2.1. Machine Learning Approaches for Oil-Painting Style Classification
Style classification has long been a focus of both traditional image-processing and deep learning research. Early approaches to painting-style analysis relied on handcrafted features designed to capture brushwork, color palettes, and texture. For instance, Gao et al. [
14] applied sparse coding to grayscale patches in order to model local structural patterns for style discrimination. Liu et al. [
15] showed that simple statistics of color histograms, such as palette entropy, can effectively distinguish painters. Berezhnoy et al. [
16] employed Gabor-basis energy combined with normalized mutual information to quantify stylistic variations in Van Gogh’s oeuvre. More recently, Qian et al. [
17] introduced a multi-entropy framework that jointly models block, color, and contour entropy to capture complementary cues of color, composition, and shape. Although these methods achieve competitive results, their dependence on grayscale inputs, manually selected transforms, or hand-tuned entropy measures limits their capacity to capture subtle, higher-order style characteristics inherent in complex oil paintings.
With the advent of convolutional neural networks (CNNs), researchers shifted toward end-to-end style learning. Bai et al. [
18] introduced a custom CNN to extract deep style features and evaluate inter-style similarity via an information-bottleneck distance. Early attempts on the Painting-91 dataset [
19] applied standard image-classification CNNs [
20] to artwork classification, while Folego et al. [
21] demonstrated that selecting the patch with the highest confidence score outperforms traditional voting schemes. Nanni et al. [
22] showed that combining features from multiple CNN layers yields better style, artist, and architectural classification than using only the top layer, and Peng et al. [
23] leveraged multiple CNNs to capture multi-scale representations. Kim et al. [
24] further improved accuracy by incorporating visualized depth information of brushstrokes. Menis et al. [
25] employ ensemble learning to improve classification performance. More recently, Zhang et al. [
26] and Wang et al. [
27] confirmed that ResNet-50 [
7] provides a strong baseline for oil-painting style classification. Although deep models eliminate the need for handcrafted filters, they often conflate style-relevant cues with semantic content, such as mistaking impasto textures for foliage, and do not explicitly regulate the amount of style-specific information retained. We argue that the key to improving the generalization performance of oil-painting style classification is not to incorporate multi-scale features [
23] or to combine predictions from multiple networks [
25], but rather to intelligently suppress redundant information in the extracted features. Specifically, representations that include background elements, canvas color, or object semantics may mislead the model, as these factors are often irrelevant to the stylistic identity of the painting and should therefore be compressed. Two challenges, therefore, remain: (1) how to learn features that capture genuine stylistic differences across diverse artistic movements, and (2) how to control and quantify the compression of style-irrelevant information in learned representations.
The information bottleneck (IB) framework formalizes representation learning as an explicit trade-off between compressing the input
X and preserving information about the target
Y [
8]. Recent extensions of IB parameterize this objective with deep neural networks, including the variational information bottleneck (VIB) [
9] and the nonlinear information bottleneck (NIB) [
28]. Empirically, IB methods have been shown to improve generalization in domains such as image classification [
29], signal classification [
30], text classification [
31], and robotics [
32], supported by strong theoretical guarantees [
33]. However, IB approaches remain largely unexplored in the analysis of oil paintings, where variational approximations can become unstable when disentangling overlapping style attributes (e.g., Baroque versus Rococo brushwork).
Our conditional information bottleneck (CIB) approach addresses these challenges by minimizing the conditional mutual information
using a matrix-based Rényi’s entropy estimator, rather than a variational bound. This explicit regularization forces the latent representation
Z to retain only style-predictive information, thereby bridging classical entropy-driven style metrics [
15,
17] and modern deep learning. As a result, CIB delivers robust, interpretable feature compression tailored to the unique texture and compositional dynamics of oil paintings.
2.2. Information Bottleneck Principle in Deep Neural Networks
Suppose we have two random variables,
X and
Y, linked through their joint probability distribution
. We introduce a latent variable
Z, which serves as a compressed summary of
X, while preserving the dependency structure
. The goal of the information bottleneck (IB) principle is to learn a probabilistic encoder
that captures as much relevant information about
Y as possible, measured by the mutual information
, while discarding irrelevant details from
X by limiting
. Formally, the problem can be expressed as:
where
controls how much information from the input is retained in the compressed representation.
Rather than handling this constraint explicitly, the IB objective is often reformulated into a single trade-off function:
where the parameter
adjusts the trade-off between compression and predictive performance. A higher
encourages stronger compression, potentially at the cost of reduced predictive power.
The IB principle has both practical and theoretical impacts to DNNs. Practically, it can be formulated as a learning objective (or loss function) for deep models. When parameterizing IB with a deep neural network, X denotes the input variable, Y denotes the desired output (e.g., class labels), Z refers to the latent representation of hidden layers.
However, optimizing the IB Lagrangian is usually difficult, as it involves calculating mutual information terms. Recently, several works [
9,
28,
34,
35] have been proposed to derive some lower or upper bounds to approximate the true mutual information values. The prediction term
is always approximated with the cross-entropy loss. The approximation to
differs for each method. For variational IB (VIB) [
9] and similar works [
36],
is upper bounded by:
where
v is some prior distribution such as Gaussian. Depending on application contexts,
can also be measured by the mutual information neural estimator (MINE) [
37], which requires training an extra network network to optimize a lower bound of mutual information. More recently, [
38] suggests estimating
in a non-parametric way by utilizing the Cauchy–Schwarz divergence quadratic mutual information [
39].
Theoretically, it was argued that, even though the IB objective is not explicitly optimized, deep neural networks trained with cross-entropy loss and stochastic gradient descent (SGD) inherently solve the IB compression–prediction trade-off [
40,
41]. The authors also posed the information plane (IP), i.e., the trajectory in
of the mutual information pair
across training epochs, as a lens to analyze dynamics of learning of deep neural networks. According to [
40], there are two training phases in the common SGD optimization: an early “fitting” phase, in which both
and
increase rapidly, and a later “compression” phase, in which there is a reversal such that
continually decrease. This work attracted significant attention, culminating in many follow-up works that tested the proclaimed narrative and its accompanying empirical observations. To date, the “fitting-and-compression” phenomena of the layered representation
Z have been observed in other types of deep neural networks, including the multilayer perceptrons (e.g., [
40,
42]), the autoencoders (e.g., [
43]), and the CNNs (e.g., [
44]). More recently, Kawaguchi et al. [
33], Dong et al. [
45] formally established the first generalization error bound for the IB objective, showing that an explicit compression term, expressed as either
or
, can improve generalization. However, their conclusions are drawn solely from evaluations on standard image classification benchmarks such as MNIST and CIFAR-10. In contrast, our results, obtained in a completely new application domain and on two significantly more challenging oil painting datasets, offer complementary empirical evidence supporting the claim that the IB principle can improve generalization.










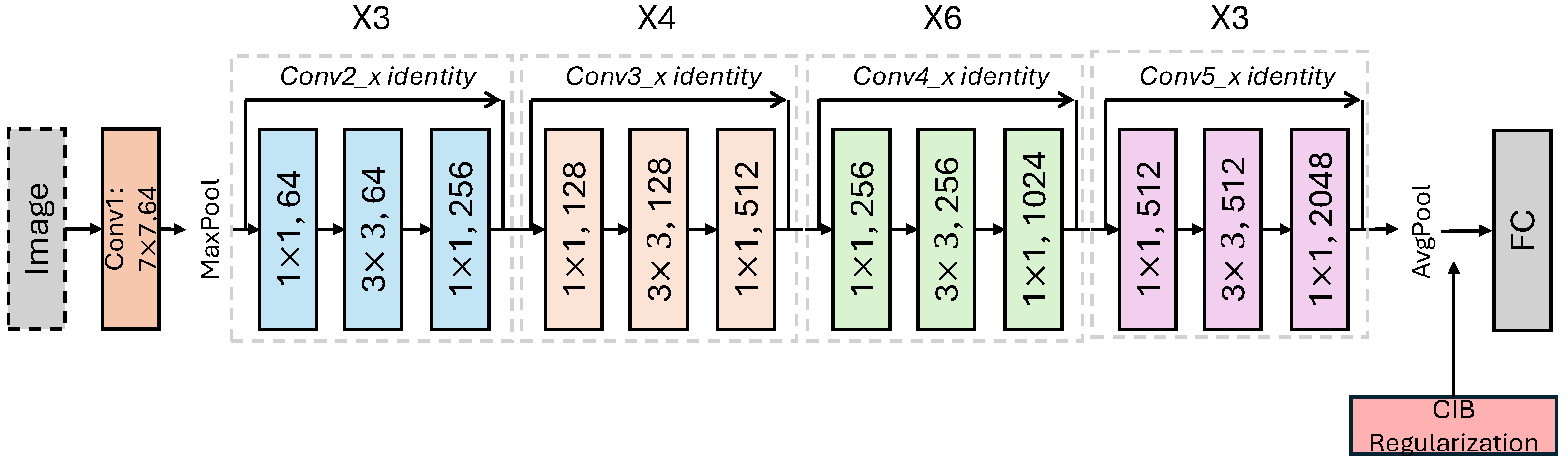


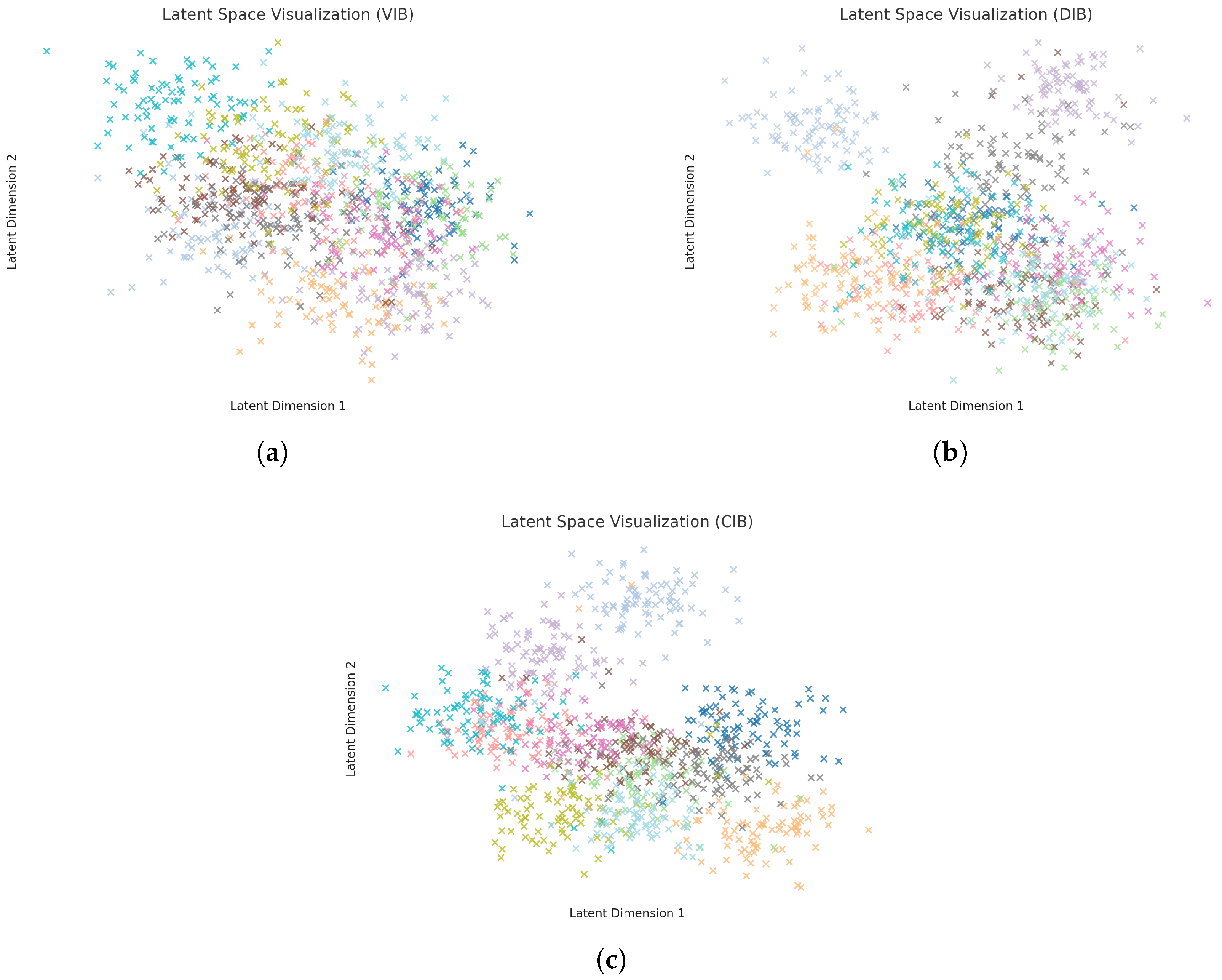
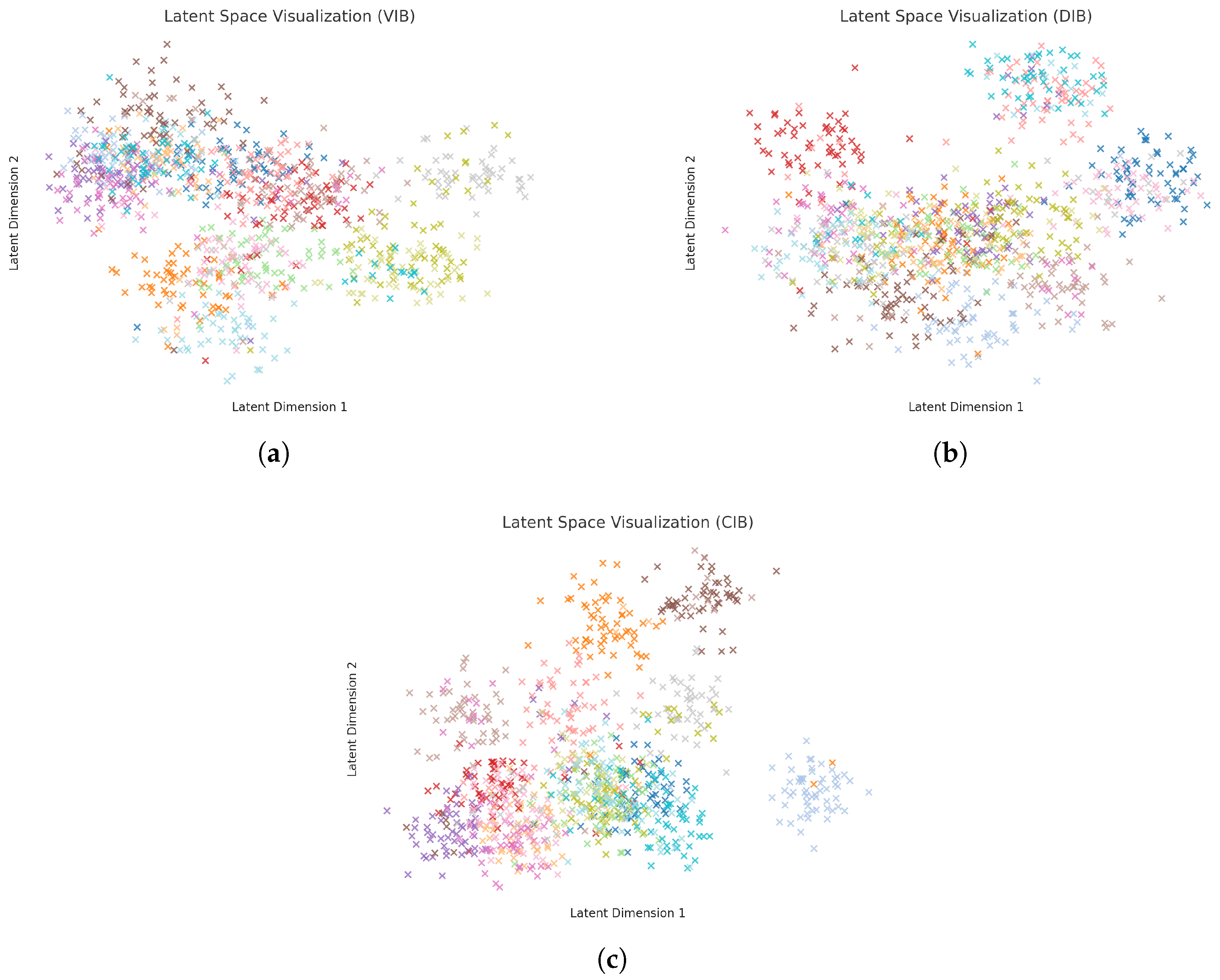

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}