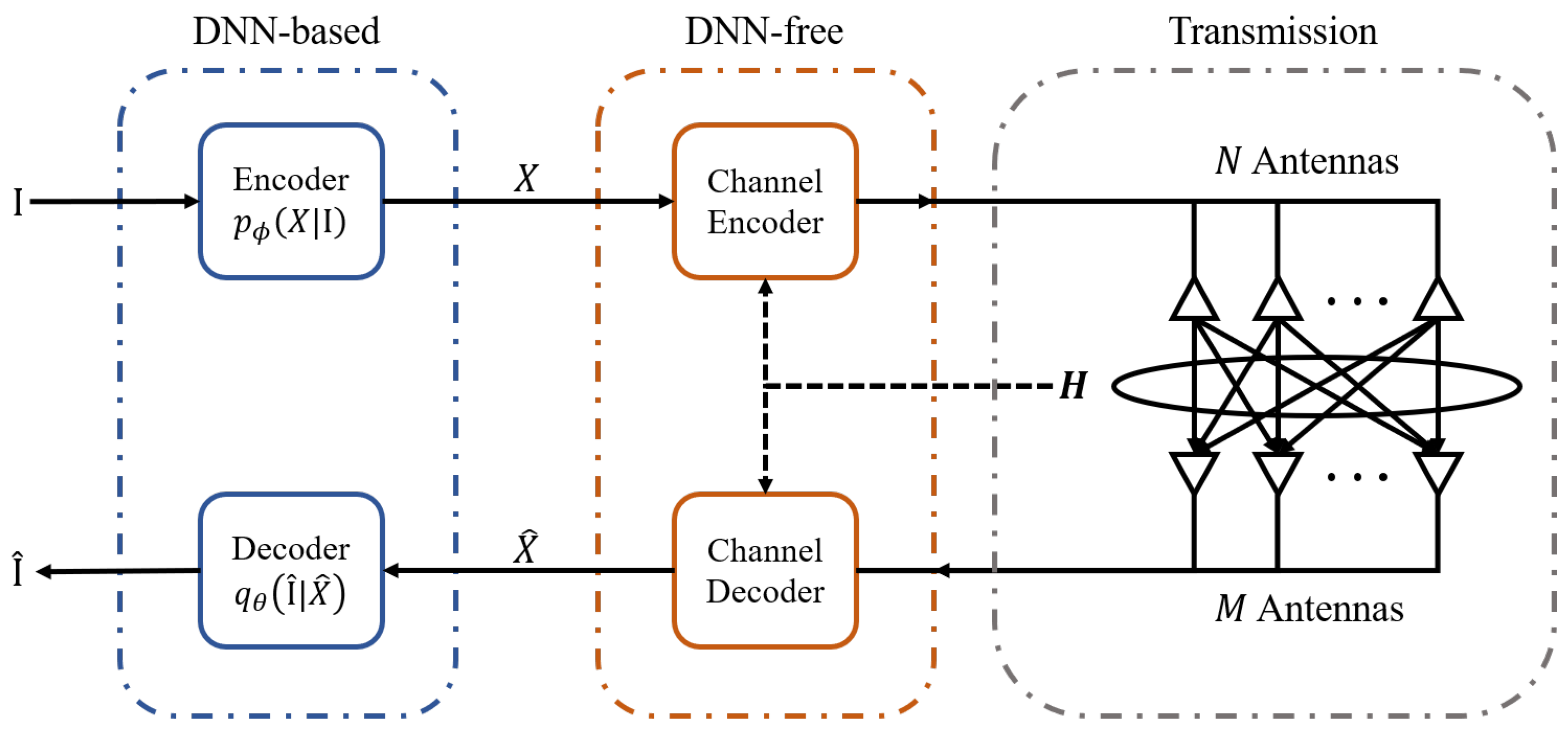
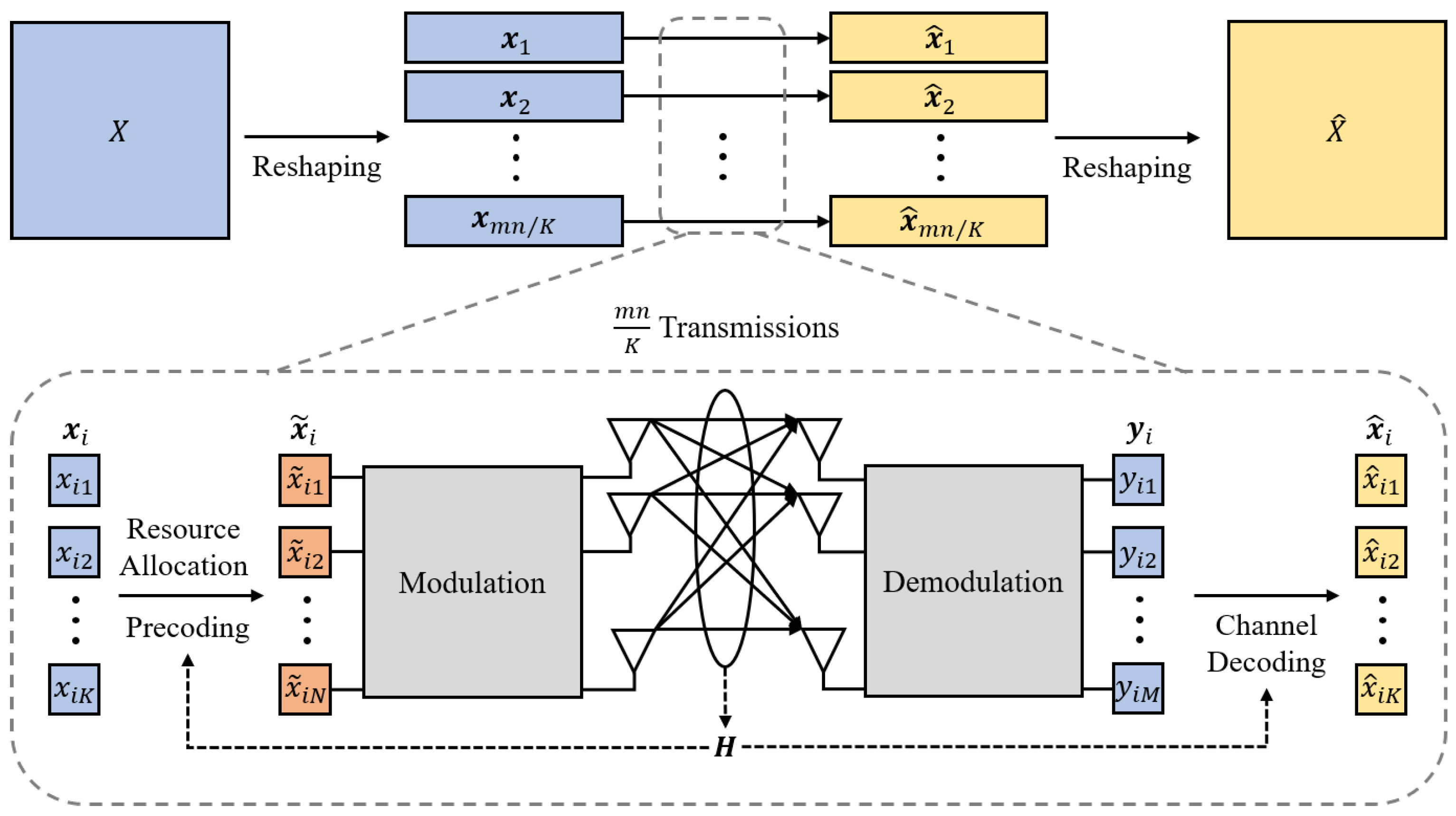
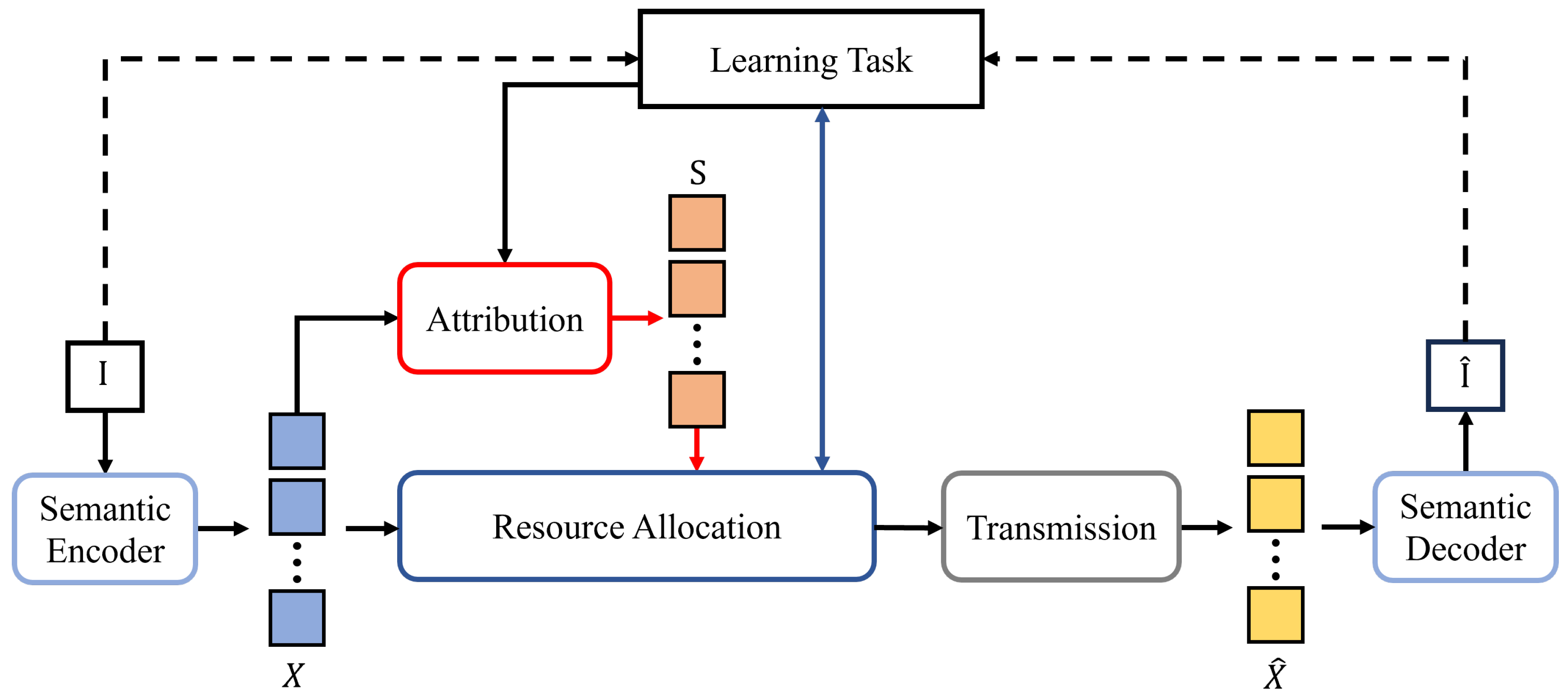
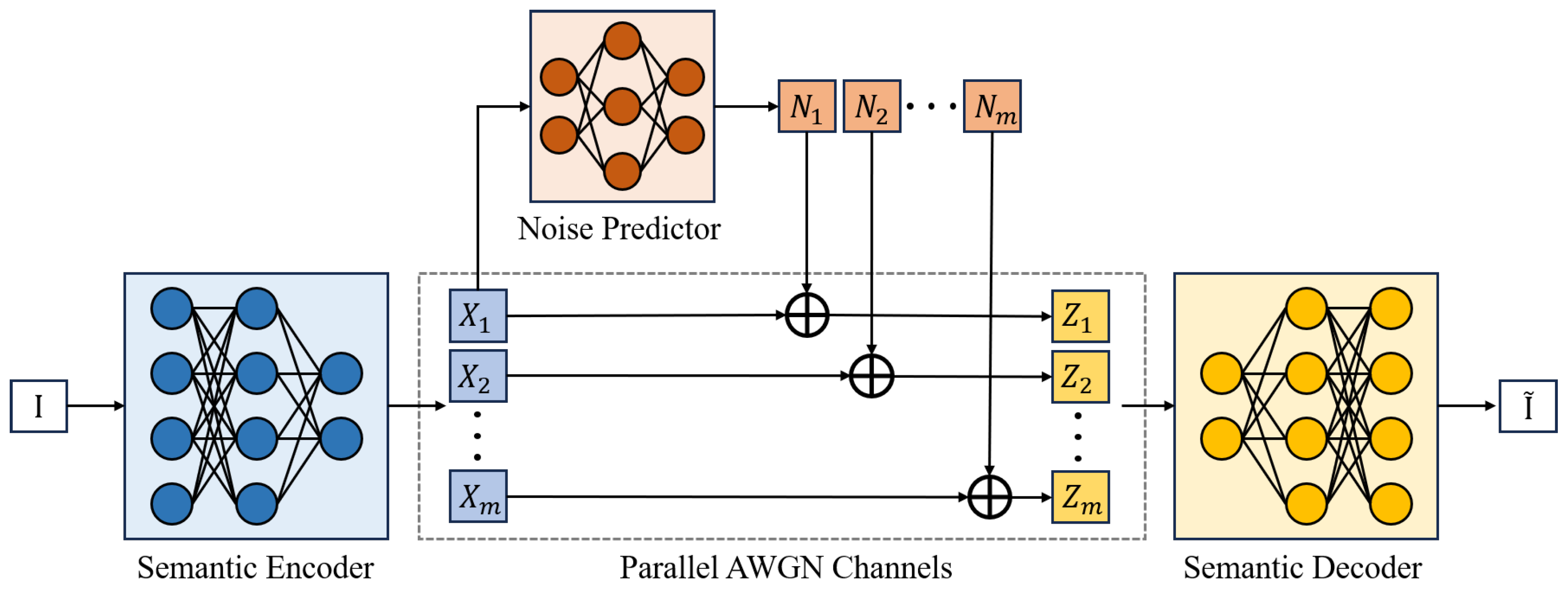
1. Introduction
Traditional communication systems are designed following Shannon’s coding theory, aiming to transmit information bits as accurately as possible over noisy channels without considering the semantic information contained within the data. In fact, with the development of artificial intelligence (AI) technologies, practical application scenarios such as semantic communications [
1] have demonstrated that accurate transmission of semantic-level information alone can achieve task objectives. In such cases, traditional communication systems’ pursuit of lossless bit-level transmission strategies would introduce significant information redundancy. Emerging 6G applications, including autonomous driving, remote robotics, meta-universe, smart healthcare, etc., involve massive data transmission demands driven by large-scale connected intelligent machines, while requiring ultra-low communication latency. It is foreseeable that in the 6G era, conventional communication systems will reach their limits in supporting future ubiquitous-connectivity and machine-intelligence services [
2]. This urgency necessitates a fundamental shift in communication system design from traditional bit-level transmission to semantic or effectiveness-level considerations. As a novel communication paradigm, semantic communication focuses on information transmission at semantic or effectiveness levels, significantly reducing communication overhead through semantic extraction and transmission. Current research progress in semantic communication has demonstrated higher communication efficiency, improved reliability, and better compatibility with emerging AI applications compared to traditional systems, particularly in text [
3], image [
4,
5], speech [
6], and video [
7] transmission scenarios.
The ultimate goal of semantic communication is to leverage intrinsic semantic information from sources to convey the sender’s intended meaning to receivers. Historically, the lack of a unified theoretical framework for representing semantics across different sources made semantic information difficult to represent and quantify. However, the powerful representation and generalization capabilities of deep neural networks (DNNs) have enabled semantic extraction. In the current research [
8], semantic communication systems typically employ DNN-parameterized feature encoders and decoders to extract and decode semantic representations. Through end-to-end training with incorporated communication constraints, these systems achieve joint design of source-channel coding. The semantic encoder integrates source and channel coding functions, enabling extracted representations to preserve semantic information while maintaining excellent communication performance. This deep learning-based joint source-channel coding (JSCC) approach, implemented through neural network parameterization and end-to-end training, has been extensively studied and validated in SISO scenarios [
9,
10,
11,
12].
However, unlike the simple model structure in SISO scenarios, MIMO systems face more complex channel conditions. The high dimensionality of MIMO channel matrices leads to exponential growth in potential channel state combinations. End-to-end JSCC semantic communication networks require parameter learning based on task datasets and the entire distribution of wireless channels, resulting in substantial training overhead and unpredictable complexity [
13]. Training end-to-end networks to adapt to diverse communication environments often proves impractical. Existing MIMO semantic communication systems, such as the speech-to-text system proposed in [
14], employ JSCC but lack CSI adaptive design. The work in [
15] utilized vision transformer models for semantic encoder and decoder with JSCC, training separate models for different Signal-to-Noise Ratio (SNR). Their results show optimal performance only when training and testing SNRs match. Although they propose a stochastic SNR training scheme for channel adaptation, this compromises performance compared to non-adaptive approaches. Parameters in JSCC models typically cannot be reused under different channel conditions, necessitating additional training resources and specialized designs for channel adaptation.
The fundamental issue in JSCC stems from semantic encoders being burdened with channel coding tasks, forcing semantic encoder and decoder to memorize complex MIMO channel conditions during training. By decoupling channel coding from source coding through separated design, we can eliminate channel dependence during training, reducing training complexity and overhead. However, a critical challenge emerges in separated designs: how to establish connections between learning tasks and communication objectives through channel coding schemes. In limited related work, Cai et al. [
16] proposed a separate source-channel coding (SSCC) design using the maximal coding rate reduction (MCR2) principle to train the source encoder and optimize the precoding matrices. This approach maximizes separation between different classes of encoded representations in feature space, enabling Maximum A Posteriori (MAP) classification at the receiver. Although it addresses channel adaptation and improves model reusability, their method is restricted to the classification task.
Building on [
16] that established clustered semantic representations in feature space for non-deep-learning-based channel coding design, we extend this concept; if we can understand how semantic representations influence task performance through their intrinsic properties, we could establish task-communication connections free from deep learning constraints. To realize this vision, we require both highly interpretable DNN models and reliable AI interpretability techniques. The Variational Autoencoder (VAE) [
17], which introduced a probabilistic latent space assuming standard normal distribution of latent variables, achieves high interpretability and structured control in generative models. Its latent variables can be disentangled into independent semantic features, enabling the generation of smoothly interpolated samples through continuous interpolation. In AI interpretability research, attribution mechanisms aim to assign relevance scores (importance metrics) to features, quantifying their impact on model outputs. By strategically aligning these importance metrics with communication resource allocation, we can effectively bridge communication objectives with learning tasks.
Based on this rationale, we propose a novel SSCC framework in this paper, the semantic encoder and decoder exclusively handle source coding, while an attribution mechanism provides importance scores for semantic representations extracted by the semantic encoder. The channel coding scheme is then designed by integrating importance scores with communication scenarios. Under this architecture, no additional design is required for the semantic encoder’s output, and appropriate models for the semantic encoder and decoder can be flexibly chosen depending on task requirements. This approach enables adaptation to various downstream task types while improving model reusability.
In current research on importance-aware communication, the definition and measurement of importance depend on specific task scenarios. Existing studies employ diverse methods to measure importance for optimizing communication processes and ensuring task performance. For example, Weng et al. [
14] directly linked semantic importance to text recovery accuracy in speech-to-text transmission tasks, enhancing semantic fidelity by precisely protecting critical information. Wang et al. [
18] evaluated the impact weights of encoder neuron activation values through backpropagation of prediction errors in semantic prediction tasks to reduce waste of communication resources. At the data level, a data importance indicator [
19] was proposed to dynamically quantify the effective value of samples in wireless channel environments by integrating the received SNR with data uncertainty. Another study [
20] addressed communication resource constraints in edge machine learning scenarios by designing importance discrimination mechanisms under centralized frameworks (prioritizing misclassified data) and distributed frameworks (emphasizing local model data trained on large-scale datasets). Furthermore, Guo et al. [
21] utilized pre-trained language modelto generate word importance rankings and implemented differentiated transmission protection, while Liu et al. [
22] defined semantic importance by analyzing the correlation between semantic features and task performance, as well as inter-feature relationships, guiding resource allocation in digital semantic communications. These studies employ different approaches to define and utilize importance, yet all adopt task-oriented importance evaluation to optimize resource allocation, thus enhancing the efficiency and performance of communication systems. Although existing research covers various communication scenarios, the problem of importance-aware resource allocation in MIMO semantic communication has not been fully explored.
In our work, we investigate importance-aware resource allocation for MIMO semantic communication within the SSCC framework. We quantify importance based on each feature’s influence on the deep learning model’s inference performance, leveraging attribution mechanisms to derive importance scores for efficient resource allocation. We propose a communication-aware attribution method applicable to the VAE model, whose results can directly reflect the relative communication resource requirements for each feature, providing explicit guidance for resource allocation.
Our main contributions can be summarized as follows:
We propose an SSCC framework that addresses critical challenges in JSCC designs: parameter reusability limitations and adaptive channel condition handling. This paradigm enables flexible model deployment across diverse scenarios by decoupling semantic processing from channel optimization.
We propose a communication-inspired attribution method for VAE models by injecting controlled noise into semantic representations. Grounded in information bottleneck theory, our approach minimizes retained information while preserving task-critical features and perturbing non-essential ones. To characterize the importance score, we model the noise injection process as a communication channel, thereby endowing the derived importance scores with physical interpretability in communication contexts. Specifically, we establish a theoretical link between feature importance scores and channel capacity. This connection facilitates an importance-aware resource allocation strategy, bridging communication principles with deep learning objectives.
Systematic experiments validate both the effectiveness of the importance scores generated by our attribution method and their pivotal role in bridging learning tasks and communication optimization. Comparisons of resource allocation schemes demonstrate that our importance-aware approach achieves superior performance in learning tasks, highlighting the advantages of integrating importance awareness into communication resource management. This work provides valuable insights for SSCC semantic communication system design while expanding the applicability of explainable AI techniques in communication scenarios.
3. Methodology
The global optimization of resource allocation strategies constitutes a core challenge in achieving semantic communication efficiency maximization within SSCC system design. In the JSCC architecture, the system obtains parameter-fixed models through end-to-end joint training, whose performance ceiling is entirely determined by the neural network’s feature extraction and channel adaptation capabilities. In contrast, the SSCC architecture requires the semantic encoder to undergo an independent pre-training convergence process, with deployment in communication links only after stabilizing its basic task performance. Here, channel transmission quality governed by resource allocation strategies becomes the critical bottleneck constraining end-to-end semantic fidelity. This paradigm divergence leads SSCC systems to confront unique optimization propositions: given the established capability boundaries of semantic models, how to design adaptive communication resource allocation mechanisms that compensate for semantic distortion induced by channel distortion through establishing mapping relationships between communication conditions and learning task.
To address this challenge, we propose an importance-aware semantic communication framework shown in
Figure 3 that establishes connections between learning tasks and communication resource allocation. The image
is encoded into semantic representations
X through a semantic encoder. An attribution mechanism analyzes the importance of each feature in
X according to the learning task objective (
15), generating importance scores
. The resource allocation strategy then combines these importance scores with the learning task objective to influence the feature transmission process, ensuring that the reconstructed image
recovered from
achieves the best possible quality, making the learning task objective as optimal as possible. We innovatively propose an attribution mechanism specifically designed for VAE models to establish connections between communication conditions and learning task performance. This framework establishes resource optimization equations with constrained conditions through quantitative evaluation of importance differences in semantic representations, providing SSCC system design with theoretical decision-making models that integrate both interpretability and adaptability.
3.1. Communication-Informed Bottleneck Attribution (CIBA)
In this paper, inspired by IBA [
23], we propose a novel perspective to establish the connection between feature importance and communication. As discussed in
Section 2.1, VAE assumes that latent variables
follow a centered isotropic multivariate Gaussian prior, with the parametric encoder modeled as
. Through the reparameterization trick, variables
X can be viewed as a series of independent Gaussian signals. To estimate the importance of these Gaussian signals, we can add specific noise to each Gaussian signal to constrain the overall information flow, then feed the perturbed signals into the decoder to observe their impact on task performance.
Figure 4 depicts the framework of the proposed CIBA method. We aim to find appropriate noise distributions that minimally affect the learning task, which implies that more important signals for the task will receive weaker noise (preserving information) while unimportant ones will be completely corrupted, thereby revealing the importance degree of each feature. Let
be a feature matrix where each element
denotes the feature element at row
i and column
j. We assume that each
follows a normal distribution, i.e.,
. We can represent the entire matrix
X using reparameterization. We have
and
, where ⊙ denotes the Hadamard product,
and each element
is independently drawn from a standard normal distribution
.
Assuming independence between feature elements, we model the information flow constraint process as an analog additive white Gaussian noise (AWGN) channel communication process. In this process, feature elements transmit through parallel AWGN channels. For each element, the relationship is given by where for all and , and represents the analog additive white Gaussian noise at position .
The noise predictor, which is a neural network parameterized by
, adjusts
to control the power of the analog additive white Gaussian noise. We fix the parameters
and
of the semantic encoder and decoder, and only optimize the parameter
of the noise predictor through the information bottleneck objective.
This optimization objective aims to preserve more
-relevant information in
Z while reducing the mutual information between
Z and
X. The hyperparameter
is used to control the relative importance of
and
. For a small
, more bits of information are flowing and less for a higher value.
In this paper, we focus on image transmission, hence employing a VAE for the image reconstruction task, the reconstructed image denoted as
.
is generated by the semantic decoder
. We optimize
by minimizing the MSE between
and
:
Considering
as a Gaussian signal, the AWGN channel capacity
becomes:
Under feature independence assumptions:
Letting
, we formulate the composite optimization objective:
The noise predictor model is optimized to minimize the loss function (
21). We use stochastic gradient descent to train the model parameters to search for the optimal parameters
with a minimal
as:
, where the expectation is taken over the training datasets. It should be noted that during the training process, the parameters of the semantic encoder and decoder are fixed, and only the parameters of the noise predictor are updated. The loss function (
21) is calculated through the original images, generated images, outputs of the semantic encoder, and outputs of the noise predictor.
This framework produces attribution results through the trained “noise power” predictor, specifically revealing the minimum channel capacity required to transmit each feature element in the AWGN channel while minimally impacting learning task performance. Defining the importance score , this metric indicates that higher importance features demand higher channel capacity. The importance score bridges learning task with communication objective, enabling rational communication resource planning that prioritizes high-importance features through enhanced resource allocation, thereby fully unleashing model potential.
3.2. Weighted Minimum Mean Squared Error (WMMSE)
As demonstrated in
Section 3.1, each feature possesses distinct importance scores. To ensure alignment between communication objective and learning task, features with higher importance scores require prioritized fulfillment of their communication demands through enhanced resource allocation.
Minimum Mean Squared Error (MMSE) serves as a statistical estimation criterion aiming to minimize MSE between estimated and true values. Widely adopted in channel equalization, multi-user detection, and MIMO signal detection, it constitutes an indispensable tool in communication algorithm design. For MIMO communication scenarios, we formulate the power allocation optimization problem based on MMSE as follows:
Despite the widespread application of MMSE, its optimization objective is solely anchored to communication goals, which complicates its integration with learning tasks. We, therefore, enhance the MMSE scheme by incorporating importance scores into the optimization objective, proposing the WMMSE formulation:
The hyperparameter
controls the magnitude of importance weights, with its value being empirically determined through systematic tuning.
Leveraging results from Equation (
14), the optimization objective (
24) simplifies to:
This leads to the refined optimization problem:
Introducing the Lagrange multiplier
, we construct the Lagrangian:
Setting
yields optimal power allocation for the
j-th subchannel during
i-th transmission:
Substitution into the constraint gives:
The resultant transmission MSE per symbol becomes the following:
WMMSE explicitly incorporates importance scores
, making MSE inversely proportional to both channel gain
and importance score
. This dual dependency ensures that high-importance features receive superior communication conditions, effectively aligning communication objectives with learning tasks. Additionally, since the optimization objective (
26) are inversely proportional to channel gains, we can introduce subchannel allocation to adjust the channel gain of each feature during transmission, thereby making the optimization objective (
26) as small as possible. To achieve this goal, we adopt the following subchannel allocation scheme:
Sort features by descending importance scores to obtain with . Given SVD-derived subchannel gains ordered as , we implement pairwise matching , establishing allocation configuration . This configuration minimizes the weighted optimization objective .
The WMMSE framework achieves systematic trade-offs between communication efficiency and learning performance by prioritizing high-importance features through joint power allocation and subchannel matching, thereby fully unleashing model inference potential. Even if the optimal subchannel allocation is not adopted, the introduction of the importance score factor can slightly counterbalance the effects of channel gain.
In our proposed scheme, compared with the JSCC approach, the channel coding is decoupled and implemented through SVD precoding combined with solving the WMMSE optimization problem. This design ensures that under given channel state information conditions, the channel coding scheme yields a unique closed-form solution. Consequently, our proposed SSCC framework can adapt to channel variations while keeping model parameters fixed, thereby enhancing the reusability of DNN models and effectively addressing channel adaptation challenges.
4. Experiments and Discussion
In this section, we present a comparative analysis of the resource allocation schemes outlined in
Section 3.2 and
Appendix B within a
MIMO communication scenario. Specifically, each element of the channel matrix
is modeled to follow a complex normal distribution, denoted as
. To quantify the signal quality, we define the average received SNR using the following formula:
We conduct experiments to demonstrate the impact of semantic importance scores. We investigate the effect of parameter
on attribution performance, and explore the configuration of parameter
in WMMSE. To evaluate the quality of the generated images, we adopt the PSNR metric. Simultaneously, we train an image classifier neural network termed the “evaluation model”, which classifies generated images to provide complementary quality assessment through classification accuracy. These experiments are conducted under various SNR scenarios using the MNIST dataset [
24], which comprises 60,000 training images and 10,000 test grayscale images of handwritten digits (0–9). Detailed information about the experiments can be found in
Appendix A.
4.1. Resource Allocation Schemes Comparison
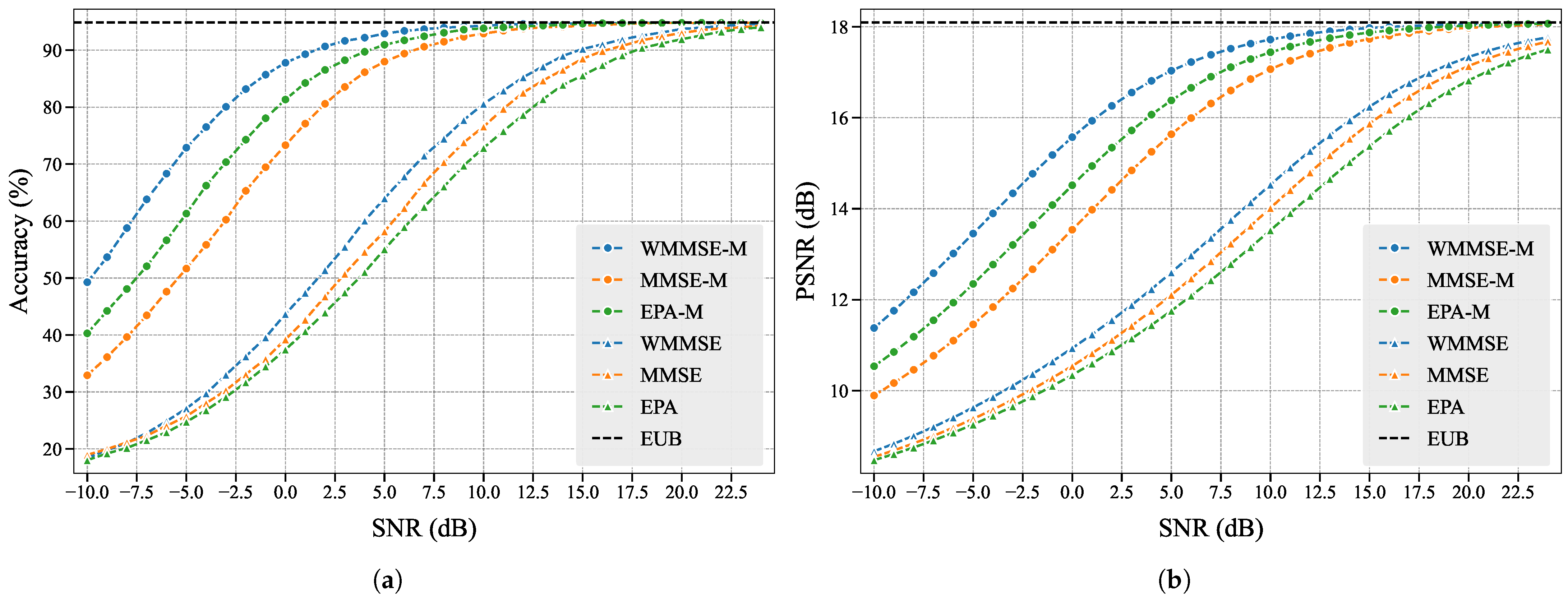
In the
Appendix B, we also introduce two baseline power allocation schemes named MMSE and Equal Power Allocation (EPA) that do not consider feature importance, along with their corresponding subchannel allocation strategies. Let WMMSE-M, MMSE-M, and EPA-M represent the proposed WMMSE, MMSE, and EPA with subchannel matching.
We experimentally test and obtain the Empirical Upper Bound (EUB) of the performance of the semantic encoder and decoder without communication processes. We use PSNR metrics and the evaluation model for comparative analysis of all six schemes.
As shown in
Figure 5, we observe that WMMSE-M achieves superior performance in both evaluation dimensions, and compared to other schemes, it maximizes the potential of the semantic encoder and decoder across various SNRs, which aligns with our design principles. The outperformance of WMMSE over MMSE and EPA stems from its incorporation of semantic importance scores to bridge learning tasks and communication objectives, whereas MMSE and EPA completely neglect learning task considerations. The enhanced performance of WMMSE-M, MMSE-M, and EPA-M compared to their counterparts demonstrates the effectiveness of our subchannel matching scheme: by assigning higher-importance features to channels with stronger gains, we ensure more accurate transmission of critical features, thereby improving learning task performance.
Notably, while EPA-M outperforms MMSE-M, EPA underperforms MMSE. This phenomenon reflects the amplified impact of channel gain variations in EPA-based schemes, consistent with our theoretical analysis in
Appendix B.2. These experimental results collectively validate that our proposed CIBA attribution method effectively evaluates importance levels of the features.
4.2. Semantic Importance Score Validation
In
Section 3.1, we know the noise predictor provides the maximum tolerable noise power
for each feature
, thus we can derive the importance score, denoted by
, for each feature
as:
The physical meaning of the importance score
can be understood as the required channel capacity for the feature
in an AWGN channel. When the actual channel capacity of
during communication falls below
, it will impact the performance of the deep learning task. To validate this perspective, after obtaining feature importance scores, we select a threshold
and designate features with
as important features, while those with
are considered unimportant. Regarding the selection of
, we will provide further details later. We posit that important features are more critical for model inference and exhibit lower tolerance to Gaussian noise perturbations, whereas unimportant features show the opposite behavior. To verify this hypothesis, we propose two perturbation modes as shown in
Figure 6: Perturbing High-Importance Features (PHIF) and Perturbing Low-Importance Features (PLIF). PHIF and PLIF, respectively, apply Gaussian noise perturbations to important and unimportant features. Under both perturbation modes, the perturbed features are fed into the semantic decoder to observe how changes in important versus unimportant features affect model inference.
We visually demonstrate the different impacts of high- and low-importance features by observing changes in generated images under these two perturbation modes.
Figure 7 presents three groups of comparisons between PLIF and PHIF when
is set to 3. The leftmost images in red boxes show the original input images, followed by generated results with progressively increasing Gaussian noise power (from left to right). We use the signal-to-noise ratio
between features and added noise to represent perturbation intensity. The upper three rows show PHIF perturbations, while the lower three rows show PLIF perturbations. Increasing progressively
, we observe that distortion in important features causes significant changes in generated images, whereas distortion in unimportant features has minimal impact on generated images.
Subsequently, we investigate the impact of two perturbation modes on the model’s performance under the dynamic change of
. Across a range of different importance score thresholds
, PHIF and PLIF apply Gaussian noise perturbations with a fixed
to important and unimportant features, respectively, resulting in distinct effects on model inference performance. The experimental results are shown in
Figure 8. It can be observed that, under both perturbation modes, the model inference performance begins to change when
. This suggests that features with importance scores
are more critical for model inference and exhibit lower tolerance to noise, requiring better transmission conditions. Thus,
can be a suitable threshold for separating important and unimportant features.
Furthermore, in the PHIF mode, where perturbations are applied to features satisfying , model performance gradually improves as increases because fewer high-importance features are perturbed. Similarly, in the PLIF mode, where perturbations target features with , model performance progressively deteriorates as increases, because more features of high importance are perturbed.
These experimental results demonstrate that low-importance features have negligible impacts on task performance, whereas high-importance features dominate model decision-making. High-importance features (which are fewer in quantity) preserve more critical information, exert greater influence on model decisions, and require better communication conditions for transmission. Therefore, incorporating considerations of feature importance is essential when designing resource allocation schemes in SSCC strategies.
4.3. Hyperparameter Selection
4.3.1. Hyperparameter Selection
The hyperparameter is determined through grid search to identify the optimal . We train our noise predictor under different values with identical training epochs, and evaluate the performance of the EPA-M scheme using predicted importance scores from different predictors on the same task. Since EPA-M’s learning performance solely depends on subchannel allocation results where features are only affected by channel gains, this setup effectively reveals the connection between communication resources and feature importance.
Figure 9 demonstrates the performance variation in the EPA-M scheme across different
values. Superior EPA-M performance indicates more accurate importance score predictions by the noise predictor. Experimental results reveal that when
, the EPA-M performance remains stable with satisfactory outcomes. However, as
increases beyond this range, excessive information flow constraints lead to significant dilution of task-relevant information, resulting in degraded prediction accuracy of the noise predictor and, consequently, diminished EPA-M performance. This empirical evidence suggests that setting
enhances the attribution effectiveness of the noise predictor.
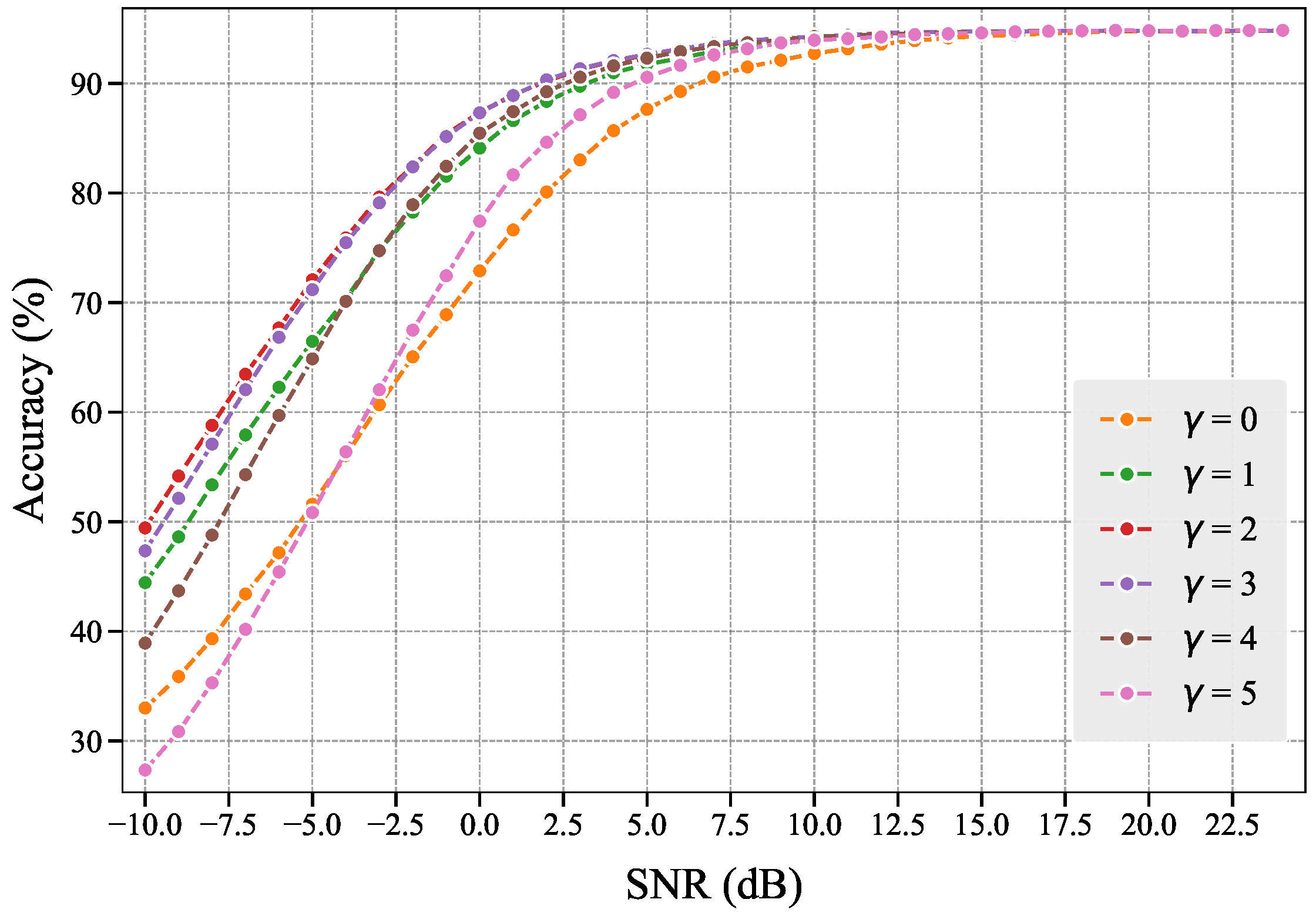
4.3.2. Hyperparameter Selection
Similarly, we determine the optimal hyperparameter
through grid search. We evaluate the performance of the WMMSE-M scheme under different
values, with experimental results shown in
Figure 10. Experimental results demonstrate that the WMMSE-M scheme achieves peak performance when
approaches 2, while values below or beyond this range degrade scheme performance. When
, the influence of
is eliminated, and WMMSE-M becomes equivalent to the MMSE-M scheme. When the value of
is excessively large, due to limited allocatable communication resources, the highest-importance features may be allocated more communication resources than required, thereby preempting the resources intended for secondary-importance features. This ultimately leads to performance degradation of the entire communication system in learning tasks. Therefore, selecting an appropriate
is crucial in importance-aware resource allocation schemes.
4.4. Extension to Classification Task
The proposed SSCC semantic communication framework can construct semantic encoders and decoders using different deep learning models, thus the framework is not limited to image reconstruction task and can be extended to other applications. To validate this capability, we select a deep learning model for the image classification task to build the semantic encoder and decoder, with model parameters detailed in
Table A2. The experimental setup is consistent with that in
Section 4.1, and we use classification accuracy as the evaluation metric. Experimental results shown in
Figure 11 demonstrate that our proposed WMMSE-M achieves the best performance, with schemes that incorporate subchannel matching outperforming those without. These findings confirm the applicability of our proposed method to image classification task, demonstrating that the proposed framework can be extended to classification task.
5. Conclusions
In this paper, we design and investigate an SSCC framework for semantic communication to address the pain points in JSCC design: low model reusability and channel adaptation issues. We propose a novel AI interpretability method called CIBA for VAE models, along with an importance-aware resource allocation strategy based on significance scores, to enable effective feature transmission in semantic communication systems and fully unleash the performance potential of semantic encoders and decoders. Through systematic experiments and analysis, we validate the effectiveness of the significance scores obtained by CIBA and their crucial role in bridging learning tasks and communication optimization. Comparative experimental results of two feature perturbation schemes (PHIF and PLIF) confirm the necessity of importance-aware resource allocation in semantic communication systems. By comprehensively comparing resource allocation schemes, we demonstrate that the importance-aware allocation scheme outperforms conventional approaches in learning task performance, highlighting the advantages of integrating importance awareness into communication resource management.
The proposed method opens up new possibilities for designing semantic communication systems, particularly in resource-constrained environments where intelligent resource allocation is crucial for maintaining semantic fidelity and task performance. Currently, our framework has only been validated on simple datasets, and future work will extend it to more complex datasets. While our CIBA interpretability scheme is currently specific to VAE models and simple communication scenarios (AWGN channels), future research should extend it to support more DNN architectures and sophisticated communication processes. Our importance-aware resource allocation scheme currently focuses on single-user MIMO power allocation and subchannel allocation, leaving the design of more complex resource allocation schemes for advanced communication scenarios as a valuable future work.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}