BIOPEP-UWM Database of Bioactive Peptides: Current Opportunities




Abstract
1. Introduction
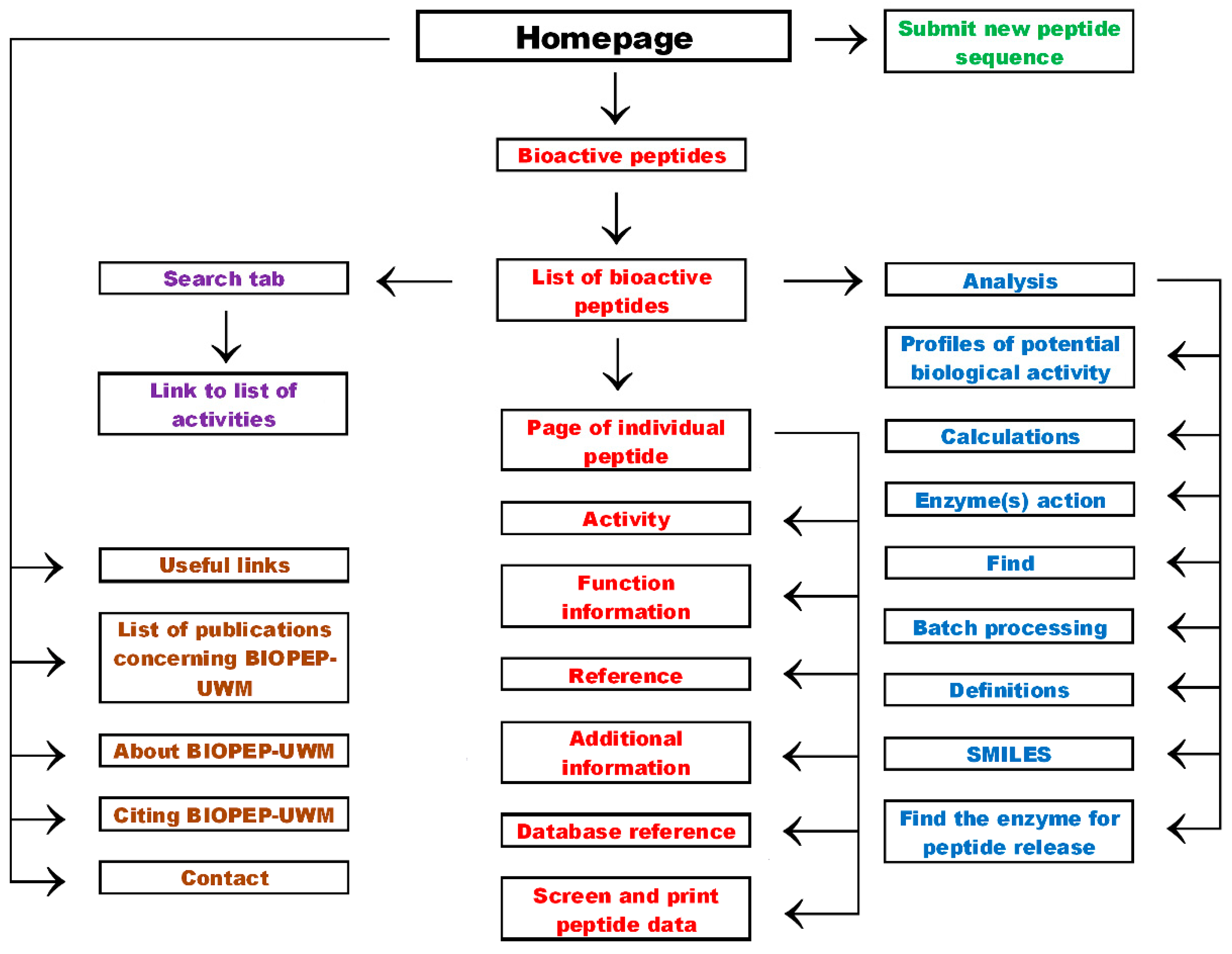
2. Database Organization
3. Enlarging the Number of Peptides in the Database by BIOPEP-UWM™ Users
4. Peptide Information
5. Search Options
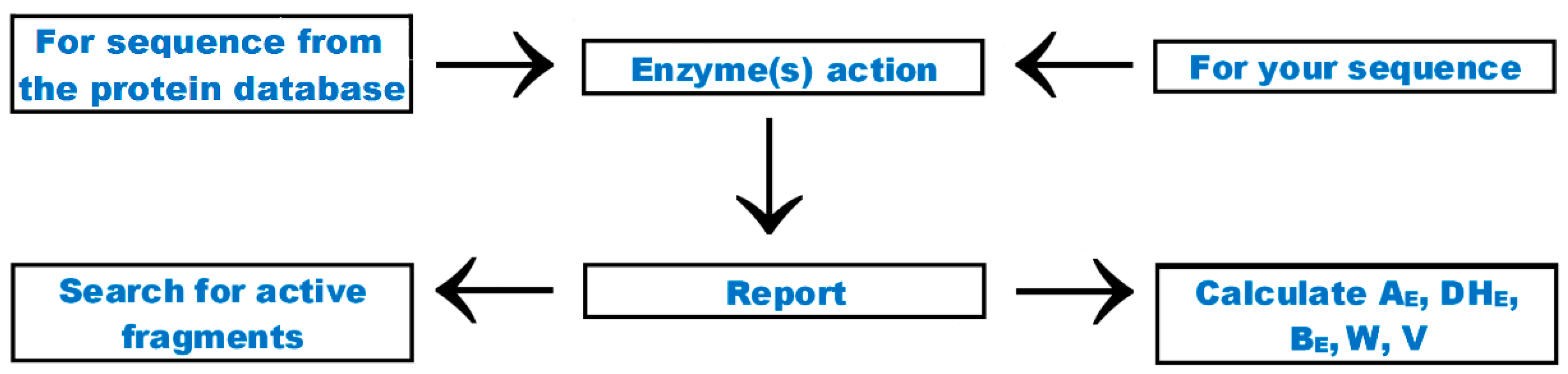
6. Analysis
7. Useful Links and Other Tabs
8. Final Remarks
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| ACE | Angiotensin-converting enzyme (EC 3.4.15.1) |
| ACToR | Aggregated Computational Toxicology Online Resource |
| AHTPDB | Antihypertensive Peptide Database |
| APD | Antimicrobial peptide database |
| BioPepDB | Bioactive Peptide Database |
| BRENDA | Braunschweig Enzyme Database |
| CAMKII | Ca2+/calmodulin-dependent protein kinase (EC 2.7.11.17) |
| CAMP | Collection of antimicrobial peptides |
| CaMPDE | Calmodulin-dependent phosphodiesterase 1 (EC 3.1.4.17) |
| CancerPPD | Anticancer protein and peptide database |
| CAS | Chemical Abstract Service provided by American Chemical Society |
| CID | Compound Identifier (in PubChem database) |
| DB | database |
| DBAASP | Database of Antimicrobial Activity and Structure of Peptides |
| EBI | European Bioinformatics Institute |
| EC50 | Concentration corresponding to half-maximal activity |
| EMBL | European Molecular Biology Laboratory |
| EROP | Endogenous Regulatory Oligopeptide knowledgebase |
| FeptideDB | Food Peptide Database |
| GPR14 | Abbreviation of urotensin II receptor |
| HMDB | Human Metabolome Database |
| IC50 | Concentration corresponding to half-maximal inhibition |
| InChI | International Chemical Identifier |
| HMG-CoA | 3-hydroxy-3-methyl-glutaryl-coenzyme A (PubChem CID: 445127; CAS registry No 1553-55-5) |
| InChIKey | Key of International Chemical Identifier |
| IUPAC | International Union of Pure and Applied Chemistry |
| KEGG | Kyoto Encyclopedia of Genes and Genomes |
| MBPDB | Milk Bioactive Peptide Database |
| MetaComBio | Meta Compound Bioactivity |
| MilkAMP | Milk antimicrobial peptide database |
| SATPdb | Structurally Annotated Therapeutic Peptide database |
| SMILES | Simplified Molecular Input Line Entry System or Simplified Molecular Input Line Entry Specification |
| UWM | University of Warmia and Mazury |
References
- Holton, T.A.; Vijayakumar, V.; Khaldi, N. Bioinformatics: Current perspectives and future directions for food and nutritional research facilitated by a food-wiki database. Trends Food Sci. Technol. 2013, 34, 5–17. [Google Scholar] [CrossRef]
- Udenigwe, C.C. Bioinformatics approaches, prospects and challenges of food bioactive peptide research. Trends Food Sci. Technol. 2014, 36, 134–143. [Google Scholar] [CrossRef]
- Iwaniak, A.; Minkiewicz, P.; Darewicz, M.; Protasiewicz, M.; Mogut, D. Chemometrics and cheminformatics in the analysis of biologically active peptides from food sources. J. Funct. Foods 2015, 16, 334–351. [Google Scholar] [CrossRef]
- Iwaniak, A.; Darewicz, M.; Mogut, D.; Minkiewicz, P. Elucidation of the role of in silico methodologies in approaches to studying bioactive peptides derived from foods. J. Funct. Foods 2019, 61, 103486. [Google Scholar] [CrossRef]
- Agyei, D.; Tsopmo, A.; Udenigwe, C.C. Bioinformatic and peptidomic approaches to the discovery and analysis of food-derived bioactive peptides. Anal. Bioanal. Chem. 2018, 410, 3463–3472. [Google Scholar] [CrossRef] [PubMed]
- Kalmykova, S.D.; Arapidi, G.P.; Urban, A.S.; Osetrova, M.S.; Gordeeva, V.D.; Ivanov, V.T.; Govorun, V.M. In silico analysis of peptide potential biological functions. Russ. J. Bioorg. Chem. 2018, 44, 367–385. [Google Scholar] [CrossRef]
- Tu, M.; Cheng, S.; Lu, W.; Du, M. Advancement and prospects of bioinformatics analysis for studying bioactive peptides from food-derived protein: Sequence, structure, and functions. Trends Anal. Chem. 2018, 105, 7–17. [Google Scholar] [CrossRef]
- Minkiewicz, P.; Dziuba, J.; Iwaniak, A.; Dziuba, M.; Darewicz, M. BIOPEP database and other programs for processing bioactive peptide sequences. J. AOAC Int. 2008, 91, 965–980. [Google Scholar]
- Iwaniak, A.; Minkiewicz, P.; Darewicz, M.; Sieniawski, K.; Starowicz, P. BIOPEP database of sensory peptides and amino acids. Food Res. Int. 2016, 85, 155–161. [Google Scholar] [CrossRef]
- Piovesana, S.; Capriotti, A.L.; Cavaliere, C.; La Barbera, G.; Montone, C.M.; Chiozzi, R.Z.; Laganà, A. Recent trends and analytical challenges in plant bioactive peptide separation, identification and validation. Anal. Bioanal. Chem. 2018, 410, 3425–3444. [Google Scholar] [CrossRef]
- Minkiewicz, P.; Iwaniak, A.; Darewicz, M. Using internet databases for food science organic chemistry students to discover chemical compound information. J. Chem. Educ. 2015, 92, 874–876. [Google Scholar] [CrossRef]
- Anekthanakul, K.; Hongsthong, A.; Senachak, J.; Ruengjitchatchawalya, M. SpirPep: An in silico digestion-based platform to assist bioactive peptides discovery from a genome-wide database. BMC Bioinform. 2018, 19, 149. [Google Scholar] [CrossRef] [PubMed]
- Panyayai, T.; Ngamphiw, C.; Tongsima, S.; Mhuantong, W.; Limsripraphan, W.; Choowongkomon, K.; Sawatdichaikul, O. FeptideDB: A web application for new bioactive peptides from food protein. Heliyon 2019, 5, e02076. [Google Scholar] [CrossRef] [PubMed]
- Dziuba, M.; Minkiewicz, P.; Dąbek, M. Peptides, specific proteolysis products as molecular markers of allergenic proteins—In Silico studies. Acta Sci. Pol. Technol. Aliment. 2013, 12, 101–112. [Google Scholar] [PubMed]
- He, R.; Malomo, S.A.; Alashi, A.; Girgih, A.T.; Ju, X.; Aluko, R.E. Glycinyl-histidinyl-serine (GHS), a novel rapeseed protein-derived peptide has blood pressure-lowering effect in spontaneously hypertensive rats. J. Agric. Food Chem. 2013, 61, 8396–8402. [Google Scholar] [CrossRef] [PubMed]
- Skrzypczak, K.; Fornal, E.; Waśko, A.; Gustaw, W. Effects of probiotic fermentation of selected milk and whey protein preparations on bioactive peptides and technological properties. Ital. J. Food Sci. 2019, 31, 437–450. [Google Scholar]
- Khazaei, H.; Subedi, M.; Nickerson, M.; Martínez-Villaluenga, C.; Frias, J.; Vandenberg, A. Seed protein of lentils: Current status, progress, and food applications. Foods 2019, 8, 391. [Google Scholar] [CrossRef]
- Hsieh, C.-C.; Martínez-Villaluenga, C.; de Lumen, B.O.; Hernández-Ledesma, B. Updating the research on the chemopreventive and therapeutic role of the peptide lunasin. J. Sci. Food Agric. 2018, 98, 2070–2079. [Google Scholar] [CrossRef]
- Savitha, M.N.; Siddesha, J.M.; Suvilesh, K.N.; Yariswamy, M.; Vivek, H.K.; D’Souza, C.J.; Umashankar, M.; Vishwanath, B.S. Active-site directed peptide L-Phe-D-His-L-Leu inhibits angiotensin converting enzyme activity and dexamethasone-induced hypertension in rats. Peptides 2019, 112, 34–42. [Google Scholar] [CrossRef]
- Zamyatnin, A.A.; Borchikov, A.S.; Vladimirov, M.G.; Voronina, O.L. The EROP-Moscow oligopeptide database. Nucleic Acids Res. 2006, 34, D261–D266. [Google Scholar] [CrossRef]
- Heller, S.R.; McNaught, A.; Pletnev, I.; Stein, S.; Tchekhovskoi, D. InChI, the IUPAC International Chemical Identifier. J. Cheminform. 2015, 7, 23. [Google Scholar] [CrossRef] [PubMed]
- Kim, S.; Chen, J.; Cheng, T.; Gindulyte, A.; He, J.; He, S.; Li, Q.; Shoemaker, B.A.; Thiessen, P.A.; Yu, B.; et al. PubChem 2019 update: Improved access to chemical data. Nucleic Acids Res. 2019, 47, D1102–D1109. [Google Scholar] [CrossRef] [PubMed]
- Ashok, A.; Aparna, B.H.S. Discovery, synthesis, and In vitro evaluation of a novel bioactive peptide for ACE and DPP-IV inhibitory activity. Eur. J. Med. Chem. 2019, 180, 99–110. [Google Scholar] [CrossRef] [PubMed]
- Gallego, M.; Mora, L.; Toldrá, F. The relevance of dipeptides and tripeptides in the bioactivity and taste of dry-cured ham. Food Prod. Process. Nutr. 2019, 1, 2. [Google Scholar] [CrossRef]
- Pinciroli, M.; Aphalo, P.; Nardo, A.E.; Añón, M.C.; Quiroga, A.V. Broken rice as a potential functional ingredient with inhibitory activity of renin and angiotensin-converting enzyme (ACE). Plant Foods Hum. Nutr. 2019, 74, 405–413. [Google Scholar] [CrossRef]
- Minkiewicz, P.; Darewicz, M.; Iwaniak, A.; Bucholska, J.; Starowicz, P.; Czyrko, E. Internet databases of the properties, enzymatic reactions, and metabolism of small molecules-search options and applications in food science. Int. J. Mol. Sci. 2016, 17, 2039. [Google Scholar] [CrossRef]
- Weininger, D. SMILES, a chemical language and information system. 1. Introduction to methodology and encoding rules. J. Chem. Inf. Comput. Sci. 1988, 28, 31–36. [Google Scholar] [CrossRef]
- Peña-Castillo, A.; Méndez-Lucio, O.; Owen, J.R.; Martínez-Mayorga, K.; Medina-Franco, J.L. Chemoinformatics in food science. In Applied Chemoinformatics: Achievements and Future Opportunities; Engel, T., Gasteiger, J., Eds.; Wiley-VCH Verlag GmbH & Co. KGaA: Weinheim, Germany, 2018; pp. 501–525. [Google Scholar]
- Scotti, L.; Júnior, F.J.; Ishiki, H.M.; Ribeiro, F.F.; Duarte, M.C.; Santana, G.S.; Oliveira, T.B.; Diniz, M.D.; Quintans-Júnior, L.J.; Scotti, M.T. Computer-aided drug design studies in food chemistry. In Natural and Artificial Flavoring Agents and Food Dyes; Grumezescu, A.M., Holban, A.M., Eds.; Elsevier: Amsterdam, The Netherlands, 2018; pp. 261–297. [Google Scholar]
- Minkiewicz, P.; Turło, M.; Iwaniak, A.; Darewicz, M. Free accessible databases as a source of information about food components and other compounds with anticancer activity–brief review. Molecules 2019, 24, 789. [Google Scholar] [CrossRef]
- Iwaniak, A.; Minkiewicz, P.; Darewicz, M.; Hrynkiewicz, M. Food protein-originating peptides as tastants-Physiological, technological, sensory, and bioinformatic approaches. Food Res. Int. 2016, 89, 27–38. [Google Scholar] [CrossRef]
- O’Boyle, N.M.; Banck, M.; James, C.A.; Morley, C.; Vandermeersch, T.; Hutchison, G.R. Open Babel: An open chemical toolbox. J. Cheminform. 2011, 3, 33. [Google Scholar] [CrossRef]
- Ortiz-Martinez, M.; Gonzalez de Mejia, E.; García-Lara, S.; Aguilar, O.; Lopez-Castillo, L.M.; Otero-Pappatheodorou, J.T. Antiproliferative effect of peptide fractions isolated from a quality protein maize, a white hybrid maize, and their derived peptides on hepatocarcinoma human HepG2 cells. J. Funct. Foods 2017, 34, 36–48. [Google Scholar] [CrossRef]
- Mojica, L.; Luna-Vital, D.A.; Gonzalez de Mejia, E. Black bean peptides inhibit glucose uptake in Caco-2 adenocarcinoma cells by blocking the expression and translocation pathway of glucose transporters. Toxicol. Rep. 2018, 5, 552–560. [Google Scholar] [CrossRef] [PubMed]
- Yu, Z.; Fan, Y.; Zhao, W.; Ding, L.; Li, J.; Liu, L. Novel angiotensin-converting enzyme inhibitory peptides derived from Oncorhynchus mykiss nebulin: Virtual screening and in silico molecular docking study. J. Food Sci. 2018, 83, 2375–2383. [Google Scholar] [CrossRef] [PubMed]
- Bradbury, A.F.; Smyth, D.G. Peptide amidation. Trends Biochem. Sci. 1991, 16, 112–115. [Google Scholar] [CrossRef]
- Lee, K.H.; Hong, S.Y.; Oh, J.E.; Kwon, M.Y.; Yoon, J.H.; Lee, J.H.; Lee, B.L.; Moon, H.M. Identification and characterization of the antimicrobial peptide corresponding to C-terminal beta-sheet domain of tenecin 1, an antibacterial protein of larvae of Tenebrio molitor. Biochem. J. 1998, 334, 99–105. [Google Scholar] [CrossRef]
- McDonald, A.G.; Boyce, S.; Tipton, K.F. ExplorEnz: The primary source of the IUBMB enzyme list. Nucleic Acids Res. 2009, 37, D593–D597. [Google Scholar] [CrossRef]
- Jeske, L.; Placzek, S.; Schomburg, I.; Chang, A.; Schomburg, D. BRENDA in 2019: A European ELIXIR core data resource. Nucleic Acids Res. 2019, 47, D542–D549. [Google Scholar] [CrossRef]
- Mendez, D.; Gaulton, A.; Bento, A.P.; Chambers, J.; De Veij, M.; Félix, E.; Magariños, M.P.; Mosquera, J.F.; Mutowo, P.; Nowotka, M.; et al. ChEMBL: Towards direct deposition of bioassay data. Nucleic Acids Res. 2019, 47, D930–D940. [Google Scholar] [CrossRef]
- Rawlings, N.D.; Barrett, A.J.; Thomas, P.D.; Huang, X.; Bateman, A.; Finn, R.D. The MEROPS database of proteolytic enzymes, their substrates and inhibitors in 2017 and a comparison with peptidases in the PANTHER database. Nucleic Acids Res. 2018, 46, D624–D632. [Google Scholar] [CrossRef]
- Carvalho-Silva, D.; Pierleoni, A.; Pignatelli, M.; Ong, C.; Fumis, L.; Karamanis, N.; Carmona, M.; Faulconbridge, A.; Hercules, A.; McAuley, E.; et al. Open Targets Platform: New developments and updates two years on. Nucleic Acids Res. 2019, 47, D1056–D1065. [Google Scholar] [CrossRef]
- Judson, R.S.; Martin, M.T.; Egeghy, P.; Gangwal, S.; Reif, D.M.; Kothiya, P.; Wolf, M.; Cathey, T.; Transue, T.; Smith, D.; et al. Aggregating data for computational toxicology applications: The U.S. Environmental Protection Agency (EPA) Aggregated Computational Toxicology Resource (ACToR) system. Int. J. Mol. Sci. 2012, 13, 1805–1831. [Google Scholar] [CrossRef] [PubMed]
- Tomasulo, P. ChemIDplus-super source for chemical and drug information. Med. Ref. Serv. Quart. 2002, 21, 53–59. [Google Scholar] [CrossRef] [PubMed]
- Kumar, R.; Chaudhary, K.; Sharma, M.; Nagpal, G.; Chauhan, J.S.; Singh, S.; Gautam, A.; Raghava, G.P. AHTPDB: A comprehensive platform for analysis and presentation of antihypertensive peptides. Nucleic Acids Res. 2015, 43, D956–D962. [Google Scholar] [CrossRef] [PubMed]
- Wang, G.; Li, X.; Wang, Z. APD3: The antimicrobial peptide database as a tool for research and education. Nucleic Acids Res. 2016, 44, D1087–D1093. [Google Scholar] [CrossRef] [PubMed]
- Gilson, M.K.; Liu, T.; Baitaluk, M.; Nicola, G.; Hwang, L.; Chong, J. BindingDB in 2015: A public database for medicinal chemistry, computational chemistry and systems pharmacology. Nucleic Acids Res. 2016, 44, D1045–D1053. [Google Scholar] [CrossRef] [PubMed]
- Li, Q.; Zhang, C.; Chen, H.; Xue, J.; Guo, X.; Liang, M.; Chen, M. BioPepDB: An integrated data platform for food-derived bioactive peptides. Int. J. Food Sci. Nutr. 2018, 69, 963–968. [Google Scholar] [CrossRef]
- Dagan-Wiener, A.; Di Pizio, A.; Nissim, I.; Bahia, M.S.; Dubovski, N.; Margulis, E.; Niv, M.Y. BitterDB: Taste ligands and receptors database in 2019. Nucleic Acids Res. 2019, 47, D1179–D1185. [Google Scholar] [CrossRef]
- Van Dorpe, S.; Bronselaer, A.; Nielandt, J.; Stalmans, S.; Wynendaele, E.; Audenaert, K.; Van De Wiele, C.; Burvenich, C.; Peremans, K.; Hsuchou, H.; et al. Brainpeps: The blood-brain barrier peptide database. Brain Struct. Funct. 2012, 217, 687–718. [Google Scholar] [CrossRef]
- Waghu, F.H.; Barai, R.S.; Gurung, P.; Idicula-Thomas, S. CAMPR3: A database on sequences, structures and signatures of antimicrobial peptides. Nucleic Acids Res. 2016, 44, D1094–D1097. [Google Scholar] [CrossRef]
- Tyagi, A.; Tuknait, A.; Anand, P.; Gupta, S.; Sharma, M.; Mathur, D.; Joshi, A.; Singh, S.; Gautam, A.; Raghava, G.P. CancerPPD: A database of anticancer peptides and proteins. Nucleic Acids Res. 2015, 43, D837–D843. [Google Scholar] [CrossRef]
- Hastings, J.; Owen, G.; Dekker, A.; Ennis, M.; Kale, N.; Muthukrishnan, V.; Turner, S.; Swainston, N.; Mendes, P.; Steinbeck, C. ChEBI in 2016: Improved services and an expanding collection of metabolites. Nucleic Acids Res. 2016, 44, D1214–D1219. [Google Scholar] [CrossRef] [PubMed]
- Williams, A.; Tkachenko, V. The Royal Society of Chemistry and the delivery of chemistry data repositories for the community. J. Comput. Aided Mol. Des. 2014, 28, 1023–1030. [Google Scholar] [CrossRef] [PubMed]
- Williams, A.J.; Grulke, C.M.; Edwards, J.; McEachran, A.D.; Mansouri, K.; Baker, N.C.; Patlewicz, G.; Shah, I.; Wambaugh, J.F.; Judson, R.S.; et al. The CompTox Chemistry Dashboard: A community data resource for environmental chemistry. J. Cheminform. 2017, 9, 61. [Google Scholar] [CrossRef] [PubMed]
- Igarashi, Y.; Eroshkin, A.; Gramatikova, S.; Gramatikoff, K.; Zhang, Y.; Smith, J.W.; Osterman, A.L.; Godzik, A. CutDB: A proteolytic event database. Nucleic Acids Res. 2007, 35, D546–D549. [Google Scholar] [CrossRef] [PubMed]
- Pirtskhalava, M.; Gabrielian, A.; Cruz, P.; Griggs, H.L.; Squires, R.B.; Hurt, D.E.; Grigolava, M.; Chubinidze, M.; Gogoladze, G.; Vishnepolsky, B.; et al. DBAASP v.2: An enhanced database of structure and antimicrobial/cytotoxic activity of natural and synthetic peptides. Nucleic Acids Res. 2016, 44, D1104–D1112. [Google Scholar] [CrossRef] [PubMed]
- Wishart, D.S.; Feunang, Y.D.; Guo, A.C.; Lo, E.J.; Marcu, A.; Grant, J.R.; Sajed, T.; Johnson, D.; Li, C.; Sayeeda, Z.; et al. DrugBank 5.0: A major update to the DrugBank database for 2018. Nucleic Acids Res. 2018, 46, D1074–D1082. [Google Scholar] [CrossRef] [PubMed]
- Gautam, A.; Chaudhary, K.; Singh, S.; Joshi, A.; Anand, P.; Tuknait, A.; Mathur, D.; Varshney, G.C.; Raghava, G.P. Hemolytik: A database of experimentally determined hemolytic and non-hemolytic peptides. Nucleic Acids Res. 2014, 42, D444–D449. [Google Scholar] [CrossRef]
- Wishart, D.S.; Feunang, Y.D.; Marcu, A.; Guo, A.C.; Liang, K.; Vázquez-Fresno, R.; Sajed, T.; Johnson, D.; Li, C.; Karu, N.; et al. HMDB 4.0: The human metabolome database for 2018. Nucleic Acids Res. 2018, 46, D608–D617. [Google Scholar] [CrossRef]
- Kanehisa, M.; Sato, Y.; Furumichi, M.; Morishima, K.; Tanabe, M. New approach for understanding genome variations in KEGG. Nucleic Acids Res. 2019, 47, D590–D595. [Google Scholar] [CrossRef]
- Nielsen, S.D.; Beverly, R.L.; Qu, Y.; Dallas, D.C. Milk bioactive peptide database: A comprehensive database of milk protein-derived bioactive peptides and novel visualization. Food Chem. 2017, 232, 673–682. [Google Scholar] [CrossRef]
- Haug, K.; Salek, R.M.; Conesa, P.; Hastings, J.; de Matos, P.; Rijnbeek, M.; Mahendraker, T.; Williams, M.; Neumann, S.; Rocca-Serra, P.; et al. MetaboLights—An open-access general-purpose repository for metabolomics studies and associated meta-data. Nucleic Acids Res. 2013, 41, D781–D786. [Google Scholar] [CrossRef] [PubMed]
- Théolier, J.; Fliss, I.; Jean, J.; Hammami, R. MilkAMP: A comprehensive database of antimicrobial peptides of dairy origin. Dairy Sci. Technol. 2014, 94, 181–193. [Google Scholar] [CrossRef]
- Ntie-Kang, F.; Telukunta, K.K.; Döring, K.; Simoben, C.V.; Moumbock, A.F.A.; Malange, Y.I.; Njume, L.E.; Yong, J.N.; Sippl, W.; Günther, S. NANPDB: A resource for natural products from northern African sources. J. Nat. Prod. 2017, 80, 2067–2076. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Wang, M.; Yin, S.; Jang, R.; Wang, J.; Xue, Z.; Xu, T. NeuroPep: A comprehensive resource of neuropeptides. Database 2015, 2015, bav038. [Google Scholar] [CrossRef] [PubMed]
- Shtatland, T.; Guettler, D.; Kossodo, M.; Pivovarov, M.; Weissleder, R. PepBank—A database of peptides based on sequence text mining and public peptide data sources. BMC Bioinform. 2007, 8, 280. [Google Scholar] [CrossRef] [PubMed]
- Liu, F.; Baggerman, G.; Schoofs, L.; Wets, G. The construction of a bioactive peptide database in Metazoa. J. Proteome Res. 2008, 7, 4119–4131. [Google Scholar] [CrossRef]
- Juhász, A.; Haraszi, R.; Maulis, C. ProPepper: A curated database for identification and analysis of peptide and immune-responsive epitope composition of cereal grain protein families. Database 2015, 2015, bav100. [Google Scholar] [CrossRef]
- Singh, S.; Chaudhary, K.; Dhanda, S.K.; Bhalla, S.; Usmani, S.S.; Gautam, A.; Tuknait, A.; Agrawal, P.; Mathur, D.; Raghava, G.P. SATPdb: A database of structurally annotated therapeutic peptides. Nucleic Acids Res. 2016, 44, D1119–D1126. [Google Scholar] [CrossRef]
- Papadatos, G.; Davies, M.; Dedman, N.; Chambers, J.; Gaulton, A.; Siddle, J. SureChEMBL: A large-scale, chemically annotated patent document database. Nucleic Acids Res. 2016, 44, D1220–D1228. [Google Scholar] [CrossRef]
- Gfeller, D.; Michielin, O.; Zoete, V. SwissSidechain: A molecular and structural database of non-natural sidechains. Nucleic Acids Res. 2013, 41, D327–D332. [Google Scholar] [CrossRef]
- Sterling, T.; Irwin, J.J. ZINC 15—ligand discovery for everyone. J. Chem. Inf. Model. 2015, 55, 2324–2337. [Google Scholar] [CrossRef] [PubMed]
- Liu, Z.P.; Wu, L.Y.; Wang, Y.; Zhang, X.S.; Chen, L. Bridging protein local structures and protein functions. Amino Acids 2008, 35, 627–650. [Google Scholar] [CrossRef] [PubMed]
- Minkiewicz, P.; Darewicz, M.; Iwaniak, A.; Sokołowska, J.; Starowicz, P.; Bucholska, J.; Hrynkiewicz, M. Common amino acid subsequences in a universal proteome-relevance for food science. Int. J. Mol. Sci. 2015, 16, 20748–20773. [Google Scholar] [CrossRef] [PubMed]
- Zamyatnin, A.A. Fragmentomics of natural peptide structures. Biochemistry (Moscow) 2009, 74, 1575–1585. [Google Scholar] [CrossRef] [PubMed]
- Martini, S.; Conte, A.; Tagliazucchi, D. Comparative peptidomic profile and bioactivities of cooked beef, pork, chicken and turkey meat after In vitro gastro-intestinal digestion. J. Proteom. 2019, 208, 103500. [Google Scholar] [CrossRef] [PubMed]
- Garcia-Vaquero, M.; Mora, L.; Hayes, M. In vitro and in silico approaches to generating and identifying angiotensin-converting enzyme I inhibitory peptides from green macroalga Ulva lactuca. Marine Drugs 2019, 17, 204. [Google Scholar] [CrossRef]
- Dziuba, J.; Minkiewicz, P.; Nałęcz, D.; Iwaniak, A. Database of biologically active peptide sequences. Nahrung 1999, 43, 190–195. [Google Scholar] [CrossRef]
- Bauchart, C.; Morzel, M.; Chambon, C.; Mirand, P.P.; Reynès, C.; Buffière, C.; Rémond, D. Peptides reproducibly released by in vivo digestion of beef meat and trout flesh in pigs. Br. J. Nutr. 2007, 98, 1187–1195. [Google Scholar] [CrossRef]
- Huang, B.-B.; Lin, H.-C.; Chang, Y.-W. Analysis of proteins and potential bioactive peptides from tilapia (Oreochromis spp.) processing co-products using proteomic techniques coupled with BIOPEP database. J. Funct. Foods 2015, 19, 629–640. [Google Scholar] [CrossRef]
- Tapal, A.; Vegarud, G.E.; Sreedhara, A.; Tiku, P.K. Nutraceutical protein isolate from pigeon pea (Cajanus cajan) milling waste by-product: Functional aspects and digestibility. Food Funct. 2019, 10, 2710–2719. [Google Scholar] [CrossRef]
- Jakubczyk, A.; Karaś, M.; Złotek, U.; Szymanowska, U.; Baraniak, B.; Bochnak, J. Peptides obtained from fermented faba bean seeds (Vicia faba) as potential inhibitors of an enzyme involved in the pathogenesis of metabolic syndrome. LWT Food Sci. Technol. 2019, 105, 306–313. [Google Scholar] [CrossRef]
- Udenigwe, C.C.; Gong, M.; Wu, S. In silico analysis of the large and small subunits of cereal RuBisCO as precursors of cryptic bioactive peptides. Process Biochem. 2013, 48, 1794–1799. [Google Scholar] [CrossRef]
- Lin, K.; Zhang, L.W.; Han, X.; Xin, L.; Meng, Z.X.; Gong, P.M.; Cheng, D.Y. Yak milk casein as potential precursor of angiotensin I-converting enzyme inhibitory peptides based on in silico proteolysis. Food Chem. 2018, 254, 340–347. [Google Scholar] [CrossRef] [PubMed]
- Dziuba, J.; Iwaniak, A.; Minkiewicz, P. Computer-aided characteristics of proteins as potential precursors of bioactive peptides. Polimery 2003, 48, 50–53. [Google Scholar] [CrossRef]
- Minkiewicz, P.; Dziuba, J.; Michalska, J. Bovine meat proteins as potential precursors of biologically active peptides—A computational study based on the BIOPEP database. Food Sci. Technol. Int. 2011, 17, 39–45. [Google Scholar] [CrossRef] [PubMed]
- Nielsen, P.M.; Petersen, D.; Dambmann, C. Improved method for determining food protein degree of hydrolysis. J. Food Sci. 2001, 65, 642–646. [Google Scholar] [CrossRef]
- Bastian, E.D.; Brown, R.J. Plasmin in milk and dairy products: An update. Int. Dairy J. 1996, 6, 435–457. [Google Scholar] [CrossRef]
- Huang, X.W.; Chen, L.J.; Luo, Y.B.; Guo, H.Y.; Ren, F.Z. Purification, characterization, and milk coagulating properties of ginger proteases. J. Dairy Sci. 2011, 94, 2259–2269. [Google Scholar] [CrossRef]
- Yu, D.; Wang, C.; Song, Y.; Zhu, J.; Zhang, X. Discovery of novel angiotensin-converting enzyme inhibitory peptides from Todarodes pacificus and their inhibitory mechanism: In silico and In vitro studies. Int. J. Mol. Sci. 2019, 20, 4159. [Google Scholar] [CrossRef]
- Kandemir-Cavas, C.; Pérez-Sanchez, H.; Mert-Ozupek, N.; Cavas, L. In silico analysis of bioactive peptides in invasive sea grass Halophila stipulacea. Cells 2019, 8, 557. [Google Scholar] [CrossRef]
- Dziuba, J.; Niklewicz, M.; Iwaniak, A.; Darewicz, M.; Minkiewicz, P. Structural properties of proteolytic-accessible bioactive fragments of selected animal proteins. Polimery 2005, 50, 424–428. [Google Scholar] [CrossRef]
- Pearson, W.R. Flexible sequence similarity searching with the FASTA3 program package. Methods Mol. Biol. 2000, 132, 185–219. [Google Scholar] [PubMed]
- Nardo, A.E.; Añón, M.C.; Parisi, G. Large-scale mapping of bioactive peptides in structural and sequence space. PLoS ONE 2018, 13, e0191063. [Google Scholar] [CrossRef] [PubMed]
- Siani, M.A.; Weininger, D.; Blaney, J.M. CHUCKLES: A method for representing and searching peptide and peptoid sequences on both monomer and atomic levels. J. Chem. Inf. Comput. Sci. 1994, 34, 588–593. [Google Scholar] [CrossRef] [PubMed]
- Duffy, F.J.; Verniere, M.; Devocelle, M.; Bernard, E.; Shields, D.C.; Chubb, A.J. CycloPs: Generating virtual libraries of cyclized and constrained peptides including nonnatural amino acids. J. Chem. Inf. Model. 2011, 51, 829–836. [Google Scholar] [CrossRef] [PubMed]
- Minkiewicz, P.; Iwaniak, A.; Darewicz, M. Annotation of peptide structures using SMILES and other chemical codes–practical solutions. Molecules 2017, 22, 2075. [Google Scholar] [CrossRef]
- Hähnke, V.D.; Kim, S.; Bolton, E.E. PubChem chemical structure standardization. J. Cheminform. 2018, 10, 36. [Google Scholar] [CrossRef]
- Brodkorb, A.; Egger, L.; Alminger, M.; Alvito, P.; Assunção, R.; Ballance, S.; Bohn, T.; Bourlieu-Lacanal, C.; Boutrou, R.; Carrière, F.; et al. INFOGEST static In vitro simulation of gastrointestinal food digestion. Nat. Protoc. 2019, 14, 991–1014. [Google Scholar] [CrossRef]
- Minkiewicz, P.; Dziuba, J.; Darewicz, M.; Iwaniak, A.; Michalska, J. Online programs and databases of peptides and proteolytic enzymes—A brief update for 2007–2008. Food Technol. Biotechnol. 2009, 47, 345–355. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ID | 9473 | ||
| Name | ACE inhibitor | ||
| Sequence | GHS | ||
| InChIKey | LPCKHUXOGVNZRS-YUMQZZPRSA-N | ||
| Function | Inhibitor of Angiotensin-Converting Enzyme (ACE) (EC 3.4.15.1) (MEROPS ID: M02-001) | ||
| Number of Amino Acid Residues | 3 | Activity Code | ah |
| Activity | ACE inhibitor | ||
| Chemical Mass | 299.2740 | Monoisotopic Mass | 299.1110 |
| IC50 | 0.00 µM | ||
| Bibliographic Data | |||
| Authors | He R., Malomo S. A., Alashi A., Girgih A. T., Ju X., Aluko R. E. | ||
| Title | Glycinyl-histidinyl-serine (GHS), a novel rapeseed protein-derived peptide, has a blood pressure-lowering effect in spontaneously hypertensive rats. J. Agric. Food Chem., 61, 8396-8402, 2013 | ||
| Year | 2013 | Source | Journal |
| Additional Information | |||
| BIOPEP-UWM database of bioactive peptides SMILES: NCC(=O)N[C@@H](Cc1c[nH]cn1)C(=O)N[C@@]([H])(CO)C(=O)O InChI=1S/C11H17N5O5/c12-2-9(18)15-7(1-6-3-13-5-14-6)10(19)16-8(4-17)11(20)21/h3,5,7-8,17H,1-2,4,12H2,(H,13,14)(H,15,18)(H,16,19)(H,20,21)/t7-,8-/m0/s1 InChIKey: LPCKHUXOGVNZRS-YUMQZZPRSA-N Inhibitor of Renin (EC 3.4.23.15) (MEROPS ID: A01.007) according to the BIOPEP-UWM database of bioactive peptides (ID 9472) | |||
| Database Reference | |||
| AHTPDB: ID 1053, 2949 BioPepDB: ID biopep00354 BIOPEP-UWM database of bioactive peptides: ID 9472 SATPdb: ID satpdb13065 | |||
| Activity | Description 1 |
|---|---|
| ACE inhibitor 2 | Inhibitors of angiotensin-converting enzyme (ACE) (EC 3.4.15.1) (MEROPS ID: M02-001) |
| activating ubiquitin-mediated proteolysis | Peptides activating proteolysis mediated by ubiquitin |
| alpha-amylase inhibitor 2 | Inhibitors of α-amylase (EC 3.2.1.1) |
| alpha-glucosidase inhibitor 2 | Inhibitors of α-glucosidase (EC 3.2.1.20) |
| anorectic | Peptides causing a decrease in food intake and suppression of appetite. |
| antiamnestic | Inhibitors of prolyl oligopeptidase (EC 3.4.21.26) (MEROPS ID: S09.001). The enzyme catalyzes degradation of neuropeptides, e.g., involved in processes associated with memory. |
| antibacterial | Peptides revealing any action against bacteria |
| anticancer | Peptides revealing any action against cancers |
| antifungal | Peptides revealing any action against fungi |
| anti-inflammatory | Peptides reducing inflammation or swelling |
| antioxidative | Peptides inhibiting oxidation |
| antithrombotic | Inhibitors of blood coagulation. Inhibitors of thrombin (EC 3.4.21.5) (MEROPS ID: S01.217) are attributed to this activity. |
| antiviral | Peptides revealing any action against viruses. Inhibitors of viral enzymes are included. |
| bacterial permease ligand | Ligands of bacterial permeases |
| binding 2 | Peptides binding any biomolecules. Mineral binding peptides are also attributed to this activity. |
| CaMKII inhibitor 2 | Inhibitors of Ca2+/calmodulin-dependent protein kinase (CaMKII) (EC 2.7.11.17) |
| CaMPDE inhibitor 2 | Inhibitors of 3′,5′-cyclic-nucleotide phosphodiesterase (Calmodulin-dependent phosphodiesterase 1—CaMPDE) (EC 3.1.4.17) |
| chemotactic | Peptides inducing chemotaxis, i.e. movement in response to a chemical stimulus |
| celiac toxic | Peptides toxic to people suffering from celiac disease |
| contracting | Peptides stimulating muscle contraction |
| dipeptidyl peptidase III inhibitor 2 | Inhibitors of dipeptidyl peptidase III (EC 3.4.14.4) (MEROPS ID M49.001) |
| dipeptidyl peptidase IV inhibitor 2 | Inhibitors of dipeptidyl peptidase IV (EC 3.4.14.5) (MEROPS ID S09.003) |
| embryotoxic | Peptides toxic to animal embryos |
| hemolytic | Peptides destroying red blood cells |
| heparin binding 2 | Heparin binding peptides |
| HMG-CoA reductase inhibitor 2 | Inhibitors of 3-hydroxy-3-methyl-glutaryl-coenzyme A reductase (HMG-CoA reductase) (EC 1.1.1.34) |
| hypotensive | Peptides causing blood pressure decrease |
| immunomodulating | Peptides modulating activity of the immune system |
| immunostimulating | Peptides stimulating activity of the immune system |
| inhibitor 2 | Peptides inhibiting various biological processes. Information about processes is provided on the pages of individual peptides. |
| membrane-active 2 | Peptides affecting transmembrane transport |
| natriuretic | Peptides inducing the excretion of sodium by kidneys (natriuresis) |
| neuropeptide | Peptides affecting activity of the nervous system |
| opioid | Ligands of opioid receptors |
| opioid agonist | Agonists of opioid receptors |
| opioid antagonist | Antagonists of opioid receptors |
| orphan receptor GPR14 agonist | Agonists of orphan receptor GPR14 |
| Protein Kinase C inhibitor 2 | Inhibitors of protein kinase C (EC 2.7.11.13) |
| regulating | Peptides regulating various biological processes. Information about processes is provided on the pages of individual peptides. |
| renin inhibitor 2 | Inhibitors of renin (EC 3.4.23.15) (MEROPS ID A01.007) |
| stimulating | Peptides stimulating various biological processes. Information about processes is provided on the pages of individual peptides. |
| toxic 2 | Toxic peptides |
| vasoconstrictor | Peptides causing blood pressure increase |
| Search Option | Output | |
|---|---|---|
| Version without Exact Search | Version with Exact Search 1 | |
| ID | Peptide with given ID | |
| Name | List of all peptides with the name containing the given word (words) | Peptide with the given name (may appear more than once if it is annotated with more activities) |
| Activity | Complete list of peptides with all activities named using the given word (e.g., inhibitor) | List of all peptides with the given activity |
| Mass | List of all peptides having molecular masses within the given range (e.g., 500–600) | |
| Reference | List of all peptides described in articles published by the given author (or authors with the same second name) | |
| Sequence | List of all peptides with sequences containing the given fragment | Peptide with the given sequence (may appear more than once if it is annotated with more activities). 2 |
| Number of amino acid residues | List of all peptides containing the given number of amino acid residues (e.g., 3) | |
| InChIKey 1 | Peptide with the given InChIKey. Peptide exhibiting more than one activity annotated in the BIOPEP-UWM will appear more than once 2 | |
| Equation No. | Parameter | Reference |
|---|---|---|
| 1. 1 | The frequency of bioactive fragments occurrence in a protein sequence (A) A = a/N a—the number of fragments with a given activity, N—the number of amino acid residues | [86] |
| 2. 1 | Potential biological activity of protein fragments (B) [μM−1] B = [Σ(ai/EC50i)]/N or B = [Σ(ai/IC50i)]/N ai—the number of repetitions of i-th bioactive fragment in a protein sequence, EC50i—the concentration of i-th bioactive peptide corresponding to its half-maximal activity [µM], IC50i—the concentration of i-th bioactive peptide corresponding to half-maximal inhibition [µM], N—the number of amino acid residues | [86] |
| 3. 2 | The frequency of release of fragments with a given activity by selected enzymes (AE) AE = d/N d—the number of peptides with a given activity (e.g., ACE inhibitors) released by a given enzyme (e.g., trypsin) N—the number of amino acid residues in protein | [87] |
| 4. 2 | The relative frequency of release of fragments with a given activity by selected enzymes (W) W = AE/A AE—the frequency of release of fragments with a given activity by selected enzymes (from Equation (3)) A—the frequency of bioactive fragments occurrence in a protein sequence (from Equation (1)) | [87] |
| 5. 2 | Activity of fragments potentially released by proteolytic enzyme (enzymes) (BE) BE = [Σ(dj/EC50j)]/N or BE = [Σ(dj/IC50j)]/N dj—the number of repetitions of j-th bioactive fragment released by a given enzyme (enzymes) from a protein sequence, EC50j—the concentration of j-th bioactive peptide corresponding to its half-maximal activity [µM], IC50j—the concentration of j-th bioactive peptide corresponding to half-maximal inhibition [µM], N—the number of amino acid residues in a protein chain | * |
| 6. 2 | Relative activity of fragments potentially released by proteolytic enzyme (enzymes) (V) V = BE/B BE—activity of fragments potentially released by proteolytic enzyme (enzymes) (from Equation (5)) B—potential biological activity of protein fragments (from Equation (2)) | * |
| 7. 2 | Theoretical degree of hydrolysis (DHT) DHT = d/D × 100% d—number of hydrolyzed peptide bonds in a protein/peptide chain D—total number of peptide bonds in a protein/peptide chain | [88] |
| 8. 3 | The number of repetitions of the bioactive fragment in all sequences of the protein/peptide set analyzed (aT) aT = a1 + a2 + … + aL a1—aL—the number of repetitions of a given bioactive fragment in particular sequences in the dataset submitted for analysis L—the number of sequences in the protein/peptide set analyzed | * |
| 9. 3 | The number of repetitions of a given fragment in all sequences of the selected protein/peptide fraction (aS) aS = aT/L aT—the number of repetitions of the bioactive fragment in all sequences of the protein/peptide set analyzed (from Equation (8)) L—the number of sequences in the protein/peptide set analyzed | * |
| 10. 3 | The mean frequency of the occurrence of a single fragment in a sequence of protein/peptide classified to a given group (AS) AS = aT/NT aT—the number of repetitions of the bioactive fragment in all sequences of the protein/peptide set analyzed NT—the total number of amino acid residues in all protein/peptide sequences belonging to the set (from Equation 10) | * |
| 11. 4 | The total number of amino acid residues in all protein/peptide sequences belonging to the set (NT) NT = N1 + N2 + … + NL N—the number of amino acid residues in a single protein/peptide chain L—the number of protein/peptide chains in the set | * |
| 12. 3 | The number of cases of release of the bioactive fragment from all sequences of the protein/peptide set analyzed (aTE) aTE = a1E + a2E + … + aLE a1E—aLE—the number of cases of release of the bioactive fragment from particular sequences of the protein/peptide set analyzed L—the number of protein/peptide chains in the set | * |
| 13. 3 | Mean number of cases of predicted release of a single fragment by a selected enzyme from the chain of protein/peptide belonging to the set analyzed (aSE) aSE = aTE/L aTE—the number of cases of release of the bioactive fragment from all sequences of the protein/peptide set analyzed L—the number of protein/peptide chains in the set | * |
| 14. 3 | Predicted frequency of release of a single peptide by proteolytic enzyme from the set of protein/peptide sequences analyzed (ASE) ATE = aTE/NT aT—the number of cases of release of the bioactive fragment from all sequences of the protein/peptide set analyzed NT—the total number of amino acid residues in all protein/peptide sequences belonging to the set (from Equation (10)) | * |
| Category | Description |
|---|---|
| Bioactive peptide databases | Databases of biologically active peptides including general databases (covering several activities) or databases of particular activities (e.g., antimicrobial) |
| Bioactivity prediction | Software predicting biological activity of peptides, especially interactions with proteins, e.g., enzymes |
| Immunology of proteins and peptides | Databases of allergens and epitopes, software for predicting allergenicity and occurrence of epitopes as well as other software from the area of immunology |
| Literature data mining | Software supporting search for biomedical data (e.g., concerning proteins and peptides) in literature |
| Miscellaneous | Databases and software not belonging to other categories. Chemical databases and metabases are attributed to this category. |
| Motifs | Programs enabling constructing sequence motifs and finding them in protein or peptide sequences |
| Physicochemical properties | Software used to predict and exploit the physicochemical properties of peptides |
| Prediction of post-translational modifications | Software used to predict the location of post-translational modifications (phosphorylation, glycosylation) in protein and peptide sequences |
| Programs supporting peptide design | Software supporting design of peptides with desired biological properties |
| Protein resources | Databases and software concerning proteins but not peptides, including databases of protein sequences and structures |
| Proteolysis | Databases annotating proteolytic enzymes, software for proteolysis simulation |
| Proteomic tools | Tools supporting proteomics research including mass spectrometry |
| Sequence alignments | Software for constructing protein and peptide sequence alignments and for searching in protein sequence databases |
| Structure prediction and visualization | Software for modeling secondary and tertiary structures of proteins and peptides |
| Option | Description |
|---|---|
| Peptide annotation | Possibility of annotation of peptides containing D-amino acids |
| Search options 1 | Search on the basis of InChIKey; addition of “exact match” search as user’s choice, designed especially for sequence search |
| List of peptide activities | List of peptide activities rearranged and enriched |
| Proteolytic enzyme annotation | Updated list of bonds susceptible to proteolytic enzyme action |
| New search options | Search on the basis of InChIKey; addition of “exact match” search as user’s choice |
| “SMILES” tab 1 | Application converting amino acid sequences into the SMILES code |
| New options available via the “enzyme(s) action” tab | New quantitative parameters describing possibility of release of bioactive peptides by proteolytic enzymes—Equations (5)–(7) in Table 5, option enabling finding enzyme with a given specificity among proteinases annotated in the database |
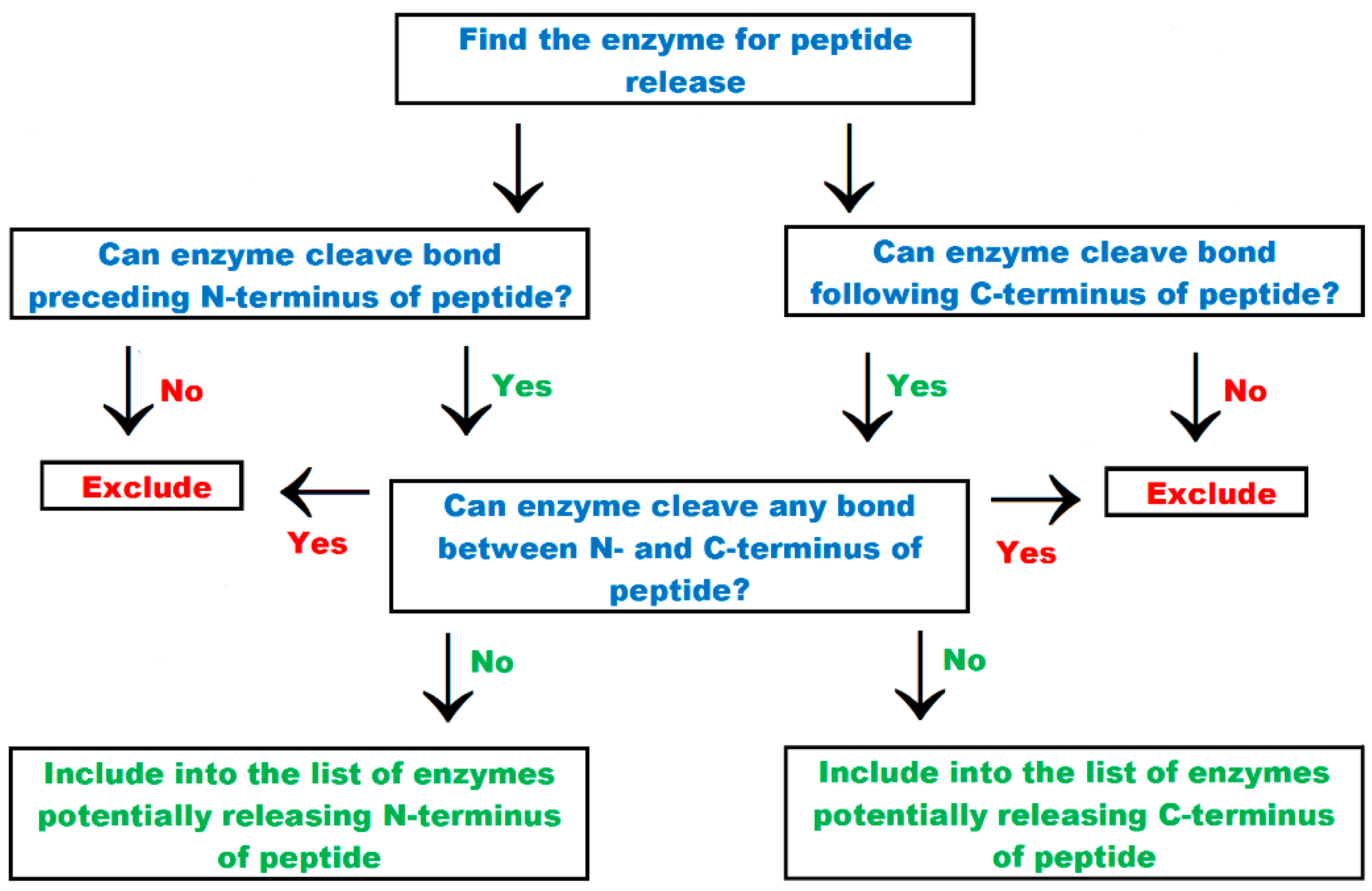
| “find the enzymes for peptide release” tab | Option which enables finding proteolytic enzymes liberating of N- and C-termini of bioactive peptides |
| “find” tab | Shortcut to the list of peptides with a given activity |
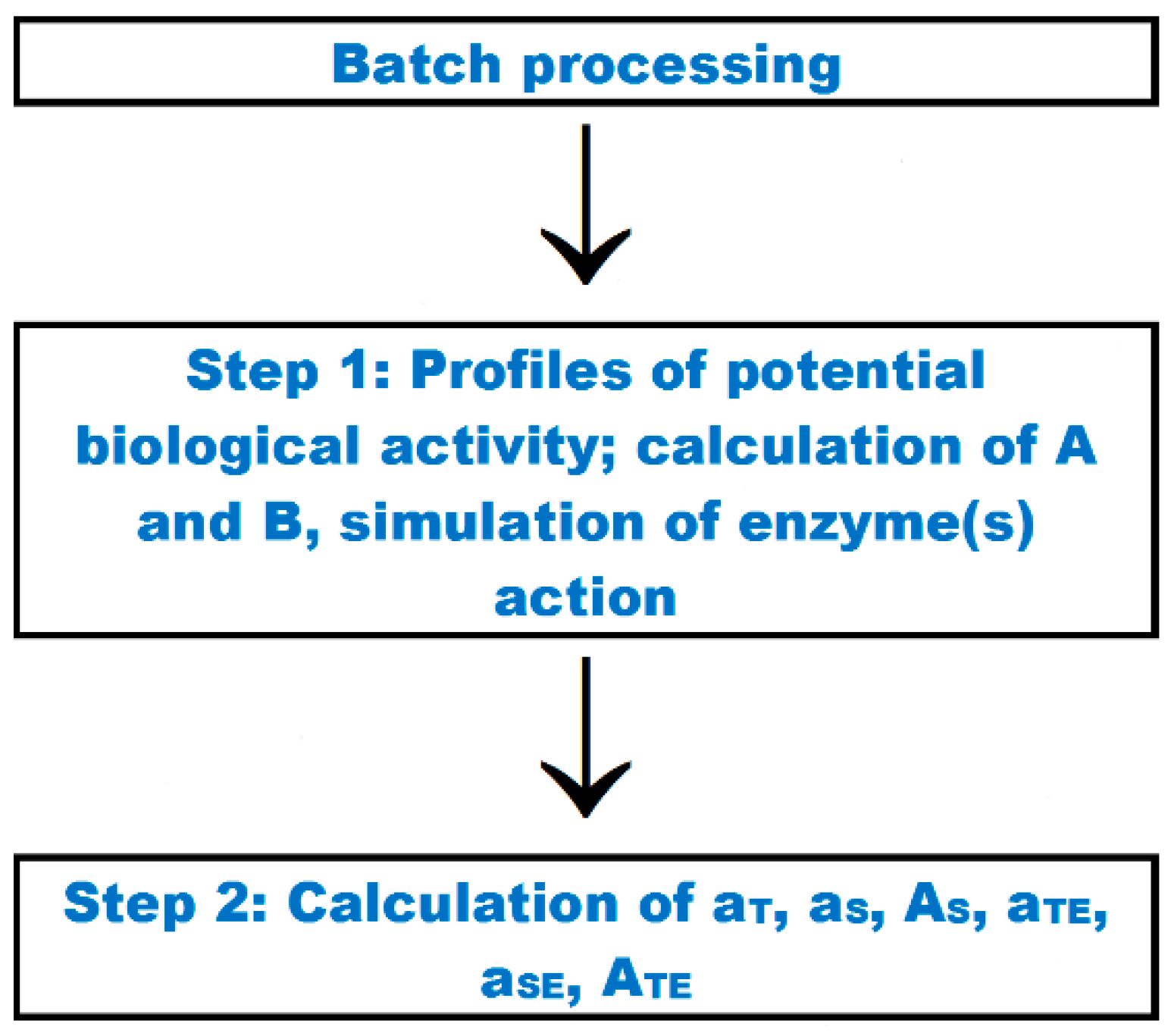
| Batch processing | Option which enables finding profiles of potential biological activity of fragments, calculating quantitative parameters that characterize protein or peptide, and simulating proteolysis for a set of sequences |
| Quantitative parameters characterizing occurrence and possibility of release of bioactive peptide from a set of sequences | Parameters calculated via the “batch processing” option—Equations (8)–(10) and (12)–(14) in the Table 5 |
| The “BIOPEP-UWM news” tab | Tab designed to provide important news concerning the database |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Minkiewicz, P.; Iwaniak, A.; Darewicz, M. BIOPEP-UWM Database of Bioactive Peptides: Current Opportunities. Int. J. Mol. Sci. 2019, 20, 5978. https://doi.org/10.3390/ijms20235978
Minkiewicz P, Iwaniak A, Darewicz M. BIOPEP-UWM Database of Bioactive Peptides: Current Opportunities. International Journal of Molecular Sciences. 2019; 20(23):5978. https://doi.org/10.3390/ijms20235978
Chicago/Turabian StyleMinkiewicz, Piotr, Anna Iwaniak, and Małgorzata Darewicz. 2019. "BIOPEP-UWM Database of Bioactive Peptides: Current Opportunities" International Journal of Molecular Sciences 20, no. 23: 5978. https://doi.org/10.3390/ijms20235978
APA StyleMinkiewicz, P., Iwaniak, A., & Darewicz, M. (2019). BIOPEP-UWM Database of Bioactive Peptides: Current Opportunities. International Journal of Molecular Sciences, 20(23), 5978. https://doi.org/10.3390/ijms20235978