
A Joint Extraction Model for Entity Relationships Based on Span and Cascaded Dual Decoding


Abstract
:1. Introduction
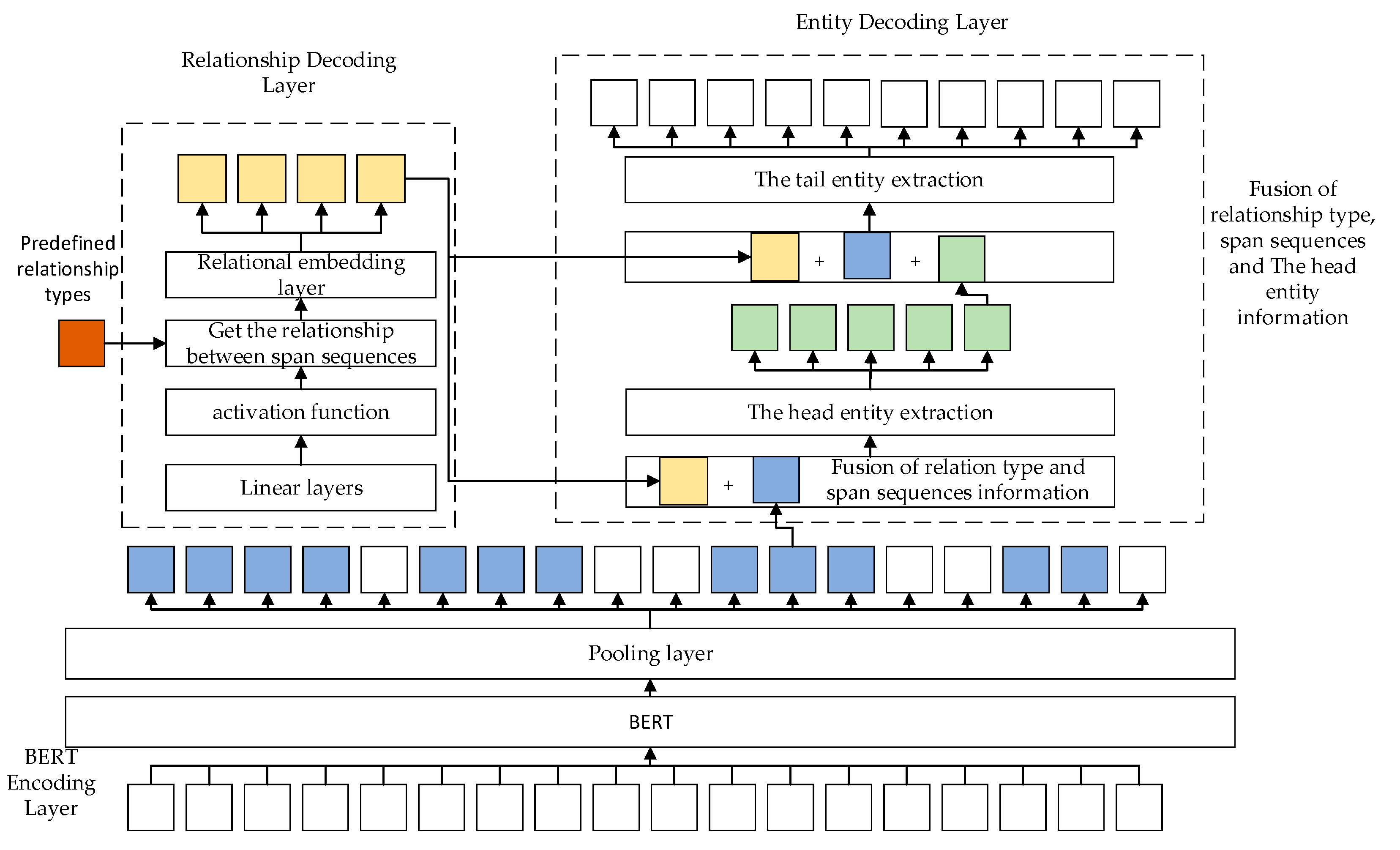
- A novel joint entity–relationship extraction model, SCDM, based on the span and a cascaded dual decoding are proposed. Different from existing methods, this paper performs the span division after the BERT preprocessing to form span sequences, and subsequent decoding tasks are performed within the span sequences. The issue of overlapping relations in the text is successfully resolved.
- This method uses a cascaded decoding mechanism, which has the advantages of a fast learning speed and a reduced error transmission. First, it decodes the relationship between entities in the span sequences, and then it decodes the entities in the span sequences to obtain the head entity and the tail entity. The relationship type information obtained by the relation decoding layer is fused when decoding the head entity, and the relationship type information and the acquired head entity information are fused when decoding the tail entity.
- Through the analysis of the NYT dataset and the WebNLG dataset, when compared to the current models, the methodology suggested in this research produced the best results.
2. Related Work
2.1. The Pipeline Extraction Model
2.2. The Joint Extraction Model
3. Methodology
3.1. Overview Network Architecture
3.2. BERT Encoder Layer
3.3. Relationship Decoding Layer
3.4. Entity Decoding Layer
3.4.1. Head Entity Extraction
3.4.2. Tail Entity Extraction
3.5. Loss Function
4. Experiments
4.1. Datasets
4.2. Experimental Environment
4.3. Experimental Parameters
4.4. Evaluation Methods
4.5. Comparative Experiments
- CopyRe [19] proposed a method based on the replication mechanism and used one combined decoder or several independent decoders as two alternative approaches to the decoding process.
- GraphRel [32] proposed a method using graph neural networks (GCN) and a copy mechanism to extract entity relation. It used GCN to make better use of spatial information and improve the extraction effect of models.
- CopyRL [33] proposed a sequence-to-sequence model based on a copy mechanism and took into account the order of relationships; the model was able to provide superior outcomes thanks to the use of reinforcement learning.
- CopyMTL [34] proposed a multitask learning method based on the replication mechanism, which enhanced the robustness of the model and could predict multitoken entities.
- WDec [30] proposed a relation strategy for representation and a decoding method based on a pointer network to realize entity relation extraction.
- AttentionRE [31] developed a supervised multihead self-attention technique to learn the token-level correlation for each individual connection type.
- CasRel [25] proposed a binary cascaded tagging framework to eliminate the issue of text’s overlapping relations, and a related theoretical analysis was carried out.
- DualDec [26] proposed a dual-decoding mechanism to extract entity–relationship triple, which first decoded the relationship in the text, and then decoded the entity pairs of a specific relationship.
4.6. Experimental Results on Different Relationships
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Zhong, Z.; Chen, D. A Frustratingly Easy Approach for Entity and Relation Extraction. In Proceedings of the Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2021. Association for Computational Linguistics (ACL), Online, 6–11 June 2021; pp. 50–61. [Google Scholar]
- Sun, W.; Liu, S.; Liu, Y.; Kong, L.; Jian, Z. Information Extraction Network Based on Multi-Granularity Attention and Multi-Scale Self-Learning. Sensors 2023, 23, 4250. [Google Scholar] [CrossRef]
- Liao, T.; Huang, R.; Zhang, S.; Duan, S.; Chen, Y.; Ma, W.; Chen, X. Nested named entity recognition based on dual stream feature complementation. Entropy 2022, 24, 1454. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Q.; Chen, M.; Liu, L. A Review on Entity Relation Extraction. In Proceedings of the 2017 Second International Conference on Mechanical, Control and Computer Engineering (ICMCCE), Harbin, China, 8–10 December 2017; pp. 178–183. [Google Scholar]
- Tian, H.; Zhang, X.; Wang, Y.; Zeng, D. Multi-task learning and improved textrank for knowledge graph completion. Entropy 2022, 24, 1495. [Google Scholar] [CrossRef] [PubMed]
- Liu, Z.; Li, H.; Wang, H.; Liao, Y.; Liu, X.; Wu, G. A novel pipelined end-to-end relation extraction framework with entity mentions and contextual semantic representation. Expert Syst. Appl. 2023, 228, 120435. [Google Scholar] [CrossRef]
- Zhou, G.; Su, J.; Zhang, J.; Zhang, M. Exploring Various Knowledge in Relation Extraction. In Proceedings of the 43rd Annual Meeting of the Association for Computational Linguistics (ACL’05), Ann Arbor, MI, USA, 25–30 June 2005; pp. 427–434. [Google Scholar]
- Mintz, M.; Bills, S.; Snow, R.; Jurafsky, D. Distant Supervision for Relation Extraction without Labeled Data. In Proceedings of the Joint Conference of the 47th Annual Meeting of the ACL and the 4th International Joint Conference on Natural Language Processing of the AFNLP, Singapore, 2–7 August 2009; pp. 1003–1011. [Google Scholar]
- Chan, Y.S.; Roth, D. Exploiting Syntactico-Semantic Structures for Relation Extraction. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologiesl, Portland, OR, USA, 19–24 June 2011; pp. 551–560. [Google Scholar]
- Gao, C.; Zhang, X.; Liu, H.; Yun, W.; Jiang, J. A joint extraction model of entities and relations based on relation decomposition. Int. J. Mach. Learn. Cybern. 2022, 13, 1833–1845. [Google Scholar] [CrossRef]
- Zeng, X.; Zeng, D.; He, S.; Liu, K.; Zhao, J. Extracting Relational Facts by An End-to-End Neural Model with Copy Mechanism. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, (Volume 1: Long Papers), Melbourne, Australia, 15–20 July 2018; pp. 506–514. [Google Scholar]
- Li, Y.; Liu, C.; Du, N.; Fan, W.; Li, Q.; Gao, J.; Zhang, C.; Wu, H. Extracting medical knowledge from crowdsourced question answering website. IEEE Trans. Big Data 2016, 6, 309–321. [Google Scholar] [CrossRef]
- Sennrich, R.; Haddow, B.; Birch, A. Neural Machine Translation of Rare Words with Sub-word Units. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics. Association for Computational Linguistics (ACL), Berlin, Germany, 7–12 August 2016; pp. 1715–1725. [Google Scholar]
- Nayak, T.; Ng, H.T. Effective Attention Modeling for Neural Relation Extraction. In Proceedings of the 23rd Conference on Computational Natural Language Learning (CoNLL), Hong Kong, China, 3–4 December 2019; pp. 603–612. [Google Scholar]
- Zeng, D.; Liu, K.; Lai, S.; Zhou, G.; Zhao, J. Relation Classification via Convolutional Deep Neural Network. In Proceedings of the COLING2014, the 25th International Conference on Computational Linguistics: Technical Papers, Dublin, Ireland, 23–29 August 2014; pp. 2335–2344. [Google Scholar]
- Guo, X.; Zhang, H.; Yang, H.; Xu, L.; Ye, Z. A single attention-based combination of CNN and RNN forrelation classification. IEEE Access 2019, 7, 12467–12475. [Google Scholar] [CrossRef]
- Guo, Z.; Zhang, Y.; Lu, W. Attention Guided Graph Convolutional Networks for Relation Extraction. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 241–251. [Google Scholar]
- Luo, L.; Yang, Z.; Cao, M.; Wang, L.; Zhang, Y.; Lin, H. A neural network-based joint learning approach for biomedical entity and relation extraction from biomedical literature. J. Biomed. Inform. 2020, 103, 103384. [Google Scholar] [CrossRef] [PubMed]
- Ma, Y.; Wang, A.; Okazaki, N. DREEAM: Guiding attention with evidence for improving document-level relation extraction. arXiv 2023, arXiv:2302.08675. [Google Scholar]
- Bhartiya, A.; Badola, K. Dis-Rex: A Multilingual Dataset for Distantly Supervised Relation Extraction. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), Dublin, Germany, 22–27 May 2022; pp. 849–863. [Google Scholar]
- Hwang, W.; Eom, S.; Lee, H.; Park, H.J.; Seo, M. Data-efficient end-to-end information extraction for statistical legal analysis. In Proceedings of the Natural Legal Language Processing Workshop, Abu Dhabi, United Arab Emirates, 8 December 2022; pp. 143–152. [Google Scholar]
- Xie, Y.; Shen, J.; Li, S.; Mao, Y.; Han, J. Eider: Empowering Document-Level Relation Extraction with Efficient Evidence Extraction and Inference-Stage Fusion. In Proceedings of the Findings of the Association for Computational Linguistics: ACL 2022, Dublin, Ireland, 22–27 May 2022; pp. 257–268. [Google Scholar]
- Shang, Y.M.; Huang, H.; Mao, X. Onerel: Joint Entity and Relation Extraction with One Module in One Step. In Proceedings of the AAAI Conference on Artificial Intelligence, Washington, DC, USA, 7–14 February 2023; pp. 11285–11293. [Google Scholar]
- Ye, D.; Lin, Y.; Li, P.; Sun, M. Packed Levitated Marker for Entity and Relation Extraction. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Dublin, Germany, 22–27 May 2022; pp. 4904–4917. [Google Scholar]
- Wei, Z.; Su, J.; Wang, Y.; Tian, Y.; Chang, Y. A Novel Cascade Binary Tagging Framework for Relational Triple Extraction. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 1476–1488. [Google Scholar]
- Ma, L.; Ren, H.; Zhang, X. Effective cascade dual-decoder model for joint entity and relation extraction. arXiv 2021, arXiv:2106.14163. [Google Scholar]
- Surdeanu, M.; Tibshirani, J.; Nallapati, R.; Manning, C.D. Multi-Instance Multi-Label Learning for Relation Extraction. In Proceedings of the 2012 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning, Jeju Island, Korea, 12–14 July 2012; pp. 455–465. [Google Scholar]
- Riedel, S.; Yao, L.; McCallum, A. Modeling Relations and Their Mentions without Labeled Text. In Proceedings of the Machine Learning and Knowledge Discovery in Databases: European Conference, ECML PKDD 2010, Barcelona, Spain, 20–24 September 2010; pp. 148–163. [Google Scholar]
- Gardent, C.; Shimorina, A.; Narayan, S.; Perez-Beltrachini, L. Creating Training Corpora for NLG Micro-Planning. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (ACL), Vancouver, BC, Canada, 30 July–4 August 2017. [Google Scholar]
- Nayak, T.; Ng, H.T. Effective Modeling of Encoder-Decoder Architecture for Joint Entity and Relation Extraction. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 8528–8535. [Google Scholar]
- Liu, J.; Chen, S.; Wang, B.; Zhang, J.; Li, N.; Xu, T. Attention as Relation: Learning Supervised Multi-Head Self-Attention for Relation Extraction. In Proceedings of the Twenty-Ninth International Conference on International Joint Conferences on Artificial Intelligence, Online, 7–15 January 2021; pp. 3787–3793. [Google Scholar]
- Fu, T.J.; Li, P.H.; Ma, W.Y. Graphrel: Modeling Text as Relational Graphs for Joint Entity and Relation Extraction. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 1409–1418. [Google Scholar]
- Zeng, X.; He, S.; Zeng, D.; Liu, K.; Liu, S.; Zhao, J. Learning the Extraction Order of Multiple Relational Facts in A Sentence with Reinforcement Learning. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; pp. 367–377. [Google Scholar]
- Zeng, D.; Zhang, H.; Liu, Q. Copymtl: Copy Mechanism for Joint Extraction of Entities and Relations with Multi-Task Learning. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 9507–9514. [Google Scholar]


{kind=link}
{kind=link}
| Type | Example Sentences and Entity Relationships | Graphic Representation |
|---|---|---|
| Normal | York is located in the England. |  |
| {<York, country, England>} | ||
| Single entity overlap | The city of Aarhus, whose mayor is Jacob Bundsgaard, is served by Aarhus Airport. | |
| {<Aarhus, leaderName, Bundsgaard >, <Aarhus airport, cityServed, Aarhus>} | ||
| Entity pair overlap | News of the list’s existence unnerved officials in Khartoum, Sudan’s capital. | |
| {<Sudan, capital, Khartoum >, <Sudan, contains, Khartoum>} |
| Datasets | NYT | WebNLG | ||
|---|---|---|---|---|
| Training Set | Test Set | Training Set | Test Set | |
| Normal | 37,015 | 3264 | 1599 | 246 |
| EPO | 9781 | 979 | 224 | 26 |
| SEO | 14,737 | 1295 | 3407 | 457 |
| Total | 56,214 | 5000 | 5017 | 703 |
| Relation type | 24 | 246 | ||
| Name | Environment |
|---|---|
| System | Windows |
| GPU | NVIDIA GeForce RTX 3090 (24 G) |
| Memory | 56 G |
| Hard disk | 2 T |
| Python version | Python 3.8 |
| PyTorch version | 1.8.0 |
| Parameter | Value |
|---|---|
| BERT model | BERT-BASE-CASED |
| Learning rate | 2e−5 |
| Batch size | 16 |
| Epochs | 100 |
| Dropout | 0.4 |
| Optim | Adam |
| Position embedding size | 20 |
| Max span | 10 |
| Methods | Partial Match | Exact Match | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| NYT(N) | WebNLG(W) | NYT(N) | WebNLG(W) | |||||||||
| Pre. | Rec. | F1 | Pre. | Rec. | F1 | Pre. | Rec. | F1 | Pre. | Rec. | F1 | |
| CopyRe | 61.0 | 56.6 | 58.7 | 37.7 | 36.4 | 37.1 | - | - | - | - | - | - |
| GraphRel | 63.9 | 60.0 | 61.9 | 44.7 | 41.1 | 42.9 | - | - | - | - | - | - |
| CopyRL | 77.9 | 67.2 | 72.1 | 63.3 | 59.9 | 61.6 | - | - | - | - | - | - |
| CopyMTL | - | - | - | - | - | - | 75.7 | 68.7 | 72.0 | 58.0 | 54.9 | 56.4 |
| WDec | - | - | - | - | - | - | 88.1 | 76.1 | 81.7 | 88.6 | 51.3 | 65.0 |
| AttentionRE | - | - | - | - | - | - | 88.1 | 78.5 | 83.0 | 89.5 | 86.0 | 87.7 |
| CasRel | 89.7 | 89.5 | 89.6 | 93.4 | 90.1 | 91.8 | 89.1 | 89.4 | 89.2 | 87.7 | 85.0 | 86.3 |
| DualDec | 90.2 | 90.9 | 90.5 | 90.3 | 91.5 | 90.9 | 89.9 | 90.3 | 90.1 | 88.0 | 88.9 | 88.4 |
| Ours | 89.8 | 92.7 | 91.2 | 91.6 | 92.2 | 91.9 | 91.0 | 90.8 | 90.9 | 88.9 | 88.4 | 88.6 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liao, T.; Sun, H.; Zhang, S. A Joint Extraction Model for Entity Relationships Based on Span and Cascaded Dual Decoding. Entropy 2023, 25, 1217. https://doi.org/10.3390/e25081217
Liao T, Sun H, Zhang S. A Joint Extraction Model for Entity Relationships Based on Span and Cascaded Dual Decoding. Entropy. 2023; 25(8):1217. https://doi.org/10.3390/e25081217
Chicago/Turabian StyleLiao, Tao, Haojie Sun, and Shunxiang Zhang. 2023. "A Joint Extraction Model for Entity Relationships Based on Span and Cascaded Dual Decoding" Entropy 25, no. 8: 1217. https://doi.org/10.3390/e25081217
APA StyleLiao, T., Sun, H., & Zhang, S. (2023). A Joint Extraction Model for Entity Relationships Based on Span and Cascaded Dual Decoding. Entropy, 25(8), 1217. https://doi.org/10.3390/e25081217