2.1. Comprehensive Evaluation Index Model
Given
n samples of
p factors, let
denote the observation value of the
i-th sample from the
j-th factor,
. From the perspective of statistical models, constructing a multi-factor comprehensive evaluation index, or the so-called composite indicator,
, requires estimating the weight coefficients,
, of each factor in the following equation
where
, and
. However, since there is no explicit dependent variable (
) for reference in the comprehensive evaluation model here, the empirical model proposed by this paper assumes that the composite indicator (
) is composed of
p factors such that
can be considered as the sum of theoretical indicator values from the
p factors. Suppose that the
j-th factor is assigned a weight
, the theoretical indicator value of each factor, also called by theoretical component denoted as
, is given by
. The proposed model and the data fitting are based on
, where
is considered as the observed values of
. Therefore,
can also be expressed in the form of the sum of its theoretical components,
Since the Equations (
1) and (
2) are equivalent from the left side, it is justified to assume that
and
are in one-to-one correspondence. Remark that
is not necessary to be equal to the true theoretical component
. Otherwise,
will be exactly equal to
, which is not practical. Considering
as the observed values of the theoretical components
, we can empirically conclude that the closer the two values are, the more representative the CEI becomes.
We define the difference between the observed and the theoretical components as the residual,
, which is considered as a fitted error of the
i-th sample of the
j-th factor. In a regression model, the parameter estimation is derived from minimizing the residual, or say the root mean square error of
, denoted by
in our case,
From Equation (
3), the residual error
can also be expressed as a weighted difference between the observed value
and the theoretical CEI
. The larger the weight coefficient of a factor, the greater its impact on the residuals, indicating that the factor is “more important”. This approach is essentially a weighted regression analysis process. It is consistent with the principle in multi-factor comprehensive analysis, where a larger weight coefficient for a factor means that the factor is more important. The fitted error term
is assumed independent of other factors, since under ideal circumstances, the component of each individual factor can be considered independent of the other factors in order to measure a specific characteristic of the CEI. The root mean square error of Equation (
3) is similar to the decomposition of the sum of squared errors in a regression model, and the corresponding degree of freedom in our case is
. Equation (
3) can be considered as an error function to be minimized when deriving the solution of weights. However, if the weight coefficient of the
j-th factor in Equation (
3) is equal to one and the weight coefficients of the rest of the factors are zeros, then
is equal to the observed value
while the residual
is minimized to zero. Obviously, directly minimizing Equation (
3) ends up with a trivial solution in which a certain weight is 1 and zero otherwise, making the corresponding factor as the CEI. Although,
, in this special case, the resulting CEI is pointless.
2.2. Maximum Entropy-Minimum Residual (MEMR) Model for Comprehensive Evaluation
Entropy is a key concept in information theory, as a unit of measurement when quantifying the total amount of information in a dataset. The maximum entropy (ME) principle in [
10] provides a method for reasoning from incomplete information. For problems in science, the more information we have, the better the models and theories we can construct. However, for a complex system, such as a multi-factor CEI model, developers never have enough information to unambiguously predict the probability distribution of the weights of individual factors. Indeed, constructing a CEI for such a complex system faces an underdetermined reasoning problem. When the ME principle is adopted by specifying available information as constraints, a model with the least bias can be chosen from all possible models consistent with the information. In establishing a CEI model, since the dimensions of the various indicators are inconsistent, the common approach is to preprocess the data using min-max normalization introduced in
Section 3 or other normalization methods so that the normalized values of each factor fall between 0 and 1. We can treat these as ratio values between 0 and 1, representing the probability of a factor’s distribution within the evaluation range. ME inference is considered the correct way to estimate an unknown probability distribution given limited information (in the form of moments of the distribution) when entropy defined by [
12] is chosen to effectively measure information for the probability distribution of random events [
13]. Distributions with higher entropy implicate greater diversity and are more likely to be observed [
13]. Thus, ME inference leads to the best probability estimate from the given information, with no need to assume any further knowledge beyond that in a set of constraints. According to ME inference, any other form will be based on nonoptimal inference, either using less information than that available or expressing unjustified bias.
The ME principle is thus adopted in the present study to determine weight coefficients of multiple factors in the construction of a CEI. If each weight coefficient follows a probability distribution for the importance of each factor, the ME form of the probability distribution can be achieved through maximization of Shannon’s information entropy, which can be expressed in the following formula containing weight coefficients
of all concerned factors,
in which information entropy is at the maximum when all weight coefficients are equal. When the weight coefficient is equal to 1 for one factor and 0 for each of the other factors, information entropy is at the minimum. This seems to contradict the optimization of a CEI by maximizing information entropy and minimizing residual error according to the ME principle.
The idea of using information entropy for CEI modeling is intuitive, similar to compression regression methods such as LASSO regression, where the optimization function for the CEI model is established in the following form,
in which taking different values for
leads to different optimization results. An appropriate
may provide a model as required. However, the biggest problem with this approach is how to choose
. At the same time, the objective function to be optimized is a hybrid because the dimensions of the residuals and information entropy are different. Combining them in the form of a sum or difference as the objective function is inappropriate, since the CEI model essentially aims to optimize the residuals defined by Equation (
3). Another possible way to combine residual and entropy is through multiplication or division as
that simply scales the residuals up or down by several times, which is a linear relationship. The result is the same as optimizing based on the residual
defined by Equation (
3), and it does not yield the desired statistical model. Given that the previous two forms are not suitable for constructing the CEI model, a natural idea is to adopt an exponential function to establish the error function, using the residual
as the base and information entropy
E as the exponent, defined as
Since the dimensions of all concerned factors are not consistent, data must be properly normalized in advance, such as using the min-max normalization method, in order to construct a CEI or MADM model. The normalized dimension value of each factor is essentially a ratio between 0 and 1, and the resulting residual
must be less than 1 accordingly, such that the error function value in Equation (
5) becomes smaller when the entropy is larger. Therefore, the property of the error function in Equation (
5) can be interpreted as the process of minimizing the residual
within the space of information entropy
E. For original data without normalization, each observed value can be divided by the maximum (absolute value) of all observed values to convert it to a ratio between 0 and 1 before the optimization begins. In summary, the maximum entropy-minimum residual (MEMR) comprehensive evaluation index model can be expressed as
where
with constraint is the optimization variable in this nonlinear regression equation model.
The nonlinear regression Equation (
6) with constraints can be solved using a variety of nonlinear optimization methods with constraints. Since convergence speed varies with different optimization algorithms, it may take a long time to achieve the bootstrap sampling estimation of model weight parameters. Thus, it is worthy of searching for an algorithm with stable operation and fast speed. We try to use the sequential unconstrained minimization technique (SUMT) for optimization and obtain optimal results (shown in
Section 3). The SUMT optimization algorithm has been included in DPS (data processing system) software package V21.05 [
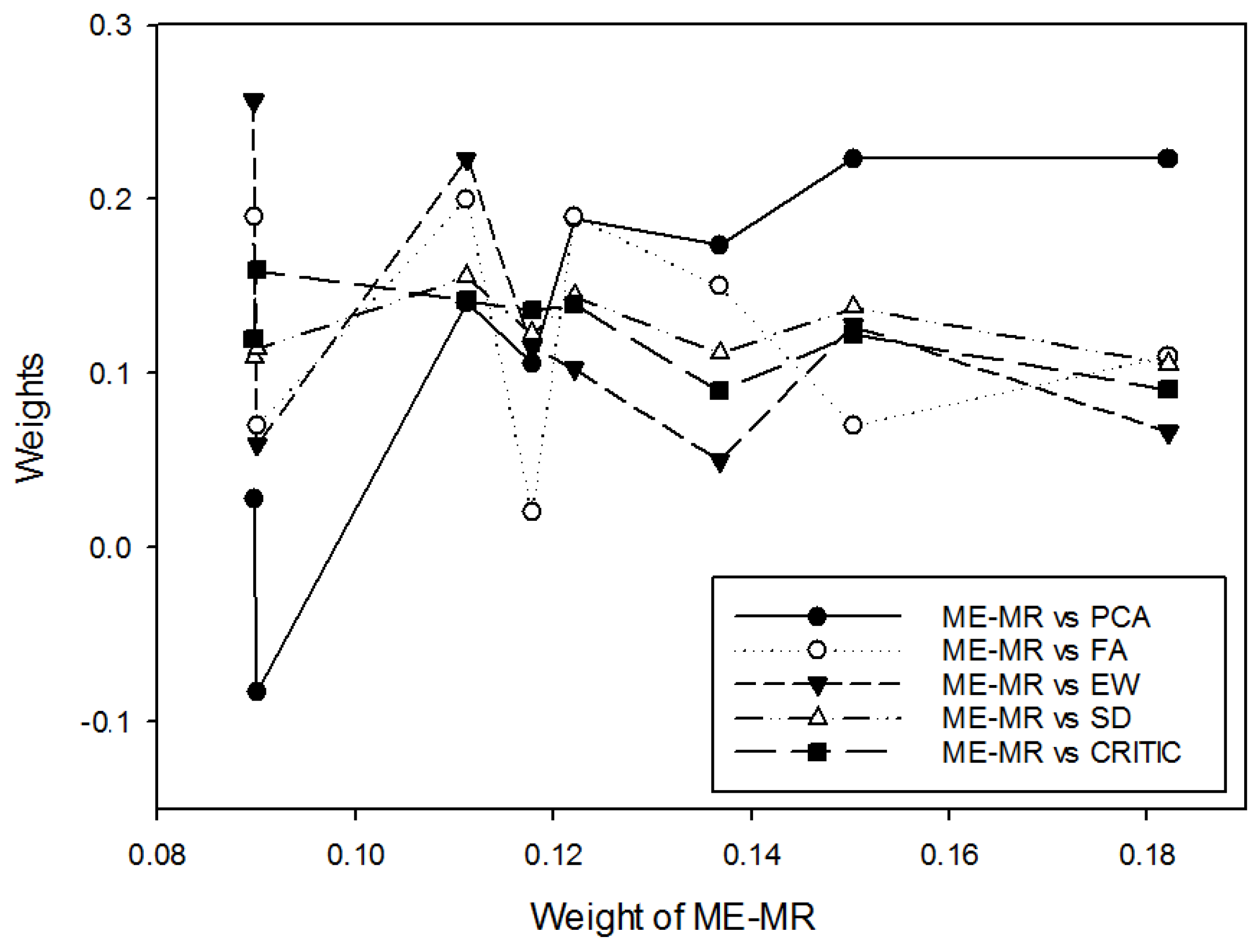
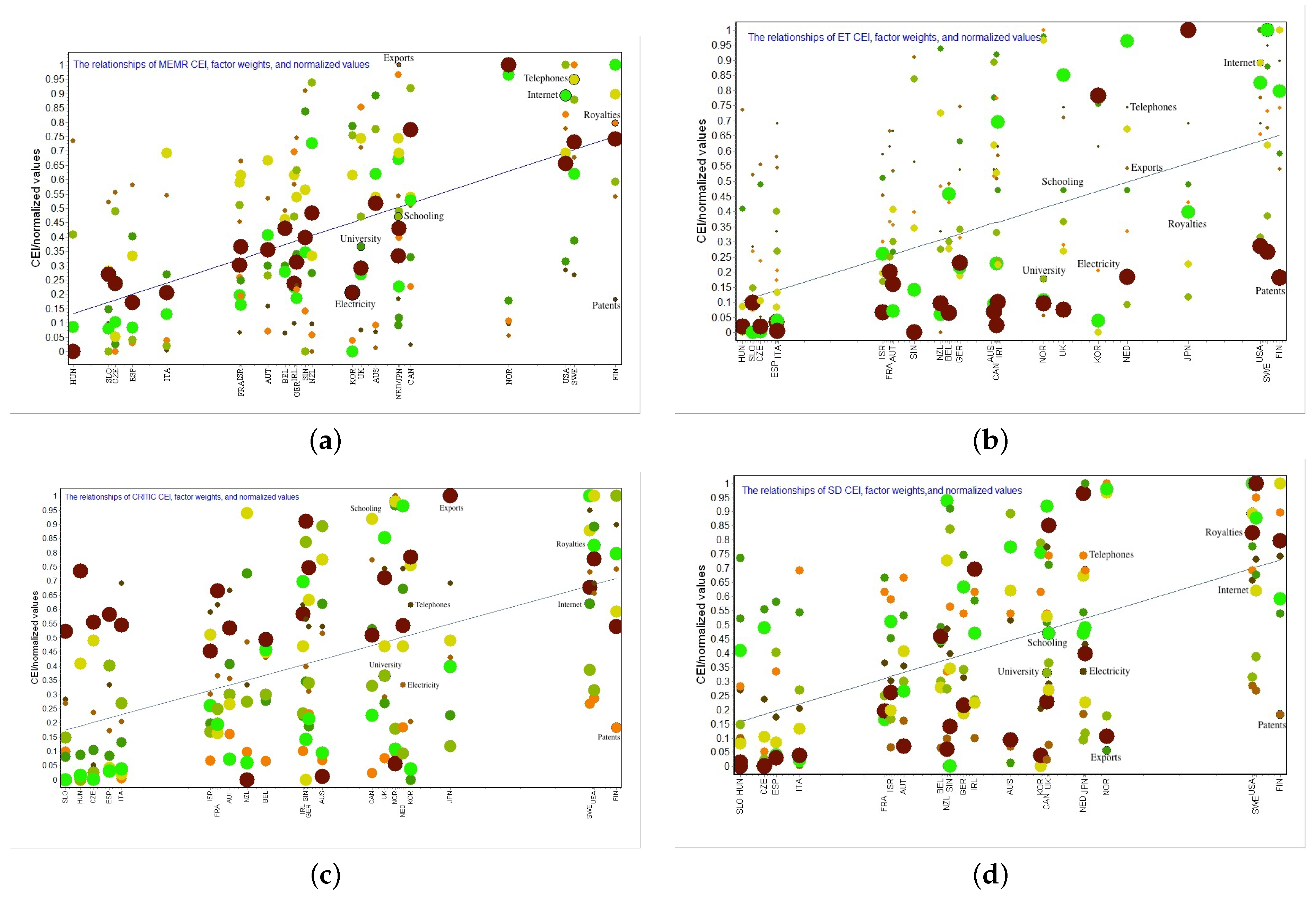
14]. In this paper, a CEI constructed with the proposed MEMR model is called MEMR index, and the corresponding weight coefficient is called MEMR weight. MEMR modeling actually uses least squares techniques to extract the common trends of various factors in the process of building a CEI model or conducting MADM while taking into account all factors (information) as comprehensively as possible. This is highly consistent with the motivation behind conducting comprehensive evaluation or MADM.
2.3. Statistical Tests in Comprehensive Evaluation Index Models
In constructing a CEI, the simplest approach is the equal weighting (EW) model, where all variables are assigned the same weight. If there are
p variables, the weight coefficients for all factors are equal to
. Clearly, in actual comprehensive evaluation and MADM processes, the importance of each evaluation factor is not the same. Here, we use the equal weighting model as a reference (null model) for the CEI model, treating it as a submodel of the MEMR model, and performing statistical tests using a nested model approach. This means we can use statistical testing methods to compare the MEMR model with the EW model, i.e., to test whether the MEMR model can be simplified into the EW model (null hypothesis). The statistical test can be conducted using the
F-test. The sum of squared residuals for each model is shown in
Table 1, in which
Currently, statistical software such as Stata V16.0 and Prism V5.0 have applied analysis of variance (ANOVA) for statistical tests in nested nonlinear models; see [
15]. In this paper, based on [
16], the
F-test statistic is expressed in terms of the sum of squared residuals and serves as a measure of the distance between the EW model and the MEMR model. A larger
F-statistic indicates that the two models differ significantly, suggesting that the EW model does not describe the data well due to its equal weight coefficients for all factors. Therefore, the more general model, MEMR, is more suitable for comprehensive evaluation and MADM. The
F-test statistic is a ratio of the last two mean square terms in
Table 1, where the numerator is the difference in the variance terms between the two models, divided by the difference in the number of parameters between the models. The denominator is the mean square error of the MEMR model (the full model). The statistical test formula is as follows:
The
F-test statistic is defined the same way as in linear models. However, unlike in linear models, the
F-distribution only holds approximately (it becomes closer as the sample size increases). Based on the
F-value and its degrees of freedom, it is not difficult to obtain the significance probability, or
p-value. From the
F-statistic test, we can conclude that if the statistical test is not significant (for example, using a 0.05 significance level), we can accept the EW model as the CEI model. However, generally speaking, the MEMR model can always improve the effectiveness of comprehensive evaluation or MADM to some extent. If
, then the EW model may not be suitable as the CEI model, and the MEMR model should be adopted. This is because, in the CEI model, at least one of the weight coefficients is different from the others, making the optimization process meaningful. The weight coefficients generated through optimization significantly improve the closeness of the composite indicator to the observed values compared to the equal weighting coefficients.
In addition, we define the model optimization index
R as the percentage decrease of the difference in the sum of squared residuals between the EW model and the MEMR model, compared to the sum of squared residuals of the EW model,
The meaning of
R is that, after optimization, it measures the extent to which the CEI model has been improved compared to the null hypothesis, where each factor is assigned an equal weight. This is reflected by the percentage decrease in the sum of squared residuals, or it can be interpreted as the degree to which the goodness of fit has been improved.
Since the MEMR model is a nonlinear model, it is difficult to accurately estimate the standard errors of the weight coefficients. Here, we apply the Bootstrap method for estimation. For the multi-factor MEMR CEI model, a set of weight coefficients can be calculated for each Bootstrap sample. If we draw Bootstrap samples, we can obtain 1000 sets of weight coefficients.
- 1.
95% Confidence Interval of Weight Coefficients
Based on these 1000 sets of weight coefficients, the 2.5th percentile and the 97.5lth percentile are calculated to obtain the 95% confidence intervals for each weight coefficient. In case one focuses on the analysis of the impact of the weight coefficients, for a given weight coefficient, if the interval does not include , then it can be considered that the influence of this factor is significantly too large or too small. In a comprehensive evaluation, a subset of the weights can be , but this does not mean that we have completely equal weights. In this case, it is not appropriate to use equal weight to calculate the composite indicator in a multi-factor comprehensive evaluation.
- 2.
95% Standard Error of Weight Coefficients and Coefficient of Variation
Based on certain samples drawn using Bootstrap sampling, each having the same sample size as the initial one, and for each sample, the mean and variance of the sample statistics are calculated. For instance, the sample means are denoted by , and the mean estimation is given by . According to the formula, , the coefficient of variation for each factor is given by .
The DPS V21.05 system calculates the average coefficient of variation for each factor to examine the fluctuation range of the weight coefficients of each factor in the CEI model, as well as the stability of the weight coefficients during the comprehensive evaluation process. Based on the size of the coefficient of variation, models with smaller coefficients of variation are selected from several models as application references.



{kind=link}
{kind=link}