1. Introduction
Instrument reading detection is a crucial process to ensure the digital transformation of the manufacturing industry [
1]. For instrument reading detection tasks in industrial scenarios, instrument images are captured using industrial cameras, inspection robots, handheld cameras, and surveillance systems. Challenges such as image blurring, distortion, and perspective transformations often arise due to varying imaging angles and illumination. These issues significantly impact the performance of existing detection algorithms, preventing the accurate identification of instrument reading regions. To address these challenges, this paper proposes a contour disentangled detection network based on computer vision techniques for instrument reading detection tasks.
With the widespread application of computer vision technology in image processing [
2] and pattern recognition [
3], object detection algorithms have gradually become effective tools in various domains, such as scene text detection [
4], intelligent transportation [
5], safety belt detection [
6], and other fields. Instrument reading detection can be regarded as a generalized object detection problem. However, it differs from common object detection tasks due to unique challenges in distinguishing the foreground from the background. These challenges include interfering factors around the instrument display area, tilted instrument angles, and complex industrial environments. Specifically, the instrument images captured by industrial cameras are often affected by distortions resulting from rotational changes or perspective transformations. Such conditions pose significant challenges for instrument reading detection tasks. In this case, common object detection algorithms often struggle to accurately locate the reading contours, as illustrated in
Figure 1. Existing detection algorithms tend to exhibit issues such as excessive inclusion of background information and insufficient capture of foreground details.
Common object detection algorithms are typically categorized into horizontal rectangular detectors, rotating rectangular detectors, and quadrilateral detectors. Among these, the “R-CNN family” [
7,
8,
9] represents the most prominent two-stage approach for horizontal rectangular detection. This framework employs thousands of class-independent anchor boxes to facilitate object detection. While two-stage methods generally offer higher accuracy, they come at the cost of increased computational complexity [
10]. Representative one-stage horizontal rectangular detectors include YOLO [
11], SSD [
12], and RetinaNet [
13]. These methods operate by directly dividing the input image into small grids, predicting the bounding boxes for each grid, and subsequently refining these predictions to match the ground-truth boxes. In recent years, horizontal rectangular detectors have been widely used in instrument reading detection [
14,
15], scene text detection [
16], remote sensing images [
17], and other related scenarios. However, these detectors generate bounding boxes aligned along the horizontal axis, which restricts their effectiveness in many real-world applications. In practical applications, target objects are often densely arranged, with a large aspect ratio, and undergo rotational transformations. Therefore, the rotating rectangle detector emerged to solve the problem of rotation transformation. The rotating rectangular detector adds angle information on the basis of the horizontal rectangular detector, which is also relatively common in remote sensing image [
18,
19,
20], scene text detection [
21,
22], and other tasks. The predicted substances include category, position coordinates, length, width, and angle, which make it more accurate than the horizontal rectangular detector. However, in practical applications, target objects often experience varying degrees of perspective transformation due to camera angle variations, which poses additional challenges. Horizontal and rotating rectangular detectors cannot accurately locate the bounding box of the target objects. In this case, the quadrilateral detector can more accurately detect the boundary box of the target objects. Consequently, some quadrilateral detection algorithms have been proposed [
23,
24,
25]. The difficulty of the quadrilateral detection algorithm mainly comes from its four twisted sides, which are irregularly and independently arranged. Quadrilateral detection algorithms typically predict bounding boxes by regressing the coordinates of four vertices, with each vertex simultaneously influencing the positioning of two adjacent edges. As a result, the sides of the quadrilateral contour are affected by two vertices, and the adjacent side is also affected to varying degrees, which is a vertex entanglement problem. This problem suppresses the learning efficiency and detection performance of the quadrilateral detector. For the entangled vertices problem, researchers have proposed solutions [
26,
27,
28,
29] which alleviate such problems by setting an appropriate vertex sequential protocol. However, these approaches primarily serve as remedial measures rather than fundamentally solving the problem.
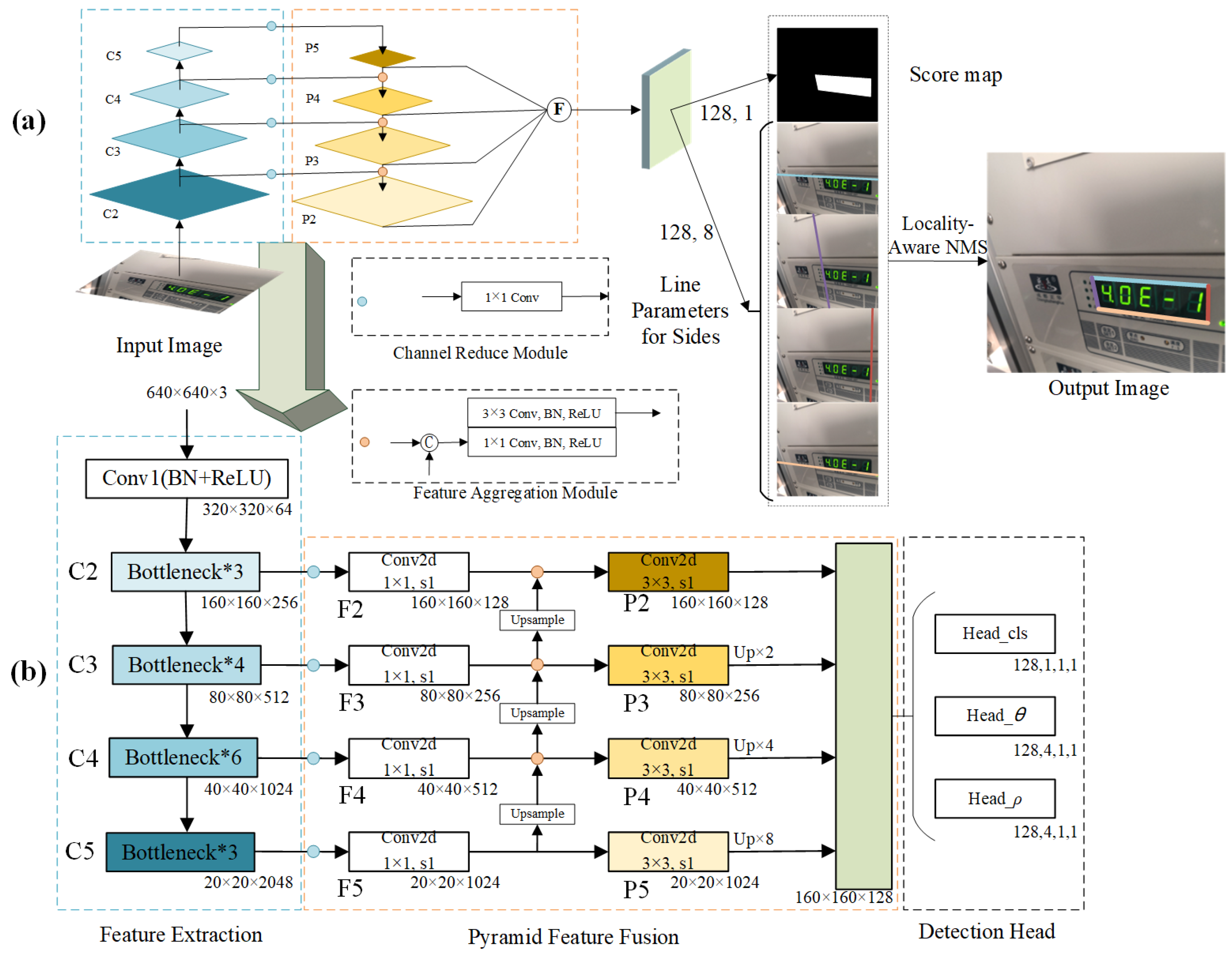
To address the challenges of distorted reading contours and vertex entanglement in instrument images, this paper proposes an instrument reading detection network based on quadrilateral contour disentanglement (QCDNet). In QCDNet, the residual network is employed as a fundamental module for feature extraction from instrument images. Then, a Multi-scale Feature Pyramid Network (MsFPN) module is developed to integrate low-level and high-level features for strong semantic feature information. Meanwhile, Polar Coordinates Decoupling Representation (PCDR) is introduced, which decouples each side of the instrument reading contour from the overall structure, as shown in
Figure 2. Additionally, the Polar-IoU and cosine angle loss function are designed to optimize the characterization parameters of each side’s geometric properties, enabling better representation in instrument images. Therefore, QCDNet can effectively solve the problem of distorted reading contours and vertex entanglement, offering a reliable solution for instrument reading detection in industrial scenarios. This paper provides a reference model for enhancing the efficiency and accuracy of instrument readings detection in industrial scenarios.
In summary, the main contributions of this work are as follows:
(1) A residual network combined with an MsFPN module is proposed to fuse low-level features and high-level features to obtain strong semantic feature information. The ablation experiment results prove the validity of MsFPN in the Instrument Dataset.
(2) A novel Polar Coordinate Decoupling Representation method is introduced, which disentangles each side of the instrument reading contour using polar coordinates. Based on the geometrical properties of instrument reading contour, the Polar-IoU and cosine angle loss functions are designed to enhance the model learning capability and decoupling performance.
(3) Extensive validation experiments were conducted on the Instrument Dataset. The experimental results demonstrate that the proposed QCDNet outperforms comparative methods in the instrument reading detection task.
2. Related Work
Based on the above introduction, it can be inferred that addressing the distortion of the reading area contour caused by rotation and perspective transformation is a crucial challenge in instrument reading detection tasks. One of the solutions to this issue is the quadrilateral detector. Recent studies [
26,
28,
30] have highlighted that the quadrilateral bounding boxes serve as a key representation for multi-directional detection algorithms. However, a significant challenge in the generation process of quadrilateral bounding boxes is the vertex entanglement problem. Existing quadrilateral detectors can be broadly categorized into anchor-free and anchor-based methods, depending on whether anchors are utilized. For the anchor-free quadrilateral detectors [
31,
32,
33], the approaches involve detecting the corner points of the target and subsequently generating bounding boxes based on these points. While this method avoids reliance on predefined anchors, it often involves complex post-processing and is highly susceptible to outliers because anchor-based quadrilateral detectors [
21,
26,
34,
35] directly learn the bounding boxes to locate the target object, reducing the complexity of post-processing. However, these detectors are sensitive to label sequences, which can affect detection accuracy.
Most of the above quadrilateral detectors directly or indirectly rely on learning four points to locate the bounding box of the target object. However, the quadrilateral bounding box is determined with four points, and their order can easily become inconsistent during training. Moreover, the four vertices of the quadrilateral bounding box are highly sensitive to the label sequence. It is difficult for the network to determine the order of the four vertices, and a small disturbance changes the whole sequence completely. Therefore, it is crucial to establish a sequential protocol prior to training. Existing solutions for mitigating label inconsistency are summarized as follows.
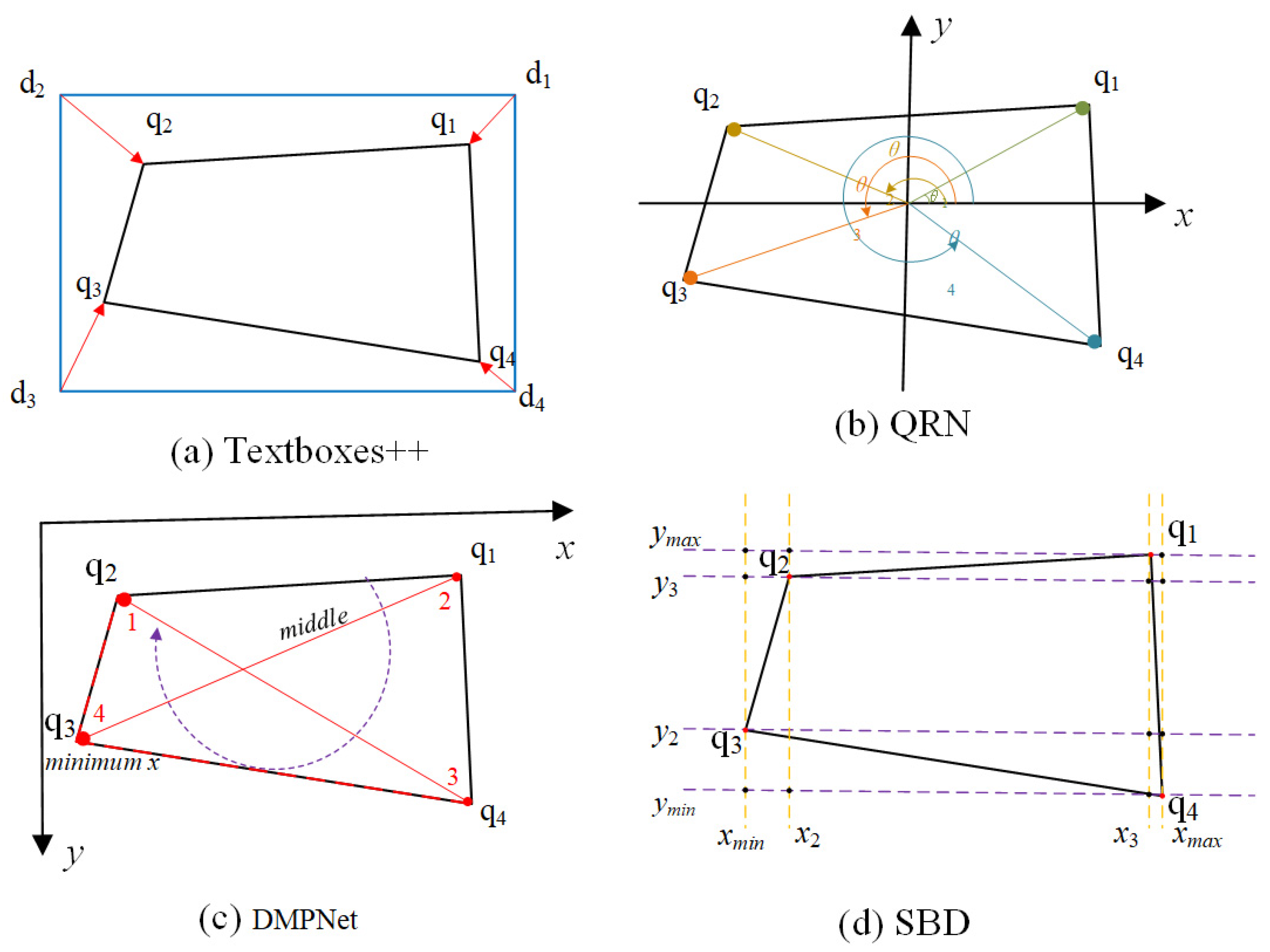
Textboxes++ [
26] solved the label inconsistency problem by implicitly regressing the four vertices of the target quadrilateral, as shown in
Figure 3a. Specifically, the algorithm determines the sequence by calculating the distance between each quadrilateral vertex q
i and the corresponding horizontal rectangular vertex d
i (
i = 1, 2, 3, 4).
QRN [
27] resolved the vertex ordering issue by sorting the vertices of the target quadrilateral and reference rectangle in ascending polar order, as shown in
Figure 3b. Specifically, QRN computes the average center point of the four vertices and constructs a Cartesian coordinate system. It then calculates the intersection angles of the four vertices with the origin and selects the vertex with the smallest angle as the starting point.
DMPNet [
28] introduced a slope-based method for determining label sequences, as shown in
Figure 3c. The first point is determined by the minimum value of x in the four vertices, and then the minimum point is connected to the other three points. The point on the other end of the middle line is the third point, the point on the top left of the middle line is the second point, and the other point is the fourth point. Finally, the slope between the two diagonal lines, 13 and 24, are compared. The vertex with the smaller
x-coordinate on the line with the larger slope is selected as the new first point. The above procedure is then repeated to identify the remaining three points in sequence.
SBD [
29] proposed a matching learning module to solve the label inconsistency problem, as shown in
Figure 3d. The method begins by plotting the
x-axes and
y-axes for each vertex of the quadrilateral. These axes are then sorted in ascending order, and their intersection points with the bounding box are marked. Next, the first point (shown as a red dot q3) is identified at the intersection of the bounding box and the axis with the minimum
xmin value. Finally, the remaining three points are labeled sequentially in a clockwise direction.
Although the above sequential protocols can alleviate label confusion to a certain extent, their performance deteriorates significantly when the instrument image is severely distorted by perspective transformations. Moreover, these methods often involve complex computations. In contrast, the proposed QCDNet focuses on decoupling each side of the instrument reading contour and representing the line equations of each side using polar coordinates. This approach minimizes the reliance on complex label sequential protocols. Additionally, it eliminates the need for intricate post-processing steps to generate quadrilateral bounding boxes, effectively resolving the vertex entanglement problem.
4. Experiments
In this section, we first describe the preparation and implementation details of the experiments. Then, the performance of functional modules is analyzed through ablation experiments. Finally, the effectiveness of the proposed model is compared with mainstream methods on an instrument reading detection task through quantitative and qualitative experiments.
4.1. Dataset Preparation
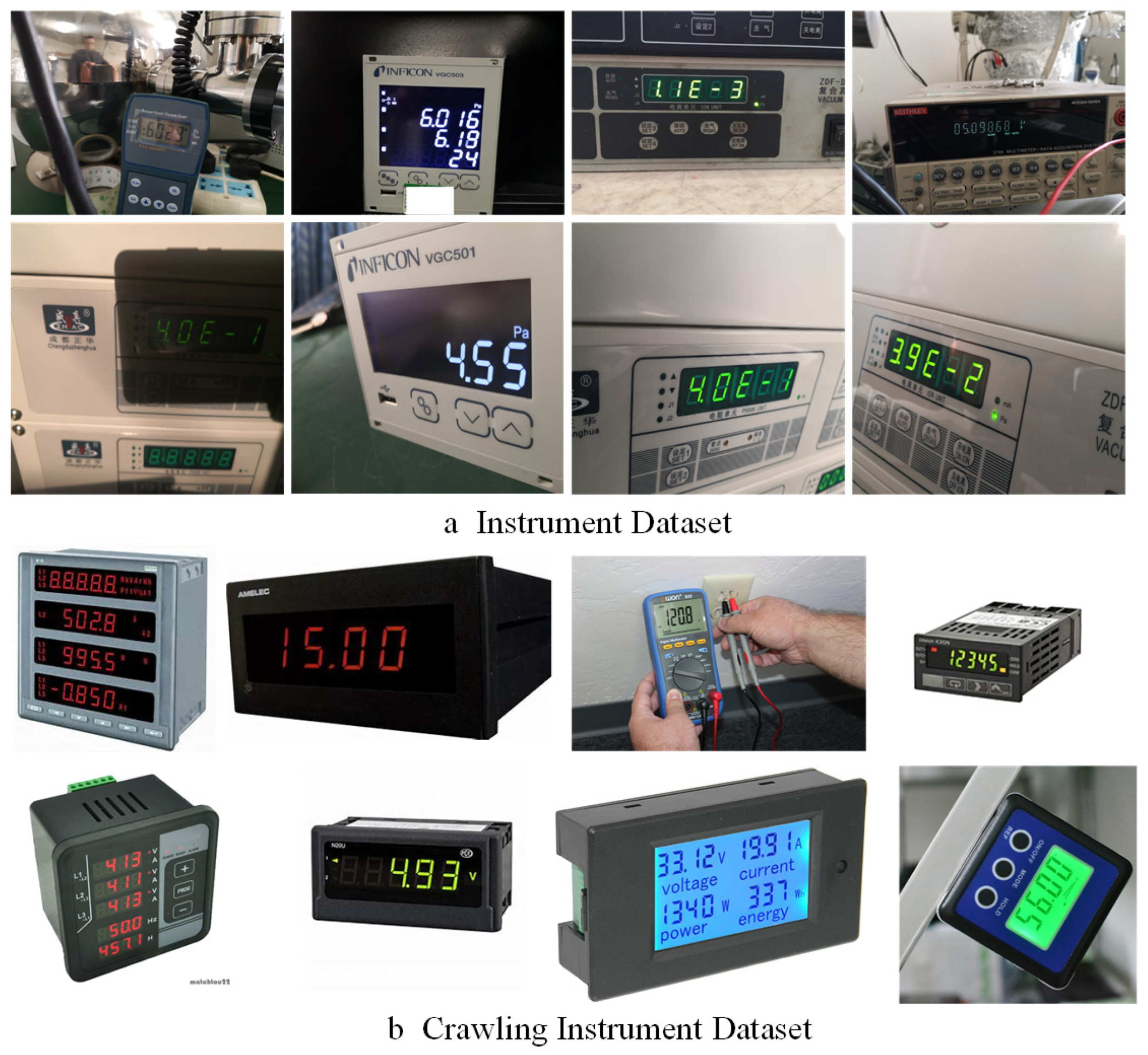
Considering the fact that no publicly available instrument image datasets have been reported so far, 1723 instrument images with a variety of lighting conditions, backgrounds, imaging angles, and resolutions were collected in industrial scenes for this study. These images were scaled to 1000 × 1000 pixels using a bilinear interpolation method to obtain the Instrument Dataset for experiment analysis, as shown in
Figure 7a. Meanwhile, in order to improve the training efficiency of the deep learning model, 10,520 instrument images were collected from the Internet, a collection called the Crawling Instrument Dataset, as shown in
Figure 7b. Both datasets were manually labeled using two different tools (LabelImg and VIA). The difference between the two annotation tools is that LabelImg uses a center point, height, and width annotation method, and the bounding box is a rectangle. VIA uses the annotation method of four vertices, and the bounding box is an arbitrary quadrilateral box. According to experimental needs, VIA is most used as the labeling tool for quadrilateral detectors, while LabelImg is often used for horizontal and rotation detectors. In our datasets, two annotation tools were used for the Instrument Dataset, and the Crawling Instrument Dataset was only annotated using the VIA. In the experiment, the labeled Crawling Instrument data were used to pre-train the model, while the Instrument Dataset was employed for the model training and testing with 8:2 ratios.
4.2. Implementation DETAILS
The Adam [
41] optimization algorithm was employed for model training, with an initial learning rate set to 1 × 10
−3, dynamically adjusted based on the number of iterations. Specifically, the model pre-training was conducted on the Crawling Instrument Dataset, where the initial learning rate decay was 1 × 10
−4 at 40,000 iterations. Subsequently, the model was fine-tuned and optimized on the Instrument Dataset over 60,000 iterations with a constant learning rate. After completing the final epoch, the model parameters were fixed to evaluate its performance on the test dataset. To ensure fairness in the experiment, all models were run in the same environment: Intel Xeon(R) W 2145@3.7 GHz CPU, NVIDIA Quadro RTX4000 GPU, Ubuntu 20.04, CUDA 11.2, and Pytorch 1.7.
During the training phase, the height and width of the instrument images were randomly scaled in the range of [640, 2560]. This scaling was implemented to account for the varying distorted shapes of the instrument reading areas. Additionally, the brightness, contrast, saturation, and color channels of the instrument image were randomly changed to improve the generalization ability of the model. Finally, 640 × 640 patches were randomly cropped from the transformed instrument images to serve as the training data.
4.3. Evaluation Protocols
In order to evaluate the detection performance of the algorithm on the instrument image dataset, we used Average Precision (AP), Precision, Recall, F-measure, and inference time (ms) as evaluation protocols. The formulas are as follows.
where TP, FN, and FP are true positives, false negatives, and false positives, respectively. In the detection task, a detected bounding box is considered true if its Intersection over Union (IoU) with the ground-truth bounding box exceeds a threshold. Incorrect bounding box predictions are counted as false positives, while false negatives are the bounding boxes that should have been detected but were missed. F-measure is used to measure the overall performance of the model.
4.4. Validation of Model Effectiveness
In order to verify the effectiveness of our proposed method in instrument reading detection tasks, some experiments were implemented for performance analysis regarding the following three aspects: (1) backbone network, a strong feature extraction network that can significantly enhance the performance of the algorithm; (2) ablation experiments, in which the effects of the proposed MsFPN, Polar-IoU loss, and cosine angle loss are analyzed by the control variable method; and (3) qualitative and quantitative analysis for the detector, in which the effectiveness of QCDNet in instrument reading detection is demonstrated through both qualitative and quantitative evaluations.
4.4.1. Backbone Network
In computer vision tasks, the network responsible for image feature extraction is called the backbone network. Commonly used CNN backbone networks include VGG [
42], GoogLeNet [
43], and ResNet [
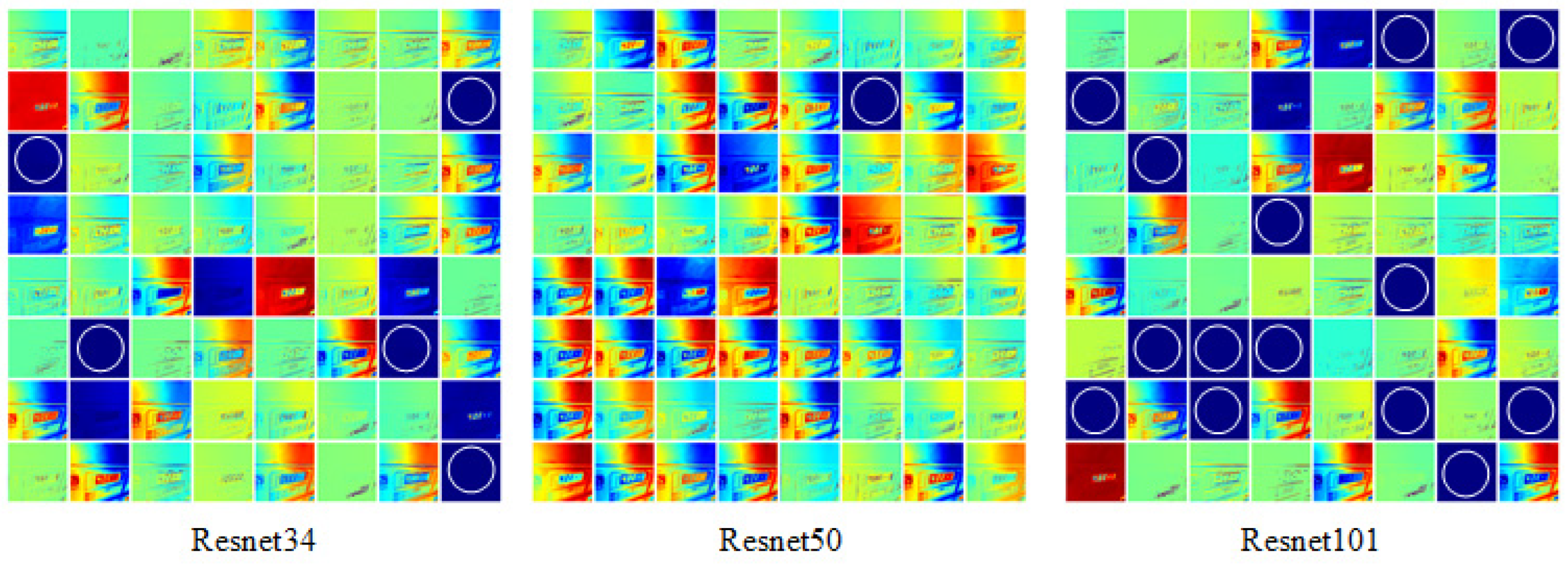
44], etc. Traditional CNN convolutional layers or fully connected layers often face issues such as information loss and high computational cost during information transmission. ResNet has the ability to solve problems such as gradient disappearance and network degradation, so we employ this structure as the backbone network in our network design. A deeper network typically offers better performance than a shallower one. However, merely increasing the number of layers can lead to higher computational costs without guaranteeing improved performance. To determine the optimal backbone network for our model, we compared the feature extraction performance of ResNet34, ResNet50, and ResNet101 by visualizing the feature maps. Specifically, we selected the feature map of the f2_BN1 layer 8 × 8, shown in
Figure 8. The rationale for choosing this layer is that its advanced features capture macro-level information of the instrument image, which might not be easily recognizable by humans. The f2_BN1 layer represents finer details of the instrument image. By observing the feature maps, we can evaluate the performance of the backbone network in extracting instrument reading features. From
Figure 8, it can be seen that only one feature map of the ResNet50 network does not clearly extract instrument image features, while ResNet34 and ResNet101 have 5 and 14 feature maps that do not extract instrument image features, respectively. So ResNet50 was selected as the backbone network for our model.
4.4.2. Ablation Experiment
To verify the effectiveness of the proposed QCDNet detection network, ablation experiments were conducted. Specifically, QCDNet integrates three designed modules: MsFPN, Polar-IoU loss, and cosine angle loss. The impact of each module was analyzed using the control variable method to isolate their effects. The baseline model was derived from QCDNet by systematically replacing or removing specific modules. For instance, when evaluating the performance of Polar-IoU loss, the baseline model employed the commonly used L1 loss instead. Similarly, the effects of the other modules were analyzed by modifying the baseline configuration accordingly. The F-measure was utilized as the evaluation metric to measure the performance of the model in each scenario.
The results of the ablation experiment on the instrument dataset test set are shown in
Table 1. It can be seen that the MsFPN module was added to integrate multi-scale features, which increased by 3.04% compared with the F-measure of the baseline model, indicating that the designed MsFPN has good competitiveness. Compared with the feature fusion method, the design of the boundary box loss function is also particularly important. Polar-IoU loss and cosine angle loss were designed for this paper, which independently predict each edge to avoid vertex entanglement. It can be seen from
Table 1 that Polar-IoU loss and cosine angle loss significantly improved the detection performance of the model. The F-measure value increased by 5.44% and 4.74%, respectively, compared with the baseline model. Finally, the overall performance of the QCDNet model was further improved to 94.89% with the combined effect of the three modules, which is 7.48% better than the baseline model. The above ablation experiments verify the effectiveness of the proposed MsFPN, Polar-IoU loss, and cosine angle loss for bounding box detection.
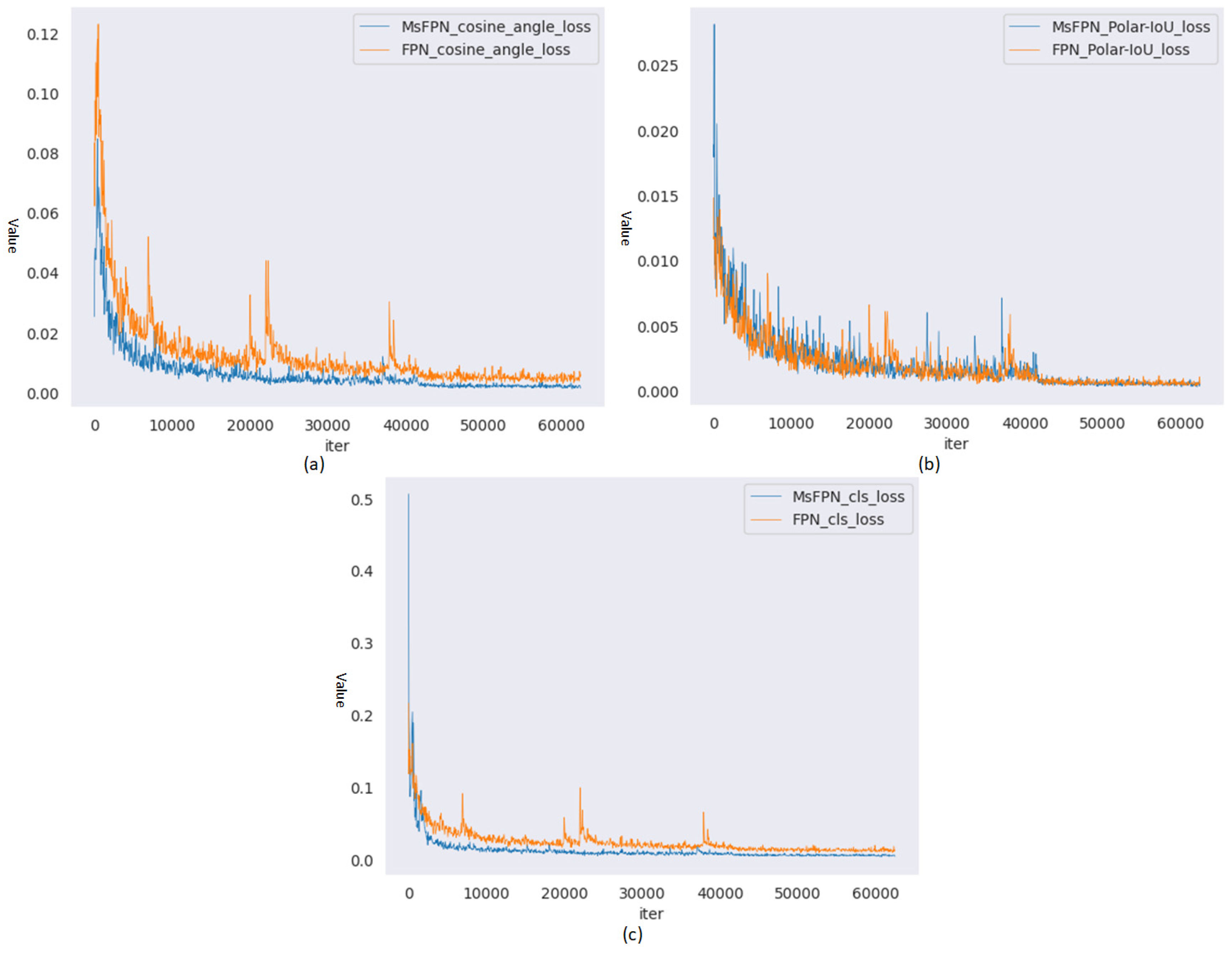
To validate the improvement in network performance obtained through MsFPN, we conducted ablation experiments on the Instrument Dataset test set. The experiments used Resnet50 as the feature extraction network to compare with the original FPN. Experimental results are shown in
Table 2. When IoU was 0.50, the AP values of both MsFPN and FPN reached 1. However, when IoU was 0.85, the proposed MsFPN was 1.19% higher than the FPN. Furthermore, we visualized three loss curves for both methods during training, as presented in
Figure 9. From the figure, it can be observed that the three loss curves of MsFPN are smoother and more stable than those of FPN. Therefore, the above ablation experiments validate the effectiveness of MsFPN. This also verifies the feasibility of the designed cosine angle loss and Polar-IoU loss in combination with other networks.
4.4.3. Qualitative and Quantitative Results
To perform a comprehensive analysis and evaluation of the proposed method, qualitative and quantitative analyses were conducted using three different types of detectors. These analyses aim to verify the effectiveness of the proposed approach in accurately detecting instrument readings.
For the horizontal rectangle detector, we choose an SSD and YOLO algorithm with higher accuracy and faster speed, RetinaNet, which solves the problem of data imbalance, and Faster-RCNN as the comparison method. To ensure fairness, we picked the instrument images with no affine transformation for model testing. As a rule of thumb, when the IoU was 0.5, the AP50 values of the five methods were equal to 1, which showed good performance, as shown in
Table 3. For a more detailed comparison, we increased the IoU to 0.85. At this threshold, the RetinaNet algorithm achieved the best performance, followed closely by our proposed method, with the AP85 values differing by only 0.0037. The IoU threshold for standard target detection is typically set to 0.5, but higher thresholds require more robust and efficient detectors. To further evaluate performance, we calculated the AP values across a range of IoU thresholds [0.5, 0.95] at intervals of 0.05, averaging these 10 AP values for the final result. This method is derived from the evaluation method of the VOC dataset. Under this more rigorous evaluation method, the proposed method had the highest AP value, which was 0.42% higher than the SSD algorithm, as shown in
Table 3. These results demonstrate the effectiveness of the proposed method for instrument reading detection tasks.
- 2.
QCDNet vs. Rotated Rectangle Detector:
Rotating rectangles are special example of quadrilaterals which are more flexible than horizontal rectangles and represent instrument reading bounding boxes in any direction. We selected five state-of-the-art rotation detectors available at the time for comparison. Compared to horizontal rectangle detectors, distinguishing the performance of rotation detectors at an IoU of 0.5 is more challenging. Therefore, we calculated Recall, Precision, and F-measure for IoU thresholds of 0.5 and 0.85, respectively. The comparison results are summarized in
Table 4. At IoU = 0.5, the proposed method achieved the highest Precision value of 0.9983, while its Recall and F-measure were slightly below those of Oriented R-CNN. However, at IoU = 0.85, the proposed method outperformed all five rotated rectangle detection methods in Recall, Precision, and F-measure. At this higher IoU threshold, the performance gap between quadrilateral detectors and rotated rectangle detectors became more pronounced. This confirms that the detector with the quadrilateral representation is more accurate than the rotated rectangle detector.
Finally, the instrument reading detection results of six methods were visualized on the instrument images, as shown in
Figure 10. From the figure, it can be seen that the five types of rotating rectangular detectors contain a lot of background information inside and the detection box is too large. The Rotated RetinaNet and Gliding Vertex algorithms failed to detect the reading in the second instrument image. For multiple-row instrument readings, as shown in the third column instrument image of
Figure 10, the detection boxes of Rotated Faster-RCNN, Oriented R-CNN, and RoI Transformer overlapped and interleaved, making it impossible to accurately detect the instrument reading bounding boxes. However, the proposed method can accurately detect the bounding box of the instrument reading, even in the presence of rotation or affine transformations in the instrument images. Therefore, the above experiments verify that the proposed method can solve the problem of instrument image distortion caused by rotation and affine transformation.
- 3.
QCDNet vs. Quadrilateral Detector:
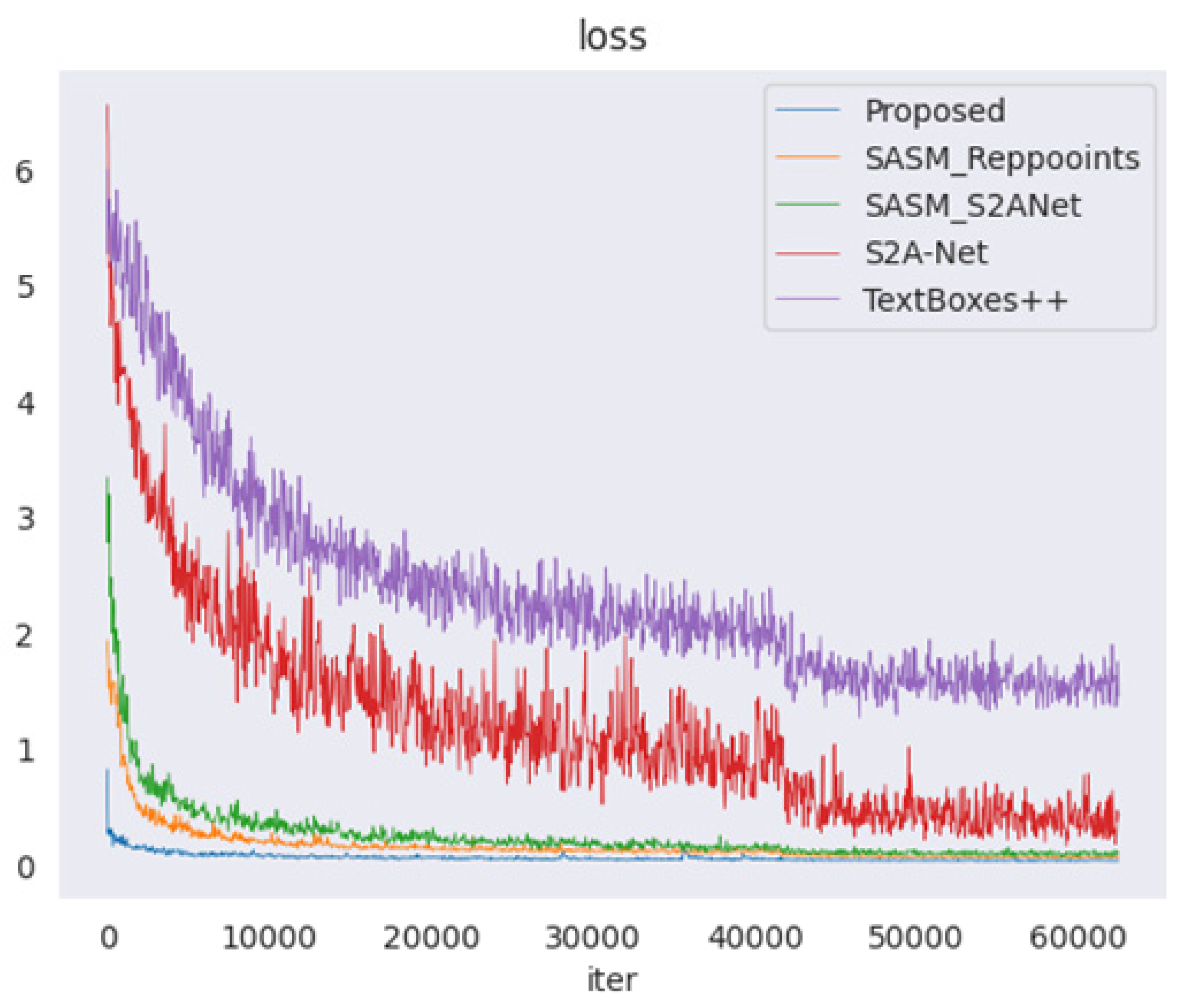
In real industrial scenarios, perspective transformation caused by the shooting angle often results in the distortion of instrument images. In this case, horizontal rectangle detectors or rotating rectangle detectors cannot accurately detect the instrument reading area. Therefore, the study of quadrilateral detectors is imperative. Existing quadrilateral detectors can be classified into anchor-based and anchor-free object detection algorithms according to whether there is a prior box. Most anchor-based quadrilateral detectors have the problem of vertex entanglement, and current solutions employ complex sequential protocols to alleviate this problem. The anchor-free quadrilateral detector eliminates the anchor generation mechanism and speeds up the model training, and these methods have higher accuracy. In this comparison test, we selected four quadrilateral detectors that were optimal at that time. Firstly, we compared the loss curves of the five detectors as shown in
Figure 11. The loss values of TextBoxes++ and S2A-Net exhibited significant jitter and slow convergence rates. However, the proposed method demonstrated the fastest convergence speed, stabilizing after approximately 10,000 iterations. This indirectly validates the effectiveness of the proposed Polar-IoU loss and cosine angle loss for instrument reading detection. Subsequently, a quantitative comparison between the proposed method and other four quadrilateral detectors was performed, as shown in
Table 5. The Recall and Precision values of the proposed method surpassed those of the second-best detector, SASM_Reppoints, by 1.8% and 3.07%, respectively. Additionally, the F-measure of the proposed method exceeded that of SASM_Reppoints by 2.89%. It is worth noting that the three evaluation indicators of the proposed method are all more than 10% higher than the TextBoxes++ algorithm.
Moreover, from
Table 5, it can be concluded that the Recall, Precision, and F-measure values of the anchor-free quadrilateral detector are higher than those of the anchor-based quadrilateral detector. To further illustrate the performance differences, the detection results of the five quadrilateral detectors on the Instrument Dataset test set are visualized in
Figure 12. It can be observed that TextBoxes++ and S2A-Net cannot accurately detect the third instrument image reading. The TextBoxes++ algorithm has a cross-connection situation, which is clearly caused by a problem with the sequential protocol. The other two detectors have issues with incomplete readings and excessive background information. On the instrument images with perspective transformation, the proposed method can still accurately detect the instrument readings with almost no background information, and the detection boxes are not cross-connected. These results verify that the proposed method effectively addresses the challenges posed by perspective transformation in instrument images while avoiding the complications associated with complex sequential protocols.
5. Conclusions
In this paper, a novel QCDNet method is proposed for detecting industrial instrument readings based on MsFPN and PCDR. In contrast to the existing detectors, QCDNet detects the contours of instrument readings in a disentangled manner, which exploits geometric properties to improve detection performance. Firstly, QCDNet utilizes MsFPN to fuse the extracted multi-scale features to obtain strong semantic feature information. Subsequently, PCDR is utilized to disentangle the parameters of the linear equations for each side of the instrument read contour in polar coordinates. By enhancing the geometric properties of instrument contour sides through customized Polar IoU loss and cosine angle loss, QCDNet can independently learn the representation of each disentangled side. Finally, extensive experiments were carried out on the Instrument Dataset, and the qualitative and quantitative results show the effectiveness of QCDNet for instrument read detection. The comparison results with the existing detectors verify that QCDNet can overcome the effects caused by rotation and perspective transformation. Meanwhile, compared with existing quadrilateral detectors, QCDNet solves the problem of vertex entanglement without relying on complex sequential protocols. Therefore, it can be concluded that QCDNet has the potential to be applied to detect instrument readings in real industrial scenarios. Considering the complexity and diversity of industrial instrument, in future research, we will improve the detection box of the proposed method so that the detection object can be extended to all kinds of instruments, including pointer meters with different shapes, and continuously enhance the detection performance of our method.





 and
and 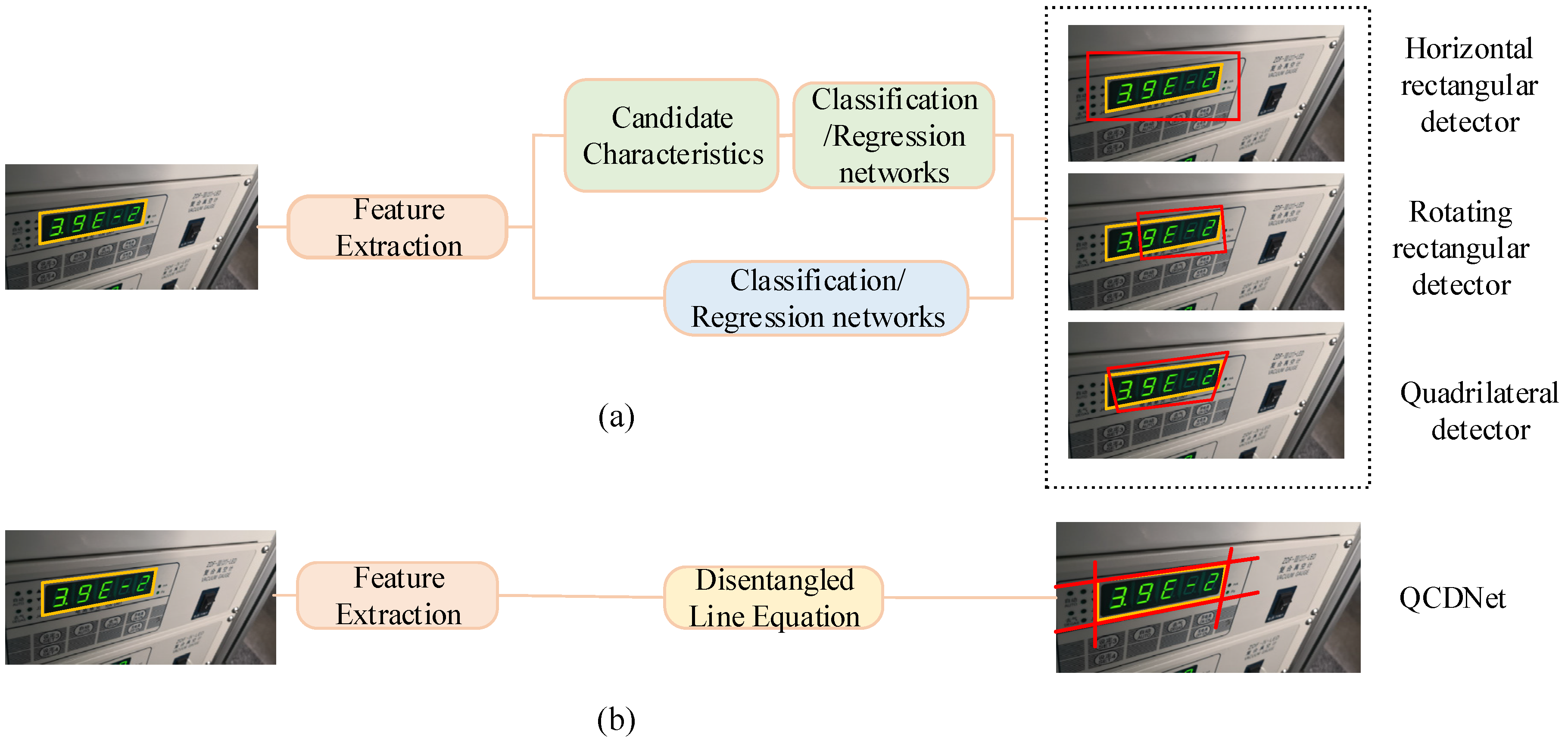






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}