




Robust Variable Selection with Exponential Squared Loss for the Spatial Single-Index Varying-Coefficient Model


Abstract
1. Introduction
- We propose a novel model: the spatial single-index varying-coefficient model, which can deal with the spatial correlation and spatial heterogeneity of data at the same time.
- We construct a robust variable selection method for the spatial single-index varying-coefficient model, which uses exponential square loss function to resist the influence of strong noise and inaccurate spatial weight matrix. Furthermore, we present the BCD (block coordinate descent) algorithm to solve the optimization problem of the objective function.
- Under reasonable assumptions, we give theoretical properties of this method. In addition, we verify the robustness and effectiveness of the variable selection method through numerical simulation studies. The numerical study shows that the method is more robust than other comparative methods in variable selection and parameter estimation when outliers or noise are presented in the observations.
2. Methodology
2.1. Model Setup
2.2. Basis Function Expansion
2.3. The Penalized Robust Regression Estimator
2.4. Estimation of the Variance of the Noise
3. Theoretical Properties
- (C1)
- The density function of is uniformly bounded on and far from 0. Furthermore, is assumed to satisfy the Lipschitz condition of order 1 on T.
- (C2)
- The function , has bounded and continuous derivatives up to order on T, where is the jth components of .
- (C3)
- and .
- (C4)
- is a strictly stationary and strongly mixing sequence with coefficient , where .
- (C5)
- Let be the interior knots of , where , . Moreover, we set , , , . Then, a positive constant exists such that
- (C6)
- Let and then as . Further, let, where .
- (C7)
- is a nonsingular matrix, invertible for any , is a compact parameter space, and the absolute row and column sums of , are uniformly bounded on ;
- (C8)
- Letwhere . Suppose that is negative definite.
- (C9)
- is positive definite.
- (i)
- ;
- (ii)
- , for
- (i)
- , ;
- (ii)
- , .
4. Algorithm
4.1. Choice of the Tuning Parameter
4.2. Choice of the Regularization Parameter and
4.3. Block Coordinate Descent (BCD) Algorithm
| Algorithm 1 The block coordinate descent (BCD) algorithm |
|
4.4. DC Decomposition and CCCP Algorithm
| Algorithm 2 The Concave–Convex Procedure |
|
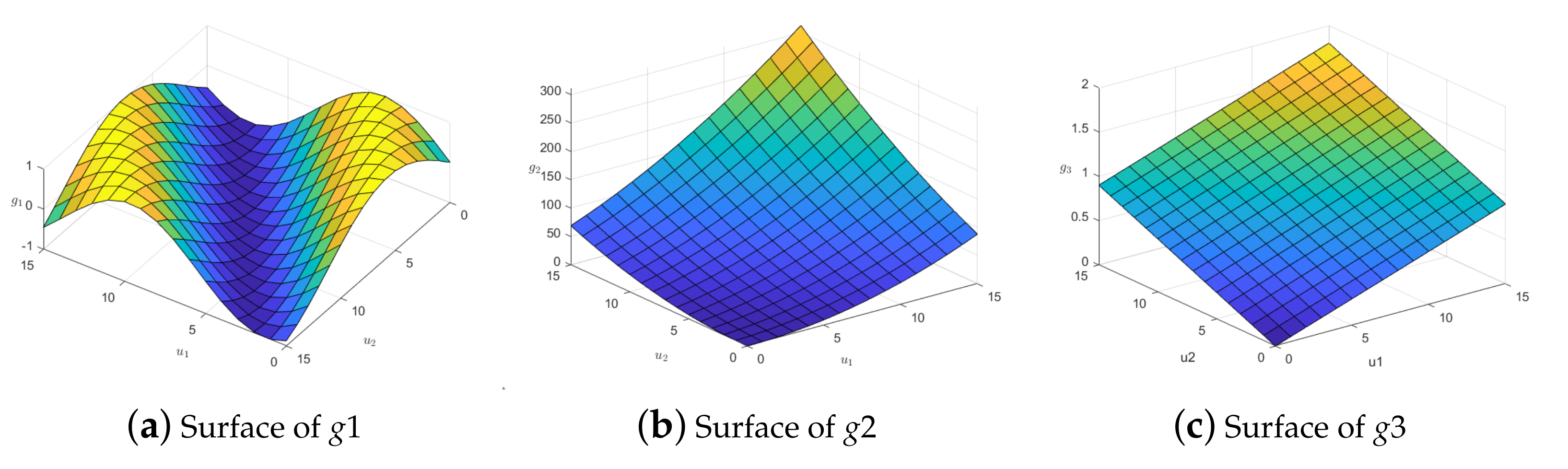
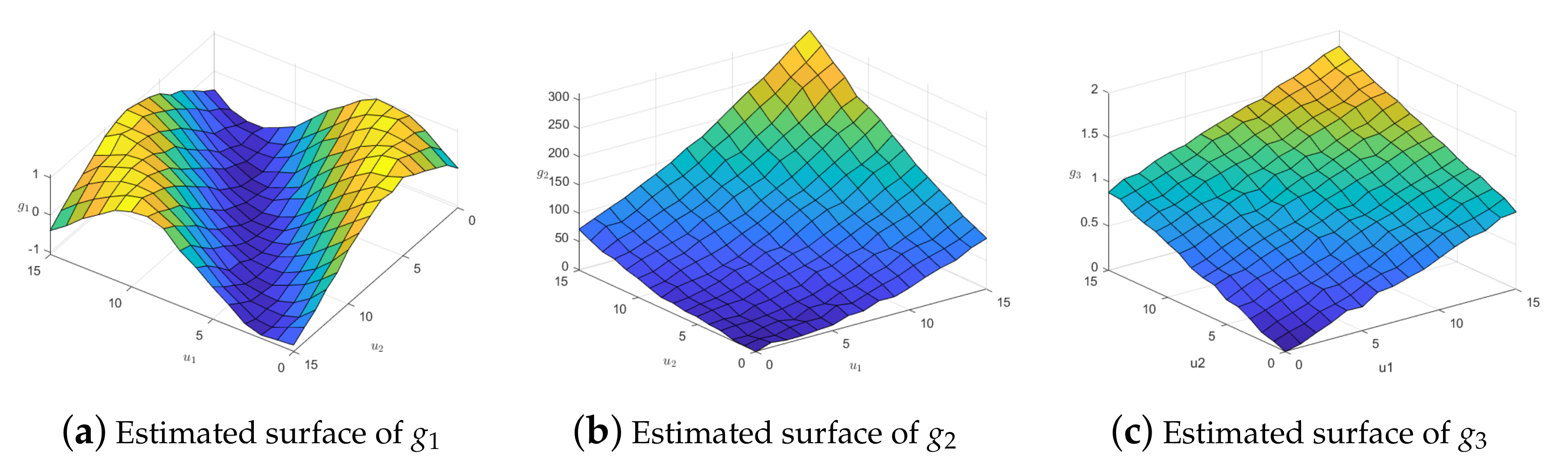
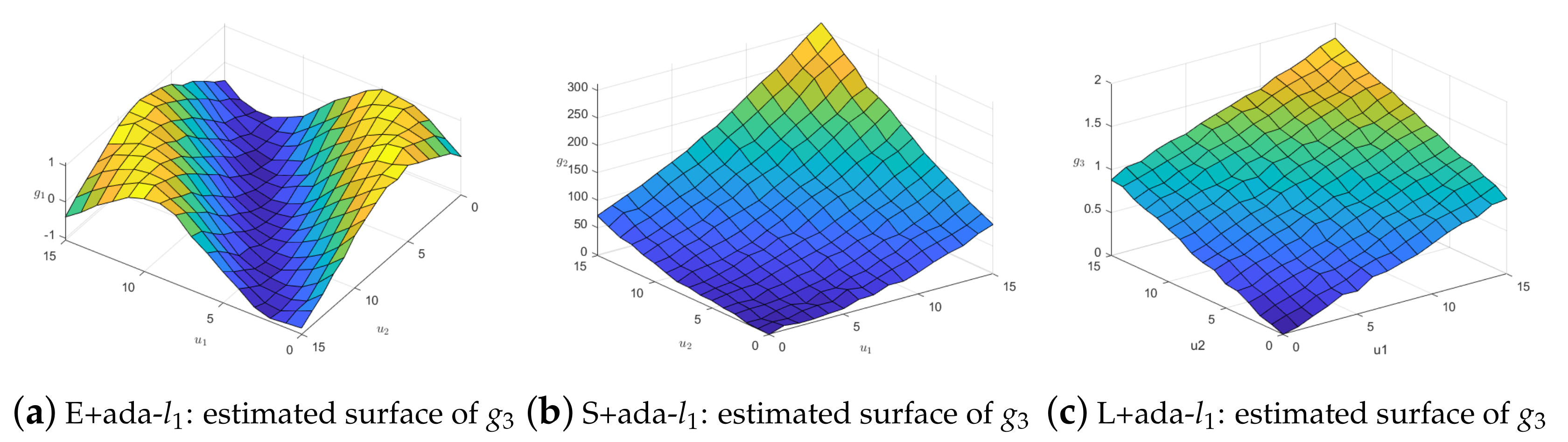
5. Simulation Studied
5.1. Simulation Sampling
5.2. Simulation Results
6. Summary
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| SAR model: | Spatial autoregressive model; |
| BCD algorithm: | Block-coordinate descent algorithm; |
| DC function: | Difference between two convex functions; |
| CCCP: | concave–convex procedure; |
| ISTA: | Iterative shrinkage-thresholding algorithm; |
| FISTA: | Fast iterative shrinkage-thresholding algorithm; |
| MedSE: | Median of squared error; |
| MAISE: | Square root of mean deviation. |
Appendix A. Proofs
Appendix A.1. The Related Lemmas
Appendix A.2. Poof of Main Theorems
References
- Cliff, A.D. Spatial Autocorrelation; Technical Report; Pion: London, UK, 1973. [Google Scholar]
- Su, L. Semiparametric GMM estimation of spatial autoregressive models. J. Econom. 2012, 167, 543–560. [Google Scholar] [CrossRef]
- Zhang, Y.; Shen, D. Estimation of semi-parametric varying-coefficient spatial panel data models with random-effects. J. Stat. Plan. Inference 2015, 159, 64–80. [Google Scholar] [CrossRef]
- Fan, J.; Yao, Q.; Cai, Z. Adaptive varying-coefficient linear models. J. R. Stat. Soc. Ser. B 2003, 65, 57–80. [Google Scholar] [CrossRef]
- Lu, Z.; Tjøstheim, D.; Yao, Q. Adaptive varying-coefficient linear models for stochastic processes: Asymptotic theory. Stat. Sin. 2007, 17, 177-S35. [Google Scholar]
- Xue, L.; Wang, Q. Empirical likelihood for single-index varying-coefficient models. Bernoulli 2012, 18, 836–856. [Google Scholar] [CrossRef]
- Huang, Z.; Zhang, R. Profile empirical-likelihood inferences for the single-index-coefficient regression model. Stat. Comput. 2013, 23, 455–465. [Google Scholar] [CrossRef]
- Wang, X.; Jiang, Y.; Huang, M.; Zhang, H. Robust variable selection with exponential squared loss. J. Am. Stat. Assoc. 2013, 108, 632–643. [Google Scholar] [CrossRef]
- Jiang, Y. Robust estimation in partially linear regression models. J. Appl. Stat. 2015, 42, 2497–2508. [Google Scholar] [CrossRef]
- Song, Y.; Jian, L.; Lin, L. Robust exponential squared loss-based variable selection for high-dimensional single-index varying-coefficient model. J. Comput. Appl. Math. 2016, 308, 330–345. [Google Scholar] [CrossRef]
- Wang, K.; Lin, L. Robust structure identification and variable selection in partial linear varying coefficient models. J. Stat. Plan. Inference 2016, 174, 153–168. [Google Scholar] [CrossRef]
- Yu, Y.; Ruppert, D. Penalized spline estimation for partially linear single-index models. J. Am. Stat. Assoc. 2002, 97, 1042–1054. [Google Scholar] [CrossRef]
- Fan, J.; Li, R. Variable selection via nonconcave penalized likelihood and its oracle properties. J. Am. Stat. Assoc. 2001, 96, 1348–1360. [Google Scholar] [CrossRef]
- Tibshirani, R. Regression shrinkage and selection via the lasso. J. R. Stat. Soc. Ser. B 1996, 58, 267–288. [Google Scholar] [CrossRef]
- Zou, H. The adaptive lasso and its oracle properties. J. Am. Stat. Assoc. 2006, 101, 1418–1429. [Google Scholar] [CrossRef]
- Wang, H.; Li, G.; Jiang, G. Robust regression shrinkage and consistent variable selection through the LAD-lasso. J. Bus. Econ. Stat. 2007, 25, 347–355. [Google Scholar] [CrossRef]
- Song, Y.; Liang, X.; Zhu, Y.; Lin, L. Robust variable selection with exponential squared loss for the spatial autoregressive model. Comput. Stat. Data Anal. 2021, 155, 107094. [Google Scholar] [CrossRef]
- Yuille, A.L.; Rangarajan, A. The concave–convex procedure (CCCP). In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 3–8 December 2001; Volume 14. [Google Scholar]
- Beck, A.; Teboulle, M. A fast iterative shrinkage-thresholding algorithm for linear inverse problems. SIAM J. Imaging Sci. 2009, 2, 183–202. [Google Scholar] [CrossRef]
- Forsythe, G.E. Computer Methods for Mathematical Computations; Prentice-Hall: Hoboken, NJ, USA, 1977; Volume 259. [Google Scholar]
- Liang, H.; Li, R. Variable selection for partially linear models with measurement errors. J. Am. Stat. Assoc. 2009, 104, 234–248. [Google Scholar] [CrossRef] [PubMed]
- Pollard, D. Asymptotics for least absolute deviation regression estimators. Econom. Theory 1991, 7, 186–199. [Google Scholar] [CrossRef]
- Schumaker, L. Spline Functions: Basic Theory; Cambridge Mathematical Library: Cambridge, UK, 1981. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| n = 25, q = 5 | n = 144, q = 5 | n = 324, q = 5 | |||||||
|---|---|---|---|---|---|---|---|---|---|
| E+null | S+null | L+null | E+null | S+null | L+null | E+null | S+null | L+null | |
| , | |||||||||
| 0.80 | 0.61 | 0.83 | 0.50 | 0.66 | 0.28 | 0.53 | 0.62 | 0.67 | |
| 0.88 | 0.61 | 0.75 | 0.78 | 0.77 | 0.66 | 0.74 | 0.79 | 0.96 | |
| 0.80 | 0.94 | 0.75 | 0.90 | 0.80 | 0.91 | 0.88 | 0.89 | 0.84 | |
| 0.45 | 0.78 | 0.82 | 0.79 | 0.72 | 0.70 | 0.86 | 0.71 | 0.80 | |
| MedSE | 0.28 | 0.44 | 0.70 | 0.22 | 0.23 | 0.42 | 0.17 | 0.16 | 0.19 |
| , | |||||||||
| 0.69 | 0.65 | 0.64 | 0.49 | 0.66 | 0.28 | 0.53 | 0.63 | 0.67 | |
| 0.82 | 0.61 | 0.88 | 0.78 | 0.76 | 0.72 | 0.74 | 0.80 | 0.96 | |
| 0.52 | 0.61 | 0.50 | 0.68 | 0.40 | 0.74 | 0.62 | 0.65 | 0.55 | |
| 0.44 | 0.82 | 0.71 | 0.83 | 0.71 | 0.74 | 0.89 | 0.73 | 0.82 | |
| MedSE | 0.22 | 0.45 | 0.77 | 0.22 | 0.23 | 0.41 | 0.17 | 0.16 | 0.19 |
| , | |||||||||
| 0.67 | 0.66 | 0.57 | 0.51 | 0.65 | 0.32 | 0.53 | 0.65 | 0.65 | |
| 0.81 | 0.59 | 0.96 | 0.80 | 0.75 | 0.72 | 0.76 | 0.81 | 0.98 | |
| 0.14 | 0.00 | 0.27 | 0.33 | 0.00 | 0.50 | 0.19 | 0.26 | 0.16 | |
| 0.44 | 0.82 | 0.68 | 0.87 | 0.70 | 0.78 | 0.91 | 0.76 | 0.84 | |
| MedSE | 0.23 | 0.49 | 0.72 | 0.21 | 0.23 | 0.41 | 0.17 | 0.16 | 0.22 |
| , | |||||||||
| 0.68 | 0.66 | 0.61 | 0.51 | 0.66 | 0.32 | 0.53 | 0.65 | 0.65 | |
| 0.81 | 0.60 | 0.95 | 0.81 | 0.73 | 0.70 | 0.76 | 0.81 | 0.98 | |
| 0.00 | 0.00 | 0.22 | 0.19 | 0.00 | 0.36 | 0.03 | 0.11 | 0.04 | |
| 0.44 | 0.83 | 0.69 | 0.88 | 0.72 | 0.79 | 0.91 | 0.76 | 0.84 | |
| MedSE | 0.22 | 0.47 | 0.70 | 0.21 | 0.25 | 0.39 | 0.16 | 0.16 | 0.22 |
| , | |||||||||
| 0.73 | 0.77 | 1.37 | 0.41 | 0.79 | 0.34 | 0.58 | 0.63 | 0.42 | |
| 0.74 | 0.27 | 0.64 | 0.66 | 0.65 | 0.55 | 0.69 | 0.68 | 0.96 | |
| 0.86 | 0.98 | 0.62 | 0.95 | 0.83 | 0.97 | 0.93 | 0.94 | 0.90 | |
| 1.83 | 3.26 | 5.78 | 3.20 | 3.08 | 2.68 | 3.53 | 2.89 | 3.25 | |
| MedSE | 0.46 | 1.00 | 1.95 | 0.49 | 0.52 | 0.90 | 0.38 | 0.33 | 0.48 |
| , | |||||||||
| 0.72 | 0.79 | 0.66 | 0.43 | 0.78 | 0.23 | 0.59 | 0.65 | 0.42 | |
| 0.74 | 0.32 | 0.90 | 0.68 | 0.68 | 0.54 | 0.72 | 0.70 | 1.01 | |
| 0.58 | 0.68 | 0.50 | 0.77 | 0.29 | 0.86 | 0.70 | 0.74 | 0.62 | |
| 1.87 | 3.49 | 3.05 | 3.44 | 3.03 | 3.00 | 3.74 | 3.08 | 3.45 | |
| MedSE | 0.46 | 0.98 | 1.59 | 0.48 | 0.48 | 0.95 | 0.38 | 0.32 | 0.48 |
| , | |||||||||
| 0.76 | 0.77 | 0.53 | 0.46 | 0.78 | 0.19 | 0.60 | 0.68 | 0.46 | |
| 0.76 | 0.35 | 1.06 | 0.72 | 0.65 | 0.65 | 0.75 | 0.72 | 1.01 | |
| 0.14 | 0.00 | 0.39 | 0.39 | 0.00 | 0.61 | 0.21 | 0.32 | 0.23 | |
| 1.88 | 3.52 | 3.00 | 3.68 | 2.99 | 3.19 | 3.88 | 3.24 | 3.57 | |
| MedSE | 0.45 | 0.97 | 1.51 | 0.46 | 0.50 | 0.84 | 0.36 | 0.32 | 0.48 |
| , | |||||||||
| 0.77 | 0.78 | 0.57 | 0.47 | 0.79 | 0.23 | 0.59 | 0.68 | 0.47 | |
| 0.77 | 0.34 | 1.07 | 0.72 | 0.64 | 0.55 | 0.76 | 0.72 | 1.04 | |
| 0.00 | 0.00 | 0.31 | 0.23 | 0.00 | 0.52 | 0.01 | 0.14 | 0.07 | |
| 1.88 | 3.54 | 3.04 | 3.74 | 3.09 | 3.32 | 3.90 | 3.26 | 3.60 | |
| MedSE | 0.45 | 0.97 | 1.50 | 0.46 | 0.52 | 0.89 | 0.35 | 0.33 | 0.48 |
| , | , | , | |||||||
|---|---|---|---|---|---|---|---|---|---|
| E+null | S+null | L+null | E+null | S+null | L+null | E+null | S+null | L+null | |
| , | |||||||||
| 0.74 | 0.39 | 0.24 | 0.04 | 0.49 | −0.21 | 0.78 | 0.72 | 0.62 | |
| 0.67 | 0.18 | 2.81 | 1.05 | 0.88 | 2.15 | 0.86 | 0.86 | 0.71 | |
| 0.84 | 0.93 | 0.50 | 0.54 | 0.80 | 0.50 | 0.80 | 0.80 | 0.50 | |
| 0.18 | 0.53 | 3.54 | 0.30 | 0.26 | 1.00 | 0.37 | 0.41 | 1.68 | |
| MedSE | 2.79 | 2.20 | 7.92 | 2.78 | 1.72 | 4.56 | 1.44 | 1.66 | 2.21 |
| , | |||||||||
| 0.72 | 0.39 | 0.10 | 0.19 | 0.49 | 0.06 | 0.75 | 0.68 | 0.56 | |
| 0.65 | 0.27 | 1.76 | 0.94 | 0.83 | 1.68 | 0.84 | 0.84 | 0.65 | |
| 0.61 | 0.66 | 0.50 | 0.46 | 0.54 | 0.50 | 0.52 | 0.53 | 0.50 | |
| 0.17 | 0.56 | 0.44 | 0.23 | 0.24 | 0.47 | 0.36 | 0.40 | 0.72 | |
| MedSE | 2.87 | 2.04 | 3.30 | 1.57 | 1.71 | 2.43 | 1.40 | 1.60 | 1.62 |
| , | |||||||||
| 0.70 | 0.37 | 0.08 | 0.17 | 0.50 | 0.24 | 0.75 | 0.67 | 0.55 | |
| 0.64 | 0.40 | 1.45 | 0.93 | 0.79 | 1.60 | 0.84 | 0.85 | 0.60 | |
| 0.45 | 0.04 | 0.50 | 0.00 | 0.31 | 0.50 | 0.13 | 0.19 | 0.50 | |
| 0.18 | 0.57 | 0.22 | 0.22 | 0.24 | 0.50 | 0.36 | 0.40 | 0.73 | |
| MedSE | 3.16 | 1.71 | 2.40 | 1.59 | 1.82 | 2.50 | 1.41 | 1.59 | 1.64 |
| , | |||||||||
| 0.71 | 0.37 | 0.06 | 0.20 | 0.50 | 0.26 | 0.75 | 0.68 | 0.61 | |
| 0.64 | 0.38 | 1.47 | 0.94 | 0.80 | 1.60 | 0.84 | 0.85 | 0.62 | |
| 0.35 | 0.00 | 0.50 | 0.00 | 0.16 | 0.50 | 0.00 | 0.04 | 0.50 | |
| 0.18 | 0.57 | 0.21 | 0.23 | 0.24 | 0.52 | 0.36 | 0.40 | 0.77 | |
| MedSE | 3.19 | 1.76 | 2.42 | 1.57 | 1.81 | 2.62 | 1.41 | 1.60 | 1.84 |
| , | |||||||||
| 0.58 | 0.08 | −0.47 | −1.05 | 0.29 | −1.22 | 0.78 | 0.68 | 0.54 | |
| 0.45 | −0.57 | 2.66 | 1.31 | 0.87 | 3.60 | 0.91 | 0.71 | 0.72 | |
| 0.77 | 0.97 | 0.50 | 0.61 | 0.81 | 0.50 | 0.84 | 0.87 | 0.50 | |
| 4.18 | 2.27 | 12.43 | 2.20 | 1.06 | 4.13 | 1.63 | 1.63 | 6.24 | |
| MedSE | 8.37 | 4.41 | 9.85 | 5.68 | 3.59 | 9.27 | 2.97 | 3.24 | 4.38 |
| , | |||||||||
| 0.63 | 0.11 | −0.38 | −0.43 | 0.33 | −0.45 | 0.75 | 0.68 | 0.57 | |
| 1.23 | −0.23 | 2.89 | 1.28 | 0.78 | 2.71 | 0.93 | 0.71 | 0.62 | |
| 0.64 | 0.60 | 0.50 | 0.47 | 0.59 | 0.50 | 0.60 | 0.61 | 0.50 | |
| 2.33 | 2.44 | 1.88 | 1.76 | 1.00 | 2.03 | 1.73 | 1.68 | 3.08 | |
| MedSE | 5.36 | 3.80 | 6.83 | 4.34 | 3.55 | 5.02 | 2.97 | 3.26 | 3.35 |
| , | |||||||||
| 0.65 | 0.13 | −0.81 | −0.15 | 0.36 | −0.17 | 0.75 | 0.69 | 0.65 | |
| 1.14 | −0.04 | 2.37 | 0.88 | 0.74 | 2.48 | 0.96 | 0.72 | 0.51 | |
| 0.37 | 0.00 | 0.50 | 0.00 | 0.31 | 0.50 | 0.26 | 0.22 | 0.50 | |
| 1.89 | 2.43 | 0.95 | 1.95 | 1.03 | 2.01 | 1.91 | 1.72 | 3.17 | |
| MedSE | 5.12 | 3.43 | 5.01 | 3.42 | 3.66 | 4.81 | 3.07 | 3.30 | 3.32 |
| , | |||||||||
| 0.64 | 0.12 | −0.80 | −0.10 | 0.35 | −0.14 | 0.76 | 0.70 | 0.64 | |
| 0.58 | −0.18 | 2.23 | 0.88 | 0.76 | 2.47 | 0.93 | 0.72 | 0.53 | |
| 0.21 | 0.00 | 0.50 | 0.00 | 0.15 | 0.50 | 0.01 | 0.01 | 0.50 | |
| 0.78 | 2.46 | 0.97 | 2.09 | 1.03 | 2.07 | 1.73 | 1.71 | 3.24 | |
| MedSE | 5.91 | 3.72 | 4.90 | 3.42 | 3.64 | 4.90 | 2.98 | 3.30 | 3.40 |
| , | , | , | |||||||
|---|---|---|---|---|---|---|---|---|---|
| E+null | S+null | L+null | E+null | S+null | L+null | E+null | S+null | L+null | |
| , 1, | |||||||||
| 0.71 | 0.70 | 0.59 | 0.52 | 0.53 | 0.54 | 0.52 | 0.60 | 0.42 | |
| 0.49 | 0.76 | 1.20 | 0.73 | 0.94 | 0.86 | 0.72 | 0.66 | 1.14 | |
| 0.45 | 0.64 | 0.50 | 0.67 | 0.54 | 0.51 | 0.59 | 0.49 | 0.55 | |
| 0.80 | 0.82 | 0.73 | 0.87 | 0.86 | 0.98 | 1.02 | 1.09 | 0.91 | |
| MedSE | 0.46 | 0.34 | 0.51 | 0.30 | 0.25 | 0.21 | 0.18 | 0.22 | 0.35 |
| , , | |||||||||
| 1.06 | 0.69 | 0.64 | 0.45 | 0.40 | 0.45 | 0.59 | 0.61 | 0.35 | |
| 0.14 | 0.86 | 1.58 | 0.62 | 1.28 | 0.80 | 0.71 | 0.54 | 1.38 | |
| 0.48 | 0.69 | 0.66 | 0.76 | 0.59 | 0.70 | 0.67 | 0.52 | 0.63 | |
| 3.84 | 3.24 | 2.82 | 3.72 | 3.48 | 3.98 | 4.21 | 4.46 | 3.79 | |
| MedSE | 1.52 | 0.70 | 1.07 | 0.55 | 0.63 | 0.56 | 0.39 | 0.40 | 0.67 |
| , , | |||||||||
| 0.88 | 1.01 | 0.67 | 0.57 | 0.74 | 0.39 | 0.42 | 0.58 | 0.58 | |
| 0.43 | 0.72 | 1.01 | 0.56 | 0.78 | 1.00 | 0.65 | 0.51 | 1.05 | |
| 0.60 | 0.75 | 0.50 | 0.75 | 0.85 | 0.60 | 0.67 | 0.74 | 0.65 | |
| 2.64 | 3.72 | 4.32 | 3.75 | 3.02 | 4.44 | 4.04 | 4.64 | 3.83 | |
| MedSE | 0.67 | 0.59 | 1.07 | 0.73 | 0.45 | 0.47 | 0.35 | 0.48 | 0.28 |
| , , | |||||||||
| 1.09 | 1.00 | 0.74 | 0.56 | 0.61 | 0.61 | 0.48 | 0.61 | 0.41 | |
| 0.23 | 0.83 | 1.58 | 0.43 | 1.13 | 0.73 | 0.64 | 0.40 | 1.42 | |
| 0.39 | 0.76 | 0.50 | 0.77 | 0.82 | 0.50 | 0.69 | 0.69 | 0.64 | |
| 5.02 | 6.17 | 6.23 | 6.13 | 5.67 | 7.62 | 7.08 | 7.94 | 6.33 | |
| MedSE | 0.98 | 0.83 | 1.61 | 0.87 | 0.59 | 0.72 | 0.46 | 0.64 | 0.67 |
| , | , | , | |||||||
|---|---|---|---|---|---|---|---|---|---|
| E+null | S+null | L+null | E+null | S+null | L+null | E+null | S+null | L+null | |
| Remove 30% nonzero weights | |||||||||
| 0.59 | 0.58 | 0.17 | 0.43 | 0.32 | 0.47 | 0.55 | 0.65 | 0.46 | |
| 0.59 | 0.97 | 1.63 | 0.82 | 0.80 | 0.97 | 0.73 | 0.78 | 1.12 | |
| 0.61 | 0.55 | 0.52 | 0.70 | 0.57 | 0.50 | 0.65 | 0.54 | 0.53 | |
| 1.05 | 1.13 | 0.99 | 1.08 | 1.08 | 1.03 | 1.14 | 1.09 | 1.22 | |
| MedSE | 0.48 | 0.45 | 1.10 | 0.35 | 0.33 | 0.49 | 0.20 | 0.25 | 0.25 |
| Remove 50% nonzero weights | |||||||||
| 0.67 | 0.57 | 0.16 | 0.44 | 0.30 | 0.31 | 0.52 | 0.66 | 0.54 | |
| 0.61 | 0.90 | 1.48 | 0.73 | 0.81 | 1.15 | 0.74 | 0.79 | 1.10 | |
| 0.54 | 0.48 | 0.50 | 0.64 | 0.49 | 0.41 | 0.57 | 0.49 | 0.49 | |
| 1.07 | 1.17 | 0.97 | 1.11 | 1.11 | 1.09 | 1.18 | 1.12 | 1.25 | |
| MedSE | 0.41 | 0.26 | 1.12 | 0.34 | 0.37 | 0.64 | 0.19 | 0.27 | 0.31 |
| Remove 80% nonzero weights | |||||||||
| 0.68 | 0.63 | 0.26 | 0.46 | 0.33 | 0.24 | 0.58 | 0.70 | 0.48 | |
| 0.59 | 0.94 | 1.29 | 0.71 | 0.82 | 1.31 | 0.77 | 0.78 | 1.19 | |
| 0.40 | 0.34 | 0.51 | 0.52 | 0.34 | 0.37 | 0.42 | 0.33 | 0.36 | |
| 1.15 | 1.30 | 0.96 | 1.26 | 1.24 | 1.14 | 1.34 | 1.26 | 1.40 | |
| MedSE | 0.50 | 0.40 | 0.89 | 0.40 | 0.40 | 0.78 | 0.20 | 0.29 | 0.33 |
| , | , | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| , | ||||||||||||
| Correct | 4.00 | 5.00 | 4.00 | 5.00 | 0.00 | 3.00 | 5.00 | 5.00 | 5.00 | 5.00 | 5.00 | 5.00 |
| Incorrect | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 1.00 |
| 0.99 | 0.86 | 0.86 | 0.97 | 0.73 | 0.82 | 0.89 | 0.88 | 0.88 | 0.89 | 0.89 | 0.92 | |
| MedSE | 0.42 | 0.37 | 0.44 | 0.36 | 1.43 | 0.54 | 0.14 | 0.14 | 0.20 | 0.16 | 0.21 | 0.24 |
| , | ||||||||||||
| Correct | 4.00 | 4.00 | 3.00 | 5.00 | 5.00 | 4.00 | 5.00 | 5.00 | 5.00 | 5.00 | 5.00 | 5.00 |
| Incorrect | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 1.00 |
| 0.52 | 0.57 | 0.58 | 0.81 | 0.51 | 0.46 | 0.50 | 0.58 | 0.58 | 0.57 | 0.56 | 0.68 | |
| MedSE | 0.24 | 0.31 | 0.45 | 0.40 | 0.49 | 0.43 | 0.17 | 0.11 | 0.15 | 0.16 | 0.23 | 0.22 |
| , | ||||||||||||
| Correct | 4.00 | 4.00 | 3.00 | 5.00 | 5.00 | 3.00 | 5.00 | 5.00 | 5.00 | 5.00 | 5.00 | 5.00 |
| Incorrect | 0.00 | 0.00 | 0.00 | 1.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 1.00 |
| 0.26 | 0.38 | 0.40 | 0.61 | 0.37 | 0.20 | 0.33 | 0.35 | 0.35 | 0.31 | 0.35 | 0.49 | |
| MedSE | 0.24 | 0.32 | 0.47 | 0.42 | 0.50 | 0.52 | 0.14 | 0.12 | 0.16 | 0.16 | 0.22 | 0.21 |
| , | ||||||||||||
| Correct | 4.00 | 4.00 | 3.00 | 5.00 | 5.00 | 3.00 | 5.00 | 5.00 | 5.00 | 5.00 | 5.00 | 5.00 |
| Incorrect | 0.00 | 0.00 | 0.00 | 1.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 1.00 |
| 0.00 | 0.06 | 0.09 | 0.30 | 0.01 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.11 | |
| MedSE | 0.24 | 0.31 | 0.46 | 0.44 | 0.56 | 0.55 | 0.14 | 0.13 | 0.17 | 0.16 | 0.17 | 0.21 |
| , | ||||||||||||
| Correct | 4.00 | 2.00 | 1.00 | 3.00 | 0.00 | 1.00 | 5.00 | 5.00 | 5.00 | 4.00 | 2.00 | 4.00 |
| Incorrect | 0.00 | 0.00 | 0.00 | 1.00 | 0.00 | 0.00 | 1.00 | 0.00 | 0.00 | 0.00 | 0.00 | 1.00 |
| 0.88 | 0.90 | 0.92 | 0.99 | 0.86 | 0.88 | 0.94 | 0.92 | 0.92 | 0.94 | 0.92 | 0.96 | |
| MedSE | 0.53 | 0.67 | 0.94 | 0.65 | 2.09 | 1.05 | 0.32 | 0.29 | 0.32 | 0.36 | 0.45 | 0.44 |
| , | ||||||||||||
| Correct | 4.00 | 2.00 | 1.00 | 2.00 | 3.00 | 3.00 | 5.00 | 5.00 | 5.00 | 4.00 | 2.00 | 4.00 |
| Incorrect | 0.00 | 0.00 | 0.00 | 1.00 | 1.00 | 0.00 | 1.00 | 0.00 | 0.00 | 0.00 | 0.00 | 1.00 |
| 0.45 | 0.64 | 0.69 | 0.89 | 0.51 | 0.52 | 0.66 | 0.63 | 0.65 | 0.64 | 0.62 | 0.81 | |
| MedSE | 0.52 | 0.67 | 0.96 | 0.70 | 0.99 | 0.95 | 0.31 | 0.29 | 0.31 | 0.35 | 0.46 | 0.48 |
| , | ||||||||||||
| Correct | 4.00 | 2.00 | 1.00 | 1.00 | 2.00 | 3.00 | 5.00 | 5.00 | 5.00 | 4.00 | 2.00 | 3.00 |
| Incorrect | 0.00 | 0.00 | 0.00 | 1.00 | 1.00 | 0.00 | 1.00 | 0.00 | 0.00 | 0.00 | 0.00 | 1.00 |
| 0.03 | 0.45 | 0.51 | 0.76 | 0.50 | 0.50 | 0.38 | 0.37 | 0.39 | 0.34 | 0.40 | 0.57 | |
| MedSE | 0.55 | 0.69 | 0.97 | 0.76 | 1.13 | 1.02 | 0.29 | 0.30 | 0.33 | 0.34 | 0.47 | 0.48 |
| , | ||||||||||||
| Correct | 4.00 | 2.00 | 1.00 | 1.00 | 2.00 | 2.00 | 5.00 | 5.00 | 5.00 | 4.00 | 3.00 | 3.00 |
| Incorrect | 0.00 | 0.00 | 0.00 | 1.00 | 1.00 | 0.00 | 1.00 | 0.00 | 0.00 | 0.00 | 0.00 | 1.00 |
| 0.00 | 0.10 | 0.18 | 0.49 | 0.03 | 0.41 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.21 | |
| MedSE | 0.51 | 0.68 | 0.96 | 0.82 | 1.09 | 1.21 | 0.28 | 0.31 | 0.36 | 0.34 | 0.38 | 0.50 |
| , | , | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| , | ||||||||||||
| Correct | 7.00 | 9.00 | 5.00 | 6.00 | 8.00 | 16.00 | 195.00 | 200.00 | 187.00 | 195.00 | 180.00 | 187.00 |
| Incorrect | 1.00 | 1.00 | 0.00 | 0.00 | 1.00 | 0.00 | 1.00 | 0.00 | 0.00 | 0.00 | 0.00 | 1.00 |
| 0.81 | 0.82 | 0.89 | 0.88 | 0.58 | 0.69 | 0.84 | 0.87 | 0.85 | 0.88 | 0.65 | 0.73 | |
| MedSE | 2.89 | 1.38 | 3.38 | 2.06 | 1.39 | 0.56 | 1.23 | 0.53 | 1.52 | 1.36 | 1.69 | 1.53 |
| , | ||||||||||||
| Correct | 6.00 | 10.00 | 5.00 | 4.00 | 17.00 | 13.00 | 197.00 | 200.00 | 192.00 | 196.00 | 199.00 | 197.00 |
| Incorrect | 0.00 | 1.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 1.00 |
| 0.50 | 0.25 | 0.55 | 0.61 | 0.51 | 0.42 | 0.62 | 0.55 | 0.54 | 0.61 | 0.50 | 0.50 | |
| MedSE | 2.02 | 1.41 | 3.38 | 2.20 | 0.64 | 0.76 | 1.05 | 0.52 | 1.43 | 1.33 | 0.88 | 1.00 |
| , | ||||||||||||
| Correct | 5.00 | 10.00 | 5.00 | 5.00 | 13.00 | 14.00 | 197.00 | 200.00 | 191.00 | 193.00 | 199.00 | 198.00 |
| Incorrect | 1.00 | 1.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 1.00 | 0.00 | 0.00 | 1.00 |
| 0.55 | 0.00 | 0.40 | 0.47 | 0.50 | 0.23 | 0.48 | 0.34 | 0.40 | 0.48 | 0.50 | 0.50 | |
| MedSE | 2.98 | 1.39 | 3.47 | 2.45 | 0.90 | 0.74 | 1.11 | 0.52 | 1.41 | 1.36 | 0.91 | 1.02 |
| , | ||||||||||||
| Correct | 9.00 | 11.00 | 5.00 | 4.00 | 13.00 | 13.00 | 197.00 | 200.00 | 192.00 | 193.00 | 200.00 | 196.00 |
| Incorrect | 1.00 | 1.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 1.00 | 0.00 | 0.00 | 1.00 |
| 0.55 | 0.00 | 0.00 | 0.12 | 0.38 | 0.00 | 0.13 | 0.00 | 0.03 | 0.16 | 0.50 | 0.49 | |
| MedSE | 1.78 | 1.24 | 3.41 | 2.28 | 1.04 | 0.82 | 1.07 | 0.52 | 1.42 | 1.36 | 0.92 | 1.13 |
| , | ||||||||||||
| Correct | 6.00 | 6.00 | 5.00 | 1.00 | 5.00 | 13.00 | 162.00 | 172.00 | 133.00 | 137.00 | 156.00 | 138.00 |
| Incorrect | 1.00 | 0.00 | 0.00 | 0.00 | 1.00 | 0.00 | 0.00 | 1.00 | 1.00 | 0.00 | 0.00 | 1.00 |
| 0.81 | 0.92 | 1.00 | 0.98 | 0.76 | 0.73 | 0.94 | 0.89 | 0.89 | 0.94 | 0.73 | 0.73 | |
| MedSE | 3.33 | 3.65 | 7.30 | 5.30 | 2.30 | 0.92 | 2.28 | 1.84 | 2.99 | 2.71 | 2.30 | 2.78 |
| , | ||||||||||||
| Correct | 8.00 | 6.00 | 4.00 | 1.00 | 9.00 | 9.00 | 160.00 | 173.00 | 134.00 | 135.00 | 185.00 | 173.00 |
| Incorrect | 1.00 | 1.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 1.00 | 1.00 | 0.00 | 0.00 | 1.00 |
| 0.77 | 0.53 | 0.91 | 0.90 | 0.60 | 0.47 | 0.74 | 0.63 | 0.61 | 0.75 | 0.50 | 0.50 | |
| MedSE | 2.52 | 3.39 | 7.63 | 5.95 | 1.87 | 1.44 | 2.34 | 1.81 | 2.96 | 2.77 | 1.64 | 1.94 |
| , | ||||||||||||
| Correct | 7.00 | 7.00 | 4.00 | 1.00 | 8.00 | 9.00 | 162.00 | 167.00 | 129.00 | 130.00 | 181.00 | 173.00 |
| Incorrect | 1.00 | 1.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 1.00 | 1.00 | 0.00 | 1.00 | 1.00 |
| 0.24 | 0.10 | 0.68 | 0.79 | 0.63 | 0.15 | 0.53 | 0.46 | 0.46 | 0.55 | 0.50 | 0.50 | |
| MedSE | 2.87 | 3.42 | 7.62 | 5.98 | 1.84 | 1.47 | 2.33 | 1.83 | 2.97 | 2.81 | 1.72 | 1.99 |
| , | ||||||||||||
| Correct | 8.00 | 6.00 | 4.00 | 1.00 | 9.00 | 9.00 | 144.00 | 172.00 | 131.00 | 131.00 | 178.00 | 171.00 |
| Incorrect | 1.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 1.00 | 1.00 | 0.00 | 1.00 | 1.00 |
| 0.00 | 0.00 | 0.32 | 0.54 | 0.50 | 0.00 | 0.35 | 0.00 | 0.00 | 0.26 | 0.50 | 0.50 | |
| MedSE | 2.98 | 3.60 | 7.65 | 5.70 | 1.95 | 1.58 | 2.73 | 1.83 | 2.99 | 2.86 | 1.87 | 2.11 |
| , | , | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| , , | ||||||||||||
| Correct | 4.00 | 4.00 | 4.00 | 5.00 | 4.00 | 3.00 | 5.00 | 5.00 | 5.00 | 5.00 | 5.00 | 5.00 |
| Incorrect | 0.00 | 0.00 | 0.00 | 1.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 1.00 | 0.00 |
| 0.77 | 0.64 | 0.63 | 0.77 | 0.70 | 0.79 | 0.74 | 0.66 | 0.66 | 0.70 | 0.64 | 0.61 | |
| MedSE | 0.48 | 0.32 | 0.48 | 0.36 | 0.62 | 0.53 | 0.14 | 0.14 | 0.17 | 0.18 | 0.31 | 0.30 |
| , , | ||||||||||||
| Correct | 3.00 | 1.00 | 2.00 | 3.00 | 1.00 | 1.00 | 5.00 | 5.00 | 5.00 | 5.00 | 3.00 | 3.00 |
| Incorrect | 0.00 | 0.00 | 0.00 | 0.00 | 2.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 1.00 | 0.00 |
| 0.58 | 0.47 | 0.52 | 0.71 | 0.51 | 0.76 | 0.57 | 0.56 | 0.58 | 0.64 | 0.50 | 0.50 | |
| MedSE | 0.61 | 0.97 | 0.93 | 0.79 | 1.19 | 1.17 | 0.18 | 0.35 | 0.35 | 0.34 | 0.66 | 0.63 |
| , , | ||||||||||||
| Correct | 1.00 | 4.00 | 3.00 | 3.00 | 0.00 | 3.00 | 3.00 | 4.00 | 4.00 | 4.00 | 4.00 | 5.00 |
| Incorrect | 0.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 0.00 | 1.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 0.78 | 0.73 | 0.73 | 0.90 | 0.77 | 0.88 | 0.83 | 0.75 | 0.79 | 0.79 | 0.83 | 0.81 | |
| MedSE | 0.69 | 0.87 | 0.92 | 0.69 | 1.75 | 0.66 | 0.38 | 0.30 | 0.35 | 0.32 | 0.52 | 0.22 |
| , , | ||||||||||||
| Correct | 1.00 | 3.00 | 1.00 | 3.00 | 0.00 | 3.00 | 5.00 | 4.00 | 4.00 | 4.00 | 4.00 | 3.00 |
| Incorrect | 0.00 | 0.00 | 1.00 | 1.00 | 1.00 | 0.00 | 0.00 | 1.00 | 0.00 | 0.00 | 1.00 | 0.00 |
| 0.65 | 0.42 | 0.41 | 0.83 | 0.51 | 0.79 | 0.75 | 0.59 | 0.64 | 0.67 | 0.63 | 0.57 | |
| MedSE | 0.96 | 1.28 | 1.26 | 0.74 | 1.93 | 0.54 | 0.36 | 0.46 | 0.46 | 0.46 | 0.75 | 0.54 |
| , | , | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Remove 30% nonzero weights | ||||||||||||
| Correct | 4.00 | 5.00 | 5.00 | 5.00 | 0.00 | 5.00 | 5.00 | 5.00 | 5.00 | 5.00 | 5.00 | 5.00 |
| Incorrect | 0.00 | 0.00 | 0.00 | 0.00 | 1.00 | 0.00 | 1.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 0.54 | 0.53 | 0.50 | 0.64 | 0.28 | 0.48 | 0.57 | 0.55 | 0.55 | 0.50 | 0.55 | 0.56 | |
| MedSE | 0.50 | 0.22 | 0.41 | 0.32 | 0.90 | 0.28 | 0.16 | 0.18 | 0.26 | 0.16 | 0.17 | 0.28 |
| Remove 50% nonzero weights | ||||||||||||
| Correct | 4.00 | 5.00 | 2.00 | 4.00 | 2.00 | 4.00 | 5.00 | 5.00 | 5.00 | 5.00 | 5.00 | 5.00 |
| Incorrect | 0.00 | 0.00 | 0.00 | 0.00 | 1.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 0.55 | 0.36 | 0.37 | 0.54 | 0.16 | 0.35 | 0.38 | 0.41 | 0.40 | 0.35 | 0.42 | 0.46 | |
| MedSE | 0.57 | 0.43 | 0.63 | 0.36 | 0.86 | 0.40 | 0.09 | 0.22 | 0.29 | 0.17 | 0.12 | 0.28 |
| Remove 80% nonzero weights | ||||||||||||
| Correct | 4.00 | 5.00 | 5.00 | 3.00 | 0.00 | 5.00 | 5.00 | 4.00 | 4.00 | 5.00 | 4.00 | 4.00 |
| Incorrect | 0.00 | 0.00 | 0.00 | 0.00 | 1.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 0.37 | 0.47 | 0.43 | 0.89 | 0.50 | 0.72 | 0.52 | 0.48 | 0.46 | 0.37 | 0.58 | 0.49 | |
| MedSE | 0.63 | 0.35 | 0.50 | 0.77 | 0.91 | 0.42 | 0.20 | 0.48 | 0.50 | 0.29 | 0.36 | 0.41 |
| 0.0437 | 0.0388 | |
| 0.0542 | 0.0539 | |
| 0.0515 | 0.0496 | |
| 0.0566 | 0.0548 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Y.; Wang, Z.; Song, Y. Robust Variable Selection with Exponential Squared Loss for the Spatial Single-Index Varying-Coefficient Model. Entropy 2023, 25, 230. https://doi.org/10.3390/e25020230
Wang Y, Wang Z, Song Y. Robust Variable Selection with Exponential Squared Loss for the Spatial Single-Index Varying-Coefficient Model. Entropy. 2023; 25(2):230. https://doi.org/10.3390/e25020230
Chicago/Turabian StyleWang, Yezi, Zhijian Wang, and Yunquan Song. 2023. "Robust Variable Selection with Exponential Squared Loss for the Spatial Single-Index Varying-Coefficient Model" Entropy 25, no. 2: 230. https://doi.org/10.3390/e25020230
APA StyleWang, Y., Wang, Z., & Song, Y. (2023). Robust Variable Selection with Exponential Squared Loss for the Spatial Single-Index Varying-Coefficient Model. Entropy, 25(2), 230. https://doi.org/10.3390/e25020230