

Normal Variance Mixture with Arcsine Law of an Interpolating Walk Between Persistent Random Walk and Quantum Walk


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
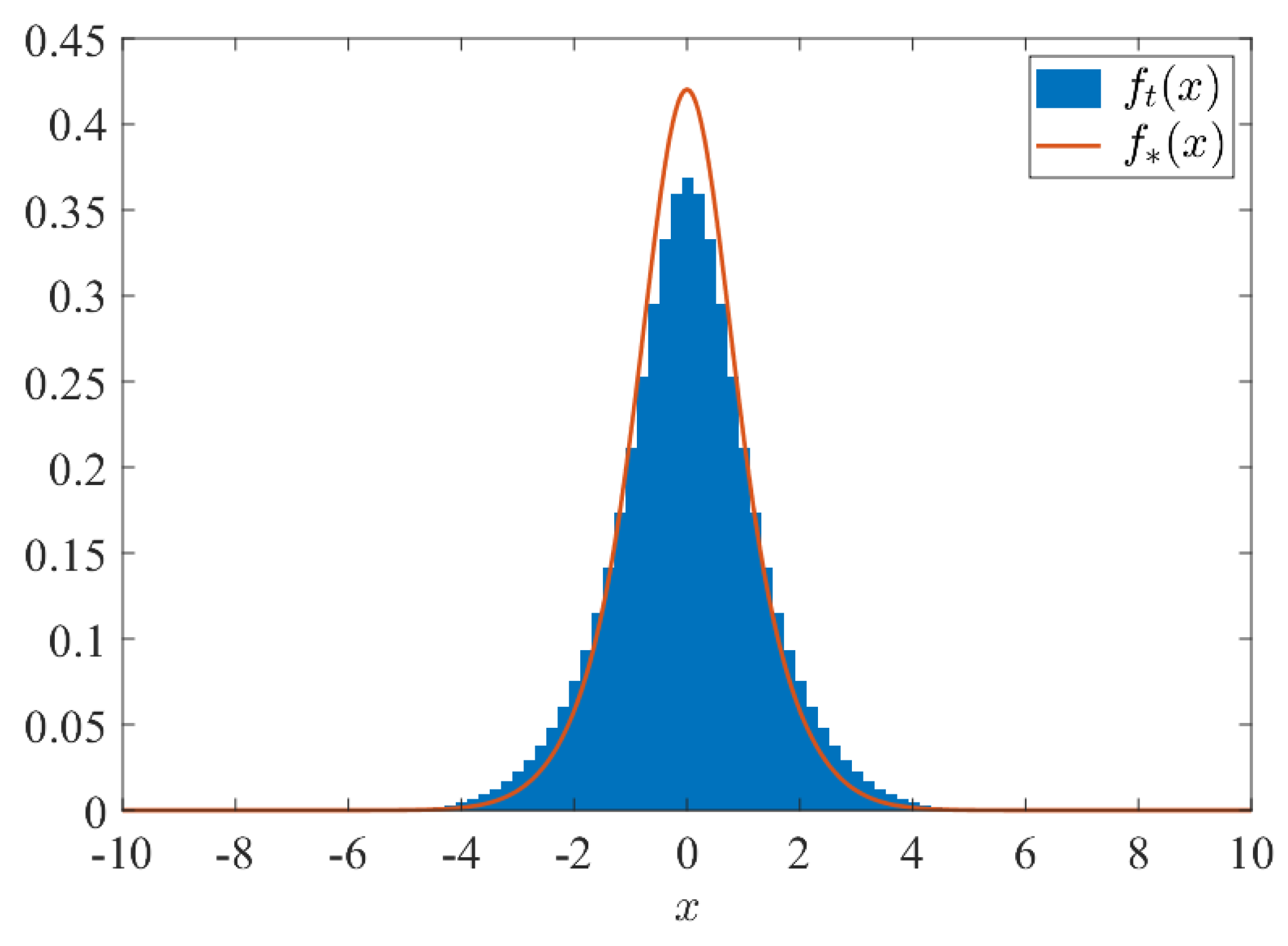
2. Numerical Demonstrations
3. Setting of Interpolating Walk
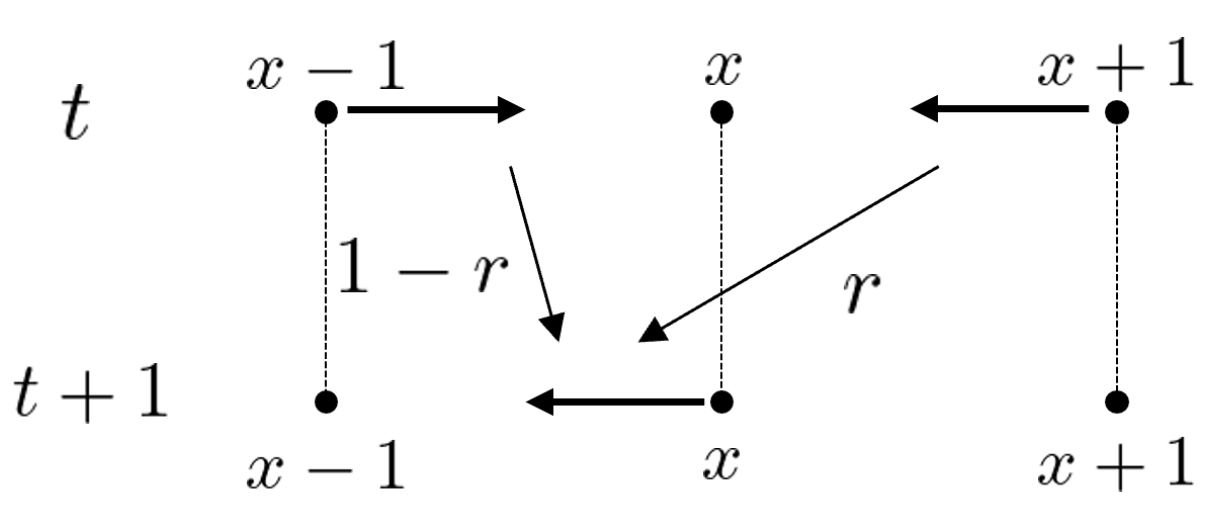
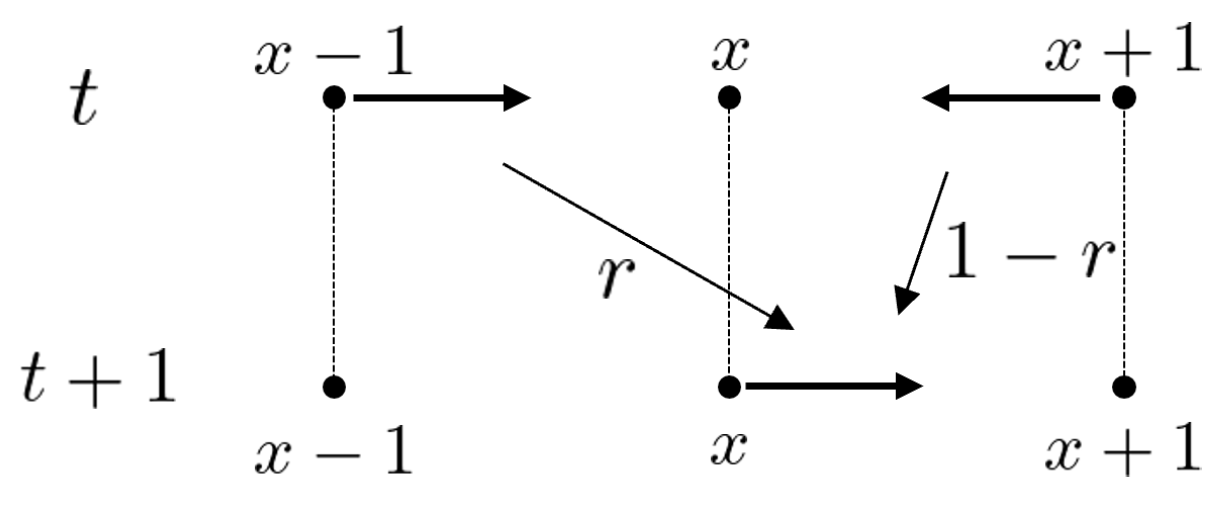
3.1. Random Walk
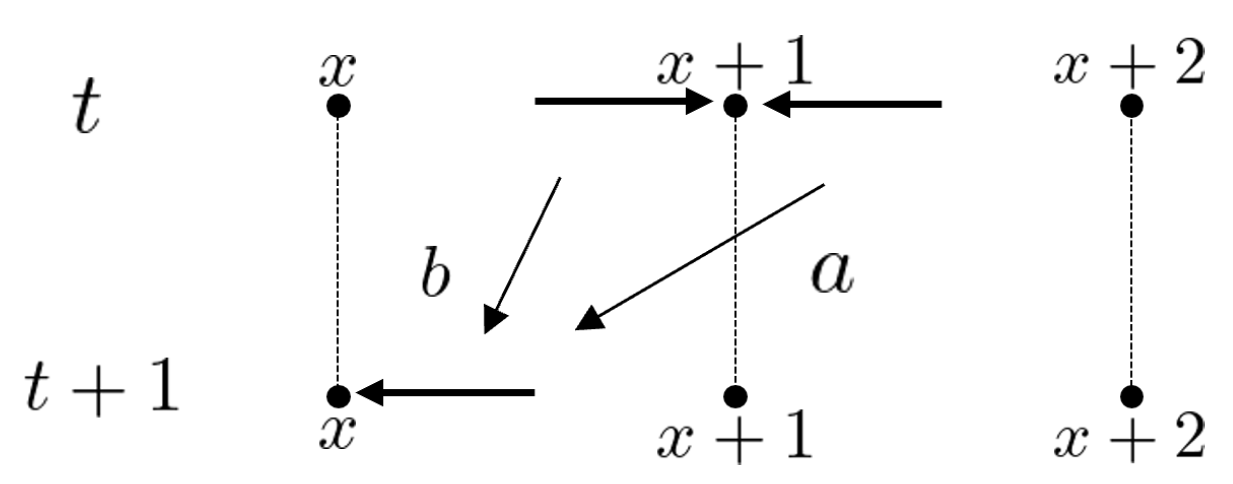
3.2. Quantum Walk
3.3. Interpolating Walk
4. Proof of Theorem 1
4.1. Fourier Transform
4.2. Asymptotics of the Eigenvalues of
4.3. Proof of Theorem 1
5. Summary and Discussion
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Proof of Proposition 3
- Step 1: First let us rewrite the time evolution operator in the Fourier space in Lemma 1 as follows so that the Kato perturbation theory [18] can be applied.whereandThe eigenvalues of the non-perturbed unitary matrix T are described byLet be the eigenvalue of which split from the non-perturbed eigenvalue 1 of T. The eigenvalues of that are close to 1 can be expanded as follows because 1 is a semi-simple eigenvalue of T:Here, according to [18], , where and is the eigenprojection associated with the eigenvalue 1 of T. The eigenprojection can be expressed by using and , which are the eigenvectors corresponding to the eigenvalue of of T, that is,Note that and are the eigenvectors of the unitary matrices and whose concrete expressions arewhere .
- Step 2: Secondly, let us obtain the closed form of . To this end, let us see that can be essentially reduced to the following 2-dimensional matrix bywherein the following. By using (A1)–(A3), and (A5), we haveHere we used the following computational results in the fourth equality:Therefore, since the 2-dimensional matrix is isomorphic to , the eigenvalues of coincide with . Then we havewith the eigenprojections
- Step 3: Finally, let us complete the proof by using (A6) and (A7). Let be the eigenprojection of the eigenvalues defined in (A4), respectively. Recall the integral expression of Lemma 1 for the characteristic function of . Since the contribution to the characteristic function of the eigenvalues in the expression of the integral form Lemma 1 other than can be estimated by in the limit of t by the Riemann–Lebesgue lemma, it is sufficient to consider restricted to the eigenspaces of with as follows:Since we set satisfyingthe characteristic function can be expressed as follows:Inserting the expressions of in (A7) and using the following factswe obtain the desired conclusion:
References
- Ambainis, A.; Bach, E.; Nayak, A.; Vishwanath, A.; Watrous, J. One-dimensional quantum walks. In Proceedings of the Thirty-Third Annual ACM Symposium on Theory of Computing, Crete, Greece, 6–8 July 2001; pp. 37–49. [Google Scholar]
- Kendon, V. Decoherence in quantum walks—A review. Math. Struct. in Comp. Sci. 2006, 17, 1169–1220. [Google Scholar] [CrossRef]
- Konno, N. Quantum Walks. In Lecture Notes in Mathematics; Springer: Berlin/Heidelberg, Germany, 2008; Volume 1954, pp. 309–452. [Google Scholar]
- Meyer, D.A. From quantum cellular automata to quantum lattice gases. J. Stat. Phys. 1996, 85, 551–574. [Google Scholar] [CrossRef]
- Portugal, R. Quantum Walk and Search Algorithm, 2nd ed.; Springer Nature: Cham, Switzerland, 2018. [Google Scholar]
- Balakrishnan, V.; Chaturvedi, S. Persistent diffusion on a line. Phys. Stat. Mech. Its Appl. 1988, 148, 581–596. [Google Scholar] [CrossRef]
- Konno, N. Limit theorems and absorption problems for one-dimensional correlated random walks. Stoch. Model. 2009, 25, 28–49. [Google Scholar] [CrossRef]
- Schuhmacher, P.K.; Govia, L.C.G.; Taketani, B.G.; Wilhelm, F.K. Quantum simulation of a discrete-time quantum stochastic walk. Lett. J. Explor. Front. Phys. 2021, 133, 50003. [Google Scholar] [CrossRef]
- Whitfield, J.D.; Rodríguez-Rosario, C.A.; AspuruGuzik, A. Quantum stochastic walks: A generalization of classical random walks and quantum walks. Phys. Rev. A 2010, 81, 022323. [Google Scholar] [CrossRef]
- Hall, P.; Heybe, C.C. Martingale Limit Theory and Its Application; Probability and Mathematical Statistics; Academic Press: Cambridge, MA, USA, 1980. [Google Scholar]
- Konno, N.; Matsue, K.; Segawa, E. A crossover between open quantum random walks to quantum walks. J. Stat. Phys. 2023, 190, 202. [Google Scholar] [CrossRef]
- Brun, T.A.; Carteret, H.A.; Ambainis, A. Quantum random walks with decoherent coins. Phys. Rev. A 2003, 67, 032304. [Google Scholar] [CrossRef]
- Ahlbrecht, A.; Vogts, H.; Werner, A.H.; Werner, R.F. Asymptotic evolution of quantum walks with random coin. J. Math. Phys. 2011, 52, 042201. [Google Scholar] [CrossRef]
- Štefănák, M.; Potoĕk, V.; Yalçınkaya, I.; Gábris, A.; Jex, I. Recurrence in discrete-time quantum stochastic walks. arXiv 2015, arXiv:2501.08674. [Google Scholar]
- Kronrod, A.S. Nodes and Weights of Quadrature Formulas: Sixteen-Place Tables; Consultants Bureau: New York, NY, USA, 1965. [Google Scholar]
- Konno, N. Quantum random walks in one dimension. Quantum Inf. Process. 2002, 1, 345–354. [Google Scholar] [CrossRef]
- Attal, S.; Petruccione, F.; Sabot, C.; Sinayskiy, I. Open quantum random walks. J. Stat. Phys. 2012, 147, 832852. [Google Scholar] [CrossRef]
- Kato, T. A Short Introduction to Perturbation Theory for Linear Operator; Springer: New York, NY, USA, 1982. [Google Scholar]
- Domino, K.; Glos, A.; Ostaszewski, M.; Pawela, Ł.; Sadowski, P. Properties of quantum stochastic walks from the asymptotic scaling exponent. Quantum Inf. Comput. 2018, 18, 181–197. [Google Scholar] [CrossRef]
- Caruso, F.; Crespi, A.; Ciriolo, A.G.; Sciarrino, F.; Osellame, R. Fast escape of a quantum walker from an integrated photonic maze. Nat. Commun. 2016, 7, 11682. [Google Scholar] [CrossRef] [PubMed]



Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yoshino, S.; Shiratori, H.; Yamagami, T.; Horisaki, R.; Segawa, E. Normal Variance Mixture with Arcsine Law of an Interpolating Walk Between Persistent Random Walk and Quantum Walk. Entropy 2025, 27, 670. https://doi.org/10.3390/e27070670
Yoshino S, Shiratori H, Yamagami T, Horisaki R, Segawa E. Normal Variance Mixture with Arcsine Law of an Interpolating Walk Between Persistent Random Walk and Quantum Walk. Entropy. 2025; 27(7):670. https://doi.org/10.3390/e27070670
Chicago/Turabian StyleYoshino, Saori, Honoka Shiratori, Tomoki Yamagami, Ryoichi Horisaki, and Etsuo Segawa. 2025. "Normal Variance Mixture with Arcsine Law of an Interpolating Walk Between Persistent Random Walk and Quantum Walk" Entropy 27, no. 7: 670. https://doi.org/10.3390/e27070670
APA StyleYoshino, S., Shiratori, H., Yamagami, T., Horisaki, R., & Segawa, E. (2025). Normal Variance Mixture with Arcsine Law of an Interpolating Walk Between Persistent Random Walk and Quantum Walk. Entropy, 27(7), 670. https://doi.org/10.3390/e27070670