1. Introduction
The Pareto distribution was originally introduced by the Italian economist Vilfredo Pareto in his seminal work on economics, where it was used as a model for income distribution [
1]. Pareto observed that a small proportion of the population tends to control the majority of wealth—a phenomenon commonly referred to as the “80/20 rule”, meaning that 20% of people own 80% of the income. Since then, this heavy-tailed distribution has been widely applied in fields such as economics, finance, and risk management [
2], particularly for modeling phenomena characterized by significant inequality or extreme outcomes. Examples include modeling stock return distributions [
3] and the extreme tails of financial and insurance loss datasets [
4]. The classical Pareto distribution, often referred to as the Pareto Type I distribution, is defined by a skewed heavy-tailed model:
where
is the scale parameter, typically representing the minimum income in income models, and
is the shape parameter, commonly referred to as the Pareto index. The Pareto index
serves as a measure of inequality, with larger values indicating more equitable distributions. For income analysis, the Pareto index typically fluctuates around 1.5 [
5].
While the Pareto Type I distribution performs well in modeling the income of high-income groups, it often fails to capture income distributions across the entire population. To address this limitation, economists and statisticians have extended the Pareto distribution by introducing additional flexibility through the location parameter
and inequality parameter
, resulting in the development of Pareto Type II, III, and IV distributions [
6]. These generalized Pareto distributions have found broader applications. For instance, the Pareto Type II distribution is used for flood modeling and rainfall analysis [
7], the Pareto Type III distribution is commonly applied to earthquake intensity modeling [
8], and the Pareto Type IV distribution is employed in insurance risk analysis [
9].
In statistical research, most studies on the Pareto family focus on data modeling and statistical inference. A major challenge in statistical inference lies in the complex expressions of the generalized Pareto family. Parameter estimation for the Pareto family often involves significant computational effort due to the lack of closed-form expressions for methods such as moment estimation (ME) and maximum likelihood estimation (MLE). Additionally, there has been a lot of research focus on the performance of parameter estimation in small samples and the robustness of these estimates [
10,
11,
12]. In practical data modeling, it is often necessary to discretize continuous data into discrete models while retaining the desirable properties of continuous distributions. For example, Ghosh [
13] proposed a discrete version of the Pareto IV distribution derived from rounding continuous random variables to improve the accuracy of lifetime modeling.
In this paper, we focus on the discretization of the Pareto family under the minimum mean squared error (MSE). In statistics, for a given continuous distribution, we can identify optimal discrete approximations, referred to as representative points (RPs), based on different kinds of errors. Different error metrics yield different types of RPs, such as mean squared error representative points (MSE-RPs) [
14], Monte Carlo representative points (MC-RPs) [
15], and quasi-Monte Carlo representative points (QMC-RPs) [
16]. Among these, MSE-RPs are the most widely used, as they demonstrate superior performance over other RPs in distribution fitting [
15].
MSE-RPs were initially applied to optimize signal transmission [
17]. Since signal distortion in transmission is defined as the expected squared error between the quantizer input and output, which aligns with the MSE-RP criterion, Max successfully applied it to minimize signal distortion using quantizers with fixed output levels [
18]. Fang and He [
14] further advanced the computation and applications of MSE-RPs. Subsequently, MSE-RPs have been widely studied and applied in various fields, including clothing standardization [
14], determining optimal sizes and shapes for protective masks [
19], signal and image processing, information theory [
20], psychiatric classification [
21], statistical inference using resampling techniques [
22], and reducing variance in one-dimensional Monte Carlo estimations [
23]. They have also been utilized in parameter estimation, such as using MSE-RPs from the gamma distribution as standard samples to improve parameter estimation accuracy [
24].
The majority of existing studies on MSE-RPs have focused on univariate continuous distributions, such as normal, exponential, gamma, Weibull, logistic, and mixed normal distributions. However, no studies have been conducted on MSE-RPs derived from Pareto distributions. Owing to the complexity of Pareto density functions, the study of MSE-RP generation and estimation presents significant challenges. Current studies propose two main approaches to generate MSE-RPs for continuous distributions. The first approach relies on the self-consistency property shared by MSE-RPs and k-means cluster centers, which has led to the development of k-means-based algorithms for generating MSE-RPs. This method was initially proposed by Lloyd [
25] and Max [
18], and is referred to as the Lloyd I algorithm, specifically designed for univariate continuous distributions. To mitigate the impact of initial values and training sets on MSE-RPs, Linde et al. [
26] proposed an iterative algorithm, referred to as the LBG algorithm. Fang et al. [
27] later developed an enhanced version of the LBG algorithm, employing number-theoretic methods to generate initial points and training sets, which is referred to as the NTLBG algorithm. The second approach derives from the definition of MSE-RPs, with the objective of finding a discrete distribution that minimizes the MSE between it and the density function. This involves solving a series of equations for obtaining the MSE-RPs, a method referred to as the Fang–He algorithm [
14]. Compared to k-means based methods, the Fang–He algorithm offers greater accuracy in the computation of MSE-RPs. However, it requires verifying the convergence of the algorithm, which needs to be addressed separately for each specific distribution.
In practical applications, it is often necessary to optimally discretize continuous data, which involves estimating the MSE-RPs of the underlying continuous distribution that the data follow. Tarpey [
28] proposed four methods for estimating the MSE-RPs of univariate continuous distributions: maximum likelihood estimation, semi-parametric estimation, quantile estimation, and the k-means algorithm. Subsequent research has expanded these methods. For instance, Matsuura et al. [
29] developed an optimal estimation approach for the t-distribution and extended it to the location–scale family and multivariate distributions. In the case of the Pareto distribution, we primarily study the latter two methods for estimating MSE-RPs.
The Pareto distribution is a right-skewed distribution, where the estimation bias of the quantiles at the tail is relatively large. Consequently, when using the quantile method to estimate the MSE-RPs located in the tail, the bias will also be significant. Similarly, due to the smaller number of samples in the tail, the k-means method also introduces substantial bias. The inaccurate estimation of MSE-RPs in the tail increases the bias of the overall estimate. In fact, the amount of information contained in the MSE-RPs at the tail is very limited. This information can be quantified using information gain (IG), which has been applied to evaluate the information content of MSE-RPs in mixed normal distributions [
30]. Based on this, we introduce a truncation method based on IG to determine the sufficient number of MSE-RPs. This approach aims to reduce the estimation bias while preserving as much information as possible in the MSE-RPs.
In conclusion, our study focus on the generation and estimation of MSE-RPs for the four types of Pareto distributions. We examine the properties of MSE-RPs for Pareto distributions and propose a reliable algorithm for their generation based on the properties. In addition, simulation results reveal that existing methods for estimating MSE-RPs suffer from significant bias when applied to skewed and heavy-tailed distributions. To address this issue, we introduce the innovative concept of IG-truncated representative points. This approach also provides a new perspective for estimating MSE-RPs for other heavy-tailed distributions.
The structure of this paper is as follows:
Section 2 introduces the fundamentals of the Pareto family.
Section 3 presents the MSE-RPs of Pareto distributions, including their properties, computation methods, and results.
Section 4 compares different methods for estimating the MSE-RPs of Pareto distributions and proposes an IG-based truncation method for selecting the number of MSE-RPs. In
Section 5, a real dataset is analyzed in order to illustrate the proposed methods. Finally, this paper is concluded in
Section 6.
4. Estimation of MSE-RPs from Pareto Distributions
Currently, methods for estimating MSE-RPs from a sample can be categorized into three types based on whether the underlying distribution type and parameters are known:
- 1.
The first type requires knowledge of the distribution type. After estimating the distribution parameters, the MSE-RPs are computed directly from the estimated distribution.
- 2.
The second type also requires knowledge of the distribution type but does not involve parameter estimation. Instead, it estimates MSE-RPs by locating the sample quantiles corresponding to the positions of MSE-RPs. This method is limited to distributions with location–scale properties.
- 3.
The third type does not require any prior information about the distribution. It directly estimates MSE-RPs from the sample by leveraging the property that k-means cluster centers are also self-consistent points. MSE-RPs are estimated as the centers of clusters formed by classifying the sample.
For the first type of method, estimating MSE-RPs for Pareto distributions, faces challenges regardless of whether the method of ME or MLE is used. The ME method requires the existence of moments, while the MLE method is computationally complex, making it difficult to achieve accurate results. Therefore, in the simulations presented in this paper, we estimate MSE-RPs under the assumption that the parameters and are known, and only and are estimated. Specifically, our estimates are as follows:
- -
For a sample following
, the MSE-RPs are estimated as
where
are the MSE-RPs of
.
- -
For a sample following
, the MSE-RPs are estimated as
where
are the MSE-RPs of
.
The second type of method views MSE-RPs as specific quantiles of the distribution. For distributions with location–scale properties, the positions of quantiles remain unchanged under parameter transformation. Thus, the MSE-RPs can be estimated by determining their corresponding quantile positions in the standard distribution and then estimating these quantiles in the sample. The steps are as follows:
- 1.
Compute the MSE-RPs of the continuous distribution .
- 2.
Compute the positions
of
in the standard distribution
:
- 3.
In an independent and identically distributed sample , estimate the sample quantiles for , which serve as the estimated MSE-RPs for the sample.
The accuracy of this method depends heavily on the choice of the quantile estimation method. Different distributions have unique characteristics, and the optimal method for quantile estimation may vary. Since the Pareto distribution is a heavy-tailed distribution, we consider the following four quantile estimation methods, which are known to perform well in the tails of distributions. Consider estimating the quantile ; the sample size is n and is the i-th order statistic of the sample:
The first two methods are modifications of kernel-based quantile estimation methods, optimized by selecting the best bandwidth under various conditions. The last two methods adjust sample quantiles based on order statistics.
We apply these methods to estimate the MSE-RPs for
,
,
, and
, and three sample sizes. Each method is tested through 1000 simulations, and the bias is reported in
Table 1. Here,
n represents the sample size,
m represents the number of MSE-RPs, and the bias is calculated as follows:
The bold numbers in
Table 1 indicate the minimum bias in each row. We analyze the impact of sample size, the number of MSE-RPs, the type of Pareto distribution, and parameter values on the accuracy of representative point estimation. From
Table 1, it can be observed that, for fixed parameter values and a fixed number of MSE-RPs, the estimation bias decreases as the sample size increases. Conversely, as the number of MSE-RPs increases, the estimation bias increases for both quantile-based methods and the k-means method. However, the bias remains nearly unchanged for parameter-based estimation methods. This is because increasing the number of MSE-RPs does not introduce new estimators, ensuring that the estimation remains highly stable.
The type of Pareto distribution also significantly affects the bias of estimation methods in
Table 1, mainly due to differences in distribution complexity and tail behavior. For Pareto I and II distributions, parameter-based estimation methods perform the best, as parameter estimation is relatively straightforward. However, for Pareto III and IV distributions, which introduce additional parameters, solving the nonlinear Equation (
17) often results in convergence issues or requires large sample sizes, leading to increased bias. In contrast, the
method utilizes quantile positions, which are more robust to heavy tails. The flexibility of Pareto III/IV in modeling the tail behavior aligns well with quantile-based estimation, thus reducing sensitivity to parameter misestimation.
The impact of parameters on MSE-RP estimation primarily manifests in the tail region. Smaller values of and increase the difficulty of estimating , which relies heavily on the sample minimum. This, in turn, exacerbates the bias of parameter-based estimation methods. However, the method remains relatively stable, particularly for Pareto III and IV distributions, where the tail dominates. The method effectively captures the critical regions, improving the accuracy of MSE-RP estimation.
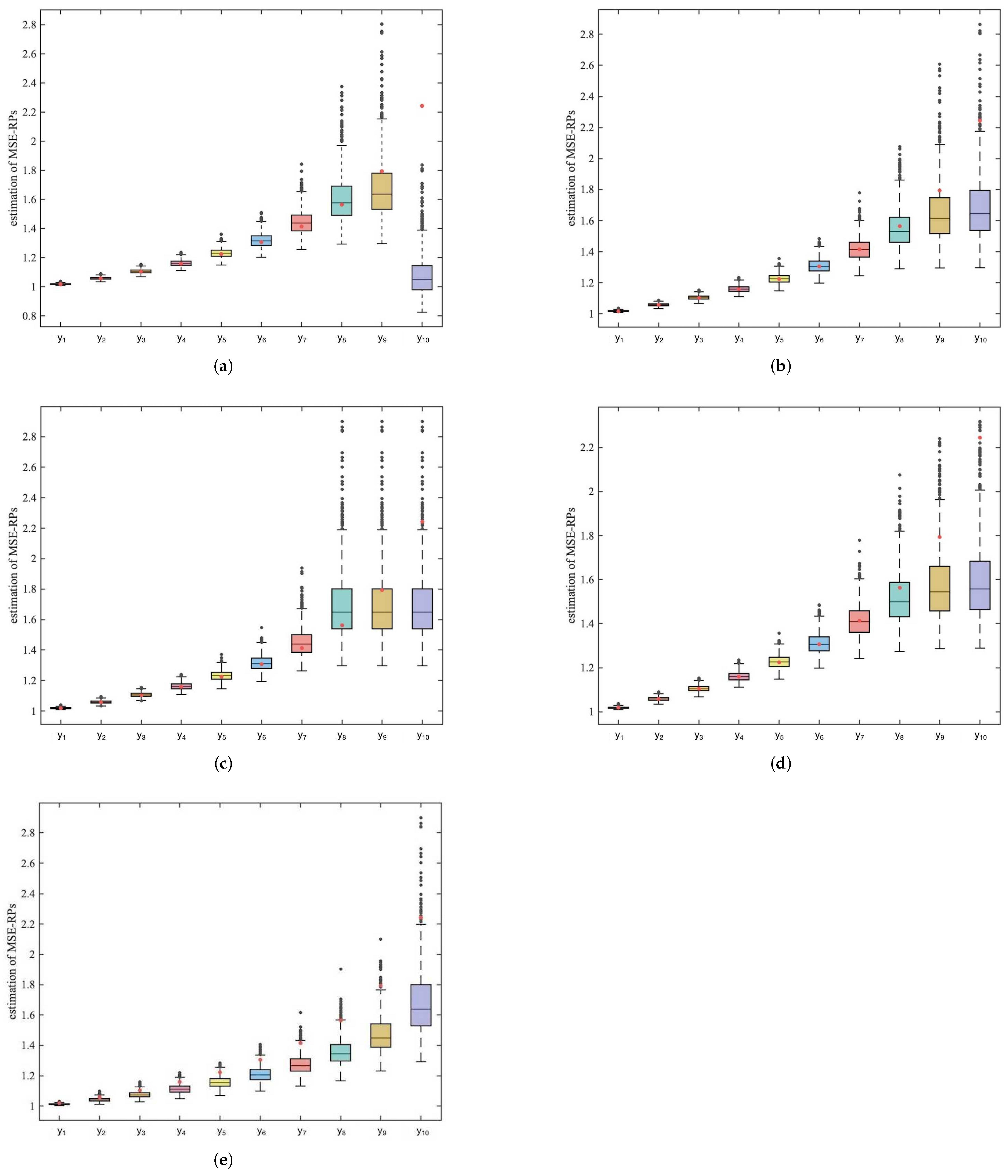
Furthermore, we analyze the sources of bias in quantile-based estimation. To investigate how different methods estimate MSE-RPs across various positions in the distribution, we plot the estimation results for
MSE-RPs of
in
Figure 1.
In
Figure 1, the red dots represent the true values of the MSE-RPs. From the box-plots, it can be observed that for the k-means and
methods, the estimation bias exhibits increasing fluctuation as the MSE-RPs move farther away from the mean of the Pareto distribution. Meanwhile, the
method shows low sensitivity to the estimation of MSE-RPs in the tail. The
method has a significant estimation bias for the last representative point, and the NO method exhibits a large overall bias with noticeable increases in fluctuation.
Therefore, considering all factors, the method is the most stable and accurate method for estimating the MSE-RPs of the Pareto distribution when and are small. However, by examining the MSE-RPs and their corresponding probabilities, it can be observed that as the number of MSE-RPs increases, the probability associated with the tail MSE-RPs becomes significantly smaller, while their corresponding values become exceedingly large. Estimating these tail MSE-RPs notably increases the overall estimation bias.
Li et al. [
30] previously proposed a method to measure the information gain (IG) of MSE-RPs, similar to the variance ratio used in principal component analysis. The range of IG is from 0 to 1, and the calculation formula is as follows:
where
is the number of MSE-RPs used in calculating the IG. We can use the same IG function to calculate the number of MSE-RPs and their corresponding coverage under different levels of information gain. See
Appendix C for details.
By calculating the information gain, we find that for the Pareto distribution, as the number of MSE-RPs increases, the information gain for the tail MSE-RPs becomes very small. For example, for the
distribution, when
, the first 12 MSE-RPs account for 90% of the information. We re-estimate the MSE-RPs for the above distributions with
under different IG proportions, and the results are presented in
Table 2.
The bold numbers in
Table 2 indicate the minimum bias in each row. From the comparison between
Table 1 and
Table 2, it can be observed that sacrificing a small amount of information gain can significantly improve the accuracy of representative point estimation. Furthermore, when the parameters
and
are small, the
quantile method provides relatively accurate and stable estimates.
The IG truncation method dynamically determines the number of MSE-RPs required to achieve a specified IG level. This process focuses on selecting the most informative points while discarding tail points, which, although having high estimation bias, contribute little to the overall information. As a result, the outcomes presented in
Table 2 can be considered robust to the choice of
m.
In practical applications, the number of MSE-RPs needed can be determined by referring to
Appendix C, which provides the number of MSE-RPs corresponding to different levels of IG and their coverage regions.
6. Conclusions
This paper primarily investigates the MSE-RPs of Pareto distributions and their estimation. We provided the uniqueness conditions for MSE-RPs and derived the corresponding unique intervals. For the computation of MSE-RPs of Pareto I and II distributions, we proposed an improved parametric k-means method.
For the estimation of MSE-RPs, we compared three categories of methods: the k-means method, the quantile-based estimation method, and methods that first estimate the parameters and then estimate the MSE-RPs. Based on simulations, we found that the k-means method is unsuitable for estimating MSE-RPs of Pareto distributions. The MLE-based parameter estimation method has the smallest bias when estimating MSE-RPs of Pareto I distributions, while the ME-based parameter estimation method performs best for Pareto II distributions. As the parameters and decrease, the bias when using the quantile method to estimate MSE-RPs becomes minimal.
Since the tail MSE-RPs of Pareto distributions contribute significant bias while having very low probabilities, we propose using the IG function to calculate the information content of MSE-RPs. We also provide the number of MSE-RPs required for three levels of IG and their corresponding covered ranges to help select an appropriate number of MSE-RPs in practical analyses. Simulation results demonstrate that sacrificing a small amount of information gain can significantly improve the accuracy of representative point estimation.
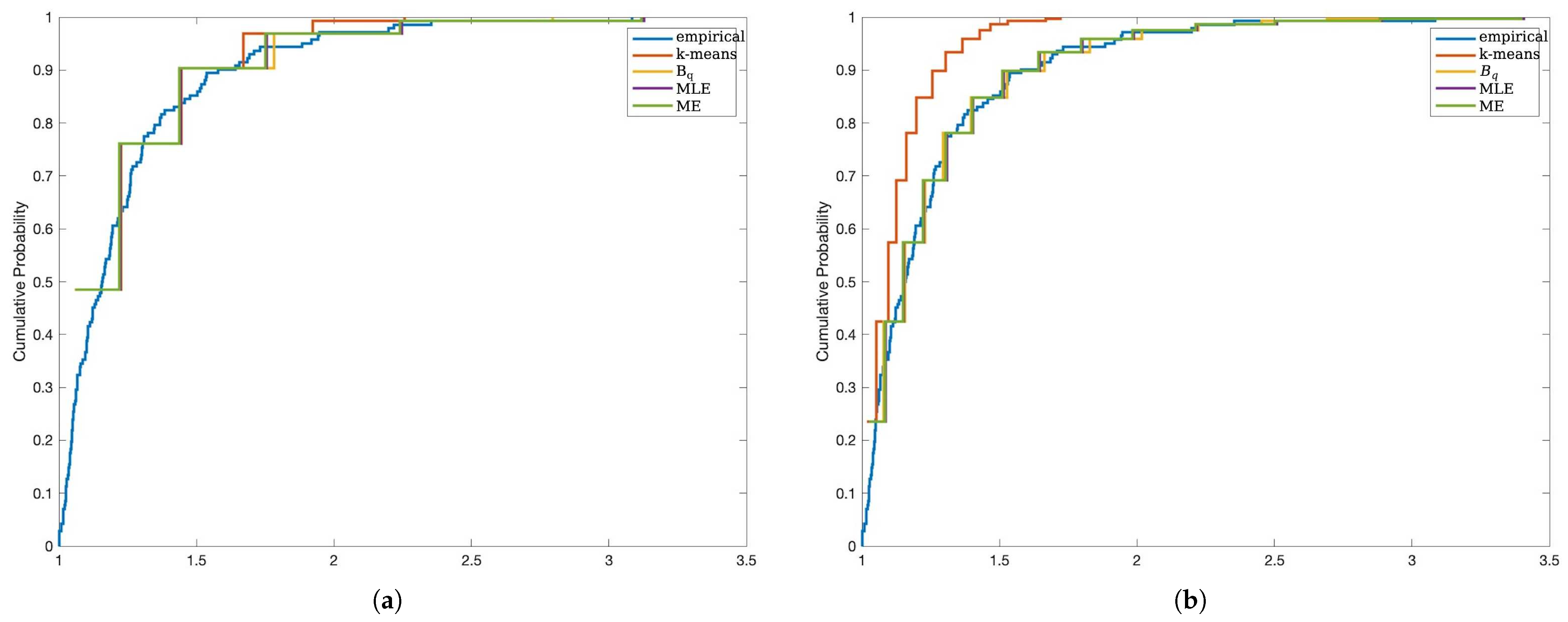
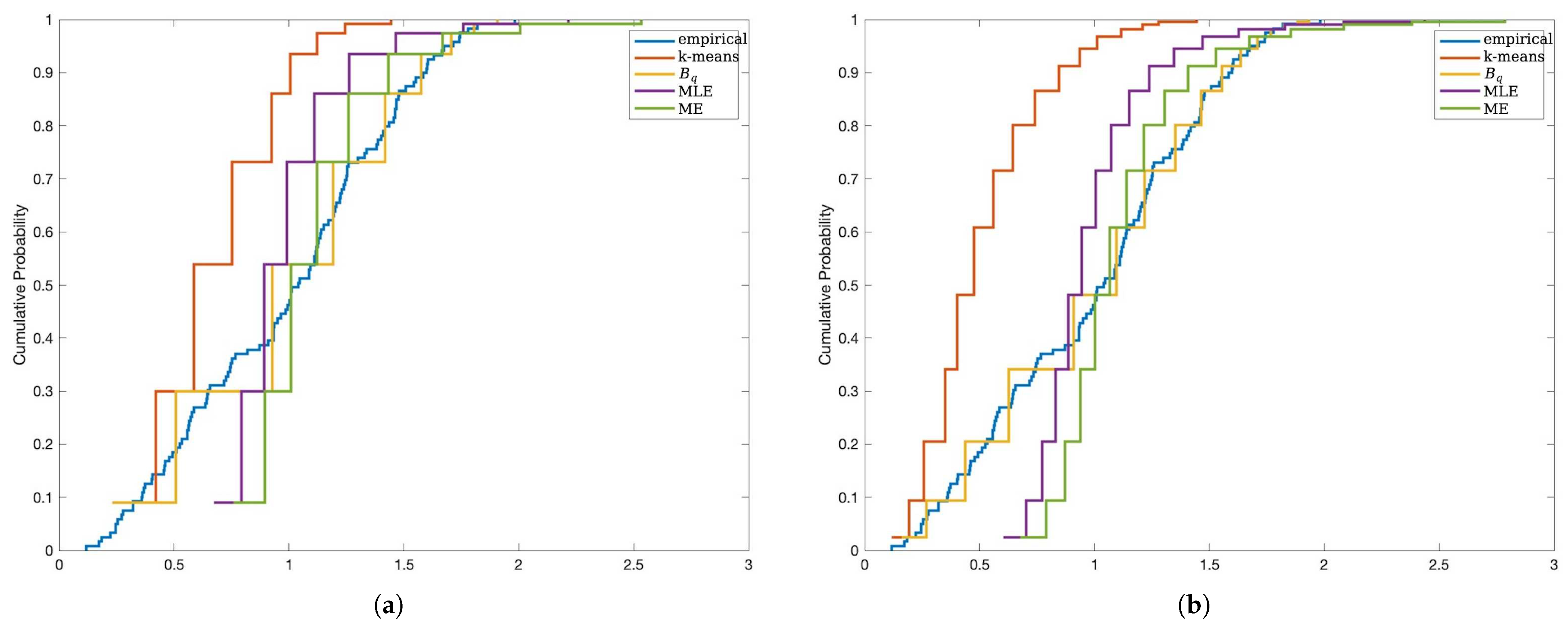
Additionally, we applied the proposed methods to estimate MSE-RPs for real data from two different distributions. Using different IG intervals, we estimated MSE-RPs for the data and used them to fit the empirical distribution functions of the real data. These results were consistent with the simulation findings.
In conclusion, this paper studies the MSE-RPs of Pareto distributions and their estimation methods, analyzes the bias characteristics of representative point estimation, and proposes an IG-based optimization method for selecting MSE-RPs. The effectiveness and applicability of the proposed method were validated through simulations and real data studies.




{kind=link}
{kind=link}
{kind=link}