


Hybrid DAER Based Cross-Modal Retrieval Exploiting Deep Representation Learning
Abstract
:1. Introduction
2. Related Work
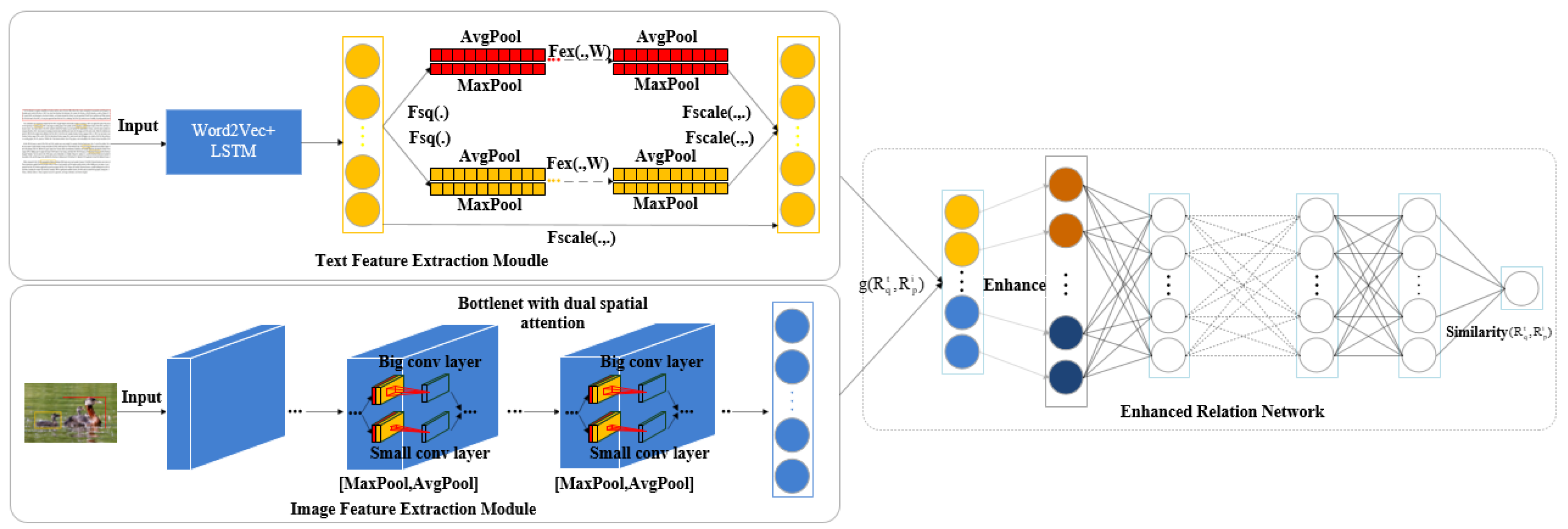
3. The Proposed Method
3.1. Text Feature Extraction Module
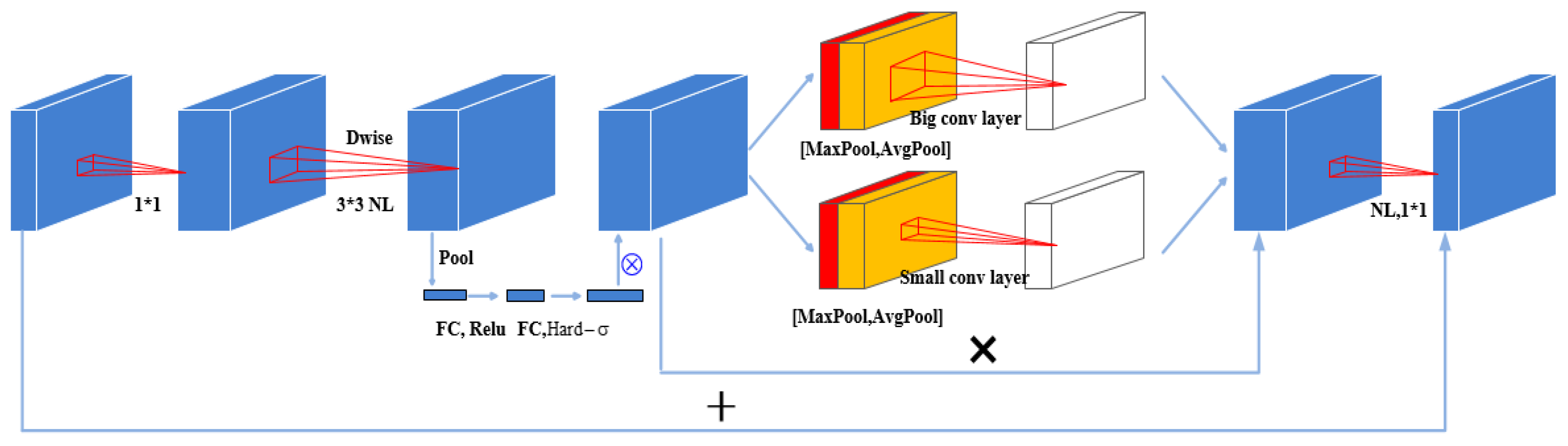
3.2. Image Feature Extraction Module
3.3. Enhanced Relation Network
3.4. Process of Model Training
| Algorithm 1: The training process of DAER. | |
| Input: The image data , the text data , the corresponding class label set and Output: The optimized DAER model. | |
The training phase:
| |
| |
| |
| |
4. Experimental Work
4.1. Datasets
4.2. Evaluation Metric
4.3. Comparison Methods
4.4. Experiment Implementation
5. Results and Discussion
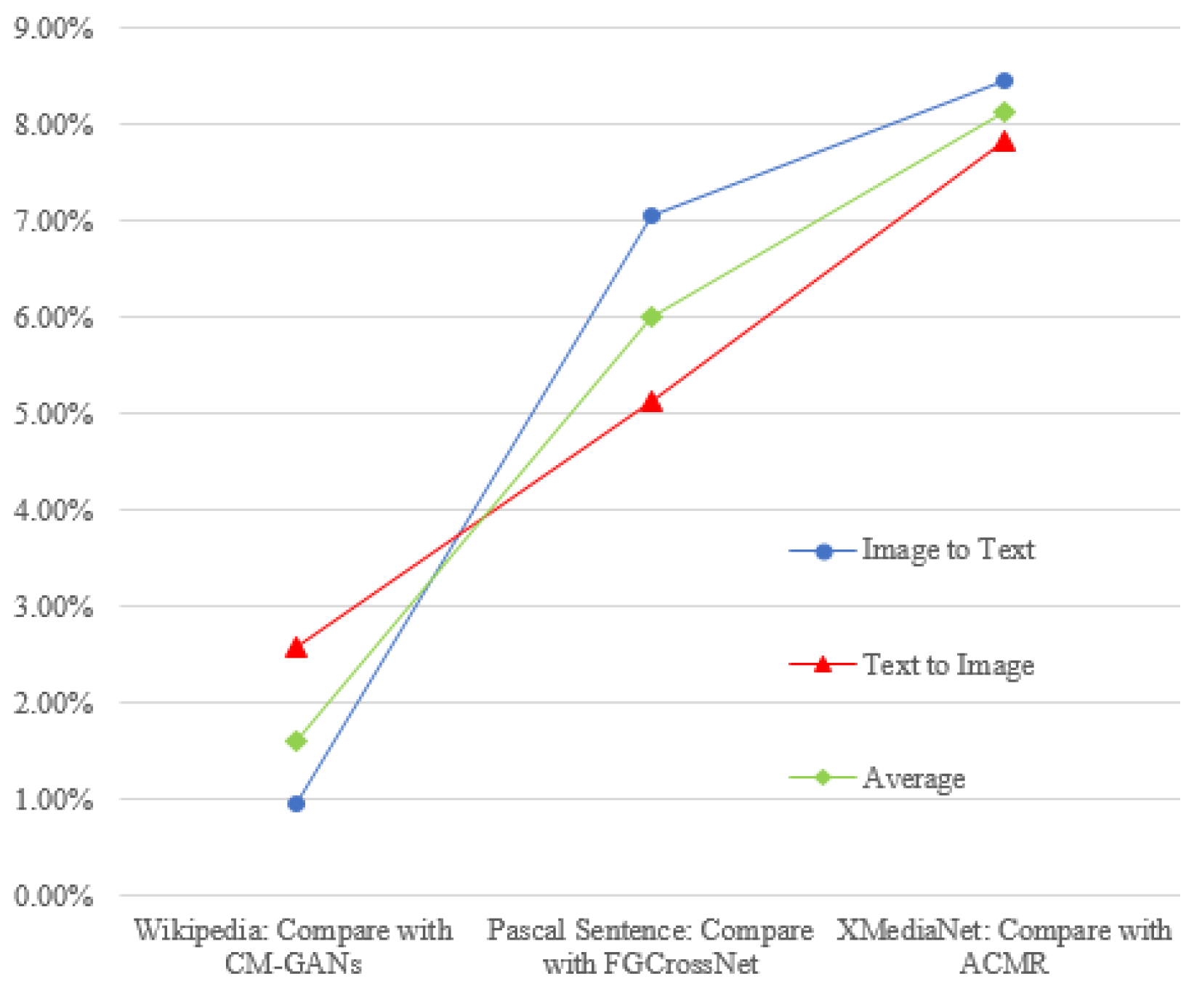
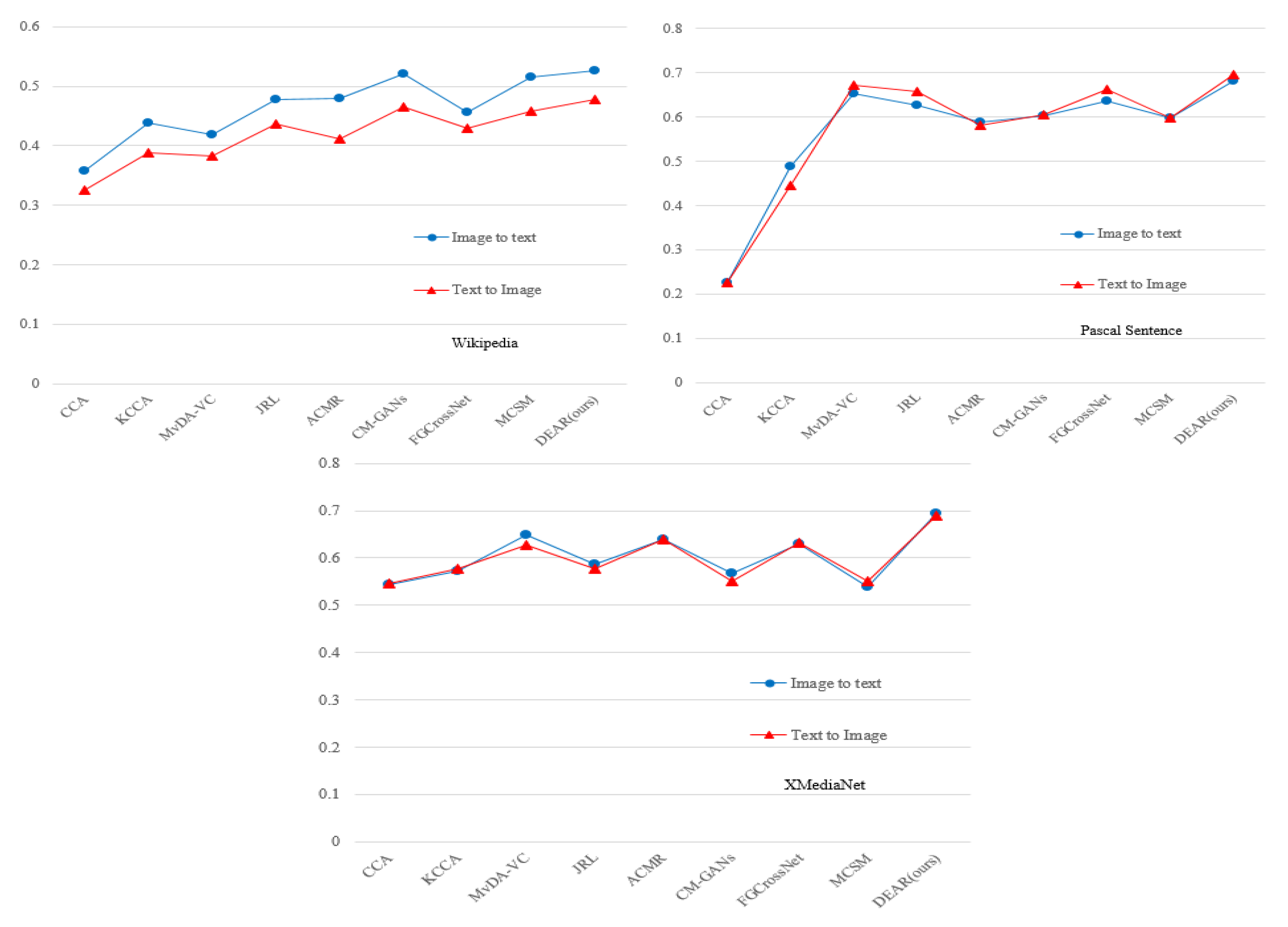
5.1. Comparison with Existing Methods
5.2. Comparison with Variants of DAER
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Li, Z.; Lu, H.; Fu, H.; Gu, G. Image-text bidirectional learning network based cross-modal retrieval. Neurocomputing 2022, 483, 148–159. [Google Scholar] [CrossRef]
- Nagrani, A.; Albanie, S.; Zisserman, A. Seeing voices and hearing faces: Cross-modal biometric matching. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8427–8436. [Google Scholar]
- Yongjun, Z.; Yan, E.; Song, I.Y. A natural language interface to a graph-based bibliographic information retrieval system. Data Knowl. Eng. 2017, 111, 73–89. [Google Scholar]
- Yuxin, P.; Jinwe, Q.; Yuxin, Y. Modality-specific cross-modal similarity measurement with recurrent attention network. IEEE Trans. Image Process. 2018, 27, 5585–5599. [Google Scholar]
- Gupta, Y.; Saini, A.; Saxena, A. A new fuzzy logic based ranking function for efficient information retrieval system. Expert Syst. Appl. 2015, 42, 1223–1234. [Google Scholar] [CrossRef]
- Bella, M.I.T.; Vasuki, A. An efficient image retrieval framework using fused information feature. Comput. Electr. Eng. 2019, 75, 46–60. [Google Scholar] [CrossRef]
- Alotaibi, F.S.; Gupta, V. A cognitive inspired unsupervised language-independent text stemmer for Information retrieval. Cogn. Syst. Res. 2018, 52, 291–300. [Google Scholar] [CrossRef]
- Tang, J.; Wang, K.; Shao, L. Supervised matrix factorization hashing for cross modal retrieval. IEEE Trans. Image Process. 2016, 25, 3157–3166. [Google Scholar] [CrossRef]
- Li, K.; Qi, G.J.; Ye, J.; Hua, K.A. Linear subspace ranking hashing for cross-modal retrieval. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1825–1838. [Google Scholar] [CrossRef]
- Hotelling, H. Relations between two sets of variates. In Breakthroughs in Statistics; Springer: New York, NY, USA, 1992; pp. 162–190. [Google Scholar]
- Shu, X.; Zhao, G. Scalable multi-label canonical correlation analysis for cross-modal retrieval. Pattern Recognit. 2021, 115, 107905. [Google Scholar] [CrossRef]
- Fukumizu, K.; Gretton, A.; Bach, F. Statistical convergence of kernel CCA. Adv. Neural Inf. Process. Syst. 2005, 18, 387–394. [Google Scholar]
- Li, J.; Li, M.; Lu, G.; Zhang, B.; Yin, H.; Zhang, D. Similarity and diversity induced paired projection for cross-modal retrieval. Inf. Sci. 2020, 539, 215–228. [Google Scholar] [CrossRef]
- Peng, Y.; Qi, J.; Huang, X.; Yuan, Y. CCL: Cross-modal correlation learning with multi grained fusion by hierarchical network. IEEE Trans. Multimed. 2018, 20, 405–420. [Google Scholar] [CrossRef]
- Kaur, P.; Pannu, H.S.; Malhi, A.K. Comparative analysis on cross-modal information retrieval: A review. Comput. Sci. Rev. 2021, 39, 100336. [Google Scholar] [CrossRef]
- Bokun, K.; Yang, Y.; Xing, X.; Alan, H. Adversarial cross-modal retrieval. In Proceedings of the 25th ACM International Conference on Multimedia (MM ‘17), Mountain View, CA, USA, 23 October 2017; pp. 154–162. [Google Scholar]
- Xu, W.A.; Peng, H.; Lz, D.; Dpab, C. DRSL: Deep relational similarity learning for cross-modal retrieval—Science direct. Inf. Sci. 2021, 546, 298–311. [Google Scholar]
- He, X.; Peng, Y.; Xie, L. A new benchmark and approach for fine-grained cross-media retrieval. In Proceedings of the 27th ACM International Conference on Multimedia, Nice, France, 21–25 October 2019; pp. 1740–1748. [Google Scholar]
- Jin, M.; Zhang, H.; Zhu, L.; Sun, J.; Liu, L. Coarse-to-fine dual-level attention for video-text cross modal retrieval. Knowl.-Based Syst. 2022, 242, 108354. [Google Scholar] [CrossRef]
- Peng, X.; Feng, J.; Xiao, S.; Yau, W.Y.; Zhou, J.T.; Yang, S. Structured auto encoders for subspace clustering. IEEE Trans. Image Process. 2018, 27, 5076–5086. [Google Scholar] [CrossRef]
- Hu, P.; Peng, D.; Wang, X.; Xiang, Y. Multimodal adversarial network for cross-modal retrieval. Knowl.-Based Syst. 2019, 180, 38–50. [Google Scholar] [CrossRef]
- Hardoon, D.R.; Szedmak, S.; Shawe-Taylor, J. Canonical correlation analysis: An over view with application to learning methods. Neural Comput. 2004, 16, 2639–2664. [Google Scholar] [CrossRef]
- Cai, J.; Tang, Y.; Wang, J. Kernel canonical correlation analysis via gradient descent. Neurocomputing 2016, 100, 322–331. [Google Scholar] [CrossRef]
- Jia, Y.; Bai, L.; Liu, S.; Wang, P.; Guo, J.; Xie, Y. Semantically-enhanced kernel canonical correlation analysis: A multi-label cross-modal retrieval. Multimed. Tools Appl. 2019, 78, 13169–13188. [Google Scholar] [CrossRef]
- Xu, M.; Zhu, Z.; Zhao, Y.; Sun, F. Subspace learning by kernel dependence maximization for cross-modal retrieval. Neurocomputing 2018, 309, 94–105. [Google Scholar] [CrossRef]
- Yan, F.; Mikolajczyk, K. Deep correlation for matching images and text. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 12 June 2015; pp. 3441–3450. [Google Scholar]
- Gao, Y.; Zhou, H.; Chen, L.; Shen, Y.; Guo, C.; Zhang, X. Cross-Modal Object Detection Based on a Knowledge Update. Sensors 2022, 22, 1338. [Google Scholar] [CrossRef] [PubMed]
- Viviana, L.; Caicedo, J.; Journet, N.; Coustaty, M.; Lecellier, F.; Doucet, A. Deep multimodal learning for cross-modal retrieval: One model for all tasks. Pattern Recognit. Lett. 2021, 146, 38–45. [Google Scholar]
- Wu, F.; Jing, X.; Wu, Z.; Ji, Y.; Dong, X.; Luo, X.; Huang, Q.; Wang, R. Modality-specific and shared generative adversarial network for cross-modal retrieval. Pattern Recogn. 2020, 104, 107335. [Google Scholar] [CrossRef]
- Zou, X.; Wu, S.; Zhang, N.; Bakker, E.M. Multi-label modality enhanced attention based self-supervised deep cross-modal hashing. Knowl. -Based Syst. 2022, 239, 107927. [Google Scholar] [CrossRef]
- Chowdhury, F.A.R.R.; Quan, W.; Moreno, I.L.; Li, W. Attention-based models for text-dependent speaker verification. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 5359–5363. [Google Scholar]
- Yang, B.; Wang, L.; Wong, D.F.; Shi, S.; Tu, Z. Context-aware self-attention networks for natural language processing. Neurocomputing 2021, 458, 157–169. [Google Scholar] [CrossRef]
- Wang, F.; Jiang, M.; Qian, C.; Yang, S.; Li, C.; Zhang, H.; Tang, X. Residual attention network for image classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3156–3164. [Google Scholar]
- Galassi, A.; Lippi, M.; Torroni, P. Attention in natural language processing. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 4291–4308. [Google Scholar] [CrossRef] [PubMed]
- Li, Y. A calibration method of computer vision system based on dual attention mechanism. Image Vis. Comput. 2020, 103, 104039. [Google Scholar] [CrossRef]
- Nasef, M.M.; Sauber, A.M.; Nabil, M.M. Voice gender recognition under unconstrained environments using self-attention. Appl. Acoust. 2021, 175, 107823. [Google Scholar] [CrossRef]
- Ding, H.; Gu, Z.; Dai, P.; Zhou, Z.; Wang, L.; Wu, X. Deep connected attention (DCA) ResNet for robust voice pathology detection and classification. Biomed. Signal Process. Control 2021, 70, 102973. [Google Scholar] [CrossRef]
- Peng, Y.; Qi, J.; Zhuo, Y. MAVA: Multi-Level Adaptive Visual-Text Align by Cross-Media Bi-Attention Mechanism. IEEE Trans. Image Process. 2020, 29, 2728–2741. [Google Scholar] [CrossRef]
- Peng, H.; He, J.; Chen, S.; Wang, Y.; Qiao, Y. Dual-supervised attention network for deep cross-modal hashing. Pattern Recognit. Lett. 2019, 128, 333–339. [Google Scholar] [CrossRef]
- Dong, X.; Zhang, H.; Dong, X.; Lu, X. Iterative graph attention memory network for cross modal retrieval. Knowl.-Based Syst. 2021, 226, 107138. [Google Scholar] [CrossRef]
- Chen, H.; Ding, G.; Liu, X.; Lin, Z.; Liu, J.; Han, J. Imram: Iterative matching with recurrent attention memory for cross-modal image-text retrieval. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13 June 2020; pp. 12655–12663. [Google Scholar]
- Wang, X.; Zou, X.; Bakker, E.M.; Wu, S. Self-constraining and attention-based hashing network for bit-scalable cross-modal retrieval. Neurocomputing 2020, 400, 255–271. [Google Scholar] [CrossRef]
- Sung, F.; Yang, Y.; Zhang, L.; Xiang, T.; Torr, P.H.; Hospedales, T.M. Learning to compare: Relation network for few-shot learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1199–1208. [Google Scholar]
- Santoro, A.; Raposo, D.; Barrett, D.G.; Malinowski, M.; Pascanu, R.; Battaglia, P.; Lillicrap, T. A simple neural network module for relational reasoning. Adv. Neural Inf. Process. Syst. 2017, 30, 4967–4976. [Google Scholar]
- Staudemeyer, R.C.; Morris, E.R. Understanding lstm—A tutorial into long short-term memory recurrent neural networks. arXiv 2019, arXiv:1909.09586v1. [Google Scholar]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.C.; Chen, B.; Tan, M.; Adam, H. Searching for mobilenetv3. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1314–1324. [Google Scholar]
- Kan, M.; Shan, S.; Zhang, H.; Lao, S.; Chen, X. Multi-view discriminant analysis. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 188–194. [Google Scholar] [CrossRef]
- Zhai, X.; Peng, Y.; Xiao, J. Learning cross-media joint representation with sparse and semi-supervised regularization. IEEE Trans. Circuits Syst. Video Technol. 2014, 24, 965–978. [Google Scholar]
- Peng, Y.; Qi, J. CM-GANs: Cross-modal generative adversarial networks for common representation learning. ACM Trans. Multimed. Comput. Commun. Appl. 2019, 15, 1–24. [Google Scholar]
- Demiar, J.; Schuurmans, D. Statistical comparisons of classifiers over multiple data sets. J. Mach. Learn. Res. 2006, 7, 1–30. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Image to Text | Text to Image | Average | ||||||
|---|---|---|---|---|---|---|---|---|---|
| D1 | D2 | D3 | D1 | D2 | D3 | D1 | D2 | D3 | |
| CCA [22] | 0.357 | 0.225 | 0.544 | 0.326 | 0.227 | 0.546 | 0.341 | 0.226 | 0.545 |
| KCCA [23] | 0.438 | 0.488 | 0.573 | 0.389 | 0.446 | 0.577 | 0.414 | 0.467 | 0.575 |
| MvDA-VC [46] | 0. 419 | 0.652 | 0.650 | 0.382 | 0.672 | 0.627 | 0.401 | 0.662 | 0.638 |
| JRL [47] | 0.478 | 0.627 | 0.586 | 0.436 | 0.658 | 0.578 | 0.457 | 0.642 | 0.582 |
| ACMR [16] | 0.480 | 0.589 | 0.639 | 0.411 | 0.582 | 0.639 | 0.431 | 0.586 | 0.639 |
| CM-GANs [29] | 0.521 | 0.603 | 0.567 | 0.466 | 0.604 | 0.551 | 0.494 | 0.604 | 0.559 |
| FGCrossNet [48] | 0.457 | 0.637 | 0.629 | 0.429 | 0.662 | 0.633 | 0.443 | 0.650 | 0.631 |
| MCSM [4] | 0.516 | 0.598 | 0.540 | 0.458 | 0.598 | 0.550 | 0.487 | 0.598 | 0.545 |
| DAER (ours) | 0.526 | 0.682 | 0.693 | 0.478 | 0.696 | 0.689 | 0.502 | 0.689 | 0.691 |
| Method | Image to Text | Text to Image | ||||
|---|---|---|---|---|---|---|
| D1 | D2 | D3 | D1 | D2 | D3 | |
| CCA [22] | 0.002 | 0.002 | 0.002 | 0.002 | 0.002 | 0.002 |
| KCCA [23] | 0.002 | 0.002 | 0.002 | 0.002 | 0.002 | 0.002 |
| MvDA-VC [46] | 0.002 | 0.002 | 0.002 | 0.002 | 0.002 | 0.002 |
| JRL [47] | 0.002 | 0.002 | 0.002 | 0.002 | 0.002 | 0.002 |
| ACMR [16] | 0.0076 | 0.002 | 0.002 | 0.002 | 0.002 | 0.002 |
| CM-GANs [29] | 0.002 | 0.002 | 0.002 | 0.002 | 0.002 | 0.002 |
| FGCrossNet [48] | 0.002 | 0.002 | 0.002 | 0.002 | 0.002 | 0.002 |
| MCSM [4] | 0.0059 | 0.002 | 0.002 | 0.002 | 0.002 | 0.002 |
| Method | Image to Text | Text to Image | Average | ||||||
|---|---|---|---|---|---|---|---|---|---|
| D1 | D2 | D3 | D1 | D2 | D3 | D1 | D2 | D3 | |
| DAER-C | 0.511 | 0.661 | 0.663 | 0.464 | 0.668 | 0.652 | 0.487 | 0.665 | 0.657 |
| DAER-I | 0.517 | 0.667 | 0.674 | 0.467 | 0.682 | 0.665 | 0.492 | 0.675 | 0.669 |
| DAER-T | 0.519 | 0.665 | 0.679 | 0.470 | 0.678 | 0.668 | 0.495 | 0.672 | 0.674 |
| DAER-I-T | 0.521 | 0.673 | 0.685 | 0.473 | 0.689 | 0.679 | 0.497 | 0.681 | 0.682 |
| DAER | 0.525 | 0.682 | 0.693 | 0.478 | 0.696 | 0.689 | 0.501 | 0.689 | 0.691 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, Z.; Hu, H.; Su, M. Hybrid DAER Based Cross-Modal Retrieval Exploiting Deep Representation Learning. Entropy 2023, 25, 1216. https://doi.org/10.3390/e25081216
Huang Z, Hu H, Su M. Hybrid DAER Based Cross-Modal Retrieval Exploiting Deep Representation Learning. Entropy. 2023; 25(8):1216. https://doi.org/10.3390/e25081216
Chicago/Turabian StyleHuang, Zhao, Haowu Hu, and Miao Su. 2023. "Hybrid DAER Based Cross-Modal Retrieval Exploiting Deep Representation Learning" Entropy 25, no. 8: 1216. https://doi.org/10.3390/e25081216
APA StyleHuang, Z., Hu, H., & Su, M. (2023). Hybrid DAER Based Cross-Modal Retrieval Exploiting Deep Representation Learning. Entropy, 25(8), 1216. https://doi.org/10.3390/e25081216