
Feature Ranking on Small Samples: A Bayes-Based Approach

Abstract
1. Introduction
- (1)
- (2)
- Since our method uses a sampling of predictions based on randomized model parameters, it is significantly less dependent on the amount of data.
- (3)
- Due to model randomization, our method is applicable to both Bayesian and non-Bayesian models.
- (4)
- In our method, unlike RFE [41], the model is trained only once.
2. Materials and Methods
2.1. Theoretical Substantiation of the Developed Method
2.2. Analytical Shortcuts for Logistic Regression
2.3. Shortcuts for Decision Tree Ensembles
2.4. Proposed Method as Related to SHAP on Larger Datasets
2.5. Bayesianization Procedure Analysis
- (1)
- .
- (2)
- , the local behavior of the function based on its Taylor expansion.
- (3)
- —the bias introduced into the output is quadratic in , which guarantees its smallness for small .
- (4)
- —the quadratic and biquadratic dependencies on guarantee that the scatter of the predictions around will be small for small .
2.6. Datasets and Metrics
- (1)
- A total of 20% of the data goes into the validation sample. From the remaining part, a fixed number of samples (10, 100, or 1000) is selected randomly without replacement into the training dataset.
- (2)
- The model is trained on the remaining part of the data, and the f1-score is calculated on the test sample.
- (3)
- The list of the top n relevant features is obtained with the trained model and the training dataset (in the case of filter methods—only with the dataset).
- (4)
- The model with the same hyperparameters is trained in the same way as in step (2), but only with the features selected in step (3) left. Then, the f1-score on the test sample is calculated.
- (5)
- The ratio of the f1-scores from step (4) and step (2) is calculated.
3. Experimental Results and Discussion
3.1. Quality Improvement and Maintenance Experiments
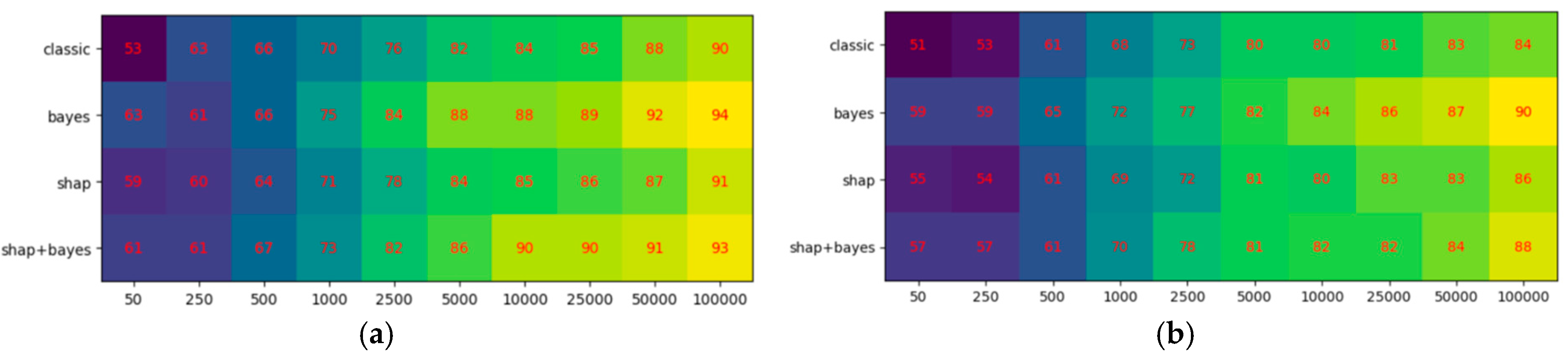
3.2. Consistency Experiments
4. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model Name | XGBoost | Random Forest | Decision Tree | |||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Method Name | Embedded Ranking | Vsi Ranking | Mrmr Ranking | Permtest Ranking | Shap Ranking | Our Method | Embedded Ranking | Vsi Ranking | Mrmr Ranking | Permtest Ranking | Shap Ranking | Our Method | Embedded Ranking | Vsi Ranking | Mrmr Ranking | Permtest Ranking | Shap Ranking | Our Method | ||
| Dataset Name | Data Size | Num Features | ||||||||||||||||||
| Heart | 10 | 1 | 0.998 | 0.773 | 0.847 | 0.722 | 0.98 | 1.17 * | 0.779 | 0.807 | 0.793 | 0.783 | 0.776 | 0.888 * | 1.086 | 0.857 | 0.887 | 0.807 | 1.086 | 1.119 * |
| 3 | 1.061 | 1.061 | 0.882 | 0.977 | 1.035 | 1.156 * | 0.838 | 0.849 | 0.838 | 0.911 | 0.854 | 0.992 * | 1.096 * | 0.929 | 0.952 | 0.99 | 1.07 | 1.07 | ||
| 6 | 1.089 | 0.953 | 1.024 | 0.99 | 1.123 * | 1.116 | 0.875 | 0.911 | 0.904 | 0.88 | 0.89 | 1.023 * | 1.046 | 0.948 | 1.002 | 1.003 | 1.053 * | 1.034 | ||
| 9 | 1.074 | 1.059 | 1.035 | 1.071 | 1.096 * | 1.058 | 0.933 | 0.961 | 0.944 | 0.948 | 0.968 | 1.033 * | 1.053 | 1.049 | 0.961 | 1.007 | 1.056 * | 1.049 | ||
| 12 | 0.993 | 0.991 | 0.981 | 1.032 | 1.057 * | 1.026 | 1.021 * | 1.012 | 1.001 | 1.017 | 1.001 | 1.014 | 1.058 * | 1.017 | 1.006 | 1.011 | 1.046 | 1.058 * | ||
| 100 | 1 | 0.769 | 0.815 | 0.745 | 0.724 | 0.838 | 0.922 * | 0.727 | 0.743 | 0.699 | 0.677 | 0.694 | 0.892 * | 0.873 | 0.863 | 0.813 | 0.715 | 0.859 | 0.995 * | |
| 3 | 0.897 | 0.882 | 0.874 | 0.869 | 0.895 | 0.991 * | 0.834 | 0.828 | 0.844 | 0.85 | 0.816 | 0.939 * | 0.967 | 0.883 | 0.858 | 0.86 | 0.952 | 1.015 * | ||
| 6 | 0.943 | 0.924 | 0.954 | 0.979 * | 0.947 | 0.953 | 0.943 | 0.909 | 0.919 | 0.954 * | 0.92 | 0.953 | 0.979 | 0.958 | 0.954 | 1.008 | 1.015 * | 0.98 | ||
| 9 | 0.975 | 0.969 | 0.961 | 1.0 * | 0.983 | 0.968 | 0.992 | 0.994 * | 0.962 | 0.979 | 0.97 | 0.967 | 0.993 | 1.012 | 0.971 | 1.031 * | 1.012 | 0.959 | ||
| 12 | 0.998 | 0.99 | 0.984 | 0.989 | 1.004 * | 0.993 | 1.002 * | 0.991 | 0.984 | 1.001 | 0.993 | 0.998 | 0.988 | 1.001 | 0.984 | 1.02 * | 0.996 | 0.992 | ||
| 1000 | 1 | 0.723 | 0.701 | 0.74 | 0.679 | 0.783 | 0.804 * | 0.717 | 0.701 | 0.735 | 0.665 | 0.731 | 0.774 * | 0.719 | 0.667 | 0.686 | 0.648 | 0.746 | 0.774 * | |
| 3 | 0.845 | 0.803 | 0.844 | 0.862 | 0.83 | 0.87 * | 0.891 | 0.79 | 0.877 | 0.899 * | 0.843 | 0.856 | 0.87 | 0.838 | 0.9 | 0.921 * | 0.834 | 0.854 | ||
| 6 | 0.915 | 0.918 | 0.937 | 0.947 * | 0.936 | 0.946 | 0.975 | 0.955 | 0.955 | 0.978 * | 0.946 | 0.974 | 0.997 | 0.999 | 0.98 | 1.002 * | 0.989 | 0.994 | ||
| 9 | 0.956 | 0.969 | 0.96 | 0.994 * | 0.987 | 0.971 | 0.992 | 0.998 | 1.001 * | 0.994 | 0.993 | 0.993 | 1.006 | 1.0 | 1.003 | 1.007 * | 1.0 | 1.003 | ||
| 12 | 1.002 * | 0.994 | 0.987 | 0.995 | 0.994 | 0.985 | 1.001 * | 0.999 | 0.996 | 1.0 | 1.0 | 0.995 | 1.003 | 1.003 | 1.006 * | 1.004 | 1.006 * | 1.005 | ||
| Heart1 | 10 | 1 | 0.989 | 0.773 | 1.046 | 0.789 | 0.995 | 1.186 * | 0.782 | 0.607 | 0.812 | 0.707 | 0.755 | 1.015 * | 0.965 | 0.827 | 0.834 | 0.779 | 0.965 | 1.093 * |
| 3 | 1.079 | 0.899 | 0.925 | 0.822 | 1.129 * | 1.092 | 0.783 | 0.791 | 0.902 | 0.771 | 0.743 | 0.984 * | 1.079 * | 0.897 | 1.012 | 0.856 | 1.034 | 1.074 | ||
| 6 | 1.122 | 1.016 | 0.985 | 0.932 | 1.138 * | 1.122 | 0.969 | 0.943 | 0.919 | 0.863 | 0.976 * | 0.944 | 1.024 | 0.985 | 0.993 | 0.924 | 1.021 | 1.047 * | ||
| 9 | 1.039 | 1.065 | 1.007 | 0.999 | 1.062 | 1.155 * | 0.986 | 0.937 | 0.964 | 0.923 | 0.976 | 0.988 * | 1.019 | 1.031 | 0.959 | 0.95 | 1.03 | 1.054 * | ||
| 12 | 1.042 * | 1.019 | 0.986 | 0.956 | 1.022 | 1.038 | 0.976 | 0.991 | 0.975 | 0.973 | 0.985 | 1.014 * | 1.055 | 1.01 | 0.965 | 0.931 | 1.059 * | 1.021 | ||
| 100 | 1 | 0.773 | 0.768 | 0.878 | 0.769 | 0.79 | 1.005 * | 0.705 | 0.712 | 0.783 | 0.728 | 0.7 | 0.975 * | 0.734 | 0.732 | 0.894 | 0.742 | 0.752 | 1.068 * | |
| 3 | 0.894 | 0.803 | 0.966 | 0.814 | 0.868 | 1.034 * | 0.801 | 0.8 | 0.914 | 0.774 | 0.806 | 0.973 * | 0.916 | 0.783 | 0.935 | 0.767 | 0.895 | 1.06 * | ||
| 6 | 0.952 | 0.95 | 0.971 | 0.88 | 0.96 | 1.0 * | 0.956 * | 0.898 | 0.942 | 0.885 | 0.953 | 0.953 | 0.975 | 0.933 | 0.976 | 0.874 | 0.971 | 1.049 * | ||
| 9 | 0.984 | 0.95 | 0.984 | 0.944 | 0.967 | 0.996 * | 0.973 | 0.949 | 0.983 | 0.929 | 0.987 * | 0.973 | 0.969 | 0.986 | 0.979 | 0.906 | 0.96 | 1.038 * | ||
| 12 | 0.992 * | 0.977 | 0.985 | 0.991 | 0.988 | 0.979 | 0.985 | 0.996 * | 0.993 | 0.994 | 0.99 | 0.987 | 0.973 | 0.979 | 0.972 | 0.974 | 0.978 | 1.0 * | ||
| 1000 | 1 | 0.772 | 0.772 | 0.784 | 0.772 | 0.772 | 0.941 * | 0.744 | 0.75 | 0.754 | 0.762 | 0.754 | 0.935 * | 0.828 | 0.828 | 0.828 | 0.828 | 0.828 | 1.047 * | |
| 3 | 0.849 | 0.782 | 0.95 | 0.866 | 0.829 | 0.959 * | 0.825 | 0.808 | 0.93 | 0.846 | 0.81 | 0.947 * | 0.986 | 0.782 | 0.987 | 0.892 | 0.934 | 1.052 * | ||
| 6 | 0.953 | 0.947 | 0.965 * | 0.883 | 0.953 | 0.952 | 0.953 | 0.954 * | 0.944 | 0.893 | 0.944 | 0.949 | 1.005 | 0.96 | 0.983 | 0.844 | 0.959 | 1.041 * | ||
| 9 | 0.967 | 0.986 * | 0.977 | 0.898 | 0.978 | 0.974 | 0.956 | 0.981 * | 0.977 | 0.924 | 0.981 * | 0.963 | 0.995 | 0.993 | 0.986 | 0.893 | 0.994 | 1.049 * | ||
| 12 | 0.983 | 0.994 | 0.995 * | 0.954 | 0.992 | 0.99 | 0.977 | 0.983 | 0.987 | 0.966 | 0.993 * | 0.982 | 0.976 | 1.01 * | 1.007 | 0.963 | 0.995 | 0.989 | ||
| winequality-red | 10 | 1 | 1520.033 | 1729.652 | 0.547 | 5769.897 | 1519.869 | 5770.483 * | 13377.531 | 17197.868 * | 9040.552 | 7993.623 | 9548.139 | 7337.792 | 0.474 | 825.162 | 1651.445 * | 952.612 | 0.474 | 0.574 |
| 3 | 5770.666 * | 0.912 | 0.868 | 5769.934 | 5770.443 | 1.362 | 0.0 | 0.0 | 2443.174 * | 952.418 | 357.329 | 900.1 | 0.275 | 0.477 | 1651.739 * | 0.357 | 0.69 | 0.549 | ||
| 6 | 1.267 | 1072.71 | 1.475 | 1.137 | 1.595 | 1072.948 * | 1111.285 | 1322.371 | 1663.641 * | 476.29 | 465.216 | 869.665 | 0.456 | 0.538 * | 0.463 | 0.521 | 0.486 | 0.421 | ||
| 9 | 1072.607 | 1072.332 | 0.982 | 1073.438 * | 1072.954 | 1072.545 | 1608.405 * | 0.076 | 1321.305 | 357.182 | 0.1 | 0.0 | 0.509 | 0.746 | 0.561 | 0.769 * | 0.379 | 0.42 | ||
| 12 | 1.171 | 0.738 | 1.079 | 1.293 * | 1.279 | 0.933 | 487.926 * | 0.135 | 0.1 | 357.237 | 0.136 | 0.1 | 0.546 | 0.634 | 0.835 | 0.559 | 0.536 | 0.872 * | ||
| 100 | 1 | 0.605 | 0.428 | 0.463 | 0.584 | 0.428 | 0.767 * | 0.482 | 0.531 | 0.579 | 0.613 | 0.589 | 0.922 * | 0.467 | 0.335 | 0.403 | 0.583 | 0.421 | 0.719 * | |
| 3 | 0.811 | 0.724 | 0.675 | 1.033 | 0.758 | 1.039 * | 0.84 | 0.766 | 0.544 | 0.787 | 0.774 | 1.091 * | 0.987 * | 0.652 | 0.579 | 0.821 | 0.875 | 0.983 | ||
| 6 | 0.906 | 0.923 | 0.885 | 0.934 | 0.809 | 1.038 * | 0.93 | 1.075 | 0.846 | 0.806 | 0.885 | 1.224 * | 0.996 | 0.872 | 0.838 | 1.068 * | 0.992 | 1.054 | ||
| 9 | 0.955 | 0.99 | 0.984 | 0.997 * | 0.984 | 0.977 | 1.08 | 1.077 | 0.944 | 1.058 | 1.11 | 1.194 * | 1.074 * | 0.959 | 0.992 | 1.035 | 1.039 | 0.945 | ||
| 12 | 0.994 | 1.022 | 1.0 | 1.021 | 0.965 | 1.024 * | 1.04 | 1.081 * | 1.078 | 1.015 | 0.961 | 1.074 | 1.011 | 1.032 | 0.932 | 0.979 | 0.973 | 1.058 * | ||
| 1000 | 1 | 0.229 | 0.229 | 0.198 | 0.298 | 0.273 | 0.426 * | 0.209 | 0.199 | 0.208 | 0.248 | 0.177 | 0.429 * | 0.213 | 0.187 | 0.266 | 0.363 * | 0.187 | 0.292 | |
| 3 | 0.751 | 0.429 | 0.54 | 0.549 | 0.694 | 0.822 * | 0.587 | 0.416 | 0.332 | 0.33 | 0.564 | 0.864 * | 0.752 | 0.821 | 0.769 | 0.731 | 0.853 | 0.947 * | ||
| 6 | 0.92 | 0.896 | 0.795 | 0.8 | 0.878 | 0.937 * | 0.882 | 0.984 | 0.768 | 0.766 | 0.945 | 0.994 * | 1.005 | 1.01 * | 0.968 | 0.958 | 0.976 | 0.986 | ||
| 9 | 0.941 | 0.965 * | 0.915 | 0.939 | 0.93 | 0.942 | 1.041 * | 1.019 | 1.006 | 0.906 | 0.986 | 1.015 | 1.036 | 1.063 * | 1.048 | 1.051 | 1.009 | 1.003 | ||
| 12 | 0.994 | 0.997 | 0.996 | 1.003 * | 0.998 | 1.0 | 1.025 | 0.997 | 0.993 | 1.028 | 1.047 * | 1.017 | 0.995 | 1.01 | 1.029 * | 1.022 | 0.992 | 1.019 | ||
| Model Name | Logistic Regression | Lasso | Ridge | Elastic Net | ||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Method Name | Embedded Ranking | Vsi Ranking | Mrmr Ranking | Permtest Ranking | Shap Ranking | Our Method | Embedded Ranking | Vsi Ranking | Mrmr Ranking | Permtest Ranking | Shap Ranking | Our Method | Embedded Ranking | Vsi Ranking | Mrmr Ranking | Permtest Ranking | Shap Ranking | Our Method | Embedded Ranking | Vsi Ranking | Mrmr Ranking | Permtest Ranking | Shap Ranking | Our Method | ||
| Dataset Name | Data Size | Num Features | ||||||||||||||||||||||||
| Heart | 10 | 1 | 0.747 | 0.877 | 0.773 | 0.814 | 0.761 | 0.896 * | 0.711 | 0.812 | 0.661 | 0.841 * | 0.746 | 0.811 | 0.564 | 0.733 | 0.53 | 0.476 | 0.564 | 0.752 * | 0.53 | 0.773 | 0.753 | 0.693 | 0.821 * | 0.812 |
| 3 | 0.968 | 0.926 | 0.934 | 0.831 | 0.915 | 1.024 * | 0.915 | 0.953 | 0.92 | 0.903 | 0.902 | 0.998 * | 1.015 | 1.016 | 0.936 | 0.813 | 1.005 | 1.034 * | 0.955 | 0.877 | 0.907 | 0.783 | 0.871 | 0.99 * | ||
| 6 | 0.935 | 0.876 | 0.967 | 0.917 | 0.912 | 0.998 * | 0.868 | 0.949 | 0.957 | 0.889 | 0.909 | 1.037 * | 1.037 | 0.982 | 1.007 | 0.964 | 1.045 | 1.05 * | 0.98 | 0.953 | 0.978 | 0.926 | 0.962 | 1.031 * | ||
| 9 | 1.012 * | 0.978 | 0.946 | 1.007 | 0.977 | 0.984 | 0.941 | 0.945 | 0.962 | 0.957 | 0.946 | 0.989 * | 1.063 | 1.048 | 1.021 | 0.997 | 1.069 * | 1.041 | 1.009 | 0.981 | 0.999 | 0.942 | 1.012 | 1.013 * | ||
| 12 | 1.013 * | 0.994 | 0.994 | 1.006 | 1.013 * | 1.013 * | 0.98 | 0.98 | 0.982 | 0.993 | 0.971 | 1.009 * | 1.056 * | 1.006 | 1.014 | 1.007 | 1.056 * | 1.029 | 1.003 | 1.015 * | 1.004 | 1.007 | 1.003 | 1.014 | ||
| 100 | 1 | 0.784 | 0.82 | 0.767 | 0.769 | 0.775 | 0.926 * | 0.696 | 0.86 | 0.849 | 0.782 | 0.718 | 0.932 * | 0.811 | 0.83 | 0.841 | 0.749 | 0.841 | 0.949 * | 0.755 | 0.802 | 0.828 | 0.79 | 0.795 | 0.932 * | |
| 3 | 0.847 | 0.866 | 0.902 | 0.849 | 0.853 | 0.942 * | 0.873 | 0.877 | 0.911 | 0.88 | 0.847 | 0.941 * | 0.904 | 0.919 | 0.891 | 0.893 | 0.901 | 0.966 * | 0.865 | 0.872 | 0.922 | 0.896 | 0.9 | 0.945 * | ||
| 6 | 0.933 | 0.908 | 0.943 | 0.934 | 0.917 | 0.977 * | 0.931 | 0.914 | 0.948 | 0.981 * | 0.91 | 0.973 | 0.951 | 0.966 | 0.974 | 0.984 * | 0.951 | 0.97 | 0.946 | 0.966 | 0.973 | 0.988 * | 0.94 | 0.983 | ||
| 9 | 0.969 | 0.983 * | 0.973 | 0.981 | 0.964 | 0.971 | 0.981 | 0.962 | 0.972 | 1.006 * | 0.971 | 0.963 | 0.983 | 0.998 * | 0.998 * | 0.998 * | 0.993 | 0.971 | 0.991 | 0.996 | 0.974 | 1.005 * | 0.993 | 0.975 | ||
| 12 | 0.993 | 0.992 | 0.991 | 1.006 | 0.994 | 1.008 * | 1.012 | 0.991 | 0.982 | 1.012 | 1.012 | 1.016 * | 0.992 | 1.008 * | 0.999 | 0.998 | 0.992 | 1.005 | 0.988 | 1.002 | 0.986 | 1.01 * | 0.988 | 1.005 | ||
| 1000 | 1 | 0.728 | 0.748 | 0.783 | 0.754 | 0.711 | 0.882 * | 0.761 | 0.837 | 0.854 | 0.757 | 0.668 | 0.898 * | 0.724 | 0.794 | 0.825 | 0.754 | 0.726 | 0.902 * | 0.749 | 0.741 | 0.824 | 0.747 | 0.733 | 0.896 * | |
| 3 | 0.872 | 0.756 | 0.827 | 0.861 | 0.869 | 0.928 * | 0.865 | 0.791 | 0.844 | 0.872 | 0.89 | 0.925 * | 0.891 | 0.795 | 0.842 | 0.864 | 0.894 | 0.928 * | 0.869 | 0.761 | 0.858 | 0.88 | 0.881 | 0.922 * | ||
| 6 | 0.891 | 0.905 | 0.91 | 0.953 | 0.876 | 0.959 * | 0.879 | 0.906 | 0.93 | 0.937 | 0.89 | 0.966 * | 0.906 | 0.9 | 0.928 | 0.957 | 0.92 | 0.963 * | 0.894 | 0.901 | 0.914 | 0.96 | 0.897 | 0.968 * | ||
| 9 | 0.944 | 0.969 | 0.935 | 0.983 * | 0.938 | 0.949 | 0.922 | 0.963 | 0.933 | 0.967 * | 0.934 | 0.949 | 0.955 | 0.959 | 0.946 | 0.976 * | 0.958 | 0.949 | 0.928 | 0.981 * | 0.943 | 0.97 | 0.936 | 0.947 | ||
| 12 | 0.973 | 0.994 | 0.975 | 1.004 * | 0.976 | 1.002 | 0.964 | 0.989 | 0.966 | 0.986 | 0.964 | 0.997 * | 0.986 | 0.997 | 0.993 | 1.0 | 0.987 | 1.005 * | 0.973 | 1.0 | 0.976 | 0.993 | 0.973 | 1.004 * | ||
| Heart1 | 10 | 1 | 0.87 | 0.866 | 0.775 | 0.831 | 0.808 | 1.136 * | 0.68 | 0.795 | 0.834 | 0.812 | 0.772 | 0.979 * | 0.921 | 0.497 | 0.678 | 0.572 | 0.921 | 1.193 * | 0.893 | 0.851 | 0.914 | 0.815 | 0.879 | 0.935 * |
| 3 | 0.874 | 0.927 | 1.058 | 0.901 | 0.915 | 1.103 * | 0.797 | 0.819 | 0.926 | 0.844 | 0.794 | 0.958 * | 1.113 | 0.816 | 1.036 | 0.7 | 1.11 | 1.135 * | 0.889 | 0.875 | 0.95 | 0.828 | 0.877 | 1.033 * | ||
| 6 | 1.007 | 1.015 | 0.94 | 0.873 | 0.942 | 1.035 * | 0.937 | 0.953 * | 0.942 | 0.88 | 0.919 | 0.949 | 0.996 | 1.07 | 1.004 | 0.979 | 1.003 | 1.08 * | 1.006 * | 0.971 | 0.979 | 0.958 | 1.002 | 1.004 | ||
| 9 | 0.977 | 1.014 | 0.945 | 0.963 | 0.931 | 1.028 * | 0.962 | 0.966 | 0.972 * | 0.925 | 0.95 | 0.955 | 1.012 | 1.037 | 1.027 | 1.066 | 1.011 | 1.101 * | 0.995 | 0.989 | 0.988 | 0.966 | 1.005 | 1.029 * | ||
| 12 | 0.973 | 1.023 * | 0.977 | 0.934 | 0.97 | 1.002 | 0.986 | 0.975 | 0.984 | 0.964 | 0.987 * | 0.978 | 1.009 | 1.031 | 1.021 | 1.038 * | 1.008 | 1.012 | 1.003 | 0.976 | 1.001 | 0.992 | 0.984 | 1.016 * | ||
| 100 | 1 | 0.849 | 0.844 | 0.869 | 0.843 | 0.83 | 0.993 * | 0.819 | 0.792 | 0.915 | 0.81 | 0.836 | 0.986 * | 0.796 | 0.805 | 0.865 | 0.835 | 0.847 | 1.004 * | 0.899 | 0.808 | 0.842 | 0.812 | 0.883 | 0.977 * | |
| 3 | 0.903 | 0.857 | 0.969 | 0.852 | 0.884 | 0.993 * | 0.854 | 0.813 | 0.965 | 0.799 | 0.871 | 0.983 * | 0.931 | 0.772 | 0.949 | 0.819 | 0.914 | 1.008 * | 0.952 | 0.839 | 0.973 | 0.817 | 0.943 | 0.992 * | ||
| 6 | 0.962 | 0.96 | 0.988 | 0.936 | 0.97 | 0.989 * | 0.954 | 0.949 | 0.967 | 0.926 | 0.951 | 0.974 * | 0.992 | 0.918 | 0.972 | 0.884 | 1.006 * | 0.984 | 0.973 | 0.95 | 0.991 | 0.906 | 0.976 | 0.996 * | ||
| 9 | 0.989 | 1.003 | 0.985 | 0.943 | 0.99 | 1.019 * | 0.977 | 0.981 | 0.985 | 0.931 | 0.973 | 0.991 * | 0.991 | 0.989 | 0.989 | 0.938 | 0.993 | 1.02 * | 0.985 | 0.977 | 0.998 | 0.914 | 0.987 | 1.01 * | ||
| 12 | 0.997 | 0.99 | 1.009 * | 0.984 | 1.003 | 1.003 | 0.981 | 0.994 | 0.992 | 0.981 | 0.983 | 0.997 * | 0.994 | 1.001 | 0.998 | 0.986 | 1.001 | 1.015 * | 0.993 | 0.989 | 0.992 | 0.994 | 0.994 | 1.002 * | ||
| 1000 | 1 | 0.766 | 0.785 | 0.839 | 0.785 | 0.733 | 0.949 * | 0.818 | 0.785 | 0.825 | 0.785 | 0.799 | 0.957 * | 0.78 | 0.795 | 0.843 | 0.795 | 0.676 | 0.957 * | 0.747 | 0.796 | 0.833 | 0.796 | 0.67 | 0.95 * | |
| 3 | 0.854 | 0.797 | 0.944 | 0.864 | 0.848 | 0.952 * | 0.873 | 0.805 | 0.954 * | 0.879 | 0.871 | 0.952 | 0.858 | 0.819 | 0.935 | 0.862 | 0.854 | 0.953 * | 0.874 | 0.809 | 0.923 | 0.854 | 0.85 | 0.953 * | ||
| 6 | 0.953 | 0.954 | 0.963 * | 0.906 | 0.938 | 0.957 | 0.952 | 0.955 | 0.97 * | 0.918 | 0.936 | 0.959 | 0.945 | 0.967 * | 0.952 | 0.94 | 0.945 | 0.962 | 0.97 * | 0.961 | 0.96 | 0.928 | 0.949 | 0.956 | ||
| 9 | 0.971 | 0.982 * | 0.974 | 0.909 | 0.958 | 0.981 | 0.959 | 0.986 | 0.983 | 0.925 | 0.951 | 0.987 * | 0.971 | 0.97 | 0.988 | 0.938 | 0.965 | 0.99 * | 0.969 | 0.989 | 0.979 | 0.927 | 0.976 | 0.992 * | ||
| 12 | 0.991 | 0.996 | 0.985 | 0.959 | 0.989 | 0.999 * | 0.99 | 0.997 | 1.0 * | 0.959 | 0.984 | 1.0 * | 0.987 | 0.986 | 1.0 * | 0.949 | 0.982 | 0.994 | 0.982 | 0.998 * | 0.989 | 0.963 | 0.991 | 0.997 | ||
| winequality-red | 10 | 1 | 0.599 | 0.435 | 0.78 | 0.958 | 0.599 | 1.495 * | 0.089 | 0.315 | 0.084 | 0.168 | 0.089 | 0.344 * | 0.0 | 0.016 | 0.021 | 0.212 | 0.047 | 0.287 * | 3714.286 | 0.0 | 0.035 | 1584.399 | 3714.286 | 3714.554 * |
| 3 | 0.973 | 0.792 | 0.784 | 1.228 | 1.081 | 1.835 * | 465.489 | 455.053 | 425.803 | 408.755 | 465.579 * | 455.398 | 0.3 | 0.033 | 408.198 * | 0.399 | 0.281 | 0.549 | 1970.529 | 416.792 | 416.964 | 2178.225 * | 1970.529 | 385.13 | ||
| 6 | 1.103 | 0.8 | 0.976 | 1.006 | 1.094 | 1.487 * | 0.593 | 889.758 * | 0.583 | 0.65 | 0.56 | 435.808 | 0.471 | 454.704 * | 0.441 | 0.403 | 0.513 | 0.625 | 0.647 | 2105.8 * | 1887.274 | 1569.186 | 0.649 | 0.471 | ||
| 9 | 1.049 | 0.756 | 1.018 | 0.87 | 0.96 | 1.089 * | 0.846 | 0.951 * | 0.735 | 0.88 | 0.874 | 0.935 | 0.571 | 454.937 | 0.58 | 0.554 | 0.613 | 851.681 * | 0.617 | 1177.146 | 1539.193 * | 0.631 | 0.617 | 0.565 | ||
| 12 | 1.0 * | 1.0 * | 1.0 * | 1.0 * | 1.0 * | 1.0 * | 0.9 * | 0.9 * | 0.9 * | 0.9 * | 0.9 * | 0.9 * | 0.6 | 0.601 * | 0.6 | 0.6 | 0.601 * | 0.6 | 0.8 * | 0.8 * | 0.8 * | 0.8 * | 0.8 * | 0.8 * | ||
| 100 | 1 | 0.06 | 0.012 | 0.078 | 0.166 | 0.06 | 0.542 * | 0.065 | 0.0 | 0.043 | 0.088 | 0.065 | 0.342 * | 0.0 | 0.029 | 0.025 | 0.089 | 0.0 | 0.479 * | 0.023 | 0.0 | 0.0 | 0.031 | 0.023 | 0.245 * | |
| 3 | 0.308 | 0.226 | 0.317 | 0.675 | 0.348 | 0.923 * | 0.29 | 0.168 | 0.128 | 0.412 | 0.315 | 0.518 * | 0.312 | 0.167 | 0.115 | 0.355 | 0.32 | 0.614 * | 0.16 | 0.059 | 0.102 | 0.505 | 0.244 | 0.629 * | ||
| 6 | 0.651 | 0.846 | 0.705 | 0.878 * | 0.614 | 0.865 | 0.718 * | 0.702 | 0.621 | 0.659 | 0.616 | 0.704 | 0.81 | 0.461 | 0.367 | 0.683 | 0.862 * | 0.758 | 0.636 | 0.758 | 0.521 | 0.608 | 0.638 | 0.881 * | ||
| 9 | 0.885 | 0.922 | 0.914 | 0.953 | 0.932 | 1.04 * | 0.896 | 1.024 * | 0.901 | 0.918 | 0.862 | 0.892 | 1.006 * | 0.921 | 0.764 | 1.003 | 0.989 | 0.87 | 0.838 | 1.035 * | 0.697 | 0.963 | 0.898 | 0.962 | ||
| 12 | 1.0 * | 1.0 * | 1.0 * | 1.0 * | 1.0 * | 1.0 * | 1.0 * | 1.0 * | 1.0 * | 1.0 * | 1.0 * | 1.0 * | 1.0 * | 1.0 * | 1.0 * | 1.0 * | 1.0 * | 1.0 * | 1.0 * | 1.0 * | 1.0 * | 1.0 * | 1.0 * | 1.0 * | ||
| 1000 | 1 | 0.024 | 0.0 | 0.009 | 0.0 | 0.008 | 0.485 * | 0.0 | 0.0 | 0.012 | 0.0 | 0.0 | 0.501 * | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.513 * | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.559 * | |
| 3 | 0.469 | 0.283 | 0.089 | 0.101 | 0.481 | 0.708 * | 0.503 | 0.251 | 0.117 | 0.206 | 0.478 | 0.765 * | 0.445 | 0.135 | 0.036 | 0.037 | 0.439 | 0.77 * | 0.366 | 0.178 | 0.092 | 0.042 | 0.316 | 0.744 * | ||
| 6 | 0.736 | 0.944 * | 0.539 | 0.513 | 0.762 | 0.782 | 0.807 | 0.993 * | 0.654 | 0.554 | 0.861 | 0.811 | 0.721 | 0.922 * | 0.497 | 0.381 | 0.708 | 0.805 | 0.58 | 0.969 * | 0.572 | 0.53 | 0.488 | 0.776 | ||
| 9 | 0.931 | 0.961 * | 0.921 | 0.835 | 0.929 | 0.922 | 0.958 | 0.973 * | 0.896 | 0.893 | 0.955 | 0.948 | 0.913 | 0.988 * | 0.834 | 0.852 | 0.906 | 0.852 | 1.009 | 1.038 * | 0.754 | 0.846 | 1.035 | 0.936 | ||
| 12 | 1.0 * | 1.0 * | 1.0 * | 1.0 * | 1.0 * | 1.0 * | 1.0 * | 1.0 * | 1.0 * | 1.0 * | 1.0 * | 1.0 * | 1.0 * | 1.0 * | 1.0 * | 1.0 * | 1.0 * | 1.0 * | 1.0 | 1.002 * | 1.002 * | 1.002 * | 1.002 * | 1.0 | ||
| Model Name | XGBoost | Random Forest | Decision Tree | |||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Method Name | Embedded Ranking | Vsi Ranking | Mrmr Ranking | Permtest Ranking | Shap Ranking | Our Method | Embedded Ranking | Vsi Ranking | Mrmr Ranking | Permtest Ranking | Shap Ranking | Our Method | Embedded Ranking | Vsi Ranking | Mrmr Ranking | Permtest Ranking | Shap Ranking | Our Method | ||
| Dataset Name | Data Size | Num Features | ||||||||||||||||||
| covid | 10 | 1 | 0.989 | 1.003 | 1.001 | 1.006 | 1.055 * | 1.044 | 0.998 | 0.995 | 0.996 | 0.998 | 1.048 * | 1.041 | 0.994 | 1.012 | 1.006 | 1.009 | 1.044 * | 1.042 |
| 3 | 0.988 | 0.99 | 0.993 | 0.98 | 1.037 * | 1.037 * | 0.996 | 0.995 | 0.996 | 0.993 | 1.045 | 1.046 * | 0.975 | 0.996 | 0.973 | 1.0 | 1.024 * | 1.024 * | ||
| 6 | 0.988 | 0.991 | 0.984 | 0.983 | 1.037 * | 1.037 * | 0.998 | 0.996 | 0.995 | 0.996 | 1.048 * | 1.046 | 0.971 | 0.988 | 1.004 | 0.995 | 1.02 * | 1.003 | ||
| 9 | 0.983 | 0.988 | 0.988 | 0.978 | 1.029 * | 1.028 | 0.997 | 0.996 | 0.995 | 0.996 | 1.047 * | 1.045 | 0.958 | 0.99 | 1.002 | 0.978 | 1.017 | 1.023 * | ||
| 12 | 0.982 | 0.991 | 0.996 | 0.99 | 1.022 | 1.033 * | 0.998 | 0.997 | 0.999 | 0.997 | 1.048 * | 1.046 | 0.955 | 0.996 | 1.004 * | 0.985 | 1.002 | 1.003 | ||
| 100 | 1 | 0.993 | 0.991 | 0.993 | 0.99 | 1.041 * | 1.041 * | 0.99 | 0.99 | 0.99 | 0.988 | 1.038 * | 1.037 | 0.994 | 0.994 | 1.001 | 0.998 | 1.047 * | 1.044 | |
| 3 | 0.987 | 0.987 | 0.992 | 0.985 | 1.034 * | 1.032 | 0.984 | 0.989 | 0.989 | 0.99 | 1.031 | 1.034 * | 0.989 | 0.993 | 1.001 | 0.989 | 1.045 * | 1.032 | ||
| 6 | 0.986 | 0.986 | 0.992 | 0.983 | 1.032 * | 1.032 * | 0.983 | 0.986 | 0.986 | 0.986 | 1.035 * | 1.032 | 0.981 | 0.98 | 0.996 | 0.99 | 1.035 * | 1.03 | ||
| 9 | 0.988 | 0.985 | 0.992 | 0.983 | 1.033 * | 1.03 | 0.987 | 0.988 | 0.985 | 0.989 | 1.035 * | 1.032 | 0.979 | 0.986 | 0.996 | 0.986 | 1.035 * | 1.029 | ||
| 12 | 0.986 | 0.991 | 0.991 | 0.989 | 1.032 * | 1.029 | 0.987 | 0.99 | 0.986 | 0.992 | 1.036 * | 1.033 | 0.976 | 0.986 | 0.991 | 0.989 | 1.033 * | 1.026 | ||
| 1000 | 1 | 0.969 | 0.967 | 0.967 | 0.966 | 1.014 | 1.015 * | 0.976 | 0.975 | 0.975 | 0.975 | 1.026 * | 1.024 | 0.972 | 0.973 | 0.973 | 0.972 | 1.022 * | 1.021 | |
| 3 | 0.967 | 0.965 | 0.966 | 0.971 | 1.015 * | 1.015 * | 0.971 | 0.973 | 0.975 | 0.977 | 1.024 * | 1.024 * | 0.972 | 0.971 | 0.971 | 0.977 | 1.02 * | 1.02 * | ||
| 6 | 0.967 | 0.964 | 0.968 | 0.971 | 1.014 * | 1.013 | 0.973 | 0.974 | 0.979 | 0.977 | 1.025 * | 1.024 | 0.969 | 0.969 | 0.972 | 0.973 | 1.016 | 1.017 * | ||
| 9 | 0.968 | 0.966 | 0.968 | 0.974 | 1.015 * | 1.014 | 0.976 | 0.975 | 0.982 | 0.979 | 1.027 * | 1.023 | 0.968 | 0.962 | 0.969 | 0.971 | 1.016 * | 1.015 | ||
| 12 | 0.968 | 0.967 | 0.97 | 0.975 | 1.016 * | 1.013 | 0.977 | 0.977 | 0.982 | 0.984 | 1.029 * | 1.024 | 0.966 | 0.963 | 0.965 | 0.972 | 1.013 | 1.014 * | ||
| withmeds | 10 | 1 | 0.082 | 0.093 | 0.214 | 0.785 * | 0.086 | 0.086 | 4762.011 * | 4000.195 | 0.146 | 4467.687 | 0.037 | 2863.881 | 0.12 | 0.332 | 0.526 | 1.13 * | 0.126 | 0.126 |
| 3 | 0.126 | 0.221 | 0.518 | 0.785 * | 0.132 | 0.132 | 3636.922 * | 1818.697 | 2222.571 | 3350.885 | 2210.907 | 0.259 | 0.351 | 0.343 | 0.483 | 1.044 * | 0.369 | 0.369 | ||
| 6 | 0.672 | 0.466 | 0.514 | 0.785 * | 0.717 | 0.724 | 3636.938 | 3334.131 | 3333.746 | 3350.863 | 2211.127 | 5250.59 * | 0.917 | 0.429 | 0.901 | 1.045 * | 0.945 | 0.964 | ||
| 9 | 0.727 * | 0.535 | 0.605 | 0.718 | 0.686 | 0.679 | 2222.879 | 2667.294 | 4615.69 * | 2978.688 | 1615.923 | 3818.736 | 0.853 | 0.416 | 1.035 | 1.045 * | 0.82 | 0.817 | ||
| 12 | 0.549 | 0.57 | 0.627 | 0.689 * | 0.573 | 0.499 | 5455.078 * | 2857.899 | 2857.665 | 3350.82 | 1500.615 | 3000.712 | 0.95 | 0.944 | 1.065 * | 1.025 | 0.913 | 0.715 | ||
| 100 | 1 | 0.0 | 0.104 | 0.089 | 0.73 * | 0.0 | 0.0 | 0.274 | 0.065 | 0.075 | 0.73 * | 0.129 | 0.0 | 0.0 | 0.018 | 0.135 | 0.734 * | 0.0 | 0.0 | |
| 3 | 0.118 | 0.288 | 0.268 | 0.73 * | 0.117 | 0.152 | 0.362 | 0.283 | 0.192 | 0.691 * | 0.414 | 0.137 | 0.232 | 0.395 | 0.382 | 0.734 * | 0.244 | 0.247 | ||
| 6 | 0.565 | 0.401 | 0.382 | 0.73 | 0.637 | 0.866 * | 0.396 | 0.285 | 0.358 | 0.721 | 0.589 | 0.864 * | 0.761 | 0.5 | 0.506 | 0.734 | 0.799 | 0.908 * | ||
| 9 | 0.732 | 0.471 | 0.472 | 0.73 | 0.745 | 0.753 * | 0.453 | 0.508 | 0.389 | 0.708 | 0.68 | 0.771 * | 0.885 | 0.528 | 0.521 | 0.734 | 0.916 * | 0.874 | ||
| 12 | 0.778 | 0.479 | 0.513 | 0.73 | 0.835 * | 0.751 | 0.418 | 0.586 | 0.561 | 0.673 | 0.707 | 0.744 * | 0.821 | 0.606 | 0.642 | 0.73 | 0.858 * | 0.819 | ||
| 1000 | 1 | 0.0 | 0.068 | 0.068 | 0.693 * | 0.0 | 0.0 | 0.067 | 0.146 | 0.079 | 0.73 * | 0.19 | 0.0 | 0.0 | 0.14 | 0.044 | 0.736 * | 0.0 | 0.0 | |
| 3 | 0.072 | 0.251 | 0.307 | 0.693 * | 0.118 | 0.091 | 0.34 | 0.174 | 0.31 | 0.687 * | 0.249 | 0.175 | 0.264 | 0.348 | 0.476 | 0.736 * | 0.277 | 0.277 | ||
| 6 | 0.327 | 0.551 | 0.426 | 0.693 | 0.248 | 0.785 * | 0.298 | 0.37 | 0.434 | 0.687 | 0.319 | 0.849 * | 0.829 | 0.344 | 0.541 | 0.736 | 0.87 | 0.932 * | ||
| 9 | 0.555 | 0.55 | 0.507 | 0.693 | 0.648 | 0.729 * | 0.401 | 0.486 | 0.501 | 0.675 | 0.339 | 0.679 * | 0.757 | 0.434 | 0.707 | 0.736 | 0.8 | 0.81 * | ||
| 12 | 0.767 | 0.61 | 0.615 | 0.693 | 0.81 * | 0.718 | 0.357 | 0.521 | 0.615 | 0.676 * | 0.499 | 0.671 | 0.732 | 0.563 | 0.698 | 0.736 | 0.779 * | 0.761 | ||
| sklearn_smal -red | 10 | 1 | 0.702 | 0.78 | 0.677 | 0.809 * | 0.704 | 0.736 | 0.797 * | 0.736 | 0.752 | 0.73 | 0.789 | 0.709 | 0.879 | 0.872 | 0.883 | 0.893 * | 0.879 | 0.842 |
| 3 | 0.777 | 0.726 | 0.847 * | 0.816 | 0.702 | 0.722 | 0.894 * | 0.804 | 0.843 | 0.818 | 0.851 | 0.665 | 0.866 | 1.014 * | 0.964 | 0.963 | 0.884 | 0.796 | ||
| 6 | 0.794 | 0.831 | 0.913 * | 0.818 | 0.796 | 0.752 | 0.946 * | 0.865 | 0.93 | 0.909 | 0.886 | 0.741 | 0.934 | 1.021 | 1.002 | 1.108 * | 0.928 | 0.878 | ||
| 9 | 0.891 | 0.895 | 0.973 * | 0.82 | 0.875 | 0.882 | 0.94 * | 0.916 | 0.939 | 0.93 | 0.924 | 0.882 | 0.97 | 1.125 * | 0.959 | 1.021 | 1.029 | 0.972 | ||
| 12 | 0.92 | 0.9 | 0.958 * | 0.848 | 0.914 | 0.88 | 0.965 * | 0.961 | 0.953 | 0.934 | 0.943 | 0.938 | 0.973 | 1.085 * | 1.026 | 1.074 | 0.939 | 0.914 | ||
| 100 | 1 | 0.661 * | 0.626 | 0.661 * | 0.658 | 0.655 | 0.606 | 0.63 | 0.636 | 0.691 | 0.701 * | 0.646 | 0.613 | 0.653 | 0.651 | 0.713 | 0.75 * | 0.626 | 0.631 | |
| 3 | 0.774 | 0.74 | 0.797 | 0.807 * | 0.766 | 0.613 | 0.741 | 0.739 | 0.801 * | 0.792 | 0.764 | 0.608 | 0.673 | 0.746 | 0.845 * | 0.828 | 0.653 | 0.661 | ||
| 6 | 0.845 | 0.816 | 0.881 * | 0.855 | 0.85 | 0.697 | 0.862 | 0.831 | 0.881 * | 0.86 | 0.845 | 0.737 | 0.788 | 0.868 | 0.911 * | 0.877 | 0.793 | 0.763 | ||
| 9 | 0.909 * | 0.901 | 0.907 | 0.896 | 0.872 | 0.878 | 0.907 | 0.896 | 0.914 * | 0.894 | 0.882 | 0.909 | 0.868 | 0.907 | 0.927 | 0.947 * | 0.875 | 0.88 | ||
| 12 | 0.924 | 0.938 | 0.956 * | 0.932 | 0.922 | 0.914 | 0.932 | 0.943 * | 0.926 | 0.943 * | 0.914 | 0.93 | 0.921 | 0.944 | 0.967 | 0.969 * | 0.925 | 0.929 | ||
| 1000 | 1 | 0.639 | 0.636 | 0.619 | 0.653 * | 0.615 | 0.552 | 0.593 | 0.629 | 0.723 * | 0.681 | 0.623 | 0.565 | 0.628 * | 0.625 | 0.62 | 0.615 | 0.617 | 0.577 | |
| 3 | 0.716 | 0.741 | 0.773 * | 0.766 | 0.724 | 0.562 | 0.724 | 0.753 | 0.81 * | 0.751 | 0.736 | 0.556 | 0.736 | 0.691 | 0.738 * | 0.724 | 0.725 | 0.596 | ||
| 6 | 0.823 | 0.823 | 0.858 * | 0.833 | 0.806 | 0.718 | 0.853 | 0.863 | 0.877 * | 0.825 | 0.848 | 0.729 | 0.843 * | 0.783 | 0.819 | 0.807 | 0.839 | 0.715 | ||
| 9 | 0.888 | 0.892 | 0.902 | 0.884 | 0.878 | 0.915 * | 0.908 | 0.931 * | 0.912 | 0.918 | 0.917 | 0.923 | 0.879 | 0.856 | 0.85 | 0.907 * | 0.889 | 0.887 | ||
| 12 | 0.936 | 0.941 | 0.935 | 0.935 | 0.939 | 0.954 * | 0.929 | 0.955 * | 0.954 | 0.932 | 0.941 | 0.946 | 0.911 | 0.915 | 0.916 | 0.93 * | 0.914 | 0.92 | ||
| sklearn_large | 10 | 1 | 0.87 | 0.949 | 0.856 | 0.957 * | 0.87 | 0.87 | 0.833 | 0.833 | 0.82 | 0.838 * | 0.756 | 0.794 | 0.842 | 0.895 * | 0.757 | 0.757 | 0.842 | 0.842 |
| 3 | 0.914 | 0.928 * | 0.858 | 0.916 | 0.882 | 0.916 | 0.783 | 0.827 | 0.834 | 0.875 * | 0.771 | 0.779 | 0.93 | 0.899 | 0.904 | 0.873 | 0.92 | 0.965 * | ||
| 6 | 0.976 | 0.955 | 0.956 | 0.913 | 0.984 * | 0.98 | 0.875 | 0.86 | 0.877 | 0.901 | 0.845 | 0.959 * | 0.995 * | 0.986 | 0.981 | 0.896 | 0.983 | 0.982 | ||
| 9 | 0.905 | 0.994 | 0.999 * | 0.953 | 0.897 | 0.935 | 0.927 * | 0.912 | 0.897 | 0.915 | 0.859 | 0.924 | 1.005 | 0.956 | 0.976 | 1.0 | 1.007 * | 0.933 | ||
| 12 | 1.107 * | 1.023 | 0.94 | 0.968 | 1.076 | 1.101 | 0.919 | 0.924 | 0.876 | 0.913 | 0.89 | 0.996 * | 1.056 | 0.972 | 0.962 | 1.021 | 1.078 | 1.117 * | ||
| 100 | 1 | 0.67 | 0.671 | 0.685 | 0.668 | 0.691 * | 0.666 | 0.662 | 0.655 | 0.654 | 0.674 | 0.676 * | 0.67 | 0.678 | 0.714 * | 0.67 | 0.653 | 0.678 | 0.678 | |
| 3 | 0.734 | 0.709 | 0.766 * | 0.721 | 0.738 | 0.721 | 0.692 | 0.687 | 0.722 | 0.669 | 0.717 | 0.732 * | 0.751 | 0.759 * | 0.747 | 0.717 | 0.744 | 0.742 | ||
| 6 | 0.734 | 0.74 | 0.807 | 0.765 | 0.783 | 0.886 * | 0.778 | 0.713 | 0.756 | 0.728 | 0.739 | 0.883 * | 0.83 | 0.776 | 0.819 | 0.809 | 0.834 | 0.906 * | ||
| 9 | 0.753 | 0.762 | 0.815 | 0.796 | 0.801 | 0.879 * | 0.804 | 0.767 | 0.788 | 0.753 | 0.803 | 0.871 * | 0.908 * | 0.816 | 0.827 | 0.862 | 0.893 | 0.878 | ||
| 12 | 0.791 | 0.81 | 0.839 | 0.814 | 0.807 | 0.961 * | 0.819 | 0.779 | 0.835 | 0.811 | 0.802 | 0.939 * | 0.954 | 0.824 | 0.851 | 0.866 | 0.934 | 0.955 * | ||
| 1000 | 1 | 0.591 | 0.65 * | 0.609 | 0.571 | 0.62 | 0.592 | 0.617 | 0.585 | 0.589 | 0.618 | 0.632 * | 0.577 | 0.644 | 0.646 * | 0.622 | 0.612 | 0.612 | 0.616 | |
| 3 | 0.636 | 0.664 | 0.69 * | 0.61 | 0.653 | 0.646 | 0.634 | 0.594 | 0.634 | 0.656 * | 0.648 | 0.648 | 0.685 * | 0.658 | 0.683 | 0.645 | 0.656 | 0.681 | ||
| 6 | 0.671 | 0.661 | 0.708 | 0.698 | 0.711 | 0.837 * | 0.675 | 0.671 | 0.754 | 0.753 | 0.677 | 0.85 * | 0.706 | 0.703 | 0.77 | 0.751 | 0.681 | 0.849 * | ||
| 9 | 0.697 | 0.699 | 0.779 | 0.716 | 0.736 | 0.836 * | 0.713 | 0.722 | 0.778 | 0.786 | 0.715 | 0.848 * | 0.749 | 0.762 | 0.79 | 0.761 | 0.726 | 0.841 * | ||
| 12 | 0.704 | 0.712 | 0.783 | 0.772 | 0.77 | 0.898 * | 0.726 | 0.778 | 0.811 | 0.809 | 0.765 | 0.904 * | 0.802 | 0.799 | 0.828 | 0.776 | 0.778 | 0.921 * | ||
| Model Name | Logistic Regression | Lasso | Ridge | Elastic Net | ||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Method Name | Embedded Ranking | Vsi Ranking | Mrmr Ranking | Permtest Ranking | Shap Ranking | Our Method | Embedded Ranking | Vsi Ranking | Mrmr Ranking | Permtest Ranking | Shap Ranking | Our Method | Embedded Ranking | Vsi Ranking | Mrmr Ranking | Permtest Ranking | Shap Ranking | Our Method | Embedded Ranking | Vsi Ranking | Mrmr Ranking | Permtest Ranking | Shap Ranking | Our Method | ||
| Dataset Name | Data Size | Num Features | ||||||||||||||||||||||||
| covid | 10 | 1 | 1.0 * | 1.0 * | 1.0 * | 1.0 * | 1.0 * | 1.0 * | 1.0 * | 1.0 * | 1.0 * | 1.0 * | 1.0 * | 1.0 * | 1.0 * | 1.0 * | 1.0 * | 1.0 * | 1.0 * | 1.0 * | 1.0 | 1.002 * | 1.002 * | 1.002 * | 1.002 * | 1.0 |
| 3 | 1.012 | 1.013 | 1.022 | 1.014 | 1.057 * | 1.057 * | 1.013 | 1.011 | 1.013 | 1.008 | 1.063 * | 1.044 | 1.017 | 1.011 | 1.019 | 1.013 | 1.068 * | 1.064 | 1.001 | 1.001 | 1.005 | 1.005 | 1.052 * | 1.044 | ||
| 6 | 0.993 | 0.998 | 1.013 | 0.995 | 1.055 | 1.058 * | 1.002 | 0.999 | 1.003 | 1.003 | 1.051 * | 1.048 | 1.013 | 1.008 | 1.013 | 0.992 | 1.064 * | 1.064 * | 0.994 | 1.002 | 0.997 | 1.005 | 1.044 | 1.05 * | ||
| 9 | 1.005 | 0.998 | 1.0 | 0.987 | 1.054 * | 1.052 | 0.999 | 1.001 | 0.999 | 1.003 | 1.049 * | 1.047 | 1.005 | 1.006 | 1.007 | 1.01 | 1.055 * | 1.054 | 0.997 | 0.998 | 1.0 | 0.996 | 1.047 | 1.05 * | ||
| 12 | 1.01 | 0.997 | 0.995 | 0.998 | 1.059 * | 1.029 | 1.0 | 1.005 | 1.004 | 0.997 | 1.05 * | 1.049 | 1.001 | 1.008 | 1.006 | 1.004 | 1.051 | 1.053 * | 0.997 | 0.998 | 0.993 | 0.997 | 1.047 | 1.05 * | ||
| 100 | 1 | 1.009 | 0.988 | 0.994 | 0.999 | 1.056 * | 1.031 | 0.999 | 0.998 | 1.007 | 0.999 | 1.049 | 1.05 * | 1.005 | 1.004 | 1.009 | 1.004 | 1.055 * | 1.051 | 0.998 | 0.997 | 0.997 | 0.996 | 1.047 | 1.05 * | |
| 3 | 1.006 | 1.007 | 1.006 | 1.005 | 1.052 | 1.055 * | 0.998 | 0.999 | 0.998 | 0.998 | 1.048 * | 1.048 * | 0.997 | 0.999 | 0.997 | 0.998 | 1.047 * | 1.047 * | 0.998 | 0.998 | 0.998 | 0.998 | 1.048 * | 1.048 * | ||
| 6 | 1.006 | 1.005 | 1.006 | 1.002 | 1.054 * | 1.052 | 0.998 | 0.998 | 0.997 | 1.0 | 1.046 * | 1.046 * | 0.999 | 0.997 | 0.998 | 1.0 | 1.05 * | 1.047 | 0.998 | 0.998 | 0.998 | 1.0 | 1.048 * | 1.046 | ||
| 9 | 1.004 | 1.002 | 1.008 | 1.003 | 1.05 | 1.051 * | 0.996 | 0.998 | 0.997 | 1.0 | 1.047 * | 1.044 | 0.999 | 0.997 | 0.998 | 1.0 | 1.053 * | 1.045 | 0.998 | 0.998 | 0.998 | 1.0 | 1.049 * | 1.047 | ||
| 12 | 1.002 | 1.005 | 1.007 | 1.004 | 1.05 * | 1.049 | 0.997 | 0.999 | 0.999 | 0.998 | 1.047 * | 1.044 | 1.001 | 0.998 | 0.998 | 1.001 | 1.051 * | 1.044 | 0.997 | 0.999 | 0.998 | 1.0 | 1.048 * | 1.045 | ||
| 1000 | 1 | 0.999 | 1.0 | 1.0 | 1.0 | 1.048 * | 1.047 | 0.996 | 0.998 | 0.998 | 1.0 | 1.047 * | 1.043 | 1.0 | 0.997 | 0.998 | 1.001 | 1.05 * | 1.044 | 0.998 | 0.999 | 1.0 | 1.0 | 1.049 * | 1.044 | |
| 3 | 0.979 | 0.979 | 0.978 | 0.979 | 1.028 * | 1.027 | 0.983 | 0.983 | 0.982 | 0.983 | 1.032 * | 1.031 | 0.981 | 0.979 | 0.979 | 0.979 | 1.03 * | 1.028 | 0.984 | 0.982 | 0.982 | 0.982 | 1.034 * | 1.031 | ||
| 6 | 0.979 | 0.979 | 0.979 | 0.982 | 1.03 * | 1.027 | 0.983 | 0.983 | 0.983 | 0.987 | 1.032 * | 1.031 | 0.98 | 0.979 | 0.979 | 0.981 | 1.031 * | 1.028 | 0.985 | 0.982 | 0.985 | 0.986 | 1.034 * | 1.031 | ||
| 9 | 0.979 | 0.979 | 0.981 | 0.984 | 1.03 * | 1.027 | 0.983 | 0.983 | 0.986 | 0.99 | 1.032 * | 1.031 | 0.982 | 0.979 | 0.983 | 0.984 | 1.03 * | 1.027 | 0.985 | 0.982 | 0.986 | 0.989 | 1.034 * | 1.031 | ||
| 12 | 0.98 | 0.979 | 0.982 | 0.987 | 1.03 * | 1.027 | 0.985 | 0.984 | 0.986 | 0.991 | 1.033 * | 1.031 | 0.982 | 0.98 | 0.986 | 0.986 | 1.03 * | 1.027 | 0.986 | 0.984 | 0.988 | 0.99 | 1.034 * | 1.031 | ||
| withmeds | 10 | 1 | 0.981 | 0.983 | 0.983 | 0.987 | 1.03 * | 1.027 | 0.985 | 0.987 | 0.988 | 0.991 | 1.034 * | 1.031 | 0.983 | 0.983 | 0.986 | 0.988 | 1.031 * | 1.027 | 0.986 | 0.985 | 0.989 | 0.99 | 1.034 * | 1.031 |
| 3 | 0.047 | 0.118 | 0.075 | 0.771 * | 0.086 | 0.217 | 0.0 | 1538.462 | 0.0 | 5025.804 | 5250.0 * | 0.0 | 0.146 | 0.1 | 0.0 | 0.691 * | 0.153 | 0.153 | 0.0 | 0.874 | 0.0 | 1.428 * | 0.0 | 0.0 | ||
| 6 | 0.412 | 0.416 | 0.311 | 0.66 * | 0.464 | 0.329 | 1250.068 | 1538.526 | 0.036 | 5025.726 * | 4200.12 | 0.043 | 0.212 | 0.239 | 0.127 | 0.68 * | 0.223 | 0.152 | 0.673 | 0.968 | 0.384 | 1.23 * | 0.707 | 0.033 | ||
| 9 | 0.548 | 0.663 | 0.629 | 0.641 | 0.721 * | 0.425 | 2222.561 | 1538.792 | 0.288 | 5518.314 * | 5250.114 | 2000.229 | 0.203 | 0.392 | 0.486 | 0.695 * | 0.213 | 0.213 | 0.47 | 1.303 * | 0.733 | 1.099 | 0.493 | 0.184 | ||
| 12 | 0.794 | 0.807 * | 0.737 | 0.545 | 0.794 | 0.591 | 6316.189 * | 1538.95 | 0.606 | 2365.371 | 6176.933 | 4667.273 | 0.539 | 0.569 | 0.631 | 0.699 * | 0.566 | 0.578 | 0.807 | 1.578 * | 0.598 | 1.136 | 0.739 | 0.448 | ||
| 100 | 1 | 0.88 * | 0.706 | 0.628 | 0.595 | 0.861 | 0.678 | 3750.445 | 1539.265 | 0.593 | 2365.322 | 6300.474 * | 0.628 | 0.507 | 0.793 * | 0.71 | 0.642 | 0.528 | 0.503 | 1.186 | 1.635 * | 1.043 | 1.019 | 1.065 | 0.72 | |
| 3 | 0.033 | 0.062 | 0.106 | 0.486 * | 0.067 | 0.0 | 0.0 | 0.075 | 0.139 | 0.532 * | 0.0 | 0.0 | 0.0 | 0.152 | 0.016 | 0.528 * | 0.0 | 0.0 | 0.0 | 0.039 | 0.06 | 0.526 * | 0.0 | 0.0 | ||
| 6 | 0.187 | 0.089 | 0.233 | 0.498 * | 0.209 | 0.122 | 0.216 | 0.075 | 0.35 | 0.541 * | 0.066 | 0.197 | 0.217 | 0.187 | 0.016 | 0.561 * | 0.107 | 0.098 | 0.233 | 0.101 | 0.22 | 0.531 * | 0.2 | 0.099 | ||
| 9 | 0.321 | 0.228 | 0.445 | 0.511 * | 0.348 | 0.112 | 0.298 | 0.124 | 0.447 | 0.532 * | 0.191 | 0.197 | 0.218 | 0.275 | 0.186 | 0.525 * | 0.154 | 0.093 | 0.363 | 0.235 | 0.342 | 0.524 * | 0.348 | 0.099 | ||
| 12 | 0.316 | 0.254 | 0.578 * | 0.519 | 0.537 | 0.426 | 0.369 | 0.232 | 0.486 | 0.517 * | 0.438 | 0.497 | 0.502 | 0.435 | 0.381 | 0.565 * | 0.481 | 0.509 | 0.439 | 0.278 | 0.428 | 0.547 * | 0.444 | 0.411 | ||
| 1000 | 1 | 0.354 | 0.357 | 0.618 * | 0.538 | 0.598 | 0.579 | 0.42 | 0.414 | 0.531 | 0.577 | 0.538 | 0.598 * | 0.561 | 0.556 | 0.47 | 0.591 | 0.625 * | 0.541 | 0.493 | 0.436 | 0.506 | 0.527 | 0.559 * | 0.461 | |
| 3 | 0.0 | 0.035 | 0.0 | 0.43 * | 0.0 | 0.0 | 0.084 | 0.0 | 0.039 | 0.458 * | 0.0 | 0.0 | 0.0 | 0.0 | 0.095 | 0.508 * | 0.0 | 0.0 | 0.0 | 0.046 | 0.225 | 0.458 * | 0.0 | 0.0 | ||
| 6 | 0.181 | 0.081 | 0.238 | 0.472 * | 0.247 | 0.27 | 0.217 | 0.204 | 0.188 | 0.507 * | 0.06 | 0.172 | 0.242 | 0.119 | 0.16 | 0.514 * | 0.299 | 0.225 | 0.106 | 0.198 | 0.215 | 0.476 * | 0.142 | 0.137 | ||
| 9 | 0.338 | 0.26 | 0.388 | 0.457 * | 0.375 | 0.259 | 0.421 | 0.363 | 0.248 | 0.482 * | 0.193 | 0.203 | 0.285 | 0.291 | 0.33 | 0.517 * | 0.349 | 0.216 | 0.391 | 0.364 | 0.283 | 0.462 * | 0.259 | 0.137 | ||
| 12 | 0.564 | 0.288 | 0.531 | 0.503 | 0.681 * | 0.587 | 0.482 | 0.405 | 0.498 | 0.504 | 0.46 | 0.555 * | 0.508 | 0.404 | 0.573 * | 0.517 | 0.47 | 0.457 | 0.527 | 0.516 | 0.344 | 0.498 | 0.537 * | 0.442 | ||
| sklearn_smal -red | 10 | 1 | 0.52 | 0.436 | 0.605 | 0.496 | 0.63 * | 0.607 | 0.544 | 0.45 | 0.646 * | 0.527 | 0.537 | 0.61 | 0.562 | 0.466 | 0.647 * | 0.562 | 0.567 | 0.51 | 0.612 | 0.696 | 0.416 | 0.534 | 0.705 * | 0.516 |
| 3 | 0.8 * | 0.784 | 0.79 | 0.743 | 0.799 | 0.703 | 0.77 | 0.8 | 0.862 | 0.846 | 0.877 * | 0.642 | 0.382 | 0.689 * | 0.598 | 0.561 | 0.382 | 0.422 | 0.574 | 0.883 * | 0.737 | 0.781 | 0.575 | 0.495 | ||
| 6 | 0.763 | 0.817 | 0.931 * | 0.817 | 0.773 | 0.682 | 0.885 | 0.897 | 0.894 | 0.933 * | 0.907 | 0.682 | 0.612 | 0.824 | 0.934 | 0.942 * | 0.612 | 0.624 | 0.76 | 0.922 | 0.938 | 0.961 * | 0.76 | 0.728 | ||
| 9 | 0.865 | 0.836 | 0.962 * | 0.864 | 0.935 | 0.796 | 0.922 | 0.941 | 0.988 * | 0.954 | 0.937 | 0.788 | 0.884 | 0.976 | 0.961 | 0.999 * | 0.884 | 0.843 | 0.799 | 0.905 | 1.013 * | 0.947 | 0.851 | 0.777 | ||
| 12 | 0.898 | 0.869 | 0.964 * | 0.942 | 0.927 | 0.909 | 0.937 | 0.939 | 0.936 | 0.959 | 0.968 * | 0.928 | 0.884 | 1.025 * | 0.95 | 1.001 | 0.884 | 0.895 | 0.863 | 0.955 | 0.996 | 1.016 * | 0.919 | 0.947 | ||
| 100 | 1 | 0.932 | 0.871 | 0.978 | 0.985 | 0.99 * | 0.915 | 0.95 | 0.995 * | 0.93 | 0.97 | 0.984 | 0.939 | 0.932 | 0.965 | 0.975 | 1.047 * | 0.901 | 0.956 | 0.968 | 0.965 | 1.023 | 1.032 * | 0.994 | 0.94 | |
| 3 | 0.747 * | 0.7 | 0.675 | 0.709 | 0.704 | 0.635 | 0.698 | 0.673 | 0.725 | 0.729 * | 0.7 | 0.65 | 0.628 | 0.552 | 0.724 * | 0.603 | 0.628 | 0.531 | 0.722 | 0.654 | 0.74 * | 0.702 | 0.721 | 0.618 | ||
| 6 | 0.84 * | 0.769 | 0.84 * | 0.775 | 0.784 | 0.603 | 0.813 | 0.75 | 0.815 | 0.842 | 0.862 * | 0.643 | 0.803 | 0.767 | 0.826 * | 0.81 | 0.822 | 0.589 | 0.761 | 0.802 | 0.861 * | 0.806 | 0.763 | 0.609 | ||
| 9 | 0.875 | 0.871 | 0.928 * | 0.904 | 0.889 | 0.731 | 0.917 | 0.836 | 0.893 | 0.917 | 0.933 * | 0.757 | 0.848 | 0.885 * | 0.882 | 0.877 | 0.864 | 0.722 | 0.845 | 0.871 | 0.897 * | 0.877 | 0.844 | 0.744 | ||
| 12 | 0.917 | 0.954 * | 0.94 | 0.954 * | 0.918 | 0.939 | 0.954 | 0.927 | 0.904 | 0.95 | 0.962 * | 0.943 | 0.883 | 0.918 | 0.934 | 0.936 * | 0.886 | 0.931 | 0.881 | 0.964 * | 0.934 | 0.926 | 0.878 | 0.933 | ||
| 1000 | 1 | 0.954 | 0.99 | 0.985 | 0.984 | 0.958 | 1.021 * | 0.974 | 0.969 | 0.939 | 0.996 * | 0.978 | 0.969 | 0.917 | 0.945 | 0.966 | 0.961 | 0.921 | 0.967 * | 0.94 | 0.979 * | 0.978 | 0.956 | 0.943 | 0.978 | |
| 3 | 0.565 | 0.596 | 0.694 * | 0.663 | 0.565 | 0.545 | 0.679 | 0.599 | 0.696 * | 0.689 | 0.672 | 0.556 | 0.659 | 0.666 | 0.676 | 0.701 * | 0.659 | 0.575 | 0.63 | 0.621 | 0.722 * | 0.57 | 0.63 | 0.569 | ||
| 6 | 0.739 | 0.77 | 0.775 | 0.792 * | 0.739 | 0.553 | 0.714 | 0.774 | 0.794 | 0.8 * | 0.706 | 0.58 | 0.788 | 0.756 | 0.819 * | 0.772 | 0.788 | 0.574 | 0.789 | 0.728 | 0.802 * | 0.753 | 0.783 | 0.575 | ||
| 9 | 0.869 | 0.854 | 0.872 * | 0.866 | 0.849 | 0.726 | 0.86 | 0.85 | 0.847 | 0.845 | 0.866 * | 0.727 | 0.856 | 0.849 | 0.861 | 0.825 | 0.866 * | 0.72 | 0.878 * | 0.839 | 0.878 * | 0.812 | 0.871 | 0.728 | ||
| 12 | 0.912 | 0.934 * | 0.928 | 0.933 | 0.895 | 0.916 | 0.927 | 0.906 | 0.876 | 0.907 | 0.928 * | 0.914 | 0.871 | 0.933 * | 0.889 | 0.9 | 0.874 | 0.916 | 0.891 | 0.91 * | 0.904 | 0.873 | 0.879 | 0.91 * | ||
| sklearn_large | 10 | 1 | 0.954 | 0.963 | 0.969 | 0.956 | 0.957 | 0.995 * | 0.966 | 0.94 | 0.946 | 0.939 | 0.965 | 0.994 * | 0.919 | 0.956 | 0.972 | 0.947 | 0.924 | 0.993 * | 0.934 | 0.943 | 0.949 | 0.926 | 0.928 | 0.991 * |
| 3 | 0.857 | 0.909 * | 0.881 | 0.87 | 0.856 | 0.827 | 0.828 * | 0.802 | 0.774 | 0.813 | 0.784 | 0.811 | 0.496 | 0.713 | 0.388 | 0.951 * | 0.496 | 0.486 | 0.561 | 0.661 | 0.835 | 0.729 | 0.888 * | 0.825 | ||
| 6 | 0.861 | 0.912 | 0.845 | 0.888 | 0.873 | 0.943 * | 0.814 | 0.859 | 0.816 | 0.872 * | 0.747 | 0.854 | 0.88 | 1.138 * | 0.887 | 1.043 | 0.88 | 0.893 | 0.91 | 1.06 * | 0.982 | 0.849 | 0.889 | 0.922 | ||
| 9 | 0.908 | 0.886 | 0.837 | 0.898 | 0.947 | 0.97 * | 0.854 | 0.843 | 0.819 | 0.806 | 0.82 | 0.919 * | 1.294 | 1.161 | 1.11 | 1.133 | 1.297 | 1.322 * | 0.908 | 1.033 * | 1.006 | 0.951 | 0.914 | 0.922 | ||
| 12 | 0.897 | 0.92 | 0.945 | 0.949 * | 0.907 | 0.903 | 0.894 | 0.796 | 0.885 | 0.82 | 0.817 | 0.913 * | 1.292 | 1.155 | 1.231 | 1.053 | 1.292 | 1.307 * | 0.901 | 1.034 | 1.058 * | 0.933 | 0.907 | 0.909 | ||
| 100 | 1 | 0.889 | 0.948 | 0.974 * | 0.941 | 0.915 | 0.954 | 0.907 | 0.798 | 0.873 | 0.837 | 0.826 | 0.963 * | 1.382 | 1.12 | 1.23 | 1.1 | 1.382 | 1.383 * | 0.937 | 1.085 * | 1.011 | 0.94 | 0.93 | 1.014 | |
| 3 | 0.738 | 0.808 * | 0.78 | 0.748 | 0.77 | 0.722 | 0.678 | 0.692 | 0.753 * | 0.684 | 0.708 | 0.682 | 0.681 | 0.51 | 0.621 | 0.704 * | 0.681 | 0.621 | 0.707 | 0.65 | 0.756 * | 0.748 | 0.707 | 0.675 | ||
| 6 | 0.827 | 0.863 | 0.832 | 0.781 | 0.796 | 0.867 * | 0.772 | 0.754 | 0.823 * | 0.716 | 0.804 | 0.812 | 0.748 | 0.766 | 0.84 * | 0.795 | 0.749 | 0.822 | 0.746 | 0.834 | 0.801 | 0.804 | 0.744 | 0.851 * | ||
| 9 | 0.864 | 0.89 | 0.888 | 0.865 | 0.815 | 0.971 * | 0.818 | 0.772 | 0.843 | 0.768 | 0.842 | 0.934 * | 0.863 | 0.835 | 0.874 | 0.912 | 0.857 | 0.929 * | 0.849 | 0.855 | 0.82 | 0.879 | 0.849 | 0.942 * | ||
| 12 | 0.928 | 0.881 | 0.879 | 0.895 | 0.944 | 0.963 * | 0.866 | 0.85 | 0.891 | 0.844 | 0.891 | 0.92 * | 0.882 | 0.873 | 0.914 | 0.976 * | 0.88 | 0.92 | 0.907 | 0.86 | 0.852 | 0.912 | 0.894 | 0.921 * | ||
| 1000 | 1 | 0.959 | 0.887 | 0.933 | 0.936 | 0.964 | 1.072 * | 0.895 | 0.852 | 0.908 | 0.885 | 0.901 | 1.013 * | 0.94 | 0.911 | 0.913 | 0.988 | 0.931 | 1.025 * | 0.934 | 0.885 | 0.878 | 0.942 | 0.923 | 1.023 * | |
| 3 | 0.609 | 0.682 | 0.66 | 0.688 * | 0.603 | 0.624 | 0.668 | 0.679 * | 0.649 | 0.642 | 0.641 | 0.574 | 0.628 | 0.617 | 0.598 | 0.597 | 0.642 * | 0.486 | 0.613 | 0.659 * | 0.617 | 0.646 | 0.626 | 0.568 | ||
| 6 | 0.702 | 0.663 | 0.737 | 0.682 | 0.689 | 0.741 * | 0.737 | 0.67 | 0.765 * | 0.684 | 0.762 | 0.746 | 0.641 | 0.671 | 0.738 | 0.683 | 0.645 | 0.74 * | 0.647 | 0.652 | 0.748 * | 0.668 | 0.657 | 0.738 | ||
| 9 | 0.774 | 0.689 | 0.784 | 0.759 | 0.768 | 0.847 * | 0.788 | 0.687 | 0.812 | 0.753 | 0.801 | 0.856 * | 0.668 | 0.679 | 0.827 | 0.81 | 0.683 | 0.843 * | 0.688 | 0.671 | 0.817 | 0.764 | 0.692 | 0.831 * | ||
| 12 | 0.8 | 0.744 | 0.804 | 0.793 | 0.771 | 0.845 * | 0.839 | 0.749 | 0.819 | 0.773 | 0.882 * | 0.856 | 0.74 | 0.769 | 0.848 * | 0.835 | 0.754 | 0.841 | 0.733 | 0.76 | 0.852 * | 0.824 | 0.734 | 0.832 | ||
References
- Jong, K.; Mary, J.; Cornuéjols, A.; Marchiori, E.; Sebag, M. Ensemble feature ranking. In PKDD Lecture Notes in Computer Science, Proceedings of the Knowledge Discovery in Databases: PKDD 2004: 8th European Conference on Principles and Practice of Knowledge Discovery in Databases, Pisa, Italy, 20–24 September 2004; Boulicaut, J.F., Esposito, F., Giannotti, F., Pedreschi, D., Eds.; Springer: Berlin/Heidelberg, Germany, 2004; Volume 3202, pp. 267–278. [Google Scholar]
- Petković, M.; Džeroski, S.; Kocev, D. Feature ranking for semi-supervised learning. Mach. Learn. 2022, 112, 4379–4408. [Google Scholar] [CrossRef]
- Halotel, J.; Demyanov, V.; Gardiner, A. Value of Geologically Derived Features in Machine Learning Facies Classification. Math. Geosci. 2020, 52, 5–29. [Google Scholar] [CrossRef]
- Miah, M.I.; Zendehboudi, S.; Ahmed, S. Log data-driven model and feature ranking for water saturation prediction using machine learning approach. J. Pet. Sci. Eng. 2020, 194, 107921. [Google Scholar] [CrossRef]
- La Fata, C.M.; Giallanza, A.; Micale, R.; La Scalia, G. Ranking of occupational health and safety risks by a multi-criteria perspective: Inclusion of human factors and application of VIKOR. Saf. Sci. 2021, 138, 105234. [Google Scholar] [CrossRef]
- Ak, M.F.; Yucesan, M.; Gul, M. Occupational health, safety and environmental risk assessment in textile production industry through a Bayesian BWM-VIKOR approach. Stoch. Environ. Res. Risk Assess. 2022, 36, 629–642. [Google Scholar] [CrossRef]
- Abdulla, A.; Baryannis, G.; Badi, I. Weighting the Key Features Affecting Supplier Selection using Machine Learning Techniques. In Proceedings of the 7th International Conference on Transport and Logistics, Niš, Serbia, 6 December 2019. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhang, H.; Zhang, B. An Effective Ensemble Automatic Feature Selection Method for Network Intrusion Detection. Information 2022, 13, 314. [Google Scholar] [CrossRef]
- Megantara, A.A.; Ahmad, T. Feature Importance Ranking for Increasing Performance of Intrusion Detection System. In Proceedings of the 3rd International Conference on Computer and Informatics Engineering (IC2IE), Yogyakarta, Indonesia, 15–16 September 2020. [Google Scholar]
- Masmoudi, S.; Elghazel, H.; Taieb, D.; Yazar, O.; Kallel, A. A machine-learning framework for predicting multiple air pollutants’ concentrations via multi-target regression and feature selection. Sci. Total Environ. 2020, 715, 136991. [Google Scholar] [CrossRef] [PubMed]
- Fang, L.; Jin, J.; Segers, A.; Lin, H.X.; Pang, M.; Xiao, C.; Deng, T.; Liao, H. Development of a regional feature selection-based machine learning system (RFSML v1.0) for air pollution forecasting over China. Geosci. Model Dev. 2022, 15, 7791–7807. [Google Scholar] [CrossRef]
- Vatian, A.S.; Golubev, A.A.; Gusarova, N.F.; Dobrenko, N.V. Intelligent Clinical Decision Support for Small Patient Datasets. Sci. Tech. J. Inf. Technol. Mech. Opt. 2023, 23, 595–607. [Google Scholar] [CrossRef]
- Remeseiro, B.; Bolon-Canedo, V. A review of feature selection methods in medical applications. Comput. Biol. Med. 2019, 112, 103375. [Google Scholar] [CrossRef] [PubMed]
- Saqlain, S.M.; Sher, M.; Shah, F.A.; Khan, I.; Ashraf, M.U.; Awais, M.; Ghani, A. Fisher score and Matthews correlation coefficient-based feature subset selection for heart disease diagnosis using support vector machines. Knowl. Inf. Syst. 2019, 58, 139–167. [Google Scholar] [CrossRef]
- Wu, L.; Hu, Y.; Liu, X.; Zhang, X.; Chen, W.; Yu, A.S.L.; Kellum, J.A.; Waitman, L.R.; Liu, M. Feature Ranking in Predictive Models for Hospital-Acquired Acute Kidney Injury. Sci. Rep. 2018, 8, 17298. [Google Scholar] [CrossRef] [PubMed]
- Zhu, L.; Li, L.; Li, R.; Zhu, L. Model-Free Feature Screening for Ultrahigh Dimensional Data. J. Am. Stat. Assoc. 2011, 106, 1464–1475. [Google Scholar] [CrossRef] [PubMed]
- Li, K.; Wang, F. Deep Feature Screening: Feature Selection for Ultra High-Dimensional Data via Deep Neural Networks. Neurocomputing 2023, 538, 126186. [Google Scholar] [CrossRef]
- Mousavi, M.; Khalili, N. VSI: An Interpretable Bayesian Feature Ranking Method Based on Vendi Score. Knowl.-Based Syst. 2025, 311, 112973. [Google Scholar] [CrossRef]
- Radivojac, P.; Obradovic, Z.; Dunker, A.K.; Vucetic, S. Feature selection filters based on the permutation test. In Lecture Notes in Computer Science, Proceedings of the Machine Learning: ECML 2004: 15th European Conference on Machine Learning, Pisa, Italy, 20–24 September 2004; Boulicaut, J.F., Esposito, F., Giannotti, F., Pedreschi, D., Eds.; Springer: Berlin/Heidelberg, Germany, 2004. [Google Scholar]
- Gao, L.; Wu, W. Relevance assignation feature selection method based on mutual information for machine learning. Knowl.-Based Systems. 2020, 209, 106439. [Google Scholar] [CrossRef]
- Bhadra, T.; Mallik, S.; Hasan, N.; Zhao, Z. Comparison of five supervised feature selection algorithms leading to top features and gene signatures from multi-omics data in cancer. BMC Bioinform. 2022, 23, 153. [Google Scholar] [CrossRef] [PubMed]
- Barraza, N.; Moro, S.; Ferreyra, M.; de la Peña, A. Mutual information and sensitivity analysis for feature selection in customer targeting: A comparative study. J. Inf. Sci. 2019, 45, 53–67. [Google Scholar] [CrossRef]
- Quinlan, J.R. C4.5: Programs for Machine Learning; Morgan Kaufmann Publishers, Inc.: San Francisco, CA, USA, 1993. [Google Scholar]
- Peng, H.; Long, F.; Ding, C. Feature Selection Based on Mutual Information: Criteria of Max-Dependency, Max-Relevance, and Min-Redundancy. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 1226–1238. [Google Scholar] [CrossRef] [PubMed]
- Reshef, D.N.; Reshef, Y.; Finucane, H.K.; Grossman, S.R.; McVean, G.; Turnbaugh, P.J.; Lander, E.S.; Mitzenmacher, M.; Sabeti, P.S. Detecting novel associations in large data sets. Science 2011, 334, 1518–1524. [Google Scholar] [CrossRef] [PubMed]
- Li, X.; Xu, S.; Yu, M.; Wang, K.; Tao, Y.; Zhou, Y.; Shi, J.; Zhou, M.; Wu, B.; Yang, Z.; et al. Risk factors for severity and mortality in adult COVID-19 inpatients in Wuhan. J. Allergy Clin. Immunol. 2020, 146, 110–118. [Google Scholar] [CrossRef] [PubMed]
- Liu, X.; Xue, S.; Xu, J.; Ge, H.; Mao, Q.; Xu, X.-H.; Jiang, H.-D. Clinical characteristics and related risk factors of disease severity in 101 COVID-19 patients hospitalized in Wuhan, China. Acta Pharmacol. Sin. 2021, 43, 64–75. [Google Scholar] [CrossRef] [PubMed]
- Phelps, M.; Christensen, D.M.; Gerds, T.; Fosbøl, E.; Torp-Pedersen, C.; Schou, M.; Køber, L.; Kragholm, K.; Andersson, C.; Biering-Sørensen, T.; et al. Cardiovascular comorbidities as predictors for severe COVID-19 infection or death. Eur. Heart J. 2021, 7, 172–180. [Google Scholar] [CrossRef] [PubMed]
- Alam, Z.; Rahman, S.; Rahman, S. A Random Forest based predictor for medical data classification using feature ranking. Inform. Med. Unlocked 2019, 15, 100180. [Google Scholar] [CrossRef]
- Joloudari, J.H.; Joloudari, E.H.; Saadatfar, H.; Ghasemigol, M.; Razavi, S.M.; Mosavi, A.; Nabipour, N.; Shamshirband, S.; Nadai, L. Coronary Artery Disease Diagnosis; Ranking the Significant Features Using Random Trees Model. Int. J. Environ. Res. Public Health 2020, 17, 731. [Google Scholar] [CrossRef] [PubMed]
- Muthukrishnan, R.; Rohini, R. LASSO: A feature selection technique in predictive modeling for machine learning. In Proceedings of the 2016 IEEE International Conference on Advances in Computer Applications (ICACA), Coimbatore, India, 24 October 2016; pp. 18–20. [Google Scholar] [CrossRef]
- Zou, H.; Hastie, T. Regularization and variable selection via the elastic net. J. R. Stat. Soc. Ser. B 2005, 67, 301–320. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD ’16), San Francisco, CA, USA, 13–17 August 2016. [Google Scholar]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Rice, J. Mathematical Statistics and Data Analysis; Duxbury Press: Pacific Grove, CA, USA, 1995; ISBN 0-534-209343. [Google Scholar]
- Schulte, R.V.; Prinsen, E.C.; Hermen, H.J.; Buurke, J.H. Genetic Algorithm for Feature Selection in Lower Limb Pattern Recognition. Sec. Biomed. Robot. 2021, 8, 710806. [Google Scholar] [CrossRef] [PubMed]
- Ali, W.; Saeed, F. Hybrid Filter and Genetic Algorithm-Based Feature Selection for Improving Cancer Classification in High-Dimensional Microarray Data. Processes 2023, 11, 562. [Google Scholar] [CrossRef]
- Abdollahi, J.; Nouri-Moghaddam, B. Feature selection for medical diagnosis: Evaluation for using a hybrid stacked-genetic approach in the diagnosis of heart disease. arXiv 2021. [Google Scholar] [CrossRef]
- Xie, H.; Zhang, L.; Lim, C.P.; Yu, Y.; Liu, H. Feature Selection Using Enhanced Particle Swarm Optimisation for Classification Models. Sensors 2021, 21, 1816. [Google Scholar] [CrossRef] [PubMed]
- Shen, X.; Yang, F.; Yang, P.; Yang, M.; Xu, L.; Zhuo, J.; Wang, J.; Lu, D.; Liu, Z.; Zheng, S.; et al. A Contrast-Enhanced Computed Tomography Based Radiomics Approach for Preoperative Differentiation of Pancreatic Cystic Neoplasm Subtypes: A Feasibility Study. Front. Oncol. 2020, 10, 248. [Google Scholar] [CrossRef] [PubMed]
- Awad, M.; Fraihat, S. Recursive Feature Elimination with Cross-Validation with Decision Tree: Feature Selection Method for Machine Learning-Based Intrusion Detection Systems. J. Sens. Actuator Netw. 2023, 12, 67. [Google Scholar] [CrossRef]
- Nizami, I.F.; Majid, M.; Khurshid, K. Efficient feature selection for Blind Image Quality Assessment based on natural scene statistics. In Proceedings of the 14th International Bhurban Conference on Applied Sciences and Technology (IBCAST), Islamabad, Pakistan, 10–14 January 2017; pp. 318–322. [Google Scholar]
- Alelyani, S. Stable bagging feature selection on medical data. J. Big Data 2021, 8, 11. [Google Scholar] [CrossRef]
- Lundberg, S.M.; Lee, S.I. A Unified Approach to Interpreting Model Predictions. arXiv 2017. [Google Scholar] [CrossRef]
- Aas, K.; Jullum, M.; Løland, A. Explaining individual predictions when features are dependent: More accurate approximations to Shapley values. Artif. Intell. 2021, 298, 103502. [Google Scholar] [CrossRef]
- Gramegna, A.; Giudici, P. Shapley Feature Selection. FinTech 2022, 1, 72–80. [Google Scholar] [CrossRef]
- Verhaeghe, J.; Van Der Donckt, J.; Ongenae, F.; Van Hoeck, S. Powershap: A Power-full Shapley Feature Selection Method. In Lecture Notes in Computer Science, Proceedings of the Machine Learning and Knowledge Discovery in Databases. European Conference, ECML PKDD 2022, Grenoble, France, 19–23 September 2022; Amini, M.R., Canu, S., Fischer, A., Guns, T., Kralj Novak, P., Tsoumakas, G., Eds.; Springer: Berlin/Heidelberg, Germany, 2022. [Google Scholar] [CrossRef]
- Kumar, I.E.; Venkatasubramanian, S.; Scheidegger, C.; Friedler, S.A. Problems with Shapley-value-based explanations as feature importance measures. arXiv 2020, arXiv:2002.11097v2. [Google Scholar]
- Yuan, H.; Liu, M.; Kang, L.; Miao, C.; Wu, Y. An empirical study of the effect of background data size on the stability of SHapley Additive exPlanations (SHAP) for deep learning models. arXiv 2022, arXiv:2204.11351v1. [Google Scholar]
- Jenul, A.; Schrunner, S.; Pilz, J.; Tomic, O. A user-guided Bayesian framework for ensemble feature selection in life science applications (UBayFS). Mach. Learn. 2022, 111, 3897–3923. [Google Scholar] [CrossRef]
- Jreich, R.; Hatte, C.; Parent, E. Review of Bayesian selection methods for categorical predictors using JAGS. J. Appl. Stat. 2021, 49, 2370–2388. [Google Scholar] [CrossRef] [PubMed]
- Bartonicek, A.; Wickham, S.R.; Pat, N.; Conner, T.S. The value of Bayesian predictive projection for variable selection: An example of selecting lifestyle predictors of young adult well-being. BMC Public Health 2021, 21, 695. [Google Scholar] [CrossRef] [PubMed]
- Boulet, S.; Ursino, M.; Thall, P.; Jannot, A.-S.; Zohar, S. Bayesian variable selection based on clinical relevance weights in small sample studies—Application to colon cancer. Stat. Med. 2019, 38, 1–20. [Google Scholar] [CrossRef] [PubMed]
- Wasserman, L. All of Statistics: A Concise Course in Statistical Inference; Springer: New York, NY, USA, 2010; 458p, ISBN -978-1-4419-2322-6. [Google Scholar]
- Bell, D.A.; Wang, H. A Formalism for Relevance and Its Application in Feature Subset Selection. Mach. Learn. 2000, 41, 175–195. [Google Scholar] [CrossRef]
- Cover, T.M.; Thomas, J.A. Elements of information theory, 2nd ed.; Wiley: Hoboken, NJ, USA, 2006; 774p. [Google Scholar]
- van der Vaart, A.W. 10.2 Bernstein–von Mises Theorem. Asymptotic Statistics; Cambridge University Press: Cambridge, UK, 1998; ISBN 0-521-49603-9. [Google Scholar]
- Hendeby, G.; Gustafsson, F. On Nonlinear Transformations of Gaussian Distributions. January 2003. Available online: https://users.isy.liu.se/en/rt/fredrik/reports/07SSPut.pdf (accessed on 10 July 2025).
- Guyon, I. Design of Experiments for the NIPS 2003 Variable Selection Benchmark. 2003. Available online: https://archive.ics.uci.edu/ml/machine-learning-databases/madelon/Dataset.pdf (accessed on 10 July 2025).
- Zoabi, Y.; Deri-Rozov, S.; Shomron, N. Machine learning-based prediction of COVID-19 diagnosis based on symptoms. Npj Digit. Med. 2021, 4, 3. [Google Scholar] [CrossRef] [PubMed]
- COVID-19. COVID-19 Patient’s Symptoms, Status, and Medical History. 2022. Available online: https://www.kaggle.com/datasets/meirnizri/covid19-dataset (accessed on 10 July 2025).
- Lapp, D. Heart Disease Dataset. Available online: https://www.kaggle.com/datasets/johnsmith88/heart-disease-dataset (accessed on 10 July 2025).
- Fedesoriano. Heart Failure Prediction Dataset. Available online: https://www.kaggle.com/datasets/fedesoriano/heart-failure-prediction (accessed on 10 July 2025).
- UCI Machine Learning and 1 Collaborator. Red Wine Quality. Available online: https://www.kaggle.com/datasets/uciml/red-wine-quality-cortez-et-al-2009 (accessed on 10 July 2025).
- Overschie, J.G.S.; Alsahaf, A.; Azzopardi, G. Fseval: A Benchmarking Framework for Feature Selection and Feature Ranking Algorithms. J. Open Source Softw. 2022, 7, 4611. [Google Scholar] [CrossRef]






| Dataset Name | Number of Features | Number of Examples |
|---|---|---|
| sklearn_small | 50 | 30,000 |
| sklearn_large | 300 | 30,000 |
| Covid | 16 | 51,831 |
| Withmeds | 21 | 1,048,576 |
| Heart | 11 | 1026 |
| Heart1 | 13 | 919 |
| Winequality-red | 11 | 1600 |
| XGBoost | Random Forest | |||||||
|---|---|---|---|---|---|---|---|---|
| Dataset | Data Size | Num Features | Top 1 | Top 2 | Top 3 | Top 1 | Top 2 | Top 3 |
| Heart | 10 | 1 | our | embed | shap | our | vsi | mrmr |
| 6 | shap | our | embed | our | vsi | mrmr | ||
| 12 | shap | permtest | our | embed | shap | our | ||
| 1000 | 1 | our | shap | mrmr | our | mrmr | shap | |
| 6 | permtest | our | mrmr | permtest | embed | our | ||
| 12 | embed | permtest | shap | embed | permtest | shap | ||
| Heart1 | 10 | 1 | our | mrmr | shap | our | mrmr | embed |
| 6 | shap | our | embed | shap | embed | our | ||
| 12 | embed | our | shap | our | vsi | shap | ||
| 1000 | 1 | our | mrmr | others | our | permtest | shap | |
| 6 | mrmr | shap | embed | vsi | embed | our | ||
| 12 | mrmr | vsi | shap | shap | mrmr | vsi | ||
| Ridge | ElasticNet | |||||||
|---|---|---|---|---|---|---|---|---|
| Dataset | Data Size | Num Features | Top 1 | Top 2 | Top 3 | Top 1 | Top 2 | Top 3 |
| Heart | 10 | 1 | our | vsi | shap | shap | our | vsi |
| 6 | our | shap | embed | our | embed | mrmr | ||
| 12 | shap | embed | our | vsi | our | permtest | ||
| 1000 | 1 | our | mrmr | vsi | our | mrmr | embed | |
| 6 | our | permtest | mrmr | our | permtest | mrmr | ||
| 12 | our | permtest | vsi | our | vsi | permtest | ||
| Heart1 | 10 | 1 | our | embed | shap | our | mrmr | embed |
| 6 | our | vsi | mrmr | embed | our | shap | ||
| 12 | permtest | vsi | mrmr | our | embed | mrmr | ||
| 1000 | 1 | our | mrmr | permtest | our | mrmr | vsi | |
| 6 | vsi | our | mrmr | embed | vsi | mrmr | ||
| 12 | mrmr | our | embed | vsi | our | shap | ||
| XGBoost | Random Forest | |||||||
|---|---|---|---|---|---|---|---|---|
| Dataset | Data Size | Num Features | Top 1 | Top 2 | Top 3 | Top 1 | Top 2 | Top 3 |
| sklearn_small | 10 | 1 | permtest | vsi | our | embed | shap | mrmr |
| 6 | mrmr | vsi | permtest | embed | mrmr | permtest | ||
| 12 | mrmr | embed | shap | embed | vsi | mrmr | ||
| 1000 | 1 | permtest | embed | vsi | mrmr | permtest | embed | |
| 6 | mrmr | permtest | vsi | mrmr | vsi | embed | ||
| 12 | our | vsi | shap | vsi | mrmr | our | ||
| 50 Samples | 1000 Samples | 10,000 Samples | |
|---|---|---|---|
| 1 | PQ in lead II | P in lead II | Lung surfactant |
| 2 | Lung surfactant | Lung surfactant | P in lead II |
| 3 | P in lead II | PQ in lead II | PQ in lead II |
| 4 | Signs of right-sided heart overload | Signs of right-sided heart overload | Arrhythmia by rate |
| 5 | Anticoagulants | Nonspecific intraventricular block | Nonspecific intraventricular block |
| 6 | QTc lengthening | QTc lengthening | QTc lengthening |
| 7 | Arrhythmia by rate | Arrhythmia by rate | Lopinavir/ritonavir |
| 8 | ST segment ischemic depression | Lopinavir/ritonavir | Signs of right-sided heart overload |
| 9 | Angle alpha x | Anticoagulants | Anticoagulants |
| 10 | Lopinavir/ritonavir | ST segment ischemic depression | Enlargement of the left atrium |
| 11 | Enlargement of the left atrium | Enlargement of the left atrium | ST segment ischemic depression |
| 12 | Nonspecific intraventricular block | Angle alpha x | Angle alpha x |
| 13 | Atrioventricular block (degree) | Atrioventricular block (degree) | Atrioventricular block (degree) |
| 14 | Chioroquine/hydroxychloroquine | Bradycardia (1), tachycardia (2), … | Bradycardia (1), tachycardia (2), … |
| 15 | Tocilizumab | Tocilizumab | Tocilizumab |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Vatian, A.; Gusarova, N.; Tomilov, I. Feature Ranking on Small Samples: A Bayes-Based Approach. Entropy 2025, 27, 773. https://doi.org/10.3390/e27080773
Vatian A, Gusarova N, Tomilov I. Feature Ranking on Small Samples: A Bayes-Based Approach. Entropy. 2025; 27(8):773. https://doi.org/10.3390/e27080773
Chicago/Turabian StyleVatian, Aleksandra, Natalia Gusarova, and Ivan Tomilov. 2025. "Feature Ranking on Small Samples: A Bayes-Based Approach" Entropy 27, no. 8: 773. https://doi.org/10.3390/e27080773
APA StyleVatian, A., Gusarova, N., & Tomilov, I. (2025). Feature Ranking on Small Samples: A Bayes-Based Approach. Entropy, 27(8), 773. https://doi.org/10.3390/e27080773