
Interpretability Is in the Mind of the Beholder: A Causal Framework for Human-Interpretable Representation Learning
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
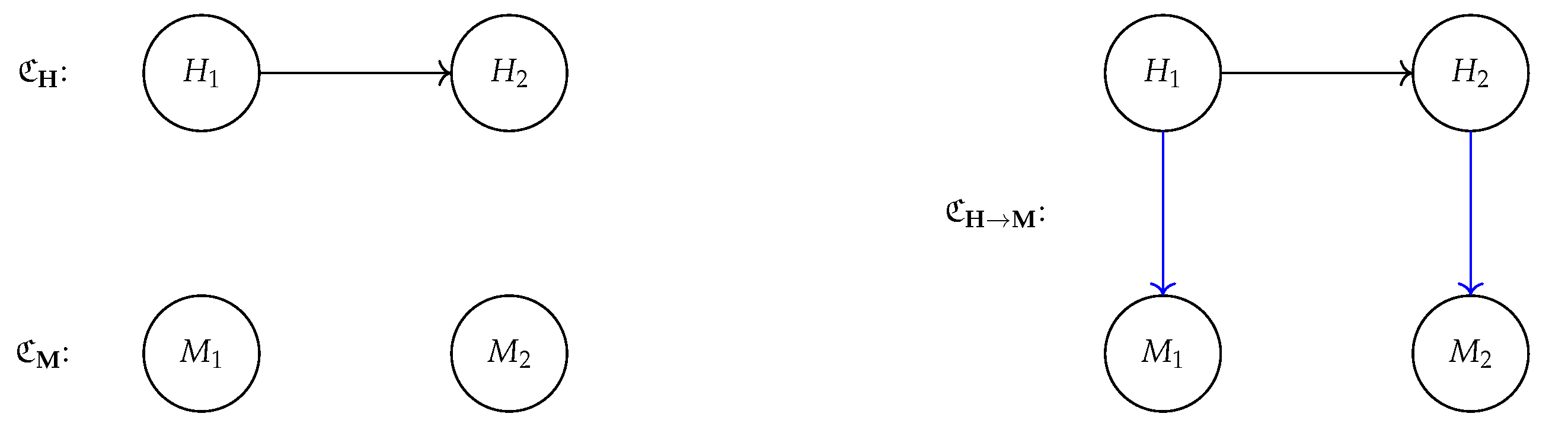{kind=link}
Abstract
:1. Introduction
1.1. Limitations of Existing Works
1.2. Our Contributions
1.3. Outline
2. Preliminaries
2.1. Structural Causal Models and Interventions
2.2. Disentanglement
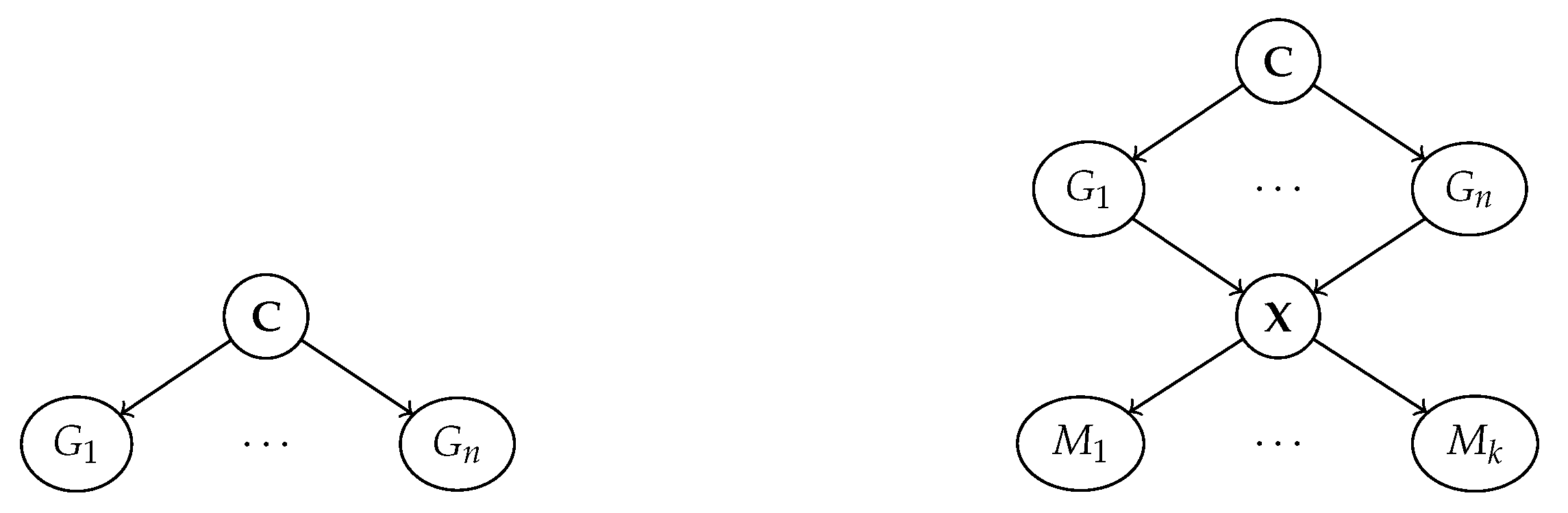
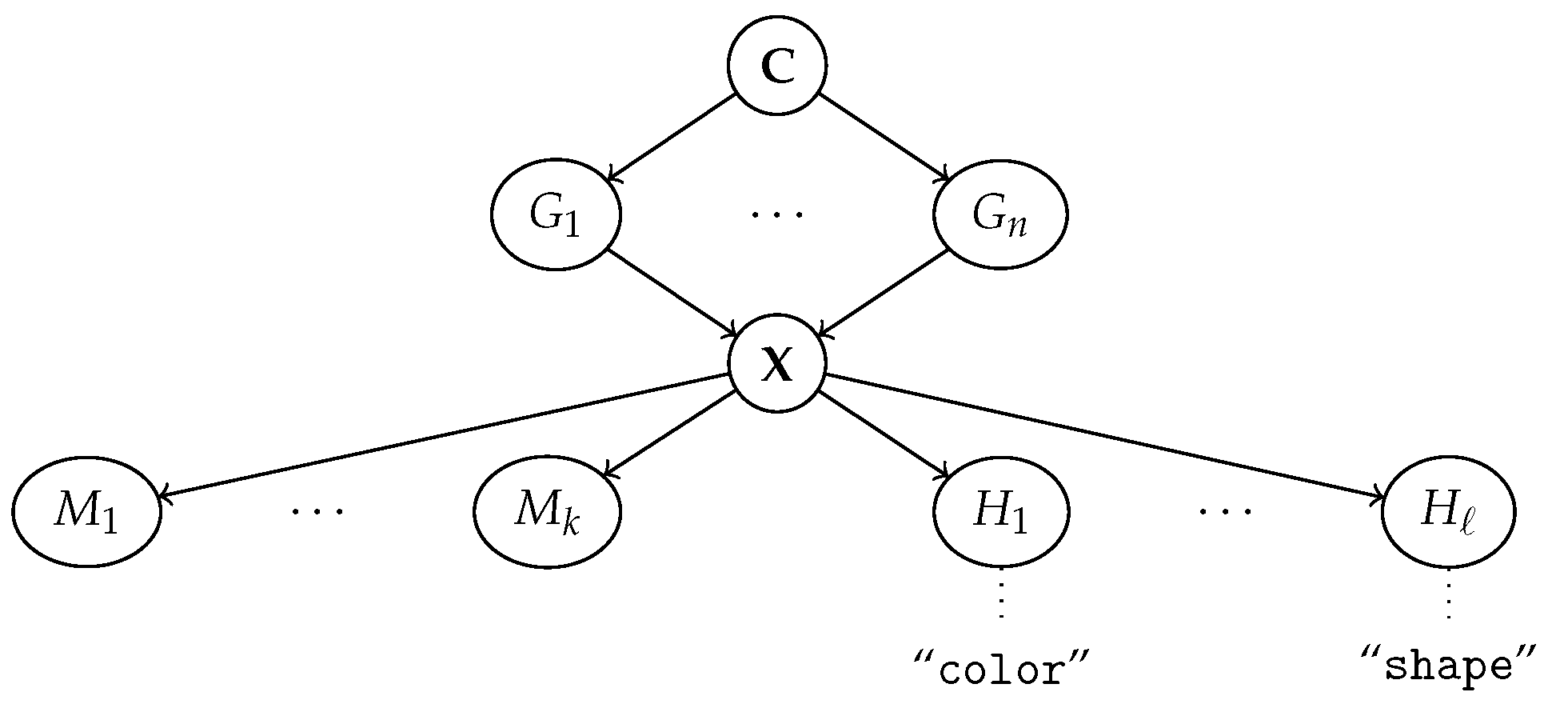
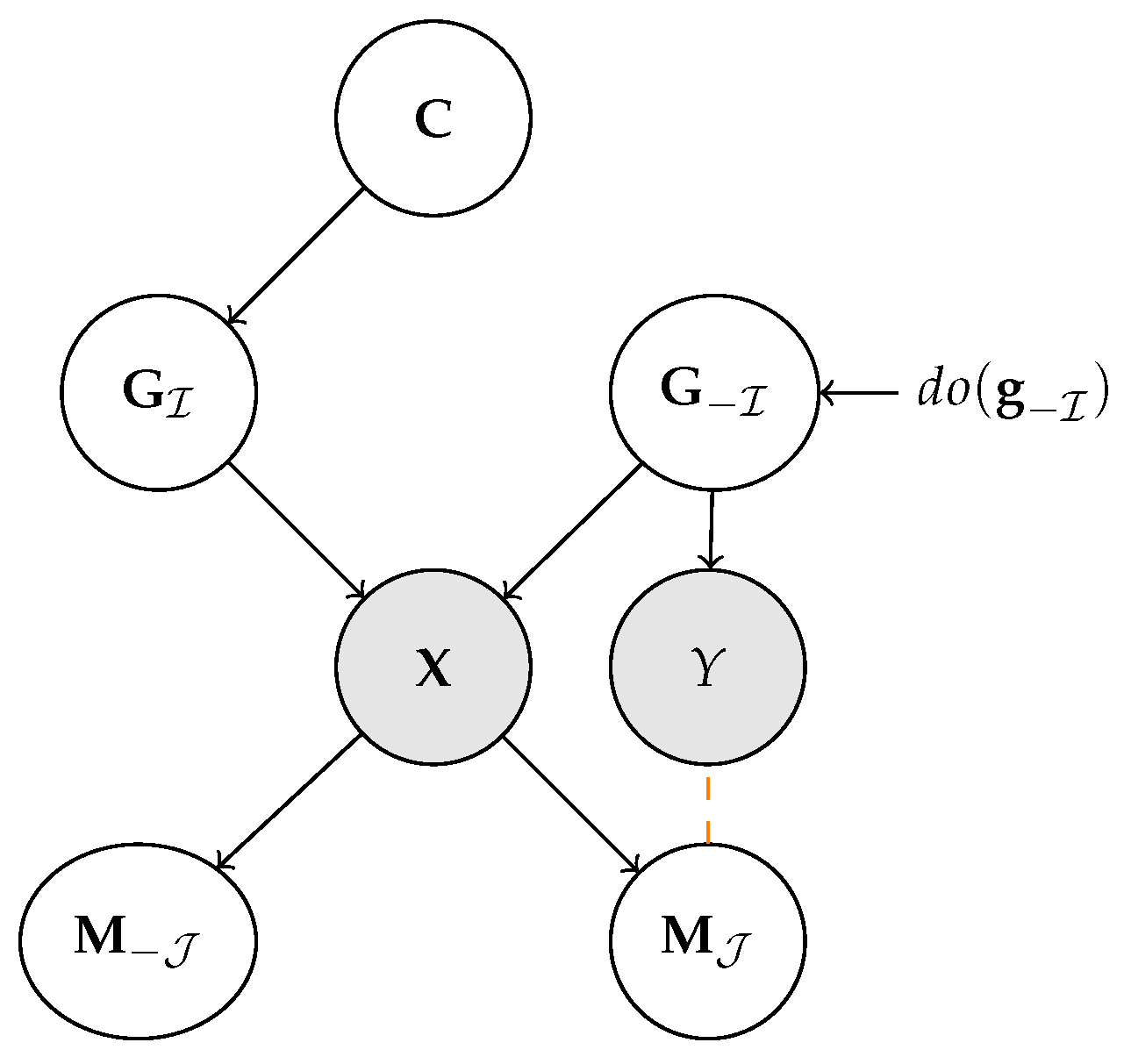
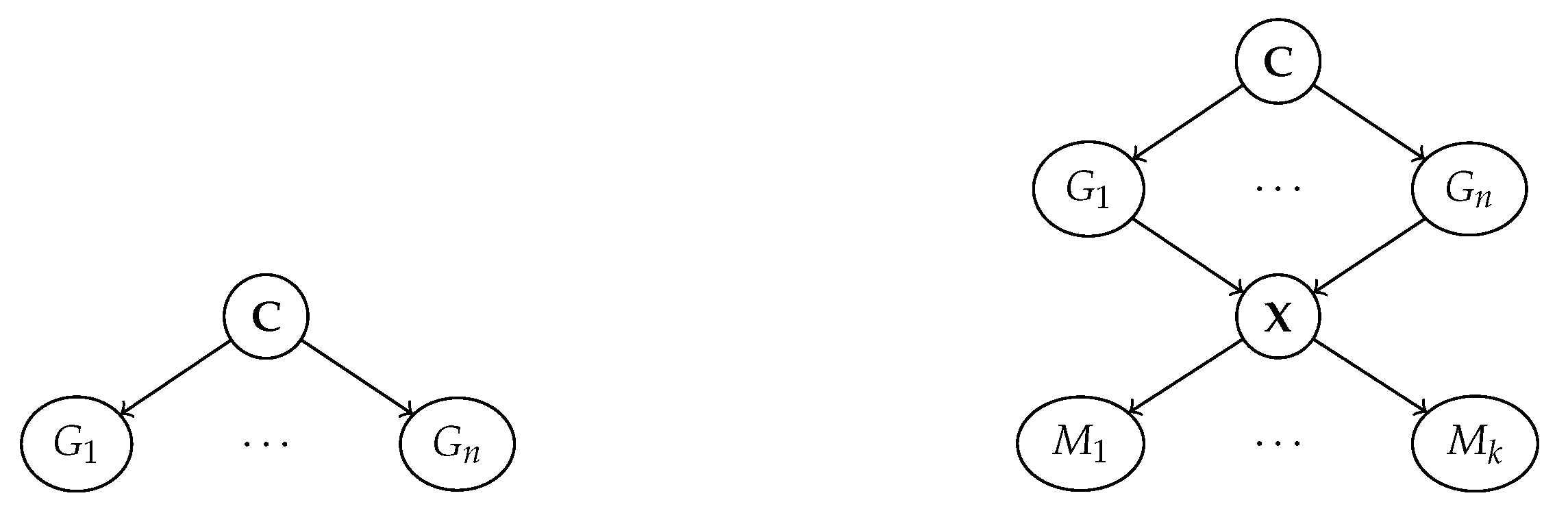
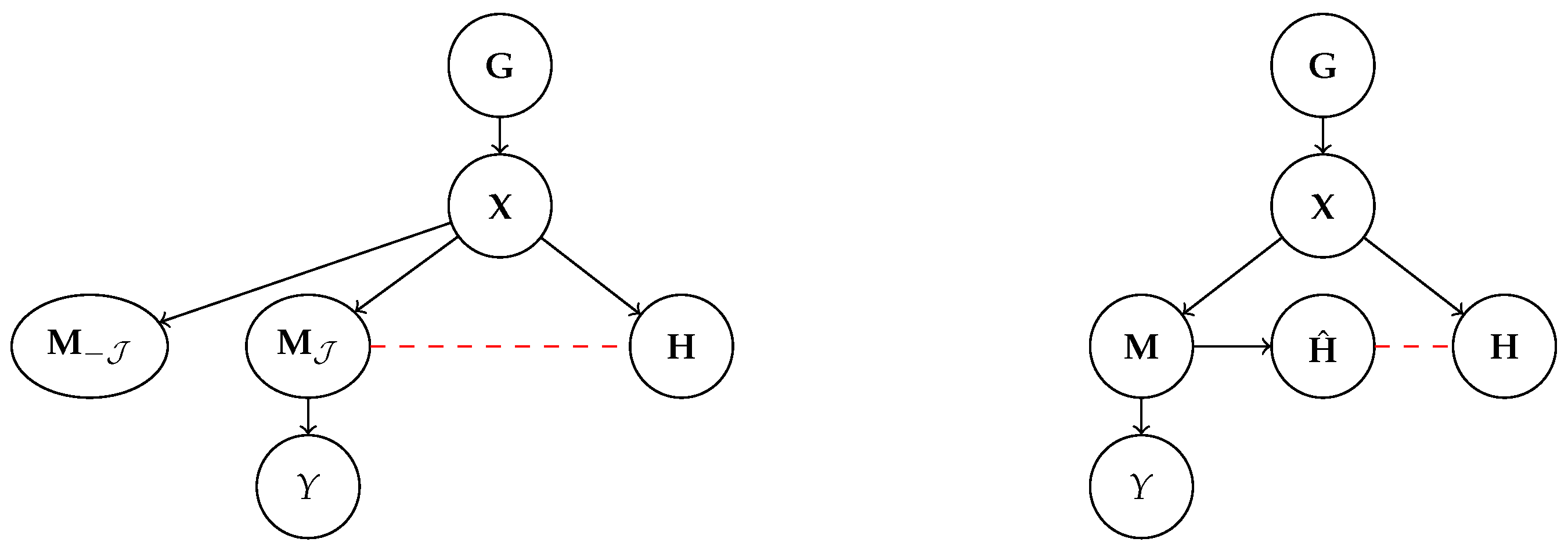
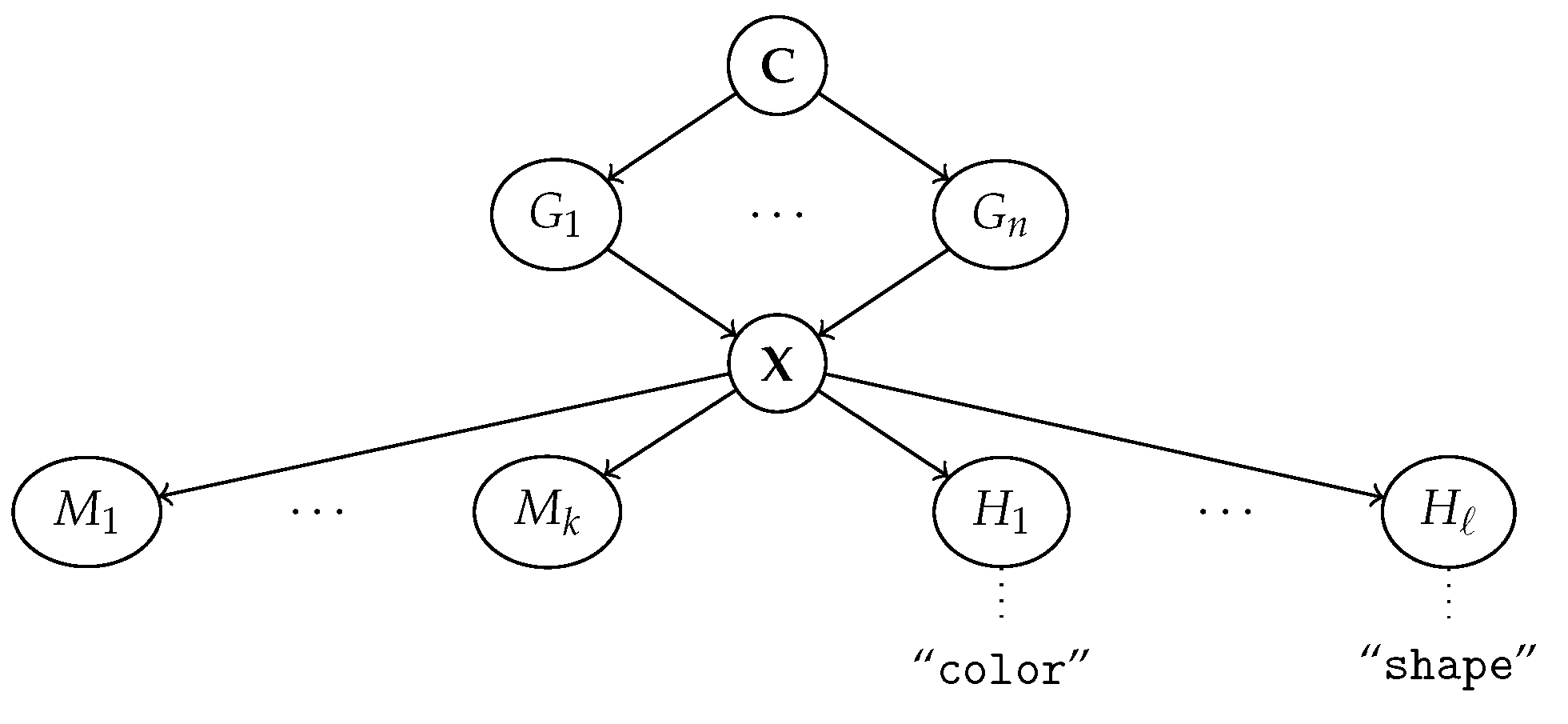
3. Human Interpretable Representation Learning
3.1. Machine Representations: The Ante-Hoc Case
3.2. Machine Representations: The Post Hoc Case
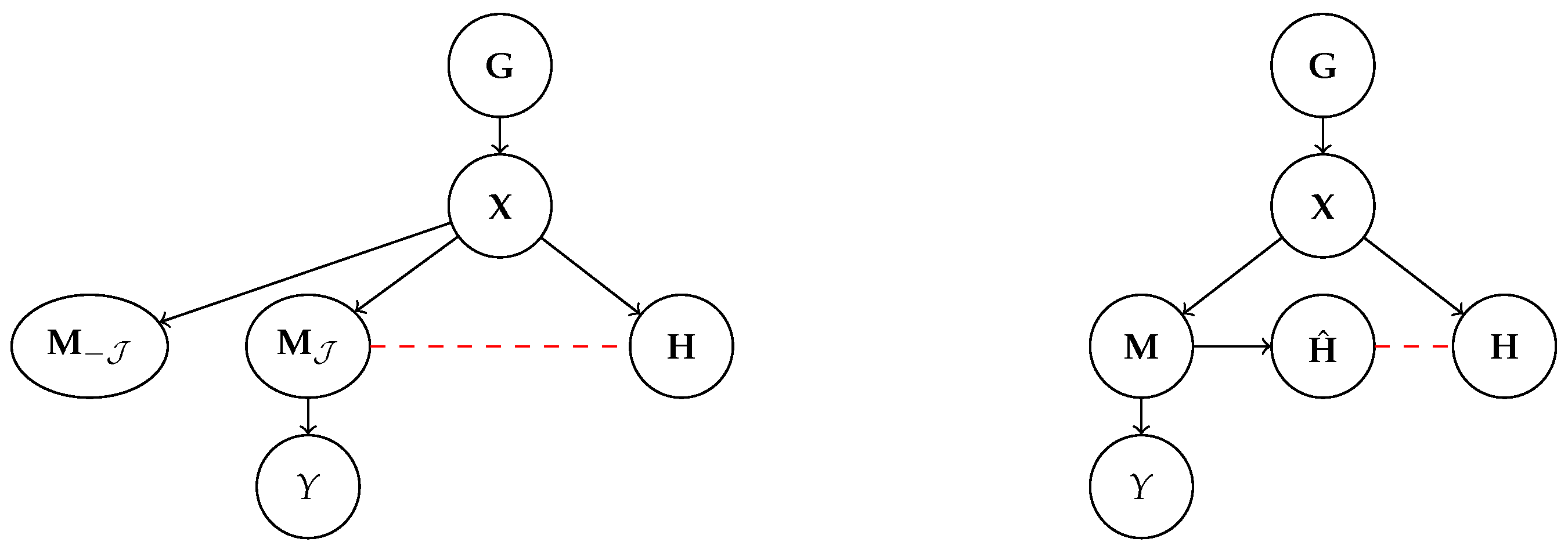
3.3. From Symbolic Communication to Alignment
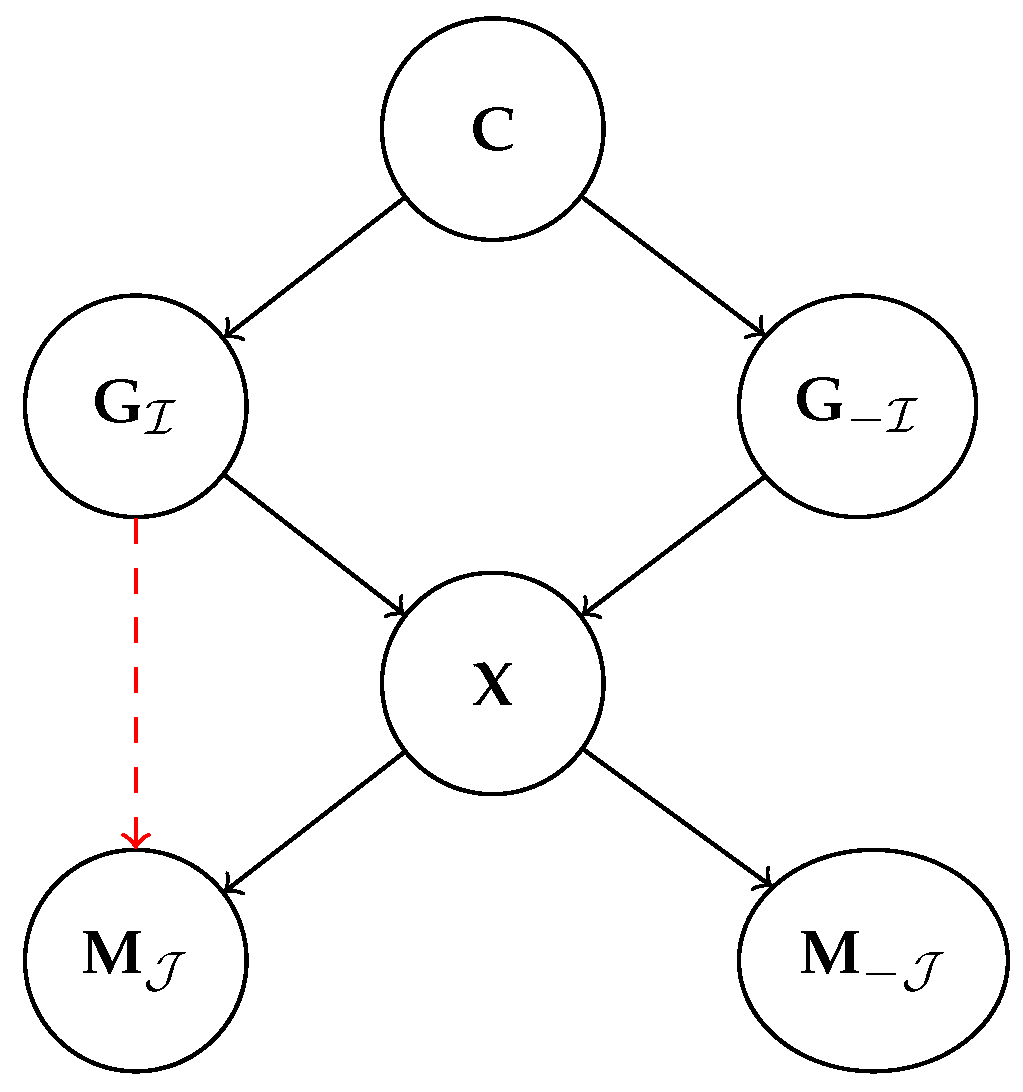
4. Alignment as Name Transfer
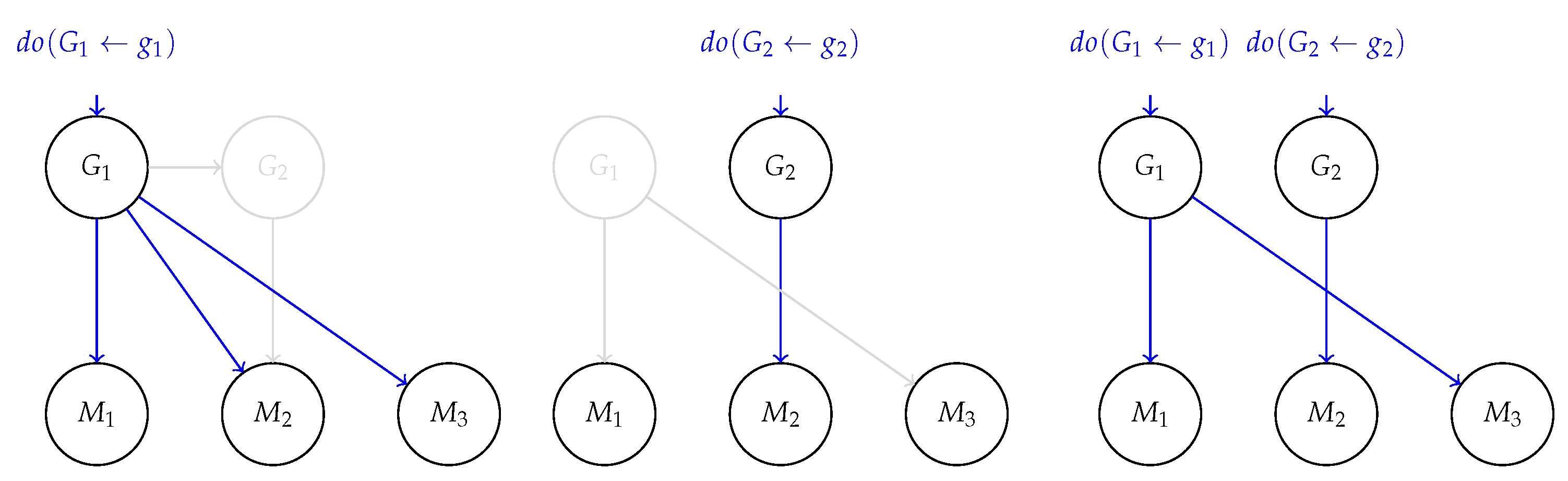
4.1. Alignment: The Disentangled Case
- D1.
- The index map is surjective and, for all , it holds that, as long as is kept fixed, remains unchanged even when the other generative factors are forcibly modified.
- D2.
- Each element-wise transformation , for , is monotonic in expectation over :
4.2. Disentanglement Does Not Entail Alignment
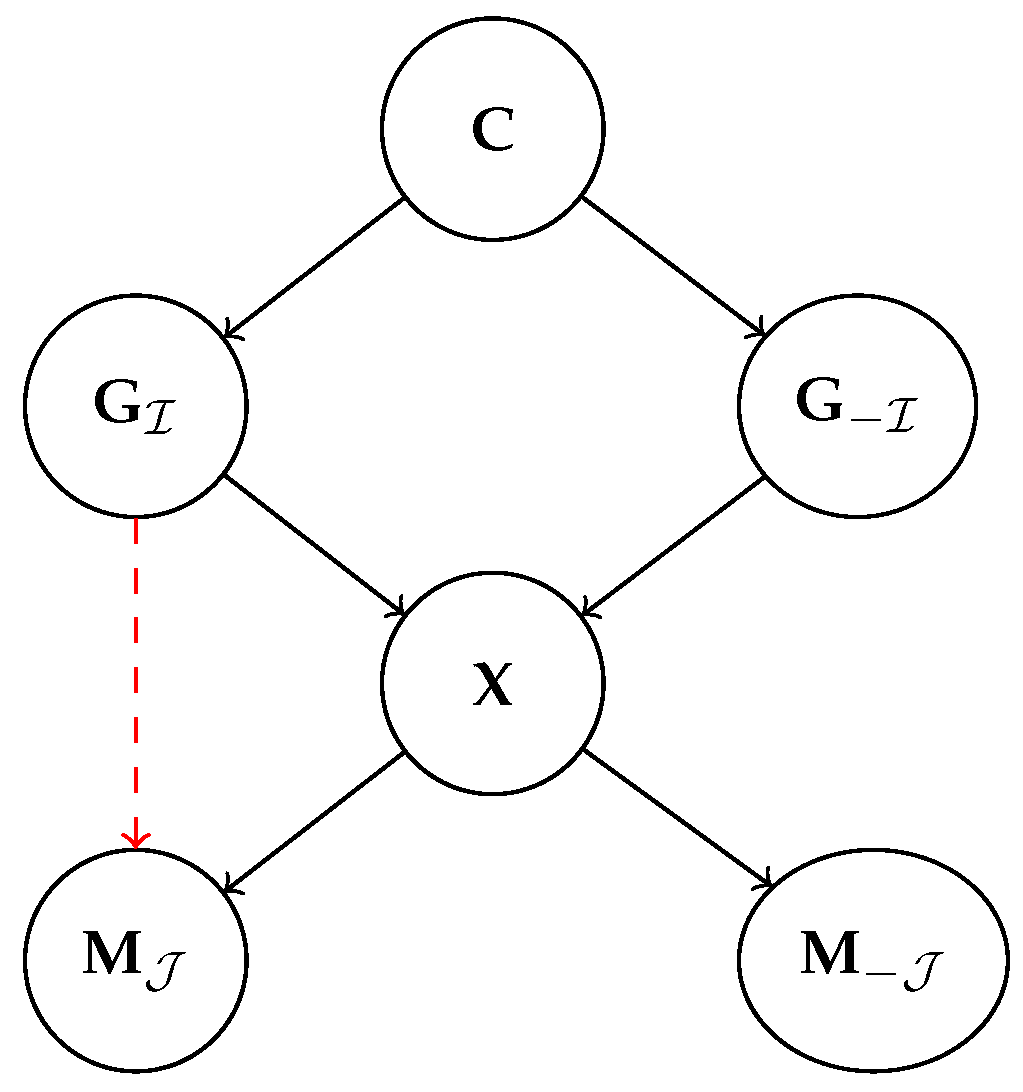
4.3. Alignment Entails No Concept Leakage
4.4. Alignment: The Block-Wise Case
- D1
- There exists a partition of such that . In principle, we can extend this notion to a family of subsets of . As an example, for positions, one can consider blocks that are mapped to, respectively, block aligned representations. We call this condition block-wise disentanglement.
- D2
- Each map is simulatable and invertible (for continuous variables, we require it to be a diffeomorphism) on the first statistical moment; that is, there exists a unique pre-image defined as:
4.5. Alignment: The General Case
4.6. Alignment and Causal Abstractions
5. Discussion and Limitations
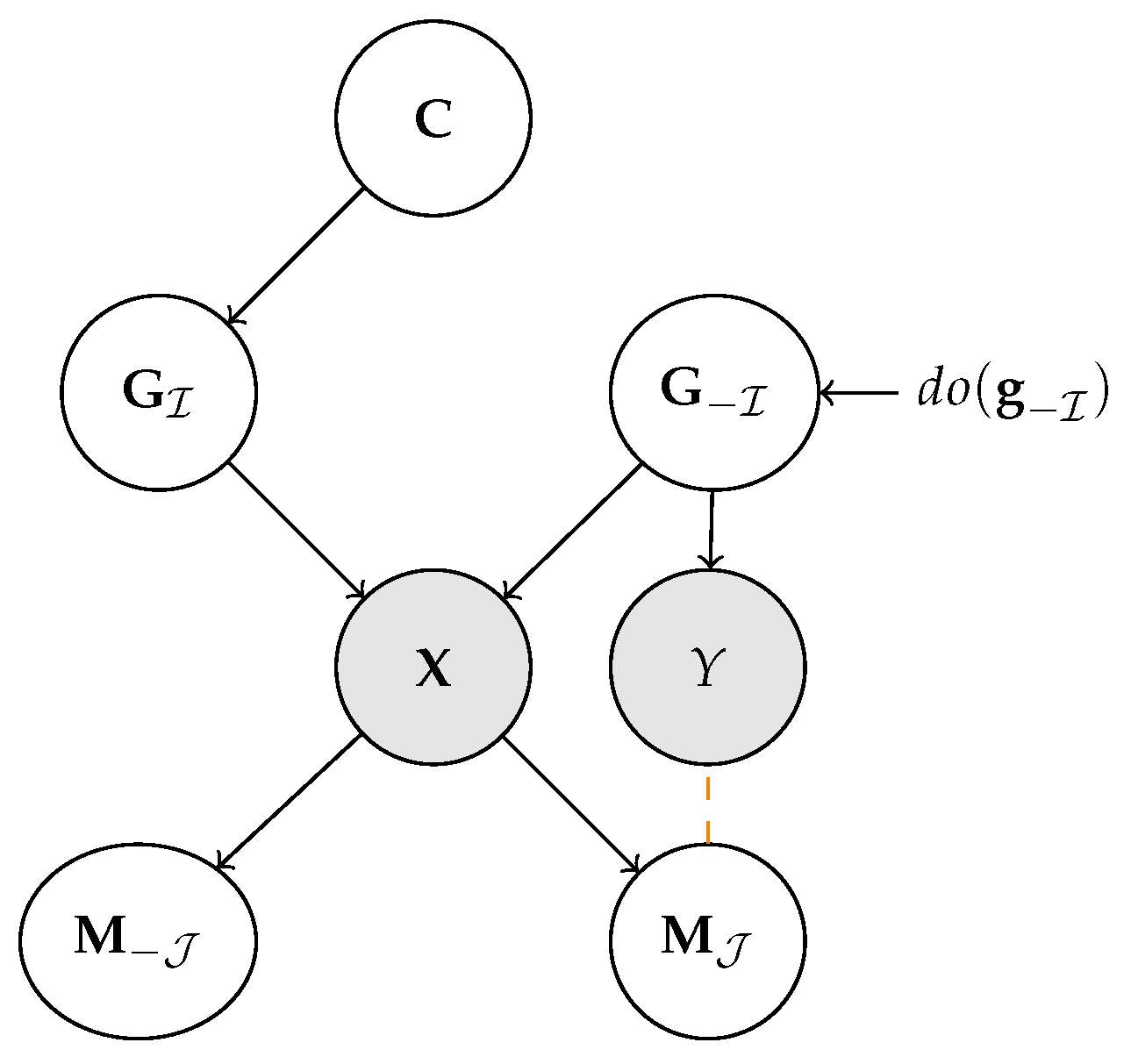
5.1. Is Perfect Alignment Sufficient and Necessary?
5.2. Measuring Alignment
5.3. Consequences for Concept-Based Explainers
5.4. Consequences for Concept-Based Models
5.5. Collecting Human Annotations
6. Related Work
6.1. Unsupervised Approaches
6.2. Supervised Strategies
6.3. Disentanglement
6.4. Metrics of Concept Quality
6.5. Neuro-Symbolic Architectures
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A. Proofs
Appendix A.1. Proof of Proposition 1
Appendix A.2. Proof of Proposition 2
Appendix A.3. Proof of Proposition 3
Appendix A.4. Proof of Corollay 1
Appendix A.5. Proof of Proposition 4
References
- Guidotti, R.; Monreale, A.; Ruggieri, S.; Turini, F.; Giannotti, F.; Pedreschi, D. A survey of methods for explaining black box models. ACM Comput. Surv. (CSUR) 2018, 51, 1–42. [Google Scholar] [CrossRef]
- Štrumbelj, E.; Kononenko, I. Explaining prediction models and individual predictions with feature contributions. Knowl. Inf. Syst. 2014, 41, 647–665. [Google Scholar] [CrossRef]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. “Why should I Trust You?” Explaining the predictions of any classifier. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 1135–1144. [Google Scholar]
- Kim, B.; Khanna, R.; Koyejo, O.O. Examples are not enough, learn to criticize! Criticism for interpretability. Adv. Neural Inf. Process. Syst. 2016, 29. [Google Scholar]
- Koh, P.W.; Liang, P. Understanding black-box predictions via influence functions. In Proceedings of the International Conference on Machine Learning, PMLR, Sydney, Australia, 6–11 August 2017; pp. 1885–1894. [Google Scholar]
- Ustun, B.; Rudin, C. Supersparse linear integer models for optimized medical scoring systems. Mach. Learn. 2016, 102, 349–391. [Google Scholar] [CrossRef]
- Wang, T.; Rudin, C.; Doshi-Velez, F.; Liu, Y.; Klampfl, E.; MacNeille, P. A bayesian framework for learning rule sets for interpretable classification. J. Mach. Learn. Res. 2017, 18, 2357–2393. [Google Scholar]
- Rudin, C. Stop explaining black box machine learning models for high stakes decisions and use interpretable models instead. Nat. Mach. Intell. 2019, 1, 206–215. [Google Scholar] [CrossRef]
- Teso, S.; Alkan, Ö.; Stammer, W.; Daly, E. Leveraging Explanations in Interactive Machine Learning: An Overview. Front. Artif. Intell. 2023, 6, 1066049. [Google Scholar] [CrossRef]
- Kambhampati, S.; Sreedharan, S.; Verma, M.; Zha, Y.; Guan, L. Symbols as a lingua franca for bridging human-ai chasm for explainable and advisable ai systems. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 28 February–1 March 2022; Volume 36, pp. 12262–12267. [Google Scholar]
- Kim, B.; Wattenberg, M.; Gilmer, J.; Cai, C.; Wexler, J.; Viegas, F. Interpretability beyond Feature Attribution: Quantitative Testing with Concept Activation Vectors (TCAV). In Proceedings of the International Conference on Machine Learning, PMLR, Stockholm, Sweden, 10–15 July 2018; pp. 2668–2677. [Google Scholar]
- Fong, R.; Vedaldi, A. Net2vec: Quantifying and explaining how concepts are encoded by filters in deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, Utah, USA, 18–22 June 2018; pp. 8730–8738. [Google Scholar]
- Ghorbani, A.; Abid, A.; Zou, J. Interpretation of neural networks is fragile. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January 27–1 February 2019; Volume 33, pp. 3681–3688. [Google Scholar]
- Zhang, R.; Madumal, P.; Miller, T.; Ehinger, K.A.; Rubinstein, B.I. Invertible concept-based explanations for cnn models with non-negative concept activation vectors. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtually, 2–9 February 2021; Volume 35, pp. 11682–11690. [Google Scholar]
- Fel, T.; Picard, A.; Bethune, L.; Boissin, T.; Vigouroux, D.; Colin, J.; Cadène, R.; Serre, T. Craft: Concept recursive activation factorization for explainability. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 2711–2721. [Google Scholar]
- Alvarez-Melis, D.; Jaakkola, T.S. Towards robust interpretability with self-explaining neural networks. In Proceedings of the 32nd International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 3–8 December 2018; pp. 7786–7795. [Google Scholar]
- Chen, C.; Li, O.; Tao, D.; Barnett, A.; Rudin, C.; Su, J.K. This Looks Like That: Deep Learning for Interpretable Image Recognition. Adv. Neural Inf. Process. Syst. 2019, 32, 8930–8941. [Google Scholar]
- Koh, P.W.; Nguyen, T.; Tang, Y.S.; Mussmann, S.; Pierson, E.; Kim, B.; Liang, P. Concept bottleneck models. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual, 13–18 July 2020; pp. 5338–5348. [Google Scholar]
- Marconato, E.; Passerini, A.; Teso, S. GlanceNets: Interpretabile, Leak-proof Concept-based Models. Adv. Neural Inf. Process. Syst. 2022, 35, 21212–21227. [Google Scholar]
- Espinosa Zarlenga, M.; Barbiero, P.; Ciravegna, G.; Marra, G.; Giannini, F.; Diligenti, M.; Shams, Z.; Precioso, F.; Melacci, S.; Weller, A.; et al. Concept Embedding Models: Beyond the Accuracy-Explainability Trade-Off. Adv. Neural Inf. Process. Syst. 2022, 35, 21400–21413. [Google Scholar]
- Lipton, Z.C. The Mythos of Model Interpretability: In machine learning, the concept of interpretability is both important and slippery. Queue 2018, 16, 31–57. [Google Scholar] [CrossRef]
- Schwalbe, G. Concept embedding analysis: A review. arXiv 2022, arXiv:2203.13909. [Google Scholar]
- Stammer, W.; Schramowski, P.; Kersting, K. Right for the Right Concept: Revising Neuro-Symbolic Concepts by Interacting with their Explanations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021; pp. 3619–3629. [Google Scholar]
- Bontempelli, A.; Teso, S.; Giunchiglia, F.; Passerini, A. Concept-level debugging of part-prototype networks. In Proceedings of the International Conference on Learning Representations, Kigali, Rwanda, 1–5 May 2023. [Google Scholar]
- Hoffmann, A.; Fanconi, C.; Rade, R.; Kohler, J. This Looks Like That… Does it? Shortcomings of Latent Space Prototype Interpretability in Deep Networks. arXiv 2021, arXiv:2105.02968. [Google Scholar]
- Xu-Darme, R.; Quénot, G.; Chihani, Z.; Rousset, M.C. Sanity Checks for Patch Visualisation in Prototype-Based Image Classification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 3690–3695. [Google Scholar]
- Chen, Z.; Bei, Y.; Rudin, C. Concept whitening for interpretable image recognition. Nat. Mach. Intell. 2020, 2, 772–782. [Google Scholar] [CrossRef]
- Margeloiu, A.; Ashman, M.; Bhatt, U.; Chen, Y.; Jamnik, M.; Weller, A. Do Concept Bottleneck Models Learn as Intended? arXiv 2021, arXiv:2105.04289. [Google Scholar]
- Mahinpei, A.; Clark, J.; Lage, I.; Doshi-Velez, F.; Pan, W. Promises and pitfalls of black-box concept learning models. In Proceedings of the International Conference on Machine Learning: Workshop on Theoretic Foundation, Criticism, and Application Trend of Explainable AI, Virtual, 8–9 February 2021; Volume 1, pp. 1–13. [Google Scholar]
- Silver, D.L.; Mitchell, T.M. The Roles of Symbols in Neural-based AI: They are Not What You Think! arXiv 2023, arXiv:2304.13626. [Google Scholar]
- Schölkopf, B.; Locatello, F.; Bauer, S.; Ke, N.R.; Kalchbrenner, N.; Goyal, A.; Bengio, Y. Toward causal representation learning. Proc. IEEE 2021, 109, 612–634. [Google Scholar] [CrossRef]
- Bengio, Y.; Courville, A.; Vincent, P. Representation learning: A review and new perspectives. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 1798–1828. [Google Scholar] [CrossRef]
- Higgins, I.; Amos, D.; Pfau, D.; Racaniere, S.; Matthey, L.; Rezende, D.; Lerchner, A. Towards a definition of disentangled representations. arXiv 2018, arXiv:1812.02230. [Google Scholar]
- Beckers, S.; Halpern, J.Y. Abstracting causal models. In Proceedings of the AAAI Conference on Artificial Intelligence, Washington, DC, USA, 7–14 February 2023; Volume 33, pp. 2678–2685. [Google Scholar]
- Beckers, S.; Eberhardt, F.; Halpern, J.Y. Approximate causal abstractions. In Proceedings of the Uncertainty in Artificial Intelligence, PMLR, Online, 3–6 August 2020; pp. 606–615. [Google Scholar]
- Geiger, A.; Wu, Z.; Potts, C.; Icard, T.; Goodman, N.D. Finding alignments between interpretable causal variables and distributed neural representations. arXiv 2023, arXiv:2303.02536. [Google Scholar]
- Lockhart, J.; Marchesotti, N.; Magazzeni, D.; Veloso, M. Towards learning to explain with concept bottleneck models: Mitigating information leakage. arXiv 2022, arXiv:2211.03656. [Google Scholar]
- Pearl, J. Causality; Cambridge University Press: Cambridge, UK, 2009. [Google Scholar]
- Peters, J.; Janzing, D.; Schölkopf, B. Elements of Causal Inference: Foundations and Learning Algorithms; MIT Press: Cambridge, MA, USA, 2017. [Google Scholar]
- Eastwood, C.; Williams, C.K. A framework for the quantitative evaluation of disentangled representations. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Suter, R.; Miladinovic, D.; Schölkopf, B.; Bauer, S. Robustly disentangled causal mechanisms: Validating deep representations for interventional robustness. In Proceedings of the International Conference on Machine Learning, PMLR, Long Beach, CA, USA, 9–15 June 2019; pp. 6056–6065. [Google Scholar]
- Reddy, A.G.; Balasubramanian, V.N. On causally disentangled representations. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 28 February–1 March 2022; Volume 36, pp. 8089–8097. [Google Scholar]
- von Kügelgen, J.; Sharma, Y.; Gresele, L.; Brendel, W.; Schölkopf, B.; Besserve, M.; Locatello, F. Self-Supervised Learning with Data Augmentations Provably Isolates Content from Style. In Proceedings of the 35nd International Conference on Neural Information Processing Systems, Online, 6–14 December 2021. [Google Scholar]
- Koller, D.; Friedman, N. Probabilistic Graphical Models: Principles and Techniques; MIT Press: Cambridge, MA, USA, 2009. [Google Scholar]
- Yang, Y.; Panagopoulou, A.; Zhou, S.; Jin, D.; Callison-Burch, C.; Yatskar, M. Language in a bottle: Language model guided concept bottlenecks for interpretable image classification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 19187–19197. [Google Scholar]
- Bontempelli, A.; Giunchiglia, F.; Passerini, A.; Teso, S. Toward a Unified Framework for Debugging Gray-box Models. In Proceedings of the The AAAI-22 Workshop on Interactive Machine Learning, Online, 28 February 2022. [Google Scholar]
- Zarlenga, M.E.; Pietro, B.; Gabriele, C.; Giuseppe, M.; Giannini, F.; Diligenti, M.; Zohreh, S.; Frederic, P.; Melacci, S.; Adrian, W.; et al. Concept embedding models: Beyond the accuracy-explainability trade-off. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: Needham, MA, USA, 2022; Volume 35, pp. 21400–21413. [Google Scholar]
- Fel, T.; Boutin, V.; Moayeri, M.; Cadène, R.; Bethune, L.; andéol, L.; Chalvidal, M.; Serre, T. A Holistic Approach to Unifying Automatic Concept Extraction and Concept Importance Estimation. arXiv 2023, arXiv:2306.07304. [Google Scholar]
- Teso, S. Toward Faithful Explanatory Active Learning with Self-explainable Neural Nets. In Proceedings of the Workshop on Interactive Adaptive Learning (IAL 2019); 2019; pp. 4–16. Available online: https://ceur-ws.org/Vol-2444/ialatecml_paper1.pdf (accessed on 9 September 2023).
- Pfau, J.; Young, A.T.; Wei, J.; Wei, M.L.; Keiser, M.J. Robust semantic interpretability: Revisiting concept activation vectors. arXiv 2021, arXiv:2104.02768. [Google Scholar]
- Gabbay, A.; Cohen, N.; Hoshen, Y. An image is worth more than a thousand words: Towards disentanglement in the wild. Adv. Neural Inf. Process. Syst. 2021, 34, 9216–9228. [Google Scholar]
- Matthey, L.; Higgins, I.; Hassabis, D.; Lerchner, A. dSprites: Disentanglement Testing Sprites Dataset. 2017. Available online: https://github.com/deepmind/dsprites-dataset/ (accessed on 9 September 2023).
- Havasi, M.; Parbhoo, S.; Doshi-Velez, F. Addressing Leakage in Concept Bottleneck Models. Adv. Neural Inf. Process. Syst. 2022, 35, 23386–23397. [Google Scholar]
- Cover, T.M. Elements of Information Theory; John Wiley & Sons: Hoboken, NJ, USA, 1999. [Google Scholar]
- Montero, M.L.; Ludwig, C.J.; Costa, R.P.; Malhotra, G.; Bowers, J. The role of disentanglement in generalisation. In Proceedings of the International Conference on Learning Representations, Addis Ababa, Ethiopia, 30 April 2020. [Google Scholar]
- Montero, M.; Bowers, J.; Ponte Costa, R.; Ludwig, C.; Malhotra, G. Lost in Latent Space: Examining failures of disentangled models at combinatorial generalisation. Adv. Neural Inf. Process. Syst. 2022, 35, 10136–10149. [Google Scholar]
- Sun, X.; Yang, Z.; Zhang, C.; Ling, K.V.; Peng, G. Conditional gaussian distribution learning for open set recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Washington, DC, USA, 14–19 June 2020; pp. 13480–13489. [Google Scholar]
- Hyvarinen, A.; Morioka, H. Nonlinear ICA of temporally dependent stationary sources. In Proceedings of the Artificial Intelligence and Statistics, PMLR, Ft. Lauderdale, FL, USA, 20–22 April 2017; pp. 460–469. [Google Scholar]
- Khemakhem, I.; Monti, R.P.; Kingma, D.P.; Hyvärinen, A. ICE-BeeM: Identifiable Conditional Energy-Based Deep Models Based on Nonlinear ICA. In Proceedings of the 34th Conference on Neural Information Processing Systems (NeurIPS 2020), Online, 6–12 December 2020. [Google Scholar]
- Rubenstein, P.K.; Weichwald, S.; Bongers, S.; Mooij, J.M.; Janzing, D.; Grosse-Wentrup, M.; Schölkopf, B. Causal consistency of structural equation models. arXiv 2017, arXiv:1707.00819. [Google Scholar]
- Zennaro, F.M. Abstraction between structural causal models: A review of definitions and properties. arXiv 2022, arXiv:2207.08603. [Google Scholar]
- Geiger, A.; Potts, C.; Icard, T. Causal Abstraction for Faithful Model Interpretation. arXiv 2023, arXiv:2301.04709. [Google Scholar]
- Marti, L.; Wu, S.; Piantadosi, S.T.; Kidd, C. Latent diversity in human concepts. Open Mind 2023, 7, 79–92. [Google Scholar] [CrossRef]
- Zaidi, J.; Boilard, J.; Gagnon, G.; Carbonneau, M.A. Measuring disentanglement: A review of metrics. arXiv 2020, arXiv:2012.09276. [Google Scholar]
- Eastwood, C.; Nicolicioiu, A.L.; Von Kügelgen, J.; Kekić, A.; Träuble, F.; Dittadi, A.; Schölkopf, B. DCI-ES: An Extended Disentanglement Framework with Connections to Identifiability. arXiv 2022, arXiv:2210.00364. [Google Scholar]
- Chen, R.T.; Li, X.; Grosse, R.; Duvenaud, D. Isolating sources of disentanglement in VAEs. In Proceedings of the 32nd International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 3–8 December 2018; pp. 2615–2625. [Google Scholar]
- Locatello, F.; Bauer, S.; Lucic, M.; Raetsch, G.; Gelly, S.; Schölkopf, B.; Bachem, O. Challenging common assumptions in the unsupervised learning of disentangled representations. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 4114–4124. [Google Scholar]
- Oikarinen, T.; Das, S.; Nguyen, L.M.; Weng, T.W. Label-free Concept Bottleneck Models. In Proceedings of the ICLR, Virtual, 25 April 2022. [Google Scholar]
- Lage, I.; Doshi-Velez, F. Learning Interpretable Concept-Based Models with Human Feedback. arXiv 2020, arXiv:2012.02898. [Google Scholar]
- Chauhan, K.; Tiwari, R.; Freyberg, J.; Shenoy, P.; Dvijotham, K. Interactive concept bottleneck models. In Proceedings of the AAAI, Washington, DC, USA, 7–14 February 2023. [Google Scholar]
- Steinmann, D.; Stammer, W.; Friedrich, F.; Kersting, K. Learning to Intervene on Concept Bottlenecks. arXiv 2023, arXiv:2308.13453. [Google Scholar]
- Zarlenga, M.E.; Collins, K.M.; Dvijotham, K.; Weller, A.; Shams, Z.; Jamnik, M. Learning to Receive Help: Intervention-Aware Concept Embedding Models. arXiv 2023, arXiv:2309.16928. [Google Scholar]
- Stammer, W.; Memmel, M.; Schramowski, P.; Kersting, K. Interactive disentanglement: Learning concepts by interacting with their prototype representations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 10317–10328. [Google Scholar]
- Muggleton, S.; De Raedt, L. Inductive logic programming: Theory and methods. J. Log. Program. 1994, 19, 629–679. [Google Scholar] [CrossRef]
- De Raedt, L.; Dumancic, S.; Manhaeve, R.; Marra, G. From Statistical Relational to Neuro-Symbolic Artificial Intelligence. In Proceedings of the IJCAI, Yokohama, Japan, 11–17 July 2020. [Google Scholar]
- Holzinger, A.; Saranti, A.; Angerschmid, A.; Finzel, B.; Schmid, U.; Mueller, H. Toward human-level concept learning: Pattern benchmarking for AI algorithms. Patterns 2023, 4, 100788. [Google Scholar] [CrossRef]
- Miller, T. Explanation in artificial intelligence: Insights from the social sciences. Artif. Intell. 2019, 267, 1–38. [Google Scholar] [CrossRef]
- Cabitza, F.; Campagner, A.; Malgieri, G.; Natali, C.; Schneeberger, D.; Stoeger, K.; Holzinger, A. Quod erat demonstrandum?—Towards a typology of the concept of explanation for the design of explainable AI. Expert Syst. Appl. 2023, 213, 118888. [Google Scholar] [CrossRef]
- Ho, M.K.; Abel, D.; Correa, C.G.; Littman, M.L.; Cohen, J.D.; Griffiths, T.L. People construct simplified mental representations to plan. Nature 2022, 606, 129–136. [Google Scholar] [CrossRef]
- Khemakhem, I.; Kingma, D.; Monti, R.; Hyvarinen, A. Variational autoencoders and nonlinear ica: A unifying framework. In Proceedings of the International Conference on Artificial Intelligence and Statistics, PMLR, Online, 26–28 August 2020; pp. 2207–2217. [Google Scholar]
- Graziani, M.; Nguyen, A.P.; O’Mahony, L.; Müller, H.; Andrearczyk, V. Concept discovery and dataset exploration with singular value decomposition. In Proceedings of the ICLR 2023 Workshop on Pitfalls of Limited Data and Computation for Trustworthy ML, Kigali, Rwanda, 5 May 2023. [Google Scholar]
- Li, O.; Liu, H.; Chen, C.; Rudin, C. Deep learning for case-based reasoning through prototypes: A neural network that explains its predictions. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Rymarczyk, D.; Struski, L.; Tabor, J.; Zieliński, B. ProtoPShare: Prototypical Parts Sharing for Similarity Discovery in Interpretable Image Classification. In Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining, Singapore, 14–18 August 2021; pp. 1420–1430. [Google Scholar]
- Nauta, M.; van Bree, R.; Seifert, C. Neural Prototype Trees for Interpretable Fine-grained Image Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021; pp. 14933–14943. [Google Scholar]
- Singh, G.; Yow, K.C. These do not look like those: An interpretable deep learning model for image recognition. IEEE Access 2021, 9, 41482–41493. [Google Scholar] [CrossRef]
- Davoudi, S.O.; Komeili, M. Toward Faithful Case-based Reasoning through Learning Prototypes in a Nearest Neighbor-friendly Space. In Proceedings of the International Conference on Learning Representations, Virtual Event, 3–7 May 2021. [Google Scholar]
- Zhou, B.; Sun, Y.; Bau, D.; Torralba, A. Interpretable basis decomposition for visual explanation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 119–134. [Google Scholar]
- Kazhdan, D.; Dimanov, B.; Jamnik, M.; Liò, P.; Weller, A. Now you see me (CME): Concept-based model extraction. arXiv 2020, arXiv:2010.13233. [Google Scholar]
- Gu, J.; Tresp, V. Semantics for global and local interpretation of deep neural networks. arXiv 2019, arXiv:1910.09085. [Google Scholar]
- Esser, P.; Rombach, R.; Ommer, B. A disentangling invertible interpretation network for explaining latent representations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 9223–9232. [Google Scholar]
- Yeh, C.K.; Kim, B.; Arik, S.; Li, C.L.; Pfister, T.; Ravikumar, P. On completeness-aware concept-based explanations in deep neural networks. Adv. Neural Inf. Process. Syst. 2020, 33, 20554–20565. [Google Scholar]
- Yuksekgonul, M.; Wang, M.; Zou, J. Post-hoc Concept Bottleneck Models. arXiv 2022, arXiv:2205.15480. [Google Scholar]
- Sawada, Y.; Nakamura, K. Concept Bottleneck Model with Additional Unsupervised Concepts. IEEE Access 2022, 10, 41758–41765. [Google Scholar] [CrossRef]
- Magister, L.C.; Kazhdan, D.; Singh, V.; Liò, P. Gcexplainer: Human-in-the-loop concept-based explanations for graph neural networks. arXiv 2021, arXiv:2107.11889. [Google Scholar]
- Finzel, B.; Saranti, A.; Angerschmid, A.; Tafler, D.; Pfeifer, B.; Holzinger, A. Generating explanations for conceptual validation of graph neural networks: An investigation of symbolic predicates learned on relevance-ranked sub-graphs. KI-Künstliche Intell. 2022; 36, 271–285. [Google Scholar] [CrossRef]
- Erculiani, L.; Bontempelli, A.; Passerini, A.; Giunchiglia, F. Egocentric Hierarchical Visual Semantics. arXiv 2023, arXiv:2305.05422. [Google Scholar]
- Higgins, I.; Matthey, L.; Pal, A.; Burgess, C.; Glorot, X.; Botvinick, M.; Mohamed, S.; Lerchner, A. β-VAE: Learning Basic Visual Concepts with a Constrained Variational Framework. In Proceedings of the International Conference on Learning Representations, San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- Kingma, D.P.; Welling, M. Auto-encoding variational bayes. In Proceedings of the International Conference on Machine Learning, PMLR, Beijing, China, 22–24 June 2014. [Google Scholar]
- Kim, H.; Mnih, A. Disentangling by factorising. In Proceedings of the International Conference on Machine Learning, PMLR, Stockholm Sweden, 10–15 July 2018; pp. 2649–2658. [Google Scholar]
- Esmaeili, B.; Wu, H.; Jain, S.; Bozkurt, A.; Siddharth, N.; Paige, B.; Brooks, D.H.; Dy, J.; Meent, J.W. Structured disentangled representations. In Proceedings of the 22nd International Conference on Artificial Intelligence and Statistics, PMLR, Naha, Okinawa, Japan, 16–18 April 2019; pp. 2525–2534. [Google Scholar]
- Rhodes, T.; Lee, D. Local Disentanglement in Variational Auto-Encoders Using Jacobian L_1 Regularization. Adv. Neural Inf. Process. Syst. 2021, 34, 22708–22719. [Google Scholar]
- Locatello, F.; Tschannen, M.; Bauer, S.; Rätsch, G.; Schölkopf, B.; Bachem, O. Disentangling Factors of Variations Using Few Labels. In Proceedings of the International Conference on Learning Representations, Addis Ababa, Ethiopia, 30 April 2020. [Google Scholar]
- Shu, R.; Chen, Y.; Kumar, A.; Ermon, S.; Poole, B. Weakly Supervised Disentanglement with Guarantees. In Proceedings of the International Conference on Learning Representations, Addis Ababa, Ethiopia, 30 April 2020. [Google Scholar]
- Locatello, F.; Poole, B.; Rätsch, G.; Schölkopf, B.; Bachem, O.; Tschannen, M. Weakly-supervised disentanglement without compromises. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual, 13–18 July 2020; pp. 6348–6359. [Google Scholar]
- Lachapelle, S.; Rodriguez, P.; Sharma, Y.; Everett, K.E.; Le Priol, R.; Lacoste, A.; Lacoste-Julien, S. Disentanglement via mechanism sparsity regularization: A new principle for nonlinear ICA. In Proceedings of the Conference on Causal Learning and Reasoning, PMLR, Eureka, CA, USA, 11–13 April 2022; pp. 428–484. [Google Scholar]
- Horan, D.; Richardson, E.; Weiss, Y. When Is Unsupervised Disentanglement Possible? Adv. Neural Inf. Process. Syst. 2021, 34, 5150–5161. [Google Scholar]
- Comon, P. Independent component analysis, a new concept? Signal Process. 1994, 36, 287–314. [Google Scholar] [CrossRef]
- Hyvärinen, A.; Karhunen, J.; Oja, E. Independent Component Analysis, Adaptive and Learning Systems for Signal Processing, Communications, and Control; John Wiley Sons, Inc.: Hoboken, NJ, USA, 2001; Volume 1, pp. 11–14. [Google Scholar]
- Naik, G.R.; Kumar, D.K. An overview of independent component analysis and its applications. Informatica 2011, 35, 63–81. [Google Scholar]
- Hyvärinen, A.; Pajunen, P. Nonlinear independent component analysis: Existence and uniqueness results. Neural Netw. 1999, 12, 429–439. [Google Scholar] [CrossRef]
- Buchholz, S.; Besserve, M.; Schölkopf, B. Function classes for identifiable nonlinear independent component analysis. Adv. Neural Inf. Process. Syst. 2022, 35, 16946–16961. [Google Scholar]
- Zarlenga, M.E.; Barbiero, P.; Shams, Z.; Kazhdan, D.; Bhatt, U.; Weller, A.; Jamnik, M. Towards Robust Metrics for Concept Representation Evaluation. arXiv 2023, arXiv:2301.10367. [Google Scholar]
- Manhaeve, R.; Dumancic, S.; Kimmig, A.; Demeester, T.; De Raedt, L. DeepProbLog: Neural Probabilistic Logic Programming. Adv. Neural Inf. Process. Syst. 2021, 31, 3753–3763. [Google Scholar] [CrossRef]
- Donadello, I.; Serafini, L.; Garcez, A.D. Logic tensor networks for semantic image interpretation. arXiv 2017, arXiv:1705.08968. [Google Scholar]
- Diligenti, M.; Gori, M.; Sacca, C. Semantic-based regularization for learning and inference. Artif. Intell. 2017, 244, 143–165. [Google Scholar] [CrossRef]
- Fischer, M.; Balunovic, M.; Drachsler-Cohen, D.; Gehr, T.; Zhang, C.; Vechev, M. Dl2: Training and querying neural networks with logic. In Proceedings of the International Conference on Machine Learning, PMLR, Long Beach, CA, USA, 9–15 June 2019; pp. 1931–1941. [Google Scholar]
- Giunchiglia, E.; Lukasiewicz, T. Coherent Hierarchical Multi-label Classification Networks. Adv. Neural Inf. Process. Syst. 2020, 33, 9662–9673. [Google Scholar]
- Yang, Z.; Ishay, A.; Lee, J. NeurASP: Embracing neural networks into answer set programming. In Proceedings of the IJCAI, Long Beach, CA, USA, 9–15 June 2019. [Google Scholar]
- Huang, J.; Li, Z.; Chen, B.; Samel, K.; Naik, M.; Song, L.; Si, X. Scallop: From Probabilistic Deductive Databases to Scalable Differentiable Reasoning. Adv. Neural Inf. Process. Syst. 2021, 34, 25134–25145. [Google Scholar]
- Marra, G.; Kuželka, O. Neural markov logic networks. In Proceedings of the Uncertainty in Artificial Intelligence, Online, 27–30 July 2021. [Google Scholar]
- Ahmed, K.; Teso, S.; Chang, K.W.; Van den Broeck, G.; Vergari, A. Semantic Probabilistic Layers for Neuro-Symbolic Learning. Adv. Neural Inf. Process. Syst. 2022, 35, 29944–29959. [Google Scholar]
- Misino, E.; Marra, G.; Sansone, E. VAEL: Bridging Variational Autoencoders and Probabilistic Logic Programming. Adv. Neural Inf. Process. Syst. 2022, 35, 4667–4679. [Google Scholar]
- Winters, T.; Marra, G.; Manhaeve, R.; De Raedt, L. DeepStochLog: Neural Stochastic Logic Programming. In Proceedings of the AAAI, Virtually, 22 February–1 March 2022. [Google Scholar]
- van Krieken, E.; Thanapalasingam, T.; Tomczak, J.M.; van Harmelen, F.; Teije, A.T. A-NeSI: A Scalable Approximate Method for Probabilistic Neurosymbolic Inference. arXiv 2022, arXiv:2212.12393. [Google Scholar]
- Ciravegna, G.; Barbiero, P.; Giannini, F.; Gori, M.; Lió, P.; Maggini, M.; Melacci, S. Logic explained networks. Artif. Intell. 2023, 314, 103822. [Google Scholar] [CrossRef]
- Marconato, E.; Bontempo, G.; Ficarra, E.; Calderara, S.; Passerini, A.; Teso, S. Neuro-Symbolic Continual Learning: Knowledge, Reasoning Shortcuts and Concept Rehearsal. In Proceedings of the 40th International Conference on Machine Learning (ICML’23), Honolulu, HI, USA, 23–29 July 2023; Volume 202, pp. 23915–23936. [Google Scholar]
- Marconato, E.; Teso, S.; Vergari, A.; Passerini, A. Not All Neuro-Symbolic Concepts Are Created Equal: Analysis and Mitigation of Reasoning Shortcuts. In Proceedings of the Thirty-Seventh Conference on Neural Information Processing Systems, New Orleans, LA, USA, 10–16 December 2023. [Google Scholar]

Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Marconato, E.; Passerini, A.; Teso, S. Interpretability Is in the Mind of the Beholder: A Causal Framework for Human-Interpretable Representation Learning. Entropy 2023, 25, 1574. https://doi.org/10.3390/e25121574
Marconato E, Passerini A, Teso S. Interpretability Is in the Mind of the Beholder: A Causal Framework for Human-Interpretable Representation Learning. Entropy. 2023; 25(12):1574. https://doi.org/10.3390/e25121574
Chicago/Turabian StyleMarconato, Emanuele, Andrea Passerini, and Stefano Teso. 2023. "Interpretability Is in the Mind of the Beholder: A Causal Framework for Human-Interpretable Representation Learning" Entropy 25, no. 12: 1574. https://doi.org/10.3390/e25121574
APA StyleMarconato, E., Passerini, A., & Teso, S. (2023). Interpretability Is in the Mind of the Beholder: A Causal Framework for Human-Interpretable Representation Learning. Entropy, 25(12), 1574. https://doi.org/10.3390/e25121574