1. Introduction
Optimal transport is the problem of finding a coupling of probability distributions that minimizes cost [
1], and it is a technique applied across various fields and literatures [
2,
3]. Although many methods exist for obtaining optimal transference plans for distributions on discrete spaces, computing the plans is not generally possible for continuous spaces [
4]. Given the prevalence of continuous spaces in machine learning, this is a significant limitation for theoretical and practical applications.
One strategy for approximating continuous OT plans is based on discrete approximation via sample points. Recent research has provided guarantees on the fidelity of discrete, sample-location-based approximations for continuous OT as the sample size
[
5]. Specifically, by sampling large numbers of points
from each marginal, one may compute a discrete optimal transference plan on
, with the cost matrix being derived from the pointwise evaluation of the cost function on
.
Even in the discrete case, obtaining minimal cost plans is computationally challenging. For example, Sinkhorn scaling, which computes an entropy-regularized approximation for OT plans, has a complexity that scales with
[
6]. Although many comparable methods exist [
7], all of them have a complexity that scales with the product of sample sizes, and they require the construction of a cost matrix that also scales with
.
We have developed methods for optimizing both sampling locations and weights for small N approximations of OT plans (see
Figure 1). In
Section 2, we formulate the problem of fixed size approximation and reduce it to discretization problems on marginals with theoretical guarantees. In
Section 3, the gradient of entropy-regularized Wasserstein distance between a continuous distribution and its discretization is derived. In
Section 4, we present a stochastic gradient descent algorithm that is based on the optimization of the locations and weights of the points with empirical demonstrations.
Section 5 introduces a parellelizable algorithm via decompositions of the marginal spaces, which reduce the computational complexity by exploiting intrinsic geometry. In
Section 6, we analyze time and space complexity. In
Section 7, we illustrate the advantage of including weights for sample points by providing a comparison with an existing location that is only based on discretization.
2. Efficient Discretizations
Optimal transport (OT): Let
,
be compact Polish spaces (complete separable metric spaces),
,
be probability distributions on their Borel-algebras, and
be a cost function. Denote the set of all joint probability measures (couplings) on
with marginals
and
by
. For the cost function
c, the optimal transference plan between
and
is defined as in [
1]:
, where
.
When , the cost , defines the k-Wasserstein distance between and for . Here, is the k-th power of the metric on X.
Entropy regularized optimal transport (EOT) [
5,
8] was introduced to estimate OT couplings with reduced computational complexity:
, where
is a regularization parameter, and the regularization term
:=
is the Kullback–Leibler divergence. The EOT objective is smooth and convex, and its unique solution with a given discrete
can be obtained using a Sinkhorn iteration (SK) [
9].
However, for large-scale discrete spaces, the computational cost of SK can still be unfeasible [
6]. Even worse, to even apply the Sinkhorn iteration, one must know the entire cost matrix over the large-scale spaces, which itself can be a non-trivial computational burden to obtain; in some cases, for example, where the cost is derived from a probability model [
10], it may require intractable computations [
11,
12].
The Framework: We propose the optimization of the location and weights of a fixed size discretization to estimate the continuous OT. The discretization on
is completely determined by those on
X and
Y to respect the marginal structure in the OT. Let
,
,
be a discrete approximation of
and
, respectively, with
,
,
,
, and
. Then, the EOT plan
for the OT problem
can be approximated by the EOT plan
for the OT problem
. There are three distributions that have their discrete counterparts; thus, with a fixed size
, a naive idea about the objective to be optimized can be
where
represents the
k-th power of
k-Wasserstein distance between measures
and
. The hyperparameter
balances between the estimation accuracy over marginals and that of the transference plan, while the weights on marginals are equal.
To properly compute
, a metric
on
is needed. We expect
on
X-slices or
Y-slices to be compatible with
or
, respectively; furthermore, we may assume that there exists a constant
such that:
For instance, (
2) holds when
is the
p-product metric for
.
The objective
is estimated by its entropy regularized approximation
for efficient computation, where
is the regularization parameter, as follows:
Here,
is estimated by
.
is computed by optimizing
One major difficulty in optimizing
is to evaluate
. In fact, obtaining
is intractable, which is the original motivation for the discretization. To overcome this drawback, by utilizing the dual formulation of EOT, the following are shown (see proof in
Appendix A):
Proposition 1. When X and Y are two compact spaces, and the cost function c is , there exists a constant such that Notice that Proposition 1 indicates that is bounded above by multiples of , i.e., when the continuous marginals and are properly approximated, so is the optimal transference plan between them. Therefore, to optimize , we focus on developing algorithms to obtain that minimize and .
Remark 1. The regularizing parameters (λ and ζ above) introduce smoothness, together with an error term, into the OT problem. To make an accurate approximation, we need λ and ζ to be as small as possible. However, when parameters become too small, the matrices to be normalized in the Sinkhorn algorithm lead to an overflow or underflow problem of numerical data types (32-bit or 64-bit floating point numbers). Thus, the value for regularizing the constant threshold is proportional to the k-th power of the diameter of the supported region. In this work, we try our best to control the value (mainly on ζ), which ranges from 10−4 to 0.01 when the diameter is 1 in different examples.
3. Gradient of the Objective Function
Let be a discrete probability measure in the position of “” in the last section. For a fixed (continuous) , the objective now is to obtain a discrete target .
In order to apply a stochastic gradient descent (SGD) to both the positions
and their weights
to achieve
, we now derive the gradient of
about
by following the discrete discussions of [
13,
14]. The SGD on
X is either derived through an exponential map, or by treating
X as (part of) an Euclidean space.
Let
, and denote the joint distribution minimizing
as
with the differential form at
being
, which is used to define
in
Section 2.
By introducing the Lagrange multipliers
i, we have
, where
with
(see [
5]). Let
be the argmax; then, we have
with
. Since
and
produce the same
for any
, the representative with
that is equivalent to
(as well as
) is denoted by
(similarly
) below in order to obtain uniqueness and make the differentiation possible.
From a direct differentiation of
, we have
With the transference plan
and the derivatives of
,
,
calculated, the gradient of
can be assembled.
Assume that
g is a Lipschitz constant that is differentiable almost everywhere (for
and a
Euclidean distance in
, differentiability fails to hold only when
and
) and that
is calculated. The derivatives of
and
can then be calculated thanks to the Implicit Function Theorem for Banach spaces (see [
15]).
The maximality of
at
and
induces
, and the Fréchet derivative vanishes. By differentiating (in the sense of Fréchet) again on
and
, respectively, we get
as a bilinear functional on
(note that, in Equation (
6), the index
i of
cannot be
m). The bilinear functional
is invertible, and we denote its inverse by
as a bilinear form on
. The last ingredient for the Implicit Function Theorem is
:
Then,
. Therefore, we have gradient
calculated.
Moreover, we can differentiate Equations (
4)–(
8) to get a Hessian matrix of
on
’s and
’s to provide a better differentiability of
(which may enable Newton’s method, or a mixture of Newton’s method and minibatch SGD to accelerate the convergence). More details about the claims, calculations, and proofs are provided in the
Appendix B.
4. The Discretization Algorithm
Here, we provide a description of an algorithm for the efficient discretizations of optimal transport (EDOT) from a distribution to with integer m, which is a given cardinality of support. In general, does not need not be explicitly accessible, and, even if it is accessible, computing the exact transference plan is not feasible. Therefore, in this construction, we assume that is given in terms of a random sampler, and we apply a minibatch stochastic gradient descent (SGD) through a set of samples that are independently drawn from of size N on each step to approximate .
To calculate the gradient
, we need: (1).
, the EOT transference plan between
and
, (2). the cost
on
X, and (3). its gradient on the second variable
. From
N samples
, we can construct
and calculate the gradients with
replaced by
as an estimation, whose effectiveness (convergence as
) is proved in [
5].
We call this discretization algorithm the
Simple EDOT algorithm. The pseudocode is stated in the
Appendix C.
Proposition 2. (Convergence of the Simple EDOT). The Simple EDOT generates a sequence in the compact set . If the set of limit points of does not intersect with , then converges to a stationary point in where represents the interior.
In simulations, we fixed to reduce the computational complexity and fixed the regularizer for X of diameter 1 and scales proportional with (see next section). Such a choice for is not only small enough to reduce the error between the EOT estimation and the true , but also ensures that and its byproduct in the SK are distinguishable from 0 in a double format.
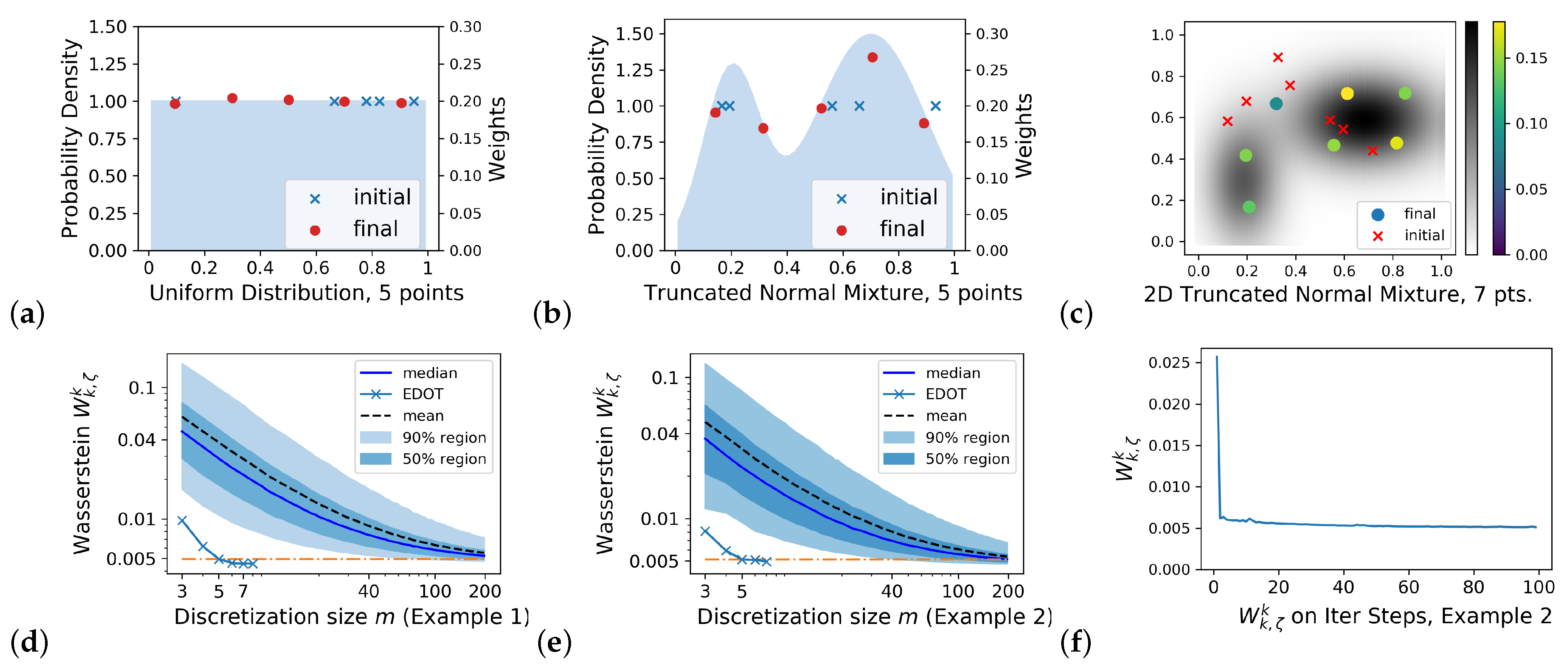
Examples of discretization: We demonstrated our algorithm on the following:
E.g., (1). is the uniform distribution on .
E.g., (2) is the mixture of two truncated normal distributions on , and the PDF is , where is the density of the truncated normal distribution on with the expectation and standard deviation .
E.g., (3) is the mixture of two truncated normal distributions on , where the two distributions are of weight and of weight .
Let
for all plots in this section.
Figure 2a–c plots the discretizations (
) for E.g., (1)–(3) with
and 7, respectively.
Figure 2f illustrates the convergence rate of
versus the SGD steps for Example (2) with
obtained by a 5-point EDOT.
Figure 2d,e plot the entropy-regularized Wasserstein
versus
m, thereby comparing EDOT and naive sampling for Examples (1) and (2). Here, the
s are: (a) from the EDOT with
in Example 1 and
in Example 2, which are shown by ×s in the figures. (b) from naive sampling, which is simulated using a Monte Carlo of volume 20,000 on each size from 3 to 200.
Figure 2d,e demonstrate the effectiveness of the EDOT: as indicated by the orange horizontal dashed line, even 5-point EDOT discretization in these two examples outperformed 95% of the naive samplings of size 40, as well as 75% of the naive samplings of size over 100 (the orange dash and dot lines).
An example of a transference plan: In
Figure 3a, we illustrate the efficiency of the EDOT on an OT problem:
, where the marginal
and
are truncated normal (mixtures), and
has two components (shown in red curve on the left), while
has only one component (shown in red curve on the top). The cost function is the squared Euclidean distance, and
.
The left of
Figure 3a shows a
EDOT approximation with
,
, and
. The high density area of the EOT plan is correctly covered by EDOT estimating points with high weights. The right shows a
naive approximation with
,
, and
. The points of the naive estimating with the highest weights missed the region where the true EOT plan was of the most density.
5. Methods of Improvement
I. Adaptive EDOT: The computational cost of a simple EDOT increases with the dimensionality and diameter of the underlying space. Discretization with a large m is needed to capture higher dimensional distributions, which result an increase in parameters for calculating the gradient of : for the positions and for the weights. Such an increment will not only increase the complexity in each step, but also require more steps for the SGD to converge. Furthermore, the calculation will have a higher complexity ( for each normalization in Sinkhorn).
We proposed to reduce the computational complexity using a “divide and conquer” approach. The Wasserstein distance took the k-th power of the distance function as a cost function. The locality of distance made the solution to the OT/EOT problem local, meaning that the probability mass was more likely to be transported to a close destination than to a remote one. Thus, we can “divide and conquer”—thereby cutting the space X into small cells and solve the discretization problem independently.
To develop a “divide and conquer” algorithm, we need: (1) an adaptive dividing procedure that is able to partition
, which balances the accuracy and computational intensity among the cells; (2) to determine the discretization size
and choose a proper regularizer
for each cell
. The pseudocodes for all variations are shown in the
Appendix C Algorithms A2 and A3.
Choosing size
m: An appropriate choice of
will balance contributions to the Wasserstein among the subproblems as follows: Let
be a manifold of dimension
d, let
be its diameter, and let
be the probability of
. The entropy-regularized Wasserstein distance can be estimated as
[
16,
17]. The contribution to
per point in support of
is
. Therefore, to balance each point’s contribution to the Wasserstein among the divided subproblems, we set
.
Occupied volume (Variation 1):A cell could be too vast (e.g., large in size with few points in a corner), thus resulting in obtaining a larger than needed. To fix it, we may replace the above with , where is the occupied volume calculated by counting the number of nonempty cells in a certain resolution (levels in previous binary division). The algorithm (Variation 1) becomes a binary tree to resolve and obtain the occupied volume for each cell, then there is tree traversal to assign .
Adjusting the regularizer : In the , the SK on is calculated. Therefore, should scale with to ensure that the transference plan is not affected by the scaling of . Precisely, we may choose for some constant .
The division: Theoretically, any refinement procedure that proceeds iteratively and eventually makes the diameter of each cell approach 0 can be applied for division. In our simulation, we used an adaptive kd-tree-style cell refinement in a Euclidean space . Let X be embedded into within an axis-aligned rectangular region. We chose an axis in and evenly split the region along a hyperplane orthogonal to (e.g., cut square along the line ); thus, we constructed and . With the sample set S given, we split it into two sample sizes and according to which subregion each sample was located in. Then, the corresponding and could be calculated as discussed above. Thus, two cells and their corresponding subproblems were constructed. If some of the was still too large, the cell was cut along another axis to construct two other cells. The full list of cells and subproblems could be constructed recursively. In addition, another cutting method (variation 2) that chooses the most sparse point as a cutting point through a sliding window is sometimes useful in practice.
After having the set of subproblems, we could apply the EDOT for the solutions in each cell, then combine the solutions into the final result .
Figure 3b shows the optimal discretization for the example in
Figure 2c with
, which was obtained by applying the EDOT with adaptive cell refinement, or
.
II. On embedded CW complexes: Although the samples on space X are usually represented as a vector in , inducing an embedding , the space X usually has its own structure as a CW complex (or simply a manifold) with a more intrinsic metric. Thus, if the CW complex structure is known, even piecewise, we may apply the refinement on X with respect to its own metric, whereas direct discretization as a subset in may result in a low expressing efficiency.
We now illustrate the adaptive EDOT by an example on a mixture normal distribution of a sphere mapped through stereographic projection. More examples of a truncated normal mixture over a Swiss roll and the discretization of a 2D optimal transference plan are detailed in the
Appendix D.5.
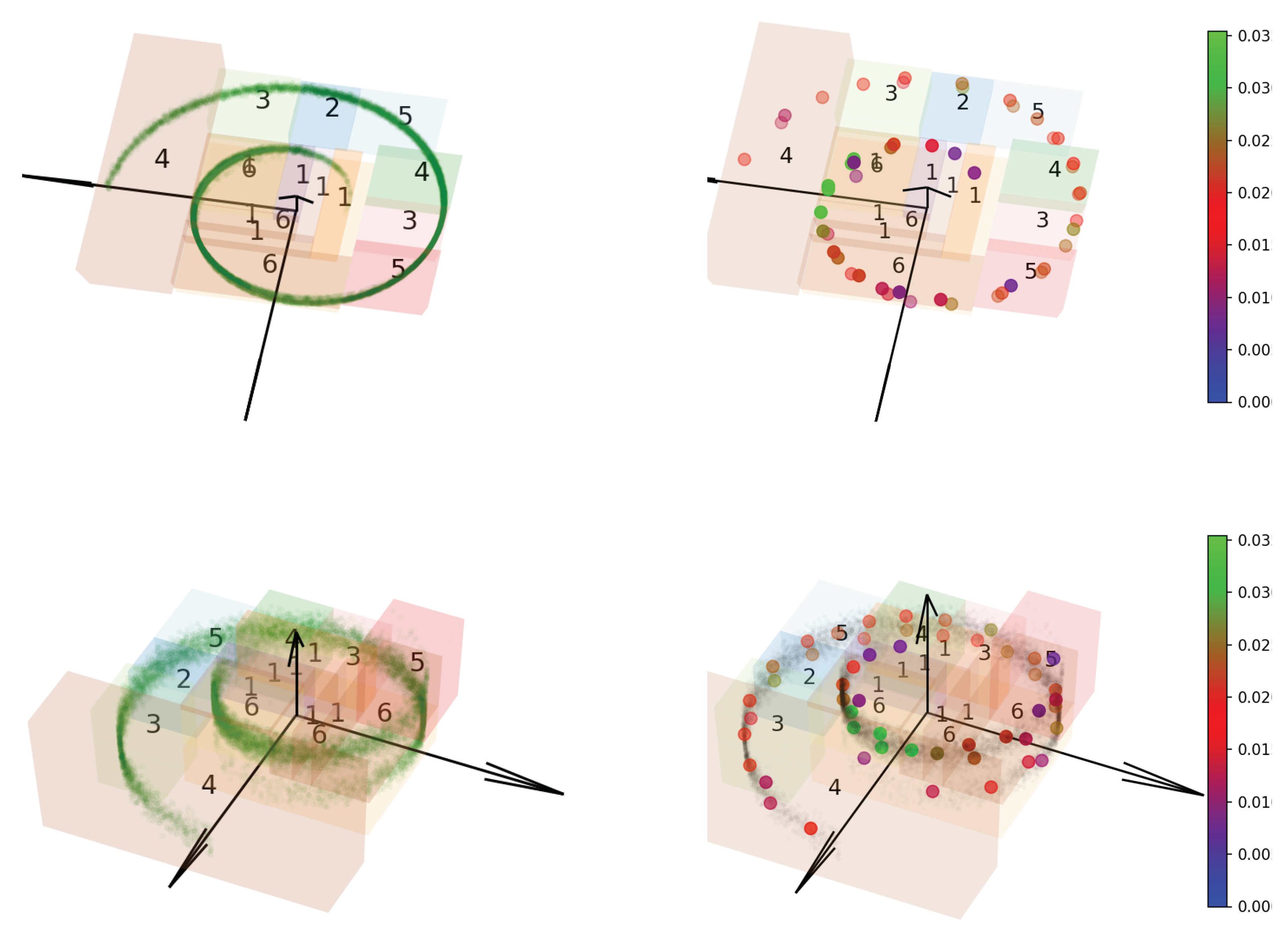
On the sphere: The underlying space
is the unit sphere in
.
is the pushforward of a normal mixture distribution on
by stereographic projection. The sample set
over
is shown on
Figure 4 on the left. Consider a (3D) Euclidean metric on the
induced by the embedding.
Figure 4a (right) plots the EDOT solution with refinement for
with
. The resulting cell structure is shown as colored boxes.
To consider the intrinsic metric, a CW complex was constructed about a point on the equator as a 0-cell structure; the rest of the equator was constructed as a 1-cell, and the upper hemisphere and lower hemisphere were constructed as two dimension 2- (open) cells. We took the upper and lower hemispheres and mapped them onto a unit disk through stereographic projection with respect to the south and north pole, respectively. Then, we took the metric from spherical geometry and rewrote the distance function and its gradient using the natural coordinate on the unit disk.
Figure 4b shows the refinement of the EDOT on the samples (in red) and the corresponding discretizations in colored points. More figures can be found in the Appendices.
6. Analysis of the Algorithms
In this section, we derive the complexity of the simple EDOT and the adaptive EDOT. In particular, we show the following:
Proposition 3. Let μ be a (continuous) probability measure on a space X. A simple EDOT of size m has time complexity and space complexity , where N is the minibatch size (to construct in each step to approximate μ), d is the dimension of X, L is the maximal number of iterations for SGD, and ϵ is the error bound in the Sinkhorn calculation for the entropy-regularized optimal transference plan between and .
Proposition 3 quantitatively shows that, when the adaptive EDOT is applied, the total complexities (in time and space) are reduced, because the magnitudes of both N and m are much smaller in each cell.
The procedure of dividing sample set S into subsets through the adaptive EDOT is similar to Quicksort; thus, the space and time complexities are similar. The similarity comes from the binary divide-and-conquer structure, as well as that each split action is based on comparing each sample with a target.
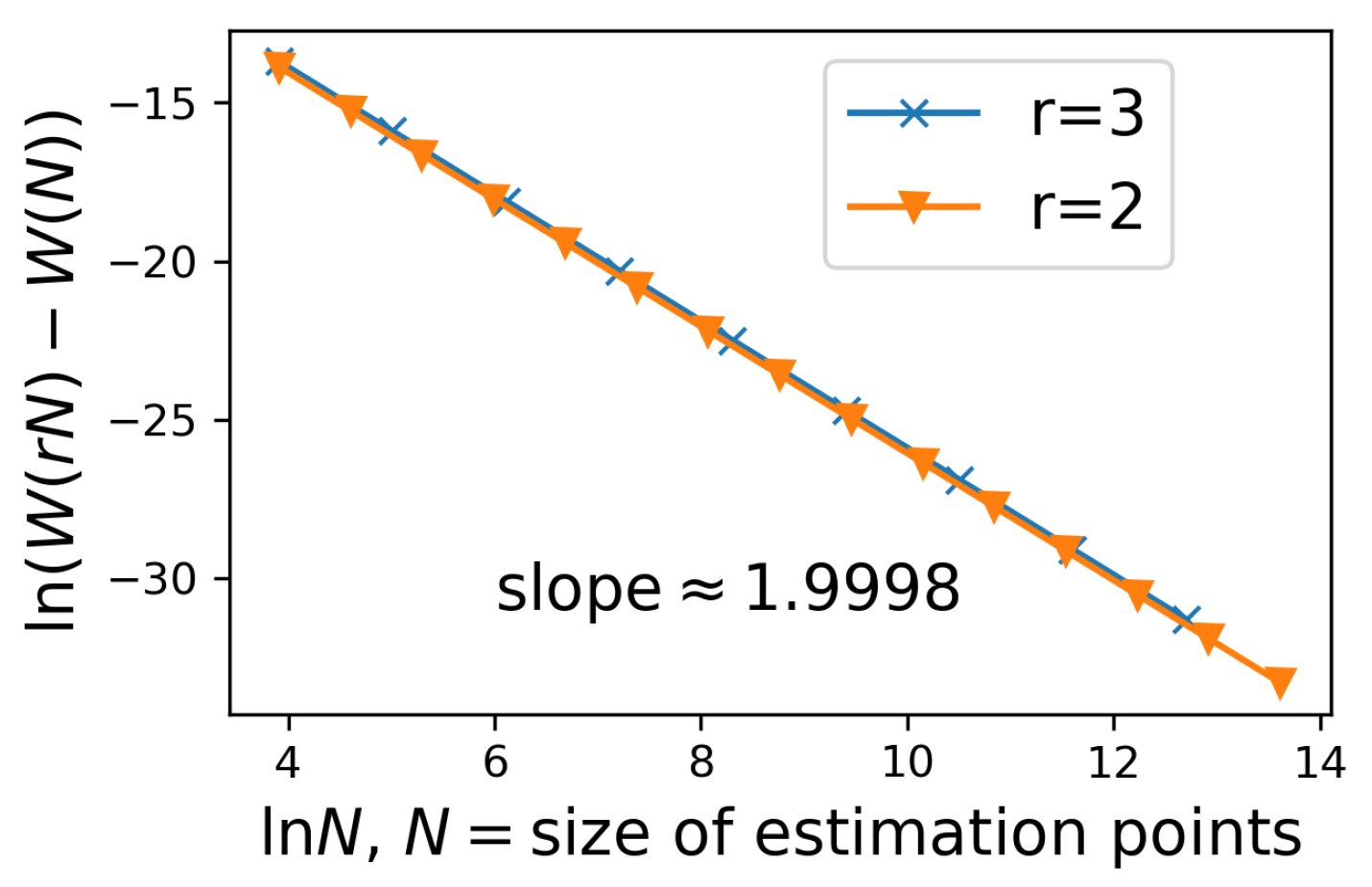
Proposition 4. For the preprocessing (job list creation) for the adaptive EDOT, the time complexity is in the best and average case and in the worst case, where is the total number of sample points, and the space complexity is , or simply as .
Remark 2. Complexity is the same as Quicksort. The set of sample points in the algorithm are treated as the “true” distribution in the adaptive EDOT, since, in the later EDOT steps for each cell, no further samples are taken, as it is hard for a sampler to produce a sample in a given cell. Postprocessing of the adaptive EDOT has complexity in both time and space.
Remark 3. For the two algorithm variations in Section 5, the occupied volume estimation works in the same way as the original preprocessing step, which has the same time complexity as before (by itself, since dividing must happen after knowing the occupied volume of all cells), but, with the tree built, the original preporcessing becomes a tree traversal and has (additional) time complexity and (additional) space complexity for the space storing occupied volume. For details on choosing cut points with window sliding, the discussion can be seen in the Appendix C.5. Comparison with naive sampling: After having a size m discretization on X and a size n discretization on Y, the EOT solution (Sinkhorn algorithm) has time complexity . In the EDOT, two discretization problems must be solved before applying the Sinkhorn, while the naive sampling requires nothing but sampling.
According to Proposition 3, solving a single continuous EOT problem using a size m simple EDOT method may result in higher time complexity than naive sampling with an even larger sample size N (than m). However, unlike the EDOT, which only requires access to a distance function and on X and Y, respectively, a known cost function is necessary for naive sampling. In real applications, the cost function may be from real world experiments (or from extra computations) done for each pair in the discretization; thus, the size of discretized distribution is critical for cost control. and usually come along with the spaces X and Y, respectively, and are easy to compute. An additional application of the EDOT is necessary when the marginal distributions and are fixed for different cost functions; then, discretizations can be reused. Thus, the cost of discretization is calculated one time, and the improvement it brings accumulates in each repeat.
7. Related Work and Discussion
Our original problem was the optimal transport problem between general distributions as samplers (instead of integration oracles). We translated that into a discretization problem and an OT problem between discretizations.
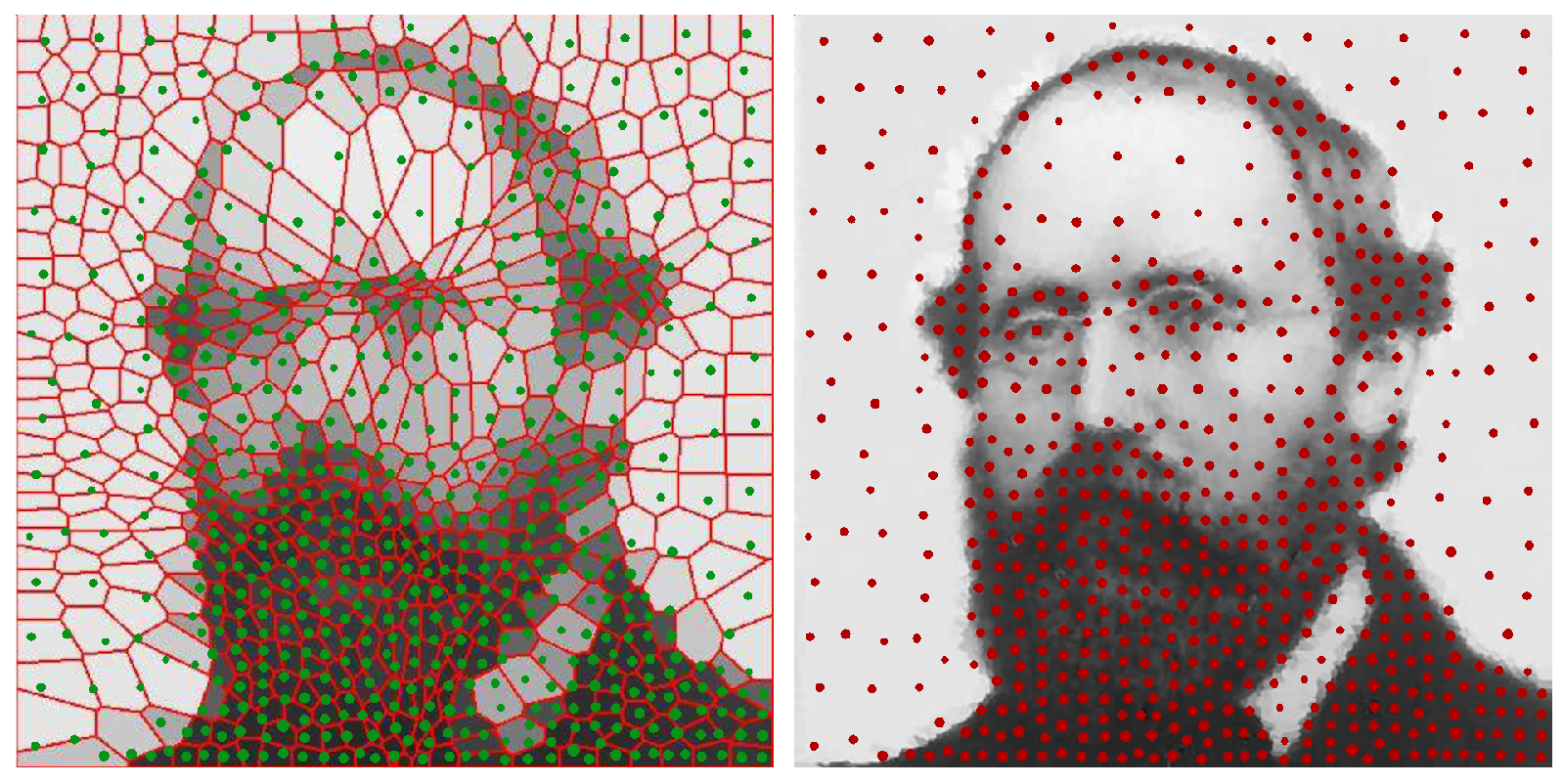
I. Comparison with other discretization methods: There are several other methods that generate discrete distributions from arbitrary distributions in the literature, which are obtained via semi-continuous optimal transport where the calculation of a weighted Voronoi diagram is needed. Calculating the weighted Voronoi diagrams usually requires 1. that the cost function be a squared Euclidean distance and 2. the application of Delaunay triangulation, which is expensive in more than two dimensions. Furthermore, semi-continuous discretization may only optimize one aspect between the position and weights of the atoms, and this process is mainly based on [
18] (the optimized position) and [
19] (the optimized weights).
We mainly compared the prior work of [
18], which focuses on the barycenter of a set of distributions under the Wasserstein metric. This work resulted in a discrete distribution called the Lagrangian discretization, which is of the form
[
2]. Other works, such as [
20,
21], find barycenters but do not create a discretization. Refs. [
19,
22] studied the discrete estimation of a 2-Wasserstein distance locating discrete points through a clustering algorithm
k-means++ and a weighted Voronoi diagram refinement, respectively. Then, they assigned weights and made them non-Lagrangian discretizations. Ref. [
19] (comparison in
Figure 5) roughly followed a “divide-and-conquer” approach in selecting positions, but the discrete positions were not tuned according to Wasserstein distance directly. Ref. [
22] converged as the number of discrete points increased. However, it lacked a criterion (such as the Wasserstein in the EDOT) to show that the choice is not just one among all possible converging algorithms, but, rather, it is a special one.
By projecting the gradient in the SGD to the tangent space of the submanifold
, or by equivalently fixing the learning rate on the weights to zero, the EDOT can estimate a Lagrangian discretization (denoted by EDOT-Equal). A comparison among the methods is held on the map of the Canary islands, which is shown in
Figure 6. This example shows that our method can get a similar result using Lagrangian discretization as the methods in the literature, while, in general, this type of EDOT can work better.
Moreover, the EDOT can be used to solve barycenter problems.
Note that, to apply adaptive EDOT for barycenter problems, compatible divisions of the target distributions are needed (i.e., a cell A from one target distribution transports onto a discrete subset D thoroughly, and D transports onto a cell B from another target distribution, etc.).
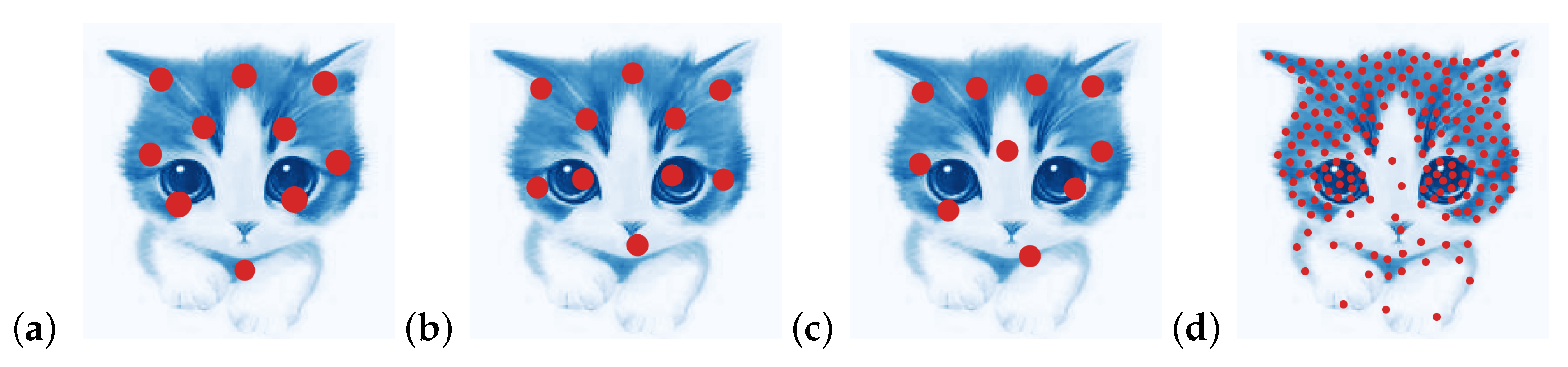
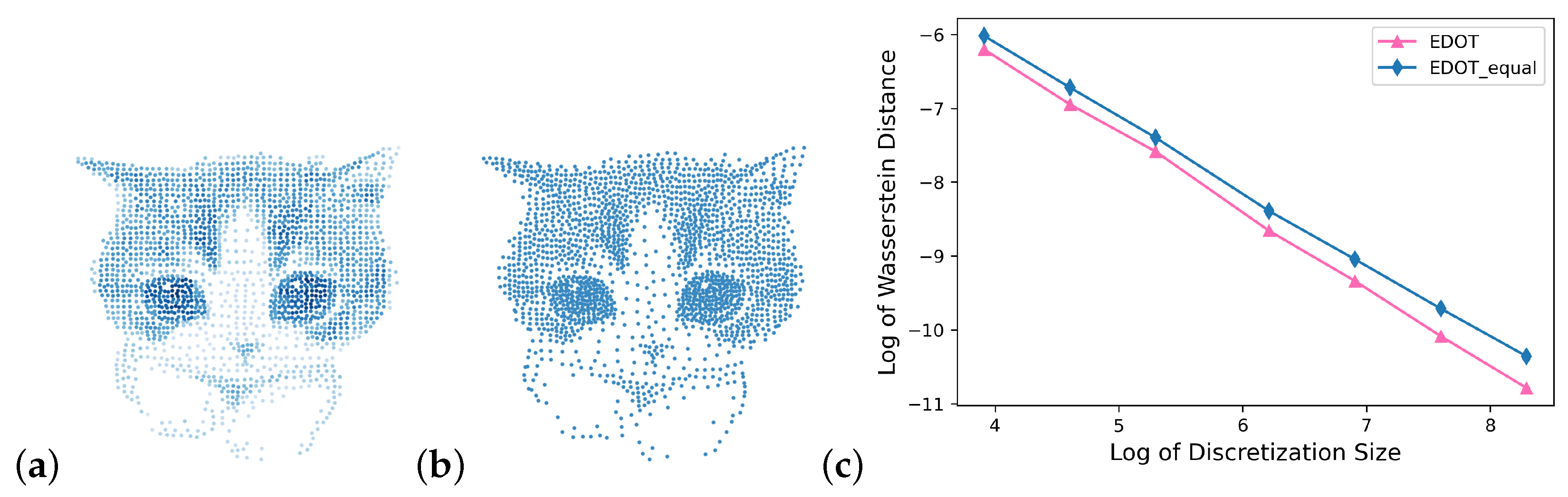
We also tested these algorithms on discretizing gray/colored scale pictures. The comparison of discretization with points varying from 10 to 4000 for a kitty image between EDOT, EDOT-equal, [
18] and estimations of their Wasserstein distances to the original image are shown in
Figure 7 and
Figure 8.
Furthermore, the EDOT may be applied on RGB channels of an image independently, which then combine plots of discretizations in the corresponding color. The results are shown in
Figure 1 at the beginning of this paper.
Lagrangian discretization may have a disadvantage in representing repetitive patterns with incompatible discretization points.
In
Figure 9, we can see that discretizing 16 objects with 24 points caused weight incompatibility locally for the Lagrangian discretization, thus making points locate between objects and increasing the Wasserstein distance. With the EDOT, the weights of points that lie outside of the blue object were much smaller. The patterned structure was better represented by the EDOT. In practice, patterns often occur as part of the data (e.g., pictures of nature), and it is easy to get an incompatible number in Lagrangian discretization, since the equal weight-requirement is rigid; consequently, patterns cannot be properly captured.
II. General
k and deneral distance
: Our algorithms (Simple EDOT, adaptive EDOT, and EDOT-Equal) work for a general choice of parameter
and
distance
on
X. For example, in
Figure 4 part (b), the distance used on each disk was spherical (arc length along the big circle passing through two points), which could not be isometrically reparametrized into a plane with Euclidean metrics because of the difference in curvatures.
III. Other possible impacts: As the OT problem widely exists in many other areas, our algorithm can be applied accordingly, e.g., the location and size of supermarkets or electrical substations in an area, or even air conditioners in the rooms of supercomputers. Our divide-and-conquer methods are suitable for solving these real-world applications.
IV. OT for discrete distributions: Many algorithms have been developed to solve OT problems between two discrete distributions [
3]. Linear programming algorithms were first developed, but their applications have been restricted by high computational complexity. Other methods such as [
23], with a cost of form
for some
h, which applies the “back-and-forth” method by hopping between two forms of a Kantorovich dual problem (on the two marginals, respectively) to get a gradient of the total cost over the dual functions, usually solve problems with certain conditions. In our work, we chose to apply an EOT developed by [
8] for an estimated OT solution of the discrete problem.
8. Conclusions
We developed methods for efficiently approximating OT couplings with fixed size approximations. We provided bounds on the relationship between a discrete approximation and the original continuous problem. We implemented two algorithms and demonstrated their efficacy as compared to naive sampling and analyzed computational complexity. Our approach provides a new approach to efficiently compute OT plans.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}















