1. Introduction
In the new century, the emphasis has shifted from mechanistic (explanatory) modeling to the widespread use of machine learning algorithms in QSAR and related fields as well. In statistics, the long-term commitment to data models only (i.e., with the assumption of a stochastic model) “led to irrelevant theory, questionable conclusions, and has kept statisticians from working on a large range of interesting current problems” [
1]. In the meantime, algorithmic modeling has developed rapidly and found its way to application domains formerly employing classic statistical tools, such as QSAR or drug design in general. Especially for larger dataset sizes, machine learning tools present much more suitable alternatives for classification than conventional statistics.
While drug design applications routinely employ two-class classification tasks (i.e., machine learning models for predicting active/inactive compounds), multiclass classification scenarios are somewhat less common and, accordingly, less studied. This is also reflected in the number of available performance parameters for two- vs. multiclass classification, although some of the performance metrics naturally extend to the multiclass case [
2]. Nonetheless, specific multiclass alternatives were also developed, e.g., by Kautz et al.: their multiclass performance score (MPS) was proven to be superior to eight performance metrics, including balanced accuracy, Cohen’s kappa, ACC (accuracy, correct classification rate), MCC (Matthews correlation coefficient), and F1 (see the abbreviations in
Section 4.3 of this paper) on six real datasets, with the use of the
k-nearest neighbor algorithm as the classifier [
3].
An important factor that affects the performance of classification models is the balance (or imbalance) of the classes, i.e., the diversity in the number of samples belonging to each class. This is especially relevant in multiclass scenarios, where there can even be more than one minority class. The past decade has seen the development of several approaches to deal with class imbalance. Synthetic minority over sampling (SMOTE) [
4] and its related methods are widely used to avoid biased results toward the majority class [
5,
6]. While oversampling can lead to overfitting in “classical” machine learning models, convolutional neural networks (CNNs) are less prone to overfitting [
7]. Robust QSAR models can be developed for imbalanced high-throughput screening datasets using multiple undersampling as well [
8]. Undersampling can also be achieved by clustering the majority class into the same number of clusters as the number of samples in the minority class: this approach proved to be efficient on small and large datasets as well [
9]. The aggregated conformal prediction procedure has a promising potential for severely imbalanced datasets “to retrieve a large majority of active minority class compounds”, i.e., in a binary class situation [
10]. An asymmetric entropy measure was recommended for classifying imbalanced data by Guermazi et al. They adapted the decision-tree algorithm to imbalanced situations, with a split criterion that discriminates the minority-class items on a binary-classification problem. They propose the ensemble approach for imbalanced learning [
11,
12].
Ensemble learning algorithms seem to be the solution for the classification of high-dimensional imbalanced data: König et al. have used mixtures of experts as a natural choice for the prediction of environmental toxicity [
13]. According to Oza and Tumer, “classifier ensembles provide an extra degree of freedom in the classical bias/variance tradeoff, allowing solutions that would be difficult (if not impossible) to reach with only a single classifier” [
14]. Fernandes et al. investigated twenty imbalanced multiclass datasets; they found that Ensemble of Classifiers based on MultiObjective Genetic Sampling for Imbalanced Classification (E-MOSAIC) provided the best predictive performance according to multiclass AUC (area under the receiver operating characteristic curve) and geometric mean [
15]. Žuvela et al. also favor ensemble learning approaches for competing objectives and imbalanced situations [
16]. Ensemble learning approaches constitute a current field of development, e.g., a new algorithm (HIBoost) applies a discount factor, which restricts the updating of weights, and hence the risk of overfitting is reduced [
17]. Sets of simultaneous classifiers are also suitable to generate separation frontiers of classes naturally present in bioinformatics. The crucial step is to select metrics that measure performance of algorithms realistically [
18].
Multiclass classification is employed for diverse applications in drug design and other fields; a few examples are listed here. Mandal and Jana have evaluated two machine learning algorithms, naïve Bayes (NB) classifier and
k-nearest neighbors (
kNN), to classify multiclass drug molecules. The
kNN method shows higher accuracy and higher precision compared to NB. Furthermore, recall and F1 score of
kNN are higher than that of NB [
19]. Sokolova and Lapalme examined twenty-four performance measures for multiclass text classification from the point of view of invariance, identifying different sets of performance measures for the classification of human communication vs. documents [
20]. (A measure is invariant if its value does not change when a confusion matrix changes; it can be beneficial or adverse, depending on the objective.) Idakwo et al. predicted androgen receptor activity (agonist, antagonist, inactive, and inconclusive) for 10,000 compounds, highlighting the use of deep neural networks (DNN), which significantly outperformed random forests (RF) according to four metrics (positive predictive value –PPV, true positive rate–TPR, F1, and area of PPV vs. TPR curve–AUprC) [
21]. Multiple approaches for predictive QSAR models for classifying androgen receptor ligands were compared by Piir et al. using random forests [
22].
Several authors have contributed with comparative studies for the better understanding of the various factors, choices, and alternatives in classification modeling. Chen et al. studied the effects of the decision threshold on three performance parameters (sensitivity, specificity, and concordance coefficient) for four classical classifiers: linear discriminant analysis (LDA), logistic regression, classification tree, and a weighted variant of
k-nearest neighbor (
kNN). A threshold of 0.5 can be used for balanced datasets; the change of decision threshold simply makes a tradeoff between the number of true positive and the number of true negative predictions, whereas the concordance coefficient does not vary much [
23]. An ensemble classification approach is suggested for different class sizes in the case of binary classifier systems [
24]. Two alternative thresholding strategies that maximize the geometric mean (GM) are suggested by Johnson and Khoshgoftaar [
25]. Škuta et al. have studied QSAR-derived affinity fingerprints and established various AUC thresholds for different types of fingerprints [
26]. Huang et al. have compared the performance of extreme learning machine (ELM) with that of least square support vector machine (LS-SVM) and proximal support vector machine (PSVM). Both LS-SVM and PSVM achieved suboptimal solutions, whereas ELM produced similar results for binary classification, but much better for the multiclass situation [
27].
In spite of the widespread use of multiclass classification and the literature resources listed, a comparative study on the effects of dataset size and train/test split ratios is still lacking. Here, we address these questions on three case studies of absorption/distribution/metabolism/excretion (ADME) and toxicity-related data. Our approach involved a detailed, systematic analysis of variance (ANOVA) and multicriteria analyses to show the effect of the mentioned factors on the performance of multiclass classification. Additionally, we compared the applied 25 performance parameters in terms of their variances across different dataset sizes and split ratios. This work is an organic continuation of a previous study, where we compared machine learning algorithms and performance parameters for both two-class and multiclass problems [
2].
2. Results and Discussion
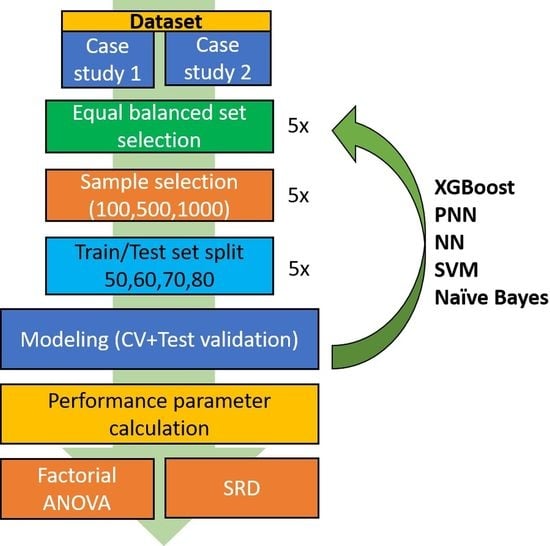
We selected three case studies for studying the effects of dataset size and training/test split ratios on various machine learning classification models. To that end, modeling was repeated many times, with different versions of the starting datasets (leaving out different molecules from the majority group(s) to produce a balanced dataset), different numbers of samples (NS) and train/test split ratios (SR), and with five iterations for each combination of these parameters. After the iterative modeling process, 25 performance parameters were calculated: these constituted the columns of the input matrix for the statistical analyses (with the rows corresponding to the different parameter combinations). The performance parameters were calculated for the cross-validation and test validation as well. An example of the data structure is shown in
Table 1. Principal component analysis (PCA) score plots were produced out for the visual description of the three datasets (see
Figure S1). The original data matrices were compared with the balanced versions.
Factorial ANOVA was performed on the data matrix, where four factors were used: (i) the split ratios for the train/test splits (SR), (ii) the number of samples (NS) or dataset size, (iii) the applied machine learning algorithms (ML), and (iv) the performance parameters (PP). The factor values are summarized in
Table 2.
2.1. Case Study 1
The first case study is a dataset of cytochrome P450 (CYP) inhibitors from the Pubchem Bioassay database (AID 1851), containing 2068 descriptors of 2710 molecules with reported inhibitory activities against either the CYP 2C9, or 3A4 isoenzyme, or both (thus, corresponding to a three-class classification). This case study therefore embodies a classification problem of selective-, medium-, and non-selective molecules, or toxic-, medium-, or nontoxic compounds, which is relevant in diverse subfields of drug design or the QSAR field. Factorial ANOVA was carried out on the input matrix of scaled performance parameters. Univariate tests showed that the ML, NS, and PP factors were significant in the analysis; however, the split ratios for the train/test splits (SR) did not have a large effect on the performance of the models. In
Figure 1, the performance parameters combined with the dataset sizes (NS) are plotted based on their average scaled values.
Based on
Figure 1, some performance parameters—such as AUC, AUAC (area under the accumulation curve), AP (average precision), TPR, TNR (true negative rate), PPV, or NPV (negative predictive value)—are not sensitive to changes in the dataset size. The most sensitive ones were the receiver operating characteristic (ROC) enrichment factors and the LRp (positive likelihood ratio) and DOR (diagnostic odds ratio) parameters, where higher performance values were detected with increasing dataset sizes.
A combination of the NS and SR factors are plotted in
Figure 2: here, the results show that the split ratios had a more significant effect on the modeling at bigger dataset sizes, and the overall performance of the models increased with the size of the dataset. The effect of the split ratio was not significant with 100 molecules in the data matrix, and generally, increasing the number of molecules in the training set from 50% to 80% conveyed only a small increase of the classification performance (
Figure 2b). Since the comparison was dedicated to multiclass classification, it is not surprising that the differences between the split ratios were not significant at small sample sizes (where the model performances were far from satisfactory anyway), but the 70% and 80% split ratios clearly performed better for larger datasets. In these cases, the test sample was much smaller, but the performance of the models in test validations was actually not far from that in cross-validation. Tukey’s post hoc test was applied to establish the significance in the performances of different split ratios: the difference was significant only between 50% and 60%. We wanted to examine this effect in more detail; thus, we used sum of ranking differences (SRD) for the comparison of the split ratios (see later).
In
Figure 3, we present a bubble plot to visualize the differences between the dataset sizes and the applied machine learning algorithms. Both the colors and the radii of the circles correspond to the average of the 25 normalized performance parameter values.
Based on
Figure 3, it is clear that the naïve Bayes (NB) algorithm had a lower performance compared to the other algorithms, even for bigger datasets. The most size-dependent methods were PNN (probabilistic neural network) and XGBoost, but these two algorithms could perform much better above 100 samples. XGBoost could achieve the best performance at the “total” level of the dataset size (2710 samples). The support vector machine (SVM) method, while performing slightly worse, was less size-dependent.
2.2. Case Study 2
The same workflow was carried out for Case Study 2, which contained 2070 descriptors of 1542 molecules with measured acute oral toxicities (from the TOXNET database [
28], downloadable here:
https://www.epa.gov/chemical-research/toxicity-estimation-software-tool-test, last accessed on 18 February 2021) that were classified into six categories (from highly toxic to nontoxic [
29]), thereby corresponding to a six-class classification into gradual categories. The 25 performance parameters were normalized and used for the ANOVA evaluation of both the cross-validation (CV) and test validation results. The univariate test showed that all of the four factors (PP, SR, NS, and ML) had a significant effect on the performance of the models.
Figure 4 shows the average normalized values of the different performance parameters in combination with the NS factor (dataset size).
It can be noticed that the pattern of the results is quite similar to Case Study 1, which is not accidental: the dataset size had less effect on AUC, AP, TNR, and NPV. On the other hand, enrichment factors, bookmaker informedness (BM), markedness (MK), MCC, and Cohen’s kappa values are highly dependent on the size of the dataset (with higher performance values at larger sample sizes).
A combination of the NS and SR factors is shown in
Figure 5, similar to Case Study 1. Clearly, the performances improved with increasing dataset sizes. Moreover, the split ratios had bigger differences compared to Case Study 1, especially at bigger dataset sizes. This is further verified by
Figure 5b and by Tukey’s post hoc test, which found significant differences between the performances at each of the four split ratios.
The effects of the dataset sizes upon the different machine learning algorithms were visualized in a bubble plot:
Figure 6 shows that once again, the naïve Bayes (NB) method provided the worst performances, while the NN (multi-layer feed-forward of resilient backpropagation network), PNN, and libSVM (library for support vector machines) algorithms are very close to each other at every dataset size. Only XGBoost can be highlighted, as it performed better than the other algorithms in the case of the total number of samples (1542). Noticeably, each method, except for NB, performed better at bigger dataset sizes.
2.3. Case Study 3
In this case study, 1834 descriptors were calculated for 1734 different molecules with experimentally measured fraction unbound in plasma values (
fu,p), based on the work of Watanabe et al. [
30]. The dataset was categorized by the
fu,p values into three classes: low, medium, and high. The low range was assigned to molecules with
fu,p values below 0.05, the medium between 0.05 and 0.2, and the high above 0.2. The modeling workflow was the same as in the case of the two other case studies, and the 25 performance parameters were used for the ANOVA analysis after the normalization process for both CV and test validation.
All of the four factors—performance parameter, split ratio (SR), number of samples (NS), and machine learning algorithm (ML)—had significant effects on the modeling, based on the univariate test in the ANOVA evaluation. The average normalized performance parameter values turned out to be similar to the other cases.
Figure 7 shows the result of the ANOVA analysis, with the combination of the performance parameters and the number of samples as factors.
In
Figure 7, it is clearly shown that TNR and NPV were less sensitive to the dataset size, while the enrichment factors or DOR, MCC, and Cohen’s kappa depended more strongly on the dataset size.
The combination of the NS and SR factors was also evaluated and is shown in
Figure 8. It is clear that the performance of the models increased with the dataset size. We can also observe a slight performance increase with increasing split ratios in
Figure 8a, even for the smallest sample size (100). This increase can be seen in
Figure 8b as well, with bigger differences between the different split ratios (as compared to Case Study 1); however, Tukey’s post hoc test still could not detect a significant difference between the 60 and 70 split ratios.
Figure 9 shows a bubble plot as the visualization of the ML and NS factors in combination. The results are very similar to the other two case studies: naïve Bayes (NB) models performed the worse in every case, NN and libSVM were moderately good, especially in the case of the total sample set (when all the 1734 molecules were used), and XGBoost had the best performance. In the smallest dataset size (100), the differences were much smaller between the methods. The findings are in good agreement with the previous case studies.
Finally, SRD analysis was carried out to compare the different split ratios. Here, the three case studies were merged, and the performance parameters were normalized together for the three case studies. In the input matrix, the performance metrics (25) were in rows and the split ratios (four) in the columns. Row-maximum was used as the reference for the analysis (corresponding to an ideal model that maximizes each performance parameter), with five-fold cross-validation. All of the four split ratios provided better results than random ranking. The cross-validated SRD results were evaluated with a one-way ANOVA, where the only factor was the split ratio (SR). The ANOVA results are presented in
Figure 10: the univariate test identified significant differences between each of the split ratios; thus, the SRD results provided a more sensitive analysis of the mentioned factor. The split ratios were farther from each other in terms of the SRD values, but still the 80% split ratio achieved the best result (smallest SRD value) by far: in fact, it was identical to the reference values, meaning that the performance was better than the other settings according to each performance parameter.
As a summary of our results, we could show that the performance of the multiclass classification models can greatly depend on all the examined parameters. As for performance parameters, there was a smaller group (such as AUC, AP, TNR and NPV), which was relatively independent from the dataset sizes. The machine learning algorithms also differed from each other in the sense of performance: in comparison with current alternatives, the naïve Bayes algorithm was not a good option for multiclass modeling. On the other hand, XGBoost was a viable one, especially for large sample sizes. The ANOVA results showed that the split ratios had a stronger effect on performance at larger dataset sizes. Moreover, the SRD analysis was sensitive enough to find smaller differences in the dataset, and we could select the most prominent factor combinations to achieve better predictive models. Based on our findings, we can suggest the use of the 80%/20% training/test split ratio, especially for larger datasets, to provide enough training samples even for multiclass classification.
3. Discussion
Several machine learning algorithms were evaluated by Valsecchi et al. [
31], comparing multitask deep (FFNL3) and shallow (FFNL1) neural networks with single-task benchmark models such as
n-nearest neighbor (N3),
k-nearest neighbor (
kNN), naïve Bayes (NB), and random forest (RF) techniques, evaluated with three performance parameters: sensitivity, specificity, and non-error rate (or accuracy). The multitask scenario presents an alternative approach to the multiclass situation in our Case Study 1, i.e., when the classification is based on multiple properties that are—theoretically—independent (here, inhibitory activities of two isoenzymes), with multitask models providing separate predictions for each property. In the work of Valsecchi et al., no approach outperformed the others consistently: task-specific differences were found, but in general, less represented classes are better described using FFNL3. Perhaps their most striking conclusion is that single task models might outperform the more complex deep learning algorithms, e.g., surprisingly, naïve Bayes is superior to FFNL3 in certain situations. There is no doubt that N3 is the best, while NB is the worst single-task algorithm, but even this limited number of performance parameters reveals the dataset-size dependence. Our present work clearly manifests the overall inferiority of NB compared to the other machine learning algorithms examined and highlights XGBoost as the best option among those that were considered.
The impact of class imbalance on binary classification was studied by Luque et al. [
32]. Ten performance metrics were evaluated based on binary confusion matrices, with the authors favoring the Matthews correlation coefficient for error consideration. For imbalanced data, the performance metrics can be distributed into three clusters considering the bias measure: zero (TPR, TNR, BM, and the geometric mean of sensitivity and specificity, GM), medium (ACC, MCC, MK), and high bias (PPV, NPV, and F1). While we worked with balanced datasets, it is interesting to observe that some of the low-bias measures—BM, MK, and MCC—exhibit a strong dataset size dependence, see
Figure 4 (Case Studies 2 and 3, high variance), when a complex interplay of various factors is considered: machine learning algorithms, training/test split ratios, number of compounds were varied.
Lin and Chen addressed the fundamental issues of class-imbalanced classification: imbalance ratio, small disjoints, overlap complexity, lack of data, and feature selection [
33]. They claim that the SVM-ensemble classifier performs the best when the class imbalance is not too severe. This is in agreement with our work: here, SVM is identified as a competitive approach (although still somewhat inferior to XGBoost).
To summarize, our 25 performance measures were exhaustive and provided a more sophisticated consensus about performance. The number of samples and the train/test split ratio exerted a significant effect on multiclass classification performance. Of course, all comparative studies are influenced by the specific structure of the datasets, but overall tendencies and optimal solutions can be identified.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}