1. Introduction
At present, the global energy emission reduction task is very urgent; the total global energy carbon emissions increased by 2%, exceeding 40 billion tons of carbon dioxide for the first time [
1]. As an important means to mitigate climate change and reduce carbon emissions, the research and application of clean energy can promote sustainable economic development and enhance the security and stability of energy systems. In the energy transition, new energy sources, such as wind and solar energy, have the characteristics of instability, while natural gas has become an ideal transition energy to reduce carbon emissions and achieve net-zero emissions [
2]. Natural gas can provide a reliable supplement to clean energy and make up for the instability of new energy sources. Its low carbon emissions, efficient combustion, flexible transportation modes, and abundant reserves make it play an important role in the energy transition [
3]. According to the 73rd edition of the Statistical Yearbook of World Energy, global primary energy consumption reached 620 EJ in 2023, with fossil energy sources still dominating, accounting for 81.5% of the global primary energy structure. Although global natural gas demand remained relatively stable, with an increase of only 0.02%—possibly due to pandemic-related policies—natural gas consumption exhibited a steady growth trend until 2022. However, natural gas still plays an important role in the global energy structure as a less carbon-intensive fossil fuel [
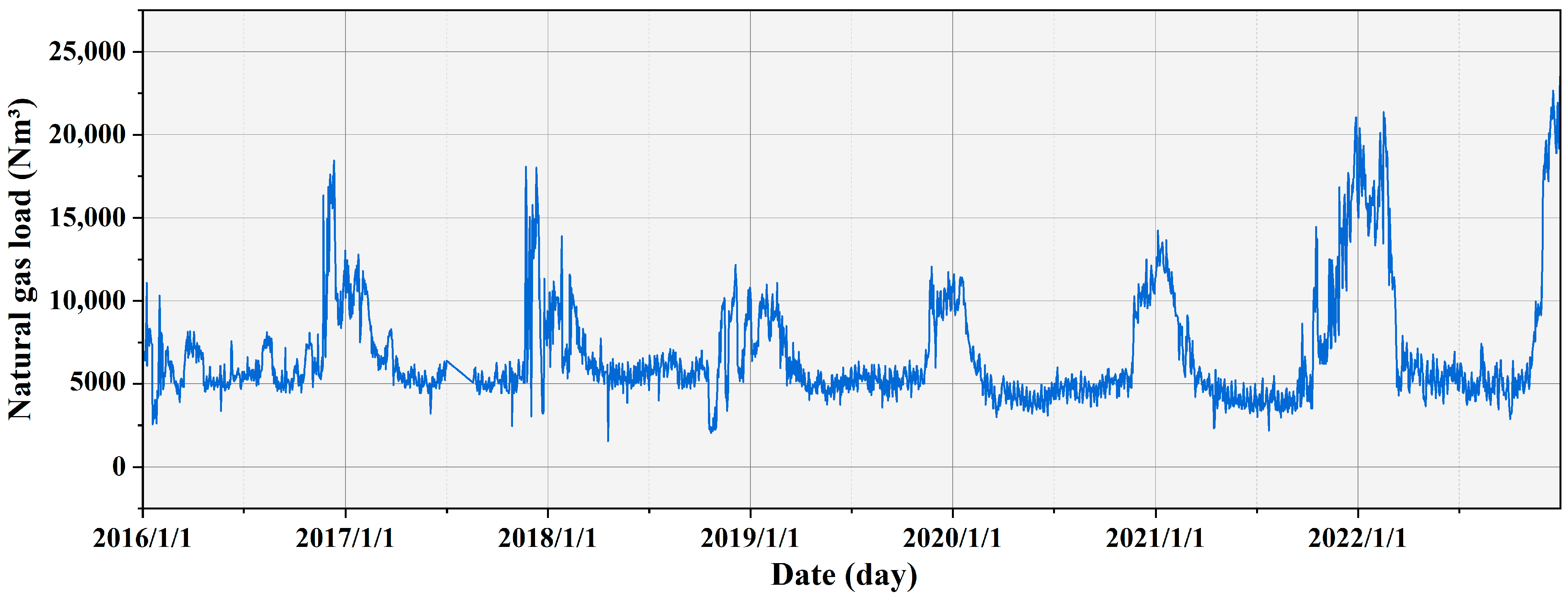
1]. Energy issues span from macro to micro levels, impacting national economic sustainability and the stability of people’s livelihoods. Accurately forecasting natural gas load (NGL) can optimize energy utilization, enhance supply security, reduce production costs, facilitate the formulation of sound energy policies, and promote economic development. Simultaneously, for industries and enterprises, forecasting aids in adjusting production and supply strategies to maintain market supply-demand equilibrium.
NGL forecasting models typically encompass statistical models, machine learning (ML) models, grey models, fuzzy logic models, and their combinations. Statistical models and ML models are widely used for short- to medium-term forecasting, leveraging their capacity to manage intricate market dynamics and fluctuations in supply and demand effectively [
4]. Statistical models offer advantages in prediction tasks due to their rapid computational speed and ability to capture temporal trends [
5,
6]. However, they exhibit relatively weaker predictive capabilities when faced with complex data or nonlinear relationships [
7]. In contrast, ML models can handle nonlinear and volatile data effectively, possessing strong generalization abilities and robustness against noise. Wei et al. utilized support vector regression (SVR) for short-term natural gas consumption (NGC) forecasting and optimized the model’s hyperparameters using a genetic algorithm (GA) [
8]. Rehman et al. compared the performance of stepwise multiple linear regression, multilayer perceptron, and long short-term memory (LSTM) models in hourly natural gas demand forecasting. They emphasized LSTM’s advantages in predictive accuracy and management of extreme events [
9]. Wang et al. applied the LMDI method to analyze influencing factors and developed a PSO-LSTM model to forecast natural gas consumption in China. The model demonstrated high prediction accuracy, and the results indicate a continued increase in future energy demand [
10].
Deep learning techniques demonstrate powerful predictive capabilities in time series forecasting. However, when confronted with complex, highly volatile, and stochastic data, individual prediction algorithms often prove inadequate, and other techniques are needed to assist prediction to address these challenges effectively. Decomposition algorithms emerged from the need for complex data structures. The original load data are decomposed into simpler, more interpretable components. This facilitates more accurate identification of underlying patterns and trends. Ding et al. introduced the Dual Convolution with a Seasonal Decomposition Network, employing multiple seasonal decompositions using loss to address common seasonal variations and periodic fluctuations in NGC data. Experimental results indicate significant potential for the practical application of this approach [
11]. Peng et al. combined local mean decomposition, wavelet threshold denoising, and LSTM in various configurations, discussing their application in NGC forecasting [
12]. Jiang et al. utilized variational mode decomposition (VMD), wavelet packet decomposition, and LSTM to forecast complex nonlinear natural gas data. The model exhibited outstanding performance in experiments [
13]. Wu and Wang significantly improved the quality of raw data preprocessing by using a two-stage decomposition strategy that combines EMD and EEMD. This approach further enhanced the extraction of valuable predictive information [
14]. Zhao et al. proposed a deep learning model based on VMD-CNN-LSTM with a self-attention mechanism for natural gas load interval forecasting. They also developed a hierarchical early warning system to enhance prediction-based risk management [
15].
In natural gas demand forecasting, it is crucial to consider the influence of external factors on prediction outcomes. Common short-term influencing factors include temperature, holidays, seasons, and others, which can significantly influence consumption patterns and production demands of natural gas. However, an excess of external factors may lead to increased redundancy in the model, thereby reducing the accuracy and interpretability of predictions. Therefore, effective feature selection is necessary. The most common method for feature selection is correlation analysis [
16,
17]. However, its effectiveness in complex real-world scenarios is often less than satisfactory. In contrast, feature selection based on embedding methods integrates the feature selection process into model training. By ranking the importance of features, it can effectively identify critical features [
18]. Rao et al. employed random forest analysis to assess the importance of factors influencing China’s energy demand, effectively addressing data redundancy and multicollinearity, thereby offering a reliable method for energy demand forecasting [
19]. Zeng et al. integrated the CatBoost algorithm into a hybrid prediction framework, significantly enhancing predictive performance by synthesizing the fluctuation parameters of GARCH models and the importance of meteorological conditions and other influencing factors [
20].
With the advancement of data science and machine learning technologies, integrating complex features for NGL forecasting has emerged as a new research direction. Current research in natural gas forecasting primarily focuses on combining different models, with data processing limited to basic operations such as preprocessing and feature analysis of raw data. However, due to the inherent complexity and variability of data, relying solely on collected influencing factors may fail to capture all the information necessary for accurate load forecasting. Therefore, achieving more accurate predictions necessitates a deeper focus on the relationship between the complexity and predictability of time series data [
21]. Self-similarity can characterize the analogous patterns of load data across various temporal scales. Randomness describes the degree of irregularity present in the load data. Karaca et al. integrated fractal analysis and entropy analysis in their predictive experiments using stock index datasets, achieving higher accuracy in stock data forecasts. This approach provides a representation of self-similarity and complexity for stock prediction [
22]. Similarly, Kim et al. combined effective transfer entropy with machine learning algorithms to enhance the prediction of stock prices [
23]. Long-term memory describes the persistent influence of past values on future values within load data. Chaos is utilized to assess the degree of chaotic behavior within a system, capturing the unpredictability of the data. Raubitzek and Neubauer found that the integration of complexity analysis results, such as approximate entropy, sample entropy, and fractal dimension, with machine learning outcomes significantly enhances the identification of predictable periods. They also explored the incorporation of complexity analysis from chaos theory to improve the accuracy of machine learning predictions [
21]. In the field of natural gas, Bai et al. proposed a complexity measurement method that integrates coefficient of variation analysis, local fluctuation coefficient analysis, and kurtosis analysis. This experiment utilizes the comprehensive complexity of data to assess the impact of various factors on prediction accuracy [
24]. Wei et al. employed the analytic hierarchy process to comprehensively address irregularities, complex cyclical variations, and volatility in consumption data. They established complexity measurement indicators to assess the relationship between complexity and predictive performance [
25]. However, the above studies have not directly integrated specific complexity features of the data into the forecasting framework, thereby limiting their practical contributions to enhancing predictive performance. They have mainly focused on assessing the correlation between data of varying complexities and predictive performance, while a detailed exploration of the specific data characteristics of complexity features remains to be thoroughly investigated.
In summary, current research lacks a thorough exploration of how to organically integrate complexity features into forecasting frameworks. A thorough exploration and precise quantification of intrinsic complexity characteristics, such as self-similarity, long-term memory, randomness, and chaos in data, are still lacking. Considering these complex features comprehensively becomes a crucial factor in enhancing predictive accuracy in the study. Although NGL forecasting techniques have become increasingly mature, their predictive performance often remains unsatisfactory when handling data with varying levels of complexity. Moreover, these models tend to underperform in capturing long-term dependencies and volatile patterns, posing a critical challenge that requires further investigation.
To achieve more precise predictions, it is essential to delve into the complex features of historical sequences and their impact on predictive performance. By integrating embedding-based feature engineering with load decomposition techniques, predictive models effectively identify inherent data patterns and dynamic trends. This framework significantly improves forecasting accuracy and robustness. In this work, an innovative load-forecasting model that takes into account the characteristics of complexity is proposed. The main contributions of this study are as follows:
- (1)
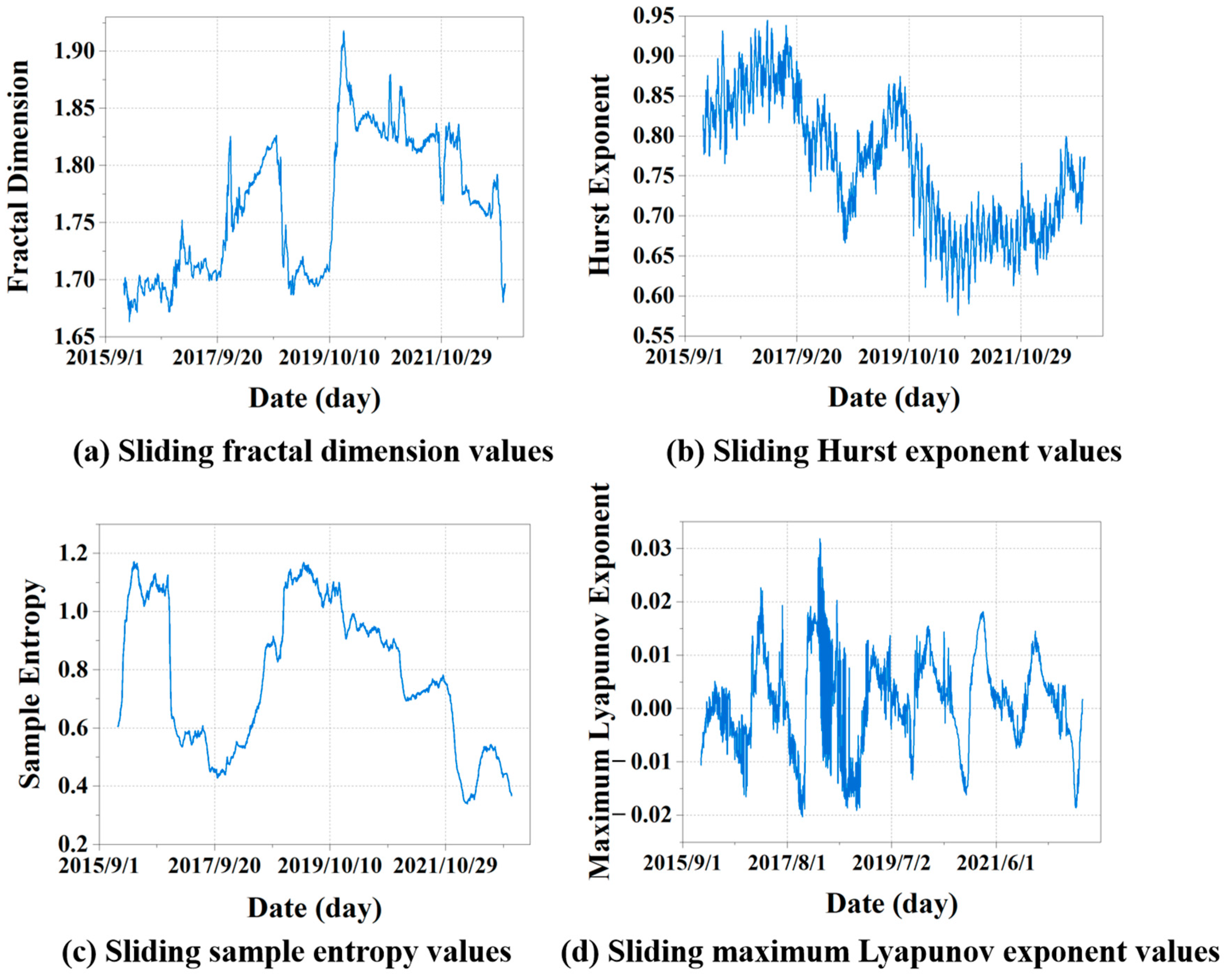
This study utilized fractal dimension, Hurst exponent, sample entropy, and maximum Lyapunov exponent to analyze the self-similarity, long-term memory, randomness, and chaotic characteristics of historical NGL data, thereby delving into the complexity of time series. These analytical findings not only contribute to a comprehensive understanding of data properties but also furnish crucial complexity feature information for predictive models.
- (2)
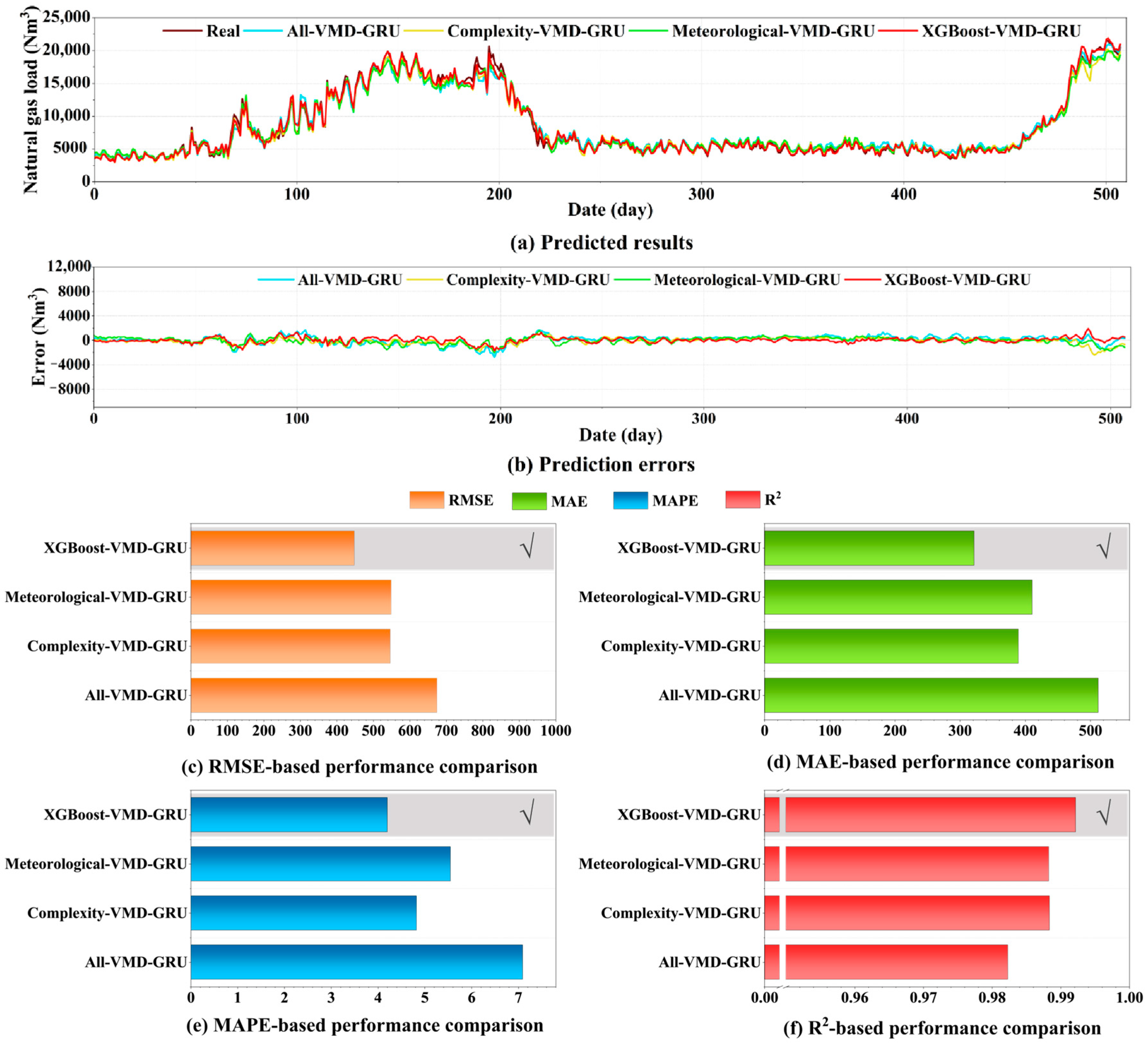
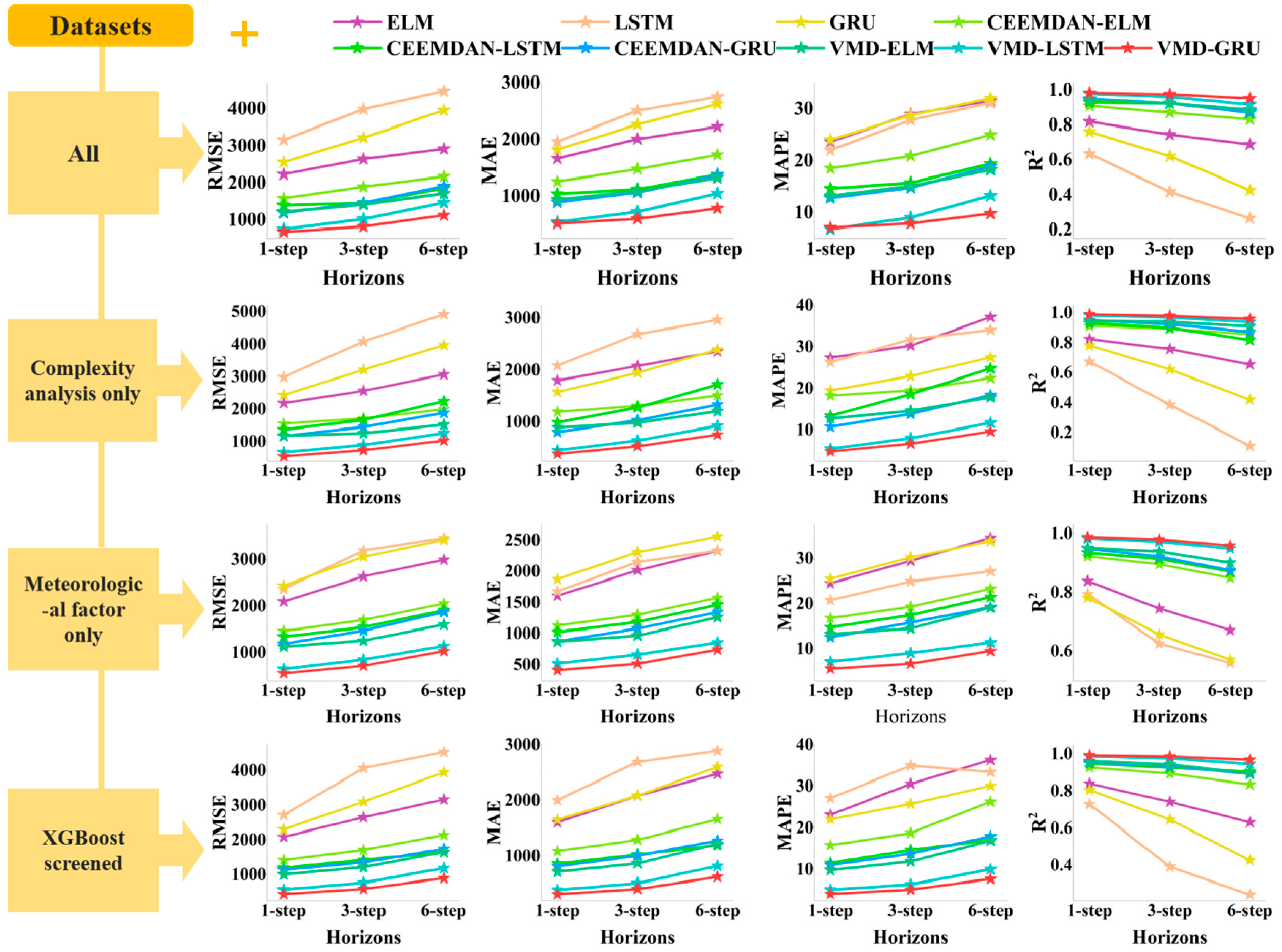
This study represents the first attempt to organically integrate complexity features into a load-forecasting model, establishing a multi-step prediction model for daily NGC. By integrating GRU with XGBoost and VMD, significant improvements in prediction accuracy and robustness were achieved. Feature importance ranking using XGBoost confirms the significance of complexity features and certain meteorological factors in forecasting. In practical applications, multi-step preprocessing and prediction strategies are designed for complex long-term prediction needs.
- (3)
This study rigorously verifies the effectiveness and feasibility of the proposed method using detailed NGL data collected from real-world sites spanning from 2016 to 2022. Additionally, to assess its robustness in practical applications, extensive simulation experiments were conducted by introducing various noise disturbances with different distributions into the original data. These experiments confirmed the superior performance of the method in real-world scenarios and demonstrated its strong adaptability to complex data and noise interference.
The rest of the paper is organized as follows.
Section 2 describes the complexity features and the related methods of the proposed model.
Section 3 elaborates on the main structure of the proposed hybrid model.
Section 4 provides a detailed description of the experiments, focusing on feature importance, data decomposition, complexity feature analysis, and comparative result analysis. Finally,
Section 5 summarizes the conclusions and proposes future directions.
5. Conclusions and Future Directions
Historical loadings of natural gas are characterized by complexity. Achieving more accurate forecasts requires a deep understanding of the complex characteristics of historical sequences and their impact on predictability. However, existing research rarely incorporates the complex features of historical load data into natural gas forecasting frameworks. Therefore, this paper proposes a load-forecasting model based on data decomposition and ensemble deep learning that combines data complexity features.
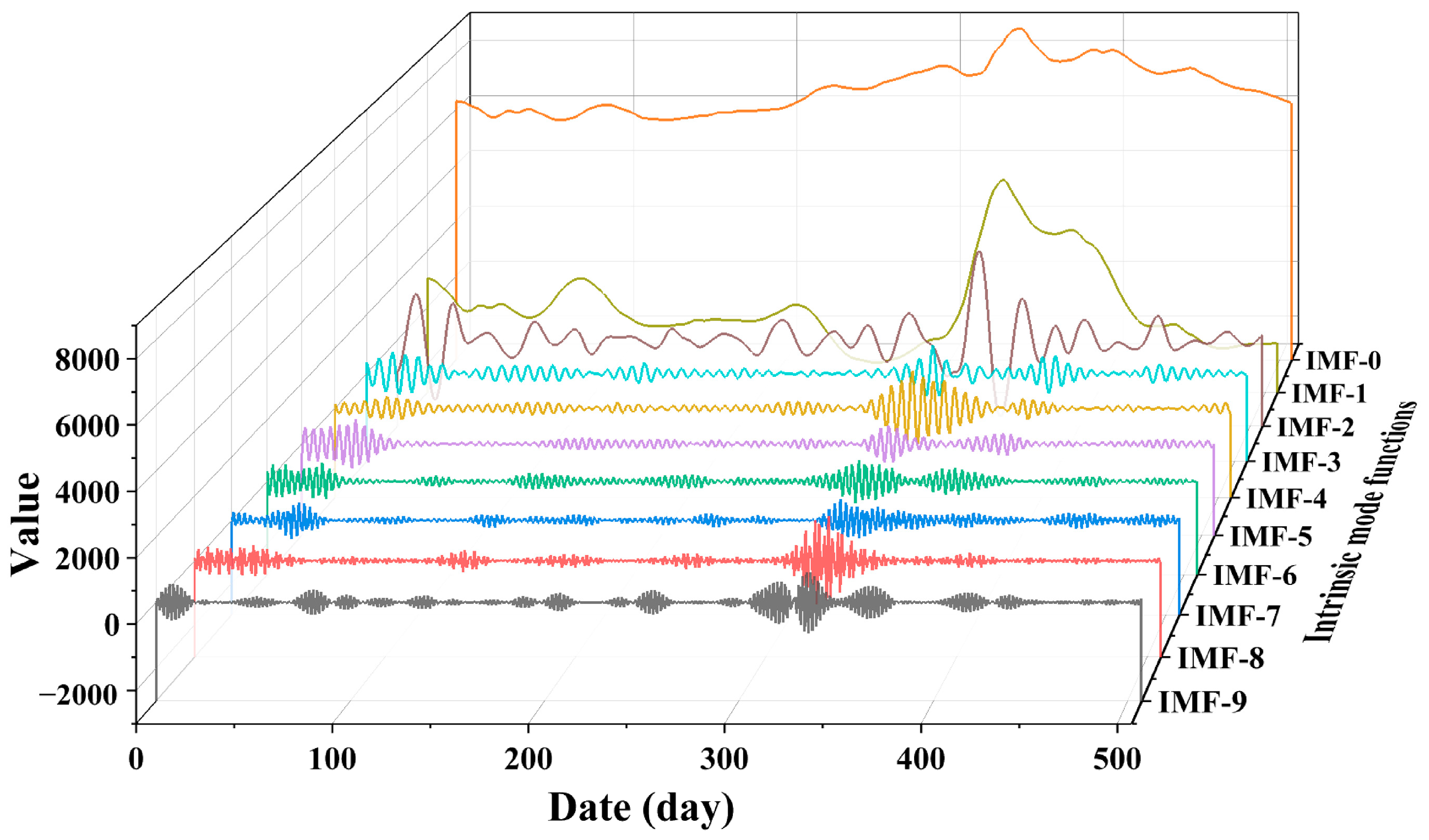
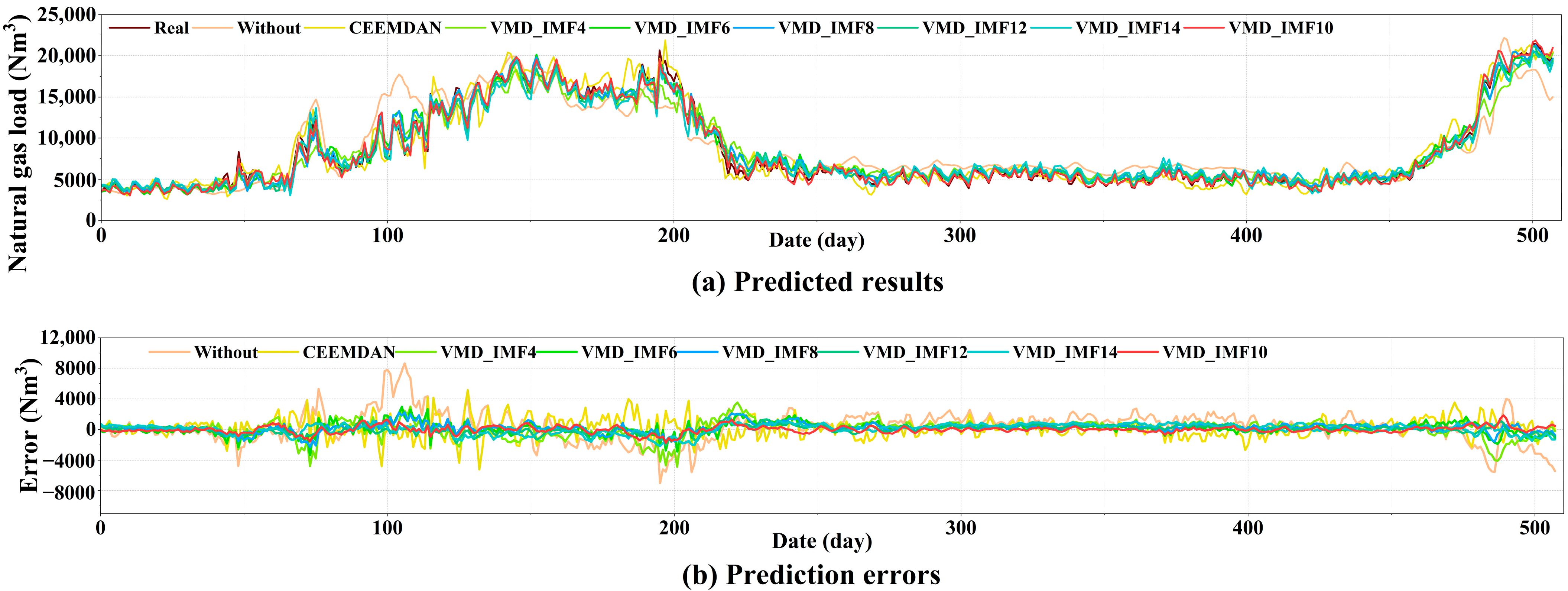
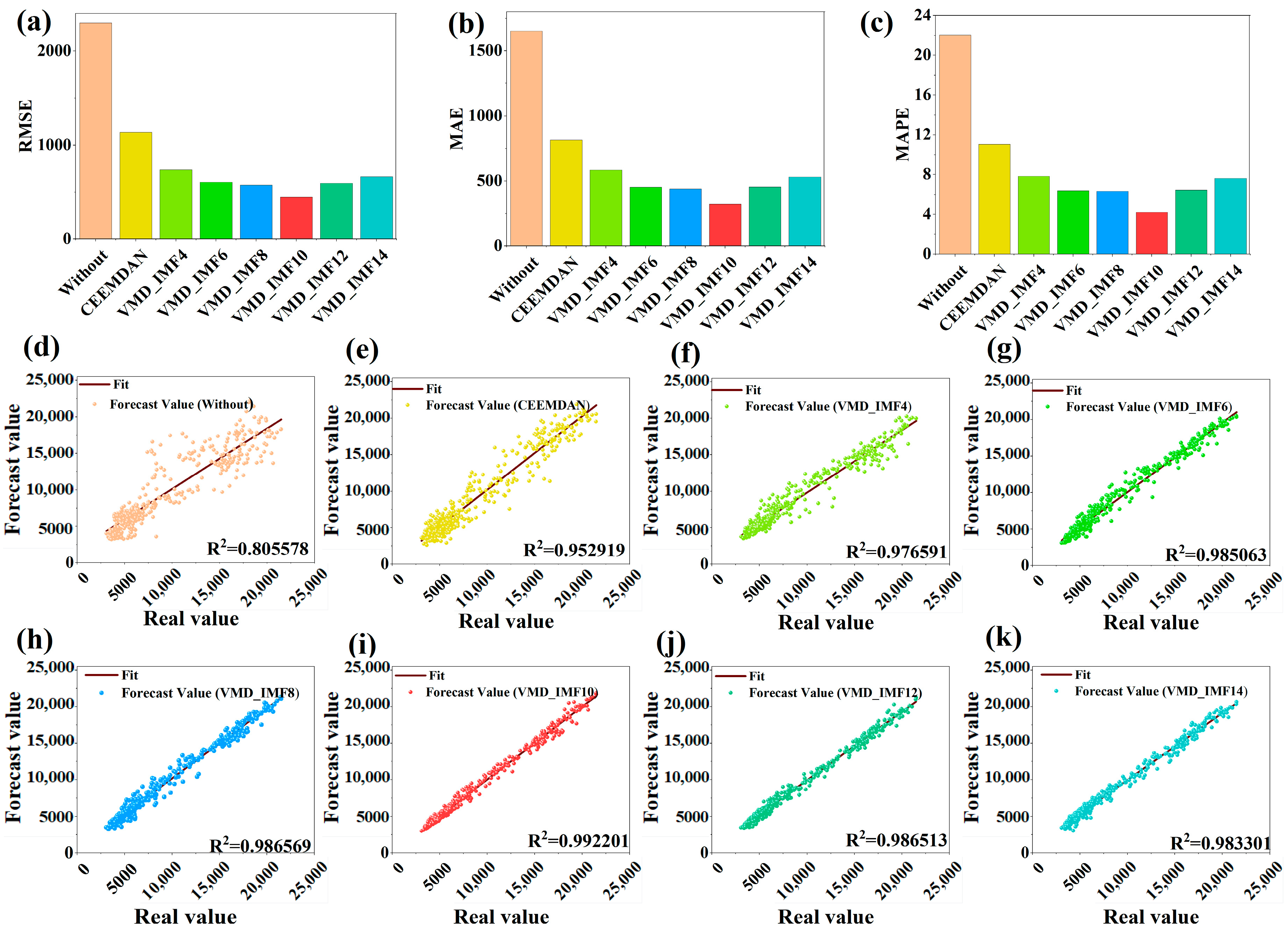
This study employs FD, HE, SE, and MLE to analyze the self-similarity, long-term memory, randomness, and chaotic features of historical NGL data, addressing the data complexity features and exploring the complexities of time series. Next, employing XGBoost, we conducted an importance ranking of four complexity features and ten collected meteorological features, identifying eight key features. Subsequently, VMD decomposed the load data into ten intrinsic mode functions (IMFs). These modes were integrated with selected key features as input vectors for the GRU network to perform multi-step forecasting. Furthermore, this study discusses the predictive performance of various feature datasets and different combinatorial models. The results further validate the efficiency of the hybrid XGBoost-VMD-GRU model considering data complexity features in multi-step NGL forecasting. To better meet practical application needs, this study conducts multi-step forecasting experiments for daily NGL using various feature datasets and comparative models. This approach aids in formulating sustainable strategies for natural gas resource planning and supply scheduling. Finally, this study performs robustness analysis and the DM test on the proposed methods, comprehensively demonstrating their superiority across various metrics.
The hybrid predictive model that accounts for data complexity features can be applied in energy load forecasting. This study validates the reliability of the method using data from Hanzhong, Shaanxi. The research findings will aid in the optimization of the current energy forecasting framework and provide valuable insights for energy demand management and market operations. Additionally, this research can serve as a theoretical reference for other fields, particularly those involving the analysis and forecasting of complex time series data, such as financial markets and environmental science.
Despite the strong performance of the proposed model, several limitations remain to be addressed. (1) Potential overfitting risk: although the model achieves high accuracy on the current dataset, it may overfit when trained on limited data. Future work will explore regularization techniques and cross-validation strategies to reduce this risk. (2) Limited regional transferability: the model has not been extensively tested in regions with different natural gas consumption patterns. Its generalizability across regions needs further validation. Subsequent research will conduct transferability assessments incorporating multi-source data to expand the model’s application scope. (3) Sensitivity to noise: this study conducted an initial robustness analysis by introducing Gaussian, Poisson, uniform, and exponential noise, demonstrating the model’s stability under certain perturbations. However, the model may still exhibit performance fluctuations when dealing with unstructured or extremely anomalous data. Subsequent work will consider integrating robust optimization methods or anomaly detection mechanisms to improve adaptability under complex data environments. These limitations suggest clear directions for future research and can support more reliable and scalable applications of the model in real-world energy systems.


 ,
, 




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}