
Machine Learning-Based Cardiovascular Disease Prediction Model: A Cohort Study on the Korean National Health Insurance Service Health Screening Database

 , and
, and 
Abstract
1. Introduction
2. Materials and Methods
2.1. Data Source and Subject Inclusion
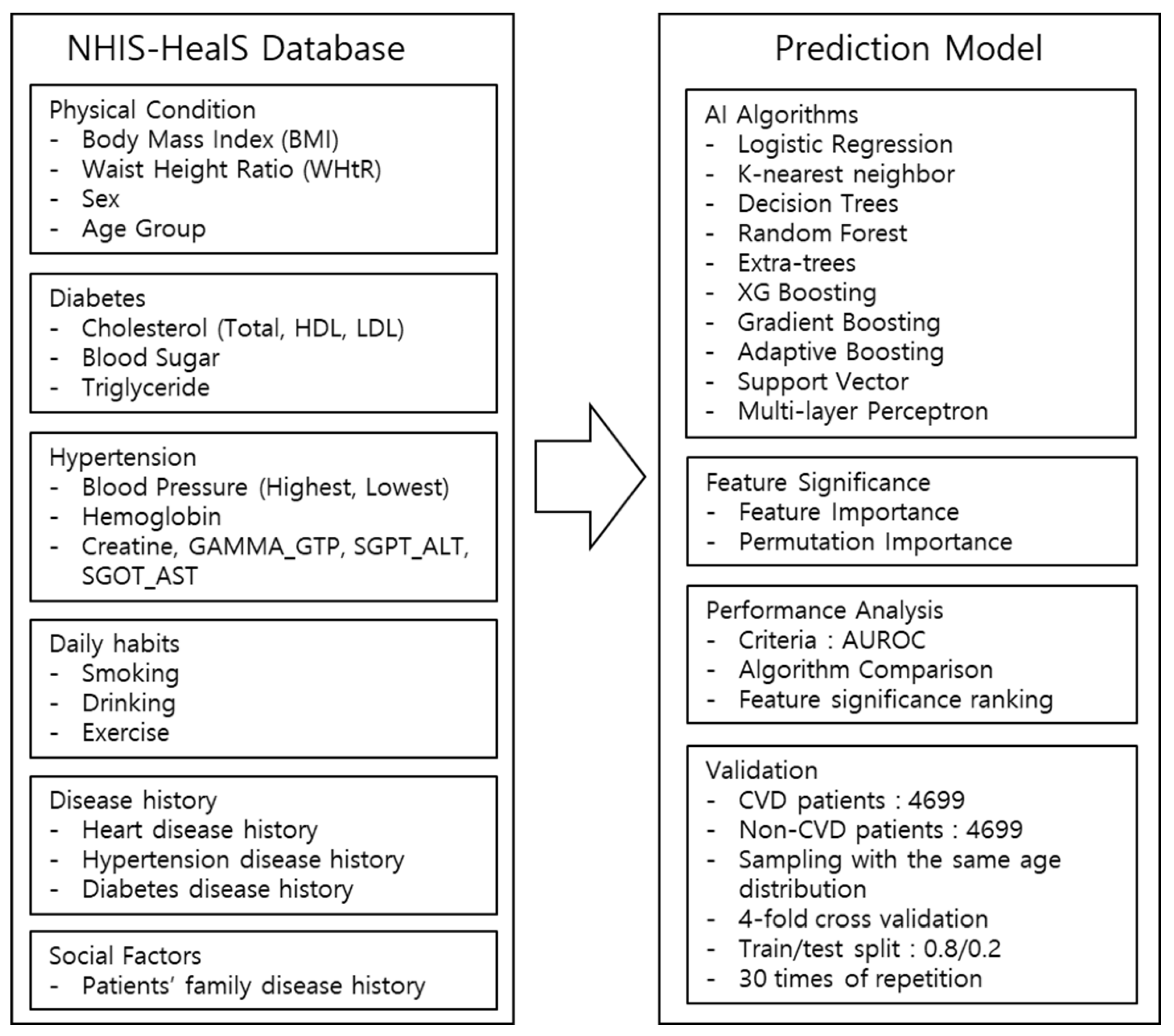
2.2. Architecture of the Cardiovascular Disease Prediction Model
2.3. Comparison of Prediction Model Performances
2.4. Analysis of Contributing Factors Affecting the Prediction Performance
2.5. Statistical Analysis of Demographic Factors
3. Results
3.1. Baseline Characteristics of Subjects
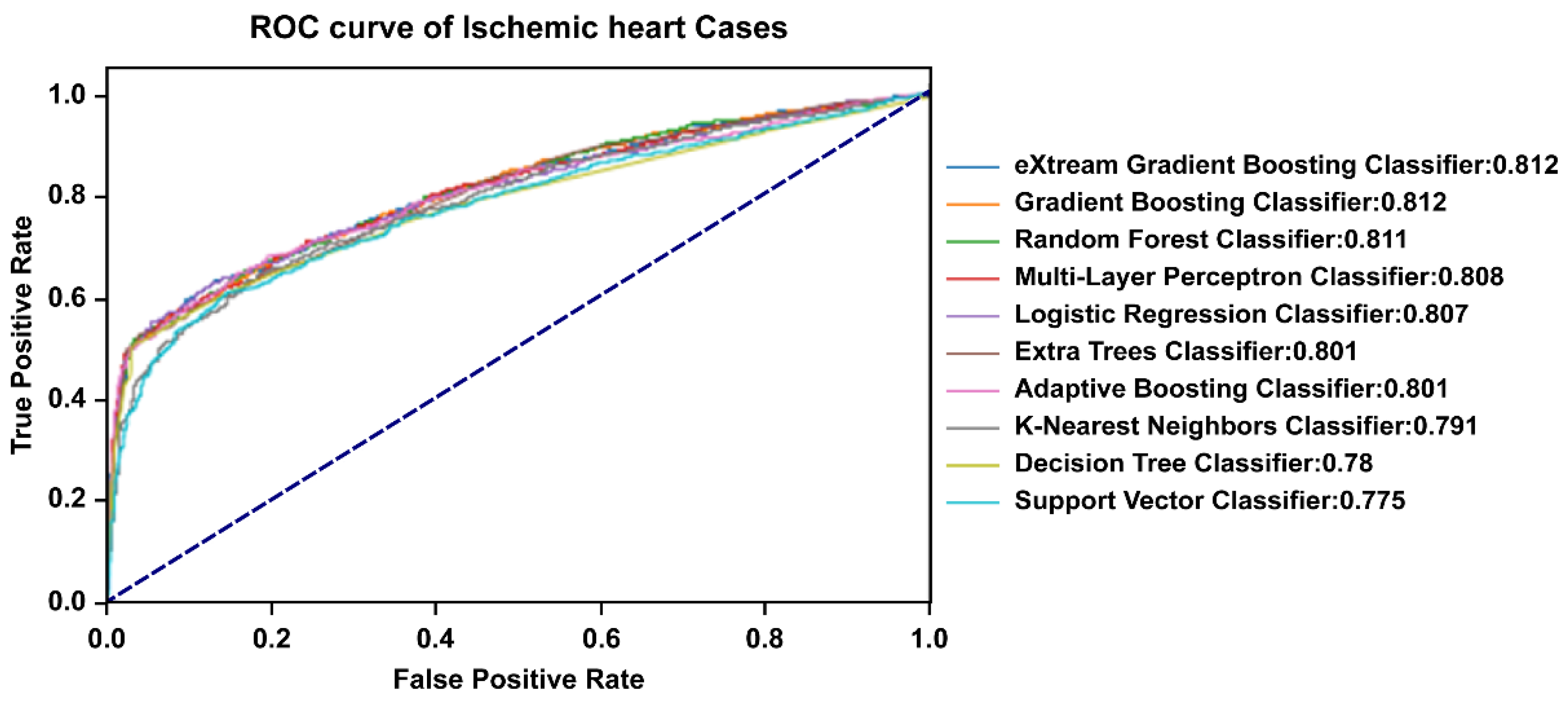
3.2. Comparisons of Prediction Model Performance
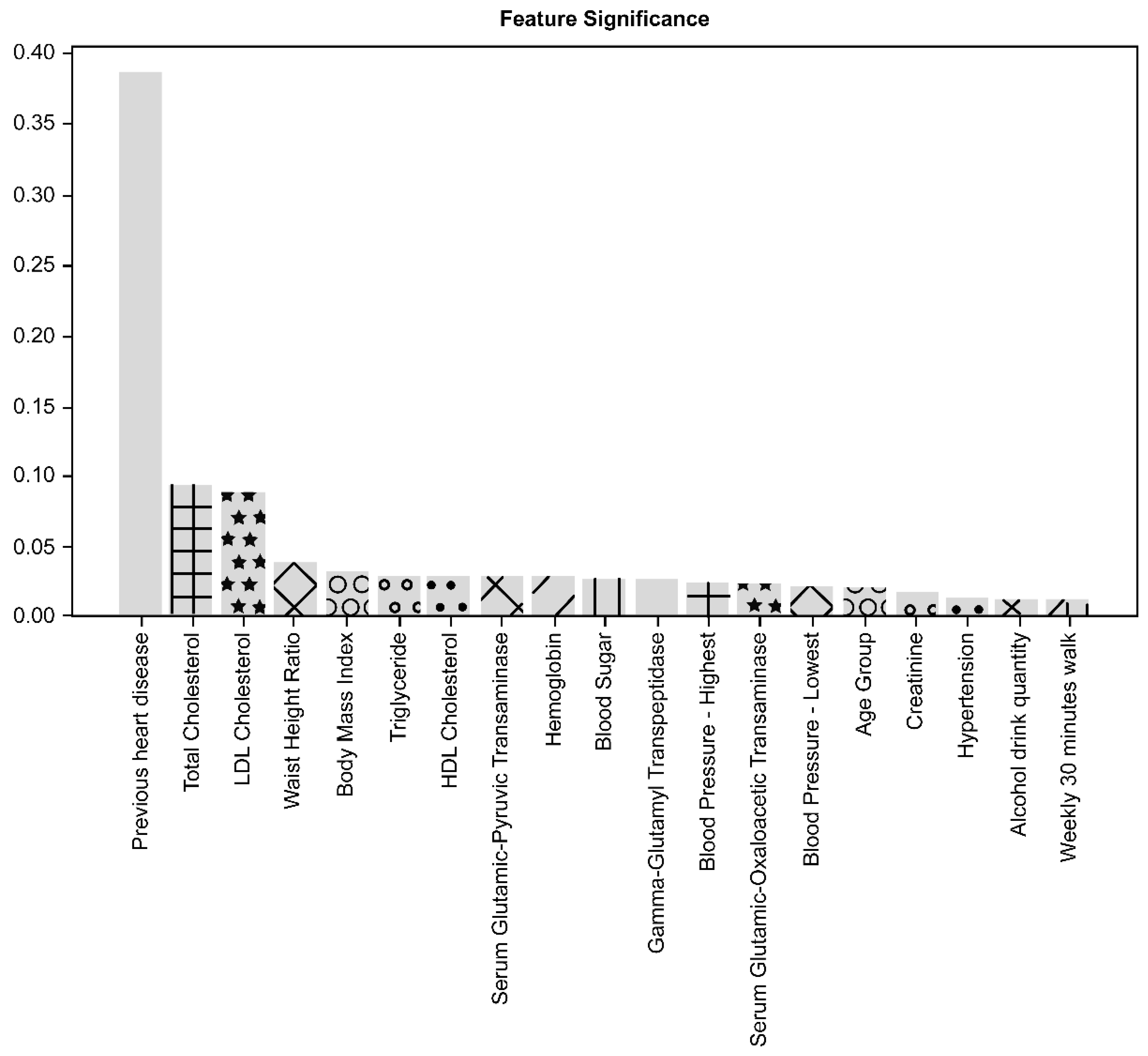
3.3. Contributing Factors for the Prediction Model Performance
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- National Cholesterol Education Program (NCEP) Expert Panel on Detection, Evaluation, and Treatment of High Blood Cholesterol in Adults (Adult Treatment Panel III). Third Report of the National Cholesterol Education Program (NCEP) Expert Panel on Detection, Evaluation, and Treatment of High Blood Cholesterol in Adults (Adult Treatment Panel III) final report. Circulation 2002, 106, 3143–3421. [Google Scholar] [CrossRef]
- McGurnaghan, S.; Blackbourn, L.A.K.; Mocevic, E.; Haagen Panton, U.; McCrimmon, R.J.; Sattar, N.; Wild, S.; Colhoun, H.M. Cardiovascular disease prevalence and risk factor prevalence in Type 2 diabetes: A contemporary analysis. Diabet. Med. 2019, 36, 718–725. [Google Scholar] [CrossRef] [PubMed]
- Jee, S.H.; Jang, Y.; Oh, D.J.; Oh, B.H.; Lee, S.H.; Park, S.W.; Seung, K.B.; Mok, Y.; Jung, K.J.; Kimm, H.; et al. A coronary heart disease prediction model: The Korean Heart Study. BMJ Open 2014, 4, e005025. [Google Scholar] [CrossRef] [PubMed]
- Statistics Korea. Annual Report on the Causes of Death Statistics. Available online: https://kosis.kr/statHtml/statHtml.do?orgId=101&tblId=DT_1B34E01&conn_path=I2&language=en (accessed on 21 April 2021).
- Karmali, K.N.; Persell, S.D.; Perel, P.; Lloyd-Jones, D.M.; Berendsen, M.A.; Huffman, M.D. Risk scoring for the primary prevention of cardiovascular disease. Cochrane Database Syst. Rev. 2017, 3, CD006887. [Google Scholar] [CrossRef]
- Muntner, P.; Colantonio, L.D.; Cushman, M.; Goff, D.C., Jr.; Howard, G.; Howard, V.J.; Kissela, B.; Levitan, E.B.; Lloyd-Jones, D.M.; Safford, M.M. Validation of the atherosclerotic cardiovascular disease Pooled Cohort risk equations. JAMA 2014, 311, 1406–1415. [Google Scholar] [CrossRef]
- Martinez-Garcia, M.; Salinas-Ortega, M.; Estrada-Arriaga, I.; Hernandez-Lemus, E.; Garcia-Herrera, R.; Vallejo, M. A systematic approach to analyze the social determinants of cardiovascular disease. PLoS ONE 2018, 13, e0190960. [Google Scholar] [CrossRef]
- de Araujo Goncalves, P.; Ferreira, J.; Aguiar, C.; Seabra-Gomes, R. TIMI, PURSUIT, and GRACE risk scores: Sustained prognostic value and interaction with revascularization in NSTE-ACS. Eur. Heart J. 2005, 26, 865–872. [Google Scholar] [CrossRef]
- Andersson, C.; Johnson, A.D.; Benjamin, E.J.; Levy, D.; Vasan, R.S. 70-year legacy of the Framingham Heart Study. Nat. Rev. Cardiol. 2019, 16, 687–698. [Google Scholar] [CrossRef]
- Goff, D.C., Jr.; Lloyd-Jones, D.M.; Bennett, G.; Coady, S.; D’Agostino, R.B., Sr.; Gibbons, R.; Greenland, P.; Lackland, D.T.; Levy, D.; O’Donnell, C.J.; et al. 2013 ACC/AHA guideline on the assessment of cardiovascular risk: A report of the American College of Cardiology/American Heart Association Task Force on Practice Guidelines. J. Am. Coll. Cardiol. 2014, 63, 2935–2959. [Google Scholar] [CrossRef]
- Jee, S.H.; Batty, G.D.; Jang, Y.; Oh, D.J.; Oh, B.H.; Lee, S.H.; Park, S.W.; Seung, K.B.; Kimm, H.; Kim, S.Y.; et al. The Korean Heart Study: Rationale, objectives, protocol, and preliminary results for a new prospective cohort study of 430,920 men and women. Eur. J. Prev. Cardiol. 2014, 21, 1484–1492. [Google Scholar] [CrossRef]
- Rezaee, M.; Putrenko, I.; Takeh, A.; Ganna, A.; Ingelsson, E. Development and validation of risk prediction models for multiple cardiovascular diseases and Type 2 diabetes. PLoS ONE 2020, 15, e0235758. [Google Scholar] [CrossRef] [PubMed]
- Kennedy, E.H.; Wiitala, W.L.; Hayward, R.A.; Sussman, J.B. Improved cardiovascular risk prediction using nonparametric regression and electronic health record data. Med. Care 2013, 51, 251–258. [Google Scholar] [CrossRef]
- Mosca, L.; Barrett-Connor, E.; Wenger, N.K. Sex/gender differences in cardiovascular disease prevention: What a difference a decade makes. Circulation 2011, 124, 2145–2154. [Google Scholar] [CrossRef] [PubMed]
- Jung, K.J.; Jang, Y.; Oh, D.J.; Oh, B.H.; Lee, S.H.; Park, S.W.; Seung, K.B.; Kim, H.K.; Yun, Y.D.; Choi, S.H.; et al. The ACC/AHA 2013 pooled cohort equations compared to a Korean Risk Prediction Model for atherosclerotic cardiovascular disease. Atherosclerosis 2015, 242, 367–375. [Google Scholar] [CrossRef] [PubMed]
- Bitton, A.; Gaziano, T.A. The Framingham Heart Study’s impact on global risk assessment. Prog. Cardiovasc. Dis. 2010, 53, 68–78. [Google Scholar] [CrossRef] [PubMed]
- Ward, A.; Sarraju, A.; Chung, S.; Li, J.; Harrington, R.; Heidenreich, P.; Palaniappan, L.; Scheinker, D.; Rodriguez, F. Machine learning and atherosclerotic cardiovascular disease risk prediction in a multi-ethnic population. NPJ Digit. Med. 2020, 3, 125. [Google Scholar] [CrossRef] [PubMed]
- Weng, S.F.; Reps, J.; Kai, J.; Garibaldi, J.M.; Qureshi, N. Can machine-learning improve cardiovascular risk prediction using routine clinical data? PLoS ONE 2017, 12, e0174944. [Google Scholar] [CrossRef] [PubMed]
- Alaa, A.M.; Bolton, T.; Di Angelantonio, E.; Rudd, J.H.F.; van der Schaar, M. Cardiovascular disease risk prediction using automated machine learning: A prospective study of 423,604 UK Biobank participants. PLoS ONE 2019, 14, e0213653. [Google Scholar] [CrossRef]
- Battineni, G.; Sagaro, G.G.; Chinatalapudi, N.; Amenta, F. Applications of Machine Learning Predictive Models in the Chronic Disease Diagnosis. J. Pers. Med. 2020, 10, 21. [Google Scholar] [CrossRef]
- Battineni, G.; Chintalapudi, N.; Amenta, F.; Traini, E. A Comprehensive Machine-Learning Model Applied to Magnetic Resonance Imaging (MRI) to Predict Alzheimer’s Disease (AD) in Older Subjects. J. Clin. Med. 2020, 9, 2146. [Google Scholar] [CrossRef]
- Saeed, A.; Nambi, V.; Sun, W.; Virani, S.S.; Taffet, G.E.; Deswal, A.; Selvin, E.; Matsushita, K.; Wagenknecht, L.E.; Hoogeveen, R.; et al. Short-Term Global Cardiovascular Disease Risk Prediction in Older Adults. J. Am. Coll. Cardiol. 2018, 71, 2527–2536. [Google Scholar] [CrossRef]
- Khanna, N.N.; Jamthikar, A.D.; Araki, T.; Gupta, D.; Piga, M.; Saba, L.; Carcassi, C.; Nicolaides, A.; Laird, J.R.; Suri, H.S.; et al. Nonlinear model for the carotid artery disease 10-year risk prediction by fusing conventional cardiovascular factors to carotid ultrasound image phenotypes: A Japanese diabetes cohort study. Echocardiography 2019, 36, 345–361. [Google Scholar] [CrossRef] [PubMed]
- Kavousi, M.; Leening, M.J.; Nanchen, D.; Greenland, P.; Graham, I.M.; Steyerberg, E.W.; Ikram, M.A.; Stricker, B.H.; Hofman, A.; Franco, O.H. Comparison of application of the ACC/AHA guidelines, Adult Treatment Panel III guidelines, and European Society of Cardiology guidelines for cardiovascular disease prevention in a European cohort. JAMA 2014, 311, 1416–1423. [Google Scholar] [CrossRef] [PubMed]
- Damen, J.A.; Hooft, L.; Schuit, E.; Debray, T.P.; Collins, G.S.; Tzoulaki, I.; Lassale, C.M.; Siontis, G.C.; Chiocchia, V.; Roberts, C.; et al. Prediction models for cardiovascular disease risk in the general population: Systematic review. BMJ 2016, 353, i2416. [Google Scholar] [CrossRef] [PubMed]
- Huntink, E.; Wensing, M.; Klomp, M.A.; van Lieshout, J. Perceived determinants of cardiovascular risk management in primary care: Disconnections between patient behaviours, practice organisation and healthcare system. BMC Fam. Pract. 2015, 16, 179. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Menze, B.H.; Kelm, B.M.; Masuch, R.; Himmelreich, U.; Bachert, P.; Petrich, W.; Hamprecht, F.A. A comparison of random forest and its Gini importance with standard chemometric methods for the feature selection and classification of spectral data. BMC Bioinform. 2009, 10, 213. [Google Scholar] [CrossRef]
- Altmann, A.; Tolosi, L.; Sander, O.; Lengauer, T. Permutation importance: A corrected feature importance measure. Bioinformatics 2010, 26, 1340–1347. [Google Scholar] [CrossRef]
- Strobl, C.; Boulesteix, A.L.; Zeileis, A.; Hothorn, T. Bias in random forest variable importance measures: Illustrations, sources and a solution. BMC Bioinform. 2007, 8, 25. [Google Scholar] [CrossRef]
- Bansilal, S.; Castellano, J.M.; Fuster, V. Global burden of CVD: Focus on secondary prevention of cardiovascular disease. Int. J. Cardiol. 2015, 201 (Suppl. 1), S1–S7. [Google Scholar] [CrossRef]
- Ortega, F.B.; Lavie, C.J.; Blair, S.N. Obesity and Cardiovascular Disease. Circ. Res. 2016, 118, 1752–1770. [Google Scholar] [CrossRef] [PubMed]
- Mozaffarian, D.; Benjamin, E.J.; Go, A.S.; Arnett, D.K.; Blaha, M.J.; Cushman, M.; de Ferranti, S.; Despres, J.P.; Fullerton, H.J.; Howard, V.J.; et al. Heart disease and stroke statistics—2015 update: A report from the American Heart Association. Circulation 2015, 131, e29–e322. [Google Scholar] [CrossRef] [PubMed]
- Gentil, A.; Bejot, Y.; Lorgis, L.; Durier, J.; Zeller, M.; Osseby, G.V.; Dentan, G.; Beer, J.C.; Moreau, T.; Giroud, M.; et al. Comparative epidemiology of stroke and acute myocardial infarction: The Dijon Vascular project (Diva). J. Neurol. Neurosurg. Psychiatry 2009, 80, 1006–1011. [Google Scholar] [CrossRef] [PubMed]
- Meschia, J.F.; Bushnell, C.; Boden-Albala, B.; Braun, L.T.; Bravata, D.M.; Chaturvedi, S.; Creager, M.A.; Eckel, R.H.; Elkind, M.S.; Fornage, M.; et al. Guidelines for the primary prevention of stroke: A statement for healthcare professionals from the American Heart Association/American Stroke Association. Stroke 2014, 45, 3754–3832. [Google Scholar] [CrossRef] [PubMed]
- Larsson, S.C.; Akesson, A.; Wolk, A. Primary prevention of stroke by a healthy lifestyle in a high-risk group. Neurology 2015, 84, 2224–2228. [Google Scholar] [CrossRef] [PubMed]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Non-CVD Group (n = 4699) | CVD Group (n = 4699) | p Value | |
|---|---|---|---|
| Sex, n (%) | 1.00 a | ||
| Male | 2789 (59.4%) | 2789 (59.4%) | |
| Female | 1910 (40.6%) | 1910 (40.6%) | |
| Age group, n (%) | 1.00 b | ||
| 45–49 | 248 (5.3%) | 248 (5.3%) | |
| 50–54 | 556 (11.8%) | 556 (11.8%) | |
| 55–59 | 658 (14.0%) | 658 (14.0%) | |
| 60–64 | 893 (19.0%) | 893 (19.0%) | |
| 65–69 | 730 (15.5%) | 730 (15.5%) | |
| 70–74 | 957 (20.4%) | 957 (20.4%) | |
| 75–79 | 411 (8.7%) | 411 (8.7%) | |
| 80–84 | 210 (4.5%) | 210 (4.5%) | |
| ≥85 | 36 (0.8%) | 36 (0.8%) | |
| Height (cm) | 161.1 ± 9.0 | 161.1 ± 8.8 | 0.82 c |
| Weight (kg) | 62.4 ± 10.4 | 64.1 ± 10.8 | <0.001 c |
| Waist (cm) | 82.8 ± 8.5 | 84.5 ± 8.5 | <0.001 c |
| Total Cholesterol | 196.63 ± 37.52 | 173.52 ± 40.06 | <0.001 c |
| LDL Cholesterol | 116.44 ± 34.55 | 96.13 ± 35.44 | <0.001 c |
| HDL Cholesterol | 50.85 ± 13.56 | 53.09 ± 16.71 | <0.001 c |
| Triglyceride | 135.07 ± 82.23 | 137.40 ± 85.16 | 0.18 c |
| Previous CVD, n (%) | <0.001 b | ||
| No | 4576 (97.4%) | 2336 (49.7%) | |
| Yes | 123 (2.6%) | 2363 (50.3%) | |
| Previous Stroke, n (%) | 0.008 b | ||
| No | 4607 (98.0%) | 4568 (97.2%) | |
| Yes | 92 (2.0%) | 131 (2.8%) | |
| Previous Hypertension, n (%) | <0.001 a | ||
| No | 2949 (62.8%) | 2364 (50.3%) | |
| Yes | 1750 (37.2%) | 2335 (49.7%) | |
| Previous Diabetes, n (%) | <0.001 a | ||
| No | 4047 (86.1%) | 3680 (78.3%) | |
| Yes | 652 (13.9%) | 1019 (21.7%) | |
| Previous Hyperlipidemia, n (%) | <0.001 a | ||
| No | 4414 (93.9%) | 4222 (89.8%) | |
| Yes | 285 (6.1%) | 477 (10.2%) | |
| FH of CVD, n (%) | <0.001 b | ||
| No | 4587 (97.6%) | 4284 (91.2%) | |
| Yes | 112 (2.4%) | 415 (8.8%) | |
| FH of Stroke, n (%) | <0.001 a | ||
| No | 4409 (93.8%) | 4273 (90.9%) | |
| Yes | 290 (6.2%) | 426 (9.1%) | |
| Smoking Type, n (%) | <0.001 a | ||
| Never Smoking | 2823 (60.1%) | 2732 (58.1%) | |
| Past Smoking | 1025 (21.8%) | 1215 (25.9%) | |
| Current Smoking | 851 (18.1%) | 752 (16.0%) | |
| Drinking (days/week), n (%) | <0.001 b | ||
| 0 | 2953 (62.8%) | 3219 (68.5%) | |
| 1 | 634 (13.5%) | 516 (11.0%) | |
| 2 | 450 (9.6%) | 395 (8.4%) | |
| 3 | 290 (6.2%) | 258 (5.5%) | |
| 4 | 115 (2.4%) | 91 (1.9%) | |
| 5 | 70 (1.5%) | 86 (1.8%) | |
| 6 | 59 (1.3%) | 44 (0.9%) | |
| 7 | 128 (2.7%) | 90 (1.9%) | |
| Walk 30 min (days/week), n (%) | 0.27 a | ||
| 0 | 1503 (32.0%) | 1482 (31.5%) | |
| 1 | 337 (7.2%) | 322 (6.9%) | |
| 2 | 507 (10.8%) | 506 (10.8%) | |
| 3 | 584 (12.4%) | 651 (13.9%) | |
| 4 | 355 (7.6%) | 328 (7.0%) | |
| 5 | 423 (9.0%) | 410 (8.7%) | |
| 6 | 304 (6.5%) | 270 (5.7%) | |
| 7 | 686(14.6%) | 730 (15.5%) |
| Trials | Mean | SD | Min | 25% | 50% | 75% | Max | |
|---|---|---|---|---|---|---|---|---|
| eXtream Gradient Boosting | 30 | 0.812 | 0.005 | 0.803 | 0.810 | 0.812 | 0.815 | 0.822 |
| Gradient Boosting | 30 | 0.812 | 0.005 | 0.800 | 0.809 | 0.812 | 0.816 | 0.821 |
| Random Forest | 30 | 0.811 | 0.005 | 0.799 | 0.809 | 0.811 | 0.815 | 0.821 |
| Multi-layer Perceptron | 30 | 0.808 | 0.006 | 0.794 | 0.805 | 0.808 | 0.812 | 0.817 |
| Adaptive Boosting | 30 | 0.806 | 0.005 | 0.798 | 0.802 | 0.806 | 0.810 | 0.818 |
| Logistic Regression | 30 | 0.805 | 0.005 | 0.793 | 0.801 | 0.805 | 0.808 | 0.814 |
| Extra-Trees | 30 | 0.802 | 0.005 | 0.791 | 0.799 | 0.803 | 0.806 | 0.811 |
| K-nearest Neighbors | 30 | 0.792 | 0.005 | 0.779 | 0.789 | 0.794 | 0.796 | 0.802 |
| Decision Tree | 30 | 0.789 | 0.005 | 0.780 | 0.786 | 0.790 | 0.793 | 0.796 |
| Support Vector Machine | 30 | 0.782 | 0.006 | 0.766 | 0.779 | 0.783 | 0.786 | 0.793 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, J.O.; Jeong, Y.-S.; Kim, J.H.; Lee, J.-W.; Park, D.; Kim, H.-S. Machine Learning-Based Cardiovascular Disease Prediction Model: A Cohort Study on the Korean National Health Insurance Service Health Screening Database. Diagnostics 2021, 11, 943. https://doi.org/10.3390/diagnostics11060943
Kim JO, Jeong Y-S, Kim JH, Lee J-W, Park D, Kim H-S. Machine Learning-Based Cardiovascular Disease Prediction Model: A Cohort Study on the Korean National Health Insurance Service Health Screening Database. Diagnostics. 2021; 11(6):943. https://doi.org/10.3390/diagnostics11060943
Chicago/Turabian StyleKim, Joung Ouk (Ryan), Yong-Suk Jeong, Jin Ho Kim, Jong-Weon Lee, Dougho Park, and Hyoung-Seop Kim. 2021. "Machine Learning-Based Cardiovascular Disease Prediction Model: A Cohort Study on the Korean National Health Insurance Service Health Screening Database" Diagnostics 11, no. 6: 943. https://doi.org/10.3390/diagnostics11060943
APA StyleKim, J. O., Jeong, Y.-S., Kim, J. H., Lee, J.-W., Park, D., & Kim, H.-S. (2021). Machine Learning-Based Cardiovascular Disease Prediction Model: A Cohort Study on the Korean National Health Insurance Service Health Screening Database. Diagnostics, 11(6), 943. https://doi.org/10.3390/diagnostics11060943