1. Introduction
Since the success of Masked Language Modeling [
1] in the natural language processing field, Masked Image Modeling (MIM) [
2,
3] has gradually become a mainstream pre-training paradigm for visual representation learning in the computer vision field. By masking parts of the input and reconstructing the original image, MIM pre-trained Vision Transformers (ViTs) [
4,
5] are able to learn rich visual representations, significantly improving performance in downstream classification, detection, and segmentation tasks. Thanks to their long-range modeling capabilities, ViTs can capture global contextual information within images and effectively model relationships between different spatial patches, thereby further advancing the development of MIM in visual representation learning.
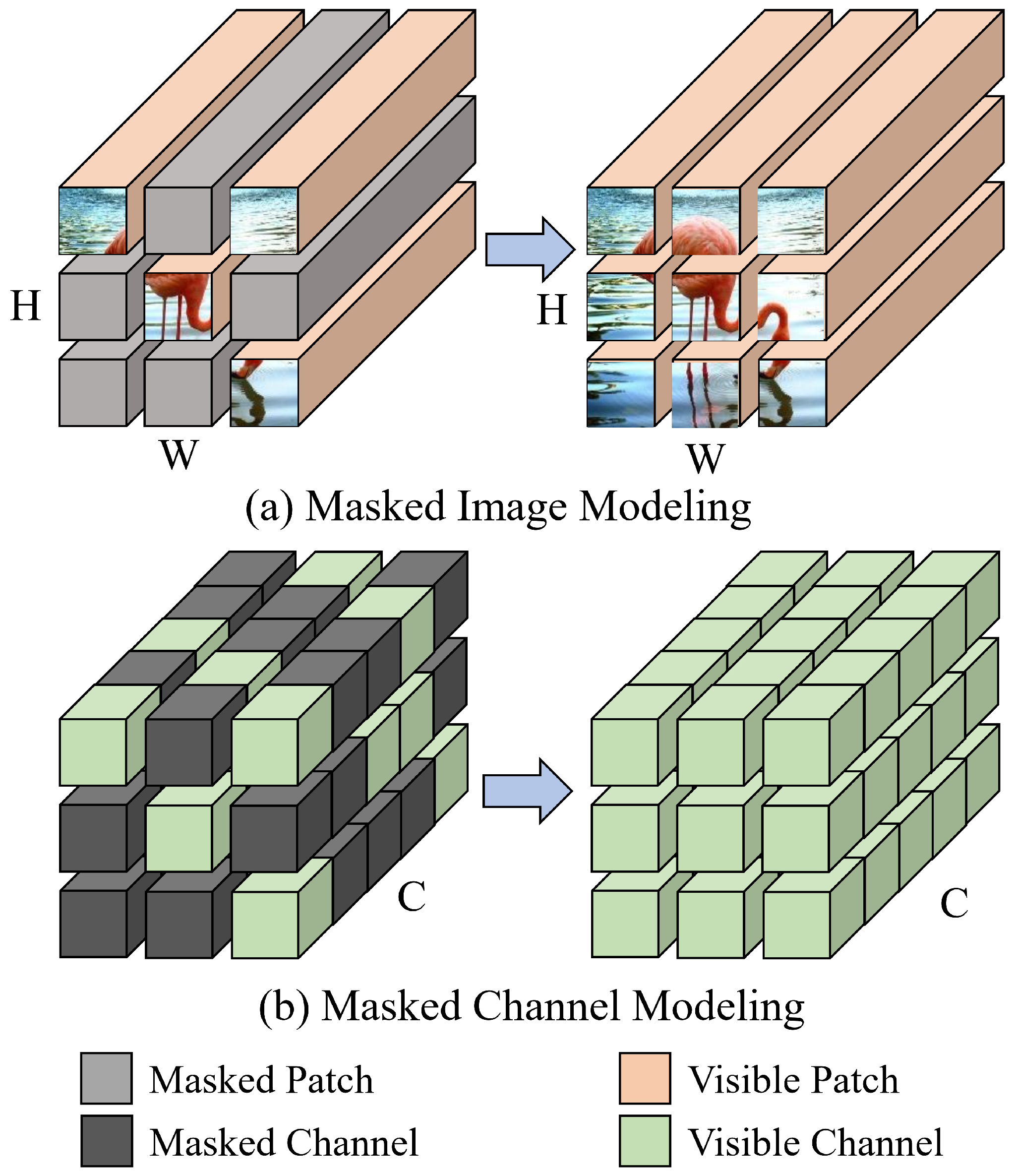
For general Vision Transformers, the features extracted from a specific spatial patch of an image should reflect a certain level of spatial continuity [
4,
6]. Simultaneously, channels within that patch that exhibit semantic continuity should be able to map to specific objects or semantic concepts [
7]. This ability allows ViTs to accurately capture the semantic structure of an image, thus promoting a deeper understanding of image semantics and facilitating cross-modal information alignment. However, as illustrated in
Figure 1a, most existing MIM methods [
2,
3,
8] focus primarily on spatial patch-level reconstruction, attempting to learn both local and global visual representations by emphasizing spatial continuity. They overlook the importance of semantic continuity in the channel dimension, specifically the transmission relationships of semantic information between channels within the same patch or across different patches. To address this limitation, as depicted in
Figure 1b, this paper proposes a new Masked Channel Modeling (MCM) paradigm, which leverages the contextual semantic information from unmasked channels to reconstruct the features of masked channels, strengthening the model’s understanding of channel semantic continuity and enriching its representational capability.
Following the classic asymmetric encoder–decoder architecture of MAE [
3], MCM first randomly masks a large proportion of the channels (e.g. 75%) in each patch and replaces the masked channels with the shared and learnable encode token. These embeddings are fed into a ViT [
5] encoder, followed by the decoder to complete channel reconstruction. Unlike traditional methods that use pixel-based targets, this paper introduces advanced features extracted by the CLIP image encoder [
9] as the reconstruction target [
10,
11]. The CLIP advanced features are closely associated with semantic information in each channel, such as object categories, attributes, and contextual relationships. This design effectively overcomes the limitations of traditional pixel-based targets, which lack sufficient channel semantic attributes, enabling the model to learn deeper semantic relationships.
By shifting the focus of modeling to the channel dimension, MCM is able to better capture the semantic continuity between feature channels and benefit from more fine-grained semantic information, such as the diversity of objects, contextual relationships in the background, and the decoupling of different semantic features [
12,
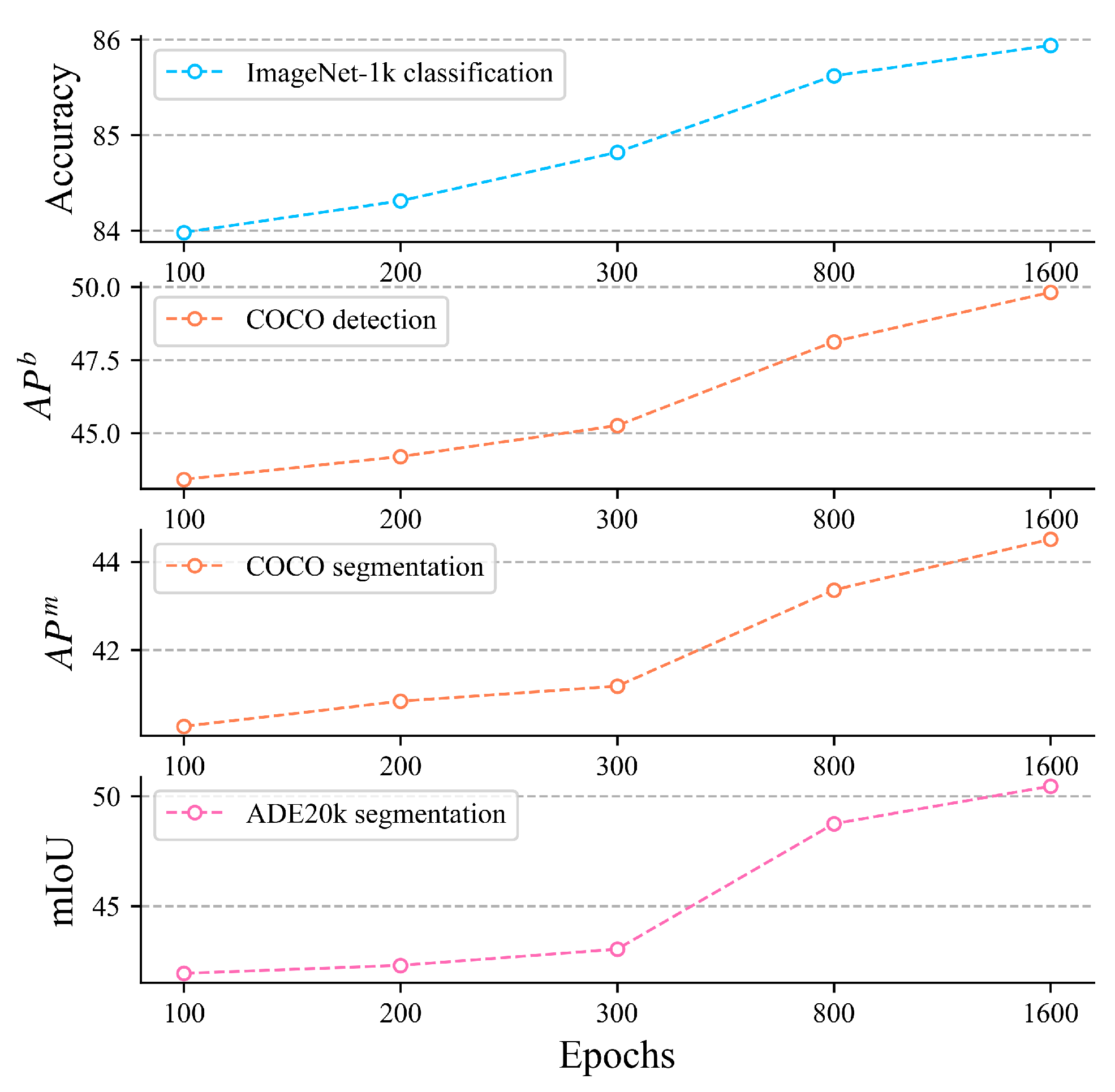
13]. Extensive experiments have demonstrated that MCM shows significant advantages in downstream image classification, object detection, and semantic segmentation, validating the crucial role of channel semantic continuity in enhancing the model’s representational capabilities.
Masked Image Modeling (MIM), such as MAE, primarily captures spatial relationships by reconstructing masked image patches, but may overlook the deeper semantic continuity among channels, often confusing visually similar yet semantically distinct regions or objects. To address this limitation, we propose Masked Channel Modeling (MCM), which explicitly targets semantic continuity across channel dimensions, compelling the model to infer missing semantic features from the remaining visible channels.
3. Masked Channel Modeling
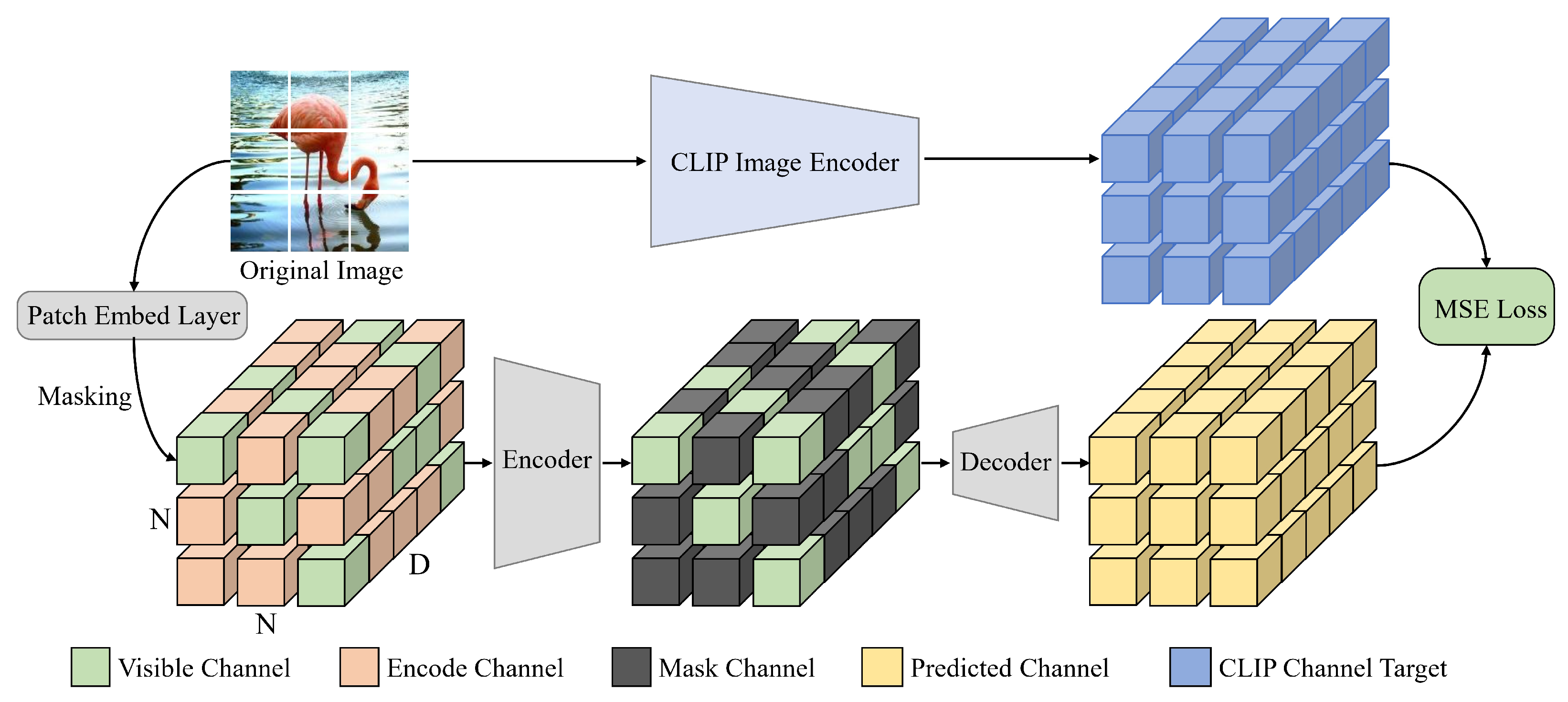
The MCM pipeline is illustrated in
Figure 2. We follow the classic MAE [
3] encoder–decoder asymmetric architecture, using a standard Vision Transformer (ViT) [
5] as the encoder and two layers of 768-dimensional ViT blocks as the decoder. Through a random masking strategy, a portion of the channels in each patch embedding is truncated. MCM aims to leverage contextual information from unmasked channels of the same patch or neighboring patch embeddings to predict the masked channels, thus forcing the model to focus on semantic continuity in channels. In addition, MCM uses the advanced features extracted by the CLIP image encoder from the input image as reconstruction targets, ensuring that the model learns high-level semantics and demonstrates stronger discriminative ability in downstream tasks.
Encoding. The input image is first patchified into a series of non-overlapping patches of size , which are then mapped into patch embeddings through a linear layer, where is the number of patches and D is the number of channels for each patch embedding. We randomly mask a proportion (e.g., 75%) of the channels of each patch embedding, ensuring that the remaining unmasked portion of each embedding (e.g., 25%) retains the same number of visible channels . Unlike traditional MIM, which discards the masked patch and only inputs the visible portion into the encoder, MCM replaces the masked channels with a shared and learnable encode channel . This ensures that the total number of input embeddings aligns with the required number of channels D for computing multi-head attention in each standard ViT block of the encoder, where .
Decoding. Before entering the decoder, if the encode channel of the embeddings extracted by the encoder is retained, the model may memorize the encoded values, reducing its reliance on contextual information during reconstruction. This information leakage significantly decreases the model’s learning efficiency and sensitivity to the masked information. To address this, we replace with another independent set of shared and learnable mask channels . Finally, the modified embeddings are fed into the decoder, which outputs for reconstruction.
CLIP target. Considering that raw pixels lack explicit deep semantic attributes and cannot effectively guide the model to learn representations with semantic continuity, MCM adopts high-level semantic features from CLIP [
9], which are highly discriminative and exhibit strong cross-modal consistency, as reconstruction targets. Specifically, the input image
is first fed into the CLIP transformer-based visual encoder
to extract advanced features
. These features are then passed through a simple linear layer to map
to
D-dimensional space, resulting in
, ensuring that the CLIP target aligns dimensionally with the decoder’s predictions. Notably, MCM reconstructs the semantics of all channels, not just the masked channels, using the CLIP features as the target. This is achieved by calculating the Mean Squared Error (MSE) loss as follows:
When reconstructing masked channels, the model generates approximate target features by leveraging the contextual information from unmasked channels. The high-level semantic features from CLIP ensure that the reconstructed channels exhibit semantic continuity with their neighboring channels, thereby guiding the model to learn more discriminative representations. Compared with feature mimicking approaches such as ref. [
16], our method differs fundamentally in the training objective. While ref. [
16] imposes supervision on visible tokens using external pre-trained features, our method formulates masked channel modeling as a self-contained reconstruction task across feature channels, encouraging semantic continuity without direct mimicking losses. This shifts the learning dynamics and facilitates different types of representation structures.
5. Conclusions
This paper proposes a novel yet simple Masked Channel Modeling (MCM) pre-training paradigm for visual representation learning. Unlike reconstructing raw pixels or features in spatial patches, MCM leverages the contextual semantics of unmasked channels to reconstruct masked channels. This forces the model to focus on semantic continuity across channels, enabling it to learn more discriminative representations. MCM randomly masks most channels in each patch and replaces the masked part with independent encode channels and mask channels during encoding and decoding, respectively. Considering the limited semantic information in raw pixel-based channels, we use CLIP advanced features as targets to guide the model in learning higher-quality representations. Extensive experiments demonstrate the effectiveness and superiority of MCM. In the future, we will explore different learning components, helping MCM’s representation learning to improve with shorter training times. We also highlight that our approach is not limited to vision tasks. The MCM framework provides a broader methodology for learning semantic dependencies across feature dimensions, which may be applicable in interdisciplinary settings such as hyperspectral analysis, multi-sensor fusion, and biomedical imaging.




{kind=link}
{kind=link}
{kind=link}
{kind=link}