1. Introduction
Gaussian processes (GPs), as described by Rasmussen [
1], are interpretable and powerful Bayesian non-parametric methods for non-linear regression. A Gaussian process is a stochastic process in which any finite subset of random variables follows a multivariate Gaussian distribution. Using Bayes’ theorem, the posterior predictive distribution of a GP is the best linear unbiased estimator (BLUE) under the assumed model, offering accurate quantification of prediction uncertainty. GPs do not require restrictive model assumptions and can effectively capture complex linear and non-linear relationships. Although GPs are widely applied in practical settings [
2,
3,
4,
5,
6,
7], their cubic training complexity and quadratic prediction costs (concerning the training set size) restrict their scalability to large-scale data problems [
8].
The major computational hurdle for GP regression is the need to estimate the kernel inversion and determinant, which is prohibitively expensive when
n is large. Due to this issue, GPs are typically restricted to relatively small training datasets in the range of
. To reduce computational expense, sparse approximation techniques use a subset of the training sets (called inducing points) and Nyström approximation to estimate posterior distributions [
9,
10,
11,
12,
13]. In this case, this approach provides a full probabilistic model and appropriate predictions based on the Bayesian framework. Despite its advantages, this method cannot handle large datasets since its capacity is limited by the number of inducing points [
14,
15].
Unlike sparse approximation methods, which rely solely on inducing points, distributed Gaussian processes (DGPs) utilize the entire training set. This method employs centralized distributed learning, where the training data are divided into subsets, the local inference is performed on each subset independently, and the local estimations are aggregated through ensemble learning [
16,
17,
18,
19]. A local GP who specializes in a particular data partition is referred to as an expert. Sharing the same hyperparameters among experts contributes to implicit regularization and helps mitigate overfitting [
8,
20].
In a DGP, the conditional independence (CI) assumption between partitions (i.e., between experts given the target) allows the factorization of the global posterior distribution as a product of local distributions. Although this assumption reduces the computational cost, it introduces inconsistencies and leads to suboptimal solutions [
21] caused by the partitioning of the dataset, such that when
, the CI-based posterior approximations fail to converge to the full GP posterior.
Relaxing the independence assumption raises the aggregation’s theoretical properties. If the experts’ predictions are assumed to be random variables, their relative correlations define dependencies between experts. The aggregated posterior distribution, in this case, provides high-quality forecasts and is capable of returning consistent results [
22,
23,
24]. However, solutions that deal with the consistency problem suffer from extra computational costs induced by the need to find the inverse of the covariance matrix between experts for each test point. This means the complexity of this model cubically depends on the number of experts (say
M), and therefore it can become computationally prohibitive when
M is large.
Few works have considered boosting the efficiency of dependency-based aggregation. In [
25,
26], the authors discuss complexity reduction as an expert-selection scenario that excludes a subset of original experts and considers only the valuable experts in the aggregation. For this purpose, the precision matrix of the experts’ predictions is estimated using the Gaussian graphical model (GGM). Experts are the nodes in the obtained undirected sparse graph, and their interactions are the edges. The nodes with fewer interactions are defined as unimportant experts and excluded from the model. This approach can lower the complexity and provide a good approximation for the original estimator. However, it is not flexible concerning new entries, and the selected experts are fixed for all test points. If new entry data points have specific behavior or are close to excluded partitions, the prediction error increases.
The critical contribution of our work lies in selecting a subset of local experts for each new data point using multi-label classification. Unlike the static expert selection by GGM [
25], the proposed method does not assign a fixed set of local experts for all test points. A dynamic and flexible mechanism for each new observation designates related experts to provide local predictions. Multi-label classification [
27] is a generalization of multi-class classification, where multiple labels may be assigned to each instance. It originates from the investigation of the text-categorization problem, where each document may belong to several predefined topics simultaneously.
To transform the distributed learning case into a multi-label classification, the indices of the partitions or experts are the labels or classes. The objective is to assign specific experts to a new data point. A multi-class classification problem would select an appropriate expert for predicting and would lead to a local approximation with only one expert per test point. This one-expert inductive model, however, produces discontinuous separation boundaries between sub-regions and therefore is not a proper solution for quantifying uncertainties [
20,
28].
Two algorithms can be adapted to assign experts to data points: k-nearest neighbors (KNN) and deep neural networks (DNN). For the first one, we use the centroid of the partition as a substitute for the corresponding local expert. By estimating the distance between a new entry point and the centroids, we can find its K nearest neighboring experts. Due to the properties of the Gaussian process experts, if a test point is close to a GP expert, the expert can provide a reliable prediction for that test point.
For the second approach, we train a neural network with a soft-max output layer and log-loss (i.e., cross-entropy loss) using the train points and their related partition index that shows the partition they belong to. After training the DNN, we send a new test point through the network, and the experts with higher probability are assigned to this test point. Relative to consistent aggregation methods that use dependency information, our approach keeps all asymptotic properties of the original baseline and substantially provides competitive prediction performance while leading to better computational costs than other SOTA approaches, which use the dependency assumption. By extending the proposed method for CI-based ensembles, we can use it in federated learning problems, which do not consider dependencies between agents, see [
29,
30].
The structure of the paper is as follows.
Section 2 introduces the problem formulation and related works. The proposed model and inference process are presented in
Section 3.
Section 4 discusses some associated details.
Section 5 shows the experimental results, and we conclude in
Section 6.
3. Expert Selection in Local Approximation GPs
The current DGP baselines rely on weighting experts to quantify their importance. In [
8], the authors analyzed various weighting schemes for local experts and concluded that none outperformed the linear mixture weights based on experts’ correlations, as defined in (
7). However, despite the high accuracy of the NPAE aggregation, its computational cost poses a significant challenge for applying the method to large datasets.
Expert selections can improve the performance of dependency-based aggregation in two ways. First, unrelated experts for a given data point can be excluded and only informative partitions can be considered to make the prediction. Second, mitigating the number of experts reduces the prediction cost and enables the ensemble to be used in large datasets.
3.1. Expert Selection Using Graphical Models
The Gaussian graphical model (GGM) is the continuous form of pairwise Markov random fields. It assumes the nodes of an undirected graph are random variables, and the joint distribution of the random variables is multivariate Gaussian distribution with zero mean and precision matrix , . The elements of the precision matrix are the unknown parameters and show interactions between experts (edges in the graph).
Let
S be the sample covariance of local predictions
, i.e.,
. Then, the log-likelihood of the Gaussian multivariate distribution and precision matrix
is equal to
. To estimate the precision matrix, Graphical Lasso (GLasso) [
40,
41] is an efficient inference algorithm that maximizes this likelihood subject to an element-wise
-norm penalty on
. More precisely, the objective function is,
where the estimated expert network is then given by the non-zero elements of
.
Modeling the dependency in distributed learning by GGMs has been studied in [
24,
42], where the precision matrix encodes the interactions between experts. The authors in [
42] used the GLasso algorithm to detect dependencies between Gaussian experts and identify clusters of strongly dependent experts. In addition, expert selection by GGM has been proposed and investigated in [
25,
26], which divides the experts into important and unimportant experts and excludes the unimportant experts in the final aggregation. The strength of an expert’s interactions in the related undirected graph defines the expert’s importance.
Definition 2 (GGM-related Expert Importance). The importance of expert based on the estimated precision matrix is defined as .
According to the interactions, the GGM-related expert-selection task uses the first K experts in the descending sorted importance set
, leading to a new expert set.
and
. The number of selected experts is defined as
, where
is a hyperparameter that indicates the percentage of original experts selected for the final aggregation. The experts in
are fixed and used for prediction at any new entry point. The GGM-based aggregation can provide consistent results, and its predictive distribution is a consistent approximation of the unbiased estimator in (
7) [
25].
Figure 3 depicts the related GGM of local experts’ predictions. The
Concrete dataset in Example 1 is divided into 10 partitions, i.e., one for each expert, and the experts’ predictions are used to quantify interactions between experts in this graph.
Figure 3a presents the original GGM related to this distributed learning case.
Figure 3b shows an expert-selection scenario when only
of the experts are selected based on their importance. In [
25,
26], the authors studied this selection method in CI-based baselines and reported remarkable improvements over state-of-the-art aggregation approaches in terms of prediction quality.
Algorithm 1 summarizes the aggregation procedure with GMM-based expert selection. Its primary input is given by the local predictions, meaning that this selection method is employed after individual experts’ predictions. Therefore, it does not depend on the entry points. Indeed, based on the Definition 2, only absolute values of conditional dependencies are used for the importance calculation, i.e.,
, indicating that the importance is affected only by the amount of the dependency, and not its direction.
| Algorithm 1 Aggregating Dependent Experts Using GGM |
- Require:
Local predictions of GP experts , sparsity hyperparameter , selection percentage . - Ensure:
Aggregated estimator . - 1:
Calculate sample covariance S of experts’ predictions. - 2:
Estimate using GLasso ( 8). - 3:
Calculate the importance values - 4:
Sort the importance values to find as defined in Definition 2. - 5:
Select percent of most important experts. - 6:
Create the expert set for Aggregation, . - 7:
Aggregate selected experts using ( 7).
|
Although GGM-based expert selection provides an interpretable method, it suffers from two significant obstacles. First, it needs GLasso to obtain the precision matrix, and the cost of the GLasso is . Hence, for massive datasets with large M, its application is impractical. In addition, the algorithm is not flexible enough to capture the specific behavior of new data points because it provides a static method that selects a fixed set of experts for all test points. Even if an expert can provide accurate prediction for some part of the dataset, it will be excluded from the model if it does not have high interactions with the other experts.
In the following subsections, we propose a novel approach that estimates the essential (i.e., data-related) experts for each new test point by converting the problem into a multi-label classification. The obtained labels for each test point define the data-point-wise selected experts.
3.2. Multi-Label Classification for Flexible Expert Selection
Assigning experts to new entry points in a distributed learning model can be seen as a classification problem. Let us assume that each expert is a class of estimators. The selection problem then for each test point is defined as a multi-label classification task where each instance can be associated with some classes. The main advantage of this method is its flexibility because the selected experts depend on the given test point, and thus different experts can be assigned to different test points.
Assume is a new test point and is the Gaussian experts set, and is the label set. The task is to find which represents K selected experts to predict at . We adapt two prominent classification models to solve this multi-label task without requiring problem transformations, K-nearest neighbors (KNN), and conventional deep neural networks (DNN).
Example 2 (Expert-Selection Models). Let us consider an example with five local experts that predict at 10 test points and . Figure 4 describes the difference between static and dynamic expert-selection models in an example with synthetic data points. Figure 4a depicts the original aggregation where all experts are used, e.g., for the ensemble model in (7). The GGM-based expert selection in Figure 4b proposes a fixed set of 3 experts for all new (i.e., 10) entry points even though they do not provide appropriate predictions in some of these 10 test points. The flexibility of the entry-based selection model is depicted in Figure 4c, where the model assigns different experts to each test point and uses the ability of experts in a better way. 3.3. Adopted K-Nearest Neighbors (KNN)
The K-nearest neighbors algorithm [
43] is a lazy, non-parametric classification approach that uses proximity to classify an individual data point. It is a supervised machine learning algorithm, working off the assumption that similar data points are located near one another. Here, we adopt this algorithm for the assignment of experts in a distributed learning scenario such that the raw training dataset is not needed for the selection process and only the partitions’ information is used.
Let be the partitions based on a disjoint partitioning strategy, i.e., K-Means clustering. Also, assume contains the related centroids of the clusters in . For each test point , there is a vector , in which the ith element is the distance between and , where is a distance metric. Therefore, the adopted KNN algorithm is defined as:
Calculate the distance between and the centroids ;
Choose K experts with centroids closest to ;
Return based on the selected experts.
To determine which experts/partitions are closest to a given query point, the distance between the query point and the other data points will need to be calculated using a distance metric. The distance metric helps to form decision boundaries, which partition test points into different subsets/experts. Several distance measures can be chosen, e.g., Euclidean, Manhattan, Minkowski, and Hamming distances. In this work, we use the conventional Euclidean distance.
The value of
K in the KNN algorithm defines how many clusters will be checked to determine the classification of a specific entry point. For example, if
, the instance will be assigned to the same class as its nearest cluster, which due to discontinuity issues, is not the desired case. Lower values of
K can have high variance, but low bias and larger values of
K may lead to higher bias, and lower variance [
44].
Figure 5 schematically shows how the KNN method works for the multi-label classification methods. It represents a KNN framework for a test point
. The red points are related training points assigned to each partition, and the blue points are the clusters’ centroids. The lines between the
and the centroids show the distances. The proposed method suggests the orange lines, which are the shortest, and the related experts are assigned to this test point.
Algorithm 2 summarizes the whole procedure of the KNN-based aggregation. The main advantage of the KNN method is that it does not include another training period. The only thing to be calculated is the distance between different points; therefore, it is straightforward to implement and accept new entry data at any time. In addition, instead of
n training points, the modified KNN proposed in Algorithm 2 only uses the
M centroids and scales the distance calculations in large datasets.
| Algorithm 2 Aggregating Dependent Experts Using KNN |
- Require:
Test point , centroids set , hyperparameter K, Local GPs moments, distance metric. - Ensure:
Aggregated estimator - 1:
Calculate distance vector for , i.e., . - 2:
Sort the elements of ascendingly. - 3:
Select the first K experts in the sorted list of expert distances to generate the set of related experts . - 4:
Estimate local GPs by the experts in using ( 2) and (3). - 5:
Aggregate local predictions from Step 4 using ( 7).
|
Generally, this selection method is defensible and justifiable because Gaussian processes predict better when a test point is close to them. Since the distance-based solution may have some drawbacks in high-dimensional datasets, we propose another multi-label classification solution in the next section that can be effective in high-dimensional cases.
3.4. Adapted Neural Networks for Classification
Conventional deep neural networks (DNNs) are widely used in machine learning problems, especially in classification tasks [
45,
46]. By converting the expert-selection task into a multi-label classification task, this supervised learning problem can be solved through DNNs. The capability of the neural networks can compensate for the possible weaknesses of KNN classifiers in dealing with high-dimensional datasets and underlying dependencies between labels.
Multi-label classification can be supported directly by neural networks simply by specifying the number of target labels in the problem as the number of nodes in the output layer. We will define a Multi-Layer Perceptron (MLP) model for the multi-label classification task described in
Section 3.2. The network requires an input layer that expects
D inputs to specify the dimension of
X,
H nodes in the hidden layers, and
M nodes in the output layer, indicating the number of experts. Each node in the output layer must use the
softmax or
sigmoid activation to predict the label’s class membership probability. Finally, the model must fit with the binary cross-entropy loss function and the Adam version of stochastic gradient descent.
To consider the expert-selection task as a multi-label classification, a label set contains required classes related to the training dataset. For each , , the related partition label is available as an output of the training step in DGP. Therefore, instead of the original training set , a new set of points and labels is constructed for training the DNN. After that, for each test point the network will provide a probability vector where represents the probability that belongs to the j’th expert. The K partitions with highest probabilities in are assigned to . This procedure is concisely presented in Algorithm 3 for clarity.
Figure 6 depicts a simple network for a multi-label classification task that assigns local approximation Gaussian process experts to new entry points. The network receives the training set
X as input and their clusters’ indices as output. After training the network, test points
are sent to the neural network, which returns the classifier’s raw output values.
Figure 7 depicts the prediction quality of expert-selection methods on the
Concrete dataset with 10 partitions for different values of
K. As can be seen, multi-label-based expert-selection models provide higher quality predictions with lower deviation from the NPAE model. The quality of the classification-based aggregations changes less as the selection parameter
K increases. The case
leads to the original NPAE baseline (the dashed green lines in
Figure 7a,b), and both KNN and DNN return proper error values in both plots.
| Algorithm 3 Aggregating Dependent Experts Using DNN |
- Require:
Test point , training points X and their indices, index set , hyperparameter K, Local GPs moments. - Ensure:
Aggregated estimator - 1:
Train the network parameters using X and indices. - 2:
Return the classifier’s output values , i.e., as produced by the softmax layer. - 3:
Sort the elements of descendingly. - 4:
Select the first K indices of the sorted . - 5:
Create the expert set for , . - 6:
Estimate local GPs by the experts in using ( 2) and (3). - 7:
Aggregate local predictions from Step 6 using ( 7).
|
4. Discussion
This section considers some specific aspects of the expert-selection models.
4.1. Restrictive Assumptions
The GGM approach assumes that the nodes in the graph are random, and their joint distribution is Gaussian. This normality assumption leads to a Gaussian likelihood, and GLasso solves this optimization problem. This assumption is strong, and in some cases, it can be restrictive. Various solutions have been proposed to relax this assumption by considering the model as a nonparametric problem and solving after some smooth monotone transformation [
47,
48,
49,
50] at the cost of requiring higher time complexity. On the other hand, expert selection using multi-label classification does not need any distributional assumption. Therefore, it can be used as a general expert-selection method in distributed/federated learning models, and not only in the context of local approximation of GPs.
In addition, the classification-based expert allocation can also be considered a self-attention mechanism that implicitly captures relationships between data points. Recently, the explicit modeling of self-attention between all data points has been shown to boost the classification performance [
51,
52]. In our case, to explain the dependencies between training and test points, the expert ensembles do not use the original training points. Instead, the final prediction benefits from the critical information of training data captured by the partitions‘ centroids and the corresponding indices for KNN and DNN, respectively.
4.2. Computational Costs of Expert-Selection Models
The aggregation cost in all three selection methods, i.e., GGM, KNN, and DNN, is where K is the number of selected experts and is the number of test observations. However, their selection strategies lead to different computational costs. GGM in Algorithm 1 needs GLasso to estimate the precision matrix, and its computational cost is , where M is the number of initial experts and is challenging for large M. Indeed, the sparsity parameter can affect the cost such that choosing a smaller value for leads to a dense graph with a more considerable computational cost.
The cost of the KNN Algorithm 2 is obtained by considering the cardinality of the training set, which refers to the number of possible labels that a feature can assume, in our case M, the dimension of each sample, i.e., D, and also the hyperparameter K. The computation time for calculating the distances is usually negligible compared to the rest of the algorithm. However, we consider this aspect as well in the overall cost estimation. Algorithm 2 computes the distance between the new observation and each centroid point, requiring work for an iteration and therefore work overall to select K closest centroids.
The cost of the DNN approach in Algorithm 3 depends on the network structure, i.e., the number of layers L, the input dimension D, the output dimension M, and the number of hidden units. Let represent the number of units in the i’th layer (), where and represent the number of units in the input and output layers, respectively. The computational complexity is thus .
In conclusion, both methods described in Algorithms 2 and 3 have linear complexity concerning M. Therefore, they are more efficient when the number of partitions is an enormous value, unlike the cubical dependency in Algorithm 1.
4.3. Activation Functions in DNN
Using a
softmax output layer for the DNN-based classification in
Section 3.4 leads to a probability vector
of the output values. Hence, when the probability of one class increases, the probability of at least one of the other classes has to decrease by an equivalent amount. Since the labels represent the interdependent experts, using the
softmax function for the classification layer is reasonable.
Figure 8 explains how different activation functions can affect the prediction quality. It considers the
Concrete dataset with
and different mini batch sizes
. Both activation functions
softmax and
sigmoid have been used to select
and
experts. The quality of the related aggregations confirms that due to the interaction between labels, the
softmax activation leads to much better results, and its sensitivity to the size of the mini batches is lower than for the
sigmoid activation.
4.4. Expert Selection for CI-Based Baselines
In [
25], the authors extended the GGM-based expert selection for CI-based ensembles. They introduce an extra step aiming to exclude the unimportant experts from the model before using the weight parameters
. The same procedure can be used for entry-based expert-selection methods. In this case, for a test point
in (
4), only
K experts are used, and the selection is based on Algorithm 2 or Algorithm 3. Since these models are fast, the selection parameter
K can also be set to relatively large values.
Table 1 describes the effect of the selection scenario on CI-based ensembles using KNN on the
Concrete dataset with
and
. Although this modification cannot improve the asymptotic properties of the baselines, it raises their prediction quality. At the same time, the running times of both original and modified models are indistinguishable.
5. Experiments
The quality of the expert-selection methods is assessed in this section. We consider the prediction quality and the required prediction time of the proposed and state-of-the-art distributed GP models using both simulated and real datasets. The quality of predictions is evaluated by the standardized mean squared error (SMSE) and the mean standardized log loss (MSLL). The standard squared exponential kernel with automatic relevance determination and a Gaussian likelihood is used. Since the disjoint partitioning of training data captures the local features more accurately and outperforms random partitioning [
25,
31], it is mainly used in our experiments. The sparsity parameter in the GGM-based expert-selection method is set to
,
Euclidean norm measures the distances in KNN, and a neural network with a single hidden layer is used for the DNN classification. The experiments were conducted in MATLAB R2022b using GPML package:
https://www.gaussianprocess.org/gpml/code/matlab/doc/ (accessed on 10 March 2022).
5.1. Sensitivity Analysis
In this section, we investigate the influence of hyperparameters on the prediction quality and computational cost of the proposed methods and available baselines. First, we consider the aggregations of dependent experts with the selection step using a synthetic one-dimensional dataset. Then, we use a medium-scale real-world dataset to study how hyperparameters affect the results in a complex multi-dimensional dataset.
5.1.1. Synthetic Example
The first experiment evaluates the effect of hyperparameters
M and
K on prediction quality and computation time in different selection scenarios. It is based on simulated data of a one-dimensional analytical function [
31],
where
. We generate
n training points in
, and
test points in
. The data are normalized to zero mean and unit variance. We vary the number of experts to consider different partition sizes. The
K-means method is used for the partitioning to compare the prediction quality of the proposed selection methods with other baselines. Since the quality of CI-based methods is low, they are excluded in these experiments.
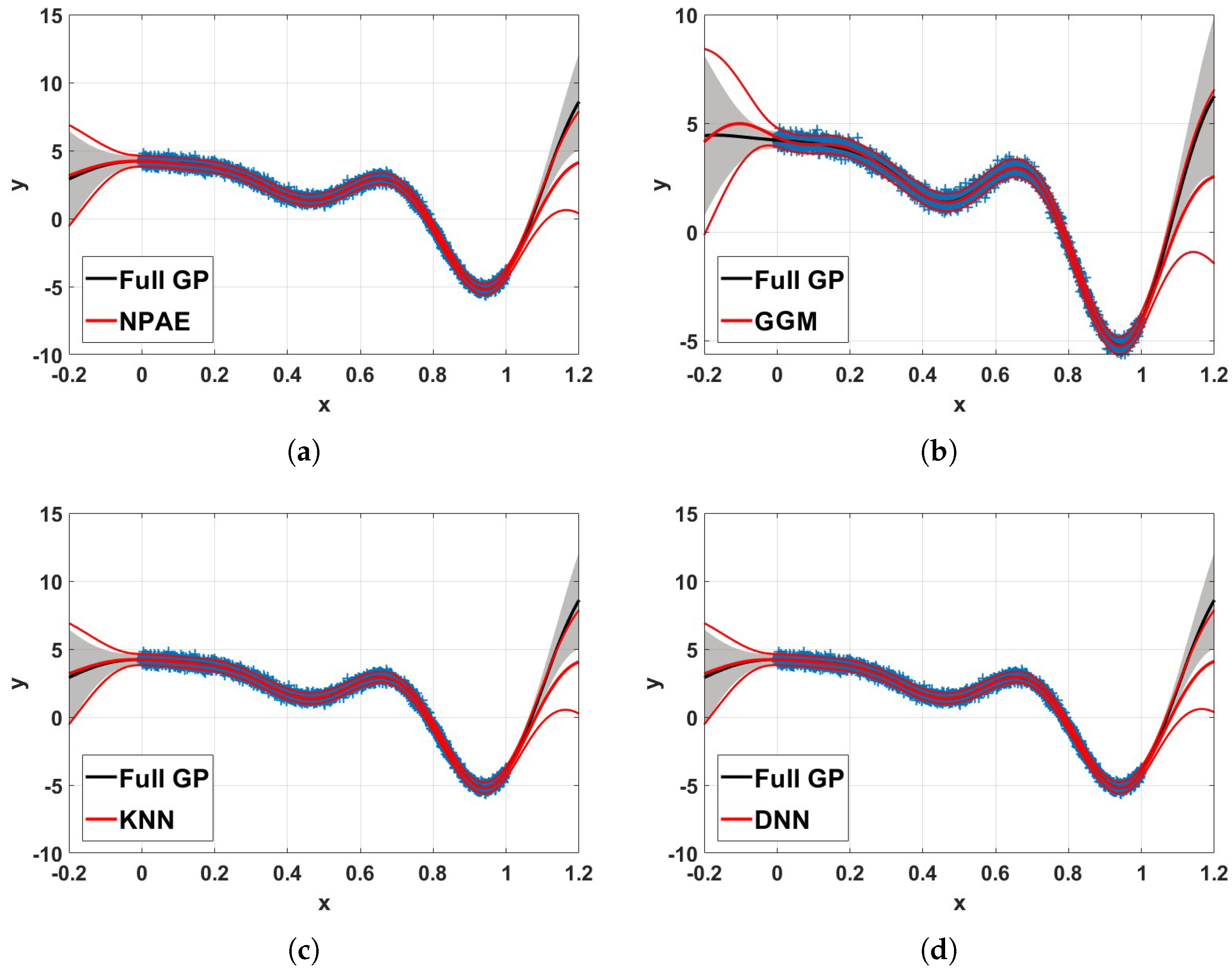
Figure 9 depicts the 99% confidence interval of NPAE, expert selection based aggregations, and the full Gaussian process. In the experiment,
training data points from Equation (
9) are used. The training set is divided into
partitions, i.e., partition size
, with K-means clustering, and
agents are used for the final prediction. The confidence intervals of KNN and DNN are closer to the original baseline NPAE, and their predictions (mean of the predictive distribution) are close to the full GP. For test points out of the training set domain, the multi-label classification leads to accurate expert-selection results; see, for example, the interval
in the GGM plot, which shows a significant deviation from the standard GP.
Figure 10 depicts the prediction quality of expert-selection methods compared to NPAE for
training points and partition size
(i.e., ten experts) with
K-means partitioning. The x-axis shows the number of selected experts (
K) used in the final aggregation. We vary the number of selected experts for selection methods and use the NPAE as a baseline that refers to
. The plots in
Figure 10a,b indicate that multi-label classification leads to a selection strategy with fast convergence to the original estimator.
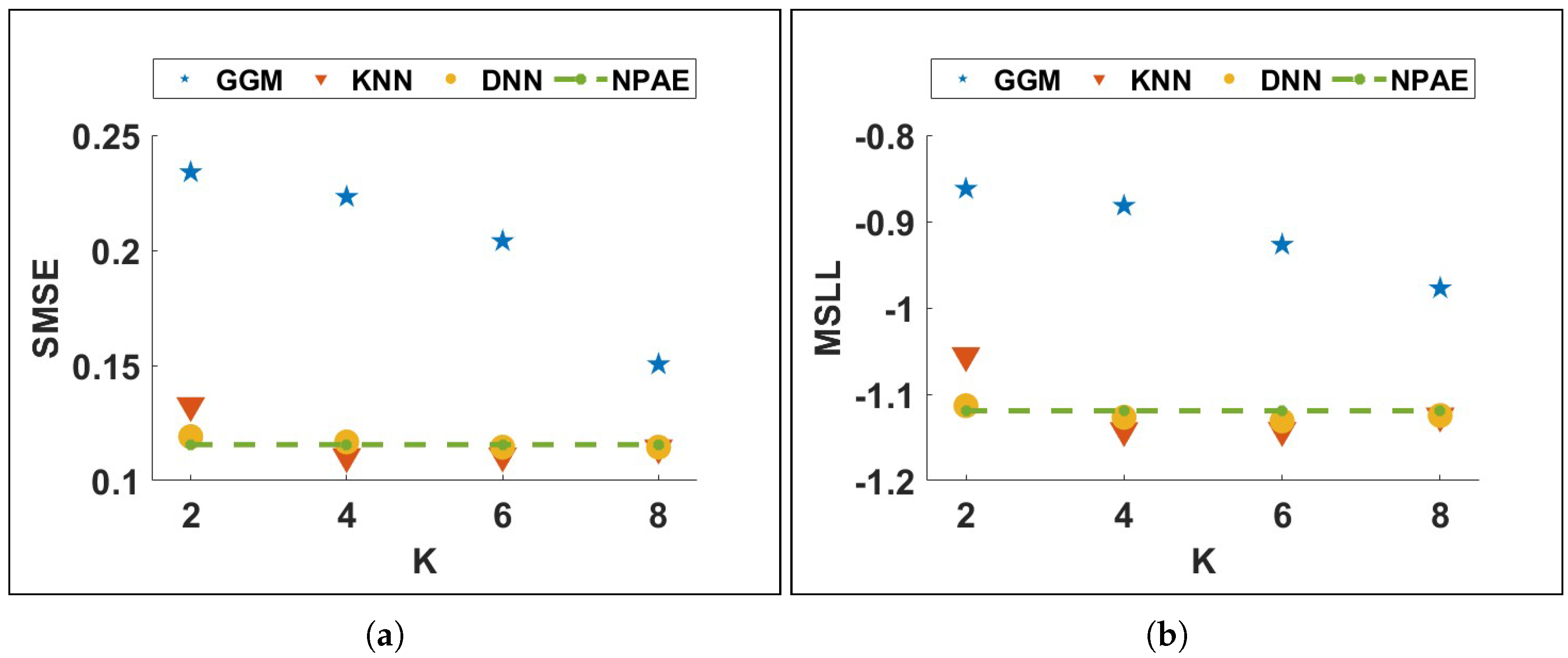
When the number of experts increases, the prediction errors of KNN and DNN do not show significant changes, indicating predictive stability. On the other hand, GGM needs more experts to provide closer results to NPAE and has a slow convergence procedure. For
, the error values of all three methods are almost the same.
Figure 10c indicates that the computational costs of the aggregations based on GGM, KNN, and DNN are at the same rate.
We evaluate the prediction quality of the expert-selection methods using
and
training points and different numbers of experts,
. All related baselines are used in this experiment with
selected experts.
Figure 11 depicts the results of both generated samples. KNN and DNN aggregations in both samples have remarkable prediction qualities, and their SMSE and MSLL values are close to each other, which means both classification methods return almost similar results.
On the other hand, when the ratio of the selected experts to the total number of experts
decreases, the prediction quality of GGM-based models decreases drastically. For instance, in
Figure 11a, the differences between SMSE values of
GGM-3 and
GGM-5 at
are almost twice the SMSE at
. Indeed, GGM requires more experts to provide qualitative predictions, and the difference between the SMSE and MSLL of
GGM-3 and
GGM-5 indicates this fact. At the same time, the quality of KNN and DNN does not change significantly when
K increases from 3 to 5.
Figure 11e,f show the baselines’ running time considering the dependencies between experts. All expert-selection-based aggregations have the same prediction process (of
), and their difference is only in the selection task. Besides enhancing the number of selected experts, K increases the computational cost of selection methods because it raises the prediction cost
, see
Section 4.2. In these experiments with smooth 1D data points, the running times of the GGM, the KNN, and the DNN are of the same rate.
5.1.2. Multi-Dimensional Real-World Dataset
The relative number of experts
defined in
Section 5.1.1 indicates the percentage of the initial experts selected to be used in the final predictive distribution. In this section, we use a medium-scale real-world dataset and
to appraise the efficacy of the data-assignment strategy on the prediction quality.
Pumadyn (
https://www.cs.toronto.edu/~delve/data/pumadyn/desc.html, accessed on 10 March 2022) is a generated dataset with 32 dimensions and 7168 training points and 1024 test points. The disjoint partitioning divides the dataset into 10, 15, and 20 subsets. We considered the GPoE [
8], GRBCM [
31], NPAE [
22], GGM-based aggregation [
25], and proposed classification-based methods with K-means clustering. The penalty term
is 0.1 for GGM, and a neural network with a single hidden layer and 50 hidden units is used in this experiment.
The expert-selection approaches based on GGM, KNN, and DNN use
and
, which means
and
of available experts are selected, respectively.
Table 2 depicts the prediction quality of local approximation methods for the
Pumadyn dataset. The column Type shows the interactions between experts in the aggregation method, D for dependent experts, and CI for conditionally independent experts.
GGM-5,
GGM-7,
KNN-5,
KNN-7,
DNN-5,
DNN-7, and NPAE are the dependency-based methods, while
GPoE and
GRBCM are CI-based aggregations. The numbers after the names of the methods indicate the ratio. For instance,
KNN-5 and
KNN-7 refer to KNN with
and
, respectively.
NPAE is a basis for comparison because it is the best linear unbiased predictor (BLUP). The multi-label classification methods provide accurate results, and their derivatives with and are close to the NPAE. This performance shows the fact that convergence occurs faster in these methods. However, the proficiency of the GGM method is sensitive to the number of agents and has more deviation from the NPAE when is small. Both KNN and DNN with of the experts return appropriate approximations. They offer a significant improvement in prediction quality when , and for , they outperform the BLUP baseline, i.e., the NPAE method. This happens because the selection step properly excludes only weak experts at each test point.
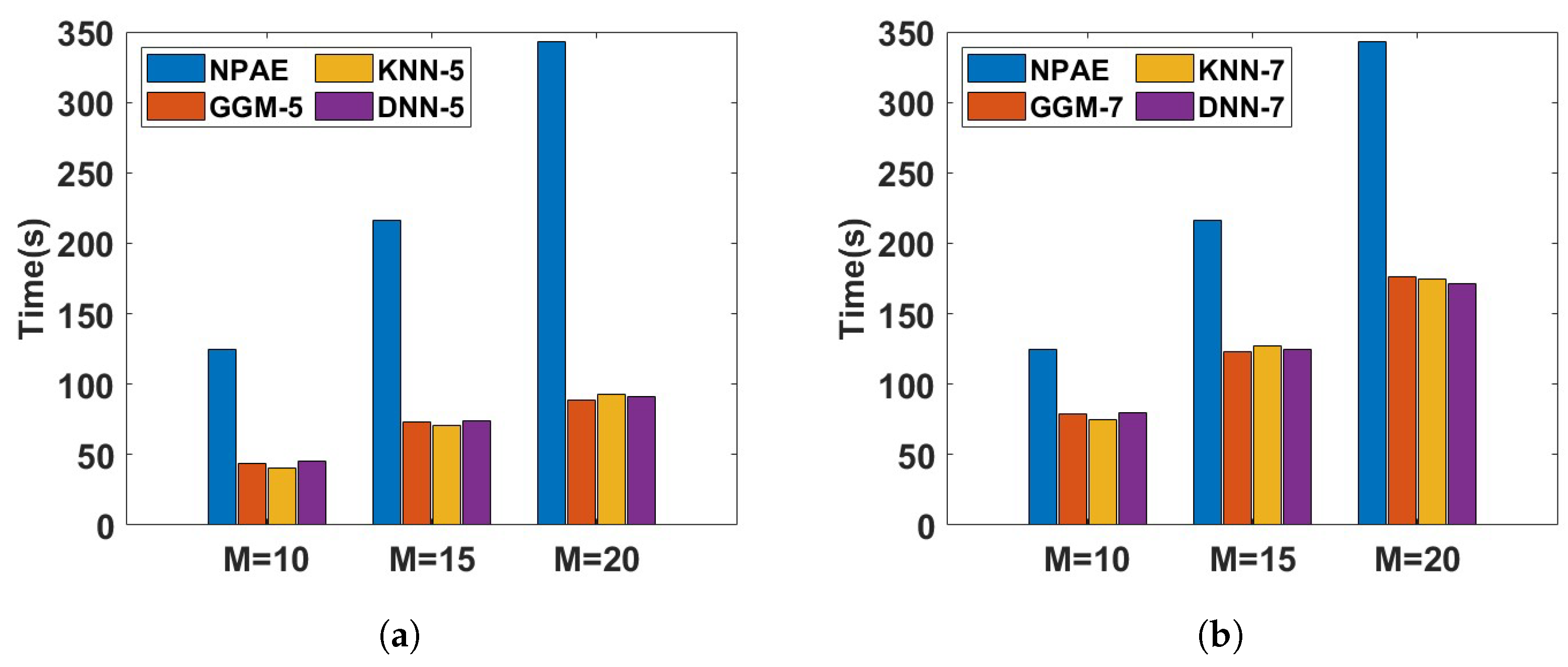
Figure 12 depicts the running time of different aggregations with dependent experts for the
Pumadyn dataset. The training dataset is divided into
partitions, and the prediction time of the related baselines is compared in two different cases, with 50% and 70% of original experts. In both cases, the NPAE method is used as a baseline that uses all dependent experts. Based on the plots, the prediction times of GGM, KNN, and DNN are almost at the same rate. However,
Table 2 shows that GGM cannot provide competitive prediction quality compared to the other selection methods. For instance, the SMSE and MSLL values of
DNN-5 for all values of
M are lower than those of
GGM-5 and
GGM-7. This issue is also confirmed by
Figure 10 and
Figure 11. The main reason for this issue is the low convergence rate of the GGM, which requires more experts.
5.2. Prediction Quality in Real-World Datasets
In this section, we use real-world datasets to evaluate the prediction quality of proposed aggregations and compare them with available baselines. The baselines that we use here are GPoE with uniform weights [
8], RBCM [
8], GRBCM [
31], NPAE [
22], GGM-based aggregation [
25], KNN and DNN-based ensemble methods. Various real-world datasets with different sizes and dimensions are used here, as explained in
Table 3.
We divide the observations in Airfoil, Parkinson, and Protein into training and test sets by extracting of the sample as training and the rest as test points. In the other datasets, there are predefined training and test sets. Indeed, in the Song dataset, we extract the first songs from this dataset for training and the first songs from the original test set for testing. We used disjoint partitioning (K-means) to divide the datasets into 5 (for Airfoil), 10 (for Parkinson and Pole Telecom), 70 (for Protein), 72 (for Sacros), and 80 (for Song) subsets.
Next, we compare SOTA baselines with classification-based aggregations. For the selection-based methods, we set to , which means of experts are selected. For the Song dataset only, we set . Since NPAE is computationally burdensome, especially when M and are large, it is only used in small- and medium-scale datasets. DNN uses a neural network with a hidden layer and 50 hidden units to evaluate the labels.
Table 4 and
Table 5 reveal the SMSE and MSLL values of the baselines. Selecting the experts enables us to encode dependency between agents efficiently while the prediction quality is comparable with the original baseline NPAE. However, their running times are acceptable, especially when dealing with high-dimensional large datasets where using the NPAE is not feasible. In addition, the convergence rate of KNN and DNN is much faster than GGM. Even with 50% of experts, the results of the GGM still have a remarkable deviation from NPAE and cannot provide relevant results in the different datasets.
We consider the
Parkinson dataset as an instance. GGM cannot provide accurate predictions when
. Our experiments confirm that increasing
to
for GGM reduces the SMSE to
and MSLL to
which are close to the SMSE and MSLL of NPAE. This indicates that GGM converges to NPAE, but the convergence is slower than KNN and DNN. Meanwhile, the SMSE values of the KNN and DNN methods for
are
and
, respectively, and (the MSLL values of the KNN and DNN methods for
are
and
, respectively). Therefore, by including more experts in the final aggregation, KNN and DNN can outperform the NPAE by excluding the effects of low-quality experts in Equation (
7).
On the other hand, a comparison of the running times of the aggregation methods confirms the results presented in
Section 5.1. Consider the
Pole Telecom dataset. The logarithm of the prediction times (in seconds) was calculated for
. The NPAE method recorded a logarithm of 3.31, while GGM, KNN, and DNN yielded logarithms of 2.66, 2.42, and 2.41, respectively. These values indicate that NPAE has the longest running time in logarithmic terms, followed by GGM, KNN, and DNN in decreasing order. However, as previously discussed, GGM requires more experts to achieve higher prediction quality and therefore requires additional time to match the performance of KNN and DNN.
In CI-based methods, the conservative GPoE does not return acceptable results and cannot outperform RBCM and GRBCM methods. The quality of the GRBCM is slightly better than RBCM because of the global communication expert. The global expert improves the quality measures of GRBCM compared to RBCM, especially in MSLL, where the values are always smaller than those of RBCM. Both methods provide competitive results with GGM when . However, their deviation from NPAE, KNN, and DNN is remarkable. Indeed, by increasing the GGM can easily outperform them.
6. Conclusions
In this work, we propose a novel expert-selection approach for distributed learning with Gaussian agents, leveraging expert selection to aggregate the predictions of dependent local experts. Existing ensemble baselines incorporate all correlated experts during the aggregation step, which can negatively impact final predictions due to the influence of weak local experts or result in impractically high computational costs.
Our proposed approach employs a multi-label classification model, where data points are allocated to experts treated as class labels. Unlike existing expert-selection methods, which assign a fixed and static set of experts to all new data points, the proposed model adapts to changes in the model and data by selecting a relevant group of experts for each input. Excluding unrelated experts for each test point enhances prediction quality and reduces computational costs. Additionally, the approach retains the original baseline’s asymptotic properties, ensuring consistent results as .
The classification methods used in this work, such as KNN and DNN, can be replaced with newer and more efficient solutions for addressing the multi-label classification problem. The proposed approach is applicable to both distributed and federated learning and imposes minimal assumptions. Empirical analyses demonstrate the superiority of our approach, which enhances the prediction quality of existing SOTA aggregation methods while maintaining high efficiency.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}