Impact of Data Distribution and Bootstrap Setting on Anomaly Detection Using Isolation Forest in Process Quality Control


Abstract
1. Introduction
2. Algorithm Review
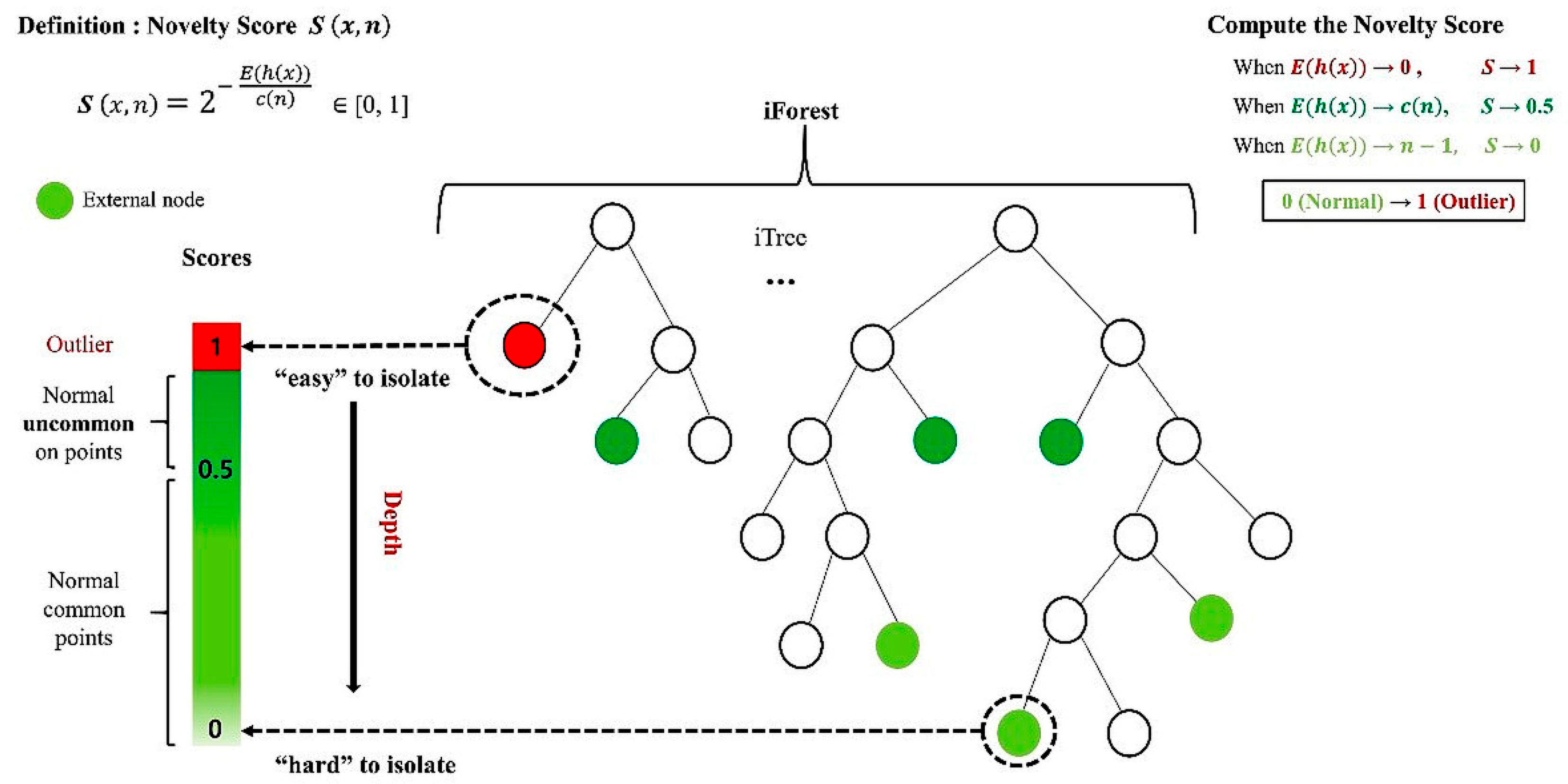
2.1. iForest Algorithm
2.2. Hotelling’s T2
3. Material and Methods
3.1. Evaluation Scenarios
3.2. Control Limits
3.3. Performance Measures
3.4. Statistical Analysis
4. Results
4.1. Effect of Distributions, Mean Shifts, and Bootstrap Settings in iForest
4.2. Comparison of iForest with T2
5. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| ARL | Average run length |
| EWMA | Exponentially weighted moving average |
| EIF | Extended isolation forest |
| FPR | False positive rate |
| KNN | K-nearest neighbors |
| LOF | Local outlier factor |
| PCA | Principal component analysis |
| SPC | Statistical process control |
| SVDD | Support vector data description |
References
- Shewhart, W.A. Control of Quality of Manufactured Product; McGraw-Hill: New York, NY, USA, 1929. [Google Scholar]
- Page, E.S. Cumulative sum charts. Technometrics 1961, 3, 1–9. [Google Scholar] [CrossRef]
- Roberts, S.W. Control chart tests based on geometric moving averages. Technometrics 1959, 1, 239–250. [Google Scholar] [CrossRef]
- Hotelling, H. Multivariate quality control. In Techniques of Statistical Analysis; Eisenhart, C., Hastay, M.W., Wills, W.A., Eds.; McGraw-Hill: New York, NY, USA, 1947; pp. 111–184. [Google Scholar]
- Crosier, R.B. Multivariate generalizations of cumulative sum quality-control schemes. Technometrics 1988, 30, 291–303. [Google Scholar] [CrossRef]
- Lowry, C.A.; Woodall, W.H.; Champ, C.W.; Rigdon, S.E. A multivariate exponentially weighted moving average control chart. Technometrics 1992, 34, 46–53. [Google Scholar] [CrossRef]
- Stoumbos, Z.G.; Sullivan, J.H. Robustness to non-normality of the multivariate EWMA control chart. J. Qual. Technol. 2002, 34, 260–276. [Google Scholar] [CrossRef]
- Chakraborti, S.; Eryilmaz, S. A nonparametric Shewhart-type signed-rank control chart based on runs. Commun. Stat. Simul. Comput. 2007, 36, 335–356. [Google Scholar] [CrossRef]
- Das, N. A new multivariate non-parametric control chart based on sign test. Qual. Technol. Quant. Manag. 2009, 6, 155–169. [Google Scholar] [CrossRef]
- Phaladiganon, P.; Kim, S.B.; Chen, V.C.P.; Jiang, W. Principal component analysis-based control charts for multivariate nonnormal distributions. Expert Syst. Appl. 2013, 40, 3044–3054. [Google Scholar] [CrossRef]
- Kang, J.H.; Yu, J.; Kim, S.B. Adaptive nonparametric control chart for time-varying and multimodal processes. J. Process Control 2016, 37, 34–45. [Google Scholar] [CrossRef]
- Moon, T.K. The expectation-maximization algorithm. IEEE Signal Process. Mag. 1996, 13, 47–60. [Google Scholar] [CrossRef]
- Mahmoud, M.A.; Saleh, N.A.; Madbuly, D.F. Phase I analysis of individual observations with missing data. Qual. Reliab. Eng. Int. 2014, 30, 559–569. [Google Scholar] [CrossRef]
- Breunig, M.M.; Kriegel, H.P.; Ng, R.T.; Sander, J. LOF: Identifying density-based local outliers. In Proceedings of the ACM SIGMOD International Conference on Management of Data, Dallas, TX, USA, 15–18 May 2000; pp. 93–104. [Google Scholar] [CrossRef]
- Kang, P.; Cho, S. A hybrid novelty score and its use in keystroke dynamics-based user authentication. Pattern Recognit. 2009, 42, 3115–3127. [Google Scholar] [CrossRef]
- Harmeling, S.; Dornhege, G.; Tax, D.; Meinecke, F.; Müller, K.R. From outliers to prototypes: Ordering data. Neurocomputing 2006, 69, 1608–1618. [Google Scholar] [CrossRef]
- Jain, M.; Kaur, G.; Saxena, V.A. A K-means clustering and SVM based hybrid concept drift detection technique for network anomaly detection. Expert Syst. Appl. 2022, 193, 116510. [Google Scholar] [CrossRef]
- Charte, D.; Charte, F.; García, S.; del Jesus, M.J.; Herrera, F. A Practical Tutorial on Autoencoders for Anomaly Detection in High-Dimensional Data. Neurocomputing 2021, 455, 137–155. [Google Scholar] [CrossRef]
- Schölkopf, B.; Platt, J.C.; Shawe-Taylor, J.; Smola, A.J.; Williamson, R.C. Estimating the support of a high-dimensional distribution. Neural Comput. 2001, 13, 1443–1471. [Google Scholar] [CrossRef] [PubMed]
- Tax, D.M.J.; Duin, R.P.W. Support vector data description. Mach. Learn. 2004, 54, 45–66. [Google Scholar] [CrossRef]
- Liu, F.T.; Ting, K.M.; Zhou, Z.H. Isolation forest. In Proceedings of the IEEE International Conference Data Mining, Pisa, Italy, 15–19 December 2008; IEEE: New York, NY, USA, 2008; pp. 413–422. [Google Scholar] [CrossRef]
- Li, W.; Jiang, M.; Zhang, X. A Comprehensive Survey on Spectral Clustering with Graph Structure Learning. arXiv 2022, arXiv:2205.03057. [Google Scholar]
- Xu, D.; Wang, Y.; Meng, Y.; Zhang, Z. An improved data anomaly detection method based on isolation forest. In Proceedings of the IEEE International Symposium on Computational Intelligence and Design, Honolulu, HI, USA, 27 November–1 December 2017; IEEE: New York, NY, USA, 2017; Volume 2, pp. 287–291. [Google Scholar] [CrossRef]
- Hariri, S.; Kind, M.C.; Brunner, R.J. Extended isolation forest. IEEE Trans. Knowl. Data Eng. 2021, 33, 1479–1489. [Google Scholar] [CrossRef]
- Cheng, X.; Liu, Z.; Tang, M.; Du, Y.; Xu, C. Anomaly detection based on improved isolated forest. In Proceedings of the IEEE International Conference on Information Technology, Big Data and Artificial Intelligence, Chongqing, China, 26–28 May 2023. [Google Scholar]
- Chen, Q.; Kruger, U.; Meronk, M.; Leung, A.Y.T. Synthesis of T2 and Q statistics for process monitoring. Control Eng. Pract. 2004, 12, 745–755. [Google Scholar] [CrossRef]
- Liu, F.T.; Ting, K.M.; Zhou, Z.H. Isolation-based anomaly detection. ACM Trans. Knowl. Discov. Data 2012, 6, 1–39. [Google Scholar] [CrossRef]
- Pyzdek, T. Non-normal Distributions in the Real World. 2006. Available online: https://www.researchgate.net/publication/230770738 (accessed on 2 May 2025).
- Genta, G.; Galetto, M. Study of measurement process capability with non-normal data distributions. Procedia CIRP 2018, 75, 385–390. [Google Scholar] [CrossRef]
- Alatefi, M.; Ahmad, S.; Alkahtani, M. Performance evaluation using multivariate non-normal process capability. Processes 2019, 7, 833. [Google Scholar] [CrossRef]
- Qiu, P. Some perspectives on nonparametric statistical process control. J. Qual. Technol. 2018, 50, 49–65. [Google Scholar] [CrossRef]
- Roscoe, J.T. Fundamental Research Statistics for the Behavioral Science; Holt, Rinehart & Winston: New York, NY, USA, 1975. [Google Scholar]
- Mukherjee, A.; Cheng, Y.; Gong, M. A new nonparametric scheme for simultaneous monitoring of bivariate processes and its application in monitoring service quality. Qual. Technol. Quant. Manag. 2018, 15, 143–156. [Google Scholar] [CrossRef]
- Tuerhong, G.; Bum Kim, S. Comparison of novelty score-based multivariate control charts. Commun. Stat. Simul. Comput. 2015, 44, 1126–1143. [Google Scholar] [CrossRef]
- Montgomery, D.C. Introduction to Statistical Quality Control, 5th ed.; John Wiley & Sons: New York, NY, USA, 2005. [Google Scholar]
- Jensen, W.A.; Jones-Farmer, L.A.; Champ, C.W.; Woodall, W.H. Effects of parameter estimation on control chart properties: A literature review. J. Qual. Technol. 2006, 38, 349–364. [Google Scholar] [CrossRef]
- Johnson, R.A.; Wichern, D.W. Applied Multivariate Statistical Analysis, 6th ed.; Pearson: Upper Saddle River, NJ, USA, 2007. [Google Scholar]
- Tan, C.W.; Yu, P. Contagion Source Detection in Epidemic and Infodemic Outbreaks: Mathematical Analysis and Network. Found. Trends Netw. 2023, 13, 107–251. [Google Scholar] [CrossRef]
- Gulanbaier, T.; Kim, S.B.; Kang, P.; Cho, S. Multivariate Control Charts Based on Hybrid Novelty Scores. Commun. Stat. Simul. Comput. 2014, 43, 115–131. [Google Scholar] [CrossRef]
- Haanchumpol, T.; Sudasna-na-Ayudthya, P.; Singhtaun, C. Modified Multivariate Control Chart Using Spatial Signs and Ranks for Monitoring Process Mean: A Case of t-Distribution. In Proceedings of the 9th International Conference on Industrial Engineering and Operations Management, Bangkok, Thailand, 5–7 March 2019; IEOM Society International. pp. 1415–1427. [Google Scholar]
- Lee, S. Machine Learning-Based Process Monitoring and Maintenance for Smart Manufacturing. Ph.D. Dissertation, Korea University, Seoul, Republic of Korea, 2018. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Metric | iForest | T2 | Statistical Significance |
|---|---|---|---|
| Accuracy | 0.8942 | 0.8642 | Yes |
| Precision | 0.9088 | 0.8464 | Yes |
| Recall | 0.4790 | 0.3288 | Yes |
| F1-score | 0.5504 | 0.3834 | Yes |
| ROC AUC | 0.9034 | 0.8908 | No |
| PR AUC | 0.7880 | 0.7349 | No |
| ARL1 | 10.3769 | 17.9133 | Yes |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Choi, H.; Jung, K. Impact of Data Distribution and Bootstrap Setting on Anomaly Detection Using Isolation Forest in Process Quality Control. Entropy 2025, 27, 761. https://doi.org/10.3390/e27070761
Choi H, Jung K. Impact of Data Distribution and Bootstrap Setting on Anomaly Detection Using Isolation Forest in Process Quality Control. Entropy. 2025; 27(7):761. https://doi.org/10.3390/e27070761
Chicago/Turabian StyleChoi, Hyunyul, and Kihyo Jung. 2025. "Impact of Data Distribution and Bootstrap Setting on Anomaly Detection Using Isolation Forest in Process Quality Control" Entropy 27, no. 7: 761. https://doi.org/10.3390/e27070761
APA StyleChoi, H., & Jung, K. (2025). Impact of Data Distribution and Bootstrap Setting on Anomaly Detection Using Isolation Forest in Process Quality Control. Entropy, 27(7), 761. https://doi.org/10.3390/e27070761