1. Introduction
Lipidomics is of increasing interest in metabolic and other biological studies. Trials comprising sizeable numbers of samples are now being attempted in order to provide sufficient statistical power to answer questions about human and animal metabolism, development and dysregulation of metabolism, and development [
1,
2,
3,
4,
5,
6], as well as in particular sample types [
7]. This has encouraged research efforts to overcome the practical concerns that pertain to determining the lipid composition of biological samples (lipidomics). This comes against a background of investigations of a variety of sample formats and scales, including mammalian plasma [
8,
9,
10,
11,
12,
13], fibrous tissues [
14,
15,
16], dried blood spots [
17,
18,
19] and even milk [
20,
21]. General methods for isolating lipids for low- and medium-throughput studies have been reviewed [
22,
23].
However, due to its relatively recent arrival and particular needs, high-throughput lipidomics and methods associated with it are less widely researched. Despite that, considerable progress has been made in recent years in laboratory infrastructure and methods for the high-throughput lipidomics required for large human trials. Spectroscopic innovations such as Direct Infusion Mass Spectrometry (DI-MS) [
21,
24] and dual spectroscopy [
14] have been published. Lipid extraction methods for the particular challenges of high-throughput lipidomics have also been developed, such as those by Maytash et al. [
8] and the Meikle group [
9,
10], and from our own laboratory [
14,
25].
However, questions and challenges about high-throughput lipidomics remain. Some of these are general questions about sample handling and lipid extraction that have existed for some time [
22]. These include problems with the suitability of solvents for the lipid species of interest, chemical degradation associated with particular solvents and the activity of endogenous enzymes
ex vivo. However, some questions are unique to high-throughput lipidomics. For example, there is a clear need to find a compromise between the practicalities of large numbers of simultaneous extractions of lipid material from small biological samples and the desire for thorough molecular profiling. Some of these problems have been solved by using glass-coated deep-well plates accompanied by 96 channel pipettes mounted on a movable platform for liquid transfer and mixing. However, the need to strike a compromise between a large number of samples, analytical soundness and acquiring quantitative data relevant to hypotheses has led to the development of at least four methods of extracting lipids for high-throughput lipidomics using mass spectrometry. However, it is not clear how they perform when compared to one another. This is partly due to the lack of an objective means for measuring extraction efficiency, but also because the reported methods are distinct from one another. For example, there are two categories of extraction, those that comprise an aqueous wash as part of the process and those that do not. The absence of an aqueous wash is attractive in practical terms, as it simplifies sample preparation for chromatography or infusion. However, it is not clear whether this approach can be applied to more proteinaceous or more viscous sample matrices. This led us to the hypothesis that a solvent-based extraction method that comprises an aqueous wash and the facility to dissolve lipid classes with a range of polarities works best for high-throughput lipidomics.
In order to test this hypothesis, we investigated for four lipid extraction methods reported for high-throughput lipidomics on four distinct matrices. The four lipid extractions were ‘TBME’ (
tert-butylmethyl ether) [
8], ‘BuMe’ (butanol/methanol, 1:1) [
9,
10], ‘DMT’ (dichloromethane/methanol/triethylammonium chloride, 3:1:0.005) [
14,
21,
26] and ‘XMI’ (xylene/methanol/isopropanol, 1:2:4) [
25]. These methods are in common use for lipidomics and have shown reliability with at least one sample type. The TBME method [
8] was amongst the first to be reported for high-throughput lipidomics, and has received wide attention and considerable use in lipidomics. It has been used particularly frequently in plasma and serum sample sets, and has been found to be consistent. DMT has been reported more recently, has been used across a number of sample types and has been used where several sample types are required in a given study [
14,
21]. BuMe was developed solely for human plasma samples, and has not yet been reviewed for other sample types [
9,
10]. XMI is the newest method, developed by us for isolating the lipid fraction from dried milk spots, and it too is untested on other matrices [
25]. Notably, DMT and TBME are both aqueous methods, they both comprise a wash with water as part of sample preparation. BuMe and XMI methods involve dispersing the biological sample into the solvent mixture before infusion into the ion source.
The four matrices used in this study were bovine milk (milk), human serum (serum), murine liver homogenate (liver) and murine heart homogenate (heart). These were chosen to represent the breadth of biological samples commonly requested in lipidomics, with heart representing a proteinaceous sample and milk representing sample types with a particularly high proportion of triglycerides (phospholipid:triglyceride = 1:49). Sets of subtypes or pools of these sample matrices were used to assess the precision of the methods. The data for this study were collected in one analytical run using Direct-Infusion Mass Spectrometry (DI-MS). This is a typical high-throughput method (30 samples/h) with a sample queue that minimizes or avoids batch effects altogether and thus tests the methods in a high-throughput manner.
It is important to test the hypothesis that the solvent-based extraction method that comprises an aqueous wash and the facility to dissolve lipid classes with a range of polarities works best for high-throughput lipidomics, as understanding the limits of lipid extraction methods is key to choosing the appropriate method for answering scientific questions about lipid metabolism. Questions requiring a focus on one or two particular classes or particular sample matrices may be answered by methods that are particularly amenable to the chemical and physical properties of that class/sample type. It may also be helpful to know which lipid classes are extracted less efficiently using a given isolation method. This study represents an advance because previous attempts at comparing extraction methods have focused on low-resolution profiling and the undried lipid extracts, meaning that data in this area is weak [
22]. The present study uses a novel method to quantify the quality of lipid extraction, using both the number of lipid isoforms (variables) identified and the total signal strength of lipid variables the extracts. Isoforms are defined by the configuration of their FA or acylated sphingosinyl portion, i.e., phosphatidylcholine with two palmitate residues will be referred to as the isoform PC(32:0), while that with two arachidonate residues will be referred to as PC(40:8). The combination of signal strength and number of variables provides an objective measure for ranking the efficiency of lipid extraction that has not previously been used in assessing the quality or efficiency of this process.
3. Discussion
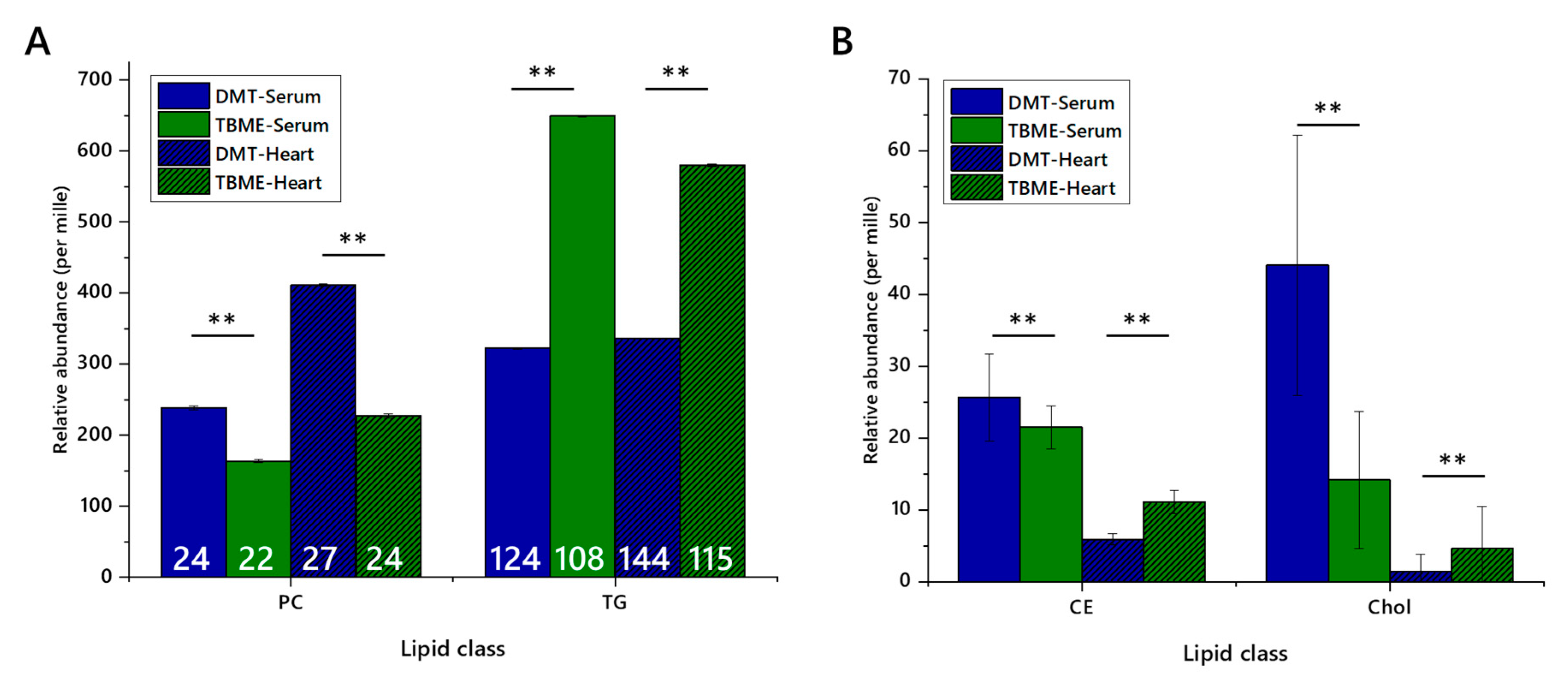
In this study, it was found that the performance of lipid extraction methods differed considerably between both the format of the extraction (solvent type, use of aqueous wash) and sample type (high/low protein). All methods tested performed well on milk samples, with human serum and tissue homogenates (mouse tissues, heart and liver) being more challenging. Investigation of both total signal and the number of variables observed showed that DMT is a more effective solvent system for isolating the lipid fraction than TBME.
The increased number of variables and apparent mass of material isolated using the DMT method is encouraging for high-throughput lipidomics studies, as it offers greater insight in the molecular composition of the biological system it represents. This also allows researchers to make better use of equipment. However, it does raise questions about how such data should be handled. A typical and very useful approach is to assess lipidomes through a normalised or semi-quantitative abundance, i.e., relative abundance based on signal strength. It is arguable that this is more difficult where more signals are found, as the abundance of any one thus falls. This means that the abundance of less prevalent species may be more difficult to compare between phenotypes. However, such a problem has been common with low-abundance species for some time. This problem may be addressed by following up DI-MS profiling of the lipidome with liquid chromatography-mass spectrometry on a select group of samples, shedding light not only on the comparative abundance of low abundance species between samples but also for isoform analysis of such species [
14].
The difference in performance of the DMT and TBME methods naturally raises the question of why this should be. It is well known that chlorinated solvents and others such as ethyl acetate are broad-spectrum solvents, often able to dissolve ionic organic compounds easily. Ethereal solvents are typically better at dissolving more lipophilic compounds, as they are less able to support salts. This suggested to us that a solvent mixture such as DMT may be a good all-round solvent system, where TBME may be better for more lipophilic compounds. The choice of solvent therefore depends upon the question being asked. Certain questions, for example, centring on the TG markers of de novo lipogenesis, may be answered by using either DMT or TBME methods, as the species of interest are abundant and expected to dissolve in either solvent. However, where hypotheses are based around changes to several members of a class or several isoforms across classes, a broader-spectrum system may be preferable.
This study was predicated on the notion that lipid extraction efficiency can be measured quantitatively. In a previous report, we collected 16–20 measurements of each sample type or method of interest and used a combination of the number of lipids identified and the total signal strength (a proxy for mass) to rank extraction methods. This was followed by a calculation of coefficient of variance to assess the precision of the method [
25]. This three-layered structure represented an advance in objective comparison of extraction protocols, which was previously wanting [
22]. This represents the strongest way yet found for comparing lipid extraction protocols objectively.
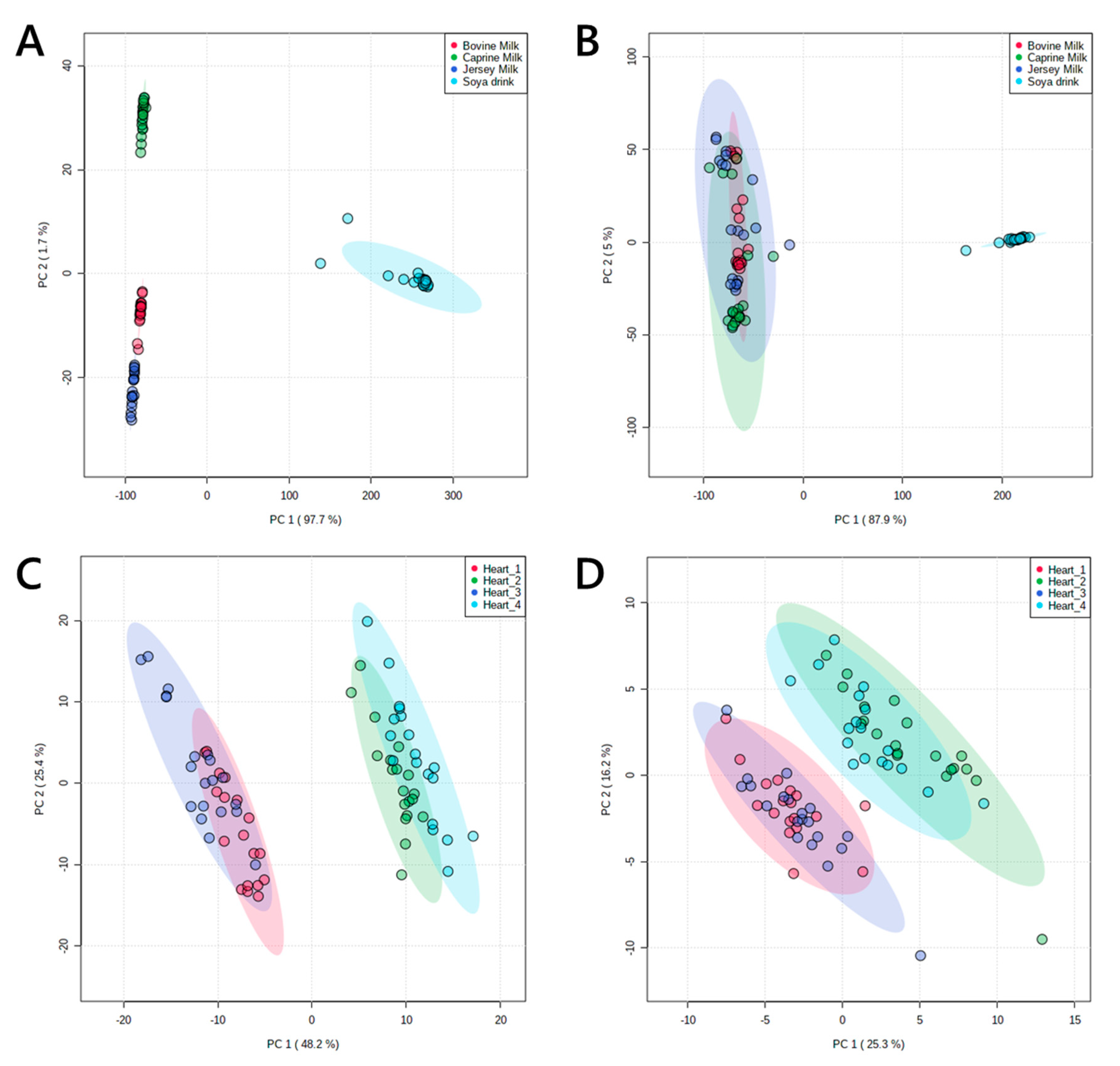
Lastly, the approach to assessing the efficiency of lipid isolation described in this paper is useful because it facilitates choice of extraction method for the sample type at hand. This is increasingly useful, as there is increasing demand for lipidomics, an on a broadening range of sample types. The present assessment characterises the available methods in greater depth. This increases our understanding of the lipidomics tools at our disposal. For example, as this study has shown that fresh milk is a suitable sample type for BuMe [
9,
10] (developed for plasma) and XMI [
25] (developed for dried milk spots) extractions, it shows that fresh milk and either plasma or dried milk spots may be extracted in the same plate easily. They may even be compatible with greater automation. Further research, comprising development of other methods for high-throughput lipidomics, may be useful for expanding our understanding of this process.
5. Materials and Methods
5.1. Ethics
All procedures were conducted in accordance with the UK Home Office Animal (Scientific Procedures) Act 1986 and local ethics committees at Aston University. Animals were maintained at Aston University’s biomedical research facility as described previously [
27].
5.2. Reagents and Standards
Solvents were purchased from Sigma-Aldrich Ltd. (Gillingham, Dorset, UK) of at least HPLC grade and were not purified further. Lipid standards were purchased from Avanti Polar lipids (Alabaster, AL; through Instruchemie, Delfzijl, NL) and used without purification. Consumables and anonymised pooled human serum were purchased from Sarstedt AG and Co (Leicester, UK) and Thermo Fisher (Hemel Hempstead, Herfordshire, UK). Milk samples were purchased from British supermarkets in 2019.
5.3. Sample Processing
The data for this study were acquired in one analytical run of 813 samples, including blank and QC samples. The four examples of heart, liver, milk and serum matrices for measuring coefficient of variance (CV) were prepared as follows. Twelve existing liver and heart homogenates each, from two feeding groups (wither low-protein/high carbohydrate or control), were mixed to make four pooled mixtures each of liver and heart homogenates, prepared as previously described [
14,
28]. Commercially available, pooled serum was used. Pasteurised Jersey, whole bovine and whole caprine animal milk and soya (
Glycine max.) drink, purchased from British supermarkets in 2019/2020 and stored at −80 °C, were used. The samples used for comparing lipid extraction methods were prepared as follows. All liver and heart homogenates used above were mixed from all stocks used above. Whole caprine milk and one commercially available human serum were used.
5.4. Quality Control
QC samples were used to establish which variables’ signal strength correlated with their concentration. Three QC levels were used, representing 0.25, 0.5 and 1.0× of the total (20 µL). Several reference materials were used, namely, (a) mouse placenta homogenate, (b) mouse liver homogenate, (c) mouse heart homogenate, (d) commercially available pooled human blood serum and (e) whole caprine milk.
5.5. Isolation of Lipid Fractions
DMT—This procedure was similar to a high-throughput technique described recently [
14,
21]. Heart homogenate (60 µL), liver homogenate (20 µL), milk (20 µL) and serum (20 µL) samples were placed along with blank and QC samples in the wells of a glass-coated 2.4 mL/well 96w plate (Plate+™, Esslab, Hadleigh, UK). Methanol (150 μL, HPLC grade, spiked with Internal Standards, See
Table S1) was added to each of the wells, followed by water (500 µL) and a mixture of solvents (500 µL) comprising dichloromethane and methanol (3:1) doped with triethylammonium chloride (500 mg/L). The mixture was agitated (96 channel pipette) before being centrifuged (3200×
g, 2 min). A portion of the organic solution (20 µL) was transferred to a high-throughput plate (384w, glass-coated, Esslab Plate+™) before being dried (N
2 (g)). The dried films were redissolved (TBME, 30 µL/well) and diluted with a stock mixture of alcohols and ammonium acetate (90 µL/well; propan-2-ol:methanol, 2:1; CH
3COO.NH
4 7.5 mM). The analytical plate was heat-sealed and run immediately.
TBME—This procedure was as similar as possible to the original protocol for extracting lipids from biological samples [
8]. Heart homogenate (60 µL), liver homogenate (20 µL), milk (20 µL) and serum (20 µL) samples were placed along with blank and QC samples in the wells of a glass-coated 2.4 mL/well 96w plate (Plate+™, Esslab, Hadleigh, UK). Methanol (150 μL, HPLC grade, spiked with Internal Standards, See
Table S1) was added to each of the wells, followed by water (500 µL) and TBME (500 µL). The mixture was centrifuged (3,200×
g, 2 min). A portion of the organic solution (20 µL) was transferred to a high-throughput plate (384w, glass-coated, Esslab Plate+™) before being dried (N
2 (g)). The dried films were redissolved (TBME, 30 µL/well) and diluted with a stock mixture of alcohols and ammonium acetate (90 µL/well; propan-2-ol:methanol, 2:1; CH
3COO.NH
4 7.5 mM). The analytical plate was heat-sealed and run immediately.
BuMe—This procedure was as similar as possible to the original protocol for extracting lipids from biological samples [
9,
10]. Heart homogenate (60 µL), liver homogenate (20 µL), milk (20 µL) and serum (20 µL) samples were placed along with blank and QC samples in the wells of a glass-coated 2.4 mL/well 96w plate (Plate+™, Esslab, Hadleigh, UK). A prepared mixture of methanol (spiked with Internal Standards, See
Table S1) and
n-butanol (1:1, 200 µL) was added to each of the wells and agitated until homogenous. A portion of the mixture (20 µL) was transferred to a shallow 96w plate before being dried (N
2 (g)). The dried films were redissolved (TBME, 30 µL/well) and diluted with a stock mixture of alcohols and ammonium acetate (90 µL/well; propan-2-ol:methanol, 2:1; CH
3COO.NH
4 7.5 mM) before being transferred to a high-throughput plate (384w, glass-coated, Esslab Plate+™) before being dried (N
2 (g)). The analytical plate was heat-sealed and run immediately.
XMI—This procedure has not been described before. Heart homogenate (60 µL), liver homogenate (20 µL), milk (20 µL) and serum (20 µL) samples were placed along with blank and QC samples in the wells of a glass-coated 2.4 mL/well 96w plate (Plate+™, Esslab, Hadleigh, UK). A prepared mixture of solvents and xylene/methanol/isopropanol (1:2:4, 500 µL, methanol spiked with Internal Standards, See
Table S1) was added to each of the wells and agitated until homogenous. A portion of the mixture (20 µL) was transferred to a shallow 96w plate before being dried (N
2 (g)). The dried films were redissolved (TBME, 30 µL/well) and diluted with a stock mixture of alcohols and ammonium acetate (90 µL/well; propan-2-ol:methanol, 2:1; CH
3COO.NH
4 7.5 mM) before being transferred to a high-throughput plate (384w, glass-coated, Esslab Plate+™) before being dried (N
2 (g)). The analytical plate was heat-sealed and run immediately.
5.6. Mass Spectrometry
Instrument—Samples were infused into an Exactive Orbitrap (Thermo, Hemel Hampstead, UK), using a Triversa Nanomate (Advion, Ithaca US). Samples were ionised at 1.2 kV in the positive ion mode. The Exactive started acquiring data 20 s after sample aspiration began. After 72 s of acquisition in positive mode, the Nanomate and the Exactive switched over to negative mode, decreasing the voltage to −1.5 kV. The spray was maintained for another 66 s, after which the analysis was stopped and the tip discarded, before the analysis of the next sample. The sample plate was kept at 15 °C throughout the acquisition. Samples were run in row order.
Data processing—Raw high-resolution mass-spectrometry data were processed using XCMS (
www.bioconductor.org) and Peakpicker v 2.0 (an in-house R script [
24]). Lists of known species (by
m/z) were used for both positive ion and negative ion mode (~8.5k species). Variables whose mass deviated by more than 9 ppm from the expected value had a signal/noise ratio of <3 and had signals for fewer than 50% of all samples that were discarded. The correlation of signal intensity to concentration of human placenta, mouse liver, human serum and pooled human seminal plasma samples as QCs (0.25, 0.5, 1.0×) was used to identify the lipid signals, the strength of which was linearly proportional to abundance (threshold for acceptance was a correlation of 0.75). Remaining signals (passes) were then divided by the sum of signals for that sample and expressed per mille (‰). Each
m/z signal identified was interpreted as a given isoform of a lipid with an appropriate adduct for that
m/z. Like isoforms with different adducts were not summed. Zero values were interpreted as not measured. All statistical calculations were done on these finalised values.
5.7. Statistical Analyses
The analysis was structured according to a prepared analysis plan. Uni- and bivariate analyses were carried out using Excel 2016. Multivariate analyses were run using MetaboAnalyst 4.0 [
29]. Abundance of lipid(s) is shown as mean ± standard deviation unless otherwise stated.










{kind=link}
{kind=link}
{kind=link}
{kind=link}