



CrackCLIP: Adapting Vision-Language Models for Weakly Supervised Crack Segmentation


Abstract
1. Introduction
2. Related Work
2.1. Weakly Supervised Crack Segmentation Methods
2.2. Vision-Language Modeling Methods
3. Methodology
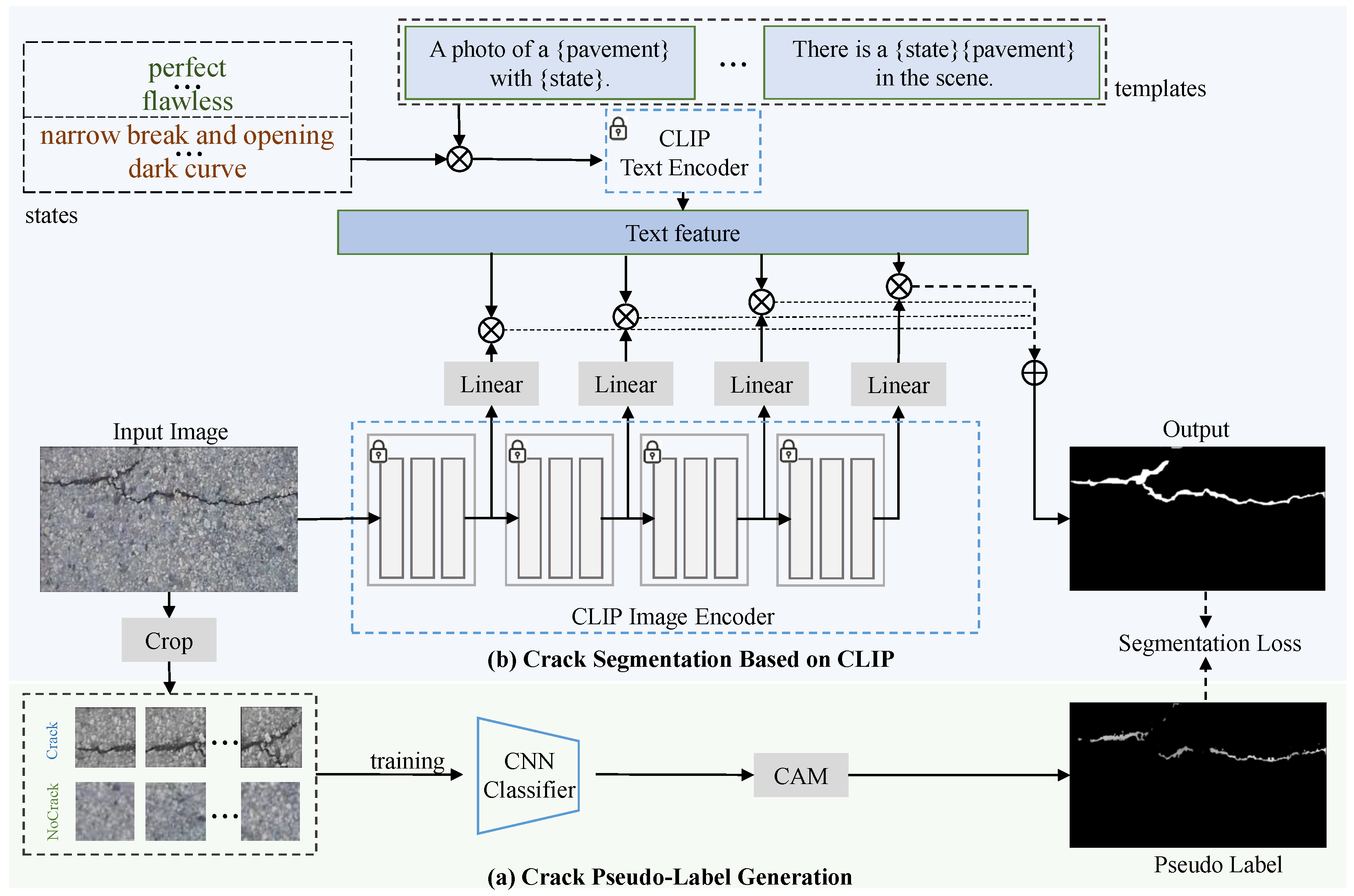
3.1. Approach Overview
3.2. Crack Pseudo-Label Generation
3.3. Crack Segmentation with Vision-Language Alignment
3.4. Segmentation Loss
4. Results
4.1. Dataset
4.2. Evaluation Metrics
4.3. Comparison Methods
- Grad-CAM [22]. This method employs Gradient-based Class Activation Mapping to generate pseudo-labels, which can be directly utilized for training crack segmentation models without any post-processing.
- PWSC [16]. This method employs patch-based Grad-CAM combined with conditional random field (CRF) post-processing for the weakly supervised crack segmentation task.
- GPLL [15]. This method generates crack pseudo-labels based on Grad-CAM using localization with a classifier and thresholding to implement the weakly supervised crack segmentation task.
- CAC [19]. This method utilizes crack pseudo-labels with varying confidence levels to co-train a weakly supervised crack segmentation framework.
- U-Net [39]. U-Net extends the encoder–decoder architecture by incorporating skip connections, which combine feature maps from the encoder with those from the decoder. This design retains more spatial information and enhances localization accuracy.
- DeepCrack1 [6]. DeepCrack1 aggregates multi-scale and multi-level features using a fully convolutional neural network to predict crack pixels. A deep supervised network is employed to directly supervise the crack features at each convolutional stage, ensuring robust and accurate feature extraction.
- OED [41]. Based on a fully convolutional U-Net, OED exploits residual connectivity within the convolutional blocks and adds an attention-based gating mechanism between the encoder and decoder parts of the architecture.
4.4. Implementation Details
4.4.1. Environment
4.4.2. Experimental Setting
4.5. Comparison with State-of-the-Art Methods
4.6. Ablation Studies
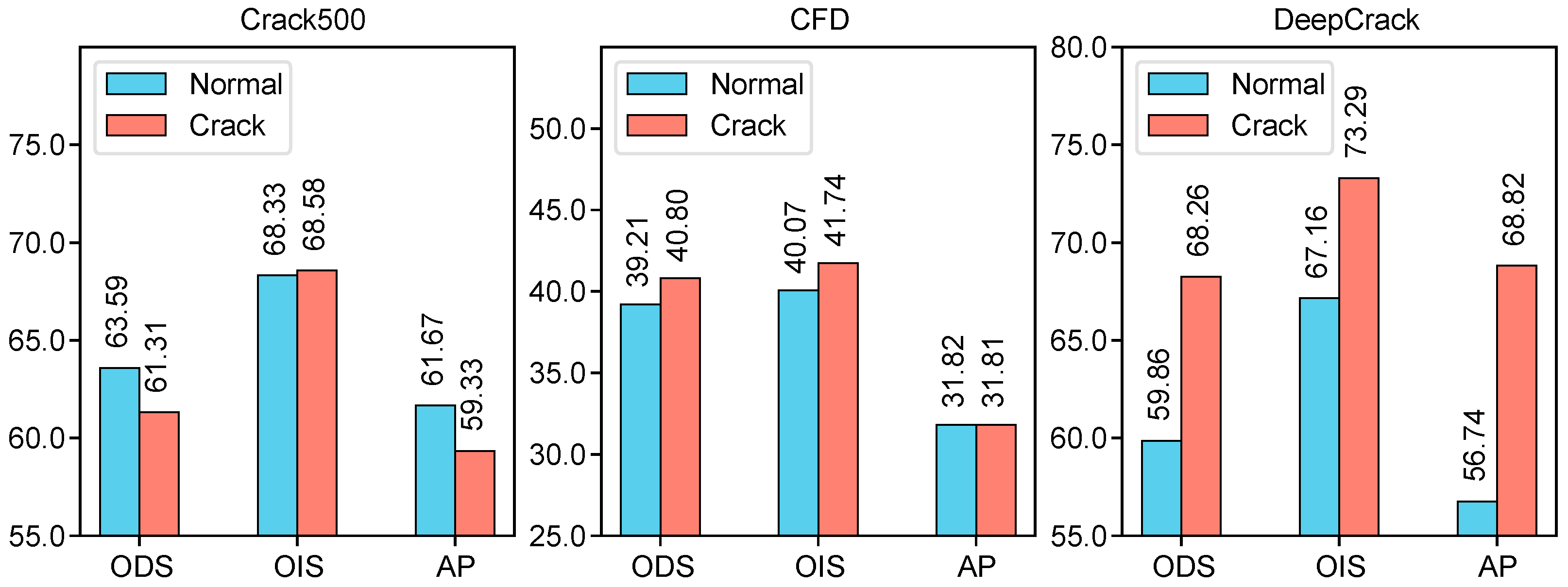
4.6.1. Pseudo-Label Type
4.6.2. Backbones
4.6.3. Crack Text Prompts
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Guo, J.; Liu, P.; Xiao, B.; Deng, L.; Wang, Q. Surface defect detection of civil structures using images: Review from data perspective. Autom. Constr. 2024, 158, 105186. [Google Scholar] [CrossRef]
- Yu, X.; Kuan, T.W.; Tseng, S.P.; Chen, Y.; Chen, S.; Wang, J.F.; Gu, Y.; Chen, T. EnRDeA U-net deep learning of semantic segmentation on intricate noise roads. Entropy 2023, 25, 1085. [Google Scholar] [CrossRef] [PubMed]
- Zhao, Y.; Yan, J.; Wang, Y.; Jing, Q.; Liu, T. Porcelain insulator crack location and surface states pattern recognition based on hyperspectral technology. Entropy 2021, 23, 486. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; He, Z.; Zeng, X.; Zeng, J.; Cen, Z.; Qiu, L.; Xu, X.; Zhuo, Q. GGMNet: Pavement-Crack Detection Based on Global Context Awareness and Multi-Scale Fusion. Remote Sens. 2024, 16, 1797. [Google Scholar] [CrossRef]
- Zou, Q.; Zhang, Z.; Li, Q.; Qi, X.; Wang, Q.; Wang, S. DeepCrack: Learning Hierarchical Convolutional Features for Crack Detection. IEEE Trans. Image Process. 2019, 28, 1498–1512. [Google Scholar] [CrossRef]
- Liu, Y.; Yao, J.; Lu, X.; Xie, R.; Li, L. DeepCrack: A deep hierarchical feature learning architecture for crack segmentation. Neurocomputing 2019, 338, 139–153. [Google Scholar] [CrossRef]
- Zhang, H.; Chen, N.; Li, M.; Mao, S. The Crack Diffusion Model: An Innovative Diffusion-Based Method for Pavement Crack Detection. Remote Sens. 2024, 16, 986. [Google Scholar] [CrossRef]
- Yeum, C.M.; Dyke, S.J. Vision-based automated crack detection for bridge inspection. Comput.-Aided Civ. Infrastruct. Eng. 2015, 30, 759–770. [Google Scholar] [CrossRef]
- Bastani, F.; He, S.; Abbar, S.; Alizadeh, M.; Balakrishnan, H.; Chawla, S.; Madden, S.; DeWitt, D. Roadtracer: Automatic extraction of road networks from aerial images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4720–4728. [Google Scholar]
- Zhang, J.; Wang, G.; Xie, H.; Zhang, S.; Huang, N.; Zhang, S.; Gu, L. Weakly supervised vessel segmentation in X-ray angiograms by self-paced learning from noisy labels with suggestive annotation. Neurocomputing 2020, 417, 114–127. [Google Scholar] [CrossRef]
- Sironi, A.; Türetken, E.; Lepetit, V.; Fua, P. Multiscale centerline detection. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 1327–1341. [Google Scholar] [CrossRef]
- Zhang, Z.; Xing, F.; Shi, X.; Yang, L. Semicontour: A semi-supervised learning approach for contour detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 251–259. [Google Scholar]
- Yuan, Q.; Shi, Y.; Li, M. A Review of Computer Vision-Based Crack Detection Methods in Civil Infrastructure: Progress and Challenges. Remote Sens. 2024, 16, 2910. [Google Scholar] [CrossRef]
- Wang, W.; Su, C. Automatic concrete crack segmentation model based on transformer. Autom. Constr. 2022, 139, 104275. [Google Scholar] [CrossRef]
- König, J.; Jenkins, M.D.; Mannion, M.; Barrie, P.; Morison, G. Weakly-Supervised Surface Crack Segmentation by Generating Pseudo-Labels Using Localization With a Classifier and Thresholding. IEEE Trans. Intell. Transp. Syst. 2022, 23, 24083–24094. [Google Scholar] [CrossRef]
- Dong, Z.; Wang, J.; Cui, B.; Wang, D.; Wang, X. Patch-based weakly supervised semantic segmentation network for crack detection. Constr. Build. Mater. 2020, 258, 120291. [Google Scholar] [CrossRef]
- Al-Huda, Z.; Peng, B.; Algburi, R.N.A.; Al-antari, M.A.; AL-Jarazi, R.; Zhai, D. A hybrid deep learning pavement crack semantic segmentation. Eng. Appl. Artif. Intell. 2023, 122, 106142. [Google Scholar] [CrossRef]
- Al-Huda, Z.; Peng, B.; Algburi, R.N.A.; Alfasly, S.; Li, T. Weakly supervised pavement crack semantic segmentation based on multi-scale object localization and incremental annotation refinement. Appl. Intell. 2023, 53, 14527–14546. [Google Scholar] [CrossRef]
- Liang, F.; Li, Q.; Li, X.; Liu, Y.; Wang, W. CAC: Confidence-Aware Co-Training for Weakly Supervised Crack Segmentation. Entropy 2024, 26, 328. [Google Scholar] [CrossRef]
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; et al. Learning Transferable Visual Models From Natural Language Supervision. In Proceedings of the 38th International Conference on Machine Learning Research (PMLR), Virtual, 18–24 July 2021. [Google Scholar]
- Yong, G.; Jeon, K.; Gil, D.; Lee, G. Prompt engineering for zero-shot and few-shot defect detection and classification using a visual-language pretrained model. Comput.-Aided Civ. Infrastruct. Eng. 2023, 38, 1536–1554. [Google Scholar] [CrossRef]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-CAM: Visual Explanations From Deep Networks via Gradient-Based Localization. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Yang, F.; Zhang, L.; Yu, S.; Prokhorov, D.; Mei, X.; Ling, H. Feature Pyramid and Hierarchical Boosting Network for Pavement Crack Detection. IEEE Trans. Intell. Transp. Syst. 2020, 21, 1525–1535. [Google Scholar] [CrossRef]
- Shi, Y.; Cui, L.; Qi, Z.; Meng, F.; Chen, Z. Automatic road crack detection using random structured forests. IEEE Trans. Intell. Transp. Syst. 2016, 17, 3434–3445. [Google Scholar] [CrossRef]
- Mishra, A.; Gangisetti, G.; Eftekhar Azam, Y.; Khazanchi, D. Weakly supervised crack segmentation using crack attention networks on concrete structures. Struct. Health Monit. 2024, 23, 3748–3777. [Google Scholar] [CrossRef]
- Tao, H. Weakly-Supervised Pavement Surface Crack Segmentation Based on Dual Separation and Domain Generalization. IEEE Trans. Intell. Transp. Syst. 2024, 25, 19729–19743. [Google Scholar] [CrossRef]
- Inoue, Y.; Nagayoshi, H. Weakly-supervised Crack Detection. IEEE Trans. Intell. Transp. Syst. 2023, 24, 12050–12061. [Google Scholar] [CrossRef]
- Wang, Z.; Leng, Z.; Zhang, Z. A weakly-supervised transformer-based hybrid network with multi-attention for pavement crack detection. Constr. Build. Mater. 2024, 411, 134134. [Google Scholar] [CrossRef]
- Zhou, B.; Khosla, A.; Lapedriza, A.; Oliva, A.; Torralba, A. Learning Deep Features for Discriminative Localization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Wang, H.; Li, Y.; Dang, L.M.; Lee, S.; Moon, H. Pixel-level tunnel crack segmentation using a weakly supervised annotation approach. Comput. Ind. 2021, 133, 103545. [Google Scholar] [CrossRef]
- Liu, F.; Liu, Y.; Kong, Y.; Xu, K.; Zhang, L.; Yin, B.; Hancke, G.; Lau, R. Referring Image Segmentation Using Text Supervision. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 2–3 October 2023. [Google Scholar]
- Rao, Y.; Zhao, W.; Chen, G.; Tang, Y.; Zhu, Z.; Huang, G.; Zhou, J.; Lu, J. Denseclip: Language-guided dense prediction with context-aware prompting. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVRR), New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- Jeong, J.; Zou, Y.; Kim, T.; Zhang, D.; Ravichandran, A.; Dabeer, O. Winclip: Zero-/few-shot anomaly classification and segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023. [Google Scholar]
- Chen, X.; Han, Y.; Zhang, J. A Zero-/Few-Shot Anomaly Classification and Segmentation Method for CVPR 2023 VAND Workshop Challenge Tracks 1&2: 1st Place on Zero-shot AD and 4th Place on Few-shot AD. arXiv 2023, arXiv:2305.17382. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. In Proceedings of the International Conference on Learning Representations (ICLR), Vienna, Austria, 4 May 2021. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollar, P. Focal Loss for Dense Object Detection. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Milletari, F.; Navab, N.; Ahmadi, S.A. V-net: Fully convolutional neural networks for volumetric medical image segmentation. In Proceedings of the 2016 Fourth International Conference on 3D Vision (3DV), Stanford, CA, USA, 25–28 October 2016. [Google Scholar]
- Ma, X.; Wu, Q.; Zhao, X.; Zhang, X.; Pun, M.O.; Huang, B. SAM-Assisted Remote Sensing Imagery Semantic Segmentation With Object and Boundary Constraints. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5636916. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention—MICCAI, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- König, J.; Jenkins, M.D.; Barrie, P.; Mannion, M.; Morison, G. A convolutional neural network for pavement surface crack segmentation using residual connections and attention gating. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. Pytorch: An imperative style, high-performance deep learning library. Adv. Neural Inf. Process. Syst. 2019, 32. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Crack500 | CFD | DeepCrack | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Metrics | ODS | OIS | AP | ODS | OIS | AP | ODS | OIS | AP |
| Grad-CAM [22] | 53.12 | 56.86 | 49.89 | 23.16 | 17.52 | 14.07 | 44.88 | 52.42 | 37.33 |
| PWSC [16] | 56.64 | 63.73 | 65.13 | 8.56 | 14.46 | 7.72 | 37.05 | 43.95 | 44.31 |
| GPLL [15] | 45.04 | 56.69 | 45.46 | 18.74 | 19.41 | 14.88 | 65.97 | 73.19 | 72.28 |
| CAC [19] | 60.43 | 64.60 | 63.65 | 23.31 | 31.55 | 18.55 | 71.01 | 77.98 | 75.51 |
| CrackCLIP | 61.31 | 68.58 | 59.33 | 40.80 | 41.74 | 31.81 | 68.26 | 73.29 | 68.82 |
| Methods | Pseudo-Label Types | Crack500 | CFD | DeepCrack | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| ODS | OIS | AP | ODS | OIS | AP | ODS | OIS | AP | ||
| CrackCLIP | FSV | 67.49 | 71.62 | 62.51 | 43.38 | 45.19 | 35.36 | 66.20 | 71.70 | 63.78 |
| CrackCLIP | CAM-CRF [16] | 63.00 | 68.07 | 60.54 | 39.15 | 39.82 | 32.01 | 58.77 | 67.05 | 55.66 |
| CrackCLIP | CAM-Location [15] | 61.31 | 68.58 | 59.33 | 40.80 | 41.74 | 31.81 | 68.26 | 73.29 | 68.82 |
| Methods | Crack500 | CFD | DeepCrack | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Metrics | ODS | OIS | AP | ODS | OIS | AP | ODS | OIS | AP |
| U-Net [39] | 55.88 | 63.20 | 65.17 | 9.09 | 16.74 | 9.58 | 44.17 | 54.32 | 56.55 |
| DeepCrack1 [6] | 56.64 | 63.73 | 65.13 | 8.56 | 14.46 | 7.72 | 37.05 | 43.95 | 44.31 |
| DeepCrack2 [5] | 57.93 | 64.44 | 62.23 | 20.18 | 26.25 | 14.79 | 44.57 | 49.61 | 48.89 |
| OED [41] | 52.01 | 61.14 | 54.02 | 10.24 | 15.89 | 4.43 | 26.16 | 32.71 | 9.42 |
| CrackCLIP | 63.00 | 68.07 | 60.54 | 39.15 | 39.82 | 32.01 | 58.77 | 67.05 | 55.66 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liang, F.; Li, Q.; Yu, H.; Wang, W. CrackCLIP: Adapting Vision-Language Models for Weakly Supervised Crack Segmentation. Entropy 2025, 27, 127. https://doi.org/10.3390/e27020127
Liang F, Li Q, Yu H, Wang W. CrackCLIP: Adapting Vision-Language Models for Weakly Supervised Crack Segmentation. Entropy. 2025; 27(2):127. https://doi.org/10.3390/e27020127
Chicago/Turabian StyleLiang, Fengjiao, Qingyong Li, Haomin Yu, and Wen Wang. 2025. "CrackCLIP: Adapting Vision-Language Models for Weakly Supervised Crack Segmentation" Entropy 27, no. 2: 127. https://doi.org/10.3390/e27020127
APA StyleLiang, F., Li, Q., Yu, H., & Wang, W. (2025). CrackCLIP: Adapting Vision-Language Models for Weakly Supervised Crack Segmentation. Entropy, 27(2), 127. https://doi.org/10.3390/e27020127