1. Introduction
As information technology continues to advance rapidly, cloud computing has become a key component of modern information technology, particularly in the areas of data storage and processing, providing powerful support. As one of the core services of cloud computing, cloud storage enables users to store their local data on cloud servers, alleviating the storage burden on physical devices while enhancing the convenience and flexibility of data access [
1,
2]. However, as cloud storage becomes more widespread, outsourcing data to cloud service providers (CSPs) introduces security and integrity challenges.
One critical issue is ensuring the integrity of cloud-stored data. As cloud storage removes direct control over data, it exposes the data to potential attacks such as unauthorized tampering, malicious deletion, or even accidental damage due to hardware or software failures. Although users depend on CSPs to preserve data integrity, the cloud’s inherent openness and sharing raise significant issues regarding data security, privacy, and reliability. Whether due to malicious actions by CSPs or external attackers, there is a pressing need for robust mechanisms to ensure that outsourced data are properly stored and remain intact.
Real-world incidents further underscore this need. For example, during a six-month high-energy physics operation involving approximately 97 petabytes of data, CERN reported that about 128 megabytes had been irreversibly corrupted, raising concerns about the impact of even minor data degradation on scientific research outcomes [
3]. In another case, Jeff Bonwick, creator of the ZFS file system, revealed that Greenplum—a high-performance database—experiences silent data corruption every 10 to 20 minutes without triggering system alerts. These cases illustrate that even in rigorously managed scientific and enterprise environments, data corruption can occur undetected, undermining both data reliability and decision making [
3].
Traditional data integrity verification solutions, such as downloading the entire dataset for inspection, have become impractical due to the large data volumes involved and the high communication and computational costs [
4]. To address this challenge, researchers have proposed various alternative approaches.
Among them, blockchain-based storage frameworks [
5,
6] leverage distributed ledgers and consensus protocols to achieve verifiability and tamper resistance. These schemes often utilize Merkle hash trees and smart contracts for auditability and state tracking. However, they typically suffer from high communication costs, significant computational overhead, and consensus-related delays, which limit their applicability in resource-constrained environments. On the other hand, coding techniques in edge computing [
3,
5] enhance data availability through redundant encoding and erasure coding, providing strong resilience against data loss or corruption. Nonetheless, these methods primarily focus on fault tolerance and recovery, and they lack fine-grained audit control or designated verifier mechanisms.
Intuitively, data owners can perform integrity verification tasks themselves, but this requires them to retrieve and check the data’s integrity individually, resulting in a significant communication and computational burden. To alleviate this burden, public auditing allows data users to delegate these tasks to a third-party auditor (TPA). Auditors can regularly check the integrity of outsourced data on behalf of the users. If the audit fails, the auditor quickly informs the user, indicating that the data may have been tampered with.
Although public auditing offers significant benefits, there are two main obstacles to its widespread application in cloud computing. On the one hand, many existing public auditing schemes [
7,
8,
9,
10,
11] are based on traditional cryptographic hardness assumptions, which will be vulnerable to the emerging threats posed by quantum computing. With the inevitable rise of quantum computing, developing post-quantum secure auditing schemes becomes increasingly vital. On the other hand, current public auditing approaches depend on third-party auditors to verify data integrity. However, these schemes often demand significant computational resources from the auditors, as they involve intensive verification processes, including operations like bilinear pairings and modular exponentiations. These procedures place a heavy computational burden on auditors and create a performance bottleneck.
In addition to these challenges, the deployment of public auditing faces another security issue: public auditing may expose user privacy. Unauthorized third parties should not have access to sensitive user information. To protect data users’ privacy, users can designate a specific verifier to carry out data integrity checks.
In addition to existing security threats, the rapid development of quantum computing poses a fundamental challenge to data integrity verification mechanisms in cloud environments. Most widely adopted integrity verification methods are based on classical number-theoretic problems, such as integer factorization and discrete logarithms. However, these foundations are no longer secure in the face of quantum attacks—particularly because Shor’s algorithm [
12] can efficiently solve these problems in polynomial time, rendering many cryptographic schemes that rely on them vulnerable. Once quantum computing becomes practical, existing integrity verification mechanisms will no longer provide long-term security guarantees, thereby seriously undermining the reliability and trustworthiness of cloud storage systems.
Consequently, designing data integrity verification mechanisms that are not only resistant to quantum attacks but also efficient in terms of computational, storage, communication, and transmission overhead has become a critical research direction for securing the next generation of cloud storage infrastructures.
1.1. Related Work
PDP is a practical method for verifying the outsourced data’s integrity, and it was first introduced by Ateniese et al. [
13] based on the integer factorization hypothesis. PDP generates verifiable metadata during the data processing phase, which are then outsourced to the cloud service provider (CSP). Afterward, the verifier checks the data’s integrity by randomly sampling blocks. For instance, Ateniese and colleagues demonstrated that with a file containing 10,000 blocks, the verifier can achieve a 99% error detection rate by requesting proofs from just 460 randomly selected blocks [
14].
Subsequently, a variety of PDP mechanisms have been developed to suit the diverse requirements of various cloud deployment environments, such as dynamic scenarios, batch verification, and privacy protection. For instance, Yuan et al. [
15] developed a new dynamic PDP scheme with multiple replicas to verify the integrity of files stored by users across multiple CSPs. He et al. [
7] introduced a PDP scheme for shared data that enables completely dynamic updates and ensures that verifier storage costs remain constant. Zhang et al. [
16] tackled enterprise private cloud data sharing challenges by employing attribute-based signatures to design a revocable integrity auditing scheme under the SIS problem. Focusing on the key management issue, Zhang et al. [
17] developed an identity-based public auditing scheme with key-exposure resistance based on lattices, which updates the user’s private key using lattice basis delegation while maintaining a constant key size. Wang et al. [
18] designed an identity-based data integrity auditing scheme from the lattice method, ensuring forward security. In short, identity-based PDP schemes can simplify key management, thereby reducing the burden on both CSPs and data owners. Sasikala and Bindu [
19] introduced a certificateless batch verification scheme over lattices designed to support integrity checking of multiple cloud-stored files. To address the inherent private key escrow problem and lower the overhead of managing public key certificates, Zhou et al. [
8] developed a certificate-based PDP scheme under the square computational Diffie–Hellman (CDH) assumption. Zhang et al. [
20] developed a revocable certificateless PDP scheme that preserves user identity privacy while also eliminating the key escrow and certificate management problems found in traditional approaches, supporting efficient user revocation.
The abovementioned schemes, referred to as public PDP schemes [
21], allow anyone to verify data integrity without downloading the full data. In these schemes, the proofs produced by cloud servers can be validated by anyone.
In contrast to public PDP schemes, Shen and Tzeng [
22] introduced a delegatable PDP scheme in 2011, enabling the data owner to create a delegation key for the designated verifier, which is then stored on the cloud server for later verification. The following year, Wang [
23] introduced the concept of proxy PDP and provided a concrete construction, allowing users to delegate auditing authority to a proxy through a delegation warrant. In fact, both of the previously discussed methods fall under the category of PDP with designated verifier (DV-PDP) schemes. In the DV-PDP scheme, the user can designate a specific verifier (proxy) to conduct the outsourced data’s integrity verification on their behalf. However, both DV-PDP schemes [
22,
23] were demonstrated to be insecure by Ren et al. [
24], as a dishonest cloud storage server could obtain the key information associated with the delegated verifier. Unfortunately, Zhang et al. [
25] demonstrated that Ren et al.’s [
24] scheme is insecure and vulnerable to forgery attacks. In 2017, Wu et al. [
21] introduced the earliest non-repudiable DV-PDP scheme aimed at addressing the non-repudiation issue and reducing possible conflicts between users and CSPs. Zhang et al. [
26] proposed a lattice-based designated verifier auditing scheme specifically designed for cloud-assisted wireless body area networks, which ensures that only the designated verifier is capable of verifying the integrity of outsourced medical data stored on the associated cloud server. To address the vulnerability of DV-PDP to replay attacks launched by malicious cloud servers, a remote data possession verification scheme with a designated verifier was proposed by Yan et al. [
27] under the CDH assumption, ensuring that only the specified verifier can validate data integrity, while others are unable to do so. However, this approach depends on public key infrastructure technology and fails to tackle data privacy concerns. To address these limitations, Bian et al. [
28] designed an identity-based remote data possession verification scheme based on the discrete logarithm and CDH assumptions, allowing data owners to designate a specific verifier.
1.2. Contribution
To address the challenge of constructing a post-quantum PDP scheme that supports both identity-based cryptosystem and designated verifier auditing, this paper proposes a lattice-based PDP framework tailored for secure and accountable cloud storage in the post-quantum era. The key contributions of this paper are summarized as follows:
This paper proposes a novel identity-based PDP scheme that employs a specially leveled IB-FHS scheme to eliminate the complexity of traditional public key infrastructures, thereby simplifying key management.
The proposed scheme introduces a designated verifier mechanism, ensuring that only authorized auditors can perform legitimate data integrity checks. This effectively mitigates the privacy risks associated with public verifiability and enhances the controllability and accountability of the auditing process.
The scheme is proven secure under the SIS and LWE assumptions in the random oracle model, ensuring its resistance against quantum attacks.
This paper conducts a comprehensive evaluation of the proposed scheme through theoretical analysis and simulation-based experiments, covering communication overhead, storage requirements, and computational cost. The experimental results under representative parameter settings demonstrate that the core algorithms maintain reasonable computation times. Compared to existing PDP schemes, although the introduction of a designated verifier mechanism leads to a certain increase in computational overhead, the proposed scheme achieves a well-balanced tradeoff between functionality and efficiency.
Overall, our work aims to construct an identity-based PDP with designated verifier scheme over lattices, offering quantum-resistant security and flexible auditing control. It is particularly suitable for cloud auditing scenarios that require authorization verification in a post-quantum setting.
1.3. Organization
The rest of this paper is organized as follows.
Section 2 introduces the necessary preliminaries.
Section 3 defines our PDP scheme and its security model.
Section 4 presents the detailed construction of the proposed PDP scheme.
Section 5 provides formal security analysis covering unforgeability, indistinguishability, and robustness.
Section 6 offers a performance evaluation in terms of computation, storage, and communication. Finally,
Section 7 provides the conclusion.
3. Framework of Our Provable Data Possession
3.1. System Model
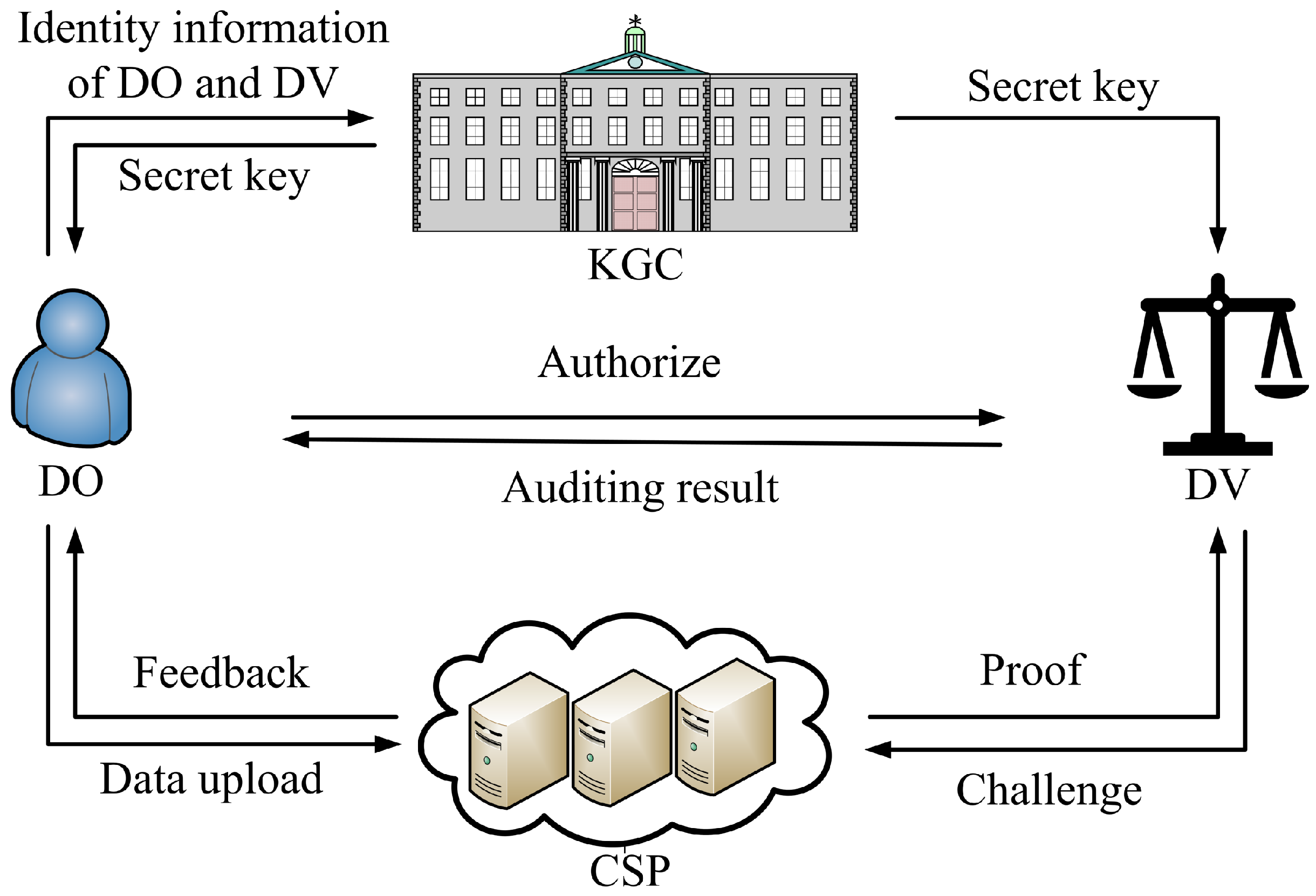
The system model of our PDP scheme involves four primary entities: the key generation center (KGC), the data owner (DO), the CSP, and the designated verifier (DV). The PDP scheme comprises four entities, as depicted in
Figure 1. Their roles and responsibilities are described as follows:
KGC: The KGC is a globally trusted authority in the system. It is tasked with generating the public parameter and master secret key. In addition, the KGC produces the data owner and the designated verifier’s private keys based on their identities.
DO: To reduce storage and management burdens, the data owner outsources their data to CSPs. Moreover, the data owner can specify a particular verifier who is exclusively authorized to perform integrity checks on the outsourced data.
CSP: With ample computational resources and storage space, the CSP provides data storage services to users. However, it is untrusted, meaning it may delete or tamper with the outsourced data for its own benefit or deceive the user for reputation.
DV: The designated verifier is a trusted entity explicitly appointed by the data owner to conduct data integrity verification. Unlike publicly verifiable schemes where any party can audit the data, the designated verifier model restricts the ability to verify to a specific, authorized party.
3.2. Syntax
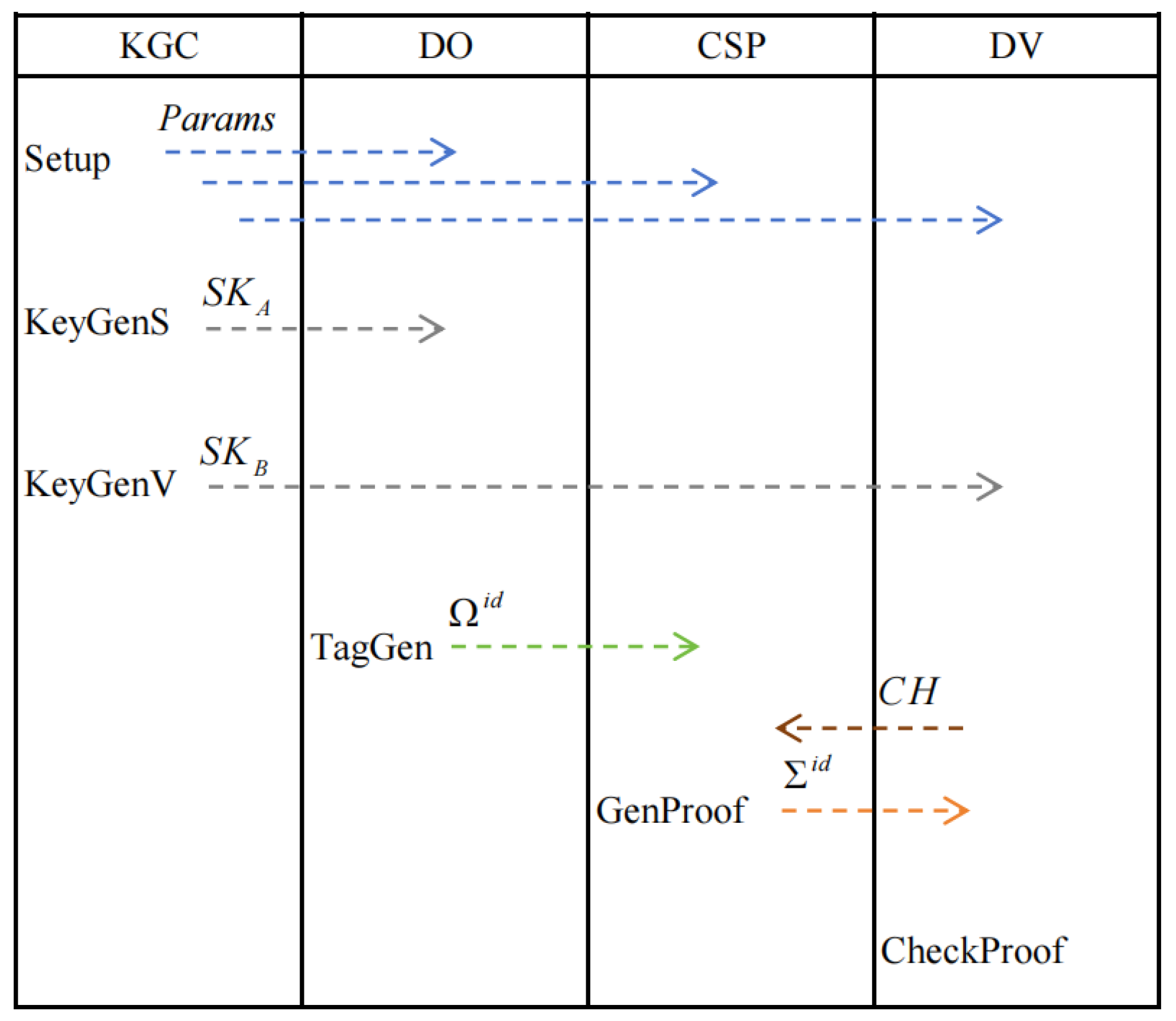
The proposed PDP scheme includes six algorithms: (Setup, KeyGenS, KeyGenV, TagGen, GenProof, and CheckProof). The following PPT algorithms constitute our PDP scheme:
: Given security parameter and the maximum data blocks l, produce public parameter and master secret key . For simplicity, is implicitly treated as an input for the remaining algorithms.
: Upon the input of master secret key and the identity , produce the public/private key of the data owner.
: Upon the input of master secret key and the identity , produce the public/private key of the designated verifier.
: Given public keys , secret key , and file , the data owner splits into l blocks (with zero padding if needed), i.e., , where for ; return , where represents the i-th block–tag pair. Let be the set of all block–tag pairs.
: Given public keys , block–tag pairs , and the designated verifier’s challenge , return a PDP proof .
: Given public keys , secret key , the challenge , and the PDP proof , output 1 (accept) or 0 (reject).
In
Figure 2, the algorithm shown below the entity name indicates that the entity is responsible for executing the algorithm. The dashed arrow indicates that the algorithm output is transmitted to the designated receiver.
Correctness: Given , for all , , , and , if , then .
3.3. Security
The unforgeability proof shows that a malicious CPS, acting as an adversary, cannot deceive the designated verifier or pass the verification by submitting a forged response auditing proof.
For the scheme , the selectively unforgeable proof is defined by the game between the PPT adversary and the challenger . Let denote identities of Alice and Bob, respectively. The game is defined as follows:
Initial: announces to the target identities and , as well as a list of messages under the target identity denoted as for .
Setup: gets and provides to while keeping confidential.
Key queries: queries any identity ’s secret key (except ). gets using and using and then transmits them to .
Block–tag queries: sends under the identity to . returns block–tag pairs to .
PDP proof queries: transmits a challenge limited to . Using , produces a PDP proof and transmits it to .
Challenge: produces restricted to and transmits it to .
Forgery: generates a forgery .
wins the game if either condition (1) or (2) is satisfied. These conditions are defined as follows:
(1) The PDP proof passes the verifier’s check.
(2) The PDP proof meets , where is an honest PDP proof.
Let represent the advantage of in winning the experiment based on the coin tosses of and . This defines the security for our PDP scheme.
Definition 6 (Unforgeability). For given the security parameters λ and the maximum number of data blocks l, if no PPT adversary can succeed in the game with non-negligible probability, i.e., is negligible, then the proposed scheme is considered selectively unforgeable.
6. Performance Evaluation
6.1. Functionality Comparison
As presented in
Table 3, several existing schemes, like Deng et al.’s (2023) [
10], Wu et al.’s [
21], and Yan et al.’s [
27], do not incorporate an identity-based cryptosystem (IBC), thereby limiting their applicability in environments that demand streamlined identity management. Although Deng et al.’s (2024) [
11], Luo et al.’s [
14], and Zhou et al.’s [
35] schemes support an IBC, they lack the capability for designated third-party auditing, which is crucial in applications such as cloud auditing—especially in scenarios where it is necessary to guard against potential malicious auditors tampering with or forging audit results.
With respect to security assumptions, certain schemes (e.g., [
10,
11,
21,
27]) rely on traditional number-theoretic problems like DL and CDH problems, which are potentially vulnerable in the presence of quantum adversaries. While schemes such as Luo et al.’s [
14], Sasikala and Bindu’s [
19], and Zhou et al.’s [
35] adopt lattice-based hardness assumptions (e.g., SIS) and offer a degree of quantum resistance, they still fail to provide a complete set of functionalities, as none of them simultaneously support both IBC and feature a designated verifier.
In contrast, the PDP scheme proposed in this work offers a more comprehensive and well-balanced design. It supports both IBC and designated third-party validation, thereby enhancing its practical deployability and ensuring stronger accountability. Moreover, this scheme relies on the hardness of both the SIS and LWE problems, offering strong resistance against quantum attacks. Consequently, the proposed scheme theoretically exhibits strong resistance against quantum attacks while fulfilling advanced functional requirements, making it particularly suitable for practical deployment and applications.
6.2. Time and Space Complexity
Table 4 presents a comparison between our scheme and the scheme by Luo et al. [
14] in terms of time and space complexity across three core phases:
TagGen,
GenProof, and
CheckProof. This comparison aims to quantitatively evaluate the computational efficiency and resource consumption of different designs.
In the
TagGen phase, the time complexity of our scheme is
, and the space complexity is
. By contrast, the scheme by Luo et al. [
14] exhibits a time complexity of
and a space complexity of
. Our scheme incurs lower computational and storage overhead in the
TagGen phase, making it especially suitable for efficient large-scale data tag generation.
Moreover, in the GenProof and CheckProof phases, our scheme incorporates a designated verifier mechanism, which embeds verifier identity information into authentication tags and proofs, thereby enabling control over verification rights. This mechanism ensures that only authorized verifiers can perform verification, significantly enhancing the system’s support for controlled auditability.
Although this mechanism introduces additional structure and computation—leading to slightly higher complexity in the
GenProof and
CheckProof phases compared to the Luo et al. [
14] scheme—the overall complexity remains within a practical polynomial range. The overhead remains moderate under typical parameters. In summary, our scheme achieves a well-balanced tradeoff between enhanced security capabilities and acceptable computational cost, offering both flexibility and efficiency.
6.3. Communication and Storage Cost
As shown in
Table 5, we evaluated the communication and storage overhead of our scheme in comparison with several lattice-based PDP constructions, focusing on public and secret key (PK + SK) size, tag size, and proof size. The findings indicate that our scheme achieves a balanced tradeoff between efficiency and functionality.
In terms of key size, our scheme requires
bits, which matches the construction proposed by Sasikala and Bindu [
19] and is smaller than those by Luo et al. [
14] and Zhou et al. [
35], demonstrating efficient storage without compromising functionality. Regarding tag size, our design incurs
, which is slightly larger than that in Sasikala and Bindu’s [
19] work and the approach by Zhou et al. [
35], but remains considerably smaller than the quadratic growth in Luo et al.’s scheme [
14], striking a balance between efficiency and security. With respect to proof size, our scheme requires
bits, which is larger than the proof sizes in Sasikala and Bindu’s [
19] and Zhou et al.’s [
35] designs, but still more efficient than the construction proposed by Luo et al. [
14]. Notably, the increased proof size in our design stems primarily from the incorporation of a designated verifier mechanism. This feature enhances privacy and accountability in audit scenarios, thus slightly increasing the communication cost during the proof generation phase.
In summary, the proposed scheme maintains reasonable efficiency while supporting IBS, designated third-party validation, and post-quantum security. It demonstrates strong practicality and is particularly well suited for secure cloud storage applications in the post-quantum era.
6.4. Computation Cost
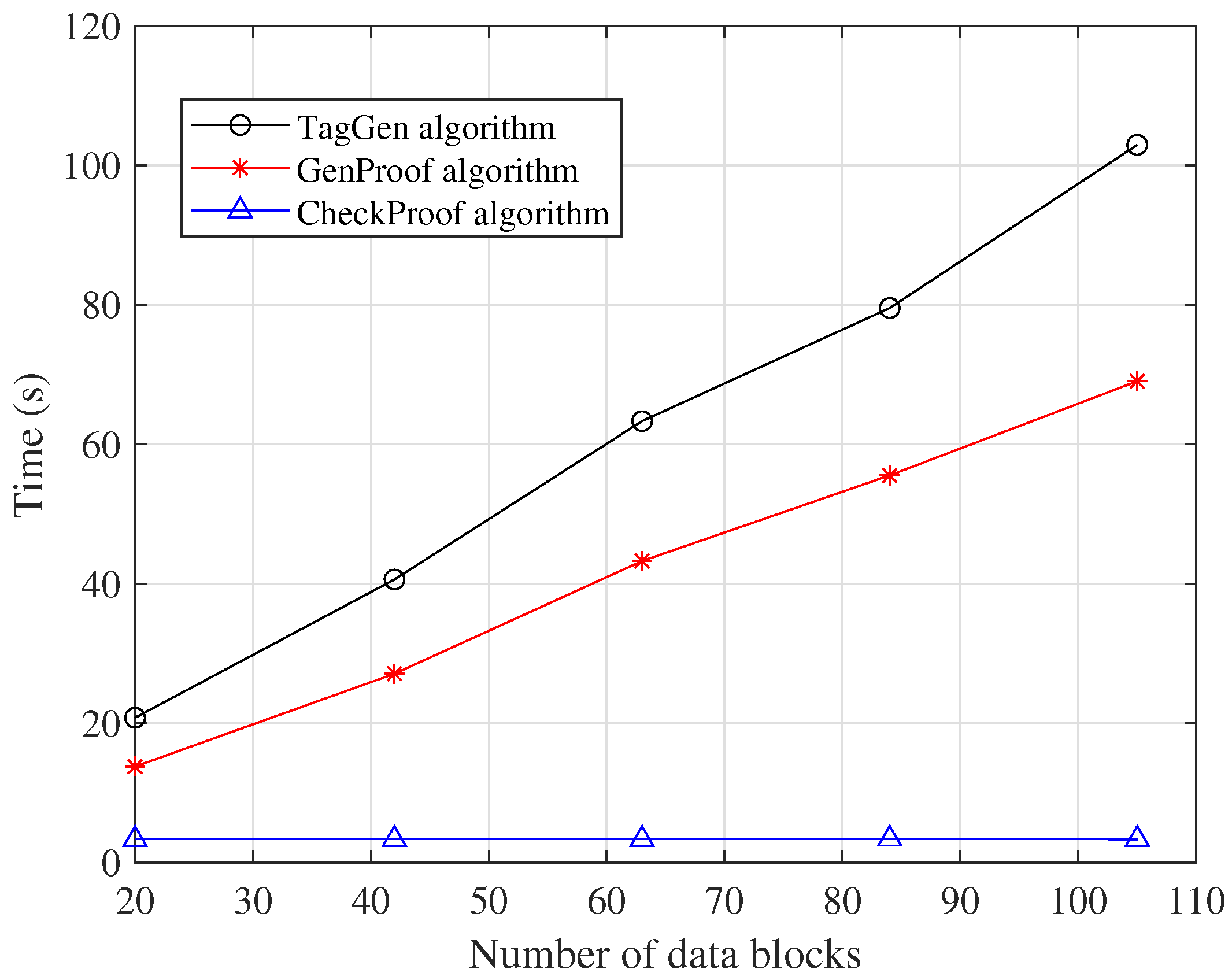
In this section, we present the experiments conducted to evaluate the proposed PDP scheme, which were executed using MATLAB 2020b on a system with an Intel(R) Core(TM) i5-13500H processor (2.60 GHz) and 16GB of RAM. The file size M used in the experiments was approximately 1MB.
The computation cost for the proposed PDP scheme algorithms (TagGen, GenProof, and CheckProof) was assessed for different lattice dimensions—denoted by n. For a file of size MB, when , the corresponding number of data blocks came out to 21, and when , the number of data blocks came out to 5. The designated verifier can challenge all the data blocks to achieve a detection probability of .
The results of the computation time for
and
are shown in
Table 6.
Figure 3 illustrates the computation time of the
TagGen,
GenProof, and
CheckProof algorithms with respect to the number of data blocks. As shown in the figure, both the
TagGen and
GenProof algorithms exhibited a linear increase in computation time as the number of data blocks grew. Notably, in the
CheckProof algorithm, the verifier could compute the matrix
offline, which helped reduce the verification time. As a result, the computation time for
CheckProof remained relatively stable even as the number of data blocks increased.
Compared with existing PDP schemes based on various insecure number-theoretic assumptions, the proposed PDP scheme requires larger parameters, including public and private keys, and exhibits higher computational costs. However, it offers promising potential for post-quantum cryptography. Compared with existing lattice-based PDP schemes, the additional overhead primarily stems from the introduction of the designated verifier mechanism. Moreover, in certain practical applications and implementations, the proposed scheme inherits the same limitations as the leveled FHS scheme—namely, suboptimal performance.
7. Conclusions
This paper presents a lattice-based PDP scheme that incorporates a designated verifier using a leveled IB-FHS. The scheme was proven secure under SIS and LWE assumptions in the random oracle model, confirming its theoretical soundness and feasibility. We have also evaluated the effectiveness and practicality of the proposed scheme through performance comparisons with existing PDP schemes in terms of computation, storage, and communication cost. The results demonstrate that our approach achieves a favorable balance between security and efficiency, making it well suited for authorization-based cloud storage auditing scenarios.
However, we also acknowledge several limitations that merit further exploration. First, compared to traditional PDP schemes, the increased computational overhead of the proposed construction is primarily attributable to its reliance on lattice-based cryptography and the inclusion of a designated verifier mechanism. Second, the current design is centered around a designated verifier and does not consider the complexities introduced by multi-tenant cloud environments, where ensuring data isolation and enforcing fine-grained access control among tenants are essential. Third, although the scheme includes theoretical performance estimates, real-world deployment may involve additional overhead and integration challenges that require practical validation. Furthermore, transitioning the construction to the standard model remains an important and meaningful direction for enhancing its theoretical robustness. As future work, we plan to (1) optimize the efficiency of the core algorithms to reduce computational costs; (2) extend the proposed scheme to support secure auditing in multi-tenant cloud settings with proper isolation mechanisms and delegated verification control; and (3) develop a standard model instantiation to eliminate reliance on idealized cryptographic assumptions.



{kind=link}
{kind=link}
{kind=link}