
Rapid Discrimination and Prediction of Ginsengs from Three Origins Based on UHPLC-Q-TOF-MS Combined with SVM

Abstract
:1. Introduction
2. Results and Discussion
2.1. Development of Analysis Method of Ginsengs from Different Origins
2.1.1. Optimization of UHPLC-Q-TOF-MS Analysis Conditions
2.1.2. Validation of the UHPLC-Q-TOF-MS Analysis Method
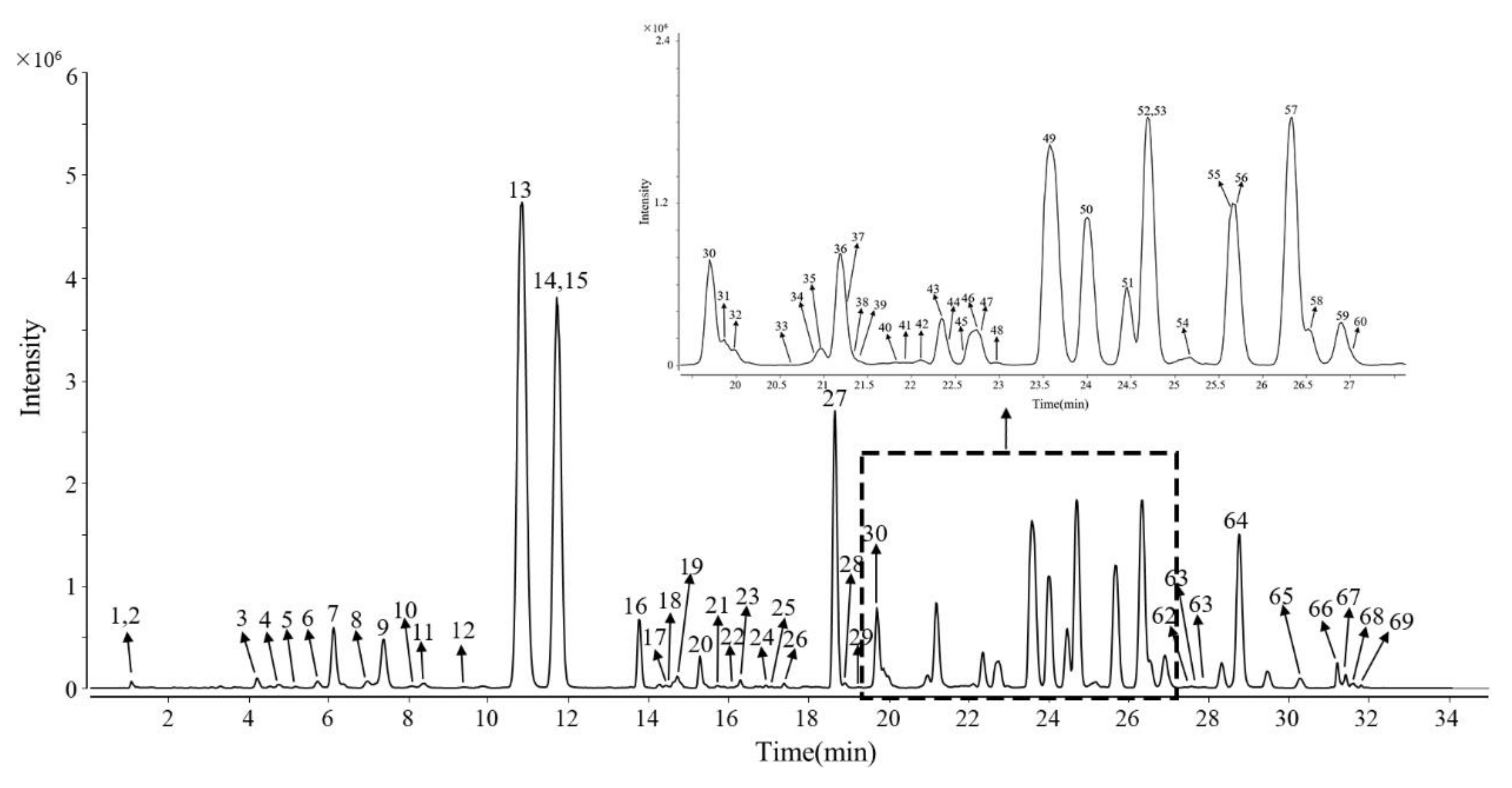
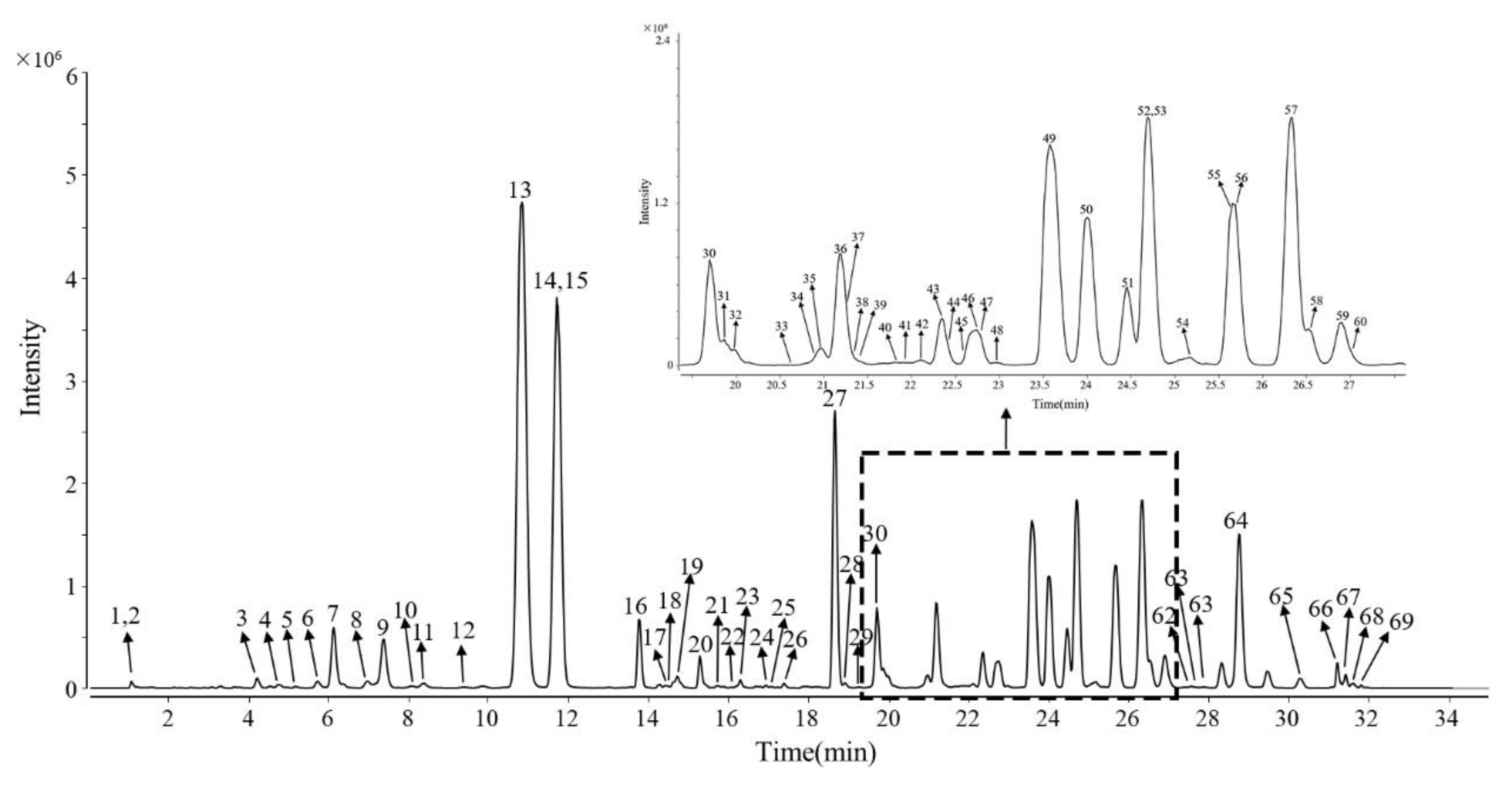
2.2. Rapid Screening and Identification of Characteristic Ginsenosides in Ginsengs from Different Regions
2.3. Classification and Prediction of Ginsengs from Different Origins by Multivariate Statistical Analysis
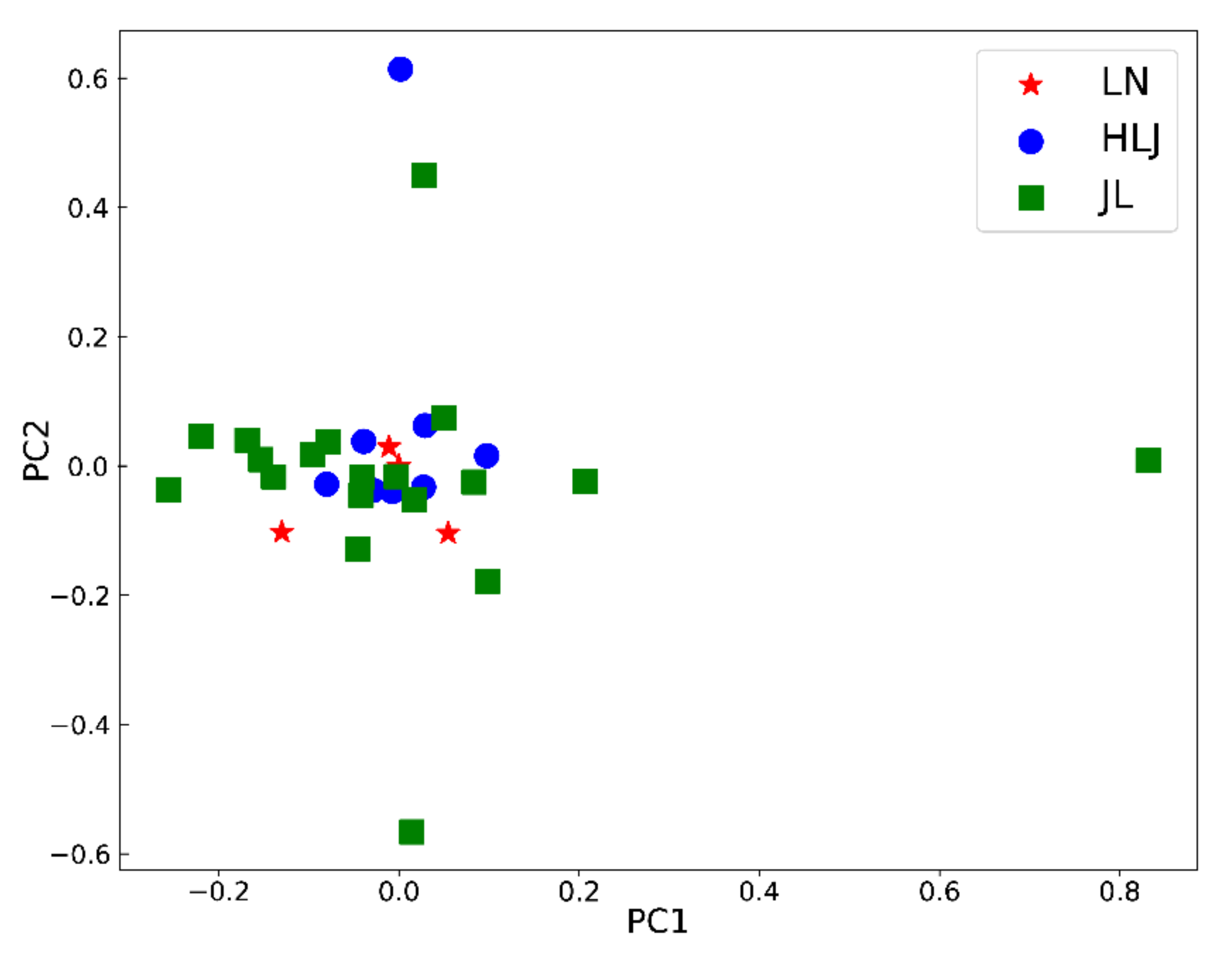
2.3.1. Traditional Multivariate Statistical Analysis
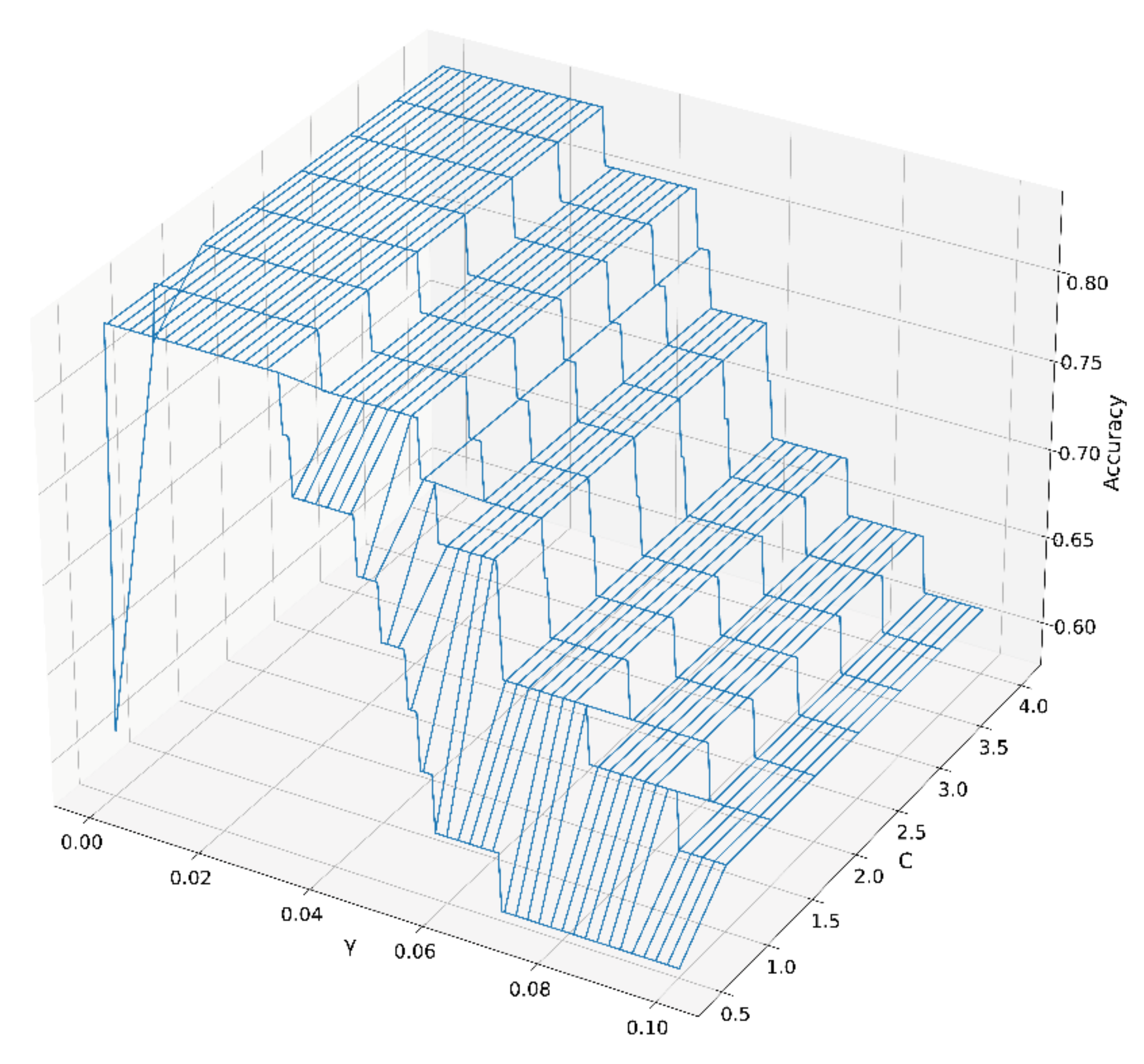
2.3.2. SVM Analysis
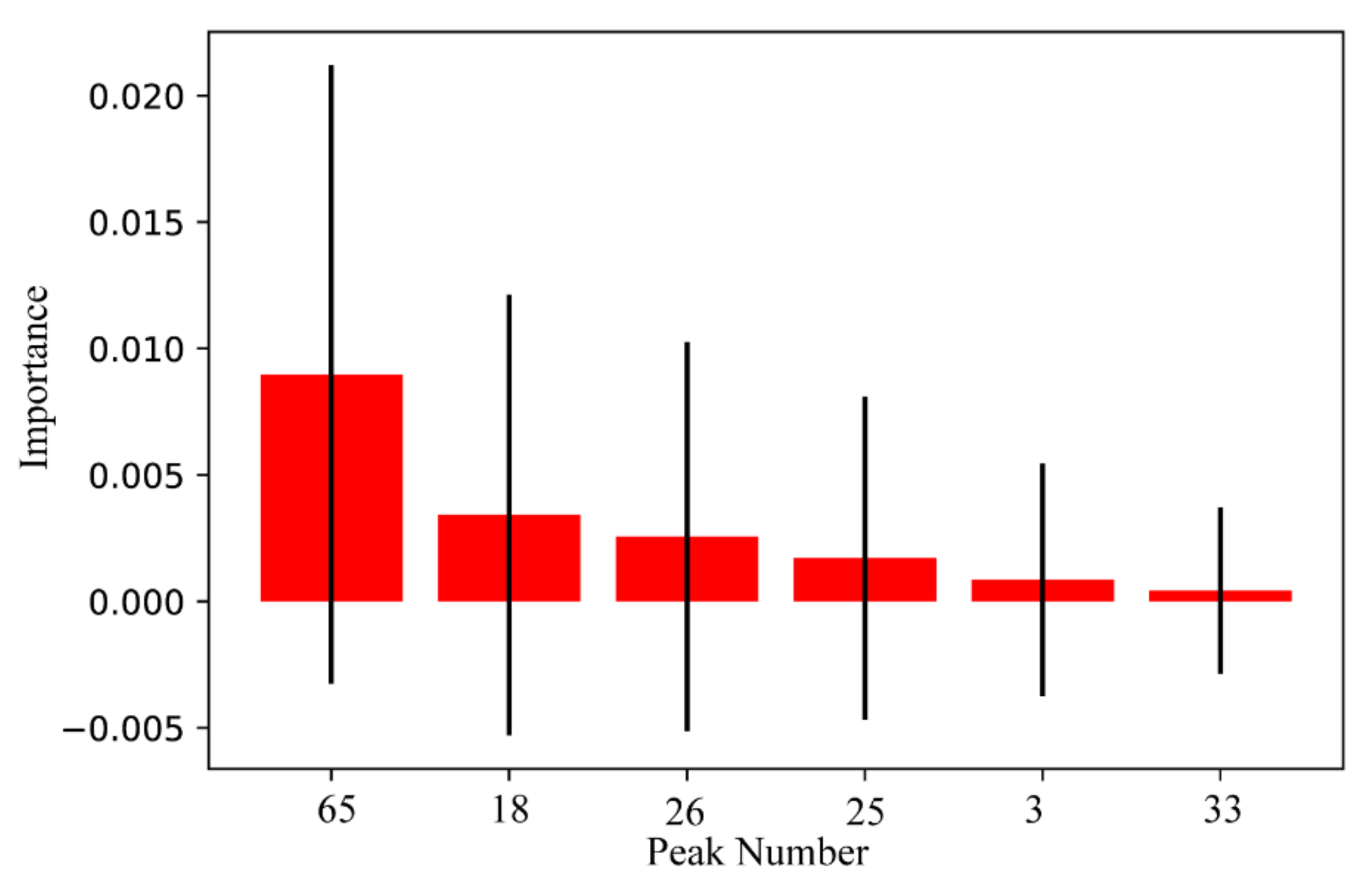
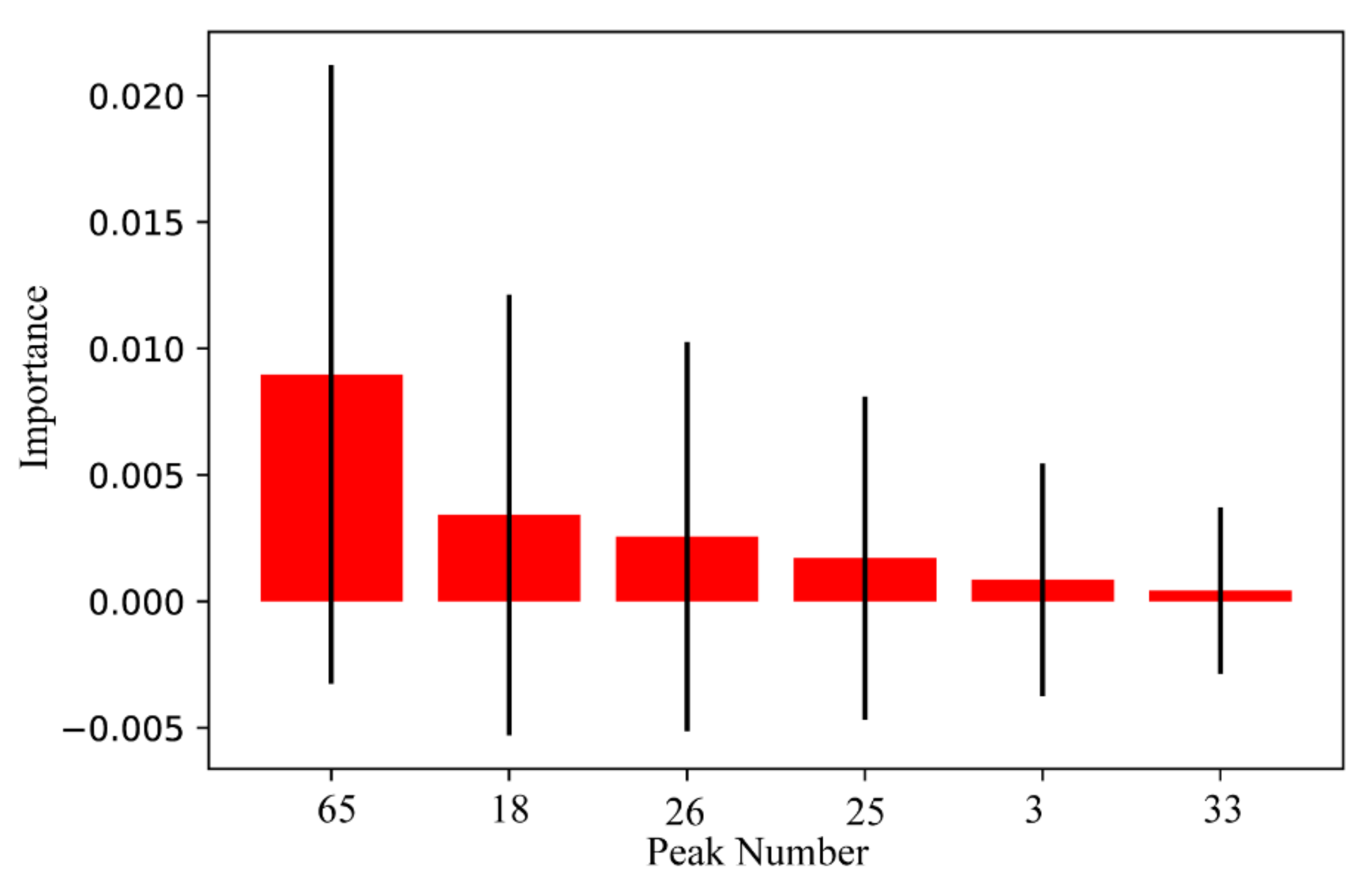
2.4. Discovery of Quality Markers of Ginsengs from Three Different Origins
2.5. Verification of This Strategy for Ginseng Identification from Different Origins Using Test Samples
3. Materials and Methods
3.1. Ginseng Samples
3.2. Chemicals and Reagents
3.3. Preparation of Samples
3.4. UHPLC-Q-TOF-MS Analysis of Ginseng Samples
3.5. Data Processing and Analysis
3.5.1. Normalization Methods
3.5.2. PCA Algorithm
3.5.3. PLS-DA Algorithm
3.5.4. SVM Algorithm
3.5.5. Permutation Importance Algorithm
4. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Sample Availability
References
- Xu, W.; Choi, H.-K.; Huang, L. State of Panax ginseng Research: A Global Analysis. Molecules 2017, 22, 1518. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tang, M.; Huang, L.; Du, Q.; Yan, C.; Gu, A.; Yang, J.; Li, Y. Ginsenoside 3β-0-Glc-DM(C3DM)Enhances the Antitumor Activity of Taxol on Lewis Lung Cancer by Targeting the lnterleukin-6/Jak2/STAT3 and Interleukin-6/AKT Signaling Pathways. World J. Tradit. Chin. Med. 2021, 6, 432–440. [Google Scholar]
- Chen, J.; Fang, W.; Li, S.; Xiao, S.; Li, H.; Situ, Y. Protective effect of ginsenoside Rd on lipopolysaccharide-induced acute lung injury through its anti-inflammatory and anti-oxidative activity. World J. Tradit. Chin. Med. 2021, 7, 383–390. [Google Scholar] [CrossRef]
- Zhou, W.; Li, J.; Zhou, Q.; Cai, F.; Chen, X.; Lu, Y.; Zhao, M.; Su, S. Ginsenoside Rb1 pretreatment attenuates myocardial ischemia by reducing calcium/calmodulin-dependent protein kinase II-medicated calcium release. World J. Tradit. Chin. Med. 2020, 6, 284–294. [Google Scholar] [CrossRef]
- Geng, J.; Dong, J.; Ni, H.; Lee, M.S.; Wu, T.; Jiang, K.; Wang, G.; Zhou, A.; Malouf, R. Ginseng for cognition. Cochrane Database Syst. Rev. 2010, 12, CD007769. [Google Scholar] [CrossRef]
- Dai, Y.; Qiao, M.; Yu, P.; Zheng, F.; Yue, H.; Liu, S. Comparing eight types of ginsenosides in ginseng of different plant ages and regions using RRLC-Q-TOF MS/MS. J. Ginseng Res. 2020, 44, 205–214. [Google Scholar] [CrossRef]
- Wang, H.; Sun, H.; Chen, W.; Ma, X.; Chen, D. Different Origin of Gingseng Splenasthenic Syndrome t-cell Subsets and IFN-γ Comparative Study of Impact. Chin. Arch. Tradit. Chin. Med. 2011, 29, 377–379. [Google Scholar] [CrossRef]
- Razgonova, M.; Veselov, V.; Zakharenko, A.; Golokhvast, K.; Nosyrev, A.; Cravotto, G.; Tsatsakis, A.; Spandidos, D. Panax ginseng components and the pathogenesis of Alzheimer’s disease (Review). Mol. Med. Rep. 2019, 19, 2975–2998. [Google Scholar] [CrossRef] [Green Version]
- Lee, D.-K.; Park, S.; Phuoc Long, N.; Min, J.; Kim, H.M.; Yang, E.; Lee, S.; Lim, J.; Kwon, S. Research Quality-Based Multivariate Modeling for Comparison of the Pharmacological Effects of Black and Red Ginseng. Nutrients 2020, 12, 2590. [Google Scholar] [CrossRef]
- Liu, Z. Chemical Insights into Ginseng as a Resource for Natural Antioxidants. Chem. Rev. 2012, 112, 3329–3355. [Google Scholar] [CrossRef]
- Chen, Y.; Zhang, Y.; Song, W.; Zhang, Y.; Dong, X.; Tan, M. Ginsenoside Rh2 Improves the Cisplatin Anti-tumor Effect in Lung Adenocarcinoma A549 Cells via Superoxide and PD-L1. Anti-Cancer Agents Med. Chem. 2020, 20, 495–503. [Google Scholar] [CrossRef] [PubMed]
- Kang, S.; Min, H. Ginseng, the ‘Immunity Boost’: The Effects of Panax ginseng on Immune System. J. Ginseng Res. 2012, 36, 354–368. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Saba, E.; Irfan, M.; Jeong, D.; Ameer, K.; Yuan, Y.L.; Park, C.K.; Hong, S.B.; Man, H.R. Mediation of antiinflammatory effects of Rg3-enriched red ginseng extract from Korean Red Ginseng via retinoid X receptor α–peroxisome-proliferating receptor γ nuclear receptors. J. Ginseng Res. 2019, 43, 442–451. [Google Scholar] [CrossRef]
- Wang, Z.; Ma, W.; Li, H.; Liu, Z.; Gu, Y.; Ma, M. Contents Differentiation of Saponins in Ginsen from Three Different Producing Areas. Inf. Tradit. Chin. Med. 2019, 36, 83–86. [Google Scholar] [CrossRef]
- Zhao, H.; Wang, Q.; Sun, X.; Li, X.; Miao, R.; Wu, D.; Liu, S.; Xiu, Y. Discrimination of Ginseng Origins and Identification of Ginsenoside Markers Based on HPLC-MS Combined with Multivariate Statistical nalysis. Chem. J. Chin. Univ. 2019, 40, 246–253. [Google Scholar]
- Wang, H.; Zhang, Y.; Yang, X.; Yang, X.; Xu, W.; Xu, F.; Cai, S.; Wang, Y.; Xu, Y.; Zhang, L. High-Performance Liquid Chromatography with Diode Array Detector and Electrospray Ionization Ion Trap Time-of-Flight Tandem Mass Spectrometry to Evaluate Ginseng Roots and Rhizomes from Different Regions. Molecules 2016, 21, 603. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, B.; Sun, X.; Guo, Y.; Wang, Y.; Liu, S. Chemical Constituents of Ginseng Radix et Rhizoma with Different Growth Years and Different Origins Based on LC-MS. Chin. J. Exp. Tradit. Med. Formulae 2020, 26, 206–212. [Google Scholar] [CrossRef]
- Xiu, Y.; Li, X.; Sun, X.; Xiao, D.; Miao, R.; Zhao, H.; Liu, S. Simultaneous determination and difference evaluation of 14 ginsenosides in Panax ginseng roots cultivated in different areas and ages by high-performance liquid chromatography coupled with triple quadrupole mass spectrometer in the multiple reaction–monitoring mode combined with multivariate statistical analysis. J. Ginseng Res. 2019, 43, 508–516. [Google Scholar] [CrossRef]
- Zhao, Q.; Zhao, N.; Ye, X.; He, M.; Yang, Y.; Gao, H.; Zhang, X. Rapid discrimination between red and white ginseng based on unique mass-spectrometric features. J. Pharm. Biomed. Anal. 2019, 164, 202–210. [Google Scholar] [CrossRef]
- Chang, X.; Zhang, Z.; Yan, H.; Su, S.; Wei, D.; Guo, S.; Shang, E.; Sun, X.; Gui, S.; Duan, J. Discovery of Quality Markers of Nucleobases, Nucleosides, Nucleotides and Amino Acids for Chrysanthemi Flos From Different Geographical Origins Using UPLC–MS/MS Combined With Multivariate Statistical Analysis. Front. Chem. 2021, 9, 689254. [Google Scholar] [CrossRef]
- Wang, H.; Zhang, Y.; Yang, X.; Zhao, D.; Wang, Y. Rapid characterization of ginsenosides in the roots and rhizomes of Panax ginseng by UPLC-DAD-QTOF-MS/MS and simultaneous determination of 19 ginsenosides by HPLC-ESI-MS. J. Ginseng Res. 2016, 40, 382–394. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, H.; Zhang, C.; Zuo, T.; Li, W.; Jia, L.; Wang, X.; Qian, Y.; Guo, D.; Yang, W. In-depth profiling, characterization, and comparison of the ginsenosides among three different parts (the root, stem leaf, and flower bud) of Panax quinquefolius L. by ultra-high performance liquid chromatography/quadrupole-Orbitrap mass spectrometry. Anal. Bioanal. Chem. 2019, 411, 7817–7829. [Google Scholar] [CrossRef] [PubMed]
- Yang, X.; Yang, X.; Liu, J. Study on Ginsenosides in the Roots and Rhizomes of Panax ginseng. Mod. Chin. Med. 2013, 15, 349–358. [Google Scholar] [CrossRef]
- Ma, L.; Zhang, Y.; Zhou, Q.; Yang, Y.; Yang, X. Simultaneous Determination of Eight Ginsenosides in Rat Plasma by Liquid Chromatography-Electrospray Ionization Tandem Mass Spectrometry: Application to Their Pharmacokinetics. Molecules 2015, 20, 21597–21608. [Google Scholar] [CrossRef] [Green Version]
- Jolliffe, I.T. Mathematical and Statistical Properties of Sample Principal Components. In Principal Component Analysis; Jolliffe, I.T., Ed.; Springer: New York, NY, USA, 1986; pp. 23–49. [Google Scholar]
- Wold, S.; Sjöström, M.; Eriksson, L. PLS-regression: A basic tool of chemometrics. Chemom. Intell. Lab. Syst. 2001, 58, 109–130. [Google Scholar] [CrossRef]
- Zheng, Z.; Hu, H.; Zeng, L.; Yang, H.; Yang, T.; Wang, D.; Zhang, C.; Deng, Y.; Zhang, M.; Guo, D.; et al. Analysis of the characteristic compounds of Citri Sarcodactylis Fructus from different geographical origins. Phytochem. Anal. 2021, 33, 72–82. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | RT (min) | Compound | Formula | Mass Ion (m/z) | Type of Ion | Error (ppm) | Fragment Ions | References |
|---|---|---|---|---|---|---|---|---|
| 1 | 1.07 | Quinquenoside L9 or its isomer | C42H74O15 | 863.4940 | [M+HCOO]- | −6.80 | / | [22] |
| 2 | 1.07 | Ginsenoside Re2 or its isomer | C48H82O19 | 1007.5422 | [M+HCOO]- | 0.05 | / | [16] |
| 3 | 4.23 | Ginsenoside Re2 or its isomer | C48H82O19 | 1007.5422 | [M+HCOO]- | 0.05 | 961.5401; 799.4824; 781.4713 | [16] |
| 4 | 4.74 | (B4-b)-glc-xyl | C41H70O14 | 831.4737 | [M+HCOO]- | −0.01 | 785.4677; 653.4273; 491.3746 | [22] |
| 5 | 5.18 | Notoginsenoside R8 or its isomer | C36H62O10 | 699.4315 | [M+HCOO]- | 0.13 | / | [22] |
| 6 | 5.73 | Ginsenoside Re4 or its isomer | C47H80O18 | 977.5353 | [M-H]- | 3.79 | 977.5353; 931.5271; 637.4358; 457.3784 | [23] |
| 7 | 6.13 | Ginsenoside Re2 or its isomer | C48H82O19 | 1007.5438 | [M+HCOO]- | 1.71 | 961.5419; 799.4876; 637.4357; 475.3806 | [16] |
| 8 | 6.97 | Notoginsenoside R1 | C47H80O18 | 931.5260 | [M-H]- | −1.28 | 931.5220; 799.4836; 638.4292; 475.3696 | [23] |
| 9 | 7.37 | Ginsenoside Re4 | C47H80O18 | 977.5330 | [M+HCOO]- | 1.43 | 931.5302; 637.4335; 475.3784 | [23] |
| 10 | 8.11 | Ginsenoside Rc or its isomer | C53H90O22 | 1077.5829 | [M-H]- | −2.06 | 945.5438; 719.3460; 433.5658 | [21] |
| 11 | 8.40 | Ginsenoside Re3 | C48H82O19 | 961.5365 | [M-H]- | −1.33 | 799.4859; 637.4300 | [23] |
| 12 | 9.37 | Ginsenoside Re4 or its isomer | C47H80O18 | 977.5308 | [M+HCOO]- | −0.81 | 931.5203; 637.4289; 475.3736 | [23] |
| 13 | 10.83 | Ginsenoside Rg1 | C42H72O14 | 845.4912 | [M+HCOO]- | 2.27 | 799.4852; 637.4337; 619.4215; 475.3802 | [23] |
| 14 | 11.70 | Ginsenoside Re | C48H82O18 | 945.5426 | [M-H]- | −0.21 | 799.4880; 783.4926; 637.4346; 475.3818 | [23] |
| 15 | 11.70 | Ginsenoside Re2 or its isomer | C48H82O19 | 961.5377 | [M-H]- | −0.11 | / | [16] |
| 16 | 12.95 | Vinaginsenoside R13 or its isomer | C48H84O20 | 979.5454 | [M-H]- | −2.94 | / | [22] |
| 17 | 14.51 | Vinaginsenoside R13 or its isomer | C48H84O21 | 979.5470 | [M-H]- | −1.38 | / | [22] |
| 18 | 14.59 | AcO-ginsenoside Re or its isomer | C50H84O19 | 987.5527 | [M-H]- | −0.74 | 945.5519; 927.5335; 783.4923; 765.5022; 637.4373 | [23] |
| 19 | 14.71 | AcO-ginsenoside Rf or its isomer | C44H74O15 | 841.4946 | [M-H]- | −1.12 | 637.4308; 619.4205; 475.3759 | [22] |
| 20 | 15.43 | Notoginsenoside G or its isomer | C48H80O19 | 1005.5209 | [M+HCOO]- | −5.57 | / | [22] |
| 21 | 15.71 | Notoginsenoside R2 | C41H70O13 | 815.4791 | [M+HCOO]- | 0.31 | / | [23] |
| 22 | 16.29 | Ginsenoside F5 | C41H70O13 | 815.4789 | [M+HCOO]- | 0.16 | / | [22] |
| 23 | 16.19 | Notoginsenoside C or its isomer | C54H92O25 | 1139.5831 | [M-H]- | −2.08 | 961.5606; 785.8238; 584.0663 | [22] |
| 24 | 17.06 | Notoginsenoside M or its isomer | C42H70O14 | 843.4734 | [M+HCOO]- | −0.40 | / | [22] |
| 25 | 16.92 | Ginsenoside Re2 or its isomer | C48H82O19 | 1007.5416 | [M+HCOO]- | −0.51 | 961.5419; 799.4876; 637.4357; 475.3806 | [16] |
| 26 | 17.39 | Ginsenoside Re2 or its isomer | C48H82O19 | 1007.5419 | [M+HCOO]- | −0.20 | 961.5314; 799.4734 | [16] |
| 27 | 18.65 | Ginsenoside Rf | C42H72O14 | 799.4858 | [M-H]- | 1.14 | 637.4327; 475.3796 | [21] |
| 28 | 18.90 | Ginsenoside Re6 or its isomer | C46H76O15 | 913.5158 | [M+HCOO]- | 0.27 | 830.6457; 765.8931; 620.4240; 475.3751 | [22] |
| 29 | 19.24 | Notoginsenoside D or its isomer | C64H108O31 | 1371.6754 | [M-H]- | −3.49 | 1273.1482; 1031.7337; 875.6615; 597.4910; 415.6329 | [22] |
| 30 | 19.62 | Notoginsenoside D or its isomer | C64H108O31 | 1371.6777 | [M-H]- | −1.84 | / | [22] |
| 31 | 19.88 | AcO-ginsenoside Rg1 | C44H74O15 | 841.4953 | [M-H]- | −0.26 | 799.4865; 679.4467; 637.4326; 619.4224; 571.3972; 475.3799 | [23] |
| 32 | 20.00 | Notoginsenoside R4 or its isomer | C59H100O27 | 1239.6365 | [M-H]- | −1.15 | 1107.5904; 1077.5822; 946.5432; 945.5391; 783.4854; 621.4298; 459.3820 | [23] |
| 33 | 20.53 | Yesanchinoside J or its isomer | C61H102O28 | 1281.6480 | [M-H]- | −0.37 | / | [22] |
| 34 | 20.98 | 20(R)-Ginsenoside Rh1 | C36H62O9 | 683.4372 | [M+HCOO]- | 1.08 | 475.3815 | [24] |
| 35 | 20.90 | Quinquenoside V | C60H102O28 | 1269.6463 | [M-H]- | −1.76 | 1107.6007 | [22] |
| 36 | 21.20 | 20(R)-Ginsenoside Rg2 | C42H72O13 | 829.4967 | [M+HCOO]- | 2.74 | 783.4923; 637.4372; 619.4248; 475.3808 | [24] |
| 37 | 21.33 | Ginsenoside Rg5 or its isomer | C42H70O12 | 811.4842 | [M+HCOO]- | 0.54 | / | [22] |
| 38 | 21.36 | Notoginsenoside D or its isomer | C64H108O31 | 1371.6762 | [M-H]- | −2.95 | 1145.2550; 838.4987; 652.4940; 438.2765 | [22] |
| 39 | 21.41 | Quinquenoside L1 or its isomer | C48H80O18 | 989.5313 | [M+HCOO]- | −0.29 | / | [22] |
| 40 | 21.80 | Ginsenoside Ra1/Ra2 or its isomer | C58H98O26 | 1209.6252 | [M-H]- | −1.83 | 1077.5829; 945.5368; 783.4866; 621.7380 | [23] |
| 41 | 21.96 | Notoginsenoside R4 or its isomer | C59H100O27 | 1239.6356 | [M-H]- | −1.85 | 1077.5843; 916.9001; 621.4288 | [23] |
| 42 | 22.08 | Quinquenoside I or its isomer | C52H86O19 | 1059.5727 | [M+HCOO]- | −0.63 | / | [22] |
| 43 | 22.11 | Ginsenoside Ro or its isomer | C48H76O19 | 955.4896 | [M-H]- | −1.29 | / | [23] |
| 44 | 22.35 | Ginsenoside Ra1/Ra2 or its isomer | C58H98O26 | 1209.6274 | [M-H]- | 0.03 | 1077.5874; 945.5440; 783.4925; 621.4390; | [23] |
| 45 | 22.55 | Ginsenoside F1 or its isomer | C36H62O9 | 683.4380 | [M+HCOO]- | 2.25 | / | [22] |
| 46 | 22.70 | Ginsenoside Rb1 | C54H92O23 | 1153.6013 | [M+HCOO]- | 1.00 | 1107.5980; 945.5438; 783.4904; 621.4370; 323.0986 | [21] |
| 47 | 22.78 | Notoginsenoside R4 or its isomer | C59H100O27 | 1239.6366 | [M-H]- | −1.09 | 1209.6298; 1077.5874; 945.5440; 783.4928; 621.4390 | [23] |
| 48 | 22.98 | Ginsenoside Ra1/Ra2 or its isomer | C58H98O26 | 1209.6188 | [M-H]- | −7.10 | 1077.5826; 945.5420 | [23] |
| 49 | 23.58 | Ginsenoside Ro | C48H76O19 | 955.4924 | [M-H]- | 1.63 | 793.4392; 569.3860; 455.3534; | [23] |
| 50 | 24.01 | Ginsenoside Rc | C53H90O22 | 1123.5915 | [M+HCOO]- | 1.77 | 1077.5879; 945.5412; 915.5334 | [21] |
| 51 | 24.46 | Ginsenoside Ra1/Ra2 or its isomer | C58H98O26 | 1209.6282 | [M-H]- | 0.68 | 1077.5846; 945.5437; 915.5327; 783.4863 | [23] |
| 52 | 25.04 | Ginsenoside F1 or its isomer | C36H62O9 | 683.4371 | [M+HCOO]- | 0.94 | / | [22] |
| 53 | 25.04 | AcO-ginsenoside Ro | C50H78O20 | 997.5001 | [M-H]- | −1.30 | / | [22] |
| 54 | 25.19 | Ginsenoside Ra1/Ra2 or its isomer | C58H98O26 | 1209.6254 | [M-H]- | −1.69 | 1077.5842; 783.4910; 621.4377 | [23] |
| 55 | 25.62 | Ginsenoside Ra1/Ra2 or its isomer | C58H98O26 | 1209.6226 | [M-H]- | −3.94 | 1077.5856; 621.3146 | [23] |
| 56 | 25.67 | Ginsenoside Rb2 | C53H90O22 | 1123.5918 | [M+HCOO]- | 2.04 | 1077.5824; 945.5402; 915.5279; 783.4881; 765.4772; 621.4359; | [21] |
| 57 | 26.24 | Ginsenoside Rb3 | C53H90O22 | 1123.5902 | [M+HCOO]- | 0.66 | 1077.5892; 945.5474; 915.5364; 783.4912; 621.4374; 459.3830 | [23] |
| 58 | 26.77 | Quinquenoside L1 or its isomer | C48H80O18 | 943.5262 | [M-H]- | −1.04 | / | [22] |
| 59 | 26.90 | m-Ginsenoside Rc/Rb2 or m-Ginsenoside Rb3 | C56H92O25 | 1163.5858 | [M-H]- | 0.23 | 1119.6012; 1077.5910; 1059.5793; 915.5332; 765.4795 | [23] |
| 60 | 27.00 | Ginsenoside Ra1/Ra2 or its isomer | C58H98O26 | 1209.6257 | [M-H]- | −1.38 | / | [23] |
| 61 | 27.37 | Notoginsenoside O or its isomer | C52H88O21 | 1093.5787 | [M+HCOO]- | −0.15 | / | [22] |
| 62 | 27.57 | Yesanchinoside J or its isomer | C61H102O28 | 1281.6451 | [M-H]- | −2.62 | / | [22] |
| 63 | 27.87 | Vinaginsenoside R3 or its isomer | C48H82O17 | 975.5511 | [M+HCOO]- | −1.22 | 739.7635; 576.8463; 481.3275; 324.4059 | [22] |
| 64 | 28.76 | Ginsenoside Rd | C48H82O18 | 991.5497 | [M+HCOO]- | 2.55 | 945.5477; 783.4920; 765.480; 621.4385; 459.3882 | [21] |
| 65 | 30.28 | AcO-ginsenoside Rd or its isomer | C50H84O19 | 987.5526 | [M-H]- | −0.84 | 987.5518; 945.5420; 927.5342; 783.4925; 765.4773; 621.4397; 459.3808 | [23] |
| 66 | 31.41 | Quinquenoside L14 or its isomer | C47H80O17 | 961.5370 | [M+HCOO]- | 0.27 | 915.5347; 783.4907; 709.1200; 621.4368; 434.0248 | [22] |
| 67 | 31.43 | Ginsenoside Re2 or its isomer | C48H82O19 | 961.5403 | [M-H]- | 2.60 | / | [16] |
| 68 | 31.55 | Quinquenoside I or its isomer | C52H86O19 | 1059.5731 | [M+HCOO]- | −0.27 | 915.5271; 783.4907; 621.4369; 459.3846 | [22] |
| 69 | 31.68 | Quinquenoside I or its isomer | C52H86O19 | 1059.5852 | [M+HCOO]- | 11.10 | / | [22] |
| Raw Data (Accuracy = 83%) | Normalized Data (Accuracy = 100%) | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Sample | Actual | Recognized | Sample | Actual | Recognized | Sample | Actual | Recognized | Sample | Actual | Recognized |
| S1 | LN | JL | S17 | JL | JL | S1 | LN | LN | S17 | JL | JL |
| S2 | LN | LN | S18 | JL | JL | S2 | LN | LN | S18 | JL | JL |
| S3 | LN | JL | S19 | JL | JL | S3 | LN | LN | S19 | JL | JL |
| S4 | LN | JL | S20 | JL | JL | S4 | LN | LN | S20 | JL | JL |
| S5 | HLJ | HLJ | S21 | JL | JL | S5 | HLJ | HLJ | S21 | JL | JL |
| S6 | HLJ | HLJ | S22 | JL | JL | S6 | HLJ | HLJ | S22 | JL | JL |
| S7 | HLJ | HLJ | S23 | JL | JL | S7 | HLJ | HLJ | S23 | JL | JL |
| S8 | HLJ | JL | S24 | JL | JL | S8 | HLJ | HLJ | S24 | JL | JL |
| S9 | JL | JL | S25 | JL | JL | S9 | JL | JL | S25 | JL | JL |
| S10 | JL | JL | S26 | JL | JL | S10 | JL | JL | S26 | JL | JL |
| S11 | JL | JL | S27 | JL | JL | S11 | JL | JL | S27 | JL | JL |
| S12 | JL | JL | S28 | JL | JL | S12 | JL | JL | S28 | JL | JL |
| S13 | HLJ | HLJ | S29 | JL | JL | S13 | HLJ | HLJ | S29 | JL | JL |
| S14 | HLJ | HLJ | S30 | JL | JL | S14 | HLJ | HLJ | S30 | JL | JL |
| S15 | HLJ | JL | S31 | JL | JL | S15 | HLJ | HLJ | S31 | JL | JL |
| S16 | HLJ | HLJ | S16 | HLJ | HLJ | ||||||
| Sample | Actual | Recognized |
|---|---|---|
| S32 | LN | LN |
| S33 | HLJ | HLJ |
| S34 | JL | JL |
| S35 | JL | JL |
| S36 | JL | JL |
| S37 | JL | JL |
| S38 | JL | JL |
| S39 | JL | JL |
| No. | Origin | Age | Batch Code | No. | Origin | Age | Batch Code |
|---|---|---|---|---|---|---|---|
| S1 | Dandong City, Liaoning Province | 4 | 20200901 | S21 | Changbai County, Jilin Province | 5 | 20190901 |
| S2 | Dandong City, Liaoning Province | 4 | 20200902 | S22 | Changbai County, Jilin Province | 5 | 20190902 |
| S3 | Dandong City, Liaoning Province | 4 | 20200903 | S23 | Changbai County, Jilin Province | 5 | 20190903 |
| S4 | Dandong City, Liaoning Province | 4 | 20200904 | S24 | Changbai County, Jilin Province | 5 | 20190904 |
| S5 | Mudanjiang City, Heilongjiang Province | 5 | RS180321-2 | S25 | Ji’an City, Jilin Province | 5 | 20180421-1 |
| S6 | Mudanjiang City, Heilongjiang Province | 5 | RS180322-2 | S26 | Ji’an City, Jilin Province | 5 | 20180421-2 |
| S7 | Mudanjiang City, Heilongjiang Province | 5 | RS180323-2 | S27 | Ji’an City, Jilin Province | 5 | 20180421-3 |
| S8 | Mudanjiang City, Heilongjiang Province | 5 | RS180324-2 | S28 | Ji’an City, Jilin Province | 5 | 20180421-4 |
| S9 | Tonghua City, Jilin Province | 5 | RS180311 | S29 | Fusong County, Jilin Province | 5 | 20180911-1 |
| S10 | Tonghua City, Jilin Province | 5 | RS180312 | S30 | Fusong County, Jilin Province | 5 | 20180911-3 |
| S11 | Tonghua City, Jilin Province | 5 | RS180313 | S31 | Fusong County, Jilin Province | 5 | 20180911-4 |
| S12 | Tonghua City, Jilin Province | 5 | RS180314 | T1 | Liaoning Province | / | / |
| S13 | Heilongjiang Province | 5 | RS180321 | T2 | Heilongjiang Province | / | / |
| S145 | Heilongjiang Province | 5 | RS180322 | T3 | Jilin Province | / | / |
| S15 | Heilongjiang Province | 5 | RS180323 | T4 | Heilongjiang Province | / | / |
| S16 | Heilongjiang Province | 5 | RS180324 | T5 | Jilin Province | / | / |
| S17 | Jingyu County, Jilin Province | 5 | 20190901 | T6 | Jilin Province | / | / |
| S18 | Jingyu County, Jilin Province | 5 | 20190902 | T7 | Jilin Province | / | / |
| S19 | Jingyu County, Jilin Province | 5 | 20190903 | T8 | Jilin Province | / | / |
| S20 | Jingyu County, Jilin Province | 5 | 20190904 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, C.; Liu, Z.; Lu, S.; Xiao, L.; Xue, Q.; Jin, H.; Gan, J.; Li, X.; Liu, Y.; Liang, X. Rapid Discrimination and Prediction of Ginsengs from Three Origins Based on UHPLC-Q-TOF-MS Combined with SVM. Molecules 2022, 27, 4225. https://doi.org/10.3390/molecules27134225
Zhang C, Liu Z, Lu S, Xiao L, Xue Q, Jin H, Gan J, Li X, Liu Y, Liang X. Rapid Discrimination and Prediction of Ginsengs from Three Origins Based on UHPLC-Q-TOF-MS Combined with SVM. Molecules. 2022; 27(13):4225. https://doi.org/10.3390/molecules27134225
Chicago/Turabian StyleZhang, Chi, Zhe Liu, Shaoming Lu, Liujun Xiao, Qianqian Xue, Hongli Jin, Jiapan Gan, Xiaonong Li, Yanfang Liu, and Xinmiao Liang. 2022. "Rapid Discrimination and Prediction of Ginsengs from Three Origins Based on UHPLC-Q-TOF-MS Combined with SVM" Molecules 27, no. 13: 4225. https://doi.org/10.3390/molecules27134225
APA StyleZhang, C., Liu, Z., Lu, S., Xiao, L., Xue, Q., Jin, H., Gan, J., Li, X., Liu, Y., & Liang, X. (2022). Rapid Discrimination and Prediction of Ginsengs from Three Origins Based on UHPLC-Q-TOF-MS Combined with SVM. Molecules, 27(13), 4225. https://doi.org/10.3390/molecules27134225