Prediction Models to Control Aging Time in Red Wine


 ,
, 
 ,
,  and
and 
Abstract
1. Introduction
Related Works WITH This Research
- (i)
- Hydrology, to model the water quality using different water quality variables [27],
- (ii)
- (iii)
- (iv)
- (i)
- To determine air specific heat ratios at elevated pressures [36],
- (ii)
- to classify glaucoma, a progressive optic neuropathy disease [37],
- (iii)
- to forecast electrical loads due to their importance in the regional power system strategy management [38] or,
- (iv)
- to evaluate real-time crash risk in active traffic management (ATM) [39], among other fields.
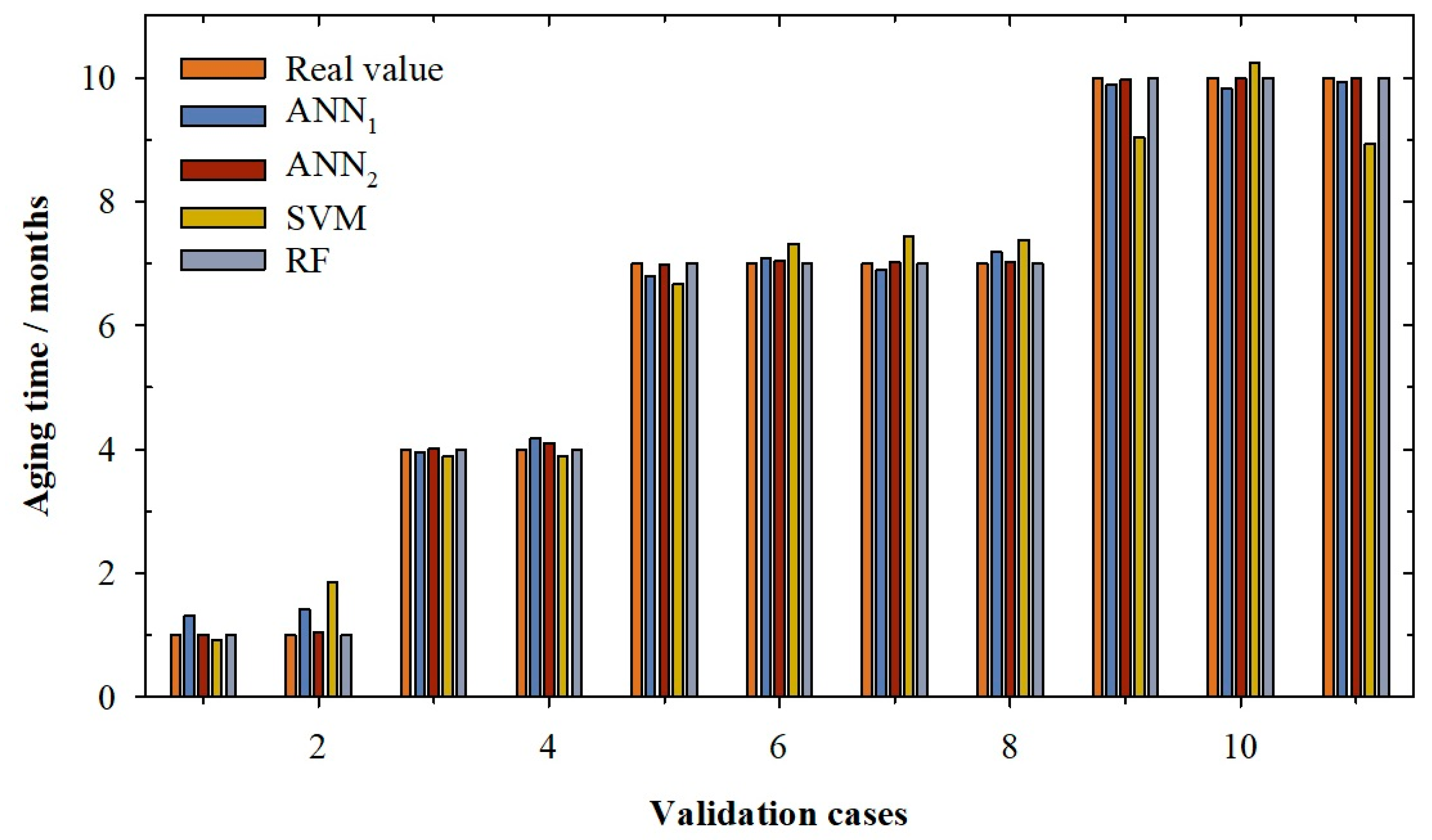
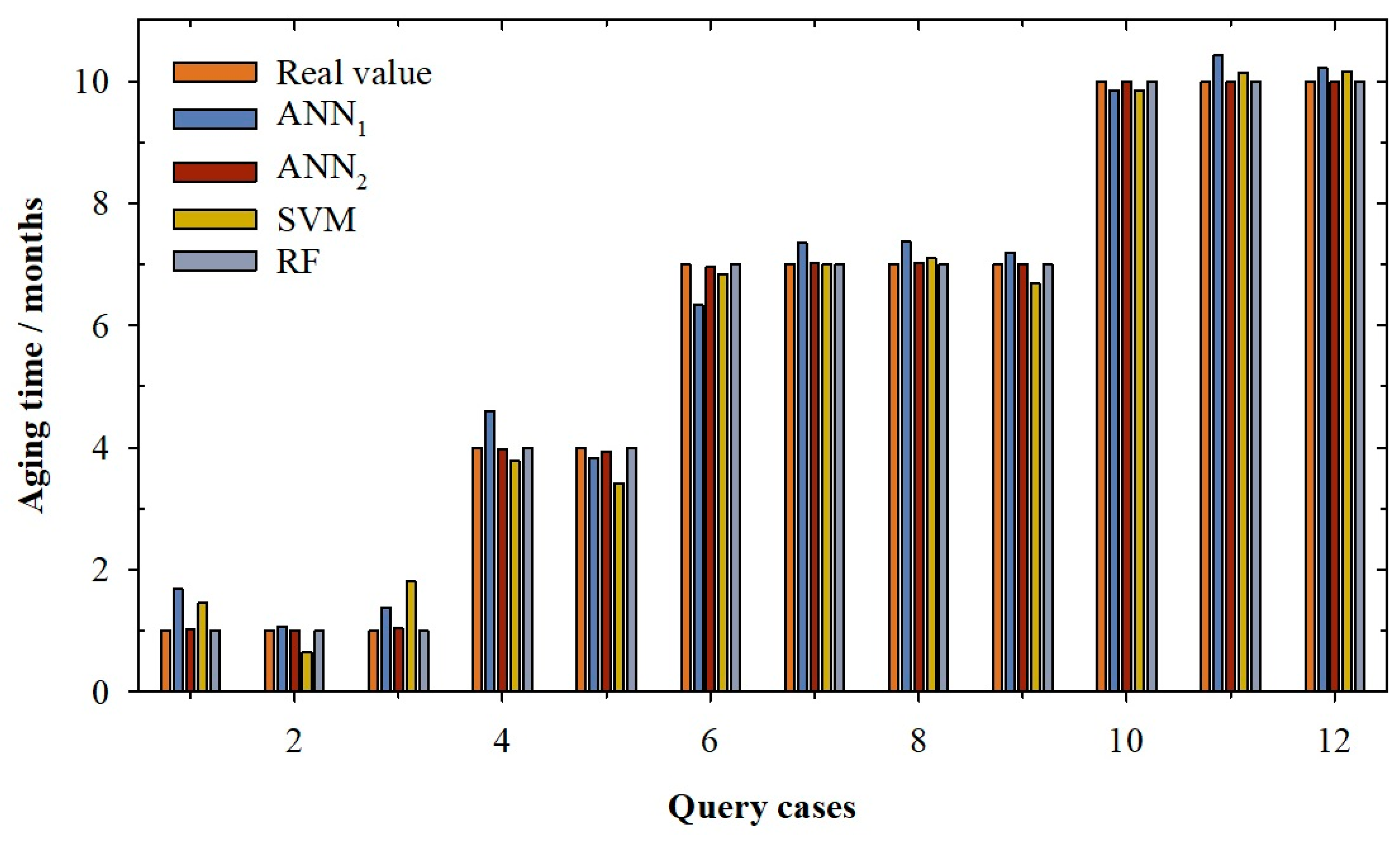
2. Results and Discussion
3. Materials and Methods
3.1. Data Set
3.2. Physical-chemical Analysis
3.3. Methodologies
3.4. Model’s Prediction Statistics
3.5. Equipment and Software
4. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Luykx, D.M.A.M.; van Ruth, S.M. An overview of analytical methods for determining the geographical origin of food products. Food Chem. 2008, 107, 897–911. [Google Scholar] [CrossRef]
- Saurina, J. Characterization of wines using compositional profiles and chemometrics. Trac-Trend Anal. Chem. 2010, 29, 234–245. [Google Scholar] [CrossRef]
- da Costa, N.L.; Llobodanin, L.A.G.; de Lima, M.D.; Castro, I.A.; Barbosa, R. Geographical recognition of Syrah wines by combining feature selection with Extreme Learning Machine. Measurement 2018, 120, 92–99. [Google Scholar] [CrossRef]
- Chen, B.; Tawiah, C.; Palmer, J.; Erol, R. Multi-class wine grades predictions with hierarchical support vector machines. In Proceedings of the ICNC-FSKD 2017-13th International Conference on Natural Computation, Fuzzy, Guilin, China, 29–31 July 2018. [Google Scholar]
- Rapeanu, G.; Vicol, C.; Bichescu, C. Possibilities to asses the wines authenticity. Innovative Romanian Food Biotech. 2009, 5, 1–9. [Google Scholar]
- Hu, L.; Yin, C.; Ma, S.; Liu, Z. Rapid detection of three quality parameters and classification of wine based on Vis-NIR spectroscopy with wavelength selection by ACO and CARS algorithms. Spectrochim. Acta Part A 2018, 205, 574–581. [Google Scholar] [CrossRef] [PubMed]
- Riovanto, R.; Cynkar, W.U.; Berzaghi, P.; Cozzolino, D. Discrimination between Shiraz wines from different Australian regions: The role of spectroscopy and chemometrics. J. Agr. Food Chem. 2011, 59, 10356–10360. [Google Scholar] [CrossRef] [PubMed]
- Quality Schemes Explained. European Commission. Available online: https://ec.europa.eu/info/food-farming-fisheries/food-safety-and-quality/certification/quality-labels/quality-schemes-explained_en (accessed on 1 February 2019).
- Danezis, G.P.; Tsagkaris, A.S.; Camin, F.; Brusic, V.; Georgiou, C.A. Food authentication: Techniques, trends & emerging approaches. TrAC, Trends Anal. Chem. 2016, 85, 123–132. [Google Scholar]
- Moldes, O.A.; Mejuto, J.C.; Rial-Otero, R.; Simal-Gandara, J. A Critical Review on the Applications of Artificial Neural Networks in Winemaking Technology. Crit. Rev. Food Sci. Nutr. 2017, 57, 2896–2908. [Google Scholar] [CrossRef] [PubMed]
- Serrano-Lourido, D.; Saurina, J.; Hernández-Cassou, S.; Checa, A. Classification and characterisation of Spanish red wines according to their appellation of origin based on chromatographic profiles and chemometric data analysis. Food Chem. 2012, 135, 1425–1431. [Google Scholar] [CrossRef] [PubMed]
- Andonie, R.; Johansen, A.M.; Mumma, A.L.; Pinkart, H.C.; Vajda, S. Cost efficient prediction of Cabernet Sauvignon wine quality. In Proceedings of the 2016 IEEE Symposium Series on Computational Intelligence, Athens, Greece, 6–9 December 2016. [Google Scholar]
- Rendall, R.; Pereira, A.C.; Reis, M.S. Advanced predictive methods for wine age prediction: Part I—A comparison study of single-block regression approaches based on variable selection, penalized regression, latent variables and tree-based ensemble methods. Talanta 2017, 171, 341–350. [Google Scholar] [CrossRef] [PubMed]
- Campos, M.P.; Sousa, R.; Pereira, A.C.; Reis, M.S. Advanced predictive methods for wine age prediction: Part II–A comparison study of multiblock regression approaches. Talanta 2017, 171, 132–142. [Google Scholar] [CrossRef] [PubMed]
- Pereira, A.C.; Reis, M.S.; Saraiva, P.M.; Marques, J.C. Development of a fast and reliable method for long- and short-term wine age prediction. Talanta 2011, 86, 293–304. [Google Scholar] [CrossRef] [PubMed]
- Pereira, A.C.; Reis, M.S.; Saraiva, P.M.; Marques, J.C. Aroma ageing trends in GC/MS profiles of liqueur wines. Anal. Chim. Acta 2010, 659, 93–101. [Google Scholar] [CrossRef] [PubMed]
- Pereira, A.C.; Reis, M.S.; Saraiva, P.M.; Marques, J.C. Madeira wine ageing prediction based on different analytical techniques: UV–vis, GC-MS, HPLC-DAD. Chemometr. Intell. Lab. 2011, 105, 43–55. [Google Scholar] [CrossRef]
- Akintunde, A.M.; Ajala, S.O.; Betiku, E. Optimization of Bauhinia monandra seed oil extraction via artificial neural network and response surface methodology: A potential biofuel candidate. Ind. Crops Prod. 2015, 67, 387–394. [Google Scholar] [CrossRef]
- Haykin, S. Neural networks, a comprehensive foundation. Knowl. Eng. Rev. 1999, 13, 409–412. [Google Scholar]
- Bishop, C.M. Neural Networks for Pattern Recognition; Oxford University Press: Oxford, UK, 1995. [Google Scholar]
- Gonzalez-Fernandez, I.; Iglesias-Otero, M.A.; Esteki, M.; Moldes, O.A.; Mejuto, J.C.; Simal-Gandara, J. A critical review on the use of artificial neural networks in olive oil production, characterization and authentication. Crit. Rev. Food Sci. Nutr. 2018. [Google Scholar] [CrossRef] [PubMed]
- McCulloch, W.S.; Pitts, W. A logical calculus of the ideas immanent in nervous activity. Bull. Math. Biophys. 1943, 5, 115–133. [Google Scholar] [CrossRef]
- Dawson, C.W.; Wilby, R.L. Hydrological modelling using artificial neural networks. Prog. Phys. Geog. 2001, 25, 80–108. [Google Scholar] [CrossRef]
- Beck, H.E.; Van Dijk, A.I.J.M.; Miralles, D.G.; De Jeu, R.A.M.; Bruijnzeel, L.A.; McVicar, T.R.; Schellekens, J. Global patterns in base flow index and recession based on streamflow observations from 3394 catchments. Water Resour. Res. 2013, 49, 7843–7863. [Google Scholar] [CrossRef]
- RapidMiner Documentation. RapidMiner. Available online: https://docs.rapidminer.com/ (accessed on 1 February 2019).
- Chiang, Y.; Chang, F. Integrating hydrometeorological information for rainfall-runoff modelling by artificial neural networks. Hydrol. Processes 2009, 23, 1650–1659. [Google Scholar] [CrossRef]
- Gazzaz, N.M.; Yusoff, M.K.; Aris, A.Z.; Juahir, H.; Ramli, M.F. Artificial neural network modeling of the water quality index for Kinta River (Malaysia) using water quality variables as predictors. Mar. Pollut. Bull. 2012, 64, 2409–2420. [Google Scholar] [CrossRef] [PubMed]
- Narisetty, V.; Astray, G.; Gullón, B.; Castro, E.; Parameswaran, B.; Pandey, A. Improved 1,3-propanediol production with maintained physical conditions and optimized media composition: Validation with statistical and neural approach. Biochem. Eng. J. 2017, 126, 109–117. [Google Scholar] [CrossRef]
- Hernández Suárez, M.; Astray Dopazo, G.; Larios López, D.; Espinosa, F. Identification of relevant phytochemical constituents for characterization and authentication of tomatoes by general linear model linked to automatic interaction detection (GLM-AID) and artificial neural network models (ANNs). PLoS ONE 2015, 10, e0128566. [Google Scholar] [CrossRef] [PubMed]
- Bucci, R.; Magrí, A.D.; Magrí, A.L.; Marini, D.; Marini, F. Chemical authentication of extra virgin olive oil varieties by supervised chemometric procedures. J. Agric. Food. Chem. 2002, 50, 413–418. [Google Scholar] [CrossRef] [PubMed]
- Montoya, L.A.; Moldes, O.A.; Cid, A.; Astray, C.; Gálvez, J.F.; Mejuto, J.C. Influence prediction of alkylamines upon electrical percolation of AOT-based microemulsions using artificial neural networks. Tenside Surfact. Det. 2015, 52, 473–476. [Google Scholar] [CrossRef]
- Ahmad, S.; Gromiha, M.M. Design and training of a neural network for predicting the solvent accessibility of proteins. J. Comput. Chem. 2003, 24, 1313–1320. [Google Scholar] [CrossRef] [PubMed]
- Capron, X.; Massart, D.L.; Smeyers-Verbeke, J. Multivariate authentication of the geographical origin of wines: A kernel SVM approach. Eur. Food Res. Technol. 2007, 225, 559–568. [Google Scholar] [CrossRef]
- Boser, B.E.; Guyon, I.M.; Vapnik, V.N. A Training Algorithm for Optimal Margin Classifiers. In Proceedings of the 5th Annual Workshop on Computational Learning Theory (COLT’92), Pittsburgh, PA, USA, 27–29 July 1992. [Google Scholar]
- Ríos-Reina, R.; Elcoroaristizabal, S.; Ocaña-González, J.A.; García-González, D.L.; Amigo, J.M.; Callejón, R.M. Characterization and authentication of Spanish PDO wine vinegars using multidimensional fluorescence and chemometrics. Food Chem. 2017, 230, 108–116. [Google Scholar] [CrossRef] [PubMed]
- Kamari, A.; Mohammadi, A.H.; Bahadori, A.; Zendehboudi, S. Prediction of air specific heat ratios at elevated pressures using a novel modeling approach. Chem. Eng. Technol. 2014, 37, 2047–2055. [Google Scholar] [CrossRef]
- Chan, K.; Lee, T.-W.; Sample, P.A.; Goldbaum, M.H.; Weinreb, R.N.; Sejnowski, T.J. Comparison of machine learning and traditional classifiers in glaucoma diagnosis. IEEE Trans. Biomed. Eng. 2002, 49, 963–974. [Google Scholar] [CrossRef] [PubMed]
- Pai, P.; Hong, W. Forecasting regional electricity load based on recurrent support vector machines with genetic algorithms. Electr. Pow Syst. Res. 2005, 74, 417–425. [Google Scholar] [CrossRef]
- Yu, R.; Abdel-Aty, M. Utilizing support vector machine in real-time crash risk evaluation. Accid. Anal. Prev. 2013, 51, 252–259. [Google Scholar] [CrossRef] [PubMed]
- Alhaj, M.A.M.; Maghari, A.Y.A. Cancer survivability prediction using random forest and rule induction algorithms. In Proceedings of the ICIT 2017—8th International Conference on Information Technology, Al-Zaytoonah University of Jordan, Amman, Jordan, 17 May 2017. [Google Scholar]
- Tian, Y.C.; Yan, T.; Zhang, H.; Tang, H.; Li, J.; Yu, J.; Bernard, L.; Chen, S.; Martin, N.; Delepine-Gilon, J.; et al. Classification of wines according to their production regions with the contained trace elements using laser-induced breakdown spectroscopy. Spectrochim. Acta B 2017, 135, 91–101. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Machine Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Breiman, L.; Friedman, J.; Olshen, R.; Stone, C. Classification and Regression Tree; CRC Press: Boca Raton, FL, USA, 1984. [Google Scholar]
- Vigneau, E.; Courcoux, P.; Symoneaux, R.; Guérin, L.; Villière, A. Random forests: A machine learning methodology to highlight the volatile organic compounds involved in olfactory perception. Food Qual. Prefer. 2018, 68, 135–145. [Google Scholar] [CrossRef]
- Cutler, D.R.; Edwards, T.C., Jr.; Beard, K.H.; Cutler, A.; Hess, K.T.; Gibson, J.; Lawler, J.J. Random forests for classification in ecology. Ecology 2007, 88, 2783–2792. [Google Scholar] [CrossRef] [PubMed]
- Mutanga, O.; Adam, E.; Cho, M.A. High density biomass estimation for wetland vegetation using WorldView-2 imagery and random forest regression algorithm. Int. J. Appl. Earth Obs. 2012, 18, 399–406. [Google Scholar] [CrossRef]
- Gallego, L.; Nevares, I.; Fernández, J.A.; Del Álamo, M. Determination of low-molecular mass phenols in red wines: The influence of chips, staves and micro-oxygenation aging tank. Food Sci. Technol. Int. 2011, 17, 429–438. [Google Scholar] [CrossRef] [PubMed]
- Gallego, L.; Del Alamo, M.; Nevares, I.; Fernández, J.A.; De Simón, B.F.; Cadahía, E. Phenolic compounds and sensorial characterization of wines aged with alternative to barrel products made of Spanish oak wood (Quercus pyrenaica Willd.). Food Sci. Technol. Int. 2012, 18, 151–165. [Google Scholar] [CrossRef] [PubMed]
- Chang, C.C.; Lin, C.J. LIBSVM: A Library for support vector machines. ACM Trans. Intell. Syst. Tech. 2011, 2. [Google Scholar] [CrossRef]
- Hsu, C.W.; Chang, C.C.; Lin, C.J. A Practical Guide to Support Vector Classification. Technical report. Department of Computer Science, National Taiwan University: Taiwan, 15 July 2003. Available online: https://www.csie.ntu.edu.tw/~cjlin/papers/guide/guide.pdf (accessed on 1 February 2019).
- Apetrei, I.M.; Rodríguez-Méndez, M.L.; Apetrei, C.; Nevares, I.; del Alamo, M.; de Saja, J.A. Monitoring of evolution during red wine aging in oak barrels and alternative method by means of an electronic panel test. Food Res. Int. 2012, 45, 244–249. [Google Scholar] [CrossRef]
- International Organisation of Vine and Wine, OIV. Recueil des méthodes internationales d’analyse des vins et des mouts. OIV: Paris, France, 2018; Volume 2. Available online: http://www.oiv.int/fr/normes-et-documents-techniques/methodes-danalyse/recueil-des-methodes-internationales-danalyse-des-vins-et-des-mouts-2-vol (accessed on 1 February 2019).
- Aires-De-Sousa, J. Verifying wine origin: A neural network approach. Am. J. Enol. Vitic. 1996, 47, 410–414. [Google Scholar]
- Kruzlicova, D.; Mocak, J.; Balla, B.; Petka, J.; Farkova, M.; Havel, J. Classification of Slovak white wines using artificial neural networks and discriminant techniques. Food Chem. 2009, 112, 1046–1052. [Google Scholar] [CrossRef]
- Šelih, V.S.; Šala, M.; Drgan, V. Multi-element analysis of wines by ICP-MS and ICP-OES and their classification according to geographical origin in Slovenia. Food Chem. 2014, 153, 414–423. [Google Scholar] [CrossRef] [PubMed]
- Yu, H.; Lin, H.; Xu, H.; Ying, Y.; Li, B.; Pan, X. Prediction of enological parameters and discrimination of rice wine age using least-squares support vector machines and near infrared spectroscopy. J. Agr. Food Chem. 2008, 56, 307–313. [Google Scholar] [CrossRef] [PubMed]
- Gaál, M.; Moriondo, M.; Bindi, M. Modelling the impact of climate change on the Hungarian wine regions using Random Forest. Appl. Ecol. Environ. Res. 2012, 10, 121–140. [Google Scholar] [CrossRef]
- Moriondo, M.; Jones, G.V.; Bois, B.; Dibari, C.; Ferrise, R.; Trombi, G.; Bindi, M. Projected shifts of wine regions in response to climate change. Climatic Change 2013, 119, 825–839. [Google Scholar] [CrossRef]
- Ahammed, B.; Abedin, M.M. Predicting wine types with different classification techniques. Model Assisted Stat. Appl. 2018, 13, 85–93. [Google Scholar] [CrossRef]
- Iglesias-Otero, M.A.; Fernández-González, M.; Rodríguez-Caride, D.; Astray, G.; Mejuto, J.C.; Rodríguez-Rajo, F.J. A model to forecast the risk periods of Plantago pollen allergy by using the ANN methodology. Aerobiologia 2015, 31, 201–211. [Google Scholar] [CrossRef]
- Dai, X.; Shi, H.; Li, Y.; Ouyang, Z.; Huo, Z. Artificial neural network models for estimating regional reference evapotranspiration based on climate factors. Hydrol. Processes 2009, 23, 442–450. [Google Scholar] [CrossRef]
- Huang, G.; Zhu, Q.; Siew, C. Extreme learning machine: Theory and applications. Neurocomputing 2006, 70, 489–501. [Google Scholar] [CrossRef]
Sample Availability: not available. |



{kind=link}
{kind=link}
| Training | Validation | Querying | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Model | R2 | RMSE | AAPD (%) | R2 | RMSE | AAPD (%) | R2 | RMSE | AAPD (%) |
| ANN1 | 0.994 | 0.28 | 8.07 | 0.998 | 0.20 | 8.20 | 0.989 | 0.40 | 13.51 |
| ANN2 | 1.000 | 0.02 | 0.42 | 1.000 | 0.04 | 0.87 | 1.000 | 0.03 | 0.84 |
| SVM | 0.995 | 0.24 | 6.72 | 0.973 | 0.56 | 12.86 | 0.988 | 0.37 | 16.35 |
| RF | 1.000 | 0.00 | 0.00 | 1.000 | 0.00 | 0.00 | 1.000 | 0.00 | 0.00 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Astray, G.; Mejuto, J.C.; Martínez-Martínez, V.; Nevares, I.; Alamo-Sanza, M.; Simal-Gandara, J. Prediction Models to Control Aging Time in Red Wine. Molecules 2019, 24, 826. https://doi.org/10.3390/molecules24050826
Astray G, Mejuto JC, Martínez-Martínez V, Nevares I, Alamo-Sanza M, Simal-Gandara J. Prediction Models to Control Aging Time in Red Wine. Molecules. 2019; 24(5):826. https://doi.org/10.3390/molecules24050826
Chicago/Turabian StyleAstray, Gonzalo, Juan Carlos Mejuto, Víctor Martínez-Martínez, Ignacio Nevares, Maria Alamo-Sanza, and Jesus Simal-Gandara. 2019. "Prediction Models to Control Aging Time in Red Wine" Molecules 24, no. 5: 826. https://doi.org/10.3390/molecules24050826
APA StyleAstray, G., Mejuto, J. C., Martínez-Martínez, V., Nevares, I., Alamo-Sanza, M., & Simal-Gandara, J. (2019). Prediction Models to Control Aging Time in Red Wine. Molecules, 24(5), 826. https://doi.org/10.3390/molecules24050826