1. Introduction
In this work, we consider a source code variant, introduced by Birk and Kol [
1], originally called informed source coding-on-demand (ISCOD), and further developed by Bar-Yossef et al. [
2]. Motivating applications include satellite transmission of large files, audio and video on demand (such as streaming networks), database data retrieval, cache management for network applications and sensor networks. The model considered in [
1] involves a source that possesses
n messages and
m receivers. Each receiver knows a proper subset of messages, which is referred to as the side information and demands a specific message unknown to it. The source, aware of the messages possessed by each receiver, uses this knowledge to develop a transmission scheme that satisfies the demands of all receivers using as few transmissions as possible, referred to as the index code length.
Index coding can be viewed as special case of rate distortion with multiple receivers, each with some side information about the source [
3]. Index coding has received considerable attention recently, motivated by applications in multi-user broadcast scenarios, such as audio and video on demand, streaming networks, satellite communications and by its connection to network coding. In [
4,
5], the equivalence between network encoding and index encoding has been established. This research topic has been extended in other directions, such as pliable index coding [
6], a variation of index coding in which we still consider a server and
m clients with side information, but where the receivers are
flexible and satisfied to receive any message that is not in their side information set; such flexibility can reduce the amount of communication, sometimes significantly. This has applications in music streaming services or internet searching, such as
content distribution networks (CDNs) [
7]; a CDN manages servers in multiple geographically distributed locations, stores copies of the web content (including documents, images, audio and others) in its servers and attempts to direct each user request to a CDN location that will provide the best user experience. In this application, each receiver may be interested in receiving any message that it does not already possess as side information. Suppose that we are searching for the latest news and we already have some information. We are happy if we obtain any additional news that we do not have, with minimum delay. Here, we do not specify the news. On a music streaming service, users do not know which song will play next; they are usually only guaranteed that it will be one of a certain group and that it will not be repeated. In online advertising systems, customers do not require a specific advertisement to view; it is the distributor who chooses which one will be placed on customers’ screens. The distributor may wish to avoid repeating the same advertisement for the same customer, as this can decrease customer satisfaction.
How much we can gain in terms of bandwidth and user satisfaction, if recommendation systems become bandwidth-aware and take into account not only the user preferences? Song and Fragouli [
8] formulated this as a new problem in the context of index coding, where they relaxed the index coding requirements and considered the case where the customer is satisfied to receive any message that they do not already have, with satisfaction proportional to their preference for that message.
A promising research area that has recently emerged is in how to use index coding to improve the communication efficiency in distributed computing systems, especially for data shuffling in iterative computations [
9,
10]. Index coding has been proposed to increase the efficiency of data shuffling, which can form a major communication bottleneck for big data applications. In particular, pliable index coding can offer a more efficient framework for data shuffling, as it can better leverage the many possible shuffling choices to reduce the number of transmissions.
The index coding problem subject to transmission errors was initially considered by Dau et al. [
11]. In this work, we establish a connection between index coding and error-correcting codes with multiple interpretations from the tree construction of nested cyclic codes proposed in [
12]. The notion of multiple interpretation using nested codes [
13] is as follows: multiple information packets are separately encoded via linear channel codes, and then combined by addition and transmitted as a single codeword, minimizing the number of channel uses and offering error protection. The resulting packet can be decoded and interpreted in different ways, yielding an increase in error correction capability, depending on the amount of side information available at each receiver.
Part of the content of this paper was presented in [
14]. In the current version, evidence to verify our claims has been added, as well as some examples. The results in this paper are an extension of the results in [
12,
14].
The main contributions of this paper are as follows.
We verify that, for cyclic codes, there will not always be an increase in error correction capability between different levels of the code tree. For this reason, we initially restrict the study to Reed–Solomon codes since they are maximum separable distance (MDS) codes, and provide an increase in Hamming distance at each level. This means that, under certain conditions, knowledge of side information can be interpreted as an increase in error correction capability.
We propose a new variant for the index coding problem, which we call “index coding with multiple interpretations”. We assume that receivers demand all the messages from the source and that the sender is unaware of the subset of messages already known by the receivers. The sender performs encoding such that any side information may be used by the decoder in order to increase its error correction capability. Moreover, if a receiver has no side information, the decoder considers the received word to belong to the highest rate code, associated with the root node of the tree.
We also propose a solution to relax some constraints on how side information should occur at the receivers, using graph coloring associated with the pliable index coding problem.
2. Preliminaries
2.1. Notation and Definitions
For any positive integer n, we let . We write to denote the finite field of size q, where q is a prime power, and use to denote the vector space of all matrices over .
2.2. Review of Linear and Cyclic Codes
We now introduce the notation and briefly review some of the relevant properties of linear and cyclic codes based on [
15,
16]. The purpose of a code is to add extra check symbols to the data symbols so that errors may be found and corrected at the receiver. That is, a sequence of data symbols is represented by some longer sequence of symbols with enough redundancy to protect the data. In general, to design coding schemes for receivers with side information, we will consider collections of linear codes that are of length
n over
.
Structure of Linear Block Codes
Recall that under componentwise vector addition and componentwise scalar multiplication, the set of
n-tuples of elements from
is the vector space called
. For the vectors
and
, the
Hamming distance between
u and
v is defined to be the number of coordinates
u and
v that differ, i.e.,
Definition 1. A k-dimensional subspace of is called a linear code over if the minimum distance of ,is equal to d. Sometimes, we only use to refer to the code , where n is the length of the codewords and k is the dimension of the code. The code’s rate is the ratio . That is, a linear code can be completely described by any set of k linearly independent codewords ; thus, any codeword is one of the linear combinations , . If we arrange the codewords into a matrix G, we say that G is a generator matrix for .
A special case of major importance is , which is the vector space of all binary codewords of length n with two such vectors added by modulo-2 addition in each component. A binary code of size for an integer k is referred to as an binary code.
We consider cyclic codes of length n over with . Label the coordinates of with the elements of and associate the vector with the polynomial . With this correspondence, a cyclic code is an ideal of the ring . We use to denote the generator polynomial of and write to describe a t-error correcting cyclic code.
2.3. Index Coding with Side Information
The system shown in
Figure 1 illustrates the index coding problem. Receiver
is requesting the message
,
and knows other messages as side information;
knows
,
knows
and
and the receiver
knows
and
.
The goal of index coding is to perform the joint encoding of the messages, in order to simultaneously meet the demands of all receivers, while transmitting the resulting messages at the highest possible rate.
Assuming a noiseless broadcast channel, the server would communicate all messages by sending one at a time, in three transmissions.
Alternatively, when transmitting the two coded messages and , the receiver decodes , from and , and recover their demands.
The index coding problem is formulated as follows. Suppose that a server S wants to send a vector , where , to receivers . Each receiver has as side information and is interested in receiving the message . The codeword is sent and allows each receiver to retrieve . is an index code scalar over of length ℓ. The purpose of S is to find an index code that has the minimum length. The index code is called linear if is a linear function.
Index Coding via Fitting Matrices
A directed graph
with
n vertices specifies an instance of the index coding problem. Each vertex of
corresponds to a receiver (and its demand) and there is a directed edge
if and only if the receiver
knows
as side information. Then, we write:
Definition 2. Let be a directed graph on n vertices without self-loops.
- 1.
A 0-1 matrix , whose rows and columns are labeled by the elements of , fits if, for all i and j,
- (i)
;
- (ii)
Thus, is the adjacency matrix of an edge-induced subgraph of , where I denotes the identity matrix.
- 2.
The minrank of over the field is defined as follows:
Remark 1. The term rank denotes the rank of such matrix M over , after has been assigned a value of 0 or 1. As an example for the index coding problem instance described in Figure 1, the matrix M would be given as follows: Example 1. Consider the side information graph and a matrix M that fits , as shown in Figure 2. As , we can select two linearly independent rows in a matrix M, namely , and design an linear index code with the shortest possible length. The codeword sent will be . Theorem 1 ([
2]).
For any side information graph , there exists a linear index code for whose length equals minrk. This bound is optimal for all linear index codes . In [
17], the index encoding problem was generalized. Suppose that a sender wants to transmit
n messages
, where
, to
m receivers
, through a noiseless channel. The receiver
is interested in recovering a single block
, where
, and knows
. The goal is to satisfy the demands of all receivers, exploiting their side information in a minimum number of transmissions.
When
,
and
, we have a
scalar index code [
2]. Otherwise, we have a
vector index code.
Let be the set of side information of all receivers. An instance of an index coding problem given by can be described by a directed hypergraph.
Definition 3. The side information hypergraph is defined by the set of vertices and the (directed) hyperedges , whereA hyperedge represents the demand and side information of the receiver . Example 2. Consider an instance of an index coding problem in Figure 3. The hypergraph in Figure 3b describes the problem, where (messages) and (receivers) requiring , , , and , and with the following side information sets , and , respectively. Definition 4. Given an instance of an index encoding problem described by ,is a - index code with length ℓ, for the instance described by , if, for each receiver , , there exists a decoding functionsatisfying . The transmission rate of the code is defined as . If , then the index code is known as a scalar index code; otherwise, it is known as a vector index code. A linear coding function is also called a linear index code. The goal of index coding is to find optimal index codes, i.e., those with the minimum possible transmission rate. For scalar linear index codes, we refer to the quantity r as the length of the code, and thus rate optimality translates to minimal length codes.
Definition 5. is a -linear index code, , where . G is the matrix that generates the linear index code .
The following definition generalizes the minrank definition over
of the side information graph
, which was defined in [
2], to a hypergraph
.
Definition 6. Let Supp, the support of a vector . The Hamming weight of v will be denoted by , the number of nonzero coordinates of v.
Definition 7 ([
11]).
Suppose that corresponds to an instance of index coding with side information (ICSI). Then, the minrank of over is defined as This may be rewritten as follows.
Definition 8. Let a side information hypergraph correspond to an instance of the ICSI problem. A matrix fits ifThe minrank of over the field is defined as follows: Theorem 2 ([
2]).
Given an instance of an index encoding problem described by the hypergraph , the optimal length of an index code on the field is . In [
2], it was proven that, in several cases, linear index codes were optimal. They conjectured that for any side information graph
, the shortest-length index code would always be linear and have length
. The conjecture was refuted by Lubetzky and Stav in [
18]. In any case, as shown by Peeters [
19], calculating the minrank of an arbitrary graph is a difficult task. More specifically, Peeters showed that deciding whether a graph has minrank three is an NP-complete problem.
Example 3. Consider the instance of the index encoding problem given in Example 2. Then, we find that the matrix M that fits the hypergraph has the form:The lines are associated with the receivers and the columns to the message indexes and 4.
The symbol can be replaced by an arbitrary element in the field . For an example, consider the field
. A matrix that fits the hypergraph
has rank at least 3. Thus, we select
which achieves the minimum rank 3. Now, we consider three linearly independent lines of
M, and suppose that
The decoding process goes as follows. Since
and
already know
and
, respectively, they obtain
and
, respectively, from the first packet. Receiver
obtains
and both
and
obtain
.
Remark 2. We have made available at [20] an algorithm (m-files) in Matlab, which is designed to solve small examples in this work, since, as we mentioned above, there is no polynomial-time algorithm for an arbitrary graph. 2.4. Pliable Index Coding
The pliable index coding problem (PICOD), introduced by Brahma and Fragouli in [
6], is a variant of the index coding problem. In PICOD, users do not have predetermined messages to decode, as in the case of classic index coding; instead, each user is satisfied to decode any message that is not present in its side information set.
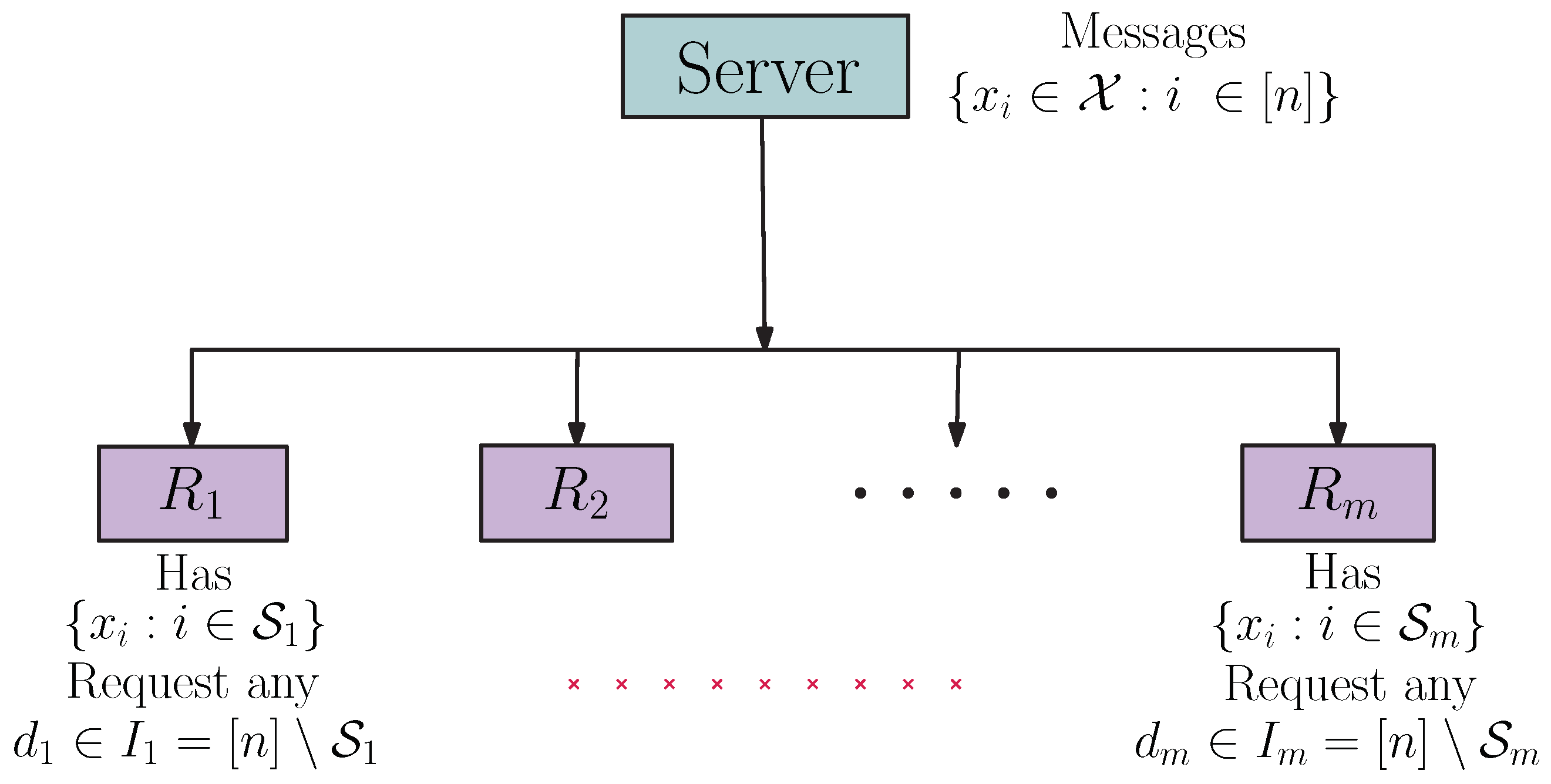
Figure 4 illustrates this system model.
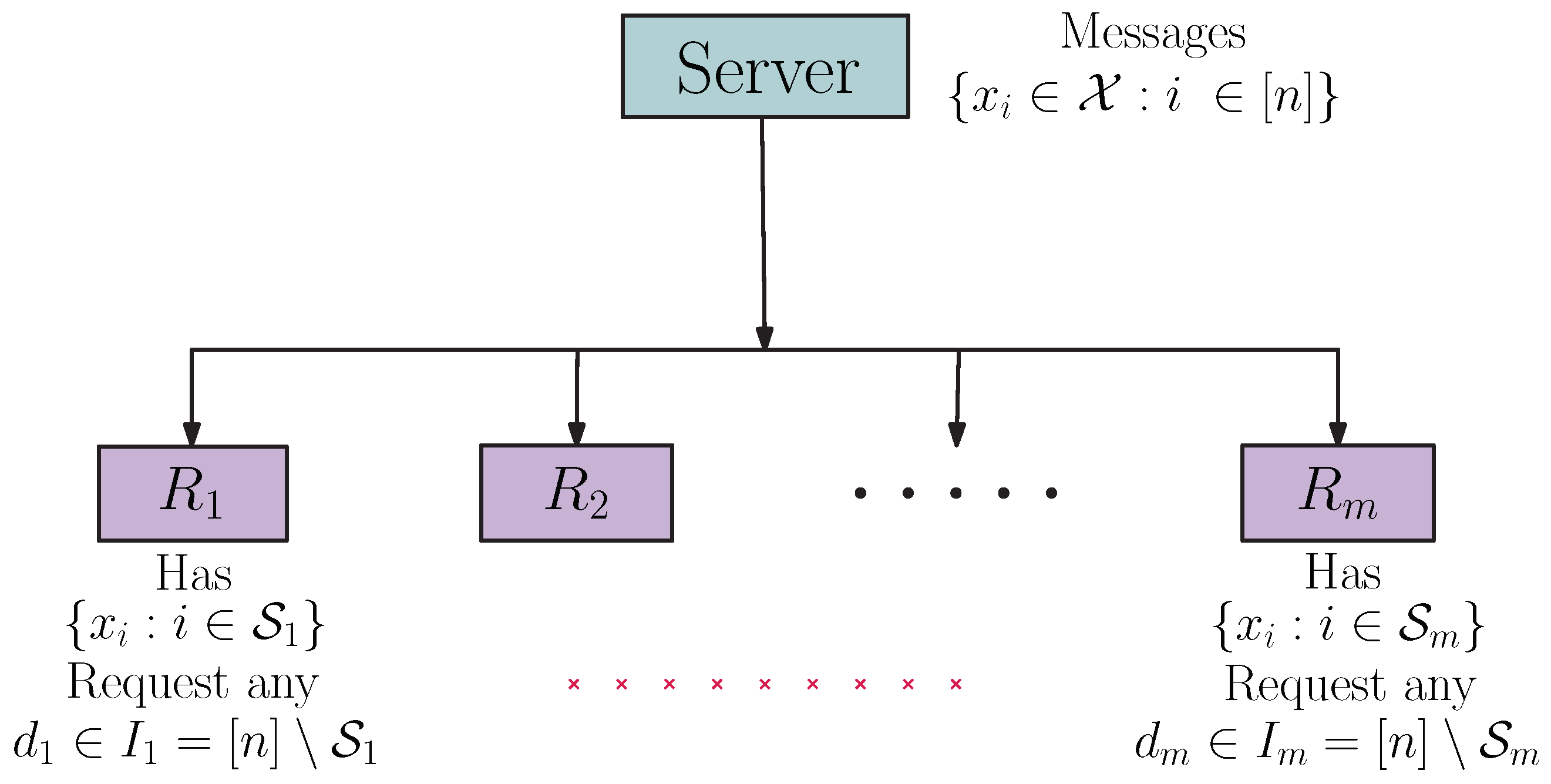
The problem is formalized as follows: a transmitter with n messages , is connected to m receivers , through a noiseless channel. Each receiver knows as side information. We denote by the index set of the unavailable messages in . Then, denotes the set of requests of . Each receiver is satisfied if it can successfully recover any message that is not present in its side information set, i.e., any message .
We can represent an instance of a pliable index coding problem using an undirected bipartite graph, one side representing the message indexes and the other side representing the receivers. We connect
to the indices belonging to
, as in
Figure 5.
Remark 3. By having this freedom to choose the desired message for each user, PICOD can satisfy all users with a significant reduction in the number of transmissions compared to the index encoding problem with the same set of messages and the same sets of user side information.
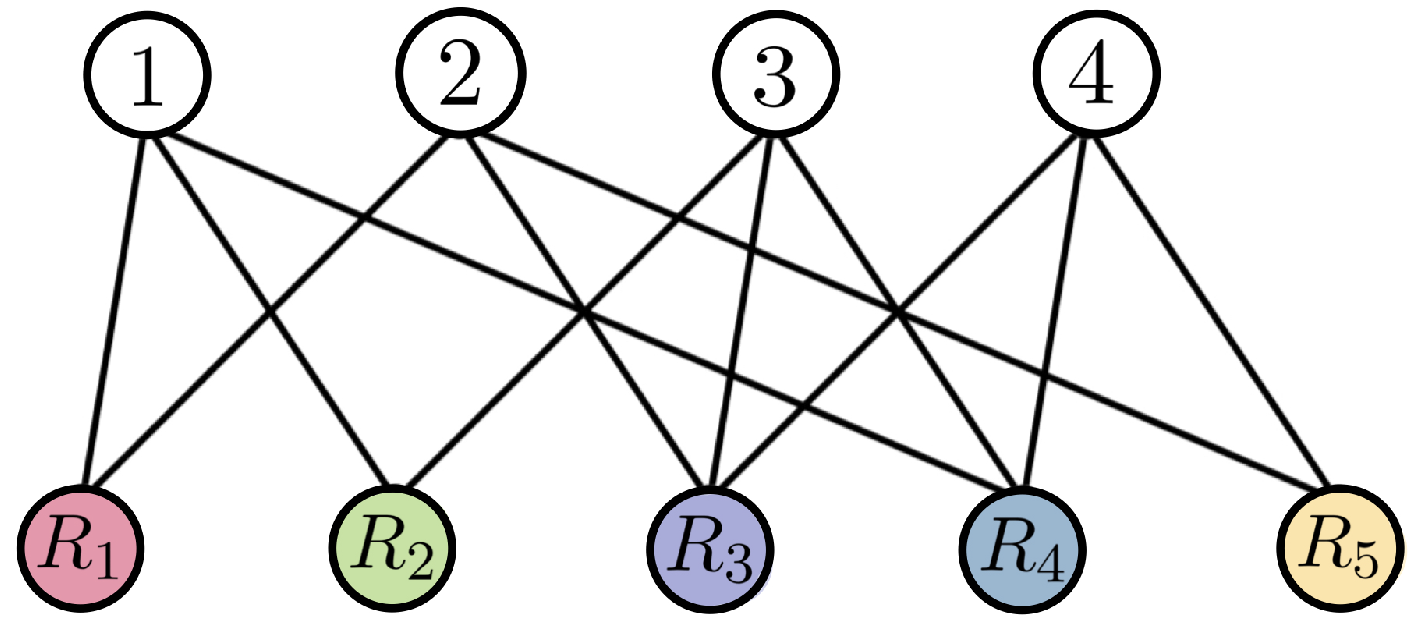
Example 4. We will consider the case described in Example 2 as a pliable index coding problem. Now, we have the bipartite graph in Figure 5 describing the problem. Note, for example, that client 1 demands any of the messages indexed in and knows the indexed messages in ; client 3 will be satisfied to receive any of the messages or , since it only knows . Pliable Index Coding via
Colorings of Hypergraphs
In [
21], a graph coloring approach was presented for pliable index coding. The authors have shown the existence of a coding scheme that has length
, where
refers to a hypergraph parameter that captures the maximum number of intersections between edges of the PICOD hypergraph.
An instance of the pliable index encoding problem is described by PICOD, onde , and can be conveniently represented by a hypergraph.
Definition 9. The hypergraph , with vertices and hyperedges, completely describes the PICOD. The hyperedge represents the set of requests for (i.e., ).
The problem illustrated in Example 5 can be represented by a hypergraph, as can be seen in
Figure 6.
Let
be a hypergraph and
be a coloring of
, where
L is a positive integer. We say that
C is a conflict-free coloring for the hyperdges, if each
of
has at least one vertex with unique color. The smallest number of colors required for such a coloring is called the conflict-free chromatic number of
, denoted by
. This parameter was first introduced by Even et al. [
22].
Remark 4. In [21], pliable index coding was given a graph coloring approach. The authors have shown the existence of a coding scheme that has length , where Γ refers to a hypergraph parameter that captures the maximum number of “incidences” of other hyperedges in any given hyperedge. This result improves the best known achievable results, in some parameter regimes. Definition 10. A pliable index code (PIC) consists of a collection of an encoding function on the server that encodes the n messages to an length codeword,and decoding functions satisfying for some . The quantity is called the length of the pliable index code. We are interested in designing pliable index codes that have small .
We will assume that for some finite field and integer . If , we refer to this code as a vector PIC, while the case is also called a scalar PIC. We will concentrate on the linear PICs. In this case, the coding function is represented by a matrix (denoted by G) such that , where The smallest ℓ for which there is a linear vector PIC for an instance of the pliable index coding problem given by the hypergraph will be denoted by .
Definition 11. Let be a conflict-free coloring of the hypergraph that represents a PICOD. The indicator matrix associated with this coloring , , is given by Teorema 1 ([
21]).
The indicator matrix generates the pliable index code for the problem described by the hypergraph . Example 5. Consider the same PICOD represented in Figure 6. The coloring shown in Figure 7 is a conflict-free coloring with two colors. Then, the matrix From the messages and , all receivers can successfully recover at least one message from their request set.
Using the same parameters as in Example 2, we see that the length of the index code for this instance is , while, for the PICOD case, .
2.5. Index Coding via MDS Codes
The index coding model defined in
Section 2.3, via graph theory, is only one of many approaches used to describe and solve an index encoding problem. One of the most interesting index coding schemes using codes has the maximum distance separable (MDS) property, which consists of transmitting
, the parity symbols of a systematic MDS code with parameters
, where
represents the minimum amount of side information available at each receiver, i.e., for a general index encoding problem with side information graph
,
Then, every receiver has
n code symbols (including its side information) and, by the MDS property, it can successfully recover its desired message.
Proposition 1 ([
1]).
Consider an index coding problem with n messages and n receivers represented by the side information graph . Let , the side information set of the receiver , and then Corollary 1. If is a complete graph, then and the transmission of the parity symbol of an MDS code over achieves minrk.
3. Results
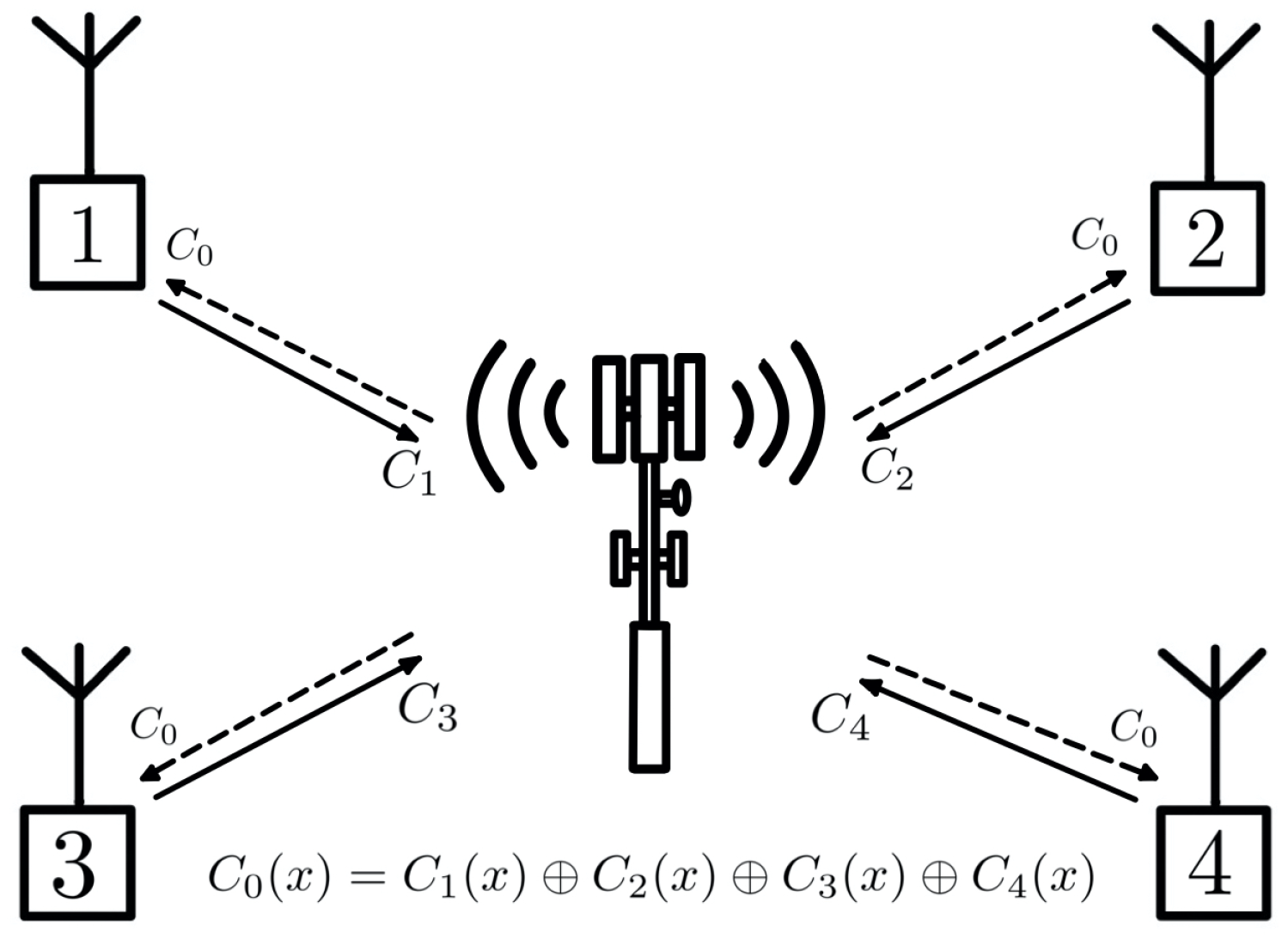
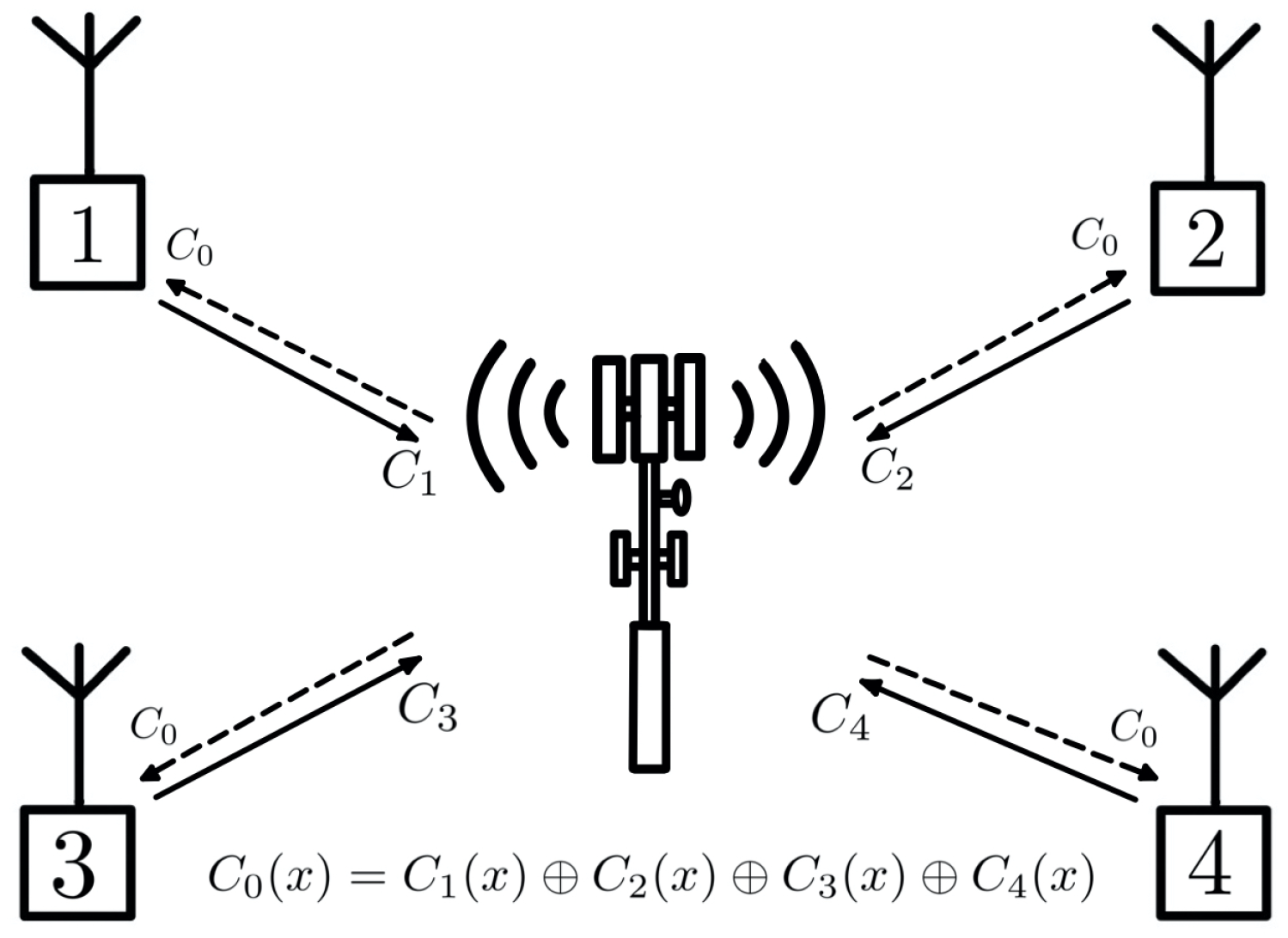
The tree construction method proposed in [
12] can be interpreted as a network coding problem with multiple sources and multiple users. In the proposed model, both encoding and decoding are performed by polynomial operations, without the need for side information; however, if they exist, they may allow multiple interpretations at the receivers, based on the side information available at each receiver.
Figure 8 illustrates this system model.
Given the connection between network and index coding problems, established in [
4], we can also interpret the coding with nested cyclic codes, at the stage where the packets are XOR-ed together, as a case of MDS index coding according to Corollary 1, in the particular case where each receiver is unaware of the message it is requesting, which may be a rare occurrence. However, it is possible to take advantage of the method’s distinguishing feature—the possibility of multiple interpretations at the receivers—and, by imposing some extra conditions, design an index code model that has greater flexibility over the side information sets.
In the next subsections, we present some results and algorithm implementations, and in
Section 4, we present in detail the proposed index encoding with multiple interpretations.
3.1. Index Coding from Reed–Solomon Codes
We establish a connection between index coding and error-correcting codes based on the tree construction method of nested cyclic codes proposed in [
12]. We implement a few algorithms to perform tree construction using the Matlab language, which allows us to work over finite bodies in a practical and efficient way and helps to solve some implementation problems encountered later in [
12]. We prove that for cyclic codes, there will not always be an increase in error correction capability between the levels of the tree, as suggested in [
12]. This is why we have initially limited this study to Reed–Solomon codes, because they are MDS codes, which guarantees an increase in Hamming distance at each level, meaning that, under certain conditions, the knowledge of side information will be interpreted as an increase in the decoder’s ability to correct errors.
A Tree Construction with Nested Cyclic Codes
A nested code is characterized by a global code where each element is given by a sum of codewords, each belonging to a different subcode. That is,
where ⊕ represents an XOR operation. For an information vector
, the codeword
belongs to a subcode
of code
and
.
Nested cyclic codes, whose subcodes are generated by generator polynomials, were originally proposed by Heegard [
23], and were originally called partitioned linear block codes. They can be defined as follows:
Definition 12. Let be a t-error-correcting cyclic code having as the generator polynomial. Note that is an ideal of the ring , but is also a vector subspace of , such thatwhere , is an encoded packet belonging to the -error-correcting subcodegenerated by and satisfying the following conditions: - 1.
;
- 2.
.
The tree-based algebraic construction of nested cyclic codes, proposed in [
12], aims to
- 1.
Encode, independently, different data packets, providing protection against channel errors;
- 2.
Encode different data packets producing codewords that are added, resulting in the packet ;
- 3.
Correct the errors on and, finally, recover the data in the receiver by polynomial operations.
Consider a tree in which the root node is associated with the vector subspace of an encompassing error correcting code. Thus, the root node is defined as the code
, such that
This subspace corresponds to a -error-correcting cyclic code , generated by the polynomial .
Definition 13. A tree of nested cyclic codes is a finite tree such that
- 1.
Each inner node (including the root node) can be subdivided into another inner node and a terminal node;
- 2.
The jth th inner node is associated with a linear subspace of dimension , and can be subdivided into the subspaces - 3.
The subspace , associated with the jth inner node, must be a cyclic linear block code generated by ;
- 4.
If e , then ; furthermore, for any ;
- 5.
To conclude, the last inner node will have no ramifications.
Remark 5. Figure 9 illustrates the model described above. Let
be the data packet associated with the terminal node, for
. The encoding is given by
Then, the encoded packets are summed up and the resulting codeword is sent out by the transmitter
After the error correction phase, the
jth packet
is decoded by the operations:
The information will be contained in the remainder of the division of
by
, since the modulo operation eliminates the influence of all messages related to polynomials of degree equal to or greater than the degree of
. Thus, the quotient of the final division operation provides the desired information, since all other messages have degree less than the degree of the divisor polynomial. Therefore, in the case of the last package, only the division operation is required. We suggest consulting [
12] for more details on the encoding process using the tree construction method.
3.2. Tree Construction: Algorithm and Considerations
We describe a few algorithms in Matlab and considerations for fitting to the model of tree construction, which can be found at [
20], allowing us to perform the calculations on finite fields by making the appropriate transformations from integer representation to powers of
. Below, we exemplify the main idea of the algorithm.
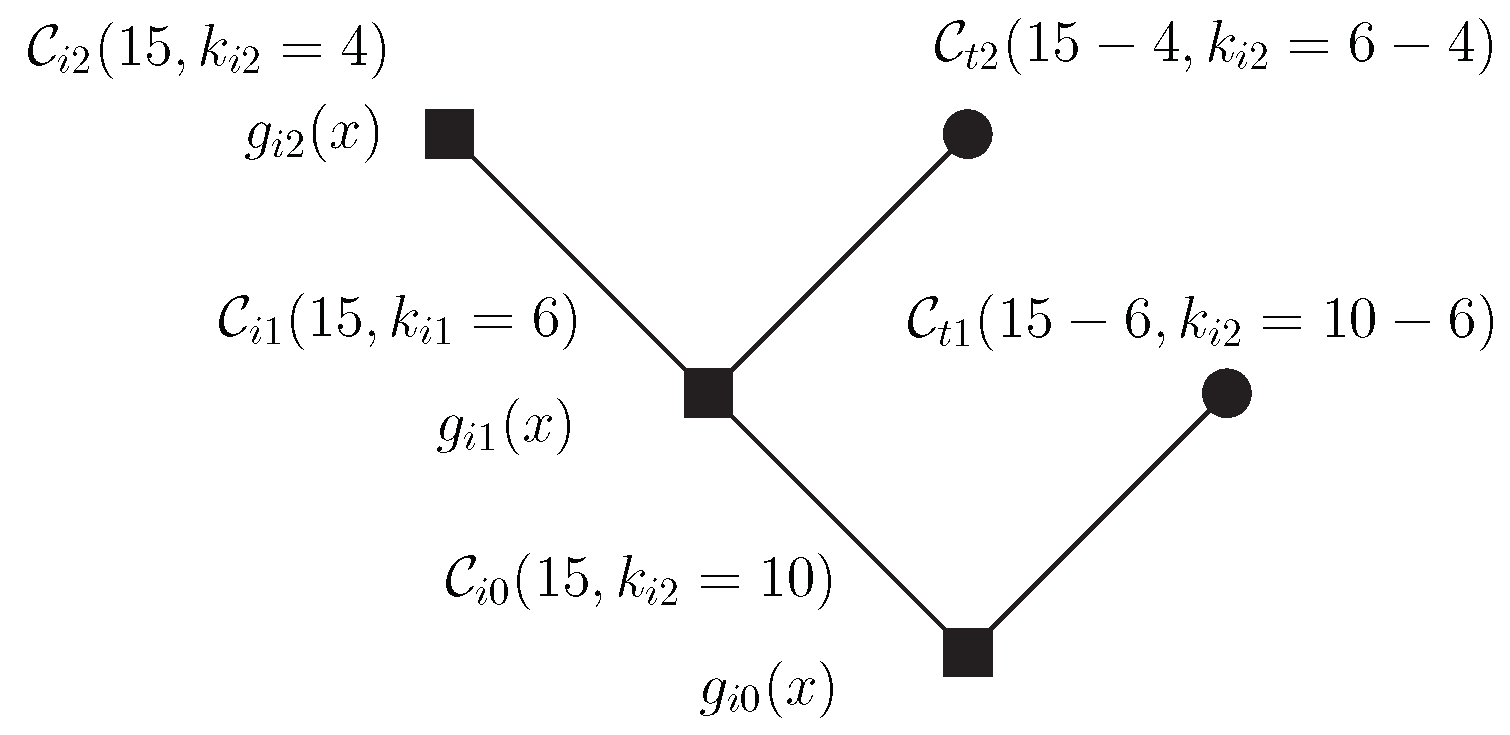
Example 6. For let be a Reed–Solomon code in and the dimensions of subspaces , respectively. They are associated with the terminal nodes of the tree; the last node of the tree, which is an inner node without ramification, is associated with of dimension .
The packets , both associated with the the terminal nodes, have length 2; has length equal to 1 and is associated with the last node. Let be the primitive element of , and the generator polynomials are
Then, the encoded packets are
The transmitted codeword is given by
Remark 6. Each terminal node is a shortened version of the code associated with the inner node from which the terminal node emanates. It is implicit that the codewords of shortened codes are prefixed with zeros to achieve length n and, therefore, that these codes are not cyclic.
3.2.1. Decoding—Error Correction
Considering tree construction based on Reed–Solomon codes and assuming that the receiver has side information available, when will there be an increase in error correction capability?
Proposition 2. Due to the nesting structure, the variable error correctability characteristic can only be observed if there is a sequential removal of the packets associated with the nodes from the root to the top of the tree.
Proof. Supposing that
is the first coded packet known at the receiver, then
therefore,
, whose error correction capability is
. Note that even though the receiver knows about other packages
, the result does not change. On the other hand, if all packages
are known to the receiver, we can write
thus,
, whose error correction capability is
, and equality occurs only when
□
Example 7. Consider the same tree as in Example 6.
If all packages are unknown ⇒ the decoding is performed by ∴;
If is known ⇒ the decoding is performed by ∴;
If is known the decoding is performed by ∴.
However, if is known but is not, then the resulting codeword still belongs to , and there is no improvement in error correction capability, since Another advantage of Reed–Solomon codes is that they are easily decoded using an algebraic method known as syndrome decoding.
Syndrome Decoding
Syndrome decoding is an algebraic method based on the Berlekamp–Massey algorithm, which became a prototype for the decoding of many other linear codes.
If the coded package
is known and an error
occurs, then the message received will be
Suppose that the error is given by
, and then
Remark 7. Notice that we need to find the error locations and their values, which is the main difference with binary codes, since, for binary codes, it is enough to determine the error locations.
The decoding process can be divided into three stages.
- 1.
Syndrome calculation
The syndrome calculation stage consists of checking the roots of the generating polynomial as inputs of . If the result is null, the sequence belongs to the set of codewords and, therefore, there are no errors. Any nonzero value indicates the presence of an error.
If the encoded packet
is known, then the error correction algorithm is executed by
, which is a
code, generated by
. Then,
Therefore, evaluating the roots of
at
, the result will only be null when there are no errors in the transmission.
- 2.
Error Localization
Let
be the number of errors
, which occur at locations
, and the error polynomial can be written as
To correct
, we must find the values and locations of the errors, which are denoted, respectively, by
and
. Substituting
, into the error polynomial
, we obtain
Obtain
and
for
, where
and
will represent, respectively, the locations and values of the errors. Note that we will have
equations and
unknowns,
t being error values and
t being locations.
It can be shown that this nonlinear system has a unique solution if
[
15]. The techniques that solve this system of equations include defining the error locator polynomial (ELP)
[
24].
Definition 14. Define the error locator polynomial , as
The inverse of the square root of , , indicates the locations of errors. To find error locations
, note that
and calculate the zeros of
; to find them, we use a syndrome matrix, as we see below:
Returning to Code RS(7,3), where the error correction capability is
, we must find
e
:
Thus,
with roots
and
, so there is an error at the locations
and
. Then,
- 3.
Determining the error values
Calculating
at the points
and
, we can use the syndromes already obtained,
and
, to determine the values of the errors, solving the following system:
Therefore, the error polynomial is given by
Now, correcting the received word
, we have
3.2.2. Decoding—Data Recovery
Example 8. For the cases in the previous examples, where , the original data can be recovered as follows: In summary, the module operation removes the branches above the node of interest and the division operation removes the branches below. Therefore, no side information is needed at the receiver in order to recover the data packets.
Will There Always Be an Increase in Error Correction Capability?
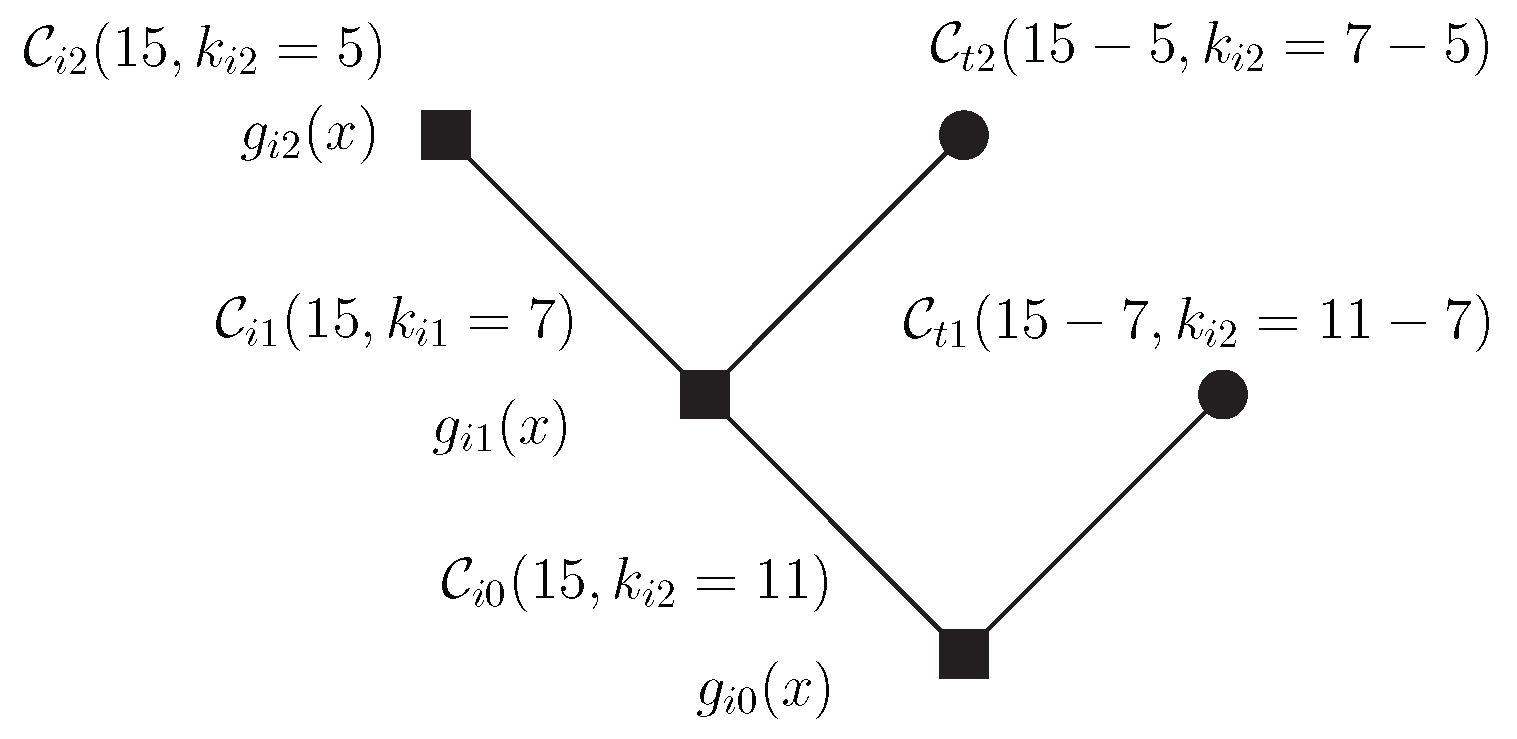
We analyze two cases of tree construction of nested cyclic codes, with the same parameters at each level. In one of them, we observe no increase in the error correction capability from the second to last internal node of the tree. This is due to the variety of possibilities of generating polynomials for a cyclic code of parameters . As a result, we demonstrate in Proposition 3 that, for Reed–Solomon codes, this feature of increasing capacity will be guaranteed provided that:
Example 9. Let be a cyclic code in and be the dimensions of the subspaces , respectively. The last node is associated with with dimension . The construction is depicted in Figure 10. We consider the factorization:
Case 1.
| • | | ⇒ | |
| • | | ⇒ | |
| • | | ⇒ | |
Case 2.
| • | | | |
| • | | | |
| • | | | |
Remark 8. We have provided an m-file algorithm at [20], which can be run through Matlab and performs the operations described in Examples 8 and 9. Proposition 3. Given a Reed–Solomon code, which has minimum distance , one can guarantee an increase in error correction capability at each level of the tree provided that .
Proof. We must prove that . For simplicity but without loss of generality, set . If , then we can write:
This completes the proof. □
The verification that, for cyclic codes, there will not always be an increase in the error correction capacity between the levels of the tree, as considered in [
12], leads us to search for answers on how to properly choose the generating polynomials for a code of parameters
and its subcodes, in order to guarantee subcodes with larger Hamming distance, with the purpose of observing an increase in the error correction capacity between the levels of the tree. An approach to constructing chains of some linear block codes while keeping the minimum distances (of the generated subcodes) as large as possible is presented in [
25] and may be the solution to this problem.
3.3. An Example with a BCH Code
According to Luo and Vinck [
25], to construct a chain of BCH subcodes with the characteristic of maintaining the minimum distance as large as possible, the task becomes more difficult because their subcodes may not be BCH and cyclic codes, and therefore the minimum distance of these subcodes might not be found easily. However, for primitive BCH codes, the minimum distance coincides with the weight of the generator polynomial, which makes it feasible to use it for the construction of the nested subcode chain that we seek. For non-primitive BCH codes, this statement is not always valid. For an extensive description of the minimum distance for BCH codes, we recommend consulting [
26].
In
Table 1, we present the parameters for binary primitive BCH codes of length
; it will guide the tree construction.
Example 10. Consider the root node associated with the BCH code . Suppose that we want to encode the packets , and associated with nodes whose dimensions are , and , respectively. The polynomials , and generate the codes associated with the internal nodes, , e , respectively, as shown in Figure 11. Encoding the packets, we have:
The transmitted codeword
is given by:
Alternatively, it is possible to represent the codeword in vector form:
After the error correction process, which will be performed on the sum of the coded packets, taking into account the side information available at each receiver, data recovery will occur as follows:
Remark 9. We have made available at [20] an m-file Matlab algorithm that performs the tree construction operations and the data recovery for the BCH code. 4. Index Coding with Multiple Interpretations
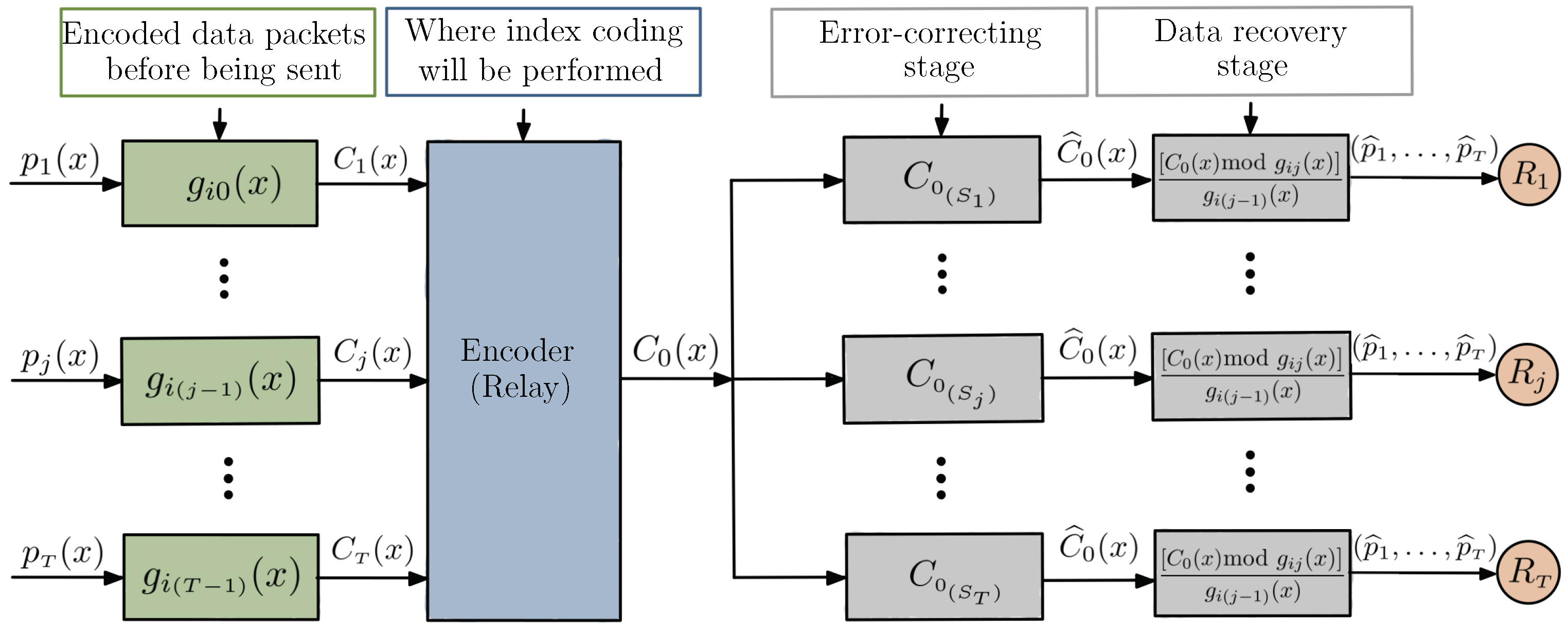
In the problem of index coding with multiple interpretations, we assume that receivers demand all the messages from the source and that the sender is unaware of the subset of messages already known in the receivers—performing an encoding so that any side information may be used by the decoder, in order to increase its error correction capability. Otherwise, if a receiver has no side information, the decoder considers the received word to belong to the highest rate code associated with the root node of the tree.
The proposed encoding process is shown in
Figure 12 and can be performed in four main steps:
- 1.
Encoding of the different data packets with nested cyclic codes, which consists of subdividing the vector space of a linear block code into vector subspaces, using each of them for encoding a different user;
- 2.
Implementation of index coding at the relay node; the basic idea is that the different data packets, encoded by polynomial multiplications with linearly independent generators, are added and then forwarded to the receivers;
- 3.
Multiple interpretations at the receivers that occur at the error correction stage, where each receiver can decode the received message at different rates depending on the known side information;
- 4.
The data recovery stage, i.e., the process of decoding
through polynomial operations (
1), as described in
Section 3.1.
The notion of multiple interpretations was introduced in [
13], indicating that the error correction capability in decoding gradually improves as the amount of side information available at the receiver increases. However, as we prove in Proposition 2, because of the nested structure of the tree, this characteristic of variable error correction capability can only be observed if there is a sequential removal of packets associated with the nodes, i.e., the side information should occur sequentially from the root to the top of the tree. However, in practice, this is not always the case. Thus, if we want to ensure that any information can be used efficiently in the decoder, it will be necessary to assume knowledge of the side information by the relay node or even the demand set, if we have a PICOD problem.
The following is a proposal for pliable index coding with multiple interpretations.
Pliable Index Coding with Multiple Interpretations
As in the pliable index coding problem [
6], we will assume that the transmitter knows the demand set of each receiver and that all receivers are satisfied by receiving any message contained in their demand set. For example, if we are searching on the internet for a red flower image and we already have some previously downloaded pictures on our computer, if we find any other image that we do not have yet, we will be satisfied.
The goal of the server is to find an encoding scheme that satisfies all receivers, using as few transmissions as possible and ensuring that all side information associated with nodes located below the node where the packet to be recovered is located may be interpreted as a gain in error correction capability, even when they do not appear in such a sequence.
The idea behind this proposal is to apply conflict-free coloring to the hypergraph that represents the demands of all receivers, and instead of sending the encoded word , we select the packets in a way that maximizes the possibility of a gain in error correction capability, since, as mentioned above, packages will only be removed if they occur sequentially.
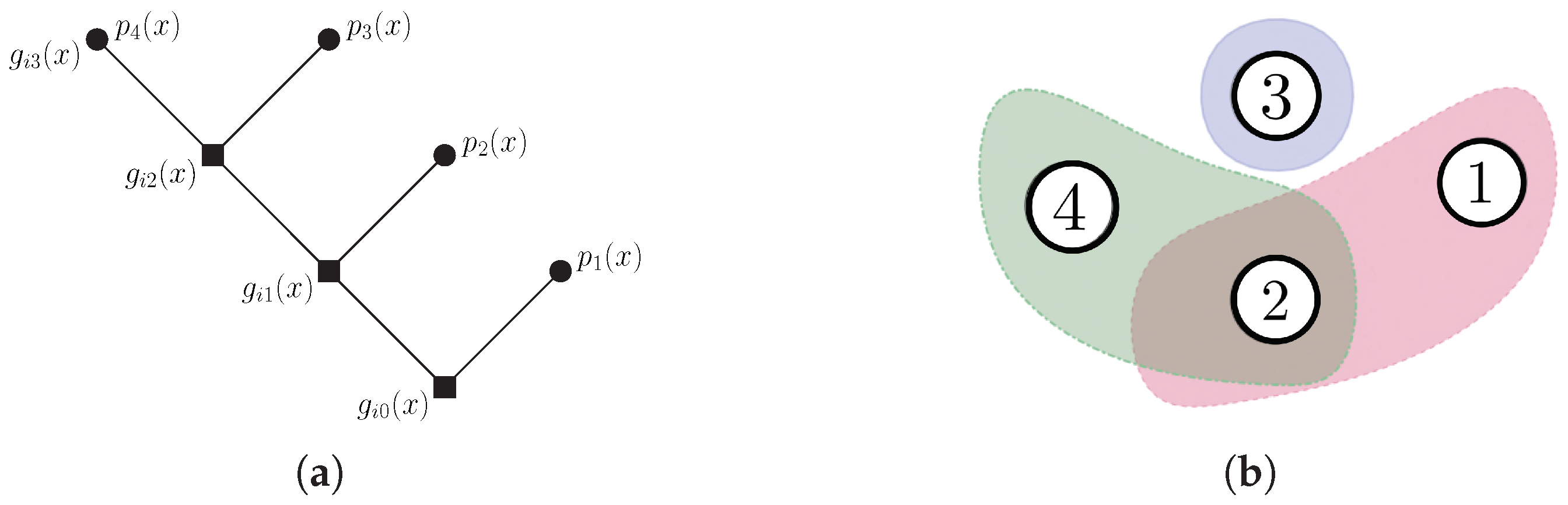
Example 11. Consider an instance of an pliable index coding with multiple interpretations in Figure 13a, where the encoded packets and will be sent to receivers and , which have demand sets , , , respectively, as we see in Figure 13b. Figure 14 shows conflict-free coloring with two colors and
, which represents the pliable index code.
Note that if we send only the message
, all receivers recover one and only one message from their request set, as we can see in
Table 2.
Depending on the problem, this would be an ideal solution, since the transmitter may want each receiver to decode
only one message, in which case we would have a PICOD(1); no client can receive more than one message from its request set. The case of PICOD(1) is dealt with in detail in [
27], and the following example, which aptly illustrates its use, is provided.
Consider a media service provider whom we pay for movies. The provider has a set of movies and customers pay for a certain number of movies, e.g., one movie. Suppose that the service is being sold in such a way that customers will be happy to receive any movie that they have not watched yet. There is a restriction on the service provider’s side, since customers who have paid for only one movie should not receive more than one. Therefore, it can only supply one film for each client.




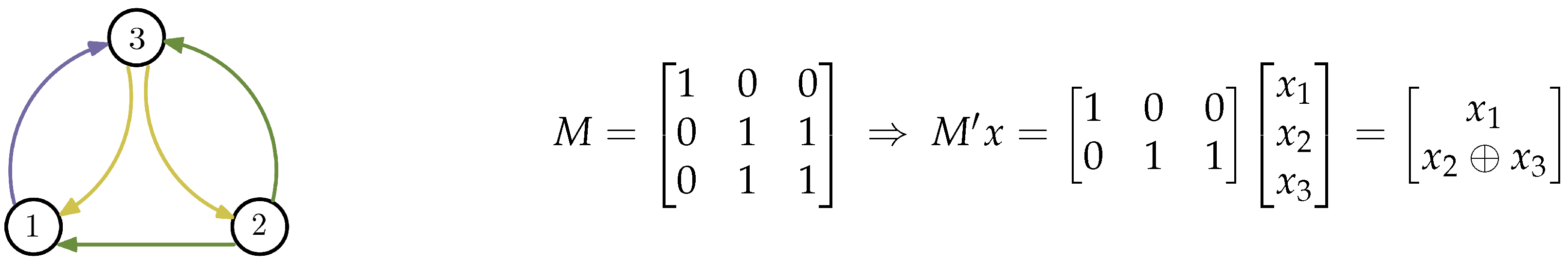





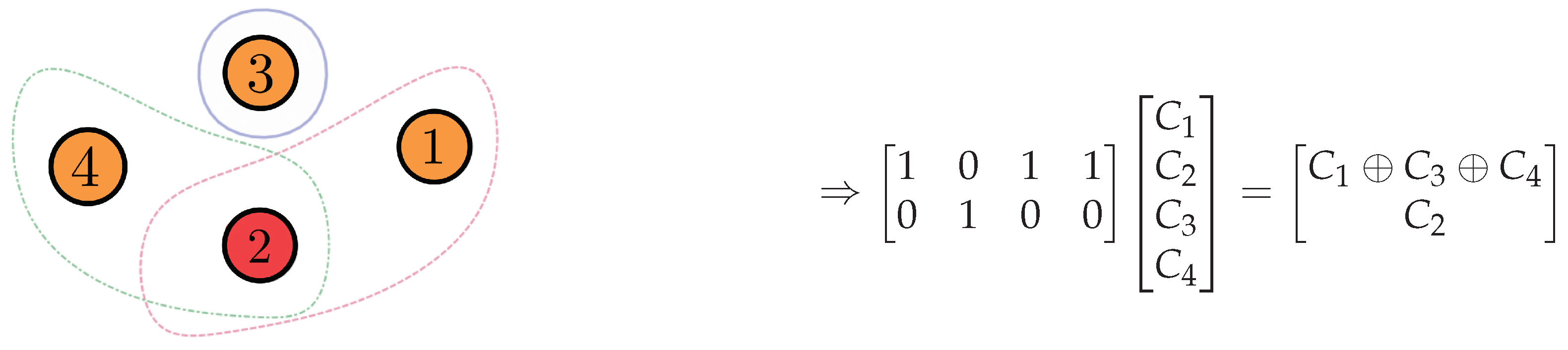

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}