1. Introduction
The black soil region is one of the most productive soils with fertile soils, characterized by a thick, dark-colored soil horizon rich in organic matter [
1], and soil types include black soil, kastanozems, chernozem, meadow soil, and dark brown soil, etc. There are black soil and chernozem mainly in the study area, which plays a vital role in guaranteeing national food security in China [
2]. Nevertheless, soil fertility decreased quickly in recent years for the reason of human activities and ecological systems changing. Compared with before reclamation, the organic matter content of black soil in Northeast China decreased 50%~60% [
3]. To protect the precious black soil, the conservational tillage is developed and carried out in China. One meaningful way is the crop residue left for covering the black soil within the nongrowing season [
4]. The crop residue covering can mitigate water erosion and wind erosion, increase the organic matter content by letting the organic matter of crop residue back to the soil [
5]. In addition, the minimum soil disturbance can be used to prevent the destruction of farmland soil layers to ensure the expected growth of crops [
6]. Therefore, whether or not there is crop residue covered in the soil surface is very important for black soil protection [
7]. Unfortunately, the traditional methods for identifying the crop residual covered area are time-consuming and laborious, which can’t be carried out in regional areas, quickly and timely.
Remote sensing is an efficient way to capture the land surface information quickly in regional areas [
8,
9]. The crop residue cover estimation and the conservative tillage monitoring based on remote sensing data have become a topic of significant interest to researchers [
10,
11]. In the past few decades, a series of methods have been proposed for estimating local and regional crop residue cover using remote sensing data, including the linear spectral unmixing [
12], the spectral index [
13,
14], and the triangle space technique [
15]. However, remote sensing techniques to estimate crop residue cover has been limited by the variations of moisture in the crop residue and soil [
16]. For example, linear spectral unmixing techniques that use fixed crop residue and soil endmember spectra may lead to inaccurate estimation resulting from the difficulty in determining the abundance of pure crop residue spectral constituents. [
17]. The cellulose and lignin absorption features are attenuated as moisture content increases, which decreases the accuracy of crop residue cover estimation using existing spectral index methods [
10]. The problem of the triangle space technique lies in the difficulty of acquiring hyperspectral images, which limits the application of this method for estimating crop residue cover on a large-scale [
15]. These studies are all about crop residue cover estimation using remote sensing data, disregarding the residue cover type (i.e., residue covering directly, stalk-stubble breaking, stubble standing, etc.). The residue cover type mapping is very significant for crop residue cover estimation for carrying out conservation tillage and crop residue quantity estimation for clean energy production. Therefore, this study focuses on regional crop residue cover mapping using high spatial resolution Chinese GF-1 B/D images.
Texture features are the essential characteristics of high spatial resolution remote sensing images, which are very useful for fine mapping of small and irregular land surface targets [
18]. Image texture analysis refers to measuring heterogeneity in the distribution of gray values within a given area [
19]. There is abundant spatial information of crop residue covered area from high spatial resolution remote sensing images. Mining the texture features will contribute to improving the accuracy of mapping crop residue covered areas. Some researchers developed some algorithms to extract spatial and shape features, including rotation invariance [
20], texture statistics [
21], and mathematical morphology [
22]. Moreover, these mid-level features mostly rely on setting some free parameters subjectively, which cannot mine the abundant spatial and textural information provided by high spatial resolution remote sensing images [
23]. Therefore, a more thorough understanding of the textural and spatial features is required for mapping crop residue covered areas that are scattered and irregular.
The fine spatial resolution and abundant textural information of high spatial resolution remote sensing images can’t work fully using traditional supervised classification methods. The traditional segmentation methods, such as turbopixel/superpixel segmentation, watershed segmentation, and active contour models, also have their own drawbacks. Specifically, turbopixel/superpixel segmentation methods [
24,
25] are subject to both under-segmentation and irregularly shaped superpixel boundaries. Watershed segmentation method [
26,
27] is fast in image segmentation, but the number and compactedness of superpixels cannot be controlled. Active contour models [
28,
29] cannot work well for the object with obvious multiple colors. Fortunately, deep learning semantic segmentation methods are developing rapidly in the field of computer vision and classification of remote sensing images [
30,
31]. In general, there are two kinds of semantic pixel-based classification methods, including patch-based and end-to-end in the convolutional neural network (CNN) architectures. The drawback of the patch-based classification method [
32] lies in that the trained network can only predict the central pixel of the input image, resulting in low classification effectiveness. Moreover, the end-to-end framework methods [
33,
34,
35,
36] are usually known as semantic segmentation networks, which became more popular for the advantages of their high process effectiveness, discovering the contextual features, and learning representativeness and distinguishing features automatically. The U-Net is a typical semantic segmentation network with a contracting path to capture context and a symmetric expanding path, which is a lightweight network and can be trained end-to-end and get-well results in segmentation of neuronal structures [
37]. Therefore, there are many improved networks based on UNET. Including combined with residual connections, atrous convolutions, pyramid scene parsing pooling [
38], and re-designed skip pathways [
39]. In addition, the attention mechanism, multiscale convolution group (MSCG), and depth-wise separable convolution can improve network performance effectively proved by Woo et al. [
40], Chen et al. [
41], and Chen et al. [
42]. These semantic segmentation network models with end-to-end structures are trained not only further excavate the relationship between the spectral and the label, but also to learn the contextual features.
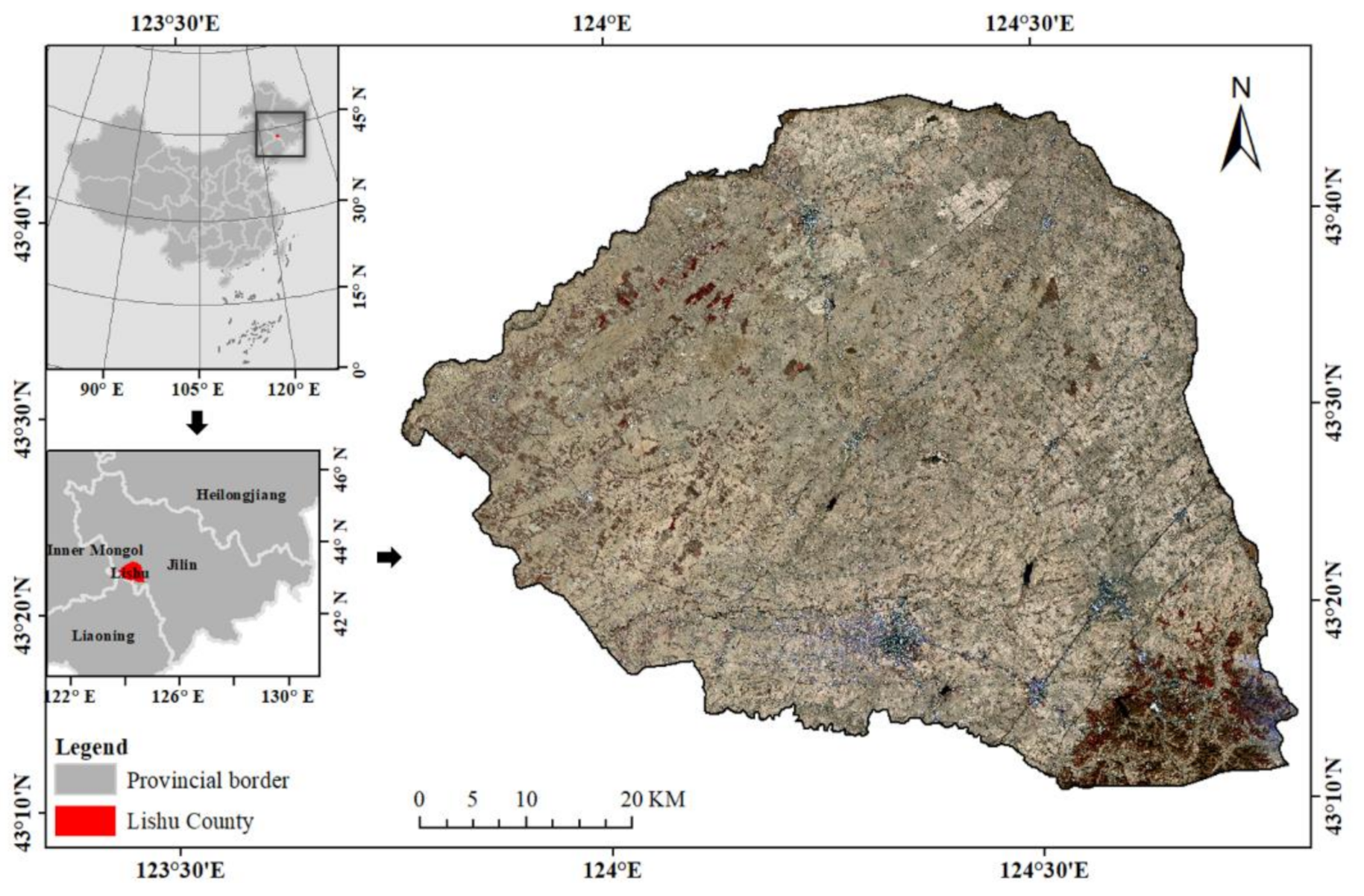
There are many kinds of different crop residue cover type in Lishu County, Siping City, Jilin Province, including residue covering directly, stalk-stubble breaking, stubble standing, where is a typical study area for crop residue cover mapping. Lishu County is located in the Golden Corn Belt of black soil in Northeast China, and there is a 93% cultivated area is planted corn. Lishu County is a typical area of corn residue covering for protecting black soil. Therefore, this study focuses on mapping corn residue covered area (CRCA) using the deep learning method based on GF-1 B/D high resolution remote sensing images. The conservation tillage is defined by The Conservation Technology Information Center (CTIC) as any tillage and planting system that has the residue cover is greater than 30% after planting [
43,
44]. Therefore, we define the CRCA as corn residues cover more significantly than 30%, and the depth semantic segmentation method is chosen for mapping the CRCA. Full Connected Conditional Random Field (FCCRF) [
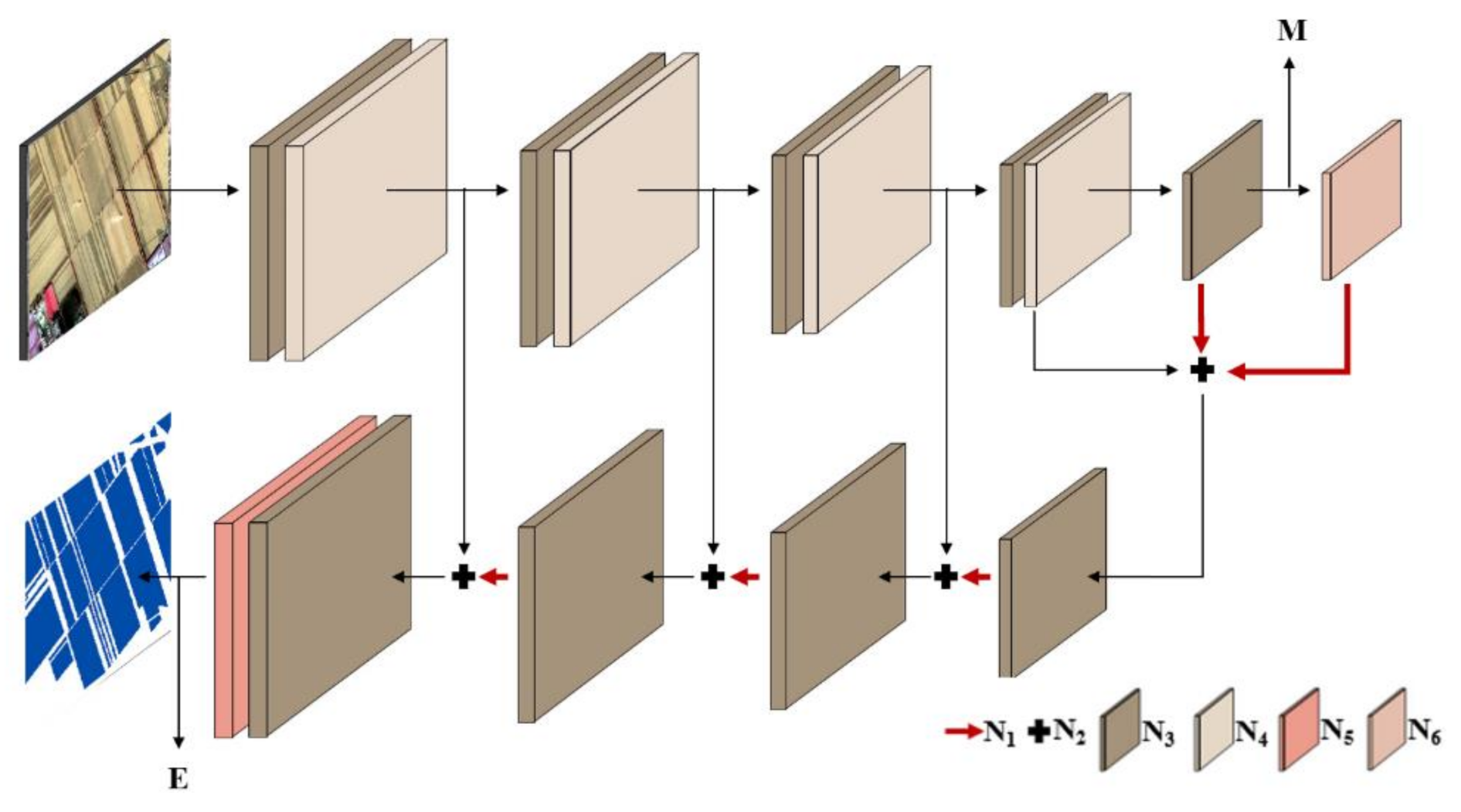
45] is a discriminative undirected graph learning model, which can fully consider the global information and structural information, and can optimize the classification results by combining MSCU-net and FCCRF. With the proposed method, the automatic mapping of CRCA from GF1 B/D high resolution remote sensing images is developed in this study. The novelties of this study are as followed. (1) A designed network MSCU-net is developed for exploring the spatial features of high resolution images by combing the U-Net with multiscale convolution group (MSCG), the global loss function, and Convolutional Block Attention Module (CBAM). (2) The FCCRF is combined with MSCU-net to construct MSCU-net+C to further optimizing CRCA to alleviate the noise in high spatial resolution results images. (3) Exploring the potential of Chinese GF1 B/D high resolution remote sensing images for mapping the CRCA accurately and automatically.
This study is structured as followed. In the next section, we introduce the study area and the data collection for corn residue cover firstly. In
Section 3, the details of our designed network architecture and assessment indexes are presented. Then, we compared different improvements strategies, different classifiers with the proposed method to prove its effectiveness on GF-1 B/D images, and the classification results in
Section 4. Next, the discussions about the strengths and weaknesses of the proposed method with respect to other relevant studies are given in
Section 5. Finally, considerations for future work and the conclusions of the study are presented in
Section 6.
5. Discussion
The CRCA mapping is important for monitoring conservation tillage and agricultural subsidy policy application. Many studies have revealed the potential of crop residue covered area mapping using medium spatial resolution remote sensing images [
58,
59,
60,
61]. Considering the inhomogeneity and randomness resulting from human management difference, the Chinese high spatial resolution GF-1 B/D image and developed MSCU-net+C deep learning method is used to mapping CRCA in this study.
Firstly, the ablation experiments reveal that the developed MSCU-net+C has potential in mapping CRCA using Chinese high spatial resolution remote sensing images, and have improvements compared with the deep semantic segmentation networks, such as U-net, MU-net, GU-net and MSCU-net, and deep semantic segmentation networks. The attention mechanism is applied in the network as a form of image feature enhancement to improve the effectiveness of feature maps [
42]. The experimental results show that the combination of attention mechanisms can capture feature information more sufficiently and achieve better performance [
62]. The improvements used in this study lie in MSCG, the global loss function, CBAM, and FCCRF. The MSCU-net+C improves 0.0477/0.0394 in
IOUAVG/
KappaAVG than U-net and get better classification performance. The MSCG can capture multiscale information and enrich the expression of feature maps [
63], which results in a more thorough understanding of the input information. The global loss function is used to balance the network parameters of the high and low layers. Then, the CBAM can obtain better important information in the process of network learning CRCA. Lastly, the FCCRF is used to optimize classification results. The quantitative and qualitative accuracy assessment results revealed that the proposed MSCU-net+C is applicable to the CRCA classification.
Secondly, the comparative experiment demonstrates that MSCU-net+C, SegNet, and Dlv3+ deep semantic segmentation methods alleviate edge information loss compared with SVM and NN traditional machine learning methods in extracting CRCA from high resolution remote sensing images. For traditional machine learning methods, most algorithms rely on the accuracy of the extracted features, including pixel values, shapes, textures, and positions, etc. However, deep semantic segmentation methods automatically can obtain high level relevant features directly from remote sensing images in CRCA classification, which reduces the work of designing feature extractors for each classification problem. In addition, the proposed MSCU-net+C method can capture contextual information and improve the effectiveness of feature information, which is the best method for classification performance in comparative experiments.
Finally, the CRCA classification results revealed that the deep semantic segmentation method can alleviate the salt-and-pepper problem effectively, which exists in the classification of high spatial resolution images commonly. Some studies adopt object-based approach to avoid the salt-and-pepper phenomenon in classification problems. However, the object-based classification depends on experience and knowledge to build the segmentation parameters, which is intend for strong subjectivity. Fortunately, the deep semantic segmentation method can preserve detailed edge information by performing both segmentation and pixel-based classification simultaneously. Thus, the deep semantic segmentation method is more suitable for identifying CRCA from high resolution multispectral remote sensing images.
Our proposed method can capture the border and details information of GF-1 B/D images for the CRCA mapping using encoder–decoder structure automatically. Thus, the prediction results of CRCA using GF-1 B/D performed well in this study. However, there are still some limitations worth noting. Firstly, more spectral information can be joined. The lignin and cellulose in crop residue are more sensitive with the spectrum of 1450–1960 nm and near 2100 nm [
64]. The spectrum of the Chinese GF-5 image is ranging from visible bands to short wave infrared bands, and the GF-5 image can be combined with GF-1 B/D image to improve crop residue covered area mapping. Secondly, multitemporal remote sensing image features have the potential to improve the crop residue covered area classification results. The combination of multitemporal images can alleviate the interference of crops with similar spectral characteristics in the classification. Finally, the low imaging coverage of GF-1 B/D results in the limitation of application in regional areas. Recent studies of deep learning reveal that the trained model can be transferred into other data sources through transfer learning. Therefore, this study can be extended to other remote sensing images and other study areas for more crop residue cover mapping.
6. Conclusions
The developed MSCU-net+C deep semantic segmentation method can extract the deep features from the input image automatically through the code-encode structure, which is used to mapping CRCA by Chinese GF-1 B/D high spatial resolution image in this study. The quantitative evaluation of the ablation experiment and comparison experiment show that this proposed method has the best results, which can alleviate noise and identify CRCA that are scattered and irregular accurately.
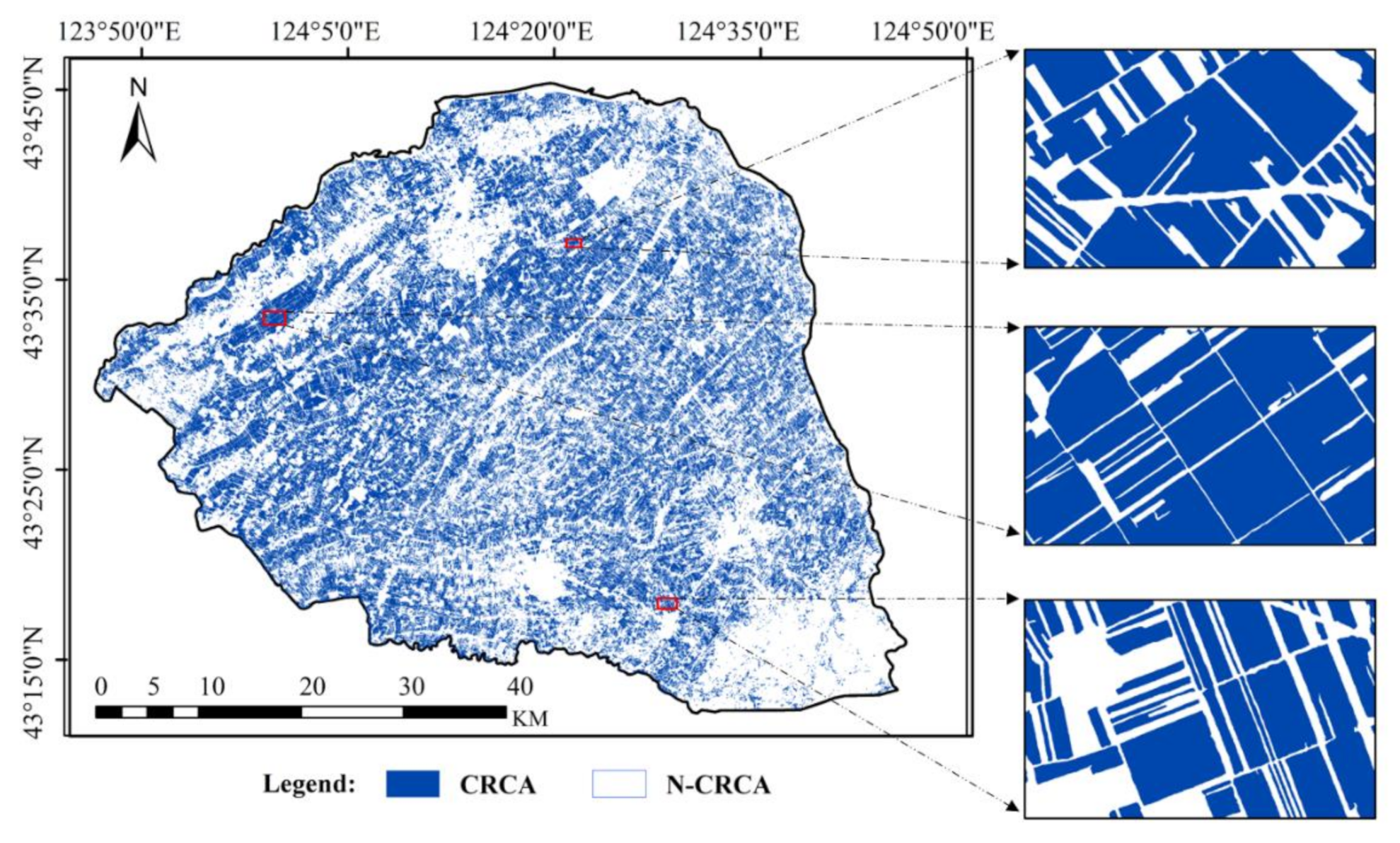
By comparing different models in the architecture ablation experiment, we found that the MSCG, the global loss function, and CBAM embed in the MSCU-net can significantly improve the network performance, especially the ability of feature maps information screening and feature expression. MSCU-net+C is constructed by combining FCCRF and MSCU-net, which can optimize the CRCA classification results further. It shows that the proposed method of MSCU-net+C is reasonable. By comparing different methods in model comparison, we found that deep semantic segmentation methods can get a higher classification accuracy and more detailed boundaries of CRCA than SVM and NN. Furthermore, we used the proposed method of MSCU-net+C to classify the CRCA in the whole study area.
The results provide evidence for the ability of MSCU-net+C to learn shape and contextual features, which reveal the effectiveness of this method for corn residue covered areas mapping. However, there are still three potential improvements and further applications in future research. (1) Multitemporal and multisource remote sensing data fusion may improve CRCA classification results further. (2) Owing to the representativeness of the study area and the generalization of the proposed model, the method can be applied to CRCA recognition in more regional areas through the transfer learning method in the North China Plain. (3) The spatial pattern and statistics result of CRCA can be used to support local government (i.e., practicing agricultural subsidies) and promote conservation tillage implementation.



 ,
, 










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}