
Chinese Paper-Cutting Style Transfer via Vision Transformer



Abstract
1. Introduction
- We propose a new style transfer method that accurately captures the unique symmetrical structures and aesthetic characteristics of Chinese paper-cutting art, achieving high-quality style transfer and efficiently generating artwork with a distinct paper-cutting style. In addition, we construct a dedicated Chinese paper-cutting dataset, providing rich training resources and benchmark data for future research, thereby filling an existing gap in the field.
- We design a frequency-domain mixture block that enhances the capture of both local textures and global symmetrical structures through Fourier convolutions, effectively distinguishing between style patterns and content details to improve style fidelity and visual coherence.
- A multi-level feature contrastive learning module is proposed, utilizing a visual Transformer encoder to extract multi-level style features, content features, and transformation features from the input image. By constructing a contrastive learning framework based on feature comparison, this module maximizes the correspondence between the transformed features and input features, thereby improving the fidelity of style transfer and content preservation.
- Extensive experiments show that, compared to existing advanced style transfer methods, the proposed method achieves superior overall performance in paper-cutting style transfer. It can quickly generate works that integrate the aesthetic and cultural value of Chinese paper-cutting art, providing new technical support for the digital creation of paper-cutting art.
2. Related Work
2.1. Characterization of Chinese Paper-Cutting
2.2. Style Transfer
2.3. Transformer
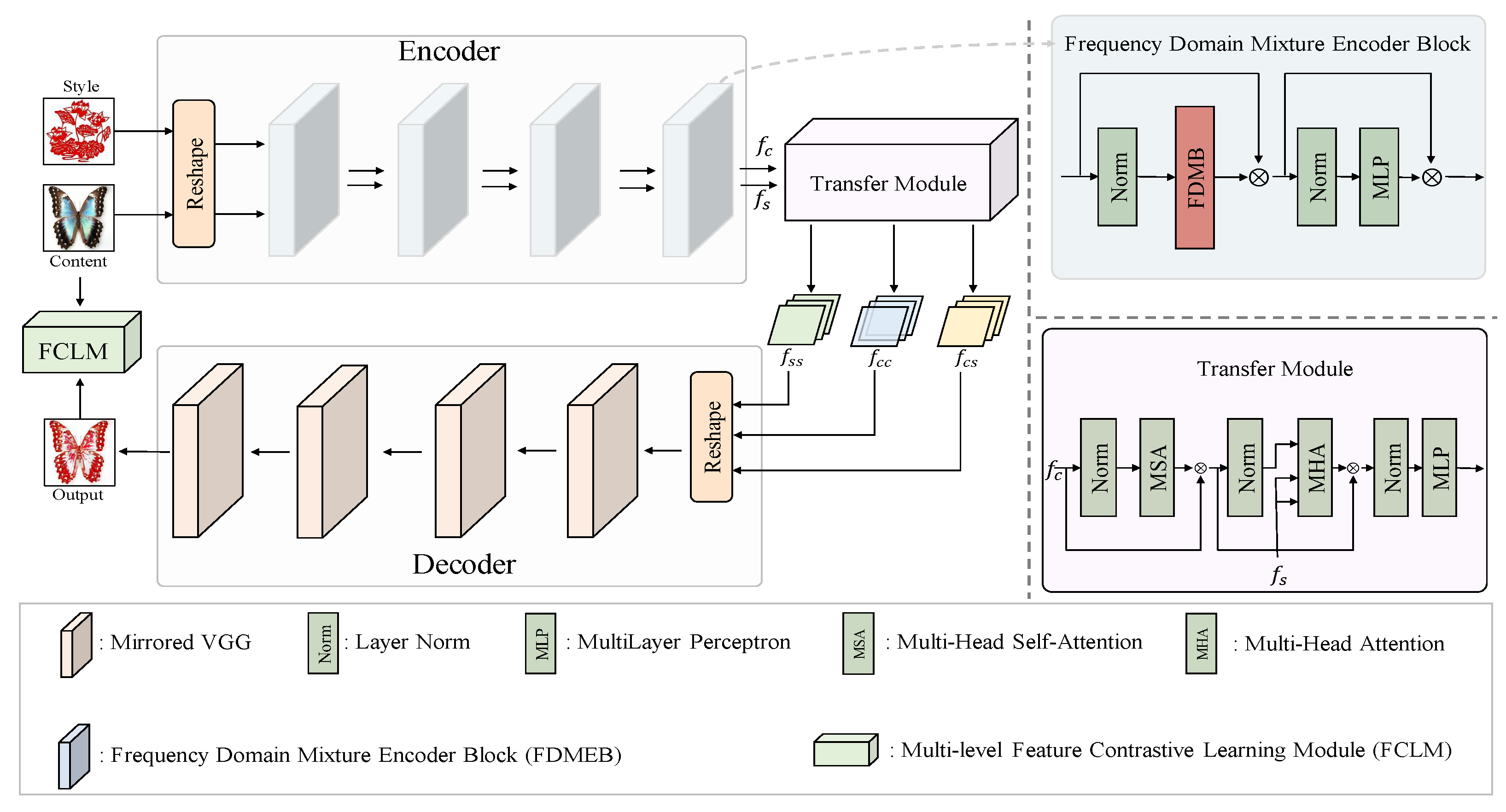
3. Methodology
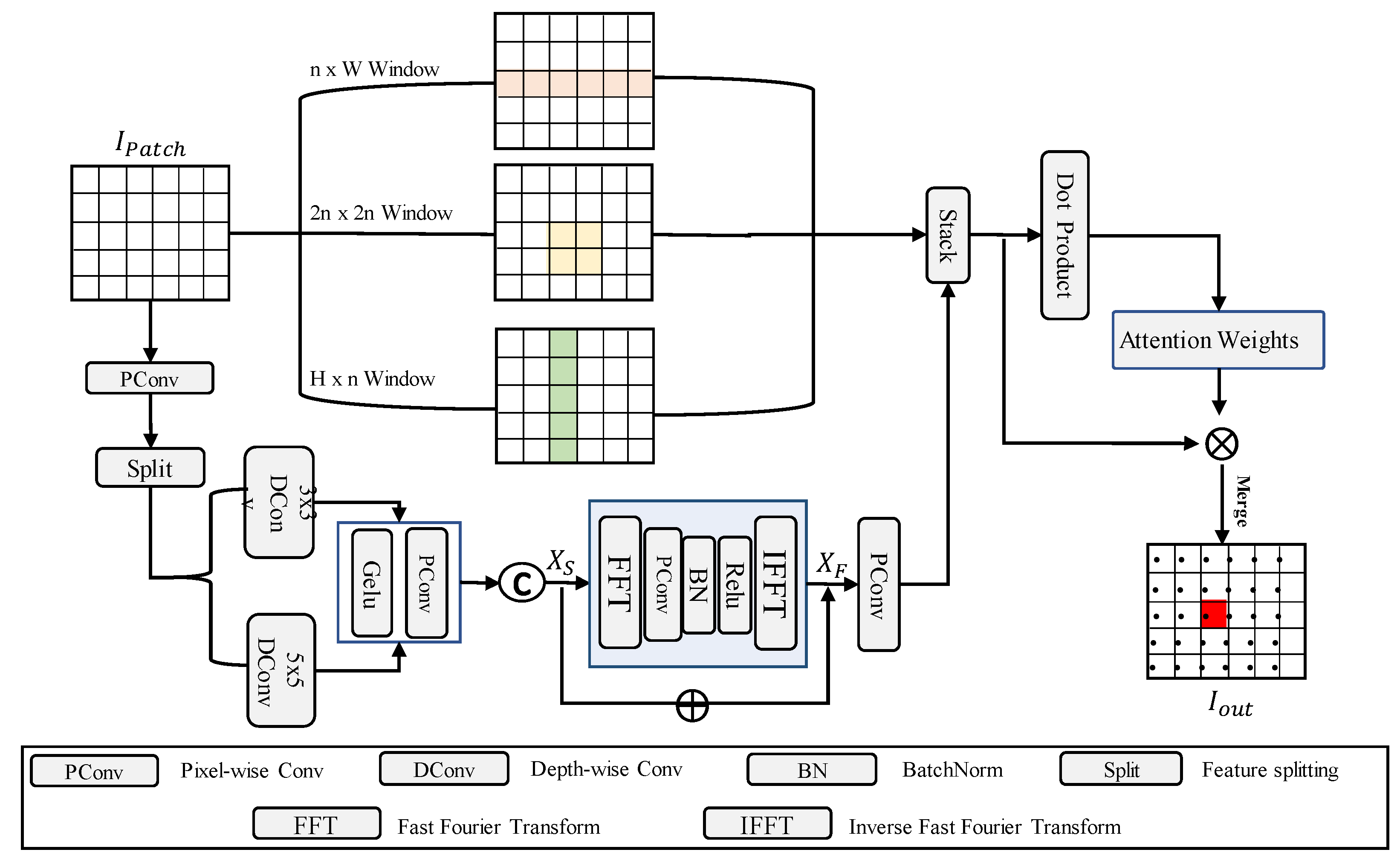
3.1. Frequency-Domain Mixture Encoder
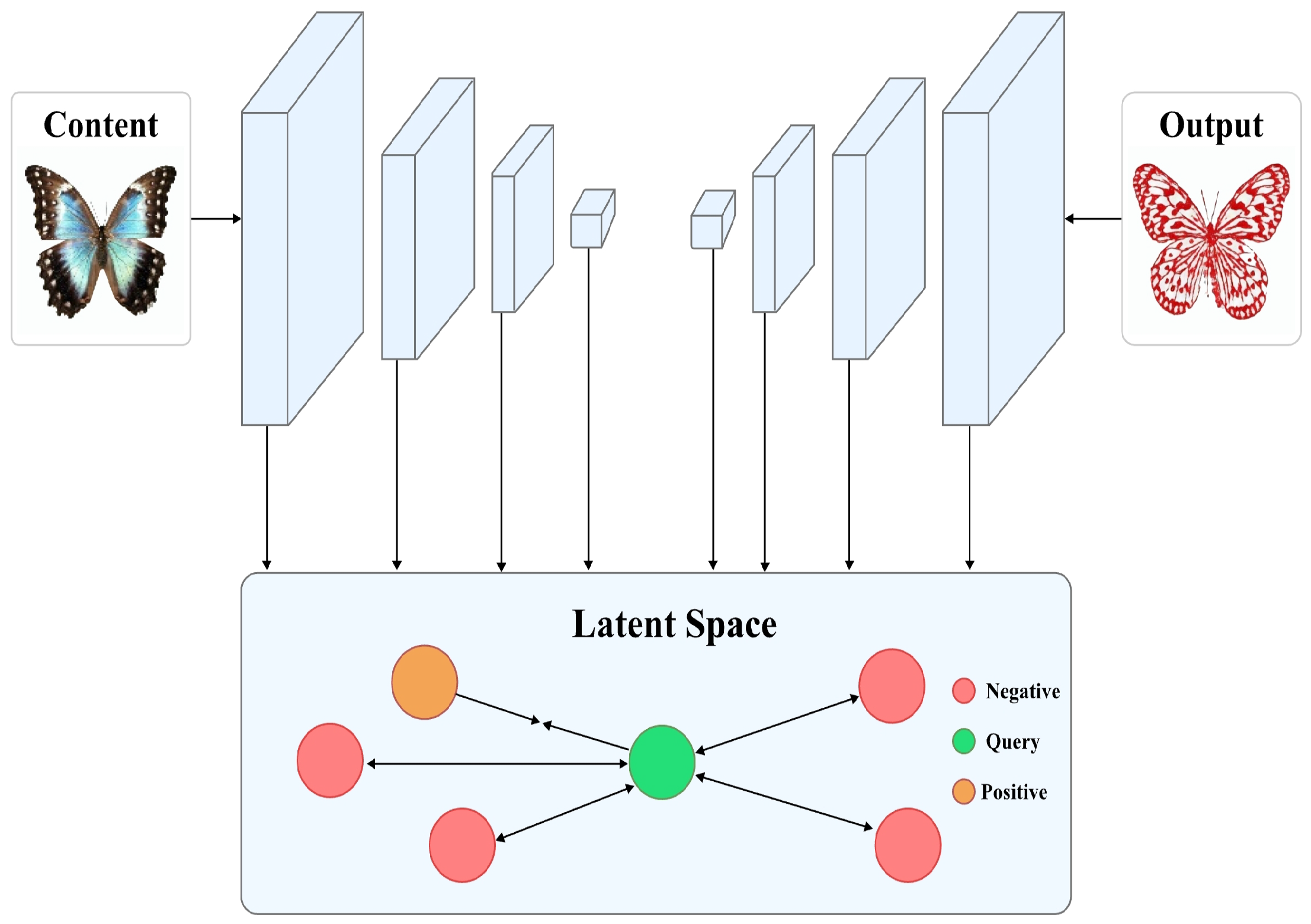
3.2. Multi-Level Feature Contrastive Learning Module
3.3. Network Training
4. Experimental
4.1. Dataset
4.2. Implementation Details
4.3. Comparative Experiments
4.3.1. Qualitative Comparison
4.3.2. Quantitative Comparison
4.3.3. User Ranking Experiment
4.3.4. Expert Scoring Experiment
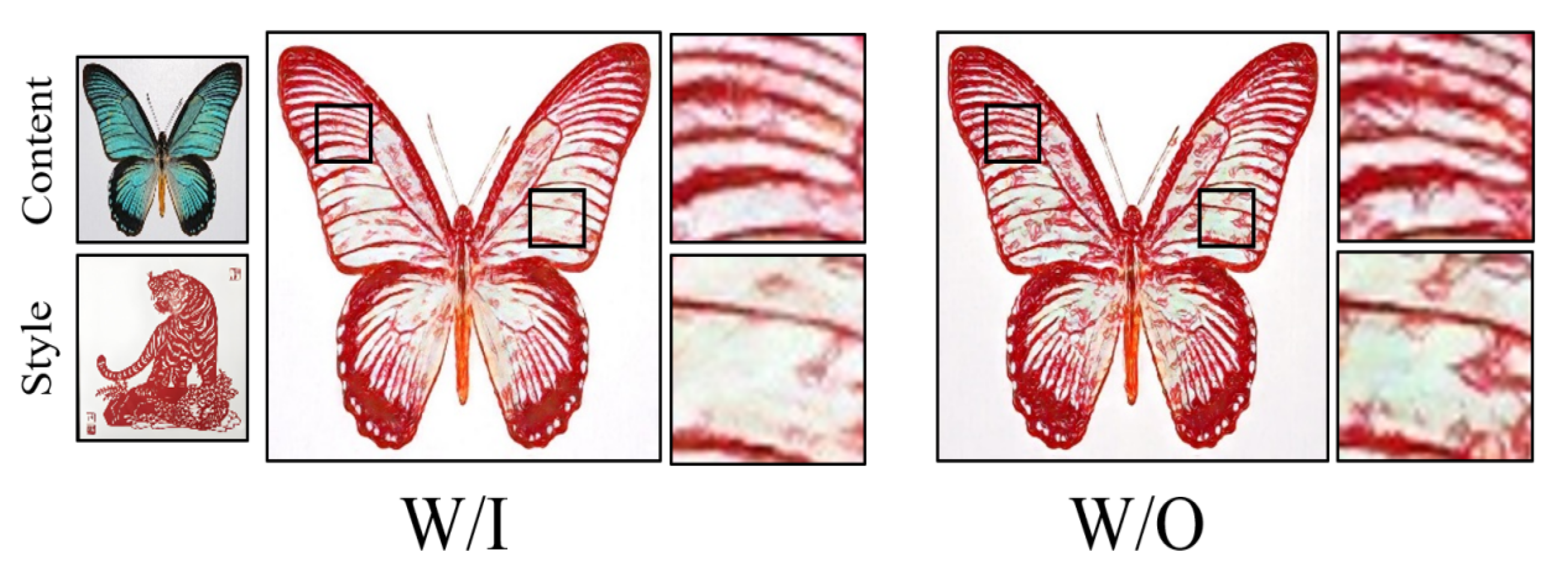
4.4. Ablation Study
4.4.1. Frequency-Domain Mixture Encoder Block
4.4.2. Multi-Level Feature Contrastive Learning Module
5. Discussion
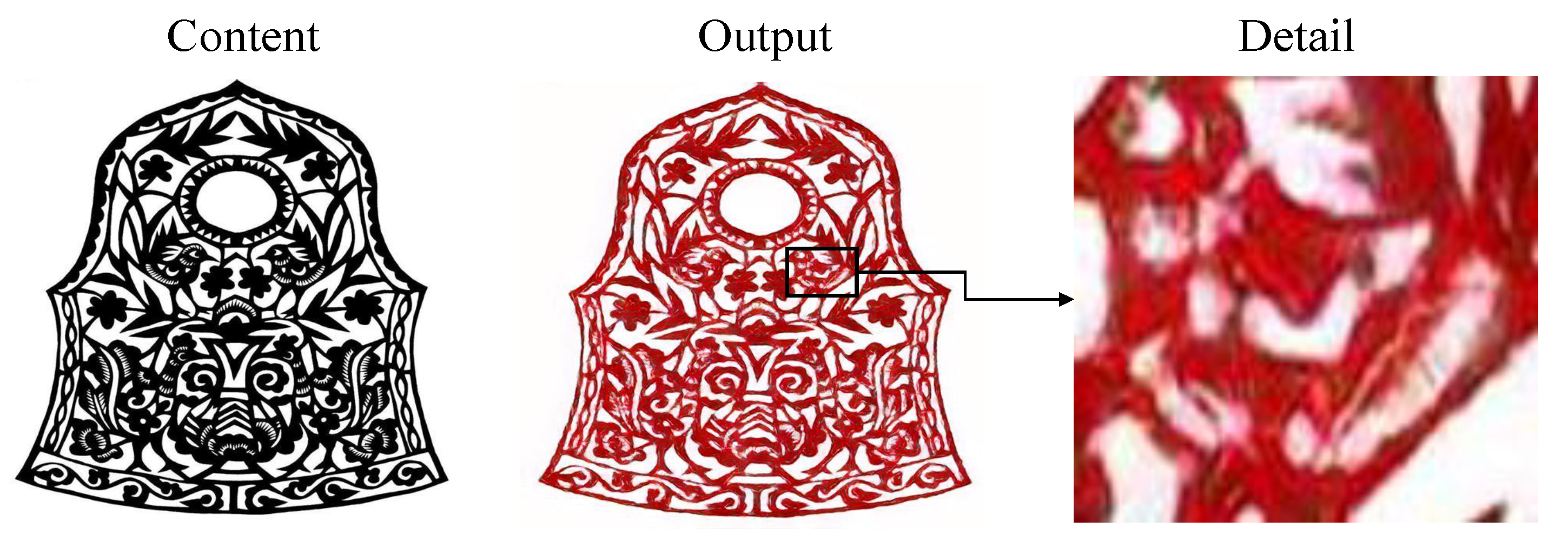
5.1. Practical Applications of Chinese Paper-Cutting Style Transformation
5.2. Limitation
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Jing, Y.; Yang, Y.; Feng, Z.; Ye, J.; Yu, Y.; Song, M. Neural style transfer: A review. IEEE Trans. Vis. Comput. Graph. 2019, 26, 3365–3385. [Google Scholar] [CrossRef] [PubMed]
- Gatys, L.A.; Ecker, A.S.; Bethge, M. Image style transfer using convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2414–2423. [Google Scholar]
- Li, W.; Chen, Y.; Guo, X.; He, X. ST2SI: Image Style Transfer via Vision Transformer using Spatial Interaction. Comput. Graph. 2024, 124, 104084. [Google Scholar] [CrossRef]
- Gatys, L.; Ecker, A.S.; Bethge, M. Texture synthesis using convolutional neural networks. Adv. Neural Inf. Process. Syst. 2015, 28, 262–270. [Google Scholar]
- Champandard, A.J. Semantic style transfer and turning two-bit doodles into fine artworks. arXiv 2016, arXiv:1603.01768. [Google Scholar]
- Hertzmann, A. Painterly rendering with curved brush strokes of multiple sizes. In Proceedings of the 25th Annual Conference on Computer Graphics and Interactive Techniques, Orlando, FL, USA, 19–24 July 1998; pp. 453–460. [Google Scholar]
- Johnson, J.; Alahi, A.; Li, F.-F. Perceptual losses for real-time style transfer and super-resolution. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part II 14. Springer: Berlin/Heidelberg, Germany, 2016; pp. 694–711. [Google Scholar]
- Ulyanov, D.; Lebedev, V.; Vedaldi, A.; Lempitsky, V. Texture networks: Feed-forward synthesis of textures and stylized images. arXiv 2016, arXiv:1603.03417. [Google Scholar]
- Zhang, H.; Dana, K. Multi-style generative network for real-time transfer. In Proceedings of the European Conference on Computer Vision (ECCV) Workshops, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Efros, A.; Freeman, W. Image Quilting for Texture Synthesis and Transfer. In Proceedings of the 28th Annual Conference on Computer Graphics and Interactive Technique, SIGGRAPH, Los Angeles, CA, USA, 12–17 August 2001. [Google Scholar]
- Chen, D.; Yuan, L.; Liao, J.; Yu, N.; Hua, G. Stylebank: An explicit representation for neural image style transfer. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1897–1906. [Google Scholar]
- Yin, W.; Yin, H.; Baraka, K.; Kragic, D.; Björkman, M. Dance style transfer with cross-modal transformer. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 2–7 January 2023; pp. 5058–5067. [Google Scholar]
- Tang, H.; Liu, S.; Lin, T.; Huang, S.; Li, F.; He, D.; Wang, X. Master: Meta style transformer for controllable zero-shot and few-shot artistic style transfer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 18329–18338. [Google Scholar]
- Zhang, C.; Xu, X.; Wang, L.; Dai, Z.; Yang, J. S2wat: Image style transfer via hierarchical vision transformer using strips window attention. In Proceedings of the AAAI Conference on Artificial Intelligence, Washington, DC, USA, 26–27 February 2024; Volume 38, pp. 7024–7032. [Google Scholar]
- Park, D.Y.; Lee, K.H. Arbitrary style transfer with style-attentional networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5880–5888. [Google Scholar]
- An, J.; Huang, S.; Song, Y.; Dou, D.; Liu, W.; Luo, J. Artflow: Unbiased image style transfer via reversible neural flows. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 862–871. [Google Scholar]
- Chen, H.; Wang, Z.; Zhang, H.; Zuo, Z.; Li, A.; Xing, W.; Lu, D. Artistic style transfer with internal-external learning and contrastive learning. Adv. Neural Inf. Process. Syst. 2021, 34, 26561–26573. [Google Scholar]
- Zhang, Y.; Tang, F.; Dong, W.; Huang, H.; Ma, C.; Lee, T.Y.; Xu, C. Domain enhanced arbitrary image style transfer via contrastive learning. In Proceedings of the ACM SIGGRAPH 2022 Conference Proceedings, Vancouver, BC, Canada, 7–11 August 2022; pp. 1–8. [Google Scholar]
- Nguyen, V.; Yago Vicente, T.F.; Zhao, M.; Hoai, M.; Samaras, D. Shadow detection with conditional generative adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4510–4518. [Google Scholar]
- Huang, S.; Xiong, H.; Wang, T.; Wen, B.; Wang, Q.; Chen, Z.; Huan, J.; Dou, D. Parameter-free style projection for arbitrary style transfer. arXiv 2020, arXiv:2003.07694. [Google Scholar]
- Ning, A.; Xue, M.; He, J.; Song, C. KAN see in the dark. IEEE Signal Process. Lett. 2025, 32, 891–895. [Google Scholar] [CrossRef]
- Pan, B.; Ke, Y. Efficient artistic image style transfer with large language model (LLM): A new perspective. In Proceedings of the 2023 8th International Conference on Communication and Electronics Systems (ICCES), Coimbatore, India, 1–3 June 2023; pp. 1729–1732. [Google Scholar]
- Zhang, Y.; Huang, N.; Tang, F.; Huang, H.; Ma, C.; Dong, W.; Xu, C. Inversion-based style transfer with diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 10146–10156. [Google Scholar]
- Cai, Q.; Ma, M.; Wang, C.; Li, H. Image neural style transfer: A review. Comput. Electr. Eng. 2023, 108, 108723. [Google Scholar] [CrossRef]
- Liu, K.; Zhan, F.; Chen, Y.; Zhang, J.; Yu, Y.; El Saddik, A.; Lu, S.; Xing, E.P. Stylerf: Zero-shot 3d style transfer of neural radiance fields. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 8338–8348. [Google Scholar]
- Woodland, M.; Wood, J.; Anderson, B.M.; Kundu, S.; Lin, E.; Koay, E.; Odisio, B.; Chung, C.; Kang, H.C.; Venkatesan, A.M.; et al. Evaluating the performance of StyleGAN2-ADA on medical images. In Proceedings of the International Workshop on Simulation and Synthesis in Medical Imaging, Singapore, 18 September 2022; pp. 142–153. [Google Scholar]
- Zhang, Y.; He, Z.; Xing, J.; Yao, X.; Jia, J. Ref-npr: Reference-based non-photorealistic radiance fields for controllable scene stylization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 4242–4251. [Google Scholar]
- Yang, G. The imagery and abstraction trend of Chinese contemporary oil painting. Linguist. Cult. Rev. 2021, 5, 454–471. [Google Scholar] [CrossRef]
- Liu, W. Analysis on the Collision and Fusion of Eastern and Western Paintings in the Context of Globalization. Thought 2021, 7, 8. [Google Scholar]
- Fan, Z.; Zhu, Y.; Yan, C.; Li, Y.; Zhang, K. A comparative study of color between abstract paintings, oil paintings and Chinese ink paintings. In Proceedings of the 15th International Symposium on Visual Information Communication and Interaction, Chur, Switzerland, 16–18 August 2022; pp. 1–8. [Google Scholar]
- Liu, F. Research on oil painting creation based on Computer Technology. J. Phys. Conf. Ser. 2021, 1915, 022005. [Google Scholar] [CrossRef]
- Wen, X.; White, P. The role of landscape art in cultural and national identity: Chinese and European comparisons. Sustainability 2020, 12, 5472. [Google Scholar] [CrossRef]
- Hongxian, L.; Tahir, A.; Bakar, S.A.S.A. The Developing Process of Ideological Trend of the Nationalization in Chinese Oil Painting. Asian J. Res. Educ. Soc. Sci. 2024, 6, 465–474. [Google Scholar]
- Ao, J.; Ye, Z.; Li, W.; Ji, S. Impressions of Guangzhou city in Qing dynasty export paintings in the context of trade economy: A color analysis of paintings based on k-means clustering algorithm. Herit. Sci. 2024, 12, 77. [Google Scholar] [CrossRef]
- Deng, Y.; Tang, F.; Dong, W.; Ma, C.; Pan, X.; Wang, L.; Xu, C. Stytr2: Image style transfer with transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 11326–11336. [Google Scholar]
- Wang, P.; Li, Y.; Vasconcelos, N. Rethinking and improving the robustness of image style transfer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 124–133. [Google Scholar]
- Feng, L.; Geng, G.; Ren, Y.; Li, Z.; Liu, Y.; Li, K. CReStyler: Text-Guided Single Image Style Transfer Method Based on CNN and Restormer. In Proceedings of the ICASSP 2024—2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Seoul, Republic of Korea, 14–19 April 2024; pp. 4145–4149. [Google Scholar]
- Liu, S.; Lin, T.; He, D.; Li, F.; Wang, M.; Li, X.; Sun, Z.; Li, Q.; Ding, E. Adaattn: Revisit attention mechanism in arbitrary neural style transfer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 6649–6658. [Google Scholar]
- Park, J.; Kim, Y. Styleformer: Transformer based generative adversarial networks with style vector. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 8983–8992. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Oord, A.v.d.; Li, Y.; Vinyals, O. Representation learning with contrastive predictive coding. arXiv 2018, arXiv:1807.03748. [Google Scholar]
- Ghiasi, G.; Lee, H.; Kudlur, M.; Dumoulin, V.; Shlens, J. Exploring the structure of a real-time, arbitrary neural artistic stylization network. arXiv 2017, arXiv:1705.06830. [Google Scholar]
- Chung, J.; Hyun, S.; Heo, J.P. Style injection in diffusion: A training-free approach for adapting large-scale diffusion models for style transfer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 17–18 June 2024; pp. 8795–8805. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Style Dimension | Style Feature | Feature Description |
|---|---|---|
| Form Dimension | Smooth and Flowing Lines | Chinese paper-cutting involves using scissors to cut paper, resulting in clear and smooth edge lines that precisely outline the shapes. During style transfer, it is essential to maintain the fluidity and clarity of the lines in the image. |
| Hollow Pattern on a Flat Surface | The hollow pattern is one of the most distinctive features of Chinese paper-cutting. Various images and patterns are presented in a flat form, with parts of the paper cut out to create transparent patterns. In style transfer, this should be represented by clear color blocks, removing unnecessary transitional color blocks, and creating rich visual effects with a flat representation. | |
| Clear Pattern Processing | Chinese paper-cutting emphasizes the display of clear and distinct shapes. Viewers should easily recognize the image shapes created by the paper-cutting. In style transfer, it is crucial to preserve the clarity and completeness of the image to ensure its recognizability. | |
| Color Dimension | Red Color | Red is the most traditional and common color in paper-cutting, and the sight of a red pattern immediately evokes an association with paper-cutting. Therefore, during style transfer, it is necessary to remove any non-representative colors and adjust the color to red. |
| Material Dimension | Paper Texture | Chinese paper-cutting primarily uses paper as the medium. Therefore, during the transfer, the texture of the paper in the pattern should be maintained. |
| Craft Dimension | Clean Background and Edges | Chinese paper-cutting is crafted using scissors, resulting in backgrounds without irregular or rough edges. Therefore, during style transfer, it is necessary to ensure that the background remains free from color residue and that the edges are clean. |
| Stage | Input Channels | Output Channels | Input Shape | Output Shape |
|---|---|---|---|---|
| Encoder | 3 | 768 | 224 × 224 | 28 × 28 |
| Transfer Module | 768 | 768 | 28 × 28 | 28 × 28 |
| Decoder | 768 | 3 | 28 × 28 | 224 × 224 |
| FDMB | C | 2 × C | H × W | H/2 × W/2 |
| Metrics | Ghiasi et al. [42] | StyTr2 [35] | CAST [18] | S2WAT [14] | StyleID [43] | InST [23] | Ours |
|---|---|---|---|---|---|---|---|
| SSIM | 0.412 | 0.620 | 0.476 | 0.696 | 0.724 | 0.355 | 0.778 |
| LPIPS | 0.677 | 0.541 | 0.607 | 0.405 | 0.413 | 0.819 | 0.392 |
| FID | 476.126 | 427.414 | 416.446 | 263.655 | 239.620 | 244.011 | 230.165 |
| Content & Style | Ours | StyTr2 [35] | CAST [18] | S2WAT [14] | Ghiasi et al. [42] |
|---|---|---|---|---|---|
 |  |  |  |  |  |
| Smoothness of Lines | 4.16 | 3.61 | 2.50 | 3.15 | 1.55 |
| Flatness of Pattern Hollowing | 3.97 | 3.25 | 3.01 | 3.04 | 1.71 |
| Clarity of Pattern Processing | 4.38 | 3.47 | 2.56 | 3.15 | 1.43 |
| Red Color Matching | 4.15 | 3.30 | 3.34 | 2.72 | 1.44 |
| Material Paper Conformity | 4.19 | 3.21 | 3.21 | 2.81 | 1.51 |
| Background Edge Cleanliness | 4.13 | 3.58 | 2.78 | 3.01 | 1.41 |
| Content Restoration | 4.45 | 3.51 | 2.53 | 2.90 | 1.56 |
| Similarity to Paper-Cutting Style | 4.19 | 3.27 | 3.15 | 2.76 | 1.57 |
| Overall Score | 4.20 | 3.40 | 2.89 | 2.94 | 1.52 |
| Overall Ranking | 1 | 2 | 4 | 3 | 5 |
| Content & Style | Ours | StyTr2 [35] | CAST [18] | S2WAT [14] | Ghiasi et al. [42] |
|---|---|---|---|---|---|
 |  |  |  |  |  |
| Smoothness of Lines | 4.30 | 2.87 | 2.68 | 3.12 | 2.02 |
| Flatness of Pattern Hollowing | 3.96 | 2.41 | 3.24 | 2.96 | 2.41 |
| Clarity of Pattern Processing | 4.42 | 2.61 | 2.67 | 3.27 | 2.01 |
| Red Color Matching | 4.04 | 2.86 | 3.16 | 3.16 | 1.78 |
| Material Paper Conformity | 4.13 | 2.87 | 3.23 | 2.90 | 1.84 |
| Background Edge Cleanliness | 4.41 | 3.24 | 3.16 | 2.67 | 1.46 |
| Content Restoration | 4.16 | 3.41 | 3.2 | 2.29 | 1.93 |
| Similarity to Paper-Cutting Style | 3.85 | 2.41 | 3.70 | 2.80 | 2.19 |
| Overall Score | 4.16 | 2.84 | 3.13 | 2.90 | 1.96 |
| Overall Ranking | 1 | 4 | 2 | 3 | 5 |
| Content & Style | Ours | StyTr2 [35] | CAST [18] | S2WAT [14] | Ghiasi et al. [42] |
|---|---|---|---|---|---|
 |  |  |  |  |  |
| Smoothness of Lines | 3.37 | 3.67 | 1.80 | 3.58 | 2.57 |
| Flatness of Pattern Hollowing | 3.39 | 3.46 | 3.27 | 2.87 | 2.01 |
| Clarity of Pattern Processing | 3.67 | 3.65 | 2.94 | 3.08 | 1.65 |
| Red Color Matching | 4.11 | 2.99 | 3.31 | 2.73 | 1.86 |
| Material Paper Conformity | 3.84 | 2.67 | 3.67 | 2.94 | 1.88 |
| Background Edge Cleanliness | 3.68 | 4.25 | 2.55 | 1.93 | 2.58 |
| Content Restoration | 3.82 | 3.46 | 2.21 | 3.58 | 1.90 |
| Similarity to Paper-Cutting Style | 3.97 | 2.73 | 3.95 | 2.74 | 1.59 |
| Overall Score | 3.73 | 3.36 | 2.96 | 2.93 | 2.01 |
| Overall Ranking | 1 | 2 | 3 | 4 | 5 |
| TYPE | Samples | |||
|---|---|---|---|---|
| Animal Samples | Plant Samples | Architectural Samples | Pattern Samples | |
 |  |  |  | |
 |  |  |  | |
| Smoothness of Lines | 4.5 | 4.63 | 4.75 | 4.13 |
| Flatness of Pattern Hollowing | 4.25 | 3.88 | 4.63 | 4.25 |
| Clarity of Pattern Processing | 4.38 | 4.5 | 4.25 | 4.5 |
| Red Color Matching | 4.75 | 4.75 | 4.63 | 4.63 |
| Material Paper Conformity | 4.25 | 4.13 | 4.13 | 4.13 |
| Background Edge Cleanliness | 4.63 | 4.13 | 4.25 | 4.38 |
| Content Restoration | 4.75 | 4.63 | 4.75 | 4.63 |
| Similarity to Paper-Cutting Style | 3.88 | 3.88 | 3.88 | 4.0 |
| Overall Score | 4.48 | 4.31 | 4.41 | 4.23 |
| Train Settings | Metrics | |||
|---|---|---|---|---|
| FDMB | FCLM | SSIM | LPIPS | FID |
| w/o | w/o | 0.699 | 0.405 | 256.333 |
| w/ | w/o | 0.768 | 0.400 | 245.863 |
| w/o | w/ | 0.745 | 0.399 | 241.742 |
| w/ | w/ | 0.778 | 0.392 | 230.165 |
| Train Settings | Metrics | ||
|---|---|---|---|
| FDMB | SSIM | LPIPS | FID |
| w/o Spatial branch | 0.712 | 0.402 | 243.498 |
| w/o Frequency branch | 0.739 | 0.411 | 250.053 |
| w/o Window | 0.767 | 0.395 | 234.402 |
| w/o Window | 0.755 | 0.397 | 238.173 |
| w/o Window | 0.764 | 0.395 | 233.951 |
| default | 0.778 | 0.392 | 230.165 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, C.; Ren, Y.; Zhou, Y.; Lou, M.; Zhang, Q. Chinese Paper-Cutting Style Transfer via Vision Transformer. Entropy 2025, 27, 754. https://doi.org/10.3390/e27070754
Wu C, Ren Y, Zhou Y, Lou M, Zhang Q. Chinese Paper-Cutting Style Transfer via Vision Transformer. Entropy. 2025; 27(7):754. https://doi.org/10.3390/e27070754
Chicago/Turabian StyleWu, Chao, Yao Ren, Yuying Zhou, Ming Lou, and Qing Zhang. 2025. "Chinese Paper-Cutting Style Transfer via Vision Transformer" Entropy 27, no. 7: 754. https://doi.org/10.3390/e27070754
APA StyleWu, C., Ren, Y., Zhou, Y., Lou, M., & Zhang, Q. (2025). Chinese Paper-Cutting Style Transfer via Vision Transformer. Entropy, 27(7), 754. https://doi.org/10.3390/e27070754