
Deep Reinforcement Learning-Based Resource Allocation for UAV-GAP Downlink Cooperative NOMA in IIoT Systems

 , , , , and
, , , , and
Abstract
1. Introduction
- We propose a SAC-based joint optimization framework addressing UAV 3D trajectory planning and resource allocation challenges in dense and dynamic IIoT scenarios.
- By integrating power allocation, user scheduling, and 3D UAV trajectory design, we develop a joint resource management scheme for UAV-GAP cooperative NOMA systems that exploits interference channels to improve spectral efficiency and system throughput under stringent reliability and latency constraints.
- Simulation results validate the proposed approach’s performance improvements in IIoT downlink scenarios, including throughput gains, energy consumption reduction, and enhanced interference management, indicating its potential applicability in industrial contexts.
2. System Model and Problem Formulation
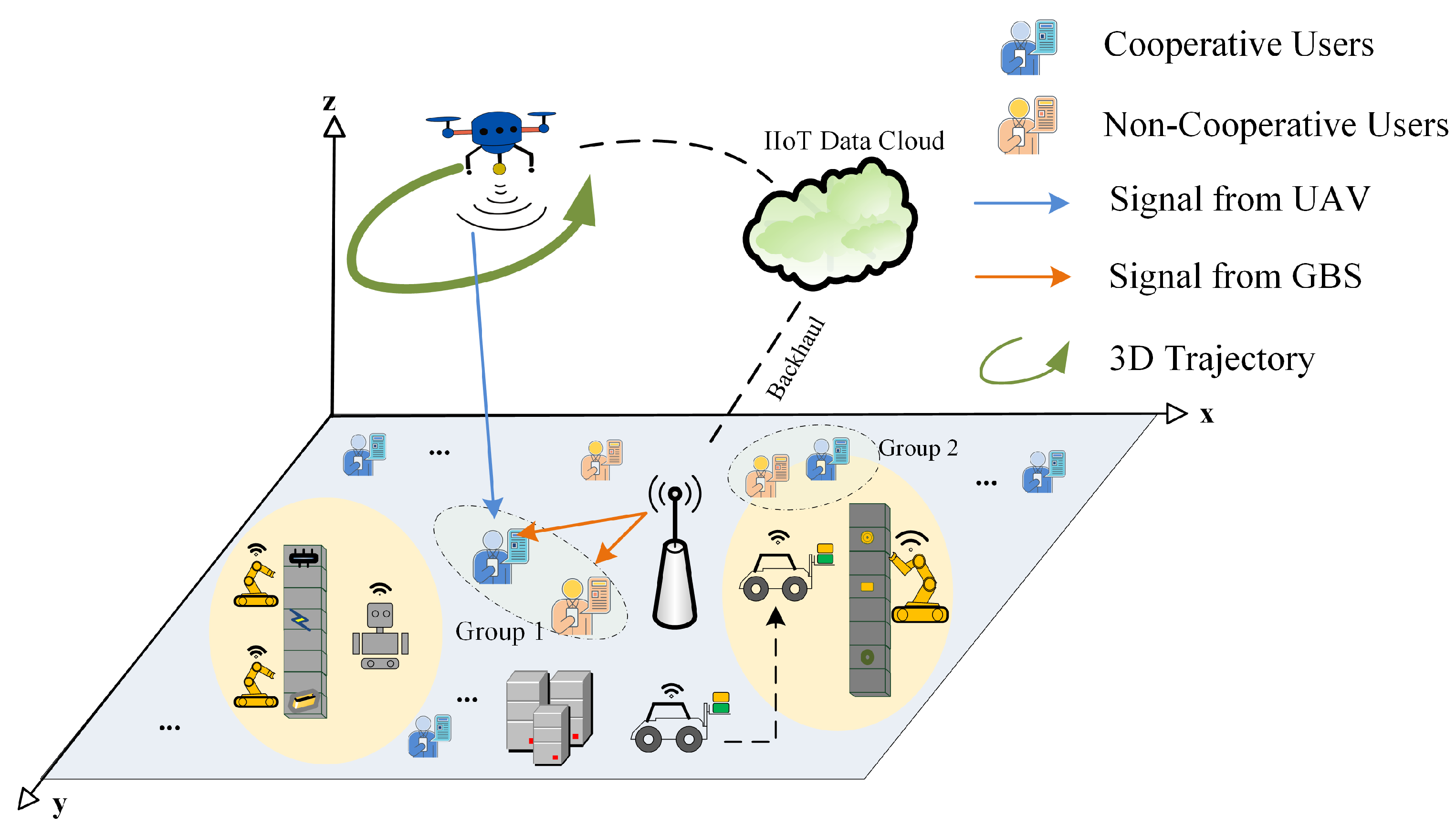
2.1. System Model
2.2. Problem Formulation
3. Joint User Scheduling and Power Allocation
3.1. Closed-Form Power Allocation with Given User Scheduling
3.2. Joint User Scheduling and Power Allocation Based on Bipartite Matching
4. Trajectory Optimization Using Deep Reinforcement Learning
4.1. Markov Decision Process Formulation
4.1.1. State Space
4.1.2. Action Space
4.1.3. State Transition Probability P
4.1.4. Reward Function R
4.1.5. Discount Factor
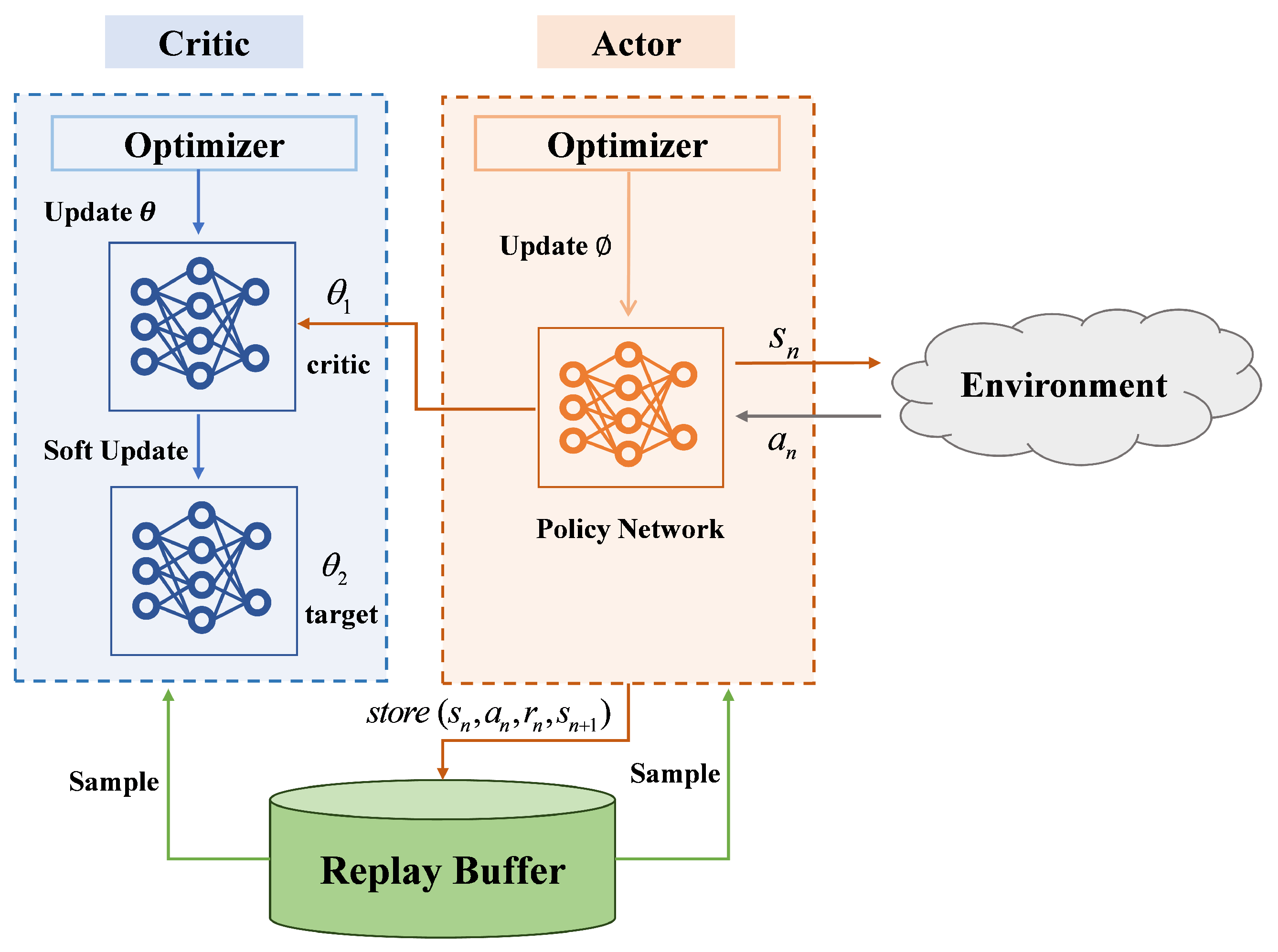
4.2. Soft Actor–Critic Algorithm
| Algorithm 1 Soft Actor–Critic-Based Trajectory Optimization |
|
4.3. Computational Complexity Analysis
4.3.1. Joint User Scheduling and Power Allocation
4.3.2. SAC-Based Trajectory Optimization
4.3.3. Overall System Complexity
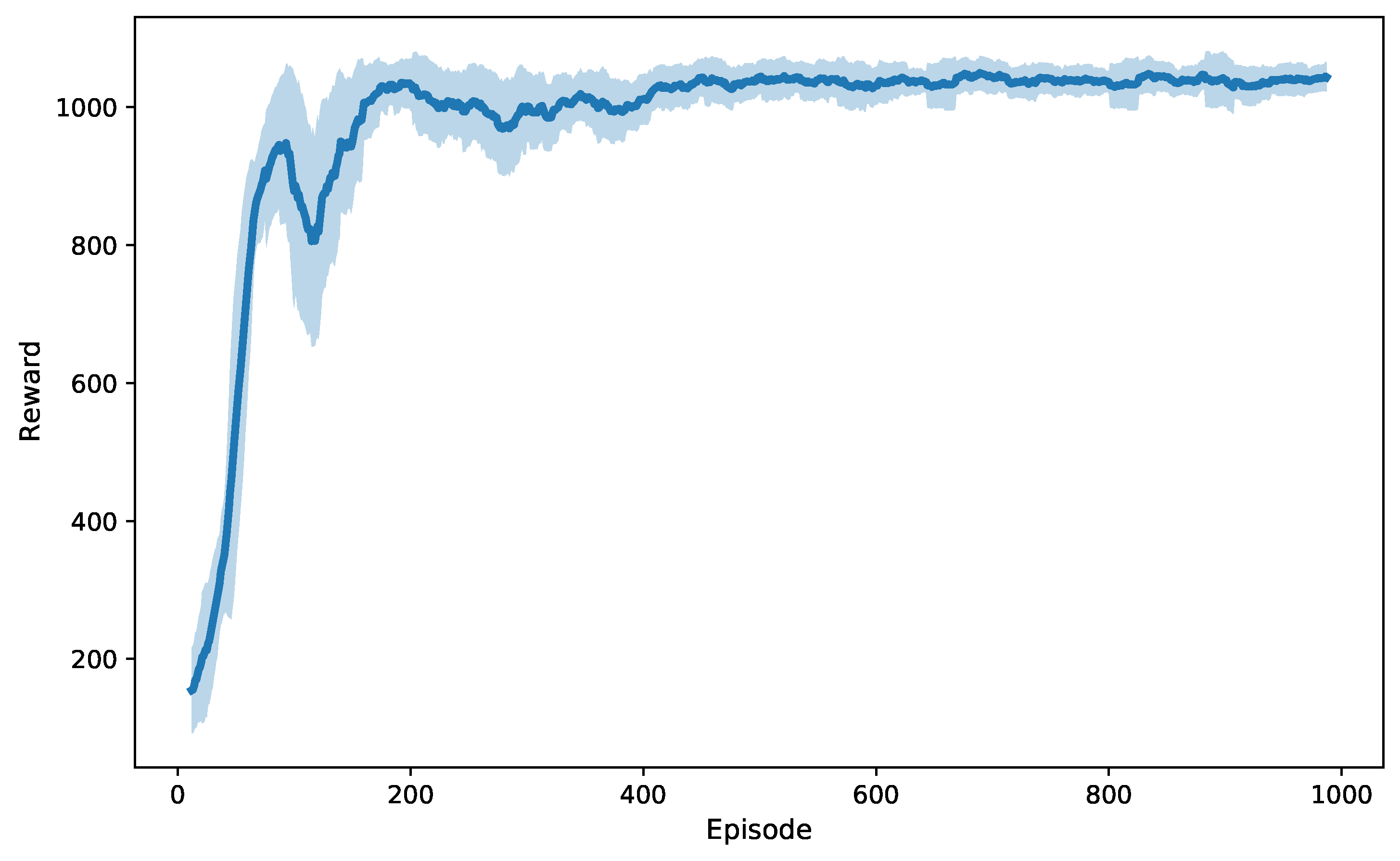
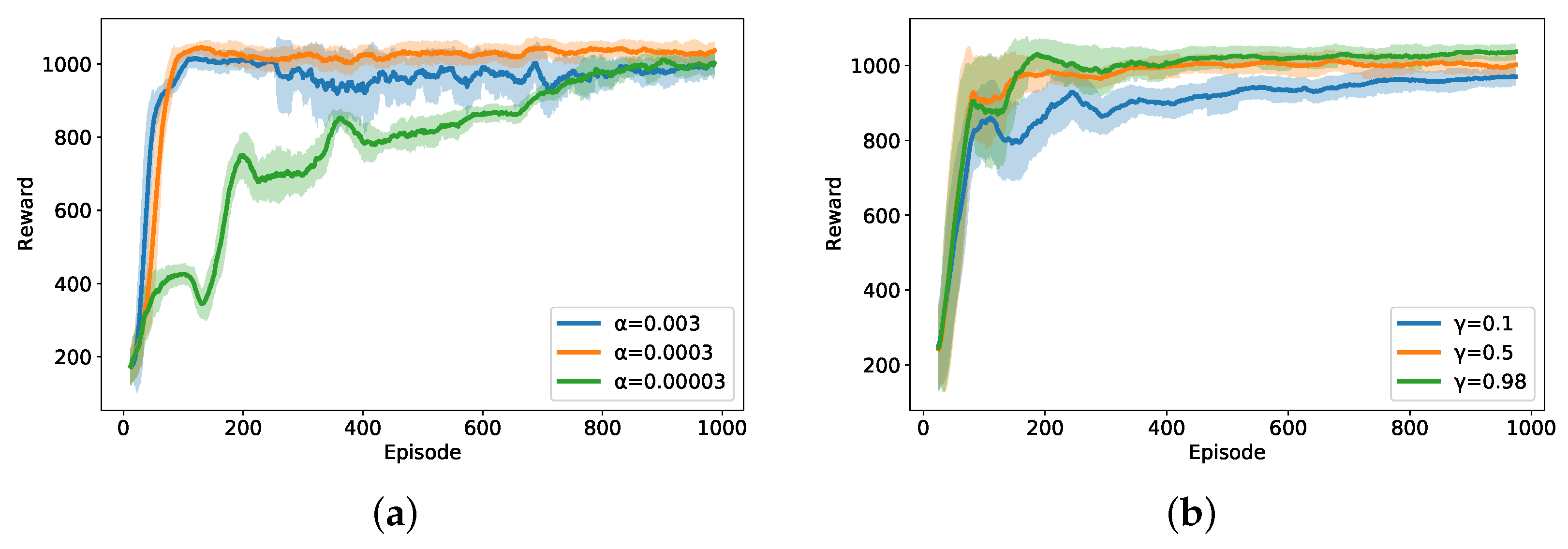
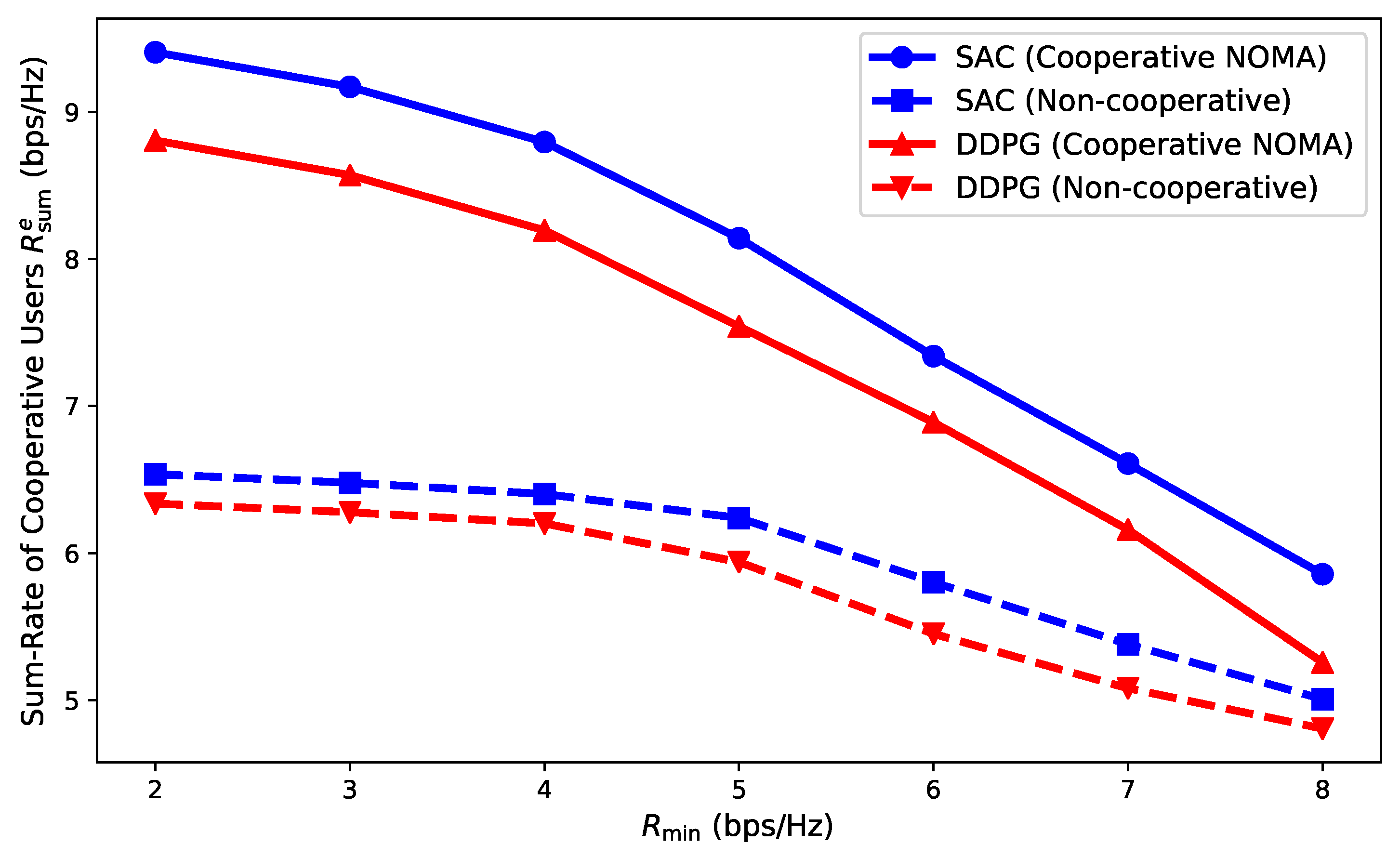
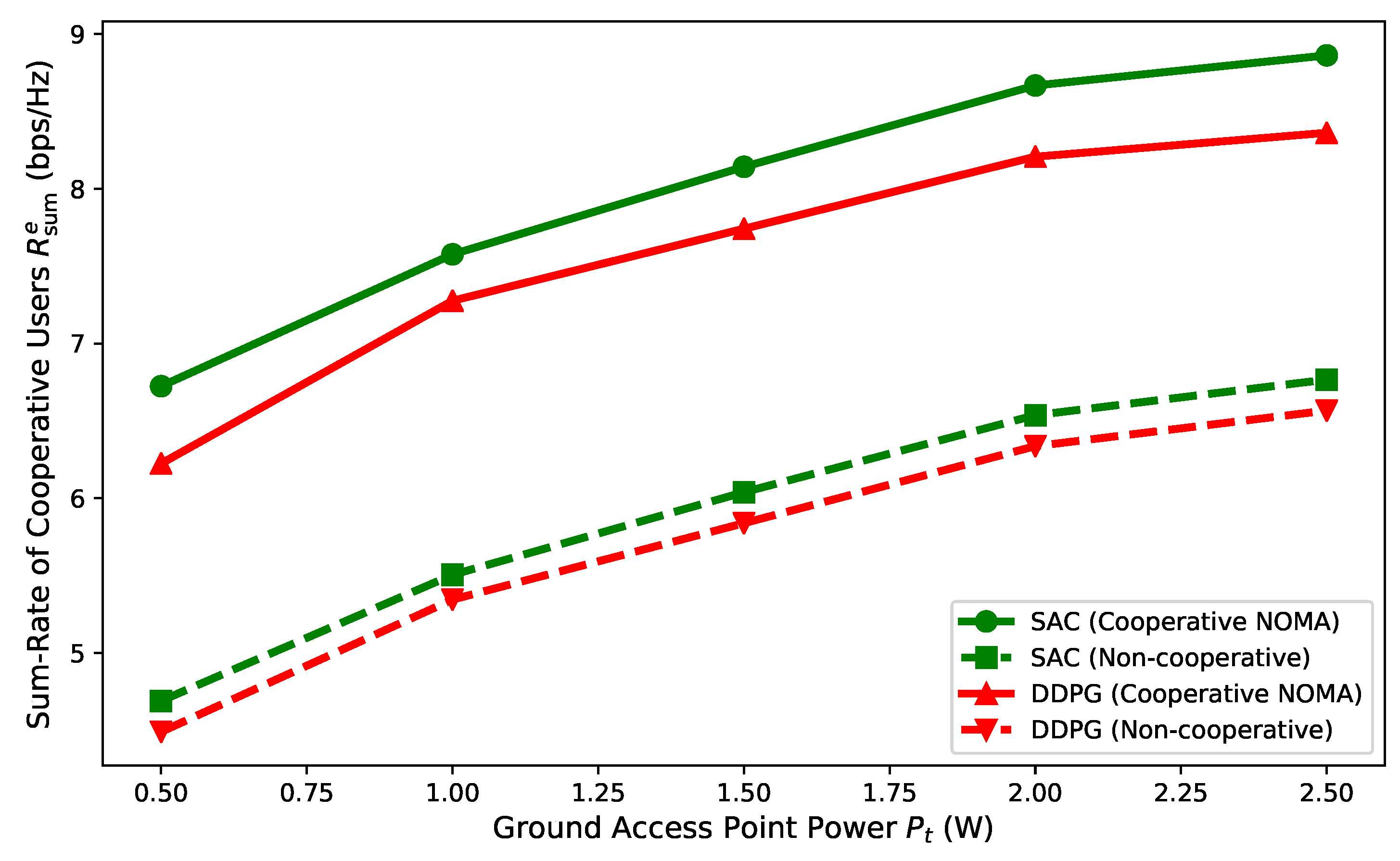
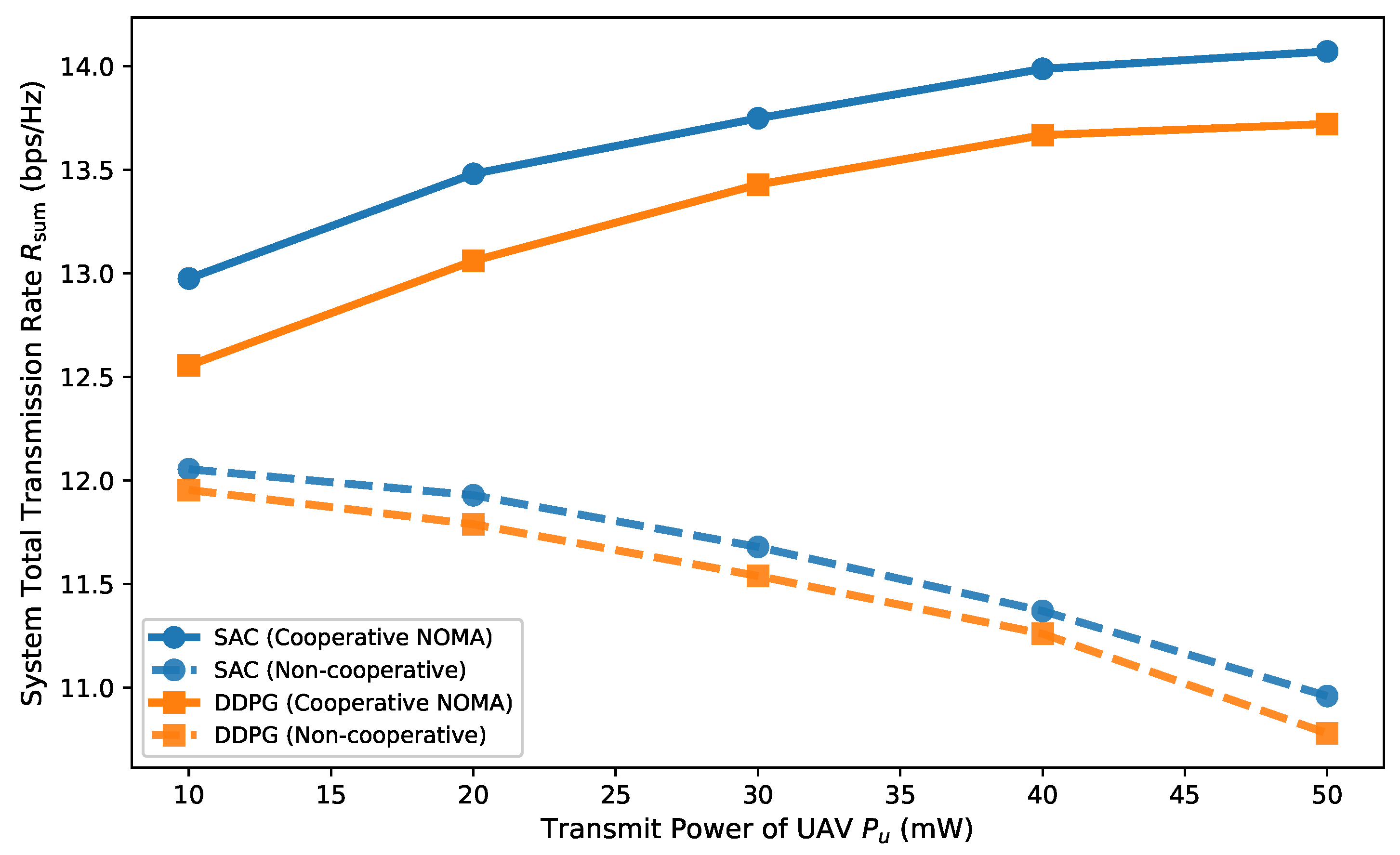
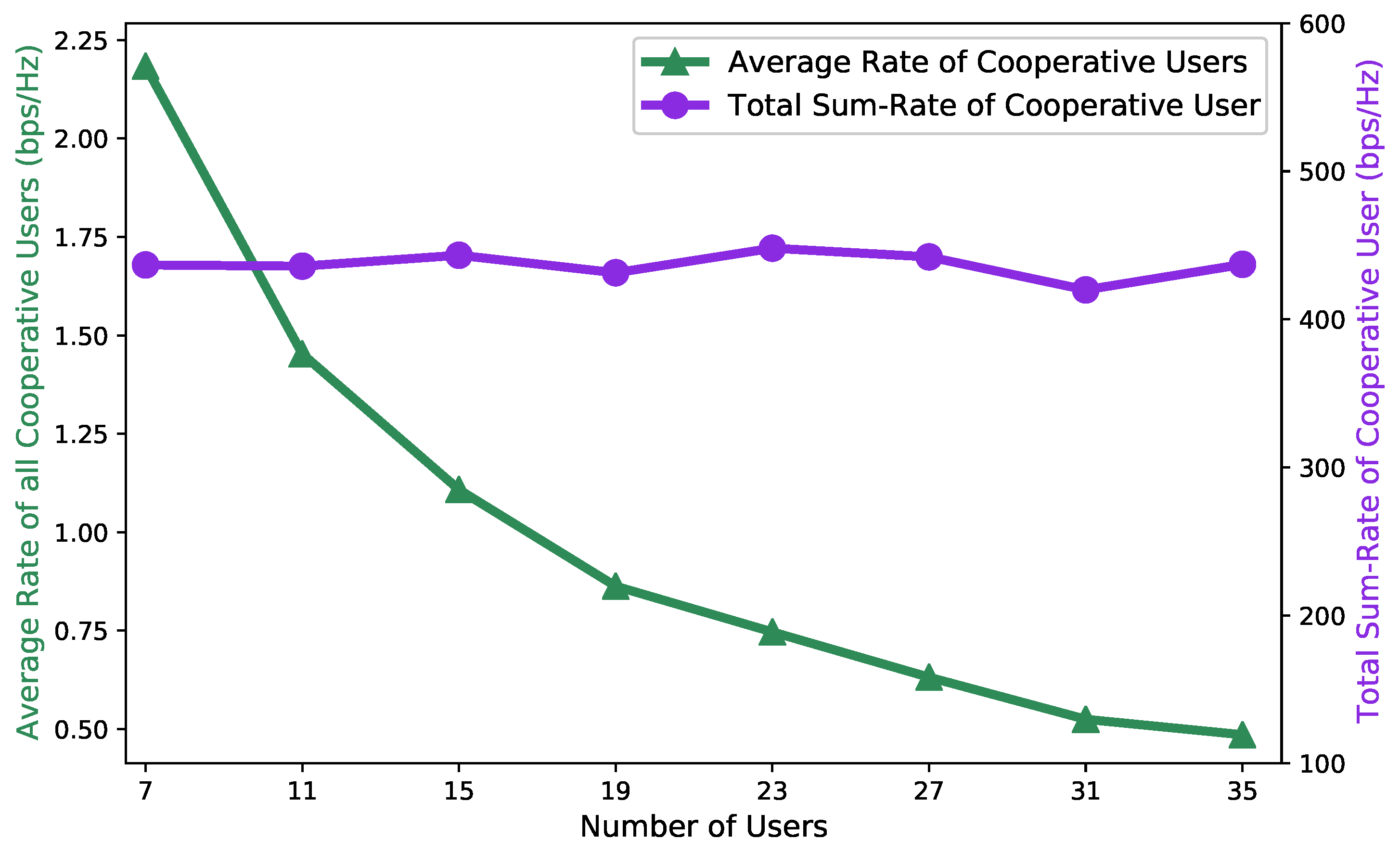
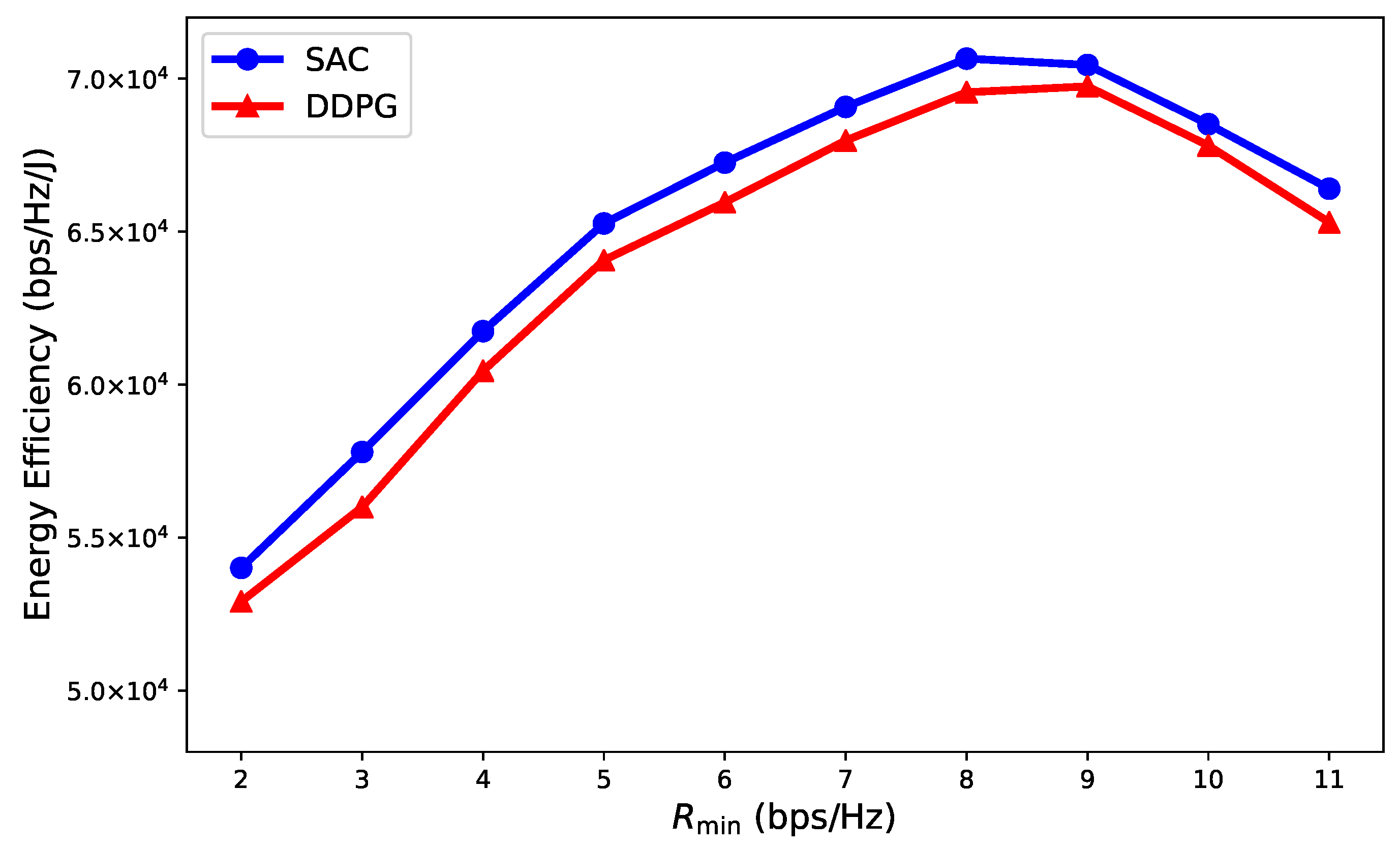
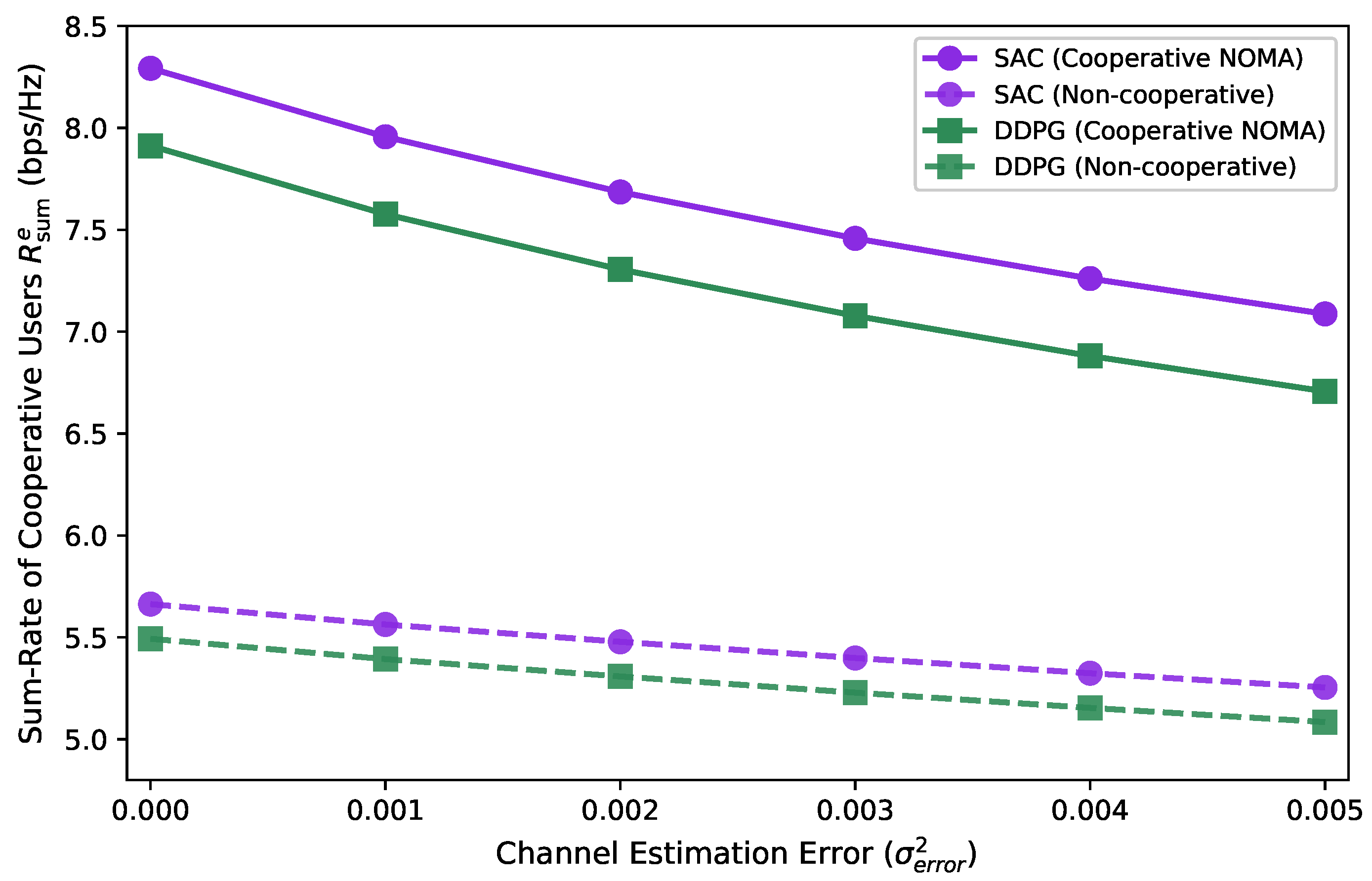
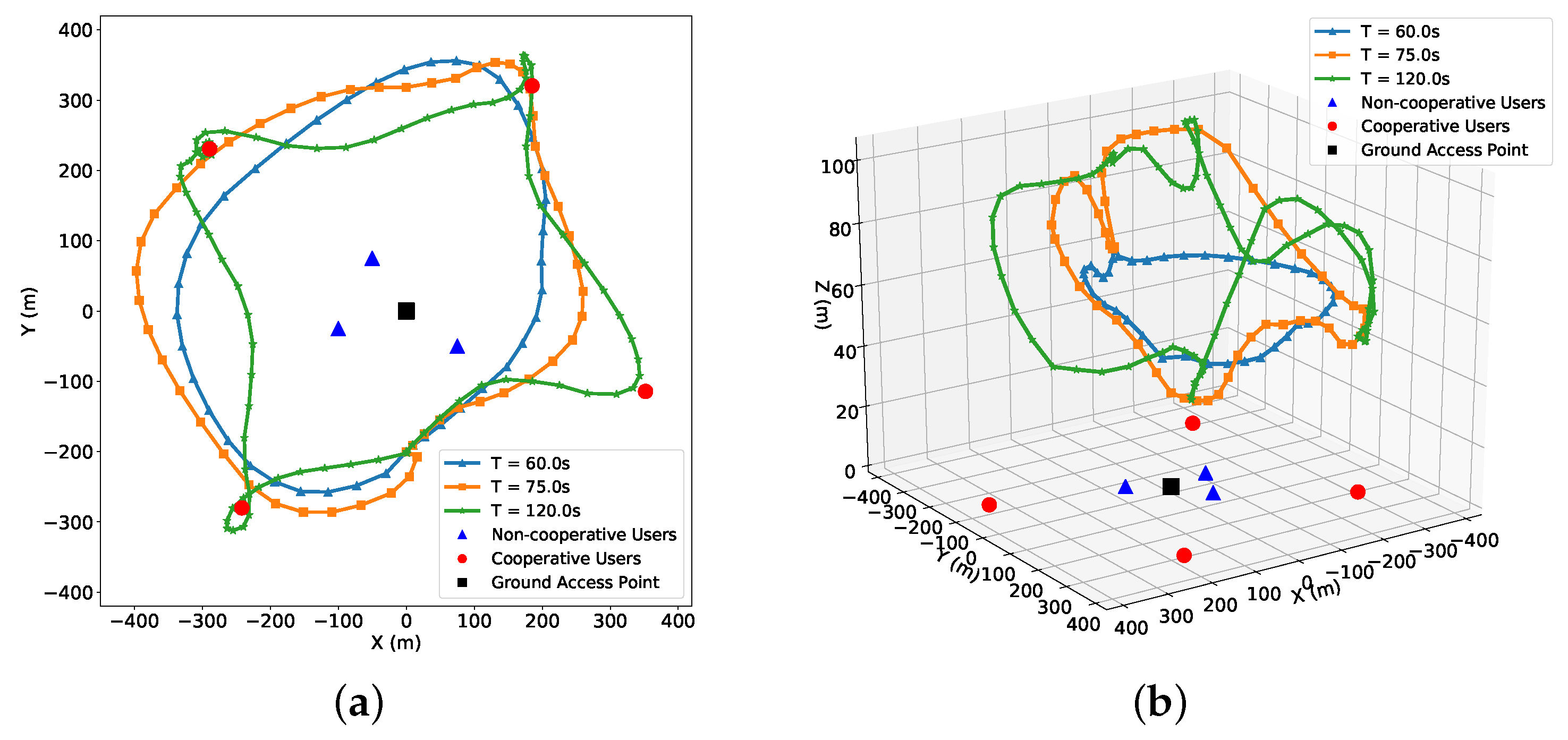
5. Results and Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zhang, X.; Liu, Y.; Zhou, S.; Bian, J.; Huang, J.; Li, X.; Xin, Z. GAN-Based Channel Generation and Modeling for 6G Intelligent IIoT Communications. IEEE Internet Things J. 2025; in press. [Google Scholar] [CrossRef]
- Mostafa, S.; Mota, M.P.; Valcarce, A.; Bennis, M. Intent-Aware DRL-Based NOMA Uplink Dynamic Scheduler for IIoT. IEEE Trans. Cogn. Commun. Netw. 2025; in press. [Google Scholar] [CrossRef]
- Wu, W.; Zhou, F.; Wang, B.; Wu, Q.; Dong, C.; Hu, R.Q. Unmanned Aerial Vehicle Swarm-Enabled Edge Computing: Potentials, Promising Technologies, and Challenges. IEEE Wireless Commun. 2022, 29, 78–85. [Google Scholar] [CrossRef]
- Zeng, H.; Zhu, X.; Jiang, Y.; Wei, Z.; Sun, S.; Xiong, X. Toward UL-DL Rate Balancing: Joint Resource Allocation and Hybrid-Mode Multiple Access for UAV-BS-Assisted Communication Systems. IEEE Trans. Commun. 2022, 70, 2757–2771. [Google Scholar] [CrossRef]
- Cheng, F.; Gui, G.; Zhao, N.; Chen, Y.; Tang, J.; Sari, H. UAV-Relaying-Assisted Secure Transmission With Caching. IEEE Trans. Commun. 2019, 67, 3140–3153. [Google Scholar] [CrossRef]
- Zhao, N.; Lu, W.; Sheng, M.; Chen, Y.; Tang, J.; Yu, F.R.; Wong, K.-K. UAV-Assisted Emergency Networks in Disasters. IEEE Wireless Commun. 2019, 26, 45–51. [Google Scholar] [CrossRef]
- Zeng, H.; Zhang, R.; Zhu, X.; Wei, Z.; Jiang, Y.; Sun, S.; Zheng, F.-C.; Cao, B. Toward 3-D AAV-Ground BS CoMP-NOMA Transmission: Optimal Resource Allocation and Trajectory Design. IEEE Internet Things J. 2025, 12, 9671–9686. [Google Scholar] [CrossRef]
- Wu, Q.; Zhang, R. Common Throughput Maximization in UAV-Enabled OFDMA Systems With Delay Consideration. IEEE Trans. Commun. 2018, 66, 6614–6627. [Google Scholar] [CrossRef]
- Zhang, H.; Zhang, J.; Long, K. Energy Efficiency Optimization for NOMA UAV Network With Imperfect CSI. IEEE J. Sel. Areas Commun. 2020, 38, 2798–2809. [Google Scholar] [CrossRef]
- Lyu, J.; Zeng, Y.; Zhang, R. UAV-Aided Offloading for Cellular Hotspot. IEEE Trans. Wireless. Commun. 2018, 17, 3988–4001. [Google Scholar] [CrossRef]
- Dai, L.; Wang, B.; Ding, Z.; Wang, Z.; Chen, S.; Hanzo, L. A Survey of Non-Orthogonal Multiple Access for 5G. IEEE Commun. Surv. Tutorials. 2018, 20, 2294–2323. [Google Scholar] [CrossRef]
- Liu, Y.; Qin, Z.; Cai, Y.; Gao, Y.; Li, G.Y.; Nallanathan, A. UAV Communications Based on Non-Orthogonal Multiple Access. IEEE Wireless. Commun. 2019, 26, 52–57. [Google Scholar] [CrossRef]
- Hou, T.; Liu, Y.; Song, Z.; Sun, X.; Chen, Y. Multiple Antenna Aided NOMA in UAV Networks: A Stochastic Geometry Approach. IEEE Trans. Commun. 2019, 67, 1031–1044. [Google Scholar] [CrossRef]
- Miuccio, L.; Panno, D.; Riolo, S. A Flexible Encoding/Decoding Procedure for 6G SCMA Wireless Networks via Adversarial Machine Learning Techniques. IEEE Trans. Veh. Technol. 2022, 72, 3288–3303. [Google Scholar] [CrossRef]
- Ülgen, O.; Tufekci, T.K.; Sadi, Y.; Erkucuk, S.; Anpalagan, A.; Baykaş, T. Sparse Code Multiple Access with Time Spreading and Repetitive Transmissions. Int. J. Commun. Syst. 2025, 38, e6121. [Google Scholar] [CrossRef]
- Wu, G.; Chen, G.; Gu, X. NOMA-Based Rate Optimization for Multi-UAV-Assisted D2D Communication Networks. Drones 2025, 9, 62. [Google Scholar] [CrossRef]
- Wu, J.; Liu, C.; Wang, X.; Cheng, C.T.; Zhou, Q. Jointly Optimizing Resource Allocation, User Scheduling, and Grouping in SBMA Networks: A PSO Approach. Entropy 2025, 27, 691. [Google Scholar] [CrossRef]
- Li, N.; Wu, P.; Zhu, L.; Ng, D.W.K. Movable-Antenna Array Enhanced Downlink NOMA. arXiv 2025, arXiv:2506.11438. [Google Scholar]
- Pereira, F.M.; de Araújo Farhat, J.; Rebelatto, J.L.; Brante, G.; Souza, R.D. Reinforcement Learning-Aided NOMA Random Access: An AoI-Based Timeliness Perspective. IEEE Internet Things J. 2024, 12, 6058–6061. [Google Scholar] [CrossRef]
- Irmer, R.; Droste, H.; Marsch, P.; Grieger, M.; Fettweis, G.; Brueck, S.; Mayer, H.-P.; Thiele, L.; Jungnickel, V. Coordinated multipoint: Concepts, performance, and field trial results. IEEE Commun. Mag. 2011, 49, 102–111. [Google Scholar] [CrossRef]
- Nguyen, T.M.; Ajib, W.; Assi, C. A Novel Cooperative NOMA for Designing UAV-Assisted Wireless Backhaul Networks. IEEE J. Sel. Areas Commun. 2018, 36, 2497–2507. [Google Scholar] [CrossRef]
- Zhao, N.; Pang, X.; Li, Z.; Chen, Y.; Li, F.; Ding, Z.; Alouini, M.-S. Joint Trajectory and Precoding Optimization for UAV-Assisted NOMA Networks. IEEE Trans. Commun. 2019, 67, 3723–3735. [Google Scholar] [CrossRef]
- Ali, M.S.; Hossain, E.; Al-Dweik, A.; Kim, D.I. Downlink Power Allocation for CoMP-NOMA in Multi-Cell Networks. IEEE Trans. Commun. 2018, 66, 3982–3998. [Google Scholar] [CrossRef]
- Zeng, H.; Zhu, X.; Jiang, Y.; Wei, Z.; Wang, T. A Green Coordinated Multi-Cell NOMA System With Fuzzy Logic Based Multi-Criterion User Mode Selection and Resource Allocation. IEEE J. Sel. Top. Signal Process. 2019, 13, 480–495. [Google Scholar] [CrossRef]
- Qu, Y.; Dai, H.; Wang, H.; Dong, C.; Wu, F.; Guo, S.; Wu, Q. Service Provisioning for UAV-Enabled Mobile Edge Computing. IEEE J. Sel. Areas Commun. 2021, 39, 3287–3305. [Google Scholar] [CrossRef]
- Bayessa, G.A.; Chai, R.; Liang, C.; Jain, D.K.; Chen, Q. Joint UAV Deployment and Precoder Optimization for Multicasting and Target Sensing in UAV-Assisted ISAC Networks. IEEE Internet Things J. 2024, 11, 33392–33405. [Google Scholar] [CrossRef]
- Zhao, N.; Cheng, F.; Yu, F.R.; Tang, J.; Chen, Y.; Gui, G.; Sari, H. Caching UAV Assisted Secure Transmission in Hyper-Dense Networks Based on Interference Alignment. IEEE Trans. Commun. 2018, 66, 2281–2294. [Google Scholar] [CrossRef]
- Song, Q.; Zheng, F.-C.; Zeng, Y.; Zhang, J. Joint Beamforming and Power Allocation for UAV-Enabled Full-Duplex Relay. IEEE Trans. Veh. Technol. 2019, 68, 1657–1671. [Google Scholar] [CrossRef]
- Yin, S.; Yu, F.R. Resource Allocation and Trajectory Design in UAV-Aided Cellular Networks Based on Multiagent Reinforcement Learning. IEEE Internet Things J. 2022, 9, 2933–2943. [Google Scholar] [CrossRef]
- Yuan, X.; Hu, S.; Ni, W.; Wang, X.; Jamalipour, A. Deep Reinforcement Learning-Driven Reconfigurable Intelligent Surface-Assisted Radio Surveillance with a Fixed-Wing UAV. IEEE Trans. Inf. Forensics Secur. 2023, 18, 4546–4560. [Google Scholar] [CrossRef]
- Dong, R.; Wang, B.; Cao, K.; Tian, J.; Cheng, T. Secure Transmission Design of RIS Enabled UAV Communication Networks Exploiting Deep Reinforcement Learning. IEEE Trans. Veh. Technol. 2024, 73, 8404–8419. [Google Scholar] [CrossRef]
- Zeng, H.; Zhang, R.; Zhu, X.; Jiang, Y.; Wei, Z.; Zheng, F.-C. Interference-Aware AAV-TBS Coordinated NOMA: Joint User Scheduling, Power Allocation and Trajectory Design. IEEE Open J. Veh. Technol. 2025, 6, 812–828. [Google Scholar] [CrossRef]
- Khawaja, W.; Guvenc, I.; Matolak, D.W.; Fiebig, U.-C.; Schneckenburger, N. A Survey of Air-to-Ground Propagation Channel Modeling for Unmanned Aerial Vehicles. IEEE Commun. Surv. Tutor. 2019, 21, 2361–2391. [Google Scholar] [CrossRef]
- Al-Hourani, A.; Kandeepan, S.; Lardner, S. Optimal LAP Altitude for Maximum Coverage. IEEE Wireless Commun. Lett. 2014, 3, 569–572. [Google Scholar] [CrossRef]
- Ju, S.; Shakya, D.; Poddar, H.; Xing, Y.; Kanhere, O.; Rappaport, T.S. 142 GHz Sub-Terahertz Radio Propagation Measurements and Channel Characterization in Factory Buildings. IEEE Trans. Wireless Commun. 2023, 23, 7127–7143. [Google Scholar] [CrossRef]
- Qin, Y.; Tang, P.; Tian, L.; Lin, J.; Chang, Z.; Liu, P.; Zhang, J.; Jiang, T. Time-Varying Channel Measurement and Analysis at 105 GHz in an Indoor Factory. In Proceedings of the 2024 18th European Conference on Antennas and Propagation (EuCAP), Rome, Italy, 17–22 March 2024; pp. 1–5. [Google Scholar]
- Yusuf, T.A.O.; Petersen, S.S.; Li, P.; Ren, J.; Mursia, P.; Sciancalepore, V.; Pérez, X.C.; Berardinelli, G.; Shen, M. AI-Assisted NLOS Sensing for RIS-Based Indoor Localization in Smart Factories. arXiv 2025, arXiv:2505.15989. [Google Scholar]
- Fang, F.; Zhang, H.; Cheng, J.; Leung, V.C.M. Energy Efficient Resource Allocation for Downlink Nonorthogonal Multiple Access Network. IEEE Trans. Commun. 2016, 64, 3722–3732. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notation | Description | Value |
|---|---|---|
| B | System bandwidth | 1 MHz |
| Ground base station transmit power | 1.5 W | |
| UAV transmit power | 40 mW | |
| Number of non-cooperative users | 3 | |
| Number of cooperative users | 4 | |
| H | UAV initial flight altitude | 70 m |
| UAV maximum horizontal speed | 50 m/s | |
| UAV maximum vertical speed | 20 m/s | |
| N | Number of time slots | 80 |
| UAV flight area | m | |
| Minimum rate requirement per user | 4 bits/s/Hz | |
| Noise power spectral density | −110 dBm | |
| a, b | Urban LoS channel parameters | 4.88, 0.43 |
| Path loss exponent | 3 | |
| , | Max scheduling counts for center and edge users | 27, 23 |
| Symbol | Parameter | Value |
|---|---|---|
| Actor learning rate | 0.0003 | |
| Critic learning rate | 0.0003 | |
| Discount factor | 0.98 | |
| Replay buffer size | ||
| B | Batch size | 64 |
| Target network update rate | 0.005 | |
| E | Episodes | 1000 |
| N | Time slots per episode | 80 |
| L | Neural network layers | 3 |
| H | Hidden units per layer | 128 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, Y.; Su, J.; Lu, X.; Huang, S.; Zhu, H.; Zeng, H. Deep Reinforcement Learning-Based Resource Allocation for UAV-GAP Downlink Cooperative NOMA in IIoT Systems. Entropy 2025, 27, 811. https://doi.org/10.3390/e27080811
Huang Y, Su J, Lu X, Huang S, Zhu H, Zeng H. Deep Reinforcement Learning-Based Resource Allocation for UAV-GAP Downlink Cooperative NOMA in IIoT Systems. Entropy. 2025; 27(8):811. https://doi.org/10.3390/e27080811
Chicago/Turabian StyleHuang, Yuanyan, Jingjing Su, Xuan Lu, Shoulin Huang, Hongyan Zhu, and Haiyong Zeng. 2025. "Deep Reinforcement Learning-Based Resource Allocation for UAV-GAP Downlink Cooperative NOMA in IIoT Systems" Entropy 27, no. 8: 811. https://doi.org/10.3390/e27080811
APA StyleHuang, Y., Su, J., Lu, X., Huang, S., Zhu, H., & Zeng, H. (2025). Deep Reinforcement Learning-Based Resource Allocation for UAV-GAP Downlink Cooperative NOMA in IIoT Systems. Entropy, 27(8), 811. https://doi.org/10.3390/e27080811