
MPHGCL-DDI: Meta-Path-Based Heterogeneous Graph Contrastive Learning for Drug-Drug Interaction Prediction

Abstract
1. Introduction
2. Results
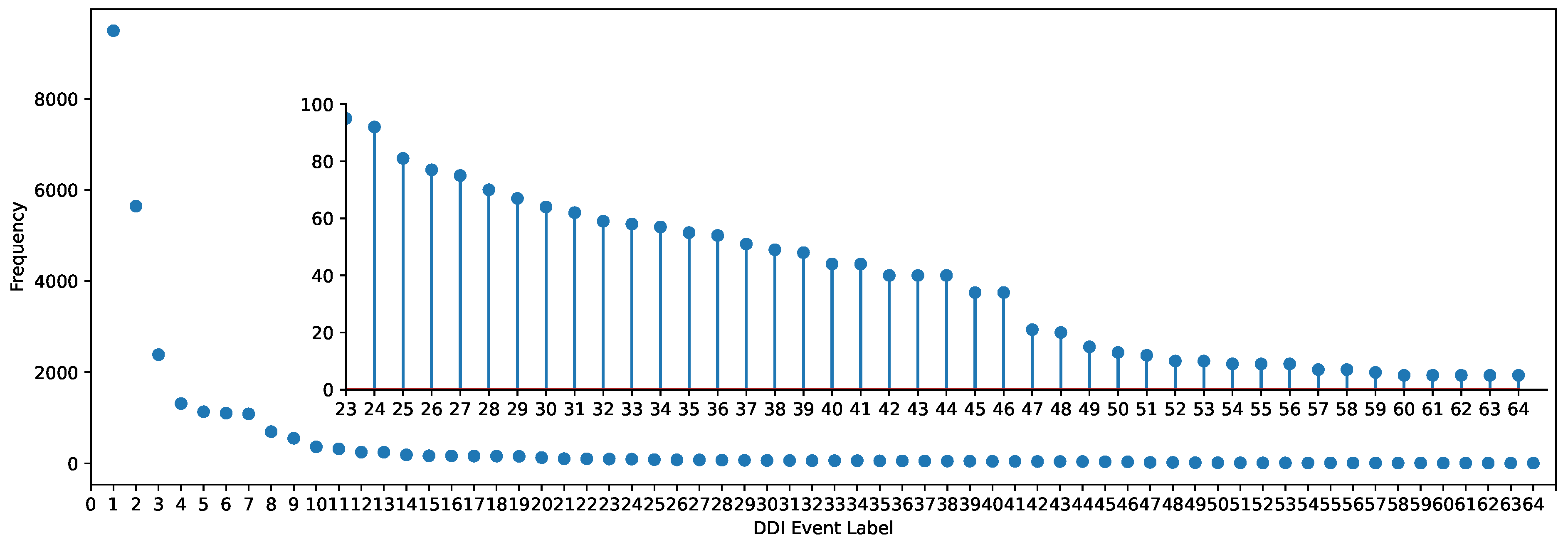
2.1. Experiment Settings
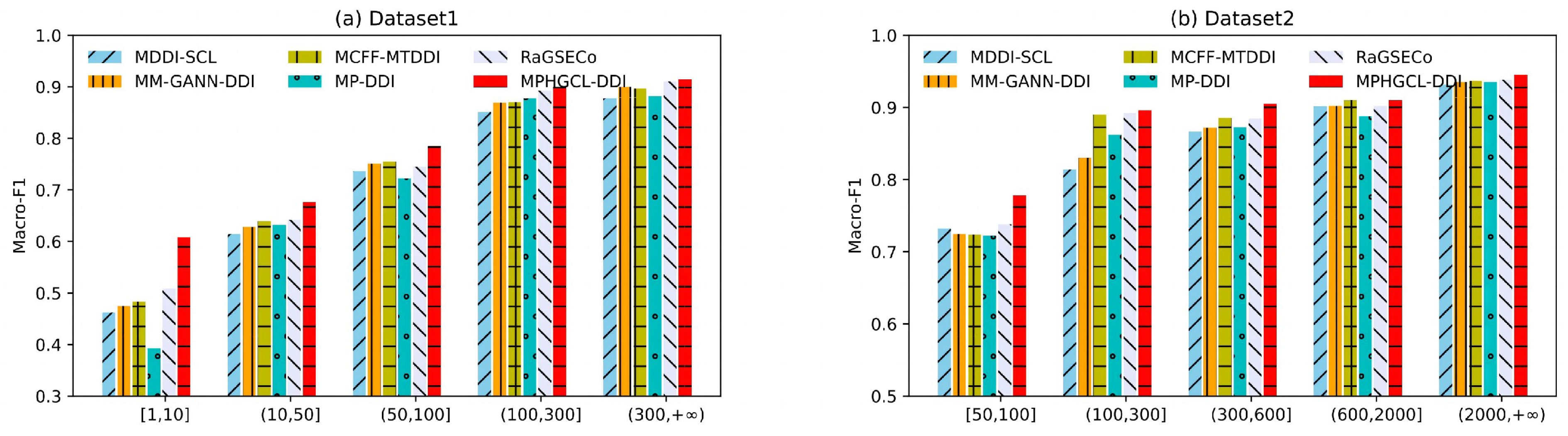
2.2. Comparison with Baselines
- MDDI-SCL [25]. It employs a multi-layer self-attention mechanism to learn the latent features of drugs and performs a multi-scale fusion to the outputs of different layers based on contrastive learning.
- MM-GANN-DDI [31]. It is a multi-modal graph-agnostic neural network for predicting DDI events. It fuses six drug modalities with the topological features of the DDI graph through a graph attention neural network.
- MCFF-MTDDI [32]. It extracts drug chemical structure features and drug pairs’ extra label features, and integrates these features through a multi-channel feature fusion module, thereby predicting multiple types of DDIs.
- MP-DDI [33]. The model captures the complex semantics and learns high-quality representations of drugs using meta-paths. The original model does not consider what type of interaction event occurs. In experiments, we changed the original model for the DDI event prediction using a multi-layer perceptron.
- RaGSECo [26]. It is based on relation-aware graph structure embedding with co-contrastive learning. The model constructs two heterogeneous graphs: a multi-relational DDI graph and a multi-attribute drug-drug similarity graph, and learns representations of drug pairs using co-contrastive learning.
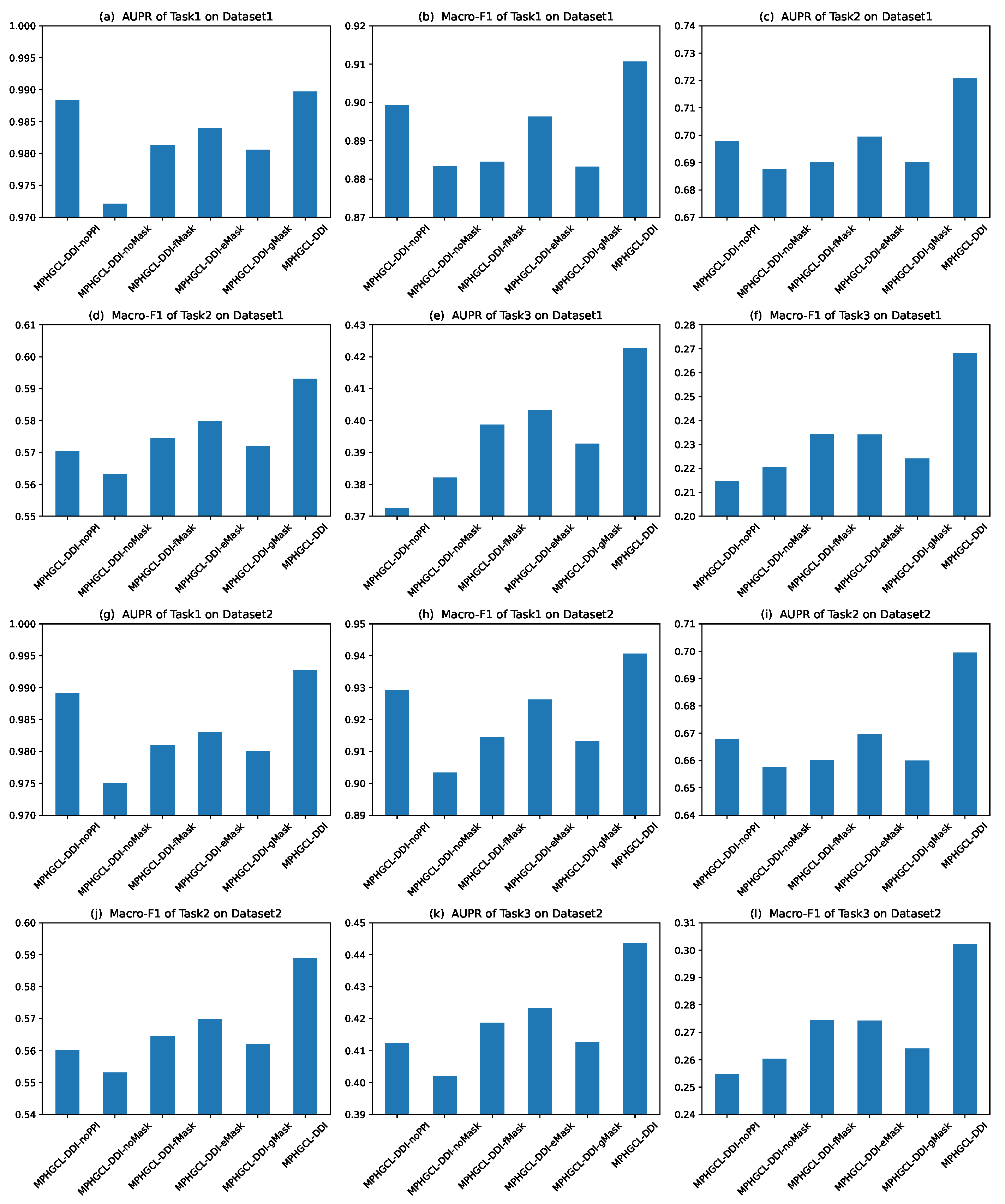
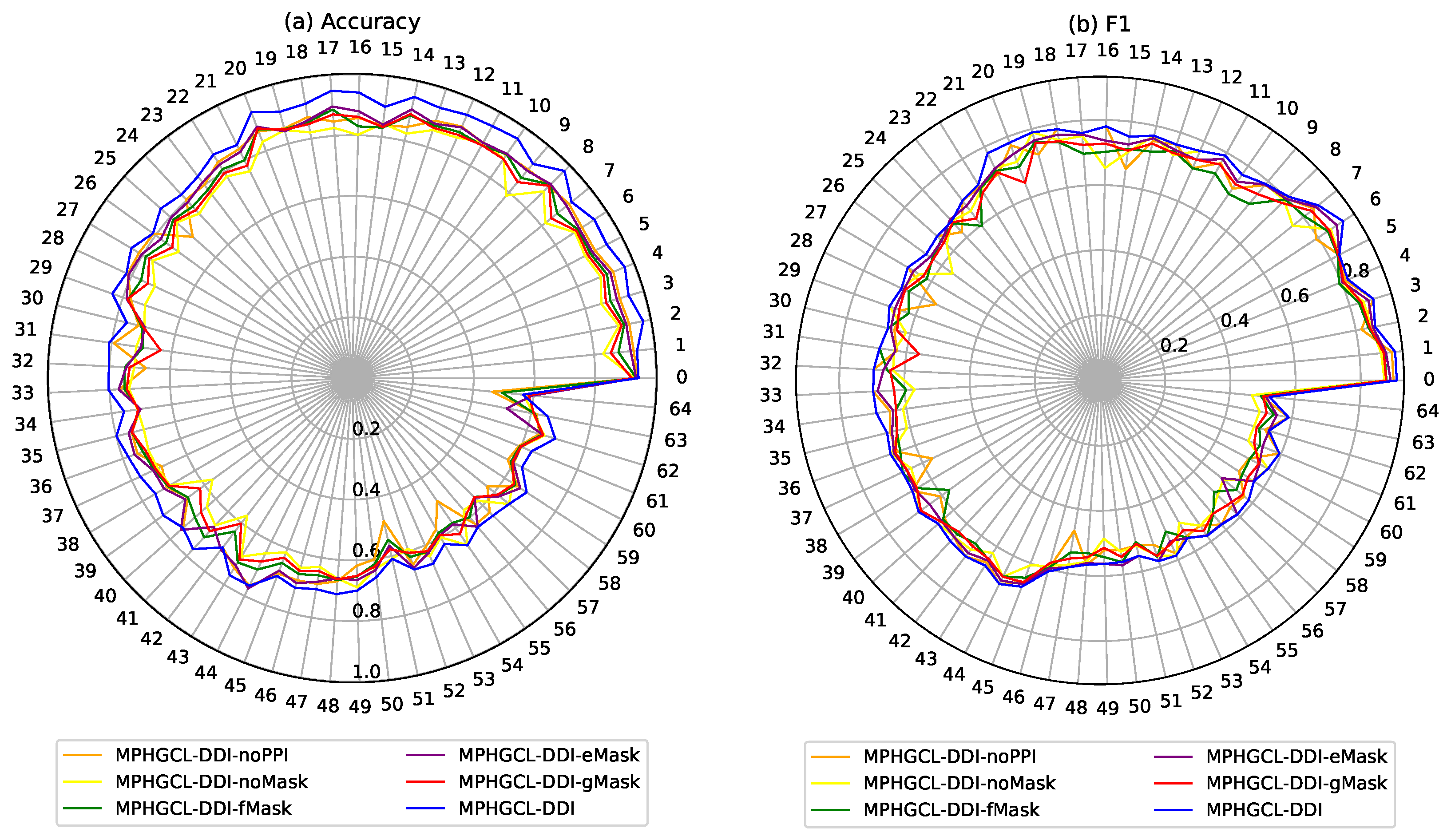
2.3. Ablation Study
- MPHGCL-DDI-noPPI: A variant without protein–protein interaction information, in which the meta-path DPPD is not considered.
- MPHGCL-DDI-noMask: The model does not perform any augmentations in the training process.
- MPHGCL-DDI-fMask: This model only performs masking of certain features of biological attributes in the training process.
- MPHGCL-DDI-eMask: This model only performs masking of certain edges of the meta-path-based sub-graphs in the training process.
- MPHGCL-DDI-gMask: This model only performs masking of certain meta-path-based sub-graphs in the training process.
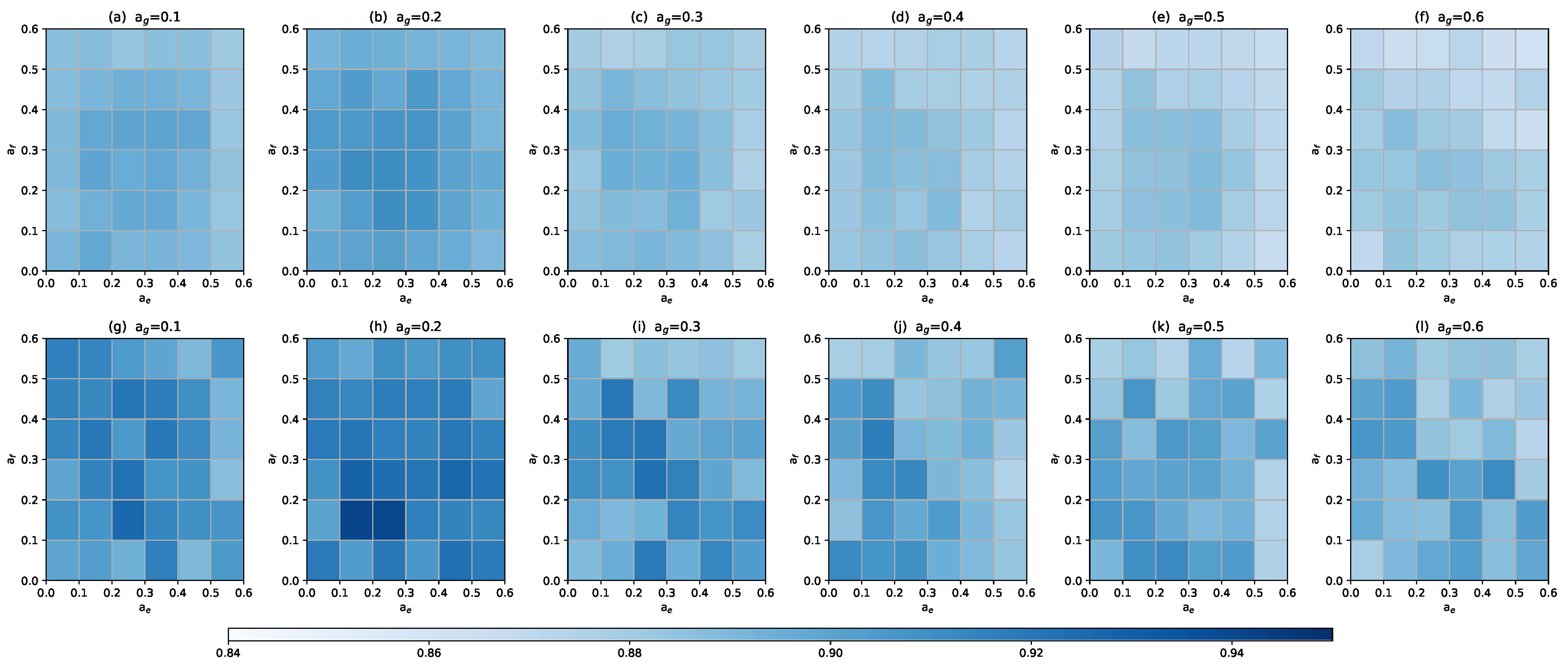
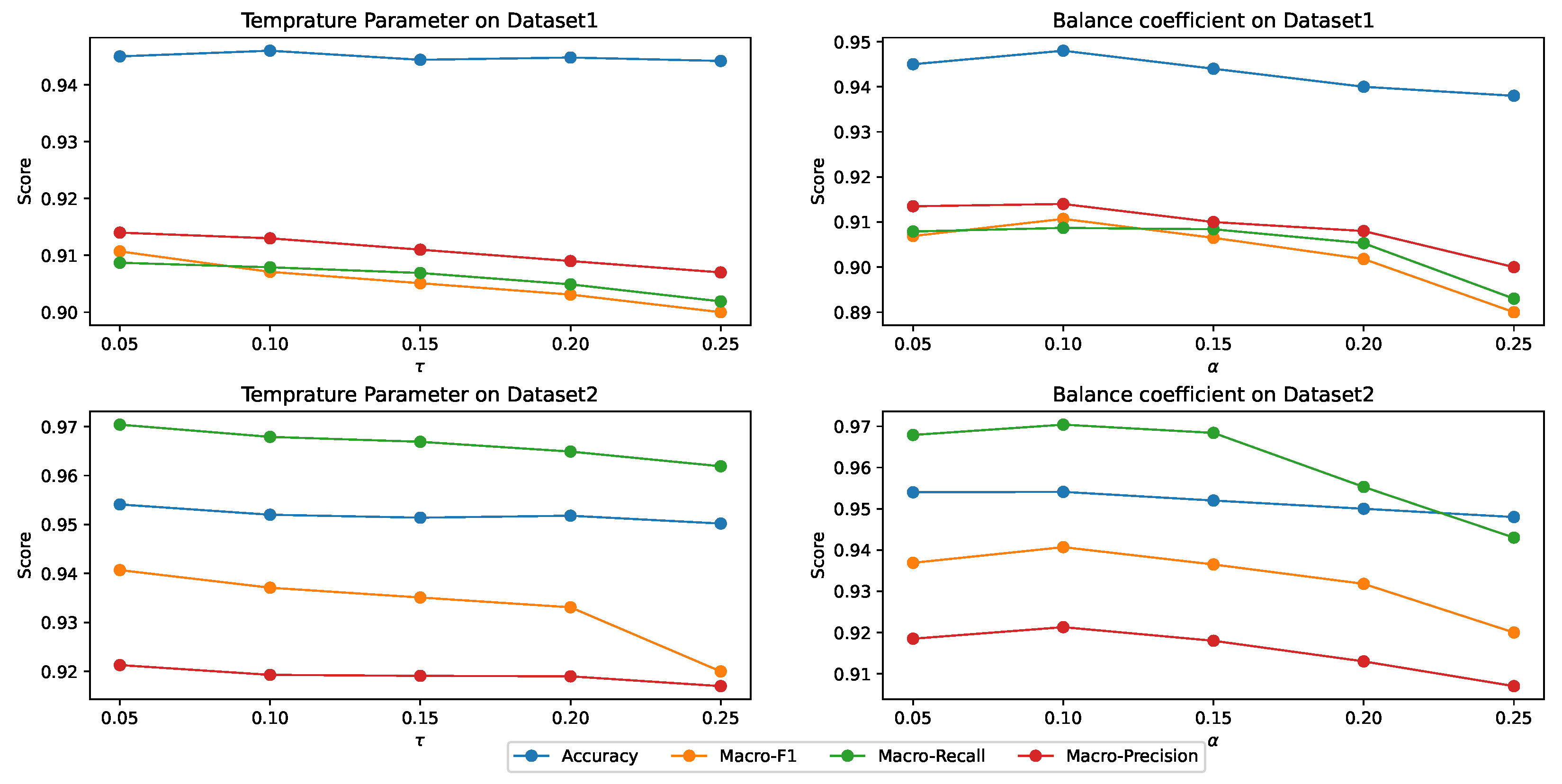
2.4. Hyper-Parameters Analysis
2.5. Case Study
3. Discussion
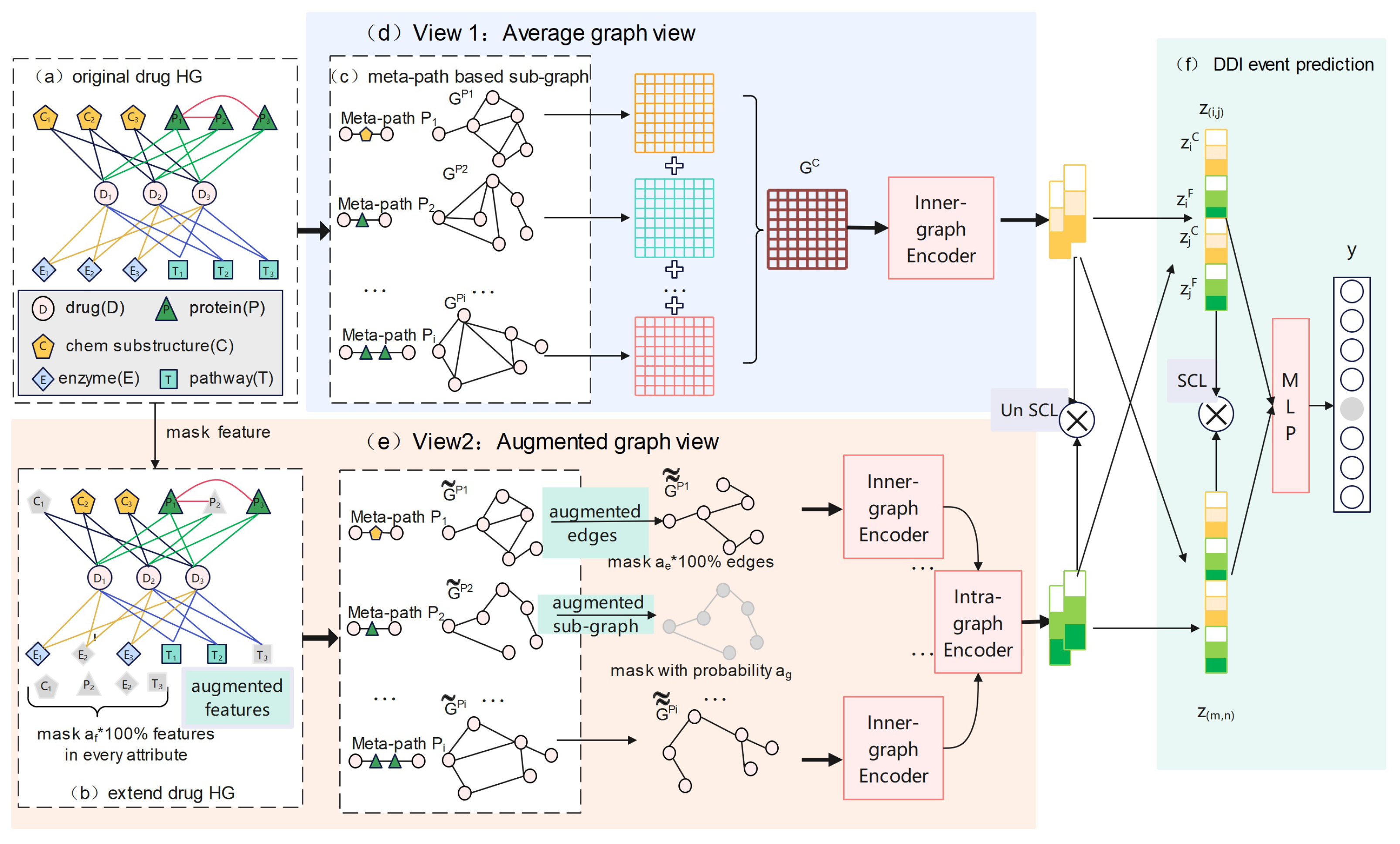
- The model utilized heterogeneous graph contrastive learning. There are two contrastive views in the model: an average graph view and an augmented graph view. The former view is an average graph of all meta-path-based sub-graphs, representing the connections between the drugs. The latter view integrates various meta-path-based sub-graphs using attention mechanisms, revealing the how the drugs connect with each other.
- The data augmentation schemes introduce more variations and differences into the drug data and enhance the model’s ability to generalize. There are three levels of data augmentation schemes: feature augmentation by masking features of biological attributes, edge augmentation by masking the edges of meta-path-based sub-graphs, and sub-graph augmentation by masking one meta-path. The three strategies progressively increase the perturbation intensity.
- The contrastive learning framework integrates both unsupervised contrastive loss and supervised contrastive loss, and improves the representation learning capacity of drug pairs.
- In addition, the model not only focuses on the direct biological attributes of drugs but also on their indirect information, including protein–protein interactions. This reveals the implicit relationships among drugs and is effective for DDI event prediction.
4. Materials and Methods
4.1. Datasets
4.2. Methods
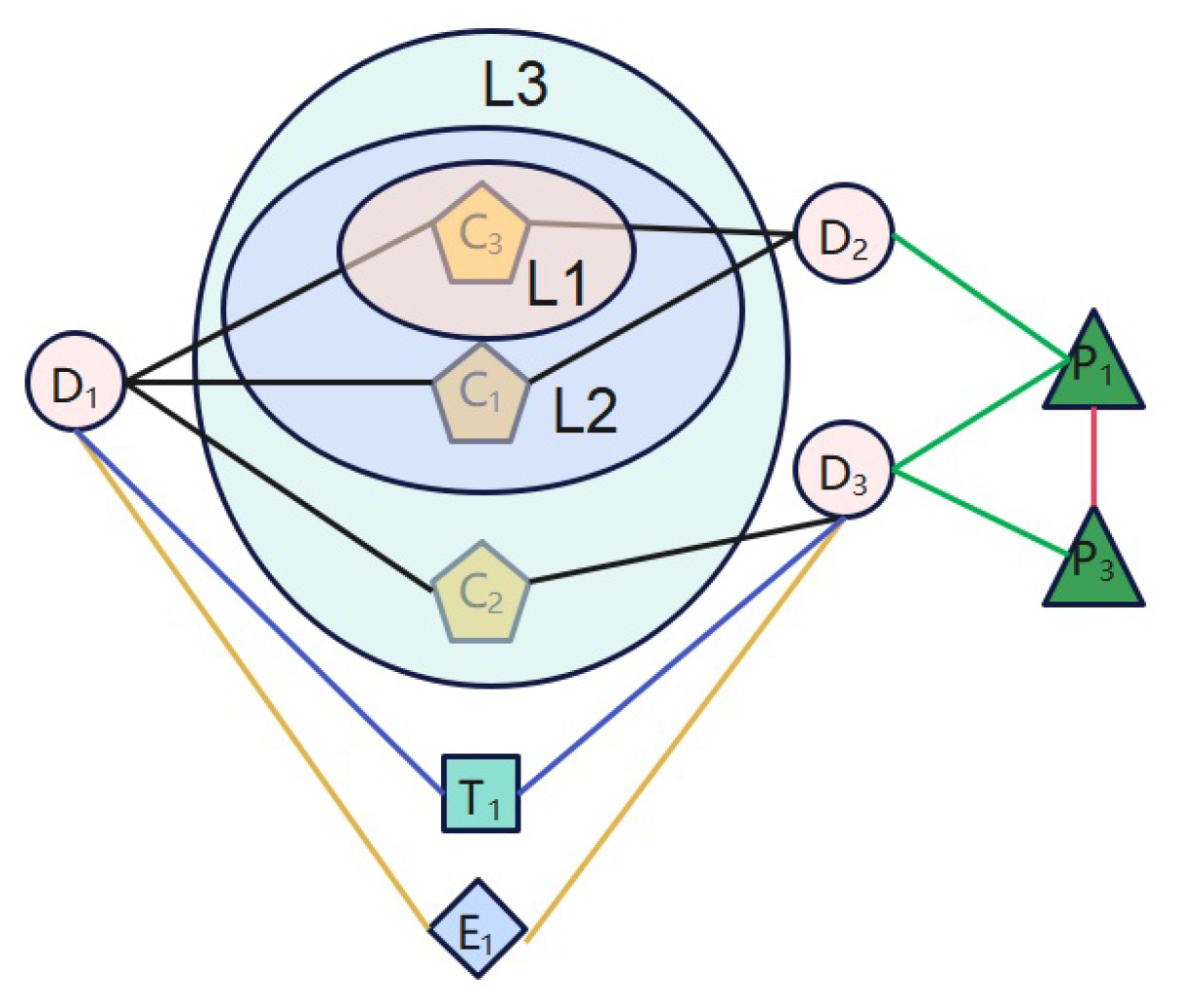
4.2.1. Drug Heterogeneous Graph
4.2.2. Meta-Path-Based Sub-Graph
4.2.3. Augmentation Schemes
- Level 1: Feature augmentationAt this level, we masked some features of every biological attribute. For each biological attribute of drugs, we randomly removed × 100% features, where is the masking ratio, and obtained an extended corrupted drug heterogeneous graph, . For example, we masked chemical substructure , as shown in Figure 8. In this way, a path, , between drug and , which belongs to meta-path , is removed.
- Level 2: Edge augmentationAt this level, we masked some edges in each meta-path-based drug sub-graph. As illustrated in Figure 8, the edge between drug and drug based on meta-path consists of two paths: and . So, at level 2, all paths between two drug pairs based on a meta-path are masked.Specifically, for each meta-path-based sub-graph, , in , we randomly removed × 100% edges in , where is the masking ratio, and we denoted the corrupted meta-path-based sub-graph as .
- Level 3: Sub-graph augmentationIn this augmentation scheme, we masked one meta-path-based sub-graph in . As shown in Figure 8, we masked the meta-path from the meta-path set. Consequently, the sub-graph based on meta-path is removed.Considering this mask scheme as a coarse-grained graph perturbation, we only performed it with a certain probability at each training stage, and only masked one sub-graph every time. Specifically, in each training epoch, we sample a number, r, from a Bernoulli distribution, , where is the masking probability. If r equals 1, we randomly select a sub-graph and remove it from ; otherwise, the augmentation is not performed.
4.2.4. Contrastive Views
- Average graph viewThe average graph view aggregates all meta-paths from the original drug HG G, as shown in Figure 7d. After sub-graph construction, defined in Section 4.2.2, we obtained a set of sub-graphs, , where represents the drug sub-graph based on meta-path . The average graph view focuses on the the connectivity between drugs and is a kind of coarse view. We adopted the average pooling operation to the meta-path-induced adjacency matrices and obtained an aggregated average graph, . The adjacency matrix of iswhere l is the number of meta-paths and is the adjacency matrix of sub-graph .
- Augmented graph viewThe augmented graph view fuses all meta-path-based augmented sub-graphs by the attention mechanism (as shown in Figure 7e). This view pays attention to each meta-path’s contextual semantic information and is a kind of fine-grained view. In each training epoch, we firstly masked features on original drug HG and constructed extended drug HG . Based on , a new set of sub-graphs can be formed following the description in Section 4.2.2. The set of sub-graphs is denoted as , and represents the new drug sub-graph based on meta-path . And then we further performed sub-graph augmentation and edge augmentation on and denoted the set of corrupted sub-graphs as . , where is the corrupted sub-graph after edge augmentation based on meta-path . The size of is or , depending on whether the sub-graph is performed.
4.2.5. Graph Encoder
- Node Feature TransformationFor the drugs in the two datasets, we collected their SMILES strings from DrugBank and adopted the ESPF algorithm [39] to extract features from the SMILES strings. The ESPF algorithm is an effective technique that decomposes the sequential structure into interpretable functional groups. It decomposes a SMILES string into a set of different sized frequent substructures, starting from the collection of all atoms and bonds.To obtain more enriched representations in the high dimension than the original vector space, for an arbitrary drug, i, we havewhere is the exacted feature of drug i using the ESPF algorithm, and is the projected feature of drug i. is the learnable mapping matrix, is the learnable bias vector and is an activation function, respectively.
- Inter-Graph EncoderFor the drug graph in the average graph view, , or each augmented sub-graph in the augmented graph view, we utilized the node attention mechanism in a graph to embed each drug.For each node, i, in the graph , we collected its neighbors, , and aggregated the embeddings of nodes in . As different neighbors exhibit different degrees of importance to the target node in contrastive tasks due to their distinct features, it is appropriate to assign different weights to them. We adopted a graph attention layer [40] to aggregate the embeddings of nodes in , which leverages a self-attention mechanism to assign different weights to neighbors, effectively and flexibly capturing the importance of each neighbor.Specifically, for node i, the importance of its neighbor node, j, is calculated as:where is a learnable node attention vector, and denotes the concatenate operation.After obtaining the importance of all neighbors for node i, we normalized them to obtain the weight coefficient and computed the weighted combination of the representations for node i:To strength the representation of embedding, we adopted a multi-head attention mechanism. Specifically, H independent attention mechanisms are executed, and the outputs are concatenated as the final node representation:where is the a transformation matrix for each head to keep the dimension of to be d, and is the normalized importance of node j to node i at the k-th attention head.Similarly, for each sub-graph, , in the augmented graph view, we also applied the aforementioned multi-head node attention mechanism to obtain node representations for each sub-graph. The embedding of drug i in the sub-graph based on meta-path , denoted as , can be calculated as:
- Intra-Graph EncoderAfter encoding every drug in each meta-path-based drug sub-graph of the augmented graph view, we further integrated these embeddings to obtain the aggregated drug embedding for contrastive learning. Similar to the node attention mechanism in the aforementioned inner-graph encoder, different meta-paths represent different semantic information and have different importance. Therefore, we employed a graph-level attention mechanism to automatically learn the importance of different meta-paths.To be specific, for each meta-path-based drug sub-graph, , we firstly calculated a summary vector by averaging the transformed node embeddings for all nodes in :where D is the drug set, is a learnable weight matrix, and is a learnable bias vector.Secondly, we computed the importance of each meta-path utilizing a learnable vector, , as follows:We normalized the importance score utilizing a Softmax function and obtained the weight co-efficient:where means the number of sub-graphs.Finally, we obtained the the aggregate final drug embedding of the augmented graph view:
4.2.6. Drug-Drug Interaction Event Prediction
4.2.7. Model Training
- Unsupervised Contrastive LossAfter the graph encoder described in Section 4.2.5, we obtained the embeddings of the two contrastive views, and . In multi-view graph contrastive learning, a contrastive objective is adopted to distinguish the embeddings of the same node from other node embeddings. The InfoNCE loss function [41] is a commonly adopted contrastive objective and defined as:where measures the similarity between node embeddings and , is a temperature hyper-parameter and N is the negative samples set.The contrastive loss in this work is:where is the size of the drug set. The first term in the parentheses represents the contrastive loss under the average graph view, while the second term is the loss under the augmented graph view.
- Supervised Contrastive LossGiven that DDI event prediction is a multi-class classification task, supervised contrastive learning can learn more comprehensive drug embeddings. Herein, we further designed a supervised contrastive learning method to learn the embeddings of drug pairs. The latent features of drug pairs obtained by supervised contrastive learning have the following property: the embeddings of drug pairs belonging to same event are more similar, while the embeddings of different events are more different.The loss function of supervised contrastive learning can be computed using the following equation:where, is the embedding of drug pair , which is obtained by Equation (13), is the DDI event label of drug pair , and is the number of instances in event .
- Prediction lossThe training objective of DDI event prediction is to minimize the loss function:where is the training set, E is the events set, indicates the predicted probability that the drug pair belongs to the event e, and is the corresponding true label.
- Total Loss
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Giacomini, K.M.; Krauss, R.M.; Roden, D.M.; Eichelbaum, M.; Hayden, M.R.; Nakamura, Y. When good drugs go bad. Nature 2007, 446, 975–977. [Google Scholar] [CrossRef]
- Bansal, M.; Yang, J.; Karan, C.; Menden, M.P.; Costello, J.C.; Tang, H.; Xiao, G.; Li, Y.; Allen, J.; Zhong, R.; et al. A community computational challenge to predict the activity of pairs of compounds. Nat. Biotechnol. 2014, 32, 1213–1222. [Google Scholar] [PubMed]
- Qato, D.M.; Wilder, J.; Schumm, L.P.; Gillet, V.; Alexander, G.C. Changes in prescription and over-the-counter medication and dietary supplement use among older adults in the United States, 2005 vs. 2011. JAMA Intern. Med. 2016, 176, 473–482. [Google Scholar] [CrossRef] [PubMed]
- Qiu, Y.; Zhang, Y.; Deng, Y.; Liu, S.; Zhang, W. A comprehensive review of computational methods for drug-drug interaction detection. IEEE/ACM Trans. Comput. Biol. Bioinform. 2021, 19, 1968–1985. [Google Scholar] [CrossRef] [PubMed]
- Ryall, K.A.; Tan, A.C. Systems biology approaches for advancing the discovery of effective drug combinations. J. Cheminform. 2015, 7, 7. [Google Scholar] [CrossRef]
- Yap, T.A.; Smith, A.D.; Ferraldeschi, R.; Al-Lazikani, B.; Workman, P.; De Bono, J.S. Drug discovery in advanced prostate cancer: Translating biology into therapy. Nat. Rev. Drug Discov. 2016, 15, 699–718. [Google Scholar] [CrossRef] [PubMed]
- Lin, S.; Wang, Y.; Zhang, L.; Chu, Y.; Liu, Y.; Fang, Y.; Jiang, M.; Wang, Q.; Zhao, B.; Xiong, Y.; et al. MDF-SA-DDI: Predicting drug-drug interaction events based on multi-source drug fusion, multi-source feature fusion and transformer self-attention mechanism. Brief. Bioinform. 2022, 23, bbab421. [Google Scholar] [CrossRef] [PubMed]
- Zhang, J.; Chen, M.; Liu, J.; Peng, D.; Dai, Z.; Zou, X.; Li, Z. A knowledge-graph-based multimodal deep learning framework for identifying drug-drug interactions. Molecules 2023, 28, 1490. [Google Scholar] [CrossRef] [PubMed]
- Salamat, A.; Luo, X.; Jafari, A. HeteroGraphRec: A heterogeneous graph-based neural networks for social recommendations. Knowl.-Based Syst. 2021, 217, 106817. [Google Scholar] [CrossRef]
- Hu, B.; Wang, H.; Wang, L. Wshe: User feedback-based weighted signed heterogeneous information network embedding. Inf. Sci. 2021, 579, 167–185. [Google Scholar] [CrossRef]
- Wang, X.; Bo, D.; Shi, C.; Fan, S.; Ye, Y.; Philip, S.Y. A survey on heterogeneous graph embedding: Methods, techniques, applications and sources. IEEE Trans. Big Data 2022, 9, 415–436. [Google Scholar] [CrossRef]
- Mukande, T. Heterogeneous Graph Representation Learning for multi-target Cross-Domain Recommendation. In Proceedings of the 16th ACM Conference on Recommender Systems, Seattle, WA, USA, 18–23 September 2022; pp. 730–734. [Google Scholar]
- Tanvir, F.; Islam, M.I.K.; Akbas, E. Predicting drug-drug interactions using meta-path based similarities. In Proceedings of the 2021 IEEE Conference on Computational Intelligence in Bioinformatics and Computational Biology (CIBCB), Melbourne, Australia, 13–15 October 2021; pp. 1–8. [Google Scholar]
- Li, M.; Cai, X.; Li, L.; Xu, S.; Ji, H. Heterogeneous graph attention network for drug-target interaction prediction. In Proceedings of the 31st ACM International Conference on Information Knowledge Management, Atlanta, GA, USA, 17–21 October 2022; pp. 1166–1176. [Google Scholar]
- Liu, W.; Tang, T.; Lu, X.; Fu, X.; Yang, Y.; Peng, L. MPCLCDA: Predicting circRNA–disease associations by using automatically selected meta-path and contrastive learning. Brief. Bioinform. 2023, 24, bbad227. [Google Scholar] [CrossRef] [PubMed]
- You, Y.; Chen, T.; Sui, Y.; Chen, T.; Wang, Z.; Shen, Y. Graph contrastive learning with augmentations. In Proceedings of the Advances in Neural Information Processing Systems 33 (NeurIPS 2020), Virtual, 6–12 December 2020; pp. 5812–5823. [Google Scholar]
- Khosla, P.; Teterwak, P.; Wang, C.; Sarna, A.; Tian, Y.; Isola, P.; Maschinot, A.; Liu, C.; Krishnan, D. Supervised contrastive learning. In Proceedings of the Advances in Neural Information Processing Systems 33 (NeurIPS 2020), Virtual, 6–12 December 2020; pp. 18661–18673. [Google Scholar]
- Wang, X.; Liu, N.; Han, H.; Shi, C. Self-supervised heterogeneous graph neural network with co-contrastive learning. In Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery Data Mining, Singapore, 14–18 August 2021; pp. 1726–1736. [Google Scholar]
- Zhu, Y.; Xu, Y.; Cui, H.; Yang, C.; Liu, Q.; Wu, S. Structure-enhanced heterogeneous graph contrastive learning. In Proceedings of the 2022 SIAM International Conference on Data Mining (SDM), Alexandria, VA, USA, 28–30 April 2022; pp. 82–90. [Google Scholar]
- Chen, X.; Wang, Y.; Fang, J.; Meng, Z.; Liang, S. Heterogeneous Graph Contrastive Learning with Metapath-Based Augmentations. IEEE Trans. Emerg. Top. Comput. Intell. 2023, 8, 1003–1014. [Google Scholar] [CrossRef]
- Yu, J.; Ge, Q.; Li, X.; Zhou, A. Heterogeneous Graph Contrastive Learning with Meta-Path Contexts and Adaptively Weighted Negative Samples. IEEE Trans. Knowl. Data Eng. 2024, 1–13. [Google Scholar] [CrossRef]
- Wang, Y.; Min, Y.; Chen, X.; Wu, J. Multi-view graph contrastive representation learning for drug-drug interaction prediction. In Proceedings of the Web Conference 2021, Ljubljana, Slovenia, 19–23 April 2021; pp. 2921–2933. [Google Scholar]
- Zhang, R.; Wang, X.; Wang, P.; Meng, Z.; Cui, W.; Zhou, Y. HTCL-DDI: A hierarchical triple-view contrastive learning framework for drug-drug interaction prediction. Brief. Bioinform. 2023, 24, bbad324. [Google Scholar] [CrossRef] [PubMed]
- Zhuang, L.; Wang, H.; Hua, M.; Li, W.; Zhang, H. Predicting drug-drug adverse reactions via multi-view graph contrastive representation model. Appl. Intell. 2023, 53, 17411–17428. [Google Scholar] [CrossRef]
- Lin, S.; Chen, W.; Chen, G.; Zhou, S.; Wei, D.Q.; Xiong, Y. MDDI-SCL: Predicting multi-type drug-drug interactions via supervised contrastive learning. J. Cheminform. 2023, 14, 81. [Google Scholar] [CrossRef] [PubMed]
- Jiang, M.; Liu, G.; Zhao, B.; Su, Y.; Jin, W. Relation-aware graph structure embedding with co-contrastive learning for drug-drug interaction prediction. Neurocomputing 2024, 572, 127203. [Google Scholar] [CrossRef]
- Suresh, S.; Li, P.; Hao, C.; Neville, J. Adversarial graph augmentation to improve graph contrastive learning. In Proceedings of the Advances in Neural Information Processing Systems 34 (NeurIPS 2021), Virtual, 6–14 December 2021; pp. 15920–15933. [Google Scholar]
- Xiong, Z.; Liu, S.; Huang, F.; Wang, Z.; Liu, X.; Zhang, Z.; Zhang, W. Multi-relational contrastive learning graph neural network for drug-drug interaction event prediction. In Proceedings of the AAAI Conference on Artificial Intelligence, Washington, DC, USA, 7–14 February 2023; pp. 5339–5347. [Google Scholar]
- Glorot, X.; Bengio, Y. Understanding the difficulty of training deep feedforward neural networks. In Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics (AISTATS 2010), Chia Laguna Resort, Sardinia, Italy, 13–15 May 2010; pp. 249–256. [Google Scholar]
- Kingma, P.D.; Ba, L.J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Feng, J.; Liang, Y.; Yu, T. MM-GANN-DDI: Multimodal graph-agnostic neural networks for predicting drug-drug interaction events. Comput. Biol. Med. 2023, 166, 107492. [Google Scholar] [CrossRef]
- Han, C.D.; Wang, C.C.; Huang, L.; Chen, X. MCFF-MTDDI: Multi-channel feature fusion for multi-typed drug-drug interaction prediction. Brief. Bioinform. 2023, 24, bbad215. [Google Scholar] [CrossRef] [PubMed]
- Zhao, W.; Yuan, X.; Shen, X.; Jiang, X.; Shi, C.; He, T.; Hu, X. Improving drug-drug interactions prediction with interpretability via meta-path-based information fusion. Brief. Bioinform. 2023, 24, bbad041. [Google Scholar] [CrossRef] [PubMed]
- Deng, Y.F.; Xu, X.R.; Qiu, Y.; Xia, J.B.; Zhang, W.; Liu, S.C. A multimodal deep learning framework for predicting drug-drug interaction events. Bioinformatics 2020, 36, 4316–4322. [Google Scholar] [CrossRef] [PubMed]
- Law, V.; Knox, C.; Djoumbou, Y.; Jewison, T.; Guo, A.C.; Liu, Y.; Maciejewski, A.; Arndt, D.; Wilson, M.; Neveu, V.; et al. DrugBank 4.0: Shedding new light on drug metabolism. Nucleic Acids Res. 2014, 42, 1091–1097. [Google Scholar] [CrossRef] [PubMed]
- Zitnik, M.; Agrawal, M.; Leskovec, J. Modeling polypharmacy side effects with graph convolutional networks. Bioinformatics 2018, 34, i457–i466. [Google Scholar] [CrossRef]
- Park, K.; Kim, D.; Ha, S.; Lee, D. Predicting pharmacodynamic drug-drug interactions through signaling propagation interference on protein-protein interaction networks. PLoS ONE 2015, 10, e0140816. [Google Scholar] [CrossRef] [PubMed]
- Sun, Y.; Han, J.; Yan, X.; Yu, P.S.; Wu, T. PathSim: Meta path-based top-K similarity search in heterogeneous information networks. In Proceedings of the VLDB Endowment 2011, Istanbul, Turkey, 31 October–2 November 2011; pp. 992–1003. [Google Scholar]
- Huang, K.; Xiao, C.; Glass, L.; Sun, J. Explainable Substructure Partition Fingerprint for Protein, Drug, and More. In Proceedings of the NeurIPS Learning Meaningful Representation of Life Workshop. 2019. Available online: https://static1.squarespace.com/static/58f7aae1e6f2e1a0f9a56616/t/5e370e2d12092f15876d5753/1580666413389/paper.pdf (accessed on 1 May 2022).
- Velickovic, P.; Cucurull, G.; Casanova, A.; Romero, A.; Lio, P.; Bengio, Y. Graph attention networks. arXiv 2017, arXiv:1710.10903. [Google Scholar]
- Oord, A.V.D.; Li, Y.; Vinyals, O. Representation learning with contrastive predictive coding. arXiv 2018, arXiv:1807.03748. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Deep Fusion | Attention Mechanism | Contrastive Learning |
|---|---|---|---|
| MDDI-SCL | No | Yes | Yes |
| MM-GANN-DDI | Yes | Yes | No |
| MCFF-MTDDI | Yes | Yes | No |
| MP-DDI | Yes | Yes | No |
| RaGSECo | Yes | No | Yes |
| MPHGCL-DDI | Yes | Yes | Yes |
| Dataset | Task | Methods | Acc | AUPR | Macro-F1 | Macro-Rec | Macro-Pre |
|---|---|---|---|---|---|---|---|
| Dataset1 | Task1 | MDDI-SCL | 0.9378 | 0.9782 | 0.8755 | 0.8767 | 0.8804 |
| MM-GANN-DDI | 0.9386 | 0.9786 | 0.8980 | 0.895 | 0.9088 | ||
| MCFF-MTDDI | 0.9350 | 0.9757 | 0.8918 | 0.8820 | 0.9100 | ||
| MP-DDI | 0.9384 | 0.9621 | 0.8768 | 0.8838 | 0.9076 | ||
| RaGSECo | 0.9461 | 0.9838 | 0.9050 | 0.9043 | 0.9121 | ||
| MPHGCL-DDI | 0.9487 | 0.9897 | 0.9107 | 0.9087 | 0.9140 | ||
| Task2 | MDDI-SCL | 0.6767 | 0.6947 | 0.5304 | 0.4814 | 0.6254 | |
| MM-GANN-DDI | 0.6705 | 0.6855 | 0.5580 | 0.5156 | 0.6518 | ||
| MCFF-MTDDI | 0.6650 | 0.6800 | 0.5574 | 0.5139 | 0.6507 | ||
| MP-DDI | 0.6685 | 0.6723 | 0.5024 | 0.4934 | 0.6144 | ||
| RaGSECo | 0.6855 | 0.7115 | 0.5860 | 0.5631 | 0.6514 | ||
| MPHGCL-DDI | 0.6872 | 0.7208 | 0.5931 | 0.5682 | 0.6561 | ||
| Task3 | MDDI-SCL | 0.4589 | 0.3938 | 0.1919 | 0.1678 | 0.2585 | |
| MM-GANN-DDI | 0.4386 | 0.3786 | 0.2505 | 0.2480 | 0.2774 | ||
| MCFF-MTDDI | 0.4400 | 0.387 | 0.2437 | 0.2351 | 0.2823 | ||
| MP-DDI | 0.4398 | 0.3813 | 0.2183 | 0.2064 | 0.2431 | ||
| RaGSECo | 0.4591 | 0.4114 | 0.2600 | 0.2513 | 0.3001 | ||
| MPHGCL-DDI | 0.4634 | 0.4227 | 0.2682 | 0.2591 | 0.3035 | ||
| Dataset2 | Task1 | MDDI-SCL | 0.9516 | 0.9862 | 0.9321 | 0.9500 | 0.9162 |
| MM-GANN-DDI | 0.9521 | 0.9868 | 0.9324 | 0.9623 | 0.9174 | ||
| MCFF-MTDDI | 0.9517 | 0.9875 | 0.9348 | 0.9513 | 0.9171 | ||
| MP-DDI | 0.9487 | 0.9743 | 0.933 | 0.9511 | 0.9146 | ||
| RaGSECo | 0.9498 | 0.9890 | 0.9354 | 0.9633 | 0.9201 | ||
| MPHGCL-DDI | 0.9541 | 0.9927 | 0.9407 | 0.9704 | 0.9213 | ||
| Task2 | MDDI-SCL | 0.6595 | 0.6794 | 0.5578 | 0.5712 | 0.5605 | |
| MM-GANN-DDI | 0.6530 | 0.6781 | 0.5627 | 0.5636 | 0.5727 | ||
| MCFF-MTDDI | 0.6543 | 0.6821 | 0.5696 | 0.5801 | 0.5683 | ||
| MP-DDI | 0.6478 | 0.6685 | 0.5603 | 0.5594 | 0.5691 | ||
| RaGSECo | 0.6632 | 0.6874 | 0.5713 | 0.5937 | 0.5773 | ||
| MPHGCL-DDI | 0.6685 | 0.6995 | 0.5889 | 0.6071 | 0.5808 | ||
| Task3 | MDDI-SCL | 0.4696 | 0.4261 | 0.2838 | 0.2773 | 0.3160 | |
| MM-GANN-DDI | 0.4731 | 0.4311 | 0.2875 | 0.2794 | 0.3323 | ||
| MCFF-MTDDI | 0.4713 | 0.4374 | 0.2913 | 0.2839 | 0.3195 | ||
| MP-DDI | 0.4704 | 0.4256 | 0.2864 | 0.2732 | 0.3069 | ||
| RaGSECo | 0.4796 | 0.4403 | 0.2950 | 0.2886 | 0.3298 | ||
| MPHGCL-DDI | 0.4847 | 0.4436 | 0.3021 | 0.2965 | 0.3346 |
| Dataset1 | [1, 10] | (10, 50] | (50, 100] | (100,300] | (300, +∞) |
| 20.00% | 21.54% | 24.62% | 15.38% | 18.46% | |
| Dataset2 | [50, 100] | (100, 300] | (300, 600] | (600, 2000] | (2000, +∞) |
| 26.00% | 19.00% | 19.00% | 17.00% | 19.00% |
| Index | DDI Event | Drug1 | Drug2 |
|---|---|---|---|
| 1 | The metabolism decreases | Dronedarone | Ketoconazole |
| 2 | The metabolism decreases | Fluvoxamine | Isoniazid |
| 3 | The metabolism decreases | Ketoconazole | Erythromycin |
| 4 | The metabolism decreases | Imatinib | Isradipine |
| 5 | The metabolism decreases | Fluvastatin | Clemastine |
| 6 | The serum concentration increases | Isradipine | Cimetidine |
| 7 | The metabolism decreases | Cimetidine | Crizotinib |
| 8 | The risk or severity of adverse effects increases | Fluticasone propionate | Fluvoxamine |
| 9 | The metabolism decreases | Atomoxetine | Abiraterone |
| 10 | The serum concentration decreases | Fosphenytoin | Clozapine |
| 11 | The risk or severity of adverse effects increases | Bromocriptine | Citalopram |
| 12 | The serum concentration increases | Haloperidol | Cinacalcet |
| 13 | The serum concentration decreases | Eszopiclone | Mitotane |
| 14 | The risk or severity of adverse effects increases | Fentanyl | Dosulepin |
| 15 | The therapeutic efficacy decreases | Carbamazepine | Mianserin |
| 16 | The therapeutic efficacy decreases | Chlorpromazine | Cortisone acetate |
| 17 | The therapeutic efficacy decreases | Bosentan | Antipyrine |
| 18 | The serum concentration increases | Bendroflumethiazide | Cocaine |
| 19 | The serum concentration increases | Enzalutamide | Candesartancilexetil |
| 20 | The serum concentration increases | Conivaptan | Bisoprolol |
| 21 | The therapeutic efficacy decreases | Amoxapine | Donepezil |
| 22 | The risk or severity of adverse effects increases | Amoxapine | Alosetron |
| Data Type | Dataset1 | Dataset2 |
|---|---|---|
| Drug number | 572 | 1258 |
| Drug-Drug interactions | 37,264 | 323,539 |
| Events | 65 | 100 |
| Drug–Chemical substructure relations | 70,350 | 58,431 |
| Drug–Target protein relations | 3047 | 7386 |
| Involved PPIs | 2018 | 2346 |
| Drug–Enzyme relations | 2133 | 4479 |
| Drug–Pathway relations | 2778 | Not included |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hu, B.; Yu, Z.; Li, M. MPHGCL-DDI: Meta-Path-Based Heterogeneous Graph Contrastive Learning for Drug-Drug Interaction Prediction. Molecules 2024, 29, 2483. https://doi.org/10.3390/molecules29112483
Hu B, Yu Z, Li M. MPHGCL-DDI: Meta-Path-Based Heterogeneous Graph Contrastive Learning for Drug-Drug Interaction Prediction. Molecules. 2024; 29(11):2483. https://doi.org/10.3390/molecules29112483
Chicago/Turabian StyleHu, Baofang, Zhenmei Yu, and Mingke Li. 2024. "MPHGCL-DDI: Meta-Path-Based Heterogeneous Graph Contrastive Learning for Drug-Drug Interaction Prediction" Molecules 29, no. 11: 2483. https://doi.org/10.3390/molecules29112483
APA StyleHu, B., Yu, Z., & Li, M. (2024). MPHGCL-DDI: Meta-Path-Based Heterogeneous Graph Contrastive Learning for Drug-Drug Interaction Prediction. Molecules, 29(11), 2483. https://doi.org/10.3390/molecules29112483