1. Introduction
The famous aphorism of George Box states that “all models are wrong, but some are useful” [
1]. It is the task of statisticians and data analysts to find a model which is most useful for a given problem. The build, compute, critique and repeat cycle [
2], also known as Box’s loop [
3], is an iterative approach for finding the most useful model. Any efforts in shortening this design cycle increase the chances of developing more useful models, which in turn might yield more reliable predictions, more profitable returns or more efficient operations for the problem at hand.
In this paper, we choose to adopt the Bayesian formalism, and therefore we specify all tasks in Box’s loop as principled probabilistic inference tasks. In addition to the well-known parameter and state inference tasks, the critique step in the design cycle is also phrased as an inference task, known as Bayesian model comparison, which automatically embodies Occam’s razor (Ch. 28.1, [
4]). As opposed to just selecting a single model in the critique step, for different models, we better quantify our confidence about which model is best, especially when data are limited (Ch. 18.5.1, [
5]). The uncertainty arising from prior beliefs
over a set of models
m and limited observations can be naturally included through the use of Bayes’ theorem:
which describes the posterior probabilities
as a function of model evidences
and where
. Starting from Bayes’ rule, we can obtain different comparison methods from the literature, such as Bayesian model averaging [
6], selection, and combination [
7], which we formally introduce in
Section 5. We use Bayesian model comparison as an umbrella term for these three methods throughout this paper.
The task of state and parameter estimation was automated in a variety of tools, e.g., [
8,
9,
10,
11,
12,
13,
14]. Bayesian model comparison, however, is often regarded as a separate task, whereas it submits to the same Bayesian formalism as state and parameter estimation. A reason for overlooking the model comparison stage in a modeling task is that the computation of model evidence
is, in most cases, not automated and therefore still requires error-prone and time-consuming manual derivations, in spite of its importance and the potential data representation improvement that can be achieved by, for example, including a Bayesian model combination stage in the modeling process [
7].
This paper aims to automate the Bayesian model comparison task and is positioned between the mixture model and ‘gates’ approaches of [
15,
16], respectively, which we will describe in more detail in
Section 2. Specifically, we specify the model comparison tasks as a mixture model, similarly to that in [
15], on a factor graph with a custom mixture node for which we derive automatable message-passing update rules, which perform both parameter and state estimation, and model comparison. These update rules generalize the model comparison to arbitrary models submitting to exact inference, as the operations of the mixture node are ignorant about the adjacent subgraphs. Additionally, we derive three common model comparison methods from the literature (Bayesian model averaging, selection, and combination) using the custom mixture node.
In short, this paper derives automated Bayesian model comparison using message passing in a factor graph. After positioning our paper in
Section 2 and after reviewing factor graphs and message passing-based probabilistic inference in
Section 3, we make the following contributions:
We show that the Bayesian model comparison can be performed through message passing on a graph, where the individual model performance results are captured in a single factor node as described in
Section 4.1.
We specify a universal mixture node and derive a set of custom message-passing update rules in
Section 4.2. Performing probabilistic inference with this node in conjunction with scale factors yields different Bayesian model comparison methods.
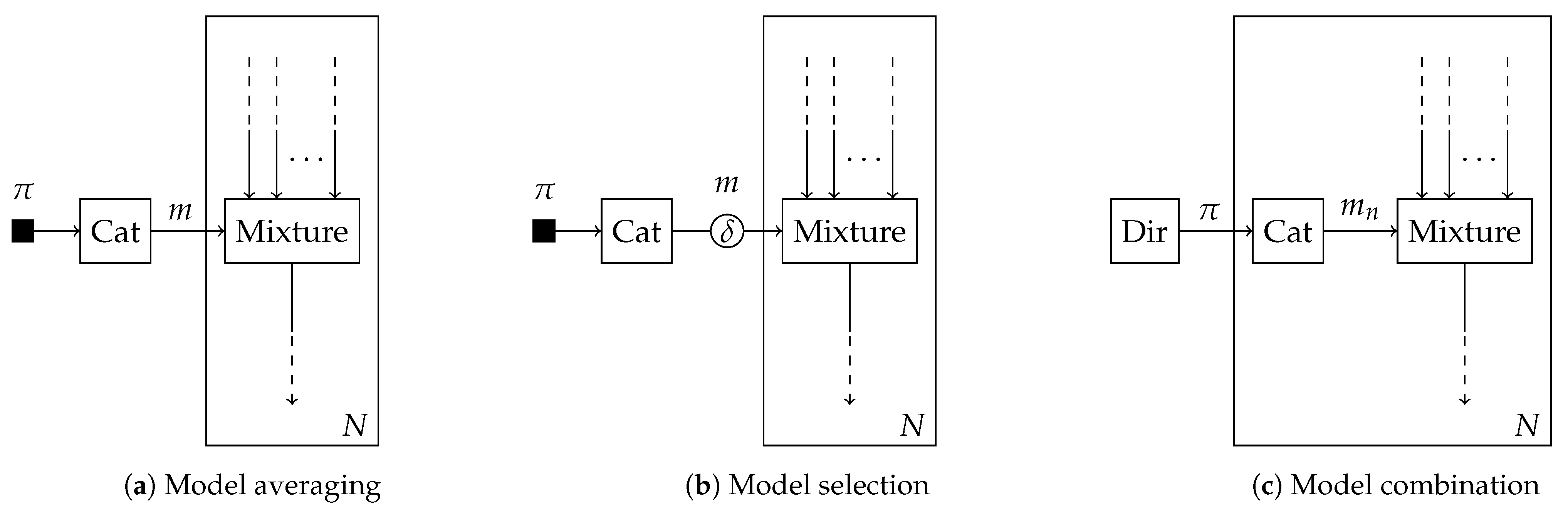
Bayesian model averaging, selection, and combination are recovered and consequently automated in
Section 5.1,
Section 5.2 and
Section 5.3 by imposing a specific structure or local constraints on the model selection variable
m.
We verify our presented approach in
Section 6.1. We illustrate its use for models with both continuous and discrete random variables in
Section 6.2.1, after which we continue with an example of voice activity detection in
Section 6.2.2, where we add temporal structure on
m.
Section 7 discusses our approach, and
Section 8 concludes the paper.
2. Related Work
This section discusses related work and aims at providing the clear positioning of this paper for our contributions that follow in the upcoming sections.
The task of model comparison is widely represented in the literature [
17], for example, concerning hypothesis testing [
18,
19]. Bayesian model averaging [
6] can be interpreted as the simplest form of model comparison that uses the Bayesian formalism to retain the first level of uncertainty in the model selection process [
20]. Bayesian model averaging has proven to be an effective and principled approach that converges with infinite data to the single best model in the set of candidate models [
21,
22,
23]. When the true underlying model is not part of this set, the data is often better represented by ad hoc methods [
24], such as ensemble methods. In [
7], the idea of Bayesian model comparison is introduced, which basically performs Bayesian model averaging between mixture models comprising the candidate models with different weights. Another ensemble method is proposed in [
23,
25], which uses (hierarchical) stacking [
26] to construct predictive densities whose weights are data dependent.
Automating the model design cycle [
2] under the Bayesian formalism has been the goal of many probabilistic programming languages [
8,
9,
10,
11,
12,
13,
14]. This paper focuses on message passing-based approaches, which leverage the conditional independencies in the model structure for performing probabilistic inference, e.g., [
27,
28,
29,
30], which will be formally introduced in
Section 3.2. Contrary to alternative sampling-based approaches, message passing excels in modularity, speed and efficiency, especially when models submit to closed-form (variational) message computations. Throughout this paper, we follow the spirit of [
31], which shows that many probabilistic inference algorithms, such as (loopy) belief propagation [
32,
33], variational message passing [
30,
34], expectation maximization [
35], and expectation propagation [
36] can all be phrased as a constrained Bethe free energy [
37] minimization procedure. Specifically, in
Section 5, we aim to phrase different Bayesian model comparison methods as automatable message-passing algorithms. Not only does this have the potential to shorten the design cycle but also to develop novel model comparison schemes.
The connection between (automatable) state and parameter inference, versus model comparison was explored recently by [
15,
22], who frame the problem of model comparison as a “mixture model estimation” task that is obtained by combining the individual models into a mixture model with weights representing the model selection variable. The exposition in [
15,
22] is based on relatively simple examples that do not easily generalize to more complex models for the model selection variable and for the individual cluster components. In the current paper, we aim to generalize the mixture model estimation approach by an automatable message passing-based inference framework. Specifically, we build on the results of the recently developed scale factors (Ch. 6, [
38,
39]), which we introduce in
Section 3.3. These scale factors support the efficient tracking of local summaries of model evidences, thus enabling model comparison in generic mixture models; see
Section 4 and
Section 5.
The approach we present in the current paper is also similar to the concept of ‘gates’, introduced in [
16]. Gates are factor nodes that switch between mixture components with which we can derive automatable message-passing procedures. Mathematically, a gate represents a factor node of the form
, where the model selection variable
m is a one-of-
K coded vector defined as
subject to
. The variables are
. Despite the universality of the Gates approach, the inference procedures in [
16] focus on variational inference [
30,
34,
40] and expectation propagation [
36]. The mixture selection variable
m is then updated based on “evidence-like quantities”. In the variational message-passing case, these quantities resemble local Bethe free energy contributions, which only take into account the performance around the gate factor node, disregarding the performance contributions of other parts in the model. Because of the local contributions, the message-passing algorithm can be very sensitive to its initialization, which has the potential to yield suboptimal inference results.
In the current paper, we extend gates to models submitting to exact inference using scale factors, which allows for generalizing and automating the mixture models of [
15,
22]. With these advances we can automate well-known Bayesian model comparison methods using message passing, enabling the development of novel comparison methods.
4. Universal Mixture Modeling
This section derives a custom factor node that allows for performing model comparison as an automatable message-passing procedure in
Section 5. In
Section 4.1, we specify a variational optimization objective for multiple models at once, where the optimization of the model selection variable can be rephrased as a probabilistic inference procedure on a separate graph with a factor node encapsulating the model-specific performance metrics.
Section 4.2 further specifies this node and derives custom message-passing update rules that allow for jointly computing (
1) and for performing state and parameter inference.
Before continuing our discussion, let us first describe the notational conventions adopted throughout this section. In
Section 3, only a single model is considered. Here, we cover
K normalized models, selected by the model selection variable
m, which comprises a 1-of-
K binary vector with elements
constrained by
. The individual models
are indexed by
k, where
and
collect the observed and latent variables in that model.
4.1. A Variational Free Energy Decomposition for Mixture Models
Consider the normalized joint model
specifying a mixture model over the individual models
, with a prior
on the model selection variable
m and where
and
. Based on this joint model, let us define its variational free energy
as
in which the joint variational posterior
factorizes as
, and where
denotes the variational free energy of the
k-th model. This decomposition is obtained by noting that
m is a 1-of-
K binary vector. Furthermore, derivations of this decomposition are provided in
Appendix B.1.
This definition also appeared in a similar form in (Ch.10.1.4, [
42]) and in the reinforcement learning and active inference community as an approach to policy selection (Section 2.1, [
45]). From this definition, it can be noted that the VFE for mixture models can also be written as
where
as shown in
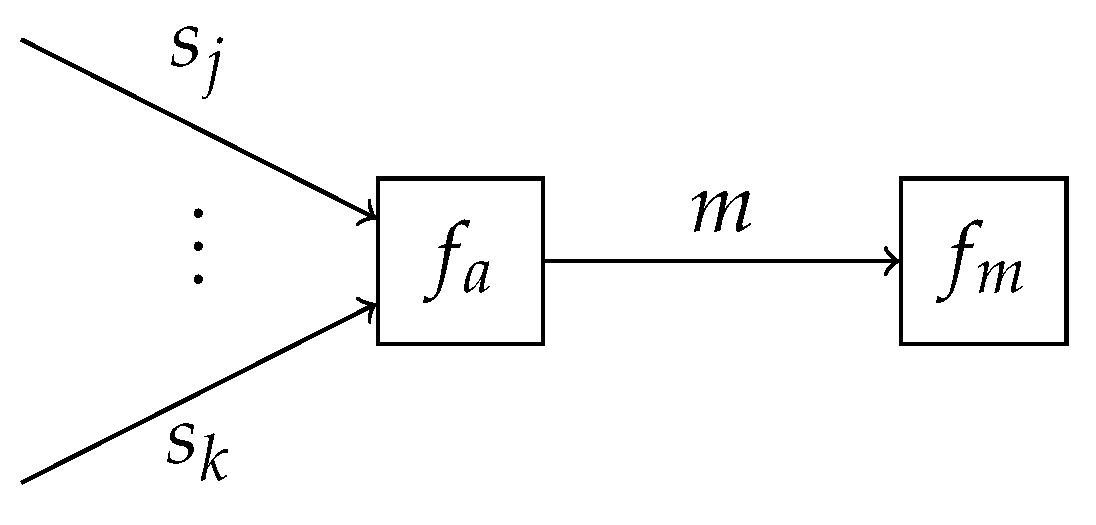
Appendix B.1. This observation implies that the obtained VFEs of the individual submodels can be combined into a single factor node
, representing a scaled categorical distribution, which terminates the edge corresponding to
m as shown in
Figure 2. The specification of
allows for performing inference in the overcoupling model following existing inference procedures, similar to that for the individual submodels. This is in line with the validity of Bayes’ theorem in (
1) for both state and parameter inference, and model comparison. Importantly, the computation of the VFE in acyclic models can be automated [
31]. Therefore, model comparison itself can also be automated. For cyclic models, one can resort to approximating the VFE with the Bethe free energy [
31,
37].
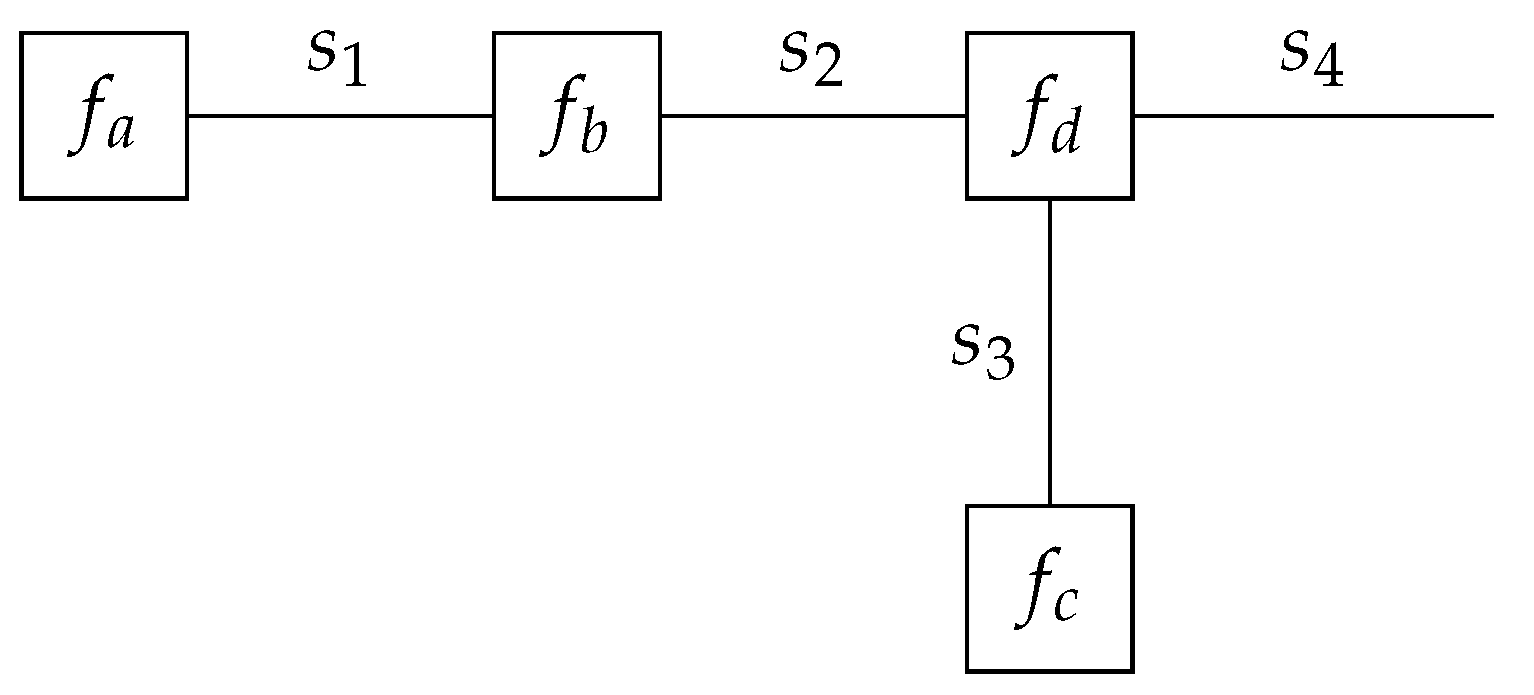
In practice, the prior model
might have hierarchical or temporal dynamics, including additional latent variables. These can be incorporated without loss of generality due to the factorizable structure of the joint model, supported by the modularity of factor graphs and the corresponding message-passing algorithms, as shown in
Figure 2.
4.2. A Factor Graph Approach to Universal Mixture Modeling: A General Recipe
In this subsection, we present the general recipe for computing the posterior distributions over the variables
s and model selection variable
m in universal mixture models.
Section 4.3 provides an illustrative example that aids the exposition in this section. The order in which these two section are read is a matter of personal preference.
In many practical applications, distinct models
partly overlap in both structure and variables. These models may, for example, just differ in terms of priors or likelihood functions. Let
be the product of factors which are present in all different factorizable models
, with overlapping variables
and
. Based on this description, we define a universal mixture model as in [
15] encompassing all individual models as
with model selection variable
m. Here, the overlapping factors are factored out from the mixture components.
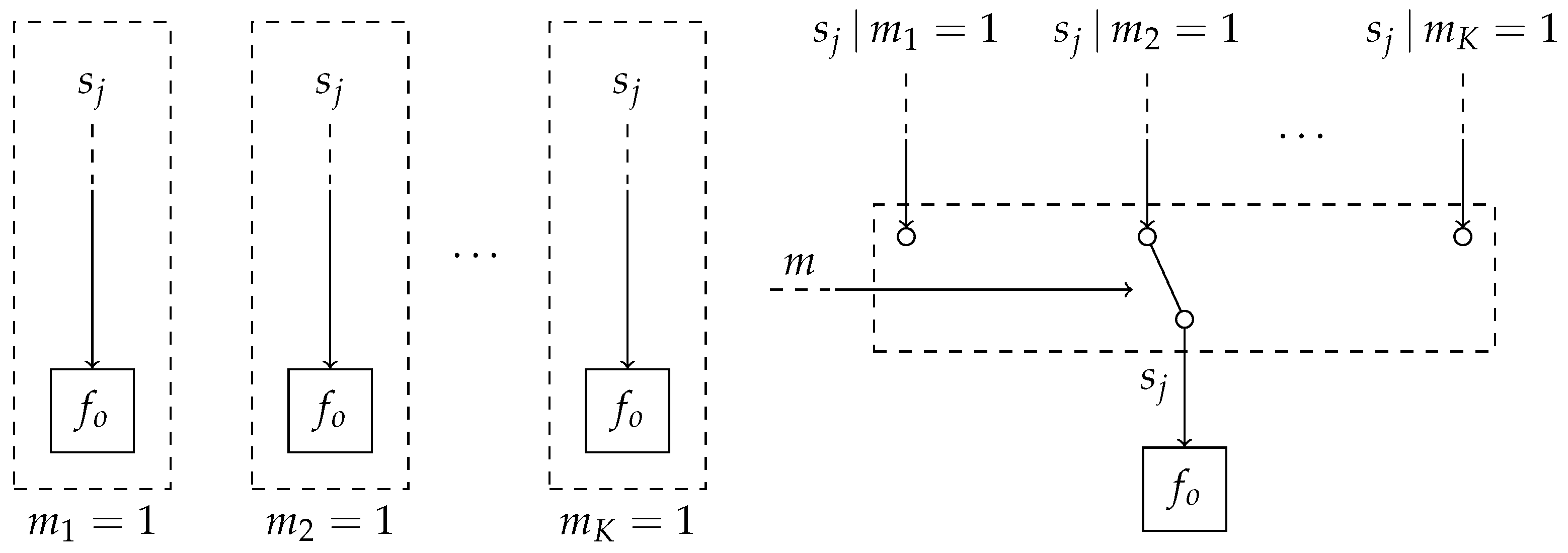
Figure 3 shows a visualization of the transformation from
K distinct models into a single mixture model. With the transformation from the different models into a single mixture model presented in
Figure 3, it becomes possible to include the model selection variable
m into the same probabilistic model.
In these universal mixture models, we are often interested in computing the posterior distributions of (1) the overlapping variables
marginalized over the distinct models and of (2) the model selection variable
m. Given the posterior distributions
over variables
in a single model
, we can compute the joint posterior distribution over all overlapping variables
as
marginalized over the different models
m. In the generic case, this computation follows a three-step procedure. First, the posterior distributions
are computed in the individual submodels through an inference algorithm of choice. Then, based on the computed VFE
of the individual models, the variational posterior
can be calculated. Finally, the joint posterior distribution
can be computed using (
16).
Here, we restrict ourselves to acyclic submodels. We show that the previously described inference procedure for computing the joint posterior distributions can be performed jointly with the process of model comparison through message passing with scale factors. In order to arrive at this point, we combine the different models into a single mixture model inspired by [
15,
22]. Our specification of the mixture model, however, is more general compared to that of [
15,
22], as it does not constrain the hierarchical depth of the overlapping or distinct models and also works for nested mixture models.
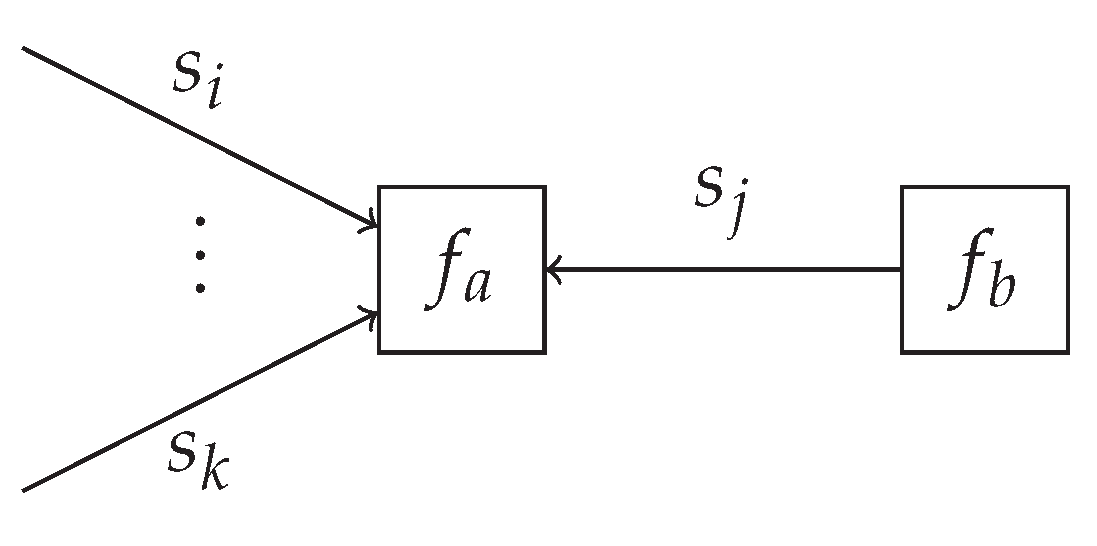
Table 1 introduces the novel mixture node, which acts as a switching mechanism between different models, based on the selection variable
m. It connects the model selection variable
m and the overlapping variables
for the different models
, to the variable
marginalized over
m. Here, the variables
connect the overlapping to the non-overlapping factors.
The messages in
Table 1 are derived in Appendices
Appendix B.2 and
Appendix B.3, and can be intuitively understood as follows. The message
represents the unnormalized distribution over the model evidence corresponding to the individual models. Based on the scale factors of the incoming messages, the model evidence can be computed. The message
equals the incoming message from the likelihood
. It will update
as if the
k-th model is active. The message
represents a mixture distribution over the incoming messages
, where the weightings are determined by the message
and the scale factors of the messages
. This message can be propagated as a regular message over the overlapping model segment yielding the marginal posterior distributions over all variables in the overlapping model segment.
Theorem 2. Consider multiple acyclic FFGs. Given the message in Table 1 that is marginalized over the different m models, propagating this message through the factor , which overlaps for all models with , yields again messages which are marginalized over the different models.
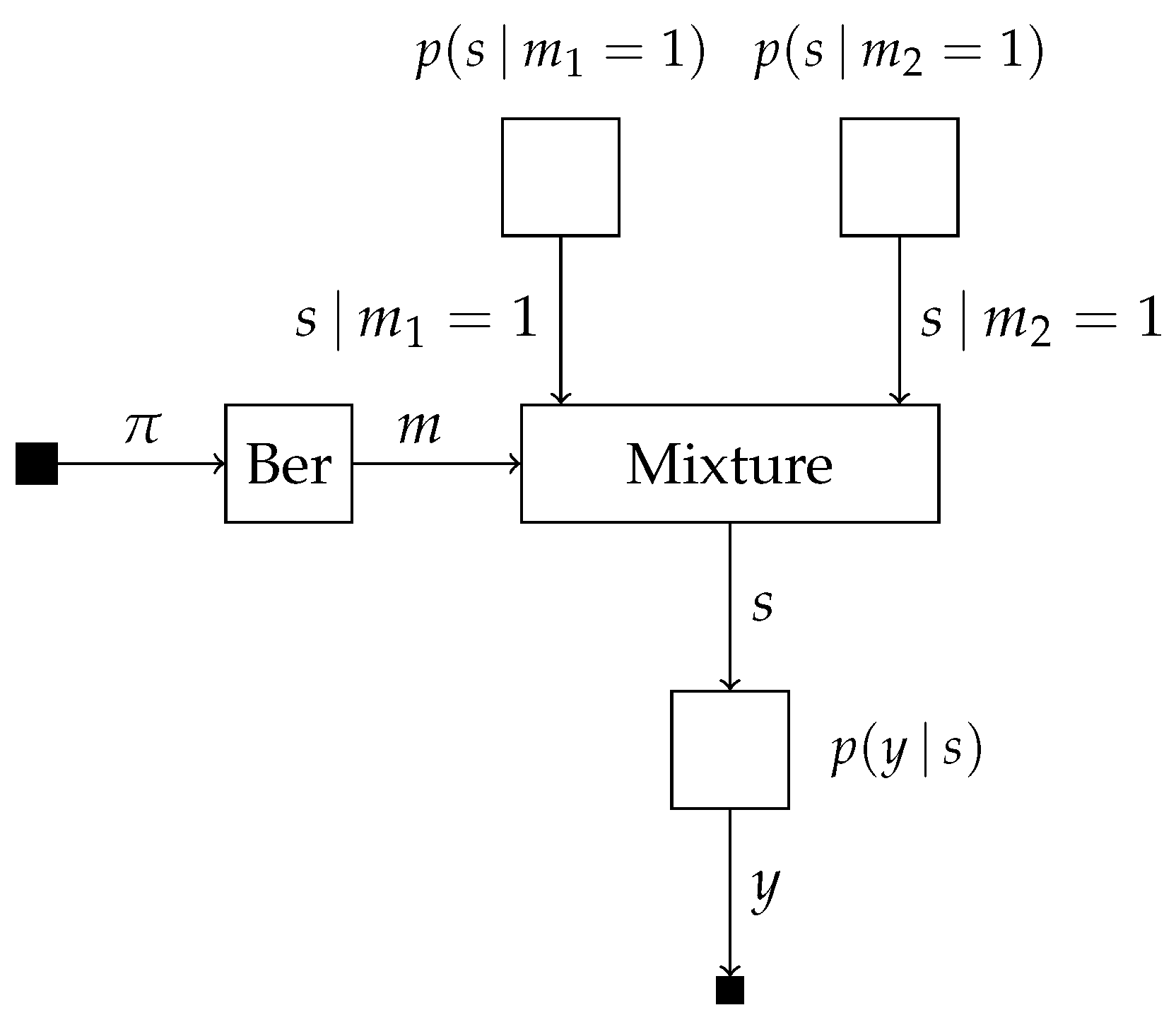
4.3. A Factor Graph Approach to Universal Mixture Modeling: An Illustrative Example
Consider the two probabilistic models
which share the same likelihood model with a single observed and latent variable
y and
s, respectively. The model selection variable
m is subject to the prior
with
denoting the success probability. This allows for the specification of the mixture model
which we visualize in
Figure 4.
Suppose we are interested in computing the posterior probabilities
, marginalized over the distinct models, and
. The model evidence of both models can be computed using scale factors locally on the edge corresponding to
s as
which takes place inside the mixture node for computing
. Together with the forward message over edge
m, we obtain the posterior
The posterior distribution over
s for the first model can be computed as
From (
16), we can then compute the posterior distribution over
s marginalized over both models as
6. Experiments
In this section, a set of experiments is presented for the previously presented message passing-based model comparison techniques.
Section 6.1 verifies the basic operations of the inference procedures for model averaging, selection and combination for data generated from a known mixture distribution. In
Section 6.2, the model comparison approaches are validated on application-based examples.
All experiments were performed using the scientific programming language Julia [
48] with the state-of-the-art probabilistic programming package RxInfer.jl [
9]. The mixture node specified in
Section 4.2 was integrated in its message-passing engine ReactiveMP.jl [
49,
50]. Aside from the results presented in the upcoming subsections, interactive Pluto.jl notebooks are available online (all experiments are publicly available at
https://github.com/biaslab/AutomatingModelComparison, (accessed on 9 June 2023)), allowing the reader to change hyperparameters in real time.
6.1. Verification Experiments
For verification of the mixture node in
Table 1,
observations
are generated from the mixture distribution
where
represents a normal distribution with mean
and variance
.
represents the additional observation noise variance. For the obtained data, we construct the probabilistic model
which is completed by the structures imposed on
m as introduced in
Section 5. Depending on the comparison method as outlined in
Section 5.1,
Section 5.2 and
Section 5.3, we add an uninformative categorical prior on
z or an uninformative Dirichlet prior on the event probabilities
that model
z. The aim is to infer the marginal (approximate) posterior distributions over component assignment variable
z, for model averaging and selection, and over event probabilities
, for model combination.
The Bayesian model combination preliminary experiments show that the results relied significantly on the initial prior
in the online setting. Choosing this term to be uninformative, i.e.,
and
, led to a posterior distribution which became dominated by the inferred cluster assignment of the first observation. As a result, the predictive class probability approached a delta distribution, centered around the class label of the first observation, leading to all consecutive observations being assigned to the same cluster. This observation is as expected, as the concentration parameters
of the posterior distribution
after the first model assignment
were updated as
, with prior concentration parameters
. When the entries of
are small, this update will have a significant effect of the updated prior distribution over
and consecutively over the prior belief over the model assignment
. To remedy this undesirable behavior, the prior
was chosen to prefer uniformly distributed class labels, i.e.,
and
. Although this prior yields the same forward message
, consecutive forward messages will be less affected by the selected models
. After the inference procedure was completed, the informativeness of this prior was removed using Bayesian model reduction [
43,
44], where the approximate posterior over
was recomputed based on an alternative uninformative prior.
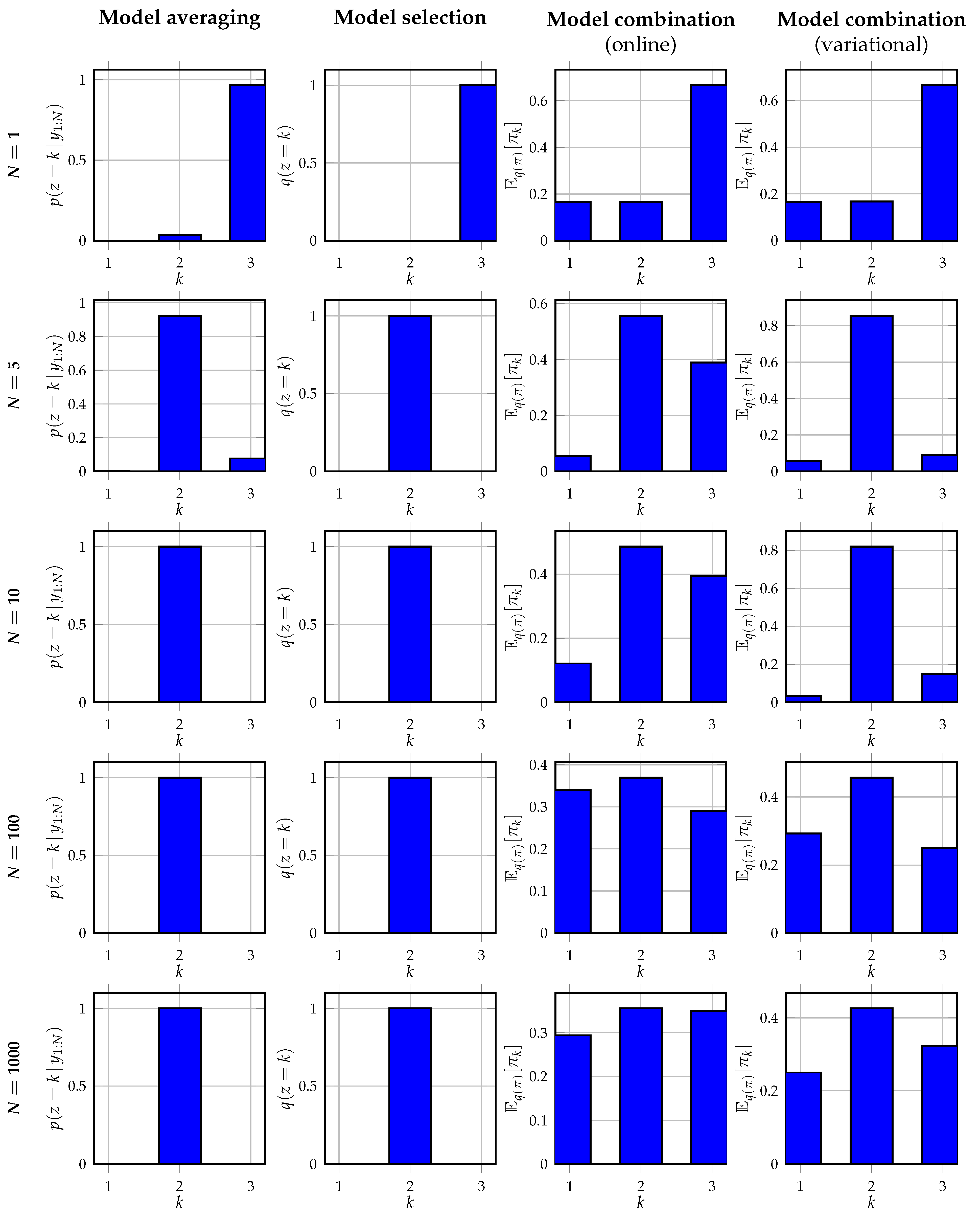
Figure 6 shows the inferred posterior distributions of
z or the predictive distributions for
z obtained from the posterior distributions
, for an observation noise variance
. From the results, it can be observed that Bayesian model averaging converges with increasing data to a single cluster as expected. This selected cluster corresponds to the cluster inferred by Bayesian model selection, which also corresponds to the cluster with the highest mixing weight in (
29). Contrary to Bayesian model selection, the alternative event probabilities obtained with Bayesian model averaging are non-zero. Both Bayesian model combination approaches do not converge to a single cluster assignment as expected. Instead, they better recover the data-generating mixing weights in the data-generating distribution. It can be seen that the variational approach to model combination is better capable of retrieving the original mixing weights, despite the high noise variance of
. The online model combination approach is less capable of retrieving the original mixing weights. This is also as expected since the online approach performs an approximate filtering procedure, contrary to the approximate smoothing procedure of the variational approach. For smaller values of the noise variance, we observe in our experiments that the online model combination strategy approaches the variational strategy.
6.2. Validation Experiments
Aside from verifying the correctness of the message-passing implementations of
Section 5 using the mixture node, this section further illustrates its usefulness in a set of validation experiments, covering real-world problems.
6.2.1. Mixed Models
In order to illustrate an application of the mixture node from
Table 1, we show how it can be used in a mixed model, where it connects continuous to discrete variables. Consider the hypothetical situation, where we wish to fit a mixture with fixed components but unknown mixing coefficients to some set of observations. To highlight the generality of the mixture node, the mixture components are chosen to reflect shifted product distributions, where the possible shifts are limited to a discrete set of values. The assumed probabilistic model of a single observation
y is given by
The variables
a and
b are latent variables defining the product distribution.
c specifies the shift introduced on this distribution, which is picked by the selector variable
z, comprising a 1-of-3 binary vector with elements
constrained by
.
denotes a vector of ones of length
K. The goal is to infer the posterior distribution of
z and to, therefore, fit this exotic mixture model to some set of data.
We perform offline probabilistic inference in this model using Bayesian model averaging and Bayesian model combination. For the latter approach, we extend the prior on
z with a Dirichlet distribution following
Section 5.3 and by assuming a variational mean-field factorization. The shifted product distributions do not yield tractable closed-form messages; therefore, these distributions are approximated following [
51].
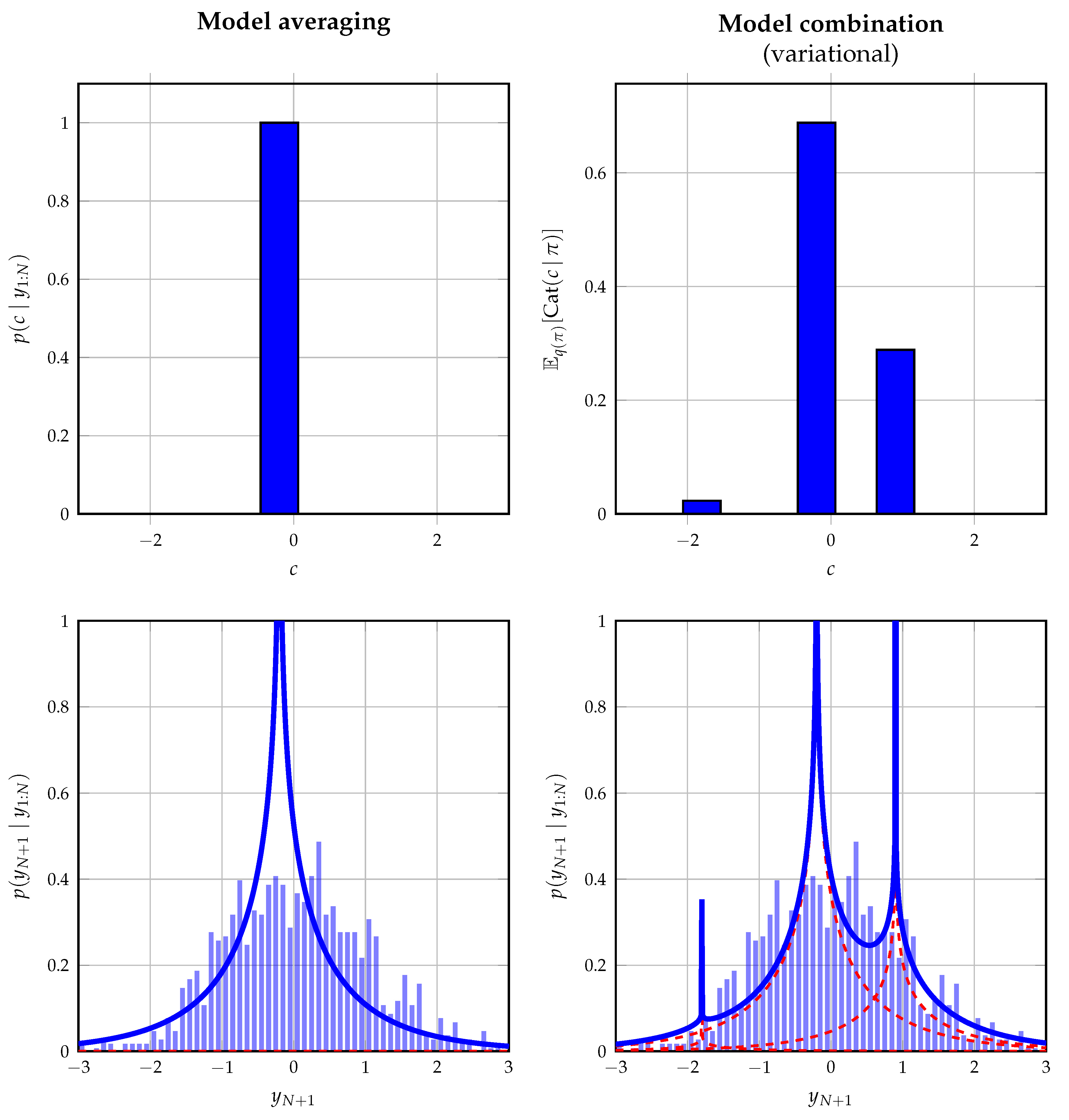
Figure 7 shows the obtained data fit on a data set of 1500 observations drawn from a standard normal distribution. This distribution does not reflect the used model in (31) on purpose to illustrate its behavior when the true underlying model is not one of the components. As expected, model averaging converges to the most dominant component, whereas model combination attempts to improve the fit by combining the different components with fixed shifts.
6.2.2. Voice Activity Detection
In this section, we illustrate a message-passing approach to voice activity detection in speech that is corrupted by additive white Gaussian noise using the mixture node from
Table 1. We model speech signal
as a first-order auto-regressive process as
with auto-regressive parameter
and process noise variance
. The absence of speech is modeled by independent and identically distributed variables
, which are enforced to be close to 0 as
We model our observations by the mixture distribution, where we include the corruption from the additive white Gaussian noise as
Here,
indicates the voice activity of the observed signal as a 1-of-2 binary vector with elements
constrained by
. Because periods of speech are often preceded by more speech, we add temporal dynamics to
as
where the transition matrix is specified as
.
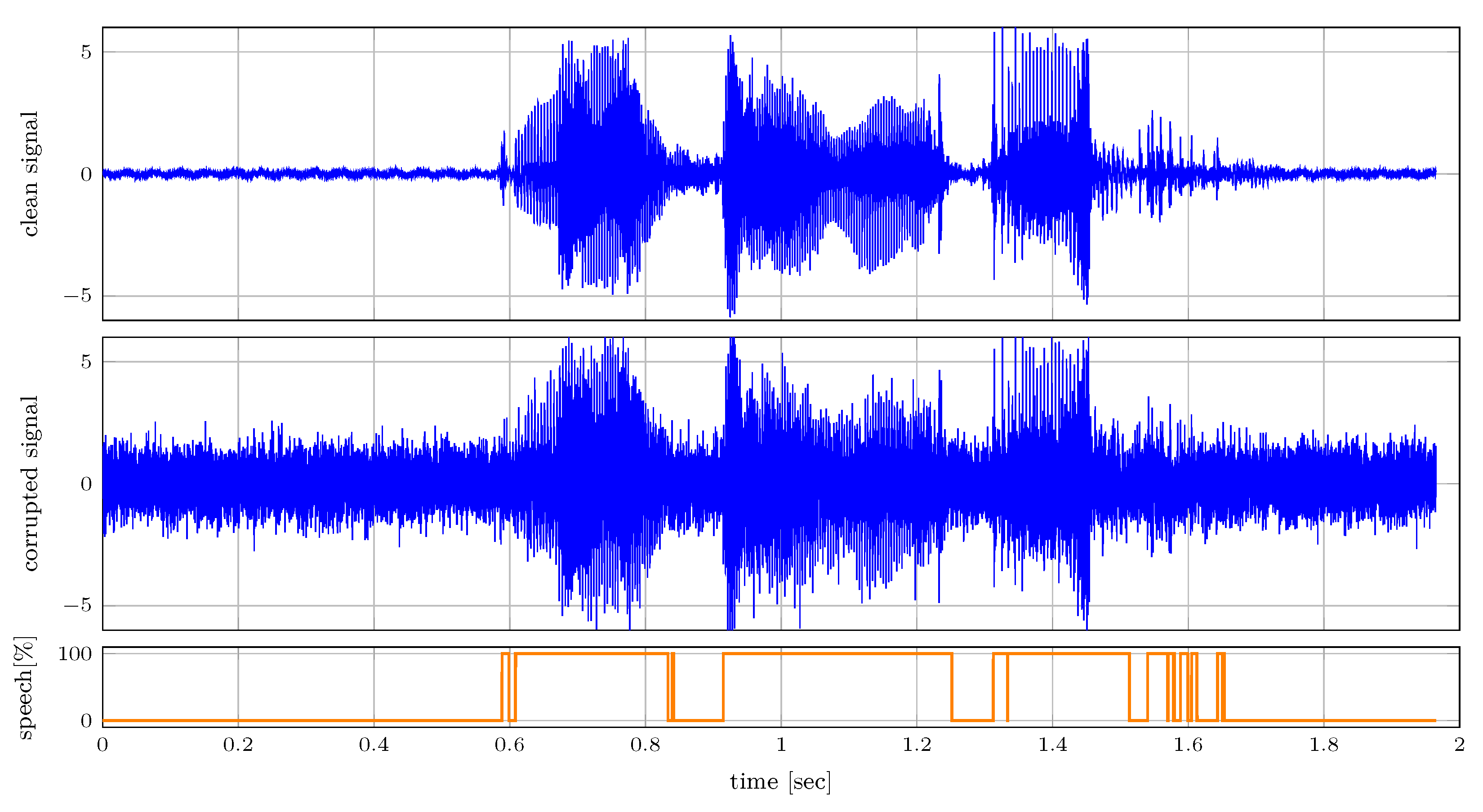
Figure 8 shows the clean and corrupted audio signals. The audio is sampled with a sampling frequency of 16 kHz. The corrupted signal is used for inferring
, which is presented in the bottom plot. Despite the corruption inflicted on the audio signal, this presented simple model is capable of detecting voice effectively as illustrated in the bottom plot of
Figure 8.
7. Discussion
The unifying view between probabilistic inference and model comparison as presented by this paper allows us to leverage the efficient message-passing schemes for both tasks. Interestingly, this view allows for the use of belief propagation [
32], variational message passing [
30,
34,
40] and other message passing-based algorithms around the subgraph connected to the model selection variable
m. This insight gives rise to a novel class of model comparison algorithms, where the prior on the model selection variable is no longer constrained to be a categorical distribution but where we now can straightforwardly introduce hierarchical and/or temporal dynamics. Furthermore, a consequence of the automatability of the message-passing algorithms is that these model comparison algorithms can easily and efficiently be implemented, without the need for error-prone and time-consuming manual derivations.
Although this paper solely focused on message passing-based probabilistic inference, we envision interesting directions for alternative probabilistic programming packages, such as Stan [
14], Pyro [
11], Turing [
10], UltraNest [
12], and PyMC [
13]. Currently, only the PyMC framework allows for model comparison through their compare() function. However, often these packages allow for estimating the (log-)evidence through sampling, or for computing the evidence lower bound (ELBO), which resembles the negative VFE of (
10), which is optimized using stochastic variational inference [
52]. An interesting direction of future research would be to use these estimates to construct the factor node
in (
14), with which novel model comparison algorithms can be designed, for example, where the model selection variables becomes observation dependent as in [
25].
The presented approach is especially convenient when the model allows for the use of scale factors (Ch.6, [
38,
39]). In this way, we can efficiently compute the model evidence as shown in [
39]. The introduced mixture node in
Table 1 consecutively enables a simple model specification as illustrated in the
Supplementary Materials source code of our experiments (all experiments are publicly available at
https://github.com/biaslab/AutomatingModelComparison, (accessed on 9 June 2023)).
A limitation of the scale factors is that they can only be efficiently computed when the model submits to exact inference [
39]. Extensions of the scale factors towards a variational setting would allow the use of the mixture node with a bigger variety of models. If this limitation is resolved, then the introduced approach can be combined with more complicated models, such as, for example, Bayesian neural networks, whose performance is measured by the variational free energy, see, e.g., [
53,
54]. This provides a novel solution to multi-task machine learning problems, where the number of tasks is not known beforehand [
55]. Each Bayesian neural network can then be trained for a specific task, and additional components or networks can be added if appropriate.
The mixture nodes presented in this paper can also be nested on top of each other. As a result, hierarchical mixture models can be realized, which can quickly increase the complexity of the nested model. The question quickly arises as to where to stop. An answer to this question is provided by Bayesian model reduction [
43,
44]. Bayesian model reduction allows for the efficient computation of the model evidence when parts of the hierarchical model are pruned. This approach allows for the pruning of hierarchical models in an effort to bound the complexity of the entire model.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
