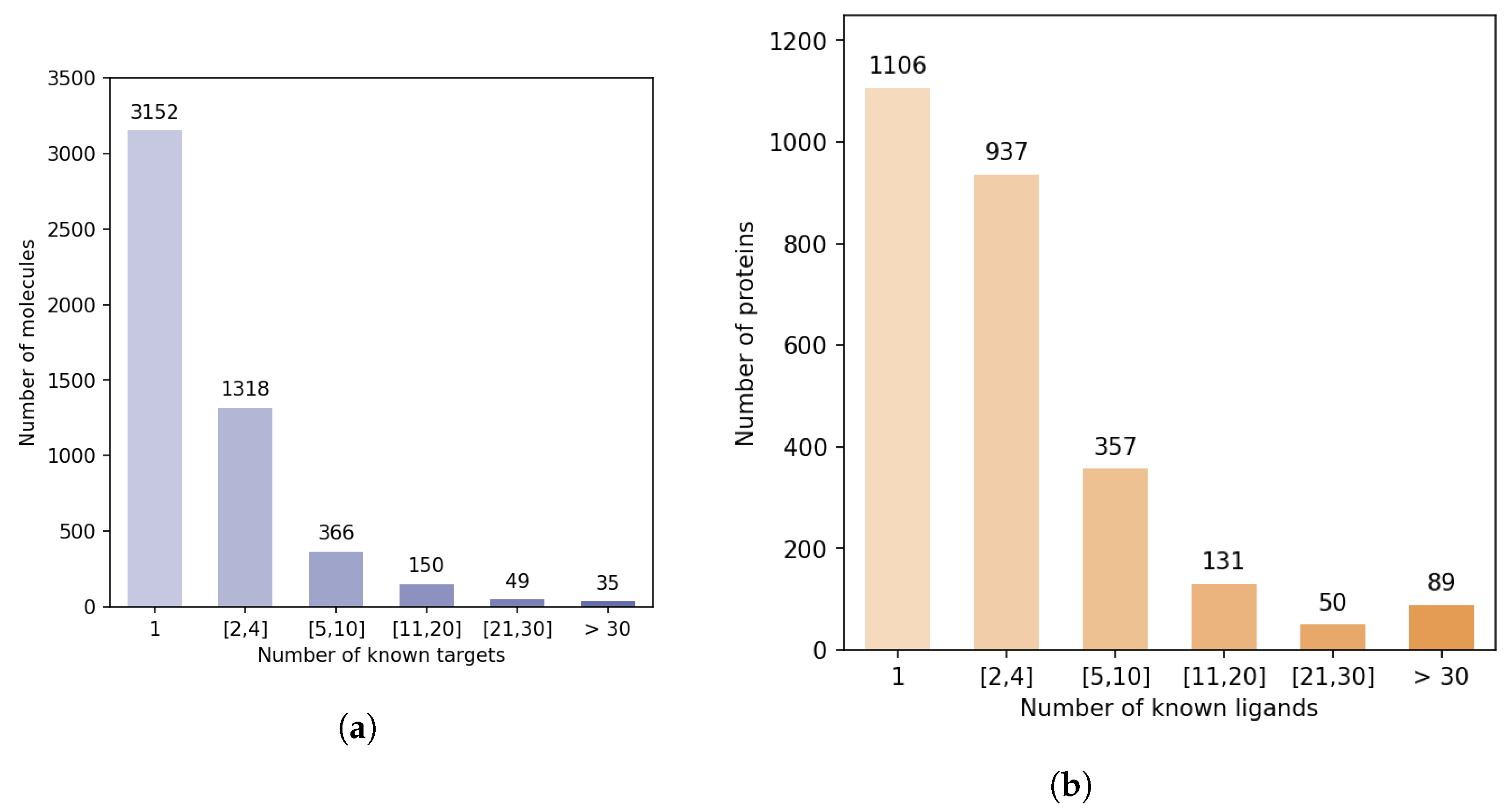
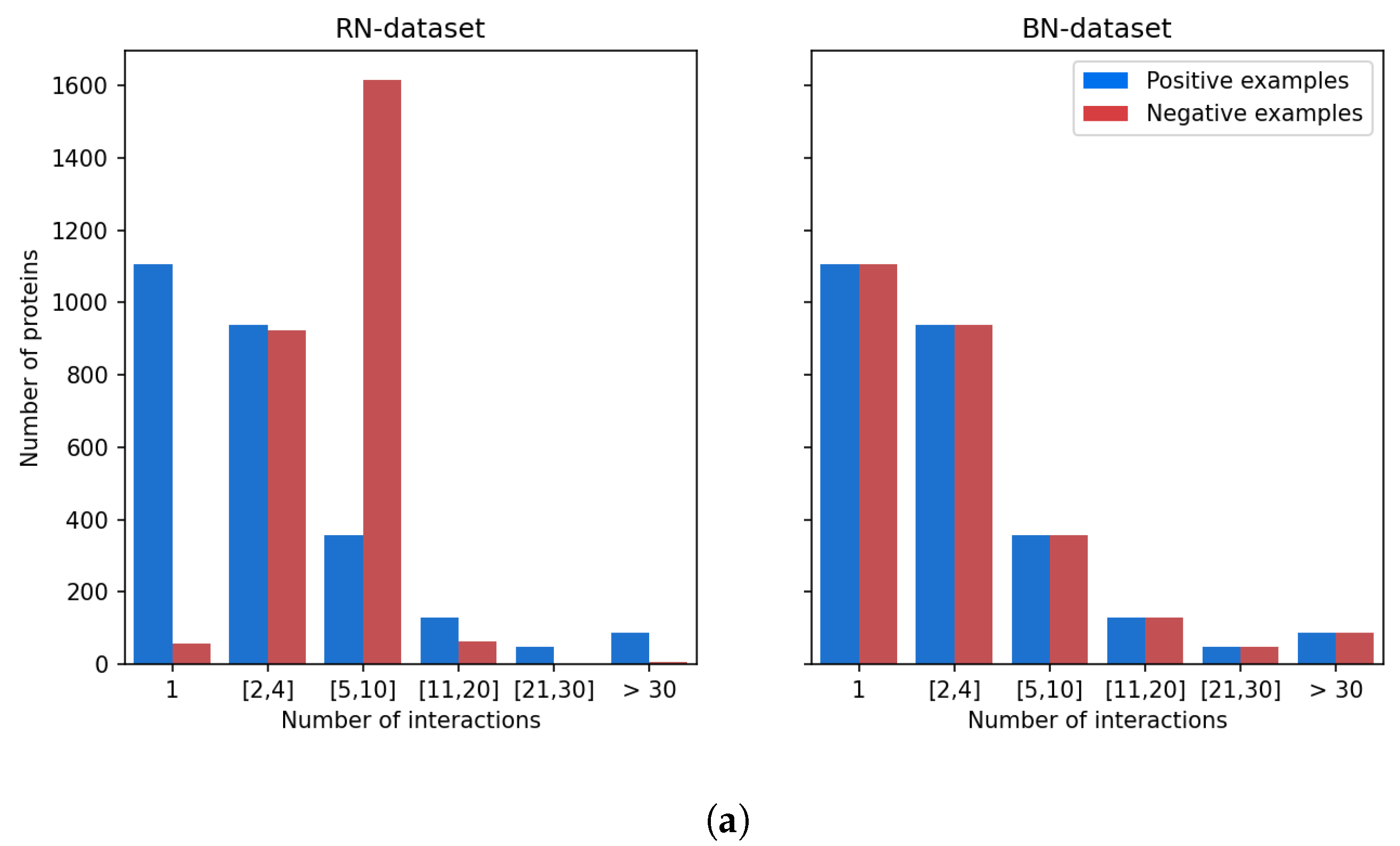
Figure 5 shows that there is a strong discrepancy between the number of known ligands per protein, or known protein targets per molecule.
Indeed, the majority of proteins have 4 or fewer known ligands, while around 140 proteins have more than 21 ligands. We defined categories of proteins, depending on their number of known ligands (1, 2 to 4, 5 to 10, 11 to 20, 21 to 30, more than 30), and calculated the number of DTIs in the DB-Database in each category. Overall, according to
Table 2, 5.2% of the proteins are involved in 44% of DB-Database DTIs.
This bias arises from the fact that a few diseases like cancer or inflammatory diseases have attracted most research efforts, and many ligands have been identified against related therapeutic targets, compared to other less studied human proteins. For example, Prostaglandin G/H synthase 2, a well-known protein involved in inflammation, has 109 drugs reported at DrugBank. This statistical bias affects training of the SVM and is expected to perturb identification of targets for hit molecules, potentially by enriching top ranked proteins in false positive targets that have many known ligands.
3.3. Examples Illustrating the Impact of Learning Bias for Target Identification
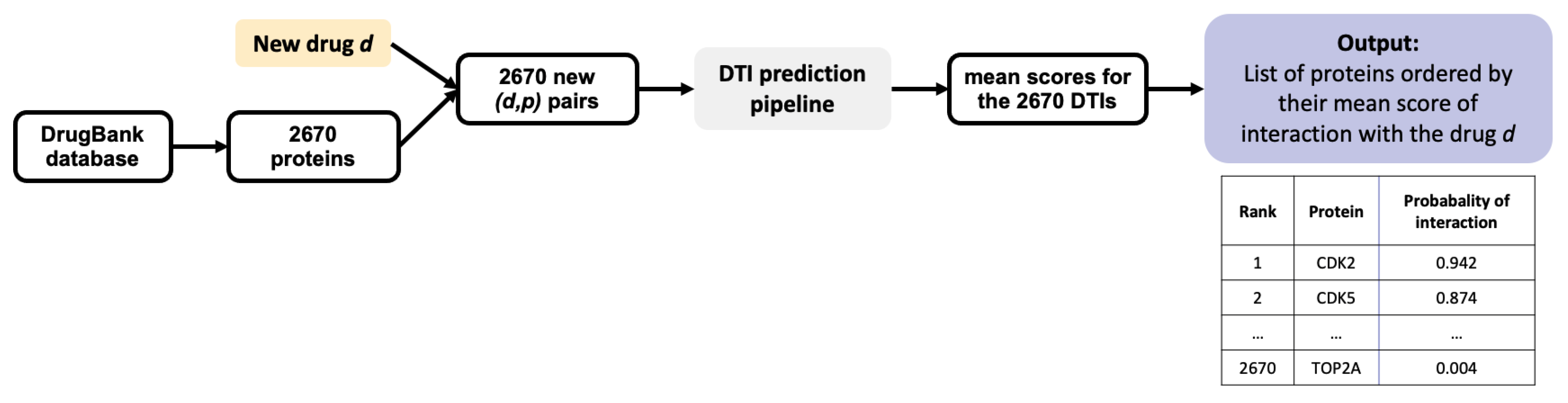
Once trained, a ML algorithm identifies targets for a hit molecule by providing a list of proteins ranked by decreasing order of the estimated probability score of all (protein, hit) pairs. Candidate targets are chosen based on their probability score, their rank, and on potential prior biological knowledge that would highlight their relation to the considered disease. For example, a top ranked protein involved in cell cycle would be considered as a realistic candidate target for a hit identified in a cell proliferation screen in cancer research. The presence of many false positive targets among the top ranked proteins will not only lead to undertake useless experiments, but also potentially to discard true predicted targets pushed further down the list. Let us illustrate this problem in the case of 3 molecules, randomly chosen among marketed drugs with only one known target in DrugBank. Assuming that their targets have been well characterized because they are marketed molecules, most of the other top ranked predicted targets will be false positive predictions. The 3 considered molecules are: alectinib (DrugBank ID DB11363, target: ALK), lasmiditan (DrugBank ID DB11732, target: HTR1F), and doxapram also known as angiotensin II (DrugBank ID DB11842, target: AGTR1). We orphanized these 3 molecules (i.e., we suppressed their single known target from the train set), as if they were hits from phenotypic screens, and used the SVM algorithm presented in
Section 2.2 on the RN-datasets to predict their targets. For each molecule, the results consist in a list of the 2670 proteins in the DB-Database, ranked by decreasing order of score.
As shown in the RN-datasets columns of
Table 3, none of the known targets for those drugs are among the candidate targets as defined in
Section 3.1. More precisely, for DB11363 and DB11842, although the probability scores of their known targets are above 0.7 (values of 0.8 and 0.76 respectively), their rank is 31 in both cases, above the threshold of 27. For DB11732, the probability score of HTR1F is 0.67, with a rank of 107, and HTR1F would not either have been classified among the candidate targets for testing.
Analysis of the results highlighted that some of the best ranked candidate targets are frequent targets. For example, prothrombin F2 (120 ligands), cyclin dependant kisase CDK2 (137 ligands), and dopamine receptor 2 DRD2 (109 ligands) are top ranked predicted targets respectively for DB11842 (score of 0.97, rank 2), DB11732 (score 0.98, rank 1) and DB11363 (score 0.94, rank 5). The three ranked lists are provided in full in the github repository mentioned under “Data Availability Statement”.
These examples illustrate the impact of false positive predictions for target identification, because they can lead to discard even high-scoring true targets as for DB11363 and DB11842.
3.4. Choice of Negative Examples to Correct Statistical Bias
Our observation that high-scoring false positives tend to have a large number of known ligands led us to make the assumption that the model trained using randomly sampled negative interactions is biased towards proteins with many known ligands, as well as possibly drugs with many known targets. This suggested us to choose negative DTIs in such a way that the training dataset contains, for each molecule and for each protein, as many positive than negative DTIs. The corresponding so-called BN-datasets (for Balanced Negatives-datasets) are detailed in
Section 2.1. Note that what we mean by “balanced” in the BN-dataset is that negative examples present the same bias as the positive examples: all molecules and all proteins appear in the same number of positive and negative DTIs. As shown in
Figure 6: (1) in the positive examples, the distribution of known protein targets per molecule is similar to that of proteins known (chosen, in fact) not to interact per molecule in the negative examples; (2) in the positive examples, the distribution of known ligands per protein is similar to that of molecules known (chosen, in fact) not to interact per protein in the negative examples. This prevents proteins with many known ligands to be viewed by the algorithm as statistically much more probable targets, leading to many false positive predictions among this category of proteins. We recall that the BN-datasets contains the same positive DTIs as the RN-datasets, the former differing from the latter only by the negative DTIs.
The SVM algorithm presented in
Section 2.2 was trained on the BN-datasets. As discussed above, for the problem of target identification, reducing the number of false positives among the top-ranked proteins is critical.
Table 4 reports, for prediction score thresholds of 0.5 (usually considered) and 0.7 (considered in the present paper), the cross-validated FPR scores on these two training sets. It shows a strong statistical bias in FPR for the RN-datasets between proteins with few or with many known ligands, and it illustrates that training on the BN-datasets greatly reduced this bias.
To highlight the impact of this bias correction in terms of target prediction, we show in
Table 3 the prediction results for the 3 molecules discussed in
Section 3.3, when the algorithm is trained with the RN-datasets or with the BN-datasets. When trained on the RN-datasets, none of the true targets would have been considered as a positive candidate target for testing, because of a score below 0.7 or a rank above 27, as discussed above. Training on the BN-datasets greatly improved the ranks and scores of the three true targets, and reduced the number of false positives, allowing the 3 corresponding true targets to fulfill the rank and score criteria defined in
Section 3.1 to become candidate target for testing.
To better illustrate the interest of the proposed scheme for the choice of negative DTIs on a larger number of drugs we considered the 200-positive-dataset consisting of 200 DTIs involving 200 marketed drugs with 4 of less known targets, as described in
Section 2.1. This “difficult” test set was chosen because the aim was to mimic newly identified phenotypic hits, for which known targets are expected to be scarce. For each drug, we artificially reproduced the process of target identification: the corresponding DTI was removed from the train set, a new SVM classifier was trained and used to score 2670 DTIs involving this drug and all proteins of the DB-Database. We compared the top-ranked predicted targets obtained when the algorithm is trained on the RN-datasets versus on the BN-datasets, as well as the number of removed false positive DTIs that would have been retrieved as candidates for testing (i.e., with a score above 0.7 and a rank lower or equal to 27).
Overall, training with the BN-datasets improved the predictions: the number of false positive DTIs decreased for 106 drugs, remained unchanged in 85 drugs, and increased in 9 drugs, as compared to training with the RN-datasets. In particular, this improvement allowed one additional true positive interaction to reach a score above 0.7 and a rank below 27: 104 true targets were retrieved as candidates when training with BN-datasets, compared to 103 when training with RN-datasets. For the corresponding 104 drugs, the number of false positives decreased by 2.9 in average, and the rank of the true interactions decreased by 1.8 in average, bringing them even closer to the top ranked predicted proteins, and more likely to be chosen for experimental validation. Consistent with the results in
Section 3.3 for the 3 example molecules, on average over the 200 considered molecules, the number of useless experiments potentially undertaken would have decreased when training with the BN-datasets.
We also made predictions for the 200 negative DTIs of the corresponding 200-negative-dataset, involving the same molecules as the 200-positive-dataset. Predictions were made by the classifier trained on the RN- or BN- datasets. Overall the distributions of the prediction scores were very similar in both cases, centered around 0.2, and similar to that shown for the RN-dataset in
Figure 4. Among the 200 negative pairs, only 2 pairs were predicted as positives, for the two RN- and BN- datasets. This can be viewed as a sanity check indicating that the proposed method did not introduce bias in the prediction of negative DTIs, while it globally improved the predictions of positive DTIs.
4. Discussion
The goal of the present paper was to tackle the question of protein target identification for new drug candidates, using ML-based chemogenomics. Indeed, these approaches can be run at a large scale in the protein space, including in their scope proteins with no known 3D structures, or proteins for which few, or even no ligands are known. Another key asset is that they can be applied to drugs with few, or even no known targets, as illustrated on the 200-positive-dataset. This is of particular importance because new phenotypic drugs are often orphan (i.e., have no known protein target) when they are identified. No other computational method presents these advantages. However, before making predictions, ML chemogenomic algorithms need to be trained on a database of known DTIs, which raises a few issues.
First, these databases are biased in terms of the number of protein targets per molecule, or of ligand molecules per protein, as shown for the DrugBank database used in our study. While we are aware that other and larger DTIs databases could have been used, the purpose of our study was not to discuss the choice of training set, in particular because other databases will also present the same type of bias as the DrugBank, for the same reasons. This point is rarely discussed in ML chemogenomic studies.
Second, the performance of ML algorithms in chemogenomics are usually evaluated based on AUPR and ROC-AUC scores in cross-validation procedures. However, the identification of true protein targets for phenotypic hit molecules in real case studies may become a challenge when the algorithm is trained on a biased dataset. Indeed, despite very high AUPR and ROC-AUC scores, false positive targets can be found among top-ranked proteins, and correspond to proteins with many known ligands. In target identification studies, biological experiments are guided by the predicted scores and ranks of candidate proteins. Training on a biased dataset may lead not only to conduct useless experiments, but also to discard true positive targets because their scores are below the considered threshold, or because their rank is too high due to the presence of false positives among the top-ranked proteins. This point is also rarely discussed in ML chemogenomic studies, usually focusing on cross-validation schemes that does not correspond to real case applications.
Third, training databases such as the DrugBank only contain positive examples, and therefore, negative examples are usually randomly chosen among unlabeled DTIs in order to train the ML algorithms. It is however unclear that this is an optimal choice for target identification.
The key result of the present paper was to show that choosing an equal number of positive and negative DTIs per molecule and per protein helps decrease the FPR in biased datasets, and improves the identification of true targets for a given drug. Three striking examples are given for the case study of three drugs (DB11363, DB11842, and DB11732) that were “orphanized” (all their known DTIs were removed from the training set) to illustrate the most difficult situation encountered in the case of new phenotypic drugs: training with the BN-datasets allowed to recover the true target in all cases, while none of them would have been retrieved when training with the RN-datasets. To illustrate the advantage of the proposed scheme for the choice of negative interactions, we used a threshold of 0.7 over the probability scores to identify candidate targets for experimental testing, although proteins with scores above 0.5 are classified as positives. This threshold of 0.7 was guided by the results in
Figure 4, in order to select highly probable positive targets. It can be adjusted to a different value if the algorithm is trained with other databases, whether through the same kind of plot, or through a ROC-curve in order to correspond to a predefined false positive rate.
We added the stringent threshold of 1% on the ranks of proteins to define which targets would be tested. This threshold could also be adjusted depending on available resources for experimental validation. The issue we identified and addressed in this paper does not depend on the scores and rank thresholds used, and choosing equal numbers of positive and negative DTIs per molecule and per protein for the training set will limit the number of false positives independently of the choice of thresholds, as shown in
Table 4 in the case of the threshold on the prediction score. Finally, while the proposed scheme for the choice of negative examples was presented here in the context of target identification for hit molecules, it is of general interest and should be applicable to other types of PU learning problems when bias is present in the training set, which is a very common situation, in particular in many biological databases.


 ,
, 







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}